
Abstract
Graphical designs are an extension of spherical designs to functions on graphs. We connect linear codes to graphical designs on cube graphs, and show that the Hamming code in particular is a highly effective graphical design. We show that even in highly structured graphs, graphical designs are distinct from the related concepts of extremal designs, maximum stable sets in distance graphs, and t-designs on association schemes.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction to Graphical Designs
In this paper, we establish several new results about graphical designs, which are an analog of the well-known spherical designs to the discrete domain of graphs. We show that linear codes are effective graphical designs on the cube graph, which is the graph that has the vertices and edges of the unit cube. We then show that graphical designs are not the same as several related combinatorial concepts. We begin this section with the history and motivation for defining graphical designs, and then introduce the graphical design problem.

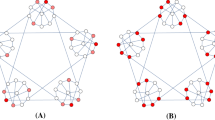
The Hoffman–Singleton graph on 50 vertices. The 10 red vertices form a graphical design which integrate the first 49 eigenvectors of the graph Laplacian in a suitable basis. The induced subgraph of this design is 3-regular (Color figure online)
1.1 Spherical Designs
We begin with a quick introduction to quadrature rules on the sphere. For more complete references on spherical harmonics, see, for instance, [21] or [3].
It may be impossible or computationally prohibitive to exactly integrate a function on the sphere \({{\mathbb {S}}}^{d-1}\), so it is useful to find good numerical approximations. Spherical quadrature approaches this problem by looking for well distributed points over the sphere. A quadrature rule is a set of points \(\{x_1,\ldots , x_N\} \subset {{\mathbb {S}}}^{d-1}\) and weights \(\alpha _i \in {{\mathbb {R}}}\) chosen so that
whenever f is smooth in some suitable way. For instance, a spherical t-design is a quadrature rule which integrates all polynomials up to degree t exactly ([11]). As one might guess, there are numerous ideas about how best to distribute the points. The strategy of Sobolev–Lebedev quadrature is to fix a finite-dimensional vector space of functions and find points which integrate the entire vector space exactly. This raises the question, what functions should one try to integrate?

The vertex sets of the icosahedron and dodecahedron both form spherical 5-designs, integrating a 36-dimensional vector space of functions exactly. The icosahedron is also a Sobolev–Lebedev quadrature rule
Sobolev suggested that a suitable vector space of functions should respect the symmetries of the sphere (see [17, 26]), leading us to spherical harmonics. Spherical harmonics are the eigenfunctions of the Laplace-Beltrami operator \(\Delta \), where a function \(f:{{\mathbb {S}}}^{d-1} \rightarrow {{\mathbb {R}}}\) is called an eigenfunction of \(\Delta \) if \(\Delta f= \lambda f\) for some eigenvalue \(\lambda \in {{\mathbb {R}}}\). The eigenfunctions of \(\Delta \) form an orthogonal basis for \(L^2({{\mathbb {S}}}^{d-1})\) consisting of harmonic, homogeneous polynomials. In the one dimensional case, spherical harmonics lead to the standard trigonometric polynomials; expanding a function in this basis is its Fourier series. Spherical harmonics can be naturally ordered by frequency: a spherical harmonic with eigenvalue \(\lambda \) has a low frequency if \(|\lambda |\) is small. The idea behind Sobolev–Lebedev quadrature is to integrate all low-frequency spherical harmonics up to a chosen threshold for \(|\lambda |\).
1.2 Graphical Designs
The graphical design problem is an extension of spherical quadrature to functions on graphs, first introduced by Steinerberger in [28]. This notion of graphical design is distinct from the graphical designs in design theory (see [29, p. 222]). Let \(G = (V,E)\) be a graph with vertex set \(V= [n] := \{1,\ldots , n\}\) and edge set E, and consider a class of functions \(\varphi _i: V\rightarrow {{\mathbb {R}}}\) which are “smooth” with respect to the geometry of G, a notion which we will make precise shortly. A quadrature rule on G is a subset \(W\subset V\) and a set of weights \(\{\alpha _w\}_{w\in W}\) such that for each \(\varphi _i,\)
In this paper, we only consider equal weights; we would like that for each \(\varphi _i,\)
To mirror quadrature on the sphere, we use eigenvectors of the discrete Laplacian of \(G=(V,E)\) as the class of smooth functions. We define the Laplacian as
The adjacency matrix A is defined by \(A_{ij} = 1\) if \(ij\in E\) and 0 otherwise, D is the diagonal matrix with \(D_{ii} = \deg (v_i)\), and I is the \(n \times n\) identity matrix. In the smooth case, Taylor expansion shows that the Laplace-Beltrami operator is essentially the average value in a neighborhood of a point. This graph Laplacian analogously captures averaging over the neighborhood of a vertex.
The definition of a graphical design is dependent on the choice of Laplacian. Other common graph Laplacians include \(D-A\) and the normalized Laplacian \(I - D^{-1/2}A D^{-1/2}\). We refer the reader to [9] for more on the various graph Laplacians. We focus on regular graphs where these notions of Laplacian coincide; if \(G = (V,E)\) is \(\delta \)-regular, then
Note that the operator \(AD^{-1}\) is a nonnegative Markov matrix, and hence has spectrum \(\sigma (AD^{-1}) \subseteq [-1,1]\). Thus \(\sigma (L) \subseteq [-2,0]\). We order the eigenvalues as in [28], where \(\lambda _1\) has the lowest frequency and \(\lambda _n\) has the highest:
We now provide some intuition for how this is analogous to the frequency ordering on spherical harmonics. In a regular graph, \(L \mathbb {1}= 0 = \lambda _1\), where \(\mathbb {1}\) is the all-ones vector. The eigenvector \(\mathbb {1}\) is constant across all vertices, and hence is the “smoothest” possible with respect to the structure of any graph. By smooth, we mean the function does not change dramatically across vertices which are highly connected or in some sense representative of the same part of the graph. Likewise, if G is bipartite, then L has an eigenvector \(\varphi \) with eigenvalue \(\lambda _2=-2\), and \(\varphi \) is constant on each part of the bipartition. Eigenvectors with eigenvalue near \(-1\) do not exhibit this type of smoothness (see Fig. 3).

The contiguous United States graph. Vertices represent states, which are connected by an edge if they share a border. The first two eigenvectors by frequency are “smooth” with respect to the graph geometry—they vary smoothly across the country. The eleventh eigenvector does not. Average annual precipitation by state varies relatively smoothly across geography. Most of the information of this function resides in the low-frequency eigenvectors of the graph Laplacian
We will denote the associated eigenvectors as \(\varphi _1,\ldots , \varphi _n\) and interpret them as functions \(\varphi _i: V\rightarrow {{\mathbb {R}}}\), where \(\varphi _i(v) \) is the value of the i-th eigenvector at the vertex v. In highly symmetric graphs, we would expect vertices to reflect graph symmetries, but not otherwise be distinguished. Therefore we focus on the case of equal weights, where a graphical design is as follows.
Definition 1.1
Given a finite, simple, unweighted, connected graph \(G = (V,E)\), we say a subset \(W \subset V\) integrates an eigenvector \(\varphi \) of \(L= AD^{-1}-I\) if
We say a subset \(W \subset V\) integrates an eigenspace \(\Lambda \) of L if W integrates every eigenvector in a basis of \(\Lambda \). A k-graphical design is \(W \subset V\) such that W integrates the first k eigenspaces with respect to the frequency ordering. If the context is clear, we may drop the word graphical and refer to k-designs.
By linearity, if W integrates every eigenvector in a basis of the eigenspace \(\Lambda \), then W integrates every vector in \(\Lambda \), and therefore every basis of \(\Lambda \). Thus the definition of integrating an eigenspace is unambiguous. Given Definition 1.1, it is natural to ask how good a design can be, in the sense that a small number of vertices integrates a large number of eigenspaces. In order to quantify this, we define the following.
Definition 1.2
Let \(G = (V,E)\) be a finite, simple, connected, and unweighted graph with m distinct eigenspaces ordered from low to high frequency as \(\Lambda _1 \le ... \le \Lambda _m\), where the eigenvalue of \(\Lambda _1\) has the lowest frequency and the eigenvalue of \(\Lambda _m\) has the highest frequency. An optimal design is \(W \subset V\) integrating \(\Lambda _1,\ldots , \Lambda _k\) with
We define \({\text {efficacy}}(W)\) to be the ratio on the left hand side of this equality.

The truncated tetrahedral graph is a 3-regular graph on 12 vertices. This graph has the following eigenvalues ordered by frequency, where the exponents represent multiplicity: \( 0^1, (-5/3)^3,(-1/3)^3,(-4/3)^3,(-1)^2. \) The subset of red vertices integrates all eigenspaces but the eigenspace for \(\lambda = -1\). This is thus a 4-graphical design with efficacy 4/10 (Color figure online)
The problem posed by Steinerberger [28] investigated how large k can be given |W|. A dual question is, given k, how large must |W| be? The optimal design framework is distinct from both questions, as one could be interested in designs which are smaller than the optimal design or which integrate more eigenspaces than the optimal design. We find the notion of optimality a natural way to balance the trade off between |W| and k.
1.3 Related Work
Quadrature rules for surfaces other than spheres are a relatively new field. For more on the smooth case, see, for instance, [4, 5, 12, 27]. The graph sampling problem has been investigated primarily from an engineering perspective; see, for instance, [2, 31, 33]. We also refer to the work of Pesenson (e.g. [22,23,24]).
The graphical design problem was first introduced by Steinerberger in [28]. Its main theorem loosely states that if W is a good graphical design, then either |W| is large, or the j-neighborhoods of W grow exponentially. Steinerberger and Linderman ([18]) consider the numerical integration side of graphical designs. They find an upper bound on the integration error for any quadrature rule on a graph, which multiplicatively separates out the size of a function f and a quantity which can be interpreted as the quality of the quadrature scheme.
Extremal designs, which are graphical designs that integrate all but one eigenvector, were introduced in [13]. Golubev shows that stable sets in \(G=(V,E)\) which attain the Hoffman bound and subsets of V which attain the Cheeger bound are extremal. He applies these results to several families of graphs, including Kneser graphs and graphs of the d-cube. We discuss this in more detail in Sect. 5.

The vertices in red are a subset which attains the Cheeger bound for the cube graph \(Q_4\). By [13, Theorem 2.4], this is an extremal design (Color figure online)
2 Main Results
We present an overview of the structure of this paper and the main results. In broad strokes, we summarize our findings with the following two principles:
Principle 1
Linear codes are a good place to look for graphical designs in cube graphs. The Hamming code and some of its variants are effective graphical designs.
Principle 2
Graphical designs are distinct from several related and previously established combinatorial constructions on graphs. Even in highly structured graphs, graphical designs are not the same as extremal designs, maximum stable sets in distance graphs, and t-designs on association schemes.
Table 1 collects our main results and examples, and compares how they stack up among the variety of concepts we consider. We encourage the reader to revisit this table after encountering these combinatorial concepts in the text.
2.1 Eigenspaces vs. Eigenvectors
Graphical designs were originally defined in terms of integrating eigenvectors, not eigenspaces in [28]. We show in Lemma 3.2 that a graphical design W can either integrate an entire eigenspace \(\Lambda \), or if W cannot integrate the eigenspace \(\Lambda \), then for any \(i \in \{0,1,\ldots , \dim (\Lambda )-1\}\), there is an eigenbasis B of \(\Lambda \) such that W integrates i eigenvectors of B. The proof is constructive – we provide what is essentially an algorithm for constructing B. Due to this lemma, we have made the choice to define graphical designs in terms of eigenspaces, not eigenvectors.
2.2 Designs on Cube Graphs
An open question in [28] was to find graphical designs on families of graphs. To this end, Sect. 4 focuses on graphical designs on the graph of the d-cube, which we denote \(Q_d\). We show that linear codes are generally good candidates [Theorem 4.8]. The Hamming code for the \((2^r-1)\)-cube, in particular, integrates all but the last eigenspace in the frequency ordering [Theorem 4.9]. Moreover, we show that the Hamming code is the unique smallest linear code which integrates all but the last eigenspace by frequency of the \((2^r-1)\)-cube [Theorem 4.10]. We can derive other highly effective graphical designs on \(Q_{2^{r}}\) and \(Q_{2^{r}+1}\) by lifting the Hamming code [Theorem 4.12], and fairly effective graphical designs on \(Q_{2^r-2}\) by projecting the Hamming code [Theorem 4.14].
2.3 Extremal Designs
We next turn to the concept of extremal designs in Sect. 5. By definition, extremal designs do not consider the frequency ordering on eigenspaces, nor do they take into account the size of the graphical design. The main results in [13] find extremal designs through the Hoffman bound and Cheeger bound. We show that stable sets achieving the Hoffman bound and subsets achieving the Cheeger bound do not integrate an eigenspace which is generally early in the frequency ordering [Theorems 5.6, 5.11]. We show the Hamming code on the 3-cube is an optimal design by showing it is a stable set which meets the Hoffman bound for a different distance graph on the cube. We compare the efficacy of several graphical designs on cube graphs found here and in [13]. The Hoffman bound connects graphical designs to maximum stable sets. We show through an example that optimal designs need not be maximum stable sets, or stable sets at all.
2.4 Association Schemes
Another combinatorial object that seems, at first glance, to coincide with graphical designs are classical t-designs. We show that this is not the case in Sect. 6. Classical t-designs do integrate some eigenvectors of \(L=AD^{-1} -I\) [Theorem 6.5]. However, optimal graphical designs need not be t-designs for any choice of t. We exhibit a family of graphs arising from the Johnson scheme which have an extremal design that is not a classical t-design for any choice of t [Proposition 6.10]. In particular, we show a graph arising from the (8, 3) Johnson scheme for which this subset is optimal (Example 6.12). We also show that the Hamming code is a better graphical design than t-design, integrating about twice as many eigenspaces in the frequency ordering as opposed to the ordering imposed in the association scheme framework [Proposition 6.17].
3 The Problem of Eigenspaces vs. Eigenvectors
Graphical designs were originally defined by ordered integration of eigenvectors, not eigenspaces, in [28]. It was left undetermined how to handle eigenspaces with multiplicity in the discrete case. In the continuous case, multiplicity of eigenspaces is typically ignored due to the following folklore result.
Lemma 3.1
(Folklore). For a smooth manifold, the dimension of an eigenspace of the Laplace-Beltrami operator \(\Delta \) is small compared to the prior number of eigenvalues (with multiplicity) ordered by frequency.
Idea. Weyl’s law ( [35]) states that for a sufficiently smooth compact manifold embedded in \({{\mathbb {R}}}^d\), the number of eigenvalues \(\le \lambda \) of \(\Delta \) (with multiplicity) is
for some constant \(\beta \). So, suppose there is an eigenvalue \(\lambda \) whose eigenspace \(\Lambda \) has multiplicity. Then for some small \(\varepsilon \), \(N(\lambda +\varepsilon ) - N(\lambda -\varepsilon ) = \dim (\Lambda ).\) By applying Weyl’s law twice, we have that \( \dim (\Lambda ) = {{\mathcal {O}}}(\lambda ^{(d-1)/2}).\) On the other hand, the total number of eigenvalues \(<\lambda \) (with multiplicity) is on the order of \(\lambda ^{d/2}\), which is comparatively much bigger than \(\dim (\Lambda )\). \(\square \)
In the discrete case, the problem of eigenspaces with multiplicity is more substantial. There is ambiguity when confronted with infinitely many eigenbases, each of which can behave differently in terms of integration by a subset \(W\subset V\). Some graphs come with a well-known set of eigenvectors; for example, the eigenvectors of a Cayley graph can be found using group characters. However, from a numerical integration perspective, there is no obvious reason for why such an eigenbasis is better than any other eigenbasis. Moreover, the majority of graphs do not come paired with a well-known eigenbasis. The following lemma justifies Definitions 1.2 and 1.3 in terms of eigenspaces, by arguing that an eigenspace should be thought of as a single unit, rather than as a collection of eigenvectors.
For \(W\subset V\), let \(\mathbb {1}_W \in {{\mathbb {R}}}^V\) be the indicator vector of W, that is \(\mathbb {1}_W(x) = 1\) if \(x\in W\) and \(\mathbb {1}_W(x) =0\) if \(x\notin W\). We denote the all-ones vector \(\mathbb {1}_V \in {{\mathbb {R}}}^V\) by \(\mathbb {1}.\)
Lemma 3.2
Let \(G=(V,E)\) have an eigenspace \(\Lambda \) of L with \(\dim \Lambda >1\). For any \(W \subset V\), either W integrates \(\Lambda \), or for each \(j =0, \ldots , \dim \Lambda -1\), there is an orthonormal basis of \(\Lambda \) such that W integrates precisely j eigenvectors in this basis.
Proof
Suppose W does not integrate \(\Lambda \). We will first show that if W integrates precisely \(j \in \{1,\ldots , \dim \Lambda -1\}\) eigenvectors in a basis of \(\Lambda \), we can construct an orthonormal B of \(\Lambda \) for which W integrates precisely \(j-1\) eigenvectors in B. Let \(\{\varphi _i\}_{i=1}^{\dim \Lambda } \) be an orthonormal basis for \(\Lambda \) where W integrates j eigenvectors of this basis. We may reorder the basis vectors and suppose that W integrates \(\varphi _2\) but not \(\varphi _1\). Consider
Then \({\text {span}}(B) = \Lambda \),
Thus B is an orthogonal basis for \(\Lambda \). Since W does not integrate \(\varphi _1\) and does integrate \(\varphi _2\), we have
Therefore,
Thus W integrates \(j-1\) eigenvectors in B, and we can normalize to obtain an orthonormal basis of \(\Lambda \) with this property.
Next, we show that if W integrates exactly \(j \in \{0, \ldots , \dim \Lambda -2\}\) eigenvectors in a basis of \(\Lambda \), we can construct an orthonormal B of \(\Lambda \) for which W integrates precisely \(j+1\) eigenvectors in B. Let \(\{\varphi _i\}_{i=1}^{\dim \Lambda } \) be an orthonormal basis for \(\Lambda \) where W integrates j vectors of \(\{\varphi _i\}_{i=1}^{\dim \Lambda } \). We may reorder the basis vectors and suppose that W does not integrate \(\varphi _1\) and \(\varphi _2\). Let \(\alpha _1 = \varphi _1^T( \mathbb {1}/|V| - \mathbb {1}_W/|W|)\) and \(\alpha _2 = \varphi _2^T ( \mathbb {1}/|V| - \mathbb {1}_W/|W|)\). Since W does not integrate \(\varphi _1\),
Likewise we have that \(\alpha _2 \ne 0\). Consider
Then \({\text {span}}(B) = \Lambda \),
so B is an orthogonal eigenbasis for \(\Lambda \). Moreover, W integrates \(\varphi _1/\alpha _1 - \varphi _2/\alpha _2\):
However W does not integrate \(\alpha _1\varphi _1 +\alpha _2 \varphi _2\):
Thus B is a orthogonal basis for \(\Lambda \) such that W integrates precisely \(j+1\) eigenvectors in B. We can normalize to obtain an orthonormal basis with this property.
Thus if W does not integrate a given a basis \(\{\varphi _i\}_{i=1}^{\dim \Lambda }\) of \(\Lambda \) entirely, we can iterate one of these two processes to find orthonormal eigenbases for \(\Lambda \) such that W integrates j eigenvectors for \(j = 0,\ldots , \dim \Lambda -1\). \(\square \)
In light of this lemma, we conclude that Definitions 1.2 and 1.3, which define k-graphical designs, optimal designs, and efficacy in terms of eigenspaces, are sensible. There is too much flexibility when choosing the basis of an eigenspace.
Example 3.3
We illustrate eigenspace multiplicity with \(K_5\), the complete graph on 5 vertices. For \(K_5\), L has only one nontrivial 4-dimensional eigenspace \(\Lambda = \{ x: \mathbb {1}^T x =0\}\). The subset \(\{1\}\) does not integrate \(\Lambda \). By Lemma 3.2, there are bases of \(\Lambda \) such that \(\{1\}\) integrates 0, 1, 2 and 3 eigenvectors in the basis, which we exhibit below. The columns of the following matrices form orthogonal bases for \(\Lambda \). The subset \(\{1\}\) integrates an eigenvector \(\varphi \in \Lambda \) if and only if \(\varphi (1)=0\). For \(i =0,\ldots , 3\), \(\{1\} \) integrates precisely the first i columns of \(U_i\).
4 The d-Dimensional Cube
In this section we show that linear codes can provide effective graphical designs on the graphs of cubes, and that constructions from the Hamming code are particularly effective. We denote by \(Q_d\) the graph of the d-cube, which has vertex set \(\{0,1\}^d\) and an edge between vertices v and w if they differ in exactly one coordinate. Later we will build graphs on \(\{0,1\}^d\) with other types of edges.

The graph \(Q_3\) and a matrix of its eigenvectors for \(L= AD^{-1} - I\). The i-th row and i-th column are indexed by the vertex which is the binary expansion of \(i-1\). The first column spans \(\Lambda _0\) with eigenvalue 0, columns 2, 3, and 4 span \(\Lambda _1\) with eigenvalue \(-2/3\), columns 5, 6, and 7 span \(\Lambda _2\) with eigenvalue \(-4/3\), and column 8 spans \(\Lambda _3\) with eigenvalue \(-2\)
The graph \(Q_d\) is a Cayley graph, where the underlying group is \(\{0,1\}^d\) with addition mod 2, and the generating set is \(\{e_i\}_{i=1}^d\), the standard basis vectors. For more on Cayley graphs and their spectra, see [7, Chapter 6]; we also provide a brief discussion before Theorem 5.8. The graph \(Q_0\) is trivial and \(Q_1\) is non-regular, so we consider \(d \ge 2\), where \(Q_d\) is d-regular. From the Cayley graph structure, we can derive the eigenvectors and eigenvalues of \(Q_d\) using the group characters of \(\{0,1\}^d\). For more on the representation of finite groups, we recommend [25, Chapter 1]. Each \(v \in \{0,1\}^d\) gives an eigenvector \(\varphi _v(x) = (-1)^{v^Tx}\) with eigenvalue \((1/d) \sum _{i=1}^d (-1)^{v_i} -1.\) To determine the frequency ordering, we introduce the Hamming distance.
Definition 4.1
(see [19]). The Hamming distance \(d_H\) between two vectors v and w in \(\{0,1\}^d\) is the number of coordinates they differ on. That is,
The weight of v is \(wt(v) = d_H(v,0) = \mathbb {1}^T v\), which is the number of ones in v.
To better reflect the structure of the spectrum of \(Q_d\), we make a slight change of notation. We have distinct eigenspaces \(\Lambda _i ={\text {span}}\{ \varphi _v: wt(v) = i\}\) with multiplicity \(\genfrac(){0.0pt}1{d}{i}\) and eigenvalue \(-2i/d\) for each \(i = 0,\ldots ,d\). The ordering of eigenspaces by frequency for d odd is then
where \(\Lambda _i<\Lambda _j\) denotes that the eigenvalue of \(\Lambda _i\) has a strictly lower frequency than that of \(\Lambda _j,\) and \(\Lambda _i\equiv \Lambda _j\) denotes eigenspaces which are interchangeable in the frequency ordering. If d is even, the eigenspace ordering is
See Fig. 6 for \(Q_3\) and its eigenspaces.
4.1 Preliminary Results
We first provide some simple graphical designs on \(Q_d\). A regular graph has a trivial one-dimensional eigenspace with eigenvalue 0 spanned by \(\mathbb {1}\). This agrees with the Cayley graph structure: \(\varphi _0(x) = (-1)^{x^T0} = 1\) for all \(x\in \{0,1\}^d\). Any \( W \subset \{0,1\}^d\) integrates \(\mathbb {1}\). We will often use the following fact.
Lemma 4.2
Let \(G=(V,E)\) be regular. A subset \(W\subset V\) integrates a nontrivial eigenvector \(\varphi \) if and only if \(\varphi ^T \mathbb {1}_W =0\).
Proof
Since G is regular, \({\text {span}}\{\mathbb {1}\}\) is an eigenspace of L. Since eigenspaces are orthogonal, every nontrivial eigenvector \(\varphi \) is such that \(\varphi ^T \mathbb {1}=0\). Thus W integrates \(\varphi \) if and only if
\(\square \)
The first nontrivial eigenspace by frequency is \(\Lambda _d={\text {span}}\{\varphi _\mathbb {1}\}\) with eigenvalue \(-2\).
Lemma 4.3
A subset \(W\subset \{0,1\}^d\) integrates the eigenspace \(\Lambda _d={\text {span}}\{\varphi _\mathbb {1}\}\) of \(Q_d\) if and only if it has an equal number of even and odd weight vertices.
Proof
A subset \(W\subset \{0,1\}^d\) satisfies
if and only if the number of even and odd weight vertices in W are equal. \(\square \)
The next eigenspace by frequency is \(\Lambda _1 = {\text {span}}\{\varphi _{e_i}\}_{i=1}^{d}\). The following lemma addresses all odd eigenspaces. We abbreviate the subset \(\{1,\ldots , d\}\) as [d].
Lemma 4.4
If \(W\subset \{0,1\}^d \) is such that \(w\in W \iff \mathbb {1}-w \in W\) and \(i \in [d]\) is odd, then W integrates the eigenspace \(\Lambda _i\) of \(Q_d\).
Proof
Let \(I\subseteq [d]\) be an index set of odd size, and let \(e_I= \sum _{i\in I} e_i\) be its indicator vector. To integrate \(\varphi _{e_I} \), we need to show that
It then suffices to find a bijection between the sets
If |I| is odd, then \(e_I^T (\mathbb {1}-w) \mod 2 = 1 - e_I^T w \mod 2,\) and so \(e_I^T w\) and \(e_I^T (\mathbb {1}-w)\) have opposite parity. Thus mapping \(w \mapsto \mathbb {1}- w\) provides the desired bijection. \(\square \)
As a consequence, for any d, we can find some very small graphical designs which are moderately effective. More precisely,
Lemma 4.5
If d is odd, the subset \(\{0, \mathbb {1}\}\) is a 3-design, and
If \(d>2\) is even, a subset such as \(W = \left\{ e_1, e_1+e_2, \mathbb {1}- e_1 , \mathbb {1}- e_1 -e_2\right\} \) is at least a 4-design, and
Moreover, a 4-design must contain at least 4 vertices for any value of d.
Proof
Recall that \(\dim {\Lambda _0} = \dim {\Lambda _d} =1\), and \(\dim {\Lambda _1} = \dim {\Lambda _{d-1}} =d\). By Lemma 4.3, a design which integrates \(\Lambda _d\) must have an even number of vertices. We claim that a subset of two vertices integrates \(\Lambda _1\) if and only if it is of the form \(\{v, \mathbb {1}-v\}\). Lemma 4.4 shows one direction of this statement. Suppose that \(\{v,w\} \) integrates \(\Lambda _1\). Then for each \(i=1,\ldots , d\),
Hence \(w_i = 1-v_i\) for each i, and so \(w = \mathbb {1}- v\). This ends the proof of the claim.
Suppose \(d>1\) is odd. Then \(\{v,\mathbb {1}-v\}\) integrates \(\Lambda _0, \Lambda _d,\) and \(\Lambda _1\) by Lemma 4.4. Additionally, since \(wt(\mathbb {1}- e_i)\) is even,
Hence \(\varphi _{\mathbb {1}- e_i}(v) + \varphi _{\mathbb {1}- e_i}(\mathbb {1}- v) = 2\varphi _{\mathbb {1}- e_i}(v) \ne 0\) for any v, and so \(\{v,\mathbb {1}-v\}\) cannot integrate \(\Lambda _{d-1}\). Thus a 4-graphical design on \(Q_d\) must contain at least 4 vertices.
Now, let \(d>2\) be even. Then v and \(\mathbb {1}-v\) have the same parity and hence cannot integrate \(\Lambda _d\). Thus a design which integrates \(\Lambda _0, \Lambda _1,\) and \(\Lambda _d\) contains at least 4 vertices. An example of a minimal subset which integrates \(\Lambda _0, \Lambda _1,\) and \(\Lambda _d\) is \(W = \left\{ e_1, e_1+e_2, \mathbb {1}- e_1 , \mathbb {1}- e_1 -e_2\right\} \). W has two odd weight vectors, two even weight vectors, and \(w\in W \iff \mathbb {1}-w \in W\). Thus by Lemmas 4.3 and 4.4, W integrates \(\Lambda _0, \Lambda _d, \) and \(\Lambda _1,\) as well as \(\Lambda _{d-1}\) since \(d-1\) is odd. \(\square \)
We note that these subsets remain fixed no matter how large d is.
4.2 Linear Codes as Designs
We begin with a little background on codes. For a more complete exposition, see Chapter 1 of [19], for instance. A code is a subset \(C \subset \{0,1\}^d\), where \(\{0,1\}^d\) is the set of all words. An element \(c\in C\) is called a codeword. We will stick with the case of transmitting bits, but one can also consider codes on a larger “alphabet” than \(\{0,1\}\). The distance of a code is
A linear code is a linear subspace of \(\{0,1\}^d\), viewed as a vector space with addition mod 2. It is quick to check that the distance of a linear code is the minimum weight of a nonzero codeword. Every linear code C can be described as the kernel of a check matrix M:
If M is the \(K \times d\) check matrix for a code C, then C is an \((d-K)\)-dimensional vector space over \(\{0,1\}\), and the row span of M is a K-dimensional vector space over \(\{0,1\}\). We will also need the concept of dual codes.
Definition 4.6
(see Sect. 1.8 of [19]). Let \(C \subset \{0,1\}^d\) be a linear code with check matrix M. The dual code of C is
In other words, \(C^\perp \) is the row span of M in \(\{0,1\}^d\).
A good code is both spread out among the vertices of \(Q_d\) and in some sense near all the other vertices, which aligns with what we desire from a graphical design. So, we investigate linear codes as designs on \(Q_d\). We will use the following technique.
Lemma 4.7
([13]). Let \(G=(V,E)\) be regular and let \(\{\varphi _1 = \mathbb {1},\ldots , \varphi _n\}\) be an orthogonal basis of eigenvectors for L. If \(W\subset V\) is such that \(\mathbb {1}_W\) can be written as a linear combination of the eigenvectors \(\mathbb {1}, \varphi _{j_1},\ldots , \varphi _{j_N}\), then W integrates the eigenvectors other than \(\varphi _{j_1},\ldots , \varphi _{j_N}\).
Proof
Suppose \(\mathbb {1}_W = \alpha _0\mathbb {1}+ \sum _{i=1}^N \alpha _i\varphi _{j_i}.\) Let \(j \notin \{1, j_1,\ldots , j_N\}\). Since G is regular, Lemma 4.2 gives us that W integrates \(\varphi _j\) if \(\varphi _j^T\mathbb {1}_W=0\). Then
by orthogonality. Thus W integrates \(\varphi _j\). \(\square \)
Note that being able to express \(\mathbb {1}_W\) as \( \alpha _0\mathbb {1}+ \sum \alpha _i\varphi _{j_i}\) does not necessarily preclude W from integrating some of \(\{\varphi _{j_i}\}_{i=1}^N\).
Theorem 4.8
Let \(C = \{x: Mx =0\}\) be a linear code in \(\{0,1\}^d\), where M is a \(K \times d\) matrix. C integrates \(\varphi _v\) if and only if \(v \notin C^{\perp }\) or v is the zero vector.
Proof
Let C be a linear code with check matrix M, which has rows \(a_i\), \(i =1,\ldots , K.\) For \(I \subseteq [K]\), denote \(a_I =\sum _{i\in I} a_i.\) We take \(a_\varnothing = 0\), the all-zeros vector. Since \(C^\perp \) is the rowspan of M, \(C^{\perp }= \{a_I: I\subseteq K\}.\) By Lemma 4.7, showing
proves that if \(v \notin C^\perp \), then C integrates \(\varphi _v\). Let \(c\in C\). Then \(a_i^Tc =0\) for each \(i=1,\ldots , K\). Hence \(\varphi _{a_I}(c)= 1 \text { for each } I\subseteq [K].\) There are \(2^K\) subsets of [K], so
Let \(v\notin C\). Then there is a row \(a_j\) such that \(a_j^Tv =1\). Then, consider all subsets \(I\subseteq [K]\) such that \(j\notin I\). We see that
Therefore, by pairing off the eigenvectors \(\varphi _{a_I}\) and \(\varphi _{a_{I \cup j}}\), we have
To show the other direction, we first note that the eigenvectors \(\varphi _v\) are orthogonal. If \(v,w \in \{0,1\}^d\) are distinct, then
since all nontrivial eigenspaces are orthogonal to \(\mathbb {1}\). Now, suppose \(v \in C^\perp \) is nonzero. Then, \(v = a_{J}\) for some \(\varnothing \ne J \subseteq [K]\). By orthogonality, we see that
Hence C does not integrate \(\varphi _v\). \(\square \)
The dual code may contain eigenvectors of any weight, so the unintegrable eigenvectors may come anywhere in the frequency ordering. Thus we seek linear codes where all rows of M are near d/2 in weight, so that the unintegrable eigenspaces are as far out in the frequency ordering as possible.
4.3 Hamming Codes
In this section, we look at Hamming codes and extensions of them as designs. Hamming codes are linear codes first introduced by Hamming in [15] which are built on the idea of parity checking. For each \(r\ge 2\), there is a Hamming code \(H_r\) in the \((2^r -1)\)-cube. \(H_r\) is a vector subspace of dimension \(2^r-r-1\), and \({\text {dist}}(H_r) =3\). The cardinality of \(H_r \) is \(2^{2^r-r-1}\). We again refer the reader to Chapter 1 of [19] for a more complete introduction.
The check matrix \(M_r\) of the Hamming code \(H_r\) is the \(r \times (2^r -1)\) matrix whose columns are the nonzero vertices of the r-cube. We can see this in the check matrix
The dual code \(H_r^\perp \), which we recall is the rowspan of \(M_r\), is called the simplex code, so named because its vectors form the vertex set of a regular \((2^r-1)\)-simplex. We will use the following facts about the simplex code (see [19, Sect. 1.9]). The simplex code in dimension \(2^{r}-1\) consists of the zero vector and \(2^r-1\) vectors of weight \(2^{r-1}\). For all \(v,w\in H_r^\perp ,\) \(d_H(v,w) = 2^{r-1}\).
Theorem 4.9
The Hamming code \(H_r\) is a \((2^r-1)\)-design on \(Q_{2^r-1}\), and
Proof
All nonzero vectors in \(H_r^\perp \) have weight \(2^{r-1}\). By Theorem 4.8, any eigenvector which \(H_r\) cannot integrate must lie in the eigenspace \(\Lambda _{2^{r-1}}\). Thus \(H_r\) integrates all eigenspaces besides \(\Lambda _{2^{r-1}}\). Recall that the frequency ordering of \(Q_{2^r-1} \) is
Thus \(\Lambda _{2^{r-1}}\) can be ordered last by frequency in \(Q_{2^r-1}\). Recall that the numerator of \({\text {efficacy}}(H_r)\) is \(|H_r| = 2^{2^r-r-1}\), and since \(\dim (\Lambda _{2^{r-1}})=\left( {\begin{array}{c}2^{r}-1\\ 2^{r-1}\end{array}}\right) \), we have that
Asymptotically,
thus as r grows,
\(\square \)
Theorem 4.10
The Hamming code \(H_r\) is the smallest linear code in cardinality which integrates all eigenspaces of \(Q_{2^r-1}\) except for the eigenspace \(\Lambda _{2^{r-1}}\).
Proof
Let M be the \(K \times (2^r -1)\) check matrix of an arbitrary linear code C. If \(K < r\), then \(|C| > |H_r|\).
Suppose \(K =r\) and C integrates all eigenspaces except for \(\Lambda _{2^{r-1}}\). Then \(C^\perp \), the row span of M, consists of \(2^r\) vectors of weight \(2^{r-1}\). Since \(C^\perp \) is linear, it follows that \(C^\perp \) consists of \(2^r\) vectors all at distance \(2^{r-1}\) from each other. It is a standard result in discrete geometry that \(2^r\) equally spaced vertices in dimension \(2^r-1\) must form the vertex set of a regular \((2^r-1)\)-simplex. Therefore, \(C^\perp \) is the simplex code, and so \(C =H_r\), up to relabeling of the vertices.
If \(K>r,\) then \(C^\perp \) consists of more than \(2^r\) points. Another standard result in discrete geometry is that the maximum number of equidistant points in \({{\mathbb {R}}}^{2^r-1}\) is \(2^r\). Hence there must be nonzero vectors u and v in \(C^\perp \) such that \( wt(u) \ne wt(v)\). Thus C cannot integrate the distinct eigenspaces \(\Lambda _{wt(u)}\) and \(\Lambda _{wt(v)} \) by Lemma 4.8. \(\square \)
We show in Theorem 5.8 that the Hamming code \(H_2\) is optimal in the sense of Definition 1.3 on \(Q_3\), but it is unknown whether any other Hamming codes are optimal. Recall that in \(Q_d\), \(\dim (\Lambda _j) = \left( {\begin{array}{c}d\\ j\end{array}}\right) \). In light of Theorem 4.10 and the increasing dimension of higher frequency eigenspaces, we suspect the following.
Conjecture 4.11
The Hamming code \(H_r\) is an optimal design on \(Q_{2^{r}-1}\).
4.4 Extensions of Hamming Codes
Variations of the Hamming code provide effective designs on other cube graphs. We start by lifting \(H_r\) to higher dimensions. Let \(M_r\) be the check matrix of the Hamming code \(H_r\), and \(H_r'\) be the code with check matrix \(M_r' = [M_r \ 0]\), where 0 represents a column of zeros. For instance, for \(r=3\), this would yield a linear code on the 8-cube with check matrix
We can do this again. Let \(H_r''\) be the code with check matrix \(M_r'' = [M_r \ 0 \ 0]\).

The design \(H_2'\) on \(Q_4\)
Theorem 4.12
The lifted Hamming code \(H_r'\) is a \(2^r\)-design on \(Q_{2^r}\), and \(H_r''\) is a \((2^r+1)\)-design on \(Q_{2^r+1}\). We have that
Proof
The row spans of \(M_r' \) and \(M_r''\) are contained in \(\Lambda _{2^{r-1}}\). By Theorem 4.8, \(H_r'\) and \(H_r''\) then integrate all eigenspaces but \(\Lambda _{2^{r-1}}\). The frequency ordering of \(Q_{2^r} \) is
and the frequency ordering on the eigenspaces of \(Q_{2^r+1} \) is
Since \(\Lambda _{2^{r-1}}\) is last by frequency for \(Q_{2^r}\), \(H_r'\) is a \(2^r\)-design on \(Q_{2^r}\). Since \(\Lambda _{2^{r-1}}\) may be ordered last by frequency for \(Q_{2^r+1}\), \(H_r''\) is a \((2^r+1)\)-design on \(Q_{2^r+1}\). We calculate the efficacy of these designs both exactly and asymptotically in the same manner as in Theorem 4.9. \(\square \)
We show in Theorem 5.12 that \(H_2'\) is optimal on \(Q_{4}\), but it is otherwise unknown whether lifted Hamming codes are optimal. Geometrically, the lift \(H_r'\) to the \(2^r\)- cube is an embedding of two copies of \(H_r\), one on the \(x_{2^r}= 0\) facet and one on the \(x_{2^r}= 1\) facet. Likewise, \(H_r''\) embeds four copies of \(H_r\) in the \((2^r+1)\)-cube. Unfortunately, we cannot push this pattern further without a loss of efficacy, as \(\Lambda _{2^{r-1}} \) cannot be ordered last by frequency in other dimensions.
Conjecture 4.13
The lifted Hamming codes \(H_r'\) and \(H_r ''\) are optimal designs on their respective graphs \(Q_{2^{r}}\) and \(Q_{2^{r}+1}\).
To extend \(H_r\) as a design to cubes of lower dimension, we consider projections. Consider the check matrix \(\pi (M_r)\), the matrix with all but the last column of \(M_r.\) For instance, for \(r=3\), this provides a code on the 6-cube with check matrix
We denote the linear code with this check matrix by \(\pi (H_r)\), which we call the projected Hamming code.
Theorem 4.14
The linear code \(\pi (H_r)\) is a \((2^r-3)\)-design on \(Q_{2^r-2}\) with
Proof
Let \(\{a_1,\ldots , a_r\}\) be the rows of \(M_r\), and let
We recall that \(a_I\) is an element of the simplex code, and hence has weight \(2^{r-1}\). Since the last coordinate of \(a_i\) is 1 for each \(i=1,\ldots ,r\), the last coordinate of \(a_I\) is \(|I| \mod 2 \). Thus \(\pi (a_I)\) has weight \(2^{r-1}\) when |I| is even and weight \(2^{r-1}-1\) when |I| is odd. Therefore \(\pi (H_r)\) integrates all eigenspaces except for \(\Lambda _{2^{r-1}-1}\) and \(\Lambda _{2^{r-1}}\). The frequency ordering on \(Q_{2^r-2}\) is
Thus the eigenspaces \(\Lambda _{2^{r-1}-1}\) and \(\Lambda _{2^{r-1}}\) may be ordered last by frequency. The efficacy calculation follows since \(\dim \Lambda _{2^{r-1}-1} = \left( {\begin{array}{c}2^r-2\\ 2^{r-1}-1\end{array}}\right) \) and \(\dim \Lambda _{2^{r-1}} = \left( {\begin{array}{c}2^r-2\\ 2^{r-1}\end{array}}\right) \). The asymptotics follow similarly to Theorem 4.9. \(\square \)
While we conjectured that \(H_r\) and its lifts are optimal, we are less optimistic about \(\pi (H_r)\). On \(Q_6\), we have that \({\text {efficacy}}(\pi (H_3))=8/29 \approx .276\). Lemma 4.5 provides a design W on \(Q_6\) with \({\text {efficacy}}(W) = 4/14 \approx .286.\) As r grows, we suspect there may be designs which are more effective than \(\pi (H_r)\) on \(Q_{2^r-2}\).
5 Extremal Designs
We next turn to the concept of extremal designs, as introduced in [13].
Definition 5.1
([13]). An extremal design on a regular graph \(G=(V,E)\) is a subset \(W\subset V\) which integrates all but one eigenvector in some eigenbasis of L.
If \(G=(V,E)\) is regular, \(W\subset V\) is extremal if \(\mathbb {1}_W\) can be written as a linear combination of \(\mathbb {1}\) and one other eigenvector of L by Lemma 4.7. Moreover, this condition is equivalent to being extremal by the following lemma.
Lemma 5.2
Let \(G=(V,E)\) be regular. A proper subset \(W\subset V\) cannot integrate every eigenvector of L.
Proof
Let \(G = (V,E)\) be a regular graph on n vertices and let \(\{ \mathbb {1}= \varphi _1, \varphi _2, \ldots , \varphi _n\}\) be an orthonormal basis of eigenvectors for L. Suppose a subset \(W\subseteq V\) integrates every eigenvector in this basis, that is, \( \varphi _j^T \mathbb {1}_W = 0 \) for each \(j=2,\ldots , n.\) We can expand \(\mathbb {1}_W\) in this basis: \( \mathbb {1}_W = \alpha _1 \mathbb {1}+ \sum _{i=2}^n \alpha _i\varphi _i\) for some \(\alpha _i\in {{\mathbb {R}}}\). Therefore,
for each \( j = 2,\ldots , n.\) Thus \(\mathbb {1}_W = \alpha _1 \mathbb {1}\) implies \(\alpha _1 =1\) and \(W= V\). \(\square \)
Golubev’s two main results show that subsets which meet known spectral bounds are extremal. We start with a quick positive result.
Corollary 5.3
The Hamming code \(H_r\) and its lifts \(H_r'\) and \(H_r''\) are extremal designs in \(Q_{2^r-1}, Q_{2^r}\), and \(Q_{2^r+1}\), respectively.
Proof
These designs integrate all but one eigenspace by Theorems 4.9 and 4.12. By Lemma 3.2, there is an eigenbasis for the unintegrable eigenspace such that a design fails to integrate only one eigenvector of the eigenbasis. \(\square \)
This principal applies more generally. A graphical design is extremal as in Definition 5.1 if and only if it integrates all but one eigenspace.
5.1 Graphical Designs from the Hoffman Bound
Recall that the stability number of a graph is \(\alpha (G) = \{\max |W|: W\subset V \text { is a stable set}\}.\) Golubev’s first result makes use of the Hoffman bound. Though often provided as the reference, Hoffman’s bound does not appear in [16]. The murky origins of the Hoffman bound are described in [14].
Theorem 5.4
(Hoffman) Let G be a regular graph on n vertices, and let \(\lambda _{\min }\) be the least eigenvalue of L. Then,
Golubev shows that stable sets which attain this bound are extremal designs.
Theorem 5.5
([13, Theorem 2.2]) Let G be a regular graph on n vertices for which the Hoffman bound is sharp. Let \(W \subset V\) be a stable set realizing \(\alpha (G),\) i.e.
Then W is an extremal design.
As we will now show, extremal designs found through Golubev’s methods are unlikely to perform well in the frequency ordering.
Theorem 5.6
A stable set for which the Hoffman bound is sharp is unable to integrate the eigenspace corresponding to \(\lambda _{\min }\).
Proof
Let \(G=(V,E)\) be a regular graph for which the Hoffman bound is sharp, and let \(W \subset V\) be a stable set which achieves the Hoffman bound. Let \(\mathbb {1}_W = \sum _{i=1}^n \alpha _i\varphi _i\), \(\alpha _i \in {{\mathbb {R}}}\), \(\varphi _1 = \mathbb {1}\) be a decomposition of \(\mathbb {1}_W\) with respect to a fixed eigenbasis of L. In the proof of the Hoffman bound (see [13, Theorem 2.1]), there is a chain of inequalities
In order for the bound to be sharp, the proof of [13, Theorem 2.2] notes that this chain of inequalities must be sharp. If
then for \(i \ge 2\), \(\alpha _i=0\) whenever \(\lambda _i \ne \lambda _{\min }\). Hence we can write \(\mathbb {1}_W = \mathbb {1}+ \beta \varphi \), where \(L\varphi =\lambda _{\min } \varphi \) , \(\beta \in {{\mathbb {R}}}\). Thus W cannot integrate the eigenspace for \( \lambda _{\min }.\) \(\square \)
Without further information, one might expect the minimum eigenvalue of L to be near the lower bound of \(-2\), which we recall is early in the frequency ordering. This conundrum is seen most strikingly in bipartite graphs.
Example 5.7
If \(G = (U \sqcup V, E)\) is bipartite, then the eigenvalue \(\lambda _{\min } = -2\) of L is second in the frequency ordering. Thus an extremal design which achieves the Hoffman bound on a bipartite graph is at best a 1-graphical design.

The complete bipartite graph \(K_{4,4}\). The red subset attains the Hoffman bound and so is extremal. However, it is only a 1-graphical design. The blue subset is a 2-graphical design, extremal, and optimal (Color figure online)
We can make use of Theorem 5.5 to find optimal designs on Cayley graphs. Recall that a connected, undirected Cayley graph \(\Gamma (H,S)\) arises from a group H and symmetric generating set \(S\subseteq H\), where symmetric means \(S = S^{-1}:=\{s^{-1}:s\in S\}\). The vertex set of \(\Gamma (H,S)\) is H, and xy is an edge if \(y = xs\) for some \(s\in S\). If H is an abelian group with n elements, then there are n group characters \(\chi :H \rightarrow {{\mathbb {C}}}^*\), each of which provides an eigenvector \((\chi (h))_{h\in H}\) of L with eigenvalue \((1/|S|)\sum _{s\in S} \chi (s) -1\). Thus if \(\chi \) is an eigenvector of \(\Gamma (H,S)\) with eigenvalue \((1/|S|)\sum _{s\in S} \chi (s) -1 \), then \(\chi \) is an eigenvector of \(\Gamma (H,S')\) with eigenvalue \((1/|S'|)\sum _{s\in S'} \chi (s) -1\). Therefore an extremal design on a Cayley graph \(\Gamma (H,S)\) is also extremal on \(\Gamma (H,S')\) for all other symmetric generating sets \(S'\). Theorem 5.5 (see also Theorem 5.10) gives a sufficient condition for a design to be extremal, though we have shown the frequency order of the unintegrated eigenspace may not be ideal. However, given a different generating set, the unintegrated eigenspace may be last in the frequency ordering.
We use this idea to show that \(H_2\) is optimal on \(Q_3\). This is equivalent to using a sledgehammer on a thumbtack, but we think the strategy may be more generally useful. Consider the distance graph \(Q_d(N)\), with the same vertex set as \(Q_d\), and edge set \(E = \{vw: 0 < d_H(v,w) \le N\}\). Note that \(Q_d(1) = Q_d\), and that \(Q_d(N)\) is the Cayley graph \( \Gamma (H,S)\) with \(H= \{0,1\}^d\) and \(S=\{ \sum _{i\in I} e_i\}_{I\subseteq [d],|I|\le N}\).
Theorem 5.8
The Hamming code \(H_2 = \{000,111\}\) is an optimal design on \(Q_3\).
Proof
We compute the spectral information of L for \(Q_3\) and \(Q_3(2)\), described in Table 2. Thus the Hoffman bound gives us that
The Hamming code \(H_2 \) is a stable set in \(Q_3(2)\) which attains the Hoffman bound, hence \(H_2\) is extremal on \(Q_3(2)\). By Theorem 5.6, the eigenspace \(H_2\) fails to integrate is \(\Lambda _2\), since \(-4/3\) is the least eigenvalue of L of \(Q_3(2)\). The eigenspace \(\Lambda _2\) can be ordered last by frequency on \(Q_3\). Therefore, \({\text {efficacy}}(H_2) = 2/5\). Since no single vertex integrates \(\Lambda _3\) by Lemma 4.3, \(H_2\) is then optimal on \(Q_3\). \(\square \)
5.2 Graphical Designs from the Cheeger Bound
The other main result of [13] relies on the following variant of the Cheeger bound. We use \(E(W, V {\setminus } W)\) to denote the set of edges with one vertex in W and the other in \(V{\setminus } W\).
Theorem 5.9
([1, 32]) Let G be a connected \(\delta \)-regular graph and \(\lambda ^*\) be the second largest eigenvalue of L. Then
In a manner similar to Theorem 5.5, Golubev shows that subsets which attain the Cheeger bound are extremal.
Theorem 5.10
([13, Theorem 2.4]) Let \(G = (V,E)\) be a \(\delta \)-regular graph for which the Cheeger bound is sharp. Suppose \(\varnothing \ne W \subset V\) realizes the Cheeger bound:
Then W is an extremal design.
The proof of this result in [13] indicates which eigenspace cannot be integrated.
Theorem 5.11
A subset \(W\subset V\) for which the Cheeger bound is sharp cannot integrate the eigenspace with eigenvalue \(\lambda ^*\).
Proof
Let \(G=(V,E)\) be a \(\delta \)-regular graph, and suppose \(W \subset V\) achieves the Cheeger bound. Let \(\mathbb {1}_W = \sum _{i=1}^n \alpha _i\varphi _i\). \(\alpha _i \in {{\mathbb {R}}}\), \(\varphi _1 = \mathbb {1}\) be a decomposition of \(\mathbb {1}_W\) with respect to a fixed eigenbasis of L. In the proof of the Cheeger bound (see [13, Theorem 2.3]), there is a chain of inequalities which we abbreviate here:
In order for the bound to be sharp, the proof of [13, Theorem 2.4] notes that this chain of inequalities must be sharp. Thus if
then for \(i \ge 2\), \(\alpha _i =0\) whenever \(\lambda _i \ne \lambda ^*\). Hence we can write \(\mathbb {1}_W = \mathbb {1}+ \beta \varphi \), where \(\varphi \) is an eigenvector of L with eigenvalue \(\lambda ^*\) and \(\beta \in {{\mathbb {R}}}\). Therefore W cannot integrate the eigenspace with eigenvalue \(\lambda ^*\). \(\square \)
Since \(\lambda ^*\) is the second largest eigenvalue of L, one might expect it to be near 0, which corresponds to an eigenspace early in the frequency ordering of L. Theorems 5.6 and 5.11 may then be a way to tie expander graphs into the theory of graphical designs. If \(\lambda _{\min }\) is near \(-1\), then the Hoffman bound may work well with the frequency ordering. Similarly, if \(\lambda ^*\) is near \(-1\), then the Cheeger bound may work well with the frequency ordering.
5.3 More on Cube Graphs
We first compare several designs on \(Q_d\).

\(Q_3\). The red subset, which attains the Cheeger bound, and the blue subset, \(H_2\), both integrate the eigenspaces \(\Lambda _0, \Lambda _1,\) and \(\Lambda _3\), which come first in the frequency ordering. Since the Hamming code has fewer vertices, it is more effective (Color figure online)
Our Theorem 4.8 can be thought of as an extension of [13, Theorem 3.3], which considers linear codes on \(Q_d\) with \(1 \times d\) check matrices. The most effective design on \(Q_d\) by this method has efficacy \((2^{d-1})/(2^d-\left( {\begin{array}{c}d\\ \lceil d/2\rceil \end{array}}\right) )>.5\). We recall the efficacies of \(H_r\) and its lifts approach \( 1/2^r\). For a concrete example, consider the 7-cube. The most effective design from [13, Theorem 3.3] will have efficacy \(64 /93 \approx .688\). We calculate \({\text {efficacy}}(H_3) = 16/93 \approx .172\).
Section 3.5 of [13] shows that the Cheeger bound is attained for \(Q_d\) by the subset \(S =\{ v\in \{0,1\}^d: v_1 =1\}.\) In this graph, the eigenspace with eigenvalue \(\lambda ^* = - 2/d\) of L can at best be ordered fourth by frequency, behind \(\lambda _1 =0, \lambda _d =-2\) and \(\lambda _{d-1} = -2 + 2/d\). Thus S is a 3-design. Since \(|S| = |V|/2\), \({\text {efficacy}}(S)=(2^{d-1})/(d+2)\), which grows exponentially in d. We also note that \(Q_d\) is bipartite, where the bipartition separates even and odd weight vertices. Example 5.7 thus shows that the set of even (or odd) weight vertices is an extremal design on \(Q_d\) which consist of \(2^{d-1}\) vertices.
Lastly, we show that optimal designs are a distinct concept from stable sets using \(Q_4\) and the lifted Hamming code \(H_2'\) as an example. Theorem 5.5 is a link between graphical designs and maximum stable sets. The Hamming code \(H_r\) is a maximum stable set in the graph \(Q_{2^r-1}(2)\). In several of the striking examples shown in [28], the graphical designs found are maximum stable sets. The proof of Theorem 5.8 was inspired by the work utilizing maximum stable sets in distance graphs following Delsarte’s linear programming bound for codes ( [10]). This body of work computes upper bounds for the largest codes of a fixed distance in some setting through semidefinite programming. See [34] for a more complete overview of this area. We find it natural to then wonder whether graphical designs are the same as maximum stable sets, possibly in a distance graph, or whether optimal designs are stable sets at all. The lifted Hamming code \(H_r'\) as described in Sect. 4.4 (see Fig. 7) is not a stable set in \(Q_{2^r}\), but \({\text {efficacy}}(H_r')\) is small. Moreover, we have the following optimality result for \(Q_4\).
Theorem 5.12
The lifted Hamming code \(H_2'= \{ 0000,0001,1111,1110\}\) is an optimal design on \(Q_4\), and no optimal design on \(Q_4\) is a stable set.
Proof
Since \(Q_4\) has an even number of vertices, Lemmas 4.3 and 4.4 imply that if \(W\subset Q_4\) is such that \(|W| \le 3\), then W integrates at most the first two eigenspaces \(\Lambda _0\) and \(\Lambda _4\), a total of two eigenvectors. Theorem 4.12 shows that \(H'_2\) integrates all but the last eigenspace in the frequency ordering. Thus the minimal efficacy of a design on \(Q_4\) is 4/10, and \(H_2'\) achieves this minimum. A brute force search finds 16 4-element subsets in \(Q_4\) which are optimal, none of which are stable sets. \(\square \)
6 Association Schemes and t-Designs
At first glance, there are obvious similarities between t-designs on association schemes, introduced in full generality by Delsarte [10], and our graphical designs. We will show that they are not the same concepts despite these formal similarities. We will exhibit extremal and optimal graphical designs on association schemes that are not t-designs (Proposition 6.10 and Example 6.12) and also show that that even if a graphical design is a t-design, it may be a k-graphical design where k and t are quite different (Proposition 6.17). We start with a brief introduction to association schemes. This exposition is based primarily on [19, Chap. 21].
6.1 Association Schemes
Definition 6.1
(see Chapter 21 of [19]). A (symmetric) association scheme \((X, {{\mathcal {R}}})\) with s classes is a finite set X and \(s+1\) relations \({{\mathcal {R}}}= \{R_0,\ldots R_s\}\) on X such that
-
(1)
\((x,y) \in R_i \iff (y,x) \in R_i\).
-
(2)
For all \(x,y\in X\), \((x,y) \in R_i\) for exactly one i.
-
(3)
\(R_0 = \{(x,x): x\in X\}\).
-
(4)
If \((x,y) \in R_q\), then the number of \(z\in X\) such that \((x,z)\in R_i\) and \((y,z) \in R_j\) is a constant \(\alpha _{ijq}\) which does not depend on the choice of x or y.
If \((x,y) \in R_i\), we say that y is an i-th associate of x. It can help to visualize an association scheme as a complete graph on X with labeled edges as in Fig. 10.

The Hamming association scheme on the 3-cube, where \(X = \{0,1\}^3 \) and \(R_i = \{(x,y): d_H(x,y) =i\}\). We indicate \(R_0\) by green, \(R_1\) by black, \(R_2\) by red, and \(R_3\) by blue (Color figure online)
We can reformulate Definition 6.1 using matrices. Let \(A_i \in {{\mathbb {R}}}^{X \times X}\) be the adjacency matrix of \(R_i\). That is,
Then conditions (1) through (4) of Definition 6.1 are
-
(1)
\(A_i\) is a symmetric matrix for each i.
-
(2)
\(\sum _{i=0}^{s} A_i\) is the all-ones matrix.
-
(3)
\(A_0 =I\).
-
(4)
\(A_iA_j = \sum _{q=0}^s \alpha _{ijq}A_q = A_jA_i\).
Consider the real vector space \({{\mathcal {A}}}= \{\sum _{i=0}^s \beta _i A_i : \beta _i \in {{\mathbb {R}}}\}\). By (2) of Definition 6.1, the dimension of \({{\mathcal {A}}}\) is \(s+1\), and by (4) of Definition 6.1, \({{\mathcal {A}}}\) is closed under matrix multiplication, which is commutative. Thus \({{\mathcal {A}}}\) is an associative, commutative algebra, called the Bose-Mesner algebra of the association scheme after [6]. It can be shown that \({{\mathcal {A}}}\) is semisimple, and thus has a unique basis of primitive idempotents \(J_0, \ldots , J_s.\) These \(J_i \in {{\mathbb {R}}}^{X \times X}\) satisfy
-
(1)
\(J_i\) is a symmetric matrix for each i.
-
(2)
\(J_i^2 = J_i, \ i=0,\ldots , s.\)
-
(3)
\(J_iJ_j = 0 \) for \( i \ne j\).
-
(4)
\(\sum _{i=0}^s J_i = I\).
We always take \(J_0\) to be the all-ones matrix scaled appropriately, but in general, there is no ordering imposed on the \(J_i\). We now have two distinct bases for \({{\mathcal {A}}}\). Let’s express one in terms of the other:
for some \(p_j(i) \in {{\mathbb {R}}}\). By the properties of idempotents, we then have that
Thus the eigenspace of \(A_j\) with eigenvalue \(p_j(i)\) contains \({\text {col}}(J_i),\) the column span of \(J_i\). Each eigenspace of \(A_j\) consists of the collected column spans of some of the matrices \(J_i\). So if \(p_j(i) \ne p_j(q)\) for each \(q\ne i\), then the eigenspace with eigenvalue \(p_j(i)\) is exactly \({\text {col}}(J_i)\). To be clear, distinct adjacency matrices \(A_j \) and \(A_q\) will generally have different sets of eigenvalues \(\{p_j(i)\}_{i=0}^s\) and \(\{p_q(i)\}_{i=0}^s\), respectively, though it can be that \(p_j(i) = p_q(i)\). However, for each i, \({\text {col}}(J_i)\) is contained in the eigenspaces of \(p_j(i)\) and \(p_q(i)\). The next lemma mirrors the discussion of Cayley graphs on a fixed group with different generating sets preceding Theorem 5.8.
Lemma 6.2
Let \((X, {{\mathcal {R}}})\) be an s-class association scheme, let \(I \subset [s]\), and denote \(R_I = \cup _{j\in I} R_j\). If \(Y\subset X\) integrates \({\text {col}}(J_i)\) for all but one \(i\in [s]\), then Y is an extremal design in the graph \(G_I = (X, R_I)\). The eigenspace of \(A_I = \sum _{j\in I} A_j\), the adjacency matrix of \(G_I\), that Y does not integrate has eigenvalue \(\sum _{j\in I} p_j(i)\).
Proof
Let \(\varphi \in {\text {col}}( J_i)\), \(i\in [s].\) Since \(A_j \varphi = p_j(i)\varphi \) for each \(j =0,\ldots s,\) we have that
So we see that \(\varphi \) is an eigenvector of \(A_I\) with eigenvalue \(\sum _{j\in I} p_j(i)\).
Suppose Y integrates all but \({\text {col}}(J_{i'})\) for some \(i'\in [s]\). Then the only eigenvectors Y cannot integrate lie in \({\text {col}}(J_{i'})\) which is contained in the eigenspace with eigenvalue \(\sum _{j\in I} p_j(i')\) for \(A_I\). \(\square \)
Note that the above lemma was proven in terms of the adjacency matrices \(A_i\), not the Laplacian. It is sufficient to work with the adjacency matrices in the case of regular graphs by the following lemma.
Lemma 6.3
Let \(G = (V,E)\) be a \(\delta \)-regular graph with adjacency matrix A. Then v is an eigenvector of A with eigenvalue \(\lambda \) if and only if v is an eigenvector of \(L = AD^{-1} - I\) with eigenvalue \(\lambda /\delta -1\).
Proof
If G is \(\delta \)-regular, then \(AD^{-1} = A/\delta \). So,
\(\square \)
6.2 T-Designs, t-Designs, and the Johnson Scheme
We begin relating T-designs in association schemes to graphical designs in our sense. We then examine the more structured case of t-designs in cometric association schemes. We use the Johnson scheme as an example where the ordering of eigenspaces due to the cometric structure is incompatible with the frequency ordering.
Definition 6.4
(see Theorem 3.10 of [10]). Let \((X, {{\mathcal {R}}})\) be an association scheme with s classes and \(T \subseteq [s].\) A T-design is \(Y \subset X\) such that \(J_i \mathbb {1}_Y =0\) for each \(i\in T\).
From the definition, it is clear that T-designs integrate the eigenvectors in \({\text {col}}(J_i)\) for \( i \in [T]\) in the sense of graphical designs. However, without more information, there is no guarantee that any \({\text {col}}(J_i)\) spans an eigenspace, and we know nothing about where any integrated eigenspaces are in the frequency ordering.
Lemma 6.5
Let \((X, {{\mathcal {R}}})\) be an association scheme with s classes, \(I \subset [s]\) be an index set, and let \(G_I = (X,R_I)\) be the graph with edge set \(R_I = \cup _{i\in I} R_i\). If \(Y\subset X\) is a k-graphical design, then Y is a T-design for some \(|T| \ge k-1\).
Proof
Let \( \Lambda _1 = {\text {span}}\{\mathbb {1}\} \le \Lambda _2 \le \ldots \le \Lambda _m\) be the eigenspaces of \(G_I\) ordered by frequency. Suppose \(Y\subset X\) integrates \(\Lambda _1, \Lambda _2, \ldots , \Lambda _{k}\). For \(j \in [k]\), \(\Lambda _j\) contains the column span of at least one idempotent, call it \(J_{i_j}\). Let \(T = \{i_j: j=2,\ldots , k\}\). Since \(J_{i_j}^T \mathbb {1}_Y =0\) for each \(j=2,\ldots ,k,\) we have that Y is a T-design. \(\square \)
If an association scheme has the property that it is cometric, or equivalently Q-polynomial, there is a natural ordering of the idempotents as \(J_0, J_1,\ldots , J_s\). For definitions and more details on this matter, see Sect. 2.7 and 2.8 of [8] and Sect. 5.3 in [10]. An association scheme can have at most two idempotent orderings which are cometric, and it is fairly unusual to have more than one [30]. If an association scheme is cometric, one can define the following.
Definition 6.6
(See Sect. 5.3 in [10]). For a cometric association scheme \((X, {{\mathcal {R}}}),\) \(Y\subset X\) is called a t-design on X if Y is a T-design for \(T = [t]\).
Due to the formal similarities, it is natural to wonder whether graphical designs reduce to classical t-designs for graphs from cometric association schemes. To show that this is not the case, we introduce the Johnson scheme. Let X be all s-element subsets of [l], and call \(A,B \in X\) i-th associates if \(|A \cap B| = s-i\). This forms a cometric association scheme with s classes, which we call the (l, s) Johnson scheme. Typically, one considers \(s\in \left[ \lfloor l/2 \rfloor \right] \), as \(s=0\) is the trivial graph, and the (l, s) Johnson scheme is equivalent to the \((l,l-s)\) Johnson scheme by symmetry of the binomial coefficient. See [10, Sect. 4.2.1] for the eigenspace ordering. We can understand t-designs on the (l, s) Johnson scheme as classical t-\((l,s,\gamma )\) designs.

The (5, 2) Johnson scheme. We indicate \(R_1\) by black and \(R_2\) by red. We omit the loops at each vertex from \(R_0\). \(G_2\) is the Petersen graph, and \(G_1\) is its complement (Color figure online)
Definition 6.7
(see Sect. 2.5 of [19]). A t-\((l,s,\gamma )\) design is a collection of s-element subsets of [l], called blocks, such that any subset of t elements chosen from [l] is in contained in exactly \(\gamma \) blocks.
Example 6.8
The projective plane PG(2, 2), as visualized below, forms a 2-(7, 3, 1) design. The nodes are elements of [7], and the lines visualize blocks of size 3. For any two points, there is exactly one line through them. The lines are elements of the (7, 3) Johnson scheme.

Classical t-\((l,s,\gamma )\) designs are connected to the Johnson scheme by the following.
Theorem 6.9
(Theorem 4.7 of [10]). Let \((X, {{\mathcal {R}}})\) be the (l, s) Johnson scheme. Then \(Y \subset X\) is a t-\((l,s,\gamma )\) design for some \(\gamma \) if and only if Y is a t-design on X for the cometric ordering given in [10, Sect. 4.2.1].
We note that for \(s >2\), the ordering of the idempotents in [10, Sect. 4.2.1] is the only cometric ordering possible. We will exhibit an optimal graphical design on a graph from a cometric association scheme which is not a classical t-design for any \( t>0.\) The Kneser graph KG(l, s) is the graph \(G_s=(X,R_s)\) from the (l, s) Johnson scheme, which is to say its vertices are s-element subsets of [l], and there is an edge between subsets which do not intersect.
Proposition 6.10
Let \((X, {{\mathcal {R}}})\) be the (l, s) Johnson scheme with \(s>2\), and let \(Y \subset X\) be the s-element subsets of [l] with exactly one fixed element in common. Then Y is extremal on \(G_s= KG(l,s)\), but Y is not a t-design.
Proof
The Hoffman bound (see Theorem 5.4) is sharp for KG(l, s). Fix an element in [l], and let \(Y\subset X\) be the s-element subsets of [l] which contain that fixed element. Sect. 3.2 of [13] shows that Y is a maximum stable set in KG(l, s) and hence extremal on KG(l, s) by Theorem 5.5.
It suffices to show that Y is not a t-\((l,s,\gamma )\) design for any t by Theorem 6.9. Let the shared element among the subsets of Y be l. That is, \(A \in Y\) is of the form
Let \(t \in [s]\). Consider the t-element subset \(S = \{ l-(t-1), \ldots ,l-1, l\}\). Then S is contained in \(\left( {\begin{array}{c}l-t\\ s-t\end{array}}\right) \) s-element subsets, all of which contain l and so are in Y. Thus if Y is a t-\((l,s,\gamma )\) design, it must be that \(\gamma = \left( {\begin{array}{c}l-t\\ s-t\end{array}}\right) .\)
We will exhibit a subset of t elements which is not contained in \(\gamma = \left( {\begin{array}{c}l-t\\ s-t\end{array}}\right) \) elements of Y. Consider \(S' = \{ l-t, \ldots ,l-1\}.\) Since \(l \notin S'\), a subset in Y containing \(S'\) will be of the form
Hence there are \( \left( {\begin{array}{c}l-(t+1)\\ s-(t+1)\end{array}}\right) \ne \gamma \) subsets in Y containing \(S'\). Thus for any \(t \in [s]\), there is no \(\gamma \) such that Y is a t-\((l,s,\gamma )\) design. \(\square \)
Corollary 6.11
Let \((X, {{\mathcal {R}}})\) be the (l, s) Johnson scheme with \(s>2\), let \(I\subset [s]\) and let \(G_I=(X, R_I)\). The subset Y in Proposition 6.10 is extremal on \(G_I\).
Proof
The Kneser graph KG(l, s) has \(s+1\) distinct eigenvalues given by
By a counting argument, it must be that the distinct eigenspaces of KG(l, s) are precisely \({\text {col}}(J_i)\), \(i =0,1,\ldots , s\). So if Y is extremal on KG(l, s), then Y integrates \({\text {col}}(J_i)\) for all but one \(i\in [s]\). Thus by Lemma 6.2, Y is extremal on \(G_I\). \(\square \)

KG(6, 2). The red vertices form an extremal design, and are a t-design for \(t=1\) on the (6, 2) Johnson scheme (Color figure online)
The case \(s=2\) is omitted due to a technical detail which we briefly outline here. The (l, 2) Johnson scheme is cometric for both possible orderings of the eigenspaces: \(J_0, J_1, J_2\) and \(J_0, J_2, J_1\). The design Y of Proposition 6.10 integrates one nontrivial eigenspace, which will come first in the t-design ordering for one of these cometric structures on the (l, 2) Johnson scheme. Y is thus a t-design for \(t=1\) in one cometric ordering. We now exhibit an optimal design in the graph \(G_2\) of the (8, 3) Johnson scheme that is not a t-design.
Example 6.12
Let \((X,{{\mathcal {R}}})\) be the (8, 3) Johnson scheme, and let \(Y\subset X\) be the set consisting of all vertices which contain the fixed element \(\{1\}\). Then Y is a stable set in \(G_3 = KG(8,3)\) which attains the Hoffman bound, as was shown in [13].
By Theorem 5.6, Y fails to integrate the eigenspace \({\text {col}}(J_1)\), which has eigenvalue \( -16/15\) in \(G_2\). The eigenspace \({\text {col}}(J_1)\) is last in the frequency ordering for \(G_2\). Thus Y has efficacy 7/49 on \(G_2\). A brute force search shows that no subset of 6 or fewer vertices integrates \({\text {col}}(J_2)\), the first nontrivial eigenspace by frequency for \(G_2\). Thus Y is an optimal design on \(G_2\). We note that Y is not a stable set in \(G_2\).
This indicates that the eigenspace ordering enforced by the concept of a classical t-design is unrelated to the frequency ordering.
6.3 The Hamming Scheme
Take \(X = \{0,1\}^d\) and say that \((x,y) \in R_i\) if \(d_H(x,y) =i\). Then \((X,{{\mathcal {R}}})\) forms an association scheme with d classes, called the Hamming scheme (see Fig. 10). The Hamming scheme is cometric for the ordering \({\text {col}}( J_i) = {\text {span}}\{ \varphi _v : wt(v)=i\}\). Note that \(G_1=Q_d\) and \(G_{[N]}= Q_d(N)\). We further distinguish graphical designs from t-designs by comparing how the Hamming code performs in each setting.
Like with Johnson schemes, classical t-designs in the Hamming scheme have been characterized in terms of a separate combinatorial object called orthogonal arrays.
Definition 6.13
(see Sect. 11.8 of [19]). Let F be a set with q elements. An orthogonal array is a \(K \times d\) matrix with entries from F such that any set of i columns contains all possible \(q^i\) row vectors exactly \(\gamma \) times. The array has size K, d constraints, q levels, strength i, and index \(\gamma \), and is denoted (K, d, q, i). An orthogonal array is linear if q is a prime power and the rows of the orthogonal array form a vector subspace of \(F^d\).
Example 6.14
Consider the matrix
Here, \(F= \{0,1\}\), so \(q=2.\) Every choice of two columns of A contains each vector in \(\{0,1\}^2\) exactly once. Thus A is a (4, 3, 2, 2) orthogonal array of index 1. There is no zero row, so the rows of A are not a subspace of \(\{0,1\}^3\). Hence A is not linear.
In the Hamming scheme, t-designs are equivalent to orthogonal arrays.
Theorem 6.15
(Theorem 4.4 of [10]). \(Y\subset X= \{0,1\}^d\) is a t-design in the Hamming scheme if and only if the vectors of Y are a (|Y|, d, 2, t) orthogonal array.
We can use this result to compare how the Hamming code \(H_r\) performs as a classical t-design versus as a graphical design. We also use the following result for codes and orthogonal arrays.
Proposition 6.16
(see Theorem 10.17 of [29]). Let \(C \subset \{0,1\}^d\) be a linear code of dimension K. Then, \({\text {dist}}(C) =\rho \) if and only if \(C^\perp \) is a linear \((2^K, d, 2, \rho -1)\) orthogonal array.
The Hamming code integrates nearly twice as many eigenspaces in the graphical design ordering than in the ordering from classical t-designs.
Proposition 6.17
The Hamming code \(H_r\) is a \((2^r-1)\)-graphical design on \(Q_{2^r-1}\), but only a classical t-design for \(t = 2^{r-1}-1\).
Proof
See Theorem 4.9 for the result that \(H_r\) is a \((2^r-1)\)-graphical design on \(Q_{2^r-1}\). Recall that \(H_r^\perp \) is the simplex code, and \({\text {dist}}(H_r^\perp ) = 2^{r-1}\). Thus \(H_r\) forms a \((2^{2^r-r-1}, 2^r-1, 2, 2^{r-1}-1)\) orthogonal array by Proposition 6.16. Hence \(H_r\) is a t-design where \(t = 2^{r-1}-1\) by Theorem 6.15. \(\square \)
References
Alon, N., Milman, V.D.: \(\lambda _1\), Isoperimetric inequalities for graphs, and superconcentrators. J. Comb. Theory 38(1), 73–88 (1985)
Anis, A., Gadde, A., Ortega, A.: Efficient sampling set selection for bandlimited graph signals using graph spectral proxies. In: IEEE Transactions on Signal Processing a Publication of the IEEE Signal Processing Society, vol. 64(14), pp. 3775–3789 (2016)
Axler, S., Bordon, P., Ramey, W.: Harmonic Function Theory. Springer, New York (1992)
Bondarenko, A., Radchenko, D., Viazovska, M.: Optimal asymptotic bounds for spherical designs. Ann. Math. 178(2), 443–452 (2013)
Bondarenko, A., Radchenko, D., Viazovska, M.: Well-separated spherical designs. Construct. Approx. 41(1), 93–112 (2015)
Bose, R.C., Mesner, D.M.: On linear associative algebras corresponding to association schemes of partially balanced designs. Ann. Math. Stat. 30(1), 21–38 (1959). https://doi.org/10.1214/aoms/1177706356
Brouwer, A.E., Haemers, W.H.: Spectra of Graphs. Springer, New York (2012)
Brouwer, A.E., Cohen, A.M., Neumaier, A.: Distance-Regular Graphs. Springer, Berlin (1989)
Chung, F.R.K.: Spectral graph theory. Published for the Conference Board of the Mathematical Sciences by the American Mathematical Society, Providence, RI (1997)
Delsarte, Ph.: An algebraic approach to the association schemes of coding theory. Philips Res. Rept. Suppl. (1973). https://doi.org/10.1007/978-94-010-1826-5_7
Delsarte, Ph., Goethal, J.M., Seidel, J.J.: Spherical codes and designs. Geometr. Ded. 6(3), 363–388 (1977)
Gariboldi, B., Gigante, G.: Optimal asymptotic bounds for designs on manifolds (2018). arXiv: 1811.12676 [math.AP]
Golubev, K.: Graphical designs and extremal combinatorics. Linear Algebra Appl. 604, 490 (2020)
Haemers, W.H.: Hoffman’s ratio bound (2021). arXiv: 2102.05529 [math.CO]
Hamming, R.W.: Error detecting and error correcting codes. Bell Syst. Techn. J. 29(2), 147–160 (1950)
Hoffman, A.J.: On eigenvalues and colorings of graphs. In: Harris, B. (ed.) Graph Theory and Its Applications. Routledge, London (1970)
Lebedev, V.I.: Quadratures on the sphere. Zh. Vchisl. Mat. Mat. Fiz. i. 16(2), 293–306 (1976)
Linderman, G.C., Steinerberger, S.: Numerical integration on graphs: where to sample and how to weigh. Math. Comput. 89(324), 1933–1952 (2020)
MacWilliams, F.J., Sloane, N.J.A.: The Theory of Error Correcting Codes. North Holland, Amsterdam (1977)
MATLAB. version 9.9.0 (R2020b). The MathWorks Inc., Natick (2020)
Mohlenkamp, M.J.: A User’s Guide to Spherical Harmonics. http://www.ohiouniversityfaculty.com/mohlenka/research/uguide.pdf (version: 10.18.2016)
Pesenson, I.Z.: Sampling by averages and average splines on Dirichlet spaces and on combinatorial graphs (2019). arXiv: 1901.08726
Pesenson, I.Z.: A sampling theorem on homogeneous manifolds. Trans. Am. Math. Soc. 352(9), 4257–4269 (2000)
Pesenson, I.Z.: Sampling in Paley–Wiener spaces on combinatorial graphs. Trans. Am. Math. Soc. 360(10), 5603–5627 (2008)
Sagan, B.E.: The Symmetric Group: Representations, Combinatorial Algorithms, and Symmetric Functions, vol. 203, 2nd edn. Springer, New York (2001)
Sobolev, S.: Cubature formulas on the sphere which are invariant under transformations of finite rotation groups. Dokl. Akad. Nauk SSSR 146, 310–313 (1962)
Steinerberger, S.: Spectral Limitations of Quadrature Rules and Generalized Spherical Designs. In: IMRN (2019). https://arxiv.org/abs/1708.08736 (accepted)
Steinerberger, S.: Generalized designs on graphs: sampling, spectra, symmetries. J. Graph Theory 93(2), 253–267 (2020)
Stinson, D.R.: Combinatorial Designs: Construction and Analysis. Springer, New York (2004)
Suzuki, H.: Association schemes with multiple Q-polynomial structures. J. Algebraic Comb. 7, 181–196 (1998)
Tanaka, Y., et al.: Sampling signals on graphs: from theory to applications. IEEE Signal Process. Mag. 37(6), 14–30 (2020). https://doi.org/10.1109/msp.2020.3016908
Tanner, R.M.: Explicit concentrators from generalized n-gons. SIAM J. Algebra. Discret. Methods 5(3), 287–293 (1984)
Tsitsvero, M., Barbarossa, S., Di Lorenzo, P.: Signals on graphs: uncertainty principle and sampling. In: IEEE Transactions on Signal Processing a Publication of the IEEE Signal Processing Society, vol. 64(18), pp. 4845–4860 (2016)
Vallentin, F.: Semidefinite programming bounds for error-correcting codes. In: CoRR abs/1902.01253 (2019). arXiv: 1902.01253
Weyl, H.: Das asymptotische Verteilungsgesetz der Eigenwerte linearer partieller Differentialgleichungen (mit einer Anwendung auf die Theorie der Hohlraumstrahlung). Math. Ann. 71(4), 441–479 (1912)
Acknowledgements
The author would like to thank Rekha Thomas and Stefan Steinerberger for their guidance and help preparing this manuscript, Shahar Kovalsky for sharing code that assisted in computations, and Ferdinand Ihringer for noting some missing details in Sect. 6. Figures 1 and 3a–c are due to Stefan Steinerberger. Figure 3d is used with permission, copyright \(\copyright \)2015, PRISM Climate Group, Oregon State University, http://prism.oregonstate.edu/normals/; retrieved 3 Dec 2020. Computations were done in [20].
Funding
Research partially supported by the U.S. National Science Foundation grant DMS-1719538.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Babecki, C. Codes, Cubes, and Graphical Designs. J Fourier Anal Appl 27, 81 (2021). https://doi.org/10.1007/s00041-021-09852-z
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00041-021-09852-z
Keywords
- Graphical designs
- Error correcting codes
- Hamming code
- Hoffman bound
- Cheeger bound
- Graph Laplacian
- Graph sampling
- Stable sets
- Association schemes
- t-Designs
- Spherical designs
- Sobolev–Lebedev quadrature