
Abstract
In this paper we introduce an efficient soft demapping method for amplitude phase shift keying (APSK) constellations using extreme learning machine (ELM). The ELM algorithm is used as a classification framework to perform correct symbol detection in additive white Gaussian noise channels. Despite its spectral efficiency, the demapping process of APSK-like high-order modulation schemes is a computationally complex task. The proposed algorithm can alternatively be used as a neural soft demapper and easily be adapted in conventional receivers. The proposed algorithm has been tested with uncoded data and also applied to coded data that combines iterative decoding process to achieve error-free transmission. In this mean, the study contains both uncoded and coded modulation scenarios and employs two types of networks parameters, namely fixed-type and mixed-type parameters, which has been obtained from fixed-type and mixed-type SNR data sets. The validity of the proposed method has been verified by comparing its symbol- and bit-error rate performance with the well-known max-log-MAP algorithm.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Amplitude phase shift keying (APSK) is a high-order modulation scheme with its high spectral efficiency and power [1] and also known to be very reliable in nonlinear wireless channels. In this respect, it has been adopted and employed in many commercial standards related to digital video broadcasting, such as second-generation digital video broadcasting DVB.S2 [2]. It achieves a high-rate transmission and shows better error performance, near to the Shannon limit, when compared with customary modulation schemes like QAM or PSK, especially when combined with distinguished channel codes like low-density parity-check (LDPC) codes or turbo codes [3, 4]. For the same coding scheme, it was shown in [5] that double-ring APSK modulation scheme has outperformed 16-QAM and 16-PSK due to its inherent robustness against the nonlinearities of the high-power amplifiers (HPAs). However, the demodulation process of APSK modulation scheme requires an exhaustive computation, where the complexity gradually increases with the size of the constellation.
In traditional receivers, after the demodulation process the received complex-valued signals are passed through a demapper, or decoder, which can be either an independent or an iterative decoder. The decoders can be divided mainly into two broad categories, namely hard-decision decoders and soft-decision decoders, where the former gets use of Hamming distances and the latter gets use of Euclidian distances between the received signal samples and the associated code words. In hard-decision decoding, hard bit information (0 or 1) is passed through the decoder, while in soft-decision decoding a probabilistic decoding algorithm is used in which soft bit information is passed through the decoder that carries the probability value associated with that particular bit. Although hard-decision decoding is computationally simpler, soft-decision decoding has better performance in terms of low bit-error rate (BER). A detailed performance analysis of soft- and hard-decision decoding can be found in [6].
In [7], the concept of APSK using product constellation labeling was introduced and two simplified demappers were proposed. It was concluded that the performance degradation introduced by the simplified demappers was negligible compared with the conventional max-log-MAP demappers over either AWGN or Rayleigh channels, i.e., for a code rate of 1/2 and gray labeling it is about 0.05 dB for independent demapping and about 0.1 dB for iterative demapping. A new bits-to-symbol mapping for 4 + 12 + 16-APSK in the nonlinear AWGN channel was proposed in [8] by analyzing the relation among the signal constellation, using both Hamming and Euclidean distances between the signal points on the constellation and BER performance depending on the nonlinearity of high-power amplifier (HPA). The proposed scheme was stated to have a simpler mapping structure, and the BER performance is better than that of the bit mapping in the DVB.S2 standard. In [9], a simplification method with a binary search scheme for linear regions was proposed for demodulation of general APSK signals, which can be applied to all types of APSK constellations where the complexity was stated to grow logarithmically with the constellation size, as opposed to existing schemes where the complexity grows linearly. An efficient soft demapping method was proposed in [10] for high-order modulation schemes combined with iterative decoding. The method employs a decision threshold instead of using Euclidean distance estimation, where computing operations are reduced. It was stated that larger complexity reduction with higher modulation order can be obtained, and simulation results using block turbo codes showed that approximating BER performance to that of the exhaustive estimation demapping algorithm can be achieved.
In [11], an alternative approximation to [10] in the computation of the LLR was presented where it consists of avoiding square root operations and the comparisons such as those required in max-log method, and about 0.5-dB degradation with respect to the max-log approach was noted for the proposed scheme. A simplified soft-decision demapping algorithm was presented in [12] to reduce the computational complexity compared to conventional algorithms with negligible performance degradation and a reduction of hardware resources required by about 81%. Similarly, another soft-decision demapping algorithm with low computational complexity for coded 4 + 12-APSK was proposed in [13]. It was noted that the proposed algorithm requires only a few summation, subtraction and multiplication operations to calculate the LLR value of each bit, and shows the same error performance as a conventional max-log algorithm.
A few soft demapping algorithms using maximum-a-posteriori (MAP) approach have been proposed in the literature to convey soft or hard bit information to decoders. Even though MAP-based decoding is known to be the optimal solution for symbol detection, one can exploit the parallel nature of artificial neural networks (ANN) as an alternative solution to that problem. In this respect, the problem of correct symbol detection can be considered as a constrained optimization problem that seeks for the nearest code word for each received symbol among the given code words. It was shown by Huang and Babri [14] that a single-hidden layer feedforward neural network (SLFN) can be trained with a finite training set to learn N distinct observations with zero error. A simplified version of SLFNs, which randomly chooses the input weights and analytically adjusts the output weights of SLFNs, is called extreme learning machine (ELM) [15] and is widely used in a variety of regression and classification problems [16, 17].
An ANN-based solution to the problem of detection and correction of linear block codes in AWGN channel was proposed in [18]. A multilayer perceptron (MLP) trained by the back-propagation (BP) algorithm was used to compare the performance of BPSK signaling with soft- and hard-decision decoders, and it was stated to have better performance for low signal-to-noise ratios. The behavior of a neural receiver combined with conventional equalizers was investigated in [19] to improve the detection of QAM modulated signals by compensating for nonlinear distortions of amplifiers. In [20], a radial basis function (RBF) neural network was proposed to learn the characteristic of M-QAM signal constellations in OFDM systems under the effect of noise and phase error, where hybrid learning process was used to train the RBF network. It was stated that neural networks combined with conventional equalizers improve the performance especially in compensating for nonlinear distortions of the amplifier. It was shown that neural equalizers were less disturbed by a small shift of operation point and, in general, QAM modulation with larger amount of levels can get more advantageous on neural equalizers. A learning-based framework to solve both equalization and symbol detection for QAM was studied in [21], where the received signal was transformed to a 2-tuple real-valued vector and then fed into a real-valued ELM. The proposed algorithm was compared with other learning-based equalizers using complex-valued ELM, complex-valued radial basis function (CRBF), complex-valued minimal resource allocation network (CMRAN), k-nearest neighbor (k-NN), back-propagation (BP) neural network and stochastic gradient boosting (SG-boosting). Obtained results in the study showed that ELM-based proposed scheme quite outperforms other ANN algorithms in terms of both symbol error rate (SER) and also training and testing times. In this sense, this framework emphasizes the strength of ELM-based classification in both equalization and symbol detection.
In this study, we propose a novel soft demapping algorithm for APSK signaling based on extreme learning machine, for both coded and uncoded scenarios. To the best of our knowledge, ELM-based demappers have not been used for the state-of-the-art APSK modulation scheme before. It will be shown that symbol detection using ELM can be efficiently employed as a good alternative to other proposed soft demappers. For the sake of clarity, we restrict our work to the cases of 16-APSK and 32-APSK constellations, where our model can be applied for higher-order (64-, 128- or 256-APSK) constellations as well.
2 Preliminaries
2.1 Amplitude phase shift keying (APSK)
The M-ary APSK constellation, either be a regular or an irregular type, is composed of \(R\) arbitrarily concentric rings where each ring having uniformly spaced by symbols with an arbitrary phase. The size of the constellation and the points are designed in a way to optimize the performance of the overall modulation scheme in terms of low peak-to-average power ratio (PAPR), low BER and high transmission rate [2]. In this respect, DVB-S2 gets use of irregular constellations where each concentric ring has different number of constellation points [9]. A detailed analysis considering the optimization of constellation performance can be found in [22].
The APSK signal points form a complex number set which is given by
where \(n_{\ell }\) denotes the number of points, \(r_{\ell }\) denotes the radius, and \(\theta_{\ell }\) denotes the relative phase shift of the \(\ell\)th ring, and \(1 \le \ell \le R\). This type of modulation schemes is termed as \(n_{1} + n_{2} + \cdots + n_{{n_{R} }}\)-APSK constellations. The optimum constellation radius ratio γ for 4 + 12-APSK is defined as \(\gamma = {{R_{2} } \mathord{\left/ {\vphantom {{R_{2} } {R_{1} }}} \right. \kern-0pt} {R_{1} }}\) and for 4 + 12 + 16-APSK as \(\gamma_{1} = {{R_{2} } \mathord{\left/ {\vphantom {{R_{2} } {R_{1} }}} \right. \kern-0pt} {R_{1} }}\) and \(\gamma _{2} = {{R_{3} } \mathord{\left/ {\vphantom {{R_{3} } {R_{1} }}} \right. \kern-0pt} {R_{1} }}\), where Fig. 1a, b depicts the 4 + 12-APSK and 4 + 12 + 16-APSK constellations, respectively.

a 4 + 12-APSK, b 4 + 12 + 16-APSK constellations
2.2 Log-likelihood ratio (LLR)
A major part of conventional receivers employ the maximum-a posteriori (MAP) rule for optimum detection [23]. In many cases, having a priori information about message probabilities is difficult and actually not available, so symbolling at the transmitter is commonly assumed to be equal likely. In this sense, a MAP detector becomes a maximum-likelihood (ML) detector [23]. MAP detectors, i.e., ML detectors, exploit the bit-wise likelihood ratios to make a decision on the received bit to be either a zero or one. The logarithmic MAP (log-MAP) and the max-logarithmic MAP (max-log-MAP) [24] are the simplified approximations of the MAP decision rule, usually employed in most of the receivers to decrease the hard burden of calculations.
The log-likelihood ratios (LLRs) are known to be very operative metrics that offer low dynamic range and simplification for decoding of many powerful codes, such as LDPC or turbo codes. The LLR for a given received symbol r is defined as the logarithmic ratio of the conditional probabilities \(P_{r} \left( {b_{j} | r} \right)\) of a particular bit (\(b_{j}\)) to be zero or one
and for an independent demapping (no a priori information, i.e., assuming equiprobable symbols) of M-ary modulation over an AWGN channel, it can be written as
where \({\mathcal{X}}_{j}^{\left( b \right)}\) is the constellation subset with the \(j\)th bit being \(b \left\{ {0,1} \right\}\) and \(f_{i}\) is the conditional probability density function of the received symbol given by
where \(\sigma^{2}\), \(r\) and \(s_{i}\) denote the variance, received symbol and \(i\)th symbol of the constellation, respectively. Obviously, the computational cost dramatically increases with the constellation size, since a large amount of exponential, square root and logarithm operations are need to be performed by the decoder. However, the amount of operations can be significantly reduced by using the max-log approximation [24] which is based on the Jacobian logarithm [25] identity expressed by
Using the given approximation in Eq. (3), Eq. (5) can be simplified to
where
It can be concluded that Eq. (6) actually implies that the max-log LLR approximation leads to the minimum Euclidian distance between the received symbol and the constellation points, in bit-wise manner.
2.3 Extreme learning machine (ELM)
It is known that a single-hidden layer feedforward neural network (SLFN) with N hidden neurons can be trained to learn N distinct observations with arbitrarily small error [15]. Unlike the traditional applications of feedforward networks, input weights and first hidden layer biases are not needed to be tuned, where they can be chosen arbitrarily and the output weights of SLFNs can be analytically determined [15]. In fact, this approach makes extreme learning fast and simple and also provides a good generalization performance for SLFNs, which is known as extreme learning machine (ELM) algorithm.
ELM has several significant superiorities over other classical popular gradient-based learning algorithms such as back-propagation. It offers the following benefits: (1) It is extremely fast, i.e., it can train SLFNs much faster; (2) it provides the smallest norm of weights while tending to reach the smallest training error; (3) it can be trained to work for nondifferentiable activation functions; (4) it uses only single-hidden layer, and it is much simpler than most learning algorithms for feedforward neural networks [26].
The output of standard SLFNs can be calculated using the equation given by Huang et al. [15].
where \(x_{i }\) is the input, and \(n\) and \(k\) are the number of neurons in the input and hidden layer, respectively. \(w_{ij }\) represents the input, and \(\beta_{i}\) represents the output weights, \(b_{j}\) is the biases of the neurons in the hidden layer, and \(g\left( . \right)\) is the activation function. Equation (5) can be written compactly in the following form as
where
\({\mathbf{H}}\) is called the hidden layer output matrix of the neural network. To obtain the SLFNs with zero error mean, i.e., \(\sum\nolimits_{j = 1}^{N} {y_{j} - t_{j} = 0,}\) where \(t\) indicates the desired output and \(N\) indicates the number of events, the input weights and biases are randomly assigned and output weights can be determined by using the smallest minimum norm least squares solution proposed by Huang et al. [15]:
where \(\bf H^\dag\) is the Moore–Penrose generalized inverse of matrix \({\mathbf{H}}\).
Obviously, ELM is a very powerful tool and can be applied to a general class of classification and regression frameworks. In his excellent studies given in [27, 28], Huang et al. showed that ELM has high generalization and approximation capabilities. As stated before, the complexity of demapping of APSK signals is quite a tedious work, especially in high-order constellations. Although there are several proposed studies in the literate for simplification of the MAP rule at the expense of moderate performance degradation, nearly most of the proposed algorithms are application-specific, either for the given particular constellation size or proper only for independent decoding. On the other side, the literature surveys given in the previous section show that the ANN-based frameworks are almost dedicated to channel equalization, except the proposed study given by Muhammad et al. [21]. This study successfully considers both QAM equalization and symbol detection in OFDM systems using ELM, and it is important to show that ELM outperforms other ANN algorithms and can be effectively used in symbol detection, as well as equalization.
In this manner, the strength of ELM in classification can be effectively exploited for symbol detection of the state-of-the-art modulation scheme APSK. Unlike [21], our study involves only symbol detection over an AWGN channel and compares the performance of ELM-based demapping against the optimal MAP-based demapping.
3 System model and proposed algorithm
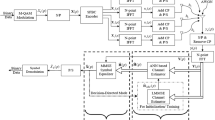
The general layout of a digital communication system used in our model is illustrated in Fig. 2. First, a random binary signal is generated and fed into a constellation mapper and then sent to the M-APSK modulator to be transmitted. The transmitted symbols \(s_{k}\) passing through the channel get affected with random noise. In our simulations, different signal-to-noise ratios (SNR) are tested to measure the performance of our proposed model. At the receiver side, the received noisy symbols \(r_{k}\) are demodulated and fed into an ELM-based constellation demapper for symbol detection.

A model of a digital communication system utilizing ELM-based demapper
Before starting the simulation, the proposed ELM-based demapper, which is given in Fig. 2, has been trained and tested with a sufficient amount of data sets at different noise levels. During the training and testing stages, two types of data sets have been used to check the performance of the proposed demapper. The first type data set consists of symbols affected by different noise levels, which will be hereafter called as mixed-type SNR data set, whereas the second type of data set consists of symbols affected only by one level of noise, which will be called as fixed-type SNR data set. In fact, the purpose of this distinction between the two data sets is to implement a demapper employing two types of scenarios. In the first case, the tuning parameters gained from mixed-type SNR data set will be used equally for all received symbols, without looking at their SNRs (i.e., noise level). In the second case, since we have a priori knowledge about SNR of each upcoming symbol, we can use the relevant tuning parameters gained from each fixed-type SNR accordingly. In other words, we will have a lookup table composed of different parameters for different SNRs, and ELM-based demapper will check for the SNR level of the received symbols (i.e., frames) at particular time intervals and use relevant parameters from the table. It should be noted that these checking instants for the SNR of the received signal depend on the time-varying nature of the channel and can be adequately adjusted.
An illustration for the training and testing process is depicted in Fig. 3, where 4 + 12-APSK constellation has been considered here as an example, and this analogy actually applies for all constellation sizes. The red-colored squares represent the complex symbol points, and the blue-colored dots represent the noisy complex symbol points, as shown in the left side of Fig. 3. The constructed noisy symbols are then used in the ELM network for training and testing process. The steps of our training and testing process can be summarized as follows:

Training and testing process given for 4 + 12-APSK constellation with SNR = 5 dB
-
1.
First, a sufficient number of complex random noisy signals have been generated for each complex symbol, at each different SNR level (i.e., between 0 and 20 dB at multiples of 1 dB).
-
2.
The real and imaginary parts of each complex symbol and its corresponding noisy patterns have been collected in a data set.
-
3.
For the first case scenario, the whole data set obtained in step 2 has been shuffled to obtain mixed-type SNR data set. The ELM network shown in Fig. 3 has been trained and tested with this type data set applying 10-fold cross-validation, and the obtained weights and biases have been saved to be used as mixed-type SNR parameters.
-
4.
For the second case scenario, the whole data set in obtained step 2 has been grouped with respect to SNR levels, maintaining 21 different sub-data sets associated with 21 different SNRs. For each obtained sub-data set, i.e., fixed-type SNR data set, the ELM network given in Fig. 3, has been trained and tested in the same way as in step 3. Finally, the relevant weights and biases obtained for each SNR have been saved into a lookup table, respective to its SNR value.
During the training and testing stages, different activation functions (sigmoid, sinusoidal, hard limiter, triangular basis and radial basis) and different number of hidden neurons have been used to choose the case which optimizes our network. The training and test accuracies versus number of hidden neurons (NHN) for different activation functions obtained from mixed-type data set are given in Fig. 4a–d and for both 4 + 12- and 4 + 12 + 16-APSK constellations. The test results show that sigmoid, sinusoidal and radial basis activation functions have the best accuracies among them in both constellations, and each of them has nearly the same performance. In our simulations, we have utilized sigmoid activation function with 50 neurons and radial basis activation function with 75 neurons for 4 + 12- and 4 + 12 + 16-APSK constellations to get maximum test accuracy, respectively.

Training and test accuracies of mixed-type data set, a, b 4 + 12-APSK and c, d 4 + 12 + 16-APSK constellation
For the second type of data set, the same activation functions were used with different number of neurons for each SNR and similarly sigmoid and sinusoidal activation functions gave the best accuracies among them. Therefore, for the sake of figure readability, only the performances of these two activation functions versus SNR for different NHNs are individually illustrated in Fig. 5a–f for both 4 + 12- and 4 + 12 + 16-APSK constellations. In both constellations, both sigmoid and sinusoidal activation functions gave nearly identical test accuracies, as can be seen from the given figures. The training and test results for both constellations showed that for data sets with SNRs between 0 and 5 dB a number of 30 neurons, for data sets with SNRs between 6 and 12 dB a number of 25 neurons and for data sets with SNRs between 12 and 20 dB a number of 20 neurons were sufficient to obtain reasonable test accuracies. Our decision rule here was based on using minimum neurons and also obtaining a wider range of SNRs in which the same training parameters could be applied without losing a major degradation in the performance. In this regard, we could minimize the number of parameters to be used in the lookup table.

Test accuracies of fixed-type data set, a–c 4 + 12-APSK and d–f 4 + 12 + 16-APSK constellation
The parameters obtained from the training stage are summarized in Table 1. After completing the selection of parameters from training stage, Monte-Carlo based simulations were carried out in the application stage.
A detailed test accuracy analysis is provided in Table 2, where we have conducted a numerous tests to check for the performance of the selected network parameters indicated in Table 1 versus different type of data sets. It can be clearly seen from Table 2 that the best test accuracy for mixed-type data set was achieved using mixed-type parameters. Similarly, the best test accuracies for fixed-type data sets were achieved using related fixed-type parameters. Therefore, the test results obtained in Table 2 indicate the validity of the chosen network parameters.
4 Simulation results
After completing the training and test stages, obtained net parameters (i.e., input/output weights and number of hidden neurons) have been used to simulate our proposed model. The parameters used in the simulations are given in Table 3. The simulation stage consists of both uncoded and coded data scenarios, where we have tried to validate and compare the performance of the proposed ELM-based demapper algorithm against the max-log LLR algorithm (Eq. 6).
4.1 Uncoded modulation
For uncoded data case, the two type networks that have been obtained in training stages with mixed- and fixed-type SNR have been used in the simulation stage, which we will shortly call as ELM-mixed and ELM-fixed, respectively. The bit-error rate (BER) and symbol error rate (SER) results of ELM-mixed, ELM-fixed and log-max LLR algorithms for both constellations are given in Fig. 6a–d.

The BER and SER results of uncoded simulation versus SNR, a, b 4 + 12-APSK and c, d 4 + 12 + 16-APSK constellation
The results show that the BER and SER of the proposed ELM-based demappers have a competitive performance against the optimal LLR algorithm, where ELM-mixed slightly outperforms ELM-fixed. It is also important to note that for especially low amount of SNRs (i.e., the worst cases), both of the proposed algorithms have nearly the same performance with the max-log LLR algorithm, whereas for higher SNRs, ELM-mixed has approximately less than 0.5-dB degradation and ELM-fixed has approximately less than 1-dB degradation than max-log LLR algorithm, respectively. In fact, this gap could be further reduced by increasing the number of hidden neurons which have been tried to be kept low enough to decrease the complexity of the design. Although the implementation of ELM-mixed requires approximately a double number of hidden neurons when compared with ELM-fixed, it uses less parameter than ELM-fixed so it can be preferred when dealing with constraint memory. On the other hand, ELM-fixed can be alternatively used to decrease the number of computations.
4.2 Coded modulation
In the second case scenario which uses coded data simulation, we have considered the low-density parity-check (LDPC) [3] codes which is known to have an excellent performance among other error correcting mechanisms. LDPC codes can be efficiently decoded through iterative decoding process, using either hard-decision or soft-decision decoding. In this regard, our study will also highlight the capability of LDPC codes in error correction. Although soft-decision decoding enhances the performance of LDPC codes, the proposed ELM-based demapper employs a hard-decision strategy; therefore, we have used the bit flipping (BF) algorithm for hard-decision decoding of LDPC codes.
The BF algorithm is a simple hard-decision message-passing algorithm based on the idea of belief propagation used to decode LDPC codes. Tanner graph is a bipartite graph which is used to represent LDPC codes in graphical form [29], and it has check nodes and variable nodes to pass the message along the edges. First, the variable node (message node) sends its bit information to the check node and then the check node returns an updated message to the variable node according to the parity-check equation. This process is repeated until maximum number of pre-defined decoder iterations has been passed or the decoder halts automatically when the parity-check equations get satisfied.
The BER of ELM-mixed, ELM-fixed and log-max LLR algorithms using hard-decision decoding for both 4 + 12- and 4 + 12 + 16-APSK constellations is shown in Fig. 7a, b. The results show that a similar performance like in uncoded scenario has been achieved, where ELM-mixed slightly outperforms ELM-fixed, as expected. A maximum amount of 20 iterations has been used in the coded simulation where the results of the 1st and the 10th iterations are only depicted in Fig. 7a–b, since there was not a significant improvement in the BER results after the 10th iteration. It can be easily seen from the figure that for low amount of SNRs both of the proposed algorithms have nearly the same performance with the max-log LLR algorithm, and for high amount of SNRs, a max of 0.5- and 1-dB degradations has been obtained with ELM-mixed and ELM-fixed, respectively. Moreover, in the case of 4 + 12 + 16-APSK, ELM-mixed even outperforms the max-log LLR algorithm after about 10 dB SNR in the 1st iteration and after about 6 dB SNR in the 10th iteration, as shown in Fig. 7b.

The BER results of coded simulation versus SNR, a 4 + 12-APSK and b 4 + 12 + 16-APSK constellation
Simulation results show that the performance of the proposed soft demapping algorithm using ELM works quite well for both coded and uncoded APSK. At low SNRs nearly the same performance with the max-log LLR algorithm has been achieved, and at high SNRs only a maximum of 0.5- and 1-dB performance degradation is introduced for ELM-mixed and ELM-fixed-type scenarios, respectively. It is evident that the obtained successful performances indicate the high generalization and approximation capabilities of ELM [27, 28]. These results also well suit to the literature findings obtained in [21]. Although obtaining inverse matrix seems as a complex issue for real-time applications, it should be noted that the training stage is carried out only for one time to obtain optimum weights and biases before starting the application. And after they have been obtained, the only issue is to weigh the inputs and sum them to acquire the output, which is a straightforward algebraic process. Based on this fact, the proposed approach can be easily applied in real-time applications.
5 Conclusions
The symbol detection in high-order modulation schemes like APSK is a crucial issue. In this study, symbol demapping process was considered as a classification framework and an extreme learning machine (ELM)-based demapper was proposed to perform an efficient detection as an alternative to other soft demappers. The proposed algorithm has been tested for both uncoded and coded modulation scenarios using both fixed-type and mixed-type network parameters obtained from the training stage of fixed-type and mixed-type SNR data sets. The simulation results showed that ELM-based demapper can be adequately used in hard-decision decoders to perform symbol detection task with a good BER and SER performance. Especially in low SNRs, the proposed algorithm has nearly the same performance with the optimal max-log LLR algorithm. And in the case of high SNRs the performance of the proposed algorithm is comparatively successful. Furthermore, this study also demonstrates the power of LDPC codes in error correction when comparing the simulation results obtained from uncoded and coded modulation.
References
De Gaudenzi R, et al (2006) Turbo-coded APSK modulations design for satellite broadband communications. Int J Satell Commun Netw 24(4):261–281
ETSI EN 302 307 V1. 3.1 (2013) Digital video broadcasting (DVB): second generation framing structure, channel coding and modulation systems for broadcasting, interactive services, news gathering and other broadband satellite applications (DVB-S2)
Gallager R (1962) Low-density parity-check codes. IRE Trans Inf Theory 8(1):21–28
Berrou C, Glavieux A (1996) Near optimum error correcting coding and decoding: turbo-codes. IEEE Trans Commun 44(10):1261–1271
De Gaudenzi R, i Fabregas AG, Vicente AM, Ponticelli B (2002) APSK coded modulation schemes for nonlinear satellite channels with high power and spectral efficiency. In: The proceedings of the AIAA satellite communication systems conference
Jose R, Pe A (2015) Analysis of hard decision and soft decision decoding algorithms of LDPC codes in AWGN. In: Advance computing conference (IACC), 2015 IEEE international, IEEE, pp 430–435
Xie Q, Wang Z, Yang Z (2012) Simplified soft demapper for APSK with product constellation labeling. IEEE Trans Wirel Commun 11(7):2649–2657
Lee JY, Yoon DW, Hyun KM (2010) Simple signal detection algorithm for 4 + 12 + 16 APSK in satellite and space communications. J Astron Space Sci 27(3):221–230
Sandell M, Tosato F, Ismail A (2016) Efficient demodulation of general APSK constellations. IEEE Signal Process Lett 23(6):868–872
Ryoo S, Kim S, Lee SP (2003) Efficient soft demapping method for high order modulation schemes. In: CDMA international conference (CIC)
Olivatto VB, Lopes RR, de Lima ER (2015) Simplified LLR calculation for DVB-S2 LDPC decoder. In: Communication, networks and satellite (COMNESTAT), 2015 IEEE international conference on, IEEE, pp 26–31
Ryu CD, Park JW, Sunwoo MH (2010) Simplified soft-decision demapping algorithm for digital video broadcasting system. Electron Lett 46(12):840–842
Lee J, Yoon D (2013) Soft-decision demapping algorithm with low computational complexity for coded 4 + 12 APSK. Int J Satell Commun Netw 31(3):103–109
Huang GB, Babri HA (1998) Upper bounds on the number of hidden neurons in feedforward networks with arbitrary bounded nonlinear activation functions. IEEE Trans Neural Netw 9(1):224–229
Huang GB, Zhu QY, Siew CK (2006) Extreme learning machine: theory and applications. Neurocomputing 70(1):489–501
Ertuğrul ÖF, Tağluk ME (2017) A fast feature selection approach based on extreme learning machine and coefficient of variation. Turk J Electr Eng Comput Sci 25(4):3409–3420
Kaya Y, Kayci L, Tekin R, Faruk Ertuğrul Ö (2014) Evaluation of texture features for automatic detecting butterfly species using extreme learning machine. J Exp Theor Artif Intell 26(2):267–281
El-Khamy SE, Youssef EA, Abdou HM (1995) Soft decision decoding of block codes using artificial neural network. In: Computers and communications, 1995. Proceedings, IEEE symposium on, IEEE, pp 234–240
Raivio K, Henriksson J, Simula O (1998) Neural detection of QAM signal with strongly nonlinear receiver. Neurocomputing 21(1):159–171
Lerkvaranyu S, Dejhan K, Miyanaga Y (2004) M-QAM demodulation in an OFDM system with RBF neural network. In: Circuits and systems, 2004. MWSCAS’04. The 2004 47th midwest symposium on, IEEE, vol 2, pp II–II
Muhammad IG, Tepe KE, Abdel-Raheem E (2013) QAM equalization and symbol detection in OFDM systems using extreme learning machine. Neural Comput Appl 22(3–4):491–500
Liolis KP, Alagha NS (2008) On 64-APSK constellation design optimization. In: Signal processing for space communications, 2008. SPSC 2008. 10th international workshop on, IEEE, pp 1–7
Proakis JG, Salehi M (2008) Digital communications, 5th edn. McGraw-Hill, New York
Viterbi AJ (1998) An intuitive justification and a simplified implementation of the MAP decoder for convolutional codes. IEEE J Sel Areas Commun 16(2):260–264
Martina M, Masera G, Papaharalabos S, Mathiopoulos PT, Gioulekas F (2012) On Practical Implementation and Generalizations of max* Operator for Turbo and LDPC Decoders. IEEE Trans Instrum Meas 61(4):888–895
Ertuğrul ÖF (2016) Forecasting electricity load by a novel recurrent extreme learning machines approach. Int J Electr Power Energy Syst 78:429–435
Huang GB, Chen L, Siew CK (2006) Universal approximation using incremental constructive feedforward networks with random hidden nodes. IEEE Trans Neural Netw 17(4):879–892
Huang GB, Zhou H, Ding X, Zhang R (2012) Extreme learning machine for regression and multiclass classification. IEEE Trans Syst Man Cybern Part B Cybern 42(2):513–529
Tanner R (1981) A recursive approach to low complexity codes. IEEE Trans Inf Theory 27(5):533–547
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors (Abdulkerim Öztekin and Ergun Erçelebi) of paper (Title: An Efficient Soft Demapper for APSK signals using Extreme Learning Machine) declare that there is no conflict of interests.
Rights and permissions
About this article

Cite this article
Öztekin, A., Erçelebi, E. An efficient soft demapper for APSK signals using extreme learning machine. Neural Comput & Applic 31, 5715–5727 (2019). https://doi.org/10.1007/s00521-018-3392-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-018-3392-6