
Abstract
In this manuscript, we describe a unique dataset of human locomotion captured in a variety of out-of-the-laboratory environments captured using Inertial Measurement Unit (IMU) based wearable motion capture. The data contain full-body kinematics for walking, with and without stops, stair ambulation, obstacle course navigation, dynamic movements intended to test agility, and negotiating common obstacles in public spaces such as chairs. The dataset contains 24.2 total hours of movement data from a college student population with an approximately equal split of males to females. In addition, for one of the activities, we captured the egocentric field of view and gaze of the subjects using an eye tracker. Finally, we provide some examples of applications using the dataset and discuss how it might open possibilities for new studies in human gait analysis.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Background & Summary
Gait analysis is a fundamental tool that is used broadly. Motion capture can be used for clinical gait analysis, with real implications for prescription of interventions, functional classification, and prescription of assistive devices. For basic science, motion capture provides a window into how the brain generates movement, captures sensation, and how neural operations interact with the biomechanics of the body.
Practical considerations have generally restricted gait analysis to within-laboratory experiments. Motion capture has required controlled conditions and apparatus, and this has resulted in relatively controlled and restricted movement datasets. In order to make justifiable comparisons, we have generally narrowed the scope of movement analysis into that which was reasonably measurable given the technology of the time. This has proven fruitful. We now understand a great deal about movement in laboratory conditions. What is less clear is how different movement is outside of those conditions. Are movements generated by people in their daily lives significantly different than those they perform in laboratory experiments?
In other words, those studying movement intuit that outside of laboratory conditions, behavior is likely to be less clean and of greater complexity. The precise nature of this complexity, and a quantitative understanding of it, remains open. In addition, there is evidence that artificial environments can compromise ecological validity. For example, it has been shown1 that how participants walk changes by a small but significant amount depending on the number of researchers present during the experiment. With the dataset we present here, we intend to contribute data captured outside of the lab to enable comparative analyses with in-laboratory activities. This kind of data can be used to train data-driven predictive models of human movement2,3, or activity4,5 or terrain6 classification.
In this manuscript we describe a multi-subject full body kinematics dataset that captures diverse movements including forward walking, backward walking, side stepping, avoiding obstacles by stepping over them, navigating around obstacles in controlled environments as well as in uncontrolled and unrestricted natural environments like classrooms, atrium and staircases. For the unrestricted activities, we also present the corresponding egocentric video and gaze data captured using an eyetracker. These data provide a window into the role that the environment plays in determining how we move.
On the uniqueness of the dataset
Most gait datasets currently available fall under the following categories: (1) Full-body kinematics or kinetics from level-ground walking or running in a lab environment, comprised of straight walking (~10 m) at different self-selected speeds7,8,9,10,11, (2) full-body kinematics or kinetics from treadmill walking or running at pre-defined speeds7,11,12,13, (3) standing data collected on perturbation platforms14,15, and (4) staircase walking on in-lab staircases with 4–7 steps11,16. For a more comprehensive review of stair ambulation, please refer to17. These datasets were collected using in-lab motion capture systems and collectively comprise most of the publicly available gait datasets.
Recently, several gait datasets of diverse and more complex activities have been made publicly available11,18,19,20,21,22. HuGaDB18 is a dataset collected from 18 participants performing several activities. The data include inertial measurement unit (IMU) recordings from sensors strapped to the thigh, shank and feet, and don’t include full body joint kinematics19. captured full-body kinematics from different activities in a lab environment. Most of the activities included data from 1–2 subjects (maximum 27 subjects for walking). In that dataset, most subjects performed 1–2 trials (maximum 27 trials from 1 subject, for walking) where each trial consisted of 7–10 seconds of walking20. captured full-body kinematics on a ramp, level ground, and stairs. Data were collected from 10 subjects, with 2 trials from each subject. A ramp and an 8-step staircase were replicated inside the lab. The exact dimensions of the course are not specified, but from the provided image of the environment, we estimate that each trial consisted of 60–70 steps21. collected data in a natural out-of the lab environment in 3 different terrain types. However, movement captured is mostly straight-line walking, and the data size is relatively small (6 subjects with 5–6 minutes or 500–600 steps of walking data per subject). In this dataset, we present full body kinematics data from multiple activities, with at least 5 minutes of data per subject for each activity.
Usually, human movement datasets focus on capturing several instances of a narrow activity or a specific maneuver. However, humans perform high-level tasks like going into a room or moving towards a goal, and select the lower level maneuvers instinctively, as per the moment to moment requirements. In order to best replicate this kind of behavior, in the dataset we present here, specific paths were not prescribed to subjects. The subjects were only given ‘high-level’ instructions like ‘go into that classroom’ or ‘Walk up that stairwell’ or ‘Walk towards and sit on that chair’. Then, the ‘lower-level’ movements were decided by the subject. We expect this to have captured more natural movements as well as variability in movement strategies.
In this dataset, subjects naturally transition between different classrooms, an atrium, and stairwells. These transitions include opening doors, changing between flat ground and stair walking, and performing sit to stand and stand to sit movements.
In addition, few datasets include full body motion capture along with the egocentric vision and gaze of the subjects. This limits our understanding of how environments affects human gait from moment to moment. We are aware of only one dataset21 that captures full body motion capture and egocentric vision data in natural environments. Here, we provide another, in an effort to enable improved understanding of how movement is conditioned on the environment.
Methods
Experiments and participants
The dataset is comprised of 6 activities: (1) Level-ground obstacle-free walking, (2) Level-ground walking with random stops, (3) Staircases spanning a 6-storey building, (4) The Comprehensive High-Level Activity Mobility Predictor (CHAMP) activity set, (5) Controlled obstacle course, and (6) Unrestricted walking in public spaces. What we mean by controlled, as well as detailed descriptions of the activities, are presented in the Methods section. Numbers of participants and demographic information for each of the activities is shown in Table 1. The IDs column shows the subject naming convention for the activity i.e. data for a given activity can be found in the directories with the corresponding subject ID.
Subjects were recruited through campus email and social media. All activities were approved by the Institutional Review Board at University of Washington (STUDY00004707 “Smart Step”).
Equipment
Subjects’ joint kinematics and center of mass positions were recorded using an Xsens full body motion capture system23, using IMUs, recorded at 60 Hz for all the activities. For activity 6, egocentric vision and gaze data were collected using a binocular eye tracker from Pupil Labs24 recorded at 30 Hz.
Description of activities
As listed in Table 1, we collected data from 6 activities. These activities were recorded in out-of-the lab environments. The environments include a long corridor, staircases spanning 6 floors of building with flat sections the middle, Classrooms, an Atrium. The environments are not controlled, with large number of people using the atria and classrooms in some instances, and several encounters with unexpected people while turning are present in the dataset. Here, we describe each of these activities in detail.
Activity 1: Level ground walking in an obstacle free environment
This activity involved walking on flat ground in a long corridor (see Fig. 1) in the Paul Allen Building at University of Washington. Subjects were requested to walk along the corridor back and forth, at a self-selected pace. Each trial took approximately 2.5 minutes, with 4–5 rounds of the corridor. The duration of data per subject is 11.97 ± 6.66 minutes (mean ± std).

(left) Corridor for flat ground walking, and (right) Staircases spanning 6 floors.
Activity 2: Level ground walking with random stops
This activity was performed in the same corridor as activity 1 (Fig. 1). For this activity, subjects followed instructions to stop and start walking at random. The instruction were provided using a voice recording, which was repeated across users. Subjects were not given any instructions on how fast to start or stop. The duration of data per subject is 13.55 ± 5.70 minutes (mean ± std).
Activity 3: Staircases spanning a 6-storey building
This activity consisted of stair ascent and descent in a 6-storey public building. This included sections of flat ground transitions in between levels (see Fig. 1). There are 13 consecutive stairs between flat sections and 26 stairs between 2 floors. The data was collected during regular work hours and there are other people using the stairs. The duration of data per subject is 11.52 ± 3.92 minutes (mean ± std).
Activity 4: Modified CHAMP
This data was collected as part of an experiment inspired from the standard Comprehensive High-Level Activity Mobility Predictor (CHAMP) test25,26, which is used to assess the agility of athletes and non-athletes. For the standard CHAMP test, the subject is asked to perform the task as fast as possible, and the time they take is used to assess their agility. We instructed the subjects to perform the task at a self-selected pace, with no requirement to finish the task as fast as possible. It is comprised of the following sub-activities:
-
Modified Edgren Side-step Test: The subject started at rest with arm to the side. When cued by the experimenter, they side-stepped to the left for 10 seconds, stopped, and then side-stepped to the right for 10 seconds. This was repeated 3 times in each trial. The dataset includes 4 trials of the Edgren test per subject. The duration of data per subject is 4.48 ± 0.38 minutes (mean ± std).
-
Modified Illinois Agility Test: The Illinois obstacle course is depicted in Fig. 2a. The subject began behind the start line with arms to the side and facing forward. When cued by the experimenter, the subject walked forward along the 10 m stretch, and then turned around and started walking towards the middle cone at the start line, then weaved up and down through the 4 center cones. Following this, they moved towards the center of 2.5 m line on the top-right side of the course, and touched the line. Lastly, they turned around and walked straight to the finish line. Five trials were collected from each subject. The duration of data per subject is 4.60 ± 0.41 minutes (mean ± std).
Fig. 2 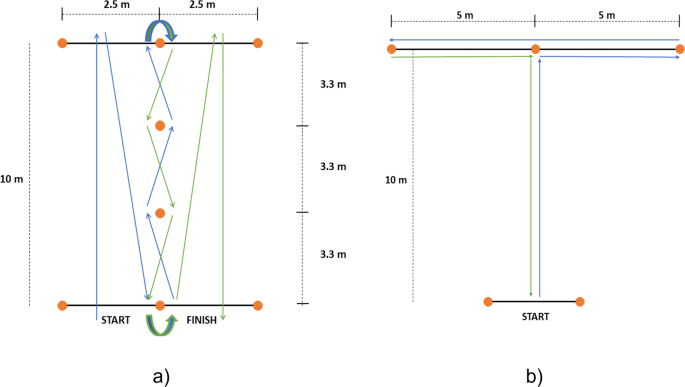
Modified CHAMP activities.
-
Modified T-Test: Fig. 2b shows the activity course for the T-Test. Before beginning, subjects were asked to decide if they would first go left, or right. The subject started with walking forward for 10 meters, then stopped and started side-stepping to the right (or left) for 5 m, followed by side-stepping to the left (or right) for 10 m, and then returned to the middle cone. Lastly, they started backward walking, and stopped at the start position. The T-Test activity set consisted of 7 trials per subject. The duration of data per subject is 5.06 ± 0.49 minutes (mean ± std).

Activity 5: Controlled obstacle course
The obstacle course is depicted in Fig. 3. The subject started with arms at rest to the sides. On ‘Go’ command, the subject started weaving up around the cones and was commanded at random to shift towards the left of the course and step over the boxes or to turn around and weave around the cones. Each trial consisted of the subject performing 5–7 rounds (some clockwise, some counter-clockwise) of the obstacle course. The duration of data per subject is 18.95 ± 4.54 minutes (mean ± std).

Controlled Obstacle Course: Cones in Orange; Boxes in Green. Box positions were randomly shuffled. Subjects avoid boxes by stepping over them.
Activity 6: Unrestricted walking in public places
The environment was comprised of 3 main types of obstacle courses (Fig. 4): (1) Classrooms with dense obstacle arrangement, (2) An atrium with sparse obstacle arrangement, and (3) Two stairwells with a 33-step staircase each. The architectures for the classroom course and the atrium course are shown in Figs. 5, 6 respectively. The arrangement of obstacles was not controlled. Each trial consisted of the subject walking in each of the obstacle courses (except for subject xUD005, for whom there is no classroom data due to a scheduling conflict). An obstacle course from the three was randomly chosen and the subject was asked to go there and perform movements. Transitions while going from one obstacle course to another were also captured in the data. These included opening doors and flat ground to staircase transitions and vice-versa. Each subject’s movement speed and chosen path within an obstacle course was not constrained. Only which obstacle course to perform movements in was specified to them. If the subject started performing repetitive movements, e.g. always taking a left on encountering a particular obstacle or moving in a fixed loop several times, then they were instructed to vary their path by the experimenter. data per subject is 29.50 ± 5.40 minutes (mean ± std).

Environments: Classroom, Atrium and Staircases. Obstacles and other people using the spaces were not controlled.

Classroom: Architecture of one of the classrooms. The arrangement of obstacles is not controlled and varies across subjects. The subject walks at self-selected speed and along self-selected path, The experimenter directed the subject to change their path only if the subject repeated the same path more than 2 times.

Atrium: Architecture of the Atrium. The arrangement of obstacles is not controlled and varies across subjects. The subject walks at self-selected speed and along self-selected path, The experimenter directed the subject to change their path only if the subject repeated the same path more than 2 times.
Protocol
For each data collection session, the subject was briefed about the task to be performed and the equipment to be donned. Then, informed consent was obtained and documented. The participants then wore the Xsens suit and performed the standard n-pose calibration routine from Xsens. For activity 6 (unrestricted walking in public places), each subject also wore the pupil eye-tracker. Then, a pupil screen-marker calibration routine was performed, in which the subjects are instructed to gaze at several bullseye markers displayed on a laptop screen (https://docs.pupil-labs.com/core/software/pupil-capture/#calibration). Following this, the data collection began. The duration of each trial is described in the Tasks section above. Participants were encouraged to take breaks after each trial. The duration of the entire setup and data collection was around 1.5–2 hours.
Data processing and synchronization
For activity 6, the vision and kinematics data was synced in post-processing using the timestamp data. Since the visual data frame rate is 30 Hz while the kinematics frame rate is 60 Hz, each vision frame was assigned a kinematics frame that was within 10 ms of it. The rest of the kinematics frames were dropped. All post-processing, including extraction of kinematics data from raw Xsens files and syncing with vision data, is done using a custom MATLAB script. Image frames from the videos were extracted using FFMPEG. Raw gaze coordinates are available in a csv file generated by the Pupil Player Software. These processes are described in more detail in the documentation provided with the data.
Data Records
Raw data
The raw data files are available on figshare27,28. The xsens motion capture files are available in ‘*.mvn’ file format. These files can be used for visualization using the MVN analyze software by Xsens29. This requires an Xsens license to be able to use the software. The corresponding xml files (‘*.mvnx’) are also available. These files contain the sensor position, segment orientation and joint angle data. An example MATLAB script is provided demonstrating how to read these raw data files. The corresponding raw eye-tracker data has also been uploaded. These files can be analyzed using the freely available Pupil Player software30.
Processed data
In addition to the raw data files, we have also uploaded the processed motion capture and egocentric vision data. The kinematics data is available in csv file format. Each trial is stored in a separate csv file. The raw unnormalized joint data is stored in ‘jointDataRaw.csv’ (See Fig. 7). The min-max normalized joint data is stored in ‘jointDataNorm.csv’ (See Fig. 7). In a csv file, each row represents a single time instant. The columns store the corresponding timestamps, the names of the corresponding vision frames, and joint angle, joint velocity and acceleration data from the 66 joints. The python code for loading these files is available on (https://github.com/abs711/The-way-of-the-future). Vision frames are stored in the folder ‘frames’(See Fig. 7). The path to each vision frame is stored in the ‘jointDataRaw.csv’ and ‘jointDataNorm’ files.

The data is stored in a hierarchical structure. Each leaf node (green, far right) is a file, stored in folders and subfolders (blue boxes) as depicted here.
Data storage format
The dataset is structured in the format shown in Fig. 7. Each subject directory is comprised of raw data (mvn, mvnx, pupil) and processed files. The ‘raw_mvn’ folder contains all the trials for all the activities (named Activity-001). These files can be visualized using the MVN analyze software. The corresponding xml files are stored in the ‘raw_mvnx’ folder. The eyetracker and vision data is stored in the pupil folder. Each activity trial has a separate folder (named Activity-001), which can be dropped in the Pupil Player GUI (https://docs.pupil-labs.com/core/software/pupil-player/) to generate the egocentric video and the overlapped gaze. The processed kinematics data is stored in ‘.csv’ files, with jointDataRaw.csv containing the raw joint angle data and ‘jointDataNorm.csv’ containing the normalized data. The data is normalized using min-max scaling based on the joint-wise minimum and maximum values for the given trial. The processed vision data is stored in the frames folder in form of ‘.jpg’ images. Each row in the kinematics ‘.csv’ file, stores the name of the corresponding vision frame.
Technical Validation
Sensor placement and calibration
Subjects wore tight clothes provided by Xsens to prevent the slipping of IMUs. The sensors were placed as described in the Xsens Awinda documentation31 and the prescribed calibration procedure was followed. After the calibration, the body poses were verified manually in the MVN analyze software. This system has been validated using concurrent optical motion tracking and has been shown to be accurate, especially for sagittal plane movements32.
For the eye-tracker, the screen marker calibration procedure was followed as described in the Pupil documentation (https://docs.pupil-labs.com/core/software/pupil-capture/#calibration). The quality of calibration was verified manually by having the subject track the moving fingertip of the experimenter.
Data synchronization
The data from the motion capture and the eye tracker was synchronized using the UNIX timestamps. The synchronization was validated by recording the hands of a subject while clapping. The instant the hands join was visualized in the MVN analyze visualization and the corresponding vision frame was also inspected. Another custom MATLAB script ‘custom_humanoid.m’ is available for verification on (https://github.com/abs711/The-way-of-the-future). The script generates a video which can be seen on the github repository.
Usage Notes
This dataset can be used to reason about human movement, and especially how movement relates to the visual data arising from the environment. Here we will provide a brief overview of four studies we have conducted that use this dataset, as examples of the kinds of analysis that are possible. These notes will also serve as examples of how the data can be used in supervised vs. unsupervised ways, and with or without including the visual modality.
Bootstrapping a visual classifier
The first study33 is an approach for classifying ambulation modes, such as flat ground walking and stair ascent. Instead of defining these modes a priori, they are identified by clustering the movements of the knee joint. During different kinds of ambulation, the profile of knee movements is distinct. These clusters serve as pseudolabels of the terrain, requiring no human-annotated ground truth labels of terrain types. Figure 8 shows the clustered movement types and characteristic joint motions for each of the clusters.

(left) Clustered gait types identified in33. Depending on how low in the hierarchy, the data could be divided into flat ground vs. stair walking, or further subdivided into turning gait, straight walking, and stair ascent and descent. (right) Mean knee angles for each of the clusters. The kinematic trajectories are distinct for different kinds of ambulation, leading to clusters that differentiate ambulation modes.
The pseudolabels derived from kinematic clustering can then be used to train a supervised visual terrain classifier using the corresponding video data. The result is a visual terrain classifier with an accuracy of 96% that required no ground truth annotation. This kind of self-supervised bootstrapping is likely to become an important tool as datasets become increasingly large and large models become desirable to train. Example scripts for performing this analysis are available on Github in the directory named “Bootstrapping the visual classifier.” The file “gaitsteps_dataprep.m” performs gait segmentation in Matlab. The file “cluster_kinematics.py” performs the clustering of kinematics using sklearn libraries and saves the resultant labels as a pickle format. Finally, “cluster_classify_vision_train.py” and “cluster_vision_infer.py perform training and classification of images using the kinematic labels, based on transfer learning from the pretrained ResNet provided in the FastTorch library. These files may be used to reproduce the results33 and should serve as a basis for performing similar analysis.
Optical flow for kinematics prediction
The second example analysis is using either the kinematic data alone2 or also combining the the visual data3 to predict knee and ankle motion. See Fig. 9 for a depiction of how the data types are processed and combined to generate predictions. The idea here is that the movement of particular joints is highly predictable from a time history of the rest of the body motion and the visual scene. These predictions could be used as a reference trajectory for controlling an assistive wearable robot such as a prosthetic limb.

The neural network architecture combining vision and kinematics data3. The performance of this network (named as ‘Optical Flow’) is compared with the optical flow features zeroed out (named as ‘No Flow’). We find that using egocentric optical flow helps improve prediction of knee and ankle joint ankles from the rest of the body. The prediction performance is measured in terms of the root mean squared error (RMSE) between the predicted trajectory and the actual measured trajectory using motion capture.
Figure 9 depicts the flow of data used in a regressor neural network. Visual data is processed into optical flow features, and then both sensory modalities are initially processed by a Long Short Term Memory (LSTM) neural network that models temporal dynamics. These two sensory streams are then fused in a network that predicts the target joint movements. “Optical Flow” refers to the full network and “No Flow” is an ablation case with the visual data zeroed out, to show its relative contribution. An interesting feature of this approach is that the system can target either instantaneous joint angles2 or can predict into the future3. We expect that predicting further into the future should be more difficult, but this has yet to be systematically studied to our knowledge.
Figures 10, 11 show representative snippets of knee angle trajectories above, and three corresponding video frames. The actual measured trajectory of the participant (blue solid line) is somewhat estimable using only the kinematic measurements from the rest of the body (red square-dotted line). In general, however, additionally including the video data results in much better estimates (green circular-dotted line). More examples of this are provided in the manuscript3, including some examples of when visual data was not informative and did not improve predictions.

Gait kinematics (above) and the first, 40th, and 80th vision frames (below) during the maneuver. The subject exited the classroom and executed a right turn while entering the atrium. Optical Flow RMSE = 0.082, No Flow RMSE = 0.110.

Frames number 15, 60 and 100 are shown. The subject opened the door and entered the classroom. Optical Flow RMSE = 0.131, No Flow RMSE = 0.188.
Complexity of movement
The third example34 is an analysis of the relative complexity of various locomotion activities. Forward walking, backward walking, sidestepping, and classroom walking were manually annotated using the Xsens Analyze visualizer. These annotations are used to organize the activities in the processed, but not the raw, form of the dataset files (see Fig. 7.) These activity types were compared in terms of their apparent complexity using a variety of measures from statistics, information theory and dynamical system theory. While not exhaustive, the study raised the important question of how should we measure the complexity of human locomotion, particularly when some of the standard complexity measures in the gait literature give counterintuitive results. For example, we expect locomotion in tight spaces with obstacles like a classroom to be more complex than obstacle free sidestepping. However, our analysis shows otherwise (See Fig. 12). A commmon measure of complexity, the number of principal components necessary to express 95 percent of the variability, rates left and right sidestepping as the most complex. This analysis is especially important considering that the data is measured from movement outside of an artificial laboratory environment. Although there has previously been some comparative analysis of treadmill walking and overground straight line walking, eg.35, this dataset provides the opportunity to analyze and compare more diverse activities outside of the lab.

Commonly used measures of complexity provide quantitative insight into differences in activity type or behavior in and out of the laboratory. (a) depicts the percent variance explained by an increasing number of principal components, and (b) depicts the number of components necessary to represent 95% of the variability. These are both commonly used quantitative measures of complexity, yet they indicate, counterintuitively, that left and right sidestepping are more complex than obstacle avoidance or backward walking.
Dimensionality reduction and movement representations
The final usage example is a means for representing the full-body kinematic data using a dimensionality reduction technique36. We compare principal component analysis (PCA) with two styles of autoencoding neural networks, dubbed Pose-AE and Move-AE. The Move-AE network uses recurrent neural network components to represent temporal dynamics, leading to higher Variance Accounted For (VAF) than the “snapshot” methods. We also show that the geometry of the low-dimensional latent space has human-interpretable structure, with different kinds of movement and different individuals occupying distinct regions (Fig. 13). This allows for simple classification of movement type and individual in the latent representations. Scripts demonstrating these techniques are made available in the directory named “Dimensionality reduction and movement representation”.

(left) Movements recorded from stair ambulation, in red, form a distinct cloud mostly separable from those recorded from flat ground walking, in blue. (right) Movements recorded from 8 individuals occupy distinct annular regions in the latent representation. In36 we show that a simple classifier can achieve 97% accuracy for distinguishing flat from stair walking, and 91% accuracy for discriminating amongst 8 individuals. These examples show that dimensionality reduction can assist in visualization, interpretation, or creating representations suitable for classification.
Code availability
We provide an example python script for loading the processed motion capture and vision data, named ‘main.py’ in the directory ‘data_loading_example’ on the Github repository. In addition we provide scripts for synchronization and frame-dropping, and examples of loading into pytorch machine learning pipeline. All code is available on (https://github.com/abs711/The-way-of-the-future).
References
Friesen, K. B., Zhang, Z., Monaghan, P. G., Oliver, G. D. & Roper, J. A. All eyes on you: how researcher presence changes the way you walk. Scientific Reports 10, 1–8 (2020).
Rai, V., Sharma, A., Boe, D., Preechayasomboon, P. & Rombokas, E. Continuous and unified modelling of joint kinematics for multiple activities. IEEE Access (2022).
Sharma, A. & Rombokas, E. Improving imu-based prediction of lower limb kinematics in natural environments using egocentric optical flow. IEEE Transactions on Neural Systems and Rehabilitation Engineering 30, 699–708, https://doi.org/10.1109/TNSRE.2022.3156884 (2022).
Fathi, A., Farhadi, A. & Rehg, J. M. Understanding egocentric activities. In 2011 international conference on computer vision, 407–414 (IEEE, 2011).
Pirsiavash, H. & Ramanan, D. Detecting activities of daily living in first-person camera views. In 2012 IEEE conference on computer vision and pattern recognition, 2847–2854 (IEEE, 2012).
Laschowski, B., McNally, W., Wong, A. & McPhee, J. Environment classification for robotic leg prostheses and exoskeletons using deep convolutional neural networks. bioRxiv https://doi.org/10.1101/2021.06.24.449600 (2021).
Fukuchi, C. A., Fukuchi, R. K. & Duarte, M. A public dataset of overground and treadmill walking kinematics and kinetics in healthy individuals. PeerJ 6, e4640 (2018).
Burdack, J. et al. A public dataset of overground walking kinetics in healthy adult individuals on different sessions within one day. Mendeley Data 1 (2020).
Schreiber, C. & Moissenet, F. A multimodal dataset of human gait at different walking speeds established on injury-free adult participants. Scientific data 6, 1–7 (2019).
Horst, F., Lapuschkin, S., Samek, W., Müller, K. & Schöllhorn, W. A public dataset of overground walking kinetics and full-body kinematics in healthy individuals. Mendeley Data (2019).
Camargo, J., Ramanathan, A., Flanagan, W. & Young, A. A comprehensive, open-source dataset of lower limb biomechanics in multiple conditions of stairs, ramps, and level-ground ambulation and transitions. Journal of Biomechanics 119, 110320 (2021).
Moore, J. K., Hnat, S. K. & van den Bogert, A. J. An elaborate data set on human gait and the effect of mechanical perturbations. PeerJ 3, e918 (2015).
Fukuchi, R. K., Fukuchi, C. A. & Duarte, M. A public dataset of running biomechanics and the effects of running speed on lower extremity kinematics and kinetics. PeerJ 5, e3298 (2017).
Santos, D. A. & Duarte, M. A public data set of human balance evaluations. PeerJ 4, e2648 (2016).
Dos Santos, D. A., Fukuchi, C. A., Fukuchi, R. K. & Duarte, M. A data set with kinematic and ground reaction forces of human balance. PeerJ 5, e3626 (2017).
Ackermans, T. M. et al. A novel multivariate approach for biomechanical profiling of stair negotiation. Experimental gerontology 124, 110646 (2019).
Sie, A. et al. Descending 13 real world steps: a dataset and analysis of stair descent. Gait & Posture 92, 383–393 (2022).
Chereshnev, R. & Kertész-Farkas, A. Hugadb: Human gait database for activity recognition from wearable inertial sensor networks. In International Conference on Analysis of Images, Social Networks and Texts, 131–141 (Springer, 2017).
Carnegie Mellon University - CMU Graphics Lab - motion capture library.
Brantley, J. A., Luu, T. P., Nakagome, S., Zhu, F. & Contreras-Vidal, J. L. Full body mobile brain-body imaging data during unconstrained locomotion on stairs, ramps, and level ground. Scientific data 5, 1–10 (2018).
Matthis, J. S., Yates, J. L. & Hayhoe, M. M. Gaze and the control of foot placement when walking in natural terrain. Current Biology 28, 1224–1233 (2018).
Luo, Y. et al. A database of human gait performance on irregular and uneven surfaces collected by wearable sensors. Scientific data 7, 1–9 (2020).
Mtw awinda - products - xsens 3d motion tracking. https://www.xsens.com/products/mtw-awinda/. (Accessed on 10/29/2018).
Kassner, M., Patera, W. & Bulling, A. Pupil: An open source platform for pervasive eye tracking and mobile gaze-based interaction. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct Publication, UbiComp ‘14 Adjunct, 1151–1160, https://doi.org/10.1145/2638728.2641695 (ACM, New York, NY, USA, 2014).
Gailey, R. S. et al. Construct validity of comprehensive high-level activity mobility predictor (champ) for male servicemembers with traumatic lower-limb loss. Journal of Rehabilitation Research & Development 50, 919–931 (2013).
Raya, M. A. et al. Comparison of three agility tests with male servicemembers: Edgren side step test, t-test, and illinois agility test. Journal of Rehabilitation Research & Development 50, 951–961 (2013).
Sharma, A. et al. A non-laboratory gait dataset of full body kinematics and egocentric vision. figshare https://doi.org/10.6084/m9.figshare.c.6076607 (2023).
Sharma, A. et al. A non-laboratory gait dataset of full body kinematics and egocentric vision (part 2). figshare https://doi.org/10.25452/figshare.plus.21761465 (2023).
Mvn analyze. https://www.xsens.com/products/mvn-analyze. (Accessed on 5/7/2022).
Pupil player. https://docs.pupil-labs.com/core/software/pupil-player/. (Accessed on 5/7/2022).
Mvn user manual. https://www.xsens.com/software-downloads. (Accessed on 12/28/2021).
Al-Amri, M. et al. Inertial measurement units for clinical movement analysis: Reliability and concurrent validity. Sensors 18, 719 (2018).
Rai, V., Boe, D. & Rombokas, E. Vision for prosthesis control using unsupervised labeling of training data. In 2020 IEEE-RAS 20th International Conference on Humanoid Robots (Humanoids), 326–333, https://doi.org/10.1109/HUMANOIDS47582.2021.9555789 (2021).
Sharma, A. & Rombokas, E. Complexity of locomotion activities in an outside-of-the-lab wearable motion capture dataset. Frontiers in Bioengineering and Biotechnology 10, https://doi.org/10.3389/fbioe.2022.918939 (2022).
Riley, P. O., Paolini, G., Della Croce, U., Paylo, K. W. & Kerrigan, D. C. A kinematic and kinetic comparison of overground and treadmill walking in healthy subjects. Gait & posture 26, 17–24 (2007).
Boe, D. et al. Dimensionality reduction of human gait for prosthetic control. Frontiers in Bioengineering and Biotechnology 925 (2021).
Acknowledgements
This work was supported in part by the NSF National Robotics Initiative Integrative Grant 2024446/2024237.
Author information
Authors and Affiliations
Contributions
A.S. conceived the experiments, resolved hardware challenges, contributed to data collection, developed the code for data processing and synchronization, visualizations, example scripts, the code for ‘Optical flow for kinematic prediction’, and wrote the original manuscript. V.R. conceived the experiments, conceived the data formatting, developed the code for data processing, and the code for ‘Bootstrapping the visual classifier’. M.C., Z.D., Z.G. collected most of the data. D.B. developed the code for ‘Dimensionality reduction and movement representation’. E.R. conceived the experiments, wrote the original manuscript, supervised this research and provided scientific guidance. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sharma, A., Rai, V., Calvert, M. et al. A Non-Laboratory Gait Dataset of Full Body Kinematics and Egocentric Vision. Sci Data 10, 26 (2023). https://doi.org/10.1038/s41597-023-01932-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-023-01932-7
- Springer Nature Limited
This article is cited by
-
NONAN GaitPrint: An IMU gait database of healthy young adults
Scientific Data (2023)