
Abstract
Surrogate modeling has become the method of choice in solving an increasing number of antenna design tasks, especially those involving expensive full-wave electromagnetic (EM) simulations. Notwithstanding, the curse of dimensionality considerably affects conventional metamodeling methods, and their capability to efficiently handle nonlinear antenna characteristics over broad ranges of the system parameters is limited. Performance-driven (or constrained) modeling frameworks may be employed to mitigate these issues by considering a construction of surrogates from the standpoint of the antenna performance figures rather than directly geometry parameters. This permits a significant reduction of the model setup cost without restricting its design utility. This paper proposes a novel modeling framework, which capitalizes on the domain confinement concepts and also incorporates variable-fidelity EM simulations, both at the surrogate domain definition stage, and when rendering the final surrogate. The latter employs co-kriging as a method of blending simulation data of different fidelities. The presented approach has been validated using three microstrip antennas, and demonstrated to yield reliable models at remarkably low CPU costs, as compared to both conventional and performance-driven modeling procedures.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Introduction
Design of contemporary antenna structures is to a large degree based on full-wave electromagnetic (EM) simulation models1,2,3,4, which are used for the development of antenna topology5, parametric studies6, as well as geometry adjustment7,8. The need for EM analysis arises from the fact that alternative representations (e.g. parameterized equivalent networks) are either non-reliable or non-existent. Moreover, EM simulations reliably account for mutual coupling, the effects of housing, connectors, etc. Furthermore, antenna structures become increasingly sophisticated to realize the assumed functionalities (multi-band and MIMO operation, circular polarization, etc.)9,10,11,12,13. To enable these, a variety of topological alterations are incorporated (stubs, defected grounds structures and so on)14,15,16,17, all of which have to be properly dimensioned. EM analysis is CPU intensive, which impedes execution of EM-driven procedures that entail repetitive simulations, such as optimization18, statistical analysis19,20, design centering21,22, let alone global23 or multi-objective search24, especially for complex devices25,26,27.
Accelerating EM-based procedures is a matter of practical necessity. Numerous techniques have been developed for that purpose. In the realm of local optimization, we have adjoint sensitivities28, mesh deformation29, selective gradient updates30,31, or the employment of customized EM solvers32. In a broader context, surrogate-assisted approaches has been growing in popularity, both concerning physics-based models (space33 or manifold mapping34, shape-preserving response prediction35, or adaptive response scaling36), and data-driven ones, e.g. kriging37, artificial neural networks (ANN)38, radial-basis functions (RBF)39, support vector regression (SVR)40, Gaussian process regression (GPR)41, or polynomial chaos expansion42. The latter are frequently used in global and multi-criterial optimization43,44,45. Among other noteworthy methods feature-based optimization (FBO)46,47,48 and cognition-based design49, in which the design task is re-mapped into the space of adequately pinpointed attributes (points) of the system outputs, the latter being in weakly nonlinear relationship with the geometry parameters.
Needless to say, replacing EM analysis by fast surrogates is invaluable as an acceleration tool. Approximation models (kriging50, RBF51, PCE52, SVR53, ANNs and numerable variants thereof, e.g. convolutional neural networks (CNN)54 or deep neural networks (DNN)55) are particularly popular due to their accessibility56,57. However, data-driven modeling methodologies are largely influenced by the curse of dimensionality and at the same time, have limited capability to represent highly nonlinear antenna characteristics. Available mitigation tools, e.g. least-angle regression (LAR)58, high-dimensional model representation (HDMR)59, are not suitable for general-purpose antenna modeling. Meanwhile, variable-resolution methods have been demonstrated to be beneficial in this context (co-kriging60, two-level GPR61), also in combination with sequential sampling62,63,64,65.
Recent performance-driven (or constrained) modeling66 proposes a different manner of alleviating the problems of standard techniques by limiting the metamodel domain to a small district that contains increased-quality designs (w.r.t. the assumed figures of interest, e.g. operating frequencies). Domain confinement remarkably lowers computational expenditures of acquiring the training data without restricting the design utility of the model67. Constrained modeling comes in several variations that incorporate, among others, dimensionality reduction and variable-fidelity EM models68,69,70,71. The fundamental problem of the aforementioned techniques is an inflated initial cost associated with identification of the database designs, otherwise necessary to set up the domain of the surrogate68. To some extent, this issue can be mitigated by involving sensitivity information72. In73, an alternate way to performance-driven modeling has been introduced, which abandons the use of reference designs in favor of random trial points. Information extracted therefrom is used to define the domain with the use of an auxiliary inverse regression model. The method of73 has been shown to retain the benefits of constrained modeling which reduces the initial cost by almost seventy percent in some cases.
In this paper, we propose a novel antenna modeling approach, which employs the performance-driven paradigm, and advances over the reference-design-free approach presented in73 by exploiting variable-resolution EM simulations. More specifically, generation of the trial points, necessary to identify the inverse regression model, is executed at the level of a coarse-discretization EM simulations. Furthermore, the majority of the training data points acquired to build the final metamodel are obtained at the same level, and supplemented by a small amount of high-fidelity samples. The data of both resolution levels is then blended using co-kriging74. Numerical validation performed using three antenna structures demonstrates that our framework allows to achieve additional computational savings of up to 64 percent over the technique of73, and as high as 82 percent over the nested kriging framework68 with regard to the model setup costs. This speedup is obtained without degrading the predictive power of the surrogate. Moreover, it ensures a remarkable accuracy improvement over conventional modeling methods.
Two-level variable-fidelity modeling within restricted domain
This section formulates the modeling methodology proposed in the paper. First, the concept of performance-driven modeling is recalled, along with an outline of the trial point acquisition (section “Performance-driven modeling basics”). In sections two-stage modeling: trial points and inverse regression model and surrogate domain definition, inverse regression model and surrogate domain definition are delineated, respectively. Section final surrogate. variable-resolution models and co-kriging discusses a construction of the final model using co-kriging, whereas section modeling procedure summary summarizes the complete procedure.
Performance-driven modeling basics
Here, we recall the basics of constrained (or performance-driven) modeling. The main concept is to construct the surrogate in a small portion of the parameter space, which encloses the designs being nearly optimum with regard to the target objective vectors. The computational benefits are due to a small volume of such a subset and a smaller sizes of training data sets that are needed to construct model of a satisfactory predictive power75.
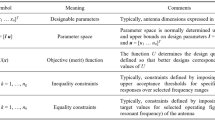
Table 1 outlines the notation used by constrained modeling frameworks68. The figures of interest may include antenna operating frequencies (but also the bandwidths or permittivity of a dielectric substrate). The central idea here pertains to the objective space F that determines the validity zone of the metamodel. Another important entity is the model domain. Its establishment involves the concept of design optimality, that is measured using a merit function U(x, f)69. The solution x*, which is optimal with respect to a performance vector f ∈ F, is given as
The optimum design manifold, consisting of designs (1) obtained for all f ∈ F, constitutes an N-dimensional object in X, given as
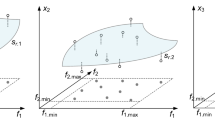
The domain of the surrogate model is determined as a neighborhood of UF(F)69. In a majority of performance-driven frameworks, its definition exploits database designs x(j) = [x1(j) … xn(j)]T, j = 1, …, p, optimal with respect to (1) for objective vectors f(j) = [f1(j) … fN(j)], distributed in F. More specifically, the couples {f(j),x(j)}, j = 1, …, p, serve as a training points to build the first-layer model sI(f) : F → X 68 that approximates UF(F), see Fig. 1. The metamodel domain itself constitutes an orthogonal extension of the first-level surrogate69.

Basics of confined modeling68: (a) the objectives’ space F, (b) design space X (black circles mark the trial points, grey surface indicates the manifold of optimum designs UF(F)). The image of the first-layer metamodel sI(F) yields a rough assessment of the manifold, so it needs to be outstretched to encompass entire UF(F).
Acquisition of the database designs is a bottleneck of performance-driven modeling procedures because it requires a large number (a few hundreds to over a thousand) of antenna simulations73. These extra expenses contribute to the overall model setup cost. As mentioned earlier, the number of trial points can be reduced by exploiting the sensitivity information72, whereas their identification costs may be diminished by warm-start optimization algorithms (e.g.76).
The recent constrained modeling framework73 introduced an alternative method for defining the model domain, which utilizes random trial points in place of the reference designs. The details of this method will be recalled in section two-stage modeling: trial points and inverse regression model, as it is one of the constituent parts of the introduced modeling procedure proposed.
Two-stage modeling: trial points and inverse regression model
First, we will define the surrogate model domain. Toward this end, we need to roughly assess the optimum design manifold UF(F) of Eq. (2). We follow the methodology of73, where the required information is extracted from a set of random trial points, allocated in the design space X.
We denote by xr(j) = [xr.1(k) … xr.n(k)]T, j = 1, 2, … a series of random trial points yielded according to a uniform probability distribution and by fr(j) = [fr.1(j) … fr.N(j)]T the performance figure vectors derived from the antenna response rendered by the full-wave model at xr(j). The performance figures are the same as the elements of the objective space F, e.g. the antenna resonant frequencies. The trial point is accepted if the extracted fr(j) resides in F and rejected otherwise (i.e. if the entries of fr(j) are located outside the lower and upper limits fk.min and fk.max, cf. Table 1, or if fr(j) cannot be identified due to distorted antenna responses). Figure 2 gives a graphical illustration of the trial point selection for an exemplary dual-band antenna. The process of generating the trial points continues until the assumed number Nr (e.g. 50) has been identified. For each accepted point xr(j), an additional vector pr(j) = [pr.1(j) … pr.M(j)]T is extracted from antenna responses. The said vector pr(j) contains the information pertaining to antenna performance. In our example, these may refer to the reflection coefficient levels at the resonant frequencies, in which case M = N.

Procedure of the random trial point rendition for an exemplary dual-band antenna (the objective and parameter space are two- and three-dimensional, respectively). The random designs whose resonant frequencies reside within the required confines of the objective space are retained, the remaining ones are discarded. The inverse regression model sr(⋅) is built using the ultimate trial point set {xr(j)}j = 1,…,Nr.
Using the set {xr(j),fr(j),pr(j)}j = 1,…,Nr, an inverse regression metamodel sr: F → X is constructed, serving as a rough assessment of the manifold UF(F). The analytical form of the model is taken as (cf.73)
The rationale for adopting the specific analytical form of the inverse surrogate as in Eq. (3) is that it is sufficient to adequately reflect typically weakly-nonlinear relationships between the antenna geometry and operating parameters. Moreover, exponential terms feature only few parameters, and are flexible in the sense that they allow for modeling various curvatures, e.g. inverse proportionality occurring for certain parameters.
The coefficients of the inverse surrogate are found as the solutions of the following tasks.
The weigh factors wk are computed as
where W = max{k = 1,…,Nr, j = 1,…,N: pj(k)}. Here, we assume that pj(k) > 0, and better designs are associated with lower values of pj(k). The factors wk are introduced to promote high-quality trial points so as to increase their contribution to the inverse model, which is because these vectors are located in a closer proximity of UF(F). Figure 3 shows graphically the concepts of the model sr in accordance with the example of Fig. 2. Observe that the design space needs to be selected with a proper consideration with respect to the anticipated design quality therein, i.e. the ranges of the antenna geometry parameters have to be established reasonably. Otherwise, the number of trial points necessary to gather the assumed number of the observables of decent quality may be too excessive and thus, the computational benefits of the introduced technique may be compromised. In this work, we assume that the design space has been selected using at least a rudimentary problem-specific knowledge.

Inverse regression model sr constructed based on the pre-selected trial points xr(j) along with their respective objectives fr(j). The model elements sr.j are are shown as grey surfaces for the parameters x1 (left), x2 (middle), and x3 (right), respectively.
Surrogate domain definition
As discussed earlier, the set sr(F) approximates the manifold UF(F). The metamodel domain should contain a possibly large part of UF(F) so as to account for the designs being optimum (or close to optimum) with respect to all f ∈ F. In73, this is achieved by orthogonally extending sr(F) in all directions orthogonal to this set. Let us define a orthonormal basis of vectors normal to sr(F) at f as {vn(k)(f)}, k = 1,…,n–N. Let also T = [T1 … Tn]T denote a vector of non-negative extension factors. Further, let us compute the coefficients of the extension
Using (6), the metamodel domain XS is given as
The meaning of this definition is that XS comprises of all designs given by (7), generated for every possible combination of the objective vectors from the space F and λk ∈ [−1, 1], k = 1,…,n–N. Observe that the domain lateral bounds are the manifolds \(S_{ + } = \left\{ {{\mathbf{x}} \in X:{\mathbf{x}} = s_{r} \left( {\mathbf{f}} \right) + \sum\nolimits_{k = 1}^{n - N} {\alpha_{k} ({\mathbf{f}}){\mathbf{v}}_{n}^{(k)} ({\mathbf{f}})} } \right\}\) and \(S_{ - } = \left\{ {{\mathbf{x}} \in X:{\mathbf{x}} = s_{r} \left( {\mathbf{f}} \right) - \sum\nolimits_{k = 1}^{n - N} {\alpha_{k} ({\mathbf{f}}){\mathbf{v}}_{n}^{(k)} ({\mathbf{f}})} } \right\}\).
The extension factors Tj are established individually for all parameters using the trial points {xr(j)} and the following procedure. We denote the kth parameter’s lower and upper bounds as lk and uk, respectively. Given the pair {xr(j), fr(j)}, we define Pk(xr(j)) ∈ [lk uk] × F as the vector for which the distance between [xr.k(j) (fr(j))T]T and [sr.k(f) fT]T, f ∈ F, i.e.
is minimal; with the orthogonal projection of [xr.k(j) (fr(j))T]T onto the representation of sr.k in [lk uk] × F denoted as Pk(xr(j)). Consequently
refers to the minimal distance between the said image and [xr.k(j) (fr(j))T]T (note that dr.k may be viewed as the distance between the entries of the trial vector and the gray surfaces of Fig. 3). Based on these considerations, we define the extension factors Tk as
Thus, Tk constitutes a half of the averaged distance from the trial point entry to the corresponding image of sr.k. The value of the factor 0.5 is chosen because many trial points are of poor quality and using (full) average distance would lead to excessively large domain containing too many designs that are far from the optimum ones73.
Final surrogate. variable-resolution models and co-kriging
One of the important mechanisms employed in this work to lower the cost of surrogate model construction are variable-resolution EM models. In most cases, the modeling process is executed at a single level of fidelity, except situations where the lower-resolution model is corrected with the use of a handful of high-fidelity samples (e.g. space mapping77, co-kriging74). In this work, we employ low-fidelity models to accelerate the process of defining the surrogate model domain, as well as to downsize the training data acquisition cost.
Variable-resolution EM models
The fundamental benefit of using low-fidelity models, which typically means coarse-discretization EM simulations in the case of antennas78, is that the associated simulation time may be considerably shortened, as compared to the high-fidelity version. The latter is normally established to ensure sufficiently accurate rendition of antenna characteristics. The speedup obtained due to low-fidelity analysis is obtained at the expense of the accuracy loss (cf. Fig. 4), which may or may not be problematic, depending on the particular context. For example, in space mapping optimization, the low-fidelity model should to be corrected to make it a reliable prediction tool, at least in the vicinity of the current iteration point79. When the low-fidelity model is used to, e.g. parameter space pre-screening, it can usually be used uncorrected80.

Variable-fidelity models: (a) an exemplary dual-band antenna, (b) antenna reflection responses evaluated with the low-fidelity EM model (- - -) and the high-fidelity one (—). Here, the high-fidelity model simulation time is about 80 s, whereas the time of the coarse model is only 25 s.
In this work, the low-fidelity or coarse model, denoted as Rc(x), will be used for two purposes: (i) generation of the trial points and metamodel definition as delineated in section two-stage modeling: trial points and inverse regression model, and (ii) accelerating the acquisition of the training data by complementing sparsely-sampled high-fidelity model responses (denoted as Rf(x)) with densely-sampled low-fidelity ones. In the case of (ii), co-kriging74 is used to combine simulation data of different fidelities. As for (i), because the trial points are only employed to provide an inaccurate approximation of the manifold comprising optimum designs, there is no need to correct a low-fidelity model at this phase of the modeling process, which is advantageous from the standpoint of simplicity of implementation.
Final surrogate construction using co-kriging
The final surrogate sCO(x) is generated in the domain XS using co-kriging60. The training data set contains NBf high-fidelity pairs {xBf(k),Rf(xBf(k))}k = 1, …, NBf, where xBf(k) ∈ XS, and NBc low-fidelity pairs {xBc(k),Rc(xBc(k))}k = 1, …, NBc, xBc(k) ∈ XS. We also use notation XBf = {xBf(k)}k = 1,…,NBf, and XBc = {xBc(k)}k = 1,…,NBc.
Let us begin by a recollection of the kriging interpolation, followed by formulation of co-kriging. The kriging surrogate sKR(x) is given as
with M being a NBf × t model matrix of XBf, whereas F denotes a row vector of the design x comprising t elements (t denotes the number of regression function factors60); and γ refer to coefficients of the regression function
We also have \(r({\mathbf{x}}) = (\psi ({\mathbf{x}},{\mathbf{x}}_{Bf}^{(1)} ),...,\psi ({\mathbf{x}},{\mathbf{x}}_{Bf}^{{(N_{Bf} )}} ))\), constitutes an NBf—element row vector whose entries are the correlations between XBf and x, whereas Ψ = [Ψi,j] denotes a correlation matrix, where Ψi,j = ψ(xBf(i),xBf(j)). An exemplary widely used correlation function may be
where θk, k = 1, …, n, are the hyperparameters to be found during model identification, which is achieved through Maximum Likelihood Estimation (MLE)60 as
where \(\hat{\sigma }^{2} = ({\mathbf{R}}_{f} (X_{Bf} ) - F\alpha )^{T} {{\varvec{\Psi}}}^{ - 1} ({\mathbf{R}}_{f} (X_{Bf} ) - F\alpha )/N_{Bf} ,\) with |Ψ| being the determinant of Ψ. In practice, a correlation function of Gaussian type (P equal to 2) is often employed, as well as M = 1 and F = [1 … 1]T.
Co-kriging blends together two models: (i) a kriging surrogate sKRc set up with the low-fidelity samples (XBc, Rc(XBc)) and (ii) the model sKRf built using the residuals (XBf, r), with r = Rf(XBf) − ρ⋅Rc(XBf). In the latter, ρ is a portion of the maximum likelihood estimate of the sKRf surrogate. Rc(XBf) is roughly equal to sKRc(XBf). The correlation function of the two models is described by Eq. (13).
The co-kriging model sCO(x) is given by
where
with M = [ρMc Md], moreover matrices (Fc, σc, Ψc, Mc) and (Fd, σd, Ψd, Md) are derived, in turn, from sKRc and sKRf60.
Design of experiments
A separate note should be made about the domain sampling procedure. Performing the design of experiments in a direct manner is inconvenient, as a geometry of the set XS is relatively complex. Instead, we use the procedure explained in Fig. 5, which involves a surjective transformation between the unit cube [0, 1]n and the constrained domain. According to this procedure, the samples xB(k) = h2(h1(z(k))) ∈ XS are uniformly distributed w.r.t. the objective space F, but not w.r.t. XS. The normalized samples {z(k)}, k = 1, …, NB, are distributed using Latin Hypercube Sampling, LHS81). Observe that the proposed modeling technique belong to a wider class of performance-driven (or constrained) modeling techniques, in which the surrogate is constructed within a region of the design space confined from the point of view of the design objectives. In contrast to the conventional modeling techniques, in performance-driven modeling, the surrogate domain constitutes a thin set within the classical deign space delimited by the lower and upper bounds on the design variables. As demonstrated in82, performing sequential sampling in a constrained domain does not bring any advantages over one-shot data sampling in terms of improving the model predictive power. This can be explained by a particular geometry of the constrained domain of the performance-driven surrogate, which encompasses nearly-optimum designs, the latter forming a manifold of a lower dimension than that of the original parameters space.

Conceptual illustration of the training data sampling process: (i) samples distributed according to Latin Hypercube Sampling (LHS)81 (top), (ii) mapping onto the Cartesian product of the performance figure space F and [−1,1]n–N using function h1 (middle), (iii) black circles mark data samples projected onto the confined domain XS using function h2 (bottom); gray circles indicate the samples distributed over the image of design space F prior to orthogonal extension.
The function h2(h1()) also facilitates solving design tasks that involve the surrogate model, such as optimization. More specifically, the optimization process may be carried out over the unity cube [0, 1]n, where the design variables (i.e. geometry parameters of the antenna at hand) are transformed into the model domain for metamodel evaluation. Additionally, sr(f) can be used as an initial design of a high quality for any assumed performance figure vector f ∈ F.
It is expected that the incorporation of variable-fidelity models into the domain-confined surrogate, as described in this section, will lead to an additional computational savings over the method of73 with regard to the total costs of the model setup. This is because majority of the costs (related to the acquisition of both the trial and training points) will be reduced by the factor equal to the EM simulation time ratio between the models of low- and high-fidelity.
Modeling procedure summary
Here, we summarize the proposed modeling procedure, the components of which were described in sections performance-driven modeling basics through final surrogate. variable-resolution models and co-kriging. It should be noted that there is only one control parameter, the number of trial points Nr, which is normally set to 50. The number of training data points (NBf of high-fidelity, and NBc of low-fidelity) depends on the required model accuracy. The modeling workflow has been provided in Fig. 6. Furthermore, Fig. 7 shows the flowchart of the process.

The workflow of the proposed antenna modeling procedure with variable-resolution EM simulations.

Operational flow of the presented two-layer modeling technique with domain confinement and variable-resolution EM simulations.
Results
The modeling procedure introduced in section two-level variable-fidelity modeling within restricted domain has been validated in this section with the use of three exemplary microstrip antennas. The results obtained for various training data set sizes are compared to a number of benchmark methods including traditional (i.e. unconstrained) metamodels (kriging and RBF), along with the performance-driven frameworks (nested kriging68, and the reference-design-free approach73). The major figures of interest include the surrogates’ predictive power, its dependence on the cardinality of the training dataset, as well as the computational cost of the model setup.
Verification antennas
The antenna structures used for verification have been shown in Figs. 8, 9 and 10. These include a ring-slot antenna83, a dual-band dipole84, and a quasi-Yagi antenna with a parabolic reflector85, which henceforth are referred to as Antenna I, II and III, respectively. Figures 8, 9 and 10 also contain the relevant data, among others, designable parameters, operating parameters, and the details on the parameter and objective spaces. Furthermore, Fig. 11 shows the families of reflection responses corresponding to various model fidelities for all the benchmark antenna structures. Observe that all the benchmark antennas have been already validated, first, in their respective source papers83,84,85, and also in our previous work, e.g.68,86). Therefore, the experimental validation has not been provided, as being immaterial to the scope of the paper.

Antenna I: ring-slot microstrip antenna: (a) antenna geometry, (b) antenna parameters.

Antenna II: dual-band uniplanar dipole antenna: (a) antenna geometry, (b) antenna parameters.

Antenna III: qasi-Yagi antenna with parabolic reflector: (a) antenna geometry, (b) antenna parameters.

Grid convergence plots for: (a) Antenna I, (b) Antenna II, and (c) Antenna III for different numbers of mesh cells corresponding to various model fidelities from the lowest employed fidelity up to the highest one.
Validation experiments setup
Antennas I, II and III have been modelled utilizing the technique proposed in this paper, as well as a number of benchmark methods, as listed in Table 2. The benchmark surrogates have been built using the training sets comprising 50, 100, 200, 400 and 800 data samples. The proposed models were obtained using several combinations of the coarse and fine datasets, in particular, NBf = 50 and NBc ∈ {50, 100, 200, 400, 800}, as well as NBf = 100 and NBc ∈ {50, 100, 200, 400, 800}. The cost of model construction is calculated in terms of the equivalent number of high-fidelity simulations, which considers the simulation time ratio of Rf versus Rc. Also, the cost includes all additional expenses, e.g. those associated with the reference database designs acquisition for the nested kriging framework68, or generating the trial points for the method of73, and the introduced technique.
A relative RMS error has been used as a measure of the model accuracy. It has been computed as ||Rs(x)–Rf(x)||/||Rf(x)||, where Rs and Rf are the surrogate and EM-simulated antenna characteristics, respectively. The average errors are reported, which are obtained for one hundred independent testing points.
Discussion
The results can be found in Tables 3, 4 and 5, for Antenna I, II and III, respectively. Furthermore, Figs. 12, 13 and 14 illustrate the antenna responses at selected test locations, evaluated using the proposed model and EM simulation. The analysis of the data in the tables leads to the following observations:
-
The accuracy of the presented model outperforms that of the conventional (i.e. unconstrained) models. In particular, for Antennas I and III, the unconstrained surrogates are unable to yield the surrogates of usable accuracy: the modeling error is still beyond 25% even for the training sets of the largest sizes.
-
The predictive power of the introduced surrogate is also better than for the nested kriging metamodel68 set up using smaller training data sets, which is due to the inclusion of the random trial points into the training dataset. For larger values of NB, the models exhibit similar accuracy. This is also the case for the reference-design-free method, the accuracy of which is comparable to the proposed model due to sharing the rules for model domain definition. Yet, for the smaller training sets, the proposed model is more accurate, which is because the overall number of samples (low- and high-fidelity together) is larger than for the method of73. Perhaps the most important advantage of the proposed methodology is an excellent computational efficiency. Executing majority of the operations with the use of low-fidelity model leads to considerable savings, as reported in Tables 3, 4 and 5. For example, the cost reduction over conventional surrogates is as high as 55, 54 and 60 percent for Antennas I, II and III, respectively, assuming NB = 800 and NBf = 50.
-
The savings over the nested kriging model are even higher due to the extra expenses entailed by the reference design acquisition in68. We have 78, 79 and 88 percent savings for Antennas I through III, respectively, also for NB = 800 and NBf = 50. The savings over the reference-design-free methods73 are 61, 64 and 68 percent, for Antenna I, II and III, respectively, again assuming NB = 800 and NBf = 50. It should be reiterated that the cost reduction with respect to the benchmark performance-driven methods does not deteriorate the modeling accuracy.

Antenna I: reflection responses at the representative test designs: full-wave model (—), and the presented two-level variable-fidelity surrogate (o) with NBf = 50 and NBc = 800.

Antenna II: reflection responses at the representative test designs: full-wave model (—), and the presented two-level variable-fidelity surrogate (o) with NBf = 50 and NBc = 800.

Antenna III: reflection responses at the representative test designs: full-wave model (—), and the presented two-level variable-fidelity surrogate (o) with NBf = 50 and NBc = 800.
Conclusion
This work presented a novel framework for surrogate modeling of antenna structures. Our approach exploits a constrained modeling paradigm with the surrogate model domain established using random trial points and the operating parameter data extracted therefrom. Furthermore, variable-resolution EM models are used at the domain definition stage and the surrogate construction phase. The latter combines sparsely acquired data samples of high-fidelity with densely collected low-fidelity training points. The final surrogate is rendered using co-kriging. Extensive numerical experiments confirm that the proposed method outperforms conventional methods. Furthermore, the predictive power of the presented surrogate is comparable or slightly better than for the benchmark performance-driven models. In terms of the computational efficiency, our modeling framework by far outperforms all the techniques employed in the numerical studies, both the conventional and the performance-driven ones. The computational savings over the traditional models are as high as 56 percent on the average, whereas they are 82 and 64 percent over the nested kriging modeling technique and the database-design-free method, respectively. The procedure presented in this work can be considered a viable alternative to state-of-the-art modeling routines, especially for more demanding conditions that include multi-dimensional spaces with broad geometry and material parameters’ ranges, the same pertains to the operating conditions.
Data availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
References
Lu, K. & Leung, K. W. On the circularly polarized parallel-plate antenna. IEEE Trans. Antennas Propag. 68(1), 3–12 (2020).
Famoriji, O. J. & Xu, Z. Antenna feed array synthesis for efficient communication systems. IEEE Sensors J. 20(24), 15085–15098 (2020).
Jonsson, B. L. G., Shi, S., Wang, L., Ferrero, F. & Lizzi, L. On methods to determine bounds on the Q-factor for a given directivity. IEEE Trans. Antennas Propag. 65(11), 5686–5696 (2017).
Ullah, U. & Koziel, S. A broadband circularly polarized wide-slot antenna with a miniaturized footprint. IEEE Antennas Wirel. Propag. Lett. 17(12), 2454–2458 (2018).
Nie, L. Y., Lin, X. Q., Yang, Z. Q., Zhang, J. & Wang, B. Structure-shared planar UWB MIMO antenna with high isolation for mobile platform. IEEE Trans. Antennas Propag. 67(4), 2735–2738 (2019).
Wen, D., Hao, Y., Munoz, M. O., Wang, H. & Zhou, H. A compact and low-profile MIMO antenna using a miniature circular high-impedance surface for wearable applications. IEEE Trans. Antennas Propag. 66(1), 96–104 (2018).
Krishna, A., Abdelaziz, A. F. & Khattab, T. Patch antenna array designs for wireless communication applications inside jet engines. IEEE Trans. Antennas Propag. 67(2), 971–979 (2019).
Lei, S. et al. Power gain optimization method for wide-beam array antenna via convex optimization. IEEE Trans. Antennas Propag. 67(3), 1620–1629 (2019).
Cui, J., Zhang, A. & Chen, X. An omnidirectional multiband antenna for railway application. IEEE Antennas Wirel. Propag. Lett. 19(1), 54–58 (2020).
Wang, J., Wong, H., Ji, Z. & Wu, Y. Broadband CPW-fed aperture coupled metasurface antenna. IEEE Antennas Wirel. Propag. Lett. 18(3), 517–520 (2019).
Das, G., Sharma, A., Gangwar, R. K. & Sharawi, M. S. Performance improvement of multiband MIMO dielectric resonator antenna system with a partially reflecting surface. IEEE Antennas Wirel. Propag. Lett. 18(10), 2105–2109 (2019).
Feng, Y. et al. Cavity-backed broadband circularly polarized cross-dipole antenna. IEEE Antennas Wirel. Propag. Lett. 18(12), 2681–2685 (2019).
Liu, J. et al. A wideband pattern diversity antenna with a low profile based on metasurface. IEEE Antennas Wirel. Propag. Lett. 20(3), 303–307 (2021).
Liu, N. et al. Cross-polarization reduction of a shorted patch antenna with broadside radiation using a pair of open-ended stubs. IEEE Trans. Antennas Propag. 68(1), 13–20 (2020).
Le, T. T., Tran, H. H. & Park, H. C. Simple-structured dual-slot broadband circularly polarized antenna. IEEE Antennas Wirel. Propag. Lett. 17(3), 476–479 (2018).
Duan, J. & Zhu, L. An EH0-mode microstrip leaky-wave antenna with transversal single beam via periodical loading of shorting pins and U-shaped slots. IEEE Antennas Wirel. Propag. Lett. 19(12), 2187–2191 (2020).
Wei, K., Li, J. Y., Wang, L., Xu, R. & Xing, Z. J. A new technique to design circularly polarized microstrip antenna by fractal defected ground structure. IEEE Trans. Antennas Propag. 65(7), 3721–3725 (2017).
Kovaleva, M., Bulger, D. & Esselle, K. P. Comparative study of optimization algorithms on the design of broadband antennas. IEEE J. Multiscale Multiphysics Comp. Techn. 5, 89–98 (2020).
Easum, J. A., Nagar, J., Werner, P. L. & Werner, D. H. Efficient multiobjective antenna optimization with tolerance analysis through the use of surrogate models. IEEE Trans. Antennas Propag. 66(12), 6706–6715 (2018).
Du, J. & Roblin, C. Stochastic surrogate models of deformable antennas based on vector spherical harmonics and polynomial chaos expansions: Application to textile antennas. IEEE Trans. Antennas Propag. 66(7), 3610–3622 (2018).
Pietrenko-Dabrowska, A., Koziel, S. & Al-Hasan, M. Expedited yield optimization of narrow- and multi-band antennas using performance-driven surrogates. IEEE Access 8, 143104–143113 (2020).
Kouassi, A. et al. Reliability-aware optimization of a wideband antenna. IEEE Trans. Antennas Propag. 64(2), 450–460 (2016).
Liu, Y., Li, M., Haupt, R. L. & Guo, Y. J. Synthesizing shaped power patterns for linear and planar antenna arrays including mutual coupling by refined joint rotation/phase optimization. IEEE Trans. Antennas Propag. 68(6), 4648–4657 (2020).
Li, Q., Chu, Q., Chang, Y. & Dong, J. Tri-objective compact log-periodic dipole array antenna design using MOEA/D-GPSO. IEEE Trans. Antennas Propag. 68(4), 2714–2723 (2020).
Zhu, D. Z., Werner, P. L. & Werner, D. H. Design and optimization of 3-D frequency-selective surfaces based on a multiobjective lazy ant colony optimization algorithm. IEEE Trans. Antennas Propag. 65(12), 7137–7149 (2017).
Hosseininejad, S. E., Komjani, N. & Mohammadi, A. Accurate design of planar slotted SIW array antennas. IEEE Antennas Wirel. Propag. Lett. 14, 261–264 (2015).
Nadia, C., Tomader, M. & Benbrahim, M. Array antenna characteristics improvement: Parasitic patches (two disposals) and multilayer substrate techniques. in International Conference on Optimization and Applications (ICOA) 1–6 (Mohammedia, Morocco, 2018).
Kalantari, L. S. & Bakr, M. H. Wideband cloaking of objects with arbitrary shapes exploiting adjoint sensitivities. IEEE Trans. Antennas Propag. 64(5), 1963–1968 (2016).
Feng, F. et al. Coarse- and fine-mesh space mapping for EM optimization incorporating mesh deformation. IEEE Microw. Wirel. Comp. Lett. 29(8), 510–512 (2019).
Koziel, S. & Pietrenko-Dabrowska, A. Reduced-cost electromagnetic-driven optimization of antenna structures by means of trust-region gradient-search with sparse Jacobian updates. IET Microw. Antennas Propag. 13(10), 1646–1652 (2019).
Koziel, S. & Pietrenko-Dabrowska, A. Variable-fidelity simulation models and sparse gradient updates for cost-efficient optimization of compact antenna input characteristics. Sensors 19(8), 1806 (2019).
Wang, J., Yang, X. S. & Wang, B. Z. Efficient gradient-based optimization of pixel antenna with large-scale connections. IET Microw. Antennas Prop. 12(3), 385–389 (2018).
Xu, J., Li, M. & Chen, R. Space mapping optimisation of 2D array elements arrangement to reduce the radar cross-scattering. IET Microw. Antennas Propag. 11(11), 1578–1582 (2017).
Su, Y., Li, J., Fan, Z. & Chen, R. Shaping Optimization of Double Reflector Antenna Based on Manifold Mapping 1–2 (International Applied Computational Electromagnetics Society Symposium (ACES), 2017).
Koziel, S., Ogurtsov, S., Cheng, Q. S. & Bandler, J. W. Rapid EM-based microwave design optimization exploiting shape-preserving response prediction and adjoint sensitivities. IET Microw. Antennas Propag. 8(10), 775–781 (2014).
Koziel, S. & Unnsteinsson, S. D. Expedited design closure of antennas by means of trust-region-based adaptive response scaling. IEEE Antennas Wirel. Propag. Lett. 17(6), 1099–1103 (2018).
Salucci, M., Tenuti, L., Oliveri, G. & Massa, A. Efficient prediction of the EM response of reflectarray antenna elements by an advanced statistical learning method. IEEE Trans. Antennas Propag. 66(8), 3995–4007 (2018).
Dong, J., Qin, W. & Wang, M. Fast multi-objective optimization of multi-parameter antenna structures based on improved BPNN surrogate model. IEEE Access 7, 77692–77701 (2019).
Zhou, Q. et al. An active learning radial basis function modeling method based on self-organization maps for simulation-based design problems. Knowl.-Based Syst. 131, 10–27 (2017).
Cai, J., King, J., Yu, C., Liu, J. & Sun, L. Support vector regression-based behavioral modeling technique for RF power transistors. IEEE Microw. Wirel. Comp. Lett. 28(5), 428–430 (2018).
Jacobs, J. P. Characterization by Gaussian processes of finite substrate size effects on gain patterns of microstrip antennas. IET Microw. Antennas Propag. 10(11), 1189–1195 (2016).
Spina, D., Ferranti, F., Antonini, G., Dhaene, T. & Knockaert, L. Efficient variability analysis of electromagnetic systems via polynomial chaos and model order reduction. IEEE Trans. Comp. Packag. Manuf. Techn. 4(6), 1038–1051 (2014).
Gu, Q., Wang, Q., Li, X. & Li, X. A surrogate-assisted multi-objective particle swarm optimization of expensive constrained combinatorial optimization problems. Knowl.-Based Syst. 223, 107049 (2021).
Zhao, Y., Sun, C., Zeng, J., Tan, Y. & Zhang, G. A surrogate-ensemble assisted expensive many-objective optimization. Knowl.-Based Syst. 211, 106520 (2021).
Xiao, S. et al. Multi-objective pareto optimization of electromagnetic devices exploiting kriging with lipschitzian optimized expected improvement. IEEE Trans. Magn. 54(3), 1–4 (2018).
Koziel, S. & Pietrenko-Dabrowska, A. Expedited feature-based quasi-global optimization of multi-band antennas with Jacobian variability tracking. IEEE Access 8, 83907–83915 (2020).
Koziel, S. Fast simulation-driven antenna design using response-feature surrogates. Int. J. RF Microw. CAE 25(5), 394–402 (2015).
Pietrenko-Dabrowska, A. & Koziel, S. Fast design closure of compact microwave components by means of feature-based metamodels. Electronics 10, 10 (2021).
Zhang, C., Feng, F., Gongal-Reddy, V., Zhang, Q. J. & Bandler, J. W. Cognition-driven formulation of space mapping for equal-ripple optimization of microwave filters. IEEE Trans. Microw. Theory Technol. 63(7), 2154–2165 (2015).
Fu, C., Wang, P., Zhao, L. & Wang, X. A distance correlation-based Kriging modeling method for high-dimensional problems. Knowl.-Based Syst. 206, 106356 (2020).
Yao, R. et al. Deep neural network assisted approach for antenna selection in untrusted relay networks. IEEE Wirel. Commun. Lett. 8(6), 1644–1647 (2019).
Xiao, L.-Y., Shao, W., Jin, F.-L., Wang, B.-Z. & Liu, Q. H. Radial basis function neural network with hidden node interconnection scheme for thinned array modeling. IEEE Antennas Wirel. Propag. Lett. 19(12), 2418–2422 (2020).
Petrocchi, A. et al. Measurement uncertainty propagation in transistor model parameters via polynomial chaos expansion. IEEE Microw. Wirel. Comp. Lett. 27(6), 572–574 (2017).
Skaria, S., Al-Hourani, A., Lech, M. & Evans, R. J. Hand-gesture recognition using two-antenna doppler radar with deep convolutional neural networks. IEEE Sensors J. 19(8), 3041–3048 (2019).
Prado, D. R., López-Fernández, J. A., Arrebola, M., Pino, M. R. & Goussetis, G. Wideband shaped-beam reflectarray design using support vector regression analysis. IEEE Antennas Wirel. Propag. Lett. 18(11), 2287–2291 (2019).
Gorissen, D., Crombecq, K., Couckuyt, I., Dhaene, T. & Demeester, P. A surrogate modeling and adaptive sampling toolbox for computer based design. J. Mach. Learn. Res. 11, 2051–2055 (2010).
Marelli, S. and Sudret, B. UQLab: A framework for uncertainty quantification in Matlab. in 2nd International Conference on Vulnerability and Risk Analysis and Management (ICVRAM 2014). 13–15. 2554–2563 (University of London, 2014).
Hu, R., Monebhurrun, V., Himeno, R., Yokota, H. & Costen, F. An adaptive least angle regression method for uncertainty quantification in FDTD computation. IEEE Trans. Antennas Propag. 66(12), 7188–7197 (2018).
Yücel, A. C., Bağcı, H. & Michielssen, E. An ME-PC enhanced HDMR method for efficient statistical analysis of multiconductor transmission line networks. IEEE Trans. Comp. Packag. Manuf. Techn. 5(5), 685–696 (2015).
Kennedy, M. C. & O’Hagan, A. Predicting the output from complex computer code when fast approximations are available. Biometrika 87, 1–13 (2000).
Jacobs, J. P. & Koziel, S. Two-stage framework for efficient Gaussian process modeling of antenna input characteristics. IEEE Trans. Antennas Propag. 62(2), 706–713 (2014).
Zhou, Q. et al. A sequential multi-fidelity metamodeling approach for data regression. Knowl.-Based Syst. 34, 199–212 (2017).
Zhou, Q. et al. An active learning metamodeling approach by sequentially exploiting difference information from variable-fidelity models. Adv. Eng. Inform. 30(3), 283–297 (2016).
Lin, Q., Zhou, Q., Hu, J., Cheng, Y. & Hu, Z. A sequential sampling approach for multi-fidelity surrogate modeling-based robust design optimization. ASME. J. Mech. Des. 144(11), 111703 (2022).
Zhang, L., Wu, Y., Jiang, P., Choi, S. K. & Zhou, Q. A multi-fidelity surrogate modeling approach for incorporating multiple non-hierarchical low-fidelity data. Adv. Eng. Inform. 51, 101430 (2022).
Koziel, S. Low-cost data-driven surrogate modeling of antenna structures by constrained sampling. IEEE Antennas Wirel. Propag. Lett. 16, 461–464 (2017).
Koziel, S. & Sigurdsson, A. T. Triangulation-based constrained surrogate modeling of antennas. IEEE Trans. Antennas Propag. 66(8), 4170–4179 (2018).
Koziel, S. & Pietrenko-Dabrowska, A. Performance-based nested surrogate modeling of antenna input characteristics. IEEE Trans. Antennas Propag. 67(5), 2904–2912 (2019).
Koziel, S. & Pietrenko-Dabrowska, A. Performance-Driven Surrogate Modeling of High-Frequency Structures (Springer, 2020).
Pietrenko-Dabrowska, A. & Koziel, S. Antenna modeling using variable-fidelity EM simulations and constrained co-kriging. IEEE Access 8(1), 91048–91056 (2020).
Pietrenko-Dabrowska, A. & Koziel, S. Reliable surrogate modeling of antenna input characteristics by means of domain confinement and principal components. Electronics 9(5), 1–16 (2020).
Pietrenko-Dabrowska, A., Koziel, S. & Al-Hasan, M. Cost-efficient bi-layer modeling of antenna input characteristics using gradient kriging surrogates. IEEE Access 8, 140831–140839 (2020).
Koziel, S. & Pietrenko-Dabrowska, A. Knowledge-based performance-driven modeling of antenna structures. Knowl.-Based Syst. 237, 107698 (2021).
Pietrenko-Dabrowska, A. & Koziel, S. Surrogate modeling of impedance matching transformers by means of variable-fidelity EM simulations and nested co-kriging. Int. J. RF Microw. CAE 30(8), e22268 (2020).
Abdullah, M. & Koziel, S. A novel versatile decoupling structure and expedited inverse-model-based re-design procedure for compact single-and dual-band MIMO antennas. IEEE Access 9, 37656–37667 (2021).
Koziel, S. & Pietrenko-Dabrowska, A. On computationally-efficient reference design acquisition for reduced-cost constrained modeling and re-design of compact microwave passives. IEEE Access 8, 203317–203330 (2020).
Koziel, S. & Pietrenko-Dabrowska, A. Cost-efficient performance-driven modeling of multi-band antennas by variable-fidelity EM simulations and customized space mapping. Int. J. Numer. Model. 33(6), e2778 (2020).
Koziel, S. & Ogurtsov, S. Simulation-Based Optimization of Antenna Arrays (World Scientific, 2019).
Cheng, Q. S., Bandler, J. W. & Koziel, S. Space mapping design framework exploiting tuning elements. IEEE Trans. Microw. Theory Tech. 58(1), 136–144 (2010).
Liu, B., Koziel, S. & Zhang, Q. A multi-fidelity surrogate-model-assisted evolutionary algorithm for computationally expensive optimization problems. J. Comput. Sci. 12, 28–37 (2016).
Beachkofski, B. & Grandhi, R. Improved distributed hypercube sampling. in American Institute of Aeronautics and Astronautics Paper AIAA 2002–1274 (2002).
Pietrenko-Dabrowska, A. & Koziel, S. On inadequacy of sequential design of experiments for performance-driven surrogate modeling of antenna input characteristics. IEEE Access 8, 78417–78426 (2020).
Koziel, S. & Pietrenko-Dabrowska, A. Design-oriented modeling of antenna structures by means of two-level kriging with explicit dimensionality reduction. AEU Int. J. Electron. Commun. 127, 1–12 (2020).
Chen, Y.-C., Chen, S.-Y. & Hsu, P. Dual-Band Slot Dipole Antenna Fed by a Coplanar Waveguide 3589–3592 (IEEE International Symposium on Antennas and Propagation, 2006).
Hua, Z. et al. A Novel High-Gain Quasi-Yagi Antenna with a Parabolic Reflector (International Symposium on Antennas and Propagation (ISAP), 2015).
Koziel, S. & Pietrenko-Dabrowska, A. Fast and reliable knowledge-based design closure of antennas by means of iterative prediction-correction scheme. Eng. Comput. 38(10), 3710–3731 (2021).
Acknowledgements
The authors would like to thank Dassault Systemes, France, for making CST Microwave Studio available. This work is partially supported by the Icelandic Centre for Research (RANNIS) Grant 217771 and by National Science Centre of Poland Grant 2018/31/B/ST7/02369.
Author information
Authors and Affiliations
Contributions
Conceptualization: A.P. and S.K.; Methodology: A.P. and S.K.; Software: A.P., S.K. and L.G.; Validation: A.P. and S.K.; Formal analysis: S.K.; Investigation: A.P. and S.K.; Resources: S.K.; Data curation: A.P., S.K. and L.G.; Writing—original draft preparation: A.P., S.K. and L.G.; Writing—review and editing: A.P. and S.K.; Visualization: A.P., S.K. and L.G.; Supervision: S.K.; Project administration: S.K.; Funding acquisition: S.K. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Pietrenko-Dabrowska, A., Koziel, S. & Golunski, L. Two-stage variable-fidelity modeling of antennas with domain confinement. Sci Rep 12, 17275 (2022). https://doi.org/10.1038/s41598-022-20495-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-20495-y
- Springer Nature Limited
This article is cited by
-
Deep learning for inverse design of low-boom supersonic configurations
Advances in Aerodynamics (2023)