
Abstract
COVID-19 had a global impact, claiming many lives and disrupting healthcare systems even in many developed countries. Various mutations of the severe acute respiratory syndrome coronavirus-2, continue to be an impediment to early detection of this disease, which is vital for social well-being. Deep learning paradigm has been widely applied to investigate multimodal medical image data such as chest X-rays and CT scan images to aid in early detection and decision making about disease containment and treatment. Any method for reliable and accurate screening of COVID-19 infection would be beneficial for rapid detection as well as reducing direct virus exposure in healthcare professionals. Convolutional neural networks (CNN) have previously proven to be quite successful in the classification of medical images. A CNN is used in this study to suggest a deep learning classification method for detecting COVID-19 from chest X-ray images and CT scans. Samples from the Kaggle repository were collected to analyse model performance. Deep learning-based CNN models such as VGG-19, ResNet-50, Inception v3 and Xception models are optimized and compared by evaluating their accuracy after pre-processing the data. Because X-ray is a less expensive process than CT scan, chest X-ray images are considered to have a significant impact on COVID-19 screening. According to this work, chest X-rays outperform CT scans in terms of detection accuracy. The fine-tuned VGG-19 model detected COVID-19 with high accuracy—up to 94.17% for chest X-rays and 93% for CT scans. This work thereby concludes that VGG-19 was found to be the best suited model to detect COVID-19 and chest X-rays yield better accuracy than CT scans for the model.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
COVID-19 has been challenging to overcome for the past 2 years and it still poses a huge threat to our health and the economy. An antidote is yet to be found for this deadly disease, which makes it taxing to battle against this disease. As of January 09, 2022, 5,503,805 deaths have been recorded from the outbreak of this virus. New variants emerge constantly whose characteristics are challenging to uncover. Vulnerable groups include diabetic individuals, obese children, people with chronic lung disease or asthma, low immunity, and elderly people. The most typical signs of this illness are fever, chills, cough, headache, fatigue, loss of smell or taste, sore throat, and others. As of now, frequent washing of hands, sanitizing, wearing masks and maintaining social distance are the only means of protection other than vaccination.
While symptoms help in its identification, a fair share of the population is asymptomatic for which computed tomography (CT) scan and chest X-ray-based analysis is carried out and turns out be an effective process. The death tolls and infection spread seem to grow at an exponential rate. The common means of detection of this disease include RT-PCR test, antigen tests and isothermal nucleic acid amplification in addition to chest tomography imaging. RT-PCR tests results typically take a day to detect, but the time taken for the collected samples to reach the laboratory might lead to a delay. Antigen testing is less sensitive than the RT-PCR test, although it is faster in comparison.
Thorough study of the CT scan of lungs of the infected individual helps in detecting damage on the respiratory organ in 10–12 days after infection. Chest X-rays can help in faster detection, thereby preventing further spread, and helps in prior isolation of the patient. Deep learning techniques are used in the diagnosis of COVID-19 using multimodal imaging data by means of pre-trained convolutional neural networks (CNN).
In the proposed methodology, the pre-trained models are trained with patient records which include multimodal data to predict COVID-19 virus. With the limited resources presented, suitable techniques have been deployed to yield accurate results [1].
Moving on further, “Related Works” summarizes the related works in the diagnosis of COVID-19 using various image modes, “Methodology” explains the proposed methodology and “Experimental Results” gives insight into the experimental results, while the final section concludes the work.
Related Works
A survey of the related works done in the diagnosis of COVID-19 using multimodal data is listed in “Prediction of COVID-19 Using Chest X-Rays” and “Prediction of COVID-19 Using CT Scans”.
Prediction of COVID-19 Using Chest X-Rays
Eight different well-known pre-trained deep learning neural network architectures were compared by Sowmya et al. [2], namely, AlexNet, VGG-16, ResNet-34, ResNet-50, GoogleNet, MobileNet-V2, SqueezeNet, and Inception-V3. A dataset of 406 images was used in the tests, with 203 samples from COVID-19-positive individuals and 203 samples from healthy patients. The last layer of the pre-trained models was removed, thereby a fully connected (FC) layer was added representing two output classes.
EfficientNet, MobileNet, VGG, and ResNet models were trained by Luz et al. for predicting COVID-19 [1]. Here, hierarchical classification has been implemented to differentiate normal and pneumonia classes. The data were subjected to pre-processing and augmentation and used for further processing. Instead of training a model from scratch, a pre-trained network using the transfer learning approach was used and it was tuned to attain higher accuracy.
Jain et al. used InceptionNet V3, XceptionNet, and ResNet Xt techniques for predicting COVID-19 [3]. The model was trained on only 1560 samples, since patient data were unavailable. The pre-trained network of each model was used, the data were trained and tested, and the accuracy of each model was analysed and compared.
Diagnosis of COVID-19 with chest X-ray images using deep learning models was presented by Bsu et al. [4]. This work analysed three pre-trained models with increasing number of layers, viz. VGGNet (16 layers), AlexNet (8 layers), and ResNet (50 layers). In this work, layers with large kernels were replaced by small kernels to produce better regularization. Initially, training from scratch and fine-tuning using the TL (transfer learning) strategy were applied to the models.
Prediction of COVID-19 Using CT Scans
To address the diagnosis of COVID-19, Anwar et al. [5] in their work used three variations for learning strategies, namely, reducing the learning rate, cyclic learning rate, and constant learning rate. In the EfficientNet deep learning technique, adaptive feature selection-guided deep forest algorithm was employed to predict COVID-19 with a specific patient’s CT scan. A comparison is made between VGG16 and Resnet for the prediction of COVID-19 via CT scans by Shailender Kumar et al. [6]. The method of transfer learning was also incorporated for the prediction, and ensemble convolutional neural network technique for detecting pneumonia was also performed to check the classification nature of the model. Raj et al. [7] implemented image recognition methods of CNN for detecting COVID-19 using CT scans. Prediction algorithms such as inception and VGG were used. Computerized image processing, image segmentation, neural networks and medical image processing methods were incorporated to increase the efficiency of detection. InceptionV3, DenseNet and New-DenseNet models were implemented by Mohamed Berrimi et al. in their work [8] for the prediction of COVID-19 and the enhancement of DenseNet model performance was done by adding a convolutional layer at the top and at the bottom of the model. Regularization is also done, thus making model learning yield better results.
Jashnani et al. [9] implemented VGG-16, DenseNet21, Inception-ResNet, InceptionV3, and Xception to predict COVID-19 via CT scans. As a result of lowering the convolution operation in the CNN model, the accuracy was raised and the computation cost decreased. Abdar et al. published “Automatic Detection of Coronavirus (COVID-19) from Chest CT Images Using VGG16-Based Deep-Learning” [10], in which the VGG16 model was used because it is a less complex model when compared to other models such as ResNet, DenseNet, and xception. So the pre-trained model is fine-tuned by including layers such as dense layers, pooling layers, and dropout layers, as well as by utilizing a 50% dropout in all layers.
In their work of detection of COVID-19 with CT images using hybrid complex shearlet scattering networks [11], Ren et al. presented a hybrid framework in which a single model was constructed by combining the complex shearlet scattering transform (CSST) and a suitable convolutional neural network. The wide residual network is also implemented in this suggested hybrid model, which performs well on sparse and locally invariant images.
A Siamese convolutional neural network model (COVID-3D-SCNN) is introduced for extracting discriminative features, with augmentation performed to enlarge the dataset and three models working in parallel, the authors acquired 575 COVID-19, 1200 non-COVID, and 1400 pneumonia images, which are publicly available. In their framework, augmentation is used to enlarge the dataset [12]. When SEL-COVIDNET [13] is compared to the results of tuned DenseNet121, InceptionResNetV2, and MobileNetV3 models, it outperforms the others in multiclass classification. Deep learning techniques [14] are preferred to artificial intelligence (AI), because overfitting is a significant problem in AI-based systems and many AI-based models are unable to produce the best results. CNN-based techniques are therefore used for the classification of lung disease.
A new transfer learning approach [15] based on the convolutional neural network (CNN) is proposed using frozen layers (convolution layers, Max-Pooling layer, convolutional layers). Based on the number of convolutional layers, two distinct models are created which helps in early detection of COVID by X-rays.
As mentioned in “Prediction of COVID-19 Using Chest X-Rays” and “Prediction of COVID-19 Using CT Scans”, the hurdles faced in the majority of the existing works are: lack of patient data, low accuracy/overfitting issues in classification because of insufficient data to train the model and incompatibility of multimodal data. The proposed methodology presented in “Methodology” tries to deal with the hurdles and addresses the issues faced by the existing approaches.
Methodology
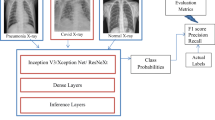
Deep learning techniques are used to diagnose COVID-19. The system architecture of the proposed model is presented in Fig. 1.

System architecture
Pre-trained deep learning models such as Inception v3, Xception, VGG-19 and ResNet-50 are optimized using custom layer to diagnose COVID-19. The following sections give insights about the architecture design of pre-trained models and the custom layer added to it.
Inception v3
Inception V3 is a 27 layers deep convolutional neural network and is utilized to help in object and image detection. The images of COVID-19 and normal chest X-rays are grouped into several network layers, which are trained by the inception V3 model, and the model is fine-tuned to get better accuracy.
Xception
Xception model involves depth-wise separable convolutions with a deep convolutional neural network architecture. This pre-trained model with 135 layers is fine-tuned with custom layers to increase the performance. The trainable parameters are trained with the collected dataset (i.e. COVID and normal X-ray/CT images) and the prediction is made.
VGG-19
VGG-19 is a deep convolutional neural network which includes 19 layers. The image of the COVID-19 and normal chest X-rays/CT scans are grouped into several network layers and it is trained by the VGG-19 model. The model is also fine-tuned to get better accuracy.
ResNet50
ResNet50, a variant of ResNet model, has 48 convolution layers, a MaxPool and an average pooling layer. This is also included in the deep convolutional neural network architecture. This pre-trained model includes 178 layers and is fine-tuned with custom layers added to improve the performance.
Procedure
The procedure involved in the diagnosis of COVID-19 is summarized below.
The datasets used for this study were collected from Kaggle which include chest X-rays [16] and CT scans [17] of COVID-19-affected and -unaffected people. A total of 2482 CT scans were included in the SARS-CoV-2 CT dataset, including 1252 scans that were positive for the virus (COVID-19) and 1230 scans from patients who were not infected with SARS-CoV-2.
3616 COVID-19-positive cases from various countries were included in an X-ray database along with 10,192 normal cases and corresponding lung masks. The image resolution of both the CT image database and X-ray database differs: 342 × 254 and 299 × 299, respectively. The collection includes 50% subset of COVID-19-affected and 50% subset of normal images of unaffected people. Figures 2 and 3 show the sample image of chest X-rays and CT scans from both affected and healthy people.

Samples of frontal view chest X-rays: a COVID-19-affected person and b unaffected person

Samples of CT scans: a COVID-19-affected person and b unaffected person
The data procured from the Kaggle repository for chest X-rays and CT scans was cleaned and then normalized. Data normalization is an important step which is frequently utilized to preserve numerical stability in CNN systems. Gradient descent is more stable with normalization and learns more quickly with a CNN model. To help with this, the pixel values of the input chest X-ray/CT images were normalized between values [0,1].
Greyscale images were used to create the training datasets, and to rescale them, the pixel values were multiplied by 1/255. The images were resized to 224 by 224 pixels, which is considered as the model’s optimal size for processing. The input tensor of shape (224, 224, 3) is added to the pre-trained model, where 3 refers to the number of channels in the pre-trained model.
A large dataset is essential to train any deep learning method and this aids in achieving reliable results. But when enough data is not available, especially in medical-related studies, data augmentation is applied.
The problem of overfitting can be controlled by augmentation techniques, so that the accuracy of the proposed model can also be enhanced. The augmentation process includes sharing, zooming and rotation of images. The data is randomized to generalize the model and decrease overfitting. The proposed model was trained using the prepared pre-processed dataset.
It has been demonstrated that CNN models produce better outcomes in many medical image processing applications. However, building them from scratch would be challenging for COVID-19 case prediction due to the scarcity of X-ray/CT image samples. For identifying COVID-19 from normal instances in this study, four pre-trained models including VGG19, Xception, ResNet50, and Inception-V3 have been deployed.
These networks have shown exemplary results in a variety of computer vision and medical image processing tasks. These networks were chosen as a way to separate COVID-19 infection from other cases. For training the models, 80% of the images were used and the remaining 20% of the images were used for testing the accuracy of the models.
Optimization of the pre-trained models discussed in “Inception v3”, “Xception”, “VGG-19” and “ResNet50” is performed by adding five custom layers.
The first layer includes the convolutional layer with sigmoid activation function and learning rate 0.0001; the second layer comprises the dropout layer to avoid overfitting; the third layer includes a dense layer with softmax activation function; the fourth layer is the pooling layer with global average pooling and the final layer is the dense output layer which is placed with the ReLU activation function.
The trainable attribute of the previous layers was set to false, because the first half of the model has already been pre-trained.
Finally, the model is optimized using the SGD optimizer with a momentum value set to 0.9 and the categorical cross entropy is used as the loss function for the optimized model.
The architectural overview of the pre-trained models is represented in Table 1 with input and output layer sizes (224, 224, 3) and (2, 1), respectively.
Fine-tuning allows to retrain the fully connected layers that aids in classification. This also retrains the convolutional and pooling layers that are included in the feature extraction stage. Optimized pre-trained models help to identify the complicated patterns which enhances the accuracy of the model.
An overall summarization of the work and its improvements from the previous work are given as follows.
As well known, numerous studies have been conducted to predict COVID-19 using chest X-rays and CT scans with pre-defined models such as Inception, Xception, ResNet, and others.
The proposed deep learning model-based methodology will be able to accurately predict the disease in less time. The proposed methodology makes use of pre-trained models available in Keras. Extra layers were added to the pre-trained models as specified in Fig. 4 before training, increasing the depth of the model and thus its accuracy. Following the addition of the custom layer, the model is trained with a batch size of 32 and 10 epochs. The proposed model can predict the disease with acceptable accuracy using these parameters.

Fine-tuned model overview
Typically, pre-trained models are trained for a minimum of 100 epochs to achieve better accuracy; however, because a custom layer is added to the corresponding pre-trained models, the proposed model can achieve better accuracy more easily and quickly. Following the training process, the model is enhanced with additional layers before fine-tuning, which distinguishes the proposed model from previous works [18], [19].
The model is then fine-tuned using the Keras-tune approach to determine the optimal hyper-parameter ranges. The Stochastic Gradient Descent (SGD) Optimizer is used to optimize the model, which updates the network weights during training.
Throughout the training process, SGD maintains a single learning rate. Although Adam optimizer updates the learning rate for each network weight individually, the proposed model was able to achieve the same accuracy in SGD optimizer as Adam optimizer. Though there are many new and efficient models available, such as ChexNet, GoogleNet and EDL-CovidNet, this work focuses on determining the highest accuracy with these basic pre-trained models with the minimum epochs.
Proceeding to the next section, the results of this study are presented.
Experimental Results
The following were the metrics taken into consideration to analyse the model’s performance:
-
True positive (TP): this combination informs us of the proportion of positive samples that a model correctly classifies as positive.
-
False negative (FN): this combination indicates how frequently a model incorrectly classifies a positive sample as negative.
-
False positive (FP): this combination reveals how frequently a model classifies a negative sample as positive.
-
True negative (TN): this combination informs us of the frequency with which a model correctly classifies a negative sample as negative.
-
Precision: precision enables us to see the machine learning model’s dependability in identifying the model as being positive.
$${\text{Precision}} = {\text{TP}}/({\text{TP}} + {\text{FP}}).$$(1) -
Recall: the recall evaluates how well the model can identify positive samples.
$${\text{Recall}} = {\text{TP}}/({\text{TP}} + {\text{FN}}).$$(2) -
F1 score: the harmonic mean of precision and recall is used to define the F1 score.
$${\text{F1score}} = {2} * (({\text{precision}} * {\text{recall}})/{\text{precision}} + {\text{recall}}).$$(3)
The harmonic mean is a metric that differs from the more commonly used arithmetic mean. It is frequently useful when calculating an average rate.
-
Accuracy: Accuracy is one metric for evaluating classification models. Informally, accuracy is the fraction of predictions our model got right. Formally, accuracy has the following definition:
-
AUC: Accuracy is a very commonly used metric. In contrast, the AUC is only used in classification problems with probabilities to further analyse the prediction. As a result, accuracy is understandable and intuitive even to non-technical people. On the other side, AUC requires a high level of concentration and some time to understand the logic behind it.
To summarize, AUC is a more understandable and intuitive metric than accuracy.
Without augmentation, the accuracy of the VGG-19 fine-tuned model is about 89.1% for chest X-rays and 88% for CT scans.
Prediction of COVID-19 Using Chest X-Rays
Xception model attained the highest performance with a precision of 93.5%, recall of 93%, F1-score of 0.935, accuracy of 93.5%, and AUC of 0.9836.
Inception V3 network attained the second-best results for COVID-19 prediction with a precision of 93.5%, recall of 93%, F1-score of 0.935, accuracy of 92%, and AUC of 0.9167 as shown in Table 2.
Prediction of COVID-19 Using CT Scans
The VGG-19 model achieved the best performance with a precision of 91%, recall of 90.5%, F1-score of 0.91, accuracy of 95%, and AUC of 0.9500836 as interpreted in Table 3.
After fine-tuning, the accuracies of the models improved by about 10% as shown in Tables 4 and 5. The optimized VGG-19 model outperformed other optimized pre-defined models with an accuracy of 94.17% and 93% for chest X-rays and CT scans, respectively.
The ROC curves for the optimized VGG-19 model for both chest X-rays and CT scans are shown in Figs. 5 and 6, respectively.

VGG-19—chest X-rays

VGG-19—CT scan
A comparison of the models with the existing models with ten epochs is given in Table 6.
A comparison of the existing models is given in Table 7.
When compared to the models mentioned above, our proposed model performed well in terms of accuracy in less time.
Conclusion
COVID-19, being a highly communicable disease, is a fatal disease that spreads rapidly. Early detection and treatment can help in isolating affected individuals to reduce its spread and prevent adverse health effects, including death. This work was aimed to find the most suitable deep learning models to predict the outbreak of the pandemic and spread of the disease. Conventional diagnostic methods, which tend to be slower, can be improved with the help of deep learning models for the betterment in healthcare facilities. Chest X-rays outperform CT scans in terms of COVID-19 diagnosis accuracy. The optimized VGG-19 model detected COVID-19 with high accuracy—up to 94.17% for chest X-rays and 93% for CT scans. These models will help to assist medical professionals in predicting and diagnosing individuals with COVID-19 and the government to anticipate the upcoming waves of this disease enabling them to take preventive measures in advance. This work also can be extended by developing a hybrid model which integrates the VGG-19 and inception model layers, thereby improving the diagnosis of COVID-19 in terms of performance metri as shown in Table 7 With the availability of more individual patient records, this model can also be extended to diagnose COVID-19 for individuals.
Change history
02 March 2023
A Correction to this paper has been published: https://doi.org/10.1007/s42979-023-01746-9
References
Luz E, Silva P, Silva R, Silva L, Guimarães J, Miozzo G, Moreira G, Menotti D. Towards an effective and efficient deep learning model for COVID-19 patterns detection in X-ray images. Res Biomed Eng. 2022;38(1):149–62. https://doi.org/10.1007/s42600-021-00151-6. PMCID: PMC8055440.
Nayak SR, Nayak DR, Sinha U, Arora V, Pachori RB. Application of deep learning techniques for detection of COVID-19 cases using chest X-ray images: a comprehensive study. Biomed Signal Process Control. 2021;64:102365.
Jain R, Gupta M, Taneja S, et al. Deep learning based detection and analysis of COVID-19 on chest X-ray images. Appl Intell. 2021;51:1690–700.
Bsu S, Mitra S, Saha N. Deep learning for screening COVID-19 using chest X-ray images. IEEE symposium series on computational intelligence (SSCI-2020).
Pinter G, Felde I, Mosavi A, Ghamisi P, Gloaguen R. COVID-19 Pandemic prediction for Hungary; a hybrid machine learning approach. Mathematics. 2020;8(6):890. https://doi.org/10.3390/math8060890.
Sanchez-Caballero S, Selles MA, Peydro MA, Perez-Bernabeu E. An efficient COVID-19 prediction model validated with the cases of China, Italy and Spain: total or partial lockdowns? J Clin Med. 2020;9(5):1547. https://doi.org/10.3390/jcm9051547.
Boudrioua MS, Boudrioua A. Predicting the COVID-19 epidemic in Algeria using the SIR model. https://doi.org/10.1101/2020.04.25.20079467
Rajesh A, Pai H, Roy V, Samanta S, Ghosh S. CoVID-19 prediction for India from existing data and SIR(D) model study. medRxiv. 2020. https://doi.org/10.1101/2020.05.05.20085902.
Zareie B, Roshani A, Mansournia MA, Rasouli MA, Moradi G. A model for COVID-19 prediction in Iran based on China parameters. medRxiv. 2020. https://doi.org/10.1101/2020.03.19.20038950.
Anwar T, Zakir S. Deep learning based diagnosis of COVID-19 using chest CT-scan images. 2020 IEEE 23rd international multitopic conference (INMIC).
Kumar SN, Talib M, Verma P. COVID Detection from X-ray and CT scans using transfer learning—a study. 2021 International Conference on Artificial Intelligence and Smart Systems (ICAIS)
Abugabah A, Mehmood A, Al Zubi AA, Sanzogni L. Smart covid-3d-scnn: a novel method to classify X-ray images of COVID-19. Comput Syst Sci Eng. 2022;41:997.
Al Smadi A, Abugabah A, Al-smadi AM, Almotairi S. SEL-COVIDNET: an intelligent application for the diagnosis of COVID-19 from chest X-rays and CT-scans. Inform Med Unlocked. 2022;32:101059.
Mehmood A, Abugabah A, Smadi AAL, Alkhawaldeh R. An intelligent information system and application for the diagnosis and analysis of COVID-19. In: Vasant P, Zelinka I, Weber GW, editors. Intelligent computing optimization. ICO 2021. Lecture notes in networks and systems, vol 371. Cham: Springer; 2022.
Mehmood A, Abugabah A, Smadi AA. Smart health care system for early detection of COVID-19 using X-ray scans. 2022 international conference on electrical, computer and energy technologies (ICECET); 2022.
https://www.kaggle.com/datasets/tawsifurrahman/covid19-radiography-database
https://www.kaggle.com/datasets/plameneduardo/sarscov2-ctscan-dataset?select=non-COVID
https://developer.ibm.com/articles/using-deep-learning-to-take-on-covid-19/
Jashnani K, Nargunde R, Shah Y, Raul N. COVID-19 prediction from CT scans using deep-learning. 2021 International Conference on Communication information and Computing Technology (ICCICT)
Berrimi M, Hamdi S, Moussaoui A, Oussalah M, Chabane M. COVID-19 detection from X-ray and CT scans using transfer learning. 2021 International Conference of Women in Data Science at Taif University (WiDSTaif)
Medina MA. Preliminary estimate of COVID-19 case fatality rate in the Philippines using linear regression analysis; 2020.
Thilakesh Raj A, NaliniPriya G, Maheswari KG, Ashwin Kumar R, Siva A. Early detection of COVID-19 using CT-scan Lungs Images. 2021 international conference on advancements in electrical, electronics, communication, computing and automation (ICAECA)
Abdar AK, Sadjadi SM, Soltanian-Zadeh H, Bashirgonbadi A, Naghibi M. Automatic detection of Coronavirus (COVID-19) from chest CT images using VGG16-based deep-learning. 2020 27th National and 5th International Iranian Conference on Biomedical Engineering (ICBME)
Ren Q, Zhou B, Tian L, Guo W. Detection of COVID-19 with CT images using hybrid complex shearlet scattering networks. IEEE J Biomed Health Inform. 2022 Jan;26(1):194-205. https://doi.org/10.1109/JBHI.2021.3132157. PMID: 34855604.
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of Interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this article was revised: Due to incorrect initial of the second author in the contribution text. Now, it has been corrected.
This article is part of the topical collection “Cyber Security and Privacy in Communication Networks” guest edited by Rajiv Misra, R K Shyamsunder, Alexiei Dingli, Natalie Denk, Omer Rana, Alexander Pfeiffer, Ashok Patel and Nishtha Kesswani.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Mukhi, S.E., Varshini, R.T. & Sherley, S.E.F. Diagnosis of COVID-19 from Multimodal Imaging Data Using Optimized Deep Learning Techniques. SN COMPUT. SCI. 4, 212 (2023). https://doi.org/10.1007/s42979-022-01653-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42979-022-01653-5