
Abstract
The standard genetic code (SGC) has a fundamental error-minimizing property which has been widely attributed to the action of selection. However, a clear mechanism for how selection can give rise to error minimization (EM) is lacking. A search through a space of alternate codes (code space) via codon reassignments would be required, to select a code optimized for EM. There are two commonly discussed mechanisms of codon reassignment; the Codon Capture mechanism, which proposes a loss of the codon during reassignment, and the Ambiguous Intermediate mechanism, which proposes that the codon underwent an ambiguous phase during reassignment. When searching of code space via the Codon Capture mechanism is simulated, an optimized genetic code can rarely be achieved (0–3.2% of the time) with most searches ending in failure. When code space is searched via the Ambiguous Intermediate mechanism, under constraints derived from empirical observations of codon reassignments from extant genomes, the searches also often end in failure. When a local minimum is avoided and optimization is achieved, 20–41 sequential improving codon reassignments are required. Furthermore, the structures of the optimized codes produced by these simulations differ from the structure of the SGC. These data are challenges for the Adaptive Code hypothesis to address, which proposes that the EM property was directly selected for, and suggests that EM is simply a byproduct of the addition of amino acids to the expanding code, as described by the alternative ‘Emergence’ hypothesis.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Deciphering of the standard genetic code (SGC) was one of the great achievements of twentieth century biology. However, the evolution of the SGC remains to be deciphered, and constitutes one of the great challenges in the field of molecular evolution. A major advance in understanding the SGC has been the elucidation and characterization of the property of error minimization (EM). EM refers to minimization of the effects of non-synonymous mutations and transcriptional/translational errors by the structure (assignment of amino acids to codon blocks) of the SGC. EM is a form of ‘intrinsic’ robustness that is an innate property of code structure (‘extrinsic’ robustness refers to robustness that may be conferred by external factors, HSPs for example, Elena et al. 2006).
The EM property was alluded to by Sonneborn (1965), subsequently Woese derived the ‘Translation Error’ model (also known as the ‘Physicochemical’ model) of genetic code evolution, which proposes that the error-minimizing structure of the SGC was directly selected for, to minimize the deleterious effects of mutational and/or translational errors (Woese 1965). The first quantitative analysis of EM in the SGC was conducted by Alff-Steinberger (1969), who compared the error-minimizing ability of the SGC with hundreds of randomly generated alternative genetic codes (all possessing the canonical 20 amino acids). The SGC was found to be near optimal when compared to the alternative codes for the property of EM. Subsequently, EM has been further explored quantitatively by numerous researchers (e.g., Di Giulio 1989; Haig and Hurst 1992; Goldman 1993; Ardell 1998; Freeland et al. 2000; Gilis et al. 2001; Goodarzi et al. 2004). These studies also utilize the approach of comparing the error-minimizing properties of the SGC with large numbers of randomly generated alternative codes, and likewise show that the SGC is optimal or near-optimal for the property of EM. These studies have been valuable in exploring and characterizing the property of EM in the SGC. Many of these studies propose that at least a proportion of the EM property was selected for; this view is termed the ‘Adaptive Code’ hypothesis (Freeland et al. 2000; note, the Adaptive Code hypothesis refers only to selection for the EM property). However, a mechanism for how EM can be directly selected is lacking from the literature.
In order to produce an error-minimizing genetic code, the Adaptive Code hypothesis implies that the space of alternate genetic codes (code space) was searched until an optimal, or near-optimal, genetic code was ‘found’. Such searching appears to necessitate the occurrence of codon reassignments, whereby a codon changes its identity to code for a different amino acid. There are two mechanisms widely discussed for the occurrence of codon reassignments; the Codon Capture theory (Osawa and Jukes 1989) and the Ambiguous Intermediate theory (Schultz and Yarus 1994). Additional mechanisms in the literature represent derivations or hybrids of these two mechanisms. For instance, Massey et al. 2003 describe a mechanism that is a hybrid of the two mechanisms that involves anticodon ambiguity and codon loss. The Codon Capture theory posits that an AT- or GC-rich codon(s) was initially lost under extreme GC/AT pressure, and on its reappearance in the genome, after reversal of the GC/AT pressure, was reassigned to code for a different amino acid. The mechanism avoids the detrimental effects of a codon reassignment on the proteome. The Ambiguous Intermediate theory proposes that a codon(s) undergoes a period of coding ambiguity, while it is reassigned to code from one amino acid to another. Consistent with this mechanism, the driving ‘force’ for codon reassignments in mitochondria has been attributed to a reduced Proteomic Constraint on the mitochondrial information apparatus due to reduction in size of the mitochondrially encoded proteome (Massey and Garey 2007; Massey 2008b).
As an alternative to the Adaptive Code hypothesis, it has been proposed that at least a proportion of EM in the SGC has arisen neutrally, as a consequence of the addition of amino acids to the expanding evolving genetic code via gene duplications of adaptor molecules and charging enzymes (Crick 1968; Stoltzfus and Yampolsky 2007; Massey 2008a). Here, several mechanistic problems with the Adaptive Code hypothesis are highlighted, lending support to a non-adaptive origin of the EM property.
Methods
Measurement of EM
The ‘EM’ value (Massey 2008a) is used in the analyses conducted here. The EM value calculates the average difference resulting from a mutation using a physicochemical amino acid similarity matrix for the SGC, and for the alternative genetic codes generated in these analyses. There are two general considerations that resulted in the choice of similarity matrices based on physicochemical properties. First, using matrices derived from substitution patterns of protein coding genes is flawed, as these patterns are influenced by the structure of the genetic code structure; applying these matrices to a study of code structure introduces a built-in bias or circularity (Di Giulio 2001). Secondly, using substitution matrices that have minimized the factor of code structure (e.g., Yampolsky and Stoltzfus 2005) is not ideal for the following reason. Such matrices are derived from observations of substitution patterns that occur in extant proteins, which possess the standard 20 amino acids. The proteinaceous physicochemical environment under which these occur is likely to be different from that which existed in primordial proteins, which only contained a subset of the present day 20 amino acids. Substitution patterns would be expected to be markedly different under those early conditions. This problem applies to the use of all knowledge-derived substitution matrices. For these reasons, two similarity matrices based on physicochemical criteria were chosen, the Grantham (1974) and Miyata et al. (1979) matrices. The Grantham matrix is a commonly used similarity matrix, based on amino acid volume, polarity, and composition. These parameters were selected and weighted to correlate with substitution frequencies. The argument could be made therefore that the weighting process may also make the Grantham matrix susceptible to the circularity problem discussed above. Hence, the Miyata matrix was also utilized. The Miyata matrix is based on two physicochemical properties (volume and polarity), these were selected for the consideration that they are the primary determinants of the three-dimensional conformation of protein molecules (Miyata et al. 1979). These properties were chosen for their effects on extant protein structure; whether the use of this matrix is appropriate for studies of EM should be a subject of debate for the community. The formulation of an unbiased matrix based on physicochemical properties would be valuable for studies on the EM property; such a formulation is outside the scope of this work. EM values derived from each matrix are described as EMGrantham and EMMiyata, respectively.
Generation of Random Alternative Genetic Codes
A random alternative genetic code was generated at the start of each analysis, as described previously (Massey 2008a). The average EM values of one million random alternative genetic codes, for each matrix, are displayed in Table 1.
Simulating Codon Reassignments to Produce an Optimized Alternative Code
Searching of code space requires the codon reassignment of a sense codon(s) to another sense codon(s). Such ‘sense to sense’ codon reassignments occur by expansion in the number of codons coding for a particular amino acid, with a concomitant decrease in the number of codons coding for the amino acid that has its codon(s) reassigned to the first amino acid. Swapping of codon assignments can lead to an optimization of the genetic code in a lower number of codon reassignments (data not shown), but this is not known to occur in vita, and it is hard to envisage a mechanism for how this could occur. Likewise, Novozhilov et al. 2007 showed that 10–12 codon swaps on average are required to lead to an optimized code, using a steepest ascent model, whereby the best possible codon reassignment is chosen at each step.
At the start of each analysis a random alternative genetic code was generated, and its EM value calculated. Then two codon blocks, donor and recipient, were randomly selected. One or two codons were randomly selected from the donor codon block, and added to the recipient codon block. The EM value of the new code resulting from altered donor and recipient codon blocks was calculated. If the EM value was lower (more optimal) than that of the previous code, then the new code was accepted. If not, then the previous code was retained and subject to a new random codon reassignment. The process was continued until the evolved alternative code possessed an EM value lower than that of the SGC (values are displayed in Table 1). The number of simulated codon reassignments required to achieve this was recorded. This procedure was repeated for 1,000 alternative random genetic codes.
During the course of each simulation, each of the 20 amino acids was instructed to possess a minimum number of 1 codon assigned to it; there was no maximum on the number of codons that an amino acid could possess. Any codon(s) could be reassigned to a particular amino acid, and any of the other amino acids could acquire one of its codons. Reassignments involved 1, 2, or 1–2 codons. If two codons were reassigned they were adjacent to each other, and coded for either purines or pyrimidines.
Simulating Codon Reassignments with Constraints to Produce an Optimized Alternative Genetic Code
Any proposed searching of code space should take into account the constraints that codon reassignments appear to be under in nature. Two set of constraints were applied. First, the Codon Capture mechanism of codon reassignment proposes that GC- or AT-rich codons were lost, under AT and GC pressure, respectively, as part of the codon reassignment mechanism. Therefore, the simulation was conducted by constraining the reassigned codons to be either GC- or AT-rich (codons GGG, CCC, GCG, CGC, GGC, GCC, CGG, CCG, AAA, TTT, TAT, ATA, TTA, TAA, ATT, AAT). Secondly, a constraint of adjacency was introduced. This entails donor and recipient codon blocks being adjacent, separated by a single nucleotide change. This mimics the observation that codon reassignments (with two exceptions; Candida CUG leucine → serine and chlorophyte mitochondria UAG stop → alanine) are separated by a single nucleotide change. Lastly, it is known from considerations of nonsense codon reassignments that there is an element of constraint in the identities of amino acids and associated stop codons involved, which is probably determined by the decoding properties of the tRNA anticodon (Massey and Garey 2007). This extra constraint was not included in the simulation as the rules governing anticodon misreading are not properly understood. The simulations were conducted using Perl scripts, which are available from the author.
Results and Discussion
Searching of Code Space Via the Codon Capture Mechanism is Extremely Difficult
The Codon Capture theory provides a mechanism for codon reassignment that avoids disruption of the proteome. Could this provide a viable pathway to an error-minimized genetic code? The theory proposes that the codon to be reassigned disappears under extreme GC/AT pressure, and upon its reappearance in the genome is reassigned to a new amino acid. However, when simulations are conducted involving only AT- or GC-containing codons, 96.8–98.8% of the simulations end in failure, being unable to reach the target of an EMGrantham value of 60.7 (Table 2a). These simulations effectively become trapped in a local minimum (Fig. 1). Those small numbers of simulations that did achieve the target value required 16 sequential improving codon reassignments on average (Table 2a), and the number of extreme fluctuations in GC/AT content necessary would be double this number. However, this is assuming that an improving codon reassignment occurred on average 16 times sequentially. The number of ‘try-out’ codon reassignments that occurred but did not present an improved EM, and therefore were not favored, would be higher than this discussed below. Using the Miyata matrix, 99.9–100% of the simulations end in failure (Table 2b). These observations provide severe problems for the Codon Capture mechanism as a route for producing EM in the SGC.
Searching of Code Space Via the Ambiguous Intermediate Mechanism Requires 20–41 Codon Reassignments
The searching of code space via codon reassignments using the Ambiguous Intermediate mechanism was simulated and indicates that 20–31 (Grantham matrix)/23–41 (Miytata matrix) codon reassignments are required on average to achieve a code with the same or better EM properties than the SGC (Fig. 2; Table 2). A caveat is that if a proportion of EM in the SGC has derived from the addition of amino acids to the code, as described previously (Massey 2008a, b), then this should reduce the number of codon reassignments required to produce a code with equivalent or superior EM to the SGC.
Surprisingly perhaps, adding the extra constraint of adjacency to the simulated codon reassignments results in a similar average number of codon reassignments to achieve an error-minimized genetic code. However, although addition of a constraint is expected to add an element of restriction to the search of code space, the observation may be explained if it is considered that reassigning adjacent codons results in an increased probability that similar amino acids are coded for by adjacent codons, which is an inherent property of EM. Larger numbers of failed searches occur when the adjacency constraint is added to the simulations (3 versus 0 (Grantham)/30 versus 0 (Miyata) for the model when only single codons are reassigned, 668 versus 292 (Grantham)/841 versus 522 (Miyata) when double codons are reassigned). Interestingly, the number of codon reassignments required to achieve an optimal genetic code is lower when only double codons are reassigned when compared to single codons (Table 2a and b, rows 1 and 2). Because of the large numbers of failed searches encountered when only double codons are reassigned (Table 2), a reasonable explanation might be that only those random codes with lower initial EM values are likely to progress to an optimal code without a failed search. However, this is not the case as the average initial EM values for codes that lead to optimized codes, and avoid a local minimum, were similar to that of random codes [a million random codes have an average EMGrantham value of 74.5 (Table 1), codes leading to optimized codes had an average EMGrantham value of 74.1 (Table 2a, Model 1b) and 73.0 (Table 2a, Model 2b). Using the Miyata matrix, a million random codes have an average EMMiyata value of 1.69 (Table 1), codes leading to optimized codes had an average EMMiyata value of 1.67 (Table 2b, Model 1b) and 1.66 (Table 2b, Model 2b)]. Why simulations involving double codons require less codon reassignments to achieve optimized codes, but encounter higher numbers of local minima, compared to simulations involving single codons is not clear.

Representation of a local minimum in code space. a Searching of code space without the presence of a local minimum allows the optimal code to be reached, b searching of code space, with a local minimum preventing access to the optimal code
The number of codon reassignments are relatively numerous compared with the scarcity of codon reassignments that is observed from extant genomes; only a handful of free living organisms have had codon reassignments in their nuclear code (Candida yeasts, diplomonads, dasyclad algae, ciliates). Indeed, the maximum number of codon reassignments that have been observed to occur in an individual genome is five; in echinoderm and platyhelminth mitochondria. These have accumulated over a long period of time, since the divergence of the metazoa from the choanoflagellates (see Massey and Garey 2007 for a list of mitochondrial codon reassignments), 1300–600 mya (Conway Morris 1998). In addition, these may have been promoted by the extreme reduction in size of the mitochondrially encoded proteome in these lineages (13 ORFs), as proposed by the Proteomic Constraint theory (Massey and Garey 2007; Massey 2008b). This is an atypical situation, associated with the intracellular, endosymbiotic location of the mitochondrion. In order to propose that the evolving code underwent this number of codon reassignments to produce EM, an explanation is required as to what was different in the primordial genome, compared to the present day that facilitated relatively numerous codon reassignments occurring in a relatively short length of time.
The data also imply that the proposed selection process ceased for some reason before full optimality had been achieved, given that the SGC is suboptimal for the property of EM (Table 1). This is consistent with the findings of others that suggest that the SGC is not at absolute optimality (although Freeland and Hurst 1998a, b suggest otherwise under certain conditions). The suboptimality of the SGC is consistent with the observation that, when the size of the improvement in EM is plotted during searching of code space, there is no apparent tendency toward a minimum (Fig. 3). Under the Adaptive Code hypothesis an explanation would be required for why the process of optimization has ceased. However, there has not been an optimizing codon reassignment since the divergence of the last universal common ancestor (LUCA). The age of the last common ancestor is elusive; however, the divergence of archaebacteria and eubacteria has been tentatively dated at 3–4 bya (Feng et al. 1997), this would give a date for the LUCA. The earth possessed oceans as early as 4.2 bya, according to geochemical data (Valley et al. 2006), implying that the earliest date for life on earth is set at this time. This means that if the Adaptive Code hypothesis is correct, there would have been relatively numerous optimizing codon reassignments in the space of 0.2–1.2 bya, and thereafter an abrupt halt. This does not include the necessity of additional ‘try-out’ codon reassignments. The rationale for the requirement of ‘try-out’ codon reassignments is as follows. Codon reassignment is a multi-step process, and therefore will evolve in a population of individuals. In order for selection to occur, then there must be a competition between two populations; the original population with the original code, and a new population that has evolved a variant code via codon reassignment. The Adaptive Code hypothesis implies that this competition will result in the superior EM code being selected. However, according to this scenario, as evolution is blind, there must be various instances of variant codes evolving that do not possess superior EM to the original code; these are the ‘try-out’ codon reassignments (Table 3). It is instructive that no extant codon reassignments display improved EM (Freeland et al. 2000).

Distribution of the number of codon reassignments required to achieve optimal alternative genetic codes, which were initially randomly generated. The number of codon reassignments required to produce an optimal genetic code was determined using the Grantham matrix. 1,000 random alternative genetic codes were generated, and the average number of codon reassignments required to produce a code that that was equal or more optimal than the SGC for EM was calculated in each case. a Simulation involved the reassignment of single codons, b Simulation involved the reassignment of two codons at a time, c Simulation involved the reassignment of a combination of one or two codons. SD denotes standard deviation
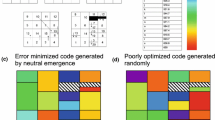
Typical codes generated from the simulations are illustrated in Fig. 4. The code resulting from codon reassignments of single codons (Fig. 4a) is structurally more fragmented than the SGC. The code resulting from codon reassignments of double codons (Fig. 4b) has three amino acids (M, Q, and T), which have large numbers of codons distributed throughout the code. The code resulting from the codon reassignment of single and double codons (Fig. 4c) displays a combination of these features. These features are not observed in the SGC. The discordance in structure of the simulated codes and the SGC is inconsistent with the Adaptive Code hypothesis.

Increase in error minimization of random alternative genetic codes, with increasing numbers of improving codon reassignments. The increase in error minimization (decrease in EMGrantham) was monitored according to the models described in Table 2a; a One codon reassigned (Model 1a; 31 codon reassignments), b two codons reassigned (Model 1b; 23 codon reassignments), c one or two codons reassigned (Model 1c; 23 codon reassignments)

Typical alternative genetic codes that have undergone optimization. a Resulting from reassignments of single codons only, having undergone 31 codon reassignments [number of codon reassignments (31) was obtained from Model 1a, Table 2a], b resulting from reassignments of two codons only, having undergone 23 codon reassignments [number of codon reassignments (23) was obtained from Model 1b, Table 2a], c resulting from reassignments of a combination of 1 or 2 codon, having undergone 23 codon reassignments [number of codon reassignments (23) was obtained from Model 1c, Table 2a]
Alternative Mechanisms for the Origin of EM in the SGC
Data has been presented that presents challenges for the Adaptive Code hypothesis. Therefore, it is appropriate to briefly consider alternative mechanisms for how EM in the SGC may have arisen. As shown previously, as least a proportion of EM in the SGC is likely to have arisen from the process of gene duplication of adaptor molecules and charging enzymes facilitating code expansion (Massey 2008a). Here, increased functionality and diversity of protein molecules would be the selective force driving the addition of amino acids to the evolving code; the selective advantage of adding an amino acid to the SGC has been demonstrated experimentally (Liu et al. 2008). The ‘Non-adaptive Code’ hypothesis was introduced previously to describe the hypothesis that EM has arisen neutrally (Massey 2008a; the term ‘non-adaptive code’ was coined by Freeland et al. 2000). However, it may be more appropriate to use the term ‘Emergence’ hypothesis; this avoids the implication that the expansion of the code itself (and not just the EM property) was the result of non-adaptive forces.
The Coevolution Theory (Wong 1975) provides a potential mechanism for how EM could emerge in the absence of selection for the property, as it proposes an expansionary scheme whereby amino acids were added to the evolving genetic code based on chemical relatedness. The Coevolution Theory and the gene duplication/emergence scenario are not mutually exclusive. The scenario that the coevolution mechanism gave rise to the EM property has been tested, but the results are inconsistent (Di Giulio and Medugno 2001 for; Freeland and Hurst 1998a; Freeland et al. 2000 against).
Conclusion
A number of mechanistic challenges for the selection of the EM property are outlined in this article. First, the Codon Capture mechanism is shown not to be viable for the efficient searching of code space. Secondly, the searching of code space via the Ambiguous Intermediate mechanism requires 20–41 codon ressignments on average. An additional number of additional ‘try-out’ codon reassignments would presumably be required. As it stands, the Adaptive Code hypothesis does not provide an explanation for the requisite burst of codon reassignments, and the subsequent relative stasis of the genetic code after the LUCA; however, this does not constitute a rejection of the Adaptive Code hypothesis. Thirdly, the structures of optimized codes produced by the searching of code space via codon reassignments are different in topology from the SGC. These considerations present challenges for the Adaptive Code hypothesis to address, and are consistent with the neutral emergence of EM in the SGC according to the Emergence hypothesis. Interestingly, there are a number of other cases of the neutral emergence of robustness in biological systems (in the absence of direct selection). These include RNA structure (van Nimwegen et al. 1999; Szollosi and Derenyi 2008), genetic networks (Barabasi and Albert 1999), and metabolic networks (Light et al. 2005).
The implications of these results are worth considering in general evolutionary terms. Although the vast majority of beneficial traits are adaptations, arising from natural selection, it does not follow that all beneficial traits arise from natural selection. EM in the SGC appears to provide an example of a beneficial trait that has arisen as an emergent property, one that affects the patterns of molecular evolution of all organisms. The words of Darwin are pertinent, on the subject of traits that may arise in the absence of explicit selection; he proposed that they may arise as a ‘correlation of growth’;
‘…owing to the law of correlation, when one part varies, and the variations are accumulated through natural selection, other modifications, often of the most unexpected nature, will ensue.’
(Chapter 4, Origin of Species)
‘….modifications of structure, viewed by systematists as of high value, may be wholly due to the laws of variation and correlation…’
(Chapter 5, Origin of Species)
I suggest that EM in the SGC be described as a ‘correlation of growth’, due to its emergence as the side-product of growth (expansion) of the genetic code. In addition, I suggest that beneficial traits that have not arisen by natural selection be described as ‘pseudaptations’.
References
Alff-Steinberger C (1969) The genetic code and error transmission. Proc Natl Acad Sci USA 64:584–591
Ardell DH (1998) On error minimization in a sequential origin of the standard genetic code. J Mol Evol 47:1–13
Barabasi A, Albert R (1999) Emergence of scaling in random networks. Science 286:509–512
Conway Morris S (1998) Early metazoan evolution: reconciling paleontology and molecular biology. Am Zool 38:867–877
Crick FHC (1968) The origin of the genetic code. J Mol Biol 38:367–379
Di Giulio M (1989) The extension reached by the minimization of polarity distances during the evolution of the genetic code. J Mol Evol 29:288–293
Di Giulio M (2001) The origin of the genetic code cannot be studied using measurements based on the PAM matrix because this matrix reflects the code itself, making any such analyses tautologous. J Theor Biol 208:141–144
Di Giulio M, Medugno M (2001) The level and landscape of optimization in the origin of the genetic code. J Mol Evol 52:372–382
Elena SF, Carrasco P, Daros J, Sanjuan R (2006) Mechanisms of genetic robustness in RNA viruses. EMBO Rep 7:168–173
Feng DF, Cho G, Doolittle RF (1997) Determining divergence times with a protein clock: update and reevaluation. Proc Natl Acad Sci 94:13028–13033
Freeland SJ, Hurst LD (1998a) Load minimization of the genetic code: history does not explain the pattern. Proc R Sci Lon B 265:2111–2119
Freeland SJ, Hurst LD (1998b) The genetic code is one in a million. J Mol Evol 47:238–248
Freeland SJ, Knight RD, Landweber LF, Hurst LD (2000) Early fixation of an optimal genetic code. Mol Biol Evol 17:511–518
Gilis D, Massar S, Cerf NJ, Rooman M (2001) Optimality of the genetic code with respect to protein stability and amino-acid frequencies. Genome Biol 2:11
Goldman N (1993) Further results on error minimization in the genetic code. J Mol Evol 37:662–664
Goodarzi H, Nejad HA, Torabi N (2004) On the optimality of the genetic code, with consideration of termination codons. BioSystems 77:163–173
Grantham R (1974) Amino acid difference formula to help explain protein evolution. Science 185:862–864
Haig D, Hurst LD (1992) A quantitative measure of error minimization in the genetic code. J Mol Evol 33:412–417
Light S, Kraulis P, Elofsson A (2005) Preferential attachment in the evolution of metabolic networks. BMC Genomics 6:159
Liu CC, Mack AV, Tsao ML, Mills JH, Lee HS, Choe H, Farzan M, Schultz PG, Smider VV (2008) Protein evolution with an expanded genetic code. Proc Natl Acad Sci USA 105:17688–17693
Massey SE (2008a) A neutral origin for error minimization in the genetic code. J Mol Evol 67:510–516
Massey SE (2008b) The proteomic constraint and its role in molecular evolution. Mol Biol Evol 25:2557–2565
Massey SE, Garey JR (2007) A comparative genomics analysis of codon reassignments reveals a link with mitochondrial proteome size and a mechanism of genetic code change via suppressor tRNAs. J Mol Evol 64:399–410
Massey SE, Moura G, Beltrao P, Almeida R, Garey JR, Tuite MF, Santos MAS (2003) Comparative evolutionary genomics unveils the molecular mechanism of reassignment of the CTG codon in Candida spp. Genome Res 13:544–557
Miyata T, Miyazawa S, Yasunaga T (1979) Two types of amino acid substitutions in protein evolution. J Mol Evol 12:219–236
Novozhilov AS, Wolf YI, Koonin EV (2007) Evolution of the genetic code: partial optimization of a random code for robustness to translation error in a rugged fitness landscape. Biol Direct 2:24
Osawa S, Jukes TH (1989) Codon reassignment (codon capture) in evolution. J Mol Evol 28:271–278
Schultz DW, Yarus M (1994) Transfer RNA mutation and the malleability of the genetic code. J Mol Biol 235:1377–1380
Sonneborn TM (1965) Evolving genes and proteins. Academic Press, New York
Stoltzfus A, Yampolsky LY (2007) Amino acid exchangeability and the adaptive code hypothesis. J Mol Evol 65:456–462
Szollosi GJ, Derenyi I (2008) The effect of recombination on the neutral evolution of genetic robustness. Math Biosci 214:58–62
Valley JW, Cavosie AJ, Fu B, Peck WH, Wilde SA (2006) Comment on “Heterogenous Hadean hafnium: evidence of continental crust at 4.4 to 4.5 Ga”. Science 312:1139
van Nimwegen E, Crutchfield JP, Huynen M (1999) Neutral evolution of mutational robustness. Proc Natl Acad Sci USA 96:9716–9720
Woese CR (1965) On the evolution of the genetic code. Proc Natl Acad Sci USA 54:1546–1552
Wong JT (1975) A coevolution theory of the genetic code. Proc Natl Acad Sci USA 72:1909–1912
Yampolsky LY, Stoltzfus A (2005) The exchangeability of amino acids in proteins. Genetics 170:1459–1472
Acknowledgments
The author would like to thank two anonymous reviewers of a previous version of this manuscript for their valuable comments. This study was supported by funds provided by the Department of Biology, University of Puerto Rico, Rio Piedras.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Massey, S.E. Searching of Code Space for an Error-Minimized Genetic Code Via Codon Capture Leads to Failure, or Requires At Least 20 Improving Codon Reassignments Via the Ambiguous Intermediate Mechanism. J Mol Evol 70, 106–115 (2010). https://doi.org/10.1007/s00239-009-9313-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00239-009-9313-7