
Abstract
Given a measure \(\mu \) of polynomial growth, we refine a deep result by David and Mattila to construct an atomic martingale filtration of \(\mathrm {supp}(\mu )\) which provides the right framework for a dyadic form of nondoubling harmonic analysis. Despite this filtration being highly irregular, its atoms are comparable to balls in the given metric—which in turn are all doubling—and satisfy a weaker but crucial form of regularity. Our dyadic formulation is effective to address three basic questions:
-
(i)
A dyadic form of Tolsa’s RBMO space which contains it.
-
(ii)
Lerner’s domination and \(A_2\)-type bounds for nondoubling measures.
-
(iii)
A noncommutative form of nonhomogeneous Calderón–Zygmund theory.
Our martingale RBMO space preserves the crucial properties of Tolsa’s original definition and reveals its interpolation behavior with the \(L_p\) scale in the category of Banach spaces, unknown so far. On the other hand, due to some known obstructions for Haar shifts and related concepts over nondoubling measures, our pointwise domination theorem via sparsity naturally deviates from its doubling analogue. In a different direction, matrix-valued harmonic analysis over noncommutative \(L_p\) spaces has recently produced profound applications. Our analogue for nondoubling measures was expected for quite some time. Finally, we also find a dyadic form of the Calderón–Zygmund decomposition which unifies those by Tolsa and López-Sánchez/Martell/Parcet.
Similar content being viewed by others

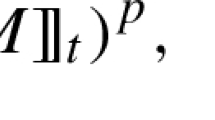
Avoid common mistakes on your manuscript.
1 Introduction
Originally inspired by the analysis of the Cauchy transform over non-Lipschitz curves in the complex plane, nonhomogeneous harmonic analysis has received much attention in the last 20 years. The theory has evolved in many different directions and nowadays a large portion of classical Calderón–Zygmund theory has been successfully transferred. Cotlar’s inequality, \(L_p\) boundedness of singular integrals, the \(\mathrm {BMO}\) class of John and Nirenberg, or Tb theorems have nonhomogeneous counterparts when the underlying metric measure space \((\Omega ,d,\mu )\) is only assumed to have polynomial growth. This means that balls are only assumed to satisfy the inequality \(\mu (B(x,r)) \lesssim r^n\) for all \(x \in \Omega \), every \(r>0\) and some positive number n. A very nice comprehensive survey on the subject can be consulted in [34]. In a different direction, dyadic techniques and more general probabilistic methods are among the most effective tools in the homogeneous setting, where the doubling condition \(\mu (B(x,2r)) \lesssim \mu (B(x,r))\) holds for all balls in the space. Dyadic maximal and dyadic square functions usually present a better behavior than their centered analogues due to their martingale nature, which has been largely exploited for doubling measures. Moreover, in the last decade or so we also find in the literature new and simple dyadic operators whose properties have deep consequences in Calderón–Zygmund theory. Indeed, Petermichl discovered in [28] that the Hilbert transform can be represented as an average of simpler dyadic operators called Haar shifts. Its implication in the so-called \(A_2\) conjecture led Hytönen to generalize this representation theorem to other Calderón–Zygmund operators [13]. Slightly earlier, Lerner also introduced in [19] his profound median oscillation formula from which he later discovered a surprising dyadic domination principle for Calderón–Zygmund operators, to which we shall go back later. Lerner’s results go far beyond the fact that they yield a very simple approach to the \(A_2\) conjecture. Unfortunately, despite some isolated exceptions like the remarkable use of random dyadic lattices by Nazarov et al. in [26] or the recent analysis of Haar shifts in [22], dyadic and more elaborated probabilistic techniques have not been explored systematically in the context of nondoubling measures.
The purpose of this paper is to provide the tools for a dyadic form of nondoubling harmonic analysis and to answer some basic questions in the theory as applications of this approach. More precisely, our main motivations and results are the following:
1.1 Dyadic Filtrations
Let \((\Omega ,\mu )\) be a \(\sigma \)-finite measure space equipped with an increasing filtration of \(\sigma \)-subalgebras \(\Sigma _1, \Sigma _2, \Sigma _3, \ldots \) whose union is dense in \((\Omega ,\mu )\). Let us write \(\mathsf {E}_k\) for the corresponding set of conditional expectations. The concept of regularity for martingale filtrations imposes that \(\mathsf {E}_kf \lesssim \mathsf {E}_{k-1}f\) for all measurable \(f: \Omega \rightarrow \mathbb {C}\). The similarity with the doubling condition is clear and in fact regularity reduces to dyadic doublingness for dyadic lattices. An elementary observation prior to developing dyadic harmonic analysis over nondoubling measures is that doublingness and dyadic doublingness are certainly very different concepts. Indeed, despite the existence of many doubling balls in measure spaces with polynomial growth, dyadically doubling lattices are not to be expected in general. A more reasonable aim is to construct an atomic martingale filtration whose atoms are comparable to balls, which in turn are all doubling. Any such filtration will generally be highly irregular, but fortunately this is not a serious obstruction for most of the key \(L_p\) martingale inequalities. In addition, we could also hope for an alternative form of regularity more adapted to the necessities in harmonic analysis. This is made precise in Theorem 1.1 below, which confirms and makes rigorous the belief—somehow reflected in our recent work [3, 5]—on a strong relationship between nondoubling measures and irregular filtrations satisfying the conditions above. Recall that a ball B(x, r) is called \((\alpha ,\beta )\)-doubling when \(\mu (B(x,\alpha r)) \le \beta \mu (B(x,r))\).
Theorem 1.1
Let \(\mu \) be a measure of n-polynomial growth on \(\mathbb {R}^d\). Then there exist positive constants \(\alpha ,\beta > 100\) and a two-sided filtration \(\{\Sigma _k: k \in \mathbb {Z}\}\) of atomic \(\sigma \)-algebras of \(\mathrm {supp}(\mu )\) that satisfy the following properties, where \(\Pi (\Sigma )\) denotes the set of atoms in the filtration\(:\)
-
(i)
The \(\sigma \)-algebras \(\Sigma _k\) are increasingly nested.
-
(ii)
The union of \(L_\infty (\mathbb {R}^d, \Sigma _k, \mu )\) is weak-\(*\) dense in \(L_\infty (\mu )\).
-
(iii)
If \(Q \in \Pi (\Sigma )\), there exists an \((\alpha ,\beta )\)-doubling ball \(B_Q\) with \(B_Q \subset Q \subset 28B_Q\).
-
(iv)
If \(x \in Q \in \Pi (\Sigma )\), then
$$\begin{aligned} R \ = {\mathop {\mathop {\bigcap }\limits _{S \in \Pi (\Sigma )}}\limits _{S \supsetneq Q}} S \qquad \Rightarrow \qquad \int _{\alpha B_R\setminus 56B_Q} \frac{d\mu (y)}{|x-y|^n} \lesssim _{n,d,\alpha ,\beta } 1. \end{aligned}$$
Our proof is based on a refinement of a remarkable construction by David and Mattila [7] that we shall modify to fit our needs. As pointed above, the fact that all atoms in \(\Pi (\Sigma )\) are doubling comes at the price of a highly irregular filtration \(\Sigma \) which is far from being dyadically doubling. Remarkably, property (iv) yields a weaker form of regularity—key for our applications—considered for the first time by Tolsa [30]. One could say that this construction plays the role in the nonhomogeneous setting of the dyadic lattice for the Lebesgue measure.
1.2 Dyadic BMO Spaces
A BMO space is a set of functions which enjoy bounded mean oscillation in a certain sense. Both mean and oscillation can be measured in many different ways. Most frequently we find BMO spaces referred to averages over balls in a metric measure space, but we may replace these averages by conditional expectations with respect to a martingale filtration or even by the action of a nicely behaved semigroup of operators. The relationship between metric and martingale BMO spaces is well-understood for doubling measures. Indeed, expanding ideas from Garnett and Jones [8], the metric BMO space is equivalent to a finite intersection of martingale BMO spaces over dyadic two-sided filtrations whose atoms look like balls. John–Nirenberg inequalities and the Fefferman–Stein duality theorem still hold for these larger BMO spaces of martingales, which also serve as an interpolation endpoint for the \(L_p\) scale. In the nonhomogeneous setting and for certain nondoubling measures satisfying some weak concentration at the boundary, martingale filtrations have provided a framework to define satisfactory BMO spaces [5]. Our aim here is to construct a dyadic form of Tolsa’s RBMO space [30]—a nonhomogeneous analogue of BMO for measures of polynomial growth—which contains it and enjoys the fundamental properties above.
Tolsa’s RBMO space is very satisfactory since it yields endpoint estimates for singular integrals and also \(L_p\) estimates via interpolation of operators. Surprisingly, it seems to be still open the problem of whether \(\mathrm {RBMO}(\mu )\) gives the desired interpolation results with the \(L_p\) scale in the category of Banach spaces. Our dyadic \(\mathrm {RBMO}\) space—\(\mathrm {RBMO}_\Sigma (\mu )\) in what follows—is nothing but the martingale BMO space defined over the filtration constructed in Theorem 1.1. It models \(\mathrm {RBMO}(\mu )\) in a way similar to how dyadic \(\mathrm {BMO}\) models the classical \(\mathrm {BMO}\) space.
Theorem 1.2
The space \(\mathrm {RBMO}_{\Sigma }(\mu )\) satisfies\(:\)
-
(i)
\(\mathrm {RBMO}(\mu ) \subset \mathrm {RBMO}_{\Sigma }(\mu )\).
-
(ii)
John–Nirenberg inequality and Fefferman–Stein duality theory.
-
(iii)
Interpolation in the category of Banach spaces
$$\begin{aligned}{}[\mathrm {RBMO}_\Sigma (\mu ), L_1(\mu )]_{\frac{1}{p}} = L_p(\mu ) \quad \text{ for } \quad 1<p<\infty . \end{aligned}$$We also have \([L_\infty (\mu ),\mathrm {H}_\Sigma ^1(\mu )]_{\frac{1}{p}} = L_p(\mu )\) for the space \(\mathrm {H}_\Sigma ^1(\mu )\) whose dual is \(\mathrm {RBMO}_\Sigma (\mu )\).
An immediate consequence of properties (i) and (iii) above is that Tolsa’s RBMO enjoys the same interpolation properties, which solves the problem recalled above. A curiosity—which we shall justify in the more general context of Theorem 1.4 below—is that Calderón–Zygmund extrapolation holds for kernels satisfying the Hörmander condition, instead of the stronger and commonly used Lipschitz smoothness. In addition, Theorems 1.1 and 1.2 are not limited to the Euclidean setting \((\mathbb {R}^d,\mu )\) but also hold for any upper doubling metric measure space \((\Omega ,\mu )\), see Remark 3.3. Properties (ii) and (iii) follow from the martingale nature of \(\mathrm {RBMO}_\Sigma (\mu )\), while property (i) exploits the structure of \(\Sigma \). It is precisely property (i) what makes \(\mathrm {RBMO}_\Sigma (\mu )\) special among martingale \(\mathrm {BMO}\) spaces because Calderón–Zygmund operators map \(L_\infty (\mu )\) into \(\mathrm {RBMO}_\Sigma (\mu )\).
1.3 Oscillation and Dyadic Domination
Consider an atomic filtration \(\{\Sigma _k : k \in \mathbb {Z}\}\) in \((\Omega ,\mu )\) whose atoms—measurable sets that are not decomposable into smaller measurable sets—are denoted by \(\Pi (\Sigma )\). Given \(Q \in \Pi (\Sigma )\), let us write  for the \(\mu \)-average of f over Q. Working with Euclidean spaces, the Lebesgue measure and the standard dyadic filtration—so that \(\Pi (\Sigma )\) becomes the set of all dyadic cubes—Haar shift operators take the form
for the \(\mu \)-average of f over Q. Working with Euclidean spaces, the Lebesgue measure and the standard dyadic filtration—so that \(\Pi (\Sigma )\) becomes the set of all dyadic cubes—Haar shift operators take the form
with \(\alpha _{QR} = 0\) when the generations of Q and R are very far apart. This difference between generations is called the complexity of the operator. Lerner’s median oscillation formula [19] relates the value of a general function f at a point x to its oscillations on a particularly nice family of dyadic cubes containing x. This led to a highly unexpected upper bound for Calderón–Zygmund operators—first in norm [20] and pointwise afterwards [4, 21], see also the recent papers [16, 18] for more general operators—in terms of very simple dyadic operators
where \(\mathcal {J}\) in the above formula is finite and the sets of cubes \(\mathcal {S}_j\) are sparse families—whose definition is given in Sect. 4—which depend on T and f. This dyadic domination principle is so accurate that it encodes all the smoothness subtleties of Calderón–Zygmund operators by the sparseness of certain positive dyadic operators. Beyond its intrinsic depth, it also yields what can be arguably considered the simplest approach to the \(A_2\) theorem. The first result in this direction for nondoubling measures is due to Hänninen [10], who has recently extended Lerner’s oscillation formula, but his approach was too limited to provide pointwise domination of nondoubling Calderón–Zygmund operators by sparse shifts or to explore related weighted inequalities.
Our dyadic approach here is simple enough to deduce the pointwise dyadic domination and related \(A_2\) bounds from Hänninen’s oscillation formula. Both results hold for standard nondoubling Calderón–Zygmund operators—whose definition is postponed to the body of the paper—in terms of sparse operators adapted to our filtration \(\Sigma \) from Theorem 1.1. However, as we just indicated above, dyadic covering lemmas are not available in our setting. Also, the negative results in [22] suggest that even if they were available, boundedness of high complexity dyadic shifts by sparse operators is not to be expected. Therefore, we are forced to introduce a modification in our formula which includes a nicely behaved maximal operator
Theorem 1.3
Let \(\mu \) be a measure of n-polynomial growth on \(\mathbb {R}^d\) and let \(\Sigma = \{\Sigma _k : k \in \mathbb {Z} \}\) the atomic filtration from Theorem 1.1. Given a Calderón–Zygmund operator T, the following pointwise estimate holds for certain \(\mu \)-sparse family \(\mathcal {S} \subset \Pi (\Sigma )\)
In particular, if w is an \(A_2\) weight with respect to \(\mu \), we have
At this point, it is important to note that a stronger \(A_2\) bound—linear in the \(A_2\)-characteristic in line with the doubling \(A_2\) theorem—was announced in [16, Theorem 5.1] as the result of a personal communication between Treil and Volberg with Lacey. At the time of this writing and after several contacts with Lacey and Volberg, it seems that such assertion was based on a pointwise domination theorem which was not properly justified, and therefore the announced \(A_2\)-bound cannot be considered to be proven so far. Besides the obstruction to use high complexity Haar shifts, Lacey’s approach [16] and subsequent work [18] do not immediately generalize to the nondoubling setting. Shortly after the completion of this work, Volberg and Zorin-Kranich proved a different sparse domination result in our setting, also based on the David-Mattila construction [33]. Their result yields a linear dependence on the \(A_2\) characteristic of the weights. However, our results and theirs seem to be non comparable since theirs requires the use of infinitely many sparse operators at the same time.
1.4 Matrix-Valued Harmonic Analysis
Calderón–Zygmund operators which act on matrix-valued functions were investigated for the first time in [27]. In fact, the aim for estimates independent of the matrix size allows to replace matrices by arbitrary von Neumann algebras at almost no cost. This particular instance of noncommutative Calderón–Zygmund theory—semicommutative algebras over Euclidean spaces equipped with the Lebesgue measure—has been the main tool in the recent solution of the Nazarov–Peller conjecture [1] and it has also served to obtain pioneering results on smooth Fourier multipliers with nonabelian frequencies [15]. In addition, it provides the optimal behavior of \(L_p\) constants which improves Bourgain’s UMD approach. These are strong applications which naturally motivate the study of nondoubling Calderón–Zygmund operators acting on matrix-valued functions. In fact, both endpoint estimates for \(p=1,\infty \) have been open for quite some time. Potential applications of it point towards the convergence of Fourier series which are frequency supported by free groups. The noncommutative setting goes beyond vector-valued harmonic analysis and introduces a number of genuine new difficulties from the lack of points after quantization, details can be found in [15, 27]. At this point, the theory of noncommutative martingale \(L_p\) inequalities—nowadays well-established—becomes crucial in conjunction with our martingale approach towards nondoubling harmonic analysis. This combination yields an operator valued form of \(\mathrm {RBMO}_\Sigma (\mu )\)—denote by \(\mathrm {RBMO}_\Sigma (\mathcal {A})\) in what follows—which admits the expected endpoint estimate for \(p=\infty \), so that Calderón–Zygmund extrapolation holds by interpolation and duality. The definition of Calderón–Zygmund operator in this context—for which we impose noncommutative forms of the size and Hörmander kernel conditions—and other notions from operator algebra will be given in the body of the paper.
Theorem 1.4
Let \(\mu \) be a measure of n-polynomial growth on \(\mathbb {R}^d\) and let \(\Sigma = \{\Sigma _k : k \in \mathbb {Z} \}\) be the atomic filtration from Theorem 1.1. Let \(\mathcal {A} = L_\infty (\mu ) \bar{\otimes }\mathcal {M}\) for some noncommutative measure space \((\mathcal {M},\tau )\) and equip \(\mathcal {A}\) with its natural trace \(\varphi = \mu \otimes \tau \). Then, every \(L_2\)-bounded Calderón–Zygmund operator satisfies \(T: \mathcal {A} \rightarrow \mathrm {RBMO}_{\Sigma }(\mathcal {A})\). Moreover, \(L_p\)-boundedness follows for \(1< p < \infty \) by interpolation and duality, which also hold in this case.
Finally, the properties of the martingale filtration \(\Sigma \) yield a dyadic form of Calderón–Zygmund decomposition for functions in \(L_1(\mu )\). It resembles the classical one although the irregularity of \(\Sigma \) forces to subtract the average over the ancestors of the maximal cubes instead of the actual maximal cubes. This is very similar to the Calderón–Zygmund–Gundy decomposition in [22] but goes beyond it, since we can deduce the weak type (1, 1) bound for Calderón–Zygmund operators from it. In summary, this new Calderón–Zygmund type decomposition—Theorem 4.2 in the text—unifies the decompositions in [22, 31] and admits potential applications in the noncommutative setting.
2 A Lattice of Cubes and a Doubling Nonregular Filtration
For the rest of the paper, fix a Radon measure \(\mu \) on \(\mathbb {R}^d\) of normalized n-polynomial growth, that is, one for which \(\mu (B(x,r)) \le r^n\) for all \(x \in \mathbb {R}^d\) and \(r>0\). Even though we work on \(\mathbb {R}^d\), we will only be concerned with what happens on the support of the measure \(\mu \). Thus, we will slightly abuse notation denoting by B the intersection of the set B with \(\mathrm {supp}(\mu )\). Another way of thinking about this is to assume that whenever we write a relation between sets , we mean that it holds up to a set of \(\mu \)-measure 0. To build the doubling filtration \(\Sigma \) as stated in the introduction, we will modify a construction that is due to David and Mattila [7, Theorem 3.2]. We give the precise statement that we need below, the main novelty being the presence of arbitrarily large cubes and the “lack of quadrants”, which means that whenever we take the union of all the ancestors of a given cube in the lattice we get the full support of the measure \(\mu \). This particular feature will be necessary to ensure that the space of \(\mathrm {BMO}\) type constructed in Sect. 3 interpolates with \(L_p(\mu )\).
Proposition 2.1
Let \(\mu \) be of n-polynomial growth on \(\mathbb {R}^d\) and fix \(\alpha \ge 100\) and \(\beta =\alpha ^{\ell }\) for some \(\ell \ge d+1\). Then, there exist \(A \gg \beta \) of the form \(A=\alpha ^{\ell m}\) and a sequence of partitions \(\mathscr {D}=\{\mathscr {D}_k\}_{k\in \mathbb {Z}}\) of \(\mathrm {supp}(\mu )\), whose elements are called cubes, with the following properties:
-
(i)
The partitions are nested, so that \(Q \cap R \in \{\emptyset ,Q,R\}\) for any pair of cubes Q, R.
-
(ii)
For each \(k \in \mathbb {Z}\) and \(Q \in \mathscr {D}_k\), there exists \(x_Q \in \mathrm {supp}(\mu )\) and a radius \(r(Q) \sim _{\beta } A^{-k}\) such that the balls \(B_Q=B(x_Q,r(Q))\) satisfy:
-
\(B_Q \cap \mathrm {supp}(\mu ) \subset Q \subset 28B_Q \cap \mathrm {supp}(\mu )\).
-
The balls \(5B_Q\) associated to cubes of the same generation are pairwise disjoint.
-
-
(iii)
For each Q, either \(B_Q\) is \((\alpha ,\beta )\)-doubling or else \(\mu (\alpha B_Q) < \beta ^{-i} \mu (\alpha ^{i+1}B_Q)\) whenever \(\alpha ^{i} \le \beta \).
-
(iv)
For every \(k\in \mathbb {Z}\) and every \(Q\in \mathscr {D}_k\),
$$\begin{aligned} \mathrm {supp}(\mu ) \subset \bigcup _{\begin{array}{c} R \; \mathrm {cube} \\ R \supset Q \end{array}} R. \end{aligned}$$
In the proof of Proposition 2.1 we shall use the 5R covering lemma allowing ourselves to choose a particular ball. The modification of the proof is trivial, but we record the statement precisely for the sake of clarity.
Lemma 2.2
Let \(A \subset \mathbb {R}^d\) be a set such that each \(x\in A\) has an associated ball \(B_x\) with radius \(r_x\). Pick some \(x_0 \in A\) such that \(r_{x_0}\ge \frac{1}{2} \sup _{x\in A} r_x\). Then, there exists a subcollection \(\mathcal {B}=\{B_j\}_{j\in \mathbb {N}} \subset \{B_x\}_{x\in A}\) satisfying:
-
The balls in \(\mathcal {B}\) are pairwise disjoint.
-
\(A \subset \cup _j 5B_j\).
-
\(B_{x_0} \in \mathcal {B}\).
The family \(\{B_j\}_j\) is called the 5R-covering of A associated to \(x_0\).
Proof of Proposition 2.1
The proof of Theorem 3.2 of [7] is highly technical and long. Our version uses most of the steps of its proof—although we cannot apply the theorem directly—and therefore we will only explain the relevant changes to avoid the repetition of arguments that we do not modify. First choose the constant A as the smallest constant of the form \(\alpha ^{m\ell }\) that is greater than the constant \(A_0\) that appears in Theorem 3.2 of [7]. Since \(\mu \) has n-polynomial growth, for \(\mu \)-almost every point x, the sequence \(\{B(x,\frac{7}{8} \beta \alpha ^j)\}_{j\in \mathbb {N}}\) contains infinitely many \((\alpha ,\beta )\)-doubling balls. Fix one such point \(x_0\). There exists \(i \in \{0,1,\ldots ,m\ell -1\}\) such that the subsequence composed of balls whose radii \(r=\frac{7}{8} \beta \alpha ^j\) satisfy
contains infinitely many \((\alpha ,\beta )\)-doubling balls. Now, for each generation \(k \in \mathbb {Z}\), we proceed as in the proof of [7, Theorem 3.2], except for the point \(x_0\):
-
For each \(k \in \mathbb {Z}\) and \(x \in \mathrm {supp}(\mu )\), \(x\not =x_0\), we choose a radius \(r_k(x)\) such that
$$\begin{aligned} \alpha ^i A^{-k} \le r_k(x) \le \beta \alpha ^i A^{-k} \end{aligned}$$according to the following algorithm: either \(r_k(x)\) is chosen so that \(B(x,r_k(x))\) is \((\alpha ,\beta )\)-doubling or, if there are no \((\alpha ,\beta )\)-doubling balls with radii satisfying the equation above, we take \(r_k(x)= \alpha ^i A^{-k}\).
-
For \(x=x_0\), if the ball \(B(x_0,\frac{7}{8} \beta \alpha ^i A^{-k})\) is \((\alpha ,\beta )\)-doubling, we choose \(r_k(x_0) = \frac{7}{8} \beta \alpha ^i A^{-k}\). Notice that, by the above reasoning, we make this choice infinitely many times. If
$$\begin{aligned} B\left( x_0,\frac{7}{8} \beta \alpha ^i A^{-k}\right) \end{aligned}$$is not \((\alpha ,\beta )\)-doubling, we choose \(r_k(x_0)\) as in the previous item.
We now fix k, and apply Lemma 2.2 to \(\{B(x,5r_k(x))\}_{x \in \mathrm {supp}(\mu )}\) to obtain the 5R-covering of \(\mathrm {supp}(\mu )\) associated to \(x_0\), whenever it is possible. This happens infinitely many times by our choices of \(r_k(x_0)\). Otherwise, we just apply Lemma 2.2 without specifying the point. In either case, the resulting family is the family of disjoint balls \(5B_Q\) associated with the cubes of generation k. The rest of the proof of properties (i)–(iii) is exactly that of Theorem 3.2 in [7]. Notice that the arguments there do not depend on the size of the cubes being uniformly bounded. This yields a collection \(\mathscr {D}=\cup _{k \in \mathbb {Z}} \mathscr {D}_k\) with the mentioned properties. It only remains to show that our construction does not have “quadrants”. But this is easy: given any cube \(Q \in \mathscr {D}\), there exists some \(R\in \mathscr {D}\) whose associated ball \(B_R=B_R(x_0,r(x_0))\) intersects it, because there are arbitrarily large balls of this kind centered at \(x_0\). Thus, the claim trivially follows.
\(\square \)
Remark 2.3
By the proof of Theorem 3.2 of [7], the cubes in \(\mathscr {D}\) have small boundaries: for each \(Q\in \mathscr {D}_k\) and \(i \in \mathbb {Z}_+\), define
Then \(\mu (N_{i}^{\mathrm {ext}}(Q) \cup N_{i}^{\mathrm {int}}(Q)) \le (c_d \beta ^{-3d-1}A)^{-i} \mu (90B_Q)\).
Remark 2.4
By a modification of the arguments above one may force the apparition of quadrants in the construction of Proposition 2.1. A quadrant is a proper subset E of \(\mathbb {R}^d\) such that a cube \(Q\in \mathscr {D}\) that is contained in E has all of its ancestors lying inside E; or, equivalently, a proper subset of \(\mathbb {R}^d\) that is a union of sets in \(\mathscr {D}_k\) for all \(k\in \mathbb {Z}\). This is clearly seen, for example, in the case of the real line with the Gaussian measure \(\gamma \), the probability measure with density given by
\(\gamma \) is nondoubling, but all intervals of the form [0, a] are (2, 2)-doubling. Therefore, if in the proof we choose the sequence of centers \(\{A^k\}_{k\in \mathbb {Z}_+}\) instead of the point \(x_0\), and then we repeat the steps of the proof, we will get that the intervals \([0,2A^k]\), for \(k\in \mathbb {Z}_+\), belong to the resulting system \(\mathscr {D}\). This divides the real line in the usual two quadrants.
Using Proposition 2.1 we may now build the filtration \(\Sigma \) and prove Theorem 1.1. We say that a cube \(Q\in \mathscr {D}\) is \((\alpha ,\beta )\)-doubling if its associated ball \(B_Q\) is \((\alpha ,\beta )\)-doubling.
Proof of Theorem 1.1
The basic idea of the construction is to exploit the abundance of doubling cubes in \(\mathscr {D}\) by constructing a filtration only with them. By Lemma 5.28 in [7], given any cube \(R\in \mathscr {D}\), there exists a (pairwise disjoint) collection of cubes \(\{Q_i\} \subset \mathscr {D}\) which are \((\alpha ,\beta )\)-doubling and such that
On the other hand, by the construction of Proposition 2.1, any cube \(Q \in \mathscr {D}\) is contained in an \((\alpha ,\beta )\)-doubling cube \(R\in \mathscr {D}\). Therefore, we may construct the filtration \(\Sigma =\{\Sigma _k\}_{k \in \mathbb {Z}}\) as follows:
-
We start with any \((\alpha ,\beta )\)-doubling cube \(Q_0 \in \mathscr {D}\). We proclaim that \(Q_0 \in \Pi (\Sigma _0)\).
-
The parent (in \(\Sigma \)) \(\widehat{Q}_0\) of \(Q_0\) is the smallest \((\alpha ,\beta )\)-doubling cube of \(\mathscr {D}\) that contains (properly) \(Q_0\). Notice that \(\widehat{Q}_0\) exists by item (iv) of Proposition 2.1. We proclaim that \(\widehat{Q}_0\) belongs to \(\Pi (\Sigma _{-1})\).
-
Inductively, for \(j\ge 1\) we define the \((j+1)\)-th ancestor of \(Q_0\) as the smallest \((\alpha ,\beta )\)-doubling cube of \(\mathscr {D}\) that contains (properly) the j-th ancestor of \(Q_0\). We proclaim that it belongs to \(\Pi (\Sigma _{-j-1})\). Notice that the union of the j-th ancestors of \(Q_0\), \(j\ge 1\), covers the whole space \(\mathrm {supp}(\mu )\).
-
Given a cube \(Q\in \Pi (\Sigma )\), its children (in \(\Sigma \)) are the maximal \((\alpha ,\beta )\)-doubling cubes of \(\mathscr {D}\) that are properly contained in Q. These always cover Q by (2.1). Notice that our definition is consistent: the j-th ancestor of \(Q_0\) is always a child of the \((j+1)\)-th ancestor of \(Q_0\). In general, we say that a cube \(R\in \Pi (\Sigma )\) belongs to \(\Sigma _k\) if its parent \(\widehat{R}\) belongs to \(\Pi (\Sigma _{k-1})\).
The previous items define the whole filtration \(\Sigma =\{\Sigma _k\}_{k\in \mathbb {Z}}\). Also, notice that \(\Pi (\Sigma ) \subset \mathscr {D}\). The construction immediately yields the properties (i) and (iii) in the statement of Theorem 1.1. Also, the Lebesgue differentiation theorem holds for sets in \(\Sigma \), which means that for \(\mu \)-a.e. \(x\in \mathrm {supp}(\mu )\),
This implies that \(\cup _k L_\infty (\mathbb {R}^d,\Sigma _k,\mu )\) is weak-\(*\) dense in \(L_\infty (\mu )\), so we have (ii). To prove (iv), we need to introduce some notation about ancestors of general cubes Q, and not only for the \(Q_0\) (which will no longer play an important role). These will be used throughout the rest of the paper. If \(k_0<k_1\), we will denote the unique cube \(R \in \mathscr {D}_{k_0}\) which contains \(Q \in \mathscr {D}_{k_1}\) by \(Q^{(k_1-k_0)}\). We will also denote by \(\widehat{Q}\) the smallest cube in \(\Sigma \) that properly contains \(Q \in \Sigma \), and write \(\mathrm {gen}(T) = k\) if \(T\in \mathscr {D}_k\). The proof of (iv) now follows from the following observation, which constitutes Lemma 5.31 in [7]: if \(Q \subset R\) are cubes in \(\mathscr {D}\) and if all intermediate cubes \(T \in \mathscr {D}\) (that is, all \(T \in \mathscr {D}\) such that \(Q \subsetneq T \subsetneq R\)) are not \((\alpha ,\beta )\)-doubling, then
Indeed, taking into account (2.2), we may compute for \(x\in Q\)
This ends the proof of Theorem 1.1. \(\square \)
Remark 2.5
Notice that (iv) in Theorem 1.1 is similar to a property that holds for sequences of concentric nondoubling cubes in \(\mathbb {R}^d\) and was key for the construction in [30] (and in the weak (1, 1) inequality in [31]). Here we reinterpret it as a (weak) regularity of the filtration \(\Sigma \).
3 A Martingale BMO for Nondoubling Measures
As we explained in the introduction, we define our dyadic RBMO space, \(\mathrm {RBMO}_\Sigma (\mu )\), as the martingale BMO space associated with the filtration \(\Sigma \) constructed in Sect. 2. We choose the values \(\alpha = 2 \times 28^2\) and \(\beta =\alpha ^{d+1}\). Given a probability (or \(\sigma \)-finite) measure space \((\Omega ,\nu )\) and a bilateral filtration \(\mathcal {F}=\{\mathcal {F}_k\}_{k\in \mathbb {Z}}\), its associated martingale BMO space is the space of \(\nu \)-measurable functions f with norm
The definition of the martingale BMO norm and the classical one are somewhat different since in the martingale case we subtract \(\mathsf {E}_{\mathcal {F}_{k-1}} f\) instead of \(\mathsf {E}_{\mathcal {F}_k} f\). This turns out to be very relevant because it is what ensures that the martingale BMO spaces interpolate regardless of the regularity of the filtration \(\mathcal {F}\). In case one subtracted \(\mathsf {E}_{\mathcal {F}_k} f\) in the definition, the resulting space, denoted as \(\mathrm {bmo}\), has different interpolation properties in the general case, see [5, 9] for more details and background on martingale BMO spaces. In our case \(\mathcal {F}=\Sigma \) is an atomic filtration, and therefore we have the expression
The equivalence of norms in the second step above follows from the John–Nirenberg inequality, which holds for all martingale BMO spaces (see below), and hence for \(\mathrm {RBMO}_{\Sigma }(\mu )\). We have arrived to an expression which we can compare to another one for the \(\mathrm {RBMO}\) norm of Tolsa, as we shall see now. Given two balls \(B_1,B_2\) in \(\mathbb {R}^d\), we define
where \(N_{B_1,B_2}\) is the smallest positive integer \(\ell \) such that \(B_2\subset 2^{\ell }B_1\). According to Lemma 2.10 (c) of [30] and the fact that the definition of the space does not change if we use balls instead of cubes, a function f belongs to \(\mathrm {RBMO}(\mu )\) if and only if the following quantity is finite:
where
Let us now justify the first item in Theorem 1.2. We want to show that
that is,
for all functions \(f \in \mathrm {RBMO}(\mu )\). The proof is just a computation for the norm in \(\mathrm {RBMO}_{\Sigma }(\mu )\). Fix some \(k\in \mathbb {Z}\) and \(Q \in \Pi (\Sigma _k)\) and split into pieces as follows:

Now, since \(B_Q \subset Q \subset 28B_Q\) and we have chosen \(\alpha \) so that \(B_Q\) is \((\alpha ,\beta )\)-doubling (which in particular implies that \(28B_Q\) is \((2,\beta )\)-doubling), we can estimate

and similarly for \(\mathrm {II}\). We are left with \(\mathrm {III}\). On the one hand, we have
and therefore \(28B_Q \subset 28^2B_{\widehat{Q}}\). So, we can write
We have that the three balls \(28B_Q\), \(28B_{\widehat{Q}}\) and \(28^2B_{\widehat{Q}}\) are \((2,\beta )\)-doubling. By definition, \(K_{28B_{\widehat{Q}},28^2B_{\widehat{Q}}} \lesssim 1\), which implies
Finally, one can check (see again [30]) that
Therefore, we can apply item (iv) of Theorem 1.1 to the cubes Q and \(\widehat{Q}\) with \(x=x_{Q}\) to obtain
which also implies that
The above argument provides an interpretation of the geometric coefficients \(K_{B_1,B_2}\) in terms of the martingale structure that we have built. In particular, one can see that if \(Q \subset R\) are such that \(Q \in \Pi (\Sigma _{k_1})\) and \(R \in \Pi (\Sigma _{k_2})\) then \(K_{B_Q,B_R} \sim k_1 - k_2\). This justifies why we view item (iv) of Theorem 1.1 as some sort of regularity of \(\Sigma \).
Remark 3.1
The inclusion \(\mathrm {RBMO}(\mu ) \subset \mathrm {RBMO}_\Sigma (\mu )\) can be—and generally will be—strict. An instance of this can be seen by taking the example of the Gaussian measure in \(\mathbb {R}\) at the end of the previous section and considering the function \(f(x) = e^{|x|^2} \log (|x|)\), see also [5] for a similar example.
Notice that our definition of \(\mathrm {RBMO}_\Sigma (\mu )\) is somewhat simpler than that of \(\mathrm {RBMO}(\mu )\). However, as we have just seen it is at least as powerful. However, the use of a martingale BMO norm—in which we subtract \(\mathsf {E}_{\Sigma _{k-1}}\) when we average over atoms of \(\Sigma _k\)—yields the rest of the good properties claimed in the statement of Theorem 1.2 essentially for free. Indeed, the John–Nirenberg property for martingale spaces (see [9] for the proof), that we already used, implies that
We now focus our attention on \(\mathrm {H}_{\Sigma }^1(\mu )\), the Hardy space whose dual is \(\mathrm {RBMO}_{\Sigma }(\mu )\). Since \(\mathrm {RBMO}_{\Sigma }(\mu )\) is a martingale \(\mathrm {BMO}\) space, \(\mathrm {H}_{\Sigma }^1(\mu )\) is the subspace of \(L_1(\mu )\) functions with norm given by
Here \(\mathsf {D}_k = \mathsf {E}_{\Sigma _k} - \mathsf {E}_{\Sigma _{k-1}}\) is the k-th martingale difference operator. This is the standard expression of the norm in martingale \(\mathrm {H}_1\) spaces. On the other hand, in [30] the predual of \(\mathrm {RBMO}(\mu )\) was described as a space of functions decomposable into atomic blocks, a generalization of the classical atoms that span the usual Euclidean \(\mathrm {H}_1\) space. A connection between the two worlds is again given by martingale theory: as was shown in [3], one can find an atomic block decomposition for functions in any martingale \(\mathrm {H}_1\) space. Let us briefly describe it in the setting of \(\mathrm {H}_{\Sigma }^1(\mu )\): a function b is said to be a p-atomic block, \(1< p \le \infty \), if the following conditions are satisfied:
-
There exists some \(k\in \mathbb {Z}\) such that \(\mathsf {E}_{\Sigma _k}b = 0\).
-
\(b= \sum _j \lambda _j a_j\), where \(\lambda _j\) are scalars and \(a_j\) are \(L_p\) functions such that
-
(1)
\(\mathrm {supp}(a_j) \subset A_j \in \Sigma _{k_j}, \; k_j \ge k\).
-
(2)
\(\Vert a_j\Vert _{L_p(\mu )} \le \mu (A_j)^{-1/p'} (k_j-k+1)^{-1}\).
-
(1)
To each p-atomic block we attach the quantity
Finally, one has the following alternative expression for the norm in \(\mathrm {H}_{\Sigma }^{1}(\mu )\):
The above expression is very similar to the one for the norm of the predual of \(\mathrm {RBMO}(\mu )\), although ours yields a greater quantity. This is proven by the inclusion \(\mathrm {RBMO}(\mu ) \subset \mathrm {RBMO}_\Sigma (\mu )\) and duality. However, it is also easy to find a direct proof, whose details are left to the interested reader. Finally, interpolation holds for \(\mathrm {RBMO}_\Sigma (\mu )\) because it holds for any martingale BMO space, see [9]. This concludes the proof of Theorem 1.2.
A consequence of the inclusion \(\mathrm {RBMO}(\mu ) \subset \mathrm {RBMO}_\Sigma (\mu )\) is that \(\mathrm {RBMO}(\mu )\) interpolates as a function space. This is something that was not achieved in [30], where only interpolation of operators was considered.
Corollary 3.2
\(\mathrm {RBMO}_\Sigma (\mu )\) serves as an interpolation endpoint with respect to the \(L_p(\mu )\) scale. That is, we have
with equivalent norms.
Proof
Indeed, since martingale BMO spaces serve as interpolation endpoints, we have
\(\square \)
Remark 3.3
Theorem 1.1 holds true in the setting of geometrically doubling metric spaces. Therefore, all our results up to now generalize in a natural way to the context of geometrically doubling metric spaces equipped with an upper doubling measure (see [12] for details).
4 Calderón–Zygmund Operators
We now consider applications to Calderón–Zygmund theory of our results in the previous sections. For us, a (n-dimensional) Calderón–Zygmund operator T will be a linear operator which is bounded on \(L_2(\mu )\) with an associated kernel k for which the representation
holds for x away from the support of sufficiently nice f. Additionally, the kernel k is assumed to satisfy the standard size condition and Hölder regularity:
Under these conditions, we know from [30] that T maps \(L_\infty (\mu )\) into \({\hbox {RBMO}(\mu )}\) and therefore \(T:L_\infty (\mu ) \rightarrow \mathrm {RBMO}_\Sigma (\mu )\), by the inclusion \(\mathrm {RBMO}(\mu ) \subset \mathrm {RBMO}_\Sigma (\mu )\). A direct proof is also possible, but we will postpone it until the next section, in which we will consider a more general setting that includes this—and, in fact, one in which Tolsa’s RBMO space is not defined–.
We shall now focus on the proof of Theorem 1.3. Our starting point is a result of Hänninen (see [10]) which is a generalization of the so-called Lerner’s formula in [19]. To state it, we need to introduce some terminology: a family of measurable sets \(\mathcal {S}\) is called \(\eta \)-sparse (or only sparse if \(\eta =1/2\)) if for each \(A\in \mathcal {S}\), there exists a measurable \(E_A \subset A\) with two properties:
-
\(\mu (E_A) \ge \eta \mu (A)\).
-
For each pair \(A,B \in \mathcal {S}\) with \(A\not =B\), \(E_A \cap E_B = \emptyset \).
The \(\lambda \)-oscillation of a function f on a set A, denoted \(\omega _\lambda (f;A)\), is defined as
Finally, a median of a function f on a set A is a (possibly non unique) number \(m_A(f)\) which satisfies
We can now restate Hänninen’s theorem in the way that we intend to use it: fix some set \(Q_0 \in \Pi (\Sigma _k)\) for some \(k \in \mathbb {Z}\), and \(0 \lambda < 1\). Then there exists a sparse family \(\mathcal {S}\)—whose sparsity constant depends on \(\lambda \)—of sets in \(\Pi (\Sigma )\) such that
for any measurable f which is supported on \(Q_0\). In [10], (4.1) is stated for a filtration of \(\sigma \)-algebras of dyadic cubes on \(\mathbb {R}^d\). However, its proof works for any filtration of atomic \(\sigma \)-algebras, so we can use the result with the filtration \(\Sigma \). We can use this version of Lerner’s oscillation formula to prove Theorem 1.3.
Proof of Theorem 1.3
Fix a function f, and assume qualitatively that it belongs to \(L_1(\mu )\) and has compact support contained in \(Q_0 \in \Pi (\Sigma )\). We apply (4.1) to Tf to obtain
We now estimate each of the terms in (4.2) separately. On the one hand, we may decompose \(Tf = T(f\chi _{56B_Q}) + T(\chi _{(56B_Q)^c})=: Tf_1 + Tf_2\). Then, by the weak (1, 1) boundedness of T [25, 31], we get that
Therefore, choosing \(C_1=C_1(\mu ,\Vert T\Vert _{L_1(\mu ) \rightarrow L_{1,\infty }(\mu )} )\) appropriately, we get
(say) and therefore
for \(\lambda < 3/4\) (recall that \(B_Q\) is doubling). On the other hand, if \(x,y \in Q\), we have
Therefore, we arrive at
for some \(1/4< \lambda < 1/2\). We are left with the median term, for which we use the notation \(m_{Q,x} (f(x,y))\) for the median in the x variable of the two variable function f(x, y). Using the monotonicity and linearity (for constants!) of the median we get
For \(\mathrm {I}\) and \(\mathrm {II}\) we just use again that \(B_Q\) and \(B_{\widehat{Q}}\) are doubling and the weak type (1, 1) of T to get
The term \(\mathrm {III}\) is estimated arguing as in the proof of the inclusion \(\mathrm {RBMO}(\mu ) \subset \mathrm {RBMO}_\Sigma (\mu )\). If \(x\in Q\), then
where we define
In the last step above we have used (2.2) as in the proof of Theorem 1.1. Finally, the term \(\mathrm {IV}\) is smaller than one of the terms that already appeared in the estimate of the oscillation. We also have to deal with the term \(m_{Q_0}(Tf)\), but this is done in the usual way: since f is supported on \(Q_0\), we have
so we can add the resulting quantity to the right hand side of the estimate via the triangle inequality. This may change the sparseness constant of the family \(\mathcal {S}\) that we have enlarged with the addition of \(Q_0\) from \(\frac{1}{2}\) to \(\frac{1}{4}\). The proof of the pointwise estimate is completed. We can therefore shift our attention to the weighted estimate. We say that a nonnegative locally integrable w which is positive a.e. is an \(A_2(\mu )\) weight if
In the formula above, we denote as usual \(w(Q)=\int _Q w \; d\mu \) and \(w^{-1}(Q) = \int _Q 1/w \; d\mu \) The sets Q are Euclidean cubes with sides parallel to the axes. We have
To control the maximal term, we start with a pointwise estimate. We are going to use a dyadic covering lemma like, say, the one in [2]. This means that there exist \(d+1\) usual dyadic systems denoted by \(\tilde{\mathscr {D}}^j\), \(0\le j \le d\), such that for any ball B, we can find a dyadic cube \(Q' \in \tilde{\mathscr {D}}^j\) for some j such that
Then, given \(x\in Q\) and its associated \(Q' \in \tilde{\mathscr {D}}^j\) for some j, we can compute
where
Now, since \(M_{\tilde{\mathscr {D}}^j}^{\nu }\) is bounded on \(L_2(\nu )\) with norm independent of \(\nu \), we get
On the other hand, all \(Q\in \mathcal {S}\) are doubling, which means that each ball \(56B_Q\) is contained in a dyadic cube \(Q'\in \tilde{\mathscr {D}}^j\) for some \(j \in \{0,\ldots ,d\}\) which is \((\alpha ',\beta )\)-doubling. The family of associated cubes \(\{Q'\}_{Q \in \mathcal {S}}\) is then \(\eta \)-sparse, for some \(\eta \) that only depends on \(\alpha '\) and d. Then, we may apply the argument in [6] (to \(d+1\)\(\eta \)-sparse dyadic operators) to conclude
which yields the desired result. \(\square \)
Remark 4.1
It may be that the bound that we have found for the norm of T in terms of \([w]_{A_2(\mu )}\) is not the best possible. Definitely, it is not for the Lebesgue measure, and in that case our method is not optimal. In any case one may wonder, in view of the results in [32], if the quantity \([w]_{A_2}\) is the most natural one to study the dependence on the weight in the nondoubling setting.
We end this section with a discussion on Calderón–Zygmund decompositions for general measures. The classical decomposition is a tool that allows to decompose an integrable function into pieces that are well suited for Calderón–Zygmund estimates, yielding the weak type (1, 1) inequality for \(L_2\)-bounded Calderón–Zygmund operators. The same decomposition can be used to study the weak type (1, 1) boundedness of dyadic models like Haar shifts. However, when the underlying measure is nondoubling, as in the setting of this paper, singular integrals and their dyadic models require different tools adapted to their particular structure. On the one hand, since centered dilations of balls/cubes are important for Calderón–Zygmund operators—to ensure that one goes far away from the diagonal in kernel estimates—Tolsa’s decomposition (see [31]) has a centered nature, and dyadic systems do not play any role in it. On the other hand, the problem with the study of Haar shifts associated to a dyadic lattice \(\tilde{\mathscr {D}}\)—when the complexity is nonzero; otherwise, the problem was understood long ago via Gundy’s martingale decomposition—is related to the interaction between cubes and their dyadic ancestors. The ‘right’ decomposition in this case, found in [22], reads as follows: given \(f \in L_1(\mu )\) and a height \(\lambda >0\), if \(\{Q_j\}_j\) is the family of maximal dyadic cubes with respect to the property \(\langle |f|\rangle _Q>\lambda \), then \(f = g + b + \beta \), where
Notice that the maximal cubes \(Q_j\) need not be doubling. Interestingly, it turns out that the natural condition on the measure \(\mu \) in this case is not the polynomial growth condition, but equilibration. In the one-dimensional case, this means the following: if the brother of a cube Q is \(Q_{\mathrm {b}}\), define
Then a locally finite Borel measure \(\mu \) is equilibrated if \(m(Q) \sim m(Q^{(1)})\) for all \(Q \in \tilde{\mathscr {D}}\), a condition that is neither implied by nor implies linear growth. As a consequence of this, Haar shift theory and Calderón–Zygmund theory are different when \(\mu \) is nondoubling. However, if we substitute the dyadic system \(\tilde{\mathscr {D}}\) by the filtration \(\Sigma \), we obtain a simple unified approach to both theories/decompositions:
Theorem 4.2
Let \(0\le f\in L_1(\mu )\) and \(\lambda >0\) (or \(\lambda > \Vert f\Vert _{L_1(\mu )} / \Vert \mu \Vert \) if \(\mu \) is finite). Consider the family of maximal sets of \(\Pi (\Sigma )\) with respect to the property \(\langle f \rangle _Q > \lambda \). We can write \(f=g+\tilde{\beta }\), where
and we have \(\sum _j \Vert \varphi _j\Vert _{L_1(\mu )} \lesssim \Vert f\Vert _{L_1(\mu )}\) and \(\Vert g\Vert _{L_2(\mu )} \lesssim \lambda \Vert f\Vert _{L_1(\mu )}\).
The proof of Theorem 4.2 is essentially the same than that of Theorem A in [22]. However, the additional properties satisfied by the filtration \(\Sigma \) yield
for Calderón–Zygmund operators T, hence recovering Tolsa’s result [31]. Also, if \(\mu \) is equilibrated with respect to \(\Sigma \), we can establish the same weak \(L_1\) estimates for Haar shift operators—defined with respect to \(\Sigma \). The details are left to the reader.
5 Noncommutative \(\mathrm {RBMO}\)
We now study the validity of our results of Sect. 3 in the operator valued setting. Our models are the operator valued \(\mathrm {BMO}\) in [23] and the large \(\mathrm {BMO}\) spaces in [5]. Hence, assume that \(\mathcal {M}\) is a—possibly noncommutative—von Neumann algebra equipped with a trace \(\tau \). This is sometimes called a ‘noncommutative measure space’, see [29] for a nice introduction of the subject. We consider the semicommutative von Neumann algebra \(\mathcal {A}\) which is the von Neumann algebra tensor product of \((\mathcal {M},\tau )\) with \(L_\infty (\mu )\), that is
(see [27] for details on a similar setting). This is both a von Neumann algebra and a vector valued \(L_\infty \) space. The trace on \(\mathcal {A}\)—the noncommutative integral—acts on functions \(f:\mathbb {R}^d \rightarrow \mathcal {M}\) by
The noncommutative \(L_p\) scale associated to \(\mathcal {A}\) is the family of spaces
Let us introduce our \(\mathrm {RBMO}_\Sigma \) norm in this setting. Define the absolute value (for operators) by \(|x|^2 = x^*x\). Notice that in the noncommutative setting, \(|x| \not = |x^*|\). Given a \(\tau \)-measurable function \(f:\mathbb {R}^d \rightarrow L_0(\mathcal {M})\) its norm in \(\mathrm {RBMO}_\Sigma (\mathcal {A})\) is its (noncommutative) martingale \(\mathrm {BMO}\) norm with respect to the filtration \(\Sigma \):
We say that f belongs to \(\mathrm {RBMO}_\Sigma = \mathrm {RBMO}_\Sigma (\mu )\) if \(\max \{\Vert f\Vert _{\mathrm {RBMO}_\Sigma ^c},\Vert f^*\Vert _{\mathrm {RBMO}_\Sigma ^c} \}<\infty \). Notice that our conditional expectations
are again operator valued: the average of a function f over an atom in \(\Pi (\Sigma )\) is still an element of \(\mathcal {M}\). In any case, \(\mathrm {RBMO}_\Sigma (\mathcal {A})\) is a noncommutative martingale \(\mathrm {BMO}\) norm, and therefore we automatically have that the following nice properties hold:
-
John–Nirenberg inequality: The correct version of John–Nirenberg inequality for noncommutative martingale \(\mathrm {BMO}\) was established in [11, 14] and applies to \(\mathrm {RBMO}_\Sigma (\mathcal {A})\).
-
Interpolation: The noncommutative interpolation theorem with \(\mathrm {BMO}\) (see [24]) gives the interpolation of \(\mathrm {RBMO}_\Sigma (\mathcal {A})\):
$$\begin{aligned} \left[ \mathrm {RBMO}_\Sigma (\mathcal {A}), L_1(\mathcal {A}) \right] _{1/p} = L_p(\mathcal {A}). \end{aligned}$$ -
Fefferman–Stein duality: the predual of \(\mathrm {RBMO}_\Sigma (\mathcal {A})\) is, as in the commutative case, the Hardy space \(\mathrm {H}_1\) associated to the noncommutative dyadic square function. However, as shown in [3], it also admits an atomic block decomposition very similar to that explained in Sect. 3.
To finish our study, let us consider Calderón–Zygmund \(L_\infty -\mathrm {RBMO}\) estimates in the noncommutative setting. We start defining what we understand by a Calderón–Zygmund operator. We essentially follow [5, 15]. Consider kernels \(k: (\mathbb {R}^d \times \mathbb {R}^d) \setminus \Delta \rightarrow \mathcal {L}(L_0(\mathcal {M}))\) defined away from the diagonal \(\Delta \) of \(\mathbb {R}^d \times \mathbb {R}^d\) and which take values in linear maps on \(\tau \)-measurable operators. The standard Hörmander kernel condition takes the same form in this setting when we replace the absolute value by the norm in the algebra \(\mathcal {B}(\mathcal {M})\) of bounded linear operators acting on \(\mathcal {M}\):
Define a Calderón–Zygmund operator in \((\mathcal {A}, \varphi )\) as any linear map T satisfying the following properties:
-
T is bounded on \(L_\infty (\mathcal {M}; L_2^r(\mu ))\):
$$\begin{aligned} \Big \Vert \int _{\mathbb {R}^d} |Tf(x)^*|^2 \, d\mu (x) \Big \Vert _{\mathcal {M}}^{\frac{1}{2}} \, \lesssim \, \Big \Vert \int _{\mathbb {R}^d} |f(x)^*|^2 \, d\mu (x) \Big \Vert _{\mathcal {M}}^{\frac{1}{2}}. \end{aligned}$$ -
T is bounded on \(L_\infty (\mathcal {M}; L_2^c(\mu ))\):
$$\begin{aligned} \Big \Vert \int _{\mathbb {R}^d} |Tf(x)|^2 \, d\mu (x) \Big \Vert _{\mathcal {M}}^{\frac{1}{2}} \, \lesssim \, \Big \Vert \int _{\mathbb {R}^d} |f(x)|^2 \, d\mu (x) \Big \Vert _{\mathcal {M}}^{\frac{1}{2}}. \end{aligned}$$ -
The kernel representation
$$\begin{aligned} Tf(x) \, = \, \int _{\mathbb {R}^d} k(x,y) (f(y)) \, d\mu (y) \quad \text{ holds } \text{ for } \quad x \notin \mathrm {supp}_{\mathbb {R}^d} (f) \end{aligned}$$and some kernel k satisfying the operator valued Hörmander condition (5.1). Here \(\mathrm {supp}_{\mathbb {R}^d}(f)\) denotes the support of f as a function on \(\mathbb {R}^d\) (and not as an operator in \(\mathcal {A}\)).
-
k satisfies the n-dimensional size condition
$$\begin{aligned} \Vert k(x,y)\Vert _{\mathcal {B}(\mathcal {M})} \lesssim \frac{1}{|x-y|^n}, \; x\not = y. \end{aligned}$$
The first two conditions are the natural replacement for the standard \(L_2\) boundedness, see [15] for explanations. Let us prove Theorem 1.4:
Proof of Theorem 1.4
We only prove that \(T:\mathcal {A} \rightarrow \mathrm {RBMO}_{\Sigma }^c(\mathcal {A})\) using the \(L_\infty (\mathcal {M}; L_2^c(\mu ))\)-boundedness. Then, the bound \(T:\mathcal {A} \rightarrow \mathrm {RBMO}_{\Sigma }^r(\mathcal {A})\) will follow analogously from \(L_\infty (\mathcal {M}; L_2^r(\mu ))\)-boundedness and the proof will be complete. Recall that

Fix \(Q\in \Pi (\Sigma )\) and \(f\in \mathcal {A}\). We can write

By the Kadison-Schwarz inequality for unital completely positive maps [17], we know that \(|\langle f\rangle _Q|^2 \le \langle |f|^2\rangle _Q\). This, combined with \(L_\infty (\mathcal {M}; L_2^c(\mu ))\)-boundedness and the fact that \(B_{\widehat{Q}}\) is \((\alpha ,\beta )\)-doubling, yields
A similar computation holds for \(\mathrm {I}\). Next, we use the triangle inequality and the \(C^*\) property \(\Vert x^*x\Vert _{\mathcal {M}} = \Vert x\Vert _{\mathcal {M}}^2\) to compute
by the size condition of k and (iv) of Theorem 1.1. The last term can be estimated using the operator valued Hörmander condition:

We are done. \(\square \)
Remark 5.1
The endpoint estimate just proven and the interpolation property of \(\mathrm {RBMO}_\Sigma (\mathcal {A})\) allows to deduce boundedness of Calderón–Zygmund operators on \(L_p(\mathcal {A})\), \(1<p<\infty \). Notice that this is a noncommutative \(L_p\) scale, and not a vector valued one. In any case, due to the fact that \(L_p(\mathcal {M})\) is UMD for \(1<p<\infty \) and observing that \(L_p(\mathcal {A})\) is also a vector valued space, this boundedness can be deduced from the vector valued theory whenever the kernel k(x, y) is scalar valued. However, as was discussed in [27], the use of a noncommutative interpolation scale yields better constants in the inequalities in terms of dependence on p.
Remark 5.2
As the proof shows, Lipschitz smoothness on the kernel is not required to obtain the \(\mathcal {A} \rightarrow \mathrm {RBMO}_\Sigma (\mathcal {A})\) endpoint estimate, and one can work only with Hörmander condition in conjunction with the size condition (of degree equal to the dimension of the measure \(\mu \)).
References
Caspers, M., Potapov, D., Sukochev, F., Zanin, D.: Weak type commutator and lipschitz estimates: resolution of the Nazarov–Peller conjecture. Preprint arXiv:1506.00778 [math.FA]
Conde, J.M.: A note on dyadic coverings and nondoubling Calderón–Zygmund theory. J. Math. Anal. Appl. 397(2), 785–790 (2013)
Conde-Alonso, J.M., Parcet, J.: Atomic blocks for noncommutative martingales. Indiana Univ. Math. J. 65(4), 1425–1443 (2016)
Conde-Alonso, J.M., Rey, G.: On a pointwise estimate for positive dyadic shifts and some applications. Math. Ann. 365(3), 1111–1135 (2016)
Conde-Alonso, J.M., Mei, T., Parcet, J.: Large BMO spaces vs interpolation. Anal. PDE 8(3), 713–746 (2015)
Cruz-Uribe, D., Martell, J.M., Pérez, C.: Sharp weighted estimates for classical operators. Adv. Math. 229(1), 408–441 (2012)
David, G., Mattila, P.: Removable sets for Lipschitz harmonic functions in the plane. Rev. Mat. Iberoam. 16(1), 137–215 (2000)
Garnett, J.B., Jones, P.W.: \(\text{ BMO }\) from dyadic\(\text{ BMO }\). Pacif. J. Math. 99(2), 351–371 (1982)
Garsia, A.M.: Martingale inequalities: Seminar notes on recent progress. In: Mathematics Lecture Notes Series. W. A. Benjamin, Inc., Reading/London/Amsterdam (1973)
Hänninen, T.S.: Remark on dyadic pointwise domination and median oscillation decomposition. Houston J. Math. 43(1), 183–197 (2017)
Hong, G., Mei, T.: John–Nirenberg inequality and atomic decomposition for noncommutative martingales. J. Funct. Anal. 263(4), 1064–1097 (2012)
Hytönen, T.P.: A framework for non-homogeneous analysis on metric spaces, and the RBMO space of Tolsa. Publ. Mat. 54(2), 485–504 (2010)
Hytönen, T.P.: The sharp weighted bound for general Calderón–Zygmund operators. Ann. of Math. (2) 175(3), 1473–1506 (2012)
Junge, M., Musat, M.: A noncommutative version of the John–Nirenberg theorem. Trans. Am. Math. Soc. 359(1), 115–142 (2007)
Junge, M., Mei, T., Parcet, J.: Smooth Fourier multipliers on group von Neumann algebras. Geom. Funct. Anal. 24(6), 1913–1980 (2014)
Lacey, M.T.: An elementary proof of the \({\rm A}_2\) bound. Israel J. Math. 217, 181–195 (2017)
Lance, E.C.: Hilbert \(C^*\)-modules: a toolkit for operator algebraists. In: Proceedings of the London Mathematical Society Lecture Note Series, vol. 210. Cambridge University Press, Cambridge (1995)
Lerner, A.K.: On pointwise estimates involving sparse operators. New York J. Math. 22, 341–349 (2016)
Lerner, A.K.: A pointwise estimate for the local sharp maximal function with applications to singular integrals. Bull. Lond. Math. Soc. 42(5), 843–856 (2010)
Lerner, A.K.: On an estimate of Calderón–Zygmund operators by dyadic positive operators. J. Anal. Math. 121, 141–161 (2013)
Lerner, A.K., Nazarov, F.: Intuitive dyadic calculus: the basics. Preprint arXiv:1508.05639
López-Sánchez, L.D., Martell, J.M., Parcet, J.: Dyadic harmonic analysis beyond doubling measures. Adv. Math. 267, 44–93 (2014)
Mei, T.: Operator valued Hardy spaces. Mem. Am. Math. Soc 188(881), vi+64 (2007)
Musat, M.: Interpolation between non-commutative BMO and non-commutative \(L_p\)-spaces. J. Funct. Anal. 202(1), 195–225 (2003)
Nazarov, F., Treil, S., Volberg, A.: Weak type estimates and Cotlar inequalities for Calderón–Zygmund operators on nonhomogeneous spaces. Int. Math. Res. Not. 9, 463–487 (1998)
Nazarov, F., Treil, S., Volberg, A.: The \(Tb\)-theorem on non-homogeneous spaces. Acta Math. 190(2), 151–239 (2003)
Parcet, J.: Pseudo-localization of singular integrals and noncommutative Calderón–Zygmund theory. J. Funct. Anal. 256(2), 509–593 (2009)
Petermichl, S.: Of some sharp estimates involving Hilbert transform. ProQuest LLC, Ann Arbor, MI. Thesis (Ph.D.), Michigan State University (2000)
Pisier, G., Xu, Q.: Non-commutative martingale inequalities. Commun. Math. Phys. 189(3), 667–698 (1997)
Tolsa, X.: BMO, \(\text{ H }^1\), and Calderón–Zygmund operators for non doubling measures. Math. Ann. 319(1), 89–149 (2001)
Tolsa, X.: A proof of the weak \((1,1)\) inequality for singular integrals with non doubling measures based on a Calderón–Zygmund decomposition. Publ. Mat. 45(1), 163–174 (2001)
Tolsa, X.: Weighted norm inequalities for Calderón–Zygmund operators without doubling conditions. Publ. Mat. 51(2), 397–456 (2007)
Volberg, A., Zorin-Kranich, P.: Sparse domination on non-homogeneous spaces with an application to \({A}_p\) weights. Preprint arXiv:1606.03340
Volberg, A.L., Eiderman, V.Y.: Nonhomogeneous harmonic analysis: 16 years of development. Uspekhi Mat. Nauk. 68(6), 3–58 (2013)
Acknowledgements
The authors thank Xavier Tolsa for bringing to our attention David and Mattila’s construction and for several fruitful discussions on the content of this paper. Both authors were partially supported by CSIC Project PIE 201650E030 and also by ICMAT Severo Ochoa Grant SEV-2015-0554, and the first named author was supported in part by ERC Grant 32501.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Dachun Yang.
Rights and permissions
About this article

Cite this article
Conde-Alonso, J.M., Parcet, J. Nondoubling Calderón–Zygmund theory: a dyadic approach. J Fourier Anal Appl 25, 1267–1292 (2019). https://doi.org/10.1007/s00041-018-9624-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00041-018-9624-4