
Abstract
Older adults demonstrate impairments in navigation that cannot be explained by general cognitive and motor declines. Previous work has shown that older adults may combine sensory cues during navigation differently than younger adults, though this work has largely been done in dark environments where sensory integration may differ from full-cue environments. Here, we test whether aging adults optimally combine cues from two sensory systems critical for navigation: vision (landmarks) and body-based self-motion cues. Participants completed a homing (triangle completion) task using immersive virtual reality to offer the ability to navigate in a well-lit environment including visibility of the ground plane. An optimal model, based on principles of maximum-likelihood estimation, predicts that precision in homing should increase with multisensory information in a manner consistent with each individual sensory cue’s perceived reliability (measured by variability). We found that well-aging adults (with normal or corrected-to-normal sensory acuity and active lifestyles) were more variable and less accurate than younger adults during navigation. Both older and younger adults relied more on their visual systems than a maximum likelihood estimation model would suggest. Overall, younger adults’ visual weighting matched the model’s predictions whereas older adults showed sub-optimal sensory weighting. In addition, high inter-individual differences were seen in both younger and older adults. These results suggest that older adults do not optimally weight each sensory system when combined during navigation, and that older adults may benefit from interventions that help them recalibrate the combination of visual and self-motion cues for navigation.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Older adults show navigation deficits that are often not fully explained by general age-related declines in cognitive or motor functioning (Lester et al. 2017). Deficits in navigation result in an increased chance of getting lost, an inability to travel independently, and feelings of isolation, making them a significant and pervasive issue for aging adults (van der Ham et al. 2020). Failures in navigation due to topographical disorientation are important to understand because they may also be early markers of pathological aging, particularly in Alzheimer’s Disease (Coughlan et al. 2018). The effects of navigational difficulty can be compounded by other age-related deficits in sensory and motor components of balance and gait. Thus, an understanding of the mechanisms underlying changes in spatial navigation with aging could address both safety and social consequences of navigational decline while also aiding in the identification of pathological age-related cognitive and mobility deficits.
Successful navigation requires sensing the environment, constructing representations of spatial layout, and guiding actions within the environment (Loomis et al. 2002). Updating a spatial representation by keeping track of one’s own position and orientation within an environment as one moves through it is referred to as spatial updating (Newman et al. 2023). Many types of cues can be used to update spatial orientation and position. One group of cues is internal self-motion cues, including vestibular cues, optic flow, and proprioceptive cues that provide information regarding velocity or acceleration. Second, exteroceptive cues, such as visual or auditory landmarks within an environment, provide information about one’s relative position and orientation.
In the current paper, we examine two primary spatial cues that are critical for navigation, visual landmarks and body-based (vestibular and proprioception signals) self-motion cues, using a homing task in which participants walk along two legs of a triangle to specified target locations and then return to a designated "home" starting point (Chen et al. 2017; Riecke et al. 2002; Xie et al. 2017; Newman et al. 2023). A homing task allows for the examination of how individuals form and update spatial representations for orientation with both internal and external cues. A cue-combination paradigm in which the cues are available individually or combined also allows for the modeling of sensory cue weighting during the homing task.
To date, studies have shown that older adults perform less accurately on homing tasks than younger adults, even when a variety of sensory cues are available to update position and orientation (Adamo et al. 2012; Allen et al. 2004; Bates and Wolbers 2014; Stangl et al. 2018). The effect of age on homing is particularly strong for older adults with sensory loss (Xie et al. 2017; Allen et al. 2004), but is also seen in relatively healthy aging populations (Allen et al. 2004; Bates and Wolbers 2014). Furthermore, the age effect appears to be independent of route learning strategy or the number of visual landmarks available for encoding (Head and Isom 2010).
One hypothesis for this age-related difference is that navigational impairments in older adults may be due, in part, to a decline in sensory integration (Bates and Wolbers 2014). Sensory integration here refers to the brain’s ability to combine multiple, separate sensory streams (e.g., vision, vestibular, etc) into a fused multisensory percept (Stein and Meredith 1990). Central integration of our senses is calibrated early in life (Nardini et al. 2008) when our sensory streams are relatively more reliable, or less variable, than they are in older age. How this integration process changes over the lifespan is not well characterized. Sensory integration has long been characterized in terms of "optimal" integration in which cues are perceptually weighted relative to their perceived reliability, often measured in terms of variability (Ernst and Banks 2002). More recently, studies have employed homing tasks to address the role of cue weighting in navigation, using a traditional cue-combination paradigm where the spatial cues for navigation may be presented individually or together. For example, the presence of cues is manipulated during the return to home leg such that there are single visual or body-based cues available, both cues, or cues in spatial conflict. Predicted weights are calculated from the variance of the individual single cue conditions and observed weights are determined from the conflict condition in which the visual landmarks are shifted relative to their initial position (so that they specify a different spatial home location than body-based cues; Newman et al. (2023)).
Optimal integration, in this context, refers to the reduction in variability given multiple sensory cues that follows the principles of maximum likelihood estimation (MLE). Because sensory inputs are typically noisy distributions, if the brain is operating in a statistically "optimal" manner, multisensory information should demonstrate greater reliability (reduced variability in homing performance) than unisensory information. Further, the cues should be combined according to each individual cue’s reliability.
Some data show sub-optimal integration of visual and body-based self-motion cues in a homing task in older adults (as compared to younger adults), suggesting that navigational deficits may be related to a diminished ability with age to effectively fuse multiple sensory systems. Although older adults did show evidence for cue combination during navigation, they did not weight the cues as an optimal model would predict (Bates and Wolbers 2014). However, other data question whether changes in multisensory integration due to age are the cause or effect of deficits in navigation (Jones and Noppeney 2021) or even self-motion perception (Ramkhalawansingh et al. 2018; Allen et al. 2004). For example, older age could interfere with the reliability of the sensory information (Humes 2015), the processing of hippocampal and entorhinal cellular encoding (Stangl et al. 2018), or the ability to use or switch between multiple reference frames or strategies (Muffato and De Beni 2020) rather than an ability to stitch multisensory information together.
To date, only a few known studies have examined the role of healthy aging in cue combination during navigation (Bates and Wolbers 2014; Adamo et al. 2012). Those that have, have done so with visually impoverished environments. Out of necessity to limit visual information to just the intended set of visual landmarks, these studies have employed a dark environment (Bates and Wolbers 2014) or other devices that prevent typical navigation strategies such as high-opacity sunglasses or blindfolds (Adamo et al. 2012). Given the recent technological development of high-fidelity immersive environments that can be viewed in near-human resolution head-mounted displays, it is now possible to study well-aging individuals in more ecologically valid navigational environments (Shayman et al. 2022; Diersch and Wolbers 2019; Creem-Regehr et al. 2024). Given that only one known study (Bates and Wolbers 2014) has examined the integration of visual and self-motion cues for older and younger adults, we set out to conceptually replicate their work using an immersive virtual environment. The main differences in our work were the display of the environment and the precision of measurement afforded by the virtual reality tracking system. In Bates and Wolbers (2014) participants navigated in a fully dark, but real world environment, using lights as targets and landmarks. While this approach allows for careful control of environmental context, it also creates a setting where the ground is not visible and the target and landmark objects may be less precisely localized (Rand et al. 2012; Meng and Sedgwick 2002). In the current study, participants’ spatial cue use was tested using immersive virtual reality with more realistic environmental conditions. In other words, we could add or remove cues during the homing task in fully lit virtual environments rather than adding or removing them from a fully dark real environment (as in Bates and Wolbers (2014)). The use of the virtual environment may allow for findings to be more generalizeable to everyday navigation environments than the prior studies conducted in severely reduced-cue real world environments. We aimed to examine whether prior sub-optimal cue combination findings in older adults could have been driven by cue-limited environments, though our hypotheses generally followed the prior findings of Bates and Wolbers (2014).
We predict many outcomes related to sensory cue combination during navigation with respect to age. First, older adults will be less accurate in returning to the home location than younger adults, overall. Further, we predict that both older and younger adults will be more accurate when multisensory cues are available compared to navigating with a single cue.
Second, older adults will be more variable in navigation performance than younger adults. Like with our accuracy hypotheses, we expect variability to decrease (increase in precision) with multisensory cues relative to single-cue conditions (evidence for sensory cue combination).
Third, although we expect both age groups to weight vision more than body-based self-motion cues overall, we will test whether there is different relative weighting of visual cues in older versus younger adults, and in what direction. One possibility is that older adults will rely on their vision less than younger adults due to well-documented, often subclinical, undetectable presbystasis and neuropathy (Wagner et al. 2021; Hicks et al. 2021). Alternatively, older adults could weight visual cues relatively more, attributed to declines in vestibular processes (Bates and Wolbers 2014). Finally, we expect that younger adults will show evidence for optimal integration of vision and self-motion in homing performance as in prior related work (Chen et al. 2017), but older adults will not (Bates and Wolbers 2014).
Method
Participants
Fifty participants split evenly between two age groups, younger adults (16 female, 9 male) and older adults (15 female, 10 male), gave voluntary informed consent to participate as approved by the university’s Institutional Review Board (IRB). All research procedures were performed in accordance with the ethical standards laid down in the 1964 Declaration of Helsinki. Older adults were recruited through a flyer sent to a continuing education group as well as by word-of-mouth and were paid $20/hr for their time. Younger adults were recruited through a combination of word-of-mouth (paid participation) and via the undergraduate psychology participant pool (compensated via class credit, as approved by the IRB). Inclusion criteria for all participants were normal or corrected-to-normal (20/40) vision (as assessed through standard Snellen chart), no history of prior inner-ear surgery, no history of previous eye surgery other than corrective LASIK surgery, and the ability to walk independently. Exclusion criteria specific to participating in VR was self-reported heart condition, history of seizures, or pregnancy. All participants passed a cognitive screen (Mini-Mental Status Exam Score > 24), and all participants completed an instrumented Romberg test with their eyes open and closed on solid ground and on foam to screen for balance impairments.Footnote 1
An a priori power analysis was based on the sample size used in Bates and Wolbers (2014) and medium effect sizes (\(\eta _{\text {G}}^{2}\) = 0.11\(-\)0.18) reported in similar studies with young adults (Bates and Wolbers 2014; Chen et al. 2017). We determined that 20–24 participants per group would be sufficient to find within- and between-group effects (80% power), so our recruitment target was set at 24 participants per group. Twenty-five participants were recruited for each group. One younger adult participant left the study early and was dropped from data analysis. Five older adult participants were dropped from data analysis due to the following reasons: inability to complete more than half of the trials due to fatigue (n = 4) and inability to complete the self-motion condition in the absence of visual landmarks (n = 1). Our final dataset comprised twenty older adults aged 61–78 years (M = 66.80, SD = 5.33, 13 female) and 24 younger adults aged 19–30 years (M = 24.33, SD = 3.17, 15 female).
Materials and procedure
Immersive virtual environment, spatial layout, and design
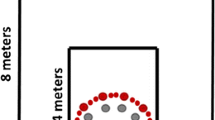
All participants completed the task in our immersive virtual reality lab. The dimensions of the room were 8.53 m \(\times\) 11.58 m, and the task made use of approximately 6 m \(\times\) 7 m of space for walking (Fig. 1). Participants were guided into the room with their eyes closed so that they did not perceive the room’s dimensions. The room lights were also kept off so that participants could not see through any potential gaps between their nose and the head-mounted display, though the computer monitor used by the experimenter and a light from an adjacent room illuminated the testing space sufficiently for 2 experimenters to safely monitor participants.
Within the virtual environment, our experiment generally resembled that of other published triangular homing tasks testing cue combination (Bates and Wolbers 2014; Chen et al. 2017; Newman et al. 2023). As can be seen in Fig. 2, participants viewed an endless grassy plane with a horizon. The environment lighting was such that no shadows were cast. The environment was developed in Unity (build 2020.3.25f1) with the SteamVR Plugin (Version 2.7.3), and executed on SteamVR (Version 1.27.5). The final build is available upon request. The coordinate system of the environment was centered on the blue waypoint (also known as waypoint 2 and indicated by the blue dot on the ground in the Figure). The target and landmark locations can be seen in Fig. 1 and the four cue conditions are described in Table 1.
During the conflict condition, landmarks were rotated 15 degrees counter-clockwise about the second waypoint. Targets (green) and waypoints (red and blue) appeared as small circular discs on top of the grassy plane with a radius of 6.25 cms and a depth of 4.75 cms. Landmarks appeared as a diamond, triangle, and rectangular colored shape set on a white board attached to a stand. The rectangular board on which the three landmarks appeared measured 36 cm wide by 50 cm tall. The top of the landmark board to the ground plane measured 1.45 m. The stand and board were modeled after a PVC pipe stand and foam board that existed in the laboratory for a real world experiment that was run on the same participants but not reported here. Overall, the landmarks were large and easy to visualize.

A schematic of the environment layout and homing task. The target and the first waypoint appeared in 1 of 4 locations, represented by the green and red circles, respectively. Waypoint 2, the blue circle, was always in the same location and defined the origin of the coordinate system
Materials
Participants viewed the immersive environment through a Varjo VR-3 head-mounted display (HMD). The HMD was spatially calibrated to the room within SteamVR. All participants’ inter-pupillary distance (IPD) was measured. The HMD was calibrated to this distance unless their IPD was smaller than the minimum setting on the headset (59 mm), in which case the HMD was set to 59 mm. The HMD was wired to the computer via a 10 m cable and attached overhead via a series of pulleys to keep the cable from becoming a tripping hazard. To prevent participants from feeling the tension in the wire and using it as a spatial cue, as well as to prevent participants from walking beyond the experimental boundaries and colliding with room walls, an experimenter walked with the participant during the entire experiment and held the tension in the cable such that the participant did not feel the cable tension. Participants wore in-ear headphones (Beats Electronics) playing pink noise. The headphone volume was set at a comfortable level where participants could still hear instructions from the experimenter, but could not hear any localized sound from the computer fan, keyboard, or the HVAC system in the room as auditory cues are known to contribute to self-motion perception (Shayman et al. 2020). Older adult participants wore a gait belt so that an experimenter could safely spot them.
The homing task
Participants began each trial from the start location, which appeared as a white disc similar to the targets and waypoints. An experimenter then triggered the target and first waypoint to appear while disabling the visibility of the starting disc. Participants were instructed to walk to the target and remember its location. Then participants walked to the first and second waypoints. At the second waypoint, the HMD went completely black for 10 s. During this time, an experimenter performed one of the following manipulations of cue-condition (see Table 1): disabling the visual landmarks (self-motion condition), disorienting the participant by turning them quickly in a rotating swivel chair (vision condition), turning the landmarks off and then back on (consistent condition), or shifting the landmarks 15 degrees counter-clockwise about the second waypoint (conflict condition).
For the vision condition, participants were spun at a quick, but comfortable, pace for 2 full rotations in each direction, though the rotation was broken up into smaller, randomized segments so that participants could not tell that they were being spun equally in each direction. After the 10 s, the HMD black screen was lifted and participants navigated back towards where they perceived the target to have been (homing leg). This was done in the absence of any of the target or waypoint markers. An experimenter confirmed with the participant that they were at the perceived location of the initial target and pressed a button to save the coordinate location of the HMD. The target and Waypoint 1 were each varied between one of four locations (see Fig. 1). Together with Waypoint 2 these locations formed a triangle. The layout of these locations was such that the three points never formed a straight line and never formed a triangle where the target and Waypoint 1 were in locations that were next to each other. This allowed for the formation of up to six different triangles with each individual leg varying between 1.3 and 2.4 ms. Participants were never made aware of the possible triangle layouts for homing. The triangle layout order was pseudo-randomized to include the same triangles for each sensory cue condition, with different triangles offering multiple turning angles to decrease any potential learning effects.

A render of the virtual environment used during the task. The duplicate set of partially transparent landmarks show how the landmarks would shift during the conflict trials. Only one set of landmarks was shown at a time (none during the self-motion condition), and participants were not aware of the conflict at the time of testing. Only the green target and red waypoint were initially visible to participants. Once participants walked to the green target, the blue waypoint (waypoint 2) appeared in the environment
Training, trials, and testing order
Participants completed 9 blocks of 5 trials each. The first block of trials was considered a training block and all data from this block were discarded. Prior to this training, participants were shown how the vision condition swivel chair disorientation would be done by watching one experimenter spin another experimenter. It was not made clear to participants that they would be spun equally in each direction. The first training trial was a consistent trial in which the experimenter talked the participant through each step of the homing task as they completed it. The participants then completed one trial of each condition. Following the training block, trials were blocked by condition and participants completed 2 blocks of every condition. Participants were given a 5–10 min break from the HMD after the first 4 non-training blocks. Block order was psuedo-randomized into 6 potential orders, and participants were randomly selected for one of these orders. The entire testing session took younger adults 1.5–2 h and older adults 2\(-\)2.5 h on average. With the exception of 1 younger participant and 1 older participant, all participants also completed the experiment on a different day in the real world (data not analyzed here).Footnote 2 The real world experiment was exactly like the virtual world experiment, though the conditions were all performed in the dark with participants wearing light-attenuating sunglasses. Targets, waypoints, and landmarks were illuminated LEDs. Half of the younger participants completed the real world experiment first.Footnote 3 All of the older participants completed the VR experiment first.
Data analysis
To assess the effect of age and sensory cue condition on the accuracy and variability of homing, data were analyzed using a series of mixed-effects models with random intercepts for each participant. All data and analyses are available on Open Science Framework: https://doi.org/10.17605/OSF.IO/P4QTV. In models of accuracy and variability, condition (vision only, self-motion only, and consistent; the condition factor was dummy coded with consistent as the reference group) and age group (younger and older) were included as the factors. Analyses were performed in R version 4.1.3 (R Core Team 2022). Mixed-effects models were run using the ANOVA formatting with lme4 (Bates et al. 2015) and lmerTest (Kuznetsova et al. 2017) packages. We conducted planned comparisons with both the accuracy and variability results to examine differences between the single cue conditions (vision and self-motion) and consistent condition (paired t-tests) and between age groups (independent-samples t-tests) as done in previous research (Bates and Wolbers 2014). As frequentist analyses cannot provide evidence for the null hypotheses, we also computed JZS Bayes Factors (\(\text {BF}_{\text {01}}\)) for analyses with non-significant p-values (p > 0.05) using the ttestBF function from the BayesFactor package (Morey and Rouder 2023). \(\text {BF}_{\text {01}}\) evaluates how strongly the evidence supports the null hypothesis (\(H_{0}\)) compared to the alternative hypothesis (\(H_{1}\)) in the form of an odds ratio. Following previous work, a \(\text {BF}_{\text {01}}\) greater than 3 shows strong evidence in favor of the null hypothesis (\(H_{0}\)) and a \(\text {BF}_{\text {01}}\) between 1 and 3 shows anecdotal evidence (Newman and McNamara 2021; Morey and Rouder 2011). Our prior was a Cauchy distribution with r scale set to 0.707 as has been done in previous cue combination studies (Newman and McNamara 2021; Chen et al. 2017; Zanchi et al. 2022). To determine whether predicted Bayesian optimal cue weights aligned with the empirical weights observed from our spatial conflict, weighting was assessed with a mixed model. Age group was a between-subjects variable and weighting type (e.g., predicted vs. observed) was a within-subjects variable. In addition, we examined the relationship between observed cue weights and predicted weights with a Pearson correlation. Within- and between-group variability was determined using intraclass correlation coefficients (ICC) and the corresponding 95% confidence interval, which were calculated based on a one-way mixed effects model using the performance package (Lüdecke et al. 2021) in R.
The waypoint 2 location (Fig. 1) for each trial was treated as the origin in a coordinate system in which the y-axis was parallel to the correct homing direction. Response centroids were determined for each sensory cue condition (\(\mu\)), and accuracy was determined as the distance from these centroids to the target location. Variability was determined as the standard deviation of the response coordinates relative to the response centroid on a condition-specific level. For trials where a spatial conflict was introduced, there was no "correct" target location. Rather, response centroids in the conflict were compared to the locations of the participants’ single-cue centroids, corrected for the spatial conflict. No data were removed as outliers due to the importance of sufficient trial numbers to calculate variability in a stable manner.
Optimal cue combination model
The predicted optimal weights for vision (v) and self-motion (sm) are computed using the relative variance (\(\sigma ^2\)) of the single cue conditions:
Note that because only two sensory systems are available to the brain to perform the task, the weights of the two sensory sources sum to one so that:
The predicted optimal weights can then be used in the computation of the predicted variance when both vision and self-motion cues are available:
The evaluation of this maximum likelihood estimation model requires the inclusion of two multi-cue conditions: a combined condition with consistent cues and a condition with conflicting cues. The consistent condition involves the vision and self-motion cues specifying the same location of the target. The conflict condition introduces a spatial conflict where one cue (vision) is covertly shifted and therefore specifies a different target location than the target location encoded by the self-motion cue. The difference in position between the mean response location in the conflict condition (\(\mu _{conflict}\)) and either the single-cue visual condition (\(\mu _{v}\)) or the self-motion condition (\(\mu _{sm}\)) define \(d_{v}\) and \(d_{sm}\), respectively.
Observed weights are computed using the relative distances calculated above (\(d_{v}\) and \(d_{sm}\)) in the following equations:
Results
Accuracy
Results from the mixed-effects model showed that older participants were significantly less accurate at homing than younger adults (main effect: F(1, 126) = 5.24, \(p<.05\), \(\eta _{\text {p}}^{2}\) = 0.04) (Fig. 3). There was also a significant main effect of sensory cue condition on accuracy (F(2, 126) = 9.01, \(p<.001\), \(\eta _{\text {p}}^{2}\) = 0.13). This main effect is parsed further with our planned comparisons below. No interaction was observed between age and sensory cue condition (F(2, 126) = 1.06, p > 0.05, \(\eta _{\text {p}}^{2}\) = 0.02).
In the accuracy planned comparisons between age groups, young adults were more accurate than the older adults in the vision condition (t(42) = 2.85, \(p<.01\), d = 0.86). There was no significant difference between the age groups in the self-motion condition (t(42) = 0.90, p = .37, d = 0.27, JZS \(\text {BF}_{\text {01}}\) = 2.44) or the consistent cue condition (t(42) = 0.57, p = .57, d = 0.18, JZS \(\text {BF}_{\text {01}}\) = 2.94).

A bar chart of mean homing error in cm for younger and older participants. Error bars denote SEM. ** denotes \(p<0.01\), * denotes \(p<0.05\), ns denotes non-significance with p > 0.05
In the accuracy planned comparisons between conditions, older adults demonstrated significantly more accurate performance with 2 consistent sensory cues than with either vision alone (t(19) = 2.35, \(p<0.05\), d = 0.53) or self-motion cues alone (t(19) = 2.56, \(p<0.05\), d = 0.57). Younger adults demonstrated more accurate performance with consistent sensory cues compared to self-motion cues alone (t(23) = 3.59, \(p<0.01\), d = 0.73). However, younger adults’ vision accuracy was not statistically different than their consistent cue accuracy (t(23) = 0.75, p > 0.05, d = 0.07, JZS \(\text {BF}_{\text {01}}\) = 4.35).

A bar chart of mean variability as defined by standard deviation in cm for younger and older participants. Error bars denote SEM. *** denotes \(p<0.001\), ** denotes \(p<0.01\), * denotes \(p<0.05\), ns denotes non-significance with \(p>0.05\)
Variability
Figure 4 demonstrates the results from the mixed-effects model that older participants were significantly more variable at homing than younger adults (F(1, 126) = 15.06, \(p<.001\), \(\eta _{\text {p}}^{2}\) = 0.18). There was also a significant main effect of sensory cue condition with respect to homing variability, investigated further in our planned comparisons below (F(2, 126) = 8.49, \(p<.001\), \(\eta _{\text {p}}^{2}\) = 0.23). No interaction was observed between age and sensory cue condition (F(2, 126) = 1.46, p > 0.05, \(\eta _{\text {p}}^{2}\) = 0.05).
Our planned comparisons for age groups showed that young adults were less variable in the vision condition (t(42) = 3.32, \(p<.01\), d = 1.01). Similarly to the accuracy comparisons, there were no significant differences between age groups in the self-motion (t(42) = 1.87, p = 0.07, d = 0.57, JZS \(\text {BF}_{\text {01}}\) = 0.55) and consistent condition (t(42) = 1.39, p = 0.17, d = 0.42, JZS \(\text {BF}_{\text {01}}\) = 1.54).
Older adults demonstrated significantly less variable performance with consistent sensory cues than with either vision alone (t(19) = 3.81, \(p<0.01\), d = 0.85) or self-motion cues alone (t(19) = 3.38, \(p<0.01\), d = 0.75). Younger adults demonstrated less variable performance with 2 consistent sensory cues than self-motion cues alone (t(23) = 2.71, \(p<0.05\), d = 0.55). However, younger adults’ vision variability was not statistically higher than their consistent cue variability (t(23) = 1.81, p > 0.05, d = 0.37, JZS \(\text {BF}_{\text {01}}\) = 1.15).

Single cue weights are shown for both younger and older participant groups. Predicted weights (green diamonds) are calculated according to equations 1 and 2. Observed weights (brown circles) are derived from the spatial conflict according to equations 7 and 8. Visual cue weights are plotted on the left y-axis and self-motion cue weights are on the right y-axis (single cue weights sum to 1). The horizontal lines on plot denote the mean and the error bars denote the SEM
Cue-weighting
The results from the cue-weight mixed effects model showed that the interaction between age group and weighting type was not significant (F (1,42) = 0.02, p > 0.05, \(\eta _{\text {p}}^{2}\) < 0.01 ). However, there was a significant main effect of weighting type (F(1,42) = 11.94, \(p<.01\), \(\eta _{\text {p}}^{2}\) = 0.22) as observed visual weights (M = 0.68, SD = 0.07) were significantly higher than predicted vision weights (M = 0.54, SD = 0.06). The main effect of age group was not significant (F(1,42) = 2.55, p > 0.05, \(\eta _{\text {p}}^{2}\) = 0.06). Results can be seen in Fig. 5. To test whether there was support for optimal integration on a within-subject level, correlational analysis was performed. A weak but significant relationship was observed for younger participants (\(R^{2}\) = 0.18, \(p<0.05\)). No relationship was observed for older participants (\(R^{2}\) = 0.10, p > 0.05, JZS \(\text {BF}_{\text {01}}\) = 1.04). Results for both correlations can be seen in Fig. 6. When the frequentist and Bayesian analyses are considered as a whole, evidence is seen in favor of optimal cue combination for the younger participant group but not for the older participant group. There is evidence that both groups are weighting vision higher than would be predicted by a maximum likelihood estimation model.

Predicted visual weights are correlated with Observed visual weights for each participant split across the younger (left) and older (right) participant groups. The solid line shows the best-fit line of the correlation and the dotted lines demonstrate the 95% confidence intervals of the best-fit lines. \(R^2\) and significance values are shown in the bottom right of each plot
Within- versus between-group variability
The ICC analysis revealed an ICC of 0.013 for the observed visual weighting (95% CI [0.001, 0.256]). This ICC value indicates that there is relatively low between-group variability compared to within-group variability. Specifically, approximately 1.3% of the total variability in observed vision weighting can be attributed to differences between participant groups. In contrast, the majority of the variability (approximately 98.7%) is explained by differences within each participant group. This suggests that there is considerable variability in sensory weighting observations within each group.
Discussion
In the current study, we tested whether there was a difference in navigation performance between older and younger adults in terms of homing accuracy and variability. An important, novel aspect of this study was that all work was performed in an immersive virtual environment that was well-lit, which differed from the prior work studying older adults. Consistent with our predictions, we found that older adults were less accurate and more variable than younger adults while navigating with a single sensory cue (either vision or body-based self-motion). Relative to multisensory cue condition performance, older adults were less accurate and more variable with visual cues alone and body-based self-motion cues alone. Younger adults also showed improved multisensory performance compared to body-based self-motion cues alone, though they did not show a multisensory benefit compared to when they had only visual cues. Our findings of reduced navigation accuracy and precision in older adults add to previous work and provide further support for age-related decline seen more generally in navigational tasks (Adamo et al. 2012; Bates and Wolbers 2014; Lester et al. 2017; Levine et al. 2023; McAvan et al. 2021; Moffat 2009). Specific to homing task performance, Bates and Wolbers (2014) found that older adults were about 15–30 cm less accurate and 5–15 cm more variable during homing than younger adults depending on the availability of sensory cues. Despite not controlling sensory cue availability directly, Adamo et al. (2012) found a similar magnitude and effect of age during homing. Our findings for navigating with only one sensory cue align with these two previous reports, albeit with a smaller effect magnitude. This reduced effect size may be due to our virtual reality paradigm offering paradoxically higher ecological validity due to more realistic environmental viewing conditions during navigation. In a well-lit environment, participants had information about their own location on the ground plane as well as additional cues for target and landmark locations. Further, visibility of the ground could have facilitated balance and walking performance, potentially more important for older adults.
Notably, the accuracy and variability differences between older and younger adults are attenuated when navigators have access to multisensory information. There are several possibilities for this interesting finding of multisensory performance equivalence that is not apparent with single cues. One possibility is that younger adults used different homing strategies (e.g., counting their own steps or always relying on their perceived distance to the visual landmarks) than older adults for the single-cue vision condition that gave them an advantage in that condition (Newman et al. 2023). Although visual acuity was normal or corrected-to-normal in both age groups, it is possible that differing levels of confidence in older adults’ vision led to different strategies. Another possibility is that the single-cue task may be more cognitively demanding as seen in other reduced-cue balance and navigation scenarios (Kotecha et al. 2013; Rand et al. 2015), particularly for older adults (Barhorst-Cates et al. 2017), leading to different strategies used during the single cue task compared to the multisensory cue condition. Other work has shown that, at least with respect to variability, multisensory cue combination experiments should carefully titrate the sensory noise provided by each cue domain to allow for integrative mechanisms to benefit a multisensory estimate (Scheller and Nardini 2023). It is possible that our targets were too close to our visual landmarks or not varied enough in their positions, allowing for younger adult performance to approach ceiling effects. Still, we do not see this relationship (similar vision and multisensory performance) for older adults.
We also assessed how each group weighted their vision relative to their self-motion cues and whether or not this weighting followed the predictions of optimal cue combination. With respect to sensory weighting, we find that, at a group level, both younger and older adults rely more on visual landmark cues than would be predicted by an optimal model of cue combination; however, we find that on an individual level, younger adults’ predicted sensory cue weighting aligns with their observed cue weighting during a multisensory spatial conflict, though the correlation was small to moderate. Importantly, we do not observe this predicted versus observed cue weighting relationship for older adults. These results support the findings of Bates and Wolbers (2014); Ramkhalawansingh et al. (2018) who showed that visual and self-motion cues are sub-optimally integrated in older adults when navigating in the dark for both homing and heading direction tasks.
There are a couple of interpretations of our results. For older adults, improved multisensory homing performance (accuracy and variability) over visual and self-motion unisensory performance suggests that older adults are integrating sensory information for navigation. However, when these results are reconciled with the lack of relationship between the predicted optimal cue combination weighting and observed multisensory cue weighting, it is clear that, though there is overall sensory integration, this integration does not follow an "optimal" MLE strategy. Thus, our results show that older adults, as a group, did not rely on each sensory stream in a manner that provided them the greatest chance to minimize the variability of their multisensory homing performance. How much this sub-optimal integration matters is another interesting question. Given that older adults’ performance was equivalent to that of younger adults’ when using consistent, multisensory cues, it may be that a less-than-optimal cue combination strategy is still "good enough" in some navigational contexts. It may be that our small-scale homing task is unable to detect functional deficits associated with sub-optimal cue combination that larger-scale environments would be able to detect. Furthermore, it may be that large inter-individual differences, as denoted by our ICC analysis, are obscuring the relationship between sub-optimal cue combination and navigational performance.
Ramkhalawansingh et al. (2018) suggested that optimal cue combination in older adults may vary with the degree of spatial conflict. Here, our conflict was toward the larger end of the range (15 degrees) compared to those provided by Ramkhalawansingh et al. (2018) (5–20 degrees). Their work suggested that older adults may switch strategies with larger conflicts whereas younger adults do not; thus, it is possible that older adults in our experiment are discounting an optimal cue-combination strategy in favor of another strategy. Future work might consider even larger shifts in discrepant cues to test effects on cue combination strategies and how they vary with age.
As for why both groups rely more on their vision than our MLE model predicts, there are several possibilities. All participants here wore head-mounted displays for the immersive virtual reality task. It could be that the act of wearing a visual display causes participants to trust their vision more than the classic cue-combination model predicts. It may also be that our target and landmark layout and trial design influenced higher weighting of a visual strategy. Although there were four different home target locations, the locations were relatively close to the landmarks which may have made use of the landmarks more salient as a memory strategy. We used this design to closely match Bates and Wolbers (2014), but future work would benefit from a greater number of target locations that also vary more in distance from the landmarks, to reduce these types of strategies.
There is still debate as to whether navigation should follow optimal cue combination principles for all environments, tasks, and sensory systems (Rahnev and Denison 2018). Zhao and Warren (2018) have suggested that visual cues often dominate when conflicts become sufficiently large (Mou and Spetch 2013) and that high inter-individual differences in navigation demonstrate that not all navigators approach each task in a fundamentally equivalent way (Zhao and Warren 2015). Chrastil et al. (2019) showed non-optimal combination of vision and proprioception in a novel circular homing task suggesting that optimal cue combination during navigation may be task- or sensory-cue-specific. Lived experience often leads us to the understanding that following a single, highly reliable cue may be more effective than integrating a reliable cue with an unreliable one. Increased cognitive resource demands, particularly for older adults navigating with only one cue, may lead to different cue reliance than when combined, explaining our finding of sub-optimal integration.
Notably, our results also demonstrate high within-group variability, especially compared to the between-group variability. Previous sensory weighting studies for navigation have not compared inter-individual differences within- and between-groups in both younger and older adults. This finding of high within-group variability adds to a literature showing that both younger adults, during navigation, (Zanchi et al. 2022) and older adults, generally, (de Dieuleveult et al. 2017) demonstrate high inter-individual differences. While a direct comparison of within- versus between-group variability for both older and younger adults has not been conducted previously, there is an abundance of work showing inter-individual differences throughout the navigation (Hegarty and Waller 2005; Newcombe et al. 2023) and cue-combination navigation literatures (Zanchi et al. 2022). It is notable that most of the variability demonstrated in our study with cue weighting was due to individual differences and not age. The older adults recruited for this study were particularly well-aging, able to walk for 90 or more minutes, sit and stand throughout the study numerous times, and did not have significant presbyopia or presbystasis. Thus, it may be that only particularly healthy, well-aging, older adults show similar cue-combination strategies as younger adults. We believe that the future inclusion of older adults who fatigue more easily (a group excluded from the current study) may help to capture and quantify inter-individual differences that were potentially missed here. Still, it is possible that cue-combination for navigation has such high variability that age effects are unable to be easily measured due to the noisy, high within-group variability. Future studies following up on inter-individual differences would benefit from additional participants and measures to help characterize these differences.
These results have important implications for healthy aging. Given that older adults performed similarly to younger adults when they had multisensory information, we may be able to aid navigation for those most vulnerable by providing multisensory references. We know that sensory substitution has worked particularly well for those with low vision (Jicol et al. 2020). Our results underscore that all adults may benefit from additional cues, even those without known impairments in sensory acuity. Previous work has shown that multisensory information aids spatial cognition by shifting the processing to extrahippocampal areas of the brain (retrosplenial cortex and posterior parietal cortex), which may help older adults, particularly those with hippocampal lesions, shift strategies towards greater self-motion (egocentric) cue use (Iggena et al. 2023). This may be one explanation for why older adults performed similarly to younger adults with multisensory cues in the current experiment. In addition, our results suggest a possible mechanism for intervention or training of sensory weighting strategy to improve navigational accuracy and decrease variability. It may be that sensory integration in the spatial domain could be facilitated by feedback-based training. This type of training has improved functional outcomes in temporal simultaneity judgment tasks (Zerr et al. 2019), and has yet to be explored for navigation. Such a training paradigm may allow participants to see and walk to the "correct location" after their response as a way to help them calibrate their spatial responses. Older adults may benefit from feedback-based training to increase the precision of their navigation homing estimates, at least at the scale of homing tested here (path length of 1.3–2.4 ms). Overall, our results show that virtual reality technologies can facilitate innovative methods to study the importance of multisensory information during navigation for older adults.
Data availability
The raw data, processing script, and analysis script for this study are available on Open Science Framework at the link below. The virtual environment build will be provided upon request. https://doi.org/10.17605/OSF.IO/P4QTV
Notes
While the Romberg test was intended as a screening tool, \(post-hoc\) Pearson correlation showed no relationship between visual sway ratio (Assländer and Peterka 2014) and visual cue weighting for navigation (defined later) for both younger (\(R^{2}\) = 0.04, p = 0.35) and older adults (\(R^{2}\) = 0.01, p = 0.75)
The real world experiment measured homing position data differently than the VR experiment because of the need to measure performance in the real world without a VR tracking system. Specifically, only absolute error (distance from the home target), not direction of error, was recorded in the real world. This particularly affected the measurements needed for the weights derived from the conflict condition. Given that a primary goal of this paper is to test a model of optimal cue combination in navigation in a virtual environment, the real world and VR experiments are not directly compared in this paper.
\(Post-hoc\) paired t-tests did not show order effects for younger adults in either accuracy (t(23) = 0.17, p = 0.87) or variability (t(23) = 0.99, p = 0.32) of navigational performance.
References
Adamo DE, Briceño EM, Sindone JA, Alexander NB, Moffat SD (2012) Age differences in virtual environment and real world path integration. Front Aging Neurosci 4:1–9. https://doi.org/10.3389/fnagi.2012.00026
Allen GL, Kirasic KC, Rashotte MA, Haun DBM (2004) Aging and path integration skill: Kinesthetic and vestibular contributions to wayfinding. Percep Psychophys 66(1):170–179. https://doi.org/10.3758/BF03194870
Assländer L, Peterka RJ (2014) Sensory reweighting dynamics in human postural control. J Neurophysiol 111(18):52–64. https://doi.org/10.1152/jn.00669.2013
Barhorst-Cates EM, Rand KM, Creem-Regehr SH (2017) Let me be your guide: physical guidance improves spatial learning for older adults with simulated low vision. Exp Brain Res 235:3307–3317
Bates D, Mächler M, Bolker B, Walker S (2015) Fitting linear mixed-effects models using lme4. J Stat Softw 67(1):1–48. https://doi.org/10.18637/jss.v067.i01
Bates SL, Wolbers T (2014) How cognitive aging affects multisensory integration of navigational cues. Neurobiol Aging 3512:2761–2769. https://doi.org/10.1016/j.neurobiolaging.2014.04.003
Chen X, McNamara TP, Kelly JW, Wolbers T (2017) Cue combination in human spatial navigation. Cogn Psychol 95:105–144. https://doi.org/10.1016/j.cogpsych.2017.04.003
Chrastil ER, Nicora GL, Huang A (2019) Vision and proprioception make equal contributions to path integration in a novel homing task. Cognition 192:103998
Coughlan G, Laczó J, Hort J, Minihane AM, Hornberger M (2018) Spatial navigation deficits—overlooked cognitive marker for preclinical Alzheimer disease? Nat Rev Neurol 148:496–506. https://doi.org/10.1038/s41582-018-0031-x
Creem-Regehr SH, Kelly JW, Bodenheimer B, Stefanucci JK (2024) Virtual reality as a tool to understand spatial navigation. Reference module in neuroscience and biobehavioral psychology
de Dieuleveult AL, Siemonsma PC, van Erp JB, Brouwer AM (2017) Effects of aging in multisensory integration: a systematic review. Front Aging Neurosci 9:1–14. https://doi.org/10.3389/fnagi.2017.00080
Diersch N, Wolbers T (2019) The potential of virtual reality for spatial navigation research across the adult lifespan. J Exp Biol 222:jeb187252
Ernst MO, Banks MS (2002) Humans integrate visual and haptic information in a statistically optimal fashion. Nature 4156870:429–433. https://doi.org/10.1038/415429a
Head D, Isom M (2010) Age effects on wayfinding and route learning skills. Behav Brain Res 209(1):49–58. https://doi.org/10.1016/j.bbr.2010.01.012
Hegarty M, Waller D (2005) Individual differences in spatial abilities. The Cambridge handbook of visuospatial thinking, pp 121–169
Hicks CW, Wang D, Windham BG, Matsushita K, Selvin E (2021) Prevalence of peripheral neuropathy defined by monofilament insensitivity in middle-aged and older adults in two US cohorts. Sci Rep 11(1):19159. https://doi.org/10.1038/s41598-021-98565-w
Humes LE (2015) Age-related changes in cognitive and sensory processing: focus on middle-aged adults. Am J Audiol 24(2):94–97. https://doi.org/10.1044/2015_AJA-14-0063
Iggena D, Jeung S, Maier PM, Ploner CJ, Gramann K, Finke C (2023) Multisensory input modulates memory-guided spatial navigation in humans. Commun Biol 6(1):1167
Jicol C, Lloyd-Esenkaya T, Proulx MJ, Lange-Smith S, Scheller M, O’Neill E, Petrini K (2020) Efficiency of sensory substitution devices alone and in combination with self-motion for spatial navigation in sighted and visually impaired. Front Psychol 11:1443. https://doi.org/10.3389/fpsyg.2020.01443
Jones SA, Noppeney U (2021) Ageing and multisensory integration: a review of the evidence, and a computational perspective. Cortex 138:1–23. https://doi.org/10.1016/j.cortex.2021.02.001
Kotecha A, Chopra R, Fahy RT, Rubin GS (2013) Dual tasking and balance in those with central and peripheral vision loss. Investig Ophthalmol Vis Sci 548:5408–5415
Kuznetsova A, Brockhoff PB, Christensen RHB (2017) lmerTest package: tests in linear mixed effects models. J Stat Softw 82(13):1–26. https://doi.org/10.18637/jss.v082.i13
Lester AW, Moffat SD, Wiener JM, Barnes CA, Wolbers T (2017) The aging navigational system. Neuron 955:1019–1035. https://doi.org/10.1016/j.neuron.2017.06.037
Levine TF, Dessenberger SJ, Allison SL, Head D, Initiative ADN (2023) Alzheimer disease biomarkers are associated with decline in subjective memory, attention, and spatial navigation ability in clinically normal adults. J Int Neuropsychol Soc 1–15
Loomis JM, Lippa Y, Klatzky RL, Golledge RG (2002) Spatial updating of locations specified by 3-d sound and spatial language. J Exp Psychol Learn Memory Cogn 282:335
Lüdecke D, Ben-Shachar MS, Patil I, Waggoner P, Makowski D (2021) Performance: an R package for assessment, comparison and testing of statistical models. J Open Source Softw 660:3139. https://doi.org/10.21105/joss.03139
McAvan AS, Du YK, Oyao A, Doner S, Grilli MD, Ekstrom A (2021) Older adults show reduced spatial precision but preserved strategy-use during spatial navigation involving body-based cues. Front Aging Neurosci 13:640188
Meng J, Sedgwick H (2002) Distance perception across spatial discontinuities. Percep Psychophys 64:1–14
Moffat SD (2009) Aging and spatial navigation: what do we know and where do we go? Neuropsychol Rev 19:478–489
Morey RD, Rouder JN (2011) Bayes factor approaches for testing interval null hypotheses. Psychol Methods 16(4):406–419. https://doi.org/10.1037/a0024377
Morey RD, Rouder JN (2023) Bayesfactor: computation of bayes factors for common designs [Computer software manual]. R package version 0.9.12-4.6
Mou W, Spetch ML (2013) Object location memory: integration and competition between multiple context objects but not between observers’ body and context objects. Cognition 126(2):181–197. https://doi.org/10.1016/j.cognition.2012.09.018
Muffato V, De Beni R (2020) Path learning from navigation in aging: the role of cognitive functioning and wayfinding inclinations. Front Hum Neurosci 14:8. https://doi.org/10.3389/fnhum.2020.00008
Nardini M, Jones P, Bedford R, Braddick O (2008) Development of cue integration in human navigation. Curr Biol 18(9):689–693. https://doi.org/10.1016/j.cub.2008.04.021
Newcombe NS, Hegarty M, Uttal D (2023) Building a cognitive science of human variation: individual differences in spatial navigation. Topics Cogn Sci 15(1):6
Newman PM, McNamara TP (2021) A comparison of methods of assessing cue combination during navigation. Behav Res Methods 531:390–398. https://doi.org/10.3758/s13428-020-01451-y
Newman PM, Qi Y, Mou W, McNamara TP (2023) Statistically optimal cue integration during human spatial navigation. Psychon Bull Rev. https://doi.org/10.3758/s13423-023-02254-w
R Core Team (2022) R: A language and environment for statistical computing [Computer software manual]. Vienna, Austria https://www.R-project.org/
Rahnev D, Denison RN (2018) Suboptimality in perceptual decision making. Behav Brain Sci 41:e223. https://doi.org/10.1017/S0140525X18000936
Ramkhalawansingh R, Butler JS, Campos JL (2018) Visual-vestibular integration during self-motion perception in younger and older adults. Psychol Aging 33(5):798–813. https://doi.org/10.1037/pag0000271
Rand KM, Creem-Regehr SH, Thompson WB (2015) Spatial learning while navigating with severely degraded viewing: the role of attention and mobility monitoring. J Exp Psychol Hum Percep Perform 41(3):649–664
Rand KM, Tarampi MR, Creem-Regehr SH, Thompson WB (2012) The influence of ground contact and visible horizon on perception of distance and size under severely degraded vision. Seeing Perceiving 25(5):425–447
Riecke BE, Veen HAHCV, Bülthoff HH (2002) Visual homing is possible without landmarks: a path integration study in virtual reality. Presence Teleoper Vir Environ 11(5):443–473. https://doi.org/10.1162/105474602320935810
Scheller M, Nardini M (2023) Correctly establishing evidence for cue combination via gains in sensory precision: why the choice of comparator matters. Behav Res Methods. https://doi.org/10.3758/s13428-023-02227-w
Shayman CS, Peterka RJ, Gallun FJ, Oh Y, Chang N-YN, Hullar TE (2020) Frequency-dependent integration of auditory and vestibular cues for self-motion perception. J Neurophysiol 123:936–944. https://doi.org/10.1152/jn.00307.2019
Shayman CS, Stefanucci JK Fino PC, Creem-Regehr SH (2022) Multisensory cue combination during navigation: lessons learned from replication in real and virtual environments. In: 2022 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct), pp 276–277
Stangl M, Achtzehn J, Huber K, Dietrich C, Tempelmann C, Wolbers T (2018) Compromised grid-cell-like representations in old age as a key mechanism to explain age-related navigational deficits. Curr Biol 28(7):1108-1115.e6. https://doi.org/10.1016/j.cub.2018.02.038
Stein BE, Meredith MA (1990) Multisensory integration: neural and behavioral solutions for dealing with stimuli from different sensory modalities. Ann NY Acad Sci 608:51–70. https://doi.org/10.1111/j.1749-6632.1990.tb48891.x
van der Ham IJ, Claessen MH, van der Evers AW, Kuil MN (2020) Large-scale assessment of human navigation ability across the lifespan. Sci Rep 10:1–12. https://doi.org/10.1038/s41598-020-60302-0
Wagner AR, Akinsola O, Chaudhari AMW, Bigelow KE, Merfeld DM (2021) Measuring vestibular contributions to age-related balance impairment: a review. Front Neurol 12:635305. https://doi.org/10.3389/fneur.2021.635305
Xie Y, Bigelow RT, Frankenthaler SF, Studenski SA, Moffat SD, Agrawal Y (2017) Vestibular loss in older adults is associated with impaired spatial navigation: data from the triangle completion task. Front Neurol 8:1–9. https://doi.org/10.3389/fneur.2017.00173
Zanchi S, Cuturi LF, Sandini G, Gori M (2022) Interindividual differences influence multisensory processing during spatial navigation. J Exp Psychol Hum Percep Perform 48(2):174–189. https://doi.org/10.1037/xhp0000973
Zerr M, Freihorst C, Schütz H, Sinke C, Müller A, Bleich S, Szycik GR (2019) Brief sensory training narrows the temporal binding window and enhances long-term multimodal speech perception. Front Psychol 10:1–10. https://doi.org/10.3389/fpsyg.2019.02489
Zhao M, Warren WH (2015) How you get there from here: interaction of visual landmarks and path integration in human navigation. Psychol Sci 26(6):915–924. https://doi.org/10.1177/0956797615574952
Zhao M, Warren WH (2018) Non-optimal perceptual decision in human navigation. Behav Brain Sci 41:e250. https://doi.org/10.1017/S0140525X18001498
Acknowledgements
The authors would like to thank all of the participants who took part in the study. We would also like to thank the following individuals for their help with data collection: Linden Carter, Juliette Connell, Karl Freeman, Rachel Hansen, Phoenix Hines, Jensen Koff, Noah Mackey, Misty Myers, and Taylor Schmidt. We also thank Nathan Seibold for his help in designing our virtual environment.
Funding
This research was supported by the University of Utah Center on Aging (Creem-Regehr, Fino, Stefanucci), the National Institute On Deafness And Other Communication Disorders under Award Number 1F30DC021360-01 (Shayman), and by the American Otological Society in the form of a Fellowship Grant (Shayman).
Author information
Authors and Affiliations
Contributions
CS, MM, PF, JS, and SC conceived and designed the experiments and analyses. CS, MM, HF, and AK collected the data. CS, MM, and HF contributed critical tools for data collection and analysis. CS, MM, JS, and SC performed the analyses. All authors contributed to the writing of the manuscript. All authors approved the submission of the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Consent for publication
All participants gave consent that their data could be published with anonymity.
Ethical approval
All participants gave voluntary informed consent to participate as approved by the university’s Institutional Review Board (IRB). All research procedures were performed in accordance with the ethical standards laid down in the 1964 Declaration of Helsinki.
Additional information
Communicated by Bill J Yates.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Shayman, C.S., McCracken, M.K., Finney, H.C. et al. Effects of older age on visual and self-motion sensory cue integration in navigation. Exp Brain Res 242, 1277–1289 (2024). https://doi.org/10.1007/s00221-024-06818-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00221-024-06818-7