
Abstract
The resource allocation problem in computer networks with a large number of links is considered. The links are used by consumers (users), whose number can also be very large. For the dual problem, numerical optimization methods are proposed, such as the fast gradient method, the stochastic projected subgradient method, the ellipsoid method, and the random gradient extrapolation method. A convergence rate estimate is obtained for each of the methods. Algorithms for distributed computation of steps in the considered methods as applied to computer networks are described. Special attention is given to the primal-dual property of the proposed algorithms.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 INTRODUCTION
1.1 Motivation
In this paper, the problem of controlling modern communication networks is considered from the point of view of optimization and stochastic modeling. To solve problems of this type, we need to represent and analyze the mathematical model arising in the simulation of large-scale broadband networks. It is expected that, in future communication networks, there appear applications that will be able to change their data transmission rates according to the available network capacity. An example of such a network is TCP traffic through the Internet.
The key issue addressed in this paper is how the available capacity of the network is to be allocated among competing flows. The use of available capacities by consumers is controlled by correcting the link prices.
Thus, we consider the problem of optimizing resource allocation in computer networks with a large number of links. The links are used by consumers (users), whose number can also be very large. The goal of this study is to determine a resource allocation mechanism, where the resources are understood as available capacities of network links. Additionally, it is necessary to ensure stable performance of the system and to prevent overloads. As an optimality criterion, we use the sum of the utilities of all users of the computer network.
Originally, standard resource allocation problems reducing to the maximization of the aggregate utility of users in the case of shared use of available resources were considered in [1]. Resource allocation in computer networks was investigated in the recent work [2]. Proposed in [3], the mechanisms of decentralized resource allocation drew much attention in economic studies (see, e.g., [4–6] and references therein). In this paper, following [7, 8], we consider various mechanisms of price adjustment. The proposed approaches are of practical importance due to their decentralized nature, which means that the price of an individual link is established and adjusted relying only on the reactions of users employing this link, rather than on the reactions of all network users. In the case of such an adjustment mechanism, all links perform independently.
Additionally, one of the approaches proposed in this paper relies on the stochastic projected subgradient method and overcomes the following difficulty arising in actual networks: data packets sent by users arrive at a link at different times, so the total traffic through the link is not known in practice. This difficulty is obviated by applying stochastic methods. They can do without the exact value of total traffic, managing only with its estimate, which can be obtained using the traffic of a single user. The idea of using the stochastic projected subgradient method for solution of this problem was proposed in [2].
1.2 Content of This Paper
This paper is organized as follows. The formulation of the problem and the construction of its dual are described in Section 2. Additionally, we state all necessary assumptions for the primal problem. In Section 3, the problem is solved by applying Nesterov’s fast gradient method [9], whose complexity bound is found to be \(O\left( {\tfrac{1}{{\sqrt \varepsilon }}} \right)\). In Section 4, this problem is solved using the stochastic projected subgradient method with \(O\left( {\tfrac{1}{{{{\varepsilon }^{2}}}}} \right)\) complexity bounds.
In Section 5, the problem is solved by applying the ellipsoid method, which is well suited for low-dimensional problems, and an algorithm for constructing the accuracy certificate for this method is described. We present complexity bounds on the order of \(O\left( {{{m}^{2}}\ln\tfrac{1}{\varepsilon }} \right)\), where \(m\) is the number of links in the network. A regularization technique for recovering the solution of the primal problem from the solution of the dual one if the method is not primal-dual is described in Section 6. The regularized problem is solved using the random gradient extrapolation method in Section 7. Its complexity bounds are presented, which are on the order of \(O\left( {\tfrac{1}{{\sqrt \varepsilon }}\ln\tfrac{1}{\varepsilon }} \right)\), where the logarithmic factor appears due to the regularization of the dual problem.
Numerical experiments supporting the theoretical results obtained in the preceding sections are presented in Section 8.
Additionally, for each algorithm, we describe its distributed computation in the context of the problem under consideration.
2 FORMULATION OF THE PROBLEM
Consider a computer network with \(m\) links and \(n\) users (or nodes), see Fig. 1.

Example of a computer network with \(m = 6\) and \(n = 3\).
The users exchange data packets through a fixed set of links. The network structure is specified by the routing matrix \(C = (C_{i}^{j}) \in {{{\mathbf{R}}}^{{m \times n}}}\). The matrix columns \({{{\mathbf{C}}}_{i}} \ne 0\), \(i = 1, \ldots ,n\), are \(m\)-dimensional Boolean vectors such that \(C_{i}^{j} = 1\) if node \(i\) uses link \(j\) and \(C_{i}^{j} = 0\) otherwise. The link capacities are described by a vector \({\mathbf{b}} \in {{{\mathbf{R}}}^{m}}\) with strictly positive components.
The users estimate the performance of the network with the help of utility functions \({{u}_{k}}({{x}_{k}})\), \(k = 1, \ldots ,n\), where \({{x}_{k}} \in {{{\mathbf{R}}}_{ + }}\) is the rate of data transmission from the \(k\)th user. As an optimality criterion for the system, we use the sum of the utility functions for all users [1].
The problem of maximizing the aggregate utility of the network under constraints imposed on the link capacities is stated as follows:
where \({\mathbf{x}} = ({{x}_{1}}, \ldots ,{{x}_{n}}) \in \mathbb{R}_{ + }^{n}\). The solution of this problem is an optimal resource allocation \({\mathbf{x}}\text{*}\).
Consider the standard transition to the dual problem for (1). Given a vector of dual multipliers \(\boldsymbol{\lambda} = ({{\lambda }_{1}}, \ldots ,{{\lambda }_{m}}) \in \mathbb{R}_{ + }^{m}\), which can be interpreted as the price vector of the links, the dual objective function is defined as
here, the users choose optimal data transmission rates \({{x}_{k}}\) by solving the optimization problem
Let \({\mathbf{x}}(\boldsymbol{\lambda} )\) denote the vector with components \({{x}_{k}}(\boldsymbol{\lambda} )\). Then, to find optimal prices \(\boldsymbol{\lambda} \text{*}\), we need to solve the problem
Assume that the Slater condition is satisfied for the primal problem. Then, by virtue of strong duality, both primal and dual problems have solutions. By using the Slater condition, it is possible to compactify the solution of the dual problem. Assume that the solution of the dual problem satisfies the estimate
Here, \(R\) has no effect on the performance of the considered algorithms, but is only involved in their convergence rate estimates.
The basic idea of this paper is to apply various optimization methods for solving dual problem (4) with the addition of primal-dual analysis of these methods, which makes it possible to recover the solution of primal problem (1). In this sense, we develop the approach addressed in our previous works [10–21]. The basic difference is that we consider inequality constraints and analyze stochastic algorithms in the terms of estimates with high probability, rather than on average.
2.1 Strongly Concave Utility Functions
In some sections, we assume that the utility functions \({{u}_{k}}({{x}_{k}})\), \(k = 1, \ldots ,n\), are strongly concave with a constant \(\mu \). In this subsection, we describe the properties of the dual problem under this assumption.
Proposition 1 (Demyanov–Danskin–Rubinov theorem, see [22, 23]). Suppose that, for any \(\boldsymbol{\lambda} \in {{\mathbb{R}}_{ + }}\), it holds that \(\varphi (\boldsymbol{\lambda} ) = \mathop {\max}\limits_{{\mathbf{x}} \in X} F({\mathbf{x}},\boldsymbol{\lambda} )\), where \(F({\mathbf{x}},\boldsymbol{\lambda} )\) is a convex and smooth function of \(\boldsymbol{\lambda} \) with a maximum reached at the only point \(x(\boldsymbol{\lambda} )\). Then \(\nabla \varphi (\boldsymbol{\lambda} ) = {{\nabla }_{\boldsymbol{\lambda} }}F(x(\boldsymbol{\lambda} ),\boldsymbol{\lambda} )\).
Proposition 2 (see [24]). Suppose that the functions \({{u}_{k}}({{x}_{k}})\) are \(\mu \)-strongly concave for all \(k = 1, \ldots ,n\). Then function (2), where \({{x}_{k}}(\boldsymbol{\lambda} ),\) \(k = 1, \ldots ,n\), solve problem (3), is \(n{{m}^{2}}{\text{/}}\mu \)-smooth, i.e., the gradient of the function \(\varphi (\boldsymbol{\lambda} )\) satisfies the Lipschitz condition with constant \(L = n{{m}^{2}}{\text{/}}\mu \):
The proof of the proposition can be found in the Appendix.
2.2 Concave Utility Functions
Now we assume that the utility functions \({{u}_{k}}({{x}_{k}})\), \(k = 1, \ldots ,n\), are concave, but not strongly concave. Then the dual problem is not smooth. In this subsection, we describe some properties of subgradients of the dual problem under these assumptions.
The subgradient of dual problem (4) is defined as
Since \({\mathbf{x}}\) is a bounded rate of data transmission and the vector \({\mathbf{b}}\) is also bounded, we see that the subgradients of the dual problem are bounded. Thus, there exists a positive constant \(M\) such that
As a rough estimate from above for the constant \(M\) in (5), we can use \(O(n\sqrt m )\). The multiplier \(n\) appears because there are \(n\) terms and \(\sqrt m \) is used as an estimate for the dependence of the \(2\)-norm on the vector dimension \(m\).
3 FAST GRADIENT METHOD
In this section, we assume that the utility functions \({{u}_{k}}({{x}_{k}})\), \(k = 1, \ldots ,n\), are strongly concave with a constant \(\mu \); therefore, the dual problem is smooth.
Dual problem (4) is solved by applying Nesterov’s fast gradient method (FGM) in the following version (PDFGM method, see Algorithm 1).
Algorithm 1. Primal-Dual Fast Gradient Method (PDFGM)
Input: \({{u}_{k}}({\mathbf{x}}),\) \(k = 1, \ldots ,n\), are strongly concave utility functions for each user; \({{\boldsymbol{\lambda} }^{0}}\) is the initial price vector, \({{\alpha }_{t}}: = \tfrac{{t + 1}}{2}\), \({{A}_{{ - 1}}}: = 0\), \({{A}_{t}}: = {{A}_{{t - 1}}} + {{\alpha }_{t}} = \tfrac{{(t + 1)(t + 2)}}{4}\), and \({{\tau }_{t}}: = \tfrac{{{{\alpha }_{{t + 1}}}}}{{{{A}_{{t + 1}}}}} = \tfrac{2}{{t + 3}}\), \(t = 0,1, \ldots ,N - 1\).
1: for \(t = 0,1, \ldots ,N - 1\)
2: Compute \(\varphi ({{\boldsymbol{\lambda} }^{t}})\), \(\nabla \varphi ({{\boldsymbol{\lambda} }^{t}})\)
3: \({{{\mathbf{y}}}^{t}}: = \mathop {\left[ {{{\boldsymbol{\lambda} }^{t}} - \tfrac{1}{L}\left( {{\mathbf{b}} - \sum\nolimits_{k = 1}^n {{{{\mathbf{C}}}_{k}}{{x}_{k}}({{\boldsymbol{\lambda} }^{t}})} } \right)} \right]}\nolimits_ + \)
4: \({{{\mathbf{z}}}^{t}}: = \mathop {\left[ {{{\boldsymbol{\lambda} }^{0}} - \tfrac{1}{L}\sum\nolimits_{j = 0}^t {{{\alpha }_{j}}} \left( {{\mathbf{b}} - \sum\nolimits_{k = 1}^n {{{{\mathbf{C}}}_{k}}{{x}_{k}}({{\boldsymbol{\lambda} }^{j}})} } \right)} \right]}\nolimits_ + \)
5: \({{\boldsymbol{\lambda} }^{{t + 1}}}: = {{\tau }_{t}}{{{\mathbf{z}}}^{t}} + (1 - {{\tau }_{t}}){{{\mathbf{y}}}^{t}}\)
6: \({{{\mathbf{\hat {x}}}}^{{t + 1}}}: = \tfrac{1}{{{{A}_{{t + 1}}}}}\sum\nolimits_{j = 0}^{t + 1} {{{\alpha }_{j}}{\mathbf{x}}({{\boldsymbol{\lambda} }^{{\mathbf{j}}}})} \)
7: end for
8: return \({{\boldsymbol{\lambda} }^{N}}\), \({{{\mathbf{\hat {x}}}}^{N}}\)
3.1 Distributed Method
The problem under consideration can also be solved using the distributed version of FGM, which means that each link can compute an optimal data transmission rate only relying on the reactions of the users that employ this link without interacting with the other links.
The process occurring at the \(t\)th iteration for link \(j\) can be described as follows.
1. Given information received from the users after the preceding iteration with index \(t - 1\) (vector \({{{\mathbf{x}}}^{t}} = {\mathbf{x}}({{\boldsymbol{\lambda} }^{t}})\)), the link \(j\) computes
Here, \(C_{k}^{j} \ne 0\) only for users employing the link \(j\). Therefore, to compute this step, the link needs only information from the users employing this link.
2. Similarly, the link \(j\) computes
3. After obtaining values at two preceding steps, link \(j\) computes the price for the next iteration \(t + 1\):
and sends out this information to all users connected to it.
4. The users compute the optimal data transmission rates \({{{\mathbf{\hat {x}}}}^{{t + 1}}}\); specifically, for user \(k\), we obtain
where, by the definition of the matrix \(C\), the user needs only data from the links it employs. Next, the user computes the optimal rate
Remark 1. A disadvantage of this algorithm is that each link has to know the reactions of all users that employ it at every iteration step. Unfortunately, in actual networks, users do not transmit data simultaneously, so it is rather difficult to collect this information for the link. However, if complete information on the users is available, the link can establish an equilibrium price more quickly.
3.2 Estimation of the Convergence Rate of FGM
Before proving the convergence of FGM for the problem under consideration, we state the key lemma necessary for estimating the residuals in the constraints and the duality gap after running PDFGM.
Lemma 1. Suppose that Algorithm 1 starts at an initial point \({{\boldsymbol{\lambda} }^{0}}\) lying in the Euclidean ball of radius \(R\) centered at the origin. Then, after performing \(N\) iterations of Algorithm 1, it holds that
where \({{{\mathbf{\hat {x}}}}^{N}} = \tfrac{1}{{{{A}_{N}}}}\sum\nolimits_{t = 0}^{N - 1} {{{\alpha }_{t}}{\mathbf{x}}({{\boldsymbol{\lambda} }^{t}})} \) and \(\hat {R} = 3R\).
The proof of the lemma can be found in the Appendix.
Now we formulate a theorem on the convergence rate estimate for Algorithm 1.
Theorem 1. Suppose that Algorithm 1 starts at an initial point \({{\boldsymbol{\lambda} }^{0}}\) lying in the Euclidean ball of radius \(R\) centered at the origin. Then, after performing
iterations of Algorithm 1, it holds that
where \({{{\mathbf{\hat {x}}}}^{N}} = \tfrac{1}{{{{A}_{N}}}}\sum\nolimits_{t = 0}^{N - 1} {{{\alpha }_{t}}{\mathbf{x}}({{\boldsymbol{\lambda} }^{t}})} \), \({\mathbf{x}}\text{*}\) is an optimal solution of problem (1), and \(\hat {R} = 3R\).
Proof. Let \(\operatorname{Opt} [P]\) denote the optimal value in the original primal problem (1), and let \(\operatorname{Opt} [D]\) denote the optimal value in the dual problem (4). By the weak duality, we have
Moreover, for all \({\mathbf{x}} \in \mathbb{R}_{ + }^{n}\), the optimal solution \(\boldsymbol{\lambda} \text{*}\) of dual problem (4) satisfies
Then
Substituting the last inequality into (6) yields the estimate
Consequently, \(\varphi ({{{\mathbf{y}}}^{N}}) - U({{{\mathbf{\hat {x}}}}^{N}}) \geqslant - \tfrac{{37L{{{\hat {R}}}^{2}}}}{{9{{A}_{N}}}}\). On the other hand, it follows from (6) that \(\varphi ({{{\mathbf{y}}}^{N}}) - U({{{\mathbf{\hat {x}}}}^{N}}) \leqslant \tfrac{{37L{{{\hat {R}}}^{2}}}}{{9{{A}_{N}}}}\). Therefore,
Since \(\varphi ({{{\mathbf{y}}}^{N}}) \geqslant \operatorname{Opt} [D] = \varphi ({\mathbf{y}}\text{*}) \geqslant \operatorname{Opt} [P] = U({\mathbf{x}}\text{*})\), we have
Expressing \(N\) from the last inequality gives the estimate from the condition of the theorem.
4 STOCHASTIC PROJECTED SUBGRADIENT METHOD
Consider the original problem (1), now assuming that the utility functions \({{u}_{k}}({{x}_{k}})\), \(k = 1, \ldots ,n\), are concave, but not strongly concave. In this case, dual problem (4) becomes nonsmooth. Accordingly, for its solution, we propose the stochastic projected subgradient method. For the first time, the idea of using this method for solving the given problem was proposed in [2].
Consider the probability space \(\left( {\Omega ,\mathcal{F},\mathbb{P}} \right)\). Suppose that a sequence of independent random variables \(\{ {{\xi }^{t}}\} _{{t = 0}}^{\infty }\) uniformly distributed on \(\{ 1, \ldots ,n\} \) is defined on \(\left( {\Omega ,\mathcal{F},\mathbb{P}} \right)\), i.e.,
If there is an oracle producing the stochastic subgradient of the dual function \(\nabla \varphi (\boldsymbol{\lambda} ,\xi )\), i.e.,
then
Algorithm 2. Primal-Dual Stochastic Projected Subgradient Method (PDSPSGM), Version 1
Input: \({{u}_{k}}({\mathbf{x}}),\) \(k = 1, \ldots ,n\), are concave utility functions for each user, and \(\beta \) is the step of the method.
1: \({{\boldsymbol{\lambda} }^{0}}: = 0\)
2: for \(t = 1, \ldots ,N - 1\)
3: Compute \(\nabla \varphi ({{\boldsymbol{\lambda} }^{{t - 1}}},\xi )\)
4: \({{\boldsymbol{\lambda} }^{t}}: = {{[{{\boldsymbol{\lambda} }^{{t - 1}}} - \beta ({\mathbf{b}} - n{{C}_{{{{\xi }^{{t - 1}}}}}}{{x}_{{{{\xi }^{{t - 1}}}}}}({{\boldsymbol{\lambda} }^{{t - 1}}}))]}_{ + }}\)
5: \({{{\mathbf{\hat {x}}}}^{{t + 1}}}: = \tfrac{1}{{t + 1}}\sum\nolimits_{j = 0}^t {{\mathbf{x}}({{\boldsymbol{\lambda} }^{j}})} \)
6: \({{\hat {\boldsymbol{\lambda} }}^{{t + 1}}}: = \tfrac{1}{{t + 1}}\sum\nolimits_{j = 0}^t {{{\boldsymbol{\lambda} }^{j}}} \)
7: end for
8: return \({{\hat {\boldsymbol{\lambda} }}^{N}},\;{{{\mathbf{\hat {x}}}}^{N}}\)
Therefore, the stochastic subgradient is an unbiased estimator of the subgradient.
An optimal solution of problem (2) is sought using PDSPSGM. We describe two versions of this method (see Algorithms 2 and 3). Algorithm 2 relies on a complete model of reconstructing the vector \({\mathbf{x}}(\boldsymbol{\lambda} )\) at every iteration. However, the computation of \({\mathbf{x}}(\boldsymbol{\lambda} )\) is nearly equivalent in complexity to the computation of a complete subgradient of \(\varphi (\boldsymbol{\lambda} )\). Therefore, the basic algorithm is Algorithm 3, in which the vector \({\mathbf{x}}(\boldsymbol{\lambda} )\) is reconstructed using an incomplete stochastic model, which means that only one component of the vector \({\mathbf{x}}(\boldsymbol{\lambda} )\) is updated at every iteration step, while the others remain unchanged. In the proof of the convergence theorem, we first establish the convergence estimate for Algorithm 2 and then show that the approximate solution of the primal problem produced by Algorithm 3 is close in accuracy to the solution obtained using Algorithm 2.
Algorithm 3. Primal-Dual Stochastic Projected Subgradient Method (PDSPSGM), Version 2
Input: \({{u}_{k}}({\mathbf{x}}),\) \(k = 1, \ldots ,n\), are concave utility functions for each user, and \(\beta \) is the step of the method.
1: \({{\boldsymbol{\lambda} }^{0}}: = 0\)
2: for \(t = 1, \ldots ,N - 1\)
3: Compute \(\nabla \varphi ({{\boldsymbol{\lambda} }^{{t - 1}}},\xi )\)
4: \({{\boldsymbol{\lambda} }^{t}}: = {{[{{\boldsymbol{\lambda} }^{{t - 1}}} - \beta ({\mathbf{b}} - n{{C}_{{{{\xi }^{{t - 1}}}}}}{{x}_{{{{\xi }^{{t - 1}}}}}}({{\boldsymbol{\lambda} }^{{t - 1}}}))]}_{ + }}\)
5: \({\mathbf{\tilde {x}}}_{{{{\xi }^{t}}}}^{{t + 1}}: = \tfrac{t}{{t + 1}}{\mathbf{\tilde {x}}}_{{{{\xi }^{t}}}}^{t} + \tfrac{1}{{t + 1}}n{{x}_{{{{\xi }^{t}}}}}({{\lambda }^{t}})\), \({\mathbf{\tilde {x}}}_{j}^{{t + 1}}: = {\mathbf{\tilde {x}}}_{j}^{t}\) for \(j \ne {{\xi }^{t}}\)
6: \({{\hat {\boldsymbol{\lambda} }}^{{t + 1}}}: = \tfrac{1}{{t + 1}}\sum\nolimits_{j = 0}^t {{{\boldsymbol{\lambda} }^{j}}} \)
7: end for
8: return \({{\hat {\boldsymbol{\lambda} }}^{N}},\;{{{\mathbf{\tilde {x}}}}^{N}}\)
4.1 Distributed Method
Let us describe how the distributed version of the stochastic projected subgradient method can be applied for solving the problem under consideration.
The process occurring at the \(t\)th iteration for link \(j\) is as follows:
1. Given the information received from the links after the preceding iteration with index \(t - 1\), the random user \({{\xi }^{t}}\) transmits data at the optimal rate
where, by the definition of the matrix \(C,\) the information required for the user is only from the links used by the user.
2. The link \(j\) computes the price for the next iteration based on the reaction of this user:
Here, \(C_{{{{\xi }^{t}}}}^{j} \ne 0\) only for users employing link \(j.\) Therefore, the price changes only for actual links of the user transmitting data.
Remark 2. The main advantage of this method is that the link changes the price relying only on the reactions of a single user, which makes the problem formulation much closer to the situation occurring in actual networks, where users do not transmit data simultaneously.
4.2 Estimation of the Convergence Rate of the Stochastic Projected Subgradient Method
Before proving the main theorem on convergence rate estimates for the proposed methods, we state the necessary assumptions for the problem under study. Assume that there exists a positive constant \(M = O(n\sqrt m )\) such that
This assumption holds, since the data transmission rate \({\mathbf{x}}\) is bounded and the capacity vector \({\mathbf{b}}\) is bounded as well in view of the physical considerations. Therefore, by its definition, the stochastic subgradient is also bounded.
Additionally, we assume that
where \(\sigma \) is a positive numerical constant and the order of dependence on \(n\) and \(m\) is the same as for \(M\).
To estimate the convergence rate of Algorithm 3, it is necessary to assume that \({{u}_{k}}({{x}_{k}}),k = 1, \ldots ,n\), are Lipschitz continuous functions with constant \({{M}_{{{{u}_{k}}}}}\). Then \(U({\mathbf{x}})\) is a Lipschitz continuous function with a constant \({{M}_{U}}\):
where \({{M}_{U}} = O(\sqrt n )\). It may happen that \({{u}_{k}}({{x}_{k}})\) is a Lipschitz continuous function everywhere, except, for instance, the point \(0\). An example of such a function is \({{u}_{k}}({{x}_{k}}) = \ln{{x}_{k}}\), which is one of the most widespread utility functions. However, by the specific features of the problem, there always exist \(\bar {\varepsilon } > 0\) and \(\underline \varepsilon > 0\) such that \(x_{k}^{*} \geqslant \underline \varepsilon \) and \(x_{k}^{*} \leqslant \bar {\varepsilon }\). Then the problem can be solved on the compact set \(Q = \left\{ {{\mathbf{x}}:\underline \varepsilon \leqslant {{x}_{k}} \leqslant \bar {\varepsilon },\;k = 1, \ldots ,n} \right\}\), and the considered function \({{u}_{k}}({{x}_{k}}) = \ln{{x}_{k}}\) becomes Lipschitz continuous on \(Q\). In the general case, a concave utility function \(u(x)\) is Lipschitz continuous on a compact set lying in the relative interior of the domain of \(u(x)\).
Suppose that
where \({{\sigma }_{x}} = O(\sqrt n )\) is a positive numerical constant and
Below is the key lemma necessary for obtaining convergence rate estimates for the residual in the constraints and the duality gap after running PDSPSGM.
Lemma 2. Suppose that Algorithm 3 starts at the initial point \({{\boldsymbol{\lambda} }^{0}} = 0\) with a step \(\beta \). Then, after performing \(N\) iterations of Algorithm 3, with probability 1 – 4\(\delta \),
where
\({{C}_{1}}\) is a positive numerical constant, \(g(N) = \ln\left( {\tfrac{N}{\delta }} \right) + \ln\ln\left( {\tfrac{F}{f}} \right)\),
\(f = {{\sigma }^{2}}{{R}^{2}}\),
and \(R\) is determined by the condition \({{\left\| {\boldsymbol{\lambda} \text{*}} \right\|}_{2}} \leqslant R\).
The proof of the lemma can be found in the Appendix.
Now we formulate a theorem on the convergence rate estimate for Algorithm 3.
Theorem 2. Suppose that Algorithm 3 starts at the initial point \({{\boldsymbol{\lambda} }^{0}} = 0\) with step \(\beta = \tfrac{R}{{M\sqrt N }}\). Define
Then, after performing
iterations of Algorithm 3, with probability 1 – 4\(\delta \),
where \({{{\mathbf{\tilde {x}}}}^{N}} = \tfrac{1}{N}\sum\nolimits_{t = 0}^{N - 1} {{\mathbf{x}}({{\boldsymbol{\lambda} }^{t}},{{\xi }^{t}})} \) and \({\mathbf{x}}\text{*}\) is an optimal solution of problem (1).
Proof. The beginning of the proof is the same as for Theorem 1, but we use the estimate from Lemma 2. As a result, for the step \(\beta = \tfrac{R}{{M\sqrt N }}\), we obtain
moreover, up to constants, \(g(N) \approx \ln\left( {\tfrac{N}{\delta }} \right)\) and \(J \approx \max\left\{ {1,\beta \sqrt {g(N)} } \right\}\). Next, we find \(N\) for which the estimate becomes less than \(\varepsilon \).
We introduce the following notation:
It is necessary to obtain the minimum estimate on the iteration number \(N\) required for achieving the prescribed accuracy \(\varepsilon \). For \(J = 1\), we obtain
Substituting \(N\) recursively, we derive from (9) the complexity bound
For \(J = \beta \sqrt {g(N)} = \tfrac{{R\sqrt {g(N)} }}{{M\sqrt N }}\), we assume that
Since the minimum \(N\) is needed, replacing the last inequality with equality and solving the resulting equation, we obtain
By analogy with the case \(J = 1\), this equality yields the estimate
The worst of the complexity bounds for \(J = 1\) and \(J = \beta \sqrt {g(N)} \) is the estimate from the condition of the theorem.
5 ELLIPSOID METHOD
In this section, the original problem (1) is solved by applying the ellipsoid method [25]. This method can be used when the dual problem has a low dimension (\(m\)) or when high accuracy of the solution is required. The method is primal-dual, i.e., the solution of the primal problem can be recovered from the solution of the dual problem.
Consider the original problem (1) and its dual (2). As in the preceding section, the functions \({{u}_{k}}({{x}_{k}})\), \(k = 1, \ldots ,n\), are assumed to be concave, but not strongly concave. Additionally, we assume that the solution of the dual problem lies in the Euclidean ball of radius \(R\) centered at the origin, i.e., \({{\left\| {\boldsymbol{\lambda} \text{*}} \right\|}_{2}} \leqslant R\). As an initial point of the method, we use the zero vector \({{\boldsymbol{\lambda} }^{0}} = 0\). The problem is solved on the set
Let us describe the ellipsoid method (Algorithm 4), which is used to solve the dual problem.
Algorithm 4. Ellipsoid Method
Input: \({{u}_{k}}({{x}_{k}}),k = 1, \ldots ,n\), are concave utility functions
1: \({{B}_{0}}: = 2R \cdot {{I}_{n}}\), \({{I}_{n}}\) is the identity matrix
2: for \(t = 0, \ldots ,N - 1\)
3: Compute \(\nabla \varphi ({{\boldsymbol{\lambda} }^{t}})\)
4: \({{{\mathbf{q}}}_{t}}: = B_{t}^{{\text{T}}}\nabla \varphi ({{\boldsymbol{\lambda} }^{t}})\)
5: \({{{\mathbf{p}}}_{t}}: = \frac{{B_{t}^{{\text{T}}}{{{\mathbf{q}}}_{t}}}}{{\sqrt {{\mathbf{q}}_{t}^{{\text{T}}}{{B}_{t}}B_{t}^{{\text{T}}}{{{\mathbf{q}}}_{t}}} }}\)
6: \({{B}_{{t + 1}}}: = \frac{m}{{\sqrt {{{m}^{2}} - 1} }}{{B}_{t}} + \left( {\frac{m}{{m + 1}} - \frac{m}{{\sqrt {{{m}^{2}} - 1} }}} \right){{B}_{t}}{{{\mathbf{p}}}_{t}}{\mathbf{p}}_{t}^{{\text{T}}}\)
7: \({{\lambda }^{{t + 1}}}: = {{\lambda }^{t}} - \frac{1}{{m + 1}}{{B}_{t}}{{{\mathbf{p}}}_{t}}\)
8: end for
9: return \({{\boldsymbol{\lambda} }^{N}}\)
To reconstruct the solution of the primal problem from the solution of the dual one, it is necessary to determine the accuracy certificate \(\xi \) for the ellipsoid method. Recall that the accuracy certificate is a sequence of weights \(\xi = \{ {{\xi }_{t}}\} _{{t = 0}}^{{N - 1}}\) such that
In our case, the accuracy certificate is constructed in the course of running the ellipsoid method (see Algorithm 5); its general scheme can be described as follows [26].
1. Find the “narrowest strip” containing the ellipsoid \({{Q}_{N}}\) remaining after iteration \(N\), i.e., a vector \({\mathbf{h}}\) such that the following inequality holds on \({{Q}_{N}}\):
For the ellipsoid method, all \({{Q}_{N}}\) are represented in the form
Then, to solve (10), we need to perform a singular value decomposition \({{B}_{N}} = UDV,\) where \(U\) and \(V\) are orthogonal matrices and \(D\) is a diagonal matrix with positive diagonal elements. Next, the desired vector \({\mathbf{h}}\) is determined as \({\mathbf{h}} = 1{\text{/}}(2{{\sigma }^{i}}\text{*}) \cdot U{{{\mathbf{e}}}^{i}}\text{*}\), where \({{i}_{*}}\) is the index of the smallest diagonal element of \(D\), \({{\sigma }^{i}}\text{*}\) is the value of this element, and \({{{\mathbf{e}}}^{i}}\) are the vectors of the standard basis.
2. For the vectors \({{{\mathbf{h}}}^{ + }} = \left[ {{\mathbf{h}}, - \left\langle {{\mathbf{h}},{{\boldsymbol{\lambda} }^{N}}} \right\rangle } \right]\) and \({{{\mathbf{h}}}^{ - }} = - {{{\mathbf{h}}}^{ + }}\), find expansions of the form
their existence follows from Proposition 4.1 in [26]. This step is described by Steps 6–13 in Algorithm 5 (see below).
3. From the expansion coefficients \({{\nu }_{t}}\) and \({{\mu }_{t}}\) of the vectors \({{{\mathbf{h}}}^{ + }}\) and \({{{\mathbf{h}}}^{ - }}\), respectively, derive expressions for \({{\xi }_{t}},\;t \in {{I}_{N}}\), where
Expansion coefficients are determined only for feasible points obtained in the course of running Algorithm 5.
Algorithm 5. Construction of the Accuracy Certificate for the Ellipsoid Method
Input: \(N - 1\) is the number of the iteration at which the accuracy certificate is computed, and \(\mathop {\left\{ {{{B}_{t}},{{\boldsymbol{\lambda} }^{t}},\nabla \varphi ({{\boldsymbol{\lambda} }^{t}})} \right\}}\nolimits_{t = 0}^{N - 1} \) is the work protocol of the ellipsoid method after \(N\) iterations
1: if \(\nabla \varphi ({{\boldsymbol{\lambda} }^{{N - 1}}}) = 0,\) then
2: \({{\xi }_{t}}: = 0\) for all \(t = 0, \ldots ,N - 2\)
3: \({{\xi }_{{N - 1}}}: = 1\)
4: otherwise
5: \({\mathbf{h}}: = 1{\text{/}}(2{{\sigma }^{i}}\text{*}) \cdot U{{{\mathbf{e}}}^{i}}\text{*}\)
6: \({{{\mathbf{g}}}_{\nu }}: = {\mathbf{h}},\) \({{{\mathbf{g}}}_{\mu }}: = - {\mathbf{h}}\)
7: for \(t = 0, \ldots ,N - 1\)
8: \({\mathbf{q}}: = B_{t}^{{\text{T}}}\nabla \varphi ({{\lambda }^{t}})\)
9: \({{\nu }_{t}}: = {{[{\mathbf{g}}_{\nu }^{{\text{T}}}{{B}_{t}}{\mathbf{q}}]}_{ + }}{\text{/}}\left\| {\mathbf{q}} \right\|_{2}^{2}\)
10: \({{{\mathbf{g}}}_{\nu }}: = {{{\mathbf{g}}}_{\nu }} - {{\nu }_{t}}\nabla \varphi ({{\boldsymbol{\lambda} }^{t}})\)
11: \({{\mu }_{t}}: = {{[{\mathbf{g}}_{\mu }^{{\text{T}}}{{B}_{t}}{\mathbf{q}}]}_{ + }}{\text{/}}\left\| {\mathbf{q}} \right\|_{2}^{2}\)
12: \({{{\mathbf{g}}}_{\mu }}: = {{{\mathbf{g}}}_{\mu }} - {{\mu }_{t}}\nabla \varphi ({{\boldsymbol{\lambda} }^{t}})\)
13: end for
14: \({{\xi }_{t}}: = ({{\nu }_{t}} + {{\mu }_{t}}){\text{/}}\sum\nolimits_{i \in {{I}_{N}}}^{} {({{\nu }_{i}} + {{\mu }_{i}})} ,\) \(t \in {{I}_{N}}\)
15: end if
16: return \(\mathop {\left\{ {{{\xi }_{t}}} \right\}}\nolimits_{t = 0}^{N - 1} \)
Remark 3. In contrast to FGM and the stochastic projected subgradient method, the computation of Steps 4–6 of Algorithm 4 in the ellipsoid method requires information about all gradient components, i.e., information from all users. Accordingly, it is necessary to have a common center for all links that collects information from them and performs these computations.
An estimate for the convergence rate of the ellipsoid method for the problem under study is provided by the following result.
Theorem 3 (see [26]). Suppose that Algorithm 4 starts from the initial ball \({{B}_{0}} = \{ \boldsymbol{\lambda} \in {{\mathbb{R}}^{m}}:\left\| \boldsymbol{\lambda} \right\| \leqslant 2R\} \) and the accuracy certificate \(\xi \) is produced by Algorithm 5. Then, after performing
iterations, it is true that
where
The proof of this theorem can be found in the Appendix.
6 REGULARIZATION OF THE DUAL PROBLEM
In previous sections, we considered primal-dual methods for solving the dual problem. However, there is a standard approach in which the solution of the primal problem can be recovered from the solution of the dual problem without using primal-dual methods. The key idea of this approach is a regularization of the dual problem such that the resulting regularized problem is strongly convex. In what follows, we describe this approach in detail and state lemmas relating the solutions of the primal and dual problems.
Functional (2) is regularized in the sense of Tikhonov:
and, instead of problem (4), we solve the regularized problem
An optimal parameter \(\delta \) will be specified later. As in Section 5, we assume that the problem is solved on the set
For the resulting regularized function, we formulate the following lemma on the smoothness of the regularized problem.
Lemma 3. Suppose that the function \(\varphi (\boldsymbol{\lambda} )\) is \(L\)-smooth. Then the regularized function \({{\varphi }_{\delta }}(\boldsymbol{\lambda} )\) is \((L + \delta )\)-smooth, i.e., for any \({{\boldsymbol{\lambda} }^{1}}\), \({{\boldsymbol{\lambda} }^{2}} \in {\mathbf{R}}_{ + }^{m}\),
Proof. The gradient of the regularized function is given by
Therefore, we have
By Proposition 2, this estimate implies (12).
Additionally, to estimate the convergence of the algorithm for the primal problem, we need the following auxiliary lemma concerning the relationship between the gradient estimate for the dual problem and convergence estimates with respect to the function and the residual in the constraint for the primal problem.
Lemma 4 (see [10]). Let \({\mathbf{x}}\text{*}\) be a solution of primal problem (1). Then
where \({\mathbf{x}}(\boldsymbol{\lambda} )\) is defined by (3).
Proof. By virtue of (3), we have
whence
Since \(\varphi (\boldsymbol{\lambda} ) = {{\varphi }_{\delta }}(\boldsymbol{\lambda} ) - \tfrac{\delta }{2}\left\| \boldsymbol{\lambda} \right\|_{2}^{2}\), it is true that
Combining this inequality with the relation \(\nabla \varphi (\boldsymbol{\lambda} ) = {\mathbf{b}} - C{\mathbf{x}}(\boldsymbol{\lambda} )\) yields (13).
Furthermore, estimate (14) follows from
Additionally, we need the following result concerning convergence with respect to the gradient of the regularized function.
Lemma 5. Let \(\boldsymbol{\lambda} _{\delta }^{*}\) be a solution of the regularized dual problem. Then
The proof follows immediately from Lemma 3 and the relation
We have formulated the lemmas necessary for the regularized problem. An example of applying this approach is considered in the next section.
7 RANDOM GRADIENT EXTRAPOLATION METHOD
Consider the random gradient extrapolation method [27]. Note that this method does not require updating the gradient at every iteration step. It is necessary to update only one of its components at every iteration, which considerably reduces the computations, especially for large-scale problems. Since this method is not primal-dual, Algorithm 6 has to be applied to the regularized problem.
The parameters \(\alpha \), \(\eta \), \(\tau \), and \({{\theta }_{t}}\) are specified as
7.1 Distributed Method
This section presents a distributed version of the considered method. By way of introduction, we note that the vectors \(\mathop {\underline {\boldsymbol{\lambda}} }\nolimits_1^0 , \ldots ,\mathop {\underline {\boldsymbol{\lambda}} }\nolimits_n^0 \) are stored by the corresponding users and influence the formation of optimal data traffic for the corresponding user. As was noted in the description of the distributed FGM, the optimal traffic for a user is influenced only by the prices of the links through which this user exchanges packets. Therefore, we can assume that the only nonzero components in the vector \(\mathop {\underline {\boldsymbol{\lambda}} }\nolimits_k^t \) are those whose indices coincide with the indices of the used links.
Algorithm 6. Random Gradient Extrapolation Method (RGEM)
Input: Parameters \(\alpha \), \(\eta \), \(\tau \), \(\{ {{\theta }_{t}}\} _{{t = 1}}^{N}\)
1: \({{{\boldsymbol{\lambda}} }^{0}}: = {\mathbf{0}}\)
2: \(\mathop {\underline {\boldsymbol{\lambda}} }\nolimits_i^0 : = {{{\boldsymbol{\lambda}} }^{0}}\), \(i = 1, \ldots ,n\)
3: \({{y}_{{ - 1}}} = {{y}_{0}} = {\mathbf{0}}\)
4: for \(t = 1, \ldots ,N\)
5: Choose \({{k}_{t}}\) at random from the set \(\{ 1, \ldots ,n\} \) uniformly over all values
6: \({\mathbf{\tilde {y}}}_{k}^{t}: = {\mathbf{y}}_{k}^{{t - 1}} + \alpha ({\mathbf{y}}_{k}^{{t - 1}} - {\mathbf{y}}_{k}^{{t - 2}}),\) \(k = 1, \ldots ,n\)
7: \({{{\boldsymbol{\lambda}} }^{t}}: = \mathop {\left[ {\eta {{{\boldsymbol{\lambda}} }^{{t - 1}}} - \tfrac{1}{n}\sum\nolimits_{k = 1}^n {{\mathbf{\tilde {y}}}_{k}^{t}} } \right]}\nolimits_ + {\text{/}}(\delta + \eta )\)
8:
9: \(\mathop {\underline {\boldsymbol{\lambda}} }\nolimits_{{{k}_{t}}}^t : = ({{{\boldsymbol{\lambda}} }^{t}} + \tau \mathop {\underline {\boldsymbol{\lambda}} }\nolimits_{{{k}_{t}}}^{t - 1} ){\text{/}}(1 + \tau )\)
10: \(\mathop {\underline {\boldsymbol{\lambda}} }\nolimits_k^t : = \mathop {\underline {\boldsymbol{\lambda}} }\nolimits_k^{t - 1} \), \(k \in \{ 1, \ldots ,n\} {{\backslash }}\{ {{k}_{t}}\} \)
11:
12: \({\mathbf{y}}_{{{{k}_{t}}}}^{t}: = {\mathbf{b}} - n{{{\mathbf{C}}}_{{{{k}_{t}}}}}{{x}_{{{{k}_{t}}}}}(\mathop {\underline {\boldsymbol{\lambda}} }\nolimits_{{{k}_{t}}}^t )\)
13: \({\mathbf{y}}_{k}^{t}: = {\mathbf{y}}_{k}^{{t - 1}}\), \(k \in \{ 1, \ldots ,n\} {{\backslash }}\{ {{k}_{t}}\} \)
14: end for
15: \({{\bar {{\boldsymbol{\lambda}} }}^{N}}: = \left( {\sum\nolimits_{t = 0}^{N - 1} {{{\theta }_{t}}{{{\boldsymbol{\lambda}} }^{t}}} } \right){\text{/}}\sum\nolimits_{t = 1}^N {{{\theta }_{t}}} \)
16: return \({{\bar {{\boldsymbol{\lambda}} }}^{N}}\)
Let us describe the distributed algorithm at the \(t\)th iteration.
1. Using information collected from the users at the preceding iteration, link \(j\) computes
Note that, by the definition of the matrix \(C,\) link \(j\) needs information only from the users exchanging packets through this link.
2. The price of link \(j\) changes according to the rule
3. One of the users, \({{k}_{t}}\), reacts to the price change and stores the local price vector
while the local prices for the other users remain unchanged, i.e., \(\mathop {\underline {\boldsymbol{\lambda}} }\nolimits_{{{k}_{t}}}^t = \mathop {\underline {\boldsymbol{\lambda}} }\nolimits_{{{k}_{t}}}^{t - 1} \).
4. The user \({{k}_{t}}\) computes
and transmits this information to the used links.
5. Link \(j\) updates the information for the user \({{k}_{t}}\):
This information is updated by the link only if the user \({{k}_{t}}\) exchanges packets through it.
7.2 Estimation of the Convergence Rate of RGEM
Following Section 3, we consider problem (2) with \(\mu \)-strongly concave cost functions \({{u}_{k}}({{x}_{k}}),k = 1, \ldots ,n\). Recall that, since the cost functions are strongly concave, the dual problem (4) is smooth with Lipschitz constant \(L = \tfrac{{n{{m}^{2}}}}{\mu }\).
To estimate the convergence rate of the method, we need the estimate for the residual with respect to the argument from Theorem 2.1 in [27], namely,
where \(\Delta = \delta \left\| {{\boldsymbol{\lambda}} _{\delta }^{*} - {{{\boldsymbol{\lambda}} }^{0}}} \right\|_{2}^{2} + \tfrac{B}{{n\delta }} + {{\varphi }_{\delta }}({{\lambda }^{0}}) - {{\varphi }_{\delta }}(\lambda _{\delta }^{*})\) and \(B = \left\| {\mathbf{b}} \right\|_{2}^{2}\).
By using (17), it is possible to prove the following convergence estimate theorem for the method as applied to problem (11).
Theorem 4. Suppose that the regularized dual problem (11) is solved by applying RGEM with parameters (15), (16), and \(\delta = \tfrac{\varepsilon }{{8{{R}^{2}}}}\) and with
iterations, where \(A = 2\left( {LR + \tfrac{\varepsilon }{{8R}}} \right)\sqrt {6 + \tfrac{{16L{{R}^{2}}n + 8B}}{{n\varepsilon }}} \). Then
Proof. Lemma 4 implies estimate (13) for the residual with respect to the constraints and estimate (14) for the residual with respect to the objective function. By the assumption \({\boldsymbol{\lambda}} \in {{\Lambda }_{{2R}}}\), we have
where \({{{\mathbf{x}}}^{N}} = {\mathbf{x}}({{{\boldsymbol{\lambda}} }^{N}})\). Combining Lemma 5 with inequality (17) yields the following estimate for \({{\left\| {\nabla {{\varphi }_{\delta }}({{{\boldsymbol{\lambda}} }^{N}})} \right\|}_{2}}\):
Let us estimate \(\Delta \). The function \({{\varphi }_{\delta }}\) with a Lipschitz continuous gradient satisfies the inequality
Since \(\nabla {{\varphi }_{\delta }}({\boldsymbol{\lambda}} _{\delta }^{*}) = 0\), we obtain
Suppose that \(\delta \) is chosen so that \(4\delta {{R}^{2}} = \tfrac{\varepsilon }{2}\). Then \(\delta = \tfrac{\varepsilon }{{8{{R}^{2}}}}\). It follows that
Assume that \(U({\mathbf{x}}\text{*}) - U({\mathbf{x}}({{{\boldsymbol{\lambda}} }^{N}})) \leqslant \varepsilon \). Then, by virtue of (18) and (19), it is true that
whence
Taking into account
we obtain the following estimate for the number of iterations:
where \(A = 2\left( {LR + \tfrac{\varepsilon }{{8R}}} \right)\sqrt {6 + \tfrac{{16L{{R}^{2}}n + 8B}}{{n\varepsilon }}} \).
Remark 4. The complexity bound for Algorithm 6 can also be represented in the form \(O\left( {\max\left\{ {n,\sqrt {nL{{R}^{2}}{\text{/}}\varepsilon } } \right\}\ln\left( {\tfrac{1}{\varepsilon }} \right)} \right)\), where the logarithmic factor appears due to the necessity of regularization of the dual problem. At every iteration, only one component of the user reaction vector to changed prices is computed; accordingly, the arithmetic complexity of the operation is better than that in the case of computing all components of these vectors. For FGM, the assumptions made about the objective function are similar, but, since the complete gradient has to be computed at every iteration step, the complexity bound for the algorithm is \(O\left( {n\sqrt {L{{R}^{2}}{\text{/}}\varepsilon } } \right)\). Thus, although the theoretical convergence estimate for RGEM has the same order as for FGM, in practice the gain is obtained due to the cheaper computations within a single iteration.
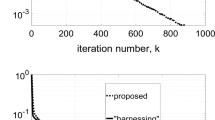
8 NUMERICAL EXPERIMENTS
The software code for numerical experiments was written in Python 3.6 and C++14. The source code for experiments and the methods considered in this paper is available at https://github.com/dmivilensky/network-resource-allocation. The running time was measured on a computer with a 2-core Intel Core i5-5250U 1.6 GHz processor and 8 GB RAM.
8.1 Strongly Convex (Quadratic) Utility Functions
Consider problem (1) for utility functions of the form
where \({{a}_{k}}\) are independent identically distributed random variables. Then problem (3) can be solved explicitly:
For a small number of users (\(n = 1500\)), the link capacities are chosen identical (in this case, \({\mathbf{b}} = (5, \ldots ,5)^{\text{T}}\)), and the demand for data transmission is uniform (\({{c}_{{ij}}} = 1\) for any \(i,j\)). For a larger number of users, the capacity vector is generated at random, so that \({{b}_{i}} \sim \mathcal{U}(1,6)\). The elements of the demand matrix are also chosen randomly and independently, so that \({{c}_{{ij}}} = 1\) with probability \(p = 0.5\) and \({{c}_{{ij}}} = 0\) with probability \(q = 0.5\).
Table 1 presents the number of iterations and the running times of the fast gradient method (FGM) and the random gradient extrapolation method (RGEM) for various network configurations (with \(m\) links), various numbers of users \(n\), and various values of the required accuracy \(\varepsilon \). The cases in which RGEM converges to the solution faster than FGM, despite the larger number of iterations than in FGM, are highlighted in the table. Indeed, for \(n \gg 0\), RGEM requires fewer queries for the optimal solution \({{x}_{k}}({\boldsymbol{\lambda}} )\) from users than in other algorithms, since a query at one RGEM iteration is sent to only one random user.
8.2 Convex (Logarithmic) Utility Functions
Consider the performance of the stochastic subgradient method (Algorithm 2) and the ellipsoid method (Algorithm 4) for the utility function
In this case, an explicit solution of problem (3) is given by
(the operation \(1/ \cdot \) as applied to a vector is understood elementwise). For a small number of users (\(n = 1500\)), the link capacities are chosen identical (in this case, \({\mathbf{b}} = {{(5, \ldots ,5)}^{{\text{T}}}}\)) and the demand for data transmission is uniform (\({{c}_{{ij}}} = 1\) for any \(i,j\)). For a larger number of users, the capacity vector is randomly generated, so that \({{b}_{i}} \sim \mathcal{U}(1,6)\). The elements of the demand matrix are also chosen randomly and independently, so that \({{c}_{{ij}}} = 1\) with probability \(p = 0.5\) and \({{c}_{{ij}}} = 0\) with probability \(q = 0.5\).
Table 2 presents the number of iterations and the running times of the stochastic subgradient method (SGM) and the ellipsoid method for various network configurations, various numbers of users, and various values of the required accuracy. The cases in which SGM converges to the solution faster than the ellipsoid method are highlighted in the table.
Note that, as in RGEM, only one component of the user reaction vector \({\mathbf{x}}({\boldsymbol{\lambda}} )\) to established prices has to be computed at every iteration in SGM. Thus, when the number of iterations of the method is large, the number of computed components \({{x}_{k}}({{{\boldsymbol{\lambda}} }^{t}})\) is smaller than in other algorithms, for example, in the ellipsoid method, and the same is true of the communication complexity in the case of distributed implementation.
9 CONCLUSIONS
To conclude, we note some possible directions of development of this work and briefly describe suitable methods without detailed analysis of their convergence estimates.
In Section 5, as applied to low-dimensional problems, we considered the ellipsoid method, which is primal-dual. There are other methods that are highly accurate and well suited for low-dimensional problems. An example is Vaidya’s cutting plane method [28]. However, to recover the solution of the primal problem when the dual one is solved using Vaidya’s method, we need convergence in the gradient norm for the dual problem. For this purpose, the dual problem has to be smooth, which is ensured by the strong convexity of the objective function in the primal problem (Proposition 2). If the primal problem is not strongly convex, it can be regularized as described in Section 6, but the convergence estimate will then degrade logarithmically.
Additionally, if the dual problem is sufficiently smooth, it can be solved by applying high-order methods [29, 30]. The steps of these methods can be computed on a distributed basis, since the given problem makes use of a centralized architecture in terms of the interaction of a link and the users using it. Note, however, that high-order optimal methods that require linesearch and do not have the primal-dual property apply to only preliminarily regularized dual problems.
Another direction is represented by variance reduced methods (see, e.g., [31, 32]), which are intermediate between the stochastic gradient method and FGM. However, these methods are not primal-dual either, so they apply to preliminarily regularized dual problems.
Of special interest are the Hogwild! method [33] and minibatching techniques. In this case, data are sent out not by all users simultaneously, but by more than one of them, in contrast to stochastic methods. By setting the size of the batch equal to the number of users transmitting data at a time, one can take into account the specific features of actual networks.
REFERENCES
F. P. Kelly, A. K. Maulloo, and D. K. H. Tan, “Rate control for communication networks: Shadow prices, proportional fairness, and stability,” J. Oper. Res. Soc. 49, 237–252 (1998).
D. B. Rokhlin, “Resource allocation in communication networks with large number of users: The stochastic gradient descent method” (2019). https://arxiv.org/abs/1905.04382
K. J. Arrow and L. Hurwicz, Decentralization and Computation in Resource Allocation (Department of Economics, Stanford Univ., Stanford, CA, 1958).
A. Kakhbod, Resource Allocation in Decentralized Systems with Strategic Agents: An Implementation Theory Approach (Springer Science & Business Media, New York, 2013).
D. E. Campbell, Resource Allocation Mechanisms (Cambridge Univ. Press, Cambridge, 1987).
E. J. Friedman and S. S. Oren, “The complexity of resource allocation and price mechanisms under bounded rationality,” Econ. Theory 6, 225–250 (1995).
Yu. Nesterov and V. Shikhman, “Dual subgradient method with averaging for optimal resource allocation,” Eur. J. Oper. Res. 270, 907–916 (2018).
A. Ivanova, P. Dvurechensky, A. Gasnikov, and D. Kamzolov, “Composite optimization for the resource allocation problem” (2018). arXiv preprint arXiv:1810.00595
Yu. E. Nesterov, “Method of minimizing convex functions with convergence rate \(O(1{\text{/}}{{k}^{2}})\),” Dokl. Akad. Nauk SSSR 269 (3), 543–547 (1983).
A. V. Gasnikov, E. V. Gasnikova, Yu. E. Nesterov, and A. V. Chernov, “Efficient numerical methods for entropy-linear programming problems,” Comput. Math. Math. Phys. 56, 514–524 (2016).
A. Chernov, P. Dvurechensky, and A. Gasnikov, “Fast primal-dual gradient method for strongly convex minimization problems with linear constraints,” Discrete Optimization and Operations Research: Proceedings of the 9th International Conference, DOOR 2016, Vladivostok, Russia, September 19–23, 2016 (Springer International, Berlin, 2016), pp. 391–403.
P. Dvurechensky, A. Gasnikov, E. Gasnikova, S. Matsievsky, A. Rodomanov, and I. Usik, “Primal-dual method for searching equilibrium in hierarchical congestion population games,” Supplementary Proceedings of the 9th International Conference on Discrete Optimization and Operations Research and Scientific School (DOOR 2016) Vladivostok, Russia, September 19–23, 2016, pp. 584–595. arXiv:1606.08988
A. Anikin, A. Gasnikov, A. Turin, and A. Chernov, “Dual approaches to the minimization of strongly convex functionals with a simple structure under affine constraints,” Comput. Math. Math. Phys. 57, 1262–1276 (2017).
P. Dvurechensky, A. Gasnikov, and A. Kroshnin, “Computational optimal transport: Complexity by accelerated gradient descent is better than by Sinkhorn’s algorithm,” Proceedings of the 35th International Conference on Machine Learning (2018), Vol. 80, pp. 1367–1376. arXiv:1802.04367
Yu. Nesterov, A. Gasnikov, S. Guminov, and P. Dvurechensky, “Primal-dual accelerated gradient methods with small-dimensional relaxation oracle” (2018). arXiv:1809.05895
S. Guminov, P. Dvurechensky, and A. Gasnikov, “On accelerated alternating minimization” (2019). arXiv:1906.03622
S. V. Guminov, Yu. E. Nesterov, P. E. Dvurechensky, and A. V. Gasnikov, “Accelerated primal-dual gradient descent with linesearch for convex, nonconvex, and nonsmooth optimization problems,” Dokl. Math. 99, 125–128 (2019).
A. Kroshnin, N. Tupitsa, D. Dvinskikh, P. Dvurechensky, A. Gasnikov, and C. A. Uribe, “On the complexity of approximating Wasserstein barycenters,” Proceedings of the 36th International Conference on Machine Learning, Ed. by K. Chaudhuri and R. Salakhutdinov (PMLR, California, US, 2019), Vol. 97, pp. 3530–3540. arXiv:1901.08686
C. A. Uribe, D. Dvinskikh, P. Dvurechensky, A. Gasnikov, and A. Nedich, “Distributed computation of Wasserstein barycenters over networks,” 2018 IEEE Conference on Decision and Control (CDC) (2018), pp. 6544–6549. arXiv:1803.02933
D. Dvinskikh, E. Gorbunov, A. Gasnikov, P. Dvurechensky, and C. A. Uribe, “On primal and dual approaches for distributed stochastic convex optimization over networks,” 2019 IEEE Conference on Decision and Control (CDC) (2019). arXiv:1903.09844
P. Dvurechensky, D. Dvinskikh, A. Gasnikov, C. A. Uribe, and A. Nedic, “Decentralize and randomize: Faster algorithm for Wasserstein barycenters,” Adv. Neural Inf. Process. Syst. 31, 10783–10793 (2018). arXiv:1806.03915
D. M. Danskin, Theory of Maximin (Sovetskoe Radio, Moscow, 1970) [in Russian].
V. F. Demyanov and V. N. Malozemov, Introduction to Minimax (Nauka, Moscow, 1972; Wiley, New York, 1974).
Yu. Nesterov, “Smooth minimization of nonsmooth functions,” Math. Program. 103, 127–152 (2005).
D. B. Yudin and A. S. Nemirovski, “Information complexity and efficient methods for solving convex optimization problems,” Ekon. Mat. Metody, No. 2, 357–369 (1976).
A. Nemirovski, S. Onn, and U. G. Rothblum, “Accuracy certificates for computational problems with convex structure,” Math. Oper. Res. 35, 52–78 (2010).
G. Lan and Y. Zhou, “Random gradient extrapolation for distributed and stochastic optimization,” SIAM J. Optim. 28, 2753–2782 (2018).
S. Bubeck, “Convex optimization: Algorithms and complexity,” Found. Trends Mach. Learn. 8 (3–4), 231–357 (2015).
Yu. Nesterov, “Implementable tensor methods in unconstrained convex optimization,” Tech. Rep. (Universite catholique de Louvain, Center for Operations Research and Econometrics (CORE), 2018).
A. Gasnikov, P. Dvurechensky, E. Gorbunov, E. Vorontsova, D. Selikhanovych, C. A. Uribe, B. Jiang, H. Wang, S. Zhang, S. Bubeck, Q. Jiang, Y. T. Lee, Y. Li, and A. Sidford, “Near optimal methods for minimizing convex functions with Lipschitz pth derivatives,” Proceedings of the Thirty-Second Conference on Learning Theory (2019), Vol. 99, pp. 1392–1393. http://proceedings.mlr.press/v99/gasnikov19b.html
K. Zhou, F. Shang, and J. Cheng, “A simple stochastic variance reduced algorithm with fast convergence rates” (2018). arXiv preprint arXiv:1806.11027
K. Zhou, “Direct acceleration of SAGA using sampled negative momentum” (2018). arXiv preprint arXiv:1806.11048
F. Niu, B. Recht, C. Re, and S. J. Wright, “Hogwild: A lock-free approach to parallelizing stochastic gradient descent,” in Advances in Neural Information Processing Systems (2011), pp. 693–701.
C. Jin, P. Netrapalli, R. Ge, S. M. Kakade, and M. I. Jordan, “A short note on concentration inequalities for random vectors with subgaussian norm” (2019). arXiv preprint arXiv:1902.03736
A. Juditsky and A. Nemirovski, “Large deviations of vector-valued martingales in 2-smooth normed spaces,” Tech. Rep. (2008). http://hal.archives-ouvertes.fr/hal-00318071
Yu. Nesterov, Lectures on Convex Optimization, 2nd ed. (Springer, 2018).
Yu. E. Nesterov, Doctoral Dissertation in Mathematics and Physics (Moscow Inst. of Physics and Technology, Dolgoprudnyi, 2013).
A. Beck, Introduction to Nonlinear Optimization: Theory, Algorithms, and Applications with MATLAB (SIAM, Philadelphia, 2014).
Funding
Gasnikov’s research was supported by the Russian Foundation for Basic Research, grant no. 18-31-20005 mol_a_ved and 19-31-51001 Scientific mentoring. Dvurechensky’s research was supported by the Russian Foundation for Basic Research, grant no. 18-29-03071 mk. Vorontsova’s research was supported by the Ministry of Science and Higher Education of the Russian Federation (state assignment no. 075-00337-20-03), project no. 0714-2020-0005.
Author information
Authors and Affiliations
Corresponding author
Additional information
Translated by I. Ruzanova
APPENDIX
APPENDIX
1.1 Auxiliary Results
Below are some lemmas from other works that are used in the proofs. Additionally, we prove assertions concerning the properties of the dual function that are used in the proof of the main theorems.
Lemma 6 (see [34], Lemma 2). For a random vector \(\xi \in {{{\mathbf{R}}}^{n}}\), the following assertions are equivalent up to a constant multiplying \(\sigma \):
1. Tails: \(\mathbb{P}\left\{ {{{{\left\| \xi \right\|}}_{2}} \geqslant \gamma } \right\} \leqslant 2\exp\left( { - \tfrac{{{{\gamma }^{2}}}}{{2{{\sigma }^{2}}}}} \right)\) \(\forall \gamma \geqslant 0\).
2. Moments: \({{(\mathbb{E}{\kern 1pt} [{{\xi }^{p}}])}^{{1/p}}} \leqslant \sigma \sqrt p \) for any positive integer \(p\).
3. Light-tail assumption: \(\mathbb{E}\left[ {\exp\left( {\tfrac{{\left\| \xi \right\|_{2}^{2}}}{{{{\sigma }^{2}}}}} \right)} \right] \leqslant \exp(1)\).
Lemma 7 (see [34, Corollary 8]). Let \(\{ {{\xi }^{k}}\} _{{k = 1}}^{N}\) be a sequence of random vectors from \({{{\mathbf{R}}}^{n}}\) such that for \(k = 1, \ldots ,N\) and any \(\gamma \geqslant 0\),
where \(\sigma _{k}^{2}\) belongs to \(\sigma ({{\xi }^{1}}, \ldots ,{{\xi }^{{k - 1}}})\) for all \(k = 1, \ldots ,N.\) Let \({{S}_{N}} = \sum\nolimits_{k = 1}^N {{{\xi }^{k}}} .\) Then there exists a constant \({{C}_{1}}\) such that, for any fixed \(\delta > 0\) and \(B > b > 0\), with probability \(1 - \delta \)
Lemma 8 (see [35, corollary to Theorem 2.1, case (ii)]). Suppose that a sequence \(\{ {{\xi }^{k}}\} _{{k = 1}}^{N}\) of random vectors from \({{{\mathbf{R}}}^{n}}\) satisfies the condition
and let \({{S}_{N}} = \sum\nolimits_{k = 1}^N {{{\xi }^{k}}} \). Assume that the sequence\(\{ {{\xi }^{k}}\} _{{k = 1}}^{N}\) satisfies the light-tail assumption
where \({{\sigma }_{1}}, \ldots ,{{\sigma }_{N}}\) are positive numbers. Then, for all \(\gamma \geqslant 0\),
Proof of Proposition 2. The dual function is represented in the form
Proposition 1 implies that
Define
The necessary maximum conditions of the first order are written as
Adding these inequalities yields
Since \({{u}_{k}}({{x}_{k}})\) is strongly concave, for any \(x_{k}^{1}\) and \(x_{k}^{2}\), \(k = 1, \ldots ,n\), we have
whence
Then the following estimate can be obtained for all gradient components \(\nabla {{\varphi }_{k}}\):
The matrix \(C\), in view of its structure, satisfies the estimate \({{\left\| {{{{\mathbf{C}}}_{k}}} \right\|}_{2}} \leqslant m\). Then the gradient of the dual function satisfies
Proof of Lemma 1. First, we state and prove a technical lemma.
Define \({{d}_{L}}({\boldsymbol{\lambda}} ) = \tfrac{L}{2}\left\| {{\boldsymbol{\lambda}} - {{{\boldsymbol{\lambda}} }^{0}}} \right\|_{2}^{2}\) and consider the sequences
and
where \({{\{ {{{\boldsymbol{\lambda}} }^{j}}\} }_{{j \geqslant 0}}}\) is the sequence of points generated by Algorithm 1.
Lemma 9. After executing \(N\) steps of Algorithm 1, it is true that
Proof. Inequality (A.20) is proved by induction. At \(t = 0\), (A.20) is true. Indeed,

where  holds, since \({{\alpha }_{0}} = 1{\text{/}}2 \leqslant 1\), while
holds, since \({{\alpha }_{0}} = 1{\text{/}}2 \leqslant 1\), while  holds, since the function \(\varphi (\lambda )\) has a Lipschitz continuous gradient (see Proposition 2 and [36, Lemma 1.2.3]). Thus, \({{A}_{0}}\varphi ({{{\mathbf{y}}}^{0}}) = \tfrac{1}{2}\varphi ({{{\mathbf{y}}}^{0}}) \leqslant {{\psi }_{0}}\).
holds, since the function \(\varphi (\lambda )\) has a Lipschitz continuous gradient (see Proposition 2 and [36, Lemma 1.2.3]). Thus, \({{A}_{0}}\varphi ({{{\mathbf{y}}}^{0}}) = \tfrac{1}{2}\varphi ({{{\mathbf{y}}}^{0}}) \leqslant {{\psi }_{0}}\).
Assume that (A.20) holds for \(t\):
Let us prove that (A.20) holds for \(t + 1\). Indeed, we have


where  holds, since the prox-function \(\tfrac{1}{2}\left\| {{\boldsymbol{\lambda}} - {{{\boldsymbol{\lambda}} }^{0}}} \right\|_{2}^{2}\) is strongly convex and in view of the properties of the extremum at the point \({{{\mathbf{z}}}^{t}}\);
holds, since the prox-function \(\tfrac{1}{2}\left\| {{\boldsymbol{\lambda}} - {{{\boldsymbol{\lambda}} }^{0}}} \right\|_{2}^{2}\) is strongly convex and in view of the properties of the extremum at the point \({{{\mathbf{z}}}^{t}}\);  follows from (A.21); and
follows from (A.21); and  holds in view of the convexity of the function \(\varphi ({\boldsymbol{\lambda}} )\).
holds in view of the convexity of the function \(\varphi ({\boldsymbol{\lambda}} )\).
Since the FGM coefficients \({{A}_{t}}\) and \({{\alpha }_{t}}\) are related by the equalities \({{A}_{{t + 1}}} = \sum\nolimits_{j = 0}^{t + 1} {{{\alpha }_{j}}} = {{A}_{t}} + {{\alpha }_{{t + 1}}}\) and \({{\tau }_{t}} = {{\alpha }_{{t + 1}}}{\text{/}}{{A}_{{t + 1}}}\), the relation \({{{\boldsymbol{\lambda}} }^{{t + 1}}} = {{\tau }_{t}}{{{\mathbf{z}}}^{t}} + (1 - {{\tau }_{t}}){{{\mathbf{y}}}^{t}}\) from Algorithm 1 can be rewritten as
Using the last relations, we can make the following transformations:
Then
After replacing the last expression in (A.22) by (A.23), we can use an extended version of the Fenchel inequality for conjugate functions [37], namely,
where \(\mathbb{E}\) is a finite-dimensional real vector space, \(\mathbb{E}\text{*}\) is the space of linear functions on \(\mathbb{E}\) (dual space), and the norm in the dual space is given by \({{\left\| {\mathbf{g}} \right\|}_{*}} = \mathop {\max}\limits_{\mathbf{x}} \{ \left\langle {{\mathbf{g}},{\mathbf{x}}} \right\rangle \,{\text{|}}\,{{\left\| {\mathbf{x}} \right\|}_{E}} = 1\} \). In our case, \({\mathbf{g}} = \nabla \varphi ({{\lambda }^{{t + 1}}})\), \({\mathbf{s}} = \lambda - {{{\mathbf{z}}}^{t}}\), \(\xi = \tfrac{L}{{{{\alpha }_{{t + 1}}}}}\). Therefore,
To complete the proof of the lemma, we need to show that \({{A}_{{t + 1}}}\varphi ({{{\mathbf{y}}}^{{t + 1}}})\) is smaller than the right-hand side of inequality (A.24).
Since the function \(\varphi ({\boldsymbol{\lambda}} )\) is \(L\)-smooth (see Proposition 2),
Multiplying both sides of the resulting inequality by \({{A}_{{t + 1}}}\) yields
Since the FGM coefficients satisfy \(\alpha _{{t + 1}}^{2} \leqslant {{A}_{{t + 1}}}\), we obtain
Therefore, by virtue of (A.24) and (A.25), \({{A}_{{t + 1}}}\varphi ({{{\mathbf{y}}}^{{t + 1}}}) \leqslant {{\psi }_{{t + 1}}}({{{\mathbf{z}}}^{{t + 1}}})\), as required.
Proof of Lemma 1. Define the set
where \(\hat {R}\) is defined by the inequalities
All \({{{\boldsymbol{\lambda}} }^{t}}\) belong to \({{\Lambda }_{{2\hat {R}}}}\), since
where the second inequality was obtained taking into account that \({{\left\| {{{{\boldsymbol{\lambda}} }^{t}} - {\boldsymbol{\lambda}} \text{*}} \right\|}_{2}} \leqslant {{\left\| {{\boldsymbol{\lambda}} \text{*} - \;{{{\boldsymbol{\lambda}} }^{0}}} \right\|}_{2}}\) for \(t = 0,1, \ldots \) .
The last inequality can be proved as follows. For any \({\boldsymbol{\lambda}} \in {\mathbf{R}}_{ + }^{m}\), by Lemma 9 and the strong convexity of the function \({{\psi }_{t}}({\boldsymbol{\lambda}} )\) with a constant \(L\), it is true that
Since the function \(\varphi ({\boldsymbol{\lambda}} )\) is convex, the last expression in (A.26) can be estimated from above as \({{A}_{t}}\varphi ({\boldsymbol{\lambda}} ) + \tfrac{L}{2}\left\| {{\boldsymbol{\lambda}} - {{{\boldsymbol{\lambda}} }^{0}}} \right\|_{2}^{2}\). Then, for \({\boldsymbol{\lambda}} = {\boldsymbol{\lambda}} \text{*}\),
Therefore,
Since \({{{\mathbf{y}}}^{t}}\) in Algorithm 1 is determined by a gradient projection step for a convex function \(\varphi ({\boldsymbol{\lambda}} )\), the sequence of points \({{{\mathbf{y}}}^{t}}\), \(t = 0,1, \ldots \), generated by the algorithm is bounded (the proof of this fact can be found, e.g., in [38, Lemma 9.17, p. 183] or in [28, p. 265]):
Furthermore,
Combining this inequality with (A.27) and (A.28) yields the required result:
By Lemma 9,

where ① holds, since
Applying the definitions of the dual objective function \(\varphi ({{{\boldsymbol{\lambda}} }^{t}})\) (see (2)) and of its gradient \(\nabla \varphi ({{{\boldsymbol{\lambda}} }^{t}})\) (see Proposition 1) yields
where the last the inequality holds, since the utility functions are concave.
Thus,
which yields estimate (6).
Proof of Lemma 2. First, we prove several auxiliary technical lemmas.
Lemma 10. Let \(A,B\), and \(\{ {{r}_{t}}\} _{{t = 0}}^{N}\) be nonnegative numbers such that, for any \(l = 1, \ldots ,N,\)
Then
where \(C\) is a positive constant satisfying \({{C}^{2}} \geqslant \max\{ 1,2A + 2BC\sqrt N \} \), i.e., for example, it is possible to use
Proof. Relation (A.31) is proved by induction. For \(l = 0\), this inequality holds, since \(C \geqslant 1\). Assuming that (A.31) holds for all \(l < N,\) we prove that it holds for \(l + 1\) as well. Indeed,
Lemma 11. Suppose that sequences of nonnegative coefficients \({{\{ {{R}_{t}}\} }_{{t \geqslant 0}}}\) and random vectors \({{\{ {{{\boldsymbol{\eta }}}^{t}}\} }_{{t \geqslant 0}}}\) and \({{\{ {{{\mathbf{a}}}^{t}}\} }_{{t \geqslant 0}}}\) are such that, for all \(l = 1, \ldots ,N,\)
where \(A\) is a nonnegative constant, \(d \geqslant 1\) is a positive constant, \({{\left\| {{{{\mathbf{a}}}^{t}}} \right\|}_{2}} \leqslant {{\widetilde R}_{t}}d\) and \({{\widetilde R}_{t}} = \max\{ {{\widetilde R}_{{t - 1}}},{{R}_{t}}\} \) for all \(t \geqslant 1\), \({{\widetilde R}_{0}} = {{R}_{0}}\), and \({{\widetilde R}_{t}}\) depends only on \({{{\boldsymbol{\eta }}}^{0}}, \ldots ,{{{\boldsymbol{\eta }}}^{t}}\). Additionally, suppose that \({{{\mathbf{a}}}^{t}}\) is a function of \({{{\boldsymbol{\eta }}}^{0}}, \ldots ,{{{\boldsymbol{\eta }}}^{{t - 1}}}\) \(\forall t \geqslant 1\), \({{a}^{0}}\) is a constant vector, and, for any \(t \geqslant 0\),
Then, with probability \(1 - 2\delta \), the inequalities
hold for all \(l = 1, \ldots ,N\) simultaneously, where \(D\) is a positive constant,
\(f = {{d}^{2}}{{\sigma }^{2}}\widetilde R_{0}^{2}\), \(g(N) = \ln\left( {\tfrac{N}{\delta }} \right) + \ln\ln\left( {\tfrac{F}{f}} \right)\), and
Proof. The Cauchy–Schwarz inequality is applied to the second term on the right-hand side of (A.32):
By Theorem 2.1 from [35], we have
Then, with probability at least
it holds that
Indeed, expressing \(\gamma \) from (A.35) yields \(\gamma = \sqrt {3\ln\tfrac{N}{\delta }} \). Plugging this expression into (A.34) and substituting a unified \(\sigma \in {{{\mathbf{R}}}_{ + }}\) for the sequence \({{\sigma }_{t}}\), \(t = 0, \ldots ,N - 1\), we obtain estimate (A.36).
Combining the resulting inequalities, we see that, with probability greater than or equal to \(1 - \delta \), the inequality
holds for all \(l = 1, \ldots ,N\) simultaneously. Note that the last term in this estimate is a nondecreasing function of \(l\). Define \(\hat {l}\) as the largest integer for which \(\hat {l} \leqslant l\) and \({{\widetilde R}_{{tl}}} = {{R}_{{\hat {l}}}}\). Then \({{R}_{{\hat {l}}}} = {{\widetilde R}_{{\hat {l}}}} = {{\widetilde R}_{{\hat {l} + 1}}} = \ldots = {{\widetilde R}_{l}}\) and, hence, with probability \( \geqslant {\kern 1pt} 1 - \delta \),
As a result, with probability \( \geqslant {\kern 1pt} 1 - \delta \), we have the estimate
Applying this estimate recursively, we conclude that, with probability \( \geqslant {\kern 1pt} 1 - \delta \),
Next, consider the sequence of random variables \({{\xi }^{t}} = \left\langle {{{{\boldsymbol{\eta }}}^{t}},{{{\mathbf{a}}}^{t}}} \right\rangle \). Note that \(\mathbb{E}{\kern 1pt} [{{\xi }^{t}}\,{\text{|}}\,{{\xi }^{0}}, \ldots ,{{\xi }^{{t - 1}}}] = \left\langle {\mathbb{E}{\kern 1pt} [{{{\boldsymbol{\eta }}}^{t}}\,{\text{|}}\,{{{\boldsymbol{\eta }}}^{0}}, \ldots ,{{{\boldsymbol{\eta }}}^{{k - 1}}}],{{{\mathbf{a}}}^{t}}} \right\rangle = 0\). Then, using the Cauchy–Schwarz inequality yields
Define \(\hat {\sigma }_{t}^{2} = {{\sigma }^{2}}{{d}^{2}}\widetilde R_{t}^{2}\). Then, with probability \( \geqslant 1 - \delta \), it is true that
for all \(l = 1, \ldots ,N\) simultaneously, where
Using Corollary 8 from [34] for \(b = \hat {\sigma }_{0}^{2}\), we see that, for any \(l = 1, \ldots ,N\) with probability \( \geqslant {\kern 1pt} 1 - \tfrac{\delta }{N}\),
where \({{C}_{1}} > 0\) is a constant independent of \(F\) or \(f\).
Combining the resulting estimates, we conclude that, with probability \( \geqslant {\kern 1pt} 1 - \delta \), estimate (A.37) holds for all \(l = 1, \ldots ,N\) simultaneously.
Taking into account the choice of \(F\), with probability \( \geqslant {\kern 1pt} 1 - 2\delta \), the estimate
holds for all \(l = 1, \ldots ,N\) simultaneously.
For convenience in what follows, we introduce \(g(N): = \ln\left( {\tfrac{N}{\delta }} \right) + \ln\ln\left( {\tfrac{F}{f}} \right) \approx \ln\left( {\tfrac{N}{\delta }} \right)\), neglecting the constant. Using \(\hat {\sigma }_{t}^{2} = {{\sigma }^{2}}{{d}^{2}}\widetilde R_{t}^{2}\), we find that, with probability \( \geqslant {\kern 1pt} 1 - 2\delta \), the estimate
holds for all \(l = 1, \ldots ,N\) simultaneously. After choosing \(A = \tfrac{A}{{\widetilde R_{0}^{2}}}\), \(B = \tfrac{1}{{{{{\widetilde R}}_{0}}}}ud{{C}_{1}}\sqrt {{{\sigma }^{2}}g(N)} \), and \({{r}_{t}} = {{\widetilde R}_{t}}\), Lemma 10 implies that, with probability \(1 - 2\delta \),
for all \(l = 1, \ldots ,N\) simultaneously, where
It follows that, with probability \(1 - 2\delta \), the estimate
holds for all \(l = 1, \ldots ,N\) simultaneously.
Proof of Lemma 2. For \({\boldsymbol{\lambda }} \in {\mathbf{R}}_{ + }^{m}\)
i.e.,
Adding \(\varphi ({{\boldsymbol{\lambda} }^{t}})\) to both sides of inequality (A.39), multiplying it by \(N\), and summing the result from \(0\) to \(N - 1\), we obtain
Since \(\varphi (\boldsymbol{\lambda} )\) is convex, for \({{\hat {\boldsymbol{\lambda} }}^{N}} = \tfrac{1}{N}\sum\limits_{t = 0}^{N - 1} \,{{\boldsymbol{\lambda} }^{t}}\), we have
Setting \(\boldsymbol{\lambda} = \boldsymbol{\lambda} \text{*}\) and adding and subtracting \(\sum\nolimits_{t = 0}^{N - 1} \,\left\langle {\nabla \varphi ({{\boldsymbol{\lambda} }^{t}}),\boldsymbol{\lambda} \text{*} - \;{{\boldsymbol{\lambda} }^{t}}} \right\rangle \) on the right-hand side, we obtain
The convexity of \(\varphi (\boldsymbol{\lambda} )\) implies that
Substituting this estimate into (A.42) yields
Define \({{R}_{t}} = {{\left\| {{{\boldsymbol{\lambda} }^{t}} - \boldsymbol{\lambda} \text{*}} \right\|}_{2}}\) and \({{\widetilde R}_{t}} = \max \{ {{\widetilde R}_{{t - 1}}},{{R}_{t}}\} \), where \({{R}_{0}} = {{\widetilde R}_{0}}\). Since \({{\boldsymbol{\lambda} }^{0}} = {\mathbf{0}}\) and \({{\left\| {\boldsymbol{\lambda} \text{*}} \right\|}_{2}} \leqslant R\), we have \({{R}_{0}} = R\). Moreover, by construction, \({{\boldsymbol{\lambda} }^{t}} \in {{B}_{{{{{\widetilde R}}_{t}}}}}(\boldsymbol{\lambda} \text{*})\). In a similar manner, we define \({{\left\| {{{{\mathbf{a}}}^{t}}} \right\|}_{2}} = {{\left\| {{{\boldsymbol{\lambda} }^{t}} - \boldsymbol{\lambda} \text{*}} \right\|}_{2}} \leqslant {{\widetilde R}_{t}}\). Then (A.43) can be rewritten as
Define \({{\eta }^{t}} = \nabla \varphi ({{\boldsymbol{\lambda} }^{t}},{{\xi }^{t}}) - \nabla \varphi ({{\boldsymbol{\lambda} }^{t}})\). By Theorem 2.1 from [35],
Using Lemma 2 from [34], we obtain
where \({{\eta }^{t}}\) depends only on \({{\xi }^{{t - 1}}}, \ldots ,{{\xi }^{0}}\). Using the new notation and (8), we have
Then, by Lemma 11 with constants \(A = \widetilde R_{0}^{2} + {{\beta }^{2}}{{M}^{2}}\), \(d = 1\), and \(u = \beta \), we conclude that, with probability \(1 - 2\delta \), where \(\tfrac{\delta }{N} = \exp\left( { - \tfrac{{{{\gamma }^{2}}}}{3}} \right)\), the estimates
hold for all \(l = 1, \ldots ,N\) simultaneously, where \(D\) is a positive constant,
\(f = {{\sigma }^{2}}\widetilde R_{0}^{2}\), \(g(N) = \ln\left( {\tfrac{N}{\delta }} \right) + \ln\ln\left( {\tfrac{F}{f}} \right)\), and
To estimate the duality gap, we use (A.41), noting that this estimate holds for any \(\boldsymbol{\lambda} \in {\mathbf{R}}_{ + }^{m}\). Therefore, taking the minimum over all \(\boldsymbol{\lambda} \) from the set \({{\Lambda }_{{2R}}} = \left\{ {\boldsymbol{\lambda} \in \mathbb{R}_{ + }^{m}:{{{\left\| \boldsymbol{\lambda} \right\|}}_{2}} \leqslant 2R} \right\}\) yields
where the last term was estimated using assumption (8). Additionally, the inequality \(\left\| {{{\boldsymbol{\lambda} }^{N}} - \boldsymbol{\lambda} } \right\|_{2}^{2} \geqslant 0\) was taken into account. By virtue of (A.29), we obtain the estimate
Adding and subtracting \(\sum\nolimits_{t = 0}^{N - 1} {\left\langle {\nabla \varphi ({{\boldsymbol{\lambda} }^{t}}),\boldsymbol{\lambda} - {{\boldsymbol{\lambda} }^{t}}} \right\rangle } \) from the expression under the minimum sign yields
Note that \( - \boldsymbol{\lambda} \text{*} \in {{\Lambda }_{{2R}}}\). Then we have
It follows that
The definition of the norm implies that
Using (A.44), we conclude that, with probability \(1 - \delta \),
Substituting the values of \(\varphi ({{\boldsymbol{\lambda} }^{t}})\) and \(\nabla \varphi ({{\boldsymbol{\lambda} }^{t}})\) into the expression \(\sum\limits_{t = 0}^{N - 1} {\left( {\varphi ({{\boldsymbol{\lambda} }^{t}}) + \left\langle {\nabla \varphi ({{\boldsymbol{\lambda} }^{t}}),\boldsymbol{\lambda} - {{\boldsymbol{\lambda} }^{t}}} \right\rangle } \right)} \) in (A.46) yields
Then, since the functions \({{u}_{k}}({{x}_{k}})\) are concave, it holds that
Combining this inequality with (A.46) gives
From this, taking into account estimate (A.47) and result (A.44), we see that, with probability \(1 - 3\delta \),
By Theorem 2.1 in [35], for all \(\gamma > 0\), it is true that
Setting \(\gamma = \sqrt {3\ln\tfrac{1}{\delta }} \), we conclude that, with probability \(1 - \delta \),
Then, with probability \(1 - \delta \),
Note that
Since the function \(U\) is Lipschitz continuous, we obtain
Then
Substituting (A.49) and (A.50) into (A.48), we conclude that, with probability \(1 - 4\delta \),
Proof of Theorem 3. Since \({{\left\| {\nabla \varphi l{\lambda} )} \right\|}_{2}} \leqslant M\) for any \(\boldsymbol{\lambda} \in {{\Lambda }_{{2R}}}\) (see (5)), we have the estimate
Theorem 4.1 from [26] yields
where \({{\varepsilon }_{N}} = 32 \times 4MR\exp\left\{ { - \tfrac{N}{{2m(m + 1)}}} \right\}\). Then
It follows that
which can be rewritten as
Next, by virtue of (3), for each \({\mathbf{x}} \geqslant 0\) and \(t \in {{I}_{N}}\), we have
Multiplying the \(t\)th inequality by \({{\xi }^{t}}\), summing the result over all indices from \({{I}_{N}}\), and taking into account that \(\sum\nolimits_{t \in {{I}_{N}}} {{{\xi }^{t}}U({{{\mathbf{x}}}^{t}}) \leqslant U({{{{\mathbf{\hat {x}}}}}^{N}})} \) and the functions \({{u}_{k}}({{x}_{k}})\), \(k = 1, \ldots ,N\), are concave, we obtain
where \({{\hat {\boldsymbol{\lambda} }}^{N}} = \sum\limits_{t \in {{I}_{N}}} \,{{\xi }^{t}}{{\boldsymbol{\lambda} }^{t}}\). Using estimate (A.51), we derive
Since \({{\hat {\boldsymbol{\lambda} }}^{N}} \in {{\Lambda }_{{2R}}}\) and, hence, \({{\hat {\boldsymbol{\lambda} }}^{N}} \geqslant 0\), whence \(\left\langle {{\mathbf{b}} - C{\mathbf{x}}{\kern 1pt} {\text{*}}{{{\hat {\boldsymbol{\lambda} }}}^{N}}} \right\rangle \geqslant 0\), it follows from (A.51) that \(U({\mathbf{x}}\text{*}) - U({{{\mathbf{\hat {x}}}}^{N}}) \leqslant {{\varepsilon }_{N}}\). Furthermore, since, by the definition of \(\boldsymbol{\lambda} \text{*}\), \(U({\mathbf{x}}\text{*}) \geqslant U({\mathbf{x}}) - \left\langle {\boldsymbol{\lambda} \text{*},C{\mathbf{x}} - {\mathbf{b}}} \right\rangle \) for all \({\mathbf{x}} \geqslant 0\), we obtain
Combining this relation with (A.52) yields \(R{{\left\| {{{{[C{{{{\mathbf{\hat {x}}}}}^{N}} - {\mathbf{b}}]}}_{ + }}} \right\|}_{2}} \leqslant {{\varepsilon }_{N}}\). Estimate (11) for the number of iterations of the method follows from the continued inequality
Rights and permissions
About this article

Cite this article
Vorontsova, E.A., Gasnikov, A.V., Dvurechensky, P.E. et al. Numerical Methods for the Resource Allocation Problem in a Computer Network. Comput. Math. and Math. Phys. 61, 297–328 (2021). https://doi.org/10.1134/S0965542521020135
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1134/S0965542521020135