
Abstract
A mediating variable is a variable that is intermediate in the causal path relating an independent variable to a dependent variable in statistical analysis. The mediation analysis of using a categorical predictor, mediator, and outcome variables has been investigated in the literature. It is extremely common to have missing data even after having a well-controlled study. It is also well known that missingness, especially the non-ignorable missing, in a dataset has often been proven to produce biased results. This paper uses the extended Baker, Rosenberger, and Dersimonian (BRD) model to estimate the mediation effect under non-ignorable missing mechanisms. This paper also proposes four identifiable models to estimate the mediation effect for missingness in one categorical variable with two fully observed categorical variables. We reported the relative bias and Mean Square Error to compare the performance of the proposed BRD models against the Complete Case and Multiple Imputation methods in estimating the mediated effect (\(\widehat{a}\widehat{b}\)) under the non-ignorable missing mechanism. The application of these models in estimating the mediated effect was demonstrated using the Multiple Risk Factor Intervention Trial datasets.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Mediation analysis plays a significant role in the exploration of a causal relationship between two variables. A mediation model effect focuses on how two variables are related directly or indirectly: for example, consider the presence or absence of coronary heart disease (CHD) in high-risk men given as the independent variable (X), death due to myocardial infarction given as the dependent variable (Y), mediated by smoking where the smoking variable is the mediator (M).
Mediation analysis, which was first developed in the psychological sciences, is now instrumental in other disease development mechanisms for identifying intermediate factors useful for treatments and clinical trials. Methodological applications have increased over the past years, and more progress has also been made in understanding and applying mediation analysis in various research fields. Wright [1] proposed the mechanism of mediation by using “Wright's path analysis.” His model demonstrates the mathematical equations and diagrammatical representation in understanding the causal relationship between two variables such that the equations included the coefficients. In contrast, the diagrammatic representation included arrows to illustrate the relation's direction. These path coefficients were useful in defining the mediation effect. Wright [2] showed that although path analysis can be useful in quantifying causal relationships, it was extremely challenging to determine a causal effect between two variables. Several studies criticize path analysis and suggest more knowledge is still needed in identifying causal relations. The use of mediation analysis for research purposes also requires more in-depth information [3].
However, the first mediation hypothetically used was in stimulus-organism-response (S–O–R) [4]. The mediation analysis concept has been applied in various areas, including psychology, medical sciences, epidemiology, and clinical trials [5]. Fisher [6] introduced the use of covariate as a third variable. Later on, Lazarsfeld and his colleague Kendall [7] worked on the expansion method to explain the relationship between the two variables to the third variable. According to Wright's path analysis model, economists and sociologists could generalize the covariance model [8,9,10,11]. Hence, this model was called the structural equation model, which improved the estimated mediated effects' accuracy. Sobel [12] used the structural equation model to reduce the direct and indirect effects of standard errors and then used the standard errors in computing the mediated effects’ confidence interval. More studies and research to identify the complexity of the causal effect in mediation analysis have been made [13], [14], [3].
The simplest mediation model, which consists of one mediator, is known as the single mediator model. In this model, in addition to the direct effect, the independent variable X affects the dependent variable Y through a mediator M. The variables in a mediation model can either be continuous or categorical. The ordinary regression model is used to analyze continuous variables, while logistic regression is used to analyze categorical variables.
Missing data are a challenge affecting datasets and medical records in many areas of research. It can also occur in mediation analysis, and improperly handling this missingness may introduce biased mediation effects. The majority of statistical modeling approaches are designed for complete observations for the variables included in the data. It is crucial to deal with missing data using various methods to have valid inferences. Rubin [15] introduced the taxonomy of missing data mechanisms, widely used in the statistical literature. The methods of handling data with missing observations depend on the underlying assumption of the missing data mechanisms, which are Missing Completely at Random (MCAR), Missing at Random (MAR), Missing Not at Random (MNAR).
Categorical mediation data for simple analyses can also be presented in terms of contingency tables. Missing counts in contingency tables are important in missing data analysis, and there exist various methods for dealing with missingness in contingency tables. We can use Model-based procedures such as the Baker, Rosenberger, and Dersimonian (BRD) Models [16]. These models were proposed by Baker, Rosenberger, and Dersimonian (BRD) for analyzing missing counts in a two-way contingency table with three supplementary margins, using log-linear and maximum likelihood estimates [16]. In two-way contingency tables, the cell counts adjustments for log-linear factorization of likelihood methods have been used in several research papers. Hocking and Oxspring [17] also explained the use of maximum likelihood estimation in factoring partially classified contingency tables. Several publications recommend using log-linear models for partially classified contingency tables using conditional probabilities [18]. This paper focuses on the application of estimation of the mediation effect under the non-ignorable missing data mechanism (MNAR) using the extension of Baker, Rosenberger, and Dersimonian (BRD) models proposed by Rochani et al. [19] for a three-way contingency table. Estimation of mediation effect by BRD model approach has two main advantages over other available methods for non-ignorable data. First, the BRD approach explicitly models the missing mechanism, which will result in a full likelihood specification of the models with unique interpretations. Second, the estimation method will not be affected by the proportion of missing information which can affect the rate of convergence of methods like the Expected maximum (EM) algorithm.
Section 2 will focus on an overview of existing methods used for mediation analysis for categorical variables under non-ignorable missing data mechanisms. New models derived using the BRD model approach used for at least two non-missing categorical variables in the mediation analysis will be discussed in Sect. 3. Simulations are presented in Sect. 4. We will include the application of proposed models using the Multiple Risk Factor Intervention Trial (MRFIT) data for the Prevention of Coronary Heart Disease in Sect. 5, followed by a discussion in Sect. 6.
2 Mediation Analysis under Non-Ignorable Missing Data Mechanisms
Several methods exist in analyzing the mediation effect of continuous and categorical variables under non-ignorable missing data mechanisms. However, the purpose of this paper focuses on the non-ignorable missing data mechanism (MNAR) using the Baker, Rosenberger, and Dersimonian (BRD) model approach in analyzing the mediation models using categorical mediation variables.
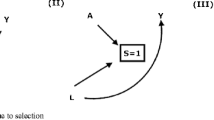
Given a mediation model, the relationship between smoking and coronary heart disease can be denoted by the regression coefficient parameter, “a.” On the other hand, the regression coefficient, which explains the relationship between the presence or absence of coronary heart disease in high-risk men and death due to myocardial infraction when controlling for smoking, can be denoted as “\(c^{\prime}\),” which is also called the direct effect. The coefficient parameter used to describe the relationship between smoking and death due to myocardial infarction can be denoted as “b.” Given these coefficients', the product value of “a” and “b" is called the indirect effect. Both the direct effect and the indirect effect make up the total effect c. Figure 1 represents the path diagram and equations for the mediation model.

Path diagram and equations for the mediation model
Researchers used mediation analysis to test the difference between the total effect c and direct effect c'. As a rule of thumb, a mediator is considered significant in the model if the value of (c- c') is greater than 20% [3]. Moreover, this is interpreted that X's independent variable affects the dependent variable Y indirectly via a mediator M. In general, for any mediation model with categorical or continuous variables, the model population coefficient a can be calculated as:
where \(Cov[X,M\)] is the covariance between variables X and M, and Var[X] is the variance of X. The model population coefficient of b and c' are given, respectively, as:
In the mediation analysis for categorical variables, logistic regression analysis is recommended when at least the dependent variable Y is categorical. Logistic regression has become well known in numerous fields, one of which is its easy transformation to the odds ratio. The equivalence (\(\hat{a}\hat{b} = \hat{c} - \hat{c^{\prime}}\)) is true when the dependent variable Y is continuous in calculating the mediated effect. However, this is not true when the dependent variable Y is categorical. The standard error is more complicated because the covariance between \(\hat{c}{\text{ and }}\hat{c^{\prime}}\) for ordinary regression does not directly apply to logistic regression. Hence, this makes the mediation effect estimation also complicated in terms of computing. Samawi et al. [20] developed a more straightforward method of analyzing the mediated effect among three variables when the dependent and mediator variables were dichotomous using a new approach called the latent variable technique to adjust for \(ab = c - c^{\prime}\).
Although the logistic regression can analyze the categorical variables, the categorical dependent variable's scale \(Y^{ * }\) cannot be observed directly. The residual variance and error terms are not the same as in terms of ordinary linear regression as explained by MacKinnon, and Dwyer [21]. This is because in ordinary linear regression, the dependent variance is observed and constant across the models while in logistic regression, the residual variance is fixed across the models. Winship and Mare [22] recommended setting the residual variance to \(\frac{{\pi^{2} }}{3}\) to fix the scale of the unobserved dependent \(Y^{ * }\) variable and hence the variance of \(Y^{ * }\) becomes
where Eq. (4) is the scale of the unobserved dependent \(Y^{ * }\) for the model of the independent variable X predicting the dependent variable Y.
By applying this recommendation, MacKinnon, and Dwyer [21] showed using a simulation study that the mediation effect estimation of \(\hat{c} - \hat{c^{\prime}}\) and \(\hat{a}\hat{b}\) were approximately equal either in the logistic or probit regression. However, in probit regression analysis, \(\frac{{\pi^{2} }}{3}\) it will be replaced with 1.
There are several methods considered for modeling missingness in mediation models with categorical variables. The commonly used method for dealing with missingness in categorical data is to substitute the missing values of each observation with the most common observation value. Although this method has been proven a common approach, its challenge is that it does not consider dependencies among the observation values. Other widely used methods include complete case analysis, multiple imputation, and Model-based analysis. This paper focuses on the extension of the model-based analysis method called Baker, Rosenberger, and Dersimonian (BRD) Models to a three-way contingency table proposed by Rochani et al. [19] for estimation of the mediation effect under the non-ignorable missing data mechanism (MNAR).
3 Estimation of Models
As mentioned earlier, a contingency table can represent categorical variables for mediation analysis, especially a three-way table for a simple medication model. An illustration of a three-way contingency table with supplementary margins for analyzing the association between two binary variables I, J while controlling for a third variable K in a 2 \(\times 2\times 2\) contingency table is given in Table 1.
These three-way tables with supplementary margins are used to apply log-linear models in the analysis for contingency tables with missing counts, where the missing data indicator \(\mathrm{for }{\mathrm{variable} I \mathrm{is denoted as} {R}_{I} (R}_{I}=1\) represents observed values for I and \({R}_{I}=2\) represents missing values for I). Similarly, \({R}_{J}\) is an indicator for J's missing data such that \({R}_{J}=1\) represents observed values for J and \({R}_{J}=2\) represents missing values for J. The same approach applies for \({R}_{K} \mathrm{where } {R}_{K}=1\) indicates that K is observed. The cell counts are denoted as {\({n}_{ijkab1}\)}, where i, j, and k are the levels for variables I, J, and K. The subscript a and b, when equal to 1, shows that I and J have been observed for the comparable cell and vice versa. The cell count \(n_{ + jk211}\) shows where \(j\) and \(k\) and both are observed but \(i\) is missing. The cell count \(n_{i + k121}\) shows where \(i\) and \(k\) and both are observed but \(j\) is missing. Furthermore, cell count \(n_{ + + k221}\) shows where \(i\) and \(j\) and both are missing but \(k\) is fully observed.
Rochani et al. [19] identified sixteen BRD models using the log-linear model to an incomplete three-way table to correct for missingness in two variables with the third variable fully observed (Fig. 2).

Schematic presentation of BRD models [23]
The Fig. 2 gives a general representation of the BRD models for the I × J two-way table with three supplementary margins. In these models, α is the missing data indicator for variable I, and β is the missing data indicator for J. The first and second subscript for parameters α and β corresponds to the variables I and J, respectively. The subscript '.' indicates that the parameter is constant over the corresponding index [16]. For example, (\({\alpha }_{i..}\),\({\beta }_{...}\))can be interpreted as missingness in a variable I depends on its own realization, while the missingness in variable J is constant across variables I and J.
This paper identifies four special case BRD models that can be used to correct for missingness in one categorical variable with the other two categorical variables fully observed. These models are model (\({\alpha }_{\dots }\)), Model (\({\alpha }_{i}\)), model (\({\alpha }_{.j.}\)), and Model (\({\alpha }_{..k}\)). Model (\({\alpha }_{\dots }\)) is under the ignorable missing mechanism assumption, while the other three are under the non-ignorable missing data mechanisms.
In deriving the proposed models for this paper, the first procedure requires deriving the models' likelihood functions and afterward solving the system of equations for each model’s maximum likelihood estimates. For illustrative purposes, we will use model (\({\alpha }_{i..}\)) to show the parameter estimates \(\widehat{\alpha }\) and \({\widehat{M}}_{ijk}\). The joint probability distribution and the log-likelihood function is given in Eq. 1 and 2, respectively.
Further simplification of the model gives the parameter estimates \(\sum_{i}{\widehat{m}}_{ijk}{\widehat{\alpha }}_{i..}\) = \({n}_{+jk211}\) \(\forall\) \({\widehat{\alpha }}_{i..}\) and.
\({\widehat{m}}_{ijk}= {n}_{ijk111}\). (For a detailed derivation of these models, refer to the appendix.)
Table 2 illustrates the estimated expected cell counts using (\({\alpha }_{i..}\)) model for complete cells and missing counts for a three-way table. Table 3 illustrates the collapsed expected cell counts for the three-way table into a 2 × 2 × 2 cross-classified table, obtained by adding the cells for the estimated cell counts of the complete cells and missing cells. Based on this estimated expected count, it can be expanded into a long-form of the data and used for the analysis of fitting the mediation models and estimating the coefficients \(\widehat{a}\widehat{, b}, \widehat{c},{c}{\prime}\), and the mediation effect estimate (\(\widehat{a}\widehat{b}\)) using logistic regressions.
We can find ad hoc boundary estimates if any solution is negative, as discussed by Baker et al. [16]. Rochani et al. [19] proposed that the ML estimates can still be computed by maximizing the likelihood function using the limited memory algorithm for constrained optimization (Byrd et al., 1995).
4 Simulations
A simulation study was conducted to evaluate the performance of estimating the mediation effect under the non-ignorable missing mechanism by the BRD model approach compared to the complete case method and commonly used Multiple imputation method under MAR assumption. We will use the proposed model for handling missingness in one categorical variable with the other two variables are fully observed. Then under model (\({\alpha }_{.j.}\)), the missing values were created for different percent missing in such a way that missingness in the independent variable X depends on the dependent variable Y. To model the missing probability for variable X, the following logistic regression model was considered as follows:
where \({\beta }_{1}=1\) and the choice of \({\gamma }_{0}\), which was selected by simulation, depends on the percent missing. For each iteration, sample sizes of 300, 500, and 1000 with mean (\(\mu\)) = \(\left[\begin{array}{ccc}0& 0& 0\end{array}\right]\) and correlation matrix (\(\rho\)) =\(\left[\begin{array}{ccc}1.000& 0.612& 0.125\\ 0.612& 1.000& 0.612\\ 0.125& 0.612& 1.000\end{array}\right]\) were used. This correlation matrix will give a 75% mediation effect [24]. Using a 75% mediation, the population correlations \({\rho }_{XM}=0.612\), \({\rho }_{MY}=0.612\) and \({\rho }_{XY}=0.612\) produce 0.612 \(\times\) 0.612 = 0.3745, which is a 3:1 ratio to 0.125. These correlations produce path coefficients of a = 0.612, b = 0.856 with the product of ab = 0.524. One thousand iterations were performed for each simulation scenario for various sample sizes and varying percentages of missingness. The multiple imputation (MI) method and the BRD model (\({\alpha }_{.j.}\)) were used for illustrative purposes to generate expected cell counts for complete cells and missing counts. These expected counts were expanded into a long-form and used to fit the mediation models using logistic regression. Table 2 shows the biases and mean squared errors (MSEs) of the mediation effect for the complete case (CC) method, multiple imputation (MI) method, and the BRD models.
By examining the overall trend and performance in Table 4, as the percent missing in the data increases, so does the bias and MSE of the mediated effect for complete case method, model-based method, and MI method, which uses the Markov Chain Monte Carlo (MCMC) method for imputation. In general, the mediated effect estimates (\(\widehat{a}\widehat{b}\)) for the proposed model under the non-ignorable missing mechanism shows decreased relative biases and reduced MSE for different percent missing in the data compared to the complete case method and multiple imputation method. This shows that the application of this simulation to a simulated dataset using any of the proposed models shown in this paper will at least fit that particular simulated model as shown in this section.
5 Application to Multiple Risk Factor Intervention Trial (MRFIT) data
This section demonstrates the application of estimating the mediation effect by applying the BRD models using the Multiple Risk Factor Intervention Trial (MRFIT) data. The MRFIT dataset was available by request from the Biologic Specimen and Data Repository Information Coordinating Center (BioLINCC), which serves as the National Heart, Lung, and Blood Institute (NHLBI) biospecimens and data under the Identifier no: NCT00000487. This dataset consisted of 12,866 men equally randomized to either an intervention or usual care group after the first two screenings. The primary endpoint in the study was death due to coronary heart disease. A total of 12,866 men were assessed to be in the upper 10–15% of CHD risk based on high serum cholesterol levels, diastolic blood pressure (BP), and cigarette use and were randomized into the study. After randomization, participants were screened annually and assessed for changes in the risk factor. The usual care group (n = 6438) was referred to their regular source of medical care and was examined annually. Participants in the particular intervention group (n = 6428) participated in an in-depth sustained multifactor intervention program to lower serum cholesterol and blood pressure and promoting smoking cessation. Participants were followed up till February 1982. Each participant was followed up for a minimum of 6 years, and the average follow-up was seven years. During follow-up, deaths were ascertained by clinical center staff, and the cause of death was determined by a committee blinded to the intervention group. The primary endpoint was CHD death and included death from MI, sudden death, Congestive heart failure (CHF), and coronary artery surgery. Other deaths from cardiovascular diseases (CVD) were from stroke, hypertension with left ventricular failure, pulmonary embolus, and unclassified CVD deaths.
Based on this MRFIT dataset, the variables of interest for this paper are the presence of coronary heart disease, which will be the independent variable, smoking which will be used as the mediating variable, and death due to myocardial infarction as the dependent variable. We will use these variables to analyze the mediation models in estimating the mediation effect using the MRFIT dataset, i.e., how smoking status mediates the relationship between coronary heart disease in high-risk men and the outcome of death due to myocardial infarction. Given the three variables of interest, missingness is present in two (Smoking and presence of coronary heart disease) while the third variable is completely observed. This is shown in Table 5.
For illustrative purposes, by focusing on one of the sixteen BRD models, say model (\({\alpha }_{i..}\),\({\beta }_{...}\)), where α represents the missing data parameter for the smoking variable and β represents the missing data parameter for the presence of coronary heart disease variable. Hence this model implies that the participant's nonresponse on smoking depends on their smoking status and implies that the probability of missingness in the presence of coronary heart disease is independent of either presence of coronary heart disease or smoking status. This model was chosen as a more probable model under the assumption that smokers are more likely not to respond to their smoking status while missing in CHD is completely at random. However, it is always important to evaluate our conclusion's robustness by conducting a sensitivity analysis based on other non-ignorable models.
Table 6 shows the model comparison and parameter estimates for the sixteen BRD models discussed in earlier chapters using the MRFIT dataset. It is important to note that conducting a sensitivity analysis aids in the confidence of the initial assumption chosen and the conclusion made. Examining the other models will give the researcher more confidence about their hypothetical level of confidence in sticking to the initial conclusion if the conclusion does not change. Hence, from this table, there is no mediation effect based on the BRD models' p values. This implies that smoking status is not a mediating factor in the relationship between coronary heart disease in high-risk men and the outcome of death due to myocardial infarction. However, it is essential to note that in practice, decisions about having a mediation effect are often based on if the indirect effect is more than 20% of the total effect or not and not solely on a significant p-value (as shown in Table 6). Therefore, by considering this method for conclusion purposes, it is left at the discretion of the researcher to decide on which models with mediation effect is plausible for use or not.
6 Conclusion
In this paper, we have shown the application of estimation of the mediation effect under the non-ignorable missing data mechanism (MNAR) using the extension of Baker, Rosenberger, and Dersimonian (BRD) models. Generally, mediation analysis is becoming very popular in several research areas. Investigators are interested in simply knowing the cause-effect relationship between two variables; they want to understand how and why a third variable mediates this relationship. This paper illustrated how well the mediation effect's estimation under the non-ignorable missing mechanism of the BRD model approach produces accurate inference compared to either the complete case method or the MI method. Performing a sensitivity analysis based on the non-ignorable BRD models was used in evaluating the robustness of the initial assumption chosen and the conclusion made. While this paper developed a sufficient method to evaluate the performance of the estimation of the single mediation effect under the non-ignorable missing mechanism by the BRD model approach, it is recommended that further research be conducted for scenarios of multiple mediation effects. In addition, although this paper considered only categorical variables for the simple mediation model, there is also a need for future research to accommodate the mediation model variables to be a combination of continuous and categorical variables.
References
Wright S (1920) The relative importance of heredity and environment in determining the piebald pattern of Guinea pigs. Proc Natl Acad Sci 6:320–332
Wright S (1923) The theory of path coefficients: a reply to Niles’s criticism. Genetics 8:239–255
MacKinnon DP (2013) Introduction to statistical mediation analysis. Routledge, New York
Woodworth RS (1928) Dynamic psychology. In: C. Murchison (Ed.). Psychologies of 1925 (pp 111–126). Worcester, MA; Clark University Press
Judd CM, Kenny DA (1981) Process analysis: estimating mediation in treatment evaluations. Eval Rev 5:602–619
Fisher RA (1934) Statistical methods for research workers, 5th edn. Oliver and Boyd Lt, Edinburgh, Scotland
Kendall PL, Lazarsfeld PF (1950) Problems of survey analysis. In: Merton RK, Lazarsfeld PF (eds) Continuities is social research: studies in the scope and method of The American soldier. Free Press, Glencoe, IL, pp 133–196
Jöreskog KG (1970) A general method for analysis of covariance structures. Biometrika 57:239–251
Jöreskog KG (1973) A general method for estimating a linear structural equation system. In: Goldberger AS, Duncan OD (eds) Structural equation models in the social sciences. Seminar Press, New York, pp 85–112
Keesling JW (1972) Maximum likelihood approaches to causal analysis [Unpublished doctoral dissertation]. University of Chicago
Wiley DE (1973) The identification problem for structural equation models with unmeasured variables. In: Goldberger AS, Duncan OD (eds) Structural equation models in the social sciences. Seminar Press, New York, pp 69–83
Sobel ME (1982) Asymptotic confidence intervals for indirect effects in structural equation models. Sociol Methodol 13:290–312. https://doi.org/10.2307/270723
Frangakis CE, Rubin DB (2002) Principal stratification in causal inference. Biometrics 58:21–29
Little R, Rubin D (2002) Statistical analysis with missing data (2nd ed.). In: Models for partially classified contingency tables, ignoring the missing-data mechanism. Wiley-Interscience
Rubin DB (1974) Estimating causal effects of treatments in randomized and nonrandomized studies. J Educ Psychol 66:688–701
Baker SG, Rosenberger WF, DerSimonian R (1992) Closed-form estimates for missing counts in two-way contingency tables. Stat Med 11:643–657
Hocking RR, Oxspring HH (1974) The analysis of partially categorized contingency data. Biometrics 30(3):469–483
Bishop YMM, Fienberg SE, Holland PW (2007) Discrete multivariate analysis. Springer, New York
Rochani HD, Vogel RL, Samawi HM, Linder DF (2017) Estimates for cell counts and common odds ratio in three-way contingency tables by homogeneous log-linear models with missing data. Adv Stat Anal AStA 101:51–65
Samawi H, Cai J, Linder DF, Rochani H, Yin J (2018) A simpler approach for mediation analysis for dichotomous mediators in logistic regression. J Stat Comput Simul 88(6):1211–1227. https://doi.org/10.1080/00949655.2018.1426762
MacKinnon DP, Dwyer JH (1993) Estimating mediated effects in prevention studies. Eval Rev 17:144–158
Winship C, Mare RD (1983) Structural equations and path analysis for discrete data. Am J Sociol 89:54–110
Jansen I (2005) Flexible model strategies and sensitivity analysis tools for non-monotone incomplete categorical data. LUC
Iacobucci D (2012) Mediation analysis with categorical variables: the final frontier. J Consum Psychol 22(4):582–594
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no conflicts of interest to declare.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix
Model (\({\boldsymbol{\alpha }}_{\dots }\))
\(\begin{gathered} L = \left\{ {\prod\limits_{i,j,k} {\frac{{e^{{ - \mu_{{_{ijk111} }} }} (\mu_{{_{ijk111} }} )^{{n_{{_{ijk111} }} }} }}{{^{{n_{{_{ijk111} }} }} }}} \times \prod\limits_{j,k} {\frac{{e^{{ - \mu_{{_{ + jk211} }} }} (\mu_{{_{ + jk211} }} )^{{n_{ + jk211} }} }}{{n_{ + jk211} }}} } \right\} - \mu_{ + + + 111} , \hfill \\ \hfill \\ \end{gathered}\)
given \({\mu }_{ijk111}= \widehat{{m}_{ijk}}\) and \({\mu }_{+jk211}= \widehat{{m}_{+jk}}\widehat{{\alpha }_{\dots }}\), the above equation can be written as
The log-likelihood function can be derived as
By differentiating with respect to \(\widehat{{\alpha_{ \ldots } }},\) we have:
Given each cell count denoted by {nijkabc}, where i, j, and k represent the categories for variables I, J, and K, respectively. Hence, we have
By differentiating with respect to \(\widehat{{m_{ + jk} }},\) we have:
This can be simplified further as
\(n_{{_{ + jk + 11} }} n_{{_{ + + + 111} }} n_{{_{ + + + + 11} }} n_{{_{ + jk + 11} }} n_{{_{ + + + 111} }} = n_{{_{ + + + + 11} }} n_{{_{ + + + 111} }} n_{{_{ + jk111} }} n_{{_{ + jk + 11} }} n_{{_{ + + + 111} }} + n_{{_{ + + + + 11} }} n_{{_{ + + + 111} }} n_{{_{ + + + + 11} }} n_{{_{ + jk211} }} \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{m}_{{_{ijk} }}\)
Therefore, we have
Model (\({\boldsymbol{\alpha }}_{{\varvec{i}}..}\))
\(\sum\limits_{j} {\sum\limits_{k} {\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{m}_{{_{ijk} }} } } = \sum\limits_{j} {\sum\limits_{k} {\left( {\frac{{n_{ + jk211} }}{{\sum\limits_{i} {(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{m}_{{_{ijk} }} \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\alpha }_{{_{i..} }} )} }}\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{m}_{{_{ijk} }} } \right)} }\),
therefore, we can deduce that given \(\boxed{\sum\limits_{i} {\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{m}_{ijk} \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\alpha }_{i..} } = n_{ + jk211} }\) \(\forall \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\alpha }_{{_{i..} }}\), then
\(\frac{dL}{{d\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{m}_{ijk} }} = \frac{{n_{ijk111} }}{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{m}_{ijk...} }} + \frac{{n_{ + jk211} }}{{\sum\limits_{i} {(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{m}_{ijk} \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\alpha }_{i..} )} }} \bullet \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\alpha }_{i..} - (1 + \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\alpha }_{i..} )\)
By assuming \(\sum\limits_{i} {(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{m}_{ijk} \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\alpha }_{i..} )} = n_{ + jk211}\), we have:
Model (\({\boldsymbol{\alpha }}_{.{\varvec{j}}.}\))
\(\therefore \frac{dL}{{d\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{m}_{{_{ijk} }} }} = \frac{{n_{{_{ijk111} }} }}{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{m}_{{_{ijk} }} }} + \frac{{n_{ + jk211} }}{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{m}_{{_{ + jk} }} \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\alpha }_{{_{.j.} }} }}\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\alpha }_{{_{.j.} }} - (1 + \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\alpha }_{{_{.j.} }} )\), since \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{m}_{{_{ + jk} }} \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\alpha }_{{_{.j.} }} = n_{ + jk211}\), then:
Model (\({\boldsymbol{\alpha }}_{..{\varvec{k}}}\))
\(\therefore \frac{dL}{{d\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{m}_{{_{ijk} }} }} = \frac{{n_{{_{ijk111} }} }}{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{m}_{{_{ijk} }} }} + \frac{{n_{ + jk211} }}{{\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{m}_{{_{ + jk} }} \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\alpha }_{{_{..k} }} }}\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\alpha }_{{_{..k} }} - (1 + \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\alpha }_{{_{..k} }} )\), since \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{m}_{{_{ + jk} }} \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\frown}$}}{\alpha }_{{_{..k} }} = n_{ + jk211}\), then:
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Ayoku, S., Rochani, H., Samawi, H. et al. Mediation Analysis in Categorical Variables under Non-Ignorable Missing Data Mechanisms. J Stat Theory Pract 17, 51 (2023). https://doi.org/10.1007/s42519-023-00346-3
Accepted:
Published:
DOI: https://doi.org/10.1007/s42519-023-00346-3