
Abstract
Cloud computing has become a highly required platform in fields of information technology due to providing inexpensive services with high availability and scalability. The dynamic and diverse nature of the cloud computing systems makes scheduling of workflow tasks a pivotal issue. This paper proposes an algorithm to schedule applications’ tasks to virtual machines (VMs) of cloud computing systems. The algorithm has three phases: level sorting, task-prioritizing and virtual machine selection. The three-phase process successfully assigns the virtual machine for each task without making any difficulties for evaluating the algorithm performance; extensive simulation experiments are performed. The introduced ICTS algorithm analyzes each incoming task which is sorted and ranked while assigning the virtual machine to the particular task which improves the overall scheduling process because it processes the job according to the importance. Then the efficiency of the system is evaluated using experimental results that indicate the improved cost task scheduling (ICTS) algorithm provides an improvement in schedule length as well as significant monetary cost saving.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Cloud computing is one of the advanced technologies, and it is increasingly adopted by large companies to host the platforms of different services. It is one of the latest technologies, which enjoys great popularity nowadays among researchers in the academic fields and industry areas [1]. It is considered as an extension of computing systems such as parallel, distributed and grid computing, and it is considered as one of them. With the help of the Internet, it provides fast and safe data storage and computing power. Cloud computing system can be offered through three main service models [2] such as infrastructure as a service (IaaS) which provides services such as storage, processing and network resources to customers in exchange of money. Amazon Elastic Compute Cloud (EC2) is a famous example of IaaS. In platform as a service (PaaS) customers can run their applications on the software and hardware platforms of the cloud. Google App Engine and Microsoft Azure are the most famous examples of PaaS clouds. Software as a service (SaaS) provides remote access for cloud software applications through the Internet to customers. Customers have no need to buy very costly software applications. Salesforce.com represents a typical example of SaaS [3]. The cloud providers establish their services according to pay and usage concept also ensure the services according to the user demands. Users can allocate the computing resources [4] according their requirements, and payment amount is based on the actual consumption of resources [5].
In general, a workflow in cloud computing is represented by directed acyclic graph (DAG). In DAGs, [6] nodes act as tasks to be executed and edges act as precedence constraints between tasks or the communication edges between tasks. In DAGs, independent or unrelated tasks can be assigned to different virtual machines of the cloud to be executed simultaneously. On the other hand, it is better for the dependent tasks to be assigned to the same virtual machine to omit or reduce the communication time between them. Simply, scheduling refers to assigning tasks of a DAG to be executed on a number of resources. Scheduling of workflows’ tasks to virtual machines of a cloud represents a fundamental issue in improving the performance of the system. Scheduling [7] can be static, which occurs prior to execution, or dynamic, which occurs during execution. In the most general case, the problem of scheduling applications represented in the form of DAGs to obtain optimal makespan or schedule length is NP-Complete. This means that to reach the optimal solution a brute-force search should be used. Most early scheduling algorithms focused on minimizing time of executing applications without considering monetary costs of using the cloud [8].
For overcoming the issue, in this study has presented and evaluated a new scheduling algorithm, which is known as improved cost task scheduling (ICTS) algorithm. It has three phases, including level sorting, task-prioritizing and virtual machine selection. The balancing between the schedule length and the mandatory cost of an application represents the main target of the algorithm developed by this study. According to the comparative study using randomly generated large graphs, ICTS provides an improvement in schedule length as well as a significant monetary cost saving. The rest of this publication is organized as follows. Section 2 briefly explains related work for scheduling in cloud computing environments. The problem is defined and the proposed algorithm is introduced in Sect. 3. Section 4 presents performance evaluation and results discussion. Finally, the paper is concluded in Sect. 5.
2 Related work
This section discusses the various authors ideas about the scheduling process in cloud computing. Due to the high complexity of the scheduling problem, it has been addressed by many researchers. The main goal of most of the algorithms is to achieve a predefined objective function that are applicable on overall workflow application when scheduling the multiple sequences tasks of a workflow application on available VMs [9]. Dubeya et al. [10] introducing the Heterogeneous Earliest Finish Time (or HEFT) algorithm assigned a priority value to each task of applications represented by DAGs in accordance with the upward rank value of task in the workflow. After assigning the priority, DAG is mapped with the highest priority task to the VM that reduces the earliest finish time (EFT). The HEFT algorithm has a better performance for both makespan (completion time) and time complexity. Critical Path on Processor (CPOP) provided scheduling of the critical tasks onto the resources that had minimized the execution time of them. Moreover, it used the summation of upward and downward rank values to determine the priorities of the tasks.
Li et al. [11] proposed the Cost-Conscious Scheduling Heuristic (CCSH). The CCSH algorithm was a form of extension of the HEFT scheduling algorithm. It scheduled the tasks of large graph computing with consideration of cost and schedule length. Nasr et al. [12] proposed the algorithm, Highest Communicated Path of Task (HCPT), provided scheduling of tasks on the heterogeneous distributed computing systems and had been famous as one of the list-scheduling techniques too. It contains three phases, which mainly include level sorting, task-prioritizing and processor selection.
Cao et al. [13] developed the Optimal Scheduling Heuristic (or POSH) and it assigns tasks to the VMs with the lowest monetary cost based on the Pareto dominance technique. The other strategy reduces monetary cost of non-critical tasks and this heuristic is called Slack Time Scheduling Heuristic (or STSH). The minimization of makespan and the monetary cost are the main objectives of this algorithm. This algorithm is called hybrid algorithm because it uses POSH and then STSH strategies. In Guo-Ning et al. [14], a scheduling algorithm is proposed based on the technique of genetic and simulated annealing. This algorithm concentrates on the user requirements such as time and cost. The algorithm performs selection of resources, and then annealing step is implemented.
In Geng et al. [15] scheduling algorithm is proposed that depends on duplicating and grouping of tasks and it has 4 steps. The first step converts DAG into in-tree, and grouping of tasks is performed during the second step. In the third step, groups of tasks are merged and machines that execute tasks are selected for allocating the resources. Alkhanaka et al. [16] analyzed the problem of cost optimization in SWFS (Scientific Workflow Scheduling) by a huge surveying in cloud and grid computing for existing SWFS approaches. The method examines each and every task according to the importance which eliminates irrelevant time consumption process. Then the efficiency of the system is evaluated in terms of using experimental results. In Zhou et al. [17], Improved Predict Earliest Finish Time algorithm is proposed that is worked based on a list static task scheduling for heterogeneous computing environment. This algorithm reduces makespan without increasing the time complexity. Reviewing literatures shows that most of the scheduling prior works focus on minimizing makespan and there is a very little work that worries about monetary charges of using the cloud resources. So, there is a need for scheduling mechanisms that consider both time and monetary costs for the cloud computing environments.
3 Improved cost task scheduling (ICTS) algorithm-based scheduling in cloud
In cloud computing, scheduling can be categorized as task-based and workflow-based. In task-based scheduling, tasks to be executed are independent without any identified relationships between them. On the other hand, task dependency plays a major role in the workflow-based scheduling [18], which is applied in this work. Figure 1 depicts the employed cloud system model used in this paper.

Employed cloud system model
Cloud users submit their workflow jobs through cloud interfaces to be executed by the cloud. These jobs are complicated and massive, so they have been partitioned into smaller and simple tasks with defined dependence. Partitioning unit has the responsibility of partitioning jobs into directed acyclic graphs (DAGs). The DAG is then passed to the Scheduler [19] which assigns each task in the graph to the suitable virtual machine. A description of DAG symbols used in this scheduling process is listed in Table 1.
Generally, a workflow is commonly represented by a DAG G = (V, E), where V is the set of \(v\) tasks and E is the set of e edges acting as precedence constraints or communication cost between tasks [20]. The weight of node \(v_{i} \in V\) is the amount of task computation time, which varies according to the computation speed of the virtual machine assigned to execute the task. The weight of edge \(\left( {i,j} \right) \in E\) is the amount of communication time between task \(v_{i}\) and task \(v_{j}\). The communication between two tasks is needed to transfer data from on task to the other task. A task that has no parents (predecessors) is called the entry task (\(v_{entry}\)), and an exit task (\(v_{exit}\)) is a task without children (successors). While there are multiple entry nodes or exit nodes in the DAG, these nodes are connected to a new node, which is assigned as a total entry or exit node, and the weight value of each edge connected to the new entry node or the new exit node is equal 0. The DAG should not contain any cyclic dependencies. A task can only be executed if all parents’ execution has been completed [21].
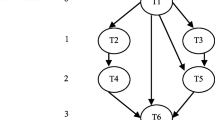
An example of workflow represented by a DAG is presented in Fig. 2. This DAG consists of 10 nodes, where node v0 is the first task to be executed, nodes v1–v8 can only start their execution after task v0 finishes execution and sends the resulting data to them, but nodes v2–v4 cannot start their execution until v1 finishes its execution and sends the required data to them. Node v9 is the last task, and it can only start execution after completion of all other tasks. The communication cost between two tasks is neglected when they are scheduled to be executed by same virtual machine [22].

An example of DAG for workflow application
Assuming the cloud has a set M of m heterogeneous virtual machines. Since each task can be carried out by multiple different virtual machines, the time of executing task \(v_{i}\) on a virtual machine \(m_{j}\) is denoted as \(t\left( {v_{i} ,m_{j} } \right)\). The model in this paper assumes that each task is an indivisible part of work and is non-preemptive [23]. After scheduling all tasks of a DAG to the virtual machines of the cloud, the schedule length (makespan) is equal to the actual finish time of exit task (\(v_{exit}\)). Let \(TES\left( {v_{i} ,m_{j} } \right),TEF\left( {v_{i} ,m_{j} } \right)\), and \(T_{LF} \left( {v_{i} ,m_{j} } \right)\) denote, respectively, the earliest allowable start time, the earliest allowable finish time, and the latest finish time of task \(v_{i}\) on a virtual machine \(m_{j}\).\(TES\left( {v_{i} ,m_{j} } \right)\) can be computed as:
where \(t\left( {m_{j} } \right)\) is the time at which virtual machine \(m_{j}\) is ready to execute task \(v_{i}\), \(m_{j}\) is the virtual machine allocated for task \(v_{i}\), and \(T_{AF} \left( {v_{p} } \right)\) is the actual finish time of task \(v_{p}\) and \(ct_{{v_{p} ,v_{i} }}\) is the communication time between task \(v_{p}\) and task \(v_{i}\). The value of \(ct_{{v_{p} ,v_{i} }}\) equals zero if the predecessor task \(v_{p}\) is assigned to the virtual machine \(m_{j}\). The \(pred\left( {v_{i} } \right)\) represents the set of parents or immediate predecessor tasks of task \(v_{i}\). The value of \(TES\left( {v_{i} ,m_{j} } \right)\) is computed as follows:
The value of \(TES\left( {v_{i} ,m_{j} } \right)\) equals the execution time of task \(v_{i}\) on a virtual machine \(m_{j}\) plus the earliest start time of task \(v_{i}\) on a virtual machine \(m_{j}\). The value of \(T_{LF} \left( {v_{i} ,m_{j} } \right)\) is computed as follows:
where \(TAS\left( {v_{s} } \right)\) is the actual start time of task \(v_{s}\),\(succ\left( {v_{i} } \right)\) represents the set of direct children or successors of task \(v_{i}\) and \(ct_{{v_{i} ,v_{s} }}\) is the communication cost between task \(v_{i}\) and task \(v_{s}\). The makespan or schedule length [24] is defined as the execution time of DAG, and it is equal the actual finish time of \(v_{\text{exit}}\). It is defined as follows:
In cloud, multiple virtual machines can execute each task. Then, the execution time of \(v_{i}\) on virtual machine \(m_{j}\) is computed as follows:
where \(W_{{v_{i} }}\) is the work load of task vi and \(cc_{{m_{j} }}\) is the number of CPU cycles allowed for \(m_{j}\). If there are n virtual machines that can execute task \(v_{i}\), the average execution time of \(v_{i}\) is as follows:
3.1 Pricing model
In clouds, there are different pricing models. Customers can be charged according to the number of virtual machines used and their types, as in Amazon EC2, or they can be charged according to the number of required CPU cycles, as in Google App Engine. The later model is considered in this paper. Therefore, a higher price is associated with a higher VM capability and a lower VM capability is associated with a lower price.
The monetary cost required to execute task \(v_{i}\) on virtual machine [25] \(m_{j }\) is denoted as \(mc\left( {v_{i} ,m_{j} } \right)\) and can be calculated as follows:
where r is a random variable applied to produce various capacity and pricing combinations of a virtual machine, \(t\left( {v_{i} ,m_{j} } \right)\) is the execution time of task \(v_{i}\) when executed on virtual machine \(m_{j }\), \(Pr_{{m_{slow} }}\) represents the price charged to \(m_{slow}\), \(cu_{{m_{j} }}\) denote the CPU cycle for virtual machine \(m_{j }\), and \(cu_{{m_{slow} }}\) represents the CPU cycle of the slowest virtual machine \(m_{slow}\).
3.2 Contribution of the paper
Customers submitted jobs are needed to be executed on the cloud. In general, the work of customers is represented in the form of DAG of tasks. Cloud’s scheduler should schedule tasks of the DAG to the most suitable virtual machines that can execute them within the time and budget needed by customers. In the cloud, however, there are virtual machines that can satisfy the time requirements of customers; they have a high monetary cost.
The major contribution of this work is to develop an algorithm that schedules tasks of customers to the VM of the cloud with the objective of minimizing both time cost and monetary costs. This objective represents a major challenge because of the competition between the two objectives.
3.3 ICTS algorithm
This section elaborates the proposed algorithm that schedules tasks in the form of DAG to the virtual machines of the cloud. The proposed algorithm is called improved cost task scheduling (ICTS) algorithm, and the main steps of it are shown in Table 2. The main objective of the algorithm is to schedule tasks to virtual machines with minimizing both time and monetary costs.
The algorithm contains three phases: level sorting phase, task ranking phase and VM selection phase. In the level sorting phase, the DAG is traversed in a manner from top to bottom to collect independent tasks in groups. In the second phase, the algorithm ranks the tasks of each level according to the rank of each task, which can be computed as follows:
where \(MCP\left( {v_{i} } \right)\) is the mean of communication time of parents and it is defined as:
where \(ct_{{v_{j} ,v_{i} }}\) is the communication time between parent task \(v_{j}\) and task \(v_{i}\) and p represents the number of parents. The algorithm starts from \(v_{exit}\) where \(Rank\left( {v_{exit} } \right)\) is defined as:
Finally, in the VM selection phase, Makespan-on-Cost Ratio (\(MKCR\left( {v_{i} ,m_{j} } \right)\) for task \(v_{i}\) on virtual machine \(m_{j}\) is calculated as follows:
where \(\beta\) is a cost-valuable factor that describes the preference of the user for both execution time and monetary cost,\(Min\_Cost\left( {v_{i} } \right)\) and \(Cost\left( {v_{i} ,m_{j} } \right)\) denote the minimum monetary cost value of task \(v_{i}\) executed on different m virtual machines set, and the cost of task \(v_{i}\) on virtual machine \(m_{j}\), respectively. \(Min\_T_{EF} \left( {v_{i} } \right)\) and \(T_{EF} \left( {v_{i} ,m_{j} } \right)\) denote the minimum \(T_{EF}\) value of task \(v_{i}\) executed on a different m virtual machines set and the \(T_{EF}\) value of task \(v_{i}\) on the virtual machine \(m_{j}\), respectively.
Each task is submitted to the VM of the largest value of \(MKCR\left( {v_{i} ,m_{j} } \right)\) by the insertion-based scheduling. This policy tries to benefit from inactive time slots between scheduled tasks in each virtual machine in order to minimize completion time of a DAG. The time required to assign each task to execute on a specific virtual machine according to specific priority is called time complexity. The time complexity of ICTS likes that of HEFT [26] and POSH [8], which is equal to \(O\left( {em} \right)\) for \(e\) edges and \(m\) virtual machines. The time complexity will be \(O\left( {v^{2} \times m} \right)\) if the number of edges is directly proportional to \(v^{2}\) where \(v\) is the number of tasks. Figure 3 shows the schedules obtained by scheduling the sample DAG by using both the hybrid algorithm [27] and ICTS algorithm, respectively. Note that the simplicity, we will denote the POSH algorithm followed by the STSH algorithm as Hybrid algorithm. A sample of execution time of tasks on 3 VMs and a sample of monetary cost are displayed in Tables 2 and 3, respectively. After the scheduling of tasks of the given DAG, Fig. 3a shows that the schedule length of the hybrid algorithm is 1000.94-time units, which costs $822. On the other hand, Fig. 3b shows that the schedule length of the ICTS algorithm is 874.19-time units, which costs $793. In this case, the overall execution time of our algorithm is decreased by about 12.66% and our algorithm provides a 3.53% monetary cost saving when compared to the Hybrid algorithm.

Schedules of DAG. a Hybrid algorithm schedule. b Proposed ICTS algorithm schedule
The above Table 3 indicates that the execution time of different task in three virtual machines. According to the above table, it clearly shows that ICTS method consumes minimum execution time for different virtual machine in different task. Even though ICTS method consumes minimum time, it should consume minimum cost that is shown in Table 4.
The above Table 4 indicates that the cost of different task in three virtual machines. According to the above table, it clearly shows that ICTS method consumes minimum Monetary cost for different virtual machine in different task. Then the evaluation of the system is examined using the following performance evaluation.
4 Performance evaluation
The efficiency of the ICTS algorithm is evaluated using the following simulation setup which is shown in Table 5.
Based on the above performance simulation setup, the ICTS scheduling system has been implemented and excellence of the system is evaluated using following performance metrics.
4.1 Performance metrics
4.1.1 Schedule length ratio and monetary cost ratio
The efficiency of the system is evaluated using makespan and monetary costs metrics that are normalized and denoted as schedule length ratio (or SLR) and monetary cost ratio (or MCR), as:
The denominator in Eq. (12) represents the summation of the minimum execution times of tasks located on the critical path (CP). The denominator in Eq. (13) represents the summation of the minimum monetary costs of tasks located on the critical path (CP).
4.1.2 Measured cost-valuable factor(β)
To measure both of the SLR and MCR, we use different values of cost-valuable factor (β). Figure 4 shows the SLR and MCR values of different randomly generated DAGs and for different values of cost-valuable factor (β). In the figure, x-axis represents the values of cost-valuable factor and y-axis represents the values that both SLR and MCR could take. The number of tasks of the randomly generated DAGs ranges from 80 to 400 tasks. It is shown from Fig. 4 that the cost-valuable factor (β) is directly proportional to the MCR and inversely proportional to the SLR. For small values of cost-valuable factor (β) such as 0.1, 0.2 and 0.3, the rate of change for both MCR and SLR is slightly smaller than the rate of change of both for \(\beta > 0.3\). Results reported for different values of cost-valuable factor show that using \(\beta < 0.4\) has much better effect in both the schedule length and the monetary cost. Also, values of \(\beta > 0.4\) show slow change rate for SLR but high rate of change for MCR. Thus, the best values of \(\beta\) chosen to test our ICTS algorithm are 0.1, 0.2 and 0.3.

Comparing different (β) for randomly generated DAGs. a 80 tasks. b 100 tasks. c 200 tasks. d 400 tasks
4.2 Experimental result
In this section, we compare the performance of the ICTS algorithm to the performance of the Hybrid algorithm. Both of normalized schedule length ratio and normalized monetary cost ratio are used as the comparison criteria. Different DAG sizes are applied in our experiments to realize results with the same VM configuration. Figure 4 depicts the SLR comparison of the ICTS algorithm and the hybrid algorithm for different number of tasks and with different CCR values. Generally, the SLR for the two algorithms increases with increasing both number of tasks and value of CCR. The figure shows that ICTS algorithm provides better SLR than hybrid algorithm for various DAG sizes.
Based on the above performance metrics, the SLR and MCR value is shown in Table 6.
According to Table 5 value the method ensures the effective SLR and MCR value of different tasks. Then the graphical presentation is shown in following Figs. 5 and 6 that shows the ICTS algorithm provides better SLR and MCR than hybrid algorithm for various DAG sizes. This is due to that ICTS algorithm considers both the communication times between the task’s parents and the task and the communication times between the task and its successors when calculating its rank, as shown in Eq. (8). Thus, the most complicated tasks in the DAG will be at the top of the ranked list and then it will be computed first. Otherwise, the hybrid algorithm considers only the communication times between the task and its successors when calculating the rank of each task.

SLR values for different values of CCR. a CCR = 1.0. b CCR = 3.0. c CCR = 5.0. d CCR = 10.0

MCR values for different values of CCR. a CCR = 1.0. b CCR = 3.0. c CCR = 5.0. d CCR = 10.0
Also, in Eq. (11) used to select the VM, the ICTS considers both the \(Min\_cost\left( {v_{i} } \right)\), which denote the minimum monetary cost value of task \(v_{i}\) executed on different m virtual machines set, and \(Min\_T_{EF} \left( {v_{i} } \right)\), which denote the minimum \(T_{EF}\) value of task \(v_{i}\) executed on a different m virtual machines set.
Figure 6 depicts the MCR comparison of the ICTS algorithm and the hybrid algorithm for different number of tasks and with different CCR values. Generally, the MCR for the two algorithms increases as the number of tasks increases and as the value of the CCR increases. The figure shows that ICTS algorithm provides better MCR than hybrid algorithm for different DAG sizes. On the other hand, the hybrid algorithm depends on ratios of time and cost and these ratios consider minimum and maximum monetary cost and execution time of any task scheduling plan.
5 Conclusion
Thus, the paper analyze the improved cost task scheduling (ICTS) algorithm, for scheduling tasks in cloud computing environment is presented and evaluated. The algorithm considers minimizing both the time and monetary cost when using cloud resources. The algorithm contains three phases: level sorting, task-prioritizing and VM selection. From experimental results, it is concluded that the ICTS algorithm provides performance superiority over the Hybrid algorithm. The improvement percentage of both time cost (SLR) and monetary cost (MCR) for the proposed algorithm (ICTS) over the hybrid algorithm for different DAG sizes. In the future work, we intend to modify the proposed algorithm to be fault tolerant one. Also, we plan to consider power consumption as a provider requirement in order to improve the performance. In addition, we will try to customize our algorithm to be applied in fog computing and mobile cloud computing environments.
Change history
10 July 2024
This article has been retracted. Please see the Retraction Notice for more detail: https://doi.org/10.1007/s00521-024-10060-1
References
Kahanwal D, Singh TP (2012) The distributed computing paradigms: P2P, grid, cluster, cloud, and jungle. Int J Latest Res Sci Technol 1:183–187
Khurana S, Verma A (2013) Comparison of cloud computing service models: SaaS, PaaS, IaaS. Int J Electron Commun Technol 4(3):29–32
Furht B, Escalante A (2010) Handbook of cloud computing, 1st edn. Springer, Berlin
Sireesha P, Deepthi R (2014) Analysis of cloud components and study on scheduling framework in local resource. Int J Sci Eng Technol Res (IJSETR) 3(10):2790–2794
Selvarani S, Udha G (2010) Improved cost-based algorithm for task scheduling in cloud computing. In: Proceedings of IEEE international conference on computational intelligence and computing research (ICCIC), Coimbatore, India, pp 1–5
Mustafa S, Nazir B, Hayat A, Khan A, Madani S (2015) Resource management in cloud computing: taxonomy, prospects, and challenges. Comput Electr Eng 47:186–203
Chawla Y, Bhonsle M (2012) A study on scheduling methods in cloud computing. Int J Emerg Trends Technol Comput Sci 1(3):12–17
Su S, Li J, Huang Q, Huang X, Shuang K, Wang J (2013) Cost-efficient task scheduling for executing large programs in the cloud. Parallel Comput 39:177–188
Man N, Huh E (2013) Cost and efficiency-based scheduling on a general framework combining between cloud computing and local thick clients. In: Proceedings of international conference on computing, management and telecommunications (ComManTel), Ho Chi Minh City, Vietnam, pp 258–263
Dubeya K, Kumarb M, Sharmaab S (2018) Modified HEFT algorithm for task scheduling in cloud environment. Procedia Comput Sci 125:725–732
Li J, Su S, Cheng X, Huang Q, Zhang Z (2011) Cost-conscious scheduling for large graph processing in the cloud. In: Proceedings of IEEE international conference on high performance computing and communications, Banff, AB, Canda, pp 808–813
Nasr A, El-Bahnasawy N, El-Sayed A (2014) Task scheduling optimization in heterogeneous distributed systems. Int J Comput Appl 107(4):5–7
Cao Q, Gong W, Wei Z (2009) An optimized algorithm for task scheduling based on activity based costing in cloud computing. In: Proceedings of third international conference on bioinformatics and biomedical engineering, Beijing, China, pp 1–3
Guo-Ning G, Ting-Lei H (2010) genetic simulated annealing algorithm for task scheduling based on cloud computing environment. In: Proceedings of international conference on intelligent computing and integrated systems, Guilin, China, pp 60–63
Geng X, Mao Y, Xiong M, Liu Y (2018) An improved task scheduling algorithm for scientific workflow in cloud computing environment. Springer, Berlin
Alkhanaka E, Leea S, Rezaeia R, Parizi R (2016) Cost optimization approaches for scientific workflows scheduling in cloud and grid computing: a review, classifications, and open issues. J Syst Softw 113:1–26
Zhou N, Qi D, Wang X, Zheng Z, Lin W (2016) A list scheduling algorithm for heterogeneous systems based on a critical node cost table and pessimistic cost table. Concurr Comput Pract Exp 29:1–11
Yang Y, Chen J, Liu X, Yuan D, Jin H (2008) An algorithm in SwinDeW-C for scheduling transaction intensive cost constrained cloud workflow. In: Proceedings of fourth IEEE international conference on eScience, pp 374–375
Bahnasawy NA, Omara F, Qotb M (2011) A New algorithm for static task scheduling for heterogeneous distributed computing systems. Afr J Math Comput Sci Res 4(6):221–234
Topcuoglu H, Hariri S, Wu MY (2002) Performance-effective and low-complexity task scheduling for heterogeneous computing. IEEE Trans Parallel Distrib Syst (TPDS) 13(3):260–274
Isard M, Budiu M, Yu Y, Birrell A, Fetterly D (2007) Distributed data-parallel programs from sequential building blocks. ACM SIGOPS Oper Syst Rev 41(3):59–72
Eswari R, Nickolas S (2010) Path-based heuristic task scheduling algorithm for heterogeneous distributed computing systems. In: Proceedings of international conference on advances in recent technologies in communication and computing, Kottayam, India, pp 30–34
Sotiriadis S, Bessis N, Buyya R (2018) Self managed virtual machine scheduling in cloud systems. Inf Sci 433–434:381–400
Topcuoglu H, Hariri S, Wu M (2002) Performance-effective and low-complexity task scheduling for heterogeneous computing. IEEE Trans Parallel Distrib Syst 13(3):260–274
Rajavel R, Mala T (2010) Achieving service level agreement in cloud environment using job prioritization in hierarchical scheduling. In: Proceedings of international conference on information system design and intelligent application, vol. 132, pp 547–554
Kumar S, Mittal S, Singh M (2017) A comparative study of metaheuristics based task scheduling in distributed environment. Indian J Sci Technol. https://doi.org/10.17485/ijst/2017/v10i26/97031
Babukarthik RG, Raju R, Dhavachelvan P (2012) Energy-aware scheduling using hybrid algorithm for cloud computing. In: Computing communication and networking technologies in IEEE
Acknowledgements
This work was supported by King Saud University, Deanship of Scientific Research, Community College Research Unit.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
This article has been retracted. Please see the retraction notice for more detail:https://doi.org/10.1007/s00521-024-10060-1
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Amoon, M., El-Bahnasawy, N. & ElKazaz, M. RETRACTED ARTICLE: An efficient cost-based algorithm for scheduling workflow tasks in cloud computing systems. Neural Comput & Applic 31, 1353–1363 (2019). https://doi.org/10.1007/s00521-018-3610-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-018-3610-2