
Abstract
Due to the important role of concrete in construction sector, a novel metaheuristic method, namely whale optimization algorithm (WOA), is employed for simulating 28-day compressive strength of concrete (CSC). To this end, the WOA is coupled with a neural network (NN) to optimize its computational parameters. Also, dragonfly algorithm (DA) and ant colony optimization (ACO) techniques are considered as the benchmark methods. The CSC influential parameters are cement, slag, water, fly ash, superplasticizer (SP), fine aggregate (FA), and coarse aggregate (CA). First, a population-based sensitivity analysis is carried out to achieve the most efficient structure of the proposed model. In this sense, the WOA-NN with the population size of 400 and five hidden nodes constructed the best-fitted network. The results revealed that the WOA-NN (Error = 2.0746 and Correlation = 0.8976) presents the most reliable prediction of the CSC, followed by the DA-NN (Error = 2.5138 and Correlation = 0.8209) and ACO-NN (Error = 2.8843 and Correlation = 0.8000) benchmark models. The findings showed that utilizing the WOA optimization technique, along with typical neural network, results in developing a promising tool for modeling the CSC.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Concrete is an excellent man-made mixture which plays an essential role in the construction sector. As is known, various elements (e.g., water, cement, fly ash, etc.) are mixed with different ratios (i.e., dosages) to produce the concrete. Regarding the strength and performance of the concretes, they can be classified in several groups like HSCs (high-strength concretes) and SCCs (self-compacting concretes). Due to the advantages of this material, it ensures a high level of compressive stress [1]. As the most significant mechanical characteristic, the compressive strength of the concrete (CSC) is a determinant factor in evaluating the quality of this non-linear material [2]. Note that it is usually measured for 28-day concrete specimens. Up to now, many scholars have used various traditional models to evaluate and estimate the mechanical characteristics of concrete, such as CSC [3, 4].
More recently, intelligent predictive models like artificial neural network (ANN), as well as fuzzy-based systems, have received growing attention for diverse prediction aims [5,6,7]. They have also shown high robustness for simulating the CSC [8,9,10,11,12]. Khademi and Jamal [13] compared the applicability of adaptive neuro-fuzzy inference system (ANFIS) and multiple linear regression (MLR) models in estimating the 28-day CSC. Their findings revealed the superiority of the ANFIS, due to the capability of non-linear modeling of this tool. Likewise, Keshavarz and Torkian [14] showed the efficiency of ANN and ANFIS in estimating the CSC using five critical factors of cement, sand, gravel, water to cement ratio, and microsilica. Referring to the obtained correlations of 0.942 and 0.923, respective for the ANN and ANFIS, they concluded that the ANN performs more efficiently. Mandal et al. [1] introduced the ANN as a capable model for predicting the CS of HSC. They compared the results with an MLR model and showed that the ANN (with nearly 95% correlation) outperforms the MLR.
Moreover, looking for more reliable predictive models, lots of researchers have employed hybrid metaheuristic algorithms in various engineering fields [15,16,17,18]. As for the CSC simulation, these techniques have been extensively used for optimizing the performance of regular intelligent models [19,20,21]. In this sense, Behnood and Golafshani [22] used multi-objective grey wolf optimization to optimize the ANN for predicting the CS of silica fume concrete. Also, Bui et al. [23] combined the ANN with a modified firefly algorithm to develop a fast and efficient model for approximating tensile and compressive strength of high-performance concrete. Moreover, Sadowski et al. [24] coupled a multilayer perceptron (MLP) neural network with imperialist competitive algorithm (ICA) to enhance its efficiency in estimating the CSC. The results indicated the superiority of the proposed ICA-ANN model compared to particle swarm optimization (PSO) and genetic algorithm (GA).
As explained in the literature above, hybrid intelligence has been widely used for the problem of CSC estimation. The main focus of this research is to present a novel optimization of ANN, namely whale optimization algorithm (WOA) for fine-tuning the computational parameters of this model. Also, two benchmark algorithms of ant colony optimization (ACO) and dragonfly algorithm (DA) are considered to be compared with the WOA. A population-based sensitivity analysis is executed to determine the most effective structure of the proposed models, and the results are evaluated in several ways to determine the elite neural ensemble.
2 Methodology
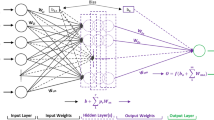
The overall methodology that is taken to achieve the goal of this research is depicted in Fig. 1. In this regard, after providing the dataset, it is randomly divided into the training and testing samples with the well-known proportion of 80:20 [25,26,27]. In other words, out of 103 data, 82 samples are used to train the proposed models, and the remaining 21 samples are put aside as unseen concrete conditions for evaluating the generalization capability of the developed models. The WOA algorithm as well as the ACO and DA (as benchmark models) are then synthesized with the MLP neural network to adjust the computational parameters. Note that the best-fitted structure of the mentioned models is determined through a trial-and-error process. Finally, the accuracy of the WOA-NN, ACO-NN, and DA-NN predictive tools is evaluated by means of three well-known criteria. As Eq. 1 denotes, the determination coefficient (R2) is used to measure the correlation between the actual and predicted CSC. Also, root mean square error (RMSE), as well as mean absolute error (MAE), is used to measure the error of the prediction. Equations 2 and 3 define the formulation of the MAE and RMSE, respectively.

The graphical methodology of the present study
where \(Y_{{i_{\text{predicted}} }}\), \(Y_{{i_{\text{observed}} }}\), and \(\bar{Y}_{\text{observed}}\) are the predicted, actual, and the average of the actual values of the CSC. Besides, the term N denotes the number of samples.
The description of the used algorithms is presented below:
2.1 Whale optimization algorithm
The name whale optimization algorithm (WOA) indicates a new metaheuristic technique that is inspired by the bubble-net hunting conduction of humpback whales (Fig. 2) [28]. It is known as a swarm-based intelligent approach designed for solving various complex optimization issues with continuous domain [29,30,31]. The whales in the swarm seek their prey within a multidimensional space. The location of each relation is demonstrated as the decision variable, where the cost function is defined as the distance between each whale concerning the prey position. The function of time-constraint as a location for the whales can be evaluated using the below operational steps [28, 32]:

The humpback whales bubble-net feeding (after [28])
-
(a)
Shrinking encircling hunt,
-
(b)
Exploitation phase (i.e., the bubble-net attacking)
-
(c)
Exploration phase (i.e., searching for the prey).
As Fig. 3 illustrates, when the position of the proposed prey is recognized, the humpback whales begin to encircle it through moving in nine shapes. The WOA remarks the target prey as the most appropriate candidate solution (or close to the elite solution) because it has no information about the optimal location of the prey within the search area. It takes into consideration every possible attempt for finding the elite search agent. Notably, other involved relations aim to update their positions close to the elite one.

The spiral updating process
in which \(\vec{X}\) indicates the whale location, \(\vec{X}^{*}\) stands for the universal elite position, and t demonstrates the recent try. Also, a is decreased from 2 to 0 linearly, and r stands for a random number which is distributed equally between 0 and 1. The stages are explained in the following:
-
(a)
Exploitation:
Figure 4 illustrates the bubble-net hunting conduct of the WOA algorithm. The equidistance between the positions of the whale and the prey is detected by applying a spiral mathematical approach. The position of the whale (in a helix environment) is aimed to be adjusted after each movement [33]:

Exploitation phase
where b and k show constant and arbitrary numbers, notably, b symbolizes the logarithmic spiral shape and k is distributed equally from − 1 to 1.
-
(b)
Exploration
As Fig. 5 shows, when A > 1 or A < − 1, the search agent upgraded by a randomly selected colleague at the location of the elite agent:

Exploration phase
In this way we have
in which \(C \cdot \overrightarrow {{X_{\text{rand}} }}\) shows arbitrarily of whales for the proposed iteration. It has been better detailed in [28]. Also, the pseudocode of this algorithm is presented in Fig. 6.

The pseudocode of the WOA algorithm
2.2 Benchmark hybrids algorithms
As mentioned, two other natural-inspired population-based metaheuristic algorithms, namely the dragonfly algorithm (DA) and ant colony optimization (ACO), are considered as the benchmark models to be compared with the proposed WOA algorithm. As their name connotes, these algorithms are inspired by the herding behavior of natural dragonflies and ants. The DA was introduced by Mirjalili [34] in 2016, and the idea of the ACO algorithm was first presented by Colorni et al. [35] in the early 1990s. With the flowchart being similar to other optimization techniques, these methods get started by producing a random population. In the following, the fitness of the suggested solution is evaluated by an objective function. The solution requires to be updated and improved in iteration, which means higher accuracy for the problem. The algorithms continue this process until a stopping criterion (e.g., the desired accuracy or the maximum number of repetitions) is met. These methods are well detailed in earlier studies, like [36, 37] for ACO, and [38, 39] for DA.
3 Data collection and statistical analysis
The reference work for the used dataset is research by Yeh [40], which gathered the information of 103 concrete tests for simulating the slump of concrete. The used dataset is available here. As well as slump, this dataset consists of flow and 28-day compressive strength of concrete as output variables. We selected the compressive strength (MPa) to model in this work. The considered influential variables (i.e., input factors) are cement, slag, water, fly ash, superplasticizer (SP), fine aggregate (FA), and coarse aggregate (CA). Figure 7 illustrates the graphical relationship between the CSC and its influential factors. Moreover, the results of statistical analysis of the mentioned parameters are presented in Table 1.

The graphical description of the CSC influential factors
4 Results and discussion
As mentioned, this study addresses a novel optimization of artificial neural networks for predicting the compressive strength of concrete. To this end, the whale optimization algorithm is considered as the metaheuristic algorithm for optimizing the structure of a back-propagation MLP network. Moreover, the performance of the proposed WOA algorithm is evaluated by comparing with two benchmark methods which are inspired by the herding behavior of artificial ants and dragonflies. More clearly, these algorithms are applied to the mathematical ruling relationship of the MLP to find the most suitable options for the connecting weights as well as the biases. This process is carried out using the programming language of MATLAB 2014. This is worth noting that, based on the authors’ experience as well as a trial-and-error process, five hidden neurons were found to be the most appropriate number of the hidden computational units.
4.1 Optimizing the MLP using ACO, DA, and WOA conventional techniques
A population-based sensitivity analysis is executed to acquire the best architecture of the used models. In this sense, nine different complexities of the models (i.e., nine population sizes of 10, 25, 50, 75, 100, 200, 300, 400, and 500) are tested within 1000 repetitions. Also, the RMSE is considered as the objective function to measure the error at the end of each iteration. Figure 8a–c illustrates the convergence curves of the optimization process of the used ACO-NN, DA-NN, and WOA-NN ensembles, respectively. As is seen, all three algorithms show different behaviors in optimizing the MLP. The ACO keeps decreasing the error until the last try, while the DA and WOA perform the majority of the error reduction within the first 400 iterations, and remain more and less steady after that. The results showed that the optimal values of the RMSE were 1.96184548, 1.849893333, and 1.357585418, obtained for the ACO-NN, DA-NN, and WOA-NN with population sizes of 10, 400, and 400, respectively.

The sensitivity analysis based on the model complexity for the a ACO-NN, b DA-NN, and c WOA-NN
The calculation time of the implemented models (the selected structures) is depicted in Fig. 9. From this figure, it can be seen that executing the ACO-NN took the lowest time (nearly 600 s). Moreover, the WOA- and DA-based neural ensembles, which used the same complexities (i.e., population sizes), took approximately 5271 and 7620 s, respectively. On the other hand, due to the lower objective function obtained for the WOA-NN, it can be concluded that this algorithm outperforms the DA-NN in terms of time-effectiveness. Remarkably, the proposed models were implemented on the operating system at 2.5 GHz and 6 Gigs of RAM.

The computation time of the used ensembles
4.2 Accuracy assessment of the implemented predictive models
After determining the best structures, the results of the models were evaluated and compared by means of the RMSE, MAE, and R2 indices. The products of the training and testing phases were compared with the desired targets to measure the accuracy of the results. Figure 10 shows the regression of the results alongside the histogram of the errors for the training phase. Note that, in this figure, the error is calculated as the difference between the observed and predicted CSCs. Likewise, the testing results are presented in Fig. 11. Based on these figures, all three used models performed satisfactorily for predicting the CSC. This is also deduced that all three models had higher accuracy in discerning the relationship between the CSC and the mentioned influential factors (i.e., the training dataset), in comparison with estimating the CSC with unseen conditions (i.e., the testing dataset).

The training results obtained for a, b ACO-NN, c, d DA-NN, and e, f WOA-NN predictions

The testing results obtained for a, b ACO-NN, c, d DA-NN, and e, f WOA-NN predictions
Based on the presented histogram charts, the frequency of the errors around 0 seems higher in the result of the WOA-based ensemble in both training and testing phases. This claim can also be supported by considering the obtained values of the standard error (SE). Accordingly, the SE is calculated 1.9739 and 3.5301 for the ACO-NN, and 1.8612 and 3.3716 for the DA-NN, respectively, in the training and testing samples. This is while these values are obtained as 1.3659 and 2.6387 for the WOA-NN.
Moreover, Table 2 summarizes the obtained values of RMSE, MAE, and R2 for all three used models. According to this table, the proposed WOA surpassed the benchmark algorithms of ACO and DA in both training and testing stages. More clearly, the WOA-NN (RMSE = 1.3576 and MAE = 1.0757) presented a higher learning quality (i.e., in the training phase), compared to the ACO-NN (RMSE = 1.9618 and MAE = 1.5282) and DA-NN (RMSE = 1.8499 and MAE = 1.4786). Moreover, the obtained values of R2 (0.9410, 0.9443, and 0.9700, respectively, for the ACO-NN, DA-NN, and WOA-NN ensembles) showed a higher correlation between the products of the WOA-based neural network and the actual CSCs. It was also deduced that the DA was more successful than ACO in optimizing the MLP. Investigating the testing result showed that the generalization power of the models is directly related to the learning capability. In other words, the calculated testing RMSEs (3.4452, 3.3325, and 2.6985), as well as the MAEs (2.8843, 2.5138, and 2.0746), revealed that the WOA estimated the CSC more accurately than ACO and DA. Referring to the obtained values of R2 (0.8000, 0.8209, and 0.8976), the WOA produced the most reliable results, followed by the DA and ACO algorithms.
In overall, the results indicated the superiority of the developed WOA-NN technique in both training and testing phases and it could be a robust alternative to traditional model in CSC evaluation. It provides an inexpensive yet accurate predictive model for investigating the relationship between this crucial characteristic of concrete and influential factors. Also, the higher learning accuracy of the model indicates the more capability in generalizing the learned pattern. In other words, there was no discrepancy between the performance of all three models in the learning and predicting the pattern of the CSC in this study. Moreover, considering the calculation time as another determinant factor for the efficiency of the used models, it was deduced that the WOA is more time-effective compared to the DA.
5 Conclusions
Due to the crucial role of concrete in building construction, having a reliable approximation of the characteristics of this material is essential. In this work, the compressive strength of concrete was modeled using a novel hybrid predictive model. In this way, the MLP neural network was coupled with WOA optimization technique to develop the WOA-NN ensemble. Also, the ACO-NN and DA-NN tools were used as the benchmark models. The results of the sensitivity analysis revealed that both DA-NN and WOA-NN presented the best results with population sizes of 400, while the ACO-NN with the least population (i.e., population size = 10) outperformed other similar networks. According to the results, the proposed WOA-NN model predicted the CSC with high accuracy. Besides, in comparison with the benchmark methods, the WOA algorithm (RMSE = 2.6985 and R2 = 0.8976) surpassed the ACO (RMSE = 3.4452 and R2 = 0.8000) and DA (RMSE = 3.3325 and R2 = 0.8209) evolutionary techniques in optimizing the MLP. Moreover, other than the higher accuracy, the WOA needed less calculation time than DA. Last, evaluating the performance of the WOA in comparison with other well-known hybrid algorithms is a good idea for future studies.
References
Mandal S, Shilpa M, Rajeshwari R (2019) Compressive strength prediction of high-strength concrete using regression and ANN models, sustainable construction and building materials. Springer, New York, pp 459–469
Henigal A, Elbeltgai E, Eldwiny M, Serry M (2016) Artificial neural network model for forecasting concrete compressive strength and slump in Egypt. J Al Azhar Univ Eng Sector 11:435–446
Abdalhmid JM, Ashour AF, Sheehan T (2019) Long-term drying shrinkage of self-compacting concrete: experimental and analytical investigations. Constr Build Mater 202:825–837
Thirumalai C, Chandhini SA, Vaishnavi M (2017) Analysing the concrete compressive strength using Pearson and Spearman. IEEE, Middlesex
Moayedi H, Hayati S (2018) Artificial intelligence design charts for predicting friction capacity of driven pile in clay. Neural Comput Appl 31:1–17
Moayedi H, Hayati S (2018) Modelling and optimization of ultimate bearing capacity of strip footing near a slope by soft computing methods. Appl Soft Comput 66:208–219
Seyedashraf O, Mehrabi M, Akhtari AA (2018) Novel approach for dam break flow modeling using computational intelligence. J Hydrol 559:1028–1038
Gao W, Guirao JLG, Basavanagoud B, Wu J (2018) Partial multi-dividing ontology learning algorithm. Inf Sci 467:35–58
Vakhshouri B, Nejadi S (2018) Prediction of compressive strength of self-compacting concrete by ANFIS models. Neurocomputing 280:13–22
Falade F, Iqbal T (2019) Compressive strength Prediction recycled aggregate incorporated concrete using adaptive neuro-fuzzy system and multiple linear regression. Int J Civ Environ Agric Eng 1:19–24
Ling H, Qian C, Kang W, Liang C, Chen H (2019) Combination of support vector machine and K-fold cross validation to predict compressive strength of concrete in marine environment. Constr Build Mater 206:355–363
Naderpour H, Rafiean AH, Fakharian P (2018) Compressive strength prediction of environmentally friendly concrete using artificial neural networks. J Build Eng 16:213–219
Khademi F, Jamal SM (2017) Estimating the compressive strength of concrete using multiple linear regression and adaptive neuro-fuzzy inference system. Int J Struct Eng 8:20–31
Keshavarz Z, Torkian H (2018) Application of ANN and ANFIS models in determining compressive strength of concrete. Soft Comput Civ Eng 2:62–70
Nguyen H, Mehrabi M, Kalantar B, Moayedi H, MaM Abdullahi (2019) Potential of hybrid evolutionary approaches for assessment of geo-hazard landslide susceptibility mapping. Geomat Nat Hazards Risk 10:1667–1693
Moayedi H, Mosallanezhad M, Mehrabi M, Safuan ARA, Biswajeet P (2019) Modification of landslide susceptibility mapping using optimized PSO-ANN technique. Eng Comput 35:967–984
Moayedi H, Mehdi R, Abolhasan S, Wan AWJ, Safuan ARA (2019) Optimization of ANFIS with GA and PSO estimating α in driven shafts. Eng Comput 35:1–12
Zhang X, Nguyen H, Bui X, Tran Q, Nguyen D, Bui D, Moayedi H (2019) Novel Soft Computing Model for Predicting Blast-Induced Ground Vibration in Open-Pit Mines Based on Particle Swarm Optimization and XGBoost. Nat Resour Res 28:1–11
Dou J, Bui DT, Yunus AP, Jia K, Song X, Revhaug I, Xia H, Zhu Z (2015) Optimization of causative factors for landslide susceptibility evaluation using remote sensing and GIS data in parts of Niigata, Japan. Plos One 10:e0133262
Dou J, Yunus AP, Bui DT, Merghadi A, Sahana M, Zhu Z, Chen C-W, Khosravi K, Yang Y, Pham BT (2019) Assessment of advanced random forest and decision tree algorithms for modeling rainfall-induced landslide susceptibility in the Izu-Oshima Volcanic Island, Japan. Sci Total Environ 662:332–346
de Almeida Neto MA, Fagundes RdAdA, Bastos-Filho CJ (2018) Optimizing support vector regression with swarm intelligence for estimating the concrete compression strength. Springer, New York
Behnood A, Golafshani EM (2018) Predicting the compressive strength of silica fume concrete using hybrid artificial neural network with multi-objective grey wolves. J Clean Product 202:54–64
Bui D-K, Nguyen T, Chou J-S, Nguyen-Xuan H, Ngo TD (2018) A modified firefly algorithm-artificial neural network expert system for predicting compressive and tensile strength of high-performance concrete. Constr Build Mater 180:320–333
Sadowski L, Nikoo M, Nikoo M (2018) Concrete compressive strength prediction using the imperialist competitive algorithm. Comput Concrete 22:355–363
Moayedi H, Abdullahi MM, Nguyen H, Rashid ASA (2019) Comparison of dragonfly algorithm and Harris hawks optimization evolutionary data mining techniques for the assessment of bearing capacity of footings over two-layer foundation soils. Eng Computers 35:1–11
Moayedi H, Osouli A, Nguyen H, Rashid ASA (2019) A novel Harris hawks’ optimization and k-fold cross-validation predicting slope stability. Eng Comput 35:1–11
Xi W, Li G, Moayedi H, Nguyen H (2019) A particle-based optimization of artificial neural network for earthquake-induced landslide assessment in Ludian county, China. Geomat Nat Hazards Risk 10:1750–1771
Mirjalili S, Lewis A (2016) The whale optimization algorithm. Adv Eng Softw 95:51–67
Mafarja MM, Mirjalili S (2017) Hybrid whale optimization algorithm with simulated annealing for feature selection. Neurocomputing 260:302–312
Trivedi IN, Jangir P, Kumar A, Jangir N, Totlani R (2018) A novel hybrid PSO–WOA algorithm for global numerical functions optimization, advances in computer and computational sciences. Springer, New York, pp 53–60
Nasiri J, Khiyabani FM (2018) A whale optimization algorithm (WOA) approach for clustering. Cogent Math Stat 5:1483565
Rana N, Latiff MSA (2018) A Cloud-based Conceptual Framework for Multi-Objective Virtual Machine Scheduling using Whale Optimization Algorithm. Int J Innovative Comput 8:53–58
Kaveh A (2017) Sizing optimization of skeletal structures using the enhanced whale optimization algorithm, applications of metaheuristic optimization algorithms in civil engineering. Springer International Publishing, Cham, pp 47–69
Mirjalili S (2016) Dragonfly algorithm: a new meta-heuristic optimization technique for solving single-objective, discrete, and multi-objective problems. Neural Comput Appl 27:1053–1073
Colorni A, Dorigo M, Maniezzo V (1992) Distributed optimization by ant colonies. Proceedings of the first European conference on artificial life. Cambridge, MIT Press, Massachusetts, USA
Dorigo M, Blum C (2005) Ant colony optimization theory: a survey. Theoret Comput Sci 344:243–278
Dorigo M, Birattari M (2010) Ant colony optimization. Springer, New York
Mafarja MM, Eleyan D, Jaber I, Hammouri A, Mirjalili S (2017) Binary dragonfly algorithm for feature selection. IEEE, Middlesex
Ks SR, Murugan S (2017) Memory based hybrid dragonfly algorithm for numerical optimization problems. Expert Syst Appl 83:63–78
Yeh I-C (2007) Modeling slump flow of concrete using second-order regressions and artificial neural networks. Cement Concr Compos 29:474–480
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Tien Bui, D., Abdullahi, M.M., Ghareh, S. et al. Fine-tuning of neural computing using whale optimization algorithm for predicting compressive strength of concrete. Engineering with Computers 37, 701–712 (2021). https://doi.org/10.1007/s00366-019-00850-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00366-019-00850-w