
Abstract
After effective investigation on various exploration activities, from a geothermal prospect, stakeholders are constantly anxious to know of its potential. Geothermal resource assessment is estimation of the amount of thermal energy that is stored beneath the earth’s surface and can be extracted from a geothermal reservoir and used economically for a time frame, normally a very long while. A study was undertaken to calculate energy potential of the Dholera Geothermal Field. Using various parameters from the geoelectrical model, the resource potential beneath the subsurface was calculated by applying Monte Carlo simulation. Using various parameters from the geoelectrical model and applying Monte Carlo simulation, the resource potential beneath the subsurface was calculated. It was calculated considering all uncertain parameters (random values) within the span of the minimum, the most likely and the maximum triangular distribution. The result shows the frequency distribution of energy values. Energy estimated at 3 km depth in Dholera is \(3.73\times 10^{10}\ \hbox {J}\) (P50 Case). Energy estimated for P90 case is \(2.90\times 10^{10}\ \hbox {J}\) and for P10 case is \(3.73\times 10^{10}\ \hbox {J}\).
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Monte Carlo simulation is a numerical demonstrating method named after the city of Monte Carlo in Monaco, where fundamental attractions are the gambling clubs. These clubs offer various games of chance like roulette wheels, slot machines, dice and card games (Sarimiento and Bjornsson 2007; Kalos and Whitlock 2007). There are different methods to estimate the maximum and minimum geothermal energy of a reservoir based on the laws of conservation of mass and energy. These methods used for resource assessment vary depending upon the available information at different stages of geothermal development and the accuracy of the methods depends upon the certainty of available information (Zarrouk and Simiyu 2013). The methods are listed below:
-
Power density method
-
Surface thermal flux method
-
Magmatic heat budget method
-
Numerical reservoir modeling
-
Stored heat or volumetric assessment
-
Lumped parameter models
-
Decline analysis
-
Natural state matching
-
History matching
-
Probabilistic and deterministic method
-
Genetic algorithm.
All of the above methods have been applied deterministically or through some form of probabilistic approach, but most of them have disadvantages or limited applicability. Assessment of available energy output based on surface heat flow method is likely to lead to an unrealistically low number for the sustainable extraction rate over a typical project life. Using summation of well output methods alone is not at all clearly defined or formulated. But if this method is combined with decline analysis method based on a suitable history of well performance it gives a better idea of resource estimation. The areal estimate method is useful in the early stages of exploration, but should not be used for anything more definitive than inferred resources. Well decline analysis is likely to be useful only in special circumstances, like in projects with a long production history and where the current production and reinjection regime is expected to remain unchanged.
Lumped parameter modeling technique is most often used in fields where only water is present. For multiphase system, this method is not reliable. Therefore, only the volumetric methods and reservoir simulation are the preferred methods for defining proven and probable reserves. However, numerical simulation method is not applicable in early stages of exploration as it is applicable only when actual well data are available. Based on aforementioned points, stored heat and volumetric methods are used for the resource estimation of geothermal reservoir. In volumetric methods, Monte Carlo method is the most reliable method for resource estimation.
The volumetric method is chosen for estimating the thermal energy of the system. In volumetric calculation, the reservoir is normally considered as a single body or it is divided into layers which are then subdivided into blocks. Each block contains one unique value for each parameter assigned. Main parameters of a reservoir are temperature, porosity, area, thickness, density, and heat capacity of the fluid and rock matrix (Martinez 2009). Quantification of uncertainties in the parameters of the probability distribution can be dealt quite well using the Monte Carlo simulation method (Gauxuan 2008).
The arbitrary conduct in a session/game of chance is the manner by which Monte Carlo chooses the event of an unknown variable in one calculation. The calculation is repeated many times until the specified iteration cycle is completed. In nutshell, Monte Carlo is a practical method which solves problems by numerical operations on random number. For instance, while playing dice, 1, 2, 3, 4, 5 or 6 are probable outcomes, yet we do not know the possible result of each roll. The same is legitimate for the distinctive parameters (area, thickness, porosity, and reservoir temperature) utilized as a part of computing the geothermal reserves. They vary within a certain range of values, which is uncertain for a particular sequence in the calculation. To deliver qualitative and accurate results, obscure variables for each reservoir property are fitted into a picked demonstrate dispersion (e.g., normal, triangular, uniform and log normal) which is based on some predetermined conditions or criteria of the geothermal field being evaluated. The simulation then continues to extract numbers representing the unknown variable and utilizing these as input to the cells in the spreadsheet until the process is complete (Sarimiento and Steingrimsson 2008). So with a combination of sampling theory and numerical analysis, the Monte Carlo method is a special contribution to the science of computing different properties (Baalousha 2016).
The Monte Carlo method uses stochastic techniques to evaluate the effect of measurements and uncertainty on the petro-physical results. Monte Carlo technique is chosen because it involves processing the interpretation model several times with randomly varying parameters. The method is frequently utilized when a model is perplexing, nonlinear or includes uncertain parameters. The method utilizes distinctive approaches; however, every one of them has a tendency to follow a particular pattern. With the help of Monte Carlo technique, all the possible of results for shale volume, porosity, water saturation, etc. are obtained with a cumulative distribution function for total heat in place, for each iteration, in the form of P10, P50 and P90 cases. It also generates a range for hydrocarbon in place, net-to-gross ratios, average porosities and saturations for the percentile cases selected by the interpreter (Stoian 1965).
The important steps in Monte Carlo calculation are:
-
Selecting or designing a probability model by statistical data reduction, analogy and theoretical considerations.
-
Generating random numbers and corresponding random variables.
-
Designing and implementing variance-reducing techniques.
The preliminary use of the Monte Carlo method for simulation of a system is that the final output from the software/program must be able to describe the system in terms of a probability density function (PDF).

Probabilistic performance forecast work flow
2 Salient characteristics of Monte Carlo method
Salient characteristics of the Monte Carlo method are as follows:
-
1.
The Monte Carlo method is associated with the probability theory. So the relationships of probability theory have been derived from theoretical considerations. Monte Carlo method uses probability to find answers to physical problems that may or may not be related to probability.
-
2.
The application of the Monte Carlo method offers a penetrating insight into the behavior of the systems being studied.
-
3.
The results of Monte Carlo computations are treated as estimates within certain limits rather than true exact values. All meaningful physical measurements are expressed in this way. Monte Carlo techniques can be used to obtain approximations too.
-
4.
The method is flexible to the extent that it elaborates the complexity of a problem. This is reflected by a fact that a greater number of parameters or complicated geometry does not alter its basic character and the penalty paid for complexity is increased computing time and costs (McGlade et al. 2013).
-
5.
A practical consideration is that the iterative calculations necessary for attaining a certain level of confidence can be distributed among several computers, working simultaneously in one or more places.
-
6.
The Monte Carlo solutions are approximate and they can be upgraded with time.
-
7.
Solutions of the Monte Carlo method are numerical and apply only to the particular case studies (Dur 2005).
3 Methodology
Monte Carlo uses different stochastic techniques and probabilistic approach to properly estimate the range of reservoir’s generating capacity, to identify major uncertainties, and to quantify the risks associated with the proposed expansion.
We applied the following process for probabilistic approach (Fig. 1).
-
1.
We have to define the reservoir’s performance-dependent variable and perform screening process to identify various parameters’ uncertainties.
-
2.
Use the different experimental methodology to create a series of dynamic reservoir simulation models which capture the full range of reservoir performance.
-
3.
Calibrate and validate these models by history matching and natural state matching.
-
4.
Create the response for reservoir performance using multiple regression analysis.
-
5.
Then apply this to the Monte Carlo simulation to generate full probabilistic performance and derive P10, P50 and P90 model, and also verify Monte Carlo simulation results.
-
6.
Use the P10, P50 and P90 models for future development like in energy calculation and plan size (Hoang et al. 2005).
Following flowchart shows the whole process:

Workflow for Monte Carlo simulation
4 Workflow of Monte Carlo method
The Monte Carlo methods vary, but they follow a particular pattern (Fig. 2):
-
(a)
Define a domain of possible inputs: each Monte Carlo simulation begins off with developing a deterministic model which intently looks like the genuine situation. In this deterministic model, we utilize the most likely value of the input parameters. The domain of these parameters is defined around an initial value, used in the standard deterministic module. This part is the core of Monte Carlo simulation. The distribution must also be specified (Square, Triangular or Gaussian) for generation of random values.
-
(b)
Generate inputs randomly from a probability distribution over the domain: once the distributions have been identified, the random numbers are generated. At the start of each simulation, every parameter is changed using a random number. If the random number generator comes up with a value outside of the selected range, then another random number will be chosen. This is done to try and keep the distribution within reasonable limits, because very large shifts in parameters can give ambiguous results. This may cause difficulty for the model to run.
-
(c)
When a satisfactory deterministic model is obtained, the risk components are added to it. Since, risk originates due to stochastic behavior of input parameters; the distribution that can represent the input parameter correctly is identified. If historical data are available for the input parameter, history matching is done by fitting the data to obtain a discrete or continuous distribution. Some of the standard procedures for fitting data to distributions are method of maximum likelihood, method of moments and nonlinear optimization.
-
(d)
Perform a deterministic computation on the inputs: parameters for each simulation iteration, IP will run the interpretation modules, like clay volume, porosity and saturation, cut-off parameters and summations, in the order displayed (in the given order)
-
(e)
Aggregate the results: parameters for each simulation are saved. Iterations are carried out to obtain the values for every desired parameter ranking from low to high probability. Result is described in terms of mean and a percentile for each parameter. Sample output is collected and statistical analysis is performed. The output is usually displayed in the form of frequency histogram which gives an idea about the probability density function of the output parameter (Raychaudhuri 2008).
5 Monte Carlo model distributions
This section describes how to generate a procedure for various single variate continuous distributions.
Major model distributions are as follows:
-
1.
Normal distribution
-
2.
Lognormal distribution
-
3.
Uniform distribution
-
4.
Triangular distribution
5.1 Normal distribution
It is the most commonly used distribution model. It is a bell-shaped curve and has a continuous probability distribution curve. Figure 3 shows a typical Normal distribution curve.
A random variable “X” has a normal distribution if its probability distribution function is defined as
It is denoted by \(N (\mu , \sigma ^{2}\)), where \(\mu \) is the mean and \(\sigma ^{2}\) is the variance (Rubinstein 1981).

Normal distribution
5.2 Lognormal distribution
It is a continuous probability distribution and skewed in either direction as shown in Fig. 4. The skewness describes/means that a random variable has a small chance of occurrence as compared to the other direction of the shape. Let “x” be form of N (\(\mu , \sigma ^{2}\)). Then \(Y= e^{x}\) has the lognormal distribution with the probability distribution function (Rubinstein 1981).

Lognormal distribution
5.3 Uniform distribution

Uniform distribution
It is a continuous probability distribution function and describes a random variable in which any numerical value has an equal chance of occurrence. Mean and median values are concurrent and occur at midpoint of the random variable as can be seen in Fig. 5 (Rubinstein 1981).
5.4 Triangular distribution

Triangular distribution
It is a continuous distribution and is in a shape of triangle. The triangle can be symmetrical or skewed in both directions and is defined by specifying minimum, most likely and maximum values of variables (Fig. 6) (Rubinstein 1981).
6 Guidelines for the determination of reservoir parameters
Current developments within the geothermic trade need guidelines on how reserve estimation is to be drawn closer. Sanyal and Sarmiento (2005) had anticipated three classes for booking of reserves: proven, probable and possible. These are all the more appropriately estimated by volumetric methods. The reserves can be expressed in kW-h and/or barrels of fuel oil equivalent (BFOE) (Sanyal 2003) (Table 1).
7 Application of Monte Carlo in geothermal
The estimation of the geothermal energy reserves in view of the different reservoir parameters could be carried out using Monte Carlo simulation. It uses a probabilistic approach for evaluating geothermal energy reserves or resources. Due to the complexity and heterogeneity of the geologic formations and geological arrangement of most geothermal reservoirs. Monte Carlo simulation method is the preferred deterministic approach. It assumes a single value for each parameter to represent the whole reservoir. Instead of assigning a fixed value to reservoir parameters, a range of values are randomly selected and drawn for each cycle of calculation over a thousand iteration (Ofwona 2011).
Understanding and managing the range of uncertainty in reserves and resources estimation are important aspects of the business of exploration and production of geothermal energy. Geothermal professionals want to capture this uncertainty to
-
1.
Make development plans that can cover the range of possible outcomes.
-
2.
Provide a range of production forecasts to evaluate the expected outcome of their ventures.
-
3.
Measure exploration, appraisal, and commercial risks.
-
4.
Ensure that they can handle an unfavorable outcome.
-
5.
Understand and communicate the confidence level of their reserves estimate.
There are two distinct methods of volumetric resource estimation
-
1.
Probabilistic method.
-
2.
Deterministic method.
7.1 Probabilistic method
In the probabilistic method, we use the full range of values that could reasonably occur for each unknown parameter (from the geosciences and engineering data) to generate a full range of possible outcomes for the resource volume. To do this, we identify the parameters that make up the reserves estimate and then determine a so-called probability density function (PDF). The PDF describes the uncertainty around each individual parameter based on geosciences and engineering data. Using a stochastic sampling procedure, we then randomly draw a value for each parameter to calculate a recoverable or heat in-place resource estimate (Lawless 2010).
7.2 Deterministic method
The deterministic method uses a single value for each parameter, based on a well-defined description of the reservoir, resulting in a single value for the resource or reserves estimate. Typically, three deterministic cases are developed to represent either low estimate (1P or 1C), best estimate (2P or 2C), or high estimate (3P or 3C), or proved, probable, and possible estimates. Each of these categories can be related to specific areas or volumes in the reservoir and a specific development plan.
Advantages of the deterministic method are
-
The method describes a specific physical case; physically inconsistent combinations of parameter values can be spotted and removed.
-
The method is direct, easy to explain, and manpower efficient.
-
The estimate is reproducible.
-
Because of the last two advantages, investors and shareholders like this method, and it is widely used to report proved reserves for regulatory purposes.
A feature and potential weakness of the deterministic model is that it handles each resource category in isolation and does not quantify the likelihood of mid, high and low case. (Swinkles 2011).
Deterministic models use a certain number of input parameters in few equations to give a set of outputs. They give the same results no matter how many times the calculation is repeated. Stochastic models, on the other hand, use variable (random) inputs and give different results depending on the distribution functions of the input parameters. They are often used when the model is complex, nonlinear or has uncertain parameters. The random numbers turn the deterministic model into a stochastic model (Sarimiento and Steingrimsson 2008; Pandey and Joshi 2015).
In Monte Carlo method the objective is to determine how random variation performance sensitivity or reliability of the system is being modeled. The inputs are randomly generated from probability distributions. General steps of the Monte Carlo simulation are:
-
1.
Create a parametric deterministic model, \(y = f(x1, x2, {\ldots }, xq)\).
-
2.
Generate a set of variable inputs, \(xi1, xi2, {\ldots }, xiq\).
-
3.
Evaluate the model and store the results as yi.
-
4.
Repeat steps 2 and 3 for \(i = 1\) to n.
-
5.
Analyze the results using different statistical methods.
8 Deterministic model for volumetric stored heat
The volumetric method is used for the calculation of total thermal energy in place of the rock and fluid which could be extracted for a specified reservoir volume and reservoir temperature (Muffler 1978).
The equations used in calculating the thermal energy for liquid-dominated reservoirs are as follows:
where
If two-phase system (water vapor system) exists in the reservoir, it is sensible to calculate the heat component of both the liquid and the two-phase or steam-dominated zone.
This approach is illustrated by the following set of equations to separately account for the liquid and steam components in the reservoir:
where

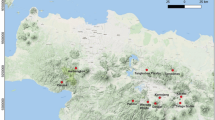
Geological map and tectonic framework of Gujarat. This figure also shows the detailed fault distribution system, MT profiles, gravity lines, hot springs, oil and gas field locations in the area (Sircar et al. 2015)
9 Monte Carlo simulation software
The Monte Carlo simulation performs the calculation of reserves’ estimates by extracting each of the uncertain parameters (random value) within the span of the minimum, most likely and maximum values (triangular distribution). The random sampling and calculations are done for 100–10,000 iterations and each result is sent to the bin to be compiled for the frequency distribution. Knowing the range of minimum, most likely and maximum values from the various input parameters, we could thus evaluate the risk and the probability of occurrence (Sarimiento and Steingrimsson 2008).

MT profiles at Dholera. MT survey with six different profiles and their orientation

Resistivity distributions at the depth of 3 km bsl. Scale 1: 100,000
The reserves’ estimation is done using commercial software which provides for a probabilistic approach. The most common commercial softwares are Crystal Ball (2007) and @Risk; these are used in assessing risks in investment, geothermal assessment, pharmaceuticals, petroleum reserves and mining evaluation. The Monte Carlo simulation can also be programmed using an Excel or Lotus spreadsheet, but using a commercial software allows the user to take advantage of many features such as
-
1.
Graphs of input parameters, output frequency, cumulative frequency, linear plot, etc.
-
2.
Statistics: minimum, mean, median, mode, and maximum values; skewness, standard deviation, etc.
-
3.
Sensitivity test.
10 Monte Carlo output
Output of a Monte Carlo simulation is a histogram for each iteration of the output value, at every depth. The strength of simulation can be determined if these histograms are unimodal. P10, P50 and P90 curves are also calculated. To observe the characteristics of each zone of the reservoir, zonal averages for each output parameter are also produced. It is a proven fact that simulation is a perfect reflection of reservoir under study, if geology of reservoir is not too complex. Even if the number of iterations is reduced in this case, the uniform distribution obtained will have a minor difference which can be neglected. And in case a complex reservoir is dealt with, more number of iterations are required (Sarimiento and Bjornsson 2007).

Cumulative energy distributions
11 Study area
The present study area is located in the Ahmedabad district of Gujarat state in India. The Dholera Geothermal Field, an ancient port city in the Gulf of Khambhat (Fig. 7), lies 30 km to the southwest of the Dhandhuka village in the Ahmedabad district and is around 60 km to the north of the city of Bhavnagar. Dholera is in close proximity to the coast. It is surrounded by water on three sides, namely on the east face by Gulf of Khambhat, on the north side by Bavaliari creek and on the southern side by Sonaria creek (Aghil et al. 2014). The Dholera Special Investment Region will be a major new industrial hub located on a greenfield site about 100 km to the south of Ahmedabad and about 130 km from Gandhinagar. The project is the first investment region to be designated under the proposed Delhi–Mumbai Industrial Corridor project (DMIC), a joint Indian and Japanese Government initiative to create a linear zone of industrial development nodes along a dedicated freight corridor (DFC).
Dholera thermal springs are located along the margin of Saurashtra Peninsula and lie in the vicinity of Western Marginal fault of Cambay basin as shown in Fig. 7. The Saurashtra peninsula is one of the three conspicuous physiographic divisions of the Gujarat state and lies between \(20{^{\circ }}30^{\prime }\hbox {N}\) to \(22{^{\circ }}30^{\prime }\hbox {N}\) latitude and \(69{^{\circ }}00^{\prime }\hbox {E}\) to \(72{^{\circ }}30^{\prime } \hbox {E}\) longitude. The Saurashtra Peninsula is located along the northwestern margin of the Indian Shield, occurs as a horst block between the three intersecting rifts, namely Kachchh, Cambay and Narmada (Biswas 1987, 1988).

Resistivity distribution at the depth of 4 km bsl. Scale 1: 100,000
Cambay basin rests on the Deccan trap, which lies at a depth of 500–600 m. Quaternary alluvial deposits of a thickness up to 100 m occur by the side of the basin (Sircar et al. 2015). Villages here show an easterly trend in elevation changes, wherein the low-lying plain falls gradually from the 8-m contour on the western boundary to 4 m in the East. The area is marked by the presence of old mud flats, flood plains and salt flat areas. The soil in this region mainly consists of alternate layers of gravels, fine to coarse grained sand and clay. Chemically the soil is loamy, mixed montmorillonitic, calcareous and mostly saline. The subsurface lithology of the area is mostly sand dominant consisting of alternating layers of coarse and fine sand.
To analyze various physicochemical properties of the reservoir fluid and subsequently establish the basic idea of the subsurface geology, prevalent temperature and other crucial reservoir parameter, geochemical analysis of the water from hot spring at Dholera was carried out. Gravity, magnetic and magnetotelluric (MT) studies were carried out to recognize the areal extension of the geothermal prospect. The Landsat imagery study was carried out to trace the candidate zones for drilling based on small Vegetation Index and positive anomalies in surficial temperature (Kumar and Shekhar 2016).
2-D magnetotelluric (MT) and audio-frequency magnetotelluric (AMT) surveys were undertaken for geothermal exploration along six profiles in the study area. Field AMT and MT measurements were performed in Dholera at 66 MT/AMT sounding stations along six profiles (Fig. 8). Orientation of five profiles was WSW–ENE and one was normal to five profiles. Frequency of the MT/AMT data is in the range of 0.001–10,000 Hz. Simultaneously synchronized measurements on reference station located in Kamalpura (Fig 7c) were carried out. The shallow geoelectric maps along with the deep maps portray that the reservoir is shale or sandstone body packed between excessively resistive basalts. 2-D data have been used to prepare cross-sectional APS at deep and shallow levels (PBG 2014) .
In addition to the magnetotelluric studies, gravity data were obtained along the same profiles with offset at some stations. Residual Bouguer gravity was modeled subsequent to application of corrections. The gravity-derived subsurface picture shows low-density zones sandwiched between high-density zones providing further evidence of the picture derived from MT cross sections presented in this paper. Integration of the gravity and magnetotelluric interpretation supports that beneath the surface manifestations (hot springs), less resistive geophysical anomaly with low density is present which indicates that a geothermal reservoir might be existent.
Resistivity closures in shallow as well as deep cross sections observed around the hot springs are true affirmation of the model postulated. Sections showing areal resistivity distribution at the depth of 3 and 4 km verify the same. Hence, the results give an optimistic idea of the study area being a promising geothermal prospect. Exploitation of this energy can be put to wide range of small-scale domestic to large-scale commercial uses. The resource potential of the prospect and the temperature gradient of the subsurface can be better described by drilling of wells and running temperature log.
12 Geothermal resource estimation: Dholera
12.1 Stored heat calculation at 3 km depth:
Figure 9 shows the resistivity distribution at the depth of 3 km below sea level at Dholera. Also low-resistivity anomalies were found between the 2nd and 3rd profiles, i.e., D2 and D5 (Fig. 8).
Various input parameters to this analysis are summarized in Table 2. Most likely estimates are given as well as estimated probability distributions and minimum and maximum values for different input parameters. Two most sensitive parameters for energy calculations are area and temperature. These input parameters are used in Monte Carlo simulation in Excel spreadsheet. The simulation runs can be as many as time and computer allows. More runs give accurate results. In this case the runs were 100. The thermal energy is usually plotted using the relative frequency histogram and the cumulative frequency distribution. The vertical axis represents the cumulative frequencies greater than or equal to given values of the random variable. The cumulative frequency greater than or equal to the maximum value is always 1 and the cumulative frequency greater than or equal to the minimum value is always 0 (Mwarania 2014; Ofwona 2011). The result shows the frequency distribution for energy values. Energy estimated at 3 km depth in Dholera is \(3.73 \times 10^{10}\ \hbox {J}\) (P50 Case) (\(\hbox {Proven} + \hbox {Probable}\)). Energy estimated for P90 case is \(2.90 \times 10^{10}\ \hbox {J}\) (proven) and for P10 case is \(3.73 \times 10^{10}\ \hbox {J}\) (\(\hbox {Proven} +\hbox {Probable} + \hbox {Possible}\)) (Fig. 10).
12.2 Stored heat calculation at 4 km depth
Figure 11 shows the resistivity distribution at the depth of 4 km below sea level. Also low-resistivity anomalies were found between the 2nd and 3rd profiles, i.e., D2 and D5 (Fig. 8).
Various input parameters to this analysis are summarized in Table 3. Most likely estimates are given as well as estimated probability distributions and minimum and maximum values for different input parameters. Two most sensitive parameters for energy calculations are area and temperature. These input parameters are used in Monte Carlo simulation in Excel spreadsheet. The simulation runs can be as much as time and computer allows. More runs give accurate results. In this case, the runs were 100. The result shows the frequency distribution for energy values. Energy estimated at 4 km depth in Dholera is \(3.82 \times 10^{10}\ \hbox {J}\) (\(\hbox {Proven} + \hbox {Probable}\)) (P50 case). Energy estimated for P90 (proven) case is \(2.812 \times 10^{10}\ \hbox {J}\) and for P10 case is \(3.852 \times 10^{10}\ \hbox {J}\) (\(\hbox {Proven} + \hbox {Probable} + \hbox {Possible}\)) (Fig. 12).

Cumulative energy distributions
13 Conclusion
The preferred method for reservoir assessment in the early phases of geothermal development is the volumetric method. The volumetric method refers to the calculation of thermal energy in the rock and the fluid which could be extracted based on specified reservoir volume, reservoir temperature, and reference or final temperature. Monte Carlo simulation is one of the best methods generally used for resource estimation. In this study, resource potential of the Dholera geothermal system has been estimated based on the geoscientific information available. The method was applied to estimate the resource of identified Dholera prospect and the energy was estimated to be \(3.7 \times 10^{10}\ \hbox {J}\) (P50 case). Estimation of power potential for Dholera Geothermal Field by Monte Carlo method produces reasonable and realistic estimates .This method has been applied in other geothermal fields around the world and will be appropriate for the estimation of power potential in geothermal fields in India.
Abbreviations
- \(\mu \) :
-
Mean
- \(\sigma ^{2}\) :
-
Variance
- \(Q_{\mathrm{T}}\) :
-
Total thermal energy (kJ/kg)
- \(Q_{\mathrm{r}}\) :
-
Heat in rock (kJ/kg)
- \(Q_{\mathrm{s}}\) :
-
Heat in steam (kJ/kg)
- \(Q_{\mathrm{w}}\) :
-
Heat in water (kJ/kg)
- A :
-
Area of the reservoir \((\hbox {m}^{2})\)
- h :
-
Average thickness of the reservoir (m)
- \(C_{\mathrm{r}}\) :
-
Specific heat of rock at reservoir condition (kJ/kgK)
- \(C_{\mathrm{l}}\) :
-
Specific heat of liquid at reservoir condition (kJ/kgK)
- \(C_{\mathrm{s}}\) :
-
Specific heat of steam at reservoir condition (kJ/kgK)
- \(\phi \) :
-
Porosity
- \(T_{{i}}\) :
-
Average temperature of the reservoir \(({^{\circ }}\hbox {C})\)
- \(T_{{c}}\) :
-
Final or abandonment temperature \(({^{\circ }}\hbox {C})\)
- \(S_{\mathrm{w}}\) :
-
Water saturation
- \({\rho }_{\mathrm{si}}\) :
-
Steam density at reservoir temperature \((\hbox {kg}/\hbox {m}^{3})\)
- \({\rho }_{\mathrm{wi}}\) :
-
Water density at reservoir temperature \((\hbox {kg}/\hbox {m}^{3})\)
- \(H_{\mathrm{si}}\) :
-
Steam enthalpy at reservoir temperature (kJ/kg)
- \(H_{\mathrm{wi}}\) :
-
Water enthalpy at reservoir temperature (kJ/kg)
- \(H_{\mathrm{wf}}\) :
-
Final water enthalpy (kJ/kg)
References
Aghil TB, Mohna K, Srinivas Y, Rahul P, Paul J, Alby ER, Nair NC, Chandrasekar N (2014) Delineation of electrical resistivity structure using Magnetotellurics: a case study from Dholera coastal region. J Coast Sci 1(1):41–46 Gujarat, India
Baalousha HM (2016) Using Monte Carlo simulation to estimate natural groundwater recharge in Qatar. Model Earth Syst Environ 2:87. https://doi.org/10.1007/s40808-016-0140-8
Biswas SK (1987) Regional tectonic framework, structure and evolution of the western marginal basins of India. Tectonophysics 135:307–327
Biswas SK (1988) Structure of the Western continental margin of India and related activity in Deccan flood Basalt. Memoir Geol Soc India 10:371–390
Dur F (2005) The usage of stochastic and multi criteria decision-aid methods evaluating geothermal energy exploitation projects. İzmir Institute of Technology, pp 1–116
Gauxuan G (2008) Assessment of the Hofsstadir geothermal field, W-Iceland, by lumped parameter modelling, Monte Carlo simulation and tracer test analysis. Geothermal training programme, Iceland, pp 247–279
Hoang V, Alamsyah O, Roberts J (2005) Darajat geothermal field performance—a probabilistic forecast. In: Proceedings world geothermal congress, antalya, pp 24–29
Kalos MH, Whitlock PA (2007) Monte Carlo methods. Wiley, New York, pp 1–203
Kumar D, Shekhar S (2016) Linear gradient analysis of kinetic temperature through geostatistical approach. Model Earth Syst Environ 2:145. https://doi.org/10.1007/s40808-016-0198-3
Lawless J (2010) Geothermal lexicon for resources and reserves definition and reporting. Australian Geothermal Energy Group, Australia, pp 1–90
Martinez AM (2009) Assessment of the Northern part of the Los Azufres geothermal field, Mexico, by Lumped Parameter modelling and Monte Carlo simulation. Geothermal training programme, iceland, pp 345–364
McGlade C, Speirs J, Sorrell S (2013) Methods of estimating shale gas resources—comparison, evaluation and implications. Elseveir, Amsterdam, pp 116–125
Muffler LJP (1978) USGS Geothermal resource assessment. In: Proceedings: Stanford geothermal workshop Stanford University, Stanford, California, pp 1–163
Mwarania FM (2014) Reservoir evaluation and modelling of the Eburru geothermal system, Kenya. Submitted at University of Iceland, pp 1–88
Ofwona C (2011) Geothermal resource assessment—case example, Olkaria I. Presented at short course VI on exploration for geothermal resources, Kenya, pp 1–8
Pandey B, Joshi PK (2015) Numerical modelling spatial patterns of urban growth in Chandigarh and surrounding region (India) using multi-agent systems. Model Earth Syst Environ 1:14. https://doi.org/10.1007/s40808-015-0005-6
PBG Report (2014) 2D Magnetotelluric survey for four locations for geothermal exploration namely (No. of MT soundings) Unai (66), Gandhar (66) and Dholera (66) (Excluding Tulsishyam, Tuwa and Chabsar). Exploration Geophysics Service. Poland, pp 1–24. (CEGE Report)
Raychaudhuri S (2008) Introduction to Monte Carlo simulation. In: Proceedings of the 2008 winter simulation conference, U.S.A., pp 91–100
Rubinstein RY (1981) Simulation and the Monte Carlo method. Wiley, New York, pp 1–277
Sanyal SK (2003) One discipline, two arenas—reservoir engineering in geothermal and petroleum industries. In: Proceedings twenty-eighth workshop geothermal reservoir engineering Stanford University, California, pp 1–11
Sanyal SK, Sarmiento Z (2005) Booking geothermal energy reserves. GRC Trans 29:467–474
Sarimiento ZF, Bjornsson G (2007) Geothermal resource assessment-volumetric reserves estimation and numerical modelling. Presented at short course on geothermal development in central America—resource assessment and environmental management, El Salvador, pp 1–13
Sarimiento ZF, Steingrimsson B (2008) Computer programme for resource assessment and risk evaluation using Monte Carlo simulation, Presented at short course on geothermal project management and developement in Uganda, pp 1–11
Sircar A, Shah M, Sahajpal S, Vaidya D, Dhale S, Choudhary A (2015) Geothermal exploration in Gujarat: case study from Dholera, India. Geotherm Energy 3:22
Stoian E (1965) Fundamentals and application of the Monte Carlo method. 16th Annual technical meeting, The Petroleum Society of C.I.M, Calgary, pp 120–129
Swinkles J (2011) Guidelines for the application of petroleum resource management system. Chapter 5:78–88
Zarrouk SJ, Simiyu F (2013) A review of geothermal resource estimation methodology. \(35{{\rm th}}\) New Zealand geothermal workshop, New Zealand, pp 1–8
Acknowledgements
Authors are thankful to PBG Geophysical Exploration Ltd., Poland, for conducting 2D and 3D magnetotelluric survey at Dholera geothermal site and providing technical support. Authors acknowledge the support provided by School of Petroleum Technology, Pandit Deendayal Petroleum University, Gandhinagar, Gujarat, India. Furthermore, authors are thankful to Ms. Hiteshri Yagnik for drafting the figures for the manuscript. Authors are also thankful to the school for giving permission to publish this research.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Availability of data and material
All relevant data and material are presented in the main paper.
Funding
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Rights and permissions
About this article

Cite this article
Shah, M., Vaidya, D. & Sircar, A. Using Monte Carlo simulation to estimate geothermal resource in Dholera geothermal field, Gujarat, India. Multiscale and Multidiscip. Model. Exp. and Des. 1, 83–95 (2018). https://doi.org/10.1007/s41939-018-0008-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41939-018-0008-x