
Abstract
We study the spaces \(B^{s(\cdot)}_{p(\cdot),q(\cdot)}(\mathbb {R}^{n})\) and \(F^{s(\cdot)}_{p(\cdot),q(\cdot)}(\mathbb{R}^{n})\) of Besov and Triebel-Lizorkin type as introduced recently in Almeida and Hästö (J. Funct. Anal. 258(5):1628–2655, 2010) and Diening et al. (J. Funct. Anal. 256(6):1731–1768, 2009). Both scales cover many classical spaces with fixed exponents as well as function spaces of variable smoothness and function spaces of variable integrability.
The spaces \(B^{s(\cdot)}_{p(\cdot),q(\cdot)}(\mathbb{R}^{n})\) and \(F^{s(\cdot)}_{p(\cdot),q(\cdot)}(\mathbb{R}^{n})\) have been introduced in Almeida and Hästö (J. Funct. Anal. 258(5):1628–2655, 2010) and Diening et al. (J. Funct. Anal. 256(6):1731–1768, 2009) by Fourier analytical tools, as the decomposition of unity. Surprisingly, our main result states that these spaces also allow a characterization in the time-domain with the help of classical ball means of differences.
To that end, we first prove a local means characterization for \(B^{s(\cdot)}_{p(\cdot),q(\cdot)}(\mathbb{R}^{n})\) with the help of the so-called Peetre maximal functions. Our results do also hold for 2-microlocal function spaces \(B^{\boldsymbol{w}}_{{p(\cdot)},{q(\cdot)}}(\mathbb{R}^{n})\) and \(F^{\boldsymbol{w}}_{{p(\cdot)},{q(\cdot)}}(\mathbb{R}^{n})\) which are a slight generalization of generalized smoothness spaces and spaces of variable smoothness.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Function spaces of variable integrability appeared in a work by Orlicz [41] already in 1931, but the recent interest in these spaces is based on the paper of Kováčik and Rákosnik [32] together with applications in terms of modelling electrorheological fluids [45]. A fundamental breakthrough concerning spaces of variable integrability was the observation that, under certain regularity assumptions on p(⋅), the Hardy-Littlewood maximal operator is also bounded on L p(⋅)(ℝn), see [14]. This result has been generalized to wider classes of exponents p(⋅) in [11, 40] and [15].
Besides electrorheological fluids, the spaces L p(⋅)(ℝn) possess interesting applications in the theory of PDE’s, variational calculus, financial mathematics and image processing. A recent overview of this vastly growing field is given in [17].
Sobolev and Besov spaces with variable smoothness but fixed integrability have been introduced in the late 60s and early 70s in the works of Unterberger [57], Višik and Eskin [58], Unterberger and Bokobza [56] and in the work of Beauzamy [7]. Leopold studied in [33] Besov spaces where the smoothness is determined by a symbol a(x,ξ) of a certain class of hypoelliptic pseudodifferential operators. In the special case a(x,ξ)=(1+|ξ|2)σ(x)/2 these spaces coincide with spaces of variable smoothness \(B^{\sigma(x)}_{p,p}(\mathbb{R}^{n})\).
A more general approach to spaces of variable smoothness are the so-called 2-microlocal function spaces \(B^{\boldsymbol{w}}_{p,q}(\mathbb{R}^{n})\) and \(F^{\boldsymbol{w}}_{p,q}(\mathbb{R}^{n})\). Here the smoothness in these spaces gets measured by a weight sequence \(\boldsymbol{w}=(w_{j})_{j=0}^{\infty}\). Besov spaces with such weight sequences appeared first in the works of Peetre [42] and Bony [9]. Establishing a wavelet characterization for 2-microlocal Hölder-Zygmund spaces in [24] it turned out that 2-microlocal spaces are well adapted in connection to regularity properties of functions [25, 35, 37]. Spaces of variable smoothness are a special case of 2-microlocal function spaces and in [34] and [8] characterizations by differences have been given for certain classes of them.
The theories of function spaces with fixed smoothness and variable integrability and function spaces with variable smoothness and fixed integrability finally crossed each other in [16], where the authors introduced the function spaces of Triebel-Lizorkin type with variable smoothness and simultaneously with variable integrability. It turned out that many of the spaces mentioned above are really included in this new structure, see [16] and references therein. The key point to merge both lines of investigation was the study of traces. From Theorem 3.13 in [16]

one immediately understands the necessity to take all exponents variable assuming p(⋅) or s(⋅) variable. So the trace embeddings may be described in a natural way in the context of these spaces. Furthermore, this was complemented in [59] by showing, that the classical Sobolev embedding theorem

holds also in this scale of function spaces if the usual condition is replaced by its point-wise analogue

Finally, Almeida and Hästö managed in [1] to adapt the definition of Besov spaces to the setting of variable smoothness and integrability and proved the Sobolev and other usual embeddings in this scale.
The properties of Besov and Triebel-Lizorkin spaces of variable smoothness and integrability known so far give a reasonable hope that these new scales of function spaces enjoy sufficiently many properties to allow a local description of many effects, which up to now could only be described in a global way. Subsequently, for the spaces \(F^{s(\cdot)}_{{p(\cdot)},{q(\cdot)}}(\mathbb{R}^{n})\) there is a characterization by local means given in [30]. This characterization still works with Fourier analytical tools but the analyzing functions \(k_{0},k\in\mathcal{S}(\mathbb{R}^{n})\) are compactly supported in the time-domain and we only need local values of f around x∈ℝn to calculate the building blocks k(2−j,f)(x). This is in sharp contrast to the definition of the spaces by the decomposition of unity, cf. Definitions 1 and 3. For the spaces \(B^{s(\cdot)}_{{p(\cdot)},{q(\cdot)}}(\mathbb{R}^{n})\) we will prove a local means assertion of this type in Sect. 3 which will be helpful later on.
The main aim of this paper is to present another essential property of the function spaces from [16] and [1]. We prove the surprising result that these spaces \(B^{s(\cdot)}_{{p(\cdot)},{q(\cdot)}}(\mathbb {R}^{n})\) and \(F^{s(\cdot)}_{{p(\cdot)},{q(\cdot)}}(\mathbb{R}^{n})\) with variable smoothness and integrability do also allow a characterization purely in the time-domain by classical ball means of differences.
The paper is organized as follows. First of all we provide all necessary notation in Sect. 2. Since the proofs for spaces of variable smoothness and 2-microlocal function spaces work very similar (see Remark 2) we present our results for both scales. The proof for the local means characterization will be given in Sect. 3 in terms of 2-microlocal function spaces and we present the version for spaces of variable smoothness in Sect. 3.2. In Sect. 4 we prove the characterization by ball means of differences for \(B^{s(\cdot)}_{{p(\cdot)},{q(\cdot)}}(\mathbb {R}^{n})\) and \(F^{s(\cdot)}_{{p(\cdot)},{q(\cdot)}}(\mathbb{R}^{n})\) and the version for 2-microlocal function spaces will be given in Sect. 4.5.
2 Notation
In this section we collect all the necessary definitions. We start with the variable Lebesgue spaces L p(⋅)(ℝn). A measurable function p:ℝn→(0,∞] is called a variable exponent function if it is bounded away from zero, i.e. if \(p^{-}=\operatornamewithlimits{ess-inf}_{x\in\mathbb{R}^{n}}p(x)>0\). We denote the set of all variable exponent functions by \(\mathcal{P}(\mathbb{R}^{n})\). We put also \(p^{+}=\operatornamewithlimits{ess-sup}_{x\in\mathbb{R}^{n}}p(x)\).
The variable exponent Lebesgue space L p(⋅)(ℝn) consists of all measurable functions f for which there exist λ>0 such that the modular

is finite, where

If we define \(\mathbb{R}^{n}_{\infty}=\{x\in\mathbb{R}^{n}:p(x)=\infty\}\) and \(\mathbb{R}^{n}_{0}=\mathbb{R}^{n}\setminus\mathbb{R}^{n}_{\infty}\), then the Luxemburg norm of a function f∈L p(⋅)(ℝn) is given by

If p(⋅)≥1, then it is a norm otherwise it is always a quasi-norm.
To define the mixed spaces ℓ q(⋅)(L p(⋅)) we have to define another modular. For \(p,q\in\mathcal{P}(\mathbb {R}^{n})\) and a sequence \((f_{\nu})_{\nu\in\mathbb{N}_{0}}\) of L p(⋅)(ℝn) functions we define

If q +<∞, then we can replace (1) by the simpler expression

The (quasi-)norm in the ℓ q(⋅)(L p(⋅)) spaces is defined as usual by

It is known, cf. [1, 31], that ℓ q(⋅)(L p(⋅)) is a norm if q(⋅)≥1 is constant almost everywhere (a.e.) on ℝn and p(⋅)≥1, or if 1/p(x)+1/q(x)≤1 a.e. on ℝn, or if 1≤q(x)≤p(x)≤∞ a.e. on ℝn. Surprisingly enough, it turned out in [31] that the condition min(p(x),q(x))≥1 a.e. on ℝn is not sufficient for ℓ q(⋅)(L p(⋅)) to be a norm. Nevertheless, it was proven in [1] that it is a quasi-norm for every \(p,q\in\mathcal {P}(\mathbb{R}^{n})\).
For the sake of completeness, we state also the definition of the space L p(⋅)(ℓ q(⋅)), which is much more intuitive then the definition of ℓ q(⋅)(L p(⋅)). One just takes the ℓ q(x) norm of \((f_{\nu}(x))_{\nu\in\mathbb{N}_{0}}\) for every x∈ℝn and then the L p(⋅)-norm with respect to x∈ℝn, i.e.
It is easy to show [16] that L p(⋅)(ℓ q(⋅)) is always a quasi-normed space and it is a normed space, if min(p(x),q(x))≥1 holds point-wise.
The summation in the definition of the norms of ℓ q(⋅)(L p(⋅)) and L p(⋅)(ℓ q(⋅)) can also be taken for ν∈ℤ. It always comes out of the context over which interval the summation is taken. Occasionally, we may indicate it by \(\Vert{(f_{\nu})_{\nu=-\infty }^{\infty}}\vert{{\ell_{q(\cdot)}(L_{p(\cdot)})}}\Vert\).
By \(\hat{f}=\mathcal{F}f\) and \(f^{\vee}=\mathcal{F}^{-1}f\) we denote the usual Fourier transform and its inverse on \(\mathcal{S}(\mathbb{R}^{n})\), the Schwartz space of smooth and rapidly decreasing functions, and on \(\mathcal{S}'(\mathbb{R}^{n})\), the dual of the Schwartz space.
2.1 Spaces \(B^{s(\cdot)}_{{p(\cdot)},{q(\cdot)}}(\mathbb{R}^{n})\) and \(F^{s(\cdot)}_{{p(\cdot)},{q(\cdot )}}(\mathbb{R}^{n})\)
The definition of Besov and Triebel-Lizorkin spaces of variable smoothness and integrability is based on the technique of decomposition of unity exactly in the same manner as in the case of constant exponents.
Definition 1
Let \(\varphi_{0}\in\mathcal{S}(\mathbb{R}^{n})\) with φ 0(x)=1 for |x|≤1 and \(\operatorname{supp}\varphi_{0}\subseteq\{x\in\mathbb{R}^{n}:|x|\leq 2\}\). For j≥1 we define

One may verify easily that
The following regularity classes for the exponents are necessary to make the definition of the spaces independent on the chosen decomposition of unity.
Definition 2
Let g∈C(ℝn).
-
(i)
We say that g is locally log-Hölder continuous, abbreviated \(g\in C^{\log}_{\mathit{loc}}(\mathbb{R}^{n})\), if there exists c log(g)>0 such that
 (2)
(2)holds for all x,y∈ℝn.
-
(ii)
We say that g is globally log-Hölder continuous, abbreviated g∈C log(ℝn), if g is locally log-Hölder continuous and there exists g ∞∈ℝ such that
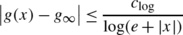
holds for all x∈ℝn.

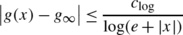
Remark 1
With (2) we obtain

This implies that all functions \(g\in C^{\log}_{\mathit{loc}}(\mathbb {R}^{n})\) always belong to L ∞(ℝn).
If an exponent \(p\in\mathcal{P}(\mathbb{R}^{n})\) satisfies 1/p∈C log(ℝn), then we say it belongs to the class \(\mathcal{P}^{\log}(\mathbb{R}^{n})\). We recall the definition of the spaces \(B^{s(\cdot)}_{{p(\cdot)},{q(\cdot )}}(\mathbb{R}^{n})\) and \(F^{s(\cdot)}_{{p(\cdot)},{q(\cdot)}}(\mathbb{R}^{n})\), as given in [16] and [1].
Definition 3
(i) Let \(p,q\in\mathcal{P}^{\log}(\mathbb{R}^{n})\) with 0<p −≤p +<∞, 0<q −≤q +<∞ and let \(s\in C^{\log}_{\mathit{loc}}(\mathbb {R}^{n})\). Then

(ii) Let \(p,q\in\mathcal{P}^{\log}(\mathbb{R}^{n})\) and let \(s\in C^{\log}_{\mathit{loc}}(\mathbb{R}^{n})\). Then

The subscript φ at the norm symbolizes that the definition formally does depend on the resolution of unity. From [30] and [1] we have that the definition of the spaces \(F^{s(\cdot)}_{{p(\cdot)},{q(\cdot )}}(\mathbb{R}^{n})\) and \(B^{s(\cdot)}_{{p(\cdot )},{q(\cdot)}}(\mathbb{R}^{n})\) is independent of the chosen resolution of unity if \(p,q\in\mathcal{P}^{\log}(\mathbb {R}^{n})\) and \(s\in C^{\log}_{\mathit{loc}}(\mathbb{R}^{n})\). That means that different start functions φ 0 and \(\tilde{\varphi }_{0}\) from Definition 1 induce equivalent norms in the above definition. So we will suppress the subscript φ in the notation of the norms.
Let us comment on the conditions on \(p,q\in\mathcal{P}^{\log}(\mathbb{R}^{n})\) for the Triebel-Lizorkin spaces. The condition 0<p −≤p +<∞ is quite natural since there exists also the restriction p<∞ in the case of constant exponents, see [51] and [63]. The second one, 0<q −≤q +<∞, is a bit unnatural and comes from the use of the convolution Lemma 21 [16, Theorem 3.2]. There is some hope that this convolution lemma can be generalized and the case q +=∞ can be incorporated in the definition of the F-spaces.
The Triebel-Lizorkin spaces with variable smoothness have first been introduced in [16] under much more restrictive conditions on s(⋅). These conditions have been relaxed in [30] in the context of 2-microlocal function spaces (see the next subsection).
Besov spaces with variable p(⋅),q(⋅) and s(⋅) have been introduced in [1].
Both scales contain as special cases a lot of well known function spaces. If s,p and q are constants, then we derive the well known Besov and Triebel-Lizorkin spaces with usual Hölder and Sobolev spaces included, see [51] and [52]. If the smoothness s∈ℝ is a constant and \(p\in\mathcal {P}^{\log}(\mathbb{R}^{n})\) with p −>1, then \(F^{s}_{{p(\cdot)},2}(\mathbb{R}^{n})=\mathcal{L}^{s}_{p(\cdot)}(\mathbb {R}^{n})\) are the variable Bessel potential spaces from [2] and [23] with its special cases \(F^{0}_{{p(\cdot)},2}(\mathbb{R}^{n})=L_{p(\cdot)}(\mathbb{R}^{n})\) and \(F^{k}_{{p(\cdot)},2}(\mathbb{R}^{n})=W^{k}_{p(\cdot)}(\mathbb{R}^{n})\) for k∈ℕ0, see [16].
Taking s∈ℝ and q∈(0,∞] as constants we derive the spaces \(F^{s}_{{p(\cdot)},q}(\mathbb{R}^{n})\) and \(B^{s}_{{p(\cdot)},q}(\mathbb {R}^{n})\) studied by Xu in [61] and [62].
Furthermore it holds \(F^{s(\cdot)}_{{p(\cdot)},{p(\cdot)}}(\mathbb {R}^{n})=B^{s(\cdot)}_{{p(\cdot)},{p(\cdot)}}(\mathbb{R}^{n})\) and \(B^{s(\cdot)}_{\infty,\infty}(\mathbb{R}^{n})\) equals the variable Hölder-Zygmund space \(\mathcal{C}^{s(\cdot)}(\mathbb{R}^{n})\) introduced in [3, 4] and [44] with 0<s −≤s +≤1, see [1].
2.2 2-Microlocal Spaces
The definition of Besov and Triebel-Lizorkin spaces of variable smoothness and integrability is a special case of the so-called 2-microlocal spaces of variable integrability. As some of the results presented here get proved in this more general scale, we present also the definition of 2-microlocal spaces. It is based on the dyadic decomposition of unity as presented above combined with the concept of admissible weight sequences.
Definition 4
Let α≥0 and let α 1,α 2∈ℝ with α 1≤α 2. A sequence of non-negative measurable functions \(\boldsymbol{w}=(w_{j})_{j=0}^{\infty}\) belongs to the class \(\mathcal{W}^{\alpha}_{\alpha_{1},\alpha_{2}}\) if and only if
-
(i)
there exists a constant C>0 such that

-
(ii)
and for all j∈ℕ0 and all x∈ℝn we have



Such a system \((w_{j})_{j=0}^{\infty}\in\mathcal{W}^{\alpha}_{\alpha _{1},\alpha_{2}}\) is called an admissible weight sequence.
Finally, here is the definition of the spaces under consideration.
Definition 5
Let \(\boldsymbol{w}=(w_{j})_{j\in\mathbb{N}_{0}}\in\mathcal{W}^{\alpha}_{\alpha_{1},\alpha_{2}}\). Further, let \(p,q\in\mathcal{P}^{\log}(\mathbb{R}^{n})\) (with p +,q +<∞ in the F-case), then we define

and

The independence of the decomposition of unity for the 2-microlocal spaces from Definition 5 follows from the local means characterization (see [30] for the Triebel-Lizorkin and Sect. 3 for the Besov spaces).
The 2-microlocal spaces with the special weight sequence

have first been introduced by Peetre in [42] and by Bony in [9]. Later on, Jaffard and Meyer gave a characterization in [24] and [25] with wavelets of the spaces \(C^{s,s'}_{x_{0}}=B^{\boldsymbol{w}}_{\infty,\infty}(\mathbb{R}^{n})\) and \(H^{s,s'}_{x_{0}}=B^{\boldsymbol{w}}_{2,2}(\mathbb{R}^{n})\) with the weight sequence (3). It turned out that spaces of this type are very useful to study regularity properties of functions. Subsequently, Lévy-Véhel and Seuret developed in [35] the 2-microlocal formalism and studied the behavior of cusps, chirps and fractal functions with respect to the spaces \(C^{s,s'}_{x_{0}}\).
A first step to a more general weight sequence w has been taken by Moritoh and Yamada in [38] and wider ranges of function spaces have been studied by Xu in [60] and by Andersson in [5].
The above definition for 2-microlocal weight sequences was presented by Besov in [8] and also in [30] by Kempka.
A different line of study for spaces of variable smoothness—using different methods—are the spaces of generalized smoothness introduced by Goldman and Kalyabin in [20, 21, 26] and [27]. A systematic treatment of these spaces based on differences has been given by Goldman in [22], see also the survey [29] and references therein.
Later on, spaces of generalized smoothness appeared in interpolation theory and have been investigated in [10, 36] and [39]. For further information on these spaces see the survey paper [19] where also a characterization by atoms and local means for these spaces is given.
From the definition of admissible sequences, d 1 σ j ≤σ j+1≤d 2 σ j , it follows directly that the spaces of generalized smoothness \(B^{(\sigma_{j})}_{p,q}(\mathbb{R}^{n})\) and \(F^{(\sigma _{j})}_{p,q}(\mathbb{R}^{n})\) of Farkas and Leopold [19] and \(B^{(s,\Psi)}_{p,q}(\mathbb{R}^{n})\) and \(F^{(s,\Psi )}_{p,q}(\mathbb{R}^{n})\) from Moura [39] are a special subclass of 2-microlocal function spaces with \(2^{\alpha_{1}}=d_{1}\), \(2^{\alpha_{2}}=d_{2}\) and α=0.
In a different approach Schneider in [48] studied spaces of varying smoothness. Here the smoothness at a point gets determined by a global smoothness s 0∈ℝ and a local smoothness function s(⋅). These spaces can not be incorporated into the scale of 2-microlocal function spaces, but there exist some embeddings.
Remark 2
Surprisingly, these 2-microlocal weight sequences are directly connected to variable smoothness functions s:ℝn→ℝ if we set

If \(s\in C^{\log}_{\mathit{loc}}(\mathbb{R}^{n})\) (which is the standard condition on s(⋅)), then \(\boldsymbol{w}=(w_{j}(x))_{j\in\mathbb{N}_{0}}=(2^{js(x)})_{j\in \mathbb{N}_{0}}\) belongs to \(\mathcal{W}^{\alpha}_{\alpha_{1},\alpha_{2}}\) with α 1=s − and α 2=s +. For the third index α we use Lemma 19 with m=0 and obtain α=c log(s), where c log(s) is the constant for s(⋅) from (2). That means that spaces of variable smoothness from Definition 3 are a special case of 2-microlocal function spaces from Definition 5. Both types of function spaces are very closely connected and the properties used in the proofs are either

for |x−y|≤c2−k. This property follows directly either from the definition of \(s\in C^{\log}_{\mathit{loc}}(\mathbb{R}^{n})\) or from Definition 4.
Nevertheless there exist examples of admissible weight sequences which can not be expressed in terms of variable smoothness functions. For example the important and well studied case of the weight sequence w from (3) can not be expressed via (4) if s′≠0. Another example are the spaces of generalized smoothness which can not be identified as spaces of variable smoothness.
Since spaces of variable smoothness are included in the scale of 2-microlocal function spaces all special cases of the previous subsection can be identified in the definition of 2-microlocal spaces.
Although the 2-microlocal spaces include the scales of spaces of variable smoothness, we will give some of our proofs in the notation of variable smoothness, since this notation is more common. We will then reformulate the results in terms of 2-microlocal spaces, the proof works then very similar; we just have to use (5).
3 Local Means Characterization
The main result of this section is the local means characterization of the spaces \(B^{\boldsymbol{w}}_{{p(\cdot)},{q(\cdot)}}(\mathbb{R}^{n})\). For the spaces \(F^{\boldsymbol{w}}_{{p(\cdot)},{q(\cdot)}}(\mathbb{R}^{n})\) there already exists a local means characterization [30, Corollary 4.7]. We shall first give the full proof for the 2-microlocal spaces and later on (in Sect. 3.2) we restate the result also for spaces \(B^{s(\cdot)}_{{p(\cdot)},{q(\cdot)}}(\mathbb{R}^{n})\) and \(F^{s(\cdot)}_{{p(\cdot)},{q(\cdot )}}(\mathbb{R}^{n})\).
The crucial tool will be the Peetre maximal operator, as defined by Peetre in [42]. The operator assigns to each system \((\Psi_{k})_{k\in\mathbb{N}_{0}}\subset\mathcal{S}(\mathbb {R}^{n})\), to each distribution \(f\in\mathcal{S}'(\mathbb {R}^{n})\) and to each number a>0 the following quantities

We start with two given functions \(\psi_{0},\psi_{1}\in\mathcal{S}(\mathbb{R}^{n})\). We define

Furthermore, for all j∈ℕ0 we write \(\Psi_{j}=\hat{\psi_{j}}\). The main theorem of this section reads as follows.
Theorem 6
Let \(\boldsymbol{w}=(w_{k})_{k\in\mathbb{N}_{0}}\in\mathcal{W}^{\alpha}_{\alpha_{1},\alpha_{2}}\), \(p,q\in\mathcal{P}^{\log}(\mathbb {R}^{n})\) and let a>0, R∈ℕ0 with R>α 2. Further, let ψ 0,ψ 1 belong to \(\mathcal{S}(\mathbb {R}^{n})\) with

and


for some ε>0. For \(a>\frac{n+c_{\mathrm{log}}(1/q)}{p^{-}}+\alpha\) and all \(f\in\mathcal{S}'(\mathbb{R}^{n})\) we have

Remark 3
-
(i)
The proof relies on [46] and will be shifted to the next section. Moreover, Theorem 6 shows that the definition of the 2-microlocal spaces of variable integrability is independent of the resolution of unity used in the Definition 5.
-
(ii)
The conditions (7) are usually called moment conditions while (8) and (9) are the so called Tauberian conditions.
-
(iii)
If R=0, then there are no moment conditions (7) on ψ 1.
-
(iv)
The notation c log(1/q) stands for the constant from (2) with 1/q(⋅).
Next we reformulate the abstract Theorem 6 in the sense of classical local means (see Sects. 2.4.6 and 2.5.3 in [52]). Since the proof is the same as the one from Theorem 2.4 in [30] we just state the result.
Corollary 1
There exist functions \(k_{0},k\in\mathcal{S}(\mathbb{R}^{n})\) with \(\operatorname{supp}k_{0},\operatorname{supp}k\subset\{x\in \mathbb{R}^{n}:|x|<1\}\) and \(D^{\beta}\hat{k}(0)=0\) for all 0≤|β|<α 2 such that for all \(f\in\mathcal{S}'(\mathbb{R}^{n})\)

is an equivalent norm on \(B^{\boldsymbol{w}}_{{p(\cdot)},{q(\cdot )}}(\mathbb{R}^{n})\).
The building blocks get calculated by

and similarly for k 0(1,f)(x).
A similar characterization for \(F^{\boldsymbol{w}}_{{p(\cdot )},{q(\cdot)}}(\mathbb{R}^{n})\) and details how these functions \(k_{0},k\in\mathcal{S}(\mathbb{R}^{n})\) can be constructed can be found in [30].
3.1 Proof of Local Means
The proof of Theorem 6 is divided into three parts. The next section is devoted to some technical lemmas needed later. Section 3.1.2 is devoted to the proof of Theorem 12, which gives an inequality between different Peetre maximal operators. Finally, Sect. 3.1.3 proves the boundedness of the Peetre maximal operator in Theorem 13. These two theorems combined give immediately the proof of Theorem 6.
3.1.1 Helpful Lemmas
Before proving the local means characterization we recall some technical lemmas, which appeared in the paper of Rychkov [46]. For some of them we need adapted versions to our situation.
The first lemma describes the use of the so called moment conditions.
Lemma 7
([46], Lemma 1)
Let \(g,h\in\mathcal{S}(\mathbb{R}^{n})\) and let M∈ℕ0. Suppose that

Then for each N∈ℕ0 there is a constant C N such that

where g t (x)=t −n g(x/t).
The next lemma is a discrete convolution inequality. We formulate it in a rather abstract notation and point out later on the conclusions we need.
Lemma 8
Let \(X\subset\{(f_{k})_{k\in\mathbb{Z}}:f_{k}:\mathbb{R}^{n}\to[-\infty ,\infty]\ \mathit{measurable}\}\) be a quasi-Banach space of sequences of measurable functions. Further we assume that its quasi-norm is shift-invariant, i.e. it satisfies

For a sequence of non-negative functions (g k ) k∈ℤ∈X and δ>0 we denote

Then there exists a constant c>0 depending only on δ and X such that for every sequence (g k ) k∈ℤ

Proof
Since X is a quasi-Banach space, there exists a r>0 such that ∥⋅|X∥ is equivalent to some r-norm, cf. [6, 43]. We have then the following

Now taking the power 1/r yields the desired estimate. □
The spaces L p(⋅)(ℓ q(⋅)) and ℓ q(⋅)(L p(⋅)) are quasi-Banach spaces which fulfill the conditions of Lemma 8. Therefore, we obtain the following
Lemma 9
Let \(p,q\in\mathcal{P}(\mathbb{R}^{n})\) and δ>0. Let (g k ) k∈ℤ be a sequence of non-negative measurable functions on ℝn and denote

Then there exist a constants C 1,C 2>0, depending on p(⋅),q(⋅) and δ, such that

Remark 4
Of course, Lemma 9 holds true also if the indices k and ν run only over natural numbers.
Since the maximal operator is in general not bounded on ℓ q(⋅)(L p(⋅)) (see [1, Example 4.1]) we need a replacement for that. It turned out that a convolution with radial decreasing functions fits very well into the scheme. A careful evaluation of the proof in [1, Lemma 4.7] together with Lemma 19 gives us the following convolution inequality.
Lemma 10
Let \(p,q\in\mathcal{P}^{\log}(\mathbb{R}^{n})\) with p(⋅)≥1 and let η ν,m (x)=2nν(1+2ν|x|)−m. For all m>n+c log(1/q) there exists a constant c>0 such that for all sequences \((f_{j})_{j\in\mathbb{N}_{0}}\in{\ell_{q(\cdot)}(L_{p(\cdot)})}\) it holds

The last technical lemma is overtaken literally from [46].
Lemma 11
([46], Lemma 3)
Let 0<r≤1 and let \((\gamma_{\nu})_{\nu\in\mathbb{N}_{0}}\), \((\beta_{\nu})_{\nu\in\mathbb{N}_{0}}\) be two sequences taking values in (0,∞). Assume that for some N 0∈ℕ0,

Furthermore, we assume that for any N∈ℕ

holds, then for any N∈ℕ

holds with the same constants C N .
3.1.2 Comparison of Different Peetre Maximal Operators
In this subsection we present an inequality between different Peetre maximal operators. Let us recall the notation given before Theorem 6. For two given functions \(\psi_{0},\psi_{1}\in\mathcal{S}(\mathbb {R}^{n})\) we define

Furthermore, for all j∈ℕ0 we write \(\Psi_{j}=\hat{\psi _{j}}\) and in an analogous manner we define Φ j from two starting functions \(\phi_{0},\phi_{1}\in\mathcal{S}(\mathbb{R}^{n})\). Using this notation we are ready to formulate the theorem.
Theorem 12
Let \(\boldsymbol{w}=(w_{j})_{j\in\mathbb{N}_{0}}\in\mathcal{W}^{\alpha}_{\alpha_{1},\alpha_{2}}\), \(p,q\in\mathcal{P}(\mathbb{R}^{n})\) and a>0. Moreover, let R∈ℕ0 with R>α 2,

and for some ε>0


then

holds for every \(f\in\mathcal{S}'(\mathbb{R}^{n})\).
Remark 5
Observe that there are no restrictions on a>0 and \(p,q\in\mathcal {P}(\mathbb{R}^{n})\) in the theorem above.
Proof
We have the fixed resolution of unity from Definition 1 and define the sequence of functions \((\lambda_{j})_{j\in\mathbb{N}_{0}}\) by

It follows from the Tauberian conditions (12) and (13) that they satisfy
and
Furthermore, we denote \(\Lambda_{k}=\hat{\lambda_{k}}\) for k∈ℕ0 and obtain together with (14) the following identities (convergence in \(\mathcal{S}'(\mathbb{R}^{n})\))

We have

where
According to Lemma 7 we get

Namely, we have for 1≤k<ν with the change of variables 2k z↦z

Similarly, we get for 1≤ν<k with the substitution 2ν z↦z

M can be taken arbitrarily large because Λ1 has infinitely many vanishing moments. Taking M=2a+|α 1|+1 we derive (19) for the cases k,ν≥1 with k≠ν. The missing cases can be treated separately in an analogous manner. The needed moment conditions are always satisfied by (11) and (16). The case k=ν=0 is covered by the constant c in (19).
Furthermore, we have

We put this into (18) and get

Multiplying both sides with w ν (x) and using

leads us to

This inequality together with (17) gives for δ:=min(1,R−α 2)>0

Taking the ℓ q(⋅)(L p(⋅)) norm and using Lemma 9 yields immediately the desired result. □
3.1.3 Boundedness of the Peetre Maximal Operator
We will present a theorem which describes the boundedness of the Peetre maximal operator. We use the same notation introduced at the beginning of the last subsection. Especially, we have the functions \(\psi_{k}\in\mathcal{S}(\mathbb{R}^{n})\) and \(\Psi_{k}=\hat{\psi}_{k}\in\mathcal{S}(\mathbb{R}^{n})\) for all k∈ℕ0.
Theorem 13
Let \((w_{k})_{k\in\mathbb{N}_{0}}\in\mathcal{W}^{\alpha}_{\alpha _{1},\alpha_{2}}\), a>0 and \(p,q\in\mathcal{P}^{\log}(\mathbb {R}^{n})\). For some ε>0 we assume \(\psi_{0},\psi_{1}\in \mathcal{S}(\mathbb{R}^{n})\) with

For \(a>\frac{n+c_{\log}(1/q)}{p^{-}}+\alpha\)

holds for all \(f\in\mathcal{S}'(\mathbb{R}^{n})\).
Remark 6
Observe that in the theorem above no moment conditions on ψ 1 are stated but this time there are restrictions on a and p(⋅),q(⋅).
Proof
As in the last proof we find the functions \((\lambda_{j})_{j\in\mathbb {N}_{0}}\) with the properties (15), (16) and

Instead of (17) we get the identity

where

The Ψ k,ν are defined similarly. For k≥1 and ν∈ℕ0 we have Ψ k,ν =Ψ k+ν and with the notation

we get ψ k (2−ν x)ψ ν (x)=σ k,ν (x)ψ k+ν (x). Hence, we can rewrite (20) as

For k≥1 we get from Lemma 7

for all k,ν∈ℕ0 and arbitrary large M∈ℕ. For k=0 we get the estimate (22) by using Lemma 7 with M=0. This together with (21) gives us

For fixed r∈(0,1] we divide both sides of (23) by (1+|2ν(x−y)|a) and we take the supremum with respect to y∈ℝn. Using the inequalities

and
we get

Now, we apply Lemma 11 with

N=M+n−a, C N =C M +n−a and N 0 in (10) equals the order of the distribution \(f\in\mathcal{S}'(\mathbb{R}^{n})\).
By Lemma 11 we obtain for every N∈ℕ, x∈ℝn and ν∈ℕ0

provided that \((\Psi_{\nu}^{*}f)_{a}(x)<\infty\).
Since \(f\in\mathcal{S}'(\mathbb{R}^{n})\), we see that \((\Psi_{\nu}^{*}f)_{a}(x)<\infty\) for all x∈ℝn and all ν∈ℕ0 at least if a>N 0, where N 0 is the order of the distribution. Thus we have (25) with C N independent of \(f\in\mathcal {S}'(\mathbb{R}^{n})\) for a≥N 0 and therefore with C N =C N,f for all a>0 (the right side of (25) decreases as a increases). One can easily check that (25) with C N =C N,f implies that if for some a>0 the right side of (25) is finite, then \((\Psi_{\nu}^{*}f)_{a}(x)<\infty\). Now, repeating the above argument resurrects the independence of C N . If the right side of (25) is infinite, there is nothing to prove. More exhaustive arguments of this type have been used in [54] and [47].
We point out that (25) holds also for r>1, where the proof is much simpler. We only have to take (23) with a+n instead of a, divide both sides by (1+|2ν(x−y)|a) and apply Hölder’s inequality with respect to k and then z.
Multiplying (25) by w ν (x)r we derive with the properties of our weight sequence

for all x∈ℝn, ν∈ℕ0 and all N∈ℕ.
Now, we choose r=p − and we have r(a−α)>n+c log(1/q). We denote \(g^{r}_{k+\nu}(z)=|(\Psi_{k+\nu}\ast f)(z)|^{r}w_{k+\nu}(z)^{r}\) then we can rewrite (26) by

For fixed N>0 with δ=N+α 1>0 we apply the \(\ell_{\frac {q(\cdot)}{r}}(L_{\frac{p(\cdot)}{r}})\) norm and derive from (27)

Now application of Lemma 9 and Lemma 10 (r(a−α)>n+c log(1/q)) on the formula above give us

which proves the theorem. □
3.2 Local Means Characterization of \(B^{s(\cdot)}_{{p(\cdot )},{q(\cdot)}}(\mathbb{R}^{n})\) and \(F^{s(\cdot )}_{{p(\cdot)},{q(\cdot)}}(\mathbb{R}^{n})\)
In this section we reformulate the local means characterization for \(B^{\boldsymbol{w}}_{{p(\cdot)},{q(\cdot)}}(\mathbb{R}^{n})\) from above and for \(F^{\boldsymbol{w}}_{{p(\cdot)},{q(\cdot)}}(\mathbb{R}^{n})\) from Corollary 4.7 in [30] in terms of variable smoothness. If we have a variable smoothness function \(s\in C_{\mathit{loc}}^{\log}(\mathbb{R}^{n})\) given, then w j (x)=2js(x) defines an admissible weight sequence \(\boldsymbol{w}\in\mathcal{W}^{\alpha}_{\alpha _{1},\alpha_{2}}\) with α 1=s −, α 2=s + and α=c log(s), cf. Remark 2. Here, we denote by c log(s) the constant in (2) for s(⋅).
Theorem 14
Let \(p,q\in\mathcal{P}^{\log}(\mathbb{R}^{n})\) (p +,q +<∞ in the F-case) and \(s\in C_{\mathit{loc}}^{\log }(\mathbb{R}^{n})\). Further let a>0, R∈ℕ0 with R>s + and let ψ 0,ψ 1 belong to \(\mathcal{S}(\mathbb {R}^{n})\) with

and

for some ε>0.
-
1.
For \(a>\frac{n+c_{\log}(1/q)}{p^{-}}+c_{\log}(s)\) and all \(f\in \mathcal{S}'(\mathbb{R}^{n})\) we have

-
2.
For \(a>\frac{n}{\min(p^{-},q^{-})}+c_{\log}(s)\) and all \(f\in \mathcal{S}'(\mathbb{R}^{n})\) we have
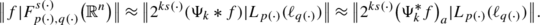

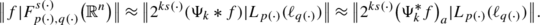
Remark 7
During the referee process of this work, there appeared in [18] a characterization by local means and a characterization by atoms for \(B^{s(\cdot)}_{{p(\cdot)},{q(\cdot)}}(\mathbb{R}^{n})\). The author moved the smoothness sequence 2ks(⋅) into the Peetre maximal operator (6) and modified it to

For this modified Peetre maximal operator he obtained in [18, Theorem 2] an equivalence of the norms similar to our Theorem 14 for \(B^{s(\cdot)}_{{p(\cdot)},{q(\cdot)}}(\mathbb{R}^{n})\). The advantage of his method is that the condition on a>0 weakens to \(a>\frac{n}{p^{-}}\).
4 Ball Means of Differences
This section is devoted to the characterization of Besov and Triebel-Lizorkin spaces \(B^{s(\cdot)}_{{p(\cdot)},{q(\cdot)}}(\mathbb{R}^{n})\) and \(F^{s(\cdot)}_{{p(\cdot)},{q(\cdot)}}(\mathbb{R}^{n})\) by ball means of differences. In the case of constant indices p,q and s, this is a classical part of the theory of function spaces. We refer especially to [51, Sect. 2.5] and references given there. It turns out that, under the restriction
in the B-case and
in the F-case, Besov and Triebel-Lizorkin spaces with constant indices may be characterized by expressions involving only the differences of the function values without any use of Fourier analysis. This was complemented in [49] and [50] by showing that these conditions are also indispensable. Of course, we are limited by (28) and (29) also in the case of variable exponents.
The characterization by (local means of) differences for 2-microlocal spaces with constant p,q>1 was given by Besov [8] and a similar characterization for Besov spaces with p=q=∞ and the special weight sequence from (3) was given by Seuret and Levy Véhél in [34]. We refer to [19] and [28] for the treatment of spaces of generalized smoothness.
Our approach follows essentially [51] with some modifications described in [53]. The main obstacle on this way is the unboundedness of the maximal operator in the frame of L p(⋅)(ℓ q(⋅)) and ℓ q(⋅)(L p(⋅)) spaces, cf. [16, Sect. 5] and [1, Example 4.1]. This is circumvented by the use of convolution with radial functions in the sense of [16] and [1] together with a certain bootstrapping argument, which shall be described in detail below.
The plan of this part of the work is as follows. First we give in Sect. 4.1 the necessary notation. We state the main assertions of this part in Sect. 4.2. Then we prove in Sect. 4.3 a certain preliminary version of these assertions. In Sect. 4.4 we prove a characterization by ball means of differences for spaces with q∈(0,∞] constant (where the maximal operator is bounded) and use this together with our preliminary characterization from Sect. 4.3 to conclude the proof. Finally, in Sect. 4.5 we will present the ball means of differences characterization also for the 2-microlocal function spaces \(B^{\boldsymbol{w}}_{{p(\cdot)},{q(\cdot)}}(\mathbb{R}^{n})\) and \(F^{\boldsymbol{w}}_{{p(\cdot)},{q(\cdot)}}(\mathbb{R}^{n})\) and in Sect. 4.6 we present separately some useful Lemmas, not to disturb the main proofs of this part.
4.1 Notation
Let f be a function on ℝn and let h∈ℝn. Then we define
The higher order differences are defined inductively by
This definition also allows a direct formula
By ball means of differences we mean the quantity
where B={y∈ℝn:|y|<1} is the unit ball of ℝn, t>0 is a real number and M is a natural number.
Let us now introduce the (quasi-)norms, which shall be the main subject of our study. We define

and its partially discretized counterpart

The norm \(\|f|F^{s(\cdot)}_{{p(\cdot)},{q(\cdot)}}(\mathbb {R}^{n})\|^{**}\) admits a direct counterpart also for Besov spaces, namely

Finally, we shall use as a technical tool also the analogues of (31)–(32) with the integration over t restricted to 0<t<1. This leads to the following expressions

4.2 Main Theorem
Using the notation introduced above, we may now state the main result of this section.
Theorem 15
(i) Let \(p,q\in\mathcal{P}^{\log}(\mathbb {R}^{n})\) with p +,q +<∞ and \(s\in C^{\mathrm{log}}_{\mathit{loc}}(\mathbb{R}^{n})\). Let M∈ℕ with M>s + and let
Then
and \(\|\cdot|F^{s(\cdot)}_{{p(\cdot)},{q(\cdot)}}(\mathbb {R}^{n})\|\) and \(\|\cdot|F^{s(\cdot)}_{{p(\cdot)},{q(\cdot )}}(\mathbb{R}^{n})\|^{*}\) are equivalent on \(F^{s(\cdot)}_{{p(\cdot)},{q(\cdot)}}(\mathbb{R}^{n})\). The same holds for \(\|f|F^{s(\cdot)}_{{p(\cdot)},{q(\cdot)}}(\mathbb{R}^{n})\|^{**}\).
(ii) Let \(p,q\in\mathcal{P}^{\log}(\mathbb {R}^{n})\) and \(s\in C^{\mathrm{log}}_{\mathit{loc}}(\mathbb{R}^{n})\). Let M∈ℕ with M>s + and let
Then
and \(\|\cdot|B^{s(\cdot)}_{{p(\cdot)},{q(\cdot)}}(\mathbb {R}^{n})\|\) and \(\|\cdot|B^{s(\cdot)}_{{p(\cdot)},{q(\cdot )}}(\mathbb{R}^{n})\|^{**}\) are equivalent on \(B^{s(\cdot )}_{{p(\cdot)},{q(\cdot)}}(\mathbb{R}^{n})\).
Remark 8
Let us comment on the rather technical conditions (33) and (34).
-
If min(p −,q −)≥1, then (33) becomes just s −>0. Furthermore, if p, q and s are constant functions, then (33) coincides with (29).
-
If p −≥1, then (34) reduces also to s −>0 and in the case of constant exponents we again recover (28).
As indicated already above, the proof is divided into several parts.
4.3 Preliminary Version of Theorem 15
This subsection contains a preliminary version of Theorem 15 (Lemma 16). Its proof represents the heart of the proof of Theorem 15. For better lucidity, it is again divided into more parts.
Lemma 16
Under the conditions of Theorem 15, the following estimates hold for all \(f\in L_{p(\cdot)}(\mathbb{R}^{n})\cap\mathcal{S}'(\mathbb{R}^{n})\):




Proof
Part I. First we prove (35) and (36). We discretize the inner part of ∥⋅∥∗ and obtain

If 2−k−1≤t≤2−k, then 2ks(x)q(x)≤t −s(x)q(x)≤2(k+1)s(x)q(x) and
Plugging these estimates into (39), we may further estimate

The estimate from below follows in the same manner. Finally, the proof of (36) is almost the same.
Part II. This part is devoted to the proof of the left hand side of (37). It is divided into several steps to make the presentation clearer.
Step 1. First, we point out that the estimate
follows from the characterization of \(B^{s(\cdot)}_{{p(\cdot )},{q(\cdot)}}(\mathbb{R}^{n})\) in terms of Nikol’skij representations (cf. Theorem 8.1 of [1]). We refer also to Remark 2.5.3/1 in [51]. The extension to F-spaces is then given by the simple embedding
with ε>0 chosen small enough.
Step 2. Let \((\varphi_{j})_{j\in\mathbb{N}_{0}}\) be the functions used in Definition 3. We use the decomposition
where \(f_{(k+l)}=(\varphi_{k+l}\hat{f})^{\vee}\), or =0 if k+l<0 and get

If q(x)≤1 then we proceed further

If q(x)>1, we use Minkowski’s inequality

We split in both cases
Step 3. We estimate the first summand with l≤0.
We use Lemma 22 in the form
where a>0 is arbitrary, b=2k+l and
Furthermore, we use this estimate with 2−k h instead of h. We obtain

The last inequality follows from max(1,|b2−k h|a)≤1 (recall that l≤0 and |h|≤1) and min(1,|b2−k h|M)≤2lM.
If q(x)≤1, we estimate the first sum in (40)

where the last estimate makes use of M>s +, q −>0 and the fact that f (k+l)=0 for k+l<0.
If q(x)>1, we proceed in a similar way to obtain

We have used in the last estimate again M>s + and the definition of f (k+l).
Hence,
holds for all x∈ℝn.
Finally, we obtain

where we used the boundedness of Peetre maximal operator as described in Theorem 14 for a>0 large enough.
Step 4. We estimate the second summand in (40) with l>0. If min(p −,q −)>1, then we put λ=1. Otherwise we choose real parameters 0<λ<min(p −,q −) and a>0 such that
and a(1−λ)<s −. Due to (33), this is always possible.
We start again with estimates of the ball means of differences. We use Lemma 22 and (30) to obtain

where the constants c j,M are given by (30).
We shall deal in detail only with the term with j=1. The term with j=0 is much simpler to handle (as there the integration over h∈B immediately disappears) and this case reduces essentially to Hölder’s inequality and boundedness of the Peetre maximal operator. The terms with 2≤j≤M may be handled in the same way as the one with j=1.
We use Lemma 20 with r=λ in the form
with m>max(n,c log(s)), Lemmas 23 and 19 to get

We insert (44) into (43) and arrive at

If q(x)>1, we proceed further with the use of Hölder’s inequality

If q(x)≤1, we obtain in a similar way

and further (with use of Lemma 24)

If we denote
and
we get for δ:=−1/2⋅(a(1−λ)−s −)>0
We use \(\|F_{1}^{1-\lambda}F_{2}^{\lambda}\|_{p(\cdot)}\le2\|F_{1}\|_{p(\cdot)}^{1-\lambda}\|F_{2}\|_{p(\cdot)}^{\lambda}\), cf. [17, Lemma 3.2.20], and suppose that the L p(⋅)-(quasi-)norm is equivalent to an r-norm with 0<r≤1. Together with Lemma 21 we arrive at

which finishes the proof.
Part III. We prove the right hand side of (37). We follow again essentially [51, Sect. 2.5.9] with some modifications as presented in [53]. Roughly speaking, compared to the case of constant exponents, only minor modifications are necessary.
Let \(\psi\in C^{\infty}_{0}(\mathbb{R}^{n})\) with ψ(x)=1, |x|≤1 and ψ(x)=0, |x|>3/2. We define
It follows that \(\varphi_{0}\in C^{\infty}_{0}(\mathbb{R}^{n})\) with φ(x)=0, |x|>3/2 and φ(x)=1, |x|<1/M. We also put φ j (x)=φ 0(2−j x)−φ 0(2−j+1 x) for j≥1. This is the decomposition of unity we used in the definition of \(\|f|F^{s(\cdot)}_{{p(\cdot)},{q(\cdot )}}(\mathbb{R}^{n})\|\), cf. Definition 3. Recall that due to [16] and [30], this (quasi-)norm of \(\|f|F^{s(\cdot )}_{{p(\cdot)},{q(\cdot)}}(\mathbb{R}^{n})\|\) does not depend on the choice of the decomposition of unity.
We observe that
and

Furthermore, a straightforward calculation shows that

holds for every j∈ℕ0. We denote \(g=\hat{\psi}\in \mathcal{S}(\mathbb{R}^{n})\) and obtain

The rest of this part consists essentially of using the property of \(g\in\mathcal{S}(\mathbb{R}^{n})\) to come from (50) to ∥⋅∥∗∗.
We denote
and use |g(h)|≤c2−ur,h∈I u with r taken large enough (recall that \(g\in\mathcal{S}(\mathbb{R}^{n})\)) and estimate

We put
and
Using (48), (49) and (51), we obtain the estimate

Choosing r>s ++n and applying Lemma 9 then finishes the proof.
Part IV. The proof of the left hand side of (38) follows in the same manner as in Part II. We shall describe the necessary modifications. First, let us mention, that the condition q +<∞ was used only in the application of Lemma 21. In the rest of the arguments also the case q(x)=∞ may be incorporated with only slight change of notation.
Let us put
We obtain (in analogue to (40))

We estimate the first sum using (41) and get
where \(g^{1}_{u}:=2^{us(x)}P_{2^{u},a}f_{(u)}(x)\). The application of Lemma 9 and Theorem 14 with a>0 large enough gives

To estimate f (k),II, we proceed as in the Step 4 of Part II. If p −>1, we choose again λ=1, otherwise we take 0<λ<p − and
such that a(1−λ)<s −. This is possible due to (34).
We use (44) with m>max(n+c log(1/q),c log(s)) to get

where \(g^{2}_{k+l}(x):=|2^{(k+l)s(x)}f_{(k+l)}(x)|\). We take the ℓ q(⋅)(L p(⋅)) (quasi-)norm of the last expression—and assume that it is equivalent to some r-norm. This gives for δ:=s −−a(1−λ)>0 the following estimate

We have used Lemma 10 and Lemma 25.
Part V. The right hand side inequality of (38) follows also along the same line as in Part III. We just combine (52) with the choice r>s ++n and apply Lemma 9. □
4.4 Proof of Theorem 15
This section is devoted to the proof of Theorem 15. We start with the case of constant q. In that case, the usual Hardy-Littlewood maximal operator
is bounded on ℓ q (L p(⋅)) and L p(⋅)(ℓ q ). Indeed, the following lemma is a consequence of [12] and [17, Theorem 4.3.8].
Lemma 17
-
(i)
Let \(p\in\mathcal{P}^{\log}(\mathbb{R}^{n})\) with 1<p −≤p +<∞ and 1<q<∞. Then
$$\bigl\Vert{(M f_j)_{j=-\infty}^\infty}\vert{L_{p(\cdot)}(\ell _q)}\bigr\Vert\lesssim\bigl\Vert{(f_j)_{j=-\infty}^\infty}\vert {L_{p(\cdot)}(\ell_q)}\bigr\Vert $$for all \((f_{j})_{j=-\infty}^{\infty}\in L_{p(\cdot)}(\ell_{q})\).
-
(ii)
Let \(p\in\mathcal{P}^{\log}(\mathbb{R}^{n})\) with p −>1 and 0<q≤∞. Then
$$\bigl\Vert{(M f_j)_{j=-\infty}^\infty}\vert{\ell_q(L_{p(\cdot )})}\bigr\Vert\lesssim\bigl\Vert{(f_j)_{j=-\infty}^\infty}\vert {\ell_q(L_{p(\cdot)})}\bigr\Vert $$for all \((f_{j})_{j=-\infty}^{\infty}\in\ell_{q}(L_{p(\cdot)})\).
Proof of Theorem 15
With the help of Lemma 17, we prove Theorem 15 for q constant. In view of Lemma 16, it is enough to prove
and a corresponding analogue for the B-spaces.
Part I. In this part we point out the necessary modifications in the proof of Lemma 16 to obtain a characterization by ball means of differences for \(B^{s(\cdot)}_{{p(\cdot)},q}(\mathbb {R}^{n})\) and \(F^{s(\cdot)}_{{p(\cdot)},q}(\mathbb{R}^{n})\). The proof follows the scheme of Part II of the proof of Lemma 16. We start with \(\sum_{k=-\infty}^{\infty}\) instead of \(\sum_{k=0}^{\infty}\). With this modification the Steps 1–3 go through without any other changes and we obtain (42) again (just recall that f (k)=0 if k<0).
Due to the boundedness of the maximal operator there is no need for the use of r-trick and convolution with η ν,m . The analogue of (43), (44) and (45) now reads as follows:

where we used Hölder’s regularity of s(⋅), see (5). As a consequence, we obtain
instead of (46). The rest then follows in the same manner with the help of Lemma 17 and the proof of (55) is finished.
The proof of
follows along the same lines. Especially, we get

instead of (53). The rest follows again by Lemma 17.
Part II. Finally, we present how the characterization for q constant can help us to improve on the case of variable exponent q(⋅).
In view of Lemma 16, it is enough to show that

But this is a consequence of

where ε>0 is small enough and we used the differences characterization for fixed q and a trivial embedding theorem.
The same arguments apply for the Besov spaces and the proof is finished. □
Remark 9
The somewhat complicated proof of Theorem 15 would work more direct and simpler if we could use versions of Lemmas 10 and 21 in (47) and (54) where the ℓ q(⋅) summation runs over ν∈ℤ.
For Triebel-Lizorkin spaces there seems to exist such an extension [13], but for Besov spaces the proof of Lemma 10 in [1] seems to be to customized to the situation ν∈ℕ0.
4.5 Ball Means of Differences for 2-Microlocal Spaces
As already remarked in Sect. 2.2 all the proofs for spaces of variable smoothness do also serve for 2-microlocal spaces. One just has to use the definition of admissible weight sequences and the property (5), see Remark 2.
First of all we give the notation for the (quasi-)norms. For simplicity we just use the discrete versions, although it is also possible to give continuous versions of 2-microlocal weights, see [55, Definition 4.1]. In analogy to the spaces of variable smoothness we introduce the following norms

and
Finally, the preceding calculations show that the following theorem is true.
Theorem 18
(i) Let \(p,q\in\mathcal{P}^{\log}(\mathbb{R}^{n})\) with p +,q +<∞ and \(\boldsymbol{w}\in\mathcal{W}^{\alpha}_{\alpha _{1},\alpha_{2}}\). Let M>α 2 and
Then
and \(\|\cdot|F^{\boldsymbol{w}}_{{p(\cdot)},{q(\cdot)}}(\mathbb{R}^{n})\|\) and \(\|\cdot|F^{\boldsymbol{w}}_{{p(\cdot )},{q(\cdot)}}(\mathbb{R}^{n})\|^{**}\) are equivalent on \(F^{\boldsymbol{w}}_{{p(\cdot)},{q(\cdot)}}(\mathbb{R}^{n})\).
(ii) Let \(p,q\in\mathcal{P}^{\log}(\mathbb{R}^{n})\) and \(\boldsymbol{w}\in\mathcal{W}^{\alpha}_{\alpha_{1},\alpha_{2}}\). Let M>α 2 and
Then
and \(\|\cdot|B^{\boldsymbol{w}}_{{p(\cdot)},{q(\cdot)}}(\mathbb{R}^{n})\|\) and \(\|\cdot|B^{\boldsymbol{w}}_{{p(\cdot )},{q(\cdot)}}(\mathbb{R}^{n})\|^{**}\) are equivalent on \(B^{\boldsymbol{w}}_{{p(\cdot)},{q(\cdot)}}(\mathbb{R}^{n})\).
Remark 10
Again, if min(p −,q −)≥1 in the F-case, or p −≥1 in the B-case, then the conditions (56) and (57) simplify to α 1>0. In the case of constant exponents p,q we obtain similar results to [8] and [34].
4.6 Lemmas
The following lemma is a variant of Lemma 6.1 from [16].
Lemma 19
Let \(s\in C^{\log}_{\mathit{loc}}(\mathbb{R}^{n})\) and let R≥c log(s) , where c log(s) is the constant from (2) for s(⋅). Then
holds for all x,y∈ℝn and m∈ℕ0.
Lemma 20
Let r>0, ν≥0 and m>n. Then there exists c>0, which depends only on m,n and r, such that for all g∈S′(ℝn) with \(\operatorname{supp}\hat{g}\subset\{\xi\in\mathbb{R}^{n}:|\xi |\le2^{\nu+1}\}\), we have
The following lemma is the counterpart to Lemma 10 for Triebel-Lizorkin spaces.
Lemma 21
([16], Theorem 3.2)
Let \(p,q\in\mathcal{P}^{\log}(\mathbb{R}^{n})\) with 1<p −≤p +<∞ and 1<q −≤q +<∞. Then the inequality

holds for every sequence \((f_{\nu})_{\nu\in\mathbb{N}_{0}}\) of \(L_{1}^{loc}(\mathbb{R}^{n})\) functions and m>n.
The following lemma is well known (cf. [51]). We sketch its proof for the sake of completeness.
Lemma 22
Let a,b>0, M∈ℕ and h∈ℝn. Let f∈S′(ℝn) with \(\operatorname{supp}\hat{f}\subset\{\xi\in \mathbb{R}^{n}:|\xi|\le b\}\). Then there is a constant C>0 independent of f,b and h, such that
holds for every x∈ℝn.
Proof
The estimate

holds for all the admissible parameters even without the assumption on \(\hat {f}\).
Hence we need to prove only
Using the Taylor formula for the (analytic) function f, we obtain by direct calculation

If \(\operatorname{supp}\hat{g}\subset\{\xi\in\mathbb{R}^{n}:|\xi|\le 1\}\), then this may be combined with the Nikol’skij inequality, cf. [51, Sect. 1.3.1], in the form
to obtain
If \(\operatorname{supp}\hat{f}\subset\{\xi\in\mathbb{R}^{n}:|\xi|\le b\}\), we define g(x)=f(x/b), apply (59) together with \(\Delta_{h}^{M}f(x)=\Delta_{bh}^{M}g(bx)\) and obtain
From this (58) follows and the proof is then complete. □
The following lemma resembles Lemma A.3 of [16].
Lemma 23
Let k∈ℤ, l∈ℕ0 and m>n. Then
Proof
Using dilations, we may suppose that k=0. If |x|≤2, then
If |x|>2 and |x−y|≤1, we obtain 1+2l|y|≳1+2l|x| and 2nl(1+2l|x|)−m≲(1+|x|)−m. This immediately implies that

□
Remark 11
Another way, how to prove Lemma 23 is to use the inequality χ B (x)≤2m η 0,m (x) and apply Lemma A.3 of [16].
The following Lemma is quite simple and we leave out its proof.
Lemma 24
Let 0<q<∞, δ>0 and let (a l ) l∈ℕ be a sequence of non-negative real numbers. Then
where the constant involved depends only on δ and q.
Finally, we shall need a certain version of Hölder’s inequality for ℓ q(⋅)(L p(⋅)) spaces.
Lemma 25
Let \(p,q\in\mathcal{P}(\mathbb{R}^{n})\) and let 0<λ<1. Then
holds for all sequences of non-negative functions \((f_{k})_{k\in\mathbb {N}_{0}}\) and \((g_{k})_{k\in\mathbb{N}_{0}}\).
Proof
Due to the homogeneity, we may assume that
Then for every ε>0, there exist two sequences of positive real numbers \((\lambda_{k})_{k\in\mathbb{N}_{0}}\) and \((\mu_{k})_{k\in\mathbb {N}_{0}}\), such that
and
We put
and use the Young inequality in the form
to obtain

Furthermore, the estimate
finishes the proof of (60) with the constant \(c=2^{1/q^{-}}\). □
References
Almeida, A., Hästö, P.: Besov spaces with variable smoothness and integrability. J. Funct. Anal. 258(5), 1628–1655 (2010)
Almeida, A., Samko, S.: Characterization of Riesz and Bessel potentials on variable Lebesgue spaces. J. Funct. Spaces Appl. 4(2), 113–144 (2006)
Almeida, A., Samko, S.: Pointwise inequalities in variable Sobolev spaces and applications. Z. Anal. Anwend. 26(2), 179–193 (2007)
Almeida, A., Samko, S.: Embeddings of variable Hajłasz-Sobolev spaces into Hölder spaces of variable order. J. Math. Anal. Appl. 353(2), 489–496 (2009)
Andersson, P.: Two-microlocal spaces, local norms and weighted spaces. Paper 2 in PhD Thesis, pp. 35–58 (1997)
Aoki, T.: Locally bounded linear topological spaces. Proc. Imp. Acad. (Tokyo) 18, 588–594 (1942)
Beauzamy, B.: Espaces de Sobolev et de Besov d’ordre variable définis sur L p. C. R. Math. Acad. Sci. Paris 274, 1935–1938 (1972)
Besov, O.V.: Equivalent normings of spaces of functions of variable smoothness. Proc. Steklov Inst. Math. 243(4), 80–88 (2003)
Bony, J.-M.: Second microlocalization and propagation of singularities for semi-linear hyperbolic equations. In: Taniguchi Symp. HERT, Katata, pp. 11–49 (1984)
Cobos, F., Fernandez, D.L.: Hardy-Sobolev spaces and Besov spaces with a function parameter. In: Proc. Lund Conf. 1986. Lect. Notes Math., vol. 1302, pp. 158–170. Springer, Berlin (1986)
Cruz-Uribe, D., Fiorenza, A., Neugebauer, C.J.: The maximal function on variable L p spaces. Ann. Acad. Sci. Fenn., Ser. A 1 Math. 28, 223–238 (2003)
Cruz-Uribe, D., Fiorenza, A., Martell, J.M., Pérez, C.: The boundedness of classical operators in variable L p-spaces. Ann. Acad. Sci. Fenn., Ser. A 1 Math. 31, 239–264 (2006)
Diening, L.: private communication
Diening, L.: Maximal function on generalized Lebesgue spaces L p(⋅). Math. Inequal. Appl. 7(2), 245–254 (2004)
Diening, L., Harjulehto, P., Hästö, P., Mizuta, Y., Shimomura, T.: Maximal functions in variable exponent spaces: limiting cases of the exponent. Ann. Acad. Sci. Fenn., Ser. A 1 Math. 34(2), 503–522 (2009)
Diening, L., Hästö, P., Roudenko, S.: Function spaces of variable smoothness and integrability. J. Funct. Anal. 256(6), 1731–1768 (2009)
Diening, L., Harjulehto, P., Hästö, P., Růžička, M.: Lebesgue and Sobolev Spaces with Variable Exponents. Lecture Notes in Mathematics, vol. 2017. Springer Berlin (2011)
Drihem, D.: Atomic decomposition of Besov spaces with variable smoothness and integrability. J. Math. Anal. Appl. 389, 15–31 (2012)
Farkas, W., Leopold, H.-G.: Characterisations of function spaces of generalised smoothness. Ann. Mat. Pura Appl. 185(1), 1–62 (2006)
Goldman, M.L.: A description of the traces of some function spaces. Tr. Mat. Inst. Steklova 150, 99–127 (1979). English transl.: Proc. Steklov Inst. Math. 150(4) (1981)
Goldman, M.L.: A method of coverings for describing general spaces of Besov type. Tr. Mat. Inst. Steklova 156, 47–81 (1980). English transl.: Proc. Steklov Inst. Math. 156(2) (1983)
Goldman, M.L.: Imbedding theorems for anisotropic Nikol’skij-Besov spaces with moduli of continuity of general type. Tr. Mat. Inst. Steklova 170, 86–104 (1984). English transl.: Proc. Steklov Inst. Math. 170(1) (1987)
Gurka, P., Harjulehto, P., Nekvinda, A.: Bessel potential spaces with variable exponent. Math. Inequal. Appl. 10(3), 661–676 (2007)
Jaffard, S.: Pointwise smoothness, two-microlocalisation and wavelet coefficients. Publ. Math. 35, 155–168 (1991)
Jaffard, S., Meyer, Y.: Wavelet Methods for Pointwise Regularity and Local Oscillations of Functions. Memoirs of the AMS, vol. 123 (1996)
Kalyabin, G.A.: Characterization of spaces of generalized Liouville differentiation. Mat. Sb. Nov. Ser. 104, 42–48 (1977)
Kalyabin, G.A.: Description of functions in classes of Besov-Lizorkin-Triebel type. Tr. Mat. Inst. Steklova 156, 82–109 (1980). English transl.: Proc. Steklov Institut Math. 156(2) (1983)
Kalyabin, G.A.: Characterization of spaces of Besov-Lizorkin and Triebel type by means of generalized differences. Tr. Mat. Inst. Steklova 181, 95–116 (1988). English transl.: Proc. Steklov Inst. Math. 181(4) (1989)
Kalyabin, G.A., Lizorkin, P.I.: Spaces of functions of generalized smoothness. Math. Nachr. 133, 7–32 (1987)
Kempka, H.: 2-microlocal Besov and Triebel-Lizorkin spaces of variable integrability. Rev. Mat. Complut. 22(1), 227–251 (2009)
Kempka, H., Vybíral, J.: A note on the spaces of variable integrability and summability of Almeida and Hästö. Proc. Am. Math. Soc. (to appear)
Kováčik, O., Rákosník, J.: On spaces L p(x) and W 1,p(x). Czechoslov. Math. J. 41(4), 592–618 (1991)
Leopold, H.-G.: On function spaces of variable order of differentiation. Forum Math. 3, 1–21 (1991)
Lévy Véhel, J., Seuret, S.: A time domain characterization of 2-microlocal spaces. J. Fourier Anal. Appl. 9(5), 473–495 (2003)
Lévy Véhel, J., Seuret, S.: The 2-microlocal formalism. In: Fractal Geometry and Applications: A Jubilee of Benoit Mandelbrot, Proceedings of Symposia in Pure Mathematics, PSPUM, vol. 72, pp. 153–215 (2004). Part 2
Merucci, C.: Applications of interpolation with a function parameter to Lorentz Sobolev and Besov spaces. In: Proc. Lund Conf., 1983. Lect. Notes Math., vol. 1070, pp. 183–201. Springer, Berlin (1983)
Meyer, Y.: Wavelets, Vibrations and Scalings. CRM Monograph Series, vol. 9. AMS, Providence (1998)
Moritoh, S., Yamada, T.: Two-microlocal Besov spaces and wavelets. Rev. Mat. Iberoam. 20, 277–283 (2004)
Moura, S.: Function spaces of generalised smoothness. Diss. Math. 398, 1–87 (2001)
Nekvinda, A.: Hardy-Littlewood maximal operator on L p(x)(ℝn). Math. Inequal. Appl. 7(2), 255–266 (2004)
Orlicz, W.: Über konjugierte Exponentenfolgen. Stud. Math. 3, 200–212 (1931)
Peetre, J.: On spaces of Triebel-Lizorkin type. Ark. Math. 13, 123–130 (1975)
Rolewicz, S.: On a certain class of linear metric spaces. Bull. Acad. Pol. Sci., Sér. Sci. Math. Astron. Phys. 5, 471–473 (1957)
Ross, B., Samko, S.: Fractional integration operator of variable order in the spaces H λ. Int. J. Math. Sci. 18(4), 777–788 (1995)
Růžička, M.: Electrorheological Fluids: Modeling and Mathematical Theory. Lecture Notes in Mathematics, vol. 1748. Springer, Berlin (2000)
Rychkov, V.S.: On a theorem of Bui, Paluszynski and Taibleson. Proc. Steklov Inst. Math. 227, 280–292 (1999)
Scharf, B.: Atomare Charakterisierungen vektorwertiger Funktionenräume. Diploma Thesis, Jena (2009)
Schneider, J.: Function spaces of varying smoothness I. Math. Nachr. 280(16), 1801–1826 (2007)
Schneider, C.: On dilation operators in Besov spaces. Rev. Mat. Complut. 22(1), 111–128 (2009)
Schneider, C., Vybíral, J.: On dilation operators in Triebel-Lizorkin spaces. Funct. Approx. Comment. Math. 41, 139–162 (2009). Part 2
Triebel, H.: Theory of Function Spaces. Birkhäuser, Basel (1983)
Triebel, H.: Theory of Function Spaces II. Birkhäuser, Basel (1992)
Ullrich, T.: Function spaces with dominating mixed smoothness, characterization by differences. Technical report, Jenaer Schriften zur Math. und Inform., Math/Inf/05/06 (2006)
Ullrich, T.: Continuous characterizations of Besov-Lizorkin-Triebel spaces and new interpretations as coorbits. J. Funct. Spaces Appl. (2012). doi:10.1115/2012/163213. Article ID 163213, 47 pages
Ullrich, T., Rauhut, H.: Generalized coorbit space theory and inhomogeneous function spaces of Besov-Lizorkin-Triebel type. J. Funct. Anal. 260(11), 3299–3362 (2011). doi:10.1016/j.jfa.2010.12.006
Unterberger, A., Bokobza, J.: Les opérateurs pseudodifférentiels d’ordre variable. C. R. Math. Acad. Sci. Paris 261, 2271–2273 (1965)
Unterberger, A.: Sobolev spaces of variable order and problems of convexity for partial differential operators with constant coefficients. In: Astérisque 2 et 3, pp. 325–341. Soc. Math. France, Paris (1973)
Višik, M.I., Eskin, G.I.: Convolution equations of variable order (russ.). Tr. Mosk. Mat. Obsc. 16, 26–49 (1967)
Vybíral, J.: Sobolev and Jawerth embeddings for spaces with variable smoothness and integrability. Ann. Acad. Sci. Fenn., Ser. A 1 Math. 34(2), 529–544 (2009)
Xu, H.: Généralisation de la théorie des chirps à divers cadres fonctionnels et application à leur analyse par ondelettes. Ph.D. thesis, Université Paris IX Dauphine (1996)
Xu, J.-S.: Variable Besov and Triebel-Lizorkin spaces. Ann. Acad. Sci. Fenn., Ser. A 1 Math. 33(2), 511–522 (2008)
Xu, J.-S.: An atomic decomposition of variable Besov and Triebel-Lizorkin spaces. Armenian J. Math. 2(1), 1–12 (2009)
Yuan, W., Sickel, W., Yang, D.: Morrey and Campanato Meet Besov, Lizorkin and Triebel. Lecture Notes in Mathematics, vol. 2005. Springer, Berlin (2010)
Acknowledgements
The first author acknowledges the financial support provided by the DFG project HA 2794/5-1 “Wavelets and function spaces on domains”. Furthermore, the first author thanks the RICAM for his hospitality and support during a short term visit in Linz.
The second author acknowledges the financial support provided by the FWF project Y 432-N15 START-Preis “Sparse Approximation and Optimization in High Dimensions”.
We thank the anonymous referee for pointing the reference [18] out to us.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Arieh Iserles.
Rights and permissions
About this article
Cite this article
Kempka, H., Vybíral, J. Spaces of Variable Smoothness and Integrability: Characterizations by Local Means and Ball Means of Differences. J Fourier Anal Appl 18, 852–891 (2012). https://doi.org/10.1007/s00041-012-9224-7
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00041-012-9224-7
Keywords
- Besov spaces
- Triebel-Lizorkin spaces
- Variable smoothness
- Variable integrability
- Ball means of differences
- Peetre maximal operator
- 2-microlocal spaces