
Abstract
POI group recommendation is one of the hottest research topics in location-based social networks, which recommends the most agreeable places for a group of users. However, traditional POI group recommendation methods only generate a consensus function to aggregate individual preference into group preference and they do not consider all the factors that can determine the results of POI group recommendation, which leads to a low recommendation accuracy. What’s more, these methods have a long running time. Therefore, in this paper, we propose a new POI group recommendation method with an extreme learning machine (ELM) called PGR-ELM. The PGR-ELM method regards POI group recommendation as a binary classification problem. First, three features are extracted from three factors: POI popularity, group members’ distance to POI, members’ interest preferences combined affinity between group members. These features simultaneously consider all the factors that can determine the results of recommendation and guarantee the effectiveness of POI group recommendation. Then, the extracted features are input to train an ELM classifier because of its fast learning speed, which guarantees the efficiency of POI group recommendation. Finally, extensive experiments verify the accuracy and efficiency of PGR-ELM method.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Location-based social networks (LBSNs) have become a popular platform to allow users to make check-in activities on the places that users visit, such as Foursquare and Gowalla [1,2,3]. Moreover, these services collect huge volumes of users’ check-in data. Based on the analysis and mining for these users’ check-in data, point-of-interest (POI) recommendation has emerged and become one of the hottest research topics in LBSNs [4,5,6,7,8].
POI recommendation recommends a user a list of POIs to perform check-in activities. Formerly, POI recommendation mainly focused on individual users. With people get more connected, there are some scenarios where POIs need to be recommended to a group of users rather than individual user [9,10,11,12,13]. For example, several friends want to find a POI as the party place. Or a group of users goes to a tourist city and finds the best tourist attractions that the group members can visit together. However, traditional POI group recommendation methods only generate a consensus function to aggregate individual preference into group preference. They cannot handle the data sparsity and cold-start recommendation problem. Next, traditional POI group recommendation methods do not consider all the factors that can determine the results of POI group recommendation, which leads to a low recommendation accuracy. What’s more, these existing methods are usually inefficient [14,15,16,17]. Guo et al. proposed a new group recommendation mechanism that only considered the members’ preference distribution and could not handle the cold-start recommendation problem [14]. Zhu et al. proposed a novel POI group recommendation method that only considered the distance and intra-group influence, thus the accuracy of method did not perform satisfactory and it required a long execution time [15].
Users’ historical check-in records in LBSNs reflect users’ preferences, experiences. Thus, LBSNs can provide rich spatial–temporal and social information which can help us to improve the performance of POI group recommendation. We can fully utilize the data resources of LBSNs to overcome the shortcomings of the existing methods. Therefore, in this paper, we propose a method from a new perspective to solve the POI group recommendation problem, called PGR-ELM. The PGR-ELM method regards POI group recommendation as a binary classification problem. As a group, all POIs are classified into two classes: “recommendation” or “non-recommendation.” The PGR-ELM method will satisfy all members’ needs and recommend the most agreeable POIs to the group members. The PGR-ELM method has two phases: feature extraction and classifier training. PGR-ELM first extracts the features by mining users’ historical check-in data in LBSNs. Then, the extracted features as input train the classifier. In PGR-ELM, we need find a classifier that has a faster training speed and can guarantee the recommendation accuracy.
For the feature extraction, three features are extracted from three factors: POI popularity, group members’ distance to POI, members’ interest preferences combined affinity between group members. These three factors are crucial to suggest the most agreeable POIs for the group. For the first factor, popular POIs can attract more users to make check-in activities in LBSNs. When the PGR-ELM method recommends a popular POI, there is a higher probability that the most members in the group will be satisfied. For the second factor, every member prefers to choose the POI nearest to him. If the travel distance is much far from the POI for the majority of members, it is an unsatisfactory recommendation. For the third factor, there is no doubt that a user’s interest preference can determine his satisfaction for POI group recommendation. However, PGR-ELM method considers that the interest preference of each user can be composed with two parts: personality preference and affinity preference. Personality preference is the group member’s real personal interest preference for the POI. Affinity preference depends on her affinity with other group members and other members’ interest preferences.
For the classifier training, extreme learning machine (ELM) [18,19,20,21,22,23] is selected as the training classifier. Compared support vector machine (SVM) [24] and (BP) [25], ELM has a faster training speed, which guarantees the efficiency of PGR-ELM method. The extracted features in the feature extraction phase are input into ELM classifier. Once the training of ELM classifier is completed, the PGR-ELM method will return the recommendation result to the group when a group of users makes a POI group recommendation request.
Specifically, our contributions can be summarized as follows:
-
In this paper, a new POI group recommendation method with the ELM classifier in LBSNs is proposed, called PGR-ELM.
-
We extract features from multiple factors that can determine the results of POI group recommendation: POI popularity, group members’ distance to POI, members’ interest preferences combined affinity between group members, which guarantee the effectiveness of PGR-ELM method.
-
A series of experiments are conducted in four real LBSN datasets to demonstrate the effectiveness and efficiency of the PGR-ELM method. The experiment results show that the PGR-ELM method indeed improves the performance of POI group recommendation.
The remainder of this paper is organized as follows: The preliminary is introduced in Sect. 2. The PGR-ELM method is described in Sect. 3. The experiment is shown in Sect. 4. The related work is introduced in Sect. 5. Our work is concluded in Sect. 6.
2 Preliminaries
In this section, first, we give the theory of ELM. Next, we describe the definitions that we mentioned. Further, we show the framework of PGR-ELM method. Finally, we show the notations of our paper in Table 1.
2.1 Extreme learning machine
ELM is one of the leading trends for fast learning [26,27,28,29,30]. The parameters of hidden layers of ELM are randomly established and need not be tuned, thus the training of hidden nodes can be established before the inputs are acquired. Give a training data set \({\mathbf {D}}=\{({\mathbf {x}}_{j},{\mathbf {t}}_{j})|{\mathbf {x}}_{j} \in {\mathbf {R}}^{n}, {\mathbf {t}}_{j}\in {\mathbf {R}}^{m}, j=1,2,\ldots ,N\}\), where \({\mathbf {x}}_{j}=[x_{j1},x_{j2},\ldots ,x_{jn}]\) and \({\mathbf {t}}_j=[t_{j1},t_{j2},\ldots ,t_{jm}]^T\). Suppose that SLFNs with \({\widetilde{N}}\) hidden nodes can be represented by the following equation:
where \(g(\cdot )\) denotes the ith hidden node activation function, \({\mathbf {w}}_{i}\) is the input weight vector connecting the ith hidden layer, \(b_i\) is the bias weight of the ith hidden layer, and \(\beta _i\) is the output weight. The target of SLFNs is to minimize the error between target output and real output that \(\sum _{j=1}^{{\widetilde{N}}}\Vert {\mathbf {o}}_j-{\mathbf {t}}_j\Vert =0\). There are proper \(\beta _i\), \({\mathbf {w}}_i\) and \(b_i\) which can satisfy that
which can be rewritten in terms as
where
where H is the output matrix of hidden layer, T is the target matrix, \(\beta\) is the output weight. Therefore, the output weight \(\beta\) is given:
where \({\mathbf {H}}^\dotplus\) is the Moore-Penrose inverse of H.
2.2 Problem definition
Some important definitions will be introduced that we mentioned: location-based social network, group, POI group recommendation.

A group example in LBSNs

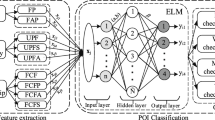
Framework of PGR-ELM method for POI group recommendation
Definition 1
(Location-Based Social Network) A LBSN is an extension of a social network which includes location dimension as well. It can be represented by a graph \(G=(U,E,P,C)\) in which U is the user set, E is the set social connections between two users, P is the POI set, and C is the set of check-ins made by users to POIs.
LBSNs generally do not show the groups’ check-in information. Therefore, “groups” and their check-in activities must be inferred from the user’s check-in information in LBSNs. Therefore, “groups” is defined:
Definition 2
(Group) A “group” is a set of users which have checked-in at a POI during a specific period of time in LBSNs.
Definition 2 is quite refined. Figure 1 gives an explanation of the “group” in LBSNs. In order to find the groups in LBSNs, we first sort all the users’ check-in activities with a specific POI and the check-in period of time, such as 30 mins or 1 hour. We need to search for these users who are connected to each other in social networks. For example, the users (black circles) in the red box of Fig. 1 can be regarded as a group. In Sect. 4, we will further give how the groups are generated in our experiments.
Definition 3
(POI Group Recommendation) Let \(P=\{p_1,p_2,\ldots ,p_n\}\) and \(U=\{u_1, u_2, \ldots , u_n\}\) denote the sets of all POIs and users, respectively. Given a group \({\widetilde{U}}\subseteq U\), POI group recommendation method will recommend a set of POIs \({\widetilde{P}}\subseteq P\) to \({\widetilde{U}}\).
2.3 The framework of PGR-ELM method
Our PGR-ELM method is shown in Fig. 2. In Fig. 2, group members first ask for a POI recommendation request. Then, PGR-ELM method will handle this request. PGR-ELM method regards POI group recommendation as a binary classification problem and handles the request by two major phases [31, 32]: feature extraction and training. PGR-ELM method first extracts the features by mining users’ historical check-in data in LBSN services, which contains two main perspectives: POI itself and group member personality. For POI itself, we extract PP feature related to POI popularity. For group member personality, we extract IPA feature related to member’s interest preferences combined affinity between group members. Besides, combined POI itself with group member personality, we extract MDP feature related to group members’ distance to POI. Then, PP, MDP, IPA features will be input to train the ELM classifier. By ELM training, POIs recommended to the group members will be returned.
3 PGR-ELM method
In this section, the process of the feature extraction is first described. Then, ELM training is introduced. Finally, PGR-ELM algorithm is shown.
3.1 Feature extraction
PP, MDP, IPA features are extracted from three aspects: POI popularity, group members’ distance to POI, members’ interest preferences combined affinity between group members. In the following, we show how to extract these features for POI group recommendation in PGR-ELM method.
3.1.1 POI popularity
The POI popularity is a crucial factor for suggesting the most agreeable POIs for a group. Popular POIs can attract more users to make check-in activities in LBSNs. When the PGR-ELM method recommends a popular POI, there is a higher probability that the most members in the group will be satisfied. Therefore, we extract PP feature by considering the POI popularity. The POI popularity is evaluated by the check-in rating of global users in the same category of POI. The highly check-in rating for POIs has a higher rank when it is considered for the POI group recommendation. Each POI is accompanied with one or multiple semantic labels, such as a POI is labeled as “restaurant” and “bar.” We regard the label class as the POI category. Therefore, a POI may belong to one or more label categories. Thus, POI popularity, as PP feature, is calculated as follows:
where p defines a POI, S defines the label set that the POI p belongs to, s defines an arbitrary category in label set S, \(|C_p|\) is all users’ total number of check-in records on the POI p, \(|C_{s}|\) is all users’ total number of check-in records with the label \(s\in S\) in our datasets.
3.1.2 Group members’ distance to POI
Unlike other recommendations, the location of POI is a crucial factor in POI group recommendation. Group members prefer to choose the POI nearest to him. If the travel distance is much far from the POI for the majority of members, it is an unsatisfactory recommendation. Therefore, we extract MDP feature by considering group members’ distance to POI. People’s movement from a POI to another POI has relevance with the distance. As the distance increases, the probability of people’s mobility will decreases [33]. The user’s every historical check-in record in LBSNs can reflect his movement behavior at a time. Therefore, for a group, we can sort group members’ check-in sequence set \(C_g=\{ c_{1}, c_{2},\ldots , c_{i}\}\) based on their check-in time. And the corresponding check-in location sequence set is \(L_g=\{ l_{1}, l_{2},\ldots , l_{i}\}\). Give a POI p, we regard the average distance from group member’s historical check-in location \(l_{i}\) to the POI p as his distance to POI. Thus, we define MDP feature as follows:
where \(\sum _{l_{i}\in L_g}||l_{i} p||\) is the total of Euclidean distance from every historical check-in location \(l_{i}\) to the POI p. \(|N_p|\) is the number of group members’ check-in location. \(\alpha \in [0,1)\) is a damping factor.
3.1.3 Interest preferences combined affinity
A user’s interest preference can determine his satisfaction for POI recommendation [34]. In fact, when making POI recommendation for group members, it may do not achieve the best recommendation effectiveness by only considering member’s personality interest preference. We think that group member will have an affinity preference for the POI depending on his affinity with other group members. For example, when with the boyfriend, a woman prefers to a cinema with a romantic movie which she does not prefer to watch with her parents. Therefore, the member’s interest preference can be influenced by other members. In this paper, each member’s interest preference is composed with two parts: personality preference and affinity preference. Personality preference is the group member’s real personality interest preference for a POI. Affinity preference depends on her affinity with other group members.
Personality preference-ppref(u,p) Given a group \({\widetilde{U}}\), this describes the personal interest preference of member \(u\in {\widetilde{U}}\) for POI \(p\in P\). Each member u’s interest preferences are obtained by extracting the textual keywords set \(W_u\) from his historical check-in records. Each POI p’s attributes are described with a textual keyword set \(W_p\). The overlapping number of \(W_u\) and \(W_p\) is regraded as the member u’s interest preference for p. ppref(u, p) can be defined as follows:
where \(|N_u^w|\) is the number of w in \(W_u\). \(\sum _{w\in W_p}|N_u^w|\) is the overlapping number between u and p.
Affinity preference-apref(u,p,\({\widetilde{U}})\) This describes that the user u may like the POI p if his close friends in the group \({\widetilde{U}}\) also like p. Affinity between group members can affect a member’s preference for the POI. More specifically, user u’s affinity preference \(apref(u,p,{\widetilde{U}})\) will be calculated by combining the affinity of user u with other members \({\widetilde{u}}\in {\widetilde{U}}\), denoted \(aff(u,{\widetilde{u}})\), with the personality preference of \({\widetilde{u}}\) for POI p, denoted \(ppref({\widetilde{u}}, p)\).
where \(aff(u,{\widetilde{u}})\) could be the clear friendship or users in the same age group or more complex, like users who like similar movies, have visited similar POIs. For simplicity, we assume that affinity between a user pair is symmetric, i.e., \(aff(u,{\widetilde{u}})=aff({\widetilde{u}},u)\), which is calculated by jaccard index. \(|u\cap {\widetilde{u}}|\) is the number of u and \({\widetilde{u}}\)’s common friends. \(|u\cup {\widetilde{u}}|\) is the total number of u and \({\widetilde{u}}\)’s friends.
Therefore, the user u’s whole interest preference pref(u, p) is a simple combination of ppref(u, p) and \(apref(u,p,{\widetilde{U}})\):
The preference of a POI p by a group \({\widetilde{U}}\), denoted \(gpref({\widetilde{U}},p)\) is an aggregation based on each group member \(u's\) preference for POI p, which will regard as IPA feature and be calculated as follow:
3.2 ELM training
In PGR-ELM method, when finishing the feature extraction, PP, MDP,IPA features will be trained by ELM classifier. The steps of ELM training can be divided into the following three steps:
-
(1)
Each group and a POI, as a \(<group, POI>\) pair, can form a training sample which is made up of \(({\mathbf {x}}_j, {\mathbf {t}}_j)\). \({\mathbf {x}}_j\) is a feature vector. There are three features, so \({\mathbf {x}}_j\) is no more than three elements. The three features do not have weighting scheme and are considered as equal. \({\mathbf {t}}_j\) is a result vector marked 0 or 1. 1 represents “recommendation” and 0 represents “non-recommendation.”
-
(2)
Train ELM classifier with a large number of the above training samples of \(<group, POI>\) pairs and obtain output weight \(\beta\). For specific training of ELM classifier, please refer to Sect. 2.1.
-
(3)
Using the output weight \(\beta\) obtained in step 2 and the test sample which is made up of \(({\mathbf {x}}_j, ?)\), we can output \({\mathbf {t}}_j\), \({\mathbf {t}}_j\) is a result vector marked 0 or 1. 1 represents “recommendation” and 0 represents “non-recommendation”. In this way, we finish the POI group recommendation.
3.3 Group recommendation algorithm

Next, algorithm 1 gives the detail of POI group recommendation. A LBSN \(<G, C>\), a group \({\widetilde{U}}\), and POI set P are the inputs. The final POI recommendation result set \({\widetilde{P}}\in P\) is the output. In the first phase, the PP, MDP, and IPA features are extracted related to three factors: POI popularity, group members’ distance to POI, members’ interest preferences combined affinity between group members (Lines 1–16). \({\mathbf {x}}\) is regarded as a feature vector, \({\mathbf {t}}\) is regarded as a class vector (Line 2). PP feature is extracted by calculated POI popularity in Eq. 7 (Lines 4–5). Then, the value of PP feature will be assigned to the first element \(\mathbf {x_{j1}}\) (Line 6). MDP feature is extracted by calculated group members’ distance to POI in Eq. 8 (Lines 7–8). Then, the value of MDP feature will be assigned to the second element \(\mathbf {x_{j2}}\) (Line 9). IPA feature is extracted by calculated group interest preference (Lines 10–15). First, for each user u in group \({\widetilde{U}}\), calculate its interest preference for POI p (Lines 11–14). Personality preference is calculated by Eq. 9 and affinity preference is calculated by Eq. 10 (Lines 12–13). The user’s final interest preference is the sum of personality preference and affinity preference (Line 14). The group preference is the average value of each member’s preference (Line 15). Then, the value of IPA feature will be assigned to the third element \(\mathbf {x_{j3}}\) (Line 15). In the second phase, these features with class vector \(\mathbf {t_j}\) are input to train ELM classifier (Line 18). When finishing training, any testing sample with a feature vector \(\mathbf {x_k}(k=1,\ldots ,K)\) is put into ELM classifier and will obtain recommendation result (Line 19). Finally, the recommendation result is returned (Line 20).
4 Experiments
In this section, we will make feature evaluation based on PP, MDP, and IPA features and demonstrate the performance of PGR-ELM method. First the dataset description and experiment setup are given. Then, the experiment result and analysis are shown.
4.1 Dataset description and experiment setup
Dataset description Foursquare, Brightkite, Gowalla and Twitter datasets which are popular LBSN platforms in the real world are used in our experiments. Each dataset contains 30,000 users’ check-in data, respectively. The numbers of 30,000 users’ check-in POIs in four datasets are 1760, 1541, 1511, 1468, respectively. And the numbers of 30,000 users’ check-in records in four datasets are 137,024, 151,325, 161,201, 134, 549. The data descriptions are given in Table 2. In our experiments, “groups” are generated in the following rules: We first group all the users at a specific POI during a period of time, say 1 hour. Then, only groups that are connected to each other in social networks are considered (refer Sect. 2.2). The time period of 1 hour is selected based on a reasonable assumption that a group members’ check-in activities at a particular POI within 30 minutes of each other. Because of a large time period and sparsity of users’ check-in, few groups can spread across two consecutive 1 hour time periods. By the above-mentioned group generated method, we randomly choose 1000 groups for each dataset. In fact, each group and a POI, as a \(<group, POI>\) pair, can form a training sample which is made up of \(({\mathbf {x}}_j, {\mathbf {t}}_j)\). \({\mathbf {x}}_j\) is a feature vector. \({\mathbf {t}}_j\) is a result vector marked 0 or 1. Then, based on the group members’ common check-in records, if the POI is a group members’ activity venue whose corresponding \({\mathbf {t}}_j\) vector element is 1, otherwise corresponding vector element is 0.
Experiment setup In this paper, the parameter \(\alpha\) is set 0.3. The group size is varying from 2 to 10, in which the default value is 4. The 80% samples are regarded as the training data and the others are regarded as testing data. For the testing samples, their class marks are removed. A series of experiments are conducted on the PC of Microsoft Windows win10, Intel Core i5 CPU, 3.20 GHz, and 16 GB memory in java JDK 1.8. Each experiment is taken for 10 times and the average result of 10 experiments will be as the final value.
The running time is employed to evaluate the efficiency of PGR-ELM. Precision, Recall, and F1-measure are used to evaluate the effectiveness of PGR-ELM, which are shown in the Eqs. (14), (15), and (16).
4.2 Experimental result and analysis
We will make our experiments in two aspects: (1) feature evaluation; (2) recommendation evaluation, in which the feature evaluation focuses on the extracted features, and then recommendation evaluation focuses on the performance of PGR-ELM method. Next, we will give the detailed introduction.
4.2.1 A. Feature evaluation
For POI group recommendation, PP, MDP, and IPA features are extracted from three factors: POI popularity, group members’ distance to POI, members’ interest preferences combined affinity between group members. We first make feature evaluation on the performance of POI group recommendation. Tables 3, 4, 5, 6 show the results. IPA feature has the best performance among these three extracted features. Therefore, we can say that the members’ interest preferences combined affinity between group members is more important than other two factors in recommending the most agreeable POIs for groups. We can theoretically analyze the reason. IPA feature is extracted from members’ interest preferences combined affinity between group members. This factor not only considers members’ interest preferences, but also considers affinity between group members. Certain external factors, such as POI popularity, group members’ distance to POI, have a few impacts on the performance of POI group recommendation. However, the main factor for the users’ final decision is still up to themselves. And IPA feature also takes the social relationship into account. Therefore, it is logical that IPA feature shows the best performance. We also see that MDP feature performs better than PP feature. Therefore, we can say that group members’ distance to POI is superior to POI popularity. Unlike other recommendations, the location of POI is a crucial factor in POI group recommendation. Group member prefers to choose the POI closed to them. Therefore, MDP feature performs better than PP feature. Furthermore, Tables 3, 4, 5, 6 also show the performance of combination two or three features, we can observe that the performance of POI group recommendation is promoted. And the combination of all three features performs the best. We can theoretically analyze the reason. When only one feature or two features are extracted, members’ preferences cannot be fully expressed. It may lead to a low accuracy of recommendation. However, when three features are extracted simultaneously, which can fully utilize the data resources of LBSNs. PP, MDP, and IPA features consider the multiple factors that guarantee the effectiveness of POI group recommendation.
4.2.2 B. Recommendation evaluation
Further, PGR-ELM will be compared with other four POI group recommendation methods. The first two methods are based on PGR-ELM method. Three extracted features with BP are called PGR-BP. Three extracted features with SVM are called PGR-SVM. The number of hidden layers in PGR-ELM and PGR-BP are set as 100. PGR-SVM selects a sigmoidal kernel function and the parameter C is set as 100. The PGR-ELM, PGR-SVM, and PGR-BP classifiers with the top 80% check-in records are as training data, and the remaining 20% check-in records are as testing data. The remaining two methods are among state-of-the-art POI group recommendation techniques, including GRE [14], and CMFC [15].
Tables 7, 8, 9, 10 show the effectiveness and efficiency of these five methods in four LBSN datasets. The effectiveness and efficiency of PGR-ELM method are the highest. The effectiveness and efficiency of GRE and CMFC are much worse than PGR-ELM. PGR-SVM and PGR-BP have the closest effectiveness to PGR-ELM. However, there is a big efficiency gap with PGR-ELM. GRE method only considered the members’ preference distribution. The CMFC method only considered the distance and intra-group influence. PGR-BP and PGR-SVM methods use BP and SVM classifiers. PGR-ELM method can fully express members’ preferences by extracted the three completely irrelevant features and has a fast training speed because of ELM classifier. As a result, the PGR-ELM is more fit than other five methods in terms of the POI group recommendation.

Running time in Foursquare dataset

Running time in Brightkite dataset

Precision in Foursquare dataset

Recall in Foursquare dataset

F1-measure in Foursquare dataset

Precision in Brightkite dataset

Recall in Brightkite dataset

F1-measure in Brightkite dataset
In Figs. 3, 4, we show the efficiency of these five methods with an increasing group size over the two datasets: Foursquare and Brightkite. In Figs. 5, 6, 7, 8, 9, 10, we show the effectiveness of these five methods with an increasing group size over the two datasets: Foursquare and Brightkite. The effectiveness and efficiency of PGR-ELM is still the highest although group size is increasing. It is proved that PGR-ELM method has a good stability. However, we can also find that the performance of these five methods decreases with the increase in group size. To be specific, Precision, Recall, and F1-measure of these five methods decrease with the increase in group size, and the running time of these five methods increases with the increase in group size. We can analyze the reasons. With the increase in group size, the interest preferences of group members have a greater difference and affinity between group members has generally declined. Therefore, when the number of group members is large, although there is a very good recommendation method, it may perform unsatisfactory recommendation results to group members. To some extent, it will inevitably lead to a decline in the effectiveness of recommendation. Furthermore, with the increase in group size, the recommendation methods will weigh the preferences of more users for feature extraction. Thus the running time of recommendation methods will definitely increase.
5 Related work
POI recommendation Recommendation is one of the hottest research topics in LBSNs [4, 5, 7, 35]. In [4], the concept of POI recommendation was first proposed in LBSNs. With the development of POI recommendation, the researchers have also focused on geographical and social influences to improve the accuracy of POI recommendation. In [5], POI recommendation was researched by considering geographical influence. In [6], the probabilistic matrix factorization with social factor was used. In [7], POI features were extracted from geographical and social aspects to handle POI recommendation. However, these existing studies focused on recommendations for individual users. As people have become more and more connected, there are certain scenarios that need to be recommended to groups of users rather than individual user.
Group recommendation Group recommendation is needed when a group of users makes an activity together. Group recommendation methods usually used the aggregation functions to model the preferences of group members [36, 37]. In [36], Jameson et al. aggregated the preferences of all group members for items and then suggested to the items with the highest preference values. With the development of group recommendation, the social factors between members are also considered to improve the performance of group recommendation [38]. When the items that were recommended to groups are locations, the spatial preferences of the group were considered. In [39], the distances from locations to the group members were used as a factor for group recommendation.
POI group recommendation Many group recommendation systems for POIs such as touristic attractions, restaurants and hotels have been proposed in the literatures. In [9], a restaurant recommendation system that considered the preferences of group users in mobile environment is proposed. In aggregating users’ preferences, the different influence weights of the users were considered. In [10], WhereToGo is a travel recommendation system that provided the personalized tourist attractions for groups. However, we can observe that these existing studies just aggregated members’ preference into single values as group preferences and recommended a particular sort of POI to a group of users.
6 Conclusions and future works
In this paper, we propose a new method to solve the POI group recommendation problem in LBSNs, called PGR-ELM. First, we extract features from multiple factors that can determine recommendation results: POI popularity, group members’ distance to POI, members’ interest preferences combined affinity between group members. Next, these extracted features are input into ELM classifier. Finally, by the experiments, we proved that the effectiveness and efficiency of the PGR-ELM method superior other methods.
In the future, we can focus on some further studies on POI group recommendation. First, we will put PGR-ELM method into a larger LBSN datasets. Next, we will make a better real-time POI group recommendation method. Finally, we will work on the user’s studies to estimate the performance of our group recommendation method.
References
Bao J, Zheng Y, Wilkie D, Mokbel M (2015) Recommendations in location-based social networks: a survey. GeoInformatica 19(3):525–565
Sohail A, Taniar D, Züfle A, Jeong-Ho P (2017) Query processing in location-based social networks. In: Proceedings of the 26th international conference on world wide web companion, Perth, Australia, April 3–7, 2017, pp 1379–1381
Ference G, Ye M, Lee WC (2013) Location recommendation for out-of-town users in location-based social networks. In: 22nd ACM international conference on information and knowledge management, CIKM’13, San Francisco, CA, USA, October 27–November 1, 2013, pp 721–726
Ye M, Yin P, Lee WC (2010) Location recommendation for location-based social networks. In: 18th ACM SIGSPATIAL international symposium on advances in geographic information systems, ACM-GIS 2010, November 3–5, 2010, San Jose, CA, USA, Proceedings, pp 458–461
Ye M, Yin P, Lee W-C, Lee D-L (2011) Exploiting geographical influence for collaborative point-of-interest recommendation. In: Proceeding of the 34th international ACM SIGIR conference on research and development in information retrieval, SIGIR 2011, Beijing, China, July 25–29, 2011, pp. 325–334
Cheng C, Yang H, King I, Lyu MR. (2012) Fused matrix factorization with geographical and social influence in location-based social networks. In Proceedings of the twenty-sixth AAAI conference on artificial intelligence, July 22–26 (2012) Toronto. Ontario, Canada
Zhao X, Ma Z, Zhang Z (2018) A novel recommendation system in location-based social networks using distributed ELM. Memetic Comput 10(3):321–331
Gao H, Tang J, Hu X, Liu H (2013) Exploring temporal effects for location recommendation on location-based social networks. In: Seventh ACM conference on recommender systems, RecSys ’13, Hong Kong, China, October 12–16, 2013, pp 93–100
Park M-H, Park H-S, Cho S-B (2008) Restaurant recommendation for group of people in mobile environments using probabilistic multi-criteria decision making. In: Proceedings Computer-human interaction, 8th Asia-Pacific Conference, APCHI 2008, Seoul, Korea, July 6–9, 2008, pp 114–122
Guo L, Shao J, Tan K-L, Yang Y (2014) Wheretogo: personalized travel recommendation for individuals and groups. In: IEEE 15th international conference on mobile data management, MDM 2014, Brisbane, Australia, July 14–18, 2014—vol 1, pp 49–58
Bok K, Lim J, Yang H, Yoo J (2016) Social group recommendation based on dynamic profiles and collaborative filtering. Neurocomputing 209:3–13
Guo C, Li B, Tian X (2016) Flickr group recommendation using rich social media information. Neurocomputing 204:8–16
Zha Z-J, Tian Q, Cai J, Wang Z (2013) Interactive social group recommendation for flickr photos. Neurocomputing 105:30–37
Guo Z, Tang C, Tang H, Yunqing F, Niu W (2018) A novel group recommendation mechanism from the perspective of preference distribution. IEEE Access 6:5865–5878
Zhu Q, Wang S, Cheng B, Sun Q, Yang F, Chang RN (2018) Context-aware group recommendation for point-of-interests. IEEE Access 6:12129–12144
Ayala-Gómez F, Daróczy B, Mathioudakis M, Benczúr AA, Gionis A (2017) Where could we go? Recommendations for groups in location-based social networks. In: Proceedings of the 2017 ACM on web science conference, WebSci 2017, Troy, NY, USA, June 25–28, 2017, pp 93–102
Yanxia X, Chen W, Jia-Jie X, Li Z, Liu G, Zhao L (2018) Discovering functional organized point of interest groups for spatial keyword recommendation. J Comput Sci Technol 33(4):697–710
Huang G-B, Siew C-K (2004) Extreme learning machine: Rbf network case. In 2004—ICARCV 2004 8th control, automation, robotics and vision conference, vol 2. IEEE, pp 1029–1036
Huang G-B, Siew C-K (2005) Extreme learning machine with randomly assigned RBF kernels. Int J Inf Technol 11(1):16–24
Huang G-B, Zhu Q-Y, Siew C-K (2006) Extreme learning machine: theory and applications. Neurocomputing 70(1):489–501
Chen H, Zhang Q, Luo J, Yueting X, Zhang X (2020) An enhanced bacterial foraging optimization and its application for training kernel extreme learning machine. Appl Soft Comput 86:105884
Yang Y, Hou M, Sun H, Zhang T, Weng F, Luo J (2020) Neural network algorithm based on legendre improved extreme learning machine for solving elliptic partial differential equations. Soft Comput 24(2):1083–1096
Chong L-Y, Ong TS, Teoh Andrew BJ (2019) Feature fusions for 2.5d face recognition in random maxout extreme learning machine. Appl Soft Comput 75:358–372
Zhang X, Ding S, Xue Y (2017) An improved multiple birth support vector machine for pattern classification. Neurocomputing 225:119–128
Chen Y, Chan AB (2015) Enhanced figure-ground classification with background prior propagation. IEEE Trans Image Process 24(3):873–885
Das SR, Mishra D, Rout M (2019) A hybridized ELM using self-adaptive multi-population-based jaya algorithm for currency exchange prediction: an empirical assessment. Neural Comput Appl 31(11):7071–7094
Yang Y, Zhang H, Yuan D, Sun D, Li G, Ranjan R, Sun M (2019) Hierarchical extreme learning machine based image denoising network for visual internet of things. Appl Soft Comput 74:747–759
Hassan S, Khanesar MA, Jaafar J, Khosravi A (2018) Optimal parameters of an elm-based interval type 2 fuzzy logic system: a hybrid learning algorithm. Neural Comput Appl 29(4):1001–1014
Tang Y, Chunning B, Liu M, Zhang L, Lian Q (2018) Application of elm-hammerstein model to the identification of solid oxide fuel cells. Neural Comput Appl 29(2):401–411
Zhang Y, Jia W, Zhou C, Cai Z (2017) Instance cloned extreme learning machine. Pattern Recognit 68:52–65
Jia W, Zhu X, Zhang C, Philip SY (2014) Bag constrained structure pattern mining for multi-graph classification. IEEE Trans Knowl Data Eng 26(10):2382–2396
Jia W, Pan S, Zhu X, Cai Z (2015) Boosting for multi-graph classification. IEEE Trans Cybern 45(3):430–443
Gonzalez MC, Hidalgo CA, Barabasi AL (2008) Understanding individual human mobility patterns. Nature 453(7196):779–782
Ou W (2014) Extracting user interests from graph connections for machine learning in location-based social networks. In: Proceedings of the MLSDA 2014 2nd workshop on machine learning for sensory data analysis. ACM, pp 41
Cui L, Wu J, Pi D, Zhang P, Kennedy P (2018) Dual implicit mining-based latent friend recommendation. In: IEEE transactions on systems, man, and cybernetics: systems, pp 1–16
Jameson A, Smyth B (2007) Recommendation to groups. In: The adaptive web, methods and strategies of web personalization, pp 596–627
Ardissono L, Goy A, Petrone G, Segnan M, Torasso P (2001) Tailoring the recommendation of tourist information to heterogeneous user groups, pp 280–295
Li C-T, Huang M-Y, Yan R (2018) Team formation with influence maximization for influential event organization on social networks. World Wide Web 21(4):939–959
Ji K, Chen Z, Sun R, Ma K, Yuan Z, Guandong X (2018) GIST: a generative model with individual and subgroup-based topics for group recommendation. Expert Syst Appl 94:81–93
Acknowledgements
This research is partially supported by the National Natural Science Foundation of China under Grant Nos. 61672145, 61702086, China Postdoctoral Science Foundation under Grant No. 2018M631806, Natural Science Foundation of Liaoning Province of China under Grant No. 20180550260, Scientific Research Foundation of Liaoning Province under Grant Nos. L2019 001, L2019003, Doctoral Business and Innavation Launching Plan of Yingkou City under Grant No. QB-2019-16.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Human and animal rights
This article does not contain any studies involving human participants and/or animals by any of the authors.
Informed consent
Informed consent was obtained from all individual participants.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Zhao, X., Zhang, Z., Bi, X. et al. A new point-of-interest group recommendation method in location-based social networks. Neural Comput & Applic 35, 12945–12956 (2023). https://doi.org/10.1007/s00521-020-04979-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-020-04979-4