
Abstract
The study aims were to compare two models (The Pediatric Risk of Mortality III (PRISM III) and Pediatric Logistic Organ Dysfunction (PELOD-2)) for prediction of mortality in a pediatric intensive care unit (PICU) and recalibrate PELOD-2 in a Portuguese population. To achieve the previous goal, a prospective cohort study to evaluate score performance (standardized mortality ratio, discrimination, and calibration) for both models was performed. A total of 556 patients consecutively admitted to our PICU between January 2011 and December 2012 were included in the analysis. The median age was 65 months, with an interquartile range of 1 month to 17 years. The male-to-female ratio was 1.5. The median length of PICU stay was 3 days. The overall predicted number of deaths using PRISM III score was 30.8 patients whereas that by PELOD-2 was 22.1 patients. The observed mortality was 29 patients. The area under the receiver operating characteristics curve for the two models was 0.92 and 0.94, respectively. The Hosmer and Lemeshow goodness-of-fit test showed a good calibration only for PRISM III (PRISM III: χ 2 = 3.820, p = 0.282; PELOD-2: χ 2 = 9.576, p = 0.022).
Conclusions: Both scores had good discrimination. PELOD-2 needs recalibration to be a better reliable prediction tool.
What is Known: • PRISM III (Pediatric Risk of Mortality III) and PELOD (Pediatric Logistic Organ Dysfunction) scores are frequently used to assess the performance of intensive care units and also for mortality prediction in the pediatric population. • Pediatric Logistic Organ Dysfunction 2 is the newer version of PELOD and has recently been validated with good discrimination and calibration. |
What is New: • In our population, both scores had good discrimination. • PELOD-2 needs recalibration to be a better reliable prediction tool. |
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Mortality reduction is an important aim of a pediatric intensive care unit (PICU). Risk-adjustment tools that predict death in PICUs are a rational and objective way to quantify severity and have become established in the past 20 years [3].
Diverse scoring systems have been developed for all age groups including pediatric [22, 26]. Mortality is the most frequently assessed outcome. These scores have been developed not to predict the outcome of individual patient, but as tools for assessing the performance of intensive care units relative to other units, to outcome measure, and/or to enrollment criteria in clinical trials. Pediatric Risk of Mortality III (PRISM III) and Pediatric Logistic Organ Dysfunction (PELOD) scores are frequently used for mortality prediction in the pediatric population [2, 11, 13, 20, 28]. PELOD-2 is the newer version of PELOD and has recently been validated with good discrimination and calibration [14].
To make use of these scores, it is important to know if the score is relevant and valid in a patient population, which is different from the population in whom it was derived. There are very few published studies which evaluated the performance of severity of illness scoring systems in Portuguese PICUS [17, 18]. PELOD-2 performance has not been estimated in Portugal.
The objectives of this study were to evaluate the performance of the PRISM III and PELOD-2 scores, investigating the relationship between observed outcomes (death/survival), the mortality and survival rates in children admitted in PICU; to determine the suitability of each score for monitoring the quality of intensive care in our unit; and to recalibrate PELOD-2 in our population.
Materials and methods
A cohort study was conducted in a Portuguese PICU. Several data were collected prospectively for PRISM III estimation. Using these data, PELOD-2 estimation was also possible. All patients (1 month to 18 years old) requiring PICU admission over a period of 24 months from January 2011 to December 2012 were included in this study.
Patients with a PICU stay less or dying within the first 8 h of admission, younger than 1 month or older than 18 years old, those transferred to other PICUs, and those with missing information on variables used to estimate the PRISM III and PELOD-2 scores were excluded from the study. Patients who left against medical advice were excluded from the study as the outcome was not known.
Age, gender, diagnosis at the time of PICU admission, post-surgical care and mechanical ventilation requirements, length of PICU stay, and outcome (survived/death) were recorded on a data collection form devised for the study.
For the PRISM III score, several variables (namely systolic and diastolic blood pressures, heart rate, respiratory rate, PaO2/FiO2 ratio (partial pressure of arterial oxygen/fraction of inspired oxygen ratio), PaCo2 (partial pressure of arterial carbon dioxide), Glasgow Coma Scale (GCS), pupillary reaction, PT (prothrombin time), ratio (test/control), total bilirubin, serum potassium, serum calcium, blood glucose, and serum bicarbonate) were collected at 24 h of PICU admission. Data collected was entered in Pediatric Intensive Care Unit Evaluations Software–PRISM III program (PICUEs version 3.2.4). Details of the components of PRISM III can be found in Pollack et al.’s paper [20].
For the PELOD-2 score, five organ systems (neurologic, cardiovascular, respiratory, renal, and hematologic) are considered and 10 variables (namely GCS, pupillary reaction, lactatemia, mean arterial blood pressures, PaO2/FiO2 ratio, PaCo2, invasive ventilation, creatinine, white blood cell count, and platelets) were collected at 24 h of PICU admission. If a variable was measured more than once in 24 h, the worst value was used in calculating the score. Details of the components of PELOD-2 score, together with the coefficients allowing calculation of mortality risk, are given elsewhere [14]. This study was reviewed by the local institutional review board and is exempt from requiring approval.
Statistical analysis
Descriptive analysis was utilized for sample characterization (mean, median, standard deviation). The distribution of variables was tested by the Kolmogorov–Smirnov test. Mann–Whitney test was used to compare two or more independent samples, according to variables’ distribution.
Comparison of the general similarity between observed mortality and that estimated by the standardized mortality rate (SMR) was calculated [6]. The SMR is the ratio of risk adjusted, observed mortality to the expected mortality derived from the development set. If the 95 % confidence intervals (95 % CI) around the SMR are less than 1.0, then mortality is lower than that seen in the development set; conversely, confidence intervals greater than 1.0 signify a higher mortality. If the 95 % confidence interval of the SMR includes the value 1.0, the observed number of deaths is not significantly different than the expected number of deaths.
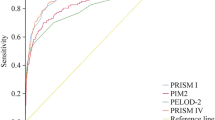
The capacity of PRISM III and PELOD-2 scores for discrimination between survived and expired patients (capacity of discrimination) was calculated by receiver operator characteristics (ROC) curve [24]. Acceptable discrimination is represented by an area under the curve of 0.70–0.79, good discrimination by an area ≥0.80, and excellent discrimination by an area ≥0.90 [8].
For scores’ aptness, the Hosmer–Lemeshow goodness-of-fit test was employed to test the agreement between observed and predicted risks of death within quintiles of risk score (calibration). Calibration signifies how well the test predicts both mortality and survival across subcategories of risk. Acceptable calibration is evidenced by a p value ≥0.05 [10]. Otherwise, the model score has no justification to be applied in that population. In this case, to recalibrate the model, an adjustment of the intercept and the regression coefficient using the calibration intercept (λ b) and calibration slope (β b) must be performed [9].
To estimate the magnitude of the association between each score and mortality occurrence, odds ratios (OR) and the respective 95 % confidence intervals were calculated using unconditional logistic regression. Two different models were considered: crude model (model 1) and model 2 adjusting for age, sex, category of illness on admission, post-surgical care, mechanical ventilation required, and length of stay in PICU. Considering that PRISM III and PELOD-2 scores do not share a common scale, the authors have standardized the scores to have a common mean of zero and a standard deviation of one (that is, convert them to z-scores). Such standardization would enable to describe impact estimates as effect sizes, which facilitate the comparison or aggregation of impact estimates based on distinct assessments. For scores not calibrated to our population, to improve its performance, a recalibration was performed by using new data.
Data was analyzed using Statistical Program for Social Science version 22.0 (SPSS Inc, Chicago, IL, USA, 2013). The significance level was set at 5 %.
Results
Out of 589 critically ill children consecutively admitted to PICU, 33 were excluded due to exclusion criteria previously described (one death in the first 8 h after PICU admission). Thus, the final sample included 556 patients (331 boys and 225 girls).
Participant’s characteristics are described in Table 1. The median age of the patients was 65 months (IQR 1–214). A median of 5 points was observed for each score. Disease categories included infection (4.7 %), respiratory (16.9 %), cardiovascular (23.9 %), neurological (14.9 %), cancer (12.1 %), and trauma (12.9 %). Sixty-nine percent of patients were mechanically ventilated. The median length of PICU stay was 3 days (IQR 0–155), and the crude mortality was 5.2 % (29/556).
Total PRISM III and PELOD-2 scores were significantly higher in patients having outcome as death, and in that order, they predicted 30.76 (5.5 %) and 22.14 (4.0 %) deaths (Tables 2 and 3). The positive predictive value (PPV) for patient’s mortality highest risk (5th quintile) was 22 % for PRISM III and 24 % for PELOD-2 (Table 3). The 22 patients who have died and been identified in the 5th quintile by PELOD-2 are also identified in the 5th quintile by PRISM III.
The prognostic scoring systems performances are showed in Table 4. The Hosmer and Lemeshow goodness of fit test showed a good calibration for PRISM III score (χ 2 = 3.820, p = 0.282). Overall, the PELOD-2 underestimated the risk of death. Goodness-of-fit chi-square test demonstrated statistically lack of fit (χ 2 = 9.576, p = 0.022) (Table 4). PELOD-2 recalibrations using the calibration intercept λ b and calibration slope β b resulted in good fit and adequate prediction of risk of death. The recalibrated model is represented by the equation: logit(mortality) = − 15, 17 + 0, 34xPELOD − 2 (χ 2 = 3.820, p = 0.282).
Nonetheless, PELOD-2 showed better discrimination using area under ROC (AUC = 0.94 (0.90–0.98)) than PRISM III (AUC = 0.92 (0.86–0.97)). This is confirmed by the logistic regression models (Table 5). After adjustment for several variables including age, sex, category of illness on admission, post-surgical care, mechanical ventilation required, and length of stay in PICU, each 1 unit (z-score) increase in PRISM III and PELOD-2 was associated with a 6.2- (OR 6.2 [95 % CI 3.4–11.3]) and 10-fold (OR 10.0 [95 % CI 4.8–20.8]) increased risk of death, respectively.
Discussion
In this study, we compared PRISM III and PELOD-2 performance evaluating the calibration and discrimination for both scores. Calibration is more important while comparing expected and observed outcome at various intervals of severity. Discrimination is important while distinguishing the outcome either survival or moribund among the admitted patients.
A discriminatory power of 0.90 (AUC) or more is considered excellent, and it was observed for PRISM III (0.92) and PELOD-2 (0.94). The closer the ROC curve area is to 1.0, the better the prediction model [5]. For PRISM III, a Chinese study has shown an area under ROC curve higher than 0.90 [4]. Other studies have also showed good performance for PRISM III [7, 4, 12, 21, 25]. PELOD-2 was only validated in one multicenter cohort study (nine PICUs from France and Belgium) [14]. Our result for PELOD-2 discrimination is similar to those published in the previous study. Leteurtre et al.’s study have shown for PELOD-2 a good discrimination (AUC of 0.94 (95 % CI, 0.93–0.96)). In the same study, the Hosmer and Lemeshow goodness-of-fit test showed also a good calibration (χ 2 = 0.931, p = 0.317). PELOD-2 seems to be not calibrated for our popu-lation. After recalibration, the original equation logit(mortality) = − 6, 61 + 0, 47xPELOD − 2 is converted into logit(mortality) = − 15, 17 + 0, 34xPELOD − 2. The coefficients allowing calculation of mortality risk are given by \( Probability\; of\; death=\frac{1}{\left(1+ \exp \left[- logit(mortality)\right]\right)} \).
As the prognostic model PELOD-2 demonstrated poor calibration, its application in the original form in our population finds no justification. However, it has been shown that when the discrimination of the model is sufficient, recalibration using new data improves its performance in a given population [9].
The mortality in the present study was 5.2 %. This mortality was similar to the documented rates at other European PICUs where the proportion of post-surgical is also higher [14, 19]. Standardized mortality ratio of the present study population with PELOD-2 was 1.31 as compared to 0.94 for the PRISM III score. The SMR reported in this study based on the PRISM III score was lower than 1.0 and so similar to that reported from 10 PICUs in Australia and New Zealand [25], Netherlands [7], and China [4]. A SMR higher than 1.0 was observed for PELOD-2, but the observed number of deaths was not significantly different than the expected number of deaths.
The underprediction of mortality by PELOD-2 compared to PRISM III could be explained because the predictive mortality models could be population sensitive, so validation studies are necessary before application in another setting. It is important to assume that the model’s prediction accuracy is affected by different case mix between our population and the original, that is, by a different distribution of outcome and predictive factors whether included in the model or not [16].
Median duration of stay in PICU (3 days) was similar to data from most PICUs in developed countries [4, 14]. This result is explained by the higher surgical post-recovery patient rates that generally require a short stay in intensive care setting.
PELOD-2 had an edge over PRISM III having fewer variables making assessment more convenient. Fewer variables could be economically more acceptable and also make the uniform training of PICU staff more convenient [1]. The collection of a large amount of information needed to calculate PRISM III is laborious.
To date, no consensus has been reached as to which score constitutes the gold standard. We can state that PRISM III and PELOD-2 offers good discrimination. But, only PRISM III is accurately calibrated for our population. So, PRISM III is a tool with better performance in our population. Although the use of clinical scoring systems to predict death in individuals is not recommended, they permit categorization into a particular risk category for clinical trials [15]. In our population, a low PPV for mortality of a patient actually being in the 5th quintile was observed, which is 22/91 (24 %) for the PELOD 2 and 24/111 (22 %) for the PRISM III.
In this study, we recognize several limitations. Given the nature of the study, the quality of recorded data could threaten the validity of findings. However, variables prospectively collected for PRISM III comprise essential clinical information for PELOD-2 estimation.
Considering the nature of the present study, comparison of different scores, the exclusion criteria defined could be not consensual. In PRISM III, patients staying in PICU <2 h and those admitted in continuous cardiopulmonary resuscitation who do not achieved stable vital signs for ≥2 h were excluded [20]. The PEDOD-2 publication does not exclude patients due to too short survival time after admission to PICU, and so the score does not require a 24-h assessment period [14]. In other comparative score performance studies, death within the first 8 and 10 h of PICU admission was an exclusion criteria [23, 27]. This time, selection could change the score prediction and introduce lead–time bias. Nonetheless, short time survival in PICU could lead a death diagnosis role of score rather than predicting it. Moreover, using this 8-h period as an exclusion criteria, we decrease the possibility of length–time bias. The score will be more able to identify patients with worse condition and early event than those with less severe condition. The study was conducted in a single center with experience in pediatric intensive care management and may not be representative of the Portuguese PICU population. However, the multidisciplinary character of the unit and big geographical area that it serves makes this limitation less possible.
It is important to stress that the recalibrated risk prediction function for both scores has not been validated in an independent cohort. PELOD-2 has only been validated in the bootstrapped original derivation patient set, and so it may have been overfit to our population. Future thoughts could include the extension of the study in the same and other Portuguese PICUs, so that potential multicentre higher population studies could offer an even better assessment of PRISM III and PELOD-2 performance and the establishment of a national standard.
In conclusion, this study shows that PRISM III had good discrimination and calibration in our pediatric population that required intensive critical care. After sample adjustment, the recalibrated PELOD-2 score seems to be credible in clinical practice and may provide useful information to physicians. Through this recalibration in our population, it is important to keep in mind that PELOD-2 does not demonstrate good calibration in this small Portuguese population.
Abbreviations
- GCS:
-
Glasgow Coma Scale
- PaO2/FiO2 ratio:
-
Partial pressure of arterial oxygen/fraction of inspired oxygen ratio
- PaCo2:
-
Partial press ure of arterial carbon dioxide
- PELOD:
-
Pediatric Logistic Organ Dysfunction
- PICU:
-
Pediatric intensive care unit
- PPV:
-
Positive predictive value
- PRISM III:
-
Pediatric Risk of Mortality III
- PT:
-
Prothrombin time
- ROC:
-
Receiver operator characteristic
- SMR:
-
Standardized mortality rate
References
Altman DG, Royston P (2000) What do we mean by validating a prognostic model? Stat Med 19(4):453–473
Bilan N, Galehgolab BA, Emadaddin A, Shiva S (2009) Risk of mortality in pediatric intensive care unit, assessed by PRISM-III. Pak J Biol Sci: PJBS 12(6):480–485
Brady AR, Harrison D, Black S, Jones S, Rowan K, Pearson G, Ratcliffe J, Parry GJ (2006) Assessment and optimization of mortality prediction tools for admissions to pediatric intensive care in the United Kingdom. Pediatrics 117(4):e733–e742. doi:10.1542/peds.2005-1853
Choi KM, Ng DK, Wong SF, Kwok KL, Chow PY, Chan CH, Ho JC (2005) Assessment of the Pediatric Index of Mortality (PIM) and the Pediatric Risk of Mortality (PRISM) III score for prediction of mortality in a paediatric intensive care unit in Hong Kong. Hong Kong Med J Xianggang Yi Xue Za Zhi Hong Kong Acad Med 11(2):97–103
Faraggi D, Reiser B (2002) Estimation of the area under the ROC curve. Stat Med 21(20):3093–3106. doi:10.1002/sim.1228
Flora JD Jr (1978) A method for comparing survival of burn patients to a standard survival curve. J Trauma 18(10):701–705
Gemke RJ, van Vught J (2002) Scoring systems in pediatric intensive care: PRISM III versus PIM. Intensive Care Med 28(2):204–207. doi:10.1007/s00134-001-1185-2
Hosmer D, Lemeshow S (2000) Applied logistic regression, 2nd edn. Wiley, New York
Janssen KJ, Moons KG, Kalkman CJ, Grobbee DE, Vergouwe Y (2008) Updating methods improved the performance of a clinical prediction model in new patients. J Clin Epidemiol 61(1):76–86. doi:10.1016/j.jclinepi.2007.04.018
Lemeshow S, Hosmer DW Jr (1982) A review of goodness of fit statistics for use in the development of logistic regression models. Am J Epidemiol 115(1):92–106
Leteurtre S, Martinot A, Duhamel A, Proulx F, Grandbastien B, Cotting J, Gottesman R, Joffe A, Pfenninger J, Hubert P, Lacroix J, Leclerc F (2003) Validation of the paediatric logistic organ dysfunction (PELOD) score: prospective, observational, multicentre study. Lancet 362(9379):192–197. doi:10.1016/S0140-6736(03)13908-6
Leteurtre S, Leclerc F, Wirth J, Noizet O, Magnenant E, Sadik A, Fourier C, Cremer R (2004) Can generic paediatric mortality scores calculated 4 hours after admission be used as inclusion criteria for clinical trials? Crit Care 8(4):R185–R193. doi:10.1186/cc2869
Leteurtre S, Duhamel A, Grandbastien B, Lacroix J, Leclerc F (2006) Paediatric logistic organ dysfunction (PELOD) score. Lancet 367(9514):897. doi:10.1016/S0140-6736(06)68371-2, author reply 900-892
Leteurtre S, Duhamel A, Salleron J, Grandbastien B, Lacroix J, Leclerc F (2013) PELOD-2: an update of the PEdiatric Logistic Organ Dysfunction Score. Crit Care Med 41(7):1761–1773. doi:10.1097/CCM.0b013e31828a2bbd
Marcin JP, Pollack MM, Patel KM, Ruttimann UE (1998) Decision support issues using a physiology based score. Intensive Care Med 24(12):1299–1304
Moons KG, Altman DG, Vergouwe Y, Royston P (2009) Prognosis and prognostic research: application and impact of prognostic models in clinical practice. BMJ 338:b606. doi:10.1136/bmj.b606
Oom P (2005) Scoring systems for mortality risk in pediatric intensive caring. Acta Pedatr Port 36(1):27–35
Oom P (2006) Prospective evaluation of mortality and morbidity in traumatized children admitted to paediatric intensive care unit. Acta Pediatr Port 37(2):37–41
Pearson GA, Stickley J, Shann F (2001) Calibration of the paediatric index of mortality in UK paediatric intensive care units. Arch Dis Child 84(2):125–128
Pollack MM, Patel KM, Ruttimann UE (1996) PRISM III: an updated Pediatric Risk of Mortality score. Crit Care Med 24(5):743–752
Pollack MM, Patel KM, Ruttimann UE (1997) The Pediatric Risk of Mortality III–Acute Physiology Score (PRISM III-APS): a method of assessing physiologic instability for pediatric intensive care unit patients. J Pediatr 131(4):575–581
Pulido-Barba J, Beltran-Ramirez P, Vazquez de Lara-Cisneros LG (1993) The validity of the index of pediatric mortality risk (PRISM) in a pediatric intensive care unit. Bol Med Hosp Infant Mex 50(12):861–864
Qureshi AU, Ali AS, Ahmad TM (2007) Comparison of three prognostic scores (PRISM, PELOD and PIM 2) at pediatric intensive care unit under Pakistani circumstances. J Ayub Med Coll Abbottabad: JAMC 19(2):49–53
Ruttimann UE (1994) Statistical approaches to development and validation of predictive instruments. Crit Care Clin 10(1):19–35
Slater A, Shann F (2004) The suitability of the Pediatric Index of Mortality (PIM), PIM2, the Pediatric Risk of Mortality (PRISM), and PRISM III for monitoring the quality of pediatric intensive care in Australia and New Zealand. Pediatr Crit Care Med J Soc Crit Care Med World Fed Pediatr Intensive Crit Care Soc 5(5):447–454. doi:10.1097/01.PCC.0000138557.31831.65
Thukral A, Lodha R, Irshad M, Arora NK (2006) Performance of Pediatric Risk of Mortality (PRISM), Pediatric Index of Mortality (PIM), and PIM2 in a pediatric intensive care unit in a developing country. Pediatr Crit Care Med J Soc Crit Care Med World Fed Pediatr Intensive Crit Care Soc 7(4):356–361. doi:10.1097/01.PCC.0000227105.20897.89
Tibby SM, Taylor D, Festa M, Hanna S, Hatherill M, Jones G, Habibi P, Durward A, Murdoch IA (2002) A comparison of three scoring systems for mortality risk among retrieved intensive care patients. Arch Dis Child 87(5):421–425
Wang JN, Wu JM, Chen YJ (2001) Validity of the updated pediatric risk of mortality score (PRISM III) in predicting the probability of mortality in a pediatric intensive care unit. Acta Paediatr Taiwan Taiwan Er Ke Yi Xue Hui Za Zhi 42(6):333–337
Financial disclosure
The authors have no financial relationships relevant to this article to disclose.
Conflict of interest
The authors declare that they have no conflict of interest.
Author’s contributions
Jean-Pierre Gonçalves (main author); Milton Severo (author and statistical analysis); Carla Rocha (author and reviewer); Joana Jardim (author and reviewer); Teresa Mota (author and reviewer); Augusto Ribeiro (author and reviewer).
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Patrick Van Reempts
Rights and permissions
About this article

Cite this article
Gonçalves, JP., Severo, M., Rocha, C. et al. Performance of PRISM III and PELOD-2 scores in a pediatric intensive care unit. Eur J Pediatr 174, 1305–1310 (2015). https://doi.org/10.1007/s00431-015-2533-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00431-015-2533-5