
Abstract
Purpose
This study explores the potential of the Chat-Generative Pre-Trained Transformer (Chat-GPT), a Large Language Model (LLM), in assisting healthcare professionals in the diagnosis of obstructive sleep apnea (OSA). It aims to assess the agreement between Chat-GPT's responses and those of expert otolaryngologists, shedding light on the role of AI-generated content in medical decision-making.
Methods
A prospective, cross-sectional study was conducted, involving 350 otolaryngologists from 25 countries who responded to a specialized OSA survey. Chat-GPT was tasked with providing answers to the same survey questions. Responses were assessed by both super-experts and statistically analyzed for agreement.
Results
The study revealed that Chat-GPT and expert responses shared a common answer in over 75% of cases for individual questions. However, the overall consensus was achieved in only four questions. Super-expert assessments showed a moderate agreement level, with Chat-GPT scoring slightly lower than experts. Statistically, Chat-GPT's responses differed significantly from experts' opinions (p = 0.0009). Sub-analysis revealed areas of improvement for Chat-GPT, particularly in questions where super-experts rated its responses lower than expert consensus.
Conclusions
Chat-GPT demonstrates potential as a valuable resource for OSA diagnosis, especially where access to specialists is limited. The study emphasizes the importance of AI-human collaboration, with Chat-GPT serving as a complementary tool rather than a replacement for medical professionals. This research contributes to the discourse in otolaryngology and encourages further exploration of AI-driven healthcare applications. While Chat-GPT exhibits a commendable level of consensus with expert responses, ongoing refinements in AI-based healthcare tools hold significant promise for the future of medicine, addressing the underdiagnosis and undertreatment of OSA and improving patient outcomes.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
In the age of advanced artificial intelligence (AI) and deep learning, Large Language Models (LLMs) represent a significant breakthrough in our ability to understand and generate natural language, mimicking human-like text. LLMs offer tremendous potential for healthcare professionals by providing quick and accessible access to the ever-expanding realm of medical knowledge. These models undergo a two-stage training process, starting with self-supervised learning from vast unannotated data and progressing to fine-tuning on small, task-specific, annotated datasets. This fine-tuning enables LLMs to perform specialized tasks tailored to end-users' needs [1].
This distinction highlights the essence of deep machine learning, underscoring the disparity between machine learning and human learning. While humans can swiftly derive general and intricate associations from limited data, machines require extensive data volumes to achieve similar results, primarily due to their lack of common sense. This AI's capacity to absorb copious amounts of data, learn from it, and instantaneously access it stands in stark contrast to our finite capabilities, largely constrained by linear time [2].
One AI model that has recently gained global recognition is the Chat-Generative Pre-Trained Transformer (Chat-GPT), equipped with over 175 billion parameters. This Chatbot extracts a wealth of information from diverse online sources, including books, articles, and websites, and refines its text generation capabilities through human feedback [3]. OpenAI, an artificial intelligence research organization and company founded in 2015, released Chat-GPT in November 2022.
Obstructive sleep apnea (OSA) is a sleep-related breathing disorder characterized by cyclic partial or complete upper airway obstruction. These cycles lead to intermittent hypoxemia, autonomic fluctuations, and sleep disruption, ultimately culminating in a chronic inflammatory systemic state associated with elevated cardiovascular risk. OSA has been linked to various complications, including hypertension, heart failure, coronary artery disease, cerebrovascular disease, metabolic syndrome, and type 2 diabetes [4]. Despite its prevalence (between 9% and 17% depending on gender) and potential repercussions, OSA remains underdiagnosed and undertreated [5].
The intersection of AI and OSA research holds immense promise for facilitating the diagnosis of this condition, not only among otolaryngologists but also among general practitioners and other medical specialists. This study aims to bridge this gap by conducting a comparative analysis of responses to a specialized OSA survey. Through a comparison between sleep surgeons’ skills and Chat-GPT, our objective is to contribute significantly to the ongoing discourse in otolaryngology concerning OSA and shed light on the role of AI-generated content in medical decision-making.
Methods
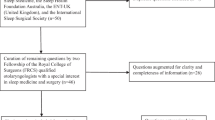
We designed a prospective, cross-sectional study to assess the level of agreement between responses to a ten-question survey provided by a panel of experts and responses generated by Chat-GPT. All experts included in the study were Otolaryngologists with specialization in sleep medicine. The ten super-experts were selected based on their exceptional expertise and academic recognition in the field of sleep-related disorders.
Survey design
We developed a comprehensive survey comprising ten questions related to OSA. Each question was designed as a clinical case and offered four potential multiple-choice answers. In one case, only one correct answer was possible (Question 5), while in others, multiple answers were acceptable.
Data collection
The survey was distributed to a panel of 350 otolaryngologists, all experts in the field of obstructive sleep apnea, representing 25 countries across four continents (Africa, America, Asia, and Europe). Responses were collected between June and July 2023. Simultaneously, from July 9th to 14th, 2023, we requested Chat-GPT (version 3.5) to provide answers to each of the survey questions. All questions were entered into Chat-GPT 3.5 by a single investigator.
Following this, we submitted the answers from both the experts and Chat-GPT to the super-experts and asked them to review and rate the level of agreement on each question. We employed a Likert-Scale method, ranging from 1 to 5 (1 = Strongly disagree, 2 = Disagree, 3 = Neutral, 4 = Agree, and 5 = Strongly agree), for their assessments (Fig. 1).

Study protocol
This study did not need ethical approval as no patient-level data were used.
Statistical analysis
Quantitative and continuous variables were expressed as the mean ± standard deviation (SD). Two-tailed t tests were used to compare the mean super-expert assessment of experts’ and Chat-GPT’s answers. The significance threshold used was p < 0.05. The kappa correlation coefficient (R) was used to analyze the agreement between super-experts, with the following guidelines for interpretation: R < 0.4: poor correlation; R [0.4–0.75]: intermediate correlation; R > 0.75 good correlation [6].
All statistical analysis were made on free and validated online tools (http://justusrandolph.net/kappa/; and https://biostatgv.sentiweb.fr/).
Results
A total of 97 responses (response rate 27.7%) from 25 countries across Africa, the Americas, Asia, and Europe were collected (refer to Fig. 1) during the period spanning from June 26th, 2023, to July 23rd, 2023. The consensus answers derived from both Chat-GPT and the experts are presented in Table 1. Table 2 showcases the agreement levels between Chat-GPT and the experts for each question.
For each multiple choice question, Chat-GPT and experts shared a common answer in more than 75% of cases (item by item analysis). However, when the whole response was taken into consideration, only 4 questions reached the 75% of consensus between experts and Chat-GPT.
Ten "super-experts" evaluated the most consensus-driven responses from both experts and Chat-GPT. The “super-experts” rated all expert’s responses at a value of 4/5 or more, while this rating was achieved only for 6 Chat-GPT responses.
The mean agreement level, as determined by the super-experts using the Likert scale for Chat-GPT's responses, was 4.07 (Minimum 1; Maximum 5; Standard Deviation 1.22). For the experts, the mean agreement level was 4.56 (Minimum 2; Maximum 5; Standard Deviation 0.78). Notably, there was a significant difference between these values (p = 0.0009, as determined by a student t test). Detailed agreement data for each question can be found in Table 3.
The kappa coefficient of agreement between super-experts for expert response assessment was R = 0.44 (CI95% [0.30; 0.58]). For ChatGPT response assessment, the kappa coefficient of agreement was R = 0.17 ([0.03; 0.30]).
Discussion
The integration of LLMs, particularly Chat-GPT, into the field of medicine has shown great promise, offering the potential to revolutionize the way healthcare professionals access and utilize medical knowledge [7, 8]. This study aimed to explore the applicability of Chat-GPT in the domain of obstructive sleep apnea (OSA), a significant health concern associated with various comorbidities and yet often underdiagnosed and undertreated [9, 10].
The results of our study, as presented in Tables 1 and 2, reveal a moderate global degree of consensus between Chat-GPT and the expert panel. In four questions the level of agreement between Chat-GPT and experts was high while in the remaining questions agreement was significantly lower. The consensus answers for the ten survey questions demonstrate that Chat-GPT might be capable of providing responses that align with those of human experts but still needs improvement.
Moreover, our findings indicate that the level of agreement between Chat-GPT and experts, as assessed by the super-experts, is substantial. The mean agreement levels, represented by a Likert scale, were 4.07 for Chat-GPT and 4.56 for the experts, with the latter showing slightly higher agreement levels. However, it is important to note that the differences in agreement between Chat-GPT and experts were statistically significant (p = 0.0009). This suggests that while Chat-GPT's responses are generally in concordance with expert opinions, there are instances where distinctions exist.
These distinctions may arise from the inherent limitations of AI models, including their reliance on data patterns and the potential absence of clinical intuition.
The data presented in Table 3 provide valuable insights into the super-expert assessments of Chat-GPT's answers compared to experts' consensual answers for each of the ten survey questions.
Examining the data, we observe some key points. For questions Q1 and Q2 Super-experts rated Chat-GPT's responses lower than the experts' consensual answers, with means of 2.8 and 3.4 compared to 4.1 and 4.6, respectively. The p-values of 0.01 for both questions indicate a significant difference in these assessments. This suggests that while Chat-GPT provided responses that were generally aligned with expert consensus, super-experts found room for improvement in these particular cases. For question Q4: Super-experts rated Chat-GPT's response lower than experts' consensual answer, with a mean of 2 compared to 4.1. The p-value of 0.0003 indicates a significant difference in these assessments. This suggests that Chat-GPT struggled to align with expert consensus on this question, with room for improvement in its response quality.
Another aspect that warrants a more in-depth examination is the level of agreement among super-experts when assessing the responses provided by both experts and ChatGPT. The degree of agreement was found to be intermediate for expert responses and low for ChatGPT responses. These findings underscore the intricate nature of managing obstructive sleep disorders, where numerous therapeutic choices exist, and there is a dearth of conclusive evidence in the literature to guide the selection of the optimal approach for a specific clinical presentation.
These results have several implications for the field of OSA diagnosis and treatment. Firstly, they highlight the potential of Chat-GPT as a valuable resource for general practitioners and medical specialists in the initial assessment of OSA cases. Chat-GPT's ability to provide accurate and consensus-driven responses can aid healthcare providers in making informed decisions and recommendations, especially in regions where access to sleep medicine specialists is limited.
Secondly, our study underscores the importance of collaboration between AI systems and human experts. While Chat-GPT can offer valuable insights, it should be seen as a complementary tool rather than a replacement for medical professionals [11,12,13,14]. Combining the strengths of AI, such as rapid data processing, with the clinical expertise of otolaryngologists can enhance the accuracy and efficiency of OSA diagnosis and management.
Finally, our findings contribute to the ongoing discourse in otolaryngology regarding OSA and the role of AI-generated content. By demonstrating the potential of Chat-GPT to align with expert opinions, this study encourages further research and development in AI-driven healthcare applications.
In conclusion, our study signifies the promise of AI, particularly Chat-GPT, in aiding healthcare professionals in the realm of OSA diagnosis. While Chat-GPT exhibits a commendable level of consensus with expert responses, the collaboration between AI and human experts is essential for optimal patient care. This research represents a significant step towards harnessing AI's capabilities to address the underdiagnosis and undertreatment of OSA, ultimately improving the health outcomes of affected individuals. Further investigations and refinements in AI-based healthcare tools hold great potential for the future of medicine.
Availability of data and materials
The data are available.
Change history
13 January 2024
First and family name of the author "Carlos Chiesa-Estomba" was published incorrectly and corrected in this version.
References
Shen Y, Heacock L, Elias J et al (2023) ChatGPT and other large language models are double-edged swords. Radiology. 307(2):e230163
Rajkomar A, Dean J, Kohane I (2019) Machine learning in medicine. N Engl J Med 380(14):1347–1358
Johnson D, Goodman R, Patrinely J et al (2023) Assessing the accuracy and reliability of AI-generated medical responses: an evaluation of the chat-GPT model. Res Sq. https://doi.org/10.21203/rs.3.rs-2566942/v1
Yeghiazarians Y, Jneid H, Tietjens JR et al (2021) Obstructive sleep apnea and cardiovascular disease: a scientific statement from the american heart association. Circulation 144(3):E56–E67
Peppard PE, Young T, Barnet JH et al (2013) Increased prevalence of sleep-disordered breathing in adults. Am J Epidemiol 177(9):1006–1014
Warrens MJ (2010) Inequalities between multi-rater kappas. Adv Data Anal Classif 4(4):271–286
Brown TB, Mann, B, Ryder, N, et al (2020) Language models are few-shot learners. arXiv preprint arXiv:2005.14165.
Radford A, Wu J, Child R et al (2019) Language models are unsupervised multitask learners. OpenAI Blog 1(8):9
Peppard PE, Young T, Palta M et al (2000) Prospective study of the association between sleep-disordered breathing and hypertension. N Engl J Med 342(19):1378–1384
Senaratna CV, Perret JL, Lodge CJ et al (2017) Prevalence of obstructive sleep apnea in the general population: a systematic review. Sleep Med Rev 34:70–81
.Lyons RJ, Arepalli SR, Fromal O, et al (2023) Artificial intelligence chatbot performance in triage of ophthalmic conditions. Can J Ophthalmol. https://doi.org/10.1016/j.jcjo.2023.07.016
Xv Y, Peng C, Wei Z et al (2023) Can Chat-GPT a substitute for urological resident physician in diagnosing diseases?: a preliminary conclusion from an exploratory investigation. World J Urol 41(9):2569–2571
Chiesa-Estomba CM, Lechien JR, Vaira LA et al (2023) Exploring the potential of Chat-GPT as a supportive tool for sialendoscopy clinical decision making and patient information support. Eur Arch Otorhinolaryngol. https://doi.org/10.1007/s00405-023-08104-8
Chen S, Kann BH, Foote MB et al (2023) Use of artificial intelligence chatbots for cancer treatment information. JAMA Oncol 9(10):1459–1462
Acknowledgements
The authors would like to express their gratutide to the following super-experts for having participated to the study Bhik Kotecha, Clemens Heiser, Nico De Vrie, Rodolfo Lugo Saldana, Joachim Maurer, Ofer Jacobowitz, Kenny Pang, Michel Cahali, Ewa Olszewska.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Ethics declaration
The author Jerome R. Lechien is also guest editor of the special issue on ‘ChatGPT and Artifcial Intelligence in Otolaryngology-Head and Neck Surgery’. He was not involved with the peer review process of this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the Topical Collection on sleep apnea syndrome. Guest editors: Manuele Casale, Rinaldi Vittorio.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Mira, F.A., Favier, V., dos Santos Sobreira Nunes, H. et al. Chat GPT for the management of obstructive sleep apnea: do we have a polar star?. Eur Arch Otorhinolaryngol 281, 2087–2093 (2024). https://doi.org/10.1007/s00405-023-08270-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00405-023-08270-9