
Abstract
Stock/futures price forecasting is an important financial topic for individual investors, stock fund managers, and financial analysts and is currently receiving considerable attention from both researchers and practitioners. However, the inherent characteristics of stock/futures prices, namely, high volatility, complexity, and turbulence, make forecasting a challenging endeavor. In the past, various approaches have been proposed to deal with the problems of stock/futures price forecasting that are difficult to resolve by using only a single soft computing technique. In this study, a hybrid procedure based on a backpropagation (BP) neural network, a feature selection technique, and genetic programming (GP) is proposed to tackle stock/futures price forecasting problems with the use of technical indicators. The feasibility and effectiveness of this procedure are evaluated through a case study on forecasting the closing prices of Taiwan Stock Exchange Capitalization Weighted Stock Index (TAIEX) futures of the spot month. Experimental results show that the proposed forecasting procedure is a feasible and effective tool for improving the performance of stock/futures price forecasting. Furthermore, the most important technical indicators can be determined by applying a feature selection method based on the proposed simulation technique, or solely on the preliminary GP forecast model.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Stock/futures price forecasting is an important issue in investment/financial decision-making among individual investors, stock fund managers, and financial analysts and is currently receiving considerable attention from both researchers and practitioners. Stock/futures price forecasting is considered a challenging task due to the fact that the prices are highly volatile, complex, and dynamic. Therefore, various approaches for tackling the problems of stock/futures price forecasting have been proposed. These approaches can be broadly classified into three categories: fundamental analysis, technical analysis, and traditional time series forecasting. Fundamental analysis examines the statistics of macroeconomics data such as interest rates, money supply, and foreign exchange rates, as well as the basic financial information of a corporation, in order to forecast stock price movements [1, 2]. Technical analysis involves studying stock prices, recent and historical price trends and cycles, factors beyond stock price, such as dividend payments, trading volume, group trends and popularity, and the volatility of a stock to forecast future stock prices [3]. The third approach, traditional time series forecasting, uses statistical tools to forecast future values of a stock based on its past values and other variables. These tools include moving average, autoregressive integrated moving average (ARIMA) [4], generalized autoregressive conditional heteroskedasticity (GARCH) [5], and multivariate regression, etc.
In recent years, data mining/computational intelligence techniques have become rapidly growing alternative methods for resolving, or assisting other approaches in resolving, the problems of stock/futures price forecasting. For example, Pai and Lin [6] exploited the strengths of the autoregressive integrated moving average (ARIMA) and support vector machine (SVM) to develop a hybrid methodology. The ARIMA technique was used to model the linear dataset, while the SVMs were employed to deal with the nonlinear data pattern in time series forecasting. The performance of the proposed model was evaluated by examining real datasets of ten stocks and adequate results were obtained. Furthermore, comparison results showed that their presented methodology can significantly improve the forecasting performance of the single ARIMA or SVM model. Chang and Liu [7] presented a Takagi–Sugeno–Kang (TSK) type fuzzy rule-based system to tackle stock price forecasting problems. They used stepwise regression to analyze and select technical indicators that are more influential to the stock price. The K-means clustering technique was then applied to partition the dataset into several clusters. Finally, a simplified fuzzy rule inference system was set up with the optimal rule parameters trained by simulated annealing to forecast stock prices. Their proposed approach was tested on the Taiwan Stock Exchange (TSE) and MediaTek Inc., and the experimental results outperformed other methodologies, such as backpropagation neural networks and multiple regression analysis. Ince and Trafalis [8] proposed an approach for stock price forecasting by using kernel principal component analysis (kPCA) and support vector regression (SVR), based on the assumption that the future value of a stock price depends on its financial indicators. The kPCA was utilized to identify the most important technical indicators, and the SVR was employed to construct the relationship between the stock price and selected technical indicators. For comparison, they also applied factor analysis to determine the most influential input technical indicators for a forecasting model and used multilayer perceptron (MLP) neural networks to build the forecasting model. The experiments were conducted on the daily stock prices of ten companies traded on the NASDAQ. The comparison results indicated that proposed heuristic models produce better results than the studied kPCA-SVR model. Furthermore, there is no significant difference in forecasting performance between the MLP neural model and SVR technique in terms of the mean square error. Huang and Tsai [9] proposed a hybrid procedure using filter-based feature selection, a self-organizing feature map (SOFM), and support vector regression (SVR), in order to forecast the stock market price index. The filter-based feature selection was first used to determine important input technical indicators thus reducing data complexity. The SOFM algorithm was then applied to cluster the training data into several disjointed clusters such that the elements in each cluster are similar. Finally, the SVR technique was employed to construct an individual forecasting model for each cluster. Their proposed model was demonstrated through a case study on forecasting the next day’s price index for Taiwan index futures (FITX), and the experiment results showed that the proposed approach can improve forecasting accuracy and reduce the training time over the traditional single SVR model. Liang et al. [10] presented a two-stage approach to improve option price forecasting by using modified conventional option pricing methods, neural networks (NNs), and support vector regressions (SVRs). In their study, three improved modified conventional parametric methods, the binomial tree method, the finite difference method, and the Monte Carlo method, were utilized to forecast the option prices in the first stage. Then, the NNs and SVRs were employed to carry out nonlinear curve approximation to further reduce the forecasting errors in the second stage. The proposed approach was demonstrated by experimental studies on the data taken from the Hong Kong options market, and the results showed that the NN and SVR approaches can significantly shrink the average forecast errors, thus improving forecasting accuracy. In yet another approach to stock price forecasting, Hadavandi et al. [11] presented a hybrid model by integrating stepwise regression analysis, artificial neural networks, and genetic fuzzy systems. They first used stepwise regression analysis to select factors that can significantly affect stock prices. A self-organizing map (SOM) neural network was then used to divide the raw data into several clusters such that the elements in each cluster are more homogeneous. Finally, data in each cluster were fed into a genetic fuzzy system to forecast stock prices. Their proposed approach was demonstrated through an experiment on forecasting the next day’s closing prices of two IT corporations and two airlines, and comparison results indicated that the proposed approach outperforms other previous methods. Lu [12] proposed an integrated stock price forecasting model by using independent component analysis (ICA) and a backpropagation (BP) neural network. The ICA was first applied to the forecasting variables in order to filter out the noise contained in these variables, thus generating the independent components (ICs). The filtered forecasting variables then served as the input variables of the BP neural network to build the forecasting model. The proposed approach was illustrated by a case study on forecasting the Taiwan Stock Exchange Capitalization Weighted Stock Index (TAIEX) closing cash index and Nikkei 225 opening cash index. The comparison results revealed that the proposed forecasting model outperforms the integrated wavelet-BP model, the BP model without filtered forecasting variables, and the random walk model. Cheng et al. [13] employed the cumulative probability distribution approach (CDPA), minimize entropy principle approach (MEPA), rough sets theory (RST), and genetic algorithms (GAs) to develop a hybrid approach for stock price forecasting. The CDPA and MEPA were first utilized to partition technical indicator values and daily price fluctuation into linguistic values according to the characteristics of data distributions. The RST was then employed to generate linguistic rules from the linguistic technical indicator dataset. Finally, the GAs were applied to refine the extracted rules, thus improving the forecasting accuracy and stock return modeling. Their proposed methodology was verified through a case study on forecasting the Taiwan Stock Exchange Capitalization Weighted Stock Index (TAIEX) and adequate results were obtained.
The above-mentioned studies prove that using neural network techniques is an effective way to address the problems of stock/futures price forecasting. Furthermore, forecasting performance can be further improved by using feature selection methods to find out the most important factors that serve as input variables for a forecasting model. These methods include stepwise regression, kernel principal component analysis, factor analysis, and independent component analysis. The current study proposes a systematic procedure based on a backpropagation (BP) neural network, a feature selection technique, and genetic programming (GP) to tackle stock/futures price forecasting problems with the use of technical indicators. First, the BP neural network is used to construct the preliminary forecasting model that describes the complex nonlinear relationship between the technical indicators and future stock/futures prices. Next, the feature selection technique based on simulation is utilized to explore the preliminary forecasting model in order to select the most important technical indicators for forecasting stock/futures prices. In addition, the GP is also employed to build another forecasting model, thus automatically screening the vital technical indicators that closely correlate with future stock/futures prices. The BP neural network is then applied again to develop the final forecasting model by using the technical indicators that are produced by the feature selection technique based on simulation or screened by the GP program as the input forecasting variables. Finally, the performance of the final forecasting model is evaluated and compared with the performance of the preliminary BP and GP forecasting models.
The remainder of this paper is organized as follows. In Sect. 2, BP neural networks, feature selection, and GP are discussed. The proposed integrated approach is presented in Sect. 3. Section 4 evaluates the feasibility and effectiveness of the proposed approach by presenting and analyzing a case study on forecasting the closing prices of Taiwan Stock Exchange Capitalization Weighted Stock Index (TAIEX) futures of the spot month. Finally, Sect. 5 concludes the paper.
2 Methodologies
Three methods are used in this study to develop the integrated procedure for solving a stock/futures price forecasting problem. This section briefly introduces these methods, beginning with the backpropagation neural network.
2.1 Backpropagation neural network
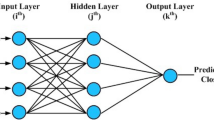
The backpropagation (BP) neural network is a widely used network that is trained through a supervised learning algorithm. The design of the network is a multi-layered neural model that consists of one input layer, at least one hidden layer, and one output layer. Each layer, which comprises several nodes called neurons, is fully connected to the succeeding layer. The number of neurons in the input and output layers can be accurately determined by the number of input and output variables in a problem. On the other hand, the optimal number of hidden layers and the neurons in each hidden layer are usually determined through a trial-and-error method based on root mean squared errors (RMSEs) found in the training and test data. Theoretically, one hidden layer is sufficient for approximating any continuous functional relationship between input and output variables with an arbitrary degree of accuracy [14]. When applying a BP neural network to a specific problem, the neural model must be learned (trained) in advance. The learning process includes three stages: (1) feed-forward of the input training pattern, (2) calculation and backpropagation of the associated error, and (3) weight and bias adjustment. The learning process proceeds repeatedly until the RMSE associated with the training data sufficiently converge to a global minimum. Furthermore, the optimal number of learning iterations is usually determined by observing the progress of test RMSE by feeding independent test data into the trained BP neural model in order to prevent over-training. During the learning process of a BP neural network, two major parameters, including the learning rate and momentum, must be specified by the users. The appropriate setting of the learning rate and momentum can help the BP neural model achieve the global minimum training and test RMSEs. However, the values of both parameters are problem dependent [15] and are usually determined through trial and error. Once the learning process is accomplished, the well-trained BP neural network can be utilized to estimate the unknown values of output variables by the recall process of feeding the input pattern into this BP model.
BP neural networks have attracted substantial research interest from a wide range of applications. As these applications demonstrate, adequate estimation results can be obtained through these neural networks [16–19].
2.2 Feature selection
Feature selection is a process of selecting a minimal subset of features based on certain reasonable criteria in order to remove irrelevant and redundant features and hence noise. In this way, the original problem can be tackled equally well, if not better, than by using a full set of features [20]. Feature selection can prevent the selection of too many or too few features (i.e., more or less than necessary) and achieve data reduction for accelerating training and increasing computational efficiency [21]. If too many (irrelevant) features are selected, the effects of noise may duplicate or shadow the valuable information in data. However, if too few features are chosen, the information contained in the selected subset of features might be low. Feature selection approaches can be classified into two categories: the wrapper approach and the filter approach. In the wrapper approach, the feature selection algorithm acts as a wrapper around the induction algorithm [22] and searches for a good subset by evaluating feature subsets via the induction algorithm. In other words, the feature selection and induction algorithms interact while searching for the best feature subset. Comparatively, the filter approach utilizes a preprocessing step to filter features and thus find a good feature subset. This method entirely ignores the performance of the selected feature subset on the induction algorithm. That is, the feature selection algorithm proceeds independently of the induction algorithm [22].
Liu and Motoda [20] provided a unified model of feature selection, which is shown in Fig. 1. First, the feature generation produces a feature subset each time using a certain search strategy based on the training data. The generated feature subset along with the training data are then evaluated by a measuring function. The feature generation mechanism stops searching once the stopping criteria are fulfilled. While the stopping criteria vary case by case, a stop may be activated by any one of the following conditions: (1) the feature subset is good enough, (2) some bound is reached, and (3) the search completes [20]. Notably, the feature subset is determined to be adequate if its estimated accuracy, i.e., classification or forecasting accuracy, is better than the accuracy obtained by using a full set of features. Next, the training data with a specified feature subset, i.e., the best feature subset generated, are fed into the learning algorithm in order to construct the classifier (or forecaster). Finally, the classifier (or forecaster) is tested on the test data with the selected features, thus obtaining the classification accuracy (or forecasting errors).

A unified model of feature selection
Researchers have attempted to resolve problems of feature selection using various techniques. These include the following: information-theoretic measures [23], rough sets and ant colony optimization [24], genetic algorithms [25], and mathematical programming [26]. Further discussions on feature selection can be found in the studies reported by Kohavi and John [22], Liu and Motoda [20], Piramuthu [21], and Mladenic [27].
2.3 Genetic programming
Genetic programming (GP) is an evolutionary methodology that can automatically create computer programs to solve a user-defined problem by genetically breeding a population of computer programs using the principles of Darwinian natural selection and biologically inspired operations. The solution technique of GP closely relates to the field of genetic algorithms (GAs). However, there exist three major differences between GAs and GP. First, GP usually evolves a tree-based structure, while GAs evolve binary or real number strings. Second, the length of the binary or real number string is fixed in traditional GAs, while the parse trees can vary in length throughout the run in GP. Finally, the solutions of GP are active structures; this means that they can be directly executed without post-processing, whereas the binary or real number strings in GAs are passive structures which require post-processing [28]. Figure 2 illustrates a tree-based representation of the solution \( [(x \times 5) + 3] - [{ \cos }(y) \div 6] \) in GP. As seen, the terminal components in the branches, i.e., x, 5, 3, y, and 6, are called terminal elements. The terminal elements (e.g., the independent variables of the problem, zero-argument functions, random constants, etc.) available for each branch of the to-be-evolved computer program in GP are defined by a terminal set. On the other hand, the remaining components in Fig. 2, i.e., +, −, ×, ÷, and cos, are called primitive functions. The primitive functions available to the medium elements of the to-be-evolved computer program, such as addition, square root, multiplication, sine, etc., are defined by a function set. Like GAs, the fitness (adaptability) of a solution in the GP population is explicitly or implicitly measured via a predefined fitness function. Furthermore, some parameters and the termination criterion must be specified in advance in order to apply GP to resolve a problem. The major parameters that control the run in GP include population size, maximum size of programs, crossover rate, and mutation rate. In addition, the time to stop the evolutionary procedure of GP is determined by the termination criterion. The general steps of GP are presented in the studies of Koza et al. [29, 30] and Ciglarič and Kidrič [31] and are summarized as follows:

Tree-based representation of a solution in GP
Step 1 Generating an initial population
This step generates an initial population of computer programs, which can be of different sizes and different shapes, appropriate to a problem subject to a prespecified maximum size.
Step 2 Evaluating computer programs
Each program in the population is executed and measured by using a predefined fitness function to obtain the fitness value.
Step 3 Creating the next generation
A pool of programs is first selected from the population using a probability based on the fitness value. Next, the genetic operations, including reproduction, crossover, mutation, and architecture-altering operations, are applied to the selected programs thus producing the offspring. Finally, the current population is replaced with the population of offspring based on a certain strategy, e.g., the elitist strategy, in order to create the next generation.
Step 4 Examining the termination criterion
When the termination criterion is satisfied, the outcome is designated as the final results of the run. Otherwise, Steps 2–4 are executed iteratively.
As shown in the studies of Etemadi et al. [32], Hwang et al. [33], and Bae et al. [34], GP has produced many novel and outstanding results in resolving problems from numerous fields. Further discussions on GP, its applications and related resources can be found in the studies of Langdon and Poli [35] and Koza et al. [29, 30].
3 Proposed forecasting procedure
In this study, a systematic procedure based on a backpropagation (BP) neural network, a feature selection technique, and genetic programming (GP) was proposed to tackle stock/futures price forecasting problems with the use of technical indicators. The proposed forecasting procedure comprises three stages and is described as follows:
3.1 Construction of preliminary forecasting models
In the first stage, the essential historical stock/futures trading data, e.g., opening price, highest price, lowest price, closing price, trade volume, etc. in each trading day are first collected. Next, the required technical indicators, e.g., moving average, Williams overbought/oversold index, psychological line, commodity channel index, etc. are calculated. To avoid variables with larger numeric ranges from dominating those with smaller numeric ranges, we normalize the technical indicators into a range between 0 and 1 using the following formula:
where \( {ti}_{ij} \) and \( x_{ij} \) are the original and normalized technical indicators, respectively; \( {ti}_{j}^{\max } \) and \( {ti}_{j}^{\min } \) are the maximum and minimum value of the jth technical indicator, respectively; and n and m are the total number of trading days and technical indicators, respectively. These normalized technical indicators, which take the full feature set as shown previously in Fig. 1, are the independent input variables in the stock/futures price forecasting model. In addition, the closing price of the stock/futures in each trading day is also normalized into a range between 0 and 1, based on the following formula:
where \( p_{i} \) and \( y_{i} \) are the original and normalized closing price of the stock/futures, respectively; \( p^{\max } \) and \( p^{\min } \) are the maximum and minimum value of the closing price of the stock/futures, respectively; and n is the total number of trading days. The normalized technical indicators in each trading day along with the normalized closing price in the future, e.g., next trading day or next second trading day, denoted by \( (x_{i1} ,x_{i2} , \ldots ,x_{im} ,y_{i} ) \), are then partitioned into training, test, and validation data, based on a prespecified proportion, e.g., 4:1:1. Next, a BP neural network is applied to the training and test data to construct several forecasting models. Then, a preliminary optimal forecasting model, named BP_Modelpre, is selected based on simultaneously minimizing the root mean squared errors (RMSEs) of the training and test data. For comparison, the GP algorithm is also utilized to construct several forecasting models, and a preliminary optimal forecasting model, denoted as GP_Modelpre, is determined according to the training and test RMSEs to describe the functional relationship between the normalized technical indicators of each trading day and the normalized closing price of stock/futures as forecasted.
3.2 Feature selection
In the second stage, the feature selection technique based on simulation is utilized to determine the impact of each technical indicator on forecasting the closing price of the stock/futures. Suppose the total numbers of trading days in the training, test, and validation data are n tr, n te, and n va, respectively. First, the mean of the jth normalized technical indicator in successive t trading days, starting from the ith trading day in the training and test periods, is calculated by:
Next, the standard deviation of the jth normalized technical indicator in successive t trading days, starting from the ith trading day in the training and test periods, can be calculated by:
Therefore, the mean of the standard deviation of the jth normalized technical indicator in successive t trading days, denoted by \( \bar{s}_{j}^{(t)} \), during the training and test periods can be expressed as:
To assess the impact of the jth technical indicator on forecasting the closing price of the stock/futures, we assume that the jth technical indicator in the ith trading day during the training and test periods can vary, based on a normal distribution, with its mean of x ij and standard deviation of \( \bar{s}_{j}^{(t)} \). Hence, the probability with which the value \( x_{ij}^{*} \) will lie in the range from \( x_{ij} - z_{\alpha /2} \bar{s}_{j}^{(t)} \) to \( x_{ij} + z_{\alpha /2} \bar{s}_{j}^{(t)} \) is \( 1 - \alpha \). That is,
where \( z_{\alpha /2} \) is the critical value such that the probability that the standard normal distribution z is greater than \( z_{\alpha /2} \) is \( {\alpha \mathord{\left/ {\vphantom {\alpha 2}} \right. \kern-\nulldelimiterspace} 2} \); \( 1 - \alpha \) is the confidence level set by the user, e.g., 0.95 or 0.99. Next, sample points of a total number of s, denoted by \( x_{ij(l)}^{*} \), are drawn from the range \( \left( {x_{ij} - z_{\alpha /2} \bar{s}_{j}^{(t)} ,\,x_{ij} + z_{\alpha /2} \bar{s}_{j}^{(t)} } \right) \), based on the following formulas:
where \( z_{{\alpha^{*} }} \) is the critical value such that the probability that the standard normal distribution z is greater than \( z_{{\alpha^{*} }} \) is \( \alpha^{*} \), and
Then, the normalized technical indicators for the ith trading day, not including the jth technical indicator which is replaced by the sample point \( x_{ij(l)}^{*} \), are fed into the well-trained BP neural network constructed in the previous stage (i.e., BP_Modelpre) to obtain the forecasted normalized closing price of the stock/futures, denoted by \( \hat{y}_{i(l)} \). Hence, the absolute percentage error (APE) of the forecast can be calculated by:
where \( y_{i} \) is the normalized actual closing price of the stock/futures as described in the first stage. Therefore, the impact of the jth normalized technical indicator on forecasting the normalized closing price of the stock/futures, denoted by IMP j , can be evaluated through the mean absolute percentage error (MAPE) expressed as:
Next, starting from one, the normalized technical indicators are ranked in ascending order based on their IMP j s. The normalized technical indicators for the ith trading day are then fed into the well-trained BP_Modelpre model, while the technical indicators whose ranks are not greater than r (\( r = 0,1, \ldots ,m - 1 \)) are replaced by 0.5, to acquire the forecasted normalized closing price of the stock/futures, denoted by \( \hat{\hat{y}}_{i(r)} \), during the training and test periods. The reason for replacing a normalized technical indicator with 0.5, which is the mean of its maximum and minimum values, is that we intend to weaken its effect on forecasting the closing price; this will assist us to determine the best feature subset. The mean absolute percentage error (MAPE) of the forecast, while weakening the effect of normalized technical indicators whose ranks are not greater than r, can then be calculated by:
The direction of change (CD) regarding the MAPE of the forecast while weakening the effect of one more normalized technical indicator can then be expressed by:
We then find a certain rank, say r*, such that \( {\text{CD}}_{{(r^{*} )}} = - 1 \) and \( {\text{CD}}_{(r)} = + 1 \) (for \( r = r^{*} + 1,r^{*} + 2, \ldots ,m - 1 \)). This implies that the absolute percentage error of the forecast always increases while weakening the effects of normalized technical indicators with ranks \( r^{*} + 1 \), \( r^{*} + 2 \), …, and \( m - 1 \). Hence, the normalized technical indicators with ranks greater than \( r^{*} \), denoted by \( \left( {f_{i1} ,f_{i2} , \ldots ,f_{{i(m - r^{*} )}} } \right) \) (for i = 1, 2…n, where n is the total number of trading days), are retained as input variables for constructing the final BP forecasting model. This completes the tasks of feature selection and finding the best feature subset, which were described by Fig. 1.
3.3 Construction and validation of final forecasting models
In the final stage, BP neural networks are re-applied to the training and test data, whose input variables are the retained normalized technical indicators in the previous stage, i.e., \( \left( {f_{i1} ,f_{i2} , \ldots ,f_{{i(m - r^{*} )}} } \right) \), to construct several forecasting models. Based on the simultaneous optimization of the training and test RMSEs, a final optimal BP neural model, named BP_BP_Modelfinal, is selected to represent the functional relationship between the retained normalized technical indicators and the normalized stock/futures closing price as forecasted. Furthermore, the preliminary optimal GP model constructed in the first stage, i.e., GP_Modelpre, is actually a computer program that is constructed automatically by using the most important normalized technical indicators. Hence, BP neural networks are also applied to the training and test data whose input variables are the normalized technical indicators that appeared in the GP_Modelpre model, and another final optimal BP neural model is determined, namely GP_BP_Modelfinal. This latter model is selected based on the training and test RMSEs and used for comparison to the BP_BP_Modelfinal model. Therefore, the forecasted closing price of the stock/futures, denoted by \( \hat{p}_{i} \), can be obtained by inputting the retained normalized technical indicators \( \left( {f_{i1} ,f_{i2} , \ldots ,f_{{i(m - r^{*} )}} } \right) \) for each trading day to BP_BP_Modelfinal, or by inputting the normalized technical indicators which appeared in the GP_Modelpre model in each trading day to GP_BP_Modelfinal, and denormalizing the output. Finally, through statistical metrics of the root mean squared error (RMSE) and mean absolute percentage error (MAPE), the effectiveness of the proposed forecasting procedure can be evaluated by applying the BP_BP_Modelfinal and GP_BP_Modelfinal models to the validation data that were not previously used. The RMSE and MAPE regarding the forecast for the validation data are defined as follows:
where \( p_{i} \) and \( \hat{p}_{i} \) are the actual and forecasted closing price of the stock/futures, respectively, and \( n_{\text{va}} \) is the total number of trading days in the validation data. At this stage, the tasks shown in the lower part of Fig. 1 are completed.
3.4 Proposed forecasting procedure
The proposed forecasting procedure in this study is conceptually illustrated in Fig. 3 and summarily restated as follows:

Proposed forecasting procedure
Stage 1: Construction of preliminary forecasting models
-
1.
Collect the essential historical stock trading data and calculate the required technical indicators.
-
2.
Normalize the technical indicators and closing prices of the stock/futures using (1) and (2), respectively.
-
3.
Partition the normalized technical indicators along with the normalized closing price in the future into training, test, and validation data.
-
4.
Apply the BP neural network and GP algorithm to the training and test data to construct preliminary optimal forecasting models.
Stage 2: Feature selection
-
1.
Calculate the mean and standard deviation of each normalized technical indicator during a number of successive trading days through (3) and (5), respectively.
-
2.
Assess the impact of each technical indicator on forecasting the closing price of the stock/futures through (10).
-
3.
Determine the best subset of normalized technical indicators according to the direction of change regarding the mean absolute percentage error of the forecast, while weakening the effect of one more normalized technical indicator, as shown in (12).
Stage 3: Construction of final forecasting models and validation
-
1.
Apply the BP neural network to the training and test data with input normalized technical indicators retained in Stage 2 to construct the final optimal forecasting model.
-
2.
Using as inputs the normalized technical indicators that appeared in the preliminary optimal GP forecasting model in Stage 1, apply the BP neural network to the training and test data to construct another final optimal forecasting model.
-
3.
Evaluate via (13) and (14) the effectiveness of the proposed forecast procedure by applying the two final optimal forecasting models constructed in Steps 1 and 2 of Stage 3 to the validation data.
4 Case study
In this section, a case study on forecasting the closing prices of Taiwan Stock Exchange Capitalization Weighted Stock Index (TAIEX) futures of the spot month is presented to demonstrate the feasibility and effectiveness of the proposed forecasting procedure. The details of the case study and the procedure are described below.
4.1 Constructing preliminary forecasting models
4.1.1 Preparing the experimental data
A total of 2,353 pairs of daily trading data, including opening price, highest price, lowest price, closing price, and trade volume, are first collected from the Taiwan Stock Exchange Corporation (TWSE) over a period of approximately nine-and-a-half years, from January 2, 2001, to June 30, 2010. Fifteen technical indicators are then selected as the input variables for forecasting the closing price of futures. This is in line with previous studies by Kim and Han [36], Kim and Lee [37], Tsang et al. [38], Chang and Liu [8], Ince and Trafalis [9], Huang and Tsai [10], and Lai et al. [39]. The formulas for these technical indicators are presented in “Appendix”, and they include the following: (1) 10-day moving average, (2) 20-day bias, (3) moving average convergence/divergence, (4) 9-day stochastic indicator K, (5) 9-day stochastic indicator D, (6) 9-day Williams overbought/oversold index, (7) 10-day rate of change, (8) 5-day relative strength index, (9) 24-day commodity channel index, (10) 26-day volume ratio, (11) 13-day psychological line, (12) 14-day plus directional indicator, (13) 14-day minus directional indicator, (14) 26-day buying/selling momentum indicator, and (15) 26-day buying/selling willingness indicator. The fifteen technical indicators are calculated according to the formulas in “Appendix” and the initial 2,353 pairs of daily trading data. Notably, the technical indicators for the first few days, beginning with January 2, 2001, are not available due to the technical indicator definitions. For example, the 9-day stochastic indicator K can be obtained only for the period after the 9th trading day from January 2, 2001. After this limitation and the validity of the technical indicators are taken into account, there are 2,318 pairs of technical indicator data. These data, along with the closing prices from March 1, 2001, to June 30, 2010, are used as the sample data in the follow-up forecasting procedure.
4.1.2 Constructing models for a forecast of 1 day ahead
The above fifteen technical indicators and the closing price in each trading day are normalized into a range between 0 and 1 using the formulas in (1) and (2), respectively. These normalized technical indicators in each trading day from March 1, 2001, to June 29, 2010, along with the normalized closing price of the next trading day from March 2, 2001, to June 30, 2010, are then partitioned into training, test, and validation sample data groups, based on the proportion of 4:1:1, as shown in Table 1. Notably, training data are usually given preference over test data. Thus, the size of training data is set as four times the size of test data. In addition, validation data of a size equal to the size of the test data are designed to verify the capability of the well-trained BP neural network or GP models obtained by using training and test data to deal with data not previously used. With this approach, the influence of partitioned sample data on the performance of the obtained forecasting model can be presumed to be eliminated. Next, Table 1 contains 16 subsets, which are achieved by slicing periods of time in order to ensure that the training, test, and validation sample data groups can cover the entire period of research. Through this manner, it is believed that the functional relationship between the normalized technical indicators and the normalized closing price of the next trading day can be estimated more accurately by using the BP neural network or GP models constructed later. Based on the training and test data in Table 1, a three-layered BP neural network is then designed by using NeuralWorks Professional II/Plus (http://www.neuralware.com) software to create a mathematical forecasting model. The total number of neurons in the input and output layers is set to 15, which is the total number of technical indicators, and 1, which is the closing price of futures on the next trading day, respectively. In addition, the learning rate and momentum are set, through trial and error, to 0.25 and 0.75, respectively, and the default values in software are applied for the remaining parameters. A hidden layer analysis is attempted where the learning process is terminated when the training RMSE sufficiently converges and over-training is prevented by observing the test RMSE. The hidden layer has a total number of neurons from 1 to 30. Table 2 summarizes the execution results. The structure 15-X-1 indicates that the BP neural model consists of X neurons in the hidden layer. Based on the simultaneous consideration of the training and test RMSEs, the neural model with the structure 15-20-1 is selected as the preliminary optimal BP forecasting model for forecasting the normalized closing price of the next trading day. It is named BP_Modelpre_1_day. For comparison, the GP algorithm is also applied to the training and test data in Table 1 to establish a futures price forecasting model. Here, the Discipulus 4.0 (http://www.rmltech.com) software is employed where the fitness of a program is evaluated through RMSE. The termination criterion is that the generations without improvement have reached 100 and the remaining parameters are set as their default values in the software. The Discipulus 4.0 software is executed 5 times, and Table 3 summarizes the obtained results. Based on the training and test RMSEs, the 2nd model, described as GP_Modelpre_1_day, is selected as the preliminary optimal GP forecasting model.
4.1.3 Constructing models for a forecast of 2 and 3 days ahead
Similarly, we intend to construct the BP neural network and GP models for forecasting the closing futures prices of the next second and third trading days. For forecasting the closing price of the next second trading day, the fifteen normalized technical indicators in each trading day from March 1, 2001, to June 28, 2010, along with the normalized closing price of the second trading day, i.e., from March 5, 2001, to June 30, 2010, are partitioned into training, test, and validation sample data groups based on the proportion of 4:1:1. The total numbers of paired data in the training, test, and validation sample data groups are 1,391, 463, and 462, respectively. With regard to the forecasting of the closing price of the next third trading day, the sample data are formed by the paired normalized technical indicators from March 1, 2001, to June 25, 2010, along with the normalized closing price of the third trading day, i.e., from March 6, 2001, to June 30, 2010. The sample data are also partitioned into training, test, and validation sample data groups, with sample sizes of 1,391, 463, and 461, respectively, based on the proportion of 4:1:1.
Next, a three-layered BP neural network using NeuralWorks Professional II/Plus software is applied to the above training and test data regarding the closing price forecast of the next second and third trading days, where the BP parameters are set to those used previously. Table 4 summarizes the partial execution results. According to this table, the neural models with the structures 15-20-1 and 15-25-1 are selected as the preliminary optimal BP forecasting models, based on the training and test RMSEs, for forecasting the normalized closing prices of the next second and third trading days; they are identified, respectively, as BP_Modelpre_2_day and BP_Modelpre_3_day. Finally, the GP algorithm using Discipulus 4.0 software is reapplied to the above training and test data concerning the closing price forecast of the next second and third trading days, where the fitness function, termination criterion, and the other remaining parameters are set to those used previously. Table 5 summarizes the results obtained by executing the Discipulus 4.0 software 5 times. Based on the training and test RMSEs, the 1st and 4th models are selected as the preliminary optimal GP forecasting models for forecasting the normalized closing prices of the next second and third trading days; they are identified, respectively, as GP_Modelpre_2_day and GP_Modelpre_3_day.
4.2 Selecting features
4.2.1 Evaluating the impact of technical indicators
Consider the training and test periods. Starting from a certain trading date, the mean of each normalized technical indicator in successive trading days is first calculated by (3). Notably, parameters n tr and n te are set to 1,391 and 463, which are, respectively, the total number of training and test paired data, as shown in Table 1. In addition, parameter m is set to 15, which is the total number of normalized technical indicators, and parameter t is set to 10, which stands for the successive 10 trading days considered in this study. Next, starting from a certain trading date, the standard deviation of each normalized technical indicator in the successive 10 trading days is calculated using (4). Thus, the mean of the standard deviation of each normalized technical indicator in the successive 10 trading days can be obtained by (5). Table 6 lists these values.
Next, we intend to assess the impact of each technical indicator on forecasting the closing price of the next trading day. Consider the first trading day in our study, March 1, 2001. The first normalized technical indicator, i.e., the 10-day moving average, is 0.381902. Hence, 200 sample points are initially drawn using the formulas in (7) and (8) where parameters α and s are set to 0.01 and 200, respectively. For example, the first and fifth sample points are, respectively, obtained by (15) and (16), as shown:
Then, the normalized technical indicators for the first trading day, not including the first technical indicator which is replaced by the first sample point, i.e., 0.418425, are fed into the neural network BP_Modelpre_1_day model. Thus, a forecasted value \( \hat{y}_{1(1)} \) regarding the normalized closing price of the next trading day, March 2, 2001, is obtained. The absolute percentage error (APE) of the forecast can be calculated based on (9) as follows:
where \( y_{1} \) and \( \hat{y}_{1(1)} \) are the normalized actual and forecasted closing price of futures on March 2, 2001. Similarly, the values of \( {\text{APE}}_{1(2)} \), \( {\text{APE}}_{1(3)} \), …, and \( {\text{APE}}_{1(200)} \) can be obtained by feeding the normalized technical indicators for the first trading day, not including the first technical indicator which is replaced by the remaining 199 sample points, into the BP_Modelpre_1_day neural model and calculating, in order, the forecast errors based on (9). Thus, the impact of the first normalized technical indicator on forecasting the normalized closing price of the next trading day can be evaluated through (10). By following the above procedure, the impact of the remaining normalized technical indicators on forecasting the normalized closing price of the next trading day can be obtained, and Table 7 summarizes these values. This table also shows the ranks of IMP j s based on their values in ascending order.
4.2.2 Determining the best subset of technical indicators
Next, we intend to determine the best subset of technical indicators by evaluating the effect of weakening normalized technical indicators on forecasting the closing price. For example, the normalized technical indicators for the first trading day are fed into the BP_Modelpre_1_day neural model to acquire the forecasted normalized closing price of the next trading day \( \hat{\hat{y}}_{1(3)} \), while the technical indicators whose ranks are not greater than 3, i.e., the 10th, 11th, and 14th, are replaced by 0.5. Similarly, the values \( \hat{\hat{y}}_{2(3)} \), \( \hat{\hat{y}}_{3(3)} \), …, and \( \hat{\hat{y}}_{1,854(3)} \) are acquired by feeding the normalized technical indicators for each trading day during the training and test periods into the BP_Modelpre_1_day neural model, while replacing the technical indicators with ranks of 1, 2, or 3 by 0.5 (the subscript 1,854 in \( \hat{\hat{y}}_{1,854(3)} \) is the total number of sample data in the training and test periods, as shown in Table 1). Then, while weakening the effect of normalized technical indicators whose ranks are not greater than 3, the mean absolute percentage error \( \left( {{\text{MAPE}}_{(3)} } \right) \) of the forecast can be obtained by (11) where parameters n tr, n te, and m are 1,391, 463, and 15, as described previously. Similarly, the values \( {\text{MAPE}}_{(0)} \), \( {\text{MAPE}}_{(1)} \), …, and \( {\text{MAPE}}_{(14)} \) can be acquired by applying the above procedure, and Table 8 summarizes these values. Hence, the direction of change (CD) regarding the MAPE of the forecast, while weakening the effect of one more normalized technical indicator, can be obtained through (12) as shown in Table 8.
In Table 8, we can observe that \( {\text{CD}}_{(10)} \) is −1 and all of \( {\text{CD}}_{(11)} \), \( {\text{CD}}_{(12)} \), …, and \( {\text{CD}}_{(14)} \) are +1. Thus, the normalized technical indicators with ranks 11–15 in Table 7, i.e., the 7th, 2nd, 4th, 1st, and 5th normalized technical indicators, denoted by \( \left( {f_{i1}^{(1)} ,f_{i2}^{(1)} , \ldots ,f_{i5}^{(1)} } \right) \), are retained as input variables for forecasting the futures closing price of the next trading day later. Then, the above procedure is applied to the training and test sample data groups for the forecasting of the closing prices of the next second and third trading days, using the neural network models previously constructed, namely, BP_Modelpre_2_day and BP_Modelpre_3_day. Thus, the impact of each normalized technical indicator on forecasting the normalized closing prices of the next second and third trading days can be obtained, as summarized in Tables 9 and 10. Furthermore, the MAPE of the forecast while weakening the effect of a certain normalized technical indicator and the direction of change regarding the MAPE of the forecast while weakening the effect of one more normalized technical indicator can be acquired. This is shown in Tables 11 and 12. According to Table 11, \( {\text{CD}}_{(10)} \) is −1 and \( {\text{CD}}_{(11)} \), \( {\text{CD}}_{(12)} \), …, and \( {\text{CD}}_{(14)} \) are all +1. Therefore, the normalized technical indicators with ranks 11–15 in Table 9, i.e., the 7th, 2nd, 4th, 1st, and 5th normalized technical indicators denoted by \( \left( {f_{i1}^{(2)} ,f_{i2}^{(2)} , \ldots ,f_{i5}^{(2)} } \right) \), are retained as input variables for forecasting the futures closing price of the next second trading day later. Similarly, it is found that \( {\text{CD}}_{(9)} \) is −1 and \( {\text{CD}}_{(10)} \), \( {\text{CD}}_{(11)} \), …, and \( {\text{CD}}_{(14)} \) are all +1. Therefore, the normalized technical indicators with ranks 10–15 in Table 10, i.e., the 7th, 9th, 2nd, 1st, 4th, and 5th normalized technical indicators denoted by \( \left( {f_{i1}^{(3)} ,f_{i2}^{(3)} , \ldots ,f_{i6}^{(3)} } \right) \), are retained as input variables for forecasting the futures closing price of the next third trading day later.
4.3 Constructing the final forecasting models
To construct the final BP neural model for forecasting the futures closing price of the next trading day, a three-layered BP neural network is applied again to the training and test data in Table 1, where the input variables are the retained normalized technical indicators \( \left( {f_{i1}^{(1)} ,f_{i2}^{(1)} , \ldots ,f_{i5}^{(1)} } \right) \) and the output variable is the normalized closing price of the next trading day. Hence, the neural model consists of 5 and 1 neurons in the input and output layers, respectively, and the remaining parameters are the same as those in Sect. 4.1.2. Table 13 summarizes the partial execution results. The 5-24-1 neural model, named BP_BP_Modelfinal_1_day, is selected as the final optimal forecasting model. Similarly, BP neural networks can be applied to the training and test data to construct the final forecasting models for the forecast of the closing prices in the next second and third trading days, as described in Sect. 4.1.3. When forecasting the closing price of the next second trading day, the normalized technical indicators \( \left( {f_{i1}^{(2)} ,f_{i2}^{(2)} , \ldots ,f_{i5}^{(2)} } \right) \) retained in the previous section serve as the input variables and the normalized closing price of the second trading day serves as the output variable. On the other hand, when creating the BP model for the forecast of the closing price of the next third trading day, the input variables are the retained normalized technical indicators \( \left( {f_{i1}^{(3)} ,f_{i2}^{(3)} , \ldots ,f_{i6}^{(3)} } \right) \) and the output variable is the normalized closing price of the third trading day. Table 13 summarizes the partial execution results. The 5-26-1 and 6-35-1 neural models are selected as the final optimal model for forecasting the closing prices of the next second and third trading days and are, respectively, named BP_BP_Modelfinal_2_day and BP_BP_Modelfinal_3_day.
In addition, the preliminary optimal GP forecasting model GP_Modelpre_1_day contains the 1st, 2nd, 4th, 5th, and 13th normalized technical indicators, denoted by \( \left( {f_{i1}^{\prime (1)} ,f_{i2}^{\prime (1)} , \ldots ,f_{i5}^{\prime (1)} } \right) \). Hence, to construct the final optimal forecasting model, a BP neural network is used again based on the training and test data in Table 1, where the input variables are \( \left( {f_{i1}^{\prime (1)} ,f_{i2}^{\prime (1)} , \ldots ,f_{i5}^{\prime (1)} } \right) \) and the output is the normalized closing price of the next trading day. Similarly, a BP neural network can be applied to the training and test data, as described in Sect. 4.1.2, to construct the final forecasting models for the forecast of the closing prices in the next second trading day, where the input variables are the 1st, 2nd, 5th, and 6th normalized technical indicators, denoted by \( \left( {f_{i1}^{\prime (2)} ,f_{i2}^{\prime (2)} ,f_{i2}^{\prime (2)} ,f_{i4}^{\prime (2)} } \right) \), that appeared in the preliminary optimal GP forecasting model (i.e., GP_Modelpre_2_day) and the output is the normalized closing price of the second trading day. When forecasting the closing price of the next third trading day, the 1st, 2nd, 4th, 5th, 9th, and 15th normalized technical indicators, denoted by \( \left( {f_{i1}^{'(3)} ,f_{i2}^{'(3)} , \ldots ,f_{i6}^{'(3)} } \right) \), that are contained in the preliminary optimal GP forecasting model (i.e., GP_Modelpre_3_day), serve as the input variables, and the normalized closing price of the third trading day serves as the output variable. Table 14 summarizes the partial execution results. The 5-23-1, 4-28-1, and 6-28-1 neural models are selected as the final optimal models for forecasting the closing prices of the next, next second, and next third trading days, and they are, respectively, named GP_BP_Modelfinal_1_day, GP_BP_Modelfinal_2_day, and GP_BP_Modelfinal_3_day.
Next, the retained normalized technical indicators \( \left( {f_{i1}^{(1)} ,f_{i2}^{(1)} , \ldots ,f_{i5}^{(1)} } \right) \), \( \left( {f_{i1}^{(2)} ,f_{i2}^{(2)} , \ldots ,f_{i5}^{(2)} } \right) \), and \( \left( {f_{i1}^{(3)} ,f_{i2}^{(3)} , \ldots ,f_{i6}^{(3)} } \right) \) for each trading day are fed into the appropriate corresponding forecast models, namely, BP_BP_Modelfinal_1_day, BP_BP_Modelfinal_2_day, and BP_BP_Modelfinal_3_day, to obtain the normalized forecasted futures prices for the next, next second, and next third trading days. The forecasted closing prices of futures can then be acquired by denormalizing these normalized forecasted futures prices. Similarly, the closing prices of the next, next second, and next third trading days can be acquired by inputting the normalized technical indicators \( \left( {f_{i1}^{\prime (1)} ,f_{i2}^{\prime (1)} , \ldots ,f_{i5}^{\prime (1)} } \right) \), \( \left( {f_{i1}^{\prime (2)} ,f_{i2}^{\prime (2)} ,f_{i2}^{\prime (2)} ,f_{i4}^{\prime (2)} } \right) \), and \( \left( {f_{i1}^{\prime (3)} ,f_{i2}^{\prime (3)} , \ldots ,f_{i6}^{\prime (3)} } \right) \) for each trading day to the appropriate corresponding final optimal BP models, namely, GP_BP_Modelfinal_1_day, GP_BP_Modelfinal_2_day, and GP_BP_Modelfinal_3_day, and denormalizing these output values.
4.4 Measuring the forecast performance
To evaluate the overall performance of the proposed forecasting procedure, the statistics, including root mean squared error (RMSE) and mean absolute percentage error (MAPE), as shown in (13) and (14), are used to assess forecast errors, as shown in Table 15. For comparison, this table also lists the performance evaluation regarding the preliminary optimal BP and GP forecasting models. In addition, the maximum and minimum absolute percentage errors (APEs), denoted by \( {\text{APE}}_{ \max } \) and \( {\text{APE}}_{ \min } \), respectively, are also available in this table. As shown in Table 15, some findings can be obtained from the forecasting results using the BP_BP_Modelfinal_1_day, BP_BP_Modelfinal_2_day, and BP_BP_Modelfinal_3_day models. The overall MAPEs of forecasting the closing futures prices of the next, next second, and next third trading days are a mere 1.36, 1.86, and 2.26%, respectively. The absolute percentage of the difference between the actual and forecasted closing prices is, on average, only 2.26%, even with respect to the most difficult case of forecasting, which is the forecast of the closing futures price of the next third trading day. This indicates that the proposed procedure in this study can yield a forecast of great precision for the closing futures prices over a given period of three trading days. In forecasting the closing futures price of the next trading day, the minimum APE attains the excellent level of 0.0001%, and the maximum APE is around 10.5%. In forecasting the closing futures price of the next third trading day, the maximum APE grows to 15.2% and the minimum APE still attains the excellent level of 0.0025%. The performance of forecasting the closing futures prices of the next 3 days via the BP_BP_Modelfinal_1_day, BP_BP_Modelfinal_2_day, and BP_BP_Modelfinal_3_day models is almost better than that obtained through the GP_BP_Modelfinal_1_day, GP_BP_Modelfinal_3_day, and GP_BP_Modelfinal_3_day models, with respect to RMSE, MAPE, the minimum APE, and the maximum APE. The only exception to this statement is that the maximum APE of BP_BP_Modelfinal_1_day is slightly larger than that acquired by GP_BP_Modelfinal_1_day. Hence, we can generally conclude that the feature selection method that uses the simulation technique based on the preliminary BP neural model is more effective in selecting important technical indicators for forecasting closing futures prices than the method that determines these indicators solely on the basis of the preliminary GP forecast models.
In addition, the final BP forecast models that use as input variables the retained normalized technical indicators based on the preliminary BP neural model and simulation technique perform better than their corresponding preliminary BP forecast models. Similarly, the final BP forecast models with input variables that appear in the preliminary GP models perform better than their corresponding preliminary GP forecast models, with one exception: the minimum APE of GP_BP_Modelfinal_2_day is somewhat larger than that of GP_Modelpre_2_day. Therefore, we can generally conclude that the technical indicators that are critical to the forecast of futures prices can be determined by applying a feature selection method that uses either a simulation technique based on the preliminary BP neural model or the screening technique of the preliminary GP forecast model. Based on the above analysis, the proposed forecasting procedure in this study can be considered an effective tool for forecasting futures prices in the next three trading days with the use of technical indicators.
5 Conclusions
With the inherent high volatility, complexity, and turbulence of stock/futures prices, financial forecasting is a challenging task that continues to be investigated by researchers and practitioners. The approaches undertaken in the past for tackling the stock/futures price forecasting problems can be broadly classified into three main categories: fundamental analysis, technical analysis, and traditional time series. Each of these approaches has its merits and limitations. In this study, a backpropagation (BP) neural network, a feature selection technique, and genetic programming (GP) were utilized to develop an integrated approach to deal with the stock/futures price forecasting problems. First, the BP neural network was used to construct a preliminary forecasting model that describes the complex nonlinear relationship between technical indicators and future stock/futures prices. Next, the feature selection technique based on simulation was utilized to explore the preliminary forecasting model; thus, the most important technical indicators for forecasting stock/futures prices were determined. For comparison, the GP algorithm was also employed to build another forecasting model that automatically screens the vital technical indicators which closely correlate with future stock/futures prices. Then, the BP neural network was applied again to construct the final stock/futures price forecasting model. At this stage, the technical indicators retained by the feature selection technique or GP algorithm were used as the input variables. Finally, the performance of the final forecasting model was evaluated and compared with that of the preliminary BP and GP forecasting models.
The feasibility and effectiveness of the proposed forecasting procedure were verified through a case study on forecasting the closing prices of Taiwan Stock Exchange Capitalization Weighted Stock Index (TAIEX) futures of the spot month over the period from January 2, 2001, to June 30, 2010. The obtained results showed that the overall mean absolute percentage errors (MAPEs) of forecasting the closing futures prices of the next and next second trading days were only 1.36 and 1.86%, respectively. Even in the most difficult case of forecasting, i.e., the forecast of the closing futures price in the next third trading day, the absolute percentage of the difference between the actual and forecasted closing prices was only 2.26%, on average. The analysis also indicated that the technical indicators which are critical to the forecast of futures prices can be determined by applying one of the following: a feature selection method that uses a simulation technique based on the preliminary BP neural model or the screening technique of the preliminary GP forecast model. Based on the above information, the proposed forecasting procedure can be considered a feasible and effective tool for stock/futures price forecasting.
However, the proposed forecasting procedure still has some limitations. First, during the construction of both the preliminary and final forecasting models, there are no absolute criteria based on the RMSE of the training and test data that will enable the selection of the optimal BP neural network or GP models. Next, the key parameter settings in BP neural networks or GP algorithms may influence the final training results; however, there are no exact rules for setting such key parameters. Finally, this study proposed the direction of change (CD) regarding the MAPE of the forecast and constructed the final BP forecasting models by developing a rule based on a simulation technique for selecting important normalized technical indicators as input variables. However, this is only a heuristic method, and the feasibility and effectiveness of the approach can only be verified through practical implementation. Further research directions suggested by this study might include using clustering techniques to divide the sample data into clusters such that the approximate functional model that describes an implicit mathematical relationship between the technical indicators and future closing stock/futures price can be constructed more easily and precisely. In addition, optimizing the parameters of BP neural networks or GP algorithms through other soft computing methods (e.g., particle swarm optimization or ant colony optimization) might be another future research direction.
References
Zarandi MHF, Rezaee B, Turksen IB, Neshat E (2009) A type-2 fuzzy rule-based expert system model for stock price analysis. Expert Syst Appl 36(1):139–154. doi:10.1016/j.eswa.2007.09.034
Thomsett MC (1998) Mastering fundamental analysis. Dearborn Finanical Publishing, Chicago
Thomsett MC (1999) Mastering technical analysis. Dearborn Finanical Publishing, Chicago
Box GEP, Jenkins GM (1970) Time series analysis, forecasting and control. Holden-Day, San Francisco
Bollerslev T (2001) Generalized autoregressive conditional heteroskedasticity. J Econ 100(1):A307–A327
Pai PF, Lin CS (2005) A hybrid ARIMA and support vector machines model in stock price forecasting. Omega-Int J Manag Sci 33(6):497–505. doi:10.1016/j.omega.2004.07.024
Chang PC, Liu CH (2008) A TSK type fuzzy rule based system for stock price prediction. Expert Syst Appl 34(1):135–144. doi:10.1016/j.eswa.2006.08.020
Ince H, Trafalis TB (2008) Short term forecasting with support vector machines and application to stock price prediction. Int J Gen Syst 37(6):677–687. doi:10.1080/03081070601068595
Huang CL, Tsai CY (2009) A hybrid SOFM-SVR with a filter-based feature selection for stock market forecasting. Expert Syst Appl 36(2):1529–1539. doi:10.1016/j.eswa.2007.11.062
Liang X, Zhang HS, Mao JG, Chen Y (2009) Improving option price forecasts with neural networks and support vector regressions. Neurocomputing 72(13–15):3055–3065. doi:10.1016/j.neucom.2009.03.015
Hadavandi E, Shavandi H, Ghanbari A (2010) Integration of genetic fuzzy systems and artificial neural networks for stock price forecasting. Knowl Based Syst 23(8):800–808. doi:10.1016/j.knosys.2010.05.004
Lu CJ (2010) Integrating independent component analysis-based denoising scheme with neural network for stock price prediction. Expert Syst Appl 37(10):7056–7064. doi:10.1016/j.eswa.2010.03.012
Cheng CH, Chen TL, Wei LY (2010) A hybrid model based on rough sets theory and genetic algorithms for stock price forecasting. Inf Sci 180(9):1610–1629. doi:10.1016/j.ins.2010.01.014
Fausett L (1994) Fundamentals of neural networks: architectures, algorithms, and applications. Prentice-Hall, Englewood Cliffs
Patterson DW (1996) Artificial neural networks: theory and applications. Prentice Hall, Singapore
Lin CT, Yeh HY (2009) Empirical of the Taiwan stock index option price forecasting model—applied artificial neural network. Appl Econ 41(15):1965–1972. doi:10.1080/00036840601131672
Yazici B, Memmedli M, Aslanargun A, Asma S (2010) Analysis of international debt problem using artificial neural networks and statistical methods. Neural Comput Appl 19(8):1207–1216. doi:10.1007/s00521-010-0422-4
Bilgili M, Sahin B (2010) Comparative analysis of regression and artificial neural network models for wind speed prediction. Meteorol Atmos Phys 109(1–2):61–72. doi:10.1007/s00703-010-0093-9
Hashemi MR, Ghadampour Z, Neill SP (2010) Using an artificial neural network to model seasonal changes in beach profiles. Ocean Eng 37(14–15):1345–1356. doi:10.1016/j.oceaneng.2010.07.004
Liu H, Motoda H (1998) Feature selection for knowledge discovery and data mining. Kluwer, Boston
Piramuthu S (2004) Evaluating feature selection methods for learning in data mining applications. Eur J Oper Res 156(2):483–494. doi:10.1016/s0377-2217(02)00911-6
Kohavi R, John GH (1997) Wrappers for feature subset selection. Artif Intell 97(1–2):273–324. doi:10.1016/s0004-3702(97)00043-x
Battiti R (1994) Using mutual information for selecting features in supervised neural-net learning. IEEE Trans Neural Netw 5(4):537–550
Jensen R, Shen Q (2005) Fuzzy-rough data reduction with ant colony optimization. Fuzzy Sets Syst 149(1):5–20. doi:10.1016/j.fss.2004.07.014
Song XP, Ding YS, Huang JW, Ge Y (2010) Feature selection for support vector machine in financial crisis prediction: a case study in China. Expert Syst 27(4):299–310. doi:10.1111/j.1468-0394.2010.00546.x
Bradley PS, Mangasarian OL, Street WN (1998) Feature selection via mathematical programming. INFORMS J Comput 10(2):209–217
Mladenic D (2006) Feature selection for dimensionality reduction. In: Saunders G, Grobelnik M, Gunn S, ShaweTaylor J (eds) Subspace, latent structure and feature selection, vol 3940. Lecture notes in computer science, pp 84–102
Sivanandam SN, Deepa SN (2008) Introduction to genetic algorithms. Springer, Berlin
Koza JR, Keane MA, Streeter MJ, Mydlowec W, Yu J, Lanza G (2005) Genetic programming IV: routine human-competitive machine intelligence
Koza JR, Streeter MJ, Keane MA (2008) Routine high-return human-competitive automated problem-solving by means of genetic programming. Inf Sci 178(23):4434–4452. doi:10.1016/j.ins.2008.07.028
Ciglaric I, Kidric A (2006) Computer-aided derivation of the optimal mathematical models to study gear-pair dynamic by using genetic programming. Struct Multidiscip Optim 32(2):153–160. doi:10.1007/s00158-006-0004-3
Etemadi H, Rostamy AAA, Dehkordi HF (2009) A genetic programming model for bankruptcy prediction: empirical evidence from Iran. Expert Syst Appl 36(2):3199–3207. doi:10.1016/j.eswa.2008.01.012
Hwang TM, Oh H, Choung YK, Oh S, Jeon M, Kim JH, Nam SH, Lee S (2009) Prediction of membrane fouling in the pilot-scale microfiltration system using genetic programming. Desalination 247(1–3):285–294. doi:10.1016/j.desal.2008.12.031
Bae H, Jeon TR, Kim S, Kim HS, Kim D, Han SS, May GS (2010) Optimization of silicon solar cell fabrication based on neural network and genetic programming modeling. Soft Comput 14(2):161–169. doi:10.1007/s00500-009-0438-9
Langdon WB, Poli R (2002) Foundations of genetic programming. Springer, New York
Kim KJ, Han I (2000) Genetic algorithms approach to feature discretization in artificial neural networks for the prediction of stock price index. Expert Syst Appl 19(2):125–132
Kim KJ, Lee WB (2004) Stock market prediction using artificial neural networks with optimal feature transformation. Neural Comput Appl 13(3):255–260. doi:10.1007/s00521-004-0428-x
Tsang PM, Kwok P, Choy SO, Kwan R, Ng SC, Mak J, Tsang J, Koong K, Wong TL (2007) Design and implementation of NN5 for Hong Kong stock price forecasting. Eng Appl Artif Intell 20(4):453–461. doi:10.1016/j.engappai.2006.10.002
Lai RK, Fan CY, Huang WH, Chang PC (2009) Evolving and clustering fuzzy decision tree for financial time series data forecasting. Expert Syst Appl 36(2):3761–3773. doi:10.1016/j.eswa.2008.02.025
Author information
Authors and Affiliations
Corresponding author
Appendix: Descriptions and definitions of technical indicators used in this study
Appendix: Descriptions and definitions of technical indicators used in this study
1.1 Notations
- i :
-
The day i
- \( {\text{HP}}_{i} \) :
-
The highest price of day i
- \( {\text{LP}}_{i} \) :
-
The lowest price of day i
- \( {\text{OP}}_{i} \) :
-
The opening price of day i
- \( {\text{CP}}_{i} \) :
-
The closing price of day i
- \( {\text{TV}}_{i} \) :
-
The trade volume of day i
-
1.
10-day moving average
The 10-day moving average is the mean price of the futures over the most recent 10 days and is calculated by:
$$ {\text{MA}}\_10_{i} = \frac{{\sum\nolimits_{j = i - 9}^{i} {{\text{CP}}_{j} } }}{10}. $$(18) -
2.
20-day bias
The 20-day bias is the deviation between the closing price and the 20-day moving average (MA_20) and is calculated by:
$$ {\text{BIAS}}\_20_{i} = \frac{{{\text{CP}}_{i} - {\text{MA}}\_20_{i} }}{{{\text{MA}}\_20_{i} }} . $$(19) -
3.
Moving average convergence/divergence
The moving average convergence/divergence is a momentum indicator that shows the relationship between two moving averages. First, define the demand index (DI) as:
$$ {\text{DI}}_{i} = {{\left( {{\text{HP}}_{i} + {\text{LP}}_{i} + 2 \times {\text{CP}}_{i} } \right)} \mathord{\left/ {\vphantom {{\left( {{\text{HP}}_{i} + {\text{LP}}_{i} + 2 \times {\text{CP}}_{i} } \right)} 4}} \right. \kern-\nulldelimiterspace} 4} . $$(20)Next, define the 12-day exponential moving average (EMA_12) and 26-day exponential moving average (EMA_26) as:
$$ {\text{EMA}}\_12_{i} = \frac{11}{13} \times {\text{EMA}}\_12_{i - 1} + \frac{2}{13} \times {\text{DI}}_{i} $$(21)and
$$ {\text{EMA}}\_26_{i} = \frac{25}{27} \times {\text{EMA}}\_26_{i - 1} + \frac{2}{27} \times {\text{DI}}_{i}, $$(22)respectively. Then, the difference between EMA_12 and EMA_26 can be calculated by:
$$ {\text{DIF}}_{i} = {\text{EMA}}\_12_{i} - {\text{EMA}}\_26_{i} . $$(23)Hence, the moving average convergence/divergence can be defined by:
$$ {\text{MACD}}_{i} = \frac{8}{10} \times {\text{MACD}}_{i - 1} + \frac{2}{10} \times {\text{DIF}}_{i} . $$(24) -
4.
9-day stochastic indicator K
The 9-day stochastic indicator K is defined as:
$$ \text{K}\_9_{i} = \frac{2}{3} \times \text{K}\_9_{i - 1} + \frac{1}{3} \times \frac{{{\text{CP}}_{i} - {\text{LP}}\_9_{i} }}{{{\text{HP}}\_9_{i} - {\text{LP}}\_9_{i} }} \times 100. $$(25)where \( {\text{LP}}\_9_{i} \) and \( {\text{HP}}\_9_{i} \) are the lowest and highest prices of the previous 9 days, i.e., days i, i − 1, …, i − 7, and i − 8, respectively.
-
5.
9-day stochastic indicator D
The 9-day stochastic indicator D is defined as:
$$ \text{D}\_9_{i} = \frac{2}{3} \times \text{D}\_9_{i - 1} + \frac{1}{3} \times {\text K}\_9_{i} . $$(26)where \( \text{K}\_9_{i} \) is the 9-day stochastic indicator K of day i, as previously defined.
-
6.
9-day Williams overbought/oversold index
The 9-day Williams overbought/oversold index is a momentum indicator that measures overbought and oversold levels and is calculated by:
$$ {\text{WMS}}\% \text{R}\_9_{i} = \frac{{{\text{HP}}\_9_{i} - {\text{CP}}_{i} }}{{{\text{HP}}\_9_{i} - {\text{LP}}\_9_{i} }} $$(27)where \( {\text{LP}}\_9_{i} \) and \( {\text{HP}}\_9_{i} \) are the lowest and highest prices of the previous 9 days, i.e., days i, i − 1, …, i − 7, and i − 8, respectively.
-
7.
10-day rate of change
The 10-day rate of change measures the percent changes of the current price relative to the price of 10 days ago and is calculated by:
$$ {\text{ROC}}\_10_{i} = \frac{{{\text{CP}}_{i} - {\text{CP}}_{i - 10} }}{{{\text{CP}}_{i - 10} }} \times 100. $$(28) -
8.
5-day relative strength index
The relative strength index is a momentum oscillator that compares the magnitude of recent gains to the magnitude of recent losses. First, define the gain of day i as:
$$ \text{G}_{i} = \left\{ {\begin{array}{*{20}c} {{\text{CP}}_{i} - {\text{CP}}_{i - 1} } \hfill & {{\text{if}}\quad {\text{CP}}_{i} > {\text{CP}}_{i - 1} } \hfill \\ 0 \hfill & {\text{otherwise}} \hfill \\ \end{array} } \right..$$(29)Similarly, the loss of day i is calculated by:
$$ \text{L}_{i} = \left\{ {\begin{array}{*{20}c} {{\text{CP}}_{i - 1} - {\text{CP}}_{i} } \hfill & {{\text{if}}\quad {\text{CP}}_{i} < {\text{CP}}_{i - 1} } \hfill \\ 0 \hfill & {\text{otherwise}} \hfill \\ \end{array} } \right..$$(30)Next, the 5-day average gain (AG_5) and 5-day average loss (AL_5) can be calculated by:
$$ {\text{AG}}\_5_{i} = \frac{4}{5} \times {\text{AG}}\_5_{i - 1} + \frac{1}{5} \times \text{G}_{i} $$(31)and
$$ {\text{AL}}\_5_{i} = \frac{4}{5} \times {\text{AL}}\_5_{i - 1} + \frac{1}{5} \times \text{L}_{i} , $$(32)respectively. Hence, the 5-day relative strength index can be defined by:
$$ {\text{RSI}}\_5_{i} = \frac{{{\text{AG}}\_5_{i} }}{{{\text{AG}}\_5_{i} + {\text{AL}}\_5_{i} }} \times 100. $$(33) -
9.
24-day commodity channel index
The commodity channel index is used to identify cyclical turns in commodities. First, define the typical price (TP) as:
$$ {\text{TP}}_{i} = \frac{{{\text{HP}}_{i} + {\text{LP}}_{i} + {\text{CP}}_{i} }}{3}. $$(34)Next, calculate the 24-day simple moving average of the typical price (SMATP_24) by:
$$ {\text{SMATP}}\_24_{i} = \frac{{\sum\nolimits_{j = i - 23}^{i} {{\text{TP}}_{j} } }}{24}. $$(35)Then, the 24-day mean deviation (MD_24) can be calculated by:
$$ {\text{MD}}\_24_{i} = \frac{{\sum\nolimits_{j = i - 23}^{i} { | {\text{TP}}_{j} - {\text{SMATP}}\_24_{i} |} }}{24}. $$(36)Hence, the 24-day commodity channel index can be defined as:
$$ {\text{CCI}}\_24_{i} = \frac{{{\text{TP}}_{i} - {\text{SMATP}}\_24_{i} }}{{0.015 \times {\text{MD}}\_24_{i} }}. $$(37) -
10.
26-day volume ratio
The 26-day volume ratio is defined by:
$$ {\text{VR}}\_26_{i} = \frac{{{{{\text{TVU}}\_26_{i} - {\text{TVF}}\_26_{i} } \mathord{\left/ {\vphantom {{{\text{TVU}}\_26_{i} - {\text{TVF}}\_26_{i} } 2}} \right. \kern-\nulldelimiterspace} 2}}}{{{{{\text{TVD}}\_26_{i} - {\text{TVF}}\_26_{i} } \mathord{\left/ {\vphantom {{{\text{TVD}}\_26_{i} - {\text{TVF}}\_26_{i} } 2}} \right. \kern-\nulldelimiterspace} 2}}} \times 100\% . $$(38)where \( {\text{TVU}}\_26_{i} \), \( {\text{TVD}}\_26_{i} \), and \( {\text{TVF}}\_26_{i} \) represent the total trade volumes of stock prices rising, falling, and holding, respectively, from the previous 26 days, i.e., days i, i − 1, …, i – 24, and i − 25.
-
11.
13-day psychological line
The psychological line is a volatility indicator based on the number of time intervals that the market was up during the preceding period. The 13-day psychological line is defined by:
$$ {\text{PSY}}\_13_{i} = \frac{{{\text{TDU}}\_13_{i} }}{13} \times 100\% . $$(39)where \( {\text{TDU}}\_13_{i} \) is the total number of days with regard to stock price rises of the previous 13 days, i.e., days i, i − 1, …, i – 11, and i − 12.
-
12.
14-day plus directional indicator
First, define plus directional movement (+DM) and minus directional movement (−DM) as:
$$ + {\text{DM}}_{i} = {\text{HP}}_{i} - {\text{HP}}_{i - 1} $$(40)and
$$ - {\text{DM}}_{i} = {\text{LP}}_{i - 1} - {\text{LP}}_{i}, $$(41)respectively. The plus true directional movement (+TDM) can be calculated by:
$$ + {\text{TDM}}_{i} = \left\{ {\begin{array}{*{20}c} { + {\text{DM}}_{i} } \hfill & {{\text{if}}\quad + {\text{DM}}_{i} > - {\text{DM}}_{i} \quad {\text{and}}\quad + {\text{DM}}_{i} > 0} \hfill \\ 0 \hfill & {\text{otherwise}} \hfill \\ \end{array} } \right.. $$(42)Similarly, the minus true directional movement (−TDM) can be calculated by:
$$ - {\text{TDM}}_{i} = \left\{ {\begin{array}{*{20}c} { - {\text{DM}}_{i} } \hfill & {{\text{if}}\quad + {\text{DM}}_{i} < - {\text{DM}}_{i} \quad {\text{and}}\quad - {\text{DM}}_{i} > 0} \hfill \\ 0 \hfill & {\text{otherwise}} \hfill \\ \end{array} } \right.. $$(43)Hence, the 14-day plus directional movement (+DM_14) can be calculated by:
$$ + {\text{DM}}\_14_{i} = \frac{13}{14} \times \left( { + {\text{DM}}\_1 4_{i - 1} } \right) + \frac{1}{14} \times \left( { + {\text{TDM}}_{i} } \right). $$(44)Similarly, the 14-day minus directional movement (−DM_14) can be calculated by:
$$ - {\text{DM}}\_14_{i} = \frac{13}{14} \times \left( { - {\text{DM}}\_14_{i - 1} } \right) + \frac{1}{14} \times \left( { - {\text{TDM}}_{i} } \right). $$(45)Next, define the true range (TR) as:
$$ {\text{TR}}_{i} = {\text{Max}}\{ {\text{HP}}_{i} - {\text{LP}}_{i} ,|{\text{HP}}_{i} - {\text{CP}}_{i - 1} |,|{\text{LP}}_{i} - {\text{CP}}_{i - 1} |\} . $$(46)The 14-day true range (TR_14) can be calculated by:
$$ {\text{TR}}\_14_{i} = \frac{13}{14} \times {\text{TR}}\_14_{i - 1} + \frac{1}{14} \times {\text{TR}}_{i} . $$(47)Therefore, the 14-day plus directional indicator can be defined as:
$$ + {\text{DI}}\_14_{i} = \frac{{ + {\text{DM}}\_14_{i} }}{{{\text{TR}}\_14_{i} }}. $$(48) -
13.
14-day minus directional indicator
The 14-day minus directional indicator is defined as:
$$ - {\text{DI}}\_14_{i} = \frac{{ - {\text{DM}}\_14_{i} }}{{{\text{TR}}\_14_{i} }}. $$(49)where \( - {\text{DM}}\_14_{i} \) and \( {\text{TR}}\_14_{i} \) are, respectively, the 14-day minus directional movement and 14-day true range of day i, as previously defined in (45) and (47).
-
14.
26-day buying/selling momentum indicator
The 26-day buying/selling momentum indicator is defined as:
$$ {\text{AR}}\_26_{i} = \frac{{\sum\nolimits_{j = i - 25}^{i} {\left( {{\text{HP}}_{j} - {\text{OP}}_{j} } \right)} }}{{\sum\nolimits_{j = i - 25}^{i} {\left( {{\text{OP}}_{j} - {\text{LP}}_{j} } \right)} }}. $$(50) -
15.
26-day buying/selling willingness indicator
The 26-day buying/selling willingness indicator is defined as:
$$ {\text{BR}}\_26_{i} = \frac{{\sum\nolimits_{j = i - 25}^{i} {\left( {{\text{HP}}_{j} - {\text{CP}}_{j - 1} } \right)} }}{{\sum\nolimits_{j = i - 25}^{i} {\left( {{\text{CP}}_{j - 1} - {\text{LP}}_{j} } \right)} }}. $$(51)
Rights and permissions
About this article
Cite this article
Hsu, CM. A hybrid procedure with feature selection for resolving stock/futures price forecasting problems. Neural Comput & Applic 22, 651–671 (2013). https://doi.org/10.1007/s00521-011-0721-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-011-0721-4