
Abstract
Purpose
To develop a predictive model for risk of cesarean section in pregnant women after induction of labor.
Methods
A retrospective cohort study was conducted of 861 induced labors during 2009, 2010, and 2011 at Hospital “La Mancha-Centro” in Alcázar de San Juan, Spain. Multivariate analysis was used with binary logistic regression and areas under the ROC curves to determine predictive ability. Two predictive models were created: model A predicts the outcome at the time the woman is admitted to the hospital (before the decision to of the method of induction); and model B predicts the outcome at the time the woman is definitely admitted to the labor room.
Results
The predictive factors in the final model were: maternal height, body mass index, nulliparity, Bishop score, gestational age, macrosomia, gender of fetus, and the gynecologist’s overall cesarean section rate. The predictive ability of model A was 0.77 [95 % confidence interval (CI) 0.73–0.80] and model B was 0.79 (95 % CI 0.76–0.83). The predictive ability for pregnant women with previous cesarean section with model A was 0.79 (95 % CI 0.64–0.94) and with model B was 0.80 (95 % CI 0.64–0.96). For a probability of estimated cesarean section ≥80 %, the models A and B presented a positive likelihood ratio (+LR) for cesarean section of 22 and 20, respectively. Also, for a likelihood of estimated cesarean section ≤10 %, the models A and B presented a +LR for vaginal delivery of 13 and 6, respectively.
Conclusion
These predictive models have a good discriminative ability, both overall and for all subgroups studied. This tool can be useful in clinical practice, especially for pregnant women with previous cesarean section and diabetes.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Labor induction (LI) is when labor is started by medical or surgical procedures before the onset of spontaneous labor [1]. It is one of the most common interventions in obstetrics, and in European countries it is practiced in 6.8–33.0 % of all pregnancies [2]. In addition, there is a growing tendency in its employment at increasingly younger gestational ages [3].
This procedure not only has significant medical implications for the mother and fetus, but also directly affects the health-care system (because of the extra workload and use of resources) and the woman’s childbirth experience [1].
LI is associated with an increase in complications compared with spontaneous labor [4–8] and results in a larger number of cesarean sections. Specifically, after controlling for other factors, LI is associated with 20 % of all cesarean sections [9]. In addition, LI that ends in cesarean section has worse outcomes when compared to cesarean section without labor [10].
Often, when there is a particular complication during pregnancy, the only options are LI or cesarean section. In such situations, clinicians must decide between these two options. However, this decision is complex, because it involves many factors and there can be great uncertainty about the outcome.
As such, one of the most important challenges facing obstetrics is being able to predict labor outcome, especially in induced labor, to minimize the risks of both induction and cesarean section. In this regard, some authors have developed predictive models aimed at determining the personal and obstetric characteristics associated with an increased risk of cesarean section.
Most of these models compare the predictive ability of cervical length as measured by ultrasound with the Bishop score (BS) right before LI, with varying results [11, 12]. However, labor outcome can also be determined by other clinical and personal aspects, and even by the professionals involved. Nevertheless, few studies have incorporated a combination of the different factors involved in LI in pregnant women, resulting in disparate predictors and outcomes [13–21].
The objective of this study was to develop a model that can be used to predict labor outcome in pregnant women who undergo LI that integrates variables related to anthropometric, obstetric, cervical and fetal characteristics and those of the attending health-care professionals.
Methods
Design
This was an observational, analytical study of retrospective cohorts. It was conducted in the Obstetrics Unit of Hospital “Mancha-Centro” in Alcázar de San Juan (Ciudad Real, Spain) during 2009, 2010, and 2011.
Subjects
The reference population was a set of pregnant women whose labor was induced at Hospital “La Mancha-Centro.” Exclusion criteria were unavoidable emergency cesarean section (breech presentation, transverse lie, deflected cephalic presentation, and vaginal delivery ruled out due to previous cesarean section), twin pregnancy, and dead fetus antepartum.
In our center, the medical criteria for LI follow the guidelines of the Spanish Society of Gynecology and Obstetrics (SEGO) [1].
The induction methods were: preinduction cervical ripening if Bishop score ≤6 and use of dinoprostone 10 mg administered vaginally; oxytocin infusion and amniotomy if Bishop score >6.
Calculating the number of subjects required
In constructing a multivariate analysis model, ten events (cesarean section) per variable are required for it to be incorporated. Assuming a maximum of ten variables in the initial model, a single year would be enough, but because of possibly incomplete records and indications for induction, the data collection period was extended to 3 years (2009, 2010, and 2011).
Sources of information
To collect the information, we used hospital records and the regional electronic information system for primary care for the patients being studied.
The following variables were collected:
Primary outcome variables: cesarean delivery (yes/no).
Independent variables:
-
Maternal: overall maternal age (years), categorized maternal age (≤20, 21–34, ≥35 years), overall maternal height (cm), categorized maternal height (<150, 150–169, ≥170 cm), overall body mass index (BMI) (kg/m2), and categorized BMI (<25, 25–29, ≥30).
-
Obstetrics: previous cesarean section, parity (nulliparous/multiparous), BS at hospital admission, BS at admission to labor room, use of prostaglandins, time since premature rupture of membranes (PROM), oligohydramnios (amniotic fluid index <5), intrauterine fetal growth restriction (IUFGR), hypertension, diabetes (gestational and pre-gestational, with or without control depending on gestational age), fertility treatment, and pathological fetal heart rate (FHR).
-
Fetal: gender of newborn, overall neonatal birth weight (grams), categorized neonatal birth weight (<2500, 2500–2999, 3000–3499, 3500–3999, ≥4000 g), macrosomia (≥4000 g), gestational age (weeks), and categorized gestational age (<37, 37–41, >41 weeks).
-
Related to the gynecologist indicating the cesarean section: age of the gynecologist (<35, 35–40, 40–45, >45 years), gender, and personal rate of emergency cesarean sections performed by the gynecologist in charge in this period.
Statistical analysis
First, a univariate analysis of potential predictive factors was performed using the Chi-squared test and/or Student’s t test for qualitative or quantitative variables, respectively. Of these variables, associations with P values of <0.25 were chosen to be included in the multivariate binary logistic regression model [22]. This model was constructed by using backward elimination (random variables in SPSS). Next, the predictive ability was studied by means of a receiver-operating characteristic (ROC) curve (Table 1).
From among the eligible models, those that best fulfilled the following characteristics were chosen: suitable calibration (Hosmer–Lemeshow test), area under the ROC curve (AUC), parsimony (small number of explanatory variables), ease of interpretation, and clinical plausibility.
Two predictive models were created: model A predicts the outcome at the time the woman is admitted to the hospital (before the decision on the method of induction); and model B predicts the outcome at the time the woman is officially admitted to the labor room (Table 2; Fig. 2).
Then the individual predictive ability of each predictor that formed the models A and B was studied and the predictive ability was studied across different subgroups: previous cesarean section, use or not of prostaglandins, and the main reasons for induction (diabetes, post-term pregnancy (PTP), and PROM) (Table 3).
Due to the possible absence of some predictor depending on the workplace, different predictive models were devised with different combinations of the predictors of model B, calculating for each one of them their AUC of ROC (Table 4).
Lastly, the following were determined from model B: sensitivity, specificity, positive predictive values (PPV), negative predictive values (NPV), positive likelihood ratio (+LR), and negative likelihood ratio (−LR) for the risk of cesarean section and vaginal delivery of different estimated probabilities (Table 5).
SPSS 20.0 was used for the statistical analysis.
Results
After applying the exclusion criteria, the study population consisted of 841 subjects, 704 (84.3 %) of whom were used in the construction of the predictive model. Figure 1 shows the screening process.

Screening process and exclusion criteria
The variables related to labor outcome (P values <0.25) and eligibility to be included in the initial model were: overall and categorized maternal height, overall and categorized BMI, parity, overall and categorized gestational age, previous cesarean section, previous induction, use of prostaglandins, Bishop score, oligohydramnios, fertility treatment, overall and categorized weight of newborn, gender of fetus, and gynecologist’s age and cesarean section rate. Table 2 shows the univariate analysis.
Next, the multivariate analysis was performed, with model A and model B consisting of the following variables: categorized maternal height, categorized BMI, parity, Bishop score, categorized gestational age, macrosomia, gender of the fetus and cesarean section rate of the gynecologist in charge. The Bishop score was different between the two models depending on the obstetric assessment at the corresponding time. The models are shown in Table 3.
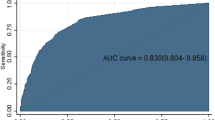
The AUC for model A was 0.77 (95 % CI 0.73–0.80), and for model B 0.79 (95 % CI 0.76–0.83) (Fig. 2).

ROC curves of predictive models A and B
Subsequently, the individual predictive ability of the variables that formed models A and B was studied. It was found that the BS in dilation [AUC = 0.65 (95 % CI 0.61–0.68)] and nulliparity [AUC = 0.63 (95 % CI 0.59–0.67)] were the ones that presented a greater capacity of prediction (Table 3).
The predictive ability of the models was then studied for the subgroups. Both models showed good predictive ability across all subgroups, particularly in previous cesarean sections and diabetes (Table 3).
In addition, several prediction models with different combinations of predictors were developed, excluding those variables with the greatest likelihood of non-availability in all the centers (Table 4). When the rate of cesarean section of the gynecologist was omitted (model 1), the predictor with greater risk of not being known, a predictive ability of 0.78 (95 % CI 0.74–0.82) was presented.
Finally, we studied the predictive characteristics for models A and B and found that for an estimated probability of cesarean section of ≥80 %, a +LR for cesarean section of 22.0 and 19.5, respectively, was observed. Also, a likelihood of estimated cesarean section ≤10 % presented a +LR for vaginal delivery of 13.7 and 6.3, respectively (Table 5).
Comment
In our study, we developed two models for predicting the risk of cesarean section in pregnant women after LI. Model A determines the risk at the time of hospital admission and model B at the time the woman is officially admitted to the labor room, with an ability to predict correctly in 0.76 and 0.79 of cases, respectively. The creation of these models for two different points of the LI process allowed us to verify the reliability of the variables used as predictors; something which had not been done before. Moreover, the model showed good predictive ability in the different subgroups studied, with the result for the previous cesarean section group at 0.79 and 0.80, respectively, of particular interest in terms of clinical utility, because many of these pregnant women prefer an elective cesarean.
With regard to the diagnostic characteristics, we can say that the models show excellent values for specificity, PPV and +LR for the cutoff points studied. The predictions are especially good for cesarean section when the odds are greater than 80 % and vaginal delivery when the likelihood of cesarean section is less than 10 %.
In this sense, although there are many works that attempt to predict the result of childbirth, only have been localized in these past 10 years, 9 models that incorporate in predicting other different variables to the BS and the length of the cervix by ultrasonography or in combination with these [13–21].
Of these, the model of Smith et al. [20] included nulliparous women and employed prostaglandins, and that of Isono et al. [16] included only low-risk nulliparous women, with an AUC of ROC of 0.67 and 0.73, respectively. Rane et al. created two models, one published in 2004 [19] and another in 2005 [18], without elaborating ROC curves, although subsequently Verhoeven et al. [23] validated this last one obtaining an AUC of 0.63. Cnattingus et al. [14] and Gomez-Laencina et al. [15] also created their own models, but did not provide the values of prediction of these. Only Cheung et al. [13], Pitarello et al. [21], and Peregrine et al. [17] presented models with capacities similar to ours, with AUC-ROC of 0.79, 0.80 and 0.83. But eventually, the model of Peregrine et al. was validated by Verhoeven et al. [23] and by Bertossa et al. [24] and its predictive capacity was reduced to 0.76 and 0.59, respectively.
In our study, in both model A and model B, the variables used were: categorized maternal height, categorized BMI, parity, Bishop score, categorized gestational age, macrosomia, gender of fetus, and gynecologist’s average individual cesarean section rate.
With regard to the factors that make up the model, we found that maternal height [13, 15–17, 21], BMI [14, 15, 17–19] and gestational age [18, 21] were incorporated into their models by several authors, although with different cutoff points according to the study.
Another predictor employed and of great significance in the various types of work was the parity [13–15, 17–19, 21]. We found in our case that pregnant nulliparous women presented a likelihood of a cesarean section in the adjusted model five times greater than multiparous women.
In spite of this, the employment of the BS to assess the cervix, at admission to the hospital and at the onset of the dilation factor was considered the most important predictor. This test was also employed in other models of IDP [13, 15, 16, 21], but was replaced or supplemented in other studies by certain measurements of the cervix by ultrasonography [13, 15, 17–19, 21]. In this respect, we believe that models that incorporate Bishop score as opposed to sonographic measurement of the cervix are more likely to be used and validated. Although this is not considered a good predictor of labor per se, it can be used in all circumstances. The measurement of cervical length, however, requires suitable training and equipment. In addition, there is no evidence of the superiority of the ultrasound measurement against the BS [25]. Since Hatfiel et al. [11] and Verhoeven et al. [12] published systematic reviews in 2007 and 2013, respectively, it was concluded that measurement by ultrasonography of the cervix was not a good predictor of the outcome of childbirth. Besides, a Canadian Guide of Clinical Practice currently continues recommending the appraisal of BS in pre-induction [26].
Based on the fetal factors included in the model, we found a relationship between the risk of cesarean section and macrosomia, although this predictor was only employed in the model of Isono et al. [16].
With regard to fetal sex, only the model of Smith et al. [20] took it into account. In our study, male fetus was 7.6 % more likely to present the risk of cesarean section than female fetus. This finding is arguably due to the females’ higher capacity to adapt to the stress of labor, as various studies have shown [27–29].
One of the most important aspects of our study is that it is the first to incorporate the responsible gynecologist’s cesarean section rate as a predictor. The likelihood of labor is also conditioned to a large extent by factors related to health care or health-care professionals. These factors may contribute to the large variability in the performance of cesarean sections among countries, centers and even professionals within a unit [30–32]. Therefore, any model that does not take this source of variability into account may be incomplete. This aspect constitutes both the primary strength and weakness of the study. It is a strength because, by considering this rate, we can see that this model has been used at other centers with different health-care characteristics; it is a weakness because the gynecologist’s cesarean section rate may not be available, although in this case it could be replaced by the rate for the center. To overcome this obstacle, we have elaborated various alternative models omitting different predictors, considering the possibility that this information may not be available in the workplace so that it can be applied in a major number of circumstances (Table 5).
We recognize as a limitation that for this predictive model to be of potential use, it must first be validated at our center with a cohort other than that used to construct the model and then again at other centers.
In spite of this, we believe that models have a good ability to predict the risk of cesarean section and they may be a useful tool to aid decision making.
References
Sociedad Española de Ginecología y Obstetricia. Inducción de parto. Protocolos prosego 2013. http://www.prosego.es
Health and Care of Pregnant Women and Babies in Europe in 2010. European Perinatal Health Report 2014:90–92. http://www.europeristat.com/reports/european-perinatal-health-report-2010.html
Caughey AB, Sundaram V, Kaimal AJ et al (2009) Maternal and neonatal outcomes of elective induction of labour. Evid Rep Technol Assess (Full Rep) 176:1–257
Guerra GV, Cecatti JG, Souza JP et al (2009) Factors and outcomes associated with the induction of labour in Latin America. BJOG 116(13):1762–1772
Janakiraman V, Ecker J, Kaimal AJ (2010) Comparing the second stage in induced and spontaneous labor. Obstet Gynecol 116(3):606–611
Selo-Ojeme D, Rogers C, Mohanty A, Zaidi N, Villar R, Shangaris P (2011) Is induced labour in the nullipara associated with more maternal and perinatal morbidity? Arch Gynecol Obstet 284(2):337–341
Al-Shaikh G1, Al-Mandeel H (2013) The outcomes of trial of labour after cesarean section following induction of labour compared to spontaneous labour. Arch Gynecol Obstet 287(6):1099–1103
Rossi AC, Prefumo F (2015) Pregnancy outcomes of induced labor in women with previous cesarean section: a systematic review and meta-analysis. Arch Gynecol Obstet 291(2):273–280
Ehrenthal DB, Jiang X, Strobino DM (2010) Labor induction and the risk of a cesarean delivery among nulliparous women at term. Obstet Gynecol 116(1):35–42
Allen VM, O’Connell CM, Baskett TF (2006) Maternal morbidity associated with cesarean delivery without labour compared with induction of labour at term. Obstet Gynecol 108(2):286–294
Hatfield AS, Sanchez-Ramos L, Kaunitz AM (2007) Sonographic cervical assessment to predict the success of labour induction: a systematic review with met analysis. Am J Obstet Gynecol 197(2):186–192
Verhoeven CJ, Opmeer BC, Oei SG, Latour V, van der Post JA, Mol BW (2013) Transvaginal sonographic assessment of cervical length and wedging for predicting outcome of labour induction at term: a systematic review and meta-analysis. Ultrasound Obstet Gynecol 42(5):500–508
Cheung CW, Leung TY, Sahota DS et al (2010) Outcome of induction of labour using maternal characteristics, ultrasound assessment and biochemical state of the cervix. J Matern Fetal Neonatal Med 23(12):1406–1412
Cnattingius R, Hoglund B, Kieler H (2005) Emergency cesarean delivery in induction of labour: an evaluation of risk factors. Act Obstet Gynecol Scand 84(5):456–462
Gomez-Laencina AM, Garcia CP, Asensio LV, Ponce JA, Martinez MS, Martinez-Vizcaino V (2012) Sonographic cervical length as a predictor of type of delivery after induced labour. Arch Gynecol Obstet 285(6):1523–1528
Isono W, Nagamatsu T, Uemura Y et al (2011) Prediction model for the incidence of emergent cesarean section during induction of labour specialized in nulliparous low-risk women. J Obstet Gynaecol Res 37(12):1784–1791
Peregrine E, O’Brien P, Omar R, Jauniaux E (2006) Clinical and ultrasound parameters to predict the risk of cesarean delivery after induction of labour. Obstet Gynecol 107(2 Pt 1):227–233
Rane SM, Guirgis RR, Higgins B, Nicolaides KH (2005) Models for the prediction of successful induction of labour based on pre-induction sonographic measurement of cervical length. J Matern Foetal Neonatal Med 17(5):315–322
Rane SM, Guirgis RR, Higgins B, Nicolaides KH (2004) The value of ultrasound in the prediction of successful induction of labour. Ultrasound ObstetGynecol 24(5):538–549
Smith GC, Dellens M, White IR, Pell JP (2004) Combined logistic and Bayesian modelling of cesarean section risk. Am J Obstet Gynecol 191(6):2029–2034
Pitarello PR, Tadashi YC, Ruano R, Zugaib M (2013) Prediction of successful labour induction using transvaginal sonographic cervical measurements. J Clin Ultrasound 41(2):76–83
Hosmer DW, Lemeshow S (2000) Applied logistic regression, 2nd edn. Willey, New York
Verhoeven CJ, Oudenaarden A, Hermus MA, Porath MM, Oei SG, Mol BW (2009) Validation of models that predict Cesarean section after induction of labour. Ultrasound Obstet Gynecol 34(3):316–321
Bertossa P, Novakov MA, Stupar ZT et al (2012) Validity of clinical and ultrasound variables to predict the risk of cesarean delivery after induction of labour. Obstet Gynecol 120(1):53–59
Kolkman DG, Verhoeven CJ, Brinkhorst SJ et al (2013) The bishop score as a predictor of labour induction success: a systematic review. Am J Perinatol 30(8):625–630
Leduc D, Biringer A, Lee L et al (2013) Induction of labour. J Obstet Gynaecol Can 35(9):840–857
Agarwal U, Anastasakis E, Kadir RA (2009) The effect of foetal sex on the outcome of labour induction. J Obstet Gynaecol 29(8):711–713
Eogan MA, Geary MP, O’Connell MP, Keane DP (2003) Effect of foetal sex on labour and delivery: retrospective review. BMJ 326(7381):137
Schuit E, Kwee A, Westerhuis ME et al (2012) A clinical prediction model to assess the risk of operative delivery. BJOG 119(8):915–923
Althabe F, Sosa C, Belizan JM, Gibbons L, Jacquerioz F, Bergel E (2006) Cesarean section rates and maternal and neonatal mortality in low-, medium-, and high-income countries: an ecological study. Birth 33(4):270–277
Declercq E, Young R, Cabral H, Ecker J (2011) Is a rising cesarean delivery rate inevitable? Trends in industrialized countries, 1987 to 2007. Birth 38(2):99–104
Grupo de variaciones en la práctica médica. Variaciones en la utilización de la cesárea en los hospitales públicos del Sistema Nacional de Salud. Documento de trabajo 04-2009. 2009
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there are no conflicts of interest and that this study has been conducted with no funding.
Rights and permissions
About this article

Cite this article
Hernández-Martínez, A., Pascual-Pedreño, A.I., Baño-Garnés, A.B. et al. Predictive model for risk of cesarean section in pregnant women after induction of labor. Arch Gynecol Obstet 293, 529–538 (2016). https://doi.org/10.1007/s00404-015-3856-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00404-015-3856-1