
Abstract
A new version of accelerated gradient descent is proposed. The method does not require any a priori information on the objective function, uses a linesearch procedure for convergence acceleration in practice, converge according to well-known lower bounds for both convex and nonconvex objective functions, and has primal-dual properties. A universal version of this method is also described.
Similar content being viewed by others
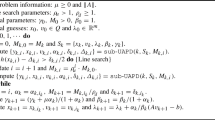

Avoid common mistakes on your manuscript.
In the late 1980s, A.S. Nemirovski showed that auxiliary low-dimensional optimization does not improve the theoretical worst-case rate of convergence of a first-order optimal gradient-type method for smooth convex minimization problems [1]. However, in practice, accelerated methods with linesearch (in particular, conjugate gradient methods) are usually more efficient than their fixed-stepsize counterparts in terms of the number of iterations. Moreover, such procedures have been successfully applied to nonconvex optimization problems [2]. Unfortunately, it is also well known that the gain in performance due to the use of linesearch is significantly reduced by the computational complexity of such procedures. It was noted in [3] that, for problems of a certain type frequently occurring in solving dual problems, the complexity of executing a linesearch step nearly coincides with the complexity of a usual gradient step. This fact motivates the study of methods with linesearch and their primal-dual properties [4–8].
Consider the minimization problem
Its solution is denoted by \({{x}_{ * }}\). Assume that the objective function is differentiable and its gradient satisfies the Lipschitz condition with a constant L: for all x, \(y\, \in \,{{\mathbb{R}}^{n}}\),
We introduce an estimating sequence \({\text{\{ }}{{\psi }_{k}}(x){\text{\} }}\) [1, 4, 9, 10] and a sequence of coefficients \({\text{\{ }}{{A}_{k}}{\text{\} }}\):
Let us describe an accelerated gradient method (AGM) with single linesearch.
Algorithm 1: AGM
Input: \({{x}^{0}} = {{{v}}^{0}}\), \(L\), \(N\)
Output: \({{x}^{N}}\)
1: k = 0
2: while\(k \leqslant N - 1\)do
3: \({{\beta }_{k}} = \mathop {{\text{argmin}}}\limits_{\beta \in \left[ {0,1} \right]} f({{{v}}^{k}} + \beta ({{x}^{k}} - {{{v}}^{k}}))\)
4: \({{y}^{k}} = {{{v}}^{k}} + {{\beta }_{k}}({{x}^{k}} - {{{v}}^{k}})\)
5: \({{x}^{{k + 1}}} = {{y}^{k}} - \frac{1}{L}\nabla f({{y}^{k}})\)
6: Choose \({{a}_{{k + 1}}}\) by solving \(\frac{{a_{{k + 1}}^{2}}}{{{{A}_{{k + 1}}}}} = \frac{1}{L}\)
7: \({{{v}}^{{k + 1}}}\, = \,{{{v}}^{k}}\, - \,{{a}_{{k + 1}}}\nabla f({{y}^{k}})\) ▷\({{{v}}^{{k + 1}}}\, = \,\mathop {{\text{argmin}}}\limits_{x \in {{\mathbb{R}}^{n}}} {\kern 1pt} {{\psi }_{{k + 1}}}(x)\)
8: \(k = k + 1\)
9: end while
The main difference of this algorithm from well-known similar accelerated gradient methods [4, 10, 11] is the stepsize selection in line 3. The previous algorithms used a fixed stepsize (e.g., \({{\beta }_{k}} = \frac{k}{{k + 2}}\)).
Instead of Step 5, one can use different stepsize selection procedures, such as the Armijo rule [2] and its modern analogues (as in the universal fast gradient method [12]). The version of the method using exact linesearch for stepsize selection will be referred to as ALSM.
Algorithm 2: ALSM
Input: \({{x}^{0}} = {{{v}}^{0}}\)
Output: xN
1: k = 0
2: while\(k \leqslant N - 1\)do
3: \({{\beta }_{k}} = \mathop {{\text{argmin}}}\limits_{\beta \in \left[ {0,1} \right]} f({{{v}}^{k}} + \beta ({{x}^{k}} - {{{v}}^{k}}))\)
4: \({{y}^{k}} = {{{v}}^{k}} + {{\beta }_{k}}({{x}^{k}} - {{{v}}^{k}})\)
5: \({{h}_{{k + 1}}} = \mathop {{\text{argmin}}}\limits_{h \geqslant 0} f({{y}^{k}} - h\nabla f({{y}^{k}}))\)
6: \({{x}^{{k + 1}}} = {{y}^{k}} - {{h}_{{k + 1}}}\nabla f({{y}^{k}})\)
7: Choose \({{a}_{{k + 1}}}\) by solving \(f({{y}^{k}}) - \frac{{a_{{k + 1}}^{2}}}{{2{{A}_{{k + 1}}}}}{\text{||}}\nabla f({{y}^{k}}){\text{||}}_{2}^{2} = f({{x}^{{k + 1}}})\)
8: \({{{v}}^{{k + 1}}} = {{{v}}^{k}} - {{a}_{{k + 1}}}\nabla f({{y}^{k}})\) ▷ \({{{v}}^{{k + 1}}} = \mathop {{\text{argmin}}}\limits_{x \in {{\mathbb{R}}^{n}}} {{\psi }_{{k + 1}}}(x)\)
9: \(k = k + 1\)
10: end while
Let us formulate the main theoretical results for these methods.
Theorem 1.For both AGM and ALSM,
If f(x) is convex, then, for both methods
where\(R = {\text{||}}{{x}_{ * }} - {{x}^{0}}{\text{|}}{{{\text{|}}}_{2}}\).
The function \(f(x)\) is called \(\gamma \)-weakly quasiconvex (where \(\gamma \in (0,1]\)) if, for all \(x \in {{\mathbb{R}}^{n}}\),
Note that γ-weakly quasiconvex functions are unimodal, but, in the general case, are not convex. If f(x) is γ-weakly quasiconvex, the AGM method can be considered with the following restarting procedure: as soon as
set \(x_{{i + 1}}^{0} = x_{i}^{N}\) and restart the method.
Theorem 2.If f(x) is γ-weakly quasiconvex, then, for the AGM and ALSM methods with the above-described restarting procedure,
where\(R = \mathop {\max}\limits_{x:f(x) \leqslant f({{x}_{0}})} {\text{||}}x{\text{|}}{{{\text{|}}}_{2}}\)and\(\{ {{\tilde {x}}^{i}}\} \)is the sequence of points generated by the method in the course of all starts.
It can be shown that the SESOP method [3] can be applied to γ-weakly quasiconvex problems and has the convergence rate estimate
with \(R = {\text{||}}{{x}^{0}} - {{x}_{ * }}{\text{|}}{{{\text{|}}}_{2}}\), but it requires solving a three-dimensional (possibly nonconvex) problem at every iteration step. On the contrary, the AGM method requires only solving a minimization problem on an interval.
Now we consider a convex optimization problem of the form
In this case, a dual minimization problem can be constructed, namely,
According to the Demyanov–Danskin theorem, \(\nabla f(x)\) = Az(x). Assume that ϕ(z) is \(\mu \)-strongly convex. Then \(\nabla f(x)\) satisfies the Lipschitz condition with the constant \(L = \frac{{{{\lambda }_{{\max }}}(A)}}{\mu }\). Let us apply our methods to problem (1) with \({{x}^{0}} = {{{v}}^{0}} = 0\). Define
Theorem 3.For the AGM and ALSM methods,
where\(R = {\text{||}}{{x}_{ * }}{\text{|}}{{{\text{|}}}_{2}}\).
Consider a class of problems in which the objective function f(x) is not necessarily smooth. Let \(\nabla f(x)\) denote some subgradient of f(x). Assume that \(\nabla f(x)\) satisfies the Hölder condition: for all \(x,y \in {{\mathbb{R}}^{n}}\) and some \(u \in \left[ {0,1} \right]\),
The following ULSM method can be proposed for solving problems of this class.
Algorithm 3: ULSM
Input: Initial point \({{x}^{0}} = {{{v}}^{0}}\), accuracy \(\varepsilon \)
Output: xN
1: k = 0
2: while\(k \leqslant N - 1\)do
3: \({{\beta }_{k}} = \mathop {{\text{argmin}}}\limits_{\beta \in \left[ {0,1} \right]} f({{{v}}^{k}} + \beta ({{x}^{k}} - {{{v}}^{k}}))\)
4: \({{y}^{k}} = {{{v}}^{k}} + {{\beta }_{k}}({{x}^{k}} - {{{v}}^{k}})\)
5: \({{h}_{{k + 1}}} = \mathop {{\text{argmin}}}\limits_{h \geqslant 0} f({{y}^{k}} - h\nabla f({{y}^{k}}))\), where \(\langle \nabla f({{y}^{k}}),{{{v}}^{k}} - {{y}^{k}}\rangle \geqslant 0\)
6: \({{x}^{{k + 1}}} = {{y}^{k}} - {{h}_{{k + 1}}}\nabla f({{y}^{k}})\)
7: Choose \({{a}_{{k + 1}}}\) by solving \(f({{x}^{{k + 1}}}) = f({{y}^{k}}) - \frac{{a_{{k + 1}}^{2}}}{{2{{A}_{{k + 1}}}}}{\text{||}}\nabla f({{y}^{k}}){\text{||}}_{2}^{2} + \frac{{\varepsilon {{a}_{{k + 1}}}}}{{2{{A}_{{k + 1}}}}}\)
8: \({{{v}}^{{k + 1}}} = {{{v}}^{k}} - {{a}_{{k + 1}}}\nabla f({{y}^{k}})\) ▷ \({{{v}}^{{k + 1}}} = \mathop {{\text{argmin}}}\limits_{x \in {{\mathbb{R}}^{n}}} {{\psi }_{{k + 1}}}(x)\)
9: k = k + 1
10: end while
Note that, in contrast to other universal methods [12, 13], this one does not require estimating the necessary stepsize in an inner loop. This leads to a somewhat better estimate for the rate of convergence and, on average, to a smaller number of oracle calls per iteration step.
Theorem 4.If\(f(x)\)is convex and its subgradient satisfies the Hölder condition, then
i.e., the method generates an ε-accurate solution after N iterations, where
with\(R = {\text{||}}{{x}_{0}} - x{\text{*|}}{{{\text{|}}}_{2}}\).
If the problem under consideration is strongly convex with a given constant \(\mu \), then use of the estimating sequence
leads to optimal (up to a multiplicative constant) analogues of the above-described methods in the class of strongly convex problems.
REFERENCES
Yu. E. Nesterov, Efficient Methods in Nonlinear Programming (Radio i Svyaz’, Moscow, 1989) [in Russian].
R. A. Waltz, J. L. Morales, J. Nocedal, and D. Orban, Math. Program. 107 (3), 391–408 (2006).
G. Narkiss and M. Zibulevsky, “Sequential subspace optimization method for large-scale unconstrained problems,” Tech. Rep. CCIT No. 559 (Dep. Electr. Eng. Tech., Haifa, 2005).
Yu. Nesterov, Math. Program. 103 (1), 127–152 (2005).
Yu. Nesterov, Math. Program. 120 (1), 221–259 (2009).
P. Dvurechensky, A. Gasnikov, and A. Kroshnin, “Computational optimal transport: Complexity by accelerated gradient descent is better than by Sinkhorn’s algorithm,” Proceedings of the 35th International Conference on Machine Learning (PMLR, Stockholm, 2018), pp. 1367–1376.
P. Dvurechensky, A. Gasnikov, E. Gasnikova, S. Ma-tsievsky, A. Rodomanov, and I. Usik, “Primal-dual method for searching equilibrium in hierarchical congestion population games,” CEUR-WS Supplementary Proceedings of the 9th International Conference on Discrete Optimization and Operations Research and Scientific School (DOOR 2016) (Springer, Berlin, 2016), pp. 584–595. http://ceur-ws.org/Vol-1623.
A. Chernov, P. Dvurechensky, and A. Gasnikov, “Fast primal-dual gradient method for strongly convex minimization problems with linear constraints,” Proceedings of the 9th International Conference on Discrete Optimization and Operations Research (DOOR 2016) (Springer, Berlin, 2016), pp. 391–403.
Yu. E. Nesterov, Dokl. Akad. Nauk SSSR 269 (3), 543–547 (1983).
Yu. E. Nesterov, Introduction to Convex Optimization (MTsNMO, Moscow, 2010) [in Russian].
Z. Allen-Zhu and L. Orecchia, “Linear coupling: An ultimate unification of gradient and mirror descent,” Proceedings of the 8th Innovations in Theoretical Computer Science (Schloss Dagstuhl, Saarbrücken, 2017).
Yu. Nesterov, Math. Program. 152 (1–2), 381–404 (2015).
S. Guminov, A. Gasnikov, A. Anikin, and A. Gornov, “A universal modification of the linear coupling method,” Optim. Methods Software (2019). https://doi.org/10.1080/10556788.2018.1517158
ACKNOWLEDGMENTS
This work was supported by the Russian Science Foundation, project no. 18-71-10108.
Author information
Authors and Affiliations
Corresponding author
Additional information
Translated by I. Ruzanova
Rights and permissions
About this article

Cite this article
Guminov, S.V., Nesterov, Y.E., Dvurechensky, P.E. et al. Accelerated Primal-Dual Gradient Descent with Linesearch for Convex, Nonconvex, and Nonsmooth Optimization Problems. Dokl. Math. 99, 125–128 (2019). https://doi.org/10.1134/S1064562419020042
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1134/S1064562419020042