
Abstract
Density-based minimum divergence procedures represent popular techniques in parametric statistical inference. They combine strong robustness properties with high (sometimes full) asymptotic efficiency. Among density-based minimum distance procedures, the methods based on the Brègman divergence have the attractive property that the empirical formulation of the divergence does not require the use of any nonparametric smoothing technique such as kernel density estimation. The methods based on the density power divergence (DPD) represent the current standard in this area of research. In this paper, we will present a more generalized divergence which subsumes the DPD as a special case, and produces several new options providing better compromises between robustness and efficiency.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
In parametric statistical inference, the likelihood based methods have several asymptotic optimality properties. Under model misspecifications, or under the presence of outliers, all classical procedures including maximum likelihood may, however, be severely affected and lead to a distorted view of the true state of nature. For the big data scenario of the present times, a certain amount of noise is never unexpected, but even a small amount of it may be sufficient to severely degrade the performance of the classical procedures.
Another approach to parametric estimation is based on minimizing density-based distances between the data density and the proposed model density; this approach generally combines high efficiency (sometimes full asymptotic efficiency) with strong robustness properties. Interestingly, the maximum likelihood estimator (MLE) itself also belongs to this class of density-based minimum distance estimators, being the minimizer of a version of the Kullback–Leibler divergence [10]. Another such divergence is the Hellinger distance and the estimator generated by minimizing this divergence is both highly robust (compared to the MLE) and is also first-order efficient [4]. However, the minimum Hellinger distance estimation method (and similar estimation methods based on \( \phi \)-divergences) is burdened by the fact that a nonparametric smoothing technique is inevitably necessary for the construction of an estimate of the data density for this procedure under continuous models. Apart from computational difficulties and the tricky bandwidth selection issue, the slow convergence of the nonparametric density estimate to the true density in high dimensions poses a major theoretical difficulty.
An alternative density-based minimum distance procedure is presented by the class of Brègman divergences [5]. This divergence class is characterized by a strictly convex function, and does not need any nonparametric smoothing for its empirical construction; see Jana and Basu [9]. Although the estimators obtained by the minimization of Brègman divergences are generally not fully efficient, they often combine high asymptotic efficiency with a strong degree of robustness and outlier stability. Most minimum Brègman divergence estimators also have bounded influence function, a property which is not shared by the minimum \(\phi \)-divergence estimators. See Basu et al. [3] and Pardo [15] for more details on robust parametric inference based on \(\phi \)-divergences (or disparities).
The DPD family [2] is a prominent subclass of Brègman divergences, and has had a significant impact on density-based minimum distance inference in recent times. This divergence family is defined by a class of convex functions indexed by a nonnegative tuning parameter \(\gamma \). Larger values of \(\gamma \) lead to divergences which endow the corresponding minimum-divergence estimator with greater outlier stability. In the following we will refer to the minimum density power divergence estimator as the MDPDE, and tag on the \(\gamma \) symbol wherever necessary. Our aim is to improve upon the MDPDE(\(\gamma \)) in terms of robustness and efficiency. It is useful to note that the minimum Brègman divergence estimator (and hence the MDPDE) belongs to the class of M-estimators as defined in, for example, Hampel et al. [8] or Maronna et al. [12]. As a consequence, the asymptotic properties of the estimators based on the newly defined divergences may be obtained from the well established M-estimation literature. The minimum density power divergence estimation method for independent and identically distributed (IID) data have been discussed in Basu et al. [2, 3] and that for independent non-homogeneous (INH) data in Ghosh and Basu [6]. We will perform similar exercises for our newly defined divergence family, and show that the resulting procedures can become useful robust tools for the applied scientist.
2 The Brègman Divergence and Related Inference
The Brègman divergence was originally proposed as a measure to define a distance between two points in \({\mathbb {R}}^{d}\). It is a divergence measure, but not a metric in the true sense of the term, as it generally does not satisfy the triangle inequality and may not even be symmetric in its arguments. Let \(B:{\mathbb {R}}^{d} \rightarrow {\mathbb {R}} \) be a twice continuously differentiable, strictly convex function defined on a closed convex set in \({\mathbb {R}}^{d} \). The Brègman divergence associated with the strictly convex function B for \(p,q \in {\mathbb {R}}^{d} \) is defined as
where \(B'\) represents the derivative of B with respect to its argument. For two given density functions g and f, the Brègman divergence between them is defined as
The function B, in the above case, is clearly not uniquely defined due to the linearity property of the integral, as both B(y) and \(B(y) + ay + b\) give rise to the exact same divergence for any real constants a and b. Here, we explore the general estimation procedure to find the minimum Brègman divergence estimator for any convex B function. Assume that an IID random sample \(X_1, X_2, \ldots , X_n \) is available from the true distribution G, and we try to model this distribution by a parametric family \({\mathscr {F}}=\{F_{\theta }: \theta \in \Theta \subset {{\mathbb {R}}}^p \} \) where \(\theta \) is unknown but the functional form of \(F_{\theta }\) is known to us. In such a scenario, the estimation of the parameter \(\theta \) consists in choosing the model density \(f_{\theta } \) which is closest to the data density in the minimum Brègman divergence sense. Let g and \(f_{\theta }\) be the probability densities of G and \(F_{\theta }\), respectively. Then the Brègman divergence between g and \(f_{\theta }\) will be as given in Eq. (1) with f replaced by \(f_\theta \).
We wish to use the minimum Brègman divergence approach for the estimation of the unknown parameter \(\theta \). Notice that we cannot directly obtain the Brègman divergence between g and \(f_\theta \) for the purpose of this minimization, as the density g is unknown. So we need an empirical estimate of this divergence, which can then be minimized over \(\theta \in \Theta \). After discarding the terms of the above divergence (objective function) that are independent of \(\theta \), the only term that needs to be empirically estimated is \(\int B'(f_\theta (x)) g(x) {\mathrm{d}}x\), which can be estimated by the corresponding sample mean \(\frac{1}{n} \sum _{i=1}^n B'(f_\theta (X_i))\), so the empirical objective function for the minimization of \(D_B(g, f_\theta )\) is now given by
Let \(u_{\theta }(x) = \nabla _{\theta } \log (f_{\theta }(x))\) be the likelihood score function of the model being considered where \(\nabla _{\theta }\) represents the gradient with respect to \(\theta \). Under appropriate differentiability conditions, the minimizer of this empirical divergence over \(\theta \in \Theta \) is obtained as a solution to the estimating equation
This may be viewed as being in the general weighted likelihood equation form given by
where the relation between the Brègman function B and the weight function \(w_{\theta }\) is given as
The nonnegativity of the above weight function is secured by the convexity of the B function with the nonnegativity of the density function. Some of the major density-based divergences that can be obtained from the Brègman divergence using different B functions are the following.
-
1.
\(B(y) = y\log (y)-y\): This generates the Kullback–Leibler divergence given by
$$\begin{aligned} D_{KL}(g,f_{\theta })= \int _{x}^{} g(x) \log \bigg ( \frac{g(x)}{f_{\theta }(x)} \bigg ) {\mathrm{d}}x. \end{aligned}$$Under our parametric setup, its estimating equation and weight function are, respectively,
$$\begin{aligned} \frac{1}{n}\sum _{i=1}^{n} u_{\theta }(X_{i})-\int _{x}^{} u_{\theta }(x)f_{\theta }(x) {\mathrm{d}}x = 0, \ \ w_\theta (x) = w(f_\theta (x)) = 1. \end{aligned}$$(5) -
2.
\(B(y) = y^2\): This leads to the squared \(L_2\) distance
$$\begin{aligned} L_{2}(g,f_{\theta }) = \int _{x}^{} \big [g(x)-f_{\theta }(x)\big ]^{2} {\mathrm{d}}x, \end{aligned}$$generating, respectively, estimating equation and weight function as
$$\begin{aligned} \frac{1}{n}\sum _ {i=1}^{n} u_{\theta }(X_{i})f_{\theta }(X_{i}) = \int _{x}^{}u_{\theta }(x)f_{\theta }^{2}(x) {\mathrm{d}}x, \ \ w_\theta (x) = w(f_\theta (x)) = f_\theta (x). \end{aligned}$$(6) -
3.
\(B(y)= (y^{1+\gamma }-1)/\gamma \): This generates the DPD(\(\gamma \)) family given by
$$\begin{aligned} d_{\gamma }(g,f_{\theta }) = \int _x \Big \{ f_{\theta }^{1+\gamma }(x)-\bigg (1 + \frac{1}{\gamma }\bigg )g(x)f_{\theta }^{\gamma }(x)+\frac{1}{\gamma } g^{1+\gamma }(x)\Big \} {\mathrm{d}}x. \end{aligned}$$(7)In this case its estimating equation and weight function are given by
$$\begin{aligned} \frac{1}{n}\sum _{i=1}^{n} u_{\theta }(X_{i})f_{\theta }^{\gamma }(X_{i})-\int _{x}^{} u_{\theta }(x)f_{\theta }^{1+\gamma }(x) {\mathrm{d}}x = 0, \ \ w_\theta (x) = w(f_\theta (x)) = f_\theta ^\gamma (x). \end{aligned}$$(8)
It may be noted that the estimating Eqs. (5), (6) and (8) are all unbiased under the model and have the same general structure as given in Eq. (3). The equations differ only in the form of the weight function \(w_\theta (x)\). And it is this weight function which determines to what extent the estimating equation is able to control the contribution of the score to the equation. In Eq. (5) the weight function is identically 1, so that the equation has no downweighting effect over the score functions of anomalous observations. The \(L_2\) case in Eq. (6), on the other hand, provides a strong downweighting effect by attaching the density function as the weight. The DPD covers a middle ground, by generating a weight of \(f^\gamma _\theta (x)\), which produces a smoother downweighting compared to the \(L_2\) case for \(\gamma \in (0, 1)\).
3 The Exponential-Polynomial Divergence
Here, our aim is to find a suitable convex function so that we can propose a generalized class of Brègman divergences that generates the DPD class as a special case. For this purpose we consider a sophisticated convex function B having the general form
where \(\alpha \), \(\beta \) and \(\gamma \) are the tuning parameters for the system. The function in Eq. (9) is considered to be a generalization of the generating function for DPD given in Eq. (7). Clearly we recover the DPD with parameter \(\gamma \) for \(\beta = 0\), but for nonzero \(\beta \) we get a combination of the generating function for the Brègman exponential-divergence (BED) [13] and the density power divergence. At \(\beta = 1\), we get the BED with tuning parameter \(\alpha \). While the value \(\beta \) moderates the level of presence (or absence, when \(\beta = 0\)) of the BED component, \(\alpha \) and \(\gamma \) represent the BED and the DPD tuning parameters, respectively. Note that when \(\beta = 0\) and \(\gamma \rightarrow 0\), the divergence converges to the Kullback–Leibler divergence. We refer to the divergence produced by Eq. (9) as the exponential-polynomial divergence (EPD) and we will be using the notation \(D_{EP}(g, f_\theta )\) to refer to the exponential-polynomial divergence between the densities g and \(f_\theta \). The tuning parameters of these families lie in the regions \(\alpha \in {{\mathbb {R}}}\), \(\beta \in [0,1]\) and \(\gamma \ge 0\). In the spirit of the notation employed so far, the B-function of the EPD may be seen to be a convex combination of the BED(\(\alpha \)) and DPD(\(\gamma \)) B-functions.
3.1 Minimum EPD Estimation as M-Estimation
Consider the parametric setup of Sect. 2 and the empirical objective function of the Brègman divergence given in Eq. (2). Note that, in case of the EPD, this objective function may be written as \(\frac{1}{n} \sum _{i=1}^n V_\theta (X_i)\), where
As \(X_1, X_2, \ldots , X_n\) are independent and identically distributed observations, \(V_\theta (X_i)\), \(i =1,2, \ldots , n\) are independent and identically distributed as well. Under differentiability of the model the estimating equation is
Direct calculations show that for the EPD the associated \(\psi \) function has the form
where
In particular, for a location model, the estimating equation reduces to \(\sum _{i=1}^n T_\theta (X_i) = 0\).
The above description shows that the minimum EPD estimator (MEPDE) is an M-estimator (which is indeed true for all minimum Brègman divergence estimators). The functional \(T_{(\alpha ,\beta ,\gamma )}(G) \), defined through the relation \(T_{(\alpha , \beta , \gamma )}(G) = {{\,{\mathrm{argmin}}\,}}_{\theta \in \Theta } D_{EP}(g, f_\theta )\), is easily seen to be Fisher consistent, so that, \(T_{(\alpha ,\beta ,\gamma )}(F_{\theta })= \theta \). If the distribution G is not in the parametric family \({\mathscr {F}}\), then \(T_{(\alpha ,\beta ,\gamma )}(G) \) is the solution of the equation
In this case we will refer to this solution as the best fitting parameter and denote it by \(\theta ^g\).
3.2 Asymptotic Properties
We define the empirical objective function to be
where \(V_\theta (x)\) is as defined in Eq. (10). The theoretical analogue of \(H_n(\theta )\) is given by
We define the information function of the model as \( i_{\theta }(x)=-\nabla u_{\theta }(x)\), and further define the quantities \(K(\theta )\), \(\xi (\theta )\) and \(J(\theta )\) as
Theorem 1
Under the conditions (A1)–(A5) given in “Appendix A”
-
(a)
The MEPDE estimating equation given by (11) has a consistent sequence of roots of \( {\hat{\theta }}_{n}. \)
-
(b)
\(\sqrt{n}({\hat{\theta }}_{n}-\theta ^{g}) \) has an asymptotic multivariate normal distribution with mean (vector) zero and covariance matrix \(J^{-1}KJ^{-1}\) where J and K are defined in Eq. (13), and evaluated at \(\theta = \theta ^g\).
The proof is a relatively straightforward extension of Theorem 6.4.1 of Lehmann [11], and is omitted. The result can also be obtained, as indicated, from the M-estimation approach, but the conditions of this proof are slightly weaker.
3.3 Influence Function, Gross Error Sensitivity and Asymptotic Efficiency
A useful advantage of the representation of the minimum Brègman divergence estimator as an M-estimator is the straightforward computation of its influence function. Another important measure of robustness, available from the influence function is the gross error sensitivity (GES). Based on the nature of its influence function or GES, we can comment on the robustness properties of the associated MEPDE. Simple calculations show that the influence function of the MEPD functional \(T_{(\alpha ,\beta ,\gamma )}(\cdot )\) has the form
where \(\xi \) and J, as in Eq. (13), are evaluated at \(\theta = \theta ^g\). Under the assumption that J and \(\xi \) are finite, this influence function is bounded only if the quantity \(\big \{u_{\theta }(y)\big (\beta f_{\theta }(y) \exp (\alpha f_{\theta }(y)) + (1-\beta )(\gamma +1)f_{\theta }^{\gamma }(y)\big )\big \}\) is bounded in y. This is indeed true for all standard models for \(\beta \in [0, 1]\), \(\alpha \in {\mathbb {R}}\) and \(\gamma >0\). The GES of the functional \( T_{(\alpha , \beta , \gamma )}(G)\) is
The influence function of the MDPDE is bounded for \(\gamma > 0\), and that for the MEPDE is bounded for \(\gamma > 0\) and any finite \(\alpha \) and \(\beta \in [0, 1]\), so that our functional has finite GES for the indicated set of tuning parameters. It should be noted that the influence function and the GES for the MLE are unbounded.
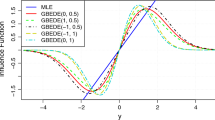
As an example, we consider a particular case for our illustration with the influence function. In Fig. 1 we present the influence function of the MEPDE functional for the mean of a normal random variable under the \(N(\mu , 1)\) model, where N(0, 1) is the true distribution. The value of \(\gamma \) is fixed to be 0.1 in this example, and while the choice \(\beta = 0\) (irrespective of the value of \(\alpha \)) refers to MDPDE(0.1), the figure shows that at different choices of \(\alpha \) and nonzero \(\beta \) at the same value of \(\gamma \) (\(=0.1\)), substantially lower peaks for the influence function (and hence smaller GES values) may be attained for the corresponding MEPDE. While there is no doubt that substantial further investigation will be necessary to get an overall feeling of the stability of the estimator for different choices of the triplet (\(\alpha \), \(\beta \), \(\gamma \)), it is clear that other parameter combinations can increase the strength of downweighting, without altering the value of \(\gamma \). In Fig. 1 we have refrained from adding the plot for the unbounded MLE to avoid unnecessary cluttering of the graph.

Influence functions of different MEPDEs in the \(N(\mu , 1)\) model
It may be noted, however, that the above exercise is not intended to suggest that for each fixed divergence within the DPD family there is a better choice of a divergence within the EPD family (with the same value of \(\gamma \)) which can dominate the former in terms of all the possible goodness measures. Indeed, detailed numerical calculations show that often there may not be another member of the EPD family which may have improved efficiency compared to the corresponding DPD with the same value of \(\gamma \). On the other hand, detailed calculations appear to suggest that given a divergence within the DPD family, often there may be another divergence within the EPD family, not necessarily with the same value of \(\gamma \), which might provide better metrics than the former.
The asymptotic variance of \(\sqrt{n}\) times the MEPDE(\(\alpha ,\beta ,\gamma \)) can be estimated through the influence function using the asymptotic distribution of M-estimators; see, e.g., Hampel et al. [8]. Let \(R_i(\theta )\), \(i= 1,\ldots ,n\), be the quantity \(u_{\theta }(X_i)\big \{\beta f_{\theta }(X_i) \exp (\alpha f_{\theta }(X_i)) + (1-\beta )(\gamma +1) f_{\theta }^{\gamma }(X_i)\big \} \) at the data point \(X_{i}\) for \(\theta = {\hat{\theta }}_{(\alpha ,\beta ,\gamma )}\), the estimator minimizing the divergence. We can estimate the J matrix by \(J(G_n)\) obtained by substituting G with \(G_n\), the empirical distribution function, in the expression of J. Then, a consistent estimate of asymptotic variance of the MEPDE may be obtained as \(J^{-1}(G_n)\big \{(n-1)^{-1}\sum _{i=1}^{n}R_{i} R_{i}^{T}\big \} J^{-1}(G_n)\).
3.4 The Weight Function
A comparison of Eqs. (4), (9) and (12) show that the weight function of the estimating equation in case of the EPD has the form
In Fig. 2 we give a description of some weight functions for different triplet combinations, with particular emphasis on what the variation in the parameters \(\alpha \) and \(\beta \) do to the estimation procedure when the value of \(\gamma \) is kept fixed. From the figure it may be noted that between the variety of cases considered, downweighting patterns of many different types are observed. In particular, in comparison to the weight function of the MDPDE (which corresponds to \(\beta = 0\), irrespective of the value of \(\alpha \)), all different kinds of variations are observed. One set of procedures apply greater downweighting for less probable observations while increasing the weights of the others. On the other hand, others exhibit a greater smoothing effect leading to more uniform weight functions. On the whole, there is a medley of possibilities, from which the experimenter can choose the optimal procedure in a given situation.

The weight function of the MEPDE for different values of \(\beta \) when a \(\alpha =1\) and \(\gamma =1\), b \(\alpha =-1\) and \(\gamma =1\), c \(\alpha =1\) and \(\gamma =0.5\), d \(\alpha =-1\) and \(\gamma =0.5\)
4 Independent and Identically Distributed (IID) Models
In this section, we will consider the parametric setup of Sect. 2 where an independent and identically distributed sample \(X_1, X_2, \ldots , X_n\) is available from the true distribution G, which is modeled by the parametric family \({\mathscr {F}}=\{F_{\theta } : \theta \in \Theta \subset {{\mathbb {R}}}^p \}\). When the true distribution belongs to the model, so that \(G = F_{\theta } \) for some \(\theta \in \Theta \), the formulae for J, K and \(\xi \) defined in Eq. (13) simplify to
When \(\beta = 0 \) and \(\gamma \downarrow 0\), \(J(\theta )\) and \(K(\theta )\) coincide with \(I(\theta )\), the Fisher information matrix, and the asymptotic variance \(J^{-1} K J^{-1}\) coincides with \(I^{-1}(\theta )\), the inverse of the Fisher information. The choice \(\beta = 0\) leads to the variance estimates of MDPDE(\(\gamma \)), while the choice \(\beta = 1\) leads to the variance estimates of MBEDE(\(\alpha \)), the minimum BED estimator for tuning parameter \(\alpha \).
4.1 Selecting the Optimal Procedure
What we have done so far in our development is that we have created a sophisticated Brègman function which is a convex combination of the Brègman functions of the DPD and the BED families, and described the related inference procedure. As the DPD is widely recognized as the current standard in density-based minimum distance inference based on divergences of the Brègman type, our main motivation is to show that our exploration allows us, in any given real situation, to select a procedure, which provides a better control in comparison to the procedures restricted to the DPD class.
Be it in the case of parametric estimation based on the density power divergence or the exponential-polynomial divergence, these estimation schemes allow millions of choices as they are indexed by one or more tuning parameters that are allowed to vary over some continuous range. The collection of procedures involves all different kinds of methods, ranging from the most efficient to highly robust ones. Yet, in any particular real data problem, the experimenter has to provide a single, most appropriate choice for the tuning parameter for the specific data at hand, without knowing the amount of anomaly that is involved in the data under consideration. In an intuitive sense it is clear that such choices should be data-based.
4.2 The Current State of the Art
In robust statistical inference, which depends on one or more tuning parameters, a perennial problem is to choose the tuning parameter(s) appropriately when it has to be applied to a given set of numerical data. Such tuning parameters inevitably control the trade-off between efficiency and robustness, and depending on what is needed and to what extent in a particular situation, the tuning parameter must strike a balance between these two conflicting requirements.
With the success of the DPD as a method of choice in robust statistical inference, several methods for the selection of the “optimal” DPD tuning parameter has been proposed in the literature. The basic idea is the construction of an empirical measure of mean square error (or some other similar objective) as a function of the tuning parameter, which can then be minimized over the latter; this generates a minimum mean square error criterion for the selection of the tuning parameter. A few variations of this technique have been tried out in the literature. Here, we will follow the approach considered in Warwick and Jones [20].
In the above approach, we will evaluate the performance of the estimator through its summed mean square error around \(\theta ^*\), which may be expressed, asymptotically, as
where \({\hat{\theta }}_n\), the MEPDE, is a function of triplet of tuning parameters \((\alpha , \beta , \gamma )\), J and K are as in Eq. (13), and \(\mathrm{tr}(\cdot )\) represents the trace of a matrix. Such a formulation may be meaningful, for example, when the data are generated by a mixture having \(f_{\theta ^*}\) as the dominant component, and \(\theta ^*\) is our target parameter; see the discussion in Warwick and Jones [20]. In practice we empirically estimate the quantity on the right-hand side of Eq. (14) by replacing the true distribution G, wherever possible, by the empirical distribution \(G_n\), \(\theta ^g\) with the MEPDE \({\hat{\theta }}_n\), and \(\theta ^*\) by a suitable robust pilot estimator. In our calculations, following the suggestion of Ghosh and Basu [7], we will use the MDPDE at \(\gamma = 0.5\) as the pilot estimator. This gives us an empirical mean square error as a function of the tuning parameters (and the pilot estimator), which can then be minimized over the tuning parameters to obtain their “optimal” estimates.
4.3 Examples
In this section we will look at several well known real data examples, and demonstrate that suitable members of the MEPDE family provide useful robust fits to these data. All of these data sets have one or more large outliers so that robust procedures are meaningful in this context.
Example 1
(Telephone Fault Data) We consider the data on telephone line faults presented and analyzed by Welch [21] and Simpson [17]. The data set is made up of the ordered differences between the inverse test rates and the inverse control rates in 14 matched pairs of areas. A normal model may otherwise work very well for these data, but the first observation is a huge outlier, and estimation by the method of maximum likelihood leads to a complete mess. The MLEs of \(\mu \) and \(\sigma \) under the normal model are 40.3571 and 311.332, respectively. For the outlier deleted data these estimates shift to 119.46 and 134.82, respectively, indicating that the single outlier suffices to completely destroy the inference based on maximum likelihood. The MEPDEs of \(\mu \) and \(\sigma \) based on the optimal Warwick Jones tuning parameters are 122.205 and 136.962, corresponding to the triplet \(\alpha = 0.98\), \(\beta = 0.367\) and \(\gamma = 0.146\). Note that this tuning parameter triplet is somewhat removed from the DPD family, which corresponds to \(\beta =0\).
Example 2
(Newcomb Data) This is an old data set representing Newcomb’s measurements on the velocity of light over a distance of 3721 meters and back [19]. The main cluster of the data is again well modeled by a normal distribution, but two individual outliers hinder the estimation based on maximum likelihood. The MLEs of \(\mu \) and \(\sigma \) for the full data equal 26.2121 and 10.6636, respectively; but with the removal of the two outliers they shift to 27.750 and 5.044, with the estimate of \(\sigma \) taking a huge drop. The MEPDEs of \(\mu \) and \(\sigma \) for the optimal Warwick Jones method are 27.6036 and 4.99074, respectively, corresponding to the triplet (0.996, 0.422, 0.297) for \((\alpha , \beta , \gamma )\); it is again somewhat removed from the DPD family.
Example 3
(Darwin Data) Charles Darwin had performed an experiment to determine whether cross-fertilized plants have higher growth rates compared to self fertilized plants [18]. Pairs of Zea mays plants, one self and the other cross-fertilized, were planted in pots, and after a certain time interval the height of each plant was measured. The paired differences (cross-fertilized minus self fertilized) of 15 such pairs of plants were considered in this example. Once again a normal model appears to be suitable for these data, except for two large outliers in the left tail. For the full data, the MLEs of \(\mu \) and \(\sigma \) are 20.9333 and 36.4645, respectively, but for the outliers deleted data they become 33 and 20.8103, respectively. The optimal Warwick Jones method selects a member of the DPD family in this case with \(\gamma = 0.5353\). The corresponding estimates are \({\hat{\mu }} = 29.8026\) and \({\hat{\sigma }} = 25.2416\).
Example 4
(Insulating Fluid data) This example represents data that may be well fitted by an exponential model [14]. It involves tests regarding times to breakdown of an insulating fluid between electrodes recorded at seven different voltages. We consider the observations corresponding to voltage 34 kV. We are interested in estimating the mean parameter under the exponential model. The data set has 19 observations, containing four large outliers and one massive outlier. The full data MLE of the mean parameter is 14.3589, whereas after deleting the five outliers, the outlier deleted MLE is 4.6457. The optimum MEPDE, on the other hand, equals 8.1599, and corresponds to the triplet \((-33.0234, 1, 0.5878)\). In this case it may be seen that the optimal solution corresponds to \(\beta = 1\), and therefore belongs to the BED family with no contribution from the DPD part.
5 Independent Non-homogeneous Observations
In real life problems we hardly encounter identically distributed data. In parametric estimation we often deal with the data which is not identical. In this section we obtain general method of robust estimation for non-homogeneous data.
5.1 Introduction
In the previous sections, we assumed that the data are independent as well as homogeneous. Now we relax the condition of homogeneity (identical distribution) and obtain the estimation procedure to be used in such cases. We consider the data \(Y_1,Y_2, \ldots ,Y_n\), where \(Y_i\)s are independent but each with a different density \(g_i\). Our aim is to model \(g_i\) by a family of distributions \({\mathscr {F}}_{i,\theta } = \{f_i(. {;} \theta ) : \theta \in \Theta \subset {\mathbb {R}}^p\} \) for some \(\theta \) for all \(i = 1, 2, \ldots ,n\), where \(\theta \) is a parameter of interest. Thus although the \(Y_i\)s are not identically distributed, their distributions are based on a common parameter. Let us consider the Brègman divergence defined in Eq. (1). The MEPDE of \(\theta \) is obtained by minimizing the empirical objective function
over \(\theta \in \Theta \), where \({\hat{g}}_i\) is an estimate of density \(g_i\). Following Eq. (2), it is sufficient to minimize
where \(V_{i}(.,\theta )\) is the term within the square brackets in Eq. (15). It leads to the following estimating equation
where \(u_{i}(y;\theta ) = \nabla _{\theta } \log (f_{i}(y;\theta ))\). It can be viewed as a weighted likelihood estimating equation similar to Eq. (3). In particular, by taking the B function as given in Eq. (9), the estimating equation for the MEPDE is given by
where the weight function \(w(t)= \beta t \exp (\alpha t) + (1-\beta )(1+\gamma ) t^{\gamma }\). Ghosh and Basu [6] derived the asymptotic distribution of the MDPDE in this setup. We will now generalize it for the EPD measure.
5.2 Asymptotic Properties
Let us define a \(p\times p\) matrix \(J^{(i)}\) whose (k, l)-th element is given by
where \(\nabla _{kl}\) represents the partial derivative with respect to the k and l-th element of \(\theta \). We also define
Suppose \(\theta ^g\) is the best fitting parameter as defined in Sect. 3.1. Following Eq. (13), we can show that
where \(I_i(y, \theta ^g)=-\nabla u_i(y;\theta ^g)\) and
Theorem 2
Under the conditions (B1)–(B7) given in “Appendix B” the following results hold
-
(a)
There exists a consistent sequence of solution \({\hat{\theta }}_{n}\) of Eq. (16).
-
(b)
The asymptotic distribution of \(\Omega _{n}^{-1/2}\Psi _{n}[\sqrt{n}({\hat{\theta }}_n-\theta _g)]\) is p-dimensional normal with mean (vector) 0 and covariance matrix \(I_{p}\), the p-dimensional identity matrix.
Remark
The proof of this theorem is similar to that of Theorem 3.1 of Ghosh and Basu [6]. Theorem 1 is a special case of Theorem 2 if we assume an IID model, i.e., \(f_{i}(\cdot ; \theta ) = f(\cdot ; \theta )\), for all \(i = 1, 2, \ldots ,n\). The asymptotic distribution of the MDPDE derived by Ghosh and Basu [6] also emerges as a special case of this theorem for \(\beta = 0\).
5.3 Linear Regression
The theory proposed above can be readily applied to the case of linear regression. Consider the linear regression model
where the error \(\epsilon _i\)’s are IID errors having \(N(0,\sigma ^2)\) distributions. Here, \(x_i\)’s are fixed design variables and \(\eta =(\eta _1, \eta _2, \ldots , \eta _p)^T\) represents the regression coefficient. The parameter of our interest is \(\theta = (\eta ^T, \sigma ^2)^T\). Note that \(Y_i\)’s are independent but not identically distributed random variables as \(Y_i \sim f_i(.; \theta )\), where \(f_i(.; \theta )\) is \(N(x_i^T\gamma ,\sigma ^2) \) distribution. The score function for the normal model is given by
So, the estimating Eq. (17) simplifies as
To obtain the asymptotic distribution of the MEPDE, for simplicity, we assume that the true data generating density \(g_i\) belongs to the model family of distributions, i.e., \(g_i=f_i(.;\theta )\) for all \(i=1,2,\ldots , n\), and \(\theta = (\eta ^T, \sigma ^2)^T\) is the true value of the parameter. It simplifies \(J^{(i)}\) in Eq. (18) to
It gives
where \(X^T = (x_1, x_2, \ldots , x_n)_{p\times n}\) is the transpose of the design matrix and
with \(\phi (\cdot , \sigma )\) being the probability density function of \(N(0,\sigma ^2)\). Similarly, \(\Omega _n\) in Eq. (19) simplifies to
where
Under the conditions (B1)–(B7) of “Appendix B”, we conclude from Theorem 2 that the MEPDE \({\hat{\theta }}_n\) is a consistent estimator of \(\theta \). Moreover, the asymptotic distribution of \(\sqrt{n}\Omega _n^{-1/2}\Psi _n({\hat{\theta }}_n - \theta )\) is multivariate normal with mean (vector) zero and covariance matrix \(I_{p}\).

Plots of different regression lines for the Hertzsprung–Russell data of the star cluster
5.4 Examples
We will give two examples to demonstrate the application of our proposed method in the independent non-homogeneous data. These data sets are also analyzed by Ghosh and Basu [6].
Example 5
(Hertzsprung–Russell data of the star cluster) Our first data set contain 47 observations based on the Hertzsprung–Russell diagram of the star cluster CYG OB1 in the direction of Cygnus [16]. We consider a simple linear regression model using the logarithm of the effective temperature at the surface of the star (x), and the logarithm of its light intensity (y). The scatter plot in Fig. 3 shows that there are two groups of stars with four observations on the upper right corner clearly separated from others. In astronomy, those four stars are known as giants. The values of different regression estimates are given on Table 1, and the fitted regression lines are added on Fig. 3. Due to four large outliers, the ordinary least squares (OLS) method completely fails to fit the data set. But the outliers deleted OLS gives a good fit for the rest of the 43 observations. Both the optimum DPD and EPD fits based on the Warwick Jones method are also close to that line. Here, the optimum EPD corresponds to the triplet (\(-4.8715, 0.9897, 0.7558\)) for (\(\alpha , \beta , \gamma \)), whereas the optimum DPD parameter is \(\gamma =0.75\). So, the optimum MEPDE lies well outside the DPD family. Also note that the estimate of \(\sigma \) is much sharper in case of the MEPDE compared to the MDPDE, indicating that the former does much better than the latter in downweighting the outliers.
Example 6
(Belgium telephone call data) We consider a real data set from the Belgian Statistical Survey published by the Ministry of Economy of Belgium; it is also available in Rousseeuw and Leroy [16]. It contains the total number (in tens of millions) of international phone calls made in a year from 1950 to 1973. There is a heavy contamination in the vertical axis due to the use of a different recording system during 1964 to 1969. The years 1963 and 1970 are also partially affected for this reason. Figure 4 and Table 2 contain the different regression estimates for this data set. It is clear that the OLS fit is very poor, but all other estimates give excellent fits to the rest of the observations. Although, the optimum EPD regression line based on the Warwick Jones method almost coincides with the optimum DPD fit, the MEPDE does not belong to the DPD family. The optimum EPD corresponds to the triplet (\(-4.2416,0.0543, 0.3205\)) for (\(\alpha , \beta , \gamma \)), whereas the optimum DPD parameter is \(\gamma =0.631\). Once again the MEPDE produces a sharper value of the estimate of \(\sigma \) compared to the MDPDE.

Plots of different regression lines for the Belgium telephone call data
6 Concluding Remarks
Density-based minimum distance procedures have become popular in recent times because of their ability to combine high asymptotic efficiency with strong robustness properties. In particular the methods based on the Brègman divergence have the major advantage that they do not involve any intermediate nonparametric smoothing component. The class of DPD family, which has proved to be a popular and useful tool in this area, represents a class of procedures ranging from highly efficient to strongly robust. In this paper, we have developed a more refined class of divergences which subsumes the DPD family providing new options which can lead to better compromises between robustness and efficiency.
In this paper, we have demonstrated the above through IID data models as well as INH models. The results show that in most cases the optimal solution is outside the DPD family. These can, however, be extended to many other data structures where the EPD can be useful. For example, this technique can be used to find the best tuning parameter in estimation with right censored survival data, and testing of hypothesis problems, issues that we want to deal with in the future.
We also hope to use a recently developed refinement of the Warwick and Jones approach, present in Basak et al. [1], for the “optimal” tuning parameter selection problem, which might further enhance the results of our method.
References
Basak S, Basu A, Jones M (2020) On the ‘optimal’ density power divergence tuning parameter. J Appl Stat. (in press)
Basu A, Harris IR, Hjort NL, Jones M (1998) Robust and efficient estimation by minimising a density power divergence. Biometrika 85(3):549–559
Basu A, Shioya H, Park C (2011) Statistical inference: the minimum distance approach. Chapman and Hall, Boca Raton
Beran R (1977) Minimum hellinger distance estimates for parametric models. Ann Stat 5(3):445–463
Brègman L (1967) The relaxation method of finding the common point of convex sets and its application to the solution of problems in convex programming. Comput Math Math Phys 7(3):200–217
Ghosh A, Basu A (2013) Robust estimation for independent non-homogeneous observations using density power divergence with applications to linear regression. Electron J Stat 7:2420–2456
Ghosh A, Basu A (2015) Robust estimation for non-homogeneous data and the selection of the optimal tuning parameter: the density power divergence approach. J Appl Stat 42(9):2056–2072
Hampel FR, Ronchetti EM, Rousseeuw PJ, Stahel WA (2011) Robust statistics: the approach based on influence functions. John Wiley and Sons, New Jersey
Jana S, Basu A (2019) A characterization of all single-integral, non-kernel divergence estimators. IEEE Trans Inf Theory 65(12):7976–7984
Kullback S, Leibler RA (1951) On information and sufficiency. Ann Math Stat 22(1):79–86
Lehmann EL (1983) Theory of point estimation. Springer, Berlin
Maronna RA, Martin RD, Yohai VJ, Salibián-Barrera M (2019) Robust statistics: theory and methods (with R). John Wiley and Sons, New Jersey
Mukherjee T, Mandal A, Basu A (2019) The B-exponential divergence and its generalizations with applications to parametric estimation. Stat Methods Appl 28(2):241–257
Nelson W (1972) Graphical analysis of accelerated life test data with the inverse power law model. IEEE Trans Reliab 21(1):2–11
Pardo L (2006) Statistical interference based on divergence measures. Chapman Hall/CRC, Boca Raton
Rousseeuw PJ, Leroy AM (2005) Robust regression and outlier detection. John Wiley and Sons, New Jersey
Simpson DG (1989) Hellinger deviance tests: efficiency, breakdown points, and examples. J Am Stat Assoc 84(405):107–113
Spiegelhalter D (1985) Exact bayesian inference on the parameter of a cauchy distribution with vague prior information. Bayesian Stat 2:743–749
Stigler SM (1977) Do robust estimators work with real data? Ann Stat 5(6):1055–1098
Warwick J, Jones M (2005) Choosing a robustness tuning parameter. J Stat Comput Simul 75(7):581–588
Welch WJ (1987) Rerandomizing the median in matched-pairs designs. Biometrika 74(3):609–614
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the topical collection “Celebrating the Centenary of Professor C. R. Rao” guest edited by, Ravi Khattree, Sreenivasa Rao Jammalamadaka, and M. B. Rao.
Appendices
Appendix A Conditions for Theorem 1
For any given values of parameters \((\alpha ,\beta , \gamma )\), we assume the following conditions as an extension of conditions given in Basu et al. [3] for MDPDE(\(\alpha \))
-
(A1)
The distributions \(F_{\theta }\) of X have a common support, such that the set \(\chi = \{ x: f_{\theta }(x)>0 \} \) is independent of \(\theta \). The true distribution G is also supported on \(\chi \) where g is positive.
-
(A2)
There is an open subset \(\omega \) of the parameter space \(\Omega \) containing the best fitting parameter \(\theta ^g\) such that for almost all \(x \in \chi \) and all \( \theta \in \Theta \), the density \(f_{\theta }(x) \) is three times differentiable with respect to \(\theta \) and the third partial derivatives are continuous with respect to \(\theta \).
-
(A3)
For the B function given in Eq. (9), the integrals \(\int _x \{f_{\theta }(x)B'(f_{\theta }(x)) - B(f_{\theta }(x))\}{\mathrm{d}}x \) and \(\int _x B'(f_{\theta }(x))g(x) {\mathrm{d}}x \) can be differentiated three times with respect to \(\theta \) and the derivatives can be taken under the integral sign.
-
(A4)
For B in Eq. (9) and
$$\begin{aligned} V_{\theta }(X) = \int _x \Big \{ B'(f_{\theta }(x))f_{\theta }(x) - B(f_{\theta }(x))\Big \}{\mathrm{d}}x - B'(f_{\theta }(x)) , \end{aligned}$$the \(p\times p\) matrix defined by \( J_{kl}(\theta ) = E_{g} ( \nabla _{kl}V_{\theta }(X) ) \) is positive definite, where \(E_{g}\) represents the expectation under the density g. When g is in the model, then \(J_{kl}(\theta ^{g}) = J_{kl}(\theta ^{g})\), where \(J(\theta )\) is as defined in (13).
-
(A5)
There exists a function \( M_{jkl}(x) \) such that \( |{ \nabla _{jkl}}V_{\theta }(X) | \le M_{jkl}(X)\) for all \(\theta \in \omega ,\) and \(E_{g}[M_{jkl}(X)] = m_{jkl} < \infty .\)
Appendix B Conditions for Theorem 2
The following assumptions are required to establish the asymptotic properties of the MEPDE for the non-homogeneous case. These are analogous to the assumptions given in Ghosh and Basu [6] for the DPD family.
-
(B1)
The support \(\chi = \{y : f_i(y; \theta ) > 0 \}\) is independent of i and \(\theta \) for all \(i=1,2,\ldots , n\), and the true distribution of \(G_{i}\) is also supported on \(\chi \) for all i.
-
(B2)
There is an open subset \(\omega \) of the parameter space \(\Omega \) containing the best fitting parameter \(\theta ^g\) such that for almost all \(x \in \chi \) and all \( \theta \in \Theta \), the densities \(f_{i}(y; \theta ), \ i=1,2,\ldots , n\), are three times differentiable with respect to \(\theta \) and the third partial derivatives are continuous with respect to \(\theta \).
-
(B3)
Consider the B function given in Eq. (9). For each \(i=1,2,\dots ,n\), the integrals \(\int _y\big [B'(f_{i}(y;\theta ))f_{i}(y;\theta )-B(f_{i}(y;\theta )\big ]{\mathrm{d}}y\) and \(\int _y B'(f_{i}(y;\theta ))g_{i}(y){\mathrm{d}}y \) can be differentiated thrice with respect to \(\theta \) and derivatives can be taken under integral sign.
-
(B4)
For each \(i=1,2,\dots , n\), the matrix \(J^{(i)}\), defined in Sect. 5.2, is positive definite and
$$\begin{aligned} \lambda _{0}= \inf _{n} \ [\text{ min } \text{ eigenvalue } \text{ of } \Psi _{n}] > 0. \end{aligned}$$ -
(B5)
There exists a function \(M_{jkl}^{(i)}(Y)\) such that
$$\begin{aligned} |\nabla _{jkl} V_{i}(Y;\theta ) |\le M^{(i)}_{jkl}(Y) , \end{aligned}$$where \(V_{i}(\cdot ;\theta )\) is defined in Eq. (15) and
$$\begin{aligned} \frac{1}{n} \sum _{i=1}^{n} E_{g_{i}}[M_{jkl}^{(i)}(Y)]=O(1) \; \text{ for } \text{ all } j,k,l. \end{aligned}$$ -
(B6)
For all j and k, we have
$$\begin{aligned} \begin{aligned} \lim _{N\rightarrow \infty } \sup _{n} \bigg (\frac{1}{n}E_{g_i}\big [|\nabla _{jk}V_{i}(Y;\theta )| I(|\nabla _{jk}V_{i}(Y;\theta )|>N)]\big ]\bigg )&=0, \\ \lim _{N\rightarrow \infty } \sup _{n} \bigg (\frac{1}{n}E_{g_i}\big [|\nabla _{jk}V_{i}(Y;\theta )-E_{g_{i}}(\nabla _{jk}((Y;\theta ))| \\ \times |I(|\nabla _{jk}V_{i}(Y;\theta )-E_{g_{i}}(\nabla _{jk}((Y;\theta ))|>N)\big ]\bigg )&=0 , \end{aligned} \end{aligned}$$where I(B) denotes the indicator variable of the event B.
-
(B7)
For all \(\epsilon >0\), we have
$$\begin{aligned} \lim _{n\rightarrow \infty } \bigg \{ \frac{1}{n}\sum _{i=1}^{n} E_{g_{i}}\big [||\Omega _{n}^{-1/2} \nabla V_{i}(Y;\theta )||^{2} I(||\Omega _{n}^{-1/2} \nabla V_{i}(Y;\theta )||>\epsilon \sqrt{n})\big ]\bigg \}=0. \end{aligned}$$
Rights and permissions
About this article

Cite this article
Singh, P., Mandal, A. & Basu, A. Robust Inference Using the Exponential-Polynomial Divergence. J Stat Theory Pract 15, 29 (2021). https://doi.org/10.1007/s42519-020-00162-z
Accepted:
Published:
DOI: https://doi.org/10.1007/s42519-020-00162-z