
Abstract
This paper investigates the impact of big data on deep learning models to help solve the full waveform inversion (FWI) problem. While it is well known that big data can boost the performance of deep learning models in many tasks, its effectiveness has not been validated for FWI. To address this gap, we present an empirical study that investigates how deep learning models in FWI behave when trained on openfwi, a collection of large-scale, multi-structural, synthetic datasets published recently. In particular, we train and evaluate the FWI models on a combination of 10 2D subsets in openfwi that contain 470 K pairs of seismic data and velocity maps in total. Our experiments demonstrate that training on the combined dataset yields an average improvement of 13.03% in MAE, 7.19% in MSE and 1.87% in SSIM compared to each split dataset, and an average improvement of 28.60%, 21.55% and 8.22% in the leave-one-out generalization test. We further demonstrate that model capacity needs to scale in accordance with data size for optimal improvement, where our largest model yields an average improvement of 20.06%, 13.39% and 0.72% compared to the smallest one.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Introduction
The recent advancements of deep learning in natural language processing and computer vision have proven that big data is one of the key ingredients for obtaining good performance1,2,3,4. Similarly, in the context of science, deep learning models such as AlphaFold5 have achieved significant breakthroughs with the help of large-scale datasets. However, unlike these tasks, large-scale public datasets are not always available for many other scientific problems due to issues such as high data acquisition costs, labeling costs, intellectual property concerns, or security concerns. Due to limited dataset sizes and variation, deep learning models in scientific applications are often limited in their ability to generalize well to out-of-sample datasets.
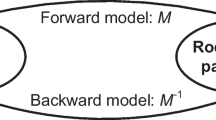
Full waveform inversion (FWI) is a technique used to image the subsurface that has the potential to benefit from deep learning and large training datasets. Specifically, FWI aims to reconstruct subsurface velocity maps v from seismic measurements p as depicted in Fig. 1. Conventional FWI methods6,7,8,9,10,11,12,13,14,15,16,17,18,19,20 leverage the forward operator f governed by a partial differential equation (PDE) and perform iterative optimization per sample, which is computationally expensive and yields poor scalability. To mitigate this issue, deep learning techniques have been recently introduced to FWI and achieved promising performance21,22,23,24,25,26. A good summary of deep learning techniques for solving FWI problems can be found in Lin et al.27. In this paper, we follow the previous studies27,28,29 and refer network-based FWI methods as data-driven methods. Inspired by the image-to-image translation task in computer vision, these data-driven methods directly learn an inverse mapping \(f^{-1}\) from seismic data directly to velocity maps. Nevertheless, due to the issue of lacking large-scale public datasets, the models in prior works were all developed on relatively small datasets (i.e. 130 to 67K data pairs)28,29,30. Thus, the question remains open: does full waveform inversion benefit from big data? Thankfully, the recently published large-scale datasets openfwi31 provide us an opportunity to start to answer this question.
In this paper, we present an empirical study that attempts to answer the question of whether FWI benefits from large-scale and multi-structural training datasets from three perspectives: model performance, the relationship between the model size and data size, and model generalization. openfwi is a collection of large-scale, multi-structural datasets that cover different domain interests, including interfaces, geological faults, and field data. We employ 10 2D synthetic datasets from openfwi, and 408K/62K pairs of seismic data and velocity maps are used to train and evaluate the deep learning models, respectively. We adopt one of the openfwi benchmark models InversionNet28 to serve as the baseline, and we compare the inversion results of the baselines trained on relatively small-scale individual datasets and the models trained on large-scale datasets that are composed of multiple datasets. We name the latter models BigFWI. Our findings are summarized as follows:
-
Big data can boost the performance of deep learning models in FWI. BigFWI outperforms the baselines on almost every dataset in terms of all the evaluation metrics.
-
Larger data requires larger models. When more training samples are introduced, larger model architectures are required in BigFWI to achieve further improvement compared to the baselines.
-
Big data can improve the generalization of deep learning models in FWI. Given a dataset that is unseen during training, BigFWI yields better performance than any baselines trained on single datasets.

Schematic illustration of data-driven FWI and forward modeling. The forward modeling process computes the simulated seismic data from velocity maps, governed by a partial differential equation. Neural networks are employed in data-driven FWI methods to reconstruct velocity maps from seismic measurements.
Methods
In this section, we first present the preliminaries of full waveform inversion and then describe the network architecture of our BigFWI and the loss function for training.
Full waveform inversion
Figure 1 provides an illustration of 2D data-driven FWI and forward modeling. The governing equation of the acoustic wave forward modeling in an isotropic medium with a constant density can be described as follows:
where \(\nabla ^2\) is the Laplace operator, \(p(\varvec{r}, t)\) denotes the pressure wavefield at spatial location \(\varvec{r}\) and time t, \(v(\varvec{r})\) represents the velocity map of wave propagation, and \(s(\varvec{r}, t)\) is the source term. As shown in Fig. 1, the goal of forward modeling is to simulate seismic data \(\tilde{p}\) from a given velocity map v. For simplicity, we formulate this process as:
where \(f(\cdot )\) represents the highly nonlinear forward operator. As mentioned above, data-driven FWI methods directly learn the inverse mapping as:
where \(\hat{v}\) is the estimated velocity map and \(g_\theta (\cdot )\) is the approximated inverse operator of \(f(\cdot )\), which is usually implemented as neural networks parameterized by \(\theta \). BigFWI is developed to leverage large-scale datasets to obtain a more precise and universal approximation of the inverse operator.
Network architecture
We introduce three variants of BigFWI, including a “Base” model, a “Middle” one with additional layers, and a “Large” one that is both deeper and wider. We denote them as BigFWI-B, BigFWI-M and BigFWI-L. The number of the parameters of each model is summarized in Supplementary Table S1. All BigFWI models share an encoder–decoder architecture. The encoder \(\mathcal {E}\) first extracts the spatial–temporal features from the seismic input \(p\in \mathbb {R}^{S\times T\times R}\) and compresses them into a latent vector \(z=\mathcal {E}(x)\in \mathbb {R}^{L\times 1\times 1}\). Here, S equals the number of sources used in seismic surveys or simulation, T represents the number of samples recorded by each receiver, R denotes the number of receivers, and L is the length of the latent vector. The decoder \(\mathcal {D}\) then transforms the latent vector z into spatial domain and generates the estimation of the velocity map \(\hat{v}=\mathcal {D}(z)\in \mathbb {R}^{1\times W\times H}\), where W and H denote the horizontal (i.e. length) and vertical (i.e. depth) dimensions of the velocity map. Both the encoder \(\mathcal {E}\) and the decoder \(\mathcal {D}\) are fully based on 2D convolutional and deconvolution layers, and the details are presented as follows. The visualized network architecture of BigFWI is provided in Supplementary Fig. S1.
In the encoder \(\mathcal {E}\), since \(T=1000\) is much larger than \(R=70\) in the seismic data p of openfwi, we first reduce temporal dimension and extract temporal features by stacking seven convolutional layers with \(n\times 1\) kernels, where \(n=7\) in the first layer, and \(n=3\) in the following six layers. The stride along the temporal dimension is set to 2 for every other layer to reduce the temporal dimension until it is close to the spatial dimension. We then stack six layers with \(3 \times 3\) kernels to extract spatial-temporal features at the same time. Stride 2 is now applied to both dimensions every other layer. In BigFWI-M, instead of stacking six layers, we stack nine layers where an additional \(3\times 3\) layer with stride 1 is added after every two layers so as to increase model capacity without changing the dimensions of the original feature maps. In BigFWI-L, we stack eight layers where two additional \(3 \times 3\) layer with 1024 features maps are appended at the end. In BigFWI-B and BigFWI-M, we use a layer with an \(8 \times 9\) kernel to flatten the feature maps of the last to a 512-length latent vector z. In BigFWI-L, a layer with \(4 \times 5\) kernel is used, and the length of latent vector is 1024.
The decoder \(\mathcal {D}\) includes five deconvolution layers for upsampling, and each of them is followed by one convolutional layer with \(3 \times 3\) kernels in BigFWI-B and two convolutional layers in BigFWI-M. The first deconvolution layer with kernel size 5 transforms the latent vector z into a \(512 \times 5 \times 5\) tensor. The rest of the deconvolution layers with kernel size 4 and stride 2 upsample the feature maps by a factor of 2, resulting in an \(80 \times 80 \times 32\) tensor. We then apply center cropping followed by a \(3 \times 3\) convolutional layer to output a single channel \(70 \times 70\) velocity map. In BigFWI-L, the kernel size of the first deconvolution layer is 2, and there are six groups of deconvolution and convolutional layers.
All the convolutional and deconvolution layers are followed by batch normalization and LeakyReLU as the activation function, except for the last output layer, which uses Tanh to generate the velocity map between \([-1, 1]\).
Loss function
The original InversionNet model was trained with pixel-wise \(\ell _1\) loss or \(\ell _2\) loss between the ground truth of velocity maps v and the predictions \(\hat{v}\). In this paper, we trained the baseline InversionNet and BigFWI using a combination of two loss functions to leverage the advantages from both sides according to the previous study29. The loss function can be written as:
where W and H denote the number of grids in horizontal length and depth directions, and \(v_{ij}\) and \(\hat{v}_{ij}\) represent the ground truth velocity and the prediction at the grid (i, j).
Results
In this section, we first describe the openfwi dataset and then present the evaluation metrics and training details, followed by the experimental results.
OpenFWI datasets
We here briefly describe the openfwi datasets which are used in all the experiments. Unlike many existing synthetic datasets for FWI, openfwi is publicly available and offers a rich collection of large-scale multi-structural benchmark datasets. The datasets in openfwi are divided into four groups: “Vel Family”, “Fault Family”, “Style Family” and “Kimberlina Family”. We exclude the “Kimberlina Family” in our experiments because the dimensions of both velocity maps and seismic data in “Kimberlina Family” are different from the other three families. This allows us to combine the data samples from different datasets to train BigFWI models. In terms of the complexity of subsurface structures, each of the three families consists of an easy version (-A) and a hard version (-B). In addition, the datasets in “Vel Family” and “Fault Family” are further divided into a flat version (Flat-) and a curved version (Curve-) in accordance with the shape of rock layers. The 10 datasets employed in our experiments are: FlatVel-A/B, CurveVel-A/B, FlatFault-A/B, CurveFault-A/B, and Style-A/B. We use dataset abbreviations such as FVA for FlatVel-A in the rest of the paper to simplify plots.
Each dataset in “Vel Family”, “Fault Family”, “Style Family” is split into 24 K/6 K, 48 K/6 K, and 60 K/7 K pairs of seismic data and velocity maps for training and testing, respectively. We follow this splitting through our experiments. Figure 1 shows an example of a velocity map and seismic data pair. Each velocity map has dimensions of \(70 \times 70\) (depth \(\times \) length in grids) with a grid spacing of 10 m in both directions. The dimensions of the seismic data are \(5 \times 1000 \times 70\) (# of sources \(\times \) # of timesteps \(\times \) # of receivers). Five sources are evenly distributed on the top surface, each of which is a Ricker wavelet with a central frequency of 15 Hz. The interval between timesteps is 1 ms, and the receivers are also placed with an interval of 10 m. For more details about the forward model algorithm and simulation, please refer to the original paper of openfwi.
Evaluation metrics
We follow the benchmarking guidelines in openfwi and compute three metrics between the ground truth and the prediction of velocity maps to evaluate the performance of a model: mean absolute error (MAE), root mean squared error (RMSE), and structural similarity (SSIM)32. Both MAE and RMSE are commonly used to measure pixel-wise errors, while SSIM aligns better with human vision and measures the perceptual similarity that is more related to structural information. When calculating MAE and RMSE, we keep the velocity maps in the normalized scale \([-1, 1]\). During the calculation of SSIM, we rescale the velocity maps to [0, 1] as required by the algorithm. We additionally compute the average quadratic Wasserstein Distance33,34 for both velocity maps and seismic data as side evaluation metrics. The details are provided in Supplementary Wasserstein Distance Section.
Training details
We use identical hyperparameters to train all the models in our experiments. Specifically, we employ AdamW optimizers with momentum parameters \(\beta _1=0.9\), \(\beta _2=0.999\), and a weight decay of \(1 \times 10^{-4}\) to update the parameters of each model. The base learning rate is set to \(8 \times 10^{-4}\), and the models are trained for 170 epochs. In the first five warm-up epochs, we linearly increase the learning rate from \(1 \times 10^{-4}\), and we decay the learning rate by a factor of 10 at epoch 150 and epoch 160, respectively. The batch size is set to 256. All the models are implemented in PyTorch and trained on 4 NVIDIA Tesla V100 GPUs. We employ the natural logarithmic transformation to make the intensity of seismic data more balanced and normalize the data to range \([- 1,1]\) before they are fed into the network. The velocity maps are also normalized to the same scale before we compute the loss. To accelerate the training process, we improve the data loading pipeline. The details are provided in Supplementary Optimized Memory-Efficient Data Loading Pipeline Section.
Big data benefits FWI
We first design an experiment to explore if the performance of the data-driven FWI models can be improved by enlarging the training set. Specifically, we train a BigFWI-B on a combination of the datasets in openfwi and compare performance with the baseline InversionNet models trained on each split dataset. For brevity, we refer to BigFWI-B as BigFWI in this section. Both the BigFWI and InversionNet models share the same training hyperparameters and network architecture. Instead of using all the training samples in openfwi, we randomly select 12 K samples from each of the four datasets in Vel Family, 24K from each of the four in the Fault Family, and 30 K from each of the two in the Style Family. The rest of the samples in the training sets are reserved for the experiment in the next section, where we further enlarge the datasets. The combined large-scale training set consists of 204K samples in total, and we name it OpenFWI-204K. The test sets are directly adopted from openfwi.

Performance improvement of BigFWI trained on OpenFWI-204K over InversionNet in terms of MAE, RMSE and SSIM. BigFWI trained on a large-scale dataset (OpenFWI-204K) yields better performance on almost every dataset, compared to InversionNet28, which was trained on relatively small-scale datasets.

Comparison of ground truth (top) and predicted velocity maps generated by InversionNet (middle) and BigFWI (bottom). In general, BigFWI yields clearer layer boundaries, more accurate fault locations, and fewer artifacts compared to InversionNet as highlighted in squares.
We plot the performance improvement of BigFWI compared to the InversionNet on each dataset in Fig. 2. The quantitative results are provided in Supplementary Tables S3 and S4. We observe that BigFWI shows a clear improvement for all the datasets except for datasets FVA and FVB, which are comprised of flat layers only. One potential reason for the model’s degraded performance on FVA and FVB is that the network focuses more on curved layers which exist in most of the other datasets, and thus has a negative impact on the prediction of flat layers. We also observe that BigFWI exhibits significant improvement in MAE and RMSE for A datasets compared to B datasets across all families. However, the comparison of SSIM demonstrates the opposite trend, with the B datasets exhibiting better SSIM improvements compared to the A datasets in the same family. This variation in performance could be attributed to the greater complexity of the B datasets. The discrepancies in the baseline structures may not impact statistical misfits such as MAE and RMSE, but they may influence the SSIM. The simpler A datasets tend to benefit slightly more from the larger data volume than the more intricate B datasets.
Figure 3 shows a comparison of velocities maps between ground truth, InversionNet, and BigFWI. We observe that InversionNet predicts the velocity maps with various errors, such as extra bottom layer anomalies (FVA), inaccurate layer values (CVA, CVB), and inaccurate structures (FVB, FFB, CFA, CFB). BigFWI models generally yield better performance in predicting the structure and values of the velocity maps than InversionNet. We see that the improved results of BigFWI are due to the knowledge learned from the large-scale training dataset that consists of a variety of velocity map distributions. Here, we define the velocity map distributions as the different geological subsurface structures in OpenFWI: i.e., flat layers vs. curved layers, faults vs. non-fault, and smooth vs. sharp. However, in addition to benefits, the variety of the velocity map distributions may also bring some negative effects such as inaccurate layer boundaries. For instance, we observe non-flat interfaces in the predictions of FVA/FVB, which are obviously affected by other velocity map distributions.
Additionally, we conduct an experiment by simply enlarging each split dataset, and this also leads to performance improvement. Results are provided in Supplementary Tables S5 and S6, followed by a discussion in Supplementary Single Enlarged Dataset Section.
Big data in FWI requires larger models
To explore the relationship between the size of the training set and the size of the data-driven FWI models, we conduct an experiment that is similar to the previous one but employs the full training set provided by openfwi. Hence, the training set now contains 408K samples, and we name it OpenFWI-408K for brevity. We keep the baselines which are InversionNet trained on OpenFWI-204K, and we additionally train the InversionNet on each split datasets of OpenFWI-408K for comparison. We also train BigFWI-B, BigFWI-M and BigFWI-L on OpenFWI-408K.

Comparison of the performance improvement of different methods trained on the further enlarged dataset (i.e. OpenFWI-408K) in terms of MAE, RMSE, and SSIM. Note that the improvement percentages are computed based on the InversionNet trained on OpenFWI-204K. For most of the datasets, the BigFWI-L, which has the largest model size, yields the best performance.
In Fig. 4, we show the statistical performance improvement of BigFWI over InversionNet (trained on the split components of OpenFWI-204K). More detailed quantitative results are provided in Supplementary Tables S7 and S8. Overall, all the models trained on OpenFWI-408K yield better performance compared to InversionNet trained on OpenFWI-204K, and the BigFWI models (coral, blue and orange bars) outperform InversionNet (green) for almost every dataset, which again verifies that larger training set brings better performance. We further observe that among three BigFWI variants, larger models yield better performance in general. In particular, BigFWI-L (coral) and BigFWI-M (blue) outperform BigFWI-B (orange) by a large amount in all three metrics for relatively simple datasets such as FVA, FVB, FFA and CFA. For relatively complicated datasets such as CFB and SA, the gap is narrower. For dataset SB, BigFWI-B even outperforms BigFWI-L. This infers that larger models are preferred for most big data scenarios, but additional efforts such as more advanced network architectures are still required for some complicated cases.
Figure 5 shows the ground truth and predictions of velocity maps InversionNet, BigFWI-B, BigFWI-M, and BigFWI-L. Though the performance of InversionNet has improved statistically when trained on larger datasets, errors in prediction such as extra bottom layer anomalies (FVA), inaccurate layer values (CVA, CVB), and inaccurate structures (FVB, FFB, CFA, CFB) still exist. In contrast, BigFWI generally offers enhanced accuracy in layer location and velocity values. Comparing the performance of the BigFWI models, BigFWI-L and BigFWI-M outperforms BigFWI-B in many aspects. For instance, the flat interfaces in FVA and FVB are more flat and sharp in the results of BigFWI-L and BigFWI-M than the ones of BigFWI-B. BigFWI-M also predicts more accurate fault slopes in FFA and FFB. A similar observation can be obtained from the Style Family results, in which BigFWI-L and BigFWI-M predict more accurate kinematic information than InversionNet and BigFWI-B. Though InversionNet predicts more high-frequency components, the scatters are inaccurate in shape, which introduces even larger data misfit.

Comparison of ground truth (first row) and predicted velocity maps generated by InversionNet (second row) and BigFWIs (from third row to fifth row). BigFWI-L yields the most accurate results, especially in deep regions, compared to other BigFWI models and the baselines as highlighted in squares.
Big data leads to better generalization
Leave-one-out generalization test
To verify whether large-scale training data also leads to better generalization, we design the experiment where the BigFWI models are trained under leave-one-out settings. Specifically, given a target dataset for testing (e.g., FVA), we train the BigFWI model on the combination of the training samples from all the other datasets in openfwi (e.g., FVB, CVA/B, FFA/B, CFA/B, and SA/B). We then compare the performance of this BigFWI model on the test samples of the target dataset (e.g., FVA) with InversionNet, which are trained on split datasets other than the target one.
In Fig. 6, we present the statistical performance improvement in the percentage of the best generalization performance of InversionNet models. BigFWI shows superior performance across all the datasets, especially in terms of MAE and RMSE. This yields that big data leads to better generalization. Notably, utilizing datasets A as the target set results in greater improvements in terms of MAE and RMSE, while datasets B show greater improvements in terms of SSIM. The detailed quantitative results are provided in Supplementary Tables S9 and S10.
Figure 7 compares the generalization results of different methods to the ground truth. We observe that InversionNet produces inaccurate layer structures for out-of-distribution (OOD) data. In FFA, FFB, CVA, FFA, and SA, InversionNet’s generalization outputs have errors of blurred borders, wrong layer positions, and inaccurate velocity values, especially in deeper parts. Moreover, the results clearly have incorrect patterns from other datasets in more complex datasets (i.e., CVB, FFB, CFA and CFB). Meanwhile, these explain why we could find higher SSIM improvement in these four datasets in Fig. 6. Conversely, our BigFWI benefits from its large-scale cross-domain training set and can effectively capture more essential features of different datasets. Thus, BigFWI has more accurate predictions on OOD data than InversionNet.
Generalization test on Marmousi and Overthrust
We further conduct generalization experiments on two more challenging standard test synthetic datasets Marmousi35,36 and Overthrust37,38. Both velocity maps contain more practical subsurface structures and have been widely adopted for the evaluation of full waveform inversion methods31,39,40,41. Furthermore, the Marmousi velocity map was used as the style image to generate the Style Family in OpenFWI, which was specifically created for the simulation of real-world velocity maps.
In this experiment, we resize the original Marmousi and Overthrust velocity maps to match our sizes and generate the seismic data using the same configuration as in OpenFWI. Since the dataset SA is a smoothed version of SB in OpenFWI, we are also interested in the generalization performance of BigFWI on the smoothed versions of Marmousi and Overthrust. To this end, we follow the previous work39 and apply Gaussian filters with a standard deviation 2 to the velocity maps to obtain the smoothed ones. For comparison, we compare the BigFWIs trained on OpenFWI-408K with the InversionNet models trained on SA and SB separately.

Generalization improvement of BigFWI models trained using leave-one-out settings in terms of MAE, RMSE and SSIM. For each target dataset, our BigFWI yields better generalization performance than all the InversionNet trained on the split datasets other than the target one.

Comparison of ground truth (first row) and generalization results of different methods. From the first to last row: the InversionNet trained on the target datasets, the InversionNet trained on the datasets other than the target one, and the BigFWIs trained using leave-one-out settings. Our BigFWIs yield relatively reasonable velocity maps that are closer to the ones generated by the InversionNet trained on the target datasets.
The generalization ability of our models to Marmousi and Overthrust are depicted in Fig. 8. We also provide the results of Reverse Time Migration (RTM) and the differences of RTM compared to the ground truth in Supplement Figs. S2 and S3, respectively. Generally, BigFWI yield more accurate inversion results compared to InversionNet. For the smoothed version of Marmousi, the results of BigFWI match the ground truth better in the shallow region. The BigFWI-M even generates some layered structures in the top-right corner. In the deep region, the results of the InversionNet models contain either too many false high-velocity predictions or a horizontal layer with relatively low velocity. In contrast, though the velocity in the results of BigFWI is lower than the ground truth, they capture the locations of high-velocity regions. For the original version of Marmousi, it is obvious that the performance of BigFWI is better than InversionNet. We observe the layered structures given by BigFWI, and we think this is learned from CVA and CVB.
For the Overthrust velocity maps, BigFWI consistently generates flat layers with geological faults in the deep region, which are more visually plausible than the results of InversionNet. We see that the behavior of BigFWI is greatly affected by FVB, which demonstrates the advantages of training models on large-scale multi-structural datasets. However, we also observe that BigFWI tends to follow one specific learned pattern per prediction; for example, in the predictions of the smoothed Overthrust, BigFWI still generates structures with sharp boundaries that exist in FVB. This indicates that there may be still much space for the improvement of BigFWI in terms of both the model architecture and the training data.
The quantitative results are provided in Supplementary Tables S11, S12 and S3, which generally align with our observations in the visualization results. From the quantitative results, we further notice that the performance improvement of BigFWI compared to InversionNet on the original velocity maps is smaller than the one on the smoothed version. This is consistent with our previous observations where the improvement of BigFWI models on SB is always smaller than the one of SA. It points out a future direction where instead of simply combining all the datasets, we may bias towards SB dataset during training by generating more samples or training more steps on SB so that the model can yield better performance on the realistic cases with high-wavenumber components. In addition, we observe that InversionNet trained on SA achieves smaller RTM differences for the smoothed version of Overthrust. The discrepancy in this case may be attributed to a velocity misfit, causing RTM image interfaces to be half-cycle shifted in depth, resulting in larger RMS and L2-norm values. However, the performance of the four models on the Overthrust-smooth is relatively comparable. Moreover, it is worth noting that although BigFWI achieves better results compared to InversionNet for both Marmousi and Overthrust, the performance is still insufficient for real-world applications, which indicates much space for improvement.

Comparison of ground truth (first column) and generalization results of different methods on Marmousi and Overthrust. For all velocity maps, Our BigFWIs yield more accurate results, especially in the shallow region of each velocity map as highlighted in squares.
Discussion
This study is a preliminary investigation into the influence of big data on deep learning FWI methods, and there still exist some limitations and promising future directions. First, our study is entirely based on openfwi, which brings us not only convenience but also several inherent limitations. Although the Style Family in openfwi has made an effort to simulate the real-world velocity maps, there is still a gap between the synthetic data and field data. Our experiments are thus limited to simulations. It is an ongoing challenge for the whole FWI community to bridge this gap by either providing more public field data or improving the fidelity of the simulation. Second, in the present study, we only made minimal modifications to the network architecture of BigFWI. As a potential direction of future work, we may develop different network architectures to further improve performance. For instance, we observed during the qualitative analysis that the cross-domain training could lead to interference between datasets and inaccurate layer boundaries. Such issues could potentially be addressed by implementing an adaptive network architecture. Another challenge we plan to take into consideration when developing the network architecture is how models can be generalized to various survey settings. Examples can be the size of the target velocity map, the type of source and the placement of source-receiver arrays. An existing method we can employ is Fourier-DeepONet42, which considers the generalization of frequencies and locations of sources. Another potential solution is to adapt Transformer43 or Vision Transformer44 with embeddings that encode the additional information. If this challenge is well-addressed, we will be able to include more diverse data during training, and the model will be more easily generalized to practical field applications. Third, throughout the experiments, we observe that the evaluation of inversion results is very complicated, and sometimes the differences in visualization results cannot be reflected in the current quantitative metrics. Hence, new evaluation metrics should also be developed in future to better reflect inversion quality.
This study offers valuable insights into the inverse problem, which can contribute to the advancement of this concept in other domains, including medical imaging, climate modeling, and astronomy. The knowledge gained from this investigation can be leveraged to support the application of AI in scientific research and enhance its capabilities in these fields.
Conclusion
We presented an empirical study to determine the extent to which big data can benefit the deep learning models in FWI from three perspectives: model performance, the relationship between model size and data size, and model generalization. To accomplish this, we utilized the large-scale, publicly available datasets openfwi and designed the experiments to compare the performance of baseline InversionNet trained on relatively small-scale individual datasets with that of BigFWIs, which are trained on combined, large-scale datasets. Through both quantitative and qualitative analysis, our study has demonstrated that big data can significantly enhance the performance of deep learning models in FWI on both in-distribution and out-of-distribution data. Moreover, we have shown that model architectures need to be scaled with data size to achieve further improvement. We trust that our findings can provide valuable guidance for the future development of deep-learning-based FWI methods.
Data availability
OpenFWI data set can be downloaded from the website (https://openfwi-lanl.github.io/).
Code availability
InversionNet codes are released and can be downloaded from the website (https://github.com/lanl/OpenFWI/). The codes with the optimized memory-efficient data loading pipeline can be downloaded from the website (https://github.com/PengJin95/BigFWI)
References
Brown, T. et al. Language models are few-shot learners. Adv. Neural. Inf. Process. Syst. 33, 1877–1901 (2020).
Sun, C., Shrivastava, A., Singh, S. & Gupta, A. Revisiting unreasonable effectiveness of data in deep learning era. In Proc. IEEE International Conference on Computer Vision 843–852 (2017).
Kolesnikov, A. et al. Big transfer (bit): General visual representation learning. In European Conference on Computer Vision 491–507 (Springer, 2020).
Schuhmann, C. et al. Laion-5b: An open large-scale dataset for training next generation image-text models. In Thirty-Sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track.
Jumper, J. et al. Highly accurate protein structure prediction with alphafold. Nature 596, 583–589 (2021).
Tarantola, A. Inversion of seismic reflection data in the acoustic approximation. Geophysics 49, 1259–1266 (1984).
Pratt, R. G., Shin, C. & Hick, G. Gauss-newton and full newton methods in frequency-space seismic waveform inversion. Geophys. J. Int. 133, 341–362 (1998).
Plessix, R.-E. A review of the adjoint-state method for computing the gradient of a functional with geophysical applications. Geophys. J. Int. 167, 495–503 (2006).
Virieux, J. & Operto, S. An overview of full-waveform inversion in exploration geophysics. Geophysics 74, 1–26 (2009).
Fichtner, A. Full Seismic Waveform Modelling and Inversion (Springer, 2010).
Zhang, Z., Huang, L. & Lin, Y. A wave-energy-based precondition approach to full-waveform inversion in the time domain. In SEG Technical Program Expanded Abstracts 2012 1–5 (Society of Exploration Geophysicists, 2012).
Ma, Y., Hale, D., Gong, B. & Meng, Z. Image-guided sparse-model full waveform inversion. Geophysics 77, R189–R198 (2012).
Zhang, Z. & Huang, L. Double-difference elastic-waveform inversion with prior information for time-lapse monitoring. Geophysics 78, R259–R273 (2013).
Feng, S. & Schuster, G. T. Transmission+ reflection anisotropic wave-equation traveltime and waveform inversion. Geophys. Prospect. 67, 423–442 (2019).
Feng, S., Fu, L., Feng, Z. & Schuster, G. T. Multiscale phase inversion for vertical transverse isotropic media. Geophys. Prospect. 69, 1634–1649 (2021).
Lin, Y. & Huang, L. Acoustic-and elastic-waveform inversion using a modified total-variation regularization scheme. Geophys. J. Int. 200, 489–502 (2014).
Lin, Y. & Huang, L. Quantifying subsurface geophysical properties changes using double-difference seismic-waveform inversion with a modified Total-Variation regularization scheme. Geophys. J. Int. 203, 2125–2149 (2015).
Hu, W., Abubakar, A. & Habashy, T. M. Simultaneous multifrequency inversion of full-waveform seismic data. Geophysics 74, R1–R14 (2009).
Guitton, A. Blocky regularization schemes for full-waveform inversion. Geophys. Prospect. 60, 870–884 (2012).
Chen, Y. et al. Multiscale reflection phase inversion with migration deconvolution. Geophysics 85, R55–R73 (2020).
Wang, W. & Ma, J. Velocity model building in a crosswell acquisition geometry with image-trained artificial neural networks. Geophysics 85, U31–U46 (2020).
Liu, B. et al. Deep-learning seismic full-waveform inversion for realistic structural modelsdl seismic fwi. Geophysics 86, R31–R44 (2021).
Araya-Polo, M., Jennings, J., Adler, A. & Dahlke, T. Deep-learning tomography. Lead. Edge 37, 58–66 (2018).
Yang, F. & Ma, J. Deep-learning inversion: A next-generation seismic velocity model building method. Geophysics 84, R583–R599 (2019).
Ren, Y., Nie, L., Yang, S., Jiang, P. & Chen, Y. Building complex seismic velocity models for deep learning inversion. IEEE Access 9, 63767–63778 (2021).
Geng, Z. et al. Deep learning for velocity model building with common-image gather volumes. Geophys. J. Int. 228, 1054–1070 (2022).
Lin, Y., Theiler, J. & Wohlberg, B. Physics-guided data-driven seismic inversion: Recent progress and future opportunities in full-waveform inversion. IEEE Signal Process. Mag. 40, 115–133 (2023).
Wu, Y. & Lin, Y. InversionNet: An efficient and accurate data-driven full waveform inversion. IEEE Trans. Comput. Imaging 6, 419–433 (2019).
Zhang, Z. & Lin, Y. Data-driven seismic waveform inversion: A study on the robustness and generalization. IEEE Trans. Geosci. Remote Sens. 58, 6900–6913 (2020).
Araya-Polo, M. et al. Automated fault detection without seismic processing. Lead. Edge 36, 208–214 (2017).
Deng, C. et al. Openfwi: Large-scale multi-structural benchmark datasets for full waveform inversion. Adv. Neural. Inf. Process. Syst. 35, 6007–6020 (2022).
Wang, Z., Bovik, A. C., Sheikh, H. R. & Simoncelli, E. P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 13, 600–612 (2004).
Yang, Y., Engquist, B., Sun, J. & Hamfeldt, B. F. Application of optimal transport and the quadratic Wasserstein metric to full-waveform inversion. Geophysics 83, R43–R62 (2018).
Bonneel, N., Rabin, J., Peyré, G. & Pfister, H. Sliced and radon wasserstein barycenters of measures. J. Math. Imaging Vis. 51, 22–45 (2015).
Brougois, A. et al. Marmousi, model and data. In EAEG Workshop-Practical Aspects of Seismic Data Inversion 108 (European Association of Geoscientists & Engineers, 1990).
Martin, G. S., Wiley, R. & Marfurt, K. J. Marmousi2: An elastic upgrade for marmousi. Lead. Edge 25, 156–166 (2006).
Aminzadeh, F., Burkhard, N., Long, J., Kunz, T. & Duclos, P. Three dimensional seg/eaeg models—An update. Lead. Edge 15, 131–134 (1996).
Aminzadeh, F., Weimer, P. & Davis, T. 3-d salt and overthrust seismic models. Stud. Geol. 42, 247–256 (1996).
Feng, S., Lin, Y. & Wohlberg, B. Multiscale data-driven seismic full-waveform inversion with field data study. IEEE Trans. Geosci. Remote Sens. 60, 1–14. https://doi.org/10.1109/TGRS.2021.3114101 (2021).
Jin, P. et al. Unsupervised learning of full-waveform inversion: Connecting CNN and partial differential equation in a loop. In Proc. Tenth International Conference on Learning Representations (ICLR) (2022).
Feng, Y. et al. An intriguing property of geophysics inversion. In Proc. Thirty-ninth International Conference on Machine Learning (ICML) (2022).
Zhu, M., Feng, S., Lin, Y. & Lu, L. Fourier-deeponet: Fourier-enhanced deep operator networks for full waveform inversion with improved accuracy, generalizability, and robustness. Comput. Methods Appl. Mech. Eng. 416, 116300 (2023).
Vaswani, A. et al. Attention is all you need. Adv. Neural Inf. Process. Syst. 30, 1 (2017).
Dosovitskiy, A. et al. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations (2020).
Acknowledgements
This work was co-funded by the University of North Carolina at Chapel Hill’s School of Data Science and Society faculty start-up grant and the U.S. Department of Energy (DOE) Office of Fossil Energy’s Carbon Storage Research Program via the Science-Informed Machine Learning to Accelerate Real-Time Decision Making for Carbon Storage (SMART-CS) Initiative.
Author information
Authors and Affiliations
Contributions
Y.C. and P.J. proposed the idea and initialized the project. P.J. conducted the experiments and plotted the figures. S.F. and H.W. contributed geophysical expertise. P.J., Y.F., S.F., and H.W. analyzed the results and wrote the manuscript. Y.C., B.C., and Y.L. provided comments on the manuscript. Y. L., Z.L., and Y.C. supervised the project.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Jin, P., Feng, Y., Feng, S. et al. An empirical study of large-scale data-driven full waveform inversion. Sci Rep 14, 20034 (2024). https://doi.org/10.1038/s41598-024-68573-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-68573-7
- Springer Nature Limited