
Abstract
This chapter discusses cross-language activation in the course of processing language by bilingual speakers. We first discuss the cross-modal lexical priming paradigm (CMLP), a powerful tool to explore online multiple language activation. We next provide an overview of research concerning multiple language activation in the course of bilingual lexical processing. Finally, we present results of four experiments examining the effects of context in connected speech on cross-language priming in Spanish-English bilinguals. Participants in Experiment 1 listened to sentences in Spanish, their first language, and named Spanish and English targets, related or unrelated to a critical prime within the sentence. Experiment 2 was similar to Experiment 1, except that prior context was biased toward the critical prime. Experiments 3–4 were identical to Experiments 1–2, respectively, but with sentences in English, their second language. Comparable cross-language priming was observed for Experiments 1–2. Likewise, Experiments 3–4 showed similar priming patterns. However, the priming effect was significantly higher for the L2–L1 language direction. Results are discussed in terms of language dominance mechanisms and the Revised Hierarchical Model of bilingual memory representation.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others


Keywords
- Bilingual priming
- Code-switching
- Cross-modal lexical priming paradigm
- Hierarchical model
- Language dominance
- Language selective lexical access
Introduction
This chapter is motivated by the observation that, in some bilingual communities, bilinguals mix their two languages simultaneously in the course of spoken interaction (cf. Heredia & Stewart, 2002; Hummel, 1993; see also Heredia & Altarriba, 2001). To illustrate, consider sentences (1a–c) below.
-
(1a) It is difficult to admit that a WAR sometimes brings more profits than losses.
-
(1b) It is difficult to admit that a GUERRA sometimes brings more profits than losses.
-
(1c) Soldiers are trained for combat and GUERRA and that is why we invest in them.
These sentences exemplify three important issues addressed in the current chapter. First, the use of both languages by a bilingual person in the same sentence indicates that the two languages must be simultaneously activated in the course of bilingual language processing. Second, notice that, unlike the monolingual English sentence (1a), Spanish words are embedded in sentences (1b–c). In these sentences the Spanish word guerra replaces the English word war. This linguistic phenomenon is known as code-switching. It is prevalent amongst bilinguals and it occurs automatically (Grosjean, 1988; Heredia & Altarriba, 2001; Li, 1996). Third, in sentence (1b) the preceding context does not influence or provide any information about the Spanish target word. In contrast, prior context in sentence (1c) is biased towards the Spanish code-switched word. This leads us to the following questions that we are discussing in this chapter: (1) Do both languages of a bilingual person become automatically simultaneously activated in the course of language processing? (2) How do bilinguals process and access information across languages during the processing of code-switched sentences? (3) What are the effects of context in the comprehension of code-switched sentences such as (1b–c) above? This chapter addresses each of these questions in turn. It starts with the description of the cross-modal lexical priming task (CMLP), the methodological paradigm that has been most frequently employed to address online multiple language activation. It then provides a brief overview of research into activation of languages in the course of bilingual processing and focuses specifically on the most influential model of bilingual lexical representation, the Revised Hierarchical Model. Next, research into code-switched sentence processing and the role of context are briefly examined. We then present the study with Spanish-English bilinguals that we conducted to look at the effects of context in connected speech on cross-language priming.
Priming and the Cross-Modal Lexical Priming Paradigm
The CMLP paradigm is a variation of the priming paradigm which combines auditory and visual modes of stimulus presentation. Priming paradigms have had a long tradition and have been used extensively in psycholinguistic research to investigate semantic memory (Meyer, Schvaneveldt, & Ruddy, 1975; Warren, 1977). Priming as such has been defined as a facilitative effect of the presentation of a word on the identification or classification of a related word (Masson, 1995, p. 3). A number of techniques have been developed to assess the priming effect. The most basic of them are the lexical decision task and the naming task. In the lexical decision task, participants are presented with a string of letters on a computer screen and are asked to quickly decide if the string of letters (i.e., a word) is a legitimate word in a given language or a nonword. In the naming task, participants are to simply name a presented word. The time taken to make the word/nonword decision is called the lexical decision time or reaction time (RT), whereas the time taken to name a letter string is called the naming latency. Both of them are affected by different types of experimental manipulation. For example, presenting another stimulus, called the prime (e.g., cat) prior to the target (e.g., dog) will affect how quickly the target word is named in the naming task and recognized as a legitimate word in the lexical decision task. Priming experiments carried out with primes semantically and associatively related to the target show a decrease in RT in a lexical decision task and a shorter naming latency in the naming task (for a review, see Neely, 1991). Decrease in reaction time to the target caused by the earlier presentation of a prime is known as a positive priming effect (Jiang & Forster, 2001).
In the CMLP paradigm, participants are simultaneously involved in a passive and active task. The passive task consists in attending to spoken sentences presented auditorily via headphones. At some point during the auditory presentation, a visual target appears on the computer screen and participants perform an active lexical decision (i.e., decide, as quickly and as accurately as possible, if a displayed probe or target is a word or a nonword). The probes for lexical decision are presented at various points throughout the sentence, depending on the experimental focus. For example, during the auditory presentation of the sentence, My diabetic cat is not at all bothered by the daily shots [*1] , as he has been getting them for over a year now, the word gun is displayed visually at the offset of the word shots (depicted by the subscript [*1]), and the participant makes a lexical decision on that word. The assumption behind the CMLP technique is that facilitation of a lexical decision will be demonstrated for those visual targets whose meanings have been primed by the auditorily presented input. Thus, if a participant’s lexical decision to the visual target gun is facilitated, in that it is shorter than the lexical decision to its matched control word (e.g., nun), then it can be concluded that a weapon-related meaning of the word shot has been automatically activated, even if it is contextually inappropriate. Because of this ability to detect automatic activation of the different senses of lexically ambiguous words like shot, the CMLP paradigm has been extensively used in lexical ambiguity research to address the question of multiple access during the comprehension of ambiguous words (e.g., Onifer & Swinney, 1981; Seidenberg, Tanenhaus, Leiman, & Bienkowski, 1982; Simpson, 1981; Swinney, 1979; Swinney, Love, Walenski, & Smith, 2007; Tabossi, 1988; Tanenhaus & Donnenworth-Nolan, 1984), as well as to explore the mechanisms underlying figurative language processing (see, for example, Blasko & Connine, 1993; Cacciari & Tabossi, 1988; Cieślicka, 2006, 2007; Hillert & Swinney, 2001; Tabossi & Zardon, 1993; Titone & Connine, 1994; Van de Voort & Vonk, 1995). The paradigm has been also employed to examine the effects of context in bilingual language processing (Cieślicka 2006); Heredia & Muñoz, 2015; Heredia & Stewart, 2002).
One of the strengths of the CMLP paradigm is that it does not draw participants’ attention to the presence of ambiguities in the experimental material. In addition, it prevents the development of anticipatory strategies by participants, as it is not predictable in terms of the point at which the visual target appears. For those reasons, the CMLP is viewed as a highly reliable experimental tool, sensitive to lexical access and processing (Onifer & Swinney, 1981; see also Garcia et al., 2015, for an extensive discussion of the CMLP paradigm).
However, the paradigm is not free from criticism, as some reservations have been raised against its use to tap online multiple activation. For example, it has been noted that multiple access demonstrated in the ambiguity studies employing the CMLP may reflect backward priming, defined as temporal overlap in the processing of two words, … . [which] can be thought of as “mutual priming” analogous to that which occurs between simultaneously presented words (Van Petten & Kutas, 1987, p. 191; see also Burgess, Tanenhaus, & Seidenberg, 1989). Under this mechanism, the priming of targets (e.g., gun) related to contextually inappropriate meanings of ambiguous words (such as [insulin] shots in the earlier example) results not from multiple access but from the backward priming effect, whereby the subsequent presentation of a target related to the unbiased meaning of an ambiguous word evokes activation of this previously irrelevant meaning (i.e., gun shots). This newly activated meaning is hence processed concurrently with its related target, leading to shortened response latency for this target. Different efforts to eliminate the backward priming effect were undertaken in studies employing the CMLP paradigm, but they failed to yield conclusive results (Glucksberg, Kreuz, & Rho, 1986).
In addition, the CMLP paradigm has been challenged on methodological grounds. Since it is a cross-modal task, consisting of an auditorily presented context which includes an ambiguous prime and a visually presented target which requires a lexical decision response, it places severe attentional demands on the participant (Sereno, 1995). Consequently, being required to constantly switch between the modes, the participant may resort to the strategy of preserving only the last one or two words of the auditory context in his or her articulatory rehearsal. Should this be the case, s/he would be responding to the visual target based on very limited contextual information and so the task might actually reflect context-free priming.
Despite those reservations regarding the use of the CMLP to explore the processing of lexical ambiguities, it is still considered a highly reliable tool to investigate online aspects of bilingual lexical access and figurative language processing (e.g., Heredia & Stewart, 2002). The paradigm can reliably reflect online processes, without being susceptible to backward priming, provided the primes are embedded in a sentential context (Cacciari & Tabossi, 1988). It has also been suggested that, while the CMLP employing the naming task can indeed be compromised by the backward priming effect, this is not true of the lexical decision task used in combination with the auditorily presented input (Cacciari & Tabossi, 1988).
Multiple Language Activation in Bilingual Lexical Processing
The question of multiple language activation in bilingual lexical processing has a long research tradition in the bilingual literature. While under the language selective view, only one language is activated and accessed at a time (e.g., Gerard & Scarborough, 1989), according to the language nonselective access view, all the languages known to an individual are activated simultaneously (Beauvillain & Grainger, 1987; Dijkstra, Grainger, & van Heuven, 1999). In one of the studies addressing this controversy, Gerard and Scarborough (1989) presented Spanish-English bilinguals with interlingual homographs (words which share spelling but have different meanings across languages, for example SIN, which means without in Spanish and denotes something morally unacceptable in English) and asked them to make a lexical decision on the presented targets, either in Spanish or English blocks. The results turned out to reflect the homographic words’ frequency in the language of the response (i.e., frequency of Spanish words in the Spanish block and of English words in the English block), thus suggesting that participants were accessing each of their two lexicons selectively when they performed a monolingual task (see also Scarborough, Gerard, & Cortese, 1984).
Dijkstra, Van Jaarsveld and Ten Brinkee (1998) extended Gerard and Scarborough’s (1989) study with a group of Dutch-English bilinguals. Experiment 1 replicated the findings of Gerard and Scarborough, in that no frequency effect was obtained in RTs to the English and Dutch readings of the interlanguage homographs used in the study. In Experiment 2, Dutch stimuli were added to the set of English targets, thus requiring the participants to respond “NO” in the English lexical decision task. This manipulation induced strong inhibition to homographs as compared to English controls. In addition, the frequency of the English or Dutch readings of the homographs had a significant effect on response latencies, unlike in the previous experiment. In Experiment 3, stimulus lists for the lexical decision included both Dutch and English items and the participants were instructed to respond “YES” to words in either language. The results showed facilitation of interlingual homographs as compared to monolingual control items and a strong frequency effect. Overall, Dijkstra et al. (1998) interpreted these results as evidence for nonselective language access which is sensitive to task demands and stimulus list composition, the claim further corroborated in a series of experiments by Dijkstra, Timmermans, and Schriefers (2000).
More specifically, Dijsktra et al. (2000) modified their methodology, task demands, and the specifics of instructions, which they viewed as essential factors influencing bilingual lexical processing. In Experiment 1, they presented highly proficient Dutch speakers of English with a list of Dutch-English non-cognate homographs and Dutch and English control items matching the homographs in terms of word frequency and length. The participants were instructed to perform a language decision task (i.e., to press one button when an English word was shown and another one if a Dutch word appeared on the screen). The results revealed that participants’ RTs were slower and they opted less often for the English language decision when they saw interlingual homographs. Moreover, evidence of nonselective lexical access was obtained, as the participants reacted to the highest frequency reading of the homograph. In cases when both readings were of comparably low frequency, participants opted for the Dutch reading, which was interpreted as a compensation strategy when dealing with their weaker language (English).
Experiment 2 further manipulated task instructions, as this time Dutch-English bilinguals responded to the same list of stimuli but were instructed to respond only to English words (the so called go/no-go task, which requires participants to respond only if a stimulus from a particular language is presented). Slower RTs and a higher miss rate were recorded in response to those homographs whose Dutch reading had a higher frequency than the English one. Finally, in the third experiment, a similar language go/no-go task was employed, but this time participants were instructed to respond only to Dutch words. Like in the previous experiment, longer RTs and more errors were obtained in reaction to interlingual homographs. The results were also influenced by the reading frequency of the interlingual homographs, such that homographs that had low frequency in Dutch and high frequency in English took the longest to respond. According to Dijkstra et al. (2000), this pattern of results is compatible with the activation of both lexicons and failure to completely suppress lexical items from the English lexicon. Overall, the results obtained by Dijkstra et al. (2000) were taken as evidence for language nonselective access, since participants’ responses were frequency-dependent in both target and nontarget languages. Presence of items from both of the participants’ languages in the stimulus lists prevented them from being able to completely suppress the nontarget language, even if this would optimize their performance in those tasks which required responding only to target language stimuli.
In the domain of lexical-level processing with single items used as experimental stimuli, a number of bilingual studies exploring the activation of phonology have likewise suggested that languages are accessed in a nonselective manner (Dijkstra, Grainger, & van Heuven, 1999). Briefly, those studies have shown that interlingual homographs and cognates (words with identical spelling and meaning across languages, for example HOSPITAL in Spanish and English) enjoy processing facilitation, in that they are identified faster than matched controls on account of sharing lexical and orthographic representations across languages. Dijkstra et al. (1999) employed a progressive demasking task to present Dutch-English bilinguals with Dutch and English stimuli similar in terms of orthography, semantics, and phonology. In a progressive demasking task the participant is shown a target word and a mask which are alternating and is instructed to react as soon as s/he can identify a word. During alternations, the time of the presentation of the mask gradually decreases and the time of the presentation of the target word increases. Participants in Dijkstra et al.’s (1999) study reacted faster to stimuli with orthographic and semantic overlap, whereas they took longer to identify those targets which shared phonology. According to Dijkstra et al. (1999), this phonological inhibition effect is caused by the simultaneous activation of two distinct phonological representations which compete at the lexical level, thus incurring delayed identification of the item in the target language. This effect was further replicated in a second experiment, which employed the lexical decision task and asked the Dutch-English bilinguals to decide if the target shown on the screen was an English word or not. Similar to the results from Experiment 1, RTs to items with similar orthography and meaning were facilitated and RTs to stimuli with phonological overlap produced inhibition (i.e., longer RTs). Overall, this brief review of bilingual lexical access studies suggests that both languages are activated simultaneously when bilinguals process individual words. Is the same true for the processing of language at the sentence level, when words are embedded in context? How will bilinguals process code-switched sentences? These questions are addressed in the next section.
Multiple Language Activation in Code-Switched Bilingual Sentence Processing and Connected Speech
In order to study lexical access during the comprehension of code-switched and monolingual sentences, Soares and Grosjean (1984) used a phoneme-triggered lexical decision task (Blank, 1980). While hearing sentences presented binaurally, bilinguals listened for a prespecified phoneme (e.g., /g/ for guerra in Spanish or /w/ for war in English) and decided whether the target containing the phoneme was a word or a nonword. Results showed that bilinguals were faster to make lexical decisions to targets in the monolingual sentences (e.g., [1a] It is difficult to admit that a WAR sometimes brings more profits than losses) than in the code-switched sentences (e.g., [1b] It is difficult to admit that a GUERRA sometimes brings more profits than losses). Thus, like previous studies (e.g., Macnamara & Kushnir, 1971; see also Kolers, 1966), Soares and Grosjean’s findings suggested that word retrieval in mixed-language, as opposed to monolingual sentences, required an extra amount of time. These differences in retrieval have been taken to support the idea of a general input mechanism that determines which of the bilingual’s two mental lexicons will be on or off during language processing at a given time (Heredia & Altarriba, 2001; Macnamara & Kushnir, 1971). Accordingly, during the comprehension of a monolingual English sentence, the input switch selects the English linguistic system and the Spanish linguistic system is deselected. Exposure to a language-mixed sentence would require the temporary deactivation of the English linguistic system to properly identify and process the Spanish word.
Other research, however, has focused on identifying some of the factors influencing the comprehension of mixed-language sentences. Li (1996) used a cue-shadowing task (Bates & Liu, 1996; Liu, Bates, Powell, & Wulfeck, 1997) and a gating task (Grosjean, 1988) to investigate two important factors of interest. The first factor was a phonological variable concerned with the permissible initial sound sequences in Chinese and English. The English language allows both consonant-consonant (CC) and consonant-vowel (CV) clusters at the beginning of a word. Chinese, on the other hand, allows CVs but lacks CCs. This manipulation examined the extent to which CC clusters, which were marked as belonging to English, would be identified faster than CVs, which were shared by both languages. That is, CC configurations would entail lexical search in only the English lexicon, whereas CV clusters would engage a lexical search in both languages. The second factor was prior context (biased vs. nonbiased preceding contextual information). In the cue-shadowing task, Chinese-English bilinguals listened to Chinese sentences and their task was to shadow or name the embedded English word within the sentence. Participants in this task were told about the predesignated point [where the target word would appear] before each block of testing (Li, 1996, p. 770). Overall, unlike the predictions, results revealed that bilinguals were faster to name English code-switched targets with initial CV than CC clusters. These findings suggested to Heredia and Stewart (2002) that the language preceding the code-switched targets determined which phonotactic configuration would be most highly activated (cf. Grosjean, 1988). Moreover, the results also indicate that during the course of sentence processing, information that overlapped across the bilingual’s two languages had priority and was activated simultaneously during lexical search. In relation to the second factor of interest, context failed to interact with phonotactics. The general trend was that the critical targets in the biased contextual condition were recognized faster than targets in the nonbiased contextual condition (see also Li & Yip, 1998; cf. Altarriba, Kroll, Sholl, & Rayner, 1996; Chaps. 5 and 8). Unlike the study by Soares and Grosjean (1984), no monolingual sentences were used in this study. Thus, it is difficult to determine differences in lexical access between the code-switched and monolingual sentences.
In another study, Hernández, Bates, and Ávila (1996) set out to explore cross-language priming using a cross-modal naming task (CMN; see also Hernández, 2002). In the CMN task, participants name (read out loud) words presented visually on the computer screen while listening to the sentences presented auditorily. Findings from bilingual cross-language priming studies show that naming a word in one language (e.g., war in English) is faster when preceded by a related word of a second language (e.g., paz Spanish for “peace”), than by an unrelated critical word (e.g., boca Spanish for “mouth”). In one language condition, for example, the prime may be in the first language (L1) and the target in the second language (L2) or vice versa (e.g., Fox, 1996; Gollan, Forster, & Frost, 1997; Keatley & De Gelder, 1992; Keatley, Spinks, & De Gelder, 1994). The same logic applies to within-language priming, with the exception that the prime (e.g., peace) and the target are both in English (e.g., war) or both in Spanish.
Hernández et al. (1996) had bilinguals listen to sentences during which, at a predetermined location, the sentence stopped and a visual related or unrelated target word appeared in the middle of a computer screen. In the within-language condition, sentences were in English with the critical target in English (E-E), such as in sentence (1a) above or all in Spanish (S-S). In the English-Spanish cross-language condition (E-S), an English sentence contained a Spanish target (e.g., sentence 1b), or the Spanish sentence contained an English target (S-E). The beginning of each sentence was always presented auditorily and the target to be named was always presented visually, either immediately or with a delay. All language conditions were either blocked or randomly mixed. In general, cross-language priming was obtained, but only when language conditions were blocked or naming was delayed. When language conditions were mixed, except in the delayed condition, no priming was observed. However, within-language priming was observed for both monolingual conditions, regardless of the experimental condition. This pattern of results led Hernández et al. to conclude that cross-language priming appears only when participants know what language to expect, when they have ample time to generate a response or both (p. 860). In other words, switching from one language to the other takes time and access to an L2 cannot occur unless the bilingual is in some type of a bilingual mode. However, Hernández et al.’s results may have been due to the high predictability of their stimuli, thus forcing participants to develop strategic anticipatory processes.
The Present Study
The present study further investigates bilingual sentence processing at the spoken and connected discourse levels. Specifically, this set of experiments has two important aims. First, a general pattern amongst the studies reviewed here utilized sentences in which the code-switched target is always embedded within the sentence (e.g., sentences 1b–c above). Although it could be argued that such practice truly reflects the manner in which bilinguals communicate, such methodology is problematic because it may encourage bilinguals to simply respond to the language switch of the target word (e.g., Heredia & Stewart, 2002). Because of the distinctiveness of the code-switched target, as the sentence unfolds, participants simply wait for the language cue to respond. Thus, in the cue-shadowing technique (e.g., Li, 1996), for example, it is not clear if the shadowing of the code-switched word is performed with or without the activation of meaning (Bates & Liu, 1996). The present study attempts to overcome this potential drawback by employing the CMN (e.g., Love, Maas, & Swinney, 2003; Heredia & Blumentritt, 2002; Heredia & Stewart, 2002; Stewart & Heredia, 2002; cf. Hernández et al., 1996; Hernández, 2002). An important feature of the CMN is that during sentence presentation, the flow of the sentence is never interrupted (cf. Hernández, 2002; Hernández et al., 1996), thus making it difficult for participants to engage in strategic processing (see for example, Bates & Liu, 1996; Li, 1996). For this reason, bilinguals in the present study are presented with monolingual sentences entirely in English (e.g., 2a) or entirely in Spanish. The participants’ objective in this task is to name a target in Spanish or English that is either related or unrelated to the critical prime.
-
(2a)
It is difficult to admit that a WAR [*1] sometimes brings more profits than losses
translation: Es difícil reconocer que una GUERRA [*1] trae más ganancias que pérdidas.
-
(2b)
Soldiers are trained for combat and WAR [*1] and that is why so much is invested in them.
translation: Los soldados se entrenan para el combate y la GUERRA [*1] y por eso se invierte en ellos.
In the E-S cross-language condition, for instance, as bilinguals listen to sentences (2a–b), the Spanish related paz (“peace”) or unrelated target boca (“mouth”) is presented at the offset (depicted by the subscript [*1]) of the critical prime war. The general idea here is to obtain a measurement of lexical access by computing a priming effect between the related and unrelated targets. Priming in this case is taken as an index of lexical access. Indeed, this task may be suitable for examining the extent to which the bilingual’s L1 lexicon remains active or inactive during L2 sentence processing. Moreover, this technique also overcomes the problem of the grammaticality of code-switching, as sentences are presented in one language. Additionally, care should be taken in constructing code-switched sentences because of the possibility of constructing unnatural linguistic groupings. Accordingly, during code-switching, the natural tendency is not to break up linguistic categories such as the noun phrase the traffic into the tráfico or the infinitival phrase to drive into to manejar (see also Lederberg & Morales, 1985; Chap. 4, this volume for similar methodological issues). Inspection of the stimuli utilized in some of the studies reviewed here (e.g., Hernández et al., 1996) reveals inconsistencies in relation to the position of the code-switched word and the preceding linguistic category.
The second purpose of the present study was to systematically manipulate context effects to examine specific assumptions of the Revised Hierarchical Model of bilingual memory representation (Kroll & Stewart, 1994). Briefly, this model is based on the assumption that the bilingual’s linguistic system is represented at the lexical and conceptual levels. At the lexical level, bilinguals represent their languages in separate, but bi-directionally interconnected lexicons. The link from the L2 to L1 lexicon is stronger than the L1 to L2 link, because it reflects the way the L2 was learned. During L2 acquisition, bilinguals learn to associate every L2 word with its L1 equivalent (e.g., learn house, associate it with casa), thus forming a lexical-level association that remains active and strong (Kroll & Stewart, 1994). At the conceptual level, both languages share one conceptual general store. Meaning or semantic information is represented at this level. Moreover, links from the L1 and L2 lexicons to the conceptual store are bi-directional and differ in strength. The conceptual link from L1 is stronger than the link from L2 to the conceptual store. This difference in strength reflects the fact that L1 is the native language, and bilinguals are more familiar with word meanings in their L1. Although it is theoretically possible that the link from L2 to the conceptual store may develop strong connections (e.g., Altarriba & Mathis, 1997), Kroll and Stewart argue that this link remains relatively weak, even for bilinguals with high L2 proficiency levels (but see Heredia, 1995; Heredia, 1997; Heredia & Altarriba, 2001; Heredia & Brown, 2003).
This model generates two important predictions: (a) Retrieval from L1 to L2 is conceptually mediated and affected by semantic and conceptual factors. Before accessing L2, L1 is more likely to activate the conceptual store, because of its strong connection to it. Thus, activation of the conceptual store should be increased with the manipulation of variables known to evoke semantic/conceptual processing. And, (b) retrieval from L2 to L1 is less likely to be affected by semantic/conceptual factors because it can be performed at the lexical level without recourse to meaning. Therefore, any increase in semantic/conceptual processing should not affect lexical access from L2 to L1.
The model’s predictions have been supported empirically in the word translation literature (Kroll & Stewart, 1994; see also, Cheung & Chen, 1998; Sholl, Sankaranarayanan, & Kroll, 1995) and the priming literature. For example, this literature reports asymmetrical cross-language priming effects. Results show that naming an L2 target word is faster, but only if preceded by a related rather than an unrelated L1 prime (e.g., Fox, 1996; Jiang & Forster, 2001, Experiment 1; Keatley et al., 1994; but see Keatley & De Gelder, 1992). In contrast, naming an L1 target is no different than naming a related or unrelated L2 prime (Fox, 1996; Keatley et al., 1994; see also; Gollan et al., 1997). That is, cross-language priming is obtained only if the prime is in L1 and the target is in L2. Indeed, consistent with the Revised Hierarchical Model, the results suggest that accessing the L2 from the L1 lexicon is conceptual because it is achieved via the conceptual store that is the locus of the semantic priming effect (Keatley et al., 1994, p. 77). In contrast, accessing the L1 from the L2 lexicon takes place only at the lexical level, thus producing no semantic priming. This prediction would be more likely to be true for bilinguals whose L2 is not the dominant language (see for example, Heredia, 1997; Heredia & Altarriba, 2001; see also Hernández, 2002).
Evidence for this model is not unequivocal. Some studies have suggested that retrieval from both language directions may be sensitive to meaning-based processing (e.g., De Groot, 1992; De Groot, Dannenburg, & Van Hell, 1994; Heredia, 1995, 1997; La Heij, Hooglander, Kerling, & Van der Velder, 1996; see also Altarriba & Mathis, 1997; Jiang & Forster, 2001). In addition, results at the sentential level suggest that, depending on whether language conditions are presented in blocked or mixed designs, both cross-language conditions exhibit or fail to show priming effects. Hernández et al. (1996) found that when language conditions were randomly mixed as to prevent participants from generating strategies or predicting the language of presentation, both cross-language conditions failed to show priming. When language conditions were blocked, both L1 to L2 and L2 to L1 conditions showed comparable priming effects. This was generally true for blocked and delayed conditions, with the exception of one experiment in which language presentation was mixed but targets were degraded. In this case, L2 to L1 conditions produced significant priming, whereas L1 to L2 conditions did not. Other similar experiments (e.g., Hernández, 2002) using sentences and the priming paradigm show that L2 to L1 language conditions reveal larger priming effects than L1 to L2 conditions. In fact, prior context seemed to increase the priming effect for the L2 to L1 condition and had no effect on the L1 to L2 cross-language conditions (cf. Heredia, 1995, 1997). These findings, as can be seen, are the opposite of what the Revised Hierarchical Model would predict. Clearly, more empirical work is required to determine the usefulness of this model to explain bilingual semantic memory and how the model could be applied to sentence processing.
Previous studies addressing this model have operated under the assumptions that conceptual and semantic information can be obtained by the manipulation of concreteness (De Groot, 1992; De Groot et al., 1994; Heredia, 1995, 1997) or category effects (Kroll & Stewart, 1994) using the isolated word (word pair) or the picture as the experimental unit. The present investigation goes a step further and systematically manipulates the effects of previous sentential context, a variable known to facilitate lexical access in monolinguals (e.g., Herron & Bates, 1997; Marslen-Wilson, 1987; Tabossi, 1988, 1996) and bilinguals (e.g., Altarriba et al., 1996; Li, 1996; Li & Yip, 1998; see also Heredia et al., this volume) during the online comprehension of spoken sentences.
Research Questions
What are the effects of context on bilingual lexical access? Does the preceding context have differential effects on how bilinguals access information from their two lexicons? Is access from the L1 to the L2 bilingual lexicon more likely to be affected by contextual effects than access from the L2 to the L1 bilingual lexicon? In Experiment 1, Spanish-English bilinguals listened to Spanish translations of a sentence (2a), where the preceding context provides no biasing information towards the meaning of the critical prime guerra. In Experiment 2, participants listened to Spanish translations of sentence (2b), where the preceding context provides relevant and biasing information about the meaning of the critical prime. As can be seen from sentence (2b), the Spanish soldados (“soldiers”) and combate (“combat”) reinforce the meaning of the critical prime guerra. In both experiments, sentences were delivered aurally without disruption, and at the offset of the critical prime participants named a related (e.g., peace) or unrelated (road) English target. Probing was done at prime offset in order to inspect L2 word activation immediately after the processing of the L1 prime. Experiments 1 and 2 represent the S-E cross-language condition or the L1 to L2 condition. In addition to the cross-language condition, a within-language manipulation was included in which participants named Spanish-related (e.g., paz) or unrelated (e.g., boca) targets. This condition was included to serve as a comparison and a baseline for the bilingual condition, and to examine differences or similarities in lexical access between monolingual and cross-language conditions. Is it possible to retrieve information from L2 as the bilingual speaker processes sentences in L1? Because the critical prime is in L1 and the target is in L2, Experiment 1 should exhibit the cross-language priming effect. In this case, naming related targets should be faster than naming unrelated targets. That is, L2 access should be possible, as the bilingual speaker processes sentences in the L1. Experiment 2 should replicate the results of Experiment 1. However, if L1 to L2 is conceptually mediated and sensitive to semantic/conceptual factors, as predicted by the Revised Hierarchical Model, the presence of prior contextual information should facilitate cross-language lexical access. In this case, cross-language priming should increase from Experiment 1 to Experiment 2.
Experiments 3 and 4 represented the E-S cross-language conditions. English sentences such as in (2a) were used for these experiments. The critical targets for this experiment were in Spanish, to represent the E-S cross-language condition or the L2 to L1, and in English, to represent the E-E or the within-language condition. Are L2 to L1 language directions sensitive to conceptual/semantic factors? A strong version of the Revised Hierarchical Model predicts no cross-language priming from L2 to L1. Therefore, no cross-language priming should be observed from the contextually-unbiased (Experiment 3) to the contextually-biased condition (Experiment 4). If there is cross-language priming, it should remain relatively unaffected by the preceding contextual information of Experiment 4. Alternatively, if L2–L1 language directions are sensitive to the semantic information provided by the contextual information of Experiment 4, an increase in cross-language priming should be observed from Experiment 3 to Experiment 4.
Method
The four experiments reported here used a standard procedure as described in this section. Where an experiment departs from this procedure, exact changes are specified within the description of the experiment.
Materials
The stimuli consisted of 129 Spanish sentences, 69 of which were experimental and 60 sentences served as fillers. Mean word length for the experimental sentences was five letters and word average per sentence was 25. Filler sentences were similar in length to the experimental sentences. Half of the fillers were paired with an unrelated Spanish word and half with an unrelated English word. Four experimental lists were constructed. For the S-S monolingual condition, 17 sentences were paired with a Spanish target word related to a critical prime (e.g., guerra-paz), and 17 sentences were paired with a Spanish control word that was unrelated to the critical prime (e.g., guerra-boca). Control words were matched in frequency and length to the related targets according to Julliand and Chang-Rodríguez (1964) Spanish word frequency counts. For the S-E cross-language condition, 17 sentences were paired with an English target word related to the critical prime (guerra-peace), and 17 sentences were paired with an English control word unrelated to the critical prime (guerra-road). Control words were matched in frequency and length to the related words according to Francis and Kučera’s (1982) frequency counts. An additional sentence appeared on every list. In one list, this sentence was paired with a Spanish-related target. In another list, this sentence appeared with an English-related target, and so on.
The procedure for creating the experimental sentences was as follows. Sixty-nine nouns and their associates (e.g., war-peace) were obtained from Nelson, McEvoy, and Schreiber (1998) English-free association norms. These words were then translated into Spanish (e.g., guerra-paz). For every word pair, two Spanish sentences were written. One sentence (for Experiment 1) was written in such a way that the preceding context provided no information towards the critical prime (see sentence 2a, above). A second sentence (for Experiment 2) was written in sucha way that the preceding context biased the meaning of the critical prime (see sentence (2b), above).
To assure that the preceding context of the sentences for Experiment 1 was not related or biasing the critical prime, a pretest study was performed. Thirty-two Spanish-English bilinguals were given the stimuli as sentence fragments with the critical word in uppercase (e.g., it is difficult to admit that a WAR) and asked to rate, on a 1–7 scale (1 = Not Biased and 7 = Very Biased), the extent to which the preceding context biased the meaning of the word in uppercase. The mean rating for the 69 experimental sentences was 3.2 (SD = .73). The same was done for the contextually-biased sentences for Experiment 2 (sentence 2b above). The mean rating for these sentences was 5.5 (SD = .84). A comparison between contextually-unbiased vs. contextually-biased sentences showed that the mean ratings for the contextually-biased ones were significantly higher, t(31) = 11.57, p < .05. Finally, care was taken to ensure that information after the critical prime was not related to the target or to the context following the critical prime.
Four lists were required to counterbalance each sentence. Each target word was assigned to one of the four lists using a Latin square design. All 129 sentences were combined in a pseudo-random order, with the only constraint that no more than three items from a given experimental condition occurred consecutively. Additionally, ten sentences (half related and half unrelated) served as practice trials. Fourteen multiple choice comprehension questions were presented throughout each experimental list that asked participants details about a preceding sentence they had just heard. The relatedness proportion (34 related trials out of 129 unrelated trials) was .26 (see Altarriba & Basnight-Brown, 2007; Garcia et al., 2015; Neely, Keefe, & Ross, 1989, for a discussion of the importance of these effects).
Stimuli were recorded by a female native speaker of Spanish. Sentences were directly read into a Sony TCD-8 Digital Audio Tape Corder. The recordings were then entered into a G3 Macintosh using Macromedia SoundEdit 16 Version 2. A sampling rate of 44.1 kHZ with a 16-bit format was used for digitizing. For every wave sound, the offset of a critical prime was located as accurately as possible by using waveforms and auditory feedback. A cue marker was placed at prime offset to indicate to the computer the point at which the visual target was to be presented during sentence presentation. For all experimental sentences, the critical prime appeared in the middle of the sentence. The filler sentences were created the same way, except that cue markers were placed at random points throughout the sentence.
Procedure
Upon arrival, participants read the experimental instructions from the computer screen. They were instructed to listen carefully to the sentences being presented over headphones, understand them, and to pronounce as fast and as accurately as possible a visually presented word, which would appear in the middle of a computer screen. Their responses were recorded and examined for pronunciation errors.
Sentences were delivered uninterrupted at a normal speaking rate. At the offset of the critical prime, a visual target word appeared in front of the computer screen for 300 milliseconds (ms). This short target presentation is standard in the CMN and it controls for any possibility of backward priming (Love & Swinney, 1996; Prather & Swinney, 1988; but see Glucksberg et al., 1986). Response time was measured from the onset of the visually presented target until the participants responded or after a 2300 ms time response window. Sentences were presented over headphones (Optimus Pro-50MX). The experiment was controlled by PsyScope (Cohen, MacWhinney, Flatt, & Provost, 1993) and participants’ responses to the visually presented targets were controlled by the CMU button box (Cohen et al., 1993) connected to a Star Max 3000 Motorola Macintosh compatible computer. The stimuli were played through a set of Apple speakers. After the experiment, each subject completed a Language History Questionnaire.
Experiment 1: Contextually-Unbiased Spanish Sentences
Participants
Forty-five Spanish-English bilinguals participated in the experiment. Participants were students from Texas A&M International University who received course credit for their participation. All bilinguals reported Spanish as their L1 and English as their L2. Participants reported receiving their formal education in English. Analyses were conducted on the participant’s language self-ratings on language usage. Self-ratings were based on a 1–7 scale (1 = Not Fluent 7 = Very Fluent). The mean age of the group was 27.6 years. The mean years spent in the United States were 23.4. Mean self-ratings showed that they used Spanish (M = 5.2) and English (M = 5.7) equally often. Their speaking ability in Spanish (M = 5.9) and English (M = 6.4) was comparable. However, their ability to read English was rated higher (M = 6.4) than their ability to read Spanish (M = 5.3), t(44) = 3.8, p < .05. Likewise, their writing ability was rated higher for English (M = 6.5) than Spanish (M = 5.1), t(44) = 4.3 p < .05. Understanding English (M = 6.7) was also rated higher than Spanish (M = 6.1), t(44) = 2.8 p < .05. It is important to note that bilinguals in the South Texas are known for their ability to mix their two languages simultaneously during their everyday communication.
Results and Discussion
In this and all subsequent experiments, naming responses in milliseconds (ms) above or below 3 SDs were treated as outliers. This procedure affected 2.2 % of the total data. Analyses were performed on error rates, and on response latencies (RTs) for correct responses.
Error rates. Pronunciation errors or failure to respond to the visually presented target word were subjected to a 2 (Relatedness: related vs. unrelated) × 2 (Language: Spanish vs. English) within-subjects analysis of variance ANOVA. This analysis was performed for both participants (F 1) and items (F 2). The main effect for relatedness was significant by subjects, F 1(1,44) = 4.12, MSE = .0013, p < .01, but not by items, F 2(1,68) = 1.84, MSE = .0023, p = .18. Bilinguals made more mistakes naming unrelated controls (M = 3.0 %), than related words (M = 1.95 %). The percentage of errors was higher in naming Spanish (M = 2.9 %), than naming English target words (M = 2.0 %); however, this trend was not statistically reliable by subjects nor by items (all Fs < 1). The interaction was significant by subjects, F 1(1,44) = 4.55, MSE = .0022, p < .05, and marginal by items, F 2(1,68) = 3.78, MSE = .0019, p = .06. The Least Significant Difference (LSD = 1.7 %) multiple comparison (Bruning & Kintz, 1987; Cohen & Cohen, 1983) was calculated to analyze the significant interaction. In all subsequent analyses, the alpha level is set at .05. The LSD revealed that bilinguals made more errors naming Spanish-unrelated (M = 4.1 %), than Spanish-related targets (M = 1.5 %). Percentage of errors in naming English unrelated (M = 1.8 %) vs. related English targets (M = 2.2 %) was not statistically significant.
Response latencies. A 2 (Relatedness: related vs. unrelated) × 2 (Language: Spanish vs. English) within-subjects ANOVA was performed. There were main effects for relatedness, F 1(1, 44) = 42.0, MSE = 1130.25, p < .01; F 2(1, 68) = 15.35, MSE = 3718.33, p < .01 and language, F 1(1, 44) = 15.40, MSE = 5426.91; F 2(1, 68) = 19.01, MSE = 4928.50, p < .01. Participants were 33 ms faster naming related (M = 688 ms, SD = 111) than unrelated controls (M = 721 ms, SD = 125). More interesting was the finding that naming an English target (M = 683, SD = 103) was 43 ms faster than naming a Spanish target (M = 726 ms, SD = 130). This finding, showing that bilinguals were faster in naming English than Spanish targets, is a surprising one considering that sentence presentation was in Spanish. This finding is counter to the base language effect (Grosjean, 1997, p. 241) that suggests that the language being spoken has a strong effect on which language will be favored during lexical access. Thus, during the processing of Spanish sentences, naming a Spanish word would be faster than naming an English word. This pattern of results supports the intuition of many bilinguals reporting that when they use their L1 (e.g., Spanish), sometimes they find themselves resorting to their L2 (e.g., English) to communicate.
The interaction between relatedness and language was significant by subjects, F 1 (1, 44) = 13.00, MSE = 1302.00, p < .01, but marginally significant by items, F 2 (1, 68) = 3.503, MSE = 5408.81, p = .07. Simple effects (LSD = 12.80) for the subject means showed that the 52 ms priming effect for the Spanish condition was reliable. Likewise, the 13 ms priming effect for the S-E condition was significant (see Table 6.1).
To summarize, both monolingual and cross-language conditions produced significant priming. Although the priming effect was greater for the monolingual condition (i.e., the within-language), this effect is not surprising given that the spoken sentences were in Spanish. The cross-language priming effect, although reliable only in the analyses by subjects, contrasts with the results reported by Hernández et al. (1996) who reported no cross-language priming under conditions in which participants were unable to predict the language of presentation (their mixed-language condition). Another important finding here is the main effect for language, which showed that naming English words was actually faster than naming Spanish visual targets. This difference could be due to the fact that bilinguals in the present study reported higher ratings in their reading and writing English ability. Moreover, the results of this experiment are consistent with the predicted priming patterns of the Revised Hierarchical Model. As predicted, we obtained cross-language priming (L1–L2), even when the critical prime was presented aurally and embedded within a sentence. In the following experiment, bilinguals listened to sentences in which the preceding context is biased towards the critical prime. If it is true that L1 to L2 bilingual direction is sensitive to contextual/semantic effects, then manipulation of the preceding context should enhance activation of the L1 concept and strengthen the activation of the conceptual links between the L1 and L2 concepts. In this case, cross-language priming should increase significantly compared to Experiment 1.
Experiment 2: Contextually Biased Spanish Sentences
Participants
Thirty-nine Spanish-English bilinguals participated in this experiment. All participants were students from the University of California, San Diego who received course credit for their participation or were paid $6.00 per hour. The mean age of the group was 21.7, and the mean number of years in the United States was 19. All bilinguals participating in this experiment reported Spanish as their L1 and English as their L2. The majority of the participants reported using Spanish with their family and English with their friends. English was the main language for their education. Analyses were conducted on the participants’ responses to a language questionnaire. Mean self-ratings show that participants used English (M = 6.2) more frequently than Spanish (M = 4.1), t(38) = 6.7, p < .05). Their speaking ability was greater for English (M = 6.6) than Spanish (M = 5.8), t(38) = 4.0, p < .05. Similarly, their ability to read (M = 6.6) and write English (M = 6.5) was rated higher than their ability to read (M = 5.7) and write (M = 5.0) Spanish, t(38) = 3.60, p < .05, and t(38) = 5.49, p < .05, respectively. Means for understanding English (M = 6.6) and Spanish (M = 6.3) were comparable.
Materials and Procedure
Materials and procedures were the same as in Experiment 1, except that the sentences were constructed in such a way that the preceding context was biased towards the meaning of the critical prime, as shown by sentence (2a) above. Mean word length for the experimental sentences was five letters, and word average per sentence was 22.
Results and Discussion
Error rates. The 3 SD cutoff procedure for the exclusion of naming responses constituted 1.5 % of all data. Pronunciation errors or failure to respond to the visually presented target words were subjected to a 2 (Relatedness) × 2 (Language) within-subjects ANOVA. The main effect for relatedness was significant, by subjects, F 1 (1,38) = 11.44, MSE = .0022, p < .01, and by items, F 2 (1,68) = 10.19, MSE = .0066, p < .001). Bilinguals made more errors naming unrelated (M = 5.2 %) than related target words (M = 2.6 %). The main effect for language was not statistically reliable by subjects nor by items (all Fs < 1). Errors naming English (M = 3.9 %) were comparable to naming Spanish target words (M = 3.9 %). The interaction was not significant by subjects nor by items (all Fs < 1), suggesting that naming English (M = 5.1 %) and Spanish (M = 5.3 %) unrelated controls produced comparable naming errors. Likewise, naming English- (M = 2.8 %) and Spanish-related targets (M = 2.5 %) showed similar error rates.
Response latencies. A 2 (Relatedness) × 2 (Language) within-subjects ANOVA showed a main effect for relatedness, F 1 (1, 38) = 31.41, MSE = 1054.89, p < .01; F 2 (1, 68) = 14.08, MSE = 4914.56, p < .01, and language, F 1 (1, 38) = 10.52, MSE = 3565.30, p < .01; F 2 (1, 68) = 16.86, MSE = 4806.10, p < .01. Participants were 29 ms faster naming related (M = 628 ms, SD = 108) than unrelated controls (M = 657, 114 ms). Like Experiment 1, naming an English target (M = 627 ms, SD = 102) was 31 ms faster than naming a Spanish target (M = 658 ms, SD = 119). This finding is important because it replicates the results of Experiment 1 that involved a Spanish-English bilingual population from a geographical area where English is the main language of communication and general interaction.
The interaction between relatedness and language was significant by subjects, F 1 (1, 38) = 9.93, MSE = 919.03, p < .01, but marginally significant by items, F 2 (1, 68) = 3.80, MSE = 4370.47, p = .06. Multiple comparisons (LSD = 11.65) for subject means indicate that the difference between the related and unrelated Spanish targets was significant (see Table 6.2). This indicates a significant priming effect for the monolingual condition. Similarly, as can be seen from Table 6.2, the difference between the related and unrelated English target words was significant, thus exhibiting a reliable priming effect. These results follow the same patterns as in Experiment 1. As predicted by the Revised Hierarchical Model, the S-E (L1–L2) conditions exhibited the priming effect.
To further explore the effects of context and bilingual lexical access, an additional 2 (Context: biased vs. unbiased) × 2 (Relatedness: related vs. unrelated) × 2 (Language: Spanish vs. English) was performed. This comparison involved Experiment 1 vs. 2. The main effect for context was significant by subjects, F 1 (1, 82) = 7.124, MSE = 4,5028.75, p < .01 and by items, F 2 (1, 136) = 132.40, MSE = 4963, p < .01. This main effect suggests that bilinguals were 62 ms faster in naming words under contextually-biased (M = 643 ms) than under contextually-unbiased conditions (M = 705 ms). There was also a language main effect, both by subjects, F 1 (1, 82) = 25.9, MSE = 4554.67, p < .01, and by items, F 2 (1, 136) = 35.91, MSE = 4867. 30, p < .01. English targets (M = 657 ms, SD = 106) were 38 ms faster than Spanish targets (M = 695 ms, SD = 129). The two-way interaction of relatedness vs. language was also significant, by subjects, F 1 (1, 82) = 22.91, MSE = 1125.56, p < .01, and by items, F 2 (1, 136) = 7.27, MSE = 4, 889.64, p < .01. This two-way interaction qualifies the interactions in Experiments 1 and 2. Simple effects (LSD = 6.12) show a significant 14 ms priming effect between English-related (M = 650 ms, SD = 107) and English-unrelated targets (M = 664 ms, SD = 106). Likewise, the 49 ms priming effect for Spanish-related (M = 670 ms, SD = 118) and unrelated targets (M = 719 ms, SD = 135) was reliable. Other two- or three-way interactions were not reliable (all Fs <1).
Taken together, the results of Experiments 1 and 2 indicate that context had an additive effect on the retrieval of both Spanish and English words. This additive effect may explain why bilinguals were generally faster in Experiment 2, as compared to Experiment 1, when naming Spanish and English targets. Naming a target word in Spanish or English is faster in conditions in which prior context biases the Spanish prime. These findings replicate other studies that have manipulated context and bilingual lexical access (e.g., Li, 1996; Li & Yip, 1998). However, previous context does not increase the priming effect. Especially for the S-E condition, cross-language priming remained constant between Experiment 1 (13 ms), and Experiment 2 (14 ms). Although the results of Experiment 1 and 2 are consistent with the hypothesis that L1 to L2 produces significant priming, the addition of context failed to increase the priming effect. These results suggest that L1 to L2 may not be as sensitive to semantic effects as predicted by the Revised Hierarchical Model.
Moreover, another important finding was that bilinguals in the present study were actually faster in naming English than Spanish targets. This finding is remarkable considering that the sentences were all in Spanish, and from two separate bilingual populations. This issue is further elaborated in the discussion. The next experiment explores E-E and E-S lexical access. In Experiment 3, bilinguals listened to English sentences and named English (the E-E condition) or Spanish (E-S cross-language condition) targets. The purpose of this experiment was to further investigate the extent to which E-S produces the priming effect, and whether or not it is affected by the addition of contextual information (Experiment 4).
Experiment 3: Contextually Unbiased English Sentences
Participants
Fifty Texas A&M International University Spanish-English bilinguals participated in this experiment. Students received course credit for their participation. Bilinguals in this study did not participate in the previous two experiments. All bilinguals reported Spanish as L1 and English as L2, with Spanish used as the family language and English as the language used with their friends. Mean age of the group was 23.2, and the mean number of years in the United States was 20.1. Mean self-ratings showed that participants used Spanish (M = 5.5) and English (M = 5.5) equally often, and their speaking ability in both languages was comparable (M = 5.9 and M = 6.1, respectively). However, their reading ability was higher for English (M = 6.3) than for Spanish (M = 5.4), t(49) = 3.28, p < .05. Likewise, their writing ability was rated higher for English (M = 6.5) than Spanish (M = 4.6), t(49) = 5.40, p < .05. Ratings for English understanding (M = 6.6) were higher than for Spanish (M = 6.1), t(49) = 3.25 p < .05.
Materials and Procedure
Sentences and stimuli construction followed the same procedure as in Experiment 1. However, sentences for this Experiment were in English (see sentence 2a). Related and unrelated targets were the same as in Experiment 1. Mean word length for the experimental sentences was five letters, and word average per sentence was 21. Sentences were recorded by a native male speaker of English. To assure that the preceding context did not bias the meaning of the critical prime, 48 bilinguals were asked to rate the experimental sentences (1 = Not Biased and 7 = Very Biased). Participants rated both the contextually-unbiased (Experiment 3) and contextually-biased (Experiment 4) sentences. The mean rating for the contextually-unbiased sentences was 3.4 (SD = .85) and the mean rating for the contextually-biased sentences was 5.4 (SD = .89). Differences between these means were statistically significant, t(46) = 7.8, p < .05).
Results and Discussion
Error rates. The 3 SD cutoff procedure for the exclusion of naming responses constituted 2.8 % of the data. Participants’ pronunciation errors or failure to respond to the visually presented target words were subjected to a 2 (Relatedness) × 2 (Language) within-subjects ANOVA. Data from one participant were deleted because of a computer error. The main effect for relatedness was significant by subjects, F 1 (1,48) = 21.35, MSE, .0030, p < .01, and by items, F 2 (1,68) = 7.32, MSE = .0120, p < .01). Bilinguals made more errors naming unrelated controls (M = 8.2 %) than related targets (M = 4.6 %). Likewise, the main effect for language was reliable by subjects, F 1 (1,48) = 21.61, MSE, .0128, p < .01, and by items, F 2 (1,68) = 27.93, MSE = .0130, p < .01). Bilinguals experienced more errors naming Spanish (M = 10.2 %) than English targets (M = 2.7 %). The interaction was significant by subjects, F 1 (1, 48) = 21.26, MSE, .0037, p < .01, and by items, F 2 (1,68) = 6.80, MSE = .0139, p < .01). This interaction (LSD = 2.1) shows that bilinguals had more difficulty naming Spanish (M = 6.4 %) than English (M = 2.9 %) related targets. Similarly, Spanish-unrelated words (M = 14.0 %) produced more naming errors than English-unrelated targets (M = 2.5 %). Clearly, bilinguals in this experiment experienced interference from English when naming Spanish targets.
Response latencies. A 2 (Relatedness) × 2 (Language) ANOVA showed a main effect of relatedness, by subjects, F 1 (1, 48) = 73.3, MSE = 863.35, p < .01, and by items, F 2 (1, 68) = 29.8, MSE = 3182.29, p < .01. Participants were 36 ms faster to name related (M = 651 ms, SD = 99.0) than unrelated targets (M = 687 ms, SD = 110.4). The language main effect was also reliable by subjects, F 1 (1, 48) = 56.24, MSE = 5219.24, p < .01, and by items, F 2 (1, 68) = 100.2, MSE = 4260.44, p < .01. Participants were about 78 ms faster to name English targets (M = 630 ms) than Spanish targets (M = 708).
The interaction between relatedness and language was significant by subjects, F 1 (1, 48) = 26.22, MSE = 1034.52, p < .01 and by items, F 2 (1, 68) = 5.60, MSE = 4744.78, p < .05. The analysis of simple effects (LSD = 11.94) in Table 6.3 shows that bilinguals were faster to name Spanish-related than unrelated targets, thus showing a significant cross-language priming effect of 60 ms. Likewise, naming differences for the English-related and unrelated target were also statistically significant. The surprising result in this experiment was the robust priming effect for the E-S cross-language condition, and the smaller, but significant effect for the within-language condition. Unlike the predictions of the Revised Hierarchical Model, L2 to L1 language directions exhibited the priming effect. However, Experiment 4 is critical in determining the extent to which L2 to L1 language directions are indeed sensitive to context.
Experiment 4: Contextually Biased English Sentences
Participants
Thirty-eight Texas A&M International University Spanish-English bilinguals participated in this experiment in exchange for course credit. All bilinguals reported Spanish as their L1 and English as their L2. Participants reported using Spanish as the family language, and Spanish and English with their friends. Mean age of the group was 23.0, and the mean number of years spent in the United States was 17.5. Mean self-ratings showed that participants used Spanish (M = 5.7) and English (M = 5.4) equally often. Their speaking ability for both Spanish (M = 6.1) and English (M = 6.1) was comparable. Similarly, their reading ability in Spanish (M = 5.7) and English (M = 6.0), and their ability to understand Spanish (M = 6.2) and English (M = 6.0) did not differ. However, their writing ability was rated higher for English (M = 6.0) than for Spanish (M = 5.2), t(37) = 2.13, p < .05, and their understanding of both languages was rated similarly.
Materials and Procedure
For this experiment, the sentences were in English (see sentence 2b, above) and prepared using the same procedure as Experiments 1, 2, and 3. Mean word length for the experimental sentences was five letters, and word average per sentence was 21. Sentences were recorded by a native female speaker of English.
Results and Discussion
Error rates. The 3 SD cutoff procedure for the exclusion of naming responses constituted 1.5 % of the data. Participants’ pronunciation errors or failure to respond to the visually presented targets words were subjected to a 2 (Relatedness) × 2 (Language) within-subjects ANOVA. Data from four participants were excluded from the analysis because of computer errors. The main effect for relatedness was significant by subjects, F 1 (1, 33) = 6.54, MSE, .0025, p < .05, and marginal by items, F 2 (1, 68) = 3.07, MSE = .0084, p = .08. Bilinguals made more errors naming unrelated controls (M = 6. 4 %) than related targets (M = 3.9 %). The main effect for language was reliable by subjects, F 1 (1, 33) = 6.24, MSE = .0058, p < .05, and by items, F 2 (1, 68) = 9.99, MSE = .0106, p < 01. Participants experienced more errors naming Spanish (M = 6.7 %) than English targets (M = 3.4 %). The interaction was significant by subjects, F 1 (1,33) = 5.27, MSE = .0032, p < .05, and marginal by items, F 2 (1, 68) = 3.08, MSE = .0109, p = .08. This interaction (LSD = 2.3 %) shows that bilinguals made similar mistakes naming Spanish (M = 4.4 %) and English (M = 3.4 %) related targets. However, Spanish-unrelated words (M = 8.8 %) produced more naming errors than English-unrelated targets (M = 3.4 %).
Response latencies. A 2 (Relatedness) × 2 (Language) within-subjects ANOVA showed a main effect for relatedness for both subjects, F 1 (1, 33) = 25.0, MSE = 1664. 28, p < .01, and items, F 2 (1, 68) = 7.53, MSE = 13,448.64, p < .01. Naming unrelated targets (M = 708 ms, SD = 155) was slower than naming related targets (M = 673 ms, SD = 143). There was a reliable language main effect by subjects, F 1 (1, 33) = 12.31, MSE = 12,545.98, p < .01, and by items F 2 (1, 68) = 30.04, MSE = 10,043.23, p < .01. In this case, English targets were named faster (M = 657, SD = 119) than Spanish targets (M = 725 ms, SD = 169).
The interaction between relatedness and language was marginally significant by subjects, F 1 (1, 33) = 3.66, MSE = 1709.77, p = .06, but not by items, F 2 (1, 68) = 2.23, MSE = 9582.47, p > .1. Multiple planned comparisons (LSD = 17. 08) show a significant priming effect for both Spanish and English targets.
To determine the effects of context and bilingual lexical access for the L2 to L1 language direction, a 2 (Context: biased vs. unbiased) × 2 (Relatedness: related vs. unrelated) × 2 (Language: Spanish vs. English) mixed ANOVA was performed. This analysis combines Experiments 3 and 4. The main effect for context was not reliable by subjects, (F 1 < 1), however, it was significant by items, F 2 (1, 136) = 8.85, MSE = 6339.21, p < .01. This main effect by items suggests that naming targets under contextually-biased conditions (M = 690, SD = 113) was actually 20 ms slower than contextually-unbiased conditions (M = 670 ms, SD = 78). These findings suggest that contextually-biased conditions actually inhibited both the naming of Spanish and English targets when listening to English sentences (cf. Altarriba et al., 1996; see also Heredia et al., this volume). The main effect for language was reliable both by subjects, F 1 (1, 181) = 54.36, MSE = 8204.20, p < .01, and items, F 2 (1, 36) = 92.37, MSE = 7757.31, p < .01. English targets (M = 641 ms, SD = 100) were named faster than Spanish targets (M = 715, SD = 138).
More importantly, relatedness interacted with language. The two-way interaction was reliable by subjects, F 1 (1, 81) = 23.97, MSE = 1309.62. 28, p < .01, and by items, F 2 (1, 136) = 4.73, MSE = 8045.85, p < .05. Multiple comparisons (LSD = 9.38 ms) show that Spanish-related targets (M = 687 ms, SD = 130) were responded to faster than unrelated targets (M = 742 ms, SD = 142). Thus the 55 ms priming effect is statistically reliable. Likewise, English-related targets (M = 633 ms, SD = 101) were faster than unrelated targets (M = 650 ms, SD = 100). The 17 ms priming effect is statistically significant. This interaction qualifies the priming effects for Experiments 3 and 4. In short, results from Experiments 3 and 4 showed priming for the E-S conditions. The lack of the 3-way interaction suggests that there was no increase of priming from Experiment 3 to Experiment 4.
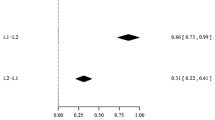
Additional analyses were performed to explore differences between S-E and E-S conditions in the four experiments reported here. Data were analyzed on a 2 (Type of sentence: Spanish vs. English) × 2 (Relatedness: related vs. unrelated) × 2 (Language Target: Spanish vs. English) ANOVA. The three-way interaction did not reach significance (all Fs < 1). However, type of sentence (Spanish vs. English) interacted with language target both by subjects, F 1 (1, 92) = 5.19, MSE = 5318.56, p < .05, and by items, F 2 (1, 136) = 13.10, MSE = 4594.47, p < .01. This interaction indicates that when the sentence was in Spanish (Experiment 1), naming an English target took about 683 ms (SD = 103) on average. When the sentence was in English (Experiment 3), naming a Spanish target took about 708 ms (SD = 112). The difference of 25 ms is statistically significant (LSD = 17). Thus, in the language of the Revised Hierarchical Model, the L1 to L2 direction was actually faster than the L2 to L1 direction. When the sentence was in Spanish (Experiment 1) and the target was in Spanish, it took 726 ms (SD = 130) on average to respond. In Experiment 3, when the sentence was in English and the target was in English, it took 631 ms (SD = 84) on average to respond.
A similar analysis was performed to explore differences between Experiments 2 (sentence in Spanish) and Experiment 4 (sentence in English). The three-way interaction was not reliable by subjects nor by items (Fs < 1). The interaction of type of sentence by language was marginal by subjects, F 1 (1, 71) = 3.11, MSE =7739.41 p = .08, and significant by items, F 2 (1, 136) = 4.18, MSE = 8030.14, p < .05. This interaction by items demonstrates that when the sentence was in Spanish, naming a target in English took 623 ms (SD = 63). When the sentence was in English and the target in Spanish, it took 722 ms (SD = 132). The 99 ms difference is statistically reliable (LSD = 17 ms). Again, unlike the predictions of the Revised Hierarchical Model, L1 to L2 is actually faster than L2 to L1. This pattern replicates across studies when comparing Experiment 1 vs. 3 and Experiment 2 vs. 4.
Summary and Conclusions
The present chapter discussed the issue of multiple activation and cross-language priming in the course of processing language by bilingual speakers. It started with a review of the CMLP, which has been used widely in both monolingual (e.g., Swinney, 1979; Swinney & Osterhout, 1990; Tabossi, 1988, 1996) and bilingual studies (e.g., Li & Yip, 1998) because of its sensitivity to semantic and associative relations, as well as contextual effects. We next provided a brief overview of research concerning multiple language activation at the lexical level, with studies using mostly interlingual homographs and cognates (cf. Libben & Titone, 2009; Schwartz & Kroll, 2006; Whitford et al., this volume), in order to determine whether bilingual lexical access is language selective or nonselective. Then, we looked at studies exploring bilingual processing at the sentence level which identified a number of factors influencing the comprehension of mixed-language sentences, such as context or language-specific phonotactic constraints. Finally, we presented our study consisting of four experiments using the CMN, which is a variant of the CMLP, and explored the effects of context and cross-language priming in Spanish-English bilinguals. We specifically wanted to systematically manipulate the effects of sentential context, a factor known to involve semantic processing, to examine some of the predictions of the Revised Hierarchical Model of bilingual memory representation (Kroll & Stewart, 1994). Previous studies addressing the claims of this model have operated under the assumption that conceptual and semantic information can be obtained by the manipulation of factors such as concreteness (e.g., De Groot, 1992) and category effects (e.g., Kroll & Stewart, 1994), using the isolated word or the picture as the experimental unit (c.f., Hummel, 1993). In the present study, we systematically manipulated the effects of biased vs. unbiased context during the online comprehension of spoken sentences.
In all four experiments, participants listened to sentences containing a critical prime (e.g., war); they then named a visually presented target that was either related (e.g., peace) or unrelated (e.g., boca) to the critical prime. Target words were either in Spanish or English, and target presentation for all experiments occurred immediately at prime offset. In Experiment 1, participants listened to Spanish sentences in which the preceding context was unbiased towards the meaning of the critical prime. The results for this experiment revealed facilitatory priming for both Spanish and English targets, in that naming related targets was faster than naming unrelated targets for both language conditions. The priming effect observed for the Spanish targets replicates the robust within-language effect reported in the bilingual literature (e.g., Hernández, 2002; Hernández et al., 1996; Keatley et al., 1994; Keatley & De Gelder, 1992). More impressive was the cross-language priming effect observed even when the sentences were entirely in Spanish. However, it is important to note that the within-language priming effect was much greater than the cross-language priming effect. This finding, of course, is not a surprising one given that the aurally presented sentences were in Spanish (cf. Grosjean’s, 1988, 1997).
Experiment 2 was similar to Experiment 1, except that the preceding context was biased towards the meaning of the critical prime. As in Experiment 1, facilitatory priming was observed for both within- and cross-language conditions. A comparison between these two experiments indicates that, while preceding biased context (Experiment 2) did not increase the priming effect for each language condition, context did have an effect on the overall processing of the target words. That is, participants were faster to name target words under biased- than under unbiased-contextual conditions (for similar results, see Li, 1996; Li & Yip, 1998; see also Becker, 1979).
Our objective for Experiments 1 and 2 was to specifically test the hypothesis generated by the Revised Hierarchical Model that lexical access from L1 to L2 is more likely to be affected by factors known to influence semantic/conceptual processing. In this case, the Revised Hierarchical Model would predict a significant increase in the cross-language priming effect, from Experiment 1 (contextually-unbiased sentences) to Experiment 2 (contextually-biased sentences). The results did not support this hypothesis, as the cross-language priming effect remained relatively constant from Experiment 1 to 2. However, the fact the cross-language priming effect was observed in both experiments supports a weak version of the hypothesis that lexical access from the L1–L2 is somewhat semantically/conceptually oriented.
Experiments 3 and 4 were identical to Experiments 1 and 2 respectively, with the exception that sentences were in English and the visually presented targets were in Spanish or English. Thus, Experiments 3 and 4 represented the L2 to L1 (English-Spanish) cross-language condition, and the within-language (English-English) condition. Both within- and cross-language priming effects were obtained in Experiments 3 and 4. More surprising was the finding that the cross-language priming effect was actually greater than the within-language priming effect. This result contrasts with both the cross- and within-language priming effects in Experiments 1 and 2, which were the exact opposite. It appears as if more semantic processing had taken place for the cross-language condition than the within-language condition in Experiments 3 and 4. A comparison between Experiments 3 and 4 showed that context actually slowed down the processing of the visually presented targets. That is, bilinguals were actually faster to name Spanish and English targets in the contextually-unbiased condition (Experiment 3), than in the contextually-biased condition (Experiment 4). This finding suggests that the contextual information present in Experiment 4 influenced bilinguals, during the comprehension process, to generate specific predictions and expectations as to the possible targets that were most likely to match the preceding context (cf. Altarriba et al., 1996). Thus, more time was necessary, relative to Experiment 3, to incorporate the visually presented targets into the sentence. Notice that one expectation would be that the Spanish target should be more affected by the contextual information than English one because of the mismatch of language. However, this expectation was not supported by the data, as a 2-way interaction between Language (Spanish vs. English) and Type of Sentence (Spanish vs. English sentence) was not reliable.
Experiments 3 and 4 were designed to specifically examine the extent to which access from L2 to L1 reflected any semantic/conceptual influence. Thus, according to the Revised Hierarchical Model, one would expect no cross-language priming (see for example, Keatley & De Gelder, 1992; Keatley et al., 1994) or relatively small priming effects during bilingual lexical access from the bilinguals’ L2 to their L1. A comparison across experiments shows that the priming effect of 60 ms for Experiment 3 (L2–L1) was significantly higher than the 13 ms priming effect for Experiment 1 (L1–L2). Likewise, the priming effect of 49 ms for Experiment 4 (L2–L1) was higher than the 14 ms priming effect for Experiment 2 (L1–L2; see Tables 6.1, 6.2, 6.3, and 6.4). As can be seen, it appears that our results in fact revealed the priming asymmetry predicted by the Revised Hierarchical Model; however, it was in the opposite direction. These results are significant and replicate the same pattern of results observed by Heredia (1995, 1997) using a translation task, and Altarriba (1992) using a translation-priming paradigm.
Other important comparisons across the four experiments revealed interesting findings. Comparisons between Experiment 1 (sentence in Spanish) and Experiment 3 (sentence in English) revealed that speed of response was faster when the sentence was in Spanish (the participants’ L1) and the target word was in English (the participants’ L2), than when the sentence was in English and the target word was in Spanish. These same patterns were consistent in Experiments 2 and 4, in that bilinguals were faster to retrieve L2 information from their L1, rather than L1 information from their L2. Again, we note the reversal of the language asymmetry.
Overall, with regards to the data presented here, the Revised Hierarchical Model does a good job of predicting some of the current findings. Significant priming was observed in the L1–L2 direction (Experiment 1). That is, the semantic or conceptual information accessed in L1 aided the retrieval and processing of subsequent material appearing in L2. However, adding a biasing context (Experiment 2) did not enhance this effect; that is, there was no further facilitation provided by strengthening the conceptual access of items in L1 on the processing of items in L2. Moreover, priming effects emerged from L2 to L1 (Experiments 3 and 4); effects that are likely based on conceptual or semantic processing more than mere lexical processing, as the model would suggest. In fact, the priming effect for this language direction was significantly higher than the L1 to L2 direction (see Tables 6.1, 6.2, 6.3 and 6.4). Although it could be argued that the present findings were due to the nature of the task, and that the Revised Hierarchical Model was not designed to address units larger than single words, other studies using single words (e.g., Altarriba, 1992; Altarriba & Mathis, 1997; Heredia, 1995, 1997; Heredia & Altarriba, 2001; Hernández, 2002; see also De Groot et al., 1994; Blot, Zárate, & Paulus, 2003) have shown similar patterns.
However, the Revised Hierarchical Model could account for the present results by assuming that, after a certain degree of proficiency in the L2, language retrieval is a function of language dominance (e.g., Heredia, 1997; Heredia & Altarriba, 2001). That is, which language is spoken and used more often would determine the ease of accessibility. Thus, according to this view, it would be possible for the bilingual’s L2 to become the dominant language and behave as if it were the L1. Indeed, this is what we hypothesize occurred with the bilingual participants in the present study. Although Spanish was clearly our participants’ L1, their usage of L2, both at the social and educational levels, was greater than that for L1. In fact, most of our participants reported feeling more comfortable communicating in their L2. They reported more code-switching as they communicated in their L1, that is, more English intrusions as they spoke Spanish, and little or no interference as they communicated in English (see for example, Heredia & Altarriba, 2001). This general experience is not unusual for most bilinguals in the Southwest of the United States. In short, results of the current study support the view of the bilingual memory storage as a dynamic system that can be influenced by such factors as language dominance (cf. Heredia, 1997; see also Cieślicka, Heredia, & Olivares, 2014). Language dominance, context, and other factors affecting bilingual processing certainly await further investigation to help us better understand the multifaceted nature of the bilingual mind. Overall, it seems from the study reported here that, in line with Garcia et al. (2015) and Cieślicka (2006), the CMLP is a sensitive tool that can reveal the nature of bilingual lexical activation. With a sensitive methodology like CMLP or the CMN task, it is possible to show, as we have done in the four experiments reported here, that both languages become activated in the course of bilingual lexical access.
List of Keywords
Backward priming, Base language effect, Biased context, Bilingual lexicon, Code-switching, Cognates, Conceptual store, Cross-language activation, Cross-modal lexical priming (CMLP), Cross-modal naming tasks (CMN), Cue-shadowing task, Demasking task, Go/No-go task, Interlingual homographs, Language mixing, Language dominance, Language selective view, Lexical access, Lexical ambiguity. Lexical decision task, Lexical decision time, lexical priming, Lexical-level processing, Multiple language activation, Naming latency, Naming task, Nonselective view, Phoneme-triggered decision task, Phonological inhibition effect, Phonotactic configuration, Positive priming effect, Prime, Priming, Revised Hierarchical Model, Semantic memory, Within-language, Word frequency
Review Questions
-
1.
What are your thoughts about the bilingual mind and multiple language activation?
-
2.
Think about the different issues addressed in this chapter. What are some of the issues that most impacted your understanding of the bilingual mind? Do you think it is possible for a bilingual/multilingual speaker to walk around with his/her multiple languages activated?
-
3.
Do you code-switch? What is your view on bilinguals mixing their two languages during the communicative process? Why do you think bilinguals code-switch?
Suggested Student Research Projects
-
1.
Design and conduct a simple word association task to see whether bilinguals activate both of their lexicons and whether the language of instruction influences this activation. You will need a group of bilinguals who share the same L1 and L2 (e.g., Spanish-English bilinguals). For your materials, prepare a list of L1 words. The list should contain at least 20 words that are cross-language homographs (e.g., SIN = “wrongdoing” in English and “without” in Spanish). The remaining 20 words should be neither cognates nor cross-language homographs. Present the words one at a time and ask your participants to write down the first word that comes to mind as they see each consecutive word. It is important that they provide immediate associations, without thinking too much. To see whether the language of instruction has an effect on their performance, divide your participants randomly into two groups. Use English only as language of interaction and instruction with one group and Spanish only with the other group. The instructions should be identical for both groups, with the exception that they will be administered in either L1 or L2. What results did you obtain? Did putting participants in a bilingual mode, by providing instructions in L2, increase the number of cross-language associations? Were cross-language homographs more likely to elicit responses in the other language than nonhomographic targets? What do you conclude about the effects of stimulus materials and language of instruction on the activation of the L1 and L2 lexicons? Do the results support the language selective or nonselective view of bilingual lexical access?
For this research project, you need experimental software that will allow you to record participant’s reaction time. You can download the demo version of E-Prime from http://www.pstnet.com/eprime.cfm. Alternatively, you can use OpenSesame, the free open source experiment builder (http://osdoc.cogsci.nl/) You are going to design and run an experiment on cross-language priming. Obtain a group of bilinguals who speak English as a second language and who share their first language background (e.g., Polish-English or Spanish-English bilinguals). Construct 20 word pairs in L1–L2 in which L1 is semantically related to the target L2 (e.g., for a Polish-English bilingual, the related stimuli pair would be KOT-DOG, where KOT = “cat” in English). Next, obtain 20 control word pairs, in which the L1 word is unrelated to the L2 word (e.g., KOC-DOG, where KOC = “blanket”). Assure that your related and unrelated L1 words are matched in terms in frequency, the number of syllables, and length. Comparing RTs to the target following the control vs. the related word will be your measure or dependent variable of the degree of priming. To check for word frequency and other word’s characteristics, use the MRC Psycholinguistic Database (http://www.psych.rl.ac.uk/). Moreover, create 40 additional pairs consisting of L1 words and L2 nonwords, such as KOT-PLOG. English Nonwords can be found at http://www.cogsci.mq.edu.au/~nwdb/nonwords.html or by using Wuggy (http://crr.ugent.be/programs-data/wuggy) to create your own nonwords in English or Spanish. It is critical that the nonwords conform to the phonological rules in English, which means they need to be pronounceable. Once all your stimuli are ready, design a lexical decision task, in which participants are presented with the stimulus pairs in such a way that they first see the L1 word for 400 ms, and then are shown the L2 target for the lexical decision (i.e., they have to decide, as fast and as accurately as possible, if the presented L2 string is a legitimate English word or not). You will need to make two different lists for stimulus presentation, so as to avoid showing the same target word twice. For example, if you show the pair KOT-DOG in one presentation list, then the control KOC-DOG needs to be in another list, to avoid priming through repetition of the same item. This is known as counterbalancing. What are your results? Did you find reaction time differences? Did the study show priming from related L1 words, as compared to the control unrelated words? What can you conclude about whether bilingual lexical access is language selective or nonselective?
-
2.
Using materials from the previous research project, you are going to check whether the direction of priming (L1–L2 vs. L2–L1) has an effect on participants’ performance. Take all the stimuli from Project 2 and reverse their order (i.e., KOT-DOG will now become DOG-KOT). In addition, prepare 20 L2–L1 pairs where L1 are nonwords. Prepare two mixed lists with half of the stimuli in the L1–L2 and half in the L2–L1 direction, making sure the same pair is not repeated in the same list (i.e., if you are presenting KOT-DOG, do not include DOG-KOT in the same list). Compare the priming effects obtained in both directions. Did you find a difference between the two conditions? Can the results be interpreted within the framework of the Revised Hierarchical Model?
Related Internet Sites
CLEARPOND (Cross-linguistic easy-access resource): http://clearpond.northwestern.edu/
Cross-modal priming task: https://en.wikipedia.org/wiki/David_Swinney
English Lexicon Project: http://elexicon.wustl.edu/
Espal (Spanish database): http://www.bcbl.eu/databases/espal/
Multiple lexical access: http://cogweb.ucla.edu/Abstracts/LexicalAccess.html
Semantic priming: https://en.wikipedia.org/wiki/Priming_%28psychology%2
Tatool Web (experiments online): http://www.tatool.ch/
Word frequency (American English): http://expsy.ugent.be/subtlexus/
Suggested Further Reading
Foss, D. (1970). Some effects of ambiguity upon sentence comprehension. Journal of Verbal Learning and Verbal Behavior, 9, 699–706.
Grosjean, F. (1996). Gating. Language and Cognitive Processes, 11, 597–604.
Kilborn, K. (1989). Sentence processing in a second language: The timing of transfer. Language and Speech, 32, 1–23.
Prather, P. A., & Swinney, D. A. (1988). Lexical processing and ambiguity resolution: An autonomous process in an interactive box. In S. I. Small., G. W. Cottrell, & M. K. Tanenhaus (Eds.), Lexical ambiguity resolution: Perspectives from psycholinguistics, neuropsychology & artificial intelligence (pp. 289–310). San Mateo, CA: Morgan Kaufmann.
References
Altarriba, J. (1992). The representation of translation equivalents in bilingual memory. In R. J. Harris (Ed.), Cognitive processing in bilinguals (pp. 157–174). Amsterdam: Elsevier.
Altarriba, J., & Basnight-Brown, D. M. (2007). Methodological considerations in performing semantic- and translation-priming experiments across languages. Behavior Research Methods, 39, 1–18.
Altarriba, J., Kroll, J. F., Sholl, A., & Rayner, K. (1996). The influence of lexical and conceptual constraints on reading mixed-language sentences: Evidence from eye fixations and naming times. Memory & Cognition, 24, 477–492.
Altarriba, J., & Mathis, K. M. (1997). Conceptual and lexical development in second language acquisition. Journal of Memory and Language, 36, 550–568.
Bates, E., & Liu, H. (1996). Cued shadowing. Language and Cognitive Processes, 11, 577–581.
Beauvillain, C., & Grainger, J. (1987). Accessing interlexical homographs: Some limitations of a language-selective access. Journal of Memory and Language, 26, 658–672.
Becker, C. A. (1979`). Semantic context and word frequency effects in word recognition. Journal of Experimental Psychology: Human Perception and Performance, 5, 252–259.
Blank, M. A. (1980). Measuring lexical access during sentence processing. Perception & Psychophysics, 28, 1–8.
Blasko, D. G., & Connine, C. M. (1993). Effects of familiarity and aptness on metaphor processing. Journal of Experimental Psychology Learning Memory and Cognition, 19(2), 295–308.
Blot, K. J., Zárate, M. A., & Paulus, P. B. (2003). Code-switching across brainstorming sessions: Implications for the revised hierarchical model of bilingual language processing. Experimental Psychology, 50, 171–183.
Bruning, J. L., & Kintz, B. L. (1987). Computational book of statistics. Glenville, IL: Harper Collins.
Burgess, C., Tanenhaus, M. K., & Seidenberg, M. S. (1989). Context and lexical access: Implications of nonword interference for lexical ambiguity resolution. Journal of Experimental Psychology Learning Memory and Cognition, 15(4), 620–632.
Cacciari, C., & Tabossi, P. (1988). The comprehension of idioms. Journal of Memory and Language, 27, 668–683.
Cheung, H., & Chen, H.-C. (1998). Lexical and conceptual processing in Chinese-English bilinguals: Further evidence for asymmetry. Memory & Cognition, 26, 1002–1013.
Cieślicka, A. (2006). Literal salience in on-line processing of idiomatic expressions by L2 speakers. Second Language Reserach, 22, 115–144.
Cieślicka, A. (2007). Language experience and fixed expressions: Differences in the salience status of literal and figurative meanings of L1 and L2 idioms. In M. Nenonen & S. Niemi (Eds.), Collocations and Idioms 1: Papers from the First Nordic Conference on Syntactic Freezes, Joensuu, Finland, May 19-20 (pp. 55–70). Joensuu, Finland: Joensuu University Press.
Cieślicka, A. B., Heredia, R. R., & Olivares, M. (2014). The eyes have it: How language dominance, salience, and context affect eye movements during idiomatic language processing. In L. Aronin & M. Pawlak (Eds.), Essential topics in applied linguistics and multilingualism. Studies in honor of David Singleton (pp. 21–42). New York: Springer.
Cohen, J., & Cohen, P. (1983). Applied multiple regression/correlation analysis for the behavioral sciences. Hillsdale, NJ: Erlbaum.
Cohen, J. D., MacWhinney, B., Flatt, M., & Provost, J. (1993). PsyScope: A new graphic interactive environment for designing psychology experiments. Behavior Research Methods, Instruments, and Computers, 25, 257–271.
De Groot, A. M. B. (1992). Determinant of word translation. Journal of Experimental Psychology: Learning, Memory, and Cognition, 18, 1001–1018.
De Groot, A. M. B., Dannenburg, L., & Van Hell, J. G. (1994). Forward and backward word translation by bilinguals. Journal of Memory and Language, 33, 600–629.
Dijkstra, T., Grainger, J., & van Heuven, W. J. B. (1999). Recognition of cognates and interlingual homographs: The neglected role of phonology. Journal of Memory and Language, 41, 496–518.
Dijkstra, T., Timmermans, M., & Schriefers, H. (2000). Cross-language effects on bilingual homograph recognition. Journal of Memory and Language, 42, 45–464.
Dijkstra, T., Van Jaarsveld, H., & Brinke, S. T. (1998). Interlingual homograph recognition: Effects of task demands and language intermixing. Bilingualism Language and Cognition, 1, 51–66.
Fox, E. (1996). Cross-language priming from ignored words: Evidence for a common representational system in bilinguals. Journal of Memory and Language, 35, 353–370.
Francis, W. N., & Kučera, H. (1982). Frequency analysis of English usage: Lexicon and grammar. Boston: Houghton Mifflin.
García, O., Cieślicka, A. B., & Heredia, R. R. (2015). Nonliteral language processing and methodological considerations. In R. R. Heredia & A. Cieślicka (Eds.), Bilingual figurative language processing (pp. 117–168). New York: Cambridge University Press.
Gerard, L., & Scarborough, D. (1989). Language-specific lexical access of homographs by bilinguals. Journal of Experimental Psychology Learning Memory and Cognition, 15, 305–315.
Glucksberg, S., Kreuz, R. J., & Rho, S. H. (1986). Context can constrain lexical access: Implications for models of language comprehension. Journal of Experimental Psychology: Learning, Memory, and Cognition, 12, 323–335.
Gollan, T. H., Forster, K. I., & Frost, R. (1997). Translation priming with different scripts: Masked priming with cognates and non-cognates in Hebrew-English bilinguals. Journal of Experimental Psychology: Learning, Memory, and Cognition, 23, 1122–1139.
Grosjean, F. (1988). Exploring the recognition of guest words in bilingual speech. Language and Cognitive Processes, 3, 233–274.
Grosjean, F. (1997). Processing mixed language: Issues, findings and models. In A. M. B. de Groot & J. F. Kroll (Eds.), Tutorials in bilingualism: Psycholinguistic perspectives (pp. 225–254). Mahwah, NJ: Erlbaum.
Heredia, R. R. (1995). Concreteness effects in high frequency words: A test of the revised hierarchical and the mixed models of bilingual memory representations. Unpublished doctoral dissertation, University of California, Santa Cruz.
Heredia, R. R. (1997). Bilingual memory and hierarchical models: A case for language dominance. Current Directions in Psychological Science, 6, 34–39.
Heredia, R. R., & Altarriba, J. (2001). Bilingual language mixing: Why do bilinguals code-switch? Current Directions in Psychological Science, 10, 164–168.
Heredia, R. R., & Blumentritt, T. L. (2002). On-line processing of social stereotypes during spoken language comprehension. Experimental Psychology, 49, 208–221.
Heredia, R. R., & Brown, J. M. (2003). Bilingual memory. In W. C. Ritchie & T. K. Bhatia (Eds.), Handbook of bilingualism (pp. 213–228). Malden, MA: Blackwell.
Heredia, R. R., & Muñoz, M. E. (2015). Metaphoric reference: A real-time analysis. In R. R. Heredia & A. B. Cieślicka (Eds.), Bilingual figurative language processing (pp. 89–116). New York: Cambridge Press.
Heredia, R. R., & Stewart, M. T. (2002). On-line methods in bilingual spoken language research. In R. R. Heredia & J. Altarriba (Eds.), Bilingual sentence processing (pp. 7–28). North Holland, The Netherlands: Elsevier.
Hernández, A. (2002). Exploring language asymmetries in early Spanish-English bilinguals: The role of lexical and sentential context effects. In R. R. Heredia & J. Altarriba (Eds.), Bilingual sentence processing (pp. 7–28). North Holland, The Netherlands: Elsevier.
Hernández, A. E., Bates, E., & Ávila, L. X. (1996). Processing across the language boundary: A cross-modal priming study of Spanish-English bilinguals. Journal of Experimental Psychology: Learning, Memory, and Cognition, 22, 846–864.
Herron, D., & Bates, E. (1997). Sentential and acoustic factors in the recognition of open- and closed-class words. Journal of Memory and Language, 37, 217–239.
Hillert, D., & Swinney, D. (2001). The processing of fixed expressions during sentence comprehension. In A. Cienki, B. J. Luka, & M. B. Smith (Eds.), Conceptual and discourse factors in linguistic structure (pp. 107–121). Stanford, CA: CSLI.
Hummel, K. M. (1993). Bilingual memory research: From storage to processing issues. Applied Psycholinguistics, 14, 267–284.
Jiang, N., & Forster, K. I. (2001). Cross-language priming asymmetries in lexical decision and episodic recognition. Journal of Memory and Language, 44, 32–51.
Julliand, A., & Chang-Rodríguez, E. (1964). Frequency dictionary of Spanish words. La Haya, Holland: Mouton.
Keatley, C., & De Gelder, B. (1992). The bilingual primed lexical decision task: Cross-language priming disappears with speeded response. European Journal of Cognitive Psychology, 4, 273–292.
Keatley, C. W., Spinks, J. A., & De Gelder, B. (1994). Asymmetrical cross-language priming effects. Memory & Cognition, 22, 70–84.
Kolers, P. (1966). Reading and talking bilingually. American Journal of Psychology, 3, 357–376.
Kroll, J. F., & Stewart, E. (1994). Category inference in translation and picture naming: Evidence for asymmetric connections between bilingual memory representations. Journal of Memory and Language, 33, 149–174.
La Heij, W., Hooglander, A., Kerling, R., & Van der Velder, E. (1996). Nonverbal context effects in forward and backward word translation: Evidence for conceptual mediation. Journal of Memory and Language, 35, 648–665.
Lederberg, A. R., & Morales, C. (1985). Code switching by bilinguals: Evidence against a third grammar. Journal of Psycholinguistic Research, 14, 113–136.
Li, P. (1996). Spoken word recognition of code-switched words by Chinese-English bilinguals. Journal of Memory and Language, 35, 757–774.
Li, P., & Yip, M. C. (1998). Context effects and the processing of spoken homophones. Reading and Writing: An Interdisciplinary Journal, 10, 223–243.
Libben, M., & Titone, D. (2009). The multidetermined nature of idiomatic expressions. Memory & Cognition, 36, 1103–1131.
Liu, H., Bates, E., Powell, T., & Wulfeck, B. (1997). Single-word shadowing and the study of lexical access. Applied Psycholinguistics, 18, 157–180.
Love, T., Maas, E., & Swinney, D. (2003). The influence of language exposure on lexical and syntactic language processing. Experimental Psychology, 50, 204–216.
Macnamara, J., & Kushnir, S. L. (1971). Linguistic independence of bilinguals: The input switch. Journal of Verbal Learning and Verbal Behavior, 10, 480–487.
Marslen-Wilson, W. D. (1987). Functional parallelism in spoken word-recognition. Cognition, 25, 71–102.
Masson, M. (1995). A distributed memory model of semantic priming. Journal of Experimental Psychology: Learning, Memory, and Cognition, 21(1), 3–23.
Meyer, D. E., Schvaneveldt, R. W., & Ruddy, M. G. (1975). Loci of contextual effects on visual word recognition. In P. M. A. Rabbit & S. Dornic (Eds.), Attention and performance (Vol. V). New York: Academic Press.
Neely, J. (1991). Semantic priming effects in visual word recognition: A selective review of current theories and findings. In D. Besner & G. Humphries (Eds.), Basic processes in reading: Visual word recognition (pp. 264–336). Hillsdale, NJ: Lawrence Erlbaum Associates.
Neely, J. H., Keefe, D. E., & Ross, K. L. (1989). Semantic priming in the lexical decision task: Roles of prospective prime-generated expectancies and retrospective semantic matching. Journal of Experimental Psychology Learning Memory and Cognition, 15(6), 1003–1019.
Nelson, D. L., McEvoy, C. L., & Schreiber, T. A. (1998). The University of South Florida word association, rhyme, and word fragment norms. http://www.usf.edu/FreeAssociation/
Onifer, W., & Swinney, D. A. (1981). Accessing lexical ambiguities during sentence comprehension: Effects of frequency of meaning and contextual bias. Memory and Cognition, 9(3), 225–236.
Prather, P. A., & Swinney, D. A. (1988). Lexical processing and ambiguity resolution: An autonomous process in an interactive box. In S. I. Small, G. W. Cottrell, & M. K. Tanenhaus (Eds.), Lexical ambiguity resolution: Perspectives from psycholinguistics, neuropsychology, and artificial intelligence (pp. 289–310). San Mateo, CA: Morgan Kaufmann.
Scarborough, D. L., Gerard, L., & Cortese, C. (1984). Independence of lexical access in bilingual word recognition. Journal of Verbal Learning and Verbal Behaviour, 23, 84–99.
Schwartz, A. I., & Kroll, J. F. (2006). Bilingual lexical activation in sentence context. Journal of Memory and Language, 55, 197–212.
Seidenberg, M. S., Tanenhaus, M. K., Leiman, J. M., & Bienkowski, M. (1982). Automatic access of the meanings of ambiguous words in context: Some limitations of knowledge-based processing. Cognitive Psychology, 14, 489–537.
Sereno, S. C. (1995). Resolution of lexical ambiguity: Evidence from an eye movement priming paradigm. Journal of Experimental Psychology Learning Memory and Cognition, 21(3), 582–595.
Sholl, A., Sankaranarayanan, A., & Kroll, J. F. (1995). Transfer between picture naming and translation: A test of asymmetries in bilingual memory. Psychological Science, 6, 45–49.
Simpson, G. B. (1981). Meaning dominance and semantic context in the processing of lexical ambiguity. Journal of Verbal Learning and Verbal Behavior, 20, 120–136.
Soares, C., & Grosjean, F. (1984). Bilinguals in a monolingual and a speech model: The effect on lexical access. Memory & Cognition, 12, 380–386.
Stewart, M. T., & Heredia, R. R. (2002). Comprehending spoken metaphoric reference: A real-time analysis. Experimental Psychology, 49, 34–44.
Swinney, D. A. (1979). Lexical access during sentence comprehension: (Re)consideration of context effects. Journal of Verbal Learning and Verbal Behavior, 18, 645–659.
Swinney, D., Love, T., Walenski, M., & Smith, E. E. (2007). Conceptual combination during sentence comprehension: Evidence for compositional processes. Psychological Science, 18(5), 397–400.
Swinney, D. A., & Osterhout, L. (1990). Inference generation during auditory language comprehension. The Psychology of Learning and Motivation, 25, 17–33.
Tabossi, P. (1988). Accessing lexical ambiguity in different types of sentential contexts. Journal of Memory and Language, 27, 324–340.
Tabossi, P. (1996). Cross-modal semantic priming. Language and Cognitive Processes, 11, 569–576.
Tabossi, P., & Zardon, F. (1993). The activation of idiomatic meaning in spoken language comprehension. In C. Cacciari & P. Tabossi (Eds.), Idioms: Processing, structure, and interpretation (pp. 145–162). Hillsdale, NJ: Lawrence Erlbaum Associates.
Tanenhaus, M. K., & Donnenwerth-Nolan, S. (1984). Syntactic context and lexical access. The Quarterly Journal of Experimental Psychology, 38A, 649–661.
Titone, D. A., & Connine, C. M. (1994). Comprehension of idiomatic expressions: Effects of predictability and literality. Journal of Experimental Psychology Learning Memory and Cognition, 20(5), 1126–1138.
Van de Voort, M. E. C., & Vonk, W. (1995). You don’t die immediately when you kick an empty bucket: A processing view on semantic and syntactic characteristics of idioms. In M. Everaert, E. J. van der Linden, A. Schenk, & R. Schreuder (Eds.), Idioms: Structural and psychological perspectives (pp. 283–300). Hillsdale, NJ: Lawrence Erlbaum Associates.
Van Petten, C., & Kutas, M. (1987). Ambiguous words in context: An event-related potential analysis of the time course of meaning activation. Journal of Memory and Language, 26, 188–208.
Warren, R. E. (1977). Time and the spread of activation in memory. Journal of Experimental Psychology: Human Learning and Memory, 3, 458–466.
Acknowledgements
The second author is grateful to the late Elizabeth Bates and David Swinney for their advice, support, and inspiration as postdoctoral advisors, at the Center for Research in Language, and the Center for Information Processing at the University of California, San Diego. We also acknowledge the Center for Research in Language for invaluable assistance with data collection in Experiment 2. Experiment 2 was supported by National Science Foundation, Grant SBR-9520489.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer Science+Business Media New York
About this chapter
Cite this chapter
Cieślicka, A.B., Heredia, R.R. (2016). Priming and Online Multiple Language Activation. In: Heredia, R., Altarriba, J., Cieślicka, A. (eds) Methods in Bilingual Reading Comprehension Research. The Bilingual Mind and Brain Book Series, vol 1. Springer, New York, NY. https://doi.org/10.1007/978-1-4939-2993-1_6
Download citation
DOI: https://doi.org/10.1007/978-1-4939-2993-1_6
Publisher Name: Springer, New York, NY
Print ISBN: 978-1-4939-2992-4
Online ISBN: 978-1-4939-2993-1
eBook Packages: Behavioral Science and PsychologyBehavioral Science and Psychology (R0)