
Abstract
Coffee, a major dietary source of caffeine, is among the most widely consumed beverages in the world and has received considerable attention regarding health risks and benefits. We conducted a genome-wide (GW) meta-analysis of predominately regular-type coffee consumption (cups per day) among up to 91 462 coffee consumers of European ancestry with top single-nucleotide polymorphisms (SNPs) followed-up in ~30 062 and 7964 coffee consumers of European and African-American ancestry, respectively. Studies from both stages were combined in a trans-ethnic meta-analysis. Confirmed loci were examined for putative functional and biological relevance. Eight loci, including six novel loci, met GW significance (log10Bayes factor (BF)>5.64) with per-allele effect sizes of 0.03–0.14 cups per day. Six are located in or near genes potentially involved in pharmacokinetics (ABCG2, AHR, POR and CYP1A2) and pharmacodynamics (BDNF and SLC6A4) of caffeine. Two map to GCKR and MLXIPL genes related to metabolic traits but lacking known roles in coffee consumption. Enhancer and promoter histone marks populate the regions of many confirmed loci and several potential regulatory SNPs are highly correlated with the lead SNP of each. SNP alleles near GCKR, MLXIPL, BDNF and CYP1A2 that were associated with higher coffee consumption have previously been associated with smoking initiation, higher adiposity and fasting insulin and glucose but lower blood pressure and favorable lipid, inflammatory and liver enzyme profiles (P<5 × 10−8).Our genetic findings among European and African-American adults reinforce the role of caffeine in mediating habitual coffee consumption and may point to molecular mechanisms underlying inter-individual variability in pharmacological and health effects of coffee.
Similar content being viewed by others

Introduction
Coffee is among the most widely consumed beverages in the world.1 North American coffee drinkers typically consume ~2 cups per day while the norm is at least 4 cups in many European countries.1 In prospective cohort studies, coffee consumption is consistently associated with lower risk of Parkinson’s disease, liver disease and type 2 diabetes.2 However, the effects of coffee on cancer development, cardiovascular and birth outcomes and other health conditions remain controversial.2 For most populations, coffee is the primary source of caffeine, a stimulant also present in other beverages, foods and medications.1,3 The fifth edition of the Diagnostic and Statistical Manual of Mental Disorders does not include a diagnosis of caffeine dependence or abuse due to a paucity of evidence but lists caffeine intoxication and withdrawal as disorders.4 Knowledge of factors contributing to coffee’s consumption and physiological effects may greatly advance the design and interpretation of population and clinical research on coffee and caffeine.5 Genetic factors could be especially valuable as they offer ways to study the potential health effects of coffee via instrumental variables or gene–environment interactions.5 Heritability estimates for coffee and caffeine use range between 36 and 58%.6 Genome-wide association studies (GWAS) of habitual caffeine and coffee intake have identified variants near CYP1A2 and aryl hydrocarbon receptor (AHR).7, 8, 9 Cytochrome P450 (CYP)1A2 is responsible for ~95% of caffeine metabolism in humans and AHR has a regulatory role in basal and substrate-induced expression of target genes, including CYP1A1 and CYP1A2.10,11
To identify additional loci, we conducted a staged genome-wide (GW) meta-analysis of coffee consumption including over 120 000 coffee consumers sourced from population-based studies of European and African-American ancestry.
Materials and methods
Study design and populations
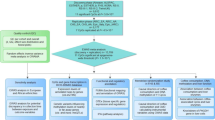
Supplementary Figure S1 depicts an overview of the current study. We performed a meta-analysis of GWAS summary statistics from 28 population-based studies of European ancestry to detect single-nucleotide polymorphisms (SNPs) that are associated with coffee consumption. Top loci were followed-up in studies of European (13 studies) and African-American (7 studies) ancestry and confirmed loci were explored in a single Pakistani population. Detailed information on study design, participant characteristics, genotyping and imputation for all contributing studies are provided in the Supplementary Information and Supplementary Tables S1–S6.
Phenotype
All phenotype data were previously collected via interviewer- or self-administered questionnaires (Supplementary Table S1). Our primary phenotype (‘phenotype 1’) was cups of predominately regular-type coffee consumed per day among coffee consumers. Coffee data collected categorically (for example, 2–3 cups per day) were converted to cups per day by taking the median value of each category (for example, 2.5 cups per day). A secondary analysis was performed comparing high with infrequent/non-coffee consumers (‘phenotype 2’). A subset of stage 1 studies collected information on decaffeinated coffee consumption; which was examined in follow-up analysis of the confirmed loci.
Statistical analysis
Each stage 1 (discovery) study performed GWA testing for each phenotype across ~2.5 million genotyped or imputed autosomal SNPs (HapMap II, Centre d’Etude du Polymorphisme Humain (CEU) reference), based on linear (cups per day, phenotype 1) or logistic (high vs none/low, phenotype 2) regression under an additive genetic model. Analyses were adjusted for age, smoking status and, when applicable, sex, case–control status, study site, family structure and/or study-specific principal components of population substructure (Supplementary Table S7). SNPs with minor allele frequency <0.02 or with low imputation quality scores were removed before meta-analysis (Supplementary Table S5). The GWAtoolbox (see Supplementary Information for URLs) was used for initial quality control. Minor allele frequencies and a plot comparing (1/median standard error of effect size) vs (square root of sample size) for each study were also reviewed for outliers and these were addressed before the final meta-analysis.
For both phenotypes, GW meta-analysis was conducted using a fixed-effects model and inverse-variance weighting with a single genomic control correction as implemented in METAL12 and GWAMA13 (r>0.99 for correlation between METAL and GWAMA results). The phenotypic variance explained by additive SNP effects was estimated in the Women’s Genome Health Study (WGHS, n=15 987 with identity-by-state <0.025) using GCTA.14 Stage 1 summary statistics were also subjected to pathway analysis using MAGENTA15 (Supplementary Information).
For regions achieving association P-values <5 × 10−8 (7p21, 7q23.11, 11p13 and 15q24), we performed conditional analysis using the summary statistics from the meta-analysis to test for the association of each SNP while conditioning on the top SNPs, with correlations between SNPs due to linkage disequilibrium (LD) estimated from the imputed genotype data from the Atherosclerosis Risk in Communities cohort,16 a large and representative cohort of men and women of European ancestry.
Our approach to select SNPs for replication (stage 2) is described in Supplementary Information. Stage 2 meta-analyses were performed separately for European and African-American populations, using the same statistical models and methods as described for stage 1, but without genomic control (Supplementary Information).
Studies from all stages were included in an overall meta-analysis using MANTRA (Meta-ANalysis of TRans-ethnic Association) studies ;17 which adopts a Bayesian framework to combine results from different ethnic groups by taking advantage of the expected similarity in allelic effects between the most closely related populations. MANTRA was limited to SNPs selected for replication thus no genomic control was applied. A random-effects analysis using GWAMA was performed in parallel to obtain effect estimates, which are not generated by MANTRA. The GW-significance threshold of log10 BF >5.64 approximates a traditional GW P-value threshold of 5 × 10−8 under general assumptions.18,19 Subgroup analysis and meta-regression were performed to investigate possible sources of between-study heterogeneity (Supplementary Information).
Fine-mapping
To assess the improvement in fine-mapping resolution due to trans-ethnic meta-analysis, we applied the methods of Franceschini et al.17 to stage 1 and stage 2 (African Americans only) GW-summary level data (Supplementary Information).
Potential SNP function and biological and clinical inferences
Details pertaining to follow-up of confirmed loci are provided in the Supplementary Information. Briefly, all confirmed index SNPs and their correlated proxies were examined for putative function using publicly available resources. Bioinformatics and computational tools were used to systematically mine available knowledge and experimental databases to inform biological hypotheses underlying the link between loci and coffee consumption as well as connections between loci. For these analyses all genes mapping to the confirmed regions were considered as potential candidates. Finally, we searched the National Human Genome Research Institute GWAS catalog20 and Metabolomics GWAS server21 for all GW-significant associations with our confirmed coffee SNPs. Complete GWAS summary data for coffee-implicated diseases or traits were additionally queried.
Results
SNPs associated with coffee consumption
Discovery stage
Results from the discovery stage are summarized in Supplementary Figures S2–S5. Little evidence for genomic inflation (λ<1.07) was observed for either phenotype. The two analyses yielded similarly ranked loci and significant enrichment of ‘xenobiotic’ genes (MAGENTA’s FDR<0.006), suggesting no major difference in the genetic influence on coffee drinking initiation compared with the level of coffee consumption among coffee consumers at these loci. Overall, ~7.1% (standard error: 2%) of the variance in coffee cups consumed per day (phenotype 1) could be explained by additive and common SNP effects in the WGHS.
Conditioning on the index SNPs of each region achieving association P-values <5 × 10−8 (7p21, 7q23.11, 11p13 and 15q24) in the discovery stage provided little evidence for multiple independent variants (Supplementary Figure S6). Only four of the SNPs on chromosome 7 were potentially independent and carried forward with other promising SNPs.
Replication and trans-ethnic meta-analysis
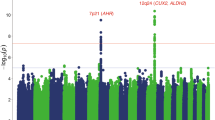
Forty-four SNPs spanning thirty-three genomic regions met significance criteria for candidate associations and were followed-up in stage 2 (Supplementary Tables S8–S13). Eight loci, including six novel, met our criteria for GW significance (log10 BF>5.64) in a trans-ethnic meta-analysis of all discovery and replication studies (Table 1; Supplementary Tables S14–S16; Supplementary Figures S7 and S8). Confirmed loci have effect sizes of 0.03–0.14 cups per day per allele and together explain ~1.3% of the phenotypic variance of coffee intake. We were underpowered to replicate these associations in a Pakistani population (Supplementary Information).
Functional and biological inferences
Enhancer (H3K4me1) and promoter (H3K4me3) histone marks densely populate many of these regions and several non-synonymous and potential regulatory SNPs are highly correlated (r2>0.8) with the lead SNP and thus strong candidates for being a causal variant (Table 2; Supplementary Information; Supplementary Tables S17–S19). Candidate genes form a highly connected network of interactions, featuring discernible clusters of genes around brain-derived neurotrophin factor (BDNF) and AHR (Figure 1; Supplementary Information; Supplementary Tables S20 and S21). At least one gene in each of the eight regions (i) is highly expressed in brain, liver and/or taste buds, (ii) results in phenotype abnormalities relevant to coffee consumption behavior when modified in mice and (iii) is differentially expressed in human hepatocytes when treated with high (7500 μM) but not low (1500 μM) doses of caffeine (Table 2; Supplementary Tables S22–S24).

Network describing direct interactions between candidate genes of confirmed loci. Relationships were retrieved from databases of transcription regulation and protein–protein interaction experiments (Supplementary Table S21). Genes are represented as nodes that are colored according to locus. Candidate genes for loci identified in the current study were supplemented with known candidate genes related to caffeine pharmacology (gray nodes). Edges indicate known interactions.
Additional genomic characterization of the top loci allows further biological inference as follows:
(i) Previously identified loci near AHR (7p21) and CYP1A2 (15q24)
Consistent with previous reports in smaller samples,7, 8, 9 the intergenic 7p21 and 15q24 loci near AHR and CYP1A1/CYP1A2 respectively remained the most prominent and highly heterogeneous loci associated with coffee consumption. The same index SNPs were identified in European and African Americans, suggesting that they are robust HapMap proxies for causal variants in these two populations. Cohort-wide mean coffee consumption explained part of the heterogeneity in study results for both loci (Supplementary Table S25; Supplementary Information). The rs2472297 T and rs4410790 C alleles associated with increased coffee consumption have recently been associated with lower plasma caffeine levels21 and shown to increase CYP1A2-mediated metabolism of olanzapine.22 The C allele of rs4410790 is also positively correlated with cerebellum AHR methylation, suggesting a novel role of Ahr in motor or learning pathways that may trigger coffee consumption. The most significant variants at 15q24 reside in the CYP1A1-CYP1A2 bidirectional promoter where AHR response elements have been identified and shown to be important for transcriptional activation of both CYP1A1 and CYP1A2.23 The rs2472297 T variant putatively weakens the binding of SP1, a co-activator in the Ahr–Arnt complex regulating CYP1 locus transcription24 and is also implicated in the expression of several neighboring genes. The latter observation, together with this region’s high LD and long range chromatin interactions (Supplementary Figure S9), suggests a regulatory network among these genes.
(ii) Novel loci at 7q11.23 (POR) and 4q22 (ABCG2) likely function in caffeine metabolism
Variants at 7q11.23 (rs17685) and 4q22 (rs1481012) map to novel yet biologically plausible candidate genes involved in xenobiotic metabolism. rs17685 maps to the 3’UTR of POR, encoding P450 oxidoreductase which transfers electrons to all microsomal CYP450 enzymes.25 The rs17685 A variant associated with higher coffee consumption is linked to increased POR expression and potentially weakens the DNA binding of several transcriptional regulatory proteins including BHLHE40, which inhibits POR expression.26 The same SNP is in LD (CEU: r2=0.93) with POR*28 (rs1057868 and Ala503Val), which is associated with differential CYP activity depending on the CYP isoform, substrate and experimental model used.27 rs1481012 at 4q22 maps to ABCG2, encoding a xenobiotic efflux transporter. rs1481012 is in LD (CEU: r2=0.92) with rs2231142 (Gln141Lys), a functional variant at an evolutionarily constrained residue.28 However, fine-mapping of this region on the basis of reduced LD in the African-American sample limited an initial 189 102-kb region to a credible span of 6249 kb (Supplementary Table S16) that excluded rs2231142.
(iii) Novel loci at 11p13 (BDNF) and 17q11.2 (‘SLC6A4’) likely mediate the positive reinforcing properties of coffee constituents
The index SNP at 11p13 is the widely investigated missense mutation (rs6265 and Val66Met) in BDNF (Supplementary Table S26). BDNF modulates the activity of serotonin, dopamine and glutamate, and neurotransmitters involved in mood-related circuits and have a key role in memory and learning.29 The Met66 allele impairs neuronal activity-dependent BDNF secretion30 and thus may attenuate the rewarding effects of coffee and, in turn, motivation to consume coffee. The increasingly recognized roles of BDNF in the chemosensory system and conditioned taste preferences may also be relevant.31 The index SNP (rs9902453) at 17q11.2 maps to the EFCAB5 gene and is in LD (CEU: r2>0.8) with SNPs that alter regulatory motifs for AhR32 in the neighboring gene NSRP1, but neither gene is an obvious candidate for coffee consumption. Upstream of rs9902453 lies a possibly stronger candidate: SLC6A4 encoding the serotonin transporter. Serotonergic neurotransmission affects a wide range of behaviors including sensory processing and food intake.33
(iv) Novel loci at 2p24 (GCKR) and 17q11.2 (MLXIPL)
Variants at 2p24 (rs1260326) and 7q11.23 (rs7800944) map to GCKR and MLXIPL, respectively. The former has been associated with plasma glucose and multiple metabolic traits and the latter with plasma triglycerides (Table 3; Supplementary Table S27). Adjustment of regression models for plasma lipids in the WGHS (n~17 000) and plasma glucose in TwinGene (n~8800) did not significantly change the relationship between SNPs at these two loci and coffee consumption (P>0.48, Supplementary Tables S28 and S29). The rs1260326 T allele encodes a non-synonymous change in the encoded, glucokinase regulatory protein leading to increased hepatic glucokinase activity.34 Glucokinase regulatory protein and glucokinase may also cooperatively function in the glucose-sensing process of the brain35 that may, in turn, influence central pathways responding to coffee constituents. A direct link between MLXIPL and coffee consumption remains unclear, except for the interactions with other candidate genes (Figure 1). Experimental evidence and results from formal prioritization analyses also warrants consideration of other candidates in these regions (Figure 1; Table 2; Supplementary Tables S23). For example, in the frontal cortex, the rs1260326 allele positively associated with coffee consumption correlates with lower methylation of PPM1G; a putative regulatory target for AhR and binding target for PPP1R1B, which mediates psychostimulant effects of caffeine.36
Pleiotropy and clinical inferences
None of the eight loci was significantly associated with caffeine taste intensity (P>0.02) or caffeine-induced insomnia (P>0.08), according to previously published GWAS of these traits.37, 38, 39 SNPs near AHR associated with higher coffee consumption were also significantly associated with higher decaffeinated coffee consumption (~0.05 cups per day, P<0.0004, n=24 426); perhaps a result of Pavlovian conditioning among individuals moderating their intake of regular coffee or the small amounts of caffeine in decaffeinated coffee.1
Across phenotypes in the GWAS catalog,20 the alleles leading to higher coffee consumption at 2p24, 4q22, 7q11.23, 11p13 and 15q24 have been associated with one or more of the following: smoking initiation, higher adiposity and fasting insulin and glucose but lower blood pressure and favorable lipid, inflammatory and liver enzyme profiles (P<5 × 10−8, Table 3; Supplementary Table S27). Focused on metabolic, neurologic and psychiatric traits for which coffee has been implicated (Table 3; Supplementary Table S32), there were additional sub-GW significant associations in published GWAS. Variants associated with higher coffee consumption increased adiposity (rs1481012, P=4.85 × 10−3), birth weight (rs7800944, P=2.10 × 10−3), plasma high-density lipoprotein (HDL, rs7800944, P=2.24 × 10−3), risk of Parkinson’s disease (rs1481012, P=7.11 × 10−3), reduced blood pressure (rs6265, P=6.58 × 10−4; rs2472297, P<6.80 × 10−5 and rs9902453, P=6.05 × 10−3), HDL (rs6968554, P=1.18 × 10−3), risk of major depressive disorder (rs17685, P=6.98 × 10−3) and bipolar disorder (rs1260326, P=2.31 × 10−3). Associations with adiposity, birth weight, blood pressure, HDL and bipolar disorder remain significant after correcting for the number of SNPs tested.
Discussion
Coffee’s widespread popularity and availability has fostered public health concerns of the potential health consequences of regular coffee consumption. Findings from epidemiological studies of coffee consumption and certain health conditions remain controversial.2 Knowledge of genetic factors contributing to coffee’s consumption and physiological effects may inform the design and interpretation of population and clinical research on coffee.5 In the current report, we present results of the largest GWAS of coffee intake to-date and the first to include populations of African-American ancestry. In addition to confirming associations with AHR and CYP1A2, we have identified six new loci, not previously implicated in coffee drinking behavior.
Our findings highlight an important role of the pharmacokinetic and pharmacodynamic properties of the caffeine component of coffee underlying a genetic propensity to consume the beverage. Loci near BDNF and SLC6A4 potentially impact consumption behavior by modulating the acute behavioral and reinforcing properties of caffeine. Others near AHR, CYP1A2, POR and ABCG2 act indirectly by altering the metabolism of caffeine and thus the physiological levels of this stimulant. The strength of these four associations with coffee intake, along with results from pathway analysis showing significant enrichment for ‘xenobiotic’ genes, emphasize an especially pronounced role of caffeine metabolism in coffee drinking behavior. The current study is the first to link GCKR and MLXIPL variation to a behavioral trait. The non-synonymous rs1260326 SNP in GCKR has been a GW signal for various metabolic traits particularly those reflecting glucose homeostasis (Table 3). GCKR variation may impact the glucose-sensing process of the brain35 that may, in turn, influence central pathways responding to coffee constituents. Methylation quantitative trait loci and binding motif analysis suggest that PPM1G may be another candidate underlying the association between rs1260326 and coffee consumption. Variants near MLXIPL have also topped the list of variants associated with plasma triglycerides (Table 3), but their link to coffee consumption remains unclear. Future studies on the potential pleiotropic effects of these two loci are clearly warranted. Interestingly, several candidate genes implicated in coffee consumption behavior, but not confirmed in our GWAS, interact with one or more of the eight confirmed loci (Figure 1). While these findings are encouraging for ongoing efforts they also emphasize the need to study sets or pathways of genes in the future.
Specific SNPs associated with higher coffee consumption have previously been associated with smoking initiation, higher adiposity and fasting insulin and glucose but lower blood pressure and favorable lipid, inflammatory and liver enzyme profiles. Whether these relationships reflect pleiotropy, confounding or offer insight to the potential causal role coffee plays in these traits merits further investigation. Future research, particularly Mendelian Randomization and gene–coffee interaction studies, will need to consider the direct and indirect roles that each SNP has in altering coffee drinking behavior as well as the potential for interactions between loci (Figure 1). The heterogeneous effects specific to AHR- and CYP1A2-coffee associations point to SNP-specific interactions with the environment or population characteristics that might also warrant consideration (Supplementary Information).
The strong cultural influences on norms of coffee drinking may have reduced our power for loci discovery. This might, in part, underlie our lack of replication in a Pakistani population, wherein coffee consumption is extremely rare. Methodological limitations specific to our approach may also have reduced our power for loci discovery or precision in estimating effect sizes (Supplementary Information). For example, some studies collected coffee data in categories of cups per day (for example, 2–3 cups per day) rendering a less precise record of intake as well as a non-Gaussian distributed trait for analysis. The precise chemical composition of different coffee preparations is also not captured by standard food frequency questionnaire and is likely to vary within and between populations. Nevertheless, the eight loci together explain ~1.3% of the phenotypic variance, a value at least as great as that reported for smoking behavior and alcohol consumption which are subjected to similar limitations in GWAS.40,41
The additive genetic variance (or narrow-sense heritability) of coffee intake as estimated by GCTA in WGHS (7%) is considerably lower than estimates based on pedigrees (36–57%).6 The marked discrepancies between the GCTA and pedigree estimates of heritability may be due to one or more of the following: the potential contribution of rare variants to heritability (not captured by GCTA’s ‘chip-based heritability’), biases in pedigree analysis resulting in overestimates of heritability, differences in phenotype ascertainment or definition and cultural differences in the populations studied.42
In conclusion, our results support the hypothesis that metabolic and neurological mechanisms of caffeine contribute to coffee consumption habits. Individuals adapt their coffee consumption habits to balance perceived negative and reinforcing symptoms that are affected by genetic variation. Genetic control of this potential ‘titrating’ behavior would incidentally govern exposure to other potentially ‘bioactive’ constituents of coffee that may be related to the health effects of coffee or other sources of caffeine. Thus, our findings may point to molecular mechanisms underlying inter-individual variability in pharmacological and health effects of coffee and caffeine.
References
Fredholm BB, Battig K, Holmen J, Nehlig A, Zvartau EE . Actions of caffeine in the brain with special reference to factors that contribute to its widespread use. Pharmacol Rev 1999; 51: 83–133.
Cornelis MC . Gene-coffee interactions and health. Curr Nutr Rep 2014; 3: 178–195.
Spiller MA . The chemical components of coffee. In: Spiller GA (eds) Caffeine. CRC: Boca Raton, 1998, pp 97–161.
American Psychiatric Association. Diagnostic and Statistical Manual of Mental Disorders, 5th edn. American Psychiatric Publishing: Arlington, VA, 2013.
Cornelis MC . Coffee intake. Prog Mol Biol Transl Sci 2012; 108: 293–322.
Yang A, Palmer AA, de Wit H . Genetics of caffeine consumption and responses to caffeine. Psychopharmacology 2010; 211: 245–257.
Cornelis MC, Monda KL, Yu K, Paynter N, Azzato EM, Bennett SN et al. Genome-wide meta-analysis identifies regions on 7p21 (AHR) and 15q24 (CYP1A2) as determinants of habitual caffeine consumption. PLoS Genet 2011; 7: e1002033.
Sulem P, Gudbjartsson DF, Geller F, Prokopenko I, Feenstra B, Aben KK et al. Sequence variants at CYP1A1-CYP1A2 and AHR associate with coffee consumption. Hum Mol Genet 2011; 20: 2071–2077.
Amin N, Byrne E, Johnson J, Chenevix-Trench G, Walter S, Nolte IM et al. Genome-wide association analysis of coffee drinking suggests association with CYP1A1/CYP1A2 and NRCAM. Mol Psychiatry 2011; 17: 1116–1129.
Kot M, Daniel WA . The relative contribution of human cytochrome P450 isoforms to the four caffeine oxidation pathways: an in vitro comparative study with cDNA-expressed P450s including CYP2C isoforms. Biochem Pharmacol 2008; 76: 543–551.
Le Vee M, Jouan E, Fardel O . Involvement of aryl hydrocarbon receptor in basal and 2,3,7,8-tetrachlorodibenzo-p-dioxin-induced expression of target genes in primary human hepatocytes. Toxicol In Vitro 2010; 24: 1775–1781.
Willer CJ, Li Y, Abecasis GR . METAL: fast and efficient meta-analysis of genomewide association scans. Bioinformatics 2010; 26: 2190–2191.
Mägi R, Morris AP . GWAMA: software for genome-wide association meta-analysis. BMC Bioinformatics 2010; 11: 288.
Yang J, Lee SH, Goddard ME, Visscher PM . GCTA: a tool for genome-wide complex trait analysis. Am J Hum Genet 2011; 88: 76–82.
Segre AV, Groop L, Mootha VK, Daly MJ, Altshuler D . Common inherited variation in mitochondrial genes is not enriched for associations with type 2 diabetes or related glycemic traits. PLoS Genet 2010; 6: e1001058.
Yang J, Ferreira T, Morris AP, Medland SE, Madden PA, Heath AC et al. Conditional and joint multiple-SNP analysis of GWAS summary statistics identifies additional variants influencing complex traits. Nat Genet 2012; 44: 369–375, S361–S363.
Franceschini N, van Rooij FJ, Prins BP, Feitosa MF, Karakas M, Eckfeldt JH et al. Discovery and fine mapping of serum protein loci through transethnic meta-analysis. Am J Hum Genet 2012; 91: 744–753.
Stephens M, Balding DJ . Bayesian statistical methods for genetic association studies. Nat Rev Genet 2009; 10: 681–690.
Sellke T, Bayarri M, Berger J . Calibration of P values for testing precise null hypotheses. Am Stat 2001; 55: 62–71.
Hindorff LA, MacArthur J, Morales J, Junkins HA, Hall PN, Klemm AK et al. A catalog of published genome-wide association studies. Available at: www.genome.gov/gwastudies; accessed 1 January 2013.
Shin SY, Fauman EB, Petersen AK, Krumsiek J, Santos R, Huang J et al. An atlas of genetic influences on human blood metabolites. Nat Genet 2014; 46: 543–550.
Soderberg MM, Haslemo T, Molden E, Dahl ML . Influence of CYP1A1/CYP1A2 and AHR polymorphisms on systemic olanzapine exposure. Pharmacogenet Genomics 2013; 23: 279–285.
Jorge-Nebert LF, Jiang Z, Chakraborty R, Watson J, Jin L, McGarvey ST et al. Analysis of human CYP1A1 and CYP1A2 genes and their shared bidirectional promoter in eight world populations. Hum Mutat 2010; 31: 27–40.
Swanson HI . DNA binding and protein interactions of the AHR/ARNT heterodimer that facilitate gene activation. Chem Biol Interact 2002; 141: 63–76.
Hu L, Zhuo W, He YJ, Zhou HH, Fan L . Pharmacogenetics of P450 oxidoreductase: implications in drug metabolism and therapy. Pharmacogenet Genomics 2012; 22: 812–819.
Rome S, Meugnier E, Lecomte V, Berbe V, Besson J, Cerutti C et al. Microarray analysis of genes with impaired insulin regulation in the skeletal muscle of type 2 diabetic patients indicates the involvement of basic helix-loop-helix domain-containing, class B, 2 protein (BHLHB2). Diabetologia 2009; 52: 1899–1912.
Pandey AV, Fluck CE . NADPH P450 oxidoreductase: structure, function, and pathology of diseases. Pharmacol Ther 2013; 138: 229–254.
Woodward OM, Tukaye DN, Cui J, Greenwell P, Constantoulakis LM, Parker BS et al. Gout-causing Q141K mutation in ABCG2 leads to instability of the nucleotide-binding domain and can be corrected with small molecules. Proc Natl Acad Sci USA 2013; 110: 5223–5228.
Numakawa T, Suzuki S, Kumamaru E, Adachi N, Richards M, Kunugi H . BDNF function and intracellular signaling in neurons. Histol Histopathol 2010; 25: 237–258.
Egan MF, Kojima M, Callicott JH, Goldberg TE, Kolachana BS, Bertolino A et al. The BDNF val66met polymorphism affects activity-dependent secretion of BDNF and human memory and hippocampal function. Cell 2003; 112: 257–269.
Nosrat IV, Margolskee RF, Nosrat CA . Targeted taste cell-specific overexpression of brain-derived neurotrophic factor in adult taste buds elevates phosphorylated TrkB protein levels in taste cells, increases taste bud size, and promotes gustatory innervation. J Biol Chem 2012; 287: 16791–16800.
Ernst J, Kheradpour P, Mikkelsen TS, Shoresh N, Ward LD, Epstein CB et al. Mapping and analysis of chromatin state dynamics in nine human cell types. Nature 2011; 473: 43–49.
Canli T, Lesch KP . Long story short: the serotonin transporter in emotion regulation and social cognition. Nat Neurosci 2007; 10: 1103–1109.
Beer NL, Tribble ND, McCulloch LJ, Roos C, Johnson PR, Orho-Melander M et al. The P446L variant in GCKR associated with fasting plasma glucose and triglyceride levels exerts its effect through increased glucokinase activity in liver. Hum Mol Genet 2009; 18: 4081–4088.
Alvarez E, Roncero I, Chowen JA, Vazquez P, Blazquez E . Evidence that glucokinase regulatory protein is expressed and interacts with glucokinase in rat brain. J Neurochem 2002; 80: 45–53.
Lindskog M, Svenningsson P, Pozzi L, Kim Y, Fienberg AA, Bibb JA et al. Involvement of DARPP-32 phosphorylation in the stimulant action of caffeine. Nature 2002; 418: 774–778.
Reed DR, Zhu G, Breslin PA, Duke FF, Henders AK, Campbell MJ et al. The perception of quinine taste intensity is associated with common genetic variants in a bitter receptor cluster on chromosome 12. Hum Mol Genet 2010; 19: 4278–4285.
Ledda M, Kutalik Z, Souza Destito MC, Souza MM, Cirillo CA, Zamboni A et al. GWAS of human bitter taste perception identifies new loci and reveals additional complexity of bitter taste genetics. Hum Mol Genet 2013; 23: 259–267.
Byrne EM, Johnson J, McRae AF, Nyholt DR, Medland SE, Gehrman PR et al. A genome-wide association study of caffeine-related sleep disturbance: confirmation of a role for a common variant in the adenosine receptor. Sleep 2012; 35: 967–975.
Tobacco and Genetics Consortium. Genome-wide meta-analyses identify multiple loci associated with smoking behavior. Nat Genet 2010; 42: 441–447.
Schumann G, Coin LJ, Lourdusamy A, Charoen P, Berger KH, Stacey D et al. Genome-wide association and genetic functional studies identify autism susceptibility candidate 2 gene (AUTS2) in the regulation of alcohol consumption. Proc Natl Acad Sci USA 2011; 108: 7119–7124.
Vinkhuyzen AA, Wray NR, Yang J, Goddard ME, Visscher PM . Estimation and partition of heritability in human populations using whole-genome analysis methods. Annu Rev Genet 2013; 47: 75–95.
Acknowledgements
Study-specific funding and acknowledgments are provided in the Supplementary Information. We collectively thank everyone who has contributed to the collection, genotyping and analysis of the individual cohorts, as well as all the study participants.
Author information
Authors and Affiliations
Consortia
Corresponding authors
Ethics declarations
Competing interests
The authors declare no conflict of interest.
Additional information
Supplementary Information accompanies the paper on the Molecular Psychiatry website
APPENDIX
The members and affiliations of the International Parkinson Disease Genomics Consortium (IPDGC) are as follows: Michael A Nalls (Laboratory of Neurogenetics, National Institute on Aging, National Institutes of Health, Bethesda, MD, USA), Vincent Plagnol (UCL Genetics Institute, London, UK), Dena G Hernandez (Laboratory of Neurogenetics, National Institute on Aging; and Department of Molecular Neuroscience, UCL Institute of Neurology, London, UK), Manu Sharma (Department for Neurodegenerative Diseases, Hertie Institute for Clinical Brain Research, University of Tübingen, and DZNE, German Center for Neurodegenerative Diseases, Tübingen, Germany), Una-Marie Sheerin (Department of Molecular Neuroscience, UCL Institute of Neurology), Mohamad Saad (INSERM U563, CPTP, Toulouse, France; and Paul Sabatier University, Toulouse, France), Javier Simón-Sánchez (Department of Clinical Genetics, Section of Medical Genomics, VU University Medical Centre, Amsterdam, Netherlands), Claudia Schulte (Department for Neurodegenerative Diseases, Hertie Institute for Clinical Brain Research), Suzanne Lesage (INSERM, UMR_S975 (formerly UMR_S679), Paris, France; Université Pierre et Marie Curie-Paris, Centre de Recherche de l’Institut du Cerveau et de la Moelle épinière, Paris, France; and CNRS, Paris, France), Sigurlaug Sveinbjörnsdóttir (Department of Neurology, Landspítali University Hospital, Reykjavík, Iceland; Department of Neurology, MEHT Broomfield Hospital, Chelmsford, Essex, UK; and Queen Mary College, University of London, London, UK), Sampath Arepalli (Laboratory of Neurogenetics, National Institute on Aging), Roger Barker (Department of Neurology, Addenbrooke’s Hospital, University of Cambridge, Cambridge, UK), Yoav Ben-Shlomo (School of Social and Community Medicine, University of Bristol), Henk W Berendse (Department of Neurology and Alzheimer Center, VU University Medical Center), Daniela Berg (Department for Neurodegenerative Diseases, Hertie Institute for Clinical Brain Research and DZNE, German Center for Neurodegenerative diseases), Kailash Bhatia (Department of Motor Neuroscience, UCL Institute of Neurology), Rob M A de Bie (Department of Neurology, Academic Medical Center, University of Amsterdam, Amsterdam, Netherlands), Alessandro Biffi (Center for Human Genetic Research and Department of Neurology, Massachusetts General Hospital, Boston, MA, USA; and Program in Medical and Population Genetics, Broad Institute, Cambridge, MA, USA), Bas Bloem (Department of Neurology, Radboud University Nijmegen Medical Centre, Nijmegen, Netherlands), Zoltan Bochdanovits (Department of Clinical Genetics, Section of Medical Genomics, VU University Medical Centre), Michael Bonin (Department of Medical Genetics, Institute of Human Genetics, University of Tübingen, Tübingen, Germany), Jose M Bras (Department of Molecular Neuroscience, UCL Institute of Neurology), Kathrin Brockmann (Department for Neurodegenerative Diseases, Hertie Institute for Clinical Brain Research and DZNE, German Center for Neurodegenerative diseases), Janet Brooks (Laboratory of Neurogenetics, National Institute on Aging), David J Burn (Newcastle University Clinical Ageing Research Unit, Campus for Ageing and Vitality, Newcastle upon Tyne, UK), Gavin Charlesworth (Department of Molecular Neuroscience, UCL Institute of Neurology), Honglei Chen (Epidemiology Branch, National Institute of Environmental Health Sciences, National Institutes of Health, NC, USA), Patrick F Chinnery (Neurology M4104, The Medical School, Framlington Place, Newcastle upon Tyne, UK), Sean Chong (Laboratory of Neurogenetics, National Institute on Aging), Carl E Clarke (School of Clinical and Experimental Medicine, University of Birmingham, Birmingham, UK; and Department of Neurology, City Hospital, Sandwell and West Birmingham Hospitals NHS Trust, Birmingham, UK), Mark R Cookson (Laboratory of Neurogenetics, National Institute on Aging), J Mark Cooper (Department of Clinical Neurosciences, UCL Institute of Neurology), Jean Christophe Corvol (INSERM, UMR_S975; Université Pierre et Marie Curie-Paris; CNRS; and INSERM CIC-9503, Hôpital Pitié-Salpêtrière, Paris, France), Carl Counsell (University of Aberdeen, Division of Applied Health Sciences, Population Health Section, Aberdeen, UK), Philippe Damier (CHU Nantes, CIC0004, Service de Neurologie, Nantes, France), Jean-François Dartigues (INSERM U897, Université Victor Segalen, Bordeaux, France), Panos Deloukas (Wellcome Trust Sanger Institute, Wellcome Trust Genome Campus, Cambridge, UK), Günther Deuschl (Klinik für Neurologie, Universitätsklinikum Schleswig-Holstein, Campus Kiel, Christian-Albrechts-Universität Kiel, Kiel, Germany), David T Dexter (Parkinson’s Disease Research Group, Faculty of Medicine, Imperial College London, London, UK), Karin D van Dijk (Department of Neurology and Alzheimer Center, VU University Medical Center), Allissa Dillman (Laboratory of Neurogenetics, National Institute on Aging), Frank Durif (Service de Neurologie, Hôpital Gabriel Montpied, Clermont-Ferrand, France), Alexandra Dürr (INSERM, UMR_S975; Université Pierre et Marie Curie-Paris; CNRS; and AP-HP, Pitié-Salpêtrière Hospital), Sarah Edkins (Wellcome Trust Sanger Institute), Jonathan R Evans (Cambridge Centre for Brain Repair, Cambridge, UK), Thomas Foltynie (UCL Institute of Neurology), Jing Dong (Epidemiology Branch, National Institute of Environmental Health Sciences), Michelle Gardner (Department of Molecular Neuroscience, UCL Institute of Neurology), J Raphael Gibbs (Laboratory of Neurogenetics, National Institute on Aging; and Department of Molecular Neuroscience, UCL Institute of Neurology), Alison Goate (Department of Psychiatry, Department of Neurology, Washington University School of Medicine, MI, USA), Emma Gray (Wellcome Trust Sanger Institute), Rita Guerreiro (Department of Molecular Neuroscience, UCL Institute of Neurology), Clare Harris (University of Aberdeen), Jacobus J van Hilten (Department of Neurology, Leiden University Medical Center, Leiden, Netherlands), Albert Hofman (Department of Epidemiology, Erasmus University Medical Center, Rotterdam, Netherlands), Albert Hollenbeck (AARP, Washington DC, USA), Janice Holton (Queen Square Brain Bank for Neurological Disorders, UCL Institute of Neurology), Michele Hu (Department of Clinical Neurology, John Radcliffe Hospital, Oxford, UK), Xuemei Huang (Departments of Neurology, Radiology, Neurosurgery, Pharmacology, Kinesiology, and Bioengineering, Pennsylvania State University– Milton S Hershey Medical Center, Hershey, PA, USA), Isabel Wurster (Department for Neurodegenerative Diseases, Hertie Institute for Clinical Brain Research and German Center for Neurodegenerative diseases), Walter Mätzler (Department for Neurodegenerative Diseases, Hertie Institute for Clinical Brain Research and German Center for Neurodegenerative diseases), Gavin Hudson (Neurology M4104, The Medical School, Newcastle upon Tyne, UK), Sarah E Hunt (Wellcome Trust Sanger Institute), Johanna Huttenlocher (deCODE genetics), Thomas Illig (Institute of Epidemiology, Helmholtz Zentrum München, German Research Centre for Environmental Health, Neuherberg, Germany), Pálmi V Jónsson (Department of Geriatrics, Landspítali University Hospital, Reykjavík, Iceland), Jean-Charles Lambert (INSERM U744, Lille, France; and Institut Pasteur de Lille, Université de Lille Nord, Lille, France), Cordelia Langford (Cambridge Centre for Brain Repair), Andrew Lees (Queen Square Brain Bank for Neurological Disorders), Peter Lichtner (Institute of Human Genetics, Helmholtz Zentrum München, German Research Centre for Environmental Health, Neuherberg, Germany), Patricia Limousin (Institute of Neurology, Sobell Department, Unit of Functional Neurosurgery, London, UK), Grisel Lopez (Section on Molecular Neurogenetics, Medical Genetics Branch, NHGRI, National Institutes of Health), Delia Lorenz (Klinik für Neurologie, Universitätsklinikum Schleswig-Holstein), Alisdair McNeill (Department of Clinical Neurosciences, UCL Institute of Neurology), Catriona Moorby (School of Clinical and Experimental Medicine, University of Birmingham), Matthew Moore (Laboratory of Neurogenetics, National Institute on Aging), Huw R Morris (MRC Centre for Neuropsychiatric Genetics and Genomics, Cardiff University School of Medicine, Cardiff, UK), Karen E Morrison (School of Clinical and Experimental Medicine, University of Birmingham; and Neurosciences Department, Queen Elizabeth Hospital, University Hospitals Birmingham NHS Foundation Trust, Birmingham, UK), Ese Mudanohwo (Neurogenetics Unit, UCL Institute of Neurology and National Hospital for Neurology and Neurosurgery), Sean S O’Sullivan (Queen Square Brain Bank for Neurological Disorders), Justin Pearson (MRC Centre for Neuropsychiatric Genetics and Genomics), Joel S Perlmutter (Department of Neurology, Radiology, and Neurobiology at Washington University, St Louis), Hjörvar Pétursson (deCODE genetics; and Department of Medical Genetics, Institute of Human Genetics, University of Tübingen), Pierre Pollak (Service de Neurologie, CHU de Grenoble, Grenoble, France), Bart Post (Department of Neurology, Radboud University Nijmegen Medical Centre), Simon Potter (Wellcome Trust Sanger Institute), Bernard Ravina (Translational Neurology, Biogen Idec, MA, USA), Tamas Revesz (Queen Square Brain Bank for Neurological Disorders), Olaf Riess (Department of Medical Genetics, Institute of Human Genetics, University of Tübingen), Fernando Rivadeneira (Departments of Epidemiology and Internal Medicine, Erasmus University Medical Center), Patrizia Rizzu (Department of Clinical Genetics, Section of Medical Genomics, VU University Medical Centre), Mina Ryten (Department of Molecular Neuroscience, UCL Institute of Neurology), Stephen Sawcer (University of Cambridge, Department of Clinical Neurosciences, Addenbrooke’s hospital, Cambridge, UK), Anthony Schapira (Department of Clinical Neurosciences, UCL Institute of Neurology), Hans Scheffer (Department of Human Genetics, Radboud University Nijmegen Medical Centre, Nijmegen, The Netherlands), Karen Shaw (Queen Square Brain Bank for Neurological Disorders), Ira Shoulson (Department of Neurology, University of Rochester, Rochester, NY, USA), Ellen Sidransky (Section on Molecular Neurogenetics, Medical Genetics Branch, NHGRI), Colin Smith (Department of Pathology, University of Edinburgh, Edinburgh, UK), Chris CA Spencer (Wellcome Trust Centre for Human Genetics, Oxford, UK), Hreinn Stefánsson (deCODE genetics), Francesco Bettella (deCODE genetics), Joanna D Stockton (School of Clinical and Experimental Medicine), Amy Strange (Wellcome Trust Centre for Human Genetics), Kevin Talbot (University of Oxford, Department of Clinical Neurology, John Radcliffe Hospital, Oxford, UK), Carlie M Tanner (Clinical Research Department, The Parkinson’s Institute and Clinical Center, Sunnyvale, CA, USA), Avazeh Tashakkori-Ghanbaria (Wellcome Trust Sanger Institute), François Tison (Service de Neurologie, Hôpital Haut-Lévêque, Pessac, France), Daniah Trabzuni (Department of Molecular Neuroscience, UCL Institute of Neurology), Bryan J Traynor (Laboratory of Neurogenetics, National Institute on Aging), André G Uitterlinden (Departments of Epidemiology and Internal Medicine, Erasmus University Medical Center), Daan Velseboer (Department of Neurology, Academic Medical Center), Marie Vidailhet (INSERM, UMR_S975, Université Pierre et Marie Curie-Paris, CNRS, UMR 7225), Robert Walker (Department of Pathology, University of Edinburgh), Bart van de Warrenburg (Department of Neurology, Radboud University Nijmegen Medical Centre), Mirdhu Wickremaratchi (Department of Neurology, Cardiff University, Cardiff, UK), Nigel Williams (MRC Centre for Neuropsychiatric Genetics and Genomics), Caroline H Williams-Gray (Department of Neurology, Addenbrooke’s Hospital), Sophie Winder-Rhodes (Department of Psychiatry and Medical Research Council and Wellcome Trust Behavioural and Clinical Neurosciences Institute, University of Cambridge), Kári Stefánsson (deCODE genetics), Maria Martinez (INSERM UMR 1043; and Paul Sabatier University), Nicholas W Wood (UCL Genetics Institute; and Department of Molecular Neuroscience, UCL Institute of Neurology), John Hardy (Department of Molecular Neuroscience, UCL Institute of Neurology), Peter Heutink (Department of Clinical Genetics, Section of Medical Genomics, VU University Medical Centre), Alexis Brice (INSERM, UMR_S975, Université Pierre et Marie Curie-Paris, CNRS, UMR 7225, AP-HP, Pitié-Salpêtrière Hospital), Thomas Gasser (Department for Neurodegenerative Diseases, Hertie Institute for Clinical Brain Research, and DZNE, German Center for Neurodegenerative Diseases), Andrew B Singleton (Laboratory of Neurogenetics, National Institute on Aging).
The members and affiliations of the North American Brain Expression Consortium (NABEC) are as follows: Andrew Singleton (Laboratory of Neurogenetics, National Institute on Aging, National Institutes of Health, Bethesda, MD, USA); Mark Cookson (Laboratory of Neurogenetics, National Institute on Aging, National Institutes of Health, Bethesda, MD, USA); J. Raphael Gibbs (Laboratory of Neurogenetics, National Institute on Aging, National Institutes of Health, Bethesda, MD, USA and Reta Lila Weston Institute and Department of Molecular Neuroscience, UCL Institute of Neurology, Queen Square, London WC1N 3BG, UK); Dena Hernandez (Laboratory of Neurogenetics, National Institute on Aging, National Institutes of Health, Bethesda, MD, USA and Reta Lila Weston Institute and Department of Molecular Neuroscience, UCL Institute of Neurology, Queen Square, London WC1N 3BG, UK); Allissa Dillman (Laboratory of Neurogenetics, National Institute on Aging, National Institutes of Health, Bethesda, MD, USA and Department of Neuroscience, Karolinska Institutet, 171 77 Stockholm, Sweden); Michael Nalls (Laboratory of Neurogenetics, National Institute on Aging, National Institutes of Health, Bethesda, MD, USA) Alan Zonderman (Research Resources Branch, National Institute on Aging, National Institutes of Health, Bethesda, MD, USA); Sampath Arepalli (Laboratory of Neurogenetics, National Institute on Aging, National Institutes of Health, Bethesda, MD, USA); Luigi Ferrucci (Clinical Research Branch, National Institute on Aging, Baltimore, MD, USA); Robert Johnson (NICHD Brain and Tissue Bank for Developmental Disorders, University of Maryland Medical School, Baltimore, MD 21201, USA); Dan Longo (Lymphocyte Cell Biology Unit, Laboratory of Immunology, National Institute on Aging, National Institutes of Health, Baltimore, MD, USA); Richard O'Brien (Brain Resource Center, Johns Hopkins University, Baltimore, MD, USA); Bryan Traynor (Laboratory of Neurogenetics, National Institute on Aging, National Institutes of Health, Bethesda, MD, USA); Juan Troncoso (Brain Resource Center, Johns Hopkins University, Baltimore, MD, USA); Marcel van der Brug (Laboratory of Neurogenetics, National Institute on Aging, National Institutes of Health, Bethesda, MD, USA and ITGR Biomarker Discovery Group, Genentech, South San Francisco, CA, USA); Ronald Zielke (NICHD Brain and Tissue Bank for Developmental Disorders, University of Maryland Medical School, Baltimore, MD 21201, USA).
The members and affiliations of the United Kingdom Brain Expression Consortium are as follows (UKBEC): John Hardy (Reta Lila Weston Institute and Department of Molecular Neuroscience, UCL Institute of Neurology, Queen Square, London WC1N 3BG, UK); Michael Weale (Department of Medical and Molecular Genetics, King’s College London, 8th Floor, Tower Wing, Guy’s Hospital, London SE1 9RT, UK); Mina Ryten (Reta Lila Weston Institute and Department of Molecular Neuroscience, UCL Institute of Neurology, Queen Square, London WC1N 3BG, UK); Adaikalavan Ramasamy (Department of Medical and Molecular Genetics, King’s College London, 8th Floor, Tower Wing, Guy’s Hospital, London SE1 9RT, UK and Reta Lila Weston Institute and Department of Molecular Neuroscience, UCL Institute of Neurology, Queen Square, London WC1N 3BG, UK); Daniah Trabzuni (Reta Lila Weston Institute and Department of Molecular Neuroscience, UCL Institute of Neurology, Queen Square, London WC1N 3BG, UK and Department of Genetics, King Faisal Specialist Hospital and Research Centre, PO Box 3354, Riyadh 11211, Saudi Arabia); Colin Smith (Department of Neuropathology, MRC Sudden Death Brain Bank Project, University of Edinburgh, Wilkie Building, Teviot Place, Edinburgh EH8 9AG); Robert Walker (Department of Neuropathology, MRC Sudden Death Brain Bank Project, University of Edinburgh, Wilkie Building, Teviot Place, Edinburgh EH8 9AG).
PowerPoint slides
Supplementary information
Rights and permissions
About this article

Cite this article
The Coffee and Caffeine Genetics Consortium., Cornelis, M., Byrne, E. et al. Genome-wide meta-analysis identifies six novel loci associated with habitual coffee consumption. Mol Psychiatry 20, 647–656 (2015). https://doi.org/10.1038/mp.2014.107
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/mp.2014.107
- Springer Nature Limited
This article is cited by
-
Beverage preference (coffee vs. tea) according to CYP1A2 gene rs2470893 SNP genotypes in the Tunisian population
Bulletin of the National Research Centre (2023)
-
Analysis of genetically determined gene expression suggests role of inflammatory processes in exfoliation syndrome
BMC Genomics (2023)
-
Genome-wide association study identifies novel loci associated with skin autofluorescence in individuals without diabetes
BMC Genomics (2022)
-
Association of caffeine and caffeine metabolites with obesity among children and adolescents: National Health and Nutrition Examination Survey (NHANES) 2009–2014
Environmental Science and Pollution Research (2022)
-
Associations of alcohol and coffee with colorectal cancer risk in East Asian populations: a Mendelian randomization study
European Journal of Nutrition (2022)