
Abstract
This study addresses the potential of geospatial information extraction by using light detection and ranging (LiDAR) data and aerial optical images in an urban landscape. We have adopted an advanced geographic object-based image analysis (GEOBIA) technique consisting of rule-based procedures relying upon the integration of spectral, textural, and spatial characteristics of aerial imagery and roughness of point cloud of LiDAR to fuse aerial imagery and airborne LiDAR for effective urban geospatial information extraction. This study is focused on the extraction of four tangible geospatial features, e.g., buildings, trees, marine vessels, and cars. LiDAR-derived normalized digital surface model (nDSM) was insufficient in delineating the polygon features because of the sparse point cloud density at the edges of features, which greatly affected the accuracy of extracting the polygon features. Therefore aerial imagery was supplemented in order to enhance the quality of extraction. The final feature extraction accuracy was assessed against manual digitization by visual interpretation, statistical analysis, and confusion matrix. The accuracy of feature extraction was found to be ranging from 90 to 95%. The accuracy of buildings class was improved using intensity image generated from LiDAR data and Hough image along with morphological operations. In a nutshell, this study highlights robust improvements in the geospatial extraction of urban features by merging more than one dataset synergistically.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The study of urban regions using earth-observation data helps in many applications from city development to sprawl modeling. However, it also implies many challenges while urban feature mapping because of numerous and diverse semantic urban land cover features, peculiar geometries of features because of the image-capture angle, and practical issues in ortho-rectification process caused by the phenomena of ghost images and occlusions. Parametric and non-parametric pixel-based classifiers are widely discussed in remote sensing literature [1, 2], however these pixel-based classifiers fail to exploit spatial and textural information, causing a salt-and-pepper effect [3]. Geographic Object-Based Image Analysis (GEOBIA) has been used to analyze very high resolution (VHR) imagery to overcome supplementary issues with pixel-based classifiers and to consider complexities in data processing that arise from the spatial and spectral heterogeneity of urban areas [4, 5]. GEOBIA results prove especially useful for complex landscapes composed of fine-grain land-cover, for example, urban parcel or neighborhood analysis [6]. Supplementary Table 1 lists the recent studies on urban feature extraction using LiDAR, unmanned aerial vehicle (UAV), high-resolution satellite data, aerial imagery, and their combinations. The difference in elevation and intensity between the first and last return of LiDAR point cloud data was employed as two key attributes [7] for clearly differentiating trees from other urban features as trees have a comparatively much larger proportion of returns, which exhibit significant elevation and intensity differences. Xu et al. [8] employed multi-temporal point cloud processing for building change detection and extraction. Xu et al. [9] used multiple entity based urban information extraction in urban areas. In this method, the authors extracted features from 3 image entities: points, planar segments and segments derived by mean shift, and classified the result with single entity classification for water, buildings, vegetation, roof, wall, and roof element. Bandyopadhyay et al. [9] dealt with LiDAR and aerial imagery for a feature level fusion exercise, which employed structural and spectral features obtained from LiDAR and aerial RGB imagery for extraction of buildings and trees. In this approach, flatness and distribution of normal vectors were approximated from the LiDAR data, while the non-calibrated normalized difference vegetation index (NDVI) was defined by combining LiDAR intensity at 1064 nm, with the red spectral band of the RGB imagery. Image fusion of optical/multispectral and LiDAR images is currently an active field of remote sensing research [10,11,12]. Therefore, in this attempt, we followed an indirect pathway to analyze spatial-spectral feature extraction using (optical + LiDAR) shared representation in a GEOBIA framework. There are various global attempts, which accentuate the importance of integration of two or more datasets for better land-cover feature extraction, like Hamedianfar & Shafri [13], in which LiDAR and WorldView-2 (WV-2) satellite data were used for GEOBIA for detailed characterization of roof types and surface materials. Supervised and unsupervised classification techniques were used for airborne laser scanner (ALS) and airborne imagery to extract buildings, trees, vegetated ground and sealed ground [14]. An object-based point cloud analysis method for vehicle extraction from an ALS point cloud is proposed elsewhere [15], wherein texture and length-to-breadth ratio plays a vital role in delineating cars and discriminating them from other features. The present study has implemented multiclass feature extraction using GEOBIA by synergistic use of VHR aerial imagery and LiDAR datasets. The study area consists of various urban features. Of these, buildings, marine vessels (or containers), trees and cars were extracted in this research. As the datasets used were having very high-resolution, the difficulty in extracting exact building boundaries and other urban features increased multi-dimensionally due to surplus spatial details. This challenge was addressed by incorporating different rule sets and validation methods (feature-wise and class-wise). Our approach pursues the need of choosing the best possible combination of data-algorithm to deal with a specific urban mapping problem. Our approach can be used or tested on various urban scenarios where multi-modal datasets have to be integrated and rule-sets have to be defined according to scene specific criteria.
2 Method
The geospatial data used in this study were made available by IGARSS 2015 data fusion contest,Footnote 1 which included 7 tiles, with the following data: (1) a 10,000 × 10,000 pixel-sized color ortho-photo (GeoTIFF, RGB, 8bit, 5 cm resolution), (2) a max 5000 × 5000 pixel-sized Digital Surface Model (DSM) (GeoTIFF, floating point, 10 cm resolution), (3) a LiDAR 3D-point cloud in XYZI format [containing X (latitude), Y (longitude), Z (elevation), and I (LiDAR intensity) information]. The imaging data (aerial ortho-imagery) were acquired on 13 March 2011, using an airborne platform flying at an altitude of 300 m over the urban and the harbor areas of Zeebrugge, Belgium (51.33°N, 3.20°E; Fig. 1). The port of Zeebrugge is a platform for large containers, bulk cargos, vehicles and passenger ferry terminal ports in the municipality of Bruges, Belgium. The study area consists of several urban features like, buildings, roads, cars, marine vessels, water-body etc. LiDAR DSM was co-registered with Ortho imagery with the projection and datum of the study area UTM zone 31N and WGS 1984 (Geographic Coordinate System, GCS–WGS-1984), respectively. We manually built ground reference data by digitizing and labeling semantic classes under consideration, i.e. buildings, cars, trees, and marine vessels.

Remotely sensed datasets used in the present study, a An aerial ortho-imagery (RGB) of the study area showing various urban and harbor features of Zeebrugge, Belgium b imagery showing spatial extent of 7 tiles over the study area. c Rasterization of a TIN generated from the ground return (DTM/DEM) of the LiDAR, and d rasterization of a TIN generated from the first return (DSM) of the LiDAR
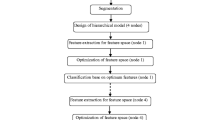
The methodology (Fig. 2) consists of two major parts; region-based segmentation and geographical object-based information extraction of multi-source (aerial imagery and LiDAR) data space. The workflow of the present research attempt is described in three sections: LiDAR data processing, GEOBIA based fusion of LiDAR and aerial imagery, and accuracy assessment.

GEOBIA based methodology protocol implemented for effective urban geospatial feature extraction
2.1 LiDAR data processing
The LiDAR point cloud was integrated as a rasterized surface (a DEM/DTM and a DSM) based on elevation or intensity (Fig. 1). DSM was constructed from the point cloud by rasterization of a TIN generated from the workflow used in LAStools (Rapidlasso, GMBH) by Khosravipour et al. [16]. DEM/DTM was generated by rasterization of the ground returns of the point cloud. Based on the derived DSM, the mean elevation of the base level was calculated (relative terrain height) as a reference to measure the elevation of features of interest. The normalized digital surface model (nDSM) gives the height variations above the ground, which was coupled with ortho-imagery for segmentation and information extraction.
2.2 GEOBIA based fusion of LiDAR and aerial imagery
A geospatial object-based information extraction of a multi-source data space can be conducted within a GEOBIA framework [17, 18]. Decision rules for 2D feature extraction through spatial, spectral and contextual analysis were conducted within the eCognition Developer (Trimble Geospatial) environment (Fig. 3). The nDSM was initially smoothed to reduce noise through filtering processes. The ortho-image and nDSM have different resolutions, therefore, application of slope filter before smoothing the nDSM produces erroneous slope values, especially in this case when the RGB data is finer in resolution than nDSM. Due to difference in resolutions, the neighboring pixels have similar elevation resulting in flat slopes, with steep slopes only at the boundary of coarser resolution pixels. This problem was tackled by smoothing the nDSM, which gives different elevations to each pixel and removes the erroneous flat slopes. The resolution of the RGB image was two times higher than that of nDSM, therefore the Kernel size = 6 (more than 4) was selected. Surface calculation algorithm was used for slope filter [19]. Multi-resolution segmentation was used to divide the image into spatially continuous, disjoint and homogeneous segments. Scale parameter is crucial here, as the criterion of homogeneity is highly dependent on this parameter, dealing with both spectral and shape homogeneity [20,21,22]. Characteristics such as elevation, spectral information, texture, roughness and shape were considered for detecting building and non-building regions. For analyzing image texture, we used the gray level co-occurrence matrix (GLCM), which deals with the relative variations in the gray values of the pixels. Texture is the spatial variation of pixel values and tonal heterogeneity along a particular direction in an image [23]. Second-order statistics or a co-occurrence matrix (contrast and angular second moment) is commonly used for quantification of the frequency of association between brightness value pairs [24]. The texture variables were calculated based on the red band. Homogeneity parameters used for segmentation, statistical parameters used for feature extraction, and texture variables derived from GLCM are depicted in Table 1. A greenness index was used to differentiate between vegetated and non-vegetated regions. It can be mathematically defined as:

Rule-sets designed on the basis of different features/properties of the data to extract target features
The above-ground and objects with high greenness values were classified as vegetation. Table 1 shows three different scale parameters used for a multi-resolution segmentation process. A scale parameter of 20 yielded the highest number of objects in the information extraction step; therefore, it was used for the segmentation process to include the maximum number of objects. For building feature extraction, the mean DSM slope was used to delineate steep areas by using a threshold value of 50. Here, we classified the steep objects around the buildings. Buildings were extracted by comparing the brightness values of neighboring objects. At this step, area threshold (> 1000) was used. Thus, the building candidates having area > 1000 pixels were classified as buildings. Brightness is calculated as:
LiDAR intensity image and Hough image were also incorporated in this workflow. Hough image was generated using Hough transform [25], which detects and links edges of the polygons. These two datasets were used in multi-resolution segmentation to enhance the quality of segmentation and visualization of the particular object generated [26]. Multi-resolution segmentation was implemented instead of mean-shift segmentation, which is better at delineating river and road boundaries and boundaries of parcels in relatively uniform elevation in addition to exhibiting heterogeneous context pertaining to brightness and/or color difference [27]. It was not suitable for this research as the study area consisted of trees/vegetation and boundaries of many buildings and marine vessels were not properly visible in the nDSM because of less point cloud density at the edges. All seven tiles were subjected to the same workflow. Various kinds of buildings were distributed unevenly or randomly over the landscape, trees were located in tiles 3, 5, 6 and 7, and marine vessels were identified in tiles 1 and 7. Two standard statistical indices, the intra-object height variance (ν) and the Moran’s I spatial autocorrelation index were used (Table 1) along with the variance of slope index for optimum feature extraction [28]. Moran’s I value was chosen as per the spatial nature of the target feature and the contextual information near the features. Previous successful methods (Yu et al.) [29] used length-to-breadth ratio for buildings and roads extraction. The shape attribute has two factors, namely, size and length-to-breadth ratio. Thresholds for these factors were defined and building features were separated from other objects by filtering. Length-to-breadth ratio was crucial in discriminating other non-vegetation features from building features, which were very thin. The length-to-breadth ratio was smaller than the threshold of 2 for buildings while it exceeded 2 for marine vessels and car features.
2.3 Accuracy assessment
We assessed the results of GEOBIA based urban feature extraction using visual and statistical analysis. We randomly picked a feature from the image to check the accuracy of the GEOBIA-based extraction method by observing the variation in compactness and completeness of the boundary of the extracted feature to the boundary of the manually extracted reference feature. A geodatabase consisting of four target features (buildings, trees, cars, marine vessels) spatially distributed over the study region was generated by manual digitization, based on the knowledge of its geography and visual interpretation of aerial and Google earth imageries. Aerial imageries were visualized in ArcGIS 10 at several scales using various RGB band combinations. Our digitized vector data was the most crucial reference set employed in this study. We compared a number of extracted features with the manually digitized reference features, and evaluated statistical significance based on accuracy assessment. It should be noted that all the four target features were unevenly distributed over the study region. Therefore, to provide robustness to our accuracy analysis, the study region was segregated into 7 tiles (Fig. 1b). The distribution of urban features over 7 tiles is depicted in Supplementary Table 3. Statistical parameters were calculated for all tiles, both separately and cumulatively. Table 2 lists the statistical parameters along with their mathematical expressions and descriptions used for accuracy analysis.
The accuracy assessment was carried out using a stratified random selection of 7000 test points to ensure approximately equal distribution of points to the four urban features [30,31,32]. Four urban feature classes were visually interpreted for 7000 random points (1750 per feature) using the high-resolution aerial imagery. The accuracy measures employed were pixels classified correctly for the entire feature extraction, errors of inclusion/commission (EC), errors of exclusion/omission (EO), user’s accuracy (UA), producer’s accuracy (PA), overall accuracy (OA, which represents the number of correctly classified pixels divided by the total number of pixels), mean accuracy, and kappa coefficients of agreement (κ). Supplementary Fig. 4 shows 7000 random points generated using ArcGIS 10 along with final extracted features. Considering the total area of study (1.62 km2), approximately 4321 points/km2 were generated for robust accuracy analysis. For the accuracy of each extracted feature class, the mapping accuracy percentage (MA) was computed. It is defined as:
where, PCC is the number of pixels assigned to the correct feature class, PCM is the number of pixels assigned to other classes along the column of the confusion matrix relevant to the class considered, and POM is the number of pixels assigned to other classes along the row of the confusion matrix relevant to the class considered.
3 Results and discussion
In the first step, visual analysis and interpretation were used to check the quality of feature extraction. However, visual analysis is the subjective measure of accuracy. Therefore, in the second step, the statistical performance and quantitative analysis of extracted features were evaluated against digitized reference features. In the third step, the accuracies of the extracted features were evaluated by computing error matrix based indices of the extracted class area.
3.1 Visual analysis and interpretation
A visual comparison shows that most of the urban features were detected, and the boundaries of the extracted features closely match the actual boundaries of the features in the aerial images or digitized reference data. Figure 4 and Supplementary Figure 5 depicts all the extracted urban features, i.e., buildings, trees, cars and marine vessels. In Fig. 4d, few cars were not detected due to lack of sufficient point cloud density which is crucial in delineating such small cars. As far as tree feature extraction is concerned (Fig. 4a), the number of extracted trees was less than the actual number of trees present in the ortho-image. All the extracted trees were correctly identified by visual interpretation on the image. Out of 571 trees extracted, 557 trees were actually interpreted in the image. The potential sources of errors (overestimation) include adjacent buildings, low point density of the LiDAR point cloud and misclassification because of defined thresholds. Proper delineation of tree canopies would have reduced the error, which can be achieved by precise canopy height model (CHM) [33]. It should be noted that building and car features were extracted as multiple polygons, i.e., multiple polygons belonging to the same building or car. Supplementary Table 2 shows that all the building features were extracted from aerial imagery, while a significant amount of underestimation was observed in the case of trees, cars, and marine vessels. We infer that the varying densities and populations of urban features in 7 different tiles caused this under-estimation. In this study, the threshold values for greenness (spectral) and texture (GLCM) produced appreciable results, however, because of erroneous filtering in point cloud, some misclassification was evident in case of building polygons. Furthermore, though the threshold values used for different attributes resulted into acceptable buildings delineation, there were few buildings with complex structures (tilted roofs) which were surrounded by trees, were not exactly delineated because of lack of contextual information and sparse point cloud density at the building edges, which enhanced the number of false negatives in building polygons. In case of cars and marine vessels, the most important discriminating factor was length-to-breadth ratio, so the threshold value of 2 yielded desired outcomes of extraction. In case of marine vessels, there was specific pattern (adjacent alignment) which was absent in case of cars due to random distribution on road and parking lots, which contributed to texture difference. For marine vessels, the total number of extracted polygons or length of extraction was observed to be less (underestimated) than those of reference polygons (length of reference). The underestimation of marine vessels appeared because of merging of few polygons causing faulty extraction. It should be noted that car features were observed to be consistently extracted by maintaining shape, size and dimensions of extracted features compared to manual reference, while the positions of extracted and manual cars were very slightly shifted. We surmise that the inherent geometrical errors in aerial imagery and LiDAR data caused this error because of moving objects at the time of capturing the data.

Extracted tangible urban geospatial features [trees (a), marine vessels (b), buildings (c) and cars (d, e)] using LiDAR and aerial imagery
3.2 Statistical accuracy analysis
Visual analysis of Fig. 5 and Supplementary Figures 5 and 6 indicated that the extracted features were similar to the features in the imagery, and manually digitized reference data, which suggested that features are mostly preserved under the same display conditions. Complex building footprints were selected for this analysis. Such buildings were extracted with multiple polygons. In other words, a single building had many polygons extracted corresponding to different parts of that building; these polygons were different from the segments/objects created during segmentation in eCognition. Segmentation gave rise to many objects in case of one part of the buildings, which were merged/split depending upon the thresholds defined. But, the finally extracted polygons displayed the portion of a house/building (after segmentation) like facades, roofs etc. which brought more complexity to the analysis. Therefore, polygon-wise accuracy was assessed. The footprints of the cars were extracted as the imagery and nDSM obtained from LiDAR data were not oblique so, side-way texture was not considered. Different polygons belonging to a single car had different elevations (intra-object height variance), which served the key factor in delineating the polygons. The extracted polygons against reference polygons over aerial imagery are depicted in Fig. 5 and Supplementary Figures 5 and 6. A robust accuracy analysis was carried out using numerous statistical parameters by interpreting extracted features vis-à-vis reference features on aerial imagery. Statistical parameters used in present analysis are misclassification (Mc) (%), false alarms (FA), accuracy (Ac) (%), false positive (FP), false negative (FN), completeness (Ce) (%), correctness (Cr) (%), bias, and root mean square error (RMSE). Accuracy analysis was carried out on all the tiles individually. Tables 3 and 4 and Supplementary Table 4 depict the statistical parameters evaluated for accuracy analysis.

Quantitative assessment of extracted a car, b building, and c marine vessel features against reference digitized features
3.2.1 Feature-wise accuracy analysis based on bias and RMSE
3.2.1.1 Extraction of buildings
The extracted building polygons were compared against manually digitized building polygons to test the accuracy of extraction. A total of 917 building features were correctly interpreted based on aerial imagery and manually digitized reference data. Polygon-wise accuracy was carried out as each building consisted of multiple polygons. An insignificant amount of underestimation was observed for building polygons. A total of 2692 building polygons were found to match a total of 2699 reference polygons, indicating that the density of extracted building polygons (1665/km2) was underestimated with respect to the reference building polygons (1669/km2). We surmised that 7 building polygons were not interpreted in manually digitized data as a consequence of adjacent urban features like trees, which might have confounded with the building polygons. Briefly, building features were extracted with an estimated bias in 7 polygons and bias in density of 4 polygons per square kilometer.
3.2.1.2 Extraction of trees
An insignificant amount of underestimation was observed for tree feature extraction. A total of 557 tree features (out of 571 reference features) were correctly interpreted on aerial imagery and manually digitized reference data. The density of extracted tree features (642/km2) was observed to be under-estimated with respect to reference tree features (659/km2). Conclusively, 14 tree features were not interpreted in manually digitized data as a consequence of adjacent urban features, such as buildings, which might have confounded with the tree features. Briefly, tree features were extracted with an estimated bias in 14 features and bias in density of 16 polygons per square kilometer.
3.2.1.3 Extraction of cars
The extracted car polygons were compared against manually digitized car polygons to test the accuracy of extraction. 312 (out of 326 total reference features) car features were correctly interpreted on aerial imagery and manually digitized reference data. However, as each car feature consisted of multiple polygons, polygon-wise accuracy was also undertaken. An insignificant amount of underestimation was observed for car polygons. A total of 948 car polygons were found to match with a total of 983 reference polygons. Inferentially, density of extracted car polygons (1093/km2) was observed to be underestimated with respect to the reference car polygons (1134/km2). We concluded that 14 car polygons were not interpreted in manually digitized data due to adjacent urban features, such as trees and buildings, which might have confounded with the car polygons. Briefly, car features were extracted with an estimated bias in 35 polygons (14 cars) and bias in density of 41 polygons (16 cars) per kilometer.
3.2.1.4 Extraction of marine vessels
In our study, 975 (out of 1043 total reference features) marine vessel features were correctly interpreted on aerial imagery as well as manually digitized reference data. A significant amount of underestimation was observed for marine vessel features. Consequently, the density of extracted marine vessel features (1125/km2) was observed to be underestimated with respect to the reference marine vessel polygons (1204/km2). Conclusively, 68 marine vessel polygons were not interpreted in manually digitized data as a result of merging of adjacent harbor features. Briefly, marine vessel features were extracted with an estimated bias in 68 features and bias in density of 79 features per square kilometer.
3.2.2 Overall accuracy analysis based on bias and RMSE
Bias (# and density) and RMSE (# and density) values were calculated for each tile to estimate overall accuracy trend. The overall trend of performance for each tile for extraction of 4 features, based on bias (# and density) and RMSE, is summarized in Table 3 and can be ranked as follows: Buildings > Cars > Trees > Marine vessels. Amongst the 4 urban features extracted by fusing LiDAR and aerial imagery, the extraction of buildings and trees outperformed the other features, while marine vessel feature extraction performed the worst in the given cohort.
3.2.3 Overall accuracy analysis based on error and accuracy measures
After estimating the bias and RMSE values, we deduced the accuracy on the basis of 4 error measures [False negative (FN), False positive (FP), Misclassification (Mc), and False alarms (FA)] and 4 accuracy measures [Accuracy (Ac), Correctness (Cr), Completeness (Ce), and Quality (Q)] (Supplementary Figures 7, 8, 9). All 8 statistical parameters were calculated by interpreting randomly selected 938 extracted features spatially distributed over 7 tiles. The interpreted features, error measures and accuracy measures are given in Table 4. The average Mc and FA values for the feature extraction ranged from ~ 3 to ~ 14% and ~ 1 to ~ 12%, respectively. The performance trend of feature extraction using the Mc values can be summarized as: Trees (3.10%) > Cars (7.42%) > Buildings (9.40%) > Marine vessels (13.09%). The performance trend using the FN (#) values can be summarized as: Cars (14) > Buildings (18) > [Marine vessels (20) = Trees (20)], while based on FP (#) the trend is illustrated as: Marine vessels (7) > Trees (10) > Cars (14) > Buildings (24). Performance trends display a trade-off between FN (#) and FP (#) values for feature extraction. The average Ac (%) and Q (%) values for the feature extraction ranged from ~ 80 to ~ 100% and ~ 72 to ~ 100%, respectively. The performance trend of feature extraction using the Ac (%) values can be summarized as: Trees (96.90%) > Buildings (95.52%) > Cars (92.58%) > Marine vessels (86.90%), while based on Q (%) the trend can be summarized as, Trees (95.87%) > Cars (88.80%) > Buildings (88.46%) > Marine vessels (82.48%). The average Cr (%) and Ce (%) values for feature extraction ranged from ~ 85 to ~ 100% and ~ 80 to ~ 100%, respectively.
3.3 Confusion matrix based accuracy analysis
A multi-sequence methodology ensured the accurate extraction of urban features from the LiDAR data and aerial imagery. Results of the final accuracy assessment for each extracted feature based on error matrix are shown in Supplementary Table 4 and 5. Confusion matrix based accuracy measures yielded applicable results for extraction with OA (98.70%), mean PA (98.43%), mean UA (98.81%), mean MA (97.29%), and kappa value (κ = 0.98). The statistics in Supplementary Table 5 indicate that building class extraction outperformed the other three feature classes, yielding MA values of 98.91% (buildings), 97.85% (trees), 95.21% (car), and 97.37% (marine vessels) respectively. In case of marine vessels (EO = 2.11%) and car features (EO = 2.87%), error of omission (EO, false negative) was more as compared to other features. For trees (EO = 1.48%), EO (false negative) was more than for buildings (EO = 0.92%). This is because, trees next to building roofs reduced the accuracy of building extraction due to improper delineation in case of urban vegetation. Building class exhibited least value of false positive (EO) (0.17%) with 99.83% user’s accuracy, while EO was observed to be 0.92, which corroborates the fact that buildings were classified with robust accuracy. The potential sources of errors include incorrect delineation of polygons for cars, marine vessels and buildings. In case of trees, improper crown periphery would be the source of error. Kappa value of 0.98 demonstrates the overall robustness of the methodology protocol in extraction of urban features.
Different segmentation scales were used from fine to coarse, to achieve an optimum solution for the feature extraction problem. Fine-scale worked excellent for vegetation—non-vegetation segmentation, whereas, the coarse scale was efficient in estimating heterogeneity within the class. Marine vessels were concentrated in particular areas, i.e., harbor. Therefore, over-segmentation was necessary to extract them distinctly. Similarly, different segmentation parameters were used for extraction of cars as their sizes were small compared to buildings and were concentrated on different roads and parking lots. The homogeneity parameters were used specifically for extracting/delineating objects pertaining to each landcover class. Rule-based hierarchical information extraction employed in this study automated the classification process of object primitives, which were grown, merged or separated based on defined rule-sets at various levels. Furthermore, Moran’s I values were chosen as per the spatial nature of the target feature and the contextual information in the vicinity of the features. We used length-to-breadth ratio and intra-spatial variance, which was more important in case of car extraction because of their different structure than other features. Morphological operations (dilation and erosion) used for preserving the shapes of objects/polygons yielded optimistic results. We also recommend to use this algorithm, particularly, cars and marine vessels extraction for oblique aerial/UAV images and LiDAR point clouds, as side-way texture is also prominent giving rise to more detailed 2.5D information.
We observed that the extraction of rectangular shaped buildings was easier and yielded better accuracies than complex shaped buildings having intricate structures. In this study, few cars which were parked nearby houses and trees were not extracted because of sparse point cloud and insufficient contextual information required for discrimination. Low point cloud density problem largely affected marine vessels as they were arranged adjacent to each other with little to no gaps in between. Spatial spacing of point cloud of LiDAR data couldn’t recognize these gaps, which resulted in merging of marine vessels and container polygons at many locations. Therefore, it is highly recommended for users to give an emphasis on LiDAR point cloud filtering as it plays a major role in identifying targeted objects. Applications of the technique used for this purpose should be implemented very carefully especially in areas where point cloud density is considerably low. The sparse point cloud density reduces the accuracy of feature extraction and 3D reconstruction of the features (especially buildings and cars) because the accurate delineation of boundaries, facades and car polygons requires high point cloud density at the edges. Users shall utilize specific contextual information, geometrical parameters and improved LiDAR point cloud filtering to use present methods optimally. Moreover, spectral context can be enhanced if more bands are available in case of optical imagery. In brief, the researchers in GEOBIA should focus on creating automatic, computationally efficient (though potentially complex), more accurate or precise and transformative workflows for robust outcomes [34,35,36,37,38,39,40,41].
4 Conclusion
Based on our results, we claim that our GEOBIA based workflow is prolific and produced optimistic results as far as data fusion is concerned. A trade-off between segmentation and merging turned out to be useful for properly delineating urban features. The subsequent merging of similar objects after segmentation of helped to grow the objects into meaningful features and overcoming over-segmentation resulting in compact features/polygons extraction. The integration of extreme spatial heterogeneity of aerial imagery and LiDAR elevation facilitated robust feature extraction and is responsible for discriminating different types of buildings like flat roofed and tilted roofed. We conclude that our workflow has yielded promising results which could have been improved if the imagery had a NIR band (especially, roof-tops and type of roof-tops extraction) and the LiDAR data had a more dense point cloud at the erroneous locations. More research is needed for precise car extraction and 3D modeling of all the extracted features. Our workflow could be used for precise urban mapping applications using new earth observation satellites such as Cartosat-2 series and Cartosat-3 in the near future.
References
Bhaskaran, S., Eric, N., Jimenez, K., & Bhatia, S. K. (2013). Rule-based classification of high-resolution imagery over urban areas in New York City. Geocarto International, 28(6), 527–545. https://doi.org/10.1080/01431161.2013.879350.
Hamedianfar, A., & Shafri, H. Z. M. (2013). Development of fuzzy rule-based parameters for urban object-oriented classification using very high resolution imagery. Geocarto International, 29(3), 268–292. https://doi.org/10.1080/10106049.2012.760006.
Blaschke, T., & Strobl, J. (2001). What’s wrong with pixels? Some recent developments interfacing remote sensing and GIS. GIS—ZeitschriftfürGeoinformationssysteme, 14(6), 12–17. https://doi.org/10.1080/13658816.2011.566569.
Hu, X., & Weng, Q. (2010). Impervious surface area extraction from IKONOS imagery using an object-based fuzzy method. Geocarto International, 26(1), 3–20. https://doi.org/10.1080/10106049.2010.535616.
Li, X., Myint, S. W., Zhang, Y., Galletti, C., Zhang, X., & Turner, B. L. (2014). Object-based land- cover classification for metropolitan Phoenix, Arizona, using aerial photography. International Journal of Applied Earth Observation and Geoinformation, 33, 321–330. https://doi.org/10.1016/j.jag.2014.04.018.
Li, X., Myint, S. W., Zhang, Y., Galletti, C., Zhang, X., & Turner, B. L. (2014). Object-based land- cover classification for metropolitan Phoenix, Arizona, using aerial photography. International Journal of Applied Earth Observation and Geoinformation, 33, 321–330. https://doi.org/10.1016/j.jag.2014.04.018.
Chen, Z., & Gao, B. (2014). An object-based method for urban land cover classification using airborne LiDAR data. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 7(10), 4243–4254. https://doi.org/10.1109/JSTARS.2014.2332337.
Xu, S., Vosselman, G., & Oude, E. S. (2014). Multiple-entity based classification of airborne laser scanning data in urban areas. ISPRS Journal of Photogrammetry and Remote Sensing, 88, 1–15. https://doi.org/10.1016/j.isprsjprs.2013.11.008.
Xu, S., Vosselman, G., & Oude, E. S. (2014). Detection and classification of changes in buildings from airborne laser scanning data. Remote Sensing, 7, 17051–17076. https://doi.org/10.3390/rs71215867.
Bandyopadhyay, M., van Aardt, J. A. N., & Cawse-Nicholson, K. (2013). Classification and extraction of trees and buildings from urban scenes using discrete return LiDAR and aerial color imagery. In M. D. Turner & G. W. Kamerman (Eds.), Laser Radar Technology and Applications XVIII, Proc. of SPIE Vol. 8731, 873105. https://doi.org/10.1117/12.2015890
Swatantran, A., Dubayah, R., Roberts, D., Hofton, M., & Blair, J. B. (2011). Mapping biomass and stress in the sierra nevada using LiDAR and hyperspectral data fusion. Remote Sensing of Environment, 115(11), 2917–2930. https://doi.org/10.1016/j.rse.2010.08.027.
Naidoo, L., Cho, M., Mathieu, R., & Asner, G. (2012). Classification of savanna tree species, in the Greater Kruger National Park region, by integrating hyperspectral and LiDAR data in a random forest data mining environment. ISPRS Journal Photogrammetry and Remote Sensing, 69, 167–179. https://doi.org/10.1016/j.isprsjprs.2012.03.005.
Chen, G., Weng, Q., Hay, G. J., & He, Y. (2018). Geographic object-based image analysis (GEOBIA): emerging trends and future opportunities. GIScience and Remote Sensing. https://doi.org/10.1080/15481603.2018.1426092.
Hamedianfar, A., & Shafri, H. Z. M. (2014). Improving detailed rule-based feature extraction of urban areas from WorldView-2 image and LiDAR data. International Journal of Remote Sensing, 35(5), 1876–1899. https://doi.org/10.1080/01431161.2013.879350.
Gerke, M., & Xiao, E. (2014). Fusion of airborne laser scanning point clouds and images for supervised and unsupervised scene classification. ISPRS Journal of Photogrammetry and Remote Sensing, 87, 78–92. https://doi.org/10.1016/j.isprsjprs.2013.10.011.
Zhang, J., Duan, M., Yan, Q., & Lin, X. (2014). Automatic vehicle extraction from airborne LiDAR data using an object-based point cloud analysis method. Remote Sensing, 6(9), 8405–8423. https://doi.org/10.3390/rs6098405.
Khosravipour, A., Skidmore, A. K., & Isenburg, M. (2016). Generating spike-free Digital Surface Models using raw LiDAR point clouds: A new approach for forestry applications. International Journal of Applied Earth Observation and Geoinformation, 52, 104–114.
Blaschke, T. (2010). Object based image analysis for remote sensing. ISPRS Journal of Photogrammetry and Remote Sensing, 65(1), 2–16.
Blaschke, T., Hay, J. G., Kelly, M., Lang, S., Hofmann, P., Addink, E., et al. (2014). Geographic object-based image analysis—towards a new paradigm. ISPRS Journal of Photogrammetry and Remote Sensing, 87, 180–191. https://doi.org/10.1016/j.isprsjprs.2013.09.014.
Trimble Definiens. (2010). Advanced example of building extraction for intermediate and advanced users; Classification of buildings using LiDAR and RGB data.
Zevenbergen, L. W., & Thorne, C. R. (1987). Quantitative analysis of land surface topography. Earth Surface Processes and Landforms [EARTH SURF. PROCESS. LANDFORMS.], 12(1), 47–56.
Crommelinck, S., Bennett, R., Gerke, M., Nex, F., Yang, M., & Vosselman, G. (2016). Review of automatic feature extraction from high-resolution optical sensor data for UAV-based cadastral mapping. Remote Sensing, 8(8), 689. https://doi.org/10.3390/rs8080689.
Crommelinck, S., Bennett, R., Gerke, M., Yang, M., & Vosselman, G. (2017). Countour detection for UAV-based cadastral mapping. Remote Sensing, 9(2), 171. https://doi.org/10.3390/rs9020171.
Singh, M., Malhi, Y., & Bhagwat, S. (2014). Biomass estimation of mixed forest landscape using a Fourier transform texture-based approach on very-high-resolution optical satellite imagery. International Journal of Remote Sensing, 35(9), 3331–3349.
Singh, M., Evans, D., Tan, B. S., & Nin, C. S. (2015). Mapping and characterizing selected canopy tree species at the Angkor world heritage site in Cambodia using aerial data. PLoS ONE, 10(4), 1–26. https://doi.org/10.1371/journal.pone.0121558.
Babawuro, U., & Beiji, Z. (2012). satellite imagery cadastral features extractions using image processing algorithms: A viable option for cadastral science. IJCSI International Journal of Computer Science, 9(4), 30–38. ISSN: 1694-0814.
Uzar, M., & Yastikli, N. (2013). Automatic Building Extraction Using LiDAR and Aerial Photographs. Boletim de Ciências Geodésicas sec. Artigos, Curitiba, 19(2), 153–171.
Wassie, Y. A., Koeva, M. N., Benett, R. M., & Lemmen, C. H. J. (2017). A procedure for semi-automated cadastral boundary feature extraction from high-resolution imagery. Journal of Spatial Science. https://doi.org/10.1080/14498596.2017.1345667.
Dragut, L., & Eisank, C. (2012). Automated object-based classification of topography from SRTM data. Geomorphology, 141–142, 21–33. https://doi.org/10.1016/j.geomorph.2011.12.001.
Yu, Q., Gong, P., Clinton, N., Biging, G., Kelly, M., & Schirokauer, D. (2006). Object-based detailed vegetation classification with airborne high spatial resolution remote sensing imagery. Photogrammetric Engineering and Remote Sensing, 72(7), 799–811. https://doi.org/10.14358/PERS.72.7.799.
Jawak, S., & Luis, A. (2013). Very-high resolution remotely sensed satellite data for improved land cover extraction of Larsemann Hills, east Antarctica. Journal of Applied Remote Sensing, 7(1), 073460. https://doi.org/10.1117/1.JRS.7.073460.
Jawak, S., & Luis, A. (2013). A spectral index ratio-based Antarctic land-cover mapping using hyperspatial 8-band WorldView-2 imagery. Polar Science, 7, 18–38. https://doi.org/10.1016/j.polar.2012.12.002.
Jawak, S., Panditrao, S., & Luis, A. (2013). Validation of high-density airborne LiDAR-based feature extraction using very high resolution optical remote sensing data. Advances in Remote Sensing, 2(4), 297–311. https://doi.org/10.4236/ars.2013.24033.
Ahmad, F., Goparaju, L., & Qayum, A. (2017). natural resource mapping using landsat and lidar towards identifying digital elevation, digital surface and canopy height models. International Journal of Environmental Sciences and Natural Resources. https://doi.org/10.19080/IJESNR.2017.02.555580.
Zabuawala, S., Nguyen, H., Wei, H., & Yadegar, J. (2009). Fusion of LiDAR and aerial imagery for accurate building footprint extraction. In K. S. Niel, & D. Fofi, (Eds.), Image processing: machine vision applications II, proceedings of SPIE-IS&T electronic imaging, SPIE 7251, 72510Z SPIE. https://doi.org/10.1117/12.806141.
Awrangjeb, M., Fraser, C., & Lu, G. (2015). Building change detection from lidar point cloud data based on connected component analysis. In ISPRS annals of the photogrammetry, remote sensing and spatial information sciences, volume II-3/W5 (pp. 393–400). https://doi.org/10.5194/isprsannals-ii-3-w5-393-2015.
Rehman, M., & Rashid, T. (2015). Urban tree damage estimation using airborne laser scanner data and geographic information systems: An example from 2007 Oklahoma Ice Storm. Urban Forestry and Urban Greening, 14(3), 562–572. https://doi.org/10.1016/j.ufug.2015.05.008.
Gerke, M., Kerle, N., Vosselman, G., & Vetrivel, A. (2015). Identification of damage in buildings based on gaps in 3D point clouds from very high resolution oblique airborne images. ISPRS Journal of Photogrammetry And Remote Sensing, 105, 61–78. https://doi.org/10.1016/j.isprsjprs.2015.03.016.
Gerke, M., Kerle, N., & Galarreta, F. (2015). UAV-based urban structural damage assessment using object-based image analysis and semantic reasoning. Natural Hazards and Earth System Sciences, 15, 1087–1101. https://doi.org/10.5194/nhess-15-1087-2015.
Gerke, M., Kerle, N., Vosselman, G., & Vetrivel, A. (2015). Segmentation of UAV-based images incorporating 3D point cloud information. In The international archives of photogrammetry, remote sensing and spatial information sciences, volume XL-3/W2. https://doi.org/10.5194/isprsarchives-xl-3-w2-261-2015.
Awrangjeb, M., & Lu, G. (2014). Automatic building footprint extraction and regularization from LIDAR point cloud data. In International conference on digital image computing: Techniques and applications (DICTA) 1-8 (2014), 25–27 Nov. 2014, Wollongong, NSW. https://doi.org/10.1109/dicta.2014.7008096.
Acknowledgements
The authors would like to thank the IEEE GRSS Data Fusion Technical Committee for organizing the 2015 Data Fusion Contest. We are thankful to Prof. Gabriele Moser for his constant support during the whole period of contest.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Jawak, S.D., Panditrao, S.N. & Luis, A.J. Synergistic object-based multi-class feature extraction in urban landscape using airborne LiDAR data. Spat. Inf. Res. 26, 483–496 (2018). https://doi.org/10.1007/s41324-018-0191-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41324-018-0191-1