
Abstract
Operating and maintenance costs, which account for 25% of total costs, are a powerful lever in reducing the electricity generation costs of onshore wind turbines (WT). These costs can be reduced by a condition-orientated maintenance approach. A condition-oriented maintenance strategy optimizes maintenance tasks by executing them with varying levels of detail and focus depending on the system and life cycle phase. OEMs evaluate operating data and structured data from the maintenance history for this purpose, but SMEs lack the capacity for this evaluation. In particular, the unstructured descriptive comments in the maintenance reports generated by service technicians remain unused. In this work, we propose a framework to incorporate this information from the maintenance reports along with the status records from the SCADA system. For this purpose, a mechanism has to be developed to make the contents of the service reports machine-evaluable. The mechanism used in this approach is an ontology, which enables the codification of implicit knowledge such as the experience knowledge of the service technicians. The ontology’s purpose is to link status codes of onshore WT with historical maintenance reports and thereby enabling an automated evaluation. Using an API (application programming interface), the ontology can be integrated into an algorithm to analyse status data and maintenance documents. In this manner, recommendations for actions can be derived and maintenance tasks can be optimized.
Zusammenfassung
Die Betriebs- und Instandhaltungskosten, die 25 % der Gesamtkosten ausmachen, sind ein starker Hebel zur Reduzierung der Stromgestehungskosten von Onshore-Windenergieanlagen (WEA). Diese Kosten können durch einen zustandsorientierten Instandhaltungsansatz reduziert werden. Eine zustandsorientierte Instandhaltungsstrategie optimiert Instandhaltungsaktivitäten, indem diese je nach Anlage und Lebenszyklusphase mit unterschiedlichem Detaillierungsgrad und Fokus ausgeführt werden. OEMs werten dazu Betriebsdaten und strukturierte Daten aus der Instandhaltungshistorie aus, KMUs fehlen jedoch die Kapazitäten für diese Auswertung. Insbesondere die unstrukturierten Kommentare in den von Servicetechnikern erstellten Berichten bleiben ungenutzt. In diesem Artikel stellen wir ein Framework vor, um diese Informationen aus Berichten zusammen mit den Statusaufzeichnungen aus dem SCADA-System nutzbar zu machen. Dazu muss ein Mechanismus entwickelt werden, der die Inhalte der Berichte maschinenverwertbar macht. Der Mechanismus, der in diesem Ansatz verwendet wird, ist eine Ontologie, die die Kodifizierung von implizitem Wissen, wie z. B. dem Erfahrungswissen der Servicetechniker, ermöglicht. Der Zweck der Ontologie ist es, Statuscodes von Onshore-WEA mit historischen Wartungsberichten zu verknüpfen und damit eine automatisierte Auswertung zu ermöglichen. Über eine API (Application Programming Interface) kann die Ontologie in einen Algorithmus zur Analyse von Zustandsdaten und Instandhaltungsdokumenten eingebunden werden. Auf diese Weise können Handlungsempfehlungen abgeleitet und Instandhaltungsaktivitäten optimiert werden.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
With a share of 41%, onshore wind turbines are the largest contributor to electricity generation from renewable energies and thus play a key role in achieving an environmentally friendly energy supply for Germany [1]. Due to the expiration of the EEG (German renewable energy law) subsidies and increasing operating and maintenance costs (O&M costs) as the turbines age [2,3,4] the cost pressure on operators of wind turbines (WTs) has increased [5]. While the annual O&M costs of a new turbine are still at 10 to 15% of the average total costs per kWh, this share rises to as much as 35% by the end of its service life. On average, the O&M costs thus make up about 25% of the total costs per kWh [6]. This makes O&M costs a powerful lever for reducing the power generation costs of onshore WTs. A closer look at O&M costs reveals that O&M costs are directly dependent on maintenance costs.
Maintenance activities include upkeep, inspection, repair and improvement [7]. A promising approach to reduce maintenance costs is a condition-based maintenance strategy [8]. Today, maintenance activities often take place at fixed intervals according to predefined maintenance specifications. A condition-oriented maintenance strategy, on the other hand, aims to carry out maintenance activities optimized for time and personnel utilization, depending on the system and life cycle phase [8]. The basis of such maintenance optimization is detailed knowledge regarding the condition of the WT. Large operators of wind farms or manufacturers of WTs evaluate operating and structured data from the maintenance history for this purpose, but small and medium enterprises (SMEs) do not always have the capacities for such an evaluation. In particular, comments on the condition of the turbine often remain completely unused. These comments are often contained in non-standardized-form in service reports and are documented by service technicians in free text fields. The latter are used to record the experience of service technicians in the otherwise standardized service reports. However, especially against the background of the increasing importance of interconnectedness and information processing in the yield optimization and maintenance cost optimization of WTs, these sources of information are becoming more and more important. The possession of data and the ability to use it as a base for decisions on process optimization brings decisive cost advantages in the highly competitive energy sector. This is exactly the point where the research project “ReStroK” comes into play. Together with industrial partners, the Institute for Industrial Management, FIR is investigating the machine evaluation of both status data and maintenance histories, which have so far been used primarily for documentation purposes. The focus is on the avoidance of breakdowns due to progressive wear and tear of individual components by timely maintenance of these components. This paper describes a procedure for converting the information contained in the free texts of service reports regarding the turbine condition into a usable form. For this purpose, an interface is required which makes the contents of the service reports machine-evaluable. An ontology was developed as a suitable interface that enables the codification and utilization of the service technicians’ experience. With the ontology developed, the implicit knowledge of the service technicians can be combined with historical data sets of status data and can be used to extract the relevant information from the maintenance history.
2 State of the art
2.1 Ontologies
The central question of an ontology deals with the categories of objects that exist and in which relation these objects stand to each other. Ontologies in computer science also tie in at this point. In computer science, an ontology is a “formal, explicit specification of a shared conceptualization” [9]. “Conceptualization” meaning, that a section of reality is represented with the help of an abstract model which represents the essential concepts of this section of reality. The concepts used within this model and their relations among each other are on the one hand explicitly defined and on the other hand displayed formally, i.e. in particular machine-readable [9]. “Shared” in this context meaning, that it is common knowledge accepted within a group [9]. Thus, ontologies serve to create a common vocabulary between different actors with the aim of facilitating the exchange and sharing of knowledge [10]. Actors are both human and machine actors [11]. Typical components of an ontology are classes, entities, properties and axioms [12, 13]. Classes are the implementation of the concepts described above. These concepts or classes represent terms of the ontology hierarchically and are therefore often designed as taxonomy. Accordingly, the concept of inheritance is applicable to classes [13]. Entities represent concrete manifestations of classes and are comparable to objects of a class in an object-oriented programming language. Properties describe characteristics and logical relationships between classes and thus distinguish the ontology from the taxonomy. Axioms can also be used to introduce statements that should always be considered true within the ontology.
2.2 Explicit and implicit knowledge
Knowledge is created through purpose-oriented interconnection of information [14] and can be defined in a business context as “the capacity for effective action” [15]. Basically two types of knowledge can be distinguished: Explicit and implicit knowledge [16]. Explicit knowledge is coded knowledge stored in various media. Examples for such media are books, numerical systems or pictures. Explicit knowledge can therefore be processed, transferred and stored by means of electronic data processing [14]. Implicit knowledge, on the other hand, comprises subjective insights and intuitions as well as ideals and values; it is deeply rooted in a person’s experiences. Because of its subjectivity and individuality, implicit knowledge is difficult to formalize and communicate, unlike explicit knowledge [11, 14]. In order to be able to perform a systematic and logical processing and evaluation of implicit knowledge, this knowledge must first be transformed into documented, explicit knowledge. This process of codification of implicit knowledge, called externalization, can be performed and supported by ontologies and ontology editors such as Protégé [11, 17].
2.3 Optimization of wind turbine maintenance based on event data and service reports
Today’s WTs transmit a variety of different data that can be used for the diverse approaches to optimizing maintenance. These data are the master data of the WT, operating data sourced from SCADA systems (Supervisory Control and Data Acquisition), which in part comprise hundreds of measuring channels, status and alarm messages as well as event and maintenance data, and data from the component-specific condition monitoring system (CMS) [18]. To summarize, the focus of approaches to increase the availability of WTs lies on the analysis of the measured values transmitted by SCADA systems and CMS. Comparatively little attention is paid to the maintenance data from service reports, which are at the center of the optimization approach developed in the context of ReStroK. There are several possible reasons for this. On the one hand, inadequate organizational structures may hinder the evaluation of already existing data, on the other hand, data may not be usable at all, since, for example, maintenance histories are often available in different formats such as paper or PDF. The situation is further aggravated by the fact that a large number of actors are involved in the various phases of the life cycle of a WT (sometimes across phases), which favors the creation of different data formats. The maintenance that takes place during the operating phase is characterized by a “service network” consisting of the operator, independent service providers (ISPs), OEMs and suppliers [19]. Since OEMs and ISPs are in direct competition with each other [20], there is usually no to little exchange of data and/or knowledge. As a result, hardly any technical system structures and standardized event classifications for the recording, storage and use of event data or information from service reports that are accepted throughout the industry exist. However, standardized data is essential for a targeted optimization of maintenance. Conversations and interviews with OEMs and ISPs confirm that software systems are mainly used for the documentation towards operators. For this reason, specific concepts have already been developed and implemented together with expert committees, which, adapted to the needs of the wind energy industry, should enable a cross-company analysis [8, 21]. Among other things, the internationally standardized RDS-PP identification system, the state-event-root cause key for generation units, the Global Service Protocol as a technical guideline of the Fördergesellschaft Windenergie (FGW), which describes an exchange format for maintenance information, and a cross-supplier database (wind-energy-information data pool) were developed. Interviews with actors in the wind energy industry revealed that although the existing solution approaches are known, the effort required to use these standards is associated with increased costs for training, preparation of the protocols and transfer of the designations into existing IT systems. In addition, OEMs and ISPs have already developed their own systems and also have a sufficiently large number of similar systems for internal company analysis. As a result, industry-wide cooperation and increased transparency is seen as a disadvantage for their own competitive position. OEMs and ISPs agree that the effort to implement the systems mentioned above is not always worthwhile. Especially SMEs do not have the appropriate capacities for in-house data analysis and maintenance optimization.
Faulstich and Hahn however, point out the added value of an evaluation of event data. Event data on the one hand includes the automatically generated status messages of the WT and on the other hand maintenance data from service reports. Status codes report status changes of the WT and can thus indicate necessary maintenance measures. The corresponding status codes already provide information about the affected systems. Yet, there is no clear assignment of a faulty condition to a causal component. Rather, as confirmed by interviews with ISPs, it is a “black box” containing a number of different components that may have caused the fault [18]. To solve this problem, an ontology is suitable as a link and common language between service technicians or maintenance reports and the SCADA system or status codes. Ontologies have already been proposed in many ways as a tool for analyzing faults and accidents of WTs. Zhou et al. developed a FMECA-based (Failure Mode and Effects and Criticality Analysis) ontology, which allows for faster identification of components causing failure and enables a common knowledge base of OEM and ISP [22]. Papadopoulos and Cipcigan propose an ontology that can be used for fault detection and diagnosis of the gear unit [23]. The ontology identifies possible faults and their exact position within the gear unit. An ontology-based analysis of the external circumstances and environmental conditions of WT accidents was performed by Ertek et al. [24]. Basis of the ontology were text documents about WT accidents. The subsequently developed ontology is based on the evaluation of service reports and establishes a connection between the formal turbine structure, status data and free texts and the experience knowledge of the service technicians.
3 Development of an ontology for the maintenance of wind turbines
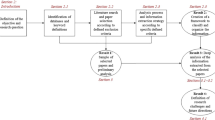
So far, no uniform approach has been established for the development of ontologies. However, there is a consensus that it should always be an iterative process. The development of the ontology in this paper is based on the approach proposed by Stuckenschmidt [25] and is shown in Fig. 2.
3.1 Definition of the domain of interest
In the first step, the domain of interest is defined. The exact boundaries of the application domain are described, i.e. it is decided which section of reality is to be described by the ontology and which is not. In addition, the level of detail of the ontology is determined. The developed ontology should enable the evaluation of maintenance reports of onshore WTs. In particular, the implicit knowledge of service technicians and maintenance experts of onshore WTs will be linked to the operating data and master data of the WTs and thus made usable. The aim is to externalize and analyze codified empirical knowledge. The ontology creates a link between the service reports and the error codes transmitted by the SCADA system via the turbine structure (Fig. 1).

Link between status codes and service reports
Since WTs differ depending on the manufacturer in terms of their construction and with regard to the existing subsystems—for example, not all WTs have a gear unit—a comprehensive and detailed illustration of the turbine structure is not practical. Instead, an ABC analysis was used to identify the most maintenance-intensive and error-prone subsystems of the turbines under consideration. As a result it was found, that the pitch system and converter are responsible for about 80% of the failures caused by faults. Against the background of the intended maintenance optimization, it is therefore reasonable to develop an ontology that focuses on the subsystems pitch system and converter with regard to maintenance optimization. It should be noted, that while the failures of these sub-systems were also responsible for a similar share in downtime in the turbines under consideration, which is a key cost driver in maintenance costs in WTs [26], there may be other components in other turbines which may cause higher downtimes and thus higher maintenance costs regardless of the frequency.
3.2 Identification of relevant terms
In the second step, after defining the ontology framework, the relevant terms for the ontology are determined [25]. Due to the fact that a large part of the problems and optimization potentials of maintenance are characterized by the interaction of people, machines and technologies, maintenance can be regarded in the local context as a socio-technical system [27]. Accordingly, the terms of ontology include both human and technical components. For the identification of relevant terms, a wide variety of sources can be considered. Besides the classical approach of conducting interviews with experts in the application domain, textual sources are also of interest [25]. The basis for the human and partly also for the technical terms are therefore 480 service reports from maintenance and repair. These service reports have been investigated using Python 3.7. Fig. 2 illustrates the procedure for analyzing the documents in steps 2 to 4.

Ontology development, based on Stuckenschmidt [25]
In a first step, the digital service reports are imported so that the extracted text can then be processed. The frequencies of the different words or terms within the scanned text are of interest here. Terms with particularly high frequencies are often found in the document templates of the service reports, while terms with very low frequencies are usually found in the non-standardized free texts of the service technicians. Within these free texts, service technicians describe unusual findings and damage to the WTs. This information is to be made usable in the ontology and in the evaluation of the logbooks. In order to have a better overview when manually filtering the ontology terms, numerous filters and conditions were applied when defining the frequency of the terms. These include, among others, the disregard of punctuation and special characters when identifying terms, so that identical terms are recognized as such even if they have not been extracted cleanly. Furthermore, terms with less than three letters are not considered. Fig. 3 shows the frequency distribution of the first collection of terms. As already described, the terms can be divided into two areas according to their frequency. For the sake of clarity and readability, only some selected terms are shown for each of these areas.

Absolute term frequency in 480 maintenance reports
Next, the first collection of terms is filtered together with experts in the application domain to obtain a list of terms relevant to the ontology. Based on this list, the classes and relations as well as instances of the ontology are then defined.
3.3 Definition of the class hierarchy and definition of relations
The creation of an ontology is accompanied by a multitude of design options; there is no fixed decision rule for choosing between classes and entities. In principle, however, only the level of classes has a claim to general validity. If a term describes a set of objects with common properties, it should be modeled as a class [25]. But if the uniqueness of the term is of central importance, the term should be modeled as an entity [28]. The terms with high frequencies coming from the document templates provide the controlled vocabulary or ontology terminology. These terms flow into classes and properties and thus represent the knowledge of concepts and relations between classes—in this context one also speaks of the TBox (terminology box). A TBox contains the schema of a description logic. The terms with low absolute frequencies—absolute frequency 1 or 2, for example—represent factual and experiential knowledge at entity level, also referred to as ABox (assertion box). An ABox contains the data of a description logic [12].
The developed ontology consists of nine classes, some of which branch out into subclasses. The classes Type of Maintenance, Performed_Work and Defect Descriptions come from the analysis of the service reports. To create a connection between these classes and the status codes of the WTs contained in the logbooks, additional classes were created in cooperation with experts in the application domain. The class Components of the WTs as well as the classes Error Group and Error Cause were introduced. The class Error Group summarizes the status codes of WTs manufacturer-independently in groups. The grouping is based on potential triggering components, i.e. error codes that can be triggered by the same components form a group. Accordingly, these components are also divided into groups with a numbering corresponding to the error groups. Finally, the classes Wind Turbine, Error Codes OEM and Determination Method were included to structure further supplementing information from the WTs considered for this paper that was extracted from logbooks or service reports. The class Determination Method referring to the method used to determine an error, while Wind Turbine and Error Codes OEM describe the specific WTs and their respective, OEM-specific error codes—found in logbooks—considered for this work.
3.4 Formalization
In the final step, the previously defined classes are formalized with necessary and sufficient conditions. In this step, restrictions—such as existence-, cardinality- or type-restrictions—are utilized to exactly specify classes and concepts of an ontology. During this step it’s imperative to ensure that restrictions for sub-classes are compatible with their superordinate classes. The formalization of the ontology was done according to the recommendation of the World Wide Web Consortium (W3C), an international standards organization for the world wide web, using the Web Ontology Language (OWL) in the ontology editor Protégé [17, 29, 30]. The focus for the developed ontology was on the detailed ABox. The list of ontology terms, which was filtered by domain experts, includes 771 terms, of which 414 have an absolute frequency of less than 10. This confirms the individual language usage of the service technicians. The extensive knowledge of the domain experts was integrated in the ABox and thus represents the core of the ontology for maintenance optimization. The nouns, adjectives and verbs with low absolute frequencies extracted from the service logs at the beginning are implemented as instances of the classes Performed_Work and Defect Descriptions.
Fig. 4 shows an excerpt of the description with the entities of the class Error Group_2. This class contains all error codes which are triggered by the emergency brake system of the pitch system. This set of error codes is potentially triggered by any element of a group of components which are combined in class Error Causes_Group_2. Fig. 4 shows a list of entities of both classes. A grouping of the error codes is preferable to a single consideration of error codes, since errors not necessarily only generate single error codes, but whole sequences of error codes as well. This does not become apparent from the error messages [18]. The division of the fault codes into component-dependent groups and their “many to many relationship” to the component groups has the additional advantage, compared to the formulation of fault chains in the sense of an FMEA, that an assignment independent of the manufacturer is possible. In concrete terms this means that fault groups can easily be supplemented with the status codes of WTs from a large number of manufacturers. An extension of the ontology, which so far contains status codes from General Electric (GE) and Enercon, is thus possible with little effort.

Assignment of GE error codes of group 2 (pitch emergency braking system) to possible causes
4 Summary and outlook
Operating and maintenance costs make up a major share of electricity generation costs in onshore wind turbines. This makes them a key lever for reduction efforts. One possible option to reduce these costs is a condition-orientated maintenance approach. A condition-oriented maintenance strategy optimizes maintenance tasks by executing them with varying levels of scope depending on the system and life cycle phase.
A condition-oriented maintenance approach requires extensive data transparency, which OEMs obtain by evaluating available operating data as well as structured data from the maintenance history. However, SMEs lack the capacity for this evaluation. In addition, the unstructured descriptive comments in the maintenance reports generated by service technicians often remain unused.
This work demonstrated how a framework to incorporate this information from the maintenance reports along with the status records from the SCADA system could be set-up. To achieve this, it is essential to link the implicit knowledge of service technicians and maintenance experts with the operating and master data of the WTs, and make it available for use. To make this possible, an ontology tailored to these data was developed. This ontology enables an automated analysis of event data through formalization utilizing Protégé. The ontology is based on 480 service reports. Terms were extracted from these and prioritized and supplemented for the creation of classes and relationships. The service technicians’ experience and knowledge is incorporated into the extensive entity level of the ontology. Through an API, the ontology can be integrated into an algorithm for the combined evaluation of status data and service reports.
In the next step, this algorithm for identifying relevant events will be developed. In a further step, the service reports are evaluated and optimized in order to perform maintenance activities in a more targeted manner. This will increase the effectiveness of maintenance activities, since emerging breakdowns can be detected and prevented at an early stage. In addition, a measure catalogue will be created, which connects damages to corresponding measures in order to quickly identify and repair the faulty component, further increasing maintenance effectiveness and lowering O&M costs.
References
Bundesumweltamt (ed) (2019) Erneuerbare Energien in Deutschland: Daten zur Entwicklung im Jahr 2018. https://www.umweltbundesamt.de/sites/default/files/medien/1410/publikationen/uba_hgp_eeinzahlen_2019_bf.pdf. Accessed 27 Nov 2020
Staffell I, Green R (2014) How does wind farm performance decline with age? Renew Energy 66:775–786. https://doi.org/10.1016/j.renene.2013.10.041
Dai J, Yang W, Cao J et al (2018) Ageing assessment of a wind turbine over time by interpreting wind farm SCADA data. Renew Energy 116(B):199–208. https://doi.org/10.1016/j.renene.2017.03.097
Ziegler L, Gonzalez E, Rubert T et al (2018) Lifetime extension of onshore wind turbines: a review covering Germany, Spain, Denmark, and the UK. Renew Sustain Energy Rev 82(Part1):1261–1271. https://doi.org/10.1016/j.rser.2017.09.100
Urbansky F (2018) Die auslaufende EEG-Förderung wirft ihre Schatten voraus. https://www.springerprofessional.de/erneuerbare-energien/erneuerbare-energien-gesetz/die-auslaufende-eeg-foerderung-wirft-ihre-schatten-voraus/16345856. Accessed 27 Nov 2020
Krohn S, Awerbuch S, Morthorst PE (2009) The economics of wind power. European Wind Energy Association, Brüssel
Deutsches Institut für Normung e. V. (ed) (2019) DIN 31051. Grundlagen der Instandhaltung. Fundamentals of maintenance. ICS 01.040.03; 03.080.10. (31051:2019-06)
IZP, IWES, SAG, Erwin Peters GmbH et al (2010) Abschlussbericht: Erhöhung der Verfügbarkeit von Windkraftanlagen. Teilprojekt: Entwicklung von zuverlässigkeitsbezogenen Betriebs- und Instandhaltungsstrategien für Windkraftanlagen unter besonderer Berücksichtigung der Offshore-Bedingungen. https://www.tib.eu/de/suchen/id/TIBKAT:634597957/. Accessed 27 Nov 2020
Studer R, Benjamins VR, Fensel D (1998) Knowledge engineering: principles and methods. Data Knowl Eng 25(1/2):161–197
Gruber TR (1993) A translation approach to portable ontology specifications. Knowl Acquis 5(2):199–220. https://doi.org/10.1006/knac.1993.1008
Staab S (2002) Wissensmanagement mit Ontologien und Metadaten. Informatik-Spektrum 25:194–209. https://doi.org/10.1007/s002870200226
Kuhlen R, Semar W, Strauch D (eds) (2013) Grundlagen der praktischen Information und Dokumentation, 6th edn. Walter de Gruyter, Berlin
Dengel A (2012) Semantische Technologien: Grundlagen – Konzepte – Anwendungen. Spektrum, Heidelberg
Rehäuser J, Krcmar H (1996) Wissensmanagement in Unternehmen. In: Schreyögg G, Conrad P (eds) Wissensmanagement, vol 98. de Gruyter, Berlin, pp 1–40
Senge P (2000) Reflection on “A leader’s new work: building learning organizations”. In: Morey D, Maybury MT, Thuraisingham B (eds) Knowledge management. MIT Press, Cambridge, pp 54–60
Nonaka I, Takeuchi H (1995) The knowledge-creating company: how Japanese companies create the dynamics of innovation. Oxford University Press, Oxford
Musen MA (2015) The Protégé project: a look back and a look forward. AI Matters 1(4):4–12. https://doi.org/10.1145/2757001.2757003
Faulstich S, Hahn B (2019) Erkenntnisse aus digitalisierten Daten von über 3000 Windenergieanlagen im Betrieb. In: VDI Wissensforum (ed) 10. VDI-Fachtagung Schwingungen von Windenergieanlagen 2019 Bremen, 4 June 2019 VDI, Düsseldorf, pp 1–16
Schuh G, Peter T, Gudergan G (2011) Designing cooperation concepts for service concepts. In: Thoben K‑D (ed) 2011 17th International Conference on Concurrent Enterprising Aachen, Germany, 20–22 June 2011 IEEE, Piscataway, pp 1–8
Parbs H (2017) Fragmentierung eines Service Ecosystem: Eine Grounded Theorystudie zur Instandhaltung in der Windenergiebranche. http://nbn-resolving.de/urn:nbn:de:gbv:46-00106483-14. Accessed 27 Nov 2020 (Bremen, University, Dissertation)
Jung H (2014) Erhöhung der Verfügbarkeit von Windkraftanlagen. EVW-Phase II: Praxisimplementierung von zuverlässigkeits- und zustandsorientierten Betriebs- und Instandhaltungsstrategien auf Basis von standardisierten Prozessabläufen. Forschungsvorhaben 0327574D‑H. http://www.wind-evw.de/fileadmin/Dokumente/Abschlussberichte/EVW_II_Abschlussbericht/EVW_Phase_II_Abschlussbericht_ohne_Anlagen.pdf. Accessed 27 Nov 2020 (IZP Dresden mbH, Dresden)
Zhou A, Yu D, Zhang W (2014) A research on intelligent fault diagnosis of wind turbines based on ontology and FMECA. Adv Eng Inform 29(1):115–125. https://doi.org/10.1016/j.aei.2014.10.001
Papadopoulos P, Cipcigan L (2009) Wind turbines’ condition monitoring: an ontology model. In: IEEE (ed) 2009 International Conference on Sustainable Power Generation and Supply SUPERGEN 2009. IEEE, Piscataway, pp 1–4
Ertek G, Chi X, Zhang AN et al (2017) Text mining analysis of wind turbine accidents: an ontology-based framework. In: Staff I (ed) 2017 IEEE International Conference on Big Data (Big Data). IEEE, Piscataway, pp 3233–3241
Stuckenschmidt H (2009) Ontologien: Konzepte, Technologien und Anwendungen. Springer, Berlin
Walford C (2006) Wind turbine reliability: understanding and minimizing wind turbine operation and maintenance costs. https://prod.sandia.gov/techlib-noauth/access-control.cgi/2006/%EE%80%80061100%EE%80%81.pdf. Accessed 2 Nov 2021 (Sandia Report)
Spath D (ed) (2011) Wissensarbeit: Zwischen strengen Prozessen und kreativem Spielraum. Schriftenreihe der Hochschulgruppe für Arbeits- und Betriebsorganisation e. V. (HAB). GITO, Berlin (Tagungsband)
Stevens R, Sattler U (2013) An object lesson in choosing between a class and an object. http://ontogenesis.knowledgeblog.org/1418. Accessed 27 Nov 2020
W3C (ed) (2009) OWL Web Ontology Language Reference. https://www.w3.org/TR/2004/REC-owl-ref-20040210/. Accessed 27 Nov 2020
Horridge M (2011) A practical guide to building OWL ontologies using Protégé 4 and CO-ODE tools. Edition 1.3. http://mowl-power.cs.man.ac.uk/protegeowltutorial/resources/ProtegeOWLTutorialP4_v1_3.pdf. Accessed 27 Nov 2020
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Strack, B., Lenart, M., Frank, J. et al. Ontology for maintenance of onshore wind turbines. Forsch Ingenieurwes 85, 265–272 (2021). https://doi.org/10.1007/s10010-021-00466-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10010-021-00466-x