
Abstract
Purpose
The main purpose of this paper is to reduce the influence of penalty parameter (\(\alpha\)) and mode number K on VMD decomposition. Furthermore, the optimized VMD is combined with support vector machine (SVM) to diagnose rolling bearing faults.
Methods
This paper proposed a parameter adaptive VMD method based on the sparrow search algorithm (SSA), which is named SSA-VMD. First, the minimum mean envelope entropy (MEE) as the objective function to find the best parameters combination. Then, VMD with the optimized parameters is used to decompose the signals and obtain the corresponding components. In order to extract fault features better, the fuzzy entropy (FE) of intrinsic mode functions (IMFs) which are attained by SSA-VMD as feature vectors. Finally, input the feature vectors into the support vector machine which is combined with the SSA to improve accuracy, so as to get the classification result.
Results
Two public data sets are used to verify the effectiveness of SSA-VMD-SVM. The experimental results show that this method is faster than other methods in decomposition speed and has better performance in fault classification of rolling bearings.
Conclusion
In this paper, a method for adaptive selection of VMD parameters is proposed, and combined with SVM, a method for fault diagnosis of rolling bearings is formed. At the same time, the method can distinguish single fault and mixed fault well, and has a good classification effect. This result helps to provide a new fault diagnosis method.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Rotating machines is widely used in social production activities, and the rolling bearing is an important part of it. Due to the complex working environment and other reasons, rolling bearing is more likely to fail compared to other parts. Therefore, it is necessary to ensure the normal operation of rolling bearings [1,2,3]. A large number of experiments and cases show that monitoring and analyzing vibration signals is a reliable method to judge the running status of roller bearings [4,5,6,7,8]. With the change of rolling bearing state (i.e. the bearing has different faults), the relevant characteristics contained in its vibration signal will also change.
Empirical mode decomposition (EMD) has been pioneered by Huang et al. and it has been widely used as an effective method in fault diagnosis [9, 10]. However, there are some phenomena of mode mixing and terminal point effect in EMD. Based on EMD theory, a variety of signals processing methods had been proposed: ensemble empirical mode decomposition (EEMD) [11, 12], local mean decomposition (LMD) [13, 14] and complete ensemble empirical mode decomposition adaptive noise (CEEMDAN) [15, 16]. However, the essence of the above method is still based on the principle of recursive decomposition, which will lead to the accumulation of errors and cannot fundamentally overcome the phenomenon of mode mixing.
A new signal decomposition method based on adaptive Wiener filter which called variational mode decomposition (VMD) was first proposed [17]. This method can effectively decompose the test signal into a set of limited bandwidth with central frequency, and it has noise robustness than EMD [18]. Compares the decomposition performance using EMD and VMD, the results show that the latter has a better effect than the former in bearing defect feature extraction. However, in the above-mentioned literature, the selection of \(\alpha\) and K are all classical values when the author uses VMD to decompose the vibration signal. The Experiments show that the choice of parameters largely determines the decomposition efficiency of VMD [19, 20]. To weaken the influence of parameter selection on the decomposition effect, we can choose an optimization algorithm to adaptively select the appropriate combination of parameters. A novel bionic algorithm which is named sparrow search algorithm (SSA) is proposed [21]. The SSA has good performance in terms of convergence speed and robustness. So, this paper uses SSA to optimize the parameters of VMD. The minimum mean envelop entropy as the optimization objective. Based on the above explanation, this paper proposed a VMD parameter adaptation method based on SSA (SSA-VMD), which can obtain the relevant parameters of the VMD quickly and effectively.
The type of the classifier is an important factor that determines the accuracy of fault diagnosis. Researchers have made an in-depth study on the fault classification algorithm of rolling bearings, commonly used fault classification algorithms include: random forest (RF) [22, 23], deep belief network (DBN) [24, 25], support vector machines (SVM) [26,27,28]. Among them, SVM can better deal with the classification of small samples. As we all know, the parameter value of SVM affects the accuracy of classification [29]. Therefore, SSA is used to optimize SVM parameters. Through the above introduction, this paper proposed a method combined with SSA-VMD and SVM (SSA-VMD-SVM) for fault diagnosis of rolling bearing. To verify the effectiveness of the proposed method, two published data sets from different experimental platform are used.
The rest sections of this paper are arranged as follows. Section 2 introduces the principles and process of VMD parameter adaptive. including the theory of VMD, the principles of SSA and the specific steps of SSA-VMD. Section 3 describes the complete fault diagnosis process, including the introduce of FE, the theory of SVM and the process of SSA-VMD-SVM. Section 4 shows the effectiveness of the proposed method through the experimental results. Section 5 gives the conclusion of this study.
SSA-VMD Method
Variational Mode Decomposition
The VMD algorithm is different from EMD for IMF and it can be redefined as:
where \({A_k}(t)\) and \({\omega _k}(t)\) are the instantaneous amplitude and instantaneous phase of \({u_k}(t)\), respectively. The original signal is decomposed into K mode functions, each of which has a center frequency. In this paper, the shorthand \({\omega _k}\) is used to represent center frequency. To achieve the purpose of decomposition, it is necessary to solve the constrained variational problem:
where t is the time scripts and \(\delta (t)\) is the Dirac distribution. \({u_k}\) and \({\omega _k}\) are abbreviation for the set of all modes and their corresponding center frequencies, respectively. By introducing Lagrangian multipliers \(\lambda\), the transformed expression is obtained as follows:
where \(\alpha\) is the secondary punitive factor, and its function is used to reducing the interference of Gaussian noise.
Sparrow Search Algorithm
A new optimization algorithm, which is called sparrow search algorithm, was proposed in 2020. In the SSA, sparrows are divided into two types: explorers and follower. Explorers lead followers to find food. The roles of followers and followers can be changed to each other, but the ratio of them in the population remains the same. This paper uses the following matrix to represent the position and fitness values of the sparrows:
where n is the quantity of the sparrows in the population and d is the dimension of the issue to be optimized. Each sparrow has its own fitness, it can be showed as the following.
In SSA, the position of explorers in each iteration is updated as follows:
where \(X_{i,j}^t\) represents the value of the j-th dimension of the i-th sparrow at the t iteration. t represents the current number of the iteration. \(ite{r_{\max }}\) is the maximum number of the iteration. \({R_2} \in \left( {0,1} \right]\) and \(\text {ST} \in \left( {0.5,1.0} \right]\) represent the warning value and the warning threshold respectively. L is a d-dimensional column vector whose every element is all 1. Q is a random number with normal distribution.
The followers need to update their location according the follow formula:
The position of these sparrows in the population is random. The following mathematical models can be established:
where \(X_{\text {best}}^t\) is the current best location. \(\beta\) is a random number with a mean value of 1 and a variance of 0, and it obeys normal distribution. \(B(B \in [0,1])\) is a random number. \({f_i}\) represents the fitness of sparrow in the current situation, \({f_g}\) is the best fitness in the current global situation and \({f_w}\) is the worst one. \(\varepsilon\) is the smallest constant.
Improved VMD Based on SSA
The objective function selected by SSA-VMD is mean envelope entropy (MEE). The definition of envelope entropy is as follows:
where \(j = 1,2, \ldots ,d\). The original signal x(t) undergoes the Hilbert transformation to get a(j). \({p_j}\) is the regularization result of a(j). The expression of the objective function MEE is as follows:
where K represents the number of IMF component obtained by VMD. Obviously, when the value of MME is smaller, the complexity of IMFs is lower and the signal is more stable. Therefore, this paper chooses the minimum MME as the optimization objective function of SSA-VMD.

The flow chart of the SSA-VMD
The structural block diagram for SSA-VMD is shown in Fig. 1 and the steps as follows.
-
1.
Initialize the sparrows population and define the relevant parameters. The current position of the sparrow is taken as the parameter combination, i.e. \({X_i} =[x{}_{i,1},{x_{i,2}}] =[{x_k},{x_\alpha }]\)
-
2.
Calculate the objective value of each sparrow, find the minimum objective value \(MEE^t\) and record the best position \(X_{\text {best}}^t\).
-
3.
Update the position of the sparrows according to Eq. (6)–(8). If the fitness value of new position is better than the previous, sparrows move to the new location. Otherwise, the position of the sparrows remains the same.
-
4.
Calculate the objective value \(MEE^{t+1}\) of the sparrow in the new position, and record the best position \(X_{\text {best}}^{t+1}\). If the objective value \(MEE^{t+1}\) is better than \(MEE^t\), the old best position \(X_{\text {best}}^t\) is replaced by \(X_{\text {best}}^{t+1}\).
-
5.
Determine whether the stop condition is reached. If not, return to step 3 until the quantity of iterations reaches the set value, output the best parameter combination \([k,\alpha ]\).
The Proposed Fault Diagnosis
Fuzzy Entropy
FE is an efficient and complete method to judge the complexity of time series, and it is widely used in fault diagnosis [30]. It is necessary for FE to set corresponding calculation parameters: embedded dimension m and similar tolerance limit r. For a given N-dimensional time series \(\left[ {u(1),u(2), \ldots ,u(N)} \right]\). It is necessary for fuzzy entropy to set corresponding calculation parameters: embedded dimension m and Similar tolerance limit r. When the value of m is larger, the amount of information it contains will be more, but a larger m requires a larger data set \((N=10^m-30^m)\). Based on this reason, the embedded size m is set to 2. Generally, The larger the value of r, the more information will be ignored. When the value of r is small, it will increase the sensitivity of the result to noise [31]. So the values of r are usually 0.1 SD and 0.25 SD (SD is the standard deviation of the data set). In this paper, we set up \(r=0.2\) SD.
Support Vector Machine
Support vector machine (SVM) is an effective tool to solve the problem of small data classification. For a given set of samples \(\left\{ X={{x_1},{x_2},\ldots , {x_N}} \right\}\) to be classified, each vector in the sample has its own label. N is the quantity of the input samples. The vectors in sample space can be mapped to high-dimensional space, and a hyperplane in hyperspace can divide the space. Samples with the same labels are divided into the same area, and samples with different labels are divided, thus the sample sets can be classified. The hyperplane can be expressed as follows:
where \(\omega\) represents the weight vector and b is the bias. In order to achieve a better result of classification. We need to select appropriate parameters to maximize the distance between various samples. The optimization problem of SVM is shown below:
where \({\xi _i}\) represents the slack variable of the given sample \({x_i}\), and the value of parameter C controls the generalization ability of SVM. Introduce the Lagrangian coefficient in Eq. (12) and get the expression is as follows
where \(L({x_i},{y_i})\) is the kernel, the advantage of kernel function is to make the value of samples in the original space equal to the value of samples in high-dimensional space. Radial basis kernel function (RBF) is a widely used kernel function. It can promote the generalization ability of SVM. The expression of RBF is as follows.
where g is the kernel parameter. The parameter of C and g are vital for the SVM. In [32], the author discussed the influence of the parameters on the results of SVM classification. Therefore, the SSA is used to optimize C and g to improve the performance of SVM in this paper.
SSA-VMD-SVM
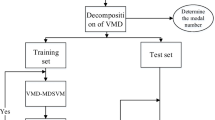
On the basis of the above theories, a fault diagnosis method of rolling bearings based on SSA-VMD and SVM is proposed in this paper, and the flow chart is shown in Fig. 2.

The flow chart of the SSA-VMD-SVM
The specific steps are shown below.
-
1.
The vibration signal is decomposed by SSA-VMD and Obtain the best parameters \(\left[ {K,\alpha } \right]\).
-
2.
Use the parameter optimized VMD to decompose the signal and get the K different IMF components.
-
3.
Fuzzy entropy of each IMF is calculated and the results is regarded as the feature vectors.
-
4.
Input the feature vectors into SVM and get the classification results.
Experiment Verification
Experiment 1
The data sets used are derived from the Bearing Data Center of Case Western Reserve University (CWRU), and the structures of its equipment are shown in Fig. 3.

CWRU bearing platform
The experimental platform is mainly composed of three parts. The left end is a two horsepower motor, the middle part is a torque sensor, and the right end is a power meter. The electrical discharge machining technology is used to punch out the fault point on the bearing, and the diameter of the fault range is 0.007 inches to 0.040 inches. Collect a data set containing the normal (NOR) conditions of the rolling bearing and the other three failure conditions [inner race (IR), outer race (OR) and ball (B)]. The bearing data parameters used in this paper: sampling frequency is 12kHz, bearing speed is 1797 rpm, load is 0HP. Select 1024 points in the data set as a sample, and the sampling duration is about 0.0853 second of each sample. The original signals in four different cases, such as inner ring fault and outer ring fault, are shown in Fig. 4.

Waveforms of vibration signal in four cases
The Analysis of Experimental Results
This paper uses the parameters of SSA are shown in the Table 1. Where Num represents the population size, Iter is the maximum number of iterations. Ub and Lb represent the upper and lower boundaries of parameter values, respectively. Dim is the number of decision variables.
The vibration signals are decomposed by SSA-VMD, the obtained optimal parameter combinations are \(\left[ {6, 4460} \right]\), \(\left[ {5, 5842} \right]\), \(\left[ {4, 5912} \right]\) and \(\left[ {3, 3346} \right]\). Fig. 5 shows the frequency spectrum of IMF after the signal is decomposed by VMD. From the decomposition results of the four cases, there are no mode mixing phenomenon in the decomposed signal, and each mode is successfully separated from the original signals.

Frequency spectrum of IMFs
SSA-VMD not only has good decomposition performance for the original signal, but also has better decomposition speed than other intelligent algorithms. Figure 6 shows the time spend by SSA-VMD and the other three algorithms to find the best combination of parameters optimize: optimize VMD parameters by particle swarm optimization (PSO-VMD), optimize VMD parameters by whale optimization algorithm (WOA-VMD) and optimize VMD parameters by firefly algorithm (FA-VMD). The time value in the figure is obtained by calculating the average running time of the algorithm under four cases. The abscissa in Fig. 6 has two parameters, they are the basic parameters of the algorithm. Iter represents the number of iterations and Num represents the number of population. For example, [10, 30] represents that the four optimization algorithms search for the best parameter combination \([K,\alpha ]\) in the same population number (Num = 10) and iteration number (Iter = 30).

The time taken for the four methods to run under different iterations and populations
When the number of iterations is fixed at 10, and the populations are respectively 30, 60, and 100, SSA-VMD spends the least time in finding the best parameters. SSA-VMD spends the least time compared with other methods. With the increase of the population, the speed advantage of the SSA-VMD is more obvious. When the number of populations is fixed at 30, and the iterations are respectively 10, 20, and 30, SSA also has certain advantages in terms of speed. In general, the optimization speed of SSA-VMD is faster than the other four optimization methods. With the increase of the number of iterations and populations, the speed advantage of SSA-VMD becomes more obvious.
Space of Feature Vectors
The dimension of feature vectors to affect the quality of the SVM classification results. From the optimization results of VMD parameters in four different situations, it can be seen that the optimized value of k under normal conditions (the value of k is 3) is smaller than the other three fault types. At the same time, the SVM model requires that dimensions of input feature vectors should be consistent. Therefore, the maximum dimension of the feature vectors is 3 in this paper. Figure 7a and b show the distribution of the feature vectors in space when their dimensions are 3 and 2, respectively. Compare these two pictures, the distribution of the features in Fig. 7a is more compact than the other one. So, the feature vector with dimension 3 is used in this part.

The space of sample feature
Result Classification
The main function of training set is to train the model through a large amount of data, reduce the error of the experimental model and improve the generalization ability. The main role of the testing set is evaluating and verifying this model. Low dependence on training data is also an advantage of a model. Collect 100 samples under each working condition, a total of 400 groups. The first 20 samples are training sets, and the last 80 samples are test sets. The classification results are shown in Fig. 8.

The Diagnosis results of SSA-VMD-SVM model
At the same time, this paper compares SSA-VMD-SVM with the other three methods in terms of classification, and the results are shown in Table 2. It can be seen that SSA-VMD-SVM has higher accuracy in the final decomposition result.
To verify the influence of SVM hyperparameters (i.e. C and g) on the classification results, we compared the classification accuracy between SSA-SVM and SVM with FE as the feature value. The specific results are shown in Table 3. It can be seen from the table that the classification accuracy of SVM in inner ring faults and rolling element faults is lower than SSA-SVM. These show that optimizing hyperparameters by SSA can improve the classification accuracy and efficiency of SVM.
In [33], the authors divided the CWRU data into three categories: diagnosable (category Y), partially diagnosable (category P) and non-diagnosable (category N), and gave detailed annotations in the appendix. According to the classification of data, the IR and OR data used belong to category Y, and the B data belongs to category N in this paper. Meanwhile, this reference argued that new algorithms might be tested by P categories or N categories. Therefore, the data used in the paper accords with the relevant conclusions in this reference regarding the validation of the new algorithm on the CWRU data. To enhance the persuasiveness of the proposed method, this part increased a category P data, and the result as shown in Table 4.
Experiment 2
The data sets used are derived from the Center for Intelligent Maintenance Systems (IMS), University of Cincinnati. And the structures of its equipment are shown in Fig. 9.

IMS bearing platform
The experimental platform consists of four ZA-2115 bearings, a motor with a speed of 2000rpm and several sensors. Two highly sensitive accelerometers are installed on each bearing, and the sampling frequency is 20kHz [34]. This platform mainly records the full cycle life of the bearing, and a total of three experimental tests have been carried out. In the first test, the inner ring (IR) of bearing 3 was damaged, and both the ball (B) elements and outer ring (OR) of bearing 4 have failed. The second and third test ended with outer ring failures of bearing 1 and bearing 3 respectively. In the first test, the bearing 3 and bearing 4 had been damaged by the 30th day [35]. Therefore, this paper regards the data of bearing 3 and bearing 4 on the 30th day of the first test as the early failure data. At the same time, the data of the first test of bearing 1 is taken as the data under normal (NOR). Select 2000 points in the data set as a sample, and the sampling duration is about 0.1 second of each sample. The original signals in three different cases, such as inner ring fault and outer ring fault are shown in Fig. 10.

Waveforms of vibration signal in three cases
The Analysis of Experimental Results
The parameters of SSA used in this part are the same as those in experiment 1, the obtained optimal parameter combinations are \(\left[ {5, 5873} \right]\), \(\left[ {9, 4908} \right]\) and \(\left[ {3, 5350} \right]\). Fig. 11 shows the frequency spectrum of IMF after decomposition.

Frequency spectrum of IMFs
Compared with the single fault in experiment 1, the compound fault types (i.e. mixed roller element and outer race faults) appeared in experiment 2. It can be seen from the decomposition of the frequency spectrum of IMFs that the method proposed in this paper can successfully decompose the various modes of the original signal for compound faults, and there are no phenomenon of modal mixing. In the same way as the experiment 1, this part also compares the decomposition speed of SSA-VMD and three other methods of the same type in IMS data set, and the specific results are shown in Fig. 12. The time value in the figure is the average running time of the decomposition algorithm under three different working conditions.

The time taken for the four methods to run under different iterations and populations
Compared with experiment 1, the samples used in this part of the experiment contain more data points, and there are compound failures (i.e. mixed roller element and outer race faults). Therefore, in experiment 2, the average decomposition time of the method proposed in this paper under various working conditions is longer than that in experiment 1, compared with the other three methods, SSA-VMD still has the fastest decomposition speed. For example, when the number of iterations is 10 and the number of population is 30, SSA-VMD with the fastest decomposition speed is nearly half less than WOA-VMD with the slowest decomposition speed. With the increase of iteration number and population number, the method proposed in this paper has more and more advantages in decomposition speed. Moreover, compared with the other three methods, SSA-VMD has a smaller fluctuation of decomposition time when the population number and iteration times change.
Space of Feature Vectors
Based on the results of VMD optimization parameters in experiment 2 and the requirement of SVM input feature values, the dimension of the feature vector in this experiment is the same as experiment 1, that is, the dimension of the input feature vector is 3. Figure 13 shows the distribution of feature values in space, from the figure, we can see that using the method proposed in this paper to decompose and extract features, the distinction between different types of feature values is obvious, and single fault and mixed fault types can be well distinguished.

The space of sample feature
Result Classification
Collect 100 samples under each working condition, a total of 400 groups. The 20 samples are training sets, and the last 80 samples are test sets. The classification results are shown in Fig. 14.

The diagnosis results of SSA-VMD-SVM model
This part compared the classification accuracy of SSA-VMD-SVM with the other three methods under the IMS data set. The specific results are shown in Table 5. It can be seen from the table that the method proposed in this paper is higher in accuracy than the other three methods. At the same time, it also has a good classification effect for mixed fault types.
Meanwhile, experiment 2 also compared the classification results of SVM and SSA-SVM, and the specific results are shown in Table 6. It can be seen from the table that SSA-SVM is superior to SVM in classification accuracy. In particular, SSA-SVM is much more accurate than SVM in identifying mixed fault types (i.e. B + OR ). In experiment 2, the advantage of SSA-SVM over SVM is much greater than that of experiment 1.
In summary, two experimental results show that SSA-VMD-SVM can quickly extract effective information from vibration signals and accurately identify the failure of rolling bearings. It can also effectively distinguish between single fault type and mixed fault type. At the same time, compared with algorithms of the same type, the method proposed in this paper has certain advantages in terms of speed and accuracy.
Conclusion
To reduce the influence of VMD parameter value on signal decomposition results and improve the accuracy of fault diagnosis, this paper proposes a fault diagnosis method of rolling bearing, namely SSA-VMD-SVM. With MME as the objective function, SSA is used to find the best parameter combination. Then, the fuzzy entropy of each IMF is extracted as the feature value and input to the SVM to obtain the classification result. The parameters of SVM are optimized by SSA to improve accuracy. Two public data sets are used to verify the effectiveness of the proposed method. Experimental results show that SSA-VMD-SVM can extract fault features contained in vibration signals more quickly and distinguish various fault types more accurately than other methods of the same type. At the same time, the single fault type and the mixed fault type can also be distinguished well, which is accordant to the current trend of multiple fault diagnosis in the field of fault diagnosis.
References
Liu H, Zhou J, Zheng Y, Jiang W, Zhang Y (2018) Fault diagnosis of rolling bearings with recurrent neural network-based autoencoders. ISA Trans 77:167–178
Qin Y (2017) A new family of model-based impulsive wavelets and their sparse representation for rolling bearing fault diagnosis. IEEE Trans Ind Electron 65(3):2716–2726
Unal M, Onat M, Demetgul M, Kucuk H (2014) Fault diagnosis of rolling bearings using a genetic algorithm optimized neural network. Measurement 58:187–196
Yan X, Liu Y, Jia M, Zhu Y (2019) A multi-stage hybrid fault diagnosis approach for rolling element bearing under various working conditions. IEEE Access 7:138426–138441
Wang Y, Peter W, Tang B, Qin Y, Deng L, Huang T, Xu G (2019) Order spectrogram visualization for rolling bearing fault detection under speed variation conditions. Mech Syst Signal Proc 122:580–596
Yang J, Huang D, Zhou D, Liu H (2020) Optimal IMF selection and unknown fault feature extraction for rolling bearings with different defect modes. Measurement 157:107660
Wang J, Peng Y, Qiao W (2016) Current-aided order tracking of vibration signals for bearing fault diagnosis of direct-drive wind turbines. IEEE Trans Ind Electron 63(10):6336–6346
Deng W, Zhang S, Zhao H, Yang X (2018) A novel fault diagnosis method based on integrating empirical wavelet transform and fuzzy entropy for motor bearing. IEEE Access 6:35042–35056
Liu X, Bo L, Luo H (2015) Bearing faults diagnostics based on hybrid LS-SVM and EMD method. Measurement 59:145–166
Mohanty S, Gupta K, Raju K (2018) Hurst based vibro-acoustic feature extraction of bearing using EMD and VMD. Measurement 117:200–220
Tan Q, Lei X, Wang X, Wang H, Wen X, Ji Y, Kang A (2018) An adaptive middle and long-term runoff forecast model using EEMD-ANN hybrid approach. J Hydrol 567:767–780
Santhosh M, Venkaiah C, Kumar D (2018) Ensemble empirical mode decomposition based adaptive wavelet neural network method for wind speed prediction. Energy Conv Manag 168:482–493
Haiyang Z, Jindong W, Lee J, Ying L (2018) A compound interpolation envelope local mean decomposition and its application for fault diagnosis of reciprocating compressors. Mech Syst Signal Proc 110:273–295
Yu J, Lv J (2017) Weak fault feature extraction of rolling bearings using local mean decomposition-based multilayer hybrid denoising. IEEE Trans Instrum Meas 66(12):3148–3159
Abdelkader R, Kaddour A, Bendiabdellah A, Derouiche Z (2018) Rolling bearing fault diagnosis based on an improved denoising method using the complete ensemble empirical mode decomposition and the optimized thresholding operation. IEEE Sens J 18(17):7166–7172
Zhang W, Qu Z, Zhang K, Mao W, Ma Y, Fan X (2017) A combined model based on CEEMDAN and modified flower pollination algorithm for wind speed forecasting. Energy Conv Manag 136:439–451
Dragomiretskiy K, Zosso D (2013) Variational mode decomposition. IEEE Trans Signal Process 62(3):531–544
Zhang M, Jiang Z, Feng K (2017) Research on variational mode decomposition in rolling bearings fault diagnosis of the multistage centrifugal pump. Mech Syst Signal Proc 93:460–493
Li Z, Chen J, Zi Y, Pan J (2017) Independence-oriented VMD to identify fault feature for wheel set bearing fault diagnosis of high speed locomotive. Mech Syst Signal Proc 85:512–529
Li Z, Jiang Y, Guo Q, Hu C, Peng Z (2018) Multi-dimensional variational mode decomposition for bearing-crack detection in wind turbines with large driving-speed variations. Renew Energy 116:55–73
Xue J, Shen B (2020) A novel swarm intelligence optimization approach: sparrow search algorithm. Syst Sci Control Eng 8(1):22–34
Subasi A, Jukic S, Kevric J (2019) Comparison of EMD, DWT and WPD for the localization of epileptogenic foci using random forest classifier. Measurement 146:846–855
Quiroz J, Mariun N, Mehrjou M, Izadi M, Misron N, Radzi M (2018) Fault detection of broken rotor bar in LS-PMSM using random forests. Measurement 116:273–280
Chen Z, Deng S, Chen X, Li C, Sanchez R, Qin H (2017) Deep neural networks-based rolling bearing fault diagnosis. Microelectron Reliab 75:327–333
Shao H, Jiang H, Zhang H, Duan W, Liang T, Wu S (2018) Rolling bearing fault feature learning using improved convolutional deep belief network with compressed sensing. Mech Syst Signal Proc 100:743–765
Zheng J, Pan H, Cheng J (2017) Rolling bearing fault detection and diagnosis based on composite multiscale fuzzy entropy and ensemble support vector machines. Mech Syst Signal Proc 85:746–759
Yan X, Jia M (2018) A novel optimized SVM classification algorithm with multi-domain feature and its application to fault diagnosis of rolling bearing. Neurocomputing 313:47–64
Wang M, Chen Y, Zhang X, Chau TK, Ching Iu HH, Fernando T, Ma M (2021) Roller bearing fault diagnosis based on integrated fault feature and SVM. J Vib Eng Technol 1–10
Li Y, Xu M, Wei Y, Huang W (2016) A new rolling bearing fault diagnosis method based on multiscale permutation entropy and improved support vector machine based binary tree. Measurement 77:80–94
Zheng J, Jiang Z, Pan H (2018) Sigmoid-based refined composite multiscale fuzzy entropy and t-SNE based fault diagnosis approach for rolling bearing. Measurement 129:332–342
Chen W, Wang Z, Xie H, Yu W (2007) Characterization of surface EMG signal based on fuzzy entropy. IEEE Trans Neural Syst Rehabil Eng 15(2):266–272
Wang Z, Yao L, Cai Y (2020) Rolling bearing fault diagnosis using generalized refined composite multiscale sample entropy and optimized support vector machine. Measurement 156:107574
Smith A, Robert B (2015) Rolling element bearing diagnostics using the Case Western Reserve University data: a benchmark study. Mech Syst Signal Proc 64:100–131
Lee J, Qiu H, Yu G, Lin J and Rexnord Technical Services (2007). IMS, University of Cincinnati. “Bearing Data Set”, NASA Ames Prognostics Data Repository (http://ti.arc.nasa.gov/project/prognostic-data-repository), NASA Ames Research Center, Moffett Field
Berredjem T, Mohamed B (2018) Bearing faults diagnosis using fuzzy expert system relying on an improved range overlaps and similarity method. Expert Syst Appl 108:134–142
Acknowledgements
This work was supported by the Natural Science Foundation of Hunan Province, China (Grant No. 2019JJ50624). The Research Foundation of Education Department of Hunan Province, China (Grant No. 20B567), and the National Natural Science Foundation of China (Grant No. 62071411).
Author information
Authors and Affiliations
Author notes
Wenjie Wang, Jinfang Zeng and Yibing Zhang have contributed equally to this work.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Wang, M., Wang, W., Zeng, J. et al. An Integrated Method Based on Sparrow Search Algorithm Improved Variational Mode Decomposition and Support Vector Machine for Fault Diagnosis of Rolling Bearing. J. Vib. Eng. Technol. 10, 2893–2904 (2022). https://doi.org/10.1007/s42417-022-00525-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s42417-022-00525-9