
Abstract
The present study explored bilingual coactivation during natural monolingual sentence-reading comprehension. Native Chinese readers who had learned Japanese as a second language and those who had not learned it at all were tested. The results showed that unrelated Chinese word pairs that shared a common Japanese translation could parafoveally prime each other. Critically, this translation-related preview effect was modulated by the readers’ language-learning experiences. It was found only among the late Chinese–Japanese bilinguals, but not among the monolingual Chinese readers. By setting a novel step, which was testing bilingual coactivation of semantic knowledge in a natural reading scenario without an explicit presentation of L2 words, our results suggest that bilingual word processing can be automatic, unconscious and nonselective. The study reveals an L2-to-L1 influence on readers’ lexical activation during natural sentence reading in an exclusively native context.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Sentence reading involves activation of different aspects of words, including phonological and semantic knowledge, not only from the currently fixated word but also from upcoming parafoveal words. Yet the priority and time course of the activation of these representations have been the focus of theoretical debates for decades. Although it was once generally accepted that readers do not access high-level semantic information from parafoveal words, this view has been challenged. Much of the research involving parafoveal processing has been carried out to understand lexical activation in a monolingual mode. Learning a second language (L2) has several noticeable benefits. How bilingual readers coactivate translation equivalents in different languages during natural reading remains an open question. The present study demonstrates for the first time that, for native Chinese readers who have learned Japanese, Chinese target words are primed by Chinese preview words that share the same L2 translation, indicating an L2-to-L1 influence on readers’ lexical activation during monolingual sentence reading.
During the natural reading of continuously written sentences, readers typically acquire information from an area beyond the foveal word on which they are fixating. The region of effective vision during a single fixation determines the perceptual span (McConkie & Rayner, 1975). In Chinese, where words are written densely, readers exhibit a narrow perceptual span, only covering up to four upcoming characters (Inhoff & Liu, 1998; Yan et al., 2015). The gaze-contingent boundary paradigm (Rayner, 1975) is often used to assess the type and priority of parafoveal information processing within the perceptual span. During a reader’s fixations on and prior to a pretarget word, a parafoveal preview word is presented at the location of the target word. The preview could be the correct target word itself (identical preview), a word related to the target, or a completely irrelevant (non-)word. All different previews are replaced immediately by the correct target word during a saccade toward it. Typically, shorter fixations are observed on the target word for identical/related previews than for unrelated ones. The time saved in target-word processing when primed by parafoveal words defines the preview benefit (PB). The type of information acquirable from parafoveal words can be evaluated by manipulating the overlap between the preview and target words. Studies have consistently revealed orthographic and phonological PBs in various writing systems (Liu et al., 2002; Pollatsek et al., 1992; Tsai et al., 2004), with somewhat mixed evidence for semantic PBs (Yan et al., 2009).
The studies reviewed above have focused exclusively on monolingual reading, and not much work has been done to understand lexical representation and access in a bilingual scenario. Bilingualism research is among the most central research topics in psycholinguistics. One theoretical question is whether bilingual readers activate lexical information automatically and unconsciously in a language not relevant to the current task. There has been ample evidence that bilinguals coactivate their two languages unselectively, even when only one language is the target (Costa et al., 2006; Green & Abutalebi, 2013). For instance, studies using the visual world paradigm have clearly demonstrated a parallel activation of the lexicons of both languages: when words/sentences in one language were presented auditorily to bilinguals, phonologically similar words in the other language were also activated, reflected by increased probabilities of looking at the pictures of the “interfering” objects. However, some studies using the same paradigm have reported little L2 interference for bilinguals when performing L1-related tasks in a strongly L1-biased context (Marian & Spivey, 2003; Weber & Cutler, 2004). This suggests that bilinguals can tune themselves into a “monolingual mode” by selectively activating only the relevant language while deactivating the other (Grosjean, 1998, 2013).
Some studies have argued that bilinguals’ language-control mechanisms are different during written word processing and production (Declerck et al., 2019; Philipp & Koch, 2016; Reynolds et al., 2016). Using the language-switching paradigm, which compares performance on consecutive trials in two languages and trials within one language, researchers have consistently reported greater language-switching costs for production and listening tasks (e.g., slower reaction time and lower accuracy) from the weaker L2 to the dominant L1 than for the reverse (Costa & Santesteban, 2004; Verhoef et al., 2009). Such asymmetry, however, appears to be less pronounced in comprehension tasks (Orfanidou & Sumner, 2005; Thomas & Allport, 2000; Von Studnitz & Green, 1997). Presumably, during bilingual reading comprehension, little parallel language activation occurs and language-specific bottom-up input determines the language that needs to be activated accordingly (see also Declerck et al., 2019). In this case, L2-to-L1 and L1-to-L2 switching costs are low and equivalent.
Alternatively, the comprehension-based reading system may recruit language-control processes in a way that is less dependent on the activation level of each language. Not only similar-sounding words, but also translation-related words in nontarget languages can be activated during word recognition (Marian, 2019). This view is particularly advocated by the translation ambiguity effect—that is, bilinguals perceive L2 word pairs as (semantically) related when they share an L1 translation form (e.g., Degani et al., 2011; Jiang, 2002, 2004). Thierry and Wu (2007) presented their Chinese–English bilingual participants with English prime and target word pairs while manipulating whether they had overlapping characters in their Chinese translations. Irrespective of the semantic relatedness between the prime and target words, the N400 component of the event-related potentials revealed a translation repletion effect among the bilinguals, albeit the Chinese translations never appeared explicitly during the experiment. Therefore, their results were attributed to an implicit activation of the L1 Chinese words, which was practically irrelevant and unnecessary. Furthermore, an L2-to-L1 influence implies the underlying mechanism independent of language dominance: Jouravlev and Jared (2020) reported that Russian–English proficient bilinguals responded to L1 (Russian) target words more rapidly, with an enhanced P200 and a reduced N400 ERP component, when L1 prime and target words shared a common L2 (English) translation than when they did not. The authors thus concluded that “the presence of a shared L2 translation leads to some convergence of corresponding L1 lexico-conceptual representations” (p.310).
Here, we point out three considerations underpinning the aim of the present study to establish a convincing case for bilingual coactivation. First, most studies have focused on the influence of ambiguous L1 translations on L2 word recognition. Because late bilinguals’ L2 lexical representation is far less established than that of L1, such an effect would serve as stronger evidence for automatic cross-language activation. It is desirable to extend the L2-to-L1 effect (Jouravlev & Jared, 2020) to nonalphabetic languages. Second, words rarely appear by themselves; instead, they are often written in continuous text for reading. In general, it is of a greater ecological validity to explore lexical activation in a sentence-reading comprehension task than in a lexical-decision task. Third, as mentioned earlier, lexical processing starts before a word is fixated on. Consequently, the gaze-contingent boundary paradigm is very helpful to determine early bilingual lexical activation. More specifically, the display change implemented in the paradigm occurs very quickly during a saccade, and readers are typically unaware of visual change when vision is suppressed (Matin, 1974). Therefore, translation-related PB can be considered as evidence for automatic lexical processing of preview words. For these reasons, the eye-tracking technique offers the best choice for studying parafoveal bilingual lexical activation in natural reading.
To our knowledge, only a few studies have examined cross-language parafoveal semantic activation. Altarriba et al. (2001) reported that, among fluent Spanish–English bilinguals, previewing translations of target words led to a PB no greater than the orthographically similar previews, indicating that no parafoveal semantic knowledge was acquired. In a later study, Wang et al. (2016) tested cross-language PBs among late Korean–Chinese bilinguals when reading L2 (Chinese) sentences using three types of L1 (Korean) previews: cognate, semantically related noncognate, and unrelated words. They reported that both the cognate and semantic PBs were significant, pointing to a cross-language semantic PB. However, it should be noted that, methodologically, both studies involved explicit presentation of materials in two languages. Although cross-language priming has been used commonly to study bilingualism, presenting stimuli in different languages may create bias towards dual-language activation and lead to the question of external validity, to what extent unconscious translation occurs in a normal monolingual reading situation.
The present study
Incorporating the research ideas reviewed above and considering the somewhat inconsistent results of L2 activation during L1 reading across different tasks, we aimed to explore how L2 experience connects unrelated L1 words during a natural reading-comprehension task by manipulating the types of parafoveal preview. A within-item design was chosen, in which each target word was paired to different previews to minimize cross-item differences. Provided that late bilinguals can deactivate their nontarget L2 when reading L1 sentences continuously for a certain amount of time, there should be little or no effect of L2 translation repletion. Alternatively, given the evidence in favor of bilingual coactivation, we predicted an interaction between language experience and preview type, with the presence of translation-related PB only for bilinguals but not for monolinguals. It was anticipated that the translation-related PB, if present, could be attributed to a series of L1–L2–L1 automatic and unconscious activations such that L1 (Chinese) preview and target words would be connected via their shared L2 (Japanese) translation.
Method
Participants
One hundred and twenty-two participants were tested in the eye-tracking experiment. The bilingual group was 22.1 years old on average (n = 56, SD = 2.2, 38 females) and had learned Japanese systematically for at least two years (M = 3.9, SD = 1.9). They indicated self-evaluated Japanese proficiency of N3 or above and completed a brief adapted version of the SPOT, which required them to listen to 65 auditorily presented sentences at a natural speed and then fill in one missing Hiragana character after each sentence (Ford-Niwa & Kobayashi, 1999), immediately before their participation in the eye-tracking session. They scored an average of 49.6 (SD = 11.7), indicating that they were intermediate learners of Japanese. In contrast, the monolingual group, aged 22.5 years old on average (n = 66, SD = 2.5, 50 females), reported no knowledge of Japanese through either systematic or casual learning (e.g., TV series or animations). Three independent groups of 10 participants in each sample were recruited, one for each of three norming studies of relatedness, translation equivalence and sentence predictability. All participants were university students with normal or corrected-to-normal vision and were native Chinese speakers. All experimental procedures were reviewed and approved by the Ethics Committee of the Department of Psychology, University of Macau (SONA-2022-06). Prior to the experiment, all participants gave their written informed consent, which conformed to the tenets of the Declaration of Helsinki.
Design and material
We adopted a 2 (language background: bilingual vs. monolingual) × 3 (preview type: identical, translation-related, and unrelated) design and selected 54 triplets of critical two-character Chinese words (see Table 1). The translation-related previews in half of the item sets served as the targets in the other half. The translation-related previews and the target words were unrelated for the monolinguals in Chinese but had a common Japanese translation. The unrelated previews were chosen from the translation-related words from other item sets, so that the three conditions included exactly the same words. To ensure the validity of the design, first, we recruited 10 monolingual readers to evaluate the relatedness between the nonidentical previews and the target words on a 5-point Likert scale (1 = completely unrelated and 5 = highly related). The results showed that the translation-related and the unrelated previews were equally unrelated to the targets (t = 1.087, p = .282). In addition, 10 bilingual readers, who had approximately the same level of L2 proficiency as the eye-tracking participants, were presented with the Japanese translations of the target words and were asked to select their corresponding Chinese translation equivalents in multiple-choice questions. As expected, the participants were able to identify the correct translations (72.8%).
The target words were embedded in sentence frames. The pretarget and target words, which were always two characters in length, were never among the first or last three words in the sentences. The sentence contexts up to the pretarget words were constructed to be non-predictive for the different previews, in order to minimize top-down processing. In the cloze test, 10 participants were presented with the sentence frames and asked to complete the sentences. The critical words were never predicted. The experimental conditions were counterbalanced across participants and a different randomized order of sentence presentation was generated for each participant.
Apparatus
The participants’ eye movements were recorded with an EyeLink Desktop system running at a sampling rate of 1000 Hz. Each sentence was presented in a single horizontal line on a 24-inch BenQ ZOWIE XL2546K (resolution: 1,920 × 1,080 pixels; frame rate: 240 Hz) using the Song font. The participants were seated 65 cm from the monitor and were tested individually in a small chamber, with their heads positioned on a forehead and chin rest. Each character subtended 0.9° of visual angle. All recordings and calibrations were done monocularly, based on the right eye, and viewing was binocular.
Procedure
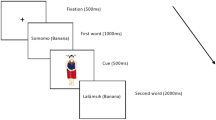
Before the experiment started, the participants’ gaze positions were calibrated with a 5-point grid (maximum errors <0.5°). The tracking accuracy was checked prior to each sentence. The participant’s gaze on the initial fixation-point initiated the presentation of the next sentence, with its first character occupying the fixation point. Otherwise, if the eye tracker did not detect the gaze around the fixation point, an additional calibration was performed. The participants were instructed to read the sentences silently for comprehension, then to fixate on a point in the lower-right corner of the monitor, and finally to press a keyboard button to signal completion of a trial. The gaze-contingent display-change technique was adopted to manipulate the parafoveal preview (see Fig. 1). The participants received 12 practice trials before reading the experimental sentences. We randomly selected 18 experimental sentences, each to be followed by an easy yes–no comprehension question, to encourage the participants’ engagement with the reading task. The bilingual and monolingual participants, on average, correctly answered 95.9% (SD = 5.2%) and 94.3% (SD = 5.9%) of the questions, respectively.

A set of example sentences with the target word primed by different types of previews. The preview and target words are highlighted with a gray background only for illustrative purposes and were presented normally during the experiment. Different previews are immediately replaced by the correct target word once a reader’s gaze crosses an invisible vertical boundary located between the pretarget and target words (as indexed by the vertical dashed line). The target sentence translates as: There are many people who go fishing on the beach on weekend afternoons
Data analysis
Fixations were determined with an algorithm for saccade-detection (Engbert & Kliegl, 2003). The data were screened in the following steps. First, 183 (2.8%) trials were removed either due to tracker errors or participants’ blinks, coughing or body movements during reading. Trials with the target words’ first-fixation durations (FFDs; duration of the first fixation on a word irrespective of the number of fixations) shorter than 60 ms or longer than 800 ms, or gaze durations (GDs; the cumulative duration of all fixations during the first-pass reading of the word) longer than 1,000 ms were removed (n = 186, 3.4%). Additionally, using an a priori criterion (Briihl & Inhoff, 1995), trials (n = 243, 4.4%) with regressions from the pretarget or target words were discarded because they may have reflected incomplete lexical processing. Specific to the gaze-contingent boundary paradigm, trials (n = 351, 6.3%) in which display changes were triggered during fixations were excluded. These data-screening procedures are standard and the data exclusion rate was comparable to those in previous similar experiments. The general pattern of results did not depend on the choice of any particular criterion mentioned above. The remaining 4,886 observations were largely distributed evenly across conditions.
Estimates were based on linear mixed models (LMMs) for continuous fixation duration measures of FFD and GD, and on generalized linear mixed models (GLMMs) for categorical skipping and refixation probabilities, using the lme4 package (Version 1.1-23; Bates et al., 2015a, b) in the R environment. Reporting experimental effects in different fixation measures provides an estimation of the time course. Experimental effects that appear in FFD are considered to arise in an earlier temporal stage than those that show up only in GD when the target word is refixated on (Inhoff, 1984; Inhoff & Radach, 1998). We focused on first-pass reading measures because previous studies consistently showed early semantic PBs in Chinese. We specified a sum contrast for the factor of language background and an orthogonal Helmert contrast for preview type, and reported parsimonious LMMs for successful convergence (Bates et al., 2015a, b; Matuschek et al., 2017). The first level of the Helmert contrast was between the translation-related preview and the unrelated preview, testing whether unrelated words in L1 that shared an L2 translation could activate each other. The second level of the contrast was between the identical preview and an average of the two nonidentical conditions and indicated an effect of parafoveal processing efficiency. We reported p values from the lmerTest package (Version 3.1-2; Kuznetsova et al., 2017). Dependent variables of viewing duration measures were log-transformed in the LMMs (Kliegl et al., 2010).
Results
As expected, the readers skipped the target words more often (b = 0.133, SE = 0.026, z = 5.138, p < .001) and made fewer refixations on them (b = −0.383, SE = 0.027, z = −13.972, p < .001) in the identical preview condition than in the nonidentical preview conditions. All other predictors were non-significant in the GLMMs (p values > 0.1). To a similar extent, both the bilingual (FFD: b = −0.098, SE = 0.005, t = −19.127 and GD: b = −0.130, SE = 0.006, t = −21.587) and monolingual readers (FFD: b = −0.096, SE = 0.005, t = −20.453, and GD: b = −0.131, SE = 0.006, t = −23.483; all p values < .001) processed the target words more briefly in the identical preview condition than in the non-identical preview conditions, leading to significant main effects of identical PBs and nonsignificant interactions (see Tables 2 and 3). These results suggest a canonical reading pattern that native Chinese readers process visual information from upcoming words, and that both groups process parafoveal information efficiently.
More importantly, we investigated whether words that are unrelated in L1 can be co-activated due to readers’ L2 learning experience. Our data showed significant interactions between the translation-related preview condition and the unrelated preview condition (Fig. 2). Decomposition of these interactions indicated translation-related PBs only among the bilinguals (FFD: b = −0.034, SE = 0.008, t = −3.735, p < .001, and GD: b = −0.029, SE = 0.011, t = −2.729, p = .006), but not among the monolinguals (p values > .1).

Means and standard errors of experimental effects for first-fixation duration (FFD; left panel) and gaze duration (GD; right panel). Error bars indicate one standard error. Plots were generated with the remef package (Version 0.6.10; Hohenstein & Kliegl, 2015) and the ggplot2 package (Version 2.1.0; Wickham, 2016). (Color figure online)
Discussion
The present study explored the impact of shared L2 translations on L1 lexical access during monolingual L1 sentence reading. We recruited native Chinese readers, some who had learned and some who had not learned Japanese and tested whether otherwise unrelated Chinese word pairs that shared a common Japanese translation could prime each other parafoveally during natural sentence reading. Our results are rather clear-cut, demonstrating robust benefits among late Chinese–Japanese bilinguals in L1 (Chinese) target-word processing induced by an L1 preview word that shared a common L2 (Japanese) translation with the target word. Note that such translation-related PBs are not attributable to any form of visual or linguistic connection between the preview and the target words in L1, as confirmed both by the pretest and by the results from the monolingual group. As such, setting a novel step to test cross-language activation in a natural monolingual sentence-reading scenario, our results in principle agree with the translation ambiguity effect in L2 (Degani et al., 2011; Jiang, 2002, 2004) and L1 word recognition (Jouravlev & Jared, 2020). Our results indicate that L2-learning experience establishes new connections between L1 words that are unrelated for monolinguals, revealing a plasticity in human mind that flexibly adapts to the language environment. Below we discuss implications for notions of three internally related aspects in reading, including parafoveal lexical processing, bilingualism, and disambiguation of homographic words.
There has been a long-standing enthusiasm in determining the type and priority of parafoveal information processing (see Rayner, 2009, for a review). To understand the nature of parafoveal processing, earlier researchers have endeavored to identify the types of information available parafoveally, such as syntax (Kim et al., 2012), sign phonology (Pan et al., 2015; Thierfelder et al., 2020), and morphology (Pan et al., 2023; Yen et al., 2008). Traditionally, there has been no evidence for parafoveal processing of high-level semantic knowledge (Inhoff, 1982; Inhoff & Rayner, 1980; Rayner et al., 1986, 2014), once leading to a conclusion that parafoveal processing is limited to visual and phonological levels. However, this seemingly reasonable conclusion was based mainly on a language with a deep orthography, English, where letter–phoneme correspondence is rather opaque. Yan et al. (2009) challenged this view and argued that parafoveal processing priority depends on the nature of the writing system involved. In Chinese, a logographic language, a close association between words’ graphic forms and their meanings leads to an expectation of early semantic activation (Hoosain, 1991; Yan & Kliegl, 2023). Indeed, previous research has consistently shown early parafoveal semantic activation in Chinese (e.g., Yan et al., 2009, 2012; Yang et al., 2012), even earlier than phonology (Pan et al., 2016, 2022; Tsai et al., 2012). Semantic PB has also been demonstrated in shallow orthographies such as German (Hohenstein & Kliegl, 2014; Hohenstein et al., 2010) and Korean (Yan et al., 2019), arguably because their regular letter-to-phoneme correspondences promote phonological decoding, which in turn can facilitate semantic access. Inspired by relevant works, recent reinvestigations of semantic PB in English have suggested its presence, but this is limited to strong semantic association (Schotter, 2013) and to contextual support (Veldre & Andrews, 2016). Therefore, the present study served not only as a replication of semantic PB, but also investigated its effects, in order to gain a better understanding of bilingualism.
Critically, in the context of cross-language semantic activation, Altarriba et al. (2001) found PBs only from previewing Spanish-English cognates but not from noncognate translations. Additionally, the cognate PB was equivalent in size to an orthographic PB. Together, they classified the cognate PB as orthographic/phonological, but not as semantic processing. Evidence for cross-language semantic PB, however, was reported among late Korean–Chinese bilinguals, when L2 Chinese target words were primed by L1 Korean cognate preview words and semantically related noncognate preview words during Chinese sentence reading (Wang et al., 2016). Compared with these studies, the present study has apparently pushed the cross-language semantic effect to a more extreme test: within the short period of time during parafoveal processing, readers may need first to access the L1 preview word, then coactivate its L2-translation via the shared concept/meaning, and finally spread the activation back to L1 and trigger other words that are semantically related to the L2 translation, including the L1 target word. The series of cognitive processes eventually triggered the observed translation-related PBs. Given that the preview and target words were unrelated in L1, we conclude that L2-learning experience has built new connections between L1 words. As such, the present results consolidate and extend previous findings of cross-language semantic activation.
From a broader perspective, our results also agree with sign-phonological preview effects among deaf readers. Pan et al. (2015) first tested the activation of sign phonology by presenting, to deaf and hearing readers, preview words that were sign phonologically similar to target words. They found a sign-phonological PB only among the deaf readers but not the hearing group. Thierfelder et al. (2020) further tested different aspects of sign phonology and found that the handshape parameter was particularly important for early sign activation (see also Morford et al., 2011). The present study agrees with the earlier reports, jointly showing that the human mind flexibly creates new links in the mental lexicon between words that are unrelated for monolinguals due to readers’ language learning experience, such as sign language and second language.
Some studies have observed that language proficiency influences the extent of coactivation (Mishra & Singh, 2016). For instance, low L2-proficiency readers failed to activate nontarget L2 during spoken and visual word recognition (Blumenfeld & Marian, 2007; Van Hell & Dijkstra, 2002). The current findings, however, speak against the possibility that low L2-proficiency bilinguals activate only L1 in a native-language environment: During the entire eye-tracking session, they were exposed only to Chinese materials. Two factors may have influenced bilingual coactivation in this study. First, our participants were given a Japanese proficiency test before the eye-tracking experiment. The procedure may implicitly have boosted bilingual coactivation. Second, natural sentence reading may allow activation of complex mental representations that are associated in a broader sense—for instance, L1 words whose L2-translation equivalents share the same word forms. In fact, this is predicted by the computational model of bilingual visual word recognition—namely Multilink. Specifically, translation is achieved “only by conceptual mediation in Multilink by connecting word forms from different languages only via their semantics” (Dijkstra et al., 2019, p. 661; see also the BIA+ model: Dijkstra & Van Heuven, 2002). Substantial evidence from different languages has converged on the view that reading L2 words in an L2-exclusive context activates L1 translations in the absence of cognate priming (Chinese–English: Jiang, 2002; Thierry & Wu, 2007; Japanese–English: Miwa et al., 2014; Korean–English: Jiang, 2004; Kim & Kim, 2018). Along this line, the present study further demonstrated that, among late Chinese–Japanese bilinguals, L1 words can be mediated by their task-irrelevant L2 translations during sentence reading, indicating that bilingual word processing is nonselective.
Degani et al. (2011) proposed that, with an increase of bilingual readers’ life experience, there will be frequent coactivation of two L1 words that share an L2 translation strengthens lexical and/or conceptual connections between them. Such convergence of lexico-conceptual representations of L1 words (see also Jouravlev & Jared, 2020) would be better supported by data from bilinguals with a wider variance in L2 proficiency, to find a developmental trend in the representations. Possibly, convergence of translation alternatives’ representations likely occurs among bilinguals with high L2 proficiency. Further studies are needed to provide solid evidence for translation processes in bilingualism research.
The Japanese items, as homographs, map onto two meanings within Japanese. Simpson and Burgess (1985) proposed a two-stage model of homograph processing. An initial spreading-activation process makes all meanings of an ambiguous word available; after that, an appropriate meaning is selected for continued processing. In Chinese reading, Tsang and Chen (2013) similarly concluded that, in an early stage, all meanings of homographic characters are activated, while the selection of appropriate interpretations happens at a later stage. In a more recent study, Pan et al. (2023) manipulated morphological similarity and found that their target word was primed in an early temporal stage by both same-morpheme and different-morpheme preview words that shared a homographic character, but only the same-morpheme PB survived in a later stage, also supporting an initial spreading-activation and a late meaning-selection mechanism. The present results may also hint at an early spreading activation: Once the shared L2-translations are activated by the preview words in an early parafoveal processing stage, alternative meanings of the Japanese words can be accessed quickly and prime the Chinese target words.
To summarize, the present results extend our understanding of parafoveal lexical activation during natural sentence reading. From a bilingual cognitive perspective, the results, based on late bilinguals, offer a novel piece of evidence suggesting that the human mind can adapt flexibly to the current multilingual environment.
Data availability and code availability
The datasets generated during and/or analyzed during the current study are available in the OSF repository (https://doi.org/10.17605/OSF.IO/DVM4N).
References
Altarriba, J., Kambe, G., Pollatsek, A., & Rayner, K. (2001). Semantic codes are not used in integrating information across eye fixations in reading: Evidence from fluent Spanish-English bilinguals. Perception & Psychophysics, 63, 875–890. https://doi.org/10.3758/BF03194444
Assche, E. V., Duyck, W., Hartsuiker, R. J. (2012). Bilingual word recognition in a sentence context. Frontiers in Psychology, 3. https://doi.org/10.3389/fpsyg.2012.00174
Bates, D., Kliegl, R., Vasishth, S., & Baayen, R. H. (2015a). Parsimonious mixed models (arXiv:1506.04967 [stat.ME]). Retrieved from https://arxiv.org/abs/1506.04967
Bates, D., Maechler, M., Bolker, B., & Walker, S. (2015b). Fitting linear mixed-effects models using lme4. Journal of Statistical Software, 67, 1–48. https://doi.org/10.18637/jss.v067.i01
Blumenfeld, H. K., & Marian, V. (2007). Constraints on parallel activation in bilingual spoken language processing: Examining proficiency and lexical status using eye-tracking. Language and Cognitive Processes, 22(5), 633–660. https://doi.org/10.1080/01690960601000746
Briihl, D., & Inhoff, A. W. (1995). Integrating information across fixations during reading: The use of orthographic bodies and of exterior letters. Journal of Experimental Psychology: Learning, Memory, and Cognition, 21, 55–67. https://doi.org/10.1037/0278-7393.21.1.55
Christoffels, I. K., De Groot, A. M. B., & Kroll, J. F. (2006). Memory and language skills in simultaneous interpreters: The role of expertise and language proficiency. Journal of Memory and Language, 54, 324–345. https://doi.org/10.1016/j.jml.2005.12.004
Costa, A., & Santesteban, M. (2004). Lexical access in bilingual speech production: Evidence from language switching in highly proficient bilinguals and L2 learners. Journal of Memory and Language, 50, 491–511. https://doi.org/10.1016/j.jml.2004.02.002
Costa, A., La Heij, W., & Navarrete, E. (2006). The dynamics of bilingual lexical access. Bilingualism: Language and Cognition, 9(2), 137–151. https://doi.org/10.1017/S1366728906002495
Declerck, M., Koch, I., Duñabeitia, J. A., Grainger, J., & Stephan, D. N. (2019). What absent switch costs and mixing costs during bilingual language comprehension can tell us about language control. Journal of Experimental Psychology: Human Perception & Performance, 45(6), 771–789. https://doi.org/10.1037/xhp0000627
Degani, T., Prior, A., & Tokowicz, N. (2011). Bidirectional transfer: The effect of sharing a translation. Journal of Cognitive Psychology, 23, 18–28. https://doi.org/10.1080/20445911.2011.445986
Dijkstra, A., & Van Heuven, W. J. B. (2002). The architecture of the bilingual word recognition system: From identification to decision. Bilingualism: Language and Cognition, 5, 175–197. https://doi.org/10.1017/S1366728902003012
Dijkstra, T., Wahl, A., Buytenhuijs, F., Van Halem, N., Al-Jibouri, Z., De Korte, M., & Rekké, S. (2019). Multilink: A computational model for bilingual word recognition and word translation. Bilingualism: Language and Cognition, 22, 657–679. https://doi.org/10.1017/S1366728918000287
Engbert, R., & Kliegl, R. (2003). Microsaccades uncover the orientation of covert attention. Vision Research, 43, 1035–1045. https://doi.org/10.1016/S0042-6989(03)00084-1
Ford-Niwa, J., & Kobayashi, N. (1999). SPOT: A test measuring “control” exercised by learners of Japanese. In K. Kazue (Ed.), The acquisition of Japanese as a second language (pp. 53–70). John Benjamins Publishing Company. https://doi.org/10.1075/lald.20.07for
Green, D. W., & Abutalebi, J. (2013). Language control in bilinguals: The adaptive control hypothesis. Journal of Cognitive Psychology, 25(5), 515–530. https://doi.org/10.1080/20445911.2013.796377
Grosjean, F. (1998). Transfer and language mode. Bilingualism: Language and Cognition, 1(3), 175–176. https://doi.org/10.1017/S1366728998000285
Grosjean, F. (2013). Bilingual and monolingual language modes. In C. A. Chapelle (Ed.), The encyclopedia of applied linguistics (p. 658). Blackwell. https://doi.org/10.1002/9781405198431.wbeal0090
Hohenstein, S., & Kliegl, R. (2014). Semantic preview benefit during reading. Journal of Experimental Psychology: Learning, Memory, and Cognition, 40, 166–190. https://doi.org/10.1037/a0033670
Hohenstein, S., Laubrock, J., & Kliegl, R. (2010). Semantic preview benefit in eye movements during reading: A parafoveal fast-priming study. Journal of Experimental Psychology: Learning Memory and Cognition, 36, 1150–1170. https://doi.org/10.1037/a0020233
Hoosain, R. (1991). Psycholinguistic implications for linguistic relativity: A case study of Chinese. Erlbaum. https://doi.org/10.1177/00238309920350030
Inhoff, A. W. (1982). Parafoveal word perception: A further case against semantic preprocessing. Journal of Experimental Psychology: Human Perception and Performance, 8, 137–145. https://doi.org/10.1037/0096-1523.8.1.137
Inhoff, A. W. (1984). Two stages of word processing during eye fixations in the reading of prose. Journal of Verbal Learning and Verbal Behavior, 23, 612–624. https://doi.org/10.1016/S0022-5371(84)90382-7
Inhoff, A. W., & Liu, W. (1998). The perceptual span and oculomotor activity during the reading of Chinese sentences. Journal of Experimental Psychology: Human Perception and Performance, 24(1), 20–34. https://doi.org/10.1037/0096-1523.24.1.20
Inhoff, A. W., & Radach, R. (1998). Definition and computation of oculomotor measures in the study of cognitive processes. In G. Underwood (Ed.), Eye guidance in reading and scene perception (pp. 29–53). UK: Elsevier Science. https://doi.org/10.1016/B978-008043361-5/50003-1
Inhoff, A. W., & Rayner, K. (1980). Parafoveal word perception: A case against semantic preprocessing. Perception & Psychophysics, 27, 457–464. https://doi.org/10.3758/BF03204463
Jiang, N. (2002). Form–meaning mapping in vocabulary acquisition in a second language. Studies in Second Language Acquisition, 24(4), 617–637. https://doi.org/10.1017/S0272263102004047
Jiang, N. (2004). Semantic transfer and its implications for vocabulary teaching in a second language. The Modern Language Journal, 88(3), 416–432. https://doi.org/10.1111/j.0026-7902.2004.00238.x
Jouravlev, O., & Jared, D. (2020). Native language processing is influenced by L2-to-L1 translation ambiguity. Language, Cognition and Neuroscience, 35(3), 310–329. https://doi.org/10.1080/23273798.2019.1652764
Kim, J., & Kim, J. H. (2018). Implicit translation during second language lexical processing. The Journal of Cognitive Science, 19, 357–375.
Kim, Y. S., Radach, R., & Vorstius, C. (2012). Eye movements and parafoveal processing during reading in Korean. Reading and Writing, 25, 1053–1078. https://doi.org/10.1007/s11145-011-9349-0
Kliegl, R., Masson, M. E. J., & Richter, E. M. (2010). A linear mixed model analysis of masked repetition priming. Visual Cognition, 18, 655–681. https://doi.org/10.1080/13506280902986058
Kuznetsova, A., Brockhoff, P. B., & Christensen, R. H. B. (2017). lmerTest package: Tests in linear mixed effects models. Journal of Statistical Software, 82, 26. https://doi.org/10.18637/jss.v082.i13
Liu, W., Inhoff, A. W., Ye, Y., & Wu, C. (2002). Use of parafoveally visible characters during the reading of Chinese sentences. Journal of Experimental Psychology: Human Perception and Performance, 28, 1213–1227. https://doi.org/10.1037/0096-1523.28.5.1213
Marian, V. (2019). The language you speak influences where your attention goes. Scientific American.https://blogs.scientificamerican.com/observations/the-language-you-speak-influences-where-your-attention-goes/
Marian, V., & Spivey, M. J. (2003). Competing activation in bilingual language processing: Within- and between-language competition. Bilingualism: Language and Cognition, 6, 97–115. https://doi.org/10.1017/S1366728903001068
Matin, E. (1974). Saccadic suppression: A review and an analysis. Psychological Bulletin, 81(12), 899–917. https://doi.org/10.1037/h0037368
Matuschek, H., Kliegl, R., Vasishth, S., Baayen, H., & Bates, D. (2017). Balancing Type I error and power in linear mixed models. Journal of Memory and Language, 94, 305–315. https://doi.org/10.1016/j.jml.2017.01.001
McConkie, G. W., & Rayner, K. (1975). The span of the effective stimulus during a fixation in reading. Perception & Psychophysics, 17, 578–586. https://doi.org/10.3758/BF03203972
Mishra, R. K., & Singh, N. (2016). The influence of second language proficiency on bilingual parallel language activation in Hindi-English bilinguals. Journal of Cognitive Psychology, 28(4), 396–411. https://doi.org/10.1080/20445911.2016.1146725
Miwa, K., Dijkstra, T., Bolger, P., & Baayen, R. H. (2014). Reading English with Japanese in mind: Effects of frequency, phonology, and meaning in different-script bilinguals. Bilingualism: Language and Cognition, 17, 445–463. https://doi.org/10.1017/S1366728913000576
Morford, J. P., Wilkinson, E., Villwock, A., Pinar, P., & Kroll, J. F. (2011). When deaf signers read English: Do written words activate their sign translations? Cognition, 118, 286–292. https://doi.org/10.1016/j.cognition.2010.11.006
Orfanidou, E., & Sumner, P. (2005). Language switching and the effects of orthographic specificity and response repetition. Memory & Cognition, 33, 355–369. https://doi.org/10.3758/BF03195323
Pan, J., Shu, H., Wang, Y., & Yan, M. (2015). Parafoveal activation of sign translation previews among deaf readers during the reading of Chinese sentences. Memory & Cognition, 43(6), 964–972. https://doi.org/10.3758/s13421-015-0511-9
Pan, J., Laubrock, J., & Yan, M. (2016). Parafoveal processing in silent and oral reading: Reading mode influences the relative weighting of phonological and semantic information in Chinese. Journal of Experimental Psychology: Learning, Memory and Cognition, 42(8), 1257–1273. https://doi.org/10.1037/xlm0000242
Pan, J., Yan, M., & Yeh, S.-L. (2022). Accessing semantic information from above: Parafoveal processing during the reading of vertically presented sentences in traditional Chinese. Cognitive Science, 46, e13104. https://doi.org/10.1111/cogs.13104
Pan, J., Wang, A., McBride, C., Cho, J.-R., & Yan, M. (2023). Online assessment of parafoveal morphological processing/awareness during reading among Chinese and Korean adults. Scientific Studies of Reading, 27(3), 232–252. https://doi.org/10.1080/10888438.2022.2149335
Philipp, A. M., & Koch, I. (2016). Action speaks louder than words, even in speaking: The influence of (no) overt speech production on language-switch costs. In J. W. Schwieter (Ed.), Cognitive control and consequences in the multilingual mind (pp. 127–144). John Benjamins.
Pollatsek, A., Lesch, M., Morris, R. K., & Rayner, K. (1992). Phonological codes are used in integrating information across saccades in word identification and reading. Journal of Experimental Psychology: Human Perception and Performance, 18(1), 148–162. https://doi.org/10.1037/0096-1523.18.1.148
R Development Core Team. (2020). R: A language and environment for statistical computing. R Foundation for Statistical Computing.
Rayner, K. (1975). The perceptual span and peripheral cues during reading. Cognitive Psychology, 7, 65–81. https://doi.org/10.1016/0010-0285(75)90005-5
Rayner, K. (2009). Eye movements and attention in reading, scene perception, and visual search. Quarterly Journal of Experimental Psychology, 62, 1457–1506. https://doi.org/10.1080/17470210902816461
Rayner, K., Balota, D. A., & Pollatsek, A. (1986). Against parafoveal semantic preprocessing during eye fixations in reading. Canadian Journal of Psychology, 40(4), 473–483. https://doi.org/10.1037/h0080111
Rayner, K., Schotter, E. R., & Drieghe, D. (2014). Lack of semantic parafoveal preview benefit in reading revisited. Psychonomic Bulletin & Review, 21, 1067–1072. https://doi.org/10.3758/s13423-014-0582-9
Reynolds, M. G., Schlöffel, S., & Peressotti, F. (2016). Asymmetric switch costs in numeral naming and number word reading: Implications for models of bilingual language production. Frontiers in Psychology, 6, 2011. https://doi.org/10.3389/fpsyg.2015.02011
Santesteban, M., & Schwieter, J. (2020). Lexical selection and competition in bilinguals. In R. Heredia & A. Cieślicka (Eds.), Bilingual lexical ambiguity resolution (pp. 126–156). Cambridge University Press. https://doi.org/10.1017/9781316535967.007
Schotter, E. R. (2013). Synonyms provide semantic preview benefit in English. Journal of Memory and Language, 69, 619–633. https://doi.org/10.1016/j.jml.2013.09.002
Simpson, G. B., & Burgess, C. (1985). Activation and selection processes in the recognition of ambiguous words. Journal of Experimental Psychology: Human Perception and Performance, 11(1), 28–39. https://doi.org/10.1037/0096-1523.11.1.28
Thierfelder, P., Wigglesworth, G., & Tang, G. (2020). Orthographic and phonological activation in Hong Kong deaf readers: An eye-tracking study. Quarterly Journal of Experimental Psychology, 73(12), 2217–2235. https://doi.org/10.1177/1747021820940223
Thierry, G., & Wu, Y. (2007). Brain potentials real unconscious translation during foreign-language comprehension. Proceedings of the National Academy of Sciences, 104(30), 12530–12535. https://doi.org/10.1073/pnas.0609927104
Thomas, M. S. C., & Allport, A. (2000). Language switching costs in bilingual visual word recognition. Journal of Memory and Language, 43(1), 44–66. https://doi.org/10.1006/jmla.1999.2700
Tsai, J.-L., Lee, C.-Y., Tzeng, O. J. L., Hung, D. L., & Yen, N.-S. (2004). Use of phonological codes for Chinese characters: Evidence from processing of parafoveal preview when reading sentences. Brain and Language, 91, 235–244. https://doi.org/10.1016/j.bandl.2004.02.005
Tsai, J.-L., Kliegl, R., & Yan, M. (2012). Parafoveal semantic information extraction in traditional Chinese reading. Acta Psychologica, 141, 17–23. https://doi.org/10.1016/j.actpsy.2012.06.004
Tsang, Y. K., & Chen, H.-C. (2013). Early morphological processing is sensitive to morphemic meanings: Evidence from processing ambiguous morphemes. Journal of Memory and Language, 68(3), 223–239. https://doi.org/10.1016/j.jml.2012.11.003
Van Hell, J. G., & Dijkstra, T. (2002). Foreign language knowledge can influence native language performance in exclusively native contexts. Psychonomic Bulletin & Review, 9(4), 780–789. https://doi.org/10.3758/bf03196335
Veldre, A., & Andrews, S. (2016). Semantic preview benefit in English: Individual differences in the extraction and use of parafoveal semantic information. Journal of Experimental Psychology: Learning, Memory, and Cognition, 42(6), 837–854. https://doi.org/10.1037/xlm0000212
Verhoef, K., Roelofs, A., & Chwilla, D. J. (2009). Role of inhibition in language switching: Evidence from event-related brain potentials in overt picture naming. Cognition, 110(1), 84–99. https://doi.org/10.1016/j.cognition.2008.1
Von Studnitz, R. E., & Green, D. W. (1997). Lexical decision and language switching. International Journal of Bilingualism, 1(1), 3–24. https://doi.org/10.1177/136700699700100102
Wang, A., Yeon, J., Zhou, W., Shu, H., & Yan, M. (2016). Cross-language parafoveal semantic processing: Evidence from Korean-Chinese bilinguals. Psychonomic Bulletin & Review, 23(1), 285–290. https://doi.org/10.3758/s13423-015-0876-6
Weber, A., & Cutler, A. (2004). Lexical competition in non-native spoken-word recognition. Journal of Memory and Language, 50(1), 1–25. https://doi.org/10.1016/S0749-596X(03)00105-0
Wickham, H. (2016). ggplot2: Elegant graphics for data analysis (2nd ed.). Springer. https://doi.org/10.1007/978-3-319-24277-4
Yan, M., & Kliegl, R. (2023). Chinese offers a test for universal cognitive processes. Behavioral and Brain Sciences, 46, e258. https://doi.org/10.1017/S0140525X23000663
Yan, M., Richter, E. M., Shu, H., & Kliegl, R. (2009). Chinese readers extract semantic information from parafoveal words during reading. Psychonomic Bulletin & Review, 16, 561–566. https://doi.org/10.3758/PBR.16.3.561
Yan, M., Zhou, W., Shu, H., & Kliegl, R. (2012). Lexical and sub-lexical semantic preview benefits in Chinese reading. Journal of Experimental Psychology: Learning, Memory and Cognition, 38, 1069–1075. https://doi.org/10.1037/a0026935
Yan, M., Zhou, W., Shu, H., & Kliegl, R. (2015). Perceptual span depends on font size during the reading of Chinese sentences. Journal of Experimental Psychology: Learning, Memory and Cognition, 41, 209–219. https://doi.org/10.1037/a0038097
Yan, M., Wang, A., Song, H., & Kliegl, R. (2019). Parafoveal processing of phonology and semantics during the reading of Korean sentences. Cognition, 193, 104009. https://doi.org/10.1016/j.cognition.2019.104009
Yang, J., Wang, S., Tong, X., & Rayner, K. (2012). Semantic and plausibility effects on preview benefit during eye fixations in Chinese reading. Reading and Writing, 25, 1031–1052. https://doi.org/10.1007/s11145-010-9281-8
Yen, M.-H., Tsai, J.-L., Tzeng, O.J.-L., & Hung, D. L. (2008). Eye movements and parafoveal word processing in reading Chinese. Memory & Cognition, 36, 1033–1045. https://doi.org/10.3758/MC.36.5.1033
Funding
This research was supported by a Fundo para o Desenvolvimento das Ciências e da Tecnologia (FDCT) grant from the Macao Science and Technology Development Fund (Project Code: 0015/2021/ITP).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest
None.
Ethics approval
All experimental procedures were reviewed and approved by the Ethics Committee of the Department of Psychology, University of Macau (SONA-2022-06).
Consent to participate and for publication
All participants gave their written informed consent to participate in the experiment and to publish their data.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Hao, Y., Luo, Y., Lin-Hong, K.Hy. et al. Shared translation in second language activates unrelated words in first language. Psychon Bull Rev 31, 1245–1255 (2024). https://doi.org/10.3758/s13423-023-02405-z
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-023-02405-z