
Abstract
Obtaining appropriate temperature sensor locations is crucial for data-driven thermal error modeling. The pseudo-correlation and variable ranking will cause inappropriate sensor selection results. In this paper, a three-step sensor selection strategy based on the detrended cross-correlation coefficient is proposed to obtain a stable and robust set of thermal key points. Combined with sensor reduction and classification, 15 sensors are reduced to 9 and classified into 3 groups. Finally, three sensors are selected as thermal key points. The sensor selection results are applied to a support vector machine model for a CNC grinding machine. The modeling results of 49 predictions based on 7 speed spectrums show that the root mean square error and maximum error are less than 2.32 μm and 3.73 μm, respectively. Compared with two traditional methods, the proposed method has higher accuracy and stronger robustness, which is effective for sensor selection of thermal error modeling.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Thermal error is one of the major errors in machine tools, which occurs due to the heat generated at the moving elements [1]. The effects of temperature can induce up to 75% of overall geometrical errors of machined workpieces [2]. Thermal error compensation is a convenient and cost-efficient way to minimize the influence of thermal error [3]. There are two kinds of models for thermal error compensation: the data-driven model and the physically-based model [4]. Many data-driven models have been used in thermal error modeling, such as multiple linear regression, BP neural network, support vector machine, principal component regression [5], and ridge regression algorithm [6]. A robust data-driven model can be established by selecting only a few temperature sensors with appropriate locations [7]. The optimal temperature sensors (known as thermal key points (TKP) or temperature-sensitive points) have two basic requirements [3]: Firstly, the temperature of TKP have close relationships with thermal error. Secondly, the number of TKP is limited. Too many sensors will increase the workload and expense, even reduce the accuracy of the model.
Initially, researchers directly use the sensors with large correlation coefficients with the thermal error as optimal sensors. However, the correlation among temperatures of different sensors can impact the correctness of selection [3]. Multicollinearity among temperature data will affect modeling accuracy. Therefore, many researchers follow two steps to select TKP: (1) classifying temperature sensors into several groups and (2) choosing one optimal sensor for each group based on some sorting criteria. There are two main classification strategies: (1) the grouping approach (GA) method [8] and (2) the unsupervised classification method. The GA method is based on such principle that the correlation coefficients between different temperature sensors are calculated to form a correlation matrix. By setting a threshold, the sensors with a coefficient greater than the threshold are classified into the same group. Pearson correlation coefficient (PCC) [9] and gray correlation coefficient [10] are the commonly used correlation coefficients in the GA method. The unsupervised classification methods, such as fuzzy c-means clustering (FCM) [11] and K-means clustering [12], are also widely used in sensor classification. Due to the unsupervised characteristics, they are sensitive to the input variables. After sensor classification, the correlation coefficients between the data of temperature sensors and thermal error are calculated. The sensor with the largest coefficient in each group is selected as TKP. The PCC [13] and gray correlation coefficient [10] are the commonly used criteria for calculating the correlation coefficient.
However, there are still some problems with the traditional sensor selection methods. In this paper, we summarize it as follows.
-
1.
The classification without preselection. Generally, when there is no prior knowledge about the locations of TKP, as many sensors as possible will be placed on the surface of the spindle system. This arrangement is reasonable because no potential optimal position will be missed. However, the following problem is that some sensors with low correlation with thermal error will be classified in the same group, and then one of them will be selected as TKP. Thus, a preselection is important for maintaining the correlation between the selected sensors and thermal error data.
-
2.
The selection based on pseudo-correlation. Many statistical methods for calculating the correlation between two time series have strict application conditions. For example, the PCC is unsuitable for non-Gaussian [14] and nonstationary [15] time series, especially when there is an obvious trend in the time series. However, the temperature and thermal error data have been proved to follow the exponential trend [16]. Thus, a new method is necessary to overcome the weakness of traditional correlation calculation methods.
-
3.
The processing based on a single speed spectrum. Ideally, the TKP selected by a single speed spectrum are also applicable to other speed spectrums. In the error compensation stage, a set of fixed TKP are more acceptable, because it will reduce the complexity and implementation difficulty of the model. But in fact, the TKP selected by different speed spectrums are variable [5, 6, 17]. It is not only the classification and ranking that will cause the instability of TKP, but also the speed spectrums with different correlation calculation methods. Therefore, it should be checked whether the speed spectrum is suitable for the correlation calculation methods, and the selection results should be determined by the results of more than one speed spectrum.
This paper proposes a three-step sensor selection strategy for thermal error modeling: reduction, classification, and selection. The theoretical reasons for inappropriate sensor selection are analyzed. The detrended cross-correlation coefficient (DCCC) is used as a robust and accurate criterion to calculate the correlation between time series. In the sensor reduction stage, the number of sensors was reduced from 15 to 9 based on the change of DCCC value. After sensor reduction, the GA method was used for sensor classification. The nine sensors were classified into three groups. Finally, the TKP were selected based on the ranking order calculated by the mean DCCC value between temperature and thermal error data.
The rest of this paper is as follows. In Sect. 2, the theoretical reasons for inappropriate sensor selection are analyzed, and the DCCC is introduced. Section 3 shows the thermal error experiment on a CNC grinding machine. Section 4 shows the detailed process of the three-step sensor selection strategy. In Sect. 5, the accuracy and robustness of the proposed method are verified with the comparison with two traditional methods. Conclusions are provided in Sect. 6.
2 The theoretical reasons for inappropriate sensor selection and detrended cross-correlation coefficient
2.1 Pseudo-correlation caused by the trend-driven time series
The PCC between two time series (x and y) is expressed as:
where \(\overline{x }\) and \(\overline{y }\) are the average value of x and y, respectively, n is the length of each variable.
As a widely used correlation calculation method, PCC has been successfully applied to many fields. But the PCC is unsuitable for nonstationary time series. If two time series are nonstationary (they have similar trends), a large PCC value could not guarantee the real correlation.
According to the exponential thermal error model, the temperature and thermal error data of the spindle system follow the exponential trend [16], as shown in Eq. (2).
where ΔZ is the change in spindle growth over time t, Z0 is the spindle deformation at time 0, ZSS is the steady state spindle deformation, and τ is the time constant.
Thus, the pseudo-correlation is inevitable when PCC is used as the evaluation index of correlation.
Figure 1 shows three nonstationary time series. The expressions are as follows:

Three nonstationary time series and the division of subseries
where x = 0.1, 0.2, 0.3, …, 30.
There are three basic terms in Eq. (3). y1 is taken as an example. The fluctuation term is 10sinx, the trend term is 200(1–2−x/30), and the base term is 20.
By taking y1, y2, and y3 into Eq. (1), the PCC value ry1, y2 is 0.973, and the ry1, y3 is 0.970. The values of ry1, y2 and ry1, y3 show a strong correlation. But the PCC values between subseries are variable. Six subseries are formed when the length of the subseries is 5, as shown in Fig. 1. Each subseries pair is calculated by Eq. (1). Table 1 tabulates the calculation results.
Similarly, when the length of subseries is 3, each time series is divided into ten subseries. The PCC values between subseries pairs are tabulated in Table 2.
Tables 1 and 2 show that the PCC is not effective for nonstationary time series. The strong correlation calculated by PCC for the whole time series cannot reflect the real correlation relationship between subseries. For example, ry1, y2 in Table 1 can be as high as 0.877 and as low as 0.027 and even show a negative correlation as -0.200.
Figure 1 shows that there are two possible cases of pseudo-correlation. The first case corresponds to the relationship between y1 and y2. The fluctuation terms of y1 and y2 are different. But with the existence of the trend term, the PCC value can be as high as 0.973. The second case corresponds to the relationship between y1 and y3. Note that y3 has only trend term and base term. It indicates that the time series affected only by the trend term will also have a large correlation coefficient.
Thus, a conclusion can be made that the pseudo-correlation sensors have two characteristics: (1) they are affected by the trend and have small temperature change in the whole measurement process; (2) they have significant variation in correlation value with the change of subseries size. To obtain these two characteristics and ensure an effective correlation relationship, a new correlation calculation method is introduced in Sect. 2.3.
2.2 Variable ranking from the geometric properties
Besides the pseudo-correlation, another noteworthy phenomenon is the variable ranking based on the correlation coefficient between different speed spectrums.
If we regard \(\left( {x_{i} - \overline{x}} \right)\) and \(\left( {y_{i} - \overline{y}} \right)\) in Eq. (1) as new vectors:
Thus, Eq. (1) is rewritten as:
Eq. (5) shows that the value of PCC is equal to the cosine of the angle between X and Y.
Considering a simplified situation that n is 3, as shown in Fig. 2, P (a, b, c) is a reference vector. If an angle θ is fixed, then all the vectors have the same angle with P will form a conical surface. For example, P1 (a1, b1, c1), P3 (a1, b1, c3), and P4 (a4, b4, c4) are three vectors on the conical surface, and the correlation coefficients for the original time series rp, p1, rp, p2, and rp, p4 are the same. From P1 to P3, there is a P2. The angle between P2 and P is 0, and the corresponding correlation coefficient is 1. Thus, with a change in Z axis from c1 to c3, the correlation coefficient increases first and then decreases. For vectors having small angle with P2, a small change in any axis will cause a large change in the correlation coefficient. When temperature sensors are densely arranged on the headstock surface, the temperature data of many sensors have strong correlation with thermal error. Thus, the vectors of these sensors also have small angles with the vector of thermal error data. It is unrealistic to achieve a complete stable ranking for different speed spectrums based on the correlation coefficient. Besides, for vectors with large modules such as P4, in order to achieve the same change in correlation coefficient (Δθ) as P1, a larger change in Z axis (ΔL) is necessary. Thus, it is inappropriate to directly sort the vectors with different module lengths based on the correlation coefficient. Besides, the variable characteristic is independent of the trend in Sect. 2.1. Thus, after removing the influence of the trend, the variable phenomenon still exists in the correlation calculation results.

Diagram of the geometric properties of the correlation coefficient calculation
In order to achieve a relatively stable ranking, some strategies need to be implemented. Firstly, the speed spectrums have to be preselected. Since the temperature and thermal error data are non-Gaussian and nonstationary, some testing has to be carried out to ensure the data of the selected speed spectrums are suitable for the determined correlation calculation method. Secondly, classification is essential before ranking. After sensor classification, the vectors in the same group have similar module length and variation, which makes the correlation coefficients comparable. Thirdly, after speed spectrums selection and classification, the ranking of sensors in the same group needs to be determined by the results of more than one speed spectrum.
2.3 Detrended cross-correlation based method
2.3.1 Detrended cross-correlation coefficient
The DCCC [18] method is a detrended strategy to calculate the correlation between two nonstationary time series. It combines the detrended fluctuation analysis [19] and the detrended cross-correlation analysis [20]. The DCCC is approximately equal to PCC after detrending [21], but it is more suitable for nonstationary time series [15] and can obtain the correlation between different subseries.
The main content of DCCC includes the following two parts: (1) removing the trend of raw data by detrended fluctuation analysis and (2) forming an evaluation index similar to PCC after detrended cross-correlation analysis.
Firstly, the original variables x (x1, x2, …, xn) and y (y1, y2, …, yn) with the same length n are calculated by (4). The new time series are x* (x1*, x2*, …, xn*) and y* (y1*, y2*, …, yn*).
Secondly, divide the time series into 2 N subseries. The length of each subseries is S, as shown in Fig. 3. The division starts from both the positive and the negative directions.

Diagram of subseries division
Thirdly, the polynomial fitting is performed for each subseries, and the covariance is calculated by following.
where \({\widehat{x}}^{*}\) and \({\widehat{y}}^{*}\) are fitted values of the polynomial fitting.
Fourthly, calculate the fluctuation function.
Finally, take either of the two vectors as the reference vector; the DCCC value is expressed as:
Thus, the DCCC is a function of the length of subseries (S). It reflects the detrended correlation of two time series with different time scales and can obtain a robust correlation coefficient.
In this section, two evaluation indexes are proposed based on the DCCC, as expressed in Eq (9).
The first index is the variation of the DCCC curve (V-DCCC), which reflects the change of correlation between different subseries. The smaller the V-DCCC, the stronger the stability of the correlation. The second index is the mean value of the DCCC curve (M-DCCC), which indicates the degree of correlation. The larger the M-DCCC, the stronger the correlation.
2.3.2 Detrended cross-correlation coefficient with sliding window
The DCCC reflects the correlation of two time series with different subseries length. In dealing with the selection of time series, such as the selection of speed spectrum, it is equally important to consider the correlation of two time series with different subseries location. Based on the sliding window method in multiple detrended cross-correlation coefficient [22], a detrended cross-correlation coefficient with sliding window (SW-DCCC) is proposed in this paper. The division starts from the first value of the time series until the last sliding window reaches the last value, and the length of the sliding window is w, as presented in Fig. 4. In each sliding window, the M-DCCC is calculated. For m sliding windows, the SW-DCCC value is a curve with m values. Similar to DCCC, if the SW-DCCC curve has small fluctuation and large value, it shows that the speed arrangement of the speed spectrum is reasonable, and every location can ensure consistent and high correlation.

Diagram of the sliding window division
3 Thermal error experiment
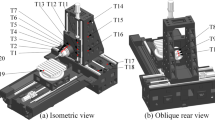
The thermal error experiment was carried out on a peripheral CNC grinding machine. As shown in Fig. 5, temperature sensors (DOCOROM PT100) were fixed on one side of the headstock after removing the grinding wheel joined to the front flange. The 15 sensors were arranged along 3 lines. The first line is from the end cap of the front bearing (sensor 09) to the connecting flange between spindle and motor (sensors 14 and 15). The second line is along the four grooves of the headstock. The third line is close to four bolted joints. Besides, another temperature sensor was placed outside the spindle to monitor the temperature variation in different seasons. The laser displacement sensor (Micro-Epsilon optoNCDT2300) was used for the axial thermal error measurement of the spindle. The sampling frequency of laser displacement sensor was 5000 Hz. To reduce the influence of spindle rotation, the average value of displacement sensor per minute was taken as the measured value. The sampling frequency of temperature sensors was 1/60 Hz. The relative value based on the value of the first minute of the measured temperature and thermal error data is used to form the dataset in thermal error modeling.

Experimental setup of spindle system
Two sets of experiments were conducted in different seasons to obtain thermal error and temperature data in different environments, as shown in Fig. 6. The speed spectrums A1 and A2 are designed based on ISO 230–3: 2020 [23]. Speed spectrums A2 and B2 are transformations based on A1 and B1. Speed spectrums A3, B3, and B4 are constant speed spectrums.

Variable speed spectrums
The experimental parameters of all speed spectrums are shown in Table 3. Figures 7, 8 and 9 show the axial thermal error and temperature data of three typical speed spectrums, where (a) corresponds to thermal error and (b) ~ (d) correspond to the temperature change of 15 sensors.

Thermal error and temperature data of A1

Thermal error and temperature data of B2

Thermal error and temperature data of B3
4 Sensor selection process
4.1 Spontaneous sensors and flow chart of sensor selection process
All the detrended cross-correlation-based methods are calculations between two time series. When using SW-DCCC and V-DCCC, a reference time series from one sensor needs to be defined. The main purpose of sensor reduction is to remove the sensors that their temperature data are affected by the trend. Thus, 15 temperature sensors can be divided into 2 types: the spontaneous sensors and the trend-driven sensors. For the spontaneous sensors, the temperature changes are related to the heat transfer process of the spindle. For the trend-driven sensors, they are affected by the trend of the headstock surface temperature. Instead of finding the trend-driven sensors, the most spontaneous sensor is determined, and other spontaneous sensors can be obtained based on the correlation coefficient.
Figure 10 shows the temperature data of 15 sensors in A1 after calculating by Eq. (4). Obviously, sensor 04 has the largest temperature change. And this phenomenon is consistent in all seven speed spectrums. The sensor with the largest temperature change will not be affected by the trend. And the correlation between the temperature data of this sensor and the thermal error data should be strong and stable. In other words, sensor 04 can be regarded as the most spontaneous sensor.

Temperature data of 15 sensors in A1 after subtracting the mean value
Figure 11 shows the flowchart of the sensor selection process. The temperature and thermal error data of different speed spectrums are used to form different datasets. After determining the most spontaneous sensor (sensor 04), the SW-DCCC between the data of sensor 04 and thermal errors is used to select the appropriate speed spectrums. Meanwhile, the V-DCCC between the data of sensor 04 and other sensors is used to reduce the trend-based sensors. Then, the M-DCCC between the data of different sensors is calculated in sensor classification process. Finally, the TKP are selected based on M-DCCC between thermal error data and the data of sensors in the same group.

Flowchart of sensor selection process
4.2 Selection of speed spectrums based on SW-DCCC
The SW-DCCC between temperature data of sensor 04 and thermal error data is calculated for seven speed spectrums, as shown in Fig. 12. The length of the sliding windows is set to 100. In each sliding window, the M-DCCC is calculated. Speed spectrums A1, A2, and B1 are selected for the sensor selection process because the most spontaneous sensor (sensor 04) shows a strong and stable correlation with the change of sliding windows.

The SW-DCCC curve of seven speed spectrums
To prove the correctness of the selection results, the histograms and distribution curves of sensor 04 for seven speed spectrums are calculated, as shown in Fig. 13. Although all the curves are not strictly conformed to Gaussian distribution, it is clear that the data of variable speed spectrums (A1, A2, B1, and B2) are more approximate to Gaussian distribution than that of constant speed spectrums (A3, B3, and B4). Combining the results of Figs. 12 and 13, the data of speed spectrums A1, A2, and B1 are used in the sensor selection process. Although the data of speed spectrums A3, B2, B3, and B4 are also real and effective, they are not suitable for the DCCC-based method.

Histograms and distribution curves of thermal error data for seven speed spectrums
4.3 Sensor reduction based on V-DCCC
The temperature data of sensor 04 are used as the reference; then each sensor is calculated with sensor 04. Figure 14 shows the DCCC value of 14 sensors in A1. The length of subseries (S) varies from 10 to 270 (n). When S is too small, the curve changes drastically, indicating the subseries are not large enough. In this paper, the DCCC value between 45 (n/6) and 270 (n) is used for the following calculation.

The DCCC value of 14 sensors in A1 (Temperature data of Sensor 04 is the reference)
It is worth noting that the V-DCCC is used in sensor reduction instead of the DCCC value itself. For example, the DCCC values of sensor 01 and sensor 13 are similar when S is greater than 135, but the V-DCCC of the whole range shows a significant difference, as shown in Fig. 15. Compared with sensor 13, sensor 01 is more suitable to be classified as a spontaneous temperature sensor.

The change of DCCC value of sensor 01 and sensor 13 in A1 (Temperature data of sensor 04 is the reference)
For each DCCC value curve between 45 ~ 270, the V-DCCC is calculated, as shown in Table 4. The threshold is set to 0.5. The sensors with V-DCCC value greater than 0.5 are reduced. For each sensor, if the reduction results of two speed spectrums are consistent, it can be considered as the final result. Thus, the original 15 sensors are reduced to 9 (sensors 01, 03, 04, 05, 07, 08, 09, 14, and 15).
4.4 Sensor classification based on M-DCCC and GA
There are two common classification strategies: (1) the unsupervised classification method; (2) the GA method. The GA method is based on a correlation matrix calculated by a correlation criterion. In this paper, the M-DCCC between different sensors is used to form the correlation matrix.
After sensor reduction, the correlation matrix is expressed as:
where \({\overline{\rho }}_{i,j}\) is the M-DCCC between sensor i and sensor j.
Table 5 shows the symmetric correlation matrix of A1. By setting different thresholds, sensors greater than the threshold are classified into the same group. For example, when the threshold is set to 0.85, the 15 sensors are classified into 3 groups, as tabulated in Table 6.
The stable classification results for different speed spectrums are necessary to keep a constant set of TKP. Besides, the number of groups is the same as the number of TKP. Considering that only 9 sensors are kept after sensor reduction, the number of TKP is set to 3 and 4, respectively.
The same sensor classification process is applied to the other three variable speed spectrums. The classification results are tabulated in Table 7. Obviously, the classification results tend to be stable only when there are three groups: (sensor 09), (sensor 01 and 05), and (sensor 03, 04, 07, 08, 14, and 15).
4.5 Sensor selection based on M-DCCC
A stable set of TKP depends on constant classification and ranking. The effective ranking is very important to evaluate the correlation between temperature data and thermal error data. After sensor reduction and classification, we use the M-DCCC between temperature data and thermal error data as the ranking criterion. For each sensor group, the sensor with the highest ranking is selected as TKP. Figure 16 shows the DCCC value curve of nine sensors in A1, where the thermal error data is used as the reference.

The DCCC value of eight sensors in A1 (Thermal error data is the reference)
The M-DCCC of the second and third groups is tabulated in Table 8. For each group, the sensor with the largest M-DCCC is selected as TKP. In group 2, the M-DCCC of sensor 01 is larger than sensor 05 for all speed spectrums. In group 3, the M-DCCC of sensor 14 is also larger than other sensors for all speed spectrums. Thus, a stable set of TKP is achieved by the proposed sensor selection method, and the TKP are sensors 09, 01, and 14.
5 Results and discussion
5.1 Modeling method and evaluation index
Figure 17 shows the relationship between thermal error data and temperature data of A1. There is a nonlinear relationship between the temperature data of each sensor and thermal error data. Thus, a nonlinear support vector machine (SVM) regression model is used in thermal error modeling.

The relationship between thermal error data and temperature data of A1
SVM has been proved to be an effective model for thermal error modeling of the spindle system. The regression model of SVM is defined as:
where f(X) is the prediction function of SVM; X is the temperature vector of TKP; Xi means support vector; l is the number of support vectors; \(\alpha_{i}\) and \(\alpha_{i}^{*}\) are Lagrange multipliers; k (Xi, X) represents kernel function; C is penalty parameter.
In this paper, the radial basis kernel function is selected as kernel function, which is defined as:
where σ is width parameter of radial basis kernel function, mark 1/σ2 as parameter g.
There are two crucial parameters in the SVM model: C and g (1/σ2). In this paper, the grid search method is used to find the correct parameters. The search range is set to 2–4 ~ 24 after several preliminary tests. After determining the parameters g and C, parameters (\(\alpha_{i} - \alpha_{i}^{*}\)) can be obtained by:
LIBSVM toolbox [24] and MATLAB R2018a software are used to obtain the four parameters of SVM: C, g, (αi-α* i), and b. The training function “svmtrain” and predictive function “svmpredict” are used to accomplish the training and prediction process.
Two evaluation indexes are used to display the modeling accuracy of the selection method: the root mean square error (RMSE) and the maximum error (MAX).
where yj is the measured value at j minute, y*j means the corresponding prediction value, n represents the total minutes of the experiment.
5.2 Modeling results for the proposed method
The temperature and thermal error data are obtained from seven speed spectrums of two different seasons. When the TKP are determined, the data of each speed spectrum can be used as both training set and test set. Thus, there are 49 (7 × 7) predictions for each set of TKP. The numbering rules of 49 predictions are tabulated in Table 9.
The data of TKP are taken into the SVM model. Figure 18 shows the modeling results (RMSE and MAX). The root mean square error and maximum error are less than 2.32 μm and 3.73 μm, respectively. The modeling results of the proposed method show a high accuracy and strong robustness.

Modeling results of 49 predictions
5.3 Traditional sensor selection method and sensor selection results
The traditional sensor selection method is a combination of classification and sorting. The correlation coefficient between temperature data of 15 sensors and thermal error data is calculated by PCC, and the ranking results are tabulated in Table 10. The direct use of PCC causes the sensor selection results to be variable. For example, sensors 02 and 06 have a high ranking in A1 but low ranking in other speed spectrums; sensors 14 and 15 have a high ranking in B2, B3, and B4 but low ranking in other speed spectrums. The variable ranking will cause variable sensor selection results, no matter whether the classification is stable or not.
This paper considers two traditional classification methods: (1) the FCM method and (2) the GA method. For the FCM method, the weighting exponent is set as 2. The temperature data of 15 sensors are normalized between 0 and 1 before being taken into the calculation. For the GA method, the PCC values between different sensors are used to form the correlation matrix. Tables 11 and 12 show the classification results of FCM and GA, respectively.
The variable sensor selection results of the two traditional strategies are tabulated in Table 13. The seven sets of TKP selected by FCM and PCC are marked as FP1 ~ FP7, and the other seven sets of TKP selected by GA and PCC are marked as GP1 ~ GP7.
5.4 Modeling results and discussion
The sensor selection result of the proposed method is marked as Model1 (sensors 01, 09, and 14). For each set of TKP, the 49 predictions are carried out. The RMSE and MAX are recorded as the evaluation index of modeling accuracy.
For example, when the prediction number is 2 (see Table 9), the training set is A1, and the test set is A2. The prediction value and residual of Model1, FP1, and GP1 are shown in Fig. 19.

Prediction value and residual of Model1, FP1, and GP1
The modeling accuracy of Model1 is compared with FP and GP, as shown in Figs. 20 and 21, respectively. Compared with FP or GP, Model1 shows high accuracy and strong robustness. The RMSE and MAX of 49 predictions of Model1 are less than 2.32 μm and 3.73 μm, respectively. Besides, the sensor selection process achieves a relatively stable TKP. With the same sensor selection results from three speed spectrums, the selected TKP are suitable for all seven speed spectrums.

Modeling accuracy comparison between Model1 and FP

Modeling accuracy comparison between Model1 and GP
Besides, after the sensor reduction and classification based on the proposed method, there are three groups: (sensor 09), (sensor 01 and 05), and (sensor 03, 04, 07, 08, 14, and 15). The PCC can also be used to sort sensors. The selection results based on PCC are tabulated in Table 14. Thus, sensors 01, 09, and 03 are selected as TKP. This selection result is marked as Model 2, and the modeling results are compared with the proposed model (Model 1), as shown in Fig. 22. With the same reduction and classification, the DCCC-based method still has higher accuracy and stronger robustness than the PCC-based method.

The modeling results of Model 1 and Model 2
6 Conclusion
This paper proposes a three-step sensor selection strategy for thermal error modeling: reduction, classification, and selection. The thermal error experiments with seven speed spectrums were carried out on a grinding machine in two seasons. The theoretical reasons for inappropriate sensor selection are discussed. The proposed method based on DCCC achieves a stable set of TKP and shows high accuracy and strong robustness. Some conclusions can be obtained as follows:
-
1.
The preselection of speed spectrums and reduction of sensors before classification are necessary. A stable set of TKP relies on stable classification and ranking. The variable speed spectrums are more suitable for the DCCC method than the constant speed spectrums due to the characteristic of data distribution.
-
2.
The temperature time series affected by trend can be calculated with a large correlation coefficient. The DCCC method can capture this pseudo-correlation phenomenon by removing the trends and dividing the time series into different subseries. The V-DCCC, M-DCCC, and SW-DCCC are effective evaluation indexes in sensor selection process.
-
3.
Sensor selection for the data-driven thermal error modeling is a complex and interactive process. Different combinations of TKP have significant differences in modeling accuracy. It is achievable to ensure high accuracy and strong robustness of the thermal error model with a stable and appropriate set of TKP.
Availability of data and material
The datasets used or analyzed during the current study are available from the corresponding author on reasonable request.
References
Ramesh R, Mannan M, Poo A (2000) Error compensation in machine tools — a review: Part II: thermal errors. Int J Mach Tools Manuf 40:1257–1284. https://doi.org/10.1016/S0890-6955(00)00010-9
Mayr J, Jedrzejewski J, Uhlmann E et al (2012) Thermal issues in machine tools. CIRP Ann 61:771–791. https://doi.org/10.1016/j.cirp.2012.05.008
Li Y, Zhao W, Lan S et al (2015) A review on spindle thermal error compensation in machine tools. Int J Mach Tools Manuf 95:20–38. https://doi.org/10.1016/J.IJMACHTOOLS.2015.04.008
Cao H, Zhang X, Chen X (2017) The concept and progress of intelligent spindles: A review. Int J Mach Tools Manuf 112:21–52. https://doi.org/10.1016/j.ijmachtools.2016.10.005
Miao E, Liu Y, Liu H et al (2015) Study on the effects of changes in temperature-sensitive points on thermal error compensation model for CNC machine tool. Int J Mach Tools Manuf 97:50–59. https://doi.org/10.1016/J.IJMACHTOOLS.2015.07.004
Liu H, Miao EM, Wei XY, Zhuang XD (2017) Robust modeling method for thermal error of CNC machine tools based on ridge regression algorithm. Int J Mach Tools Manuf 113:35–48. https://doi.org/10.1016/j.ijmachtools.2016.11.001
Hey J, Sing TC, Liang TJ (2018) Sensor Selection Method to Accurately Model the Thermal Error in a Spindle Motor. IEEE Trans Ind Informatics 14:2925–2931. https://doi.org/10.1109/TII.2017.2787655
Lo C-H, Yuan J, Ni J (1999) Optimal temperature variable selection by grouping approach for thermal error modeling and compensation. Int J Mach Tools Manuf 39:1383–1396. https://doi.org/10.1016/S0890-6955(99)00009-7
Lee J-H, Yang S-H (2002) Statistical optimization and assessment of a thermal error model for CNC machine tools. Int J Mach Tools Manuf 42:147–155. https://doi.org/10.1016/S0890-6955(01)00110-9
Ma C, Zhao L, Mei X et al (2017) Thermal error compensation based on genetic algorithm and artificial neural network of the shaft in the high-speed spindle system. Proc Inst Mech Eng Part B J Eng Manuf 231:753–767. https://doi.org/10.1177/0954405416639893
Han J, Wang L, Cheng N, Wang H (2012) Thermal error modeling of machine tool based on fuzzy c-means cluster analysis and minimal-resource allocating networks. Int J Adv Manuf Technol 60:463–472. https://doi.org/10.1007/s00170-011-3619-5
Yang B, Liu Z (2020) Thermal error modeling by integrating GWO and ANFIS algorithms for the gear hobbing machine. Int J Adv Manuf Technol 109:2441–2456. https://doi.org/10.1007/s00170-020-05791-z
Li B, Tian X, Zhang M (2019) Thermal error modeling of machine tool spindle based on the improved algorithm optimized BP neural network. Int J Adv Manuf Technol 105:1497–1505. https://doi.org/10.1007/s00170-019-04375-w
Schober P, Schwarte LA (2018) Correlation coefficients: Appropriate use and interpretation. Anesth Analg 126:1763–1768. https://doi.org/10.1213/ANE.0000000000002864
Kristoufek L (2014) Measuring correlations between non-stationary series with DCCA coefficient. Phys A Stat Mech its Appl 402:291–298. https://doi.org/10.1016/j.physa.2014.01.058
Creighton E, Honegger A, Tulsian A, Mukhopadhyay D (2010) Analysis of thermal errors in a high-speed micro-milling spindle. Int J Mach Tools Manuf 50:386–393. https://doi.org/10.1016/j.ijmachtools.2009.11.002
Liu H, Miao E, Zhang L et al (2020) Thermal error modeling for machine tools: Mechanistic analysis and solution for the pseudocorrelation of temperature-sensitive points. IEEE Access 8:63497–63513. https://doi.org/10.1109/ACCESS.2020.2983471
Zebende GF (2011) DCCA cross-correlation coefficient: Quantifying level of cross-correlation. Phys A Stat Mech its Appl 390:614–618. https://doi.org/10.1016/j.physa.2010.10.022
Peng C-K, Buldyrev SV, Havlin S et al (1994) Mosaic organization of DNA nucleotides. Phys Rev E 49:1685–1689. https://doi.org/10.1103/PhysRevE.49.1685
Podobnik B, Stanley HE (2008) Detrended cross-correlation analysis: A New method for analyzing two nonstationary time series. Phys Rev Lett 100:084102. https://doi.org/10.1103/PhysRevLett.100.084102
Zhao X, Shang P, Huang J (2017) Several fundamental properties of DCCA cross-correlation coefficient. Fractals 25:1–11. https://doi.org/10.1142/S0218348X17500177
Guedes EF, da Silva Filho AM, Zebende GF (2021) Detrended multiple cross-correlation coefficient with sliding windows approach. Phys A Stat Mech its Appl 574:125990. https://doi.org/10.1016/j.physa.2021.125990
ISO 230–3 (2020) Test code for machine tools-part 3: Determination of thermal effects
Chang C-C, Lin C-J (2011) LIBSVM: A library for support vector machines. ACM Trans Intell Syst Technol 2:1–27. https://doi.org/10.1145/1961189.1961199
Funding
This study is supported by Science and Technology Major Project of Sichuan Province (2019ZDZX0021).
Author information
Authors and Affiliations
Contributions
Qihao Liao contributed to conceptualization, methodology, writing (original draft), experiment, and software. Ling Wang contributed to methodology, experimental guidance, and writing (review and editing). Ming Yin contributed to methodology and experimental guidance. Luofeng Xie performed writing (review and editing). Guofu Yin provided resources and equipment.
Corresponding author
Ethics declarations
Ethics approval
Not applicable.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Conflicts of interest
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Liao, Q., Wang, L., Yin, M. et al. Obtaining more appropriate temperature sensor locations for thermal error modeling: reduction, classification, and selection. Int J Adv Manuf Technol 120, 5175–5192 (2022). https://doi.org/10.1007/s00170-022-09052-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00170-022-09052-z