
Abstract
Two parallel in vitro selections (denoted Selection A and Selection B) were conducted under different selection-pressure regimes, yielding a diverse community of RNA-cleaving deoxyribozymes. In Selection A, the reaction time was reduced four times (from 5 h to 5 s) over the course of 24 generations, while in Selection B the reaction time was maintained at 5 h for 30 rounds of selective amplification. Sequence alignment was conducted on more than 800 clones assembled from 18 generations that span both selections. Many prominent catalytic sequence classes, including some that extend across both selections, were identified and used to construct fitness landscapes depicting their rise and fall over time. The landscapes from both selections exhibit similar global trends despite differences in population dynamics. Some deoxyribozymes were predominant in the early rounds of selection but gave way to other species that dominated in the middle rounds. Ultimately, these middle classes disappeared from the landscape in favor of new and presumably more fit deoxyribozyme sequence classes. The shape of these landscapes alludes to the presence of many latent deoxyribozymes in the initial library, which can only be accessed by changes in the selection pressure and/or by adaptive mutations. Basic computer simulations provide theoretical corroboration of the experimentally observed pattern of staggered sequence-class transitions across the fitness landscapes. These simulations model the influence of one or more contributing factors, including catalytic rate, folding efficiency, PCR amplification efficiency, and random mutagenesis. This is the first study which thoroughly documents the topography of a deoxyribozyme fitness landscape over many generations of in vitro selection.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
In vitro selection is a combinatorial screening technique used to isolate functional nucleic acids (including aptamers, ribozymes, and deoxyribozymes) from synthetic libraries of random-sequence DNAs or RNAs (Breaker and Joyce 1994; Ellington and Szostak 1990; Robertson and Joyce 1990; Tuerk and Gold 1990). In vitro selection is characterized by iterative cycles of selective amplification, a process that cumulatively acts to enrich a DNA or RNA population for functionally active molecules, while simultaneously reducing the inactive fraction. Individual molecules are selected on the basis of fitness, which is a reflection of their differential ability to survive and reproduce under the imposed selection constraints. In vitro selection is, therefore, in many respects analogous to Darwinian evolution.
Unfortunately, the complexities of Darwinian evolution are not lost in the microenvironment of a test tube DNA population undergoing in vitro selection. Despite more than a decade of use, relatively little is known about the in vitro selection process and the factors that govern its outcome. Ultimately, this lack of knowledge may serve as a major obstacle to finding nucleic acid–based catalysts, with protein-like rate enhancements.
Our research is motivated by a desire to better our understanding of the in vitro selection process and thereby facilitate the search for functional nucleic acids. In the current study, we wanted to examine the population dynamics of a community of RNA-cleaving deoxyribozymes evolving under different levels of selection pressure. Understanding how the composition and complexity of a population changes over time, under different selection pressures, and in response to both inherent and environmental factors could potentially yield significant insight on how to implement the most effective screening measures for the isolation of nucleic acids with greater functional aptitude. Consider, for example, the original selection conducted by Santoro and Joyce that led to the isolation of two very useful RNA-cleaving deoxyribozymes referred to as 8–17 and 10–23 (Santoro and Joyce 1997). The 8–17 motif was part of a subpopulation that dominated in rounds 6–8, but the 10–23 motif was isolated from a different subpopulation that ascended to dominance in rounds 9–10, at the expense of the former. If the selection had continued beyond generation 10, would other more useful catalytic motifs have eventually ascended to dominance at the expense of 10–23? This is just one type of question that could be addressed more easily if we could identify any patterns of behavior that characterize populations undergoing in vitro selection.
The population dynamics of in vitro selection have not been studied in great detail, despite the significance of this subject. A few studies have used mathematical simulations to provide guiding principles for the optimization of in vitro selection, but the validity of these theoretical studies may suffer from simplifying assumptions and a lack of experimental corroboration (Irvine et al, 1991; Sun et al 1996; Vant-Hull et al. 1998). Unfortunately, empirical data are rather scarce. Typically, only the constituents in the terminal pool of an in vitro selection experiment are cloned and sequenced to reveal a static portrait of the population. This scenario essentially precludes analysis of population dynamics. Some studies have employed alternative techniques including the evaluation of restriction digest patterns (Bartel and Szostak 1993) and C0t analysis (Charlton and Smith 1999) to track changes in pool complexity and composition over time. However, these methods cannot provide detailed information on population dynamics, nor was it the intended focus of either study. Studies of the Tetrahymena ribozyme have provided some insight into the population dynamics of a pool of partially randomized variants as they undergo in vitro evolution for altered function (Beaudry and Joyce 1992; Lehman et al. 2000; Lehman and Joyce 1993a, b). However, to date, no study has thoroughly documented the dynamics of a completely random nucleic acid population evolving over multiple generations of in vitro selection.
Previously, we conducted an in vitro selection experiment that yielded a diverse pool of RNA-cleaving deoxyribozymes (Schlosser and Li 2004). We reasoned that the large genetic variation within this pool might provide an interesting case study to examine the population dynamics of many deoxyribozymes competing through in vitro selection. Additional rounds were conducted along two parallel but distinct paths to determine how the composition of each population would change in response to different levels of selection pressure. Multiple generations were selected for cloning and sequence analysis, and comprehensive fitness landscapes were constructed to trace the rise and fall of individual sequence classes over time.
Material and Methods
Materials and Common Procedure
Standard oligonucleotides were prepared by automated DNA synthesis using cyanoethylphosphoramidite chemistry (Keck Biotechnology Resource Laboratory, Yale University; Central Facility, McMaster University). Random-sequence DNA libraries were synthesized using an equimolar mixture of the four standard phosphoramidites. DNA oligonucleotides were purified by 10% preparative denaturing (8 M urea) polyacrylamide gel electrophoresis (PAGE) and their concentrations were determined by spectroscopic methods. Nucleoside 5′-triphosphates, [γ-32 P]ATP, and [α-32 P]dGTP were purchased from Amersham Pharmacia. Taq DNA polymerase, T4 DNA ligase, and T4 polynucleotide kinase (PNK) were purchased from MBI Fermentas. All chemical reagents were purchased from Sigma. The 50-nucleotide (nt) RNA substrate (R1) was produced by RNA transcription using T7 RNA polymerase and a double-stranded DNA template as described previously (Schlosser and Li 2004).
In Vitro Selection Procedure
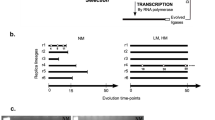
Sequences of relevant DNA and RNA molecules are shown in Fig. 1A. Each round of in vitro selection consists of steps I–VIII as illustrated in Fig. 1B.

Information on in vitro selection. A DNA sequences and their relationships. Each molecule in the library contains three key domains: a 14-nt DNA fragment (denoted A1) precedes a 50-nt RNA fragment (denoted R1), which in turn precedes another 104-nt DNA fragment (denoted L1). L1 contains 80 random-sequence nucleotides (N80) that serve as the putative catalytic domain and provides initial sequence diversity. The N80 region of L1 is flanked by 9-nt and 15-nt fixed sequence domains at the 5′ end and 3′ end, respectively, which serve as primer-binding sites for PCR amplification. A1, R1, and L1 are ligated by T4 DNA ligase in the presence of templates T1 and T2. Sequences denoted by P1, P2, and P3 serve as primers during PCR (Ar, adenine ribonucleotide). B In vitro selection of RNA-cleaving deoxyribozymes. Each round of selection consists of steps I–VIII. In step I, the A1-R1-L1 chimeras are assembled by T4 DNA ligase involving the use of A1-R1, 5′-phosphorylated L1, and a synthetic DNA template T2. The resultant DNA–RNA–DNA molecules are purified by 10% denaturing PAGE (step II), followed by incubation with a selection buffer containing divalent metal ion cofactors (7.5 mM MnCl2 and 7.5 mM MgCl2) to promote catalytic activity (step III). The reaction is allowed to proceed for a designated amount of time before being stopped with the addition of the metal-chelating agent, EDTA. The resulting cleavage fragments are isolated by 10% denaturing PAGE (step IV). The isolated DNAs are amplified by two consecutive PCRs (steps V and VI). The first PCR used P1 and P2 as the primers. In addition to the 9-nt forward priming site, P1 contained 23 extra nucleotides at the 5′ end to introduce a new forward priming site for the second PCR, which used primers P2 and P3. Since P3 is a ribo-terminated primer, the DNA product from the second PCR can be digested under alkaline conditions to regenerate single-stranded deoxyribozyme sequences (step VII). The DNA mixture is subjected to 10% denaturing PAGE followed by DNA phosphorylation (step VIII), and the resulting phosphorylated 104-nt DNA is used to initiate the next round of selection.
Step I: The 104-nt library L1 was ligated to the 64-nt A1-R1 substrate to yield 168-nt A1-R1-L1 constructs. The reaction mixture, containing 250 pmol of A1-R1, 250 pmol of L1, and 300 pmol of template T2, was heated at 90°C for 30 s, and then cooled to room temperature. A volume of 12.5 μl ligase buffer (10× stock supplied by the manufacturer) and 25 μl of T4 DNA ligase (5 units/μl) were added to the mixture (250-μl final volume). The resultant reaction mixture was incubated for 4 h at room temperature. It is noteworthy that the ligase buffer was used at a final concentration of 0.5× to minimize the activation of DNA catalysts by Mg2+ present in the buffer, because we found that T4 DNA ligase was as effective at the reduced metal ion concentration.
Step II: A1-R1-L1 chimeras were recovered by ethanol precipitation and purified by 10% denaturing PAGE.
Step III: A 2× selection buffer was added to an equal volume of H2O in which the DNA pellet from step II was dissolved. The resultant reaction mixture (with a DNA concentration of ∼0.1 μM) was allowed to stand at room temperature for the following designated times for Selection A: 5 h for G0–G7, 30 min for G8, 5 min for G9–G11, 30 s for G12–G14, and 5 s for G15–G24. For Selection B, the reaction time was maintained at 5 h. After the desired amount of time had elapsed, a 2× volume of 45 mM EDTA (pH 8.0) was added to the reaction mixture to stop the reaction. Selection buffer A (composed of 50 mM HEPES, pH 7.0, at 23°C, 400 mM NaCl, 100 mM KC1, 7.5 mM MnCl2, 50 μM CuCl2, and 7.5 mM MgCl2) was used from G0–G7, and selection buffer B (which was identical to selection buffer A with the exception that CuCl2 was eliminated) was used for the remaining selection rounds.
Step IV: The above reaction mixture was subjected to 10% denaturing PAGE. The cleavage products of interest were excised from the gel and recovered by ethanol precipitation. All cleavage fragments of lengths between 104 and 154 nt were recovered during selection rounds G0–G5. Three dominant cleavage fragments, denoted DNA-I (112 nt), DNA-II (143 nt), and DNA-III (149 nt), were recovered separately in G6. The remaining selection rounds were conducted with only the DNA-II population, and the corresponding 143-nt cleavage product was recovered.
Steps V and VI: Two successive rounds of PCR were used to amplify the recovered cleavage fragments. P1 and P2 were used as the primer set for the first PCR, and P2 and P3 for the second PCR (Fig. 1). One percent of the double-stranded DNA product from the first PCR was used as the template in the second reaction. Both reactions were performed on a SmartCycler (Cepheid) and monitored in real-time using SYBR Green (Molecular Probes) as the reporter. The second PCR mixture contained 20 μCi [α-32 P]dGTP to introduce radiolabels into the amplified DNA products for visualization purposes. The second PCR also used a ribo-terminated primer (P3) so that the 104-nt putative catalytic DNA molecules could be regenerated by alkaline digestion.
In generation 8, a 15-nt extension was engineered onto the existing 3′ primer-binding site of the population in Selection A, and a new P2 primer (5′ CCA TCA GGA TCA GCT) employed accordingly during subsequent rounds of PCR. The 15-nt extension was created during PCR2 using P3 and an elongated 30-nt primer composed of the old and new P2 primer sequences (5′ CCA TCA GGA TCA GCT ACT GCT GAT TCG ATG). The same procedure was also used for the population in Selection B using a different P2 primer (5′ TCA TCA GCT CCA GGT) for subsequent rounds of PCR and a different 30-nt primer for PCR2 (5′ TCA TCA GCT CCA GGT ACT GCT GAT TCG ATG).
Step VII: The amplified DNA from the second PCR above was recovered by ethanol precipitation, 90 μl of 0.25 M NaOH was added to the DNA pellet, and the resultant solution was heated at 90°C for 10 min, followed by the addition of 10 μl of 3 M NaOAc (pH 5.2 at 23°C). This alkaline treatment serves to cleave the embedded RNA linkage.
Step VIII: The 104-nt cleavage fragments were purified by 10% denaturing PAGE. The recovered DNA molecules were incubated with 10 units of polynucleotide kinase (PNK) at 37°C for 1 h for DNA phosphorylation in a 100-μl reaction mixture containing 50 mM Tris–HCl (pH 7.8 at 23°C), 40 mM NaCl, 10 mM MgCl2, 1 mg/ml BSA, and 0.5 mM ATP. The 5′-phosphorylated DNA (denoted G1) was used for the second round of selection. Steps I–VIII were repeated 24 times for Selection A and 30 times for Selection B, using the same procedure described for the first round of selection except that the ligation reaction scale in step I was reduced 10-fold (i.e., 25 μl final volume; however, all reaction components were maintained at the same concentrations as in round 1).
Cloning and Sequencing of Selected DNA Populations
DNA sequences from a relevant selection round were amplified by PCR and cloned into a vector by the TA cloning method. Plasmids containing individual catalysts were prepared using the Qiagen Mini-Prep Kit. DNA sequencing was performed on a CEQ 2000XL capillary DNA sequencer (Beckman-Coulter) following the manufacturer’s recommended procedures.
Quantification of Observed Sequence Identity
Sequences were aligned based on the location of their fixed primer-binding sites with the aid of the Bioedit Sequence Alignment Editor computer program, which is available free of charge over the internet at www.mbio.ncsu.edu/BioEdit/bioedit.html
Once aligned, individual sequences were grouped into common sequence classes by visual inspection, under the minimum requirement of approximately 90% sequence identity within the same generation and approximately 85% sequence identity across generations and across two selections. After the initial bulk sorting of individual sequences into common classes, the alignment was run through the ClustalW multiple alignment algorithm (with default parameters) provided in Bioedit to help identify previously undetected sequence matches due to misalignment from deletions or insertions. A sequence identity matrix was generated for sequences in each generation, using Bioedit. The sequence identity matrix is simply an N × N matrix (where N = number of sequences in a given class) that shows the sequence identity (expressed as a number between 1 and 0, where 1 represents identical sequences and 0 represents no identical bases in their current alignment) for each pairwise permutation of all sequences being considered (in this case for all sequences within a class). This identity matrix was used to determine the average sequence identity within classes by considering all constituents of the class, as well as the maximum and minimum sequence identity observed between any two sequences within the class. Likewise, the matrix was used to determine the average, maximum, and minimum sequence identity between classes for each generation. To calculate the sequence identity statistics between the 215 classes across generations and across both selections, the sequence of a single clone from each class was used to construct the identity matrix. This simplifying strategy was applied with three different data sets (using different randomly chosen sequences from each class) and yielded very similar results in every case.
Kinetic Analyses
A typical reaction involved the following steps: (1) heat denaturation of the A1-R1-DNA pool construct in water for 30 s at 90°C, (2) incubation for RNA cleavage at room temperature in selection buffer B for a designated time, (3) addition of EDTA to 30 mM to stop the reaction, (4) separation of cleavage products by denaturing 10% PAGE, and (5) quantitation using a PhosphorImager and ImageQuant software. For deriving the catalytic rate constants, aliquots of an RNA cleavage reaction solution were collected at different reaction time points that were under ∼30% completion and the rate constant for the reaction was determined by plotting the natural logarithm of the fraction of DNA that remained unreacted vs. the reaction time. The negative slope of the line produced by a least-squares fit to the data was taken as the rate constant.
Simulations
Definitions and Equations
XC,N: Number of copies of a given deoxyribozyme sequence class (or the noncatalytic class) in a given generation before the selection step. Note: Subscript C = class number; subscript N = generation or selection round.
YC,N: Number of copies of a given deoxyribozyme sequence class (or the noncatalytic class) in a given generation after the selection step.
AFC,N: Amplification factor (the fold amplification of each sequence class during PCR).
Z: Total number of molecules (catalytic and noncatalytic) in the population in a given generation after the PCR step.
∑(YC,N): Total number of molecules (catalytic and noncatalytic) in the population in a given generation after the selection step.
SRC,N: Surviving ratio (the fraction of a given sequence class that survives the selection step, 0 ≤ SRC,N ≤ 1).
FRC,N: Fraction of the population composed of a given deoxyribozyme sequence class (or noncatalytic class) in a given generation.
SRC,N is determined by one or more contributing factors. When multiple factors are considered, the overall SRC,N can be taken as the product of each individual factor. For example, if three factors collectively influence the surviving ability of a given deoxyribozyme class, SRC,N can be computed by Eq. (5):
For simulation 1 (Fig. 7), SRC,N = (SRC,N)Rate = kC/kt, where kC = catalytic rate of a given sequence class (min−1), k t = 1/t = minimum threshold rate imposed by the reaction time (t; minutes). For simulation 2 (Fig. 8), SRC,N = (SRC,N)Rate × (SRC,N)Folding, where (SRC,N)Folding is the “folding factor” or the fraction of a given deoxyribozyme sequence class that folds into a catalytically active conformation (0 ≤ (SRC,N)Folding ≤ 1).
For simulation 3 (Fig. 9), SRC,N = (SRC,N)PCR × (SRC,N)Folding, where (SRC,N)PCR is the “PCR efficiency” or the fraction of a given deoxyribozyme sequence class that is amplified during PCR (0 ≤ (SRC,N)PCR ≤ 1).
Simplifying Assumptions and Conditions
-
1
The initial random DNA library contains 1014 different molecules.
-
2
Each catalytic sequence class survives the initial round of selection despite having only single-copy representation in the initial library.
-
3
The gel-based selection method permits 0.8% of noncatalytic DNA molecules to survive each round (independent of the reaction time), and all these molecules are treated as a single class (NC).
-
4
A total of 1013 molecules are generated after each PCR (Z = 1013).
-
5
Some form of mutational event(s) leads to a change in the overall surviving ratio of a given deoxyribozyme sequence class (SRC,N).
-
6
The phenotypic properties (catalytic rate, folding factor, PCR efficiency) of specific deoxyribozyme sequence classes were chosen arbitrarily but within reasonable limits for deoxyribozyme standards.
With the preceding simplifying assumptions and conditions taken into consideration, the computer program Microsoft Excel was used to generate a spreadsheet of FRC,N values for all deoxyribozyme sequence classes versus each generation.
We will use simulation 1 (Fig. 7) as an example to illustrate the method by which the fraction of population (FRC,N) was calculated for each sequence class in our computer simulations.
For G0: The initial library contains 1014 different molecules, and therefore each of the seven deoxyribozyme sequence classes is represented by only a single molecule. Thus, XC,0 is equal to 1 molecule. Each deoxyribozyme must pass the first round of selection, so the product pool will also contain one copy of each deoxyribozyme. Therefore, YC,0 is also equal to 1 molecule. Noncatalytic DNA molecules are represented by a single class (class NC) with a surviving ratio (SRNC) of 0.008. Therefore, the number of molecules of the noncatalytic class carried into the product pool will be: YNC,0 = 1014 × 0.008 = 8 × 1011 molecules. The total number of molecules in the product pool of G0 will be ∑(YC,0) = 1 + 1 + 1 + 1 + 1 + 1 + 1 + 8 × 1011 ≈ 8 × 1011. The FRC,N value for each deoxyribozyme class will be FR1−7,0 = YC,0 / ∑(YC,0) = 1 (8 × 1011) ≈ 1.25 × 10−12. The FRNC,0 of class NC is equal to 1.
For G1: The amplification step will generate 1013 molecules from 8 × 1011 input molecules, therefore AF1−7,1 = 1013 ÷ ∑(YC,0) = 1013 (8 × 1011) = 12.5. For simulation 1 (Fig. 7) we assumed that every sequence class has the same PCR efficiency, and therefore XC,1 (for each of the seven deoxyribozyme classes, C = 1–7) = 1 × 12.5 = 12.5, and XNC,1 = 8 × 1011 × 12.5 = 1 × 1013. The kC values for all seven deoxyribozyme classes (0.004, 0.01, 0.045, 0.1, 0.25, 0.6, and 2 min−l for classes 1–7, respectively) are larger than the minimum threshold rate constant in G1 (k5h = 1/300 min−1 = 0.0033 min−1), therefore SR1−7,1 = 1. After the selection step, Y1−7,1 = X1−7,1 × SR1−7,1 = 12.5 × 1 = 12.5 copies and YNC,1 = 1013 × 0.008 = 8 × 1010 molecules. The total number of molecules in the product pool of G1 is Σ(YC,1) = 12.5 + 12.5 + 12.5 + 12.5 + 12.5 + 12.5 + 12.5 + 8 × 1010 ≈ 8 × 1010. The fraction of the population represented by each deoxyribozyme class in G1 is FRC,1 = YC,1 / Σ(YC,1) = 12.5 ÷ 8 × 1010 ≈1.56 × 10−10. The FRNC,1 of the noncatalytic group is equal to 1.
For the next generation (N+1), first calculate AFC,N+1 = 1013 ÷ Σ(YC,N), then compute XC,N+1 = YC,N × AFC,N+1; then determine SR C,N+1 = kC/k t (if kC/k t > 1, SRC,N+1 is taken as 1). After obtaining YC,N+1 for each sequence class by YC,N+1 = XC,N+1 × SRC,N+1 and YNC,N+1 = XNC,N+1 × 0.008, the total number of molecules in the product pool of G(N+1) is Σ(YC,N+1). The fraction of the population represented by each deoxyribozyme class in generation (N+1) is FRC,N+1 = YC,N+1 / Σ(YC,N+1).
Results and Discussion
Continuation of Two Parallel Selections Initiated in a Prior Study
Our laboratory has recently initiated a research program to systematically investigate the in vitro selection methodology, which has gained considerable recognition over the last decade for its ability to isolate deoxyribozymes and other functional nucleic acids from synthetic DNA and RNA libraries. Previously, we conducted a study to examine the relationship between catalytic sequence diversity and the length of the reaction time imposed during in vitro selection (Schlosser and Li 2004). We devised a selection strategy to isolate RNA-cleaving deoxyribozymes from a library of single-stranded DNA molecules coupled to a long RNA substrate and performed two parallel experiments using different selection pressure. In the current study, we sought to characterize the population dynamics of this community of RNA-cleaving deoxyribozymes. A brief recap of the relevant experimental details from the previous study will first be addressed. Approximately 1014 different DNA sequences were used in the starting library (generation 0 or G0), which is illustrated along with the in vitro selection scheme in Fig. 1. A single selection was initially carried out from G0 to G7. There was no detectable cleavage product(s) in G0–G4. However, three different cleavage bands were seen in G5, each corresponding to a unique cleavage site along the 50-nt RNA substrate. In G6, each DNA band was carefully excised, and the eluted DNA was amplified separately. One of these three DNA bands in G7, named DNA-II, was used as the common starting pool for two subsequent parallel selections. In Selection A, the reaction time was progressively decreased from 5 h (G7), to 30 min (G8), to 5 min (G9–G11), to 30 s (G12–G14), and, finally, to 5 s (G15). In Selection B, a constant reaction time of 5 h was used for each round of selection from G7 to G15. It is noteworthy to mention that the risk of cross-contamination between these two parallel selections was minimized by a design strategy, which introduced different primer-binding sites onto the existing common 3′ end of each DNA population in G8. Approximately 50 clones from G7, G8, G10, G13, and G15 of each selection were sequenced, and the change in sequence diversity was reported for both selections.
In order to create a more meaningful characterization of the potential evolutionary scenarios occurring during in vitro selection, we decided to conduct 9 more rounds of Selection A and 15 more of Selection B. These additional rounds of selection would broaden the evolutionary timescale and increase the sensitivity of our system for detecting slow or latent evolutionary trajectories. As an experimentally imposed selection pressure, the reaction time was set at 5 s for the remainder of Selection A and 5 h for the remainder of Selection B. Once again, approximately 50 clones were sequenced from G18, G21, G24 (for both Selection A and Selection B), G27, and G30 (for Selection B).
Sequence Classification Statistics for Selections A and B
The sequences of all clones were analyzed and grouped into classes, and the data are presented in Table 1 (for Selection A) and Table 2 (for Selection B). In Selection A, a total of 393 clones were sequenced and 113 unique classes were revealed. The diversity ratio is a measure of the sequence diversity within each population and is defined as the ratio of unique sequence classes over the total number of sequenced clones. The observed maximum, minimum, and average sequence identity between individual clones within classes, as well as the observed maximum, minimum, and average sequence identity between classes is tabulated for each generation and presented in Supplementary Table 1. These sequence classification statistics clearly indicate that individual clones fall into very distinct sequence classes. On average, clones within a given sequence class are more than 90% identical, while the maximum identity observed between any two classes does not exceed 60%.
Table 2 summarizes the sequencing results of Selection B. In total, 512 clones were sequenced (including the 48 common G7 clones) and 172 unique classes were revealed. Once again, clones within a given sequence class are more than 90% identical on average, while the maximum identity observed between any two classes does not exceed 60%. Across Selections A and B, 215 sequence classes were identified. The average sequence identity observed within the 215 classes is also more than 90%, while the maximum identity observed between the 215 classes (based on a single representative clone from each class) does not exceed 60%.
The fraction of the population that belongs to single-clone sequence classes and to various multiple-clone classes are illustrated in Fig. 2. Comparison of Selection A with Selection B reveals some interesting trends. In both cases the fraction of the population made up of single-clone sequence classes declines with increasing rounds of selection. However, the rate of decline in Selection A is greater than in Selection B, which is understandable given the additional selection pressure (i.e., reduced reaction time) imposed in Selection A. An opposite trend is observed in the fraction of the population composed of sequence classes containing three or more clones, which appears to increase with increasing rounds of selection. Again, the rate of increase in Selection A is greater than in Selection B. Dominant sequence classes (i.e., containing seven or more clones) begin to emerge by G10 in Selection A but do not emerge until around G21 in Selection B. The pool complexity in Selection A continues to diminish in favor of a few dominant classes, with nearly 60% of the population represented by classes with 14 or more clones. In contrast, the population in Selection B maintains a larger fraction of moderately dominant classes, with no representation by classes containing 14 or more clones. The fluctuations observed in G18 and G24 of Selection A, as well as G24 of Selection B, may be due to random genetic drift or sampling error.

General trends in population distribution over selection rounds. Changes in the fraction of the population composed of single-clone and various multiple-clone sequence classes are illustrated as a function of the generation. A Selection A. Increasing selection pressure was imposed on the population by incrementally decreasing the reaction time over the course of the experiment as shown above the graph. G0–G7, 5 h; G8, 30 min; G9–G11, 5 min; G12–G14, 30 s; G15–G24, 5 s. B Selection B. The reaction time was maintained at 5 h for every generation.
Changes in the Phenotypic and Genotypic Character of Two Evolving Populations
Figure 3 traces the change in the phenotypic (catalytic rate, kobs) and genotypic (diversity ratio) character of the composite population over the course of in vitro selection. In Selection A, the reduction in reaction time is paralleled by a rapid decrease in the diversity ratio and a dramatic increase in the catalytic rate. By G15, the population as a whole exhibits a catalytic rate of 0.62 min−1, which represents an approximate 17-fold increase over the 0.036 min−1 catalytic rate observed in G7. Interestingly, the diversity ratio appears to plateau (with some fluctuations) after G15 when the reaction time was held constant for the remainder of the study. This observation suggests that selection is no longer acting on the remaining members of the population because they are phenotypically equivalent (or nearly equivalent) under the imposed selection pressure. A further reduction in the reaction time, however, may lead to a further reduction in the diversity ratio. The rate of increase in the catalytic rate also appears to roughly level off after G15, which is consistent with the preceding analysis.

Phenotypic and genotypic progression of the composite populations. The catalytic rate, kobs, is used as one measure to describe the phenotypic character of the population, while the sequence diversity ratio is used to describe the genotypic character of the population. The diversity ratio is a measure of the sequence diversity within the population and is defined as the number of unique sequence classes divided by the number of sequenced clones. A Selection A. Increasing selection pressure was imposed on the population by incrementally decreasing the reaction time over the course of the experiment as shown above the graph. G0–G7, 5 h; G8, 30 min; G9–G11, 5 min; G12–G14, 30 s; G15–G24, 5 s. B Selection B. The reaction time was maintained at 5 h for every generation.
An entirely different scenario is observed in Selection B, where the reaction time was maintained at 5 h for every round of selection. Interestingly, the catalytic rate does not appear to increase between G7 and G30. Nevertheless, there is a steady decrease in the diversity ratio, which suggests that selection is still acting to reduce the variability in some secondary phenotypic trait(s). Alternatively, the observed decrease in the diversity ratio may be a general artifact of the in vitro selection method, which typically involves some degree of subsampling of the evolving population during every round. For instance, only a fraction of the total product from PCR1 is used to seed PCR2, and only a fraction of the DNA pool is recovered after each PAGE purification step. The subsampling that occurs with each of these laboratory manipulations decreases the effective population size, which in turn may lead to a decrease in genetic diversity. This bottleneck effect may be prominent during the initial rounds of selection when there are very few copies of each sequence variant. However, by G7 there should be numerous copies of each sequence variant that should act as a buffer against random changes in the overall genetic diversity. Therefore, the steady decrease in the diversity ratio observed in Fig. 3B is not likely to be explicitly caused by sampling bottlenecks, although this effect may facilitate the process by hastening the extinction of classes that have already dwindled in copy number due to less competitive secondary phenotypic characteristics.
Fitness Landscapes of Selection A
Fitness is a measure of an individual’s ability to survive and reproduce in a given environment. In 1932, Sewell Wright (1932) first introduced the idea of visualizing the distribution of fitness values within a population as a kind of landscape in order to study evolution. To examine the population dynamics of our model system, we have correlated the fitness of a particular sequence class to the number of clones observed in that class and constructed several fitness landscapes to trace changes in population composition and complexity over the course of in vitro selection. These fitness landscapes are not intended to convey any specific phenotypic information. The landscapes were constructed by grouping individual clones into common sequence classes as previously described and then normalizing the absolute number of clones in a given class by the total number of clones sequenced in that particular generation. This normalized number represents the fraction of the population (by generation) composed of a particular sequence class. In an effort to emphasize the pattern of dominant sequence classes and minimize the clutter created by transient classes with few clones, we imposed an arbitrary cumulative threshold value of 0.1 for inclusion into the landscape. In other words, if the sum of the fraction-of-population values across all generations is greater than or equal to 0.1, the sequence class was included in the fitness landscape. This requirement was imposed after the fraction-of-population values were calculated for all sequence classes. It should be noted that the sequence classes were arranged in such a manner as to illustrate a general progression in the level of fitness, and does not reflect any homology between the sequence classes (except by chance).
Figure 4 shows a fitness landscape composed of nine dominant sequence classes from Selection A. The landscape is characterized by a transition among three general species: those that dominate near the beginning of the selection, those that dominate during the middle of the selection, and those that dominate at the end of the selection. In addition to their absolute location on the landscape, these species also differ in distribution (i.e., broad vs. narrow peaks) and in their maximum amplitudes. Only one sequence class, E18, appears to rise steadily and predictably to dominance. The E18 sequence class is first observed in G10 and then quickly propagates to as much as 70% of the population by G21, before declining slightly to ∼55% in G24. This decline may be an artifact of the relatively small sample set of clones that were sequenced in each selection round or it may simply reflect stochastic fluctuations in the composite population. Another noteworthy feature of this landscape is the staggered appearance of the sequence classes across generational time. One possible explanation for this observation is the contribution of a secondary factor such as differential folding efficiency between classes. This issue will be addressed further in a subsequent section using computer simulations.

Deoxyribozyme fitness landscape for Selection A. Changes in the composition and distribution of dominant sequence classes are illustrated. The fraction of population values is calculated by dividing the number of observed clones in a given class by the total number of clones sequenced in that generation. Sequence classes were arbitrarily arranged to illustrate the evolutionary succession of competing classes, and the order does not reflect any homology between classes, except by chance. The color scheme (gray scale) is arbitrary and intended only to facilitate viewing.
Fitness Landscapes of Selection B
The fitness landscape corresponding to 29 prominent sequence classes from Selection B is shown in Fig. 5. Interestingly, the pattern of staggered starting positions for the sequence classes observed in Fig. 4 is also preserved in this landscape, even though the reaction time was never reduced during the entire course of in vitro selection. In this situation, the catalytic rate of individual clones becomes largely irrelevant assuming that all clones in question possess activity above the minimum threshold value of 0.0033 min−1 (100% cleavage in 300 min or 1/300). Other factors, such as differential folding ability, differential PCR efficiency, and spontaneous mutagenesis during PCR, are likely to be the major forces dictating the survival and propagation of specific deoxyribozyme sequence classes. The influence of these factors on the shape of the fitness landscape can be modeled through simple computer simulations and will be addressed in a subsequent section.

Deoxyribozyme fitness landscape for Selection B. Changes in the composition and distribution of dominant sequence classes are illustrated. The fraction of population values is calculated by dividing the number of observed clones in a given class by the total number of clones sequenced in that generation. Sequence classes were arbitrarily arranged to illustrate the evolutionary succession of competing classes, and the order does not reflect any homology between classes, except by chance. “Spacer” intervals were inserted into the chart to separate certain classes for more convenient viewing as well. The color scheme (gray scale) is arbitrary and intended only to facilitate viewing.
It is interesting to note that a particular sequence class, named E8/9R, is likely the product of a recombination event between members of the E8 and the E9 sequence classes. E8/9R is an unusual class because it exhibits extensive sequence homology to both E8 and E9, which is contrary to the general trend observed in our sequence classification statistics. On average, the sequence identity between all other classes is ∼32% with a maximum observed value of ∼56%. In contrast, the average sequence identity between E8 and E8/9R is 62%, and that between E9 and E8/9R is 81%. The “parent” E8 and E9 classes are on average only ∼48% identical. A sequence alignment reveals that the 3′ segment of E8/9R (Supplementary Fig. 1) is very similar to the 3′ end of E9, while the 5′ end of E8/9R closely resembles the 5′ end of E8. Even more suggestive is the middle G-rich motif of the E8/9R class, which shows a very high degree of sequence homology to both E8 and E9. Based on these observations, we suspect that E8/9R could very well have arisen from E8 and E9 as a result of recombination during PCR. Recombination can occur as a result of template switching by the polymerase in the extension phase, or alternatively, prematurely terminated products can anneal to nonidentical but similar templates and be extended to completion in the next cycle. Such mechanisms of PCR-induced recombination have been described elsewhere (Meyerhans et al. 1990; Odelberg et al. 1995). The recombination event may have occurred between G18 and G21 when E9 and E8 represented a significant proportion of the population. Interestingly, both parent classes appear to die out at about the same time as the manifestation of E8/9R in G27, which suggests that the recombination event served to increase the fitness of E8/9R over either parent species. This observation alludes to the possibility for the extreme antiquity of recombination in an RNA world scenario as described by Lehman (2003).

Sequence alignment of E8, E8/9R, and E9 sequence classes. Each clone is described by a title that denotes its sequence class (i.e. E8), a clone specific number within the class, followed by the generation (i.e. G24) from which it was derived and the corresponding reaction time. Clone, E8/9R.01.G30-5h, was used as the reference point to which all other clones are compared. Sequence identity is indicated by a dot. Only the 80-nt random-sequence domain is shown for simplicity. The average sequence identity within classes is as follows: E8 = 92%; E8/9R = 97%; E9 = 96%. The average sequence identity between classes is as follows: E8-E8/9R = 62%; E8-E9 = 48%; E9-E8/9R = 81%.
Deoxyribozyme Fitness Landscapes Across Selection A and Selection B
Figure 6 shows the fitness landscape corresponding to 16 prominent sequence classes identified in both Selections A and B. This landscape is also characterized by three general categories of species: those that dominate in one selection but are only observed transiently in the other; those that appear transiently in both selections; and those that show signs of dominance at both ends of selection. The majority of sequence classes falls into the first two categories. The general lack of recurrence observed between the two selections is consistent with theoretical expectations (Lehman 2004) and is largely predicted to be due to the disparity in selection pressure. However, these results may be confounded by the presence of different 15-nt 3′ primer binding sites on either population.

Deoxyribozyme fitness landscape across both Selection A and Selection B. Changes in the composition and distribution of dominant sequence classes observed in both selections are illustrated. The fraction of population values was calculated by dividing the number of observed clones in a given class by the total number of clones sequenced in that generation. Sequence classes were arbitrarily arranged to illustrate the evolutionary succession of competing classes, and the order does not reflect any homology between classes, except by chance. The color scheme (gray scale) is arbitrary and intended only to facilitate viewing.
Interestingly, the E18 class that clearly dominates Selection A is observed only transiently in generations 8, 10, and 15 of Selection B. This suggests that sequences are not being selected on the basis of catalytic rate in Selection B, which is consistent with the rate data observed in Fig. 3B. E25 is another interesting sequence class, which appears to dominate toward the end of both selections. Based on the observation that the phenotypic character of the terminal population in Selections A and B differed substantially (as measured by the catalytic rate; large kobs in Selection A vs. small kobs in Selection B), we suspected that variations in the genotypic character (in the form of base mutations) had evolved under the different selection regimes. A sequence alignment of all E25 sequence variants (Supplementary Fig. 2) indeed indicates that different base mutations in the 5′ half of sequences have been selected along each selection pathway. It is worthwhile to comment that the appearance of many AT-to-GC mutations along the Selection B pathway may indicate that Selection B favors the evolution of deoxyribozymes that exhibit stable folding as a key phenotypic trait.

Sequence alignment of the E25 class. Each clone is described by a title that denotes its sequence class (i.e. E25), a clone specific number within the class, followed by the generation (i.e. G30) from which it was derived and the corresponding reaction time. Clone, E25.27.G10-5h, was used as the reference point to which all other clones are compared. Sequence identity is indicated by a dot, gaps in the alignment are indicated by a dash. Only the 80-nt random-sequence domain is shown for simplicity.



The sequences of all 857 clones are grouped into sequence classes. Each sequence class containing more than 1 clone is denoted by a number (i.e. E#). Within each sequence class individual clones are represented by a number (i.e. G# or g#) that indicates the generation from which it was recovered, followed by an alpha-numeric designation to identify specific clones. Clones from Selection B are represented by black titles, while red titles indicate clones from Selection A. Only the ∼80-nt random-sequence domain of each clone is illustrated.
Theoretical Fitness Landscapes
Computer simulations were conducted to provide some theoretical justification for the population dynamics observed in the experimentally derived fitness landscapes of Selections A and B. These simulations model the shape of the fitness landscape when selection acts against one or more phenotypic characteristics.
Selection A Simulations
In order to survive the selection step, each deoxyribozyme molecule (cis-acting and only capable of single-turnover) has to cleave itself within the allotted reaction time (t, in minutes) imposed during each selection round. In Selection A, five different reaction times were imposed, each with an associated minimum threshold rate, kt, that is equal to 1/t. The five kt’s (min−1) are 0.0033 (t = 5 h), 0.033 (t = 30 min), 0.20 (t = 5 min), 2.0 (t = 30 s), and 12 (t = 5 s).
In simulation 1 (Fig. 7), we assumed that the ability to cleave above the minimum threshold rate is the only factor that determines the fate of DNA molecules during in vitro selection. The fraction of the population that survives the selection criterion is denoted by the “surviving ratio,” SRC,N, which is based on the following equation:
For simplicity, we decided to trace the progress of just seven different deoxyribozyme sequence classes having catalytic rate constants (kC) ranging between 0.004 and 2 min−1. A “noncatalytic” class (NC) was also included to represent all inactive sequences. During the first seven rounds of selection, all seven deoxyribozyme sequence classes have an SRC,N of 1 (because they all possess a rate that exceeds the minimum threshold rate), while the noncatalytic class is assumed to have a constant SRC,N value of 0.008 (as an artifact of the gel-based selection strategy). Therefore, the only competition during these initial rounds exists between the catalytic and the noncatalytic classes. By G7, the noncatalytic class is largely eliminated.

Simulation 1 of Selection A using a one-parameter model. A Data table. B Simulated fitness landscape. Selection A is simulated under the assumption that selection is acting on only one phenotypic trait: the catalytic rate, k. All other phenotypic traits between classes are assumed to be equal. The progress of seven different catalytic sequence classes and a group of noncatalysts (NC) are followed over generational time, in terms of their surviving ratio (SR). The surviving ratio (0 ≤ SR ≤ 1) is defined as the fraction of a given sequence class that can survive the selection step (cleaving the attached RNA substrate in the allotted time frame). Changes in the SR are emphasized by large font. Blank squares indicate that the SR of a given sequence class has diminished to a level comparable with the noncatalyst group. Sequence classes were arbitrarily arranged to illustrate the evolutionary succession of competing classes, and the order does not reflect any homology between classes, except by chance. The color scheme (gray scale) is arbitrary and intended only to facilitate viewing.
From G8 onward, the seven deoxyribozyme sequence classes begin to exhibit differential levels of surviving ability. When the selection pressure increases in G8 (i.e., the reaction time is reduced from 5 h to 30 min), only classes 3–7 will stay highly competitive because they have a catalytic rate that exceeds the minimum threshold rate of 1/30 min−1. In contrast, the first two classes have rates that fall below this minimum threshold and will, therefore, rapidly approach extinction as their copy numbers decrease with every successive generation. When the reaction time is further reduced to 5 min in G9–G11, to 30 s in G12–G14, and to 5 s in G15–G24, class 3 is the first class to become noncompetitive, followed by class 4, class 5, and class 6. Sequence class 7 represents the most catalytically proficient deoxyribozyme and is predicted to take over the selection by G13 and become the overwhelmingly dominant class in subsequent rounds.
The preceding simulation indicates that if deoxyribozyme sequences were selected solely on the basis of their catalytic rate, we would expect each class to be represented about equally at the beginning of selection and to follow the same pattern of growth until differences in their catalytic rate become manifest in response to changes in the selection pressure. Although this simulation does explain the progressive disappearance of less competitive deoxyribozyme classes under increasing selection pressure, it fails to account for the staggered starting appearance of individual deoxyribozyme classes observed across the landscape in Fig. 4. This analysis suggests that one or more other factors may also influence the outcome of Selection A. These factors may include differential folding ability, PCR efficiency, and spontaneous mutagenesis during PCR. A given sequence could potentially adopt multiple conformations that differ in catalytic activity, a phenomenon that has been well documented (Been et al. 1992; Carrigan et al. 2004; Gottlieb et al. 1994; Uhlenbeck 1995). Therefore, those sequences that have a greater tendency to fold into an active conformation would enjoy a selective advantage. Similarly, a sequence class that is more easily amplified by Taq DNA polymerase will produce more sequence copies during the PCR step. In addition, spontaneous mutations are routinely introduced by Taq DNA polymerase. If an originally less competitive deoxyribozyme acquires some adaptive mutations that significantly enhance its surviving ability (a higher catalytic rate, better PCR or folding efficiency, or some combination thereof), it will appear on the fitness landscape at some later point during the selection.
Based on the preceding discussion, we decided to perform a second simulation (Simulation 2, Fig. 8) that takes three factors into consideration: catalytic rate, structural folding efficiency, and random mutagenesis. We introduced a “folding factor” for each sequence class used in Simulation 1, such that the surviving ratio of each class can now be calculated as the product of the two individual factors (under nonmutagenic conditions):

Simulation 2 of Selection A using a three-parameter model. A Data table. B Simulated fitness landscape. Selection A is simulated under the assumption that selection is acting against two phenotypic traits (the catalytic rate and a folding factor) for most classes and a third factor (spontaneous mutagenesis) for class 1. The folding factor is represented by the fraction of a given sequence class that folds into a catalytically active conformation. The progress of seven different catalytic sequence classes and a group of noncatalysts (NC) is followed over generational time, in terms of their surviving ratio (SR). Sequence classes were arbitrarily arranged to illustrate the evolutionary succession of competing classes, and the order does not reflect any homology between classes, except by chance. The color scheme (gray scale) is arbitrary and intended only to facilitate viewing.
The folding factor is defined as the fraction of a given deoxyribozyme sequence class that folds into a catalytically active conformation. To address the potential role of random mutagenesis, we have arbitrarily chosen sequence class 1 to receive adaptive mutations in G7, which boost its surviving ability from an initial value of 0.009 to 0.4 throughout the remaining selection rounds (G7–G24).
The class 2 deoxyribozyme has a relatively small catalytic rate compared to the other sequence classes (except class 1) but has the best folding ability, with a value of 0.8. This class is most competitive during the early stages of selection when the allotted reaction time is 5 h. Classes 3–6 all have better folding abilities than class 7, but possess lower catalytic rates, and therefore are more competitive in the middle rounds of the selection. Class 7 is the most competitive in the later rounds of selection because it can exploit its superior catalytic rate under the more stringent reaction time, which is reflected as a better compounded surviving ability. Class 1 is the worst-performing class at the beginning of the selection but becomes very competitive after acquiring some advantageous mutations in the seventh generation. However, this class takes about 10 rounds to manifest because of its relatively small representation in the early stages of the population, when it was not competitive at all.
Simulation 2 (Fig. 8) is consistent with the patterns of ascending and descending catalytic species and the overall staggered shape of the landscape illustrated in Fig. 4. It is easy to predict that the population dynamics of such a selection will continue to fluctuate until the emergence of a class that best meets the given selection constraints.
Selection B Simulation
Since no significant change in the catalytic rate was observed throughout Selection B, we conclude that the catalytic rate is at best only a minor contributing factor in the progress and outcome of Selection B. In other words, there is no ostensible selection pressure favoring deoxyribozyme sequences with particularly large catalytic rates. For example, there is no significant advantage for a deoxyribozyme class with a rate constant of 10 min−1 versus those with a rate constant of just 0.01 min−1. Both deoxyribozymes should catalyze the RNA-cleavage reaction to completion within the allotted 5-h time frame. Other factors, including productive folding ability, PCR efficiency, and spontaneous mutagenesis during PCR, must have dictated the selection of individual deoxyribozyme classes in Selection B. Spontaneous mutagenesis is likely to be a very important contributing factor, or the fitness landscape is expected to be very simple: one or many deoxyribozymes with similar traits will emerge after just a few rounds of selection; after that, the population dynamics will become largely static and the landscape will remain unchanged because the selection pressure is constant throughout.
To provide a theoretical explanation, we performed a third simulation (Simulation 3; Fig. 9) that takes into account the following three factors: folding efficiency, PCR efficiency, and spontaneous mutational effects. Once again, seven catalytic sequence classes were used and their respective folding factors and PCR efficiency values are given in the table in Fig. 9. The SRC,N of each sequence class can be calculated (under nonmutagenic conditions) as the product of the PCR efficiency and folding factor:
(SRC,N)Folding is the fraction of a given deoxyribozyme class that folds into a catalytically active conformation and (SRC,N)PCR represents the corresponding PCR efficiency. We intentionally assigned similar (SRC,N)PCR values (0.5–0.75) and widely varied the folding factors (0.02–0.5) among the seven sequence classes in order to emphasize the potential influence of the folding parameter. We also assumed that one or more favorable mutational events (which result in different levels of enhancement of the surviving ability of a concerned class) have occurred to the following classes at different stages in the selection: one event for classes 2–5, two events for class 6, and three events for class 7.

Simulation 3 of Selection B using a three-parameter model. A Data table. B Simulated fitness landscape. Selection B is simulated under the assumption that folding efficiency, PCR efficiency, and spontaneous mutagenesis during PCR collectively act to shape the evolutionary fitness landscape. The folding factor is represented by the fraction of a given sequence class that folds into a catalytically active conformation. The progress of seven different catalytic sequence classes and a group of noncatalysts (NC) is followed over generational time, in terms of their surviving ratio (SR). Sequence classes were arbitrarily arranged to illustrate the evolutionary succession of competing classes, and the order does not reflect any homology between classes, except by chance. The color scheme (gray scale) is arbitrary and intended only to facilitate viewing.
Simulation 3 produces a landscape that largely parallels the fitness landscape given in Fig. 5: a continually changing population in which less fit classes disappear in favor of more fit classes. The fitness improvement for a given class is the cumulative result of one or more adaptive mutagenic events. The population dynamics of such a selection will be characterized by continual changes in the dominating species as long as higher-fitness classes can be produced along the evolutionary pathway. In the end, an individual or group of classes with the highest degree of fitness under the given conditions will “hijack” the selection. At this point, the fitness landscape will no longer experience drastic changes, that is, until a new selection pressure is imposed.
Concluding Remarks
Herein, we sought to provide additional insight into the in vitro selection process. The population dynamics of a community of RNA-cleaving DNAzymes was studied in an effort to identify characteristic patterns of behavior. Identification of these patterns, or lack thereof, may improve our understanding and ability to predict the distribution of function in sequence space, the majority of which has yet to be explored and continues to represent a very daunting challenge. The most comprehensive information on population dynamics can be obtained by directly sequencing many individual clones over multiple rounds of selection. The resulting data can then be conveniently visualized by constructing the corresponding fitness landscapes.
The experimentally derived fitness landscapes presented in Figs. 4 and 5 illustrate two very different evolutionary paths. In Selection A (Fig. 4), the population complexity decreases rapidly in favor of just a few sequence classes, with one class in particular clearly dominating (comprising as much as ∼70% of the population). This behavior can be attributed to the sharp reduction in reaction time, which causes Selection A to undergo directional selection in favor of those sequences at one end of the phenotypic spectrum (i.e., the fastest enzymes). This leads to a landscape with a relatively narrow and peaked distribution. In contrast, the population complexity of Selection B decreases at a far slower pace and is characterized by a larger number of classes of similar fitness. The landscape of Selection B appears broad and relatively flat, with most sequence classes occupying less than 15% of the population at any given time and only one class transiently comprising as much as 25% of the total population. Interestingly, both populations are characterized by a continuous transition in the dominating species, giving rise to the staggered appearance of “new” sequence classes across the fitness landscape. This observation alludes to the presence of many latent deoxyribozymes in the initial library, which will only manifest when the composite population is challenged with different selection pressure (as in Selection A) or through the acquisition of one or more adaptive mutations (as in Selection B). It is important to recognize the role of these latent deoxyribozyme species during in vitro selection, because all too frequently an implicit assumption is made that the dominant species at one moment in time (usually taken to be the “terminal” population) also represents the optimum solution at other moments in time before and after.
In vitro selection is frequently used for the expressed purpose of isolating nucleic acids with catalytic ability. The results of Selection B should serve as a cautionary tale; simply selecting for catalytic activity is not necessarily sufficient to yield a good catalyst. Evidence for this scenario has appeared elsewhere as well. Schmitt et al. selected for variants of a ligase ribozyme under decreasing Mg2+ conditions during in vitro evolution (Schmitt and Lehman 1999) and obtained a variant that did not possess a higher first-order catalytic rate constant but was, nevertheless, more active than the wild type. They suggested that the variant ribozyme was more active than the wild type because it was less likely to misfold into inactive conformers. The kobs of the composite G30 population of Selection B indicates that no enhancement in catalytic activity has occurred despite many rounds of selective amplification. Although it is possible that individual clones within the G30 population may possess high catalytic rates, the kobs of the composite population suggests that such species would exist as a minority. Moreover, we suspect that the weak selection pressure may actually help to decrease the representation of fast catalysts, by allowing the propagation of mildly deleterious mutations. For instance, an enzyme that incurs a mutation or series of mutations that cause its catalytic rate to drop from 10 to 0.01 min−1 will still survive under the imposed 5-h time constraint in our experiment. Since the number of possible deleterious mutations likely exceeds the number of possible beneficial mutations, this effect could potentially be quite substantial, especially for those employing in vitro evolution protocols that boast higher mutagenesis rates.
The current study has focused on the accumulation and analysis of large amounts of genotypic data. However, it would be very interesting to conduct a multivariable characterization of the phenotypic properties of specific clones within and between sequence classes, throughout the entire fitness landscape. This characterization represents the objective of a future study, which aims to assess the contribution of various factors including PCR amplification efficiency, folding efficiency, and catalytic rate in order to create a meaningful genotype-to-phenotype map. In the meantime, this study should be of immediate interest to those employing in vitro selection techniques and may also be of general interest to those studying population dynamics, optimization theory, and evolution.
References
DP Bartel JW Szostak (1993) ArticleTitleIsolation of new ribozymes from a large pool of random sequences Science 261 1411–1418 Occurrence Handle7690155
AA Beaudry GF Joyce (1992) ArticleTitleDirected evolution of an RNA enzyme Science 257 635–641 Occurrence Handle1496376
MD Been AT Perrotta SP Rosenstein (1992) ArticleTitleSecondary structure of the self-cleaving RNA of hepatitis delta virus: applications to catalytic RNA design Biochemistry 31 11843–11852 Occurrence Handle10.1021/bi00162a024 Occurrence Handle1445917
RR Breaker GF Joyce (1994) ArticleTitleA DNA enzyme that cleaves RNA Chem Biol 1 223–229 Occurrence Handle10.1016/1074-5521(94)90014-0 Occurrence Handle9383394
MA Carrigan A Ricardo DN Ang S A Benner (2004) ArticleTitleQuantitative analysis of a RNA-cleaving DNA catalyst obtained via in vitro selection Biochemistry 43 11446–11459 Occurrence Handle10.1021/bi049898l Occurrence Handle15350131
J Charlton D Smith (1999) ArticleTitleEstimation of SELEX pool size by measurement of DNA renaturation rates RNA 5 1326–1332 Occurrence Handle10.1017/S1355838299991021 Occurrence Handle10573123
AD Ellington JW Szostak (1990) ArticleTitleIn vitro selection of RNA molecules that bind specific ligands Nature 346 818–822 Occurrence Handle10.1038/346818a0 Occurrence Handle1697402
PA Gottlieb Y Prasad JB Smith AP Williams G Dinter-Gottlieb (1994) ArticleTitleEvidence that alternate foldings of the hepatitis delta RNA confer varying rates of self-cleavage Biochemistry 33 2802–2808 Occurrence Handle10.1021/bi00176a008 Occurrence Handle8130192
D Irvine C Tuerk L Gold (1991) ArticleTitleSELEXION. Systematic evolution of ligands by exponential enrichment with integrated optimization by non-linear analysis J Mol Biol 222 739–761 Occurrence Handle10.1016/0022-2836(91)90509-5 Occurrence Handle1721092
N Lehman (2003) ArticleTitleA case for the extreme antiquity of recombination J Mol Evol 56 770–777 Occurrence Handle10.1007/s00239-003-2454-1 Occurrence Handle12911039
N Lehman (2004) ArticleTitleAssessing the likelihood of recurrence during RNA evolution in vitro Artif Life 10 1–22 Occurrence Handle10.1162/106454604322875887 Occurrence Handle15035860
N Lehman GF Joyce (1993a) ArticleTitleEvolution in vitro of an RNA enzyme with altered metal dependence Nature 361 182–185 Occurrence Handle10.1038/361182a0
N Lehman GF Joyce (1993b) ArticleTitleEvolution in vitro: analysis of a lineage of ribozymes Curr Biol 3 723–734 Occurrence Handle10.1016/0960-9822(93)90019-K
N Lehman MD Donne M West TG Dewey (2000) ArticleTitleThe genotypic landscape during in vitro evolution of a catalytic RNA: implications for phenotypic buffering J Mol Evol 50 481–490 Occurrence Handle10824092
A Meyerhans JP Vartanian S Wain-Hobson (1990) ArticleTitleDNA recombination during PCR Nucleic Acids Res 18 1687–1691 Occurrence Handle2186361
SJ Odelberg RB Weiss A Hata R White (1995) ArticleTitleTemplate-switching during DNA synthesis by Thermus aquaticus DNA polymerase I Nucleic Acids Res 23 2049–2057 Occurrence Handle7596836
DL Robertson GF Joyce (1990) ArticleTitleSelection in vitro of an RNA enzyme that specifically cleaves single-stranded DNA Nature 344 467–468
SW Santoro GF Joyce (1997) ArticleTitleA general purpose RNA-cleaving DNA enzyme Proc Natl Acad Sci USA 94 4262–4266 Occurrence Handle10.1073/pnas.94.9.4262 Occurrence Handle9113977
K Schlosser Y Li (2004) ArticleTitleTracing sequence diversity change of RNA-cleaving deoxyribozymes under increasing selection pressure during in vitro selection Biochemistry 43 9695–9707 Occurrence Handle10.1021/bi049757j Occurrence Handle15274624
T Schmitt N Lehman (1999) ArticleTitleNon-unity molecular heritability demonstrated by continuous evolution in vitro Chem Biol 6 857–869 Occurrence Handle10.1016/S1074-5521(00)80005-8 Occurrence Handle10631514
F Sun D Galas MS Waterman (1996) ArticleTitleA mathematical analysis of in vitro molecular selection–amplification J Mol Biol 258 650–660 Occurrence Handle10.1006/jmbi.1996.0276 Occurrence Handle8636999
C Tuerk L Gold (1990) ArticleTitleSystematic evolution of ligands by exponential enrichment: RNA ligands to bacteriophage T4 DNA polymerase Science 249 505–510 Occurrence Handle2200121
OC Uhlenbeck (1995) ArticleTitleKeeping RNA happy RNA 1 4–6 Occurrence Handle7489487
B Vant-Hull A Payano-Baez RH Davis L Gold (1998) ArticleTitleThe mathematics of SELEX against complex targets J Mol Biol 278 579–597 Occurrence Handle10.1006/jmbi.1998.1727 Occurrence Handle9600840
S Wright (1932) ArticleTitleThe roles of mutation, inbreeding, cross-breeding, and selection in evolution Proc 6th Int Congr Genet 1 356–366
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Schlosser, K., Li, Y. Diverse Evolutionary Trajectories Characterize a Community of RNA-Cleaving Deoxyribozymes: A Case Study into the Population Dynamics of In Vitro Selection. J Mol Evol 61, 192–206 (2005). https://doi.org/10.1007/s00239-004-0346-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00239-004-0346-7