
Abstract
This work proposes a new integer linear programming model for tactical and operational planning of the blood supply chain. A two-stage approach is developed with a first aggregated stage to establish tactical planning decisions and a second disaggregated stage for the operational level. The model considers multi-products, multi-periods and perishability in a large planning horizon. Inventory levels as well as waste of whole blood and blood-derived products are also modelled. A purchase flow is introduced to handle situations of not enough collection to satisfy demand. The objective is cost minimisation whilst reducing waste and dependence on other regions through purchase. A case study of the South Region of Portugal is explored, demonstrating the possibility of decreased dependency and waste by adjusting allocation of facilities and allowing a more even distribution of activities between processing centres. This is the first study of the kind ever conducted on the Portuguese blood supply chain.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The blood supply chain encompasses the evolution and tracking of blood and its components from donor to recipient, comprising the processes of collecting, testing, processing and distributing blood and its derived products (Osorio et al. 2015). Blood and its components are anything but ordinary commodities. They are remarkable in the sense that they have an outstanding impact in human lives. The consequences of shortages of such products may be vast and vary between interfering with scheduled procedures or, more severely, contributing to the inability of saving patients, which translates into a powerful influence in mortality rates. Contrarily, surplus is likely to be followed by outdates, which, in turn, lead to ethical issues as waste of such scarce products is strongly frowned upon by society (Beliën and Forcé 2012). Furthermore, it is a commodity that is becoming increasingly limited, once donation numbers have reached, in general, a new low. In Portugal, donation numbers decreased from 30.70 donors per 1000 inhabitants in 2008 to 21.74 donors per 1000 inhabitants in 2016 (de Sousa et al. 2016). The need for such a commodity is not likely to cease to exist, which is why the blood supply chain is such a worthy topic that merits study, where the balance between shortages and surplus is paramount to its smooth functioning.
The management of the blood supply chain is challenging nonetheless. This is mainly due to the unpredictable nature of blood, as the demand for this product and its components is highly stochastic, while the supply of donor blood is irregular, making it even more problematic to match supply with demand and avoid the aforementioned scenarios. The perishable disposition of blood products is another obstacle to be overcome, given that the shelf life is not only considerably short but also varies between blood products, adding strict constraints to an already complex supply chain (Osorio et al. 2015). Besides the array of blood products that can be derived from whole blood, each one with its very own purpose and use, another important characteristic is the requirement for blood compatibility in some of these products, like red blood cells, increasing the complexity of the problem. This compatibility is reflected, for example, in the eight existing blood types (A, B, AB and O, each with positive and negative Rhesus factor), requiring further phenotype studies of different blood group systems. These challenges, alongside the importance of the product itself, make a clear case for the importance of studying the blood supply chain both in an integrated view and in each of the stages, in order to support decision-making.
The aim of this research is to present a mathematical programming model to address tactical and operational level decisions in a blood supply chain context. Specifically, given the existing infrastructures of the network under study (collection, production and demand facilities) as well as supply and demand, the goal is to study the flow of blood within the network, considering collection as input, assuring demand satisfaction and minimising total costs, waste and shortages, the latter represented by dependence upon other regions (i.e. purchase). With the purpose of modelling reality as closely as possible, this work considers several aspects: multi-periods; multi-products; inventory; perishability; waste generation; and external products acquisition. Although subsets of these aspects have been studied jointly in the literature, this work is, as far as we are aware, the first to address all of them simultaneously in an integrated view of the blood supply chain. Additionally, this is the first study concerning the Portuguese blood supply chain, providing both a practical and a theoretical contribution to the literature, particularly by showing that the integrated management of a blood supply chain can result in substantial reductions in operational costs and waste. This is shown through a computational study using real data, comprising the year 2015, provided by the main entity responsible for blood supply chain management in Portugal. Preliminary results showed that a monolithic model is intractable for state-of-the-art commercial solvers for solving instances based on real data of the Portuguese blood supply chain, thus a two-stage approach is proposed. The first stage addresses the tactical level, using an aggregated and simpler model. The second stage uses the network decisions of the previous stage as input and details the operational level of the chain, using a more complex and time refined model.
The remainder of this paper is structured as follows. Section 2 presents an overview of the literature on the blood supply chain, with emphasis on works addressing integrated views. Then, the problem motivated by the Portuguese blood supply chain is explained in Sect. 3, followed by the integer linear programming model in Sect. 4. The two-stage approach is introduced in Sect. 5 and is applied to the case of the South Region of Portugal in Sect. 6 where managerial insights are also provided. Finally, conclusions are stated in Sect. 7.
2 Literature review
The earliest identified work related to the blood supply chain is that of Millard (1959) who first acknowledged similarities between the inventory problem at a blood bank and the industrial inventory framework and proposed general inventory models adapted to the blood bank inventory. Subsequent early work focused in particular on the blood bank inventory problem. Elston and Pickrel (1963) used simulation to study ordering and usage policies by comparing first-in-first-out and last-in-first-out approaches. The effect of blood inventory policies on shortages and outdatedness were also studied with the use of simulation by Jennings (1968), while Pegels and Jelmert (1970) used Markov chains to evaluate policies according to shortage probability and age of blood transfused. Brodheim et al. (1976) developed an approach to set inventory levels for blood banks depending on shortage rates and average demand. An evaluation of the inventory level at blood banks was also studied by Cohen and Pierskalla (1979) who concluded that its implementation could lead to relatively low shortage and outdatedness rates. The work by Nahmias (1982) explored perishable inventory policies and the application of perishable inventory theory in blood banks, while a blood inventory management review was done by Prastacos (1984). More recent studies with a focus on blood inventory management include Duan and Liao (2014), who consider reduced shelf lives and blood group compatibility, and Dillon et al. (2017), who proposed a two-stage stochastic programming model incorporating aspects such as blood group compatibility, perishability, waste and shortage.
One of the most important works developed on blood supply chain management, which inspired further studies on this topic, is the work by Pierskalla (2004), since all three decision levels are discussed therein. In the strategic level, the discussion is around issues such as assigning donor and transfusion regions to community blood centres, establishing the number of community blood centres in a region and their location, and coordinating supply and demand. With respect to the tactical and operational levels, topics such as blood collection, multi-product production, inventory management, blood allocation, and multi-site delivery are approached. Issuing and crossmatching policies are also addressed. A fundamental aspect of the work by Pierskalla (2004) is that it studies the supply chain in a integrated view, and not as multiple independent subsystems.
Beliën and Forcé (2012) presented the first literature review paper on blood supply chain management. This review proposes a classification for existing literature up to 2010, organising it according to blood product, solution methodology, hierarchical level of decision, type of problem and approach, performance measures and case studies. Beliën and Forcé (2012) show an increasing number of studies which consider both red blood cells and platelets, mainly using so-called soft computational approaches rather than mathematical programming models. Most studies focus mainly on either the hospital level or the regional blood centre level, leading to a deficiency regarding the study of the supply chain level. This review also identified that the most-used performance measures are shortages and outdatedness. Finally, the authors also highlight an increasing tendency to include some form of practical implementation or case study. A more recent review by Osorio et al. (2015) structures the literature according to five categories, namely each of the four echelons of the blood supply chain (collection, production, inventory and delivery) and an integrated view of the blood supply chain. The authors suggest that further studies with respect to the integrated view of the blood supply chain are necessary, since most of the existing works offer a narrow approach by focusing on a single echelon and, thus, do not address the relationship between the different stages of the supply chain. The study of integrated views of the blood supply chain has been increasing, however.
Studying the blood supply chain as an integrated system is challenging since incorporating multiple aspects into a single approach leads to highly complex models. In their work, Nagurney et al. (2012) propose a mathematical programming model to optimise the blood supply chain that models the entire network consisting of collection points, testing and processing locations, storage facilities, distribution centres and demand zones, representing both the entities and their relationships. The authors also account for both whole blood and red blood cells; however, there is no clear distinction between the two in their formulation. Arvan et al. (2015) present a bi-objective model to minimise operating and transportation costs as well as expired products in a locate and allocate network with donation sites, testing and processing facilities, blood banks and demand zones. This is one of the most complete works with respect to the blood products considered, simultaneously including whole blood, red blood cells, platelets and plasma. Masoumi et al. (2017) also study blood supply chains by comparing pre- and post-merger scenarios of so-called blood organisations while accounting for perishability and waste of red blood cells. Zahiri and Pishvaee (2017) developed a bi-objective mixed integer programming model, which they validate with a case study, to minimise both total costs and shortages while also considering blood group compatibility. This is one of the first works that models this aspect of the blood supply chain.
Although more complete in terms of blood products considered, Arvan et al. (2015) and Zahiri and Pishvaee (2017) do not model inventory, another important aspect of the blood supply chain, neither at the blood centre nor at the hospital. Works accounting for inventory management include that of Fazli-Khalaf et al. (2017) who propose a tri-objective mathematical model to design the blood supply chain in emergency situations in order to minimise total costs and transportation times and maximise testing reliability. In this study, inventory at the blood centre is accounted for, both in terms of capacity and cost. Similarly, Habibi et al. (2018) developed a bi-objective multi-period optimisation model which determines the quantity, the location and the allocation of facilities, with the objective of minimising both costs and shortages. Both studies only look at a single-product blood supply chain and only consider inventory at the blood centre. The work of Ensafian and Yaghoubi (2017) presents two robust mixed integer programming models accounting for first-in-first-out and last-in-last-out issuing policies as well as both traditional and aphaeresis methods of collection. Additionally, the capacity and holding costs are taken into consideration at both the blood centre and at the hospital. Osorio et al. (2018) developed a mathematical model to optimise the blood supply chain based on the location-allocation problem. Their model finds the optimal location for collection and production facilities and assigns demand zones, with the objective of overall cost minimisation of the system. The authors consider different collection methods (e.g. aphaeresis) and also different levels of centralisation of the blood supply chain.
Even though the literature on blood supply chain management is becoming richer, most of these studies do not incorporate perishability of blood products into their models. For example, only a single-period time horizon is considered by Nagurney et al. (2012), which can be deemed unrealistic. Arvan et al. (2015) are more realistic in this aspect and take into account the time between locations in the network and the processing time of blood but not the time that blood products are held in storage, which may be relatively long. Likewise, Zahiri and Pishvaee (2017) only consider perishability with respect to the travel time between locations. Finally, Fazli-Khalaf et al. (2017) minimise total transportation time between facilities but not necessarily with the concern of perishability, whereas Habibi et al. (2018) do not address this aspect at all in their model. Conversely, Heidari-Fathian et al. (2017) present a mathematical model which includes perishability, even if only for a single blood product, while Samani et al. (2018) propose a multi-objective mixed integer linear programming model for the design of an integrated blood supply chain network in a disaster situation which, besides minimising total costs and the unsatisfied demand, minimises the time span between the production and the transfusion of blood products. The work by Samani et al. (2018) is one of the most complete in the literature, simultaneously modelling perishability, inventory levels at both demand zones and blood centres, shortages and location and allocation. However, blood groups are not considered.
Finally, another relevant aspect of blood supply chain management is the uncertainty associated with collection and demand. Most of the previously referred works studying an integrated view of the blood supply chain address uncertainty in some way, using techniques akin to robust, stochastic or fuzzy optimisation (Nagurney et al. 2012; Ensafian and Yaghoubi 2017; Samani et al. 2018; Habibi et al. 2018; Fazli-Khalaf et al. 2017; Masoumi et al. 2017; Zahiri and Pishvaee 2017), or by performing some sensitivity analysis (Arvan et al. 2015; Heidari-Fathian et al. 2017). In this work, we also present an analysis of the robustness of the solutions obtained with respect to extreme scenarios of collection and demand.
As the literature review shows, the number of studies addressing the blood supply chain as a whole has been increasing; however, simplifications in terms of considered aspects occur in order to tackle complexity. The main contribution of this work is exactly to attempt to incorporate the multitude of aspects discussed in the study of an integrated blood supply chain. More precisely, this work accounts for a multi-product supply chain with simultaneous modelling of blood groups, perishability, inventory management and shortages (this latter aspect modelled through an undesirable purchasing option). To summarise, Table 1 shows the main characteristics included in this work and compares it with the cited papers proposing integrated blood supply chain approaches.
3 Problem description
The blood supply chain is composed of four echelons, namely collection, production, delivery and inventory (Osorio et al. 2015). Volunteer donors donate blood at temporary collection facilities, fixed collection points or even directly at some processing centres. Collected blood is then shipped from the collection points to the processing centres where whole blood is processed into its derived components in order to produce the final products, which are stored awaiting shipment to demand zones (i.e. any facility that uses the blood-derived products, such as a hospital). Simultaneously, samples of the donated blood are analysed for viruses and diseases, which either clears the blood products for distribution or sentences them to disposal.
The problem studied in this work encompasses all four echelons. However, in the collection echelon we only model the outgoing flows, that is, we consider the collected blood as input. In other words, the main focus is to study the flow of whole blood between collection centres and processing centres and the flow of blood-derived products between processing centres and demand zones, while managing inventory levels. We would like to point out that this blood supply chain is similar to the one described by Zahiri and Pishvaee (2017) in Iran; however, there is a distinction of laboratory, storage and distribution facilities therein, whereas, in this case, all of those are part of the processing centres.

Problem structure and decisions
Figure 1 shows a representation of the blood supply chain under study (of which the Portuguese blood supply chain is an example), including collection points, processing centres and an example of a demand zone, namely a hospital. The flow of blood starts at the collection points, where collected blood must be allocated and shipped to a processing centre. All collected blood must be transferred to a processing centre within the same day it is collected, as it needs to be processed within 24 hours. Once at the processing centre, whole blood units are separated into its components: red blood cells, platelets and plasma. Given the long life span of plasma (3 years) and its special characteristics and purpose, this derived product is out of the scope of this work concerning the computational study; however, our approach is general enough such that its inclusion would be seamless. Tests are conducted within these processing facilities in order to determine blood type and to test for known diseases. Derived components that are cleared from previous testing must be conserved under specific conditions and have different shelf lives. In particular, red blood cells can last up to 42 days, whereas platelet pools have a life span of only 5 to 7 days. The blood-derived products are stored in the processing centres until requested by any of the demand zones which the processing centre supplies. The allocation of the blood products to the demand zones is a decision under the responsibility of the processing centre; however, there is a clear tendency to dispatch products with lower remaining shelf lives first, that is, following a first-in-first-out policy. Processing centres are also able to purchase blood-derived products from other regions. This is a particular characteristic of this blood supply chain, essentially acting as an equivalent for modelling shortages, and is the reason why a purchase flow (represented by flow g in Fig. 1) is introduced. This option is strongly discouraged in practice since it incurs in significantly higher costs and it increases the dependency on other regions. Requests from demand zones arrive daily, according to their needs and usage rates. Once at the demand zones, blood products are kept in inventory until needed for transfusion.
The decisions that can be taken are the following (as shown in Fig. 1): (a) the quantity of whole blood transported from each collection point to each processing centre at each period; (b) the quantity of whole blood transported between processing centres at each period (recall that blood may be donated directly at a processing centre); (c) the quantity of blood products produced by each processing centre at each period; (d) the quantity of whole blood wasted by each processing centre at each period due to non-processing decisions; (e) the inventory level of each blood product in each processing centre and in each demand zone at the end of each period; (f) the quantity of blood products transported between processing centres at each period; (g) the quantity of blood products purchased by each processing centre at each period; (h) the quantity of blood products transported from processing centres to demand zones at each period; (i) the quantity of blood products consumed by each demand zone at each period; and (j) the quantity of blood products wasted by each processing centre and by each demand zone at each period due to outdatedness.
Moreover, the following assumptions are made: (i) the blood supply chain is single-product prior to processing (whole blood) and multi-product thereafter (blood-derived products); (ii) the perishability of blood products is modelled since they are first stored until they are transfused; (iii) the production rate is 1:1 between whole blood and red blood cells, but 4 units of whole blood (of the same group type) are required to produce 1 unit of platelet pools; (iv) the storage capacity of the processing centres is limited; (v) minimum inventory levels are defined at both processing centres and demand zones; (vi) shortages at demand zones are not allowed, and demand (i.e. consumption at demand zones plus minimum inventory levels) needs to be satisfied; (vii) blood products can be purchased from other regions, introducing a purchase flow at the processing centre level; and (viii) waste, including both whole blood waste, associated with the decision of not processing (e.g. in the case of excessive collection), and blood product waste, associated with outdated blood products, is allowed but it is penalised through costs.
In the following section, we present a mathematical model for the problem here described.
4 Mathematical model

Blood supply chain network
This section introduces the integer linear programming model that we propose for the problem described in the previous section, and which is now schematised in Fig. 2. As previously mentioned, all four echelons of the blood supply chain are modelled, with the flow of blood entering the collection centres treated as input. The model operates on discrete uniform time periods (e.g. days), and it may be used for any generic blood supply chain network, ensuring that all demand is satisfied at minimum total cost, in particular transportation, inventory, production, purchase and waste costs. Table 2 summarises the notation used throughout the remainder of the paper, namely with respect to sets, parameters and decision variables.
Before we detail the model, we would like to observe that care must be taken in the definition of the decision variables. For example, the allocation variables \(A_{ee't}\) should be set to 0 if the allocation is not possible (e.g. a facility cannot be allocated to itself). Similarly, the transportation variables \(trp_{bgt'ee't}\) should be set to 0 when no transportation is allowed between the entities. Additionally, if the initial entity does not allow inventory (e.g. a collection centre), then \(t' \ne t\) is not possible as well. In fact, the relationship between \(t'\) and t must be carefully addressed since these indices must be such that their difference is within the life span of the corresponding product. This is particularly important when modelling inventory, as explained in the work by Dillon et al. (2017). To ease the readability of the constraints, we omit these more detailed conditions in the ensuing mathematical expressions.
The objective function (1) represents the total costs of the supply chain which we aim to minimise. The first term is related to transportation costs between the three types of facilities in the supply chain, namely collection points, processing centres and demand zones, for both unprocessed and processed blood. The second term models the holding costs associated with the inventory of blood products at both processing centres and demand zones. The third term reflects production and purchase costs of blood products. Finally, the last term is related to waste disposal costs, and it includes both whole blood waste associated with non-processing decisions and blood product waste due to outdatedness.
The blood supply chain is constrained by a number of factors. The first group of constraints (2)–(3) guarantees that, respectively, the flow of products is non-negative if and only if there is an allocation between the two facilities, and that the quantity of flow into each facility is bounded by its capacity. Observe that, in the setting described in this work where allocating an facility to another facility incurs no fixed cost, constraints (2) are redundant; however, we include them in the model for two reasons. Firstly, and more importantly, because the allocation decisions are an integral part of the proposed solution approach. Secondly, for generality, given that this aspect may then be easily incorporated with the addition of a new cost term in the objective function.
The second group of constraints is related to the collection, processing and flow of whole blood. Constraints (4) force all whole blood collected at the collection points to be transferred to the processing centres at the end of each period. At the processing centres, constraints (5) define the whole blood decomposition into the derived blood products (i.e. red blood cells and platelet pools) according to a given production ratio and to the availability of whole blood in that period. The waste of whole blood in the production process is modelled by constraints (6) and (7). The former model the minimum waste inherent in the inefficiencies in the production process (\(\alpha ^-\)), whereas the latter impose a maximum allowed waste to prevent excessive overproduction (\(\alpha ^+\)). Constraints (8) model the flow conservation of whole blood, ensuring that all whole blood arriving at the processing centres is either processed, discarded or sent to a different processing centre.
The third group of constraints (9)–(14) models the flow and the inventory of blood-derived products, and are mostly based on the formulation described by Dillon et al. (2017). An interesting study could be to use a more recent way of modelling inventory proposed by Dehghani et al. (2019), which showed potential to reduce computational times. Constraints (9) and (10) are flow conservation constraints for blood-derived products and, essentially, they ensure that products produced/purchased in a given period which are not transported, in case of constraints (9), or consumed, in case of constraints (10), are kept as inventory at processing centres or demand zones, respectively. The inventory levels of products produced/purchased in earlier periods are modelled by constraints (11) and (12) for processing centres and demand zones, respectively. Essentially, these constraints state that the inventory levels depend on the level in the previous period and on the products transported or consumed. Constraints (13) guarantee that storage capacity for blood-derived products is not exceeded, while constraints (14) ensure that the minimum level of inventory is respected, both at processing centres and demand zones.
The fourth group of constraints (15)–(16) concern waste and consumption. More precisely, constraints (15) model the quantity of wasted blood products at processing centres and demand zones due to outdatedness, whereas constraints (16) model the consumption of blood products in the demand zones. Observe that these constraints ensure that all demand is fulfilled.
Finally, the last group of constraints (17)–(18) define the domains of the decision variables.
5 Solution approach
Preliminary tests conducted on a real-life instance for a realistic time horizon based on the Portuguese blood supply chain case showed that the monolithic model presented in the previous section is intractable for state-of-the-art commercial solvers due to its complexity and the large dimension of the real-life instance. Therefore, we propose a heuristic two-stage approach to solve the problem. Stage one considers a simpler aggregated version of the original model for a longer time horizon, whereas stage two uses the original disaggregated and complex model in a shorter planning period. The two-stage approach is illustrated in Fig. 3 and the different settings are highlighted in Table 3. The approach is hierarchical in the sense that the first stage tackles the tactical level of decisions while the second stage handles the operational level.

Two-stage approach
With respect to the tactical level, the first stage model aggregates time periods and blood group types, thus providing only aggregated decisions. Constraints (2) are not present in the aggregated stage, allowing the model the possibility of freely choosing the transportation flows between facilities in a long planning horizon without regard for the consequences (e.g. cost) of the implicit allocation. Additionally, constraints (6) are also not included since in the tactical level the inefficiencies in the production process may be relaxed without considerably influencing the aggregated decisions. In fact, constraints (7) are much more relevant to preventing excessive whole blood waste and, thus, insufficient variability in the allocations. The output of the first stage is comprised of the flows between collection points and processing centres and between processing centres and demand zones, which are then used to fix the allocations that serve as input in the second stage. If no flow exists between two facilities, the corresponding allocation variable \(A_{ee't}\) will be fixed to 0, otherwise, it will be fixed to 1. Fixing the allocations in this way is optimal with respect to the transportation flow solution.
As for the operational level, that is, in the second stage, we use the monolithic model in which the allocation decisions (i.e. variables \(A_{ee't}\)) are fixed based on the solution of the first stage, resulting in a model with a reduced size. We also do not consider constraints (7) since, as mentioned above, these constraints are more relevant when defining allocations. However, constraints (6), which model the inefficiencies in the production process and were not present in the first stage, are now important to more accurately predict whole blood waste.
With this hierarchical heuristic two-stage approach it is possible to tackle both decision levels with the specific considerations and planning periods required by each decision level. This is extremely important as using solely the disaggregated model would not allow for a sufficiently long time horizon to obtain reliable allocations. In other words, the two-stage approach is a trade-off between optimality and applicability of the resulting solutions in practice. In the next section we show the results of applying our approach to instances based on real data of the Portuguese blood supply chain.
6 Case study
In this section, we present and discuss the computational results of the monolithic model and of the corresponding two-stage approach on the Portuguese blood supply chain case, in particular in the South Region of Portugal. Additionally, we compare the solutions obtained by the model to the case study data and offer insights on possible improvements suggested by this analysis. The models were implemented in GAMS and solved using CPLEX version 12.8.0 in multi-thread mode on a computer with two Intel Xeon E5-2660 v3 processors (10 cores/20 threads each with a base frequency of 2.60 GHz) and 64 GB of RAM.
We start by presenting the case study in Sect. 6.1. In Sect. 6.2 we discuss the instance characteristics as well as the performance of the monolithic model and of the two-stage approach. In Sect. 6.3 we analyse the solutions obtained for Stage 1 while comparing them to the case study data. Finally, in Sect. 6.4 we discuss the results of the computational experiment for Stage 2. Sects. 6.3 and 6.4are complementary in the sense that they provide macro and micro analyses, respectively, of the Portuguese blood supply chain.
6.1 The case study of Centro do Sangue e Transplantação de Lisboa

IPST’s regional blood centres
Instituto Português do Sangue e da Transplantação (IPST) is the institution responsible for the regulation of transfusion medicine in Portugal and is a key player in the Portuguese blood supply chain. Its mission is to guarantee and regulate transfusion medicine at a national level and to ensure donation, collection, analysis, processing, preservation and distribution of human blood and its components (IPST 2017). IPST operates in a decentralised structure divided in three areas, as shown in Fig. 4, each coordinated by a regional blood centre. Centro do Sangue e Transplantação do Porto (CSTP) is responsible for the North Region of Portugal; Centro do Sangue e Transplantação de Coimbra (CSTC) is responsible for the Central Region of Portugal; and Centro do Sangue e Transplantação de Lisboa (CSTL) is responsible for the South Region of Portugal. This study focuses on the South Region of Portugal, where CSTL is the regional blood centre, which is the blue coloured (dark grey coloured for black and white printings) region. This region is particularly dependent on the other two regions for the purchase of blood-derived products to satisfy the demand and, thus, it is also where there is more potential for improvement.
6.2 Instance characteristics and model performance
CSTL runs 12 collection points and 8 processing centres, and supplies 46 demand zones with red blood cells and platelet pools, and also plasma, which we do not consider in the computational study. Costs were calculated based on a number of different sources. In particular, transportation costs were set to 0.14€ per kilometre based on values for refrigerated biological transport (Rupprecht and Nagarajan 2015); production costs were set according to the Portuguese decree-law 234-2015; purchase costs are the same as production costs plus a penalty of 200€ per product; and, finally, inventory and waste costs were set as per Dillon et al. (2017). The life span of red blood cells and platelet pools is considered to be 42 and 6 days, respectively, with production factors of 1 and 0.25. Both whole blood waste factors (\(\alpha ^-\) and \(\alpha ^+\)) were set to 0.02. The remaining parameters, namely collection, demand, capacities and initial and minimum inventory levels are omitted here due to the excessive size required for their full descriptionFootnote 1.
Using the proposed monolithic model in this instance with a relevant time horizon of 60 days resulted in inaccurate results with a gap of 16.28% in around sixteen hours of computational time after which CPLEX ran out of memory (see Table 5). Due to these results, the two-stage approach presented in the previous section was developed. In the first stage of the approach, the aggregated model, which we recall has no blood group type distinction and a 3-day time aggregation (see Table 3), was applied to a time horizon of six months for a total of 60 time periods of three days. In the second stage of the approach, and based on the tactical planning results of the first stage with respect to the allocation of facilities, the disaggregated model was applied to a time horizon of 45 days. Table 4 summarises the dimensions of the instance for both the monolithic model and the two stages.
Table 5 shows the computational results. Considering the expectations of IPST, a time limit of 4 days (345,600 seconds) was imposed for the monolithic model, which we decided to split evenly (172,800 seconds) by the two stages. These limits turned out to be non-binding however, as all three runs finished beforehand due to lack of computational memory. As mentioned above, CPLEX ran out of memory in just over 16 hours of computational time with the monolithic model finishing with a gap of 16.28%. The performance of the first and second stage models is significantly better. In particular, the first stage model attained a final gap of 0.20% in a computational time of about 30 hours whereas the second stage model was able to reach a gap of 2.91% in close to 45 hours. The difference in the performance of the monolithic model compared to the two-stage approach may be explained by the difference in complexity. In fact, after preprocessing, the monolithic model has about 2.4 million variables, which is roughly the same as the first and second stage combined, and 338 thousand constraints, essentially about 35% more than the two stages combined.
Note that the two-stage approach is only able to provide heuristic solutions which do not take full advantage of the integration of the tactical and operational levels. Nevertheless, the substantial difference in terms of gap suggests that the global solution obtained by the two-stage heuristic approach is overall better and, most importantly, more useful than the one obtained by the monolithic model. For this reason, in the following subsections we compare the two-stage approach solution to the case study data and present suggestions of improvements based on this solution.
6.3 Stage 1 solution analysis
In this section, we analyse the solution obtained by the first stage model in two ways. First, we compare it to the case study data on a number of indicators in Sect. 6.3.1. Then, we conduct a scenario analysis by varying collection and demand values to test the impact on the solution in Sect. 6.3.2.
6.3.1 Comparison with the real case
This comparison first explores general indicators, providing a broader view of the blood supply chain and allowing to perform an analysis of self-sufficiency of the region under study. Then, we look at processing centre indicators that allow us to compare the activity of the processing centres at multiple levels of planning such as, for instance, production strategies. Afterwards, we compare planning indicators which are related to the flow of blood between the three types of infrastructures of the blood supply chain network and corresponding allocation decisions. Finally, we look at demand zone indicators, which include inventory levels and which allow the assessment of ideal inventory considering supply and demand. Concluding remarks are made at the end of the section.
General Indicators
Table 6 shows a comparison between the case study data and the first stage model solution on six general indicators, in particular the number of produced, distributed, received and purchased blood product units as well as the number of units of whole blood and blood-derived products wasted. Received units only account for those received by demand zones (i.e. they exclude transshipments between processing centres).
With respect to production, the model produces 5% more red blood cells and 21% more platelet pools. The more noticeable difference for platelet pools is explained by the fact that, in reality, whole blood is sometimes only processed into red blood cells. The differences in production are also related to the lower waste of whole blood in the model compared to reality. Note, however, that constraints (6) which model the inherent production inefficiencies are not present in Stage 1, thus, an increased, albeit artificial, production proposed by the model was expected.
Looking at the number of distributed units, which refers to the units of red blood cells and platelet pools distributed by processing centres to either other processing centres or demand zones, the model has 18% less in terms of red blood cells and only 2% more for platelets despite the increase in production. These may be explained by transshipments between demand zones and returns of close-to-expiry units occurring in reality that the model does not account for. Regarding the number of received units indicator, that is, the units received by the demand zones, similar values are observed for red blood cells. The higher variation for platelet pools is correlated with the increased production.
The purchase flow indicates the number of units that are missing from production in order to satisfy demand. This is an indicator of the dependency of the South Region on the North and Central Regions. CSTL aims to reduce this dependency (and have a more self-sufficient South Region) and, thus, this flow should ideally be equal to zero. The differences in this indicator are substantial, with decreases of 73% and 36% in purchases of red blood cells and platelet pools in the model, respectively. Although part of the decrease may be explained by the increased (artificial) production, the results of the first stage model suggest that there is room for improvement, specially concerning red blood cells.
Finally, in terms of outdates, there is a significant difference in both red blood cells and platelet pools. The model is able to reduce the outdates by 98% with respect to red blood cells; however, the outdates of platelet pools are increased by 210%. We believe that the latter is essentially explained by the increased production and by the fact that, in 3-day time aggregation periods, the effective life span of platelets is only of two time periods. As for the former, and apart from the increased production, the substantially fewer outdates in the first stage model solution further indicate possible improvements not entirely disconnected from the reduction in number of purchased units.
In general, the first stage solution has good indicators concerning red blood cells. Production is slightly increased but, most importantly, purchases and outdates are substantially decreased. As for platelet pools, the number of purchased units is lower when compared to reality but outdates are considerably increased. Recall, however, that, in reality, whole blood is sometimes only processed into red blood cells, whereas the model always produces both red blood cells and platelet pools.
Processing Centre Indicators
A comparison of indicators regarding the activity of the processing centres is presented in Table 7. A total of three indicators are compared concerning production, distribution and purchase.
Looking at production in CSTL, we see that there is a decrease in the contribution of this centre to the total number of red blood cell units produced (down from 53.4% to 48.7%). Conversely, an increase in the number of platelet pool units is observed, which is most likely explained by the increased overall production. Despite the small reduction in red blood cell production, CSTL remains the centre with the highest production rate of the South Region of Portugal. A similar but much more noticeable trend applies with respect to distribution, whereas purchases in the model are decreased substantially in CSTL.
The decrease in activity of CSTL is offset by the increase in the other centres. In particular, the HAS, the IPO and the HFVX processing centres have noticeable increases in distribution supported by additional purchases. Nevertheless, as mentioned above, most of the total activity is still associated with CSTL. These results suggest that a more homogeneous contribution in terms of production, distribution and purchase activities of the processing centres may lead to a potential gain. In fact, the region appears to be too dependent on CSTL.
Planning Indicators
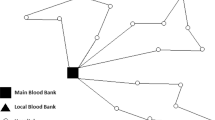
Planning indicators refer to the allocation of collection centres and demand zones to processing centres, which are established based on the flow of blood products. The most representative allocations established by the first stage model solution for both red blood cells and platelet pools can be seen in Figs. 5 and 6.

Allocation of collection centres to processing centres

Allocation of demand zones to processing centres
The allocation decisions are the main goal of the first stage. They indicate the flows that should be used to improve the overall efficiency of the blood supply chain, and are used as input for the disaggregated second stage. Their application is pivotal in several aspects, starting with better planning at the tactical level in terms of, for example, transportation arrangements. Unfortunately, there is no data available for a comparison to be made but, based on discussions with IPST, and supported by previous observations concerning general indicators, the allocations proposed by the first stage model appear to be more adequate than the ones currently established in the real case.
Demand Zone Indicators
Finally, we analyse indicators related to the activity of the demand zones. The first indicator is the variation with respect to reality of received red blood cell and platelet poll units, which is presented in Table 8. Given the large number of demand zones, only the number of demand zones with a variation within the intervals presented is shown.
The results of Table 8 show that, for red blood cells, the majority of demand zones (41 out of 46) present a difference in units received of at most 5%, when compared to reality. Observe that in Table 6 the overall difference between model and reality was negligible. This suggests that the first stage solution, although mostly in agreement with reality, is able to improve the distribution and allocation for certain demand zones. Variations encountered between real values and modelled ones for pools of platelets are higher, likely associated with the increased production in the model, as already discussed.
The inventory levels at demand zones can also be analysed. These are presented in Table 9 and they help to understand what are the ideal levels, given collection and consumption. For these results, a comparison is made for seven demand zones, where there is a considerable variability between average inventory levels in reality and the ones obtained by the model. The results show that the model, on average, requires less inventory, which is one of the aims of IPST. This supports the fact that the current inventory levels in reality at these demand zones may not be in accordance to their utilisation rates, demonstrating the need for a study on ideal inventory levels to be kept at each hospital according to demand.
Remarks
The comparison to the case study data shows that the proposed first stage model is able to accurately capture the tactical view of the Portuguese blood supply chain. Although higher artificially-induced production levels exist due to modelling specificities, the solution of the first stage model allows us to identify three (correlated) key aspects which can greatly improve the efficiency of the supply chain. The first two aspects are the number of purchases and outdates, in which the Stage 1 solution has fewer when compared to reality. This suggests that the distribution network has margin for improvement in terms of the allocations of facilities, leading to a more balanced workload with respect to production, distribution and purchase of the processing centres, thus reducing the dependency of the region on CSTL. Additionally, reducing the number of purchases allows for a more self-sufficient South Region which is another important goal. The third aspect is related to inventory levels (or blood reserves). The inventory levels of the solution of the first stage model are significantly different in some demand zones from real inventory levels. This suggests that the real inventory levels may not be adjusted to the demand.
6.3.2 Scenario analysis
To test the impact of data variability on the results, a scenario analysis, designed in accordance with IPST, is conducted in this section. The main aim is to study how this variability influences the allocation of facilities in the final solution, as this is a good indicator of the robustness of our approach. The scenarios have varying demand and collection values which reflect the best and worst cases in time periods of six consecutive months, for a total of four scenarios as follows:
-
Scenario 1: maximum demand and maximum collection values;
-
Scenario 2: maximum demand and minimum collection values;
-
Scenario 3: minimum demand and maximum collection values;
-
Scenario 4: minimum demand and minimum collection values.

Scenarios under study
The four scenarios are depicted in Fig. 7 alongside the real scenario (R), which was analysed in the previous section. Solutions of the four scenarios are compared in Table 10 based on general indicators. Note that the solutions for the four scenarios are not optimal (gaps of 0.97%, 0.76%, 2.66% and 0.65%, respectively); however, their quality is enough to establish meaningful conclusions. The general indicators show some variations between the scenarios considered. Demand and collection clearly influence the overall indicators, as demonstrated by the results for purchases. For the scenarios with the same collection level (1 and 3; 2 and 4), there are higher purchase levels for higher demands, which was expected. Regarding outdates, the lowest values for both products are reported for Scenario 2, since this scenario is the one with lowest collection value and highest demand value, meaning less units are wasted due to expiration. Conversely, Scenario 3 presents the highest outdatedness values as collection is at the highest value and demand is at the lowest.
With respect to allocations, and considering the allocation of collection points to processing centres, Table 11 shows comparison results where the existence of an agreement among all four scenarios (solutions) is indicated by a 0 (no allocation) or a 1 (allocation) and the absence of an agreement between at least two scenarios is represented by an X. By analysing these results, we see that about 74% of allocations are common among all scenarios or, in other words, three fourths of these allocations are robust. As for the allocation of processing centres to demand zones, results indicate that there is an approximately 69% agreement among all four scenarios. Due to the extension of the tables containing these latter results, we do not explicitly show them in this work. Observe that the remaining 26%/31% reflect disagreement between at least two scenarios, that is, there are cases where, for example, three scenarios are in agreement and only one is not. These results suggest that our approach is able to provide meaningful solutions which, despite not being optimal, are still mostly suitable even in extreme cases of collection and/or demand.
6.4 Stage 2 solution analysis
Recall that the second stage focuses on the operational level, in this case a more detailed and complex setting with daily time periods and blood group type differentiation (see Table 3). Additionally, as discussed in Sect. 5, the disaggregated model uses the minimum waste constraints (6), associated with the inherent inefficiency of the production process, and is given as input the (optimal with respect to the transportation flows) allocations obtained from the first stage solution analysed in Sect. 6.3.1 (see Fig. 3). A 45-day time horizon was used, chosen to be longer than the 42-day shelf life of red blood cells. At a daily level of granularity, a comparison with reality is not viable due to lack of available data. Nevertheless, we analyse the second stage solution by itself in terms of general indicators and on the adjustment of collection to demand.
General Indicators
Table 12 shows results with respect to general indicators for the second stage solution, namely whole blood waste along with produced, distributed, received, purchased and outdated units of blood products.
The most relevant aspect introduced in the second stage model is the blood group disaggregation, which considerably influences the results. These show that whole blood waste presents a non-negligible value directly influencing production. Additionally, outdates and purchases also present significant values. The explanation for this behaviour is two-fold. Firstly, the second stage model adopts the minimum waste constraints (6) in order to more accurately model reality. Thus, part of the collected whole blood is immediately wasted at the production level. Secondly, since blood group type is now differentiated, additional waste related to excessive collection of certain group types exists. Jointly, these two aspects lead to an overall increase in purchases to compensate for the lack of production as well as outdates of less needed blood-derived products of given group types. In other words, collection is not adjusted to demand, as we discuss next. Additionally, this highlights the importance of considering blood group types in integrated blood supply chain approaches, which is often omitted in the literature as shown in Table 1, but is more often considered in works dealing with single echelons (see, e.g. Dillon et al. 2017).
Analysis of the Adjustment of Collection to Demand
Figure 8 shows the distribution of units (with aggregated red blood cells and platelet pools when applicable) in production, whole blood waste, purchases, received units and outdates per blood group type (for a black and white printing, the order of the bars follows the order of the legend). Table 13 shows the corresponding values for these activities.

Distribution of units in each activity per blood group type. The order of the bars follows the order of the legend
The importance of this analysis is clear. In fact, the balance between collection and demand directly reflects on the indicators presented above. Most often we encounter one of two situations. On the one hand, collection may be excessive when compared to demand. In this situation, high levels of whole blood waste and, consequently, low levels of production are observed. On the other hand, collection may be insufficient leading to high purchase volumes and less waste.
Figure 8 and Table 13 show that no blood group type presents a perfectly adjusted collection to demand. Instead, there is a mix of the two cases discussed above. For instance, purchase levels of group type B+ are high and whole blood waste levels are low which is indicative of a need to increase collection of this blood group type. Conversely, the whole blood waste levels of group type AB+ are very significant, thus collection of this group type could be reduced. There are other similar but less extreme cases. For example, O+ is closer to the B+ situation, presenting the need for higher collection; however, purchases account for less of the overall demand satisfaction when compared to the case of the blood group type B+.
Although perfectly adjusting collection to demand is impossible due to the highly stochastic nature of both, especially when further disaggregated by blood group type, there are certain aspects which could be further explored in the future. For example, a geographical analysis of the South Region of Portugal to determine the distribution of people per blood group type could be useful to then predict demand and, consequently, adjust collection.
7 Conclusions
The relevance of studying blood supply chain management is obvious in that it includes a unique combination of aspects such as the highly stochastic nature of collection and demand along with the perishability of blood-derived products and the associated challenges related to the well-being of the population, the ethical concerns around waste and the dependency on donations for raw material. Motivated by the Portuguese blood supply chain case, this work proposes an integer linear programming model to tackle tactical and operational decisions while minimising costs, waste and dependence on other regions (purchase). The aim is to study the flow of blood within the existing network composed of collection, production and demand facilities, considering multi-periods, multi-products, inventory, perishability, waste and purchase. Due to the complexity of the model and the large dimension of real-life instances, a two-stage solution approach was developed, where the first stage handles tactical decisions by providing allocations between facilities and the second stage tackles operational decisions using these allocations as input. Moreover, this is the first study on the Portuguese blood supply chain, which also motivates further research in this context.
This study offers meaningful insights regarding the Portuguese blood supply chain case study. Results show that, when compared to the real case, the model provides a solution with lower waste and purchase values, indicating the possibility of improvement in these aspects. This may be achieved, in part, by a more balanced distribution of activities between the processing centres and optimised allocations of facilities. This work also supports the need for inventory level revision in order to better match demand and prevent excessive waste due to outdates. A scenario analysis shows that the allocations in the solutions do not vary significantly when considering extreme cases of collection and demand, demonstrating the robustness of the results. This study also reveals that incorporating blood group types in the model significantly increases complexity and introduces additional insights regarding the (lack of) adjustment of collection to demand, namely with respect to either excessive or insufficient collection of particular group types. Although the conclusions are based on a particular case study, this work shows that, in general, an integrated management of a blood supply chain allows for a better flow of information which results in clear benefits with respect to cost, waste, inventory levels and dependency on purchases from other regions.
Further aspects to address in the future are suggested by this work. First, collection can be integrated as a decision in the model allowing a better understanding of the required collection of each blood group type to match demand. Additionally, this would allow evaluation of the real situation of collections in Portugal and suggest a more appropriate strategy for collection planning. Second, a geographical study with the goal of determining the distribution of blood types in the population should also be conducted along with the simultaneous development of forecasting approaches to increase the accuracy of demand prediction. Third, further theoretical research on integrated blood collection planning and inventory management decisions should be conducted, particularly with respect to the inclusion of proper inventory management policies and demand forecast. Finally, the model should allow greater flexibility in production (e.g. deciding to not produce platelet pools along with red blood cells), and therefore more accurately mimicking reality. Moreover, the model should incorporate stochasticity in supply and demand so that the solutions produced are more robust with respect to uncertainty.
Notes
The authors are available to provide the full instance characteristics under request.
References
Arvan M, Tavakoli-Moghadam R, Abdollahi M (2015) Designing a bi-objective and multi-product supply chain network for the supply of blood. Uncertain Supply Chain Manag 3:57–68
Beliën J, Forcé H (2012) Supply chain management of blood products: a literature review. Eur J Oper Res 217(1):1–16
Brodheim E, Hirsch R, Prastacos G (1976) Setting inventory levels for hospital blood banks. Transfusion 16:63–70
Cohen MA, Pierskalla WP (1979) Target inventory levels for a hospital blood bank or a decentralized regional blood banking system. Transfusion 19(4):444–454
de Sousa G, Miranda I, Pires I, Condeço J, Escoval MA, Chin M, Santos M (2016) Relatório de atividade transfusional e sistema português de hemovigilância 2015. Technical report, IPST
Dehghani M, Abbasi B, Oliveira F (2019) Proactive transshipment in the blood supply chain: a stochastic programming approach. Omega, page 102112
Dillon M, Oliveira F, Abbasi B (2017) A two-stage stochastic programming model for inventory management in the blood supply chain. Int J Prod Econ 187:27–41
Duan Q, Liao TW (2014) Optimization of blood supply chain with shortened shelf lives and ABO compatibility. Int J Prod Econ 153:113–129
Elston RC, Pickrel JC (1963) A statistical approach to ordering and usage policies for a hospital blood bank. Transfusion 3(1):41–47
Ensafian H, Yaghoubi S (2017) Robust optimization model for integrated procurement, production and distribution in platelet supply chain. Transp Res Part E 103:32–55
Fazli-Khalaf M, Khalilpourazari S, Mohammadi M (2017) Mixed robust possibilistic flexible chance constraint optimization model for emergency blood supply chain. Ann Oper Res 283:1079–1109
Habibi M, Paydar MM, Gangraj EA (2018) Designing a bi-objective multi-echelon robust blood supply chain in disaster. Appl Math Model 55:583–599
Heidari-Fathian H, Hamid S, Pasandideh R (2017) Modeling and solving a blood supply chain network: an approach for collection of blood. Int J Supply Oper Manag 4(2):158–166
IPST (2017) Plano de atividades. Technical report, IPST
Jennings J (1968) An analysis of hospital blood whole blood inventory control policies. Transfusion 8(6):335–342
Masoumi AH, Yu M, Nagurney A (2017) Mergers and acquisitions in blood banking systems: a supply chain network approach. Int J Prod Econ 193:406–421
Millard D (1959) Industrial inventory models as applied to the problem of inventorying whole blood. http://etd.ohiolink.edu/send-pdf.cgi/Millard Donald Wesley.pdf?osu1342025734
Nagurney A, Masoumi AH, Yu M (2012) Supply chain network operations management of a blood banking system with cost and risk minimization. Comput Manag Sci 9(2):205–231
Nahmias S (1982) Perishable inventory theory: a review. Oper Res 30:680–708
Osorio AF, Brailsford SC, Smith HK (2015) A structured review of quantitative models in the blood supply chain: a taxonomic framework for decision-making. Int J Prod Res 53:7191–7212
Osorio AF, Brailsford SC, Smith HK, Blake J (2018) Designing the blood supply chain: how much, how and where? Vox Sanguinis 113(8):760–769
Pegels C, Jelmert AE (1970) An evaluation of blood-inventory policies: a Markov chain application. Oper Res 18:1087–1098
Pierskalla WP (2004) Supply chain management of blood banks. In: Brandeau ML, Sainfort F, Pierskalla WP (eds) Operations research and health care: a handbook of methods and applications. Springer, Boston, pp 103–145
Prastacos G (1984) Blood inventory management: an overview of theory and practice. Manag Sci 30(7):777–904
Rupprecht C, Nagarajan T (eds) (2015) Current laboratory techniques in rabies diagnosis, research and prevention, 1st edn. Academic Press, Cambridge
Samani MRG, Torabi SA, Hosseini-Motlagh S-M (2018) Integrated blood supply chain planning for disaster relief. Int J Disaster Risk Reduct 27:168–188
Zahiri B, Pishvaee MS (2017) Blood supply chain network design considering blood group compatibility under uncertainty. Int J Prod Res 7543:1–21
Acknowledgements
The authors would like to thank the staff members of CSTL and IPST for their time and patience on providing all the information and data required for this work. The authors also acknowledge the support provided by Fundação para a Ciência e a Tecnologia (FCT) and P2020 under project PTDC/EGE-OGE/28071/2017, Lisboa-01.0145-Feder-28071, and the support provided by FCT under project DSAIPA/AI/0033/2019. The authors also acknowledge the anonymous reviewers for their comments, which helped us improve the quality of the manuscript.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Araújo, A.M., Santos, D., Marques, I. et al. Blood supply chain: a two-stage approach for tactical and operational planning. OR Spectrum 42, 1023–1053 (2020). https://doi.org/10.1007/s00291-020-00600-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00291-020-00600-1