
Abstract
Content-based image retrieval (CBIR) has been a worthwhile topic for research for several years. A powerful CBIR system should minimize the semantic gap between the low-level features and high-level concepts in order to satisfy users requirements. Moreover, it should take into consideration the execution time. In this paper, we present a new semantic approach for CBIR supported by a parallel aggregation of content-based features extraction (shape, texture, color) using fuzzy support decision mechanisms. Shape features are based on Fast Beta Wavelet Network modeling and Hue moments. The texture descriptor is based on Energy computing at different decomposition levels. Finally, we present an implementation of a new color feature extraction based on fuzzy indexed color map. In the second stage, we propose a Fuzzy Decision Support System for feature (shape, texture, color) aggregation to improve the retrieval performance. The proposed approach is tested on four most popular datasets: Wang, INRIA Holidays, UKBench and samples from ImageNet, and the experiments showed that the proposed approach can achieve a satisfactory retrieval performance with an acceptable search time.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Indexing and searching images by content-based image retrieval (CBIR) remain the problems with important potential applications in various domains such as art collections, crime prevention, photograph archives, geographical information and remote sensing systems. These problems are mainly due to the complexity or ambiguous content of images such as pictures containing various objects with different colors. Thus, it is necessary to extract useful features that are able to depict the content of images more precisely, then synthesize them in a descriptor (or a set of descriptors). The second objective is the search technique which should be precise and fast.
Since Beta wavelet [1] is a powerful tool in various domains such as image compression [2], face recognition [3, 4], 3D face recognition [5], image classification [6, 7], phoneme recognition [8], speech recognition [9] and in particular Arabic word recognition [10] and hand tracking and recognition [11]; this study used the Fast Beta Wavelet Network (FBWN) modeling to propose a new approach for CBIR.
In this paper, we present a high-level approach for CBIR by proposing a parallel feature aggregation based on Fuzzy Decision Support System (FDSS). First, the shape descriptor is obtained, after an analysis by a FBWN, by calculating the geometric Hue’s moments. The texture descriptor is based on the calculation of energy at each of the first fifth levels of Beta wavelet decomposition. The color descriptor is based on the indexed color map of the image approximated by FBWN. Then, in the retrieval phase, the descriptors of the Query Image (QI) and those of all Reference Images (RI) are compared using a FDSS.
The paper is organized as follow: Sect. 2 will be devoted to present a survey of different CBIR techniques. In Sect. 3, we will present the main idea of the proposed approach. Section 4 will describe the methodology used to extract each of the three descriptors which are the shape , texture and fuzzy indexed color descriptors. Section 5 will be devoted to explain the proposed method for the similarity search using FDSS. Then, we will test the efficiency of our approach which is the purpose of Sect. 6 and end with a conclusion.
2 Related works
Nowadays, many approaches focus on CBIR domain which has been derived in significant applications for many professional groups. These can be categorized into two main approaches: approaches based on low-level content (shape, texture, color) and approaches based on high-level content which take into consideration the semantics of image, for example, approaches with relevance feedback, learning and optimized algorithms (neural networks, Bayesian networks, wavelet networks, ant algorithms, etc).
-
Low-level content approaches
Low-level content approaches aim to extract low-level features like shape, texture or color or a combination of them in order to measure the dissimilarity between a query image (QI) and a set of reference images (RI). Many techniques, based on low-level features, in the literature can be found. Sunkari [12] discussed the use of two retrieval methods, query by texture ( QBT) and query by color (QBC). The first is done on the basis of color histogram in RGB space, and the second by using invariant histogram. Sunkari showed that QBT performs QBC. Also, in this context, Howarth [13] proved that texture features performed better than using color features, but their combination can boost the retrieval performance results. Other approaches were proposed for features selection and dimension reduction by using principal component analysis (PCA),wavelets, Ripplets and its derivations [14–18]. Others combined the visual content in order to increase the robustness and efficiency [19–23]. Also, Lande et al. [24] presented an effective approach which combine color, texture and shape features based on the extraction of dominant color of each block, gray-level co-occurrence matrix (GLCM) and Fourier descriptors, respectively. Hiremath and Pujari [25] used a conditional co-occurrence histograms between the image tiles and corresponding complement tiles, as local descriptors of color and texture, and combined them with Gradient Vector Flow fields and Invariant moments for shape feature extraction.
Furthermore, different works can be cited, based on color features extraction such as histogram color [26], HSV histogram color [27], dominant color [23], weighted Invariant color features [28]. Others are based on texture features such as Local Binary Pattern (LBP) [29], GLCM [30], Motif Co-occurrence Matrix (MCM) [31]. Also, shape features extraction plays an important role in CBIR such as Pseudo-Zernik Moments [32], shape-Adaptive DCT [33]. A comparative survey of low-level features extraction methodologies was presented in [34]. Furthermore, many fusion techniques for descriptors merging can be found in the literature, such as CombSUM [35, 36] which aim to sum the results from different ranking lists, Borda Count combined with CombSUM [36], Z-score median combined with CombSUM [36], and Inverse Rank Position (IRP) [36, 37].
-
High-level content approaches
High-level content approaches aim to extract high-level features and analyze the semantic content of the image in order to reduce the lack of coincidence between the information that one can extract from the visual data and the interpretation that the same data have for a user in a given situation.
Bag-of-Words (BoW) model can be considered as a most popular approach for such task, based on color SIFT [38] or HSV color [39]. Also, Liang et al. showed how the integration of the SIFT visual word and binary features such as the use of Color Name (CN) descriptor [40, 41] can enhance the precision of visual matching and reduce the impact of false positive matches [42]. A comparative study of large scale categorization can be found in [43–49].
In other side, Philippe and Matthieu [50] introduced in their paper the most known active learning methods for image retrieval such as Bayes classification, k-Nearest Neighbors [51], neural networks [52, 53], wavelet network [54, 55], lattice trees [56–58], Gaussian mixtures and support vector machines. Ekta and Hardeep [59] proposed the use of bayesian algorithm, as a supervised learning and a statistical method for classification, by reducing the noise from images. Some approaches combined low-level content and genetic algorithm for features optimization [60, 61]. Others integrated the user intervention by selecting and marking images as relevant/irrelevant and the system will update the results. This is known as approaches with relevance feedback and many techniques focused on this approach [62–65]. In addition, Khadidja and Sihem presented a comparative analysis and major challenges of relevance feedback techniques [66].
-
Techniques to measure similarity
In order to establish the similarity between images, many approaches have been presented in the literature. Most of them used a simple Euclidian distance, Mahalanobis, Manhattan or Minkowski distance [67]. However, in the case of CBIR systems combining many descriptors together, these distances cannot distinguish the importance of each of these descriptors. Thus, the CBIR system can be mistaken in the results. To remedy this problem, many works concentrated on this subject such as using weighted distance. Others proposed a fuzzy neural approach for interpretation and fusion of features [68, 69]. Syam and Sharon [70] proposed a genetic algorithm in order to merge descriptors and give more flexibility to the system. Bahareh et al. [71] proposed the combination of two Short Term Learning (STL ) methods of JR-N method [72] and SVM method [73, 74], in order to retrieve similar images.
The CBIR technology boils down to two intrinsic objectives: (a) Propose a robust descriptor(s) which can represent useful information which well describe the semantic content of the image. (b) Propose an efficient matching algorithm in order to measure the similarity between the descriptor(s) of QI and those of RI. This latter should discriminate irrelevant images and be fast to satisfy users wishes.
3 Overview of the proposed approach
3.1 Fast Beta Wavelet transform (FBWT)
The FBWT aims to provide a simple way to exploit the multiresolution analysis, i.e. the weights computing of the connections with other techniques are simpler and easier than those based on the projection on dual bases. It was demonstrated [6] that the approximation of a signal f to \(V_{j+1}\) can be calculated from its projection on \(V_j\) with the following equation:
The H coordinates are known as the low-pass filter or scale function filter. The detail coefficients of the scale \((j+1)\) can be calculated using the approximation coefficients of the scale (j).
The g filter is called the low-high filter or wavelet filter. Here, we applied the multiresolution analysis using only h and g filters and their dual filters for the reconstruction and decomposition stages, respectively. To accelerate the calculation of the approximation and detail coefficients , a fast algorithm for wavelet decomposition and reconstruction using filter banks was invented. Known as FBWT, this algorithm reduced the time consuming steps of the decomposition and the reconstruction considerably. To calculate the approximation of f at scale \(j+1\), the approximation \(v^j\) at scale j is convoluted by the dual filter \(\tilde{h}\). the resulting signal is decimated by 2 to obtain the approximation coefficients. The same steps are repeated using the dual filter \(\tilde{g}\) rather than \(\tilde{h}\) to obtain the detail coefficients \(\omega ^{j+1} \).
As mentioned above, the approximation signal at scale \(j+1\) may also be analyzed. So the same algorithm is applied to obtain the \(v^{j+2}\) and \(\omega ^{j+2}\) coefficients. The process can be iterated to analyze the signal at finer scales. More details for the FBWT algorithm can be found in [6].
3.2 Proposed approach
The proposed approach consists in the combination of two stages: the indexing phase which aims to extract three descriptors of the image (shape, texture and color) and the online phase in which we proposed a new decision making method based on fuzzy logic system with three fuzzy sets.
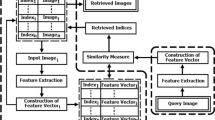
The proposed approach can be illustrated in the Fig. 1. As shown in this figure, the QI is normalized. After that, the three descriptors (shape, texture and color) are extracted and compared with all the descriptors of the reference images. Finally, the decision is taken using the proposed FDSS with three fuzzy sets.
One of the main focuses of CBIR application is to select the adequate features that describe the useful information fast. In this work, we exploited 2D FBWN analysis in order to extract fast and appropriate shape, texture and color descriptors.
The specificity of FBWN architecture is that it is a Neural Network whose hidden layer is composed of wavelet and scaling functions [1, 2, 6]. It calculates only coefficients of wavelet functions that contribute more to the reconstruction of the signal (image). The idea of this algorithm is that at each time of reconstruction, we choose an optimal wavelet functions (horizontal wavelets (\(\psi _{Hi}\)), diagonal wavelets (\(\psi _{Di}\)) and vertical ones (\(\psi _{Vi}\))) and an optimal scaling function (\(v_{i}\)) to compose the hidden layer of the wavelet network.
With the learning aspect, wavelet network can model and edit unseen visual content (shape, texture and color), which reduces and compresses the network size enormously.
It is very important to determine the features invariant to translation, scale and rotation and with low complexity thus, wavelet network can be an effective solution for such problem.

Overview of the proposed approach
So, after applying FBWN on the QI, we used wavelet coefficients in order to compute the shape descriptor. The scaling coefficients were used to extract the texture descriptor, and the color descriptor was calculated using the approximated image as shown in Fig. 2.

2D FBWN modeling-based features extraction

Shape detection using 2D FBWN modeling
4 Feature extraction
4.1 Shape feature extraction
Shape is one of the most important features and contains the most attractive visual information for human perception [41]. The term shape is used to refer to the information that can be deduced directly from images and that cannot be represented by color or texture; as such, shape defines a complementary space to color and texture. Shape representation techniques used in similarity retrieval are generally characterized as being region based and boundary based. A new 2D FBWN modeling-based shape descriptor was presented in this paper. The shape descriptor is based on three steps: Image filtering, shape detection using 2D FBWN modeling, and Hue moments calculation.
-
Step1 (Image filtering): this step consists in reducing the noise of the image. It counts the number of different colors contained in the matrix of the indexed image L. If this number is greater than a predetermined threshold (presence of noise), the colors of the entire image will be eliminated.
-
Step2 (Shape detection with 2D FBWN modeling): the image will be projected on the 2D FBWN. The coefficients of detail wavelets having the best contributions in the reconstruction of the image are summed in order to obtain the shape.
The two above steps are illustrated in the Fig. 3.
-
Step3 (Calculation of Hue moments): once we detect the shape with 2D FBWN modeling, we will calculate the seven geometric moment of Hue by dividing the binary image found into four sub-equal parts.
The moments are calculated by applying the following Eq. (1):
$$\begin{aligned} M_{p,q}=\sum _{x}{\sum _{y}{x^p y^q I(x,y)}}. \end{aligned}$$(3)where: (p, q) correspond to the moment order and I(x, y) represents the pixel value at position (x, y).

Extraction steps of texture descriptor
4.2 Texture feature extraction
Texture is one of the major defining features of an image. In image classification texture provides important information as in many images of real world. It can be characterized by energy, entropy, contrast ,or homogeneity.
In this study, the texture descriptor was essentially based on the combination of the use of wavelet and statistical techniques for more precision. Two steps are performed: The first step is to decompose the image using Beta wavelet until the fifth level, because all images are resized to 256*256, so five levels are enough to extract important coefficients of image. The second step was to compute the energy of approximation coefficients at each level, as shown in the following equation:
m and n are the dimensions of the image and X(i, j) is the pixel (i, j) value of the image X. K is the number of decomposition level.
In total, we got a vector of texture containing five components corresponding to energies of approximation coefficients of each decomposition level and the sixth component is the energy of initial image.
The steps of texture extraction of an image are presented in Fig. 4.
4.3 Fuzzy indexed color (FIC) descriptor
Color is a significant visual characteristic for both human vision and computer processing. An efficient color descriptor must characterize two important attributes: indication of the color content of an image and information about the spatial distribution of the colors. In this paper, we present a new color descriptor, based on indexed matrix analysis and FDSS, which we called a Fuzzy Indexed Color (FIC).
The algorithm steps of the proposed FIC descriptor can be divided into two sub-algorithms: the color feature extraction algorithm and the matching algorithm.
4.3.1 Color feature extraction algorithm
-
1.
All images (rgb images) are resized to 256*256 and projected on a 2D FBWN.
-
2.
The image can be defined as a function I defining RGB triplets for image positions \((x,y)\, I\,(x,y)\mapsto (R(x,y),G(x,y),B(x,y))\). So the image was converted to an indexed image with a color map that contains 256 different colors.
-
3.
We count the number of unique colors stored with the corresponding color pixel values (\(v_r,v_g ,v_b\)) and its spatial position (i, j) in the corresponding indexed matrix.
So, we note:
-
\(UC_k\) as the \(k\mathrm{th}\) unique color of an image
-
\(\omega _k\) as the \(UC_k\) weight, which measures the importance of this color in the image and can be obtained by applying the following equation:
$$\begin{aligned} \omega _k=\frac{Nbre\_ UC_k}{\mathrm{Total}\_ UC \_\mathrm{image}} \end{aligned}$$(5) -
\(CP_{i,j}\) , as the color pixel of \(UC_k\) characterized by three values \((v_r,v_g ,v_b)\) and
-
\(Pos_{i,j}\) as its corresponding position in the indexed matrix
Therefore, each image can be defined by four parameters :\(UC_k, Pos_{i,j}, \omega _k, CP_{i,j}(v_r, v_g , v_b)\).
4.3.2 Fuzzy matching algorithm for color descriptor
The objective of this fuzzy matching algorithm is to select similar RI to the QI. The algorithm is composed of two steps: similarity measure and distances fusion process.
The first step consisted in calculating the weighted Euclidean distance, for each color channel (R,G,B) between the QI and each of RI by applying the three equations below:
Each color pixel in the query image \(CP_{i,j}\)(QI) is compared with the same color pixel in the reference image \(CP_{i,j}\)(RI). If the distance between them is less than a threshold \(\varDelta \) fixed above, then the two color pixel can be considered as similar. Else, we compare it with its eight neighboring pixels.
Once, we obtained the three outputs \(find_r\), \(find_g\) and \(find_b\) corresponding to the three color channel R, G and B, respectively, we can pass to the second step.
This latter aimed to merge these three outputs through using a FDSS in order to obtain a global distance with more smoothness and flexibility.
The process of fusion will be described in details in the next section.
5 Fuzzy decision support system for image retrieval
FDSS requires a normalization of the input data, i.e. they have the same range of values for each of the inputs. This normalization can guarantee stable convergence of weight and biases.
5.1 Data normalization
The idea is to measure the similarity between the query image descriptor D with n components and all images of the database with descriptors Di with i \(\in [1 \ldots nt]\) and nt is the total number of images in the database. The similarity distances (shape and texture) of the image i were calculated by applying the Euclidean distance.
If we note, for example, \(\mathrm{Min}_{DS}\) and \(\mathrm{Max}_{DS}\) the minimum and maximum values of the similarity distances shape of n images of the dataset, the normalized value \(\textit{ND}_{Si}\) will be calculated as follows:
5.2 Fuzzy decision support system process
In order to make a final decision, we used a Fuzzy Decision Support System. As each fuzzy system, the support fuzzy decision system goes through three reasoning stages: Fuzzification, Inference and Defuzzification [45]. In this paper, a system is treated with three fuzzy sets that contribute to the decision formulation of similarity degree (SD).

Proposed functional diagram of Fuzzy Support Decision system
Figure 5 shows the diagrammatic representation of such system.
-
1.
Fuzzification
This step is to define the membership functions for the different variables, especially for the input variables. This produces the passage of real magnitudes of linguistic variables (fuzzy variables) which may then be processed by the inference. In this work, we retained a triangular membership function and three sets for each normalized distance similarity.
-
2.
Membership function
The membership functions can be selected as triangular and defined in the variation domain [0, 1]. This choice was selected because of its simplicity: it needs only a small amount of data to be defined. Also, it is easy to modify its parameters of membership functions, on the basis of measured values of the input, in order to adjust the output of a system.
-
The membership functions relative for inputs are characterized by numbers NCj:
$$\begin{aligned} NC_j=\frac{j-1}{2} ; j=1,2,3. \end{aligned}$$(8) -
The membership functions relative for output are characterized by numbers \(ss_i\):
$$\begin{aligned} ss_i=\frac{i-1}{6} ; j=1,2,\ldots ,7. \end{aligned}$$(9)
-
-
3.
Rules of inference
By linguistic terms, fuzzy rules used to determine the output Similarity Degree (SD) based on different fuzzy sets (inputs) \(DN_S, DN_T and DN_C\). Table 1 shows the rules in the case where three fuzzy sets are considered for inputs. Therefore, this table requires seven fuzzy sets for the output of system (excellent, very good, good, medium, acceptable, low, very low).
For example, the adopted rule R2 in this case is as follows (see Fig. 6):
If \(DN_S\) is low
AND \(DN_T\) is low
AND \(DN_C\) is medium
OR
If \(DN_S\) is low
AND if \(DN_T\) is medium
AND if \(DN_C\) is low
OR
If \(DN_S\) is medium
AND if \(DN_T\) is low
AND if \(DN_C\) is low
THEN, SD is excellent.
By matching a minimum to logic gate AND and a maximum to logic gate OR, the value of the output (SD), in this case, is determined by the following equation:
$$\begin{aligned} D_i\!=\!\mathrm{Max} \left\{ \mathrm{Min}\left[ \mu _{FS_{j1}}(DN_S);\mu _{FS_{j2}}(DN_T);\mu _{FS_{j3}}(DN_C) \!\right] \!\right\} \end{aligned}$$(10)With:
$$\begin{aligned} j_1,j_2,j_3 \in [1,2N+1];i \in [1,6N+1]. \end{aligned}$$(11) -
4.
Defuzzification
The defuzzification consists in converting the fuzzy magnitude to a numeric value, through the resulting membership function for the output. To achieve this transformation, several methods can be considered: Maximum method (it provides a numerical value of the abscissa of the maximum value of the resulting membership function), Method of Maxima (where several subsets have the same maximum height, and their mean is computed) and center of gravity method (the output corresponds to the abscissa of the center of gravity of the surface from the resulting membership function).
In this paper, we used the method of center of gravity because it is the most commonly used. The principle of this method is to determine the abscissa of the center of gravity of the fuzzy space of the resulting membership function in order to set the output of the system.
In this case, the knowledge of fuzzy sets \(DN_S\), \(DN_T\) and \(DN_C\) at each sampling period led to the limitation of possible values of the output and introduced new \(ESS_i\) fuzzy sets (sets of possible values for \(ss_i\) if the rule \(R_i\) is applied) . The calculation of the normalized output with the barycenter method determine the barycenter of the assigned \(ss_i\) of coefficients \(D_i\).
$$\begin{aligned} \mathrm{SS}=\frac{\sum _{i=1}^{7}\mathrm{ss}_iD_i}{\sum _{i=1}^{7}D_i}. \end{aligned}$$(12)The value SS representing the final decision of the system is a normalized value between 0 and 1.

Table of proposed rules of a FDSS with three fuzzy sets and their corresponding outputs (SD)

Examples of Wang clusters

Samples of INRIA holidays database

Samples of UKBench database

The 16 selected categories from ImageNet database

Comparison of precision rates between the proposed FIC descriptor and others color descriptors

Comparison of performance between the proposed texture descriptor and other ones

Comparison of precision between the proposed shape descriptor and shape based on Pseudo-Zernike moments

Impact of the combination of the different proposed descriptors on the precision rates

Wang Precision comparison between the proposed approach and other approaches
6 Results
To evaluate the performance of the proposed approach for image retrieval, we performed some experiments on some most popular databases:
-
Wang dataset:Footnote 1 which contains 1000 images classified into ten clusters (100 image per cluster) : buses, dinosaurs, elephants, food, flowers, African people, mountains, beaches, and horses as shown in Fig. 7. From each cluster, 50 images were randomly selected as query images.
-
INRIA Holidays dataset:Footnote 2 it is mainly composed of 5063 personal holiday photos and partitioned into 500 groups of a variety of objects (people, nature, water, houses, etc\(\dots \) ) (see Fig. 8).
-
University of Kentucky benchmark (UKBench) dataset:Footnote 3 which contains 10200 images, corresponding to 2550 groups of 4 images each. All the images are of the same size 640 \(\times \) 480. The different samples are presented in Fig. 9. The usual performance score is the mean number of images ranked in the first 4 positions (N-S score).
-
ImageNet dataset:Footnote 4 this database contains over 15 million labeled high-resolution images belonging to about 22,000 categories. In this study, we used only the 16 most popular Synsets cited in the ImageNet website:Footnote 5 Animal (fish, bird, mammal, invertebrate), Plant (tree, flower, vegetable), Activity (sport), Material (fabric), Instrumentation (utensil, appliance, tool, musical instrument), Scene (room, geological formation), Food (beverage). For each synset, we used 100 images. Some samples of the database are given in Fig. 10.
The performance of retrieval of the system can be measured in terms of its recall and precision. Recall measures the ability of the system to retrieve all the models that are relevant, while precision measures the ability of the system to retrieve only the models that are relevant.
They are defined as:
where X represents the number of relevant images that are retrieved, Y the number of irrelevant items, and Z the number of relevant items which were not retrieved. The number of relevant items retrieved is the number of the returned images that are similar to the query image in this case.
The total number of items retrieved is the number of images that are returned by the search engine.
To evaluate the performance of proposed descriptors (color, shape and texture), many experiments have been done in order measure the efficiency of each proposed descriptor.
Beginning with experiments on Wang dataset, below is a curve (Fig. 11) which compares the proposed FIC to other color descriptors such as Color Histogram, HSV color histogram, Dominant Color and Weighted Invariant Color features. We can clearly remark that our FIC descriptor gives better results and this is because, in addition to color distribution information, it treats spatial pixels relationship. Besides, the integration of a FDSS in order to merge data allows to obtain a more flexible and robust result.
Also, some Texture and shape feature extraction methods are compared with our texture and shape descriptors, and they are presented in Figs. 12 and 13 respectively.
These experiments show the robustness of our three descriptors, and this can be explained by the use of wavelets and the FWT based on multiresolution analysis which ,at each scale, analyzes the image to extract more finer details. It is clear that an image can be described with three primordial visual content (shape, texture and color). So, merging these three contents can improve the results instead of treating each content separately.
An evaluation of different descriptors fusion scenarios (color& shape/color & texture/shape & texture/color & shape & texture) is given in Fig. 14.
The recall and precision measures of our approach can be summarized in the following confusion matrix (see Table 1).

Precision rates of each of the 16 ImageNet categories

Example of retrieved images from Wang database with confusion between classes

Example of retrieved images from ImageNet database
For Wang database, we compared our approach with the three approaches presented in [19, 20] and [21] and the results reported are very promising and provide better performance (see Fig. 15).
In order to evaluate the robustness of the proposed Fuzzy Decision Support System (FDSS), four further fusion methods were tested (see [36] for more details):
-
CombSUM: This is a simple method which can be described as the addition of all normalized scores per image. The normalization of a score (Nscore) is performed by applying the Min–Max Normalization procedure, which is given by the Eq. 15.
$$\begin{aligned} Nscore=\frac{Value-MinValue}{MaxValue-MinValue} \end{aligned}$$(15)where Value is the score of the image i in the ranked list j before normalization. MaxValue and MinValue correspond to the maximum and the minimum scores, respectively in the ranked list. Therefore, CombSUM(i) is calculated as follow:
$$\begin{aligned} CombSUM(i)=\sum _{j=1}^{N_j}Nscore_j(i) \end{aligned}$$(16)where \(N_j\) refers to the number of result sets to be merged.
-
Borda Count+CombSUM: The Borda count accords the maximum Borda Count points to the most relevant image in each ranked list \(L_j\). Each ulterior image gets one point less. Therefore, the Borda Count points of the image i (\(BC_j(i)\)) in the list \(L_j\) is calculated using the following equation:
$$\begin{aligned} BC_j(i)=N-Rank_j(i) \end{aligned}$$(17)where \(Rank_j(i)\) takes integer value belonging to \([0, N-1]\).
Then, the CombSUM is applied to these \(BC_j\) for each image, as shown in Eq. 18.
$$\begin{aligned} BC(i)=\sum _{j=1}^{N_j}BC_j(i) \end{aligned}$$(18)Finally, the images are sorted according to their BC points in the descending order.
-
Z-SCORE with Median+CombSUM: The idea here is to combine CombSUM and Z-score with Median to improve the results. Z-score with Median is a linear normalization which indicates how much a score deviates from the median of the distribution. Using the median instead the mean can minimize any effects due to extreme (very high or very low) results.
Z-SCORE with Median is performed using the Eq. 19.
$$\begin{aligned} \mathrm{Z-SCORE}_\mathrm{Median}=\frac{MeasuredValue-MedianValue}{StandardDeviation} \end{aligned}$$(19)IRP: The Inverse Rank Position merges ranked lists in the decreasing order of the inverse of the sum of inverses of individual ranks.
Equation 20 indicates how compute the IRP distance for each image IRP(i).
$$\begin{aligned} \mathrm{IRP}(i)=\frac{1}{\sum _{j=1}^{N_j} {\frac{1}{Rank_j(i))}}} \end{aligned}$$(20)where \(Rank_j(i)\) \(\in \) \( \left[ 1, N \right] \). Then, the images are ranked based on their IRP distances.
Although these measures can be computed very efficiently, they lack from semantic information. However, the proposed fusion method (FDSS) is based on fuzzy decision with more flexibility which leads to get more reasonable decision demonstrating its superiority (see Table 2).
Furthermore, we validate our approach on Holidays and UKBench databases, and the reported results seem promising (see Table 3), especially for UKBench and this because the wavelet is a powerful tool and it is invariant rotation, translation and dilatation.
Also, we used some samples from ImageNet database, which can be grouped into 16 different categories of images. Figure 16 presents the precision rates obtained for each category.
Table 4 resume the performance of the proposed approach with the corresponding Query time.
We remark that merging color, shape and texture features can improve considerably the performance of the proposed system of content-based image retrieval, with a respectable search time. Some examples of retrieved images are presented in Figs. 17 and 18.
7 Conclusion
In this paper, we presented a semantic approach for content-based image retrieval. This approach consists of two stages: the first stage was for features extraction (shape, texture and color descriptors) and the second stage was for data fusion using a Fuzzy Support Decision system with three fuzzy sets.
The shape descriptor was based on FBWN modeling combined with the seven Hue moments. The texture descriptor was based on the calculation of Energy of the first fifth Beta wavelet decomposition. Finally, we presented a new fuzzy color descriptor based on indexed color map. In the second stage we tried to merge the distances between the query image and the reference ones using a FDSS in order to measure the similarity between them. The results obtained are satisfactory and ensure the robustness of the proposed approach.
Having an index with a huge number of features can increase the complexity of the computational cost algorithm. So, in a future work, we aim to decrease this computational cost through creating just one wavelet network for each class instead of one wavelet network for each image which will improve the results perfectly.
Notes
Available at: http://wang.ist.psu.edu/docs/related/.
Available at: http://lear.inrialpes.fr/~jegou/data.php#holidays.
Available at: http://www.vis.uky.edu/~stewe/ukbench/.
Available at: http://www.image-net.org/.
References
Zaied, M., Amar, C.B., Alimi, M. A.: Award a new wavelet based beta function. In: International Conference on Signal, System and Design, SSD03, Tunisia, pp. 185–191 (2003)
Amar, C.B., Zaied, M., Alimi, M.A.: Beta wavelets: synthesis and application to lossy image compression. Adv. Eng. Softw. 36(7), 459–474 (2005)
Zaied, M., Said, S., Jemai, O., Amar, C.: A novel approach for face recognition based on fast learning algorithm and wavelet network theory. Int. J. Wavelets Multiresolut. Inf. Process. 19, 923–945 (2011)
Zaied, M., Amar, C., Alimi, M.A.: Beta wavelet networks for face recognition. J. Decis. Syst. 14, 109–122 (2005)
Said, S., Amor, B.B., Zaied, M., Amar, C.B., Daoudi, M.: Fast and efficient 3D face recognition using wavelet networks. In: 16th IEEE International Conference on Image Processing, Cairo, Egypt, pp. 4153–4156 (2009)
Jemai, O., Zaied, M., Amar, C.B.: Fast learning algorithm of wavelet network based on fast wavelet transform. Int. J. Pattern Recogn. Artif. Intell. 25(8), 1297–1319 (2011)
Jemai, O., Zaied, M., Amar, C.B., Alimi, A.: Pyramidal hybrid approach. Int. J. Wavelets Multiresolut. Inf. Process. 9, 111–130 (2011)
Ejbali, R., Benayed, Y., Zaied, M., Alimi, A.: Wavelet networks for phonemes recognition. In: International Conference on Systems and Information Processing (2009)
Ejbali, R., Zaied, M., Amar, C.B.: Multi-input multi-output beta wavelet network: modeling of acoustic units for speech recognition. In: International Journal of Advanced Computer Science and Applications (IJACSA), The Science and Information Organization(SAI), Vol. 3 (2012)
Ejbali, R., Zaied, M., Amar, C.B.: Wavelet network for recognition system of Arabic word. Int. J. Speech Technol. 13, 163–174 (2010)
Bouchrika, T., Zaied, M., Jemai, O., Amar, C.B.: Ordering computers by hand gestures recognition based on wavelet networks. In: International Conference on Communications, Computing and Control Applications (CCCA), Marseilles, pp. 36–41 (2012)
Madhu, S.: Content based image retrieval: a quantitative comparison between query by color and query by texture. J. Ind. Intell. Inf. 2(2), 108–112 (2014)
Howarth, P., Rger, S.: Evaluation of texture features for content-based image retrieval. In: International Conference on Image and Video Retrieval, pp. 326–334 (2004)
Sarker, I.H., Iqbal, S.: Content-based image retrieval using Haar wavelet transform and color moment. Smart Comput. Rev. 3, (3) (2013)
Bhute, A. N., Meshram, B. B.: Content based image indexing and retrieval. Int. J. Graph. Image Process. 3(4), 235–246 (2013)
Xu, J., Wu, D.: Ripplet-II transform for feature extraction. In: Proceedings of SPIE 7744, Visual Communications and Image Processing, China (2010)
Xu, J., Wu, D.: Ripplet transform type II transform for feature extraction. IET Image Proc. 6(4), 374385 (2012)
Lamard, M., Cazuguel, G., Quellec, G., Bekri, L., Roux, C., Cochener, B.: Content based image retrieval based on wavelet transform coefficients distribution. In: Conference Proceedings : Annual International Conference of the IEEE Engineering, Lyon, pp. 4532–4535 (2007)
Jalab, H. A.: Image retrieval system based on color layout descriptor and Gabor filters. In: IEEE Conference on Open Systems (ICOS), Langkawi, pp. 32–36 (2011)
Rao, M.B., Rao, B.P., Govardhan, A.: CTDCIRS: content based image retrieval system based on dominant color and texture features. Int. J. Comput. Appl. 18(6), 40–46 (2011)
Prabhu, J., Kumar, J.S.: Wavelet based content based image retrieval using color and texture feature extraction by gray level cooccurence matrix and color cooccurence matrix. J. Comput. Sci. 10(1), 15–22 (2014)
Saad, M.H., Saleh, H.I., Konbor, H., Ashour, M.: Image retrieval based on integration between \(YC_bC_r\) color histogram and texture feature. Int. J. Comput Theory Eng. 3(5), 701–706 (2011)
Rao, M.B., Rao, B.P., Govardhan, A.: Content based image retrieval using dominant color, texture and shape. Int. J. Eng. Sci. Technol. 3(4), 2887–2896 (2011)
Lande, M.V., Bhanodiya, P., Jain, P.: An effective content-based image retrieval using color texture and shape feature. Adv. Intell. Syst. Comput. 243, 1163–1170 (2014)
Hiremath, P.S., Pujari, J.: Content based image retrieval based on color, texture and shape features using image and its complement. Int. J. Comput. Sci. Secur. 1(4), 25–35 (2007)
Kumar, D.A., Esther, J.: Comparative study on CBIR based by color histogram, gabor and wavelet transform. Int. J. Comput. Appl. 17(3), 37–44 (2011)
Atlam, H.F., Attiya, G., El-Fishawy, N.: Comparative study on CBIR based by color feature, gabor and wavelet transform. Int. J. Comput. Appl. 78(16), 9–15 (2013)
Banerjee, M., Kundu, M.K., Maji, P.: Content-based image retrieval using visually significant point features. Fuzzy Sets Syst. 160, 33233341 (2009)
Choudhary, R., Raina, N., Chaudhary, N., Chauhan, R., Goudar, R. H.: An Integrated approach to content based image retrieval. In: International Conference on Advances in Computing, Communications and Informatics (ICACCI), New Delhi, September, pp. 2404–2410 (2014)
John, D., Tharani, S.T., Sreekumar, K.: Content based image retreival using HSV-color histogram and GLCM. Int. J. Adv. Res. Comput. Sci. Manag. Studi. 2(1), 246–253 (2014)
Jhanwar, N., Chaudhuri, S., Seetharaman, G., Zavidovique, B.: Content based image retrieval using motif cooccurrence matrix. Image Vis. Comput. 22, 12111220 (2004)
Wang, X.-Y., Yu, Y.-J., Yang, H.-Y.: An effective image retrieval scheme using color, texture and shape features. Comput. Stand. Interfaces 33, 5968 (2011)
Region based image retrieval using Shape-Adaptive DCT, signal and information processing (ChinaSIP). In: IEEE China Summit & International Conference on Signal and Information Processing (ChinaSIP), July, Xian, pp. 470–474 (2014)
Madhu, S.: Content based Image retrieval: a quantitative comparison between query by color and query by texture. J. Ind. Intell. Inf. 2(2), 108–112 (2014)
Alzghool, M., Inkpen, D.: A novel class-based data fusion technique for information retrieval. J. Emerg. Technol. Web Intell. 2(3), 160–166 (2010)
Chatzichristos, S. A., Arampatzis, A., Boutalis, Y. S.: Investigating the behavior of compact composite descriptors in early fusion, late fusion and distributed image retrieval. Radioengineering 19(4), 725–733 (2010)
Jovic, M., Hatakeyama, Y., Dong, F., Hirota, K.: Image retrieval based on similarity score fusion from feature similarity ranking lists. In: Lecture Notes in Computer Science, Vol. 4223, pp. 461–470 (2006)
Wenger, C., Douze, M., Jgou, H.: Bag-of-colors for improved image search. In: The 19th ACM International Conference on Multimedia, Scottsdale, November (2011)
Liu, Z., Wang, S., Zheng, L., Tian, Q.: Visual reranking with improved image graph. In: IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), May, pp. 6889–3893 (2014)
Zheng, L., Wang, S.: Coupled binary embedding for large-scale image retrieval. IEEE Trans. Image Process. 23(8), 3368–3380 (2014)
de Weijer, J. V., Schmid, C., Verbeek, J., Larlus, D.: Learning color names for realworld applications. In: IEEE TIP (2009)
Zheng, L., Wang, S., Liu, Z., Tian, Q.: Packing and padding: coupled multi-index for accurate image retrieval. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June, Columbus, pp. 1947–1954 (2014)
Jain, M., Jgou, H., Gros, P.: Asymmetric hamming embedding: Taking the best of our bits for large scale image search. In: Proceedings of ACM Multimedia, pp. 1441–1444 (2011)
Deng, C., Ji, R., Liu, W., Tao, D., Gao, X.: Visual reranking through weakly supervised multi-graph learning. In: Proceedings of IEEE International Conference on Computer Vision (ICCV), pp. 2600–2607 (2013)
Shen, X., Lin, Z., Brandt, J., Avidan, S., Wu, Y.: Object retrieval and localization with spatially-constrained similarity measure and k-NN reranking. In: Proceedings on Computer Vision and Pattern Recognition (CVPR), June, pp. 3013–3020 (2012)
Jgou, H., Douze, M., Schmid, C.: Improving bag-of-features for large scale image search. Int. J. Comput. Vision 87(3), 316–336 (2010)
Wengert, C., Douze, M., Jgou, H.: Bag-of-colors for improved image search. In: Proceedings of 19th ACM Multimedia, pp. 1437–1440 (2011)
Jegou, H., Schmid, C., Harzallah, H., Verbeek, J.: Accurate image search using the contextual dissimilarity measure. IEEE Trans. Pattern Anal. Mach. Intell. 32(1), 2–11 (2010)
Zhang, S., Yang, M., Cour, T., Yu, K., Metaxas, D. N.: Query specific fusion for image retrieval. In: 12th European Conference on Computer Vision, October, pp. 660–673 (2012)
Madugunki, M., Bormane, D.S., Bhadoria, S., Dethe, C. G.: Comparison of different CBIR techniques. In: 3rd International Conference on Electronics Computer Technology (ICECT), Kanyakumari, pp. 372–375 (2011)
Mejdoub, M., Amar, C.B.: Classification improvement of local feature vectors over the KNN algorithm. Multimedia Tools Appl. 64(1), 197–218 (2013)
Mejdoub, M., Fonteles, L., Amar, C.B., Antonini, M.: Embedded lattices tree: an efficient indexing scheme for content based retrieval on image databases. J. Vis. Commun. Image Represent. 20(2), 145–156 (2009)
Dammak, M., Mejdoub, M., Zaied, M., Amar, C.B.: Feature vector approximation based on wavelet network. In: ICAART 2012—Proceedings of the 4th International Conference on Agents and Artificial Intelligence, pp. 394–399 (2012)
Othmani, M., Bellil, W., Amar, C.B., Alimi, A.M.: A new structure and training procedure for multi-mother wavelet networks. Int. J. Wavelets Multiresolut. Inf. Process. 8(1), 149–175 (2010)
El’Arbi, M., Amar, C.B., Nicolas, H. Video watermarking based on neural networks. In: IEEE International Conference on Multimedia and Expo, ICME 2006—Proceedings, art. no. 4036915, pp. 1577–1580 (2006)
Mejdoub, M., Fonteles, L., BenAmar, C., Antonini, M.: Fast indexing method for image retrieval using tree-structured lattices. In: International Workshop on Content-Based Multimedia Indexing, CBMI 2008. Conference Proceedings, art. 4564970, pp. 365–372 (2008)
Boughrara, H., Chtourou, M., Amar, C.B.: MLP neural network based face recognition system using constructive training algorithm. In: Proceedings of 2012 International Conference on Multimedia Computing and Systems, ICMCS 2012, art. no. 6320263, pp. 233–238 (2012)
Mejdoub, M., Fonteles, L., Amar, C.B, Antonini, M.: Fast algorithm for image database indexing based on lattice. In: European Signal Processing Conference, pp. 1799–1803 (2007)
Gosselin, P.H., Cord, M.: Active learning methods for interactive image retrieval. IEEE Trans. Image Process. 17(7), 1200–1211 (2008)
Rajput, E., Kang, H.S.: Content based Image retrieval by using the Bayesian algorithm to improve and reduce the noise from an image. Global J. Comput. Sci. Technol. Graph. Vision 13(6), 12–16 (2013)
Zhao, T., Lu, J., Zhang, Y., Xiao, Q.: Feature selection based-on genetic algorithm for CBIR. In: Congress on Image and Signal Processing, Sanya, pp. 495–499 (2008)
Liu, M.-S., Li, J.-H., Liu, H.: Image retrieval technology of multi-MPEG-7 features based on genetic algorithm. In: Proceedings of the Sixth International Conference on Machine Learning and Cybernetics, Hong Kong, pp. 19–22 (2007)
Belattar, K., Mostefai, S.: CBIR with RF: which Technique for which image. In: 3rd International Symposium ISKO-Maghreb, pp. 1–7 (2013)
Shanmugapriya, N., Nallusamy, R.: A new content based image retrieval system using GMM and relevance feedback. J. Comput. Sci. 10(2), 330–340 (2014)
Chowdhury, M., Das, S., Kundu, M.K.: Interactive content based image retrieval using Ripplet Transform and fuzzy relevance feedback. In: Proceedings of the First Indo-Japan Conference on Perception and Machine Intelligence (PerMIn’12), pp. 243–251 (2012)
Yasmin, M., Mohsin, S., Irum, I., Sharif, M.: Content based image retrieval by shape. Color and relevance feedback. Life Sci. J 10(4), 593–598 (2013)
Belattar, K., Mostefai, S.: CBIR using relevance feedback:comparative analysis and major challenges. In: 5th International Conference on Computer Science and Information Technology (CSIT), pp. 317–325 (2013)
Yasmin, M., Sharif, M., Mohsin, S.: Use of Low Level Features for Content Based Image Retrieval: Survey. Research Journal of Recent Sciences 2(11), 65–75 (2013)
Verma, B., Kulkarni, S.: A fuzzy-neural approach for interpretation and fusion of colour and texture features for CBIR systems. Appl. Soft Comput. 5, 119130 (2004)
Sriramakrishnan, C., Shanmugam, A.: An fuzzy neural approach for medical image retrieval. J. Comput. Sci. 8(11), 1809–1813 (2012)
Syam, B., Victor, J.S.R., Srinivasa Rao, Y.: Efficient similarity measure via genetic algorithm for content based medical image retrieval with extensive features. In: International Multi-Conference on Automation, Computing, Communication, Control and Compressed Sensing (iMac4s), Kottayam, pp. 704–711(2013)
Bagheri, B., Pourmahyabadi, M., Nezamabadi-pour, H.: A novel content based image retrieval approach by fusion of short term learning methods. In: 5th Conference on Information and Knowledge Technology (IKT), pp. 355–358 (2013)
Rashedi, E., Nezamabadi-pour, H., Saryazdi, S.: A Gradient Descent based Similarity Refinement Method for CBIR Systems, Tehran (2012)
Tong, S., Chang, E.: Support Vector Machine Active Learning for Image Retrieval. In: The ninth ACM International Conference on Multimedia, pp. 107–118 (2001)
Acknowledgments
The authors would like to acknowledge the financial support of this work by grants from General Direction of Scientific Research (DGRST), Tunisia, under the ARUB program.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
ElAdel, A., Ejbali, R., Zaied, M. et al. A hybrid approach for Content-Based Image Retrieval based on Fast Beta Wavelet network and fuzzy decision support system. Machine Vision and Applications 27, 781–799 (2016). https://doi.org/10.1007/s00138-016-0789-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00138-016-0789-z