
Abstract
Linguistic term sets are usually preferred to represent evaluations and preferences in qualitative group decision making (QGDM). Due to the different backgrounds and levels of knowledge of experts, linguistic term sets with different cardinality and/or semantics are used. Hence, it is vital to manage these linguistic terms from distinct information sources in QGDM. In this paper, we present a comprehensive review on relative developments of multi-granularity linguistic term sets by several perspectives, such as the transformation techniques, the aggregation functions, decision making processes and the applications. Finally, some possible directions for future research are pointed out as well.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Group decision making is a type of participatory procedure in which a group of experts or decision makers, such as committees, governing bodies, juries, business partners, teams, and families, acts collectively to consider and evaluate alternative courses of action, and then select among the alternatives. Generally, uncertainties are unavoidable due to the increasing complexity of practical decision making problems, but quite challenging to modeling by numerical techniques. For one thing, information in some situations may not be quantifiable due to its nature. When evaluating the comfort or design of a car, for example, linguistic terms like “good”, “fair”, “poor” may be used (Levrat et al. 1997; Xu 2012). For another, precise quantitative information may not be represented because its cost is too high to compute and an approximate value may be tolerated, e.g., we may use “fast”, “very fast”, “slow” to evaluate the speed of a car instead of numerical values. In this setting, qualitative group decision making (QGDM) approaches based on some specific techniques of computing with words (CWW) (Zadeh 1996) are quite suitable. In contrast with the usual sense of computing, CWW deals with words and expressions from a natural or artificial language and provides a methodology to lessen the gap between humans’ brain mechanisms and the machines’ processes to deal with imprecision. One main concept of CWW is linguistic variable. A linguistic variable is “variable whose values are not numbers, but words or sentences in a natural or artificial language” (Zadeh 1975). Thus, the use of linguistic variables is less specific than numerical ones, but much more closer to the humans’ thinking and knowledge.
The possible linguistic values of a linguistic variable are collected by a finite term set, referred to as linguistic term set (LTS), of labels or terms. A LTS is considered to let all the terms, defined by linguistic descriptors and semantics, be distributed on a predefined ordered scale (Rodriguez and Martinez 2013). The semantics of the terms are described by membership functions, such as linear trapezoidal membership functions (Delgaodi et al. 1999), taking the form of fuzzy numbers defined in a domain. The classical LTS is discrete and not convenient for calculation and analysis. Thus, two computational models, i.e., the virtual linguistic terms model and the linguistic two-tuple model, are presented to avoid the loss of information during the computational procedures. Furthermore, two extended models have been proposed to consider more than one term to enhance the representational capacity under uncertainties. If linguistic expressions do not match any original terms, but are located between two of them, Xu (2004) introduced the uncertain linguistic term which takes the form of an interval formed by two terms. Moreover, the experts may hesitate among several terms and seek for more complex linguistic expressions. Rodriguez et al. (2012) defined the concept of hesitant fuzzy LTS by an ordered finite subset of consecutive linguistic terms. Recently, Wang (2015) extended the concept of Rodriguez et al. (2012) to a general form.
When making decision with linguistic information, the following steps are usually necessary:
-
Step 1 The choice of LTSs with their semantics;
-
Step 2 The choice of aggregation operators;
-
Step 3 The choice of the best alternatives by an aggregation phase and an exploitation phase.
Generally, a granule is “a clump of objects (or points) which are drawn together by similarity, indistinguishability, proximity or functionality” (Zadeh 1997). In practice, the experts in a group usually come from different research areas, and thus have different experiential backgrounds and levels of knowledge, i.e., different granules of knowledge. Consequently, they would prefer to evaluate objects by LTSs with different granularities. We can see from Step 1 that the granularity of a LTS is an important parameter. It should be noticed that the granularity may come from uncertainties of different sources, such as the experts and the criteria. On the one hand, when different individuals have different degrees of uncertainties, a series of LTSs with different granularities may be considered. For example, one would like to express students’ course grades by two terms (e.g., “fail” and “pass”), another may use five terms (e.g., “fail”, “pass”, “good”, “very good”, and “excellent”). We will see that most of the existing researches focus on this aspect. On the other hand, LTSs with different granularities may be necessary when evaluating with respect to different criteria. For example, to express the students’ course grades, two terms (or five terms) can be used; while to express the students’ scientific research potential, four terms (e.g., “low”, “medium”, “high”, and “very high”) are more suitable. Generally, the use of multi-granularity LTSs can make the experts complete their evaluations easier.
During the latest decades, many researchers have focused on linguistic decision analysis based on multi-granularity LTSs. This paper presents a comprehensive overview of these researches. We will review the representational models of multi-granularity LTSs, the unification and aggregation techniques as well as their successful applications. To do that, the rest of the paper is organized as follows: In Sect. 2, we review the linguistic representation models. Section 3 reviews the representation models of multi-granularity LTSs. The QGDM approaches based on specified representation models are summarized in Sect. 4 and the application review is given in Sect. 5. Section 6 makes some discussions about further directions, and finally, concluding remarks are given in Sect. 7.
2 Linguistic representation models for CWW
Using linguistic information may be more straightforward and suitable than numerical one in many practical situations, such as QGDM problems. To manage the uncertainties and model the information in this situation, fuzzy linguistic approach based on fuzzy sets is a common solution. The first task is to choose the linguistic descriptors for a LTS to assign semantics to its terms. Linguistic descriptors can be selected by either a context-free grammar approach or an ordered structure approach (Herrera and Herrera-Viedma 2000). Formally, a LTS with syntax and semantics can be denoted by
where the granularity τ + 1 is a positive integer and should be neither too small nor too rich (Bordogna et al. 1997) and s α satisfies: (1) The set is ordered: s i ≥ s j iff i ≥ j; (2) The negation operator is defined: neg(s α ) = s τ−α .
In Eq. (1), if τ + 1 is odd, then S is usually used to represent symmetrically distributed term set. To facilitate this issue, Xu (2004) defined the following subscript-symmetric LTS as:
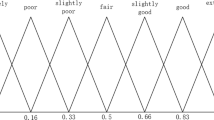
where t is a positive integer and s 0 represents the assessment of “indifference” or “fair”. The negation operator is rewritten as: neg(s α ) = s −α . For example, a LTS S could be
and its semantics are shown in Fig. 1. Obviously, it is symmetrically and uniformly distributed.

Semantics of original linguistic terms and virtual linguistic terms
A kind of symmetrically and non-uniformly distributed LTS, namely, unbalanced LTS, is defined by Xu (2009) as follows:
where t is a positive integer, \( s_{0}^{(t)} \) is the assessment of “indifference” or “fair” and other terms are placed symmetrically around it. S (t) satisfies: (1) \( s_{{\alpha_{1} }}^{(t)} \ge s_{{\alpha_{2} }}^{(t)} \) iff α 1 ≥ α 2; (2) neg(s (t) α ) = s (t)−α .
If t = 4, then a set of seven linguistic terms S (4) is (as shown in Fig. 2):

A set of seven unbalanced linguistic terms \( S^{(4)} \)
The abovementioned LTSs can be reviewed as additive LTSs similar to the one proposed in Herrera-Viedma and López-Herrera (2007). Different from which, Xu (2004) introduced two classes of multiplicative LTSs based on symmetrically and non-uniformly distributed LTSs as follows:
where in Eqs. (4) and (5), s (t)1 represents the assessment of “indifference”, and the terms in each set satisfy: (1) \( s_{\alpha }^{(t)} \ge s_{\beta }^{(t)} \) iff α ≥ β; (2) The reciprocal operator is defined: \( {\text{rec}}(s_{\alpha }^{(t)} ) = s_{\beta }^{(t)} \) such that αβ = 1.
Non-symmetrically distributed LTSs can be found in Herrera and Herrera-Viedma (2000) and Torra (1996). This situation assumes that the density of terms in a sub-domain is greater than that in other sub-domains of the reference domain because the sub-domain may be more informative than the rest. Figure 3 shows an example of this case in the context of temperature. Notice that, in this situation, the negation function (may not be one-to-one mapping) should be defined according to the semantics or the density of the reference domain.

A set of seven non-symmetrically distributed ordered linguistic terms
The use of the abovementioned LTSs may be also limited because the original terms are not convenient for computation. Thus, some extended models have been developed. The linguistic two-tuple model (Herrera and Martinez 2000) use a two-tuple (s α , x) to represent linguistic information, where s α is a term in S and x ∊ [−0.5, 0.5) is a numerical value serving as a symbolic translation. Given a LTS S and β ∊ [0, τ], then the two-tuple (s α , x) represents the equivalent information to β which can be obtained by:
Simultaneously, there is always a function Δ−1:S × [−0.5, 0.5) → [0, τ] such that Δ−1(s α , x) = α + x = β. Thus, two-tuple (s α , x) is transformed to a value β in a consecutive interval for computation.
Another consecutive computational model is the virtual linguistic model. Xu (2005) extended the LTS in Eq. (2) to a consecutive form \( \bar{S} = \{ s_{\alpha } |\alpha \in [ - q,q]\} \), where q(q > t) is a sufficiently large positive integer. The original term s α (s α ∊ S) is provided by experts, the virtual one \( \bar{s}_{\alpha } \)(\( \bar{s}_{\alpha } \in \bar{S} \)) only appears in computation. Figure 1 shows examples of the semantics of virtual terms based on the plotted LTS.
Besides, some other models are developed to ease the representation of uncertainty in linguistic setting. The first model to consider more than one term is proposed by Xu (2004). If the input linguistic expressions do not match any of the original linguistic terms, but are located between s α and s β (α ≤ β), then an interval-valued term [s α , s β ] can be formed.
3 Multi-granularity linguistic terms: representation
As introduced in Sect. 1, an important issue of decision making with linguistic information is the granularities of uncertainties corresponding to the level of discrimination among distinct degrees of uncertainties. It is interesting to develop the decision making approaches under multi-granularity linguistic information.
Generally, a multi-granularity LTS is referred to as a set of LTSs with distinct granularities. Let S MG = {S q|q = 1, 2, …, Q} be a multi-granularity LTS, where S q (q = 1, 2, …, Q) is a LTS taking the form of either Eqs. (1), (2) or (3). For example, suppose that \( S^{q} = \{ s_{0}^{q} ,s_{1}^{q} , \ldots ,s_{{\tau^{q} }}^{q} \} \), then the granularity of S q is τ q + 1 and \( s_{\alpha }^{q} \in S^{q} \) is the αth term of S q, q = 1, 2, …, Q. Furthermore, the uncertain linguistic term of S q is denoted by \( [s_{\alpha }^{q} ,s_{\beta }^{q} ] \) if \( s_{\alpha }^{q} \in S^{q} \), \( s_{\beta }^{q} \in S^{q} \) and α ≤ β (Fan and Liu 2010).
Another representational model is the linguistic hierarchies (Herrera and Martínez 2001; Espinilla et al. 2011). This model has been used in several areas [see Delgado et al. (1992) and Kbir et al. (2000) for examples]. A linguistic hierarchy is a collection of levels, each level of which is a LTS with distinct granularity to the rest of levels. Formally, a linguistic hierarchy with all levels is:
where l(t, n(t)) is the LTS of the level t with a granularity of n(t) and can be denoted by \( S^{n(t)} = \{ s_{0}^{n(t)} ,s_{1}^{n(t)} , \ldots ,s_{n(t) - 1}^{n(t)} \} \), t = 1, 2, …, T.
Two basic rules are proposed by Herrera and Martínez (2001) to construct a linguistic hierarchy:
-
Rule 1 Preserving all former modal points of the membership functions of a linguistic term from one level to the next level.
-
Rule 2 Adding a new linguistic term between each pair of terms of the LTS of the level t to build a new set of the level t + 1. Therefore, to make smooth transitions between successive levels, the new term is always located in the middle of two terms of the level t.
Based on these rules, a LTS of the level t + 1 can be induced by a predecessor as:
Figure 4 shows the graph for each LTS of a linguistic hierarchy in this case. Espinilla et al. (2011) extended this kind of linguistic hierarchy by generalizing Eq. (8). The extended rules are:
-
Extended Rule 1 The multi-granularity linguistic framework includes a finite number of the levels l(t, n(t)), where t = 1, 2, …, T. Keeping the former model points is not necessary.
-
Extended Rule 2 A new level l(t*, n(t*)) should be included to keep all the former model points of the levels l(t, n(t)) (t = 1, 2, …, T) in this new level, where t* = T + 1.

An example of linguistic hierarchy of three, five, and nine terms
Formally, an extended linguistic hierarchy with all levels is:
After optimizing the original hierarchy derived by these extended rules, the granularity of l(t*, n(t*)) is minimized by the least common multiple:
where the function LCM returns the least common multiple of its input parameters.
Huynh and Nakamori (2005) introduced a new notion about linguistic hierarchy, named hierarchical tree, to overcome the limitation of Eq. (8) based on semantics of linguistic terms. They defined a linguistic hierarchy of a linguistic variable X as a hierarchical tree, HT X , consisting by a finite number of the levels t (t = 0, 1, …, T) as follows:
-
1.
The first level (t = 0) is the root of HT X labeled by the name of the linguistic variable X.
-
2.
There is a LTS of X, denoted by S n(t), in the level t such that:
-
(a)
For any t = 1, 2, …, T − 1, n(t) < n(t + 1);
-
(b)
There exists only one mapping Γ t : \( S^{n(t)} \to 2^{{S^{n(t)} }} \backslash \{ \phi \} \) satisfying \( \varGamma_{t} (s_{i}^{n(t)} ) \cap \varGamma_{t} (s_{{i^{\prime}}}^{n(t)} ) = \phi \) for any \( s_{i}^{n(t)} \ne s_{{i^{\prime}}}^{n(t)} \), \( \cup_{{s_{i}^{n(t)} \in S^{n(t)} }} \varGamma_{t} (s_{i}^{n(t)} ) = S^{n(t + 1)} \), where t = 1, 2, …, T − 1; and
-
(c)
If \( s_{i}^{n(t)} < s_{{i^{\prime}}}^{n(t)} \) in the level t then \( s_{k}^{n(t + 1)} < s_{{k^{\prime}}}^{n(t + 1)} \) in the level t + 1 for any \( s_{k}^{n(t + 1)} \in \varGamma_{t} (s_{i}^{n(t)} ) \) and \( s_{{k^{\prime}}}^{n(t + 1)} \in \varGamma_{t} (s_{{i^{\prime}}}^{n(t)} ) \).
-
(a)
The mapping Γ t implements the semantic derivation from S n(t) to S n(t+1) for each t, where t = 1, 2, …, T − 1. Moreover, there is a pseudo-inversion Γ − t : S n(t+1) → S n(t) for the mapping Γ t defined by:
Figure 5 shows an example of hierarchical tree as well as the transformation between the level 1 and the level 2.

An example of hierarchy tree
4 Qualitative group decision making with multi-granularity information
Consider a QGDM problem with the set of alternatives A = {a 1, a 2, …, a M } and the set of experts E = {e 1, e 2, …, e P }. The alternatives are evaluated with respect to the set of criteria C = {c 1, c 2, …, c N } using a collection of multi-granularity LTSs S MG = {S q|q = 1, 2, …, Q}. LTSs S q(q = 1, 2, …, Q) have different granularity and/or semantics. Usually, it is assumed that the expert e p prefers to use the LTS S, where S ∊ S MG, p = 1, 2, …, P. The aim is to select the most desirable one(s) from A as a solution (or solutions). Based on the classical decision scheme, the QGDM problems with multi-granularity linguistic information can be solved by the following two phases (as shown in Fig. 6):
-
1.
Aggregation phase All multi-granularity linguistic performances provided by different information sources are fused and a collective linguistic performance is obtained. This phase is conducted by two steps:
-
(a)
Making the information uniform The provided linguistic values expressed by multi-granularity LTSs are transformed into a specific linguistic domain. The semantics of these values are obtained at the same time.
-
(b)
Computing the collective performances This is derived by means of the aggregation of the abovementioned uniformed values for each alternative.
-
(a)
-
2.
Exploitation phase A ranking method is considered to exploit the priority of alternatives according to the collective performances. This is usually completed by constructing a fuzzy preference relation.

The framework of multi-granularity QGDM
To highlight the unification phase of QGDM in multi-granularity linguistic setting, we specify the framework by three phases, i.e., the unification phase, the aggregation phase and the exploitation phase, in the following part of this paper. As shown in Fig. 6, the former two phases are integrated in the classical framework.
4.1 Multi-granularity QGDM based on fuzzy sets
The set of alternatives A = {a 1, a 2, …, a M } is qualified according to the set of information sources (experts) E = {e 1, e 2, …, e P }. Each e p expresses a linguistic performance value s mp for the alternative a m using the LTS S (p), where S (p) ∊ S MG. Therefore, the performance profile of a i , provided by e p , is defined as a linguistic fuzzy choice subset on A and evaluated linguistically on S (p):
and τ p + 1 is the granularity of S (p). Herrera et al. (2000) and Chen and Ben-Arieh (2006) proposed the solutions for this situation, respectively.
4.1.1 Unification phase
In Herrera et al. (2000), the linguistic performances represented by multi-granularity LTSs are transformed into a specific domain, referred to as a basic LTS (BLTS) denoted by S T, with the aim of keeping as much information as possible. Each performance value is defined as a fuzzy set on the BLTS and the associated semantics are derived by means of fuzzy sets defined in the new domain according to the following function:
Definition 1 (Herrera et al. 2000)
Let \( S^{(p)} = \{ s_{0}^{(p)} ,s_{1}^{(p)} , \ldots ,s_{{\tau_{p} }}^{(p)} \} \) and \( S^{T} = \{ s_{0}^{T} ,s_{1}^{T} , \ldots ,s_{{\tau_{T} }}^{T} \} \) be two LTSs with \( \tau_{p} < \tau_{T} \). Then a multi-granularity transformation function \( g_{{S^{(p)} S^{T} }} \) is defined as:
where F(S T) is the set of fuzzy sets defined on S T, \( \mu_{{s_{j}^{(p)} }} (y) \) and \( \mu_{{s_{k}^{T} }} (y) \) are the membership functions of the fuzzy sets associated to the terms \( s_{j}^{(p)} \) and \( s_{k}^{T} \), respectively.
This approach transforms linguistic terms in any \( S^{(p)} \) into the fuzzy sets defined in the BLTS with a grater granularity than any other term sets. Chen and Ben-Ariech (2006) proposed another method to unify the linguistic values to overcome the necessity of BLTS. This method enables to transform linguistic terms between any term sets. Their transformation function is defined as follows:
Definition 2 (Chen and Ben-Arieh 2006)
Let \( S^{(p)} = \{ s_{0}^{(p)} ,s_{1}^{(p)} , \ldots ,s_{{\tau_{p} }}^{(p)} \} \) and \( S^{(q)} = \{ s_{0}^{(q)} ,s_{1}^{(q)} , \ldots ,s_{{\tau_{q} }}^{(q)} \} \) be two LTSs with \( \tau_{p} \ne \tau_{q} \). Then a multi-granularity transformation function \( g^{\prime}_{{S^{(p)} S^{(q)} }} \) is defined as:
where k min and k max are the indices of the first and the last linguistic terms with nonzero membership function in the target set S (q).
The function \( g^{\prime}_{{S^{(p)} S^{(q)} }} \) provides a valid transformation where terms in the set have no overlap between their membership functions, as shown in Fig. 7. Generally, Fig. 7 is not the case. If overlaps exist between two terms of a set, Chen and Ben-Ariech (2006) developed an extended version of the transformation function to suit such a case. The advantage of this method is that the transformation can be done between any two LTSs. But, the main limitation lies on the necessity of symmetric membership function of semantics of terms.

The tiers of the fused LTSs
4.1.2 Aggregation phase
When all the individual performance values over an alternative a m are transformed to fuzzy sets on one LTSs, such as the BLTS, the collective performance value of a m can be obtained by the aggregation of these fuzzy sets. Formally, the linguistic performance value s mp of a m provided by the information source e p is transformed into a fuzzy set. For example, if the function \( g_{{S^{(p)} S^{T} }} \) is used, then s mp corresponds to a fuzzy set on \( S^{T} = \{ s_{0}^{T} ,s_{1}^{T} , \ldots ,s_{{\tau_{T} }}^{T} \} \) as: \( g_{{S^{(p)} S^{T} }} (s^{mp} ) = \{ (s_{0}^{T} ,\alpha_{0}^{mp} ),(s_{1}^{T} ,\alpha_{1}^{mp} ), \ldots ,(s_{{\tau_{T} }}^{T} ,\alpha_{{\tau_{T} }}^{mp} )\} . \) By means of membership degrees, the fuzzy set is denoted by \( r^{mp} = \{ \alpha_{0}^{mp} ,\alpha_{1}^{mp} , \ldots ,\alpha_{{\tau_{T} }}^{mp} \} \). Then the collective performance value of a m , denoted by \( r^{m} = \{ \alpha_{0}^{m} ,\alpha_{1}^{m} , \ldots ,\alpha_{{\tau_{T} }}^{m} \} \), is another fuzzy set defined on the BLTS characterized by its membership function: \( \alpha_{k}^{m} = f(\alpha_{k}^{m1} ,\alpha_{k}^{m2} , \ldots ,\alpha_{k}^{mP} ) \), where f is an aggregation operator, and m = 1, 2, …, M.
4.1.3 Exploitation phase
In the framework that the performance values are transformed into fuzzy sets on a certain LTS, such as BLTS, Herrera et al. (2000) defined the exploitation method by changing the representation of the collective values to a fuzzy preference relation because it can contain a large amount of information for selecting among alternatives. The proposed method is composed by two steps:
-
Step 1 Obtaining a fuzzy preference relation. The degree of possibility of dominance of a m over a n is computed according to the degree of possibility of dominance of one fuzzy number over another.
-
Step 2 Ranking the set of alternatives using a choice degree to this relation. This step can be conducted by either choice functions proposed in Roubens (1989) and Fodor and Roubens (1994).
4.2 Multi-granularity QGDM based on linguistic hierarchy
To overcome drawbacks of approaches in Sect. 4.1, such as the lack of accuracy of the computed results, Herrera and Martínez (2001) proposed another QGDM approach based on the linguistic hierarchy described in Eqs. (7, 8) and the linguistic two-tuple representation model.
4.2.1 Unification phase
Herrera and Martínez (2001) defined the following transformation function, \( {\text{TF}}_{{t^{\prime}}}^{t} \), between any two linguistic levels of the linguistic hierarchy without loss of information:
Definition 3 (Herrera and Martínez 2001)
Let \( LH = \cup_{t = 1}^{T} l(t,n(t)) \) be a linguistic hierarchy whose LTSs are denoted by \( S^{n(t)} = \{ s_{0}^{n(t)} ,s_{1}^{n(t)} , \ldots ,s_{n(t) - 1}^{n(t)} \} \), t = 1, 2, …, T. Then the transformation function \( TF_{{t^{\prime}}}^{t} \) from a linguistic term in the level t to another term in the level t′, satisfying the two basic rules, is defined as:
This transformation function between terms in different levels is one-to-one mapping, thus the transformation is carried out without loss of information. The linguistic hierarchy owns some limitation related to the representation domain, Espinilla et al. (2011) improved the approach based on the extended linguistic hierarchy. The unification on the extended linguistic hierarchy should be conducted by two steps in which the level l(t*, n(t*)) acts as the bridge for converting from the level t to the level t ′.
Definition 4 (Espinilla et al. 2011)
Let \( {\text{ELH}} = \cup_{t = 1}^{T + 1} l(t,n(t)) \) be an extended linguistic hierarchy and \( l(t*,n(t*)) \) be the level t*, where t* = T + 1. Then the extended transformation function \( {\text{ETF}}_{{t^{\prime}}}^{t} \) from a linguistic term in the level t to another term in the level t ′ is defined as:
where \( {\text{TF}}_{t*}^{t} \) and \( {\text{TF}}_{{t^{\prime}}}^{t*} \) are the transformation functions defined in Eq. (15).
The extended transformation function is also a one-to-one mapping, and thus can produce accurate computational results in the initial domains.
4.2.2 Aggregation and exploitation phase
It is obvious that any linguistic two-tuple aggregation operator can be used for aggregation once the information is unified by the function \( {\text{TF}}_{{t^{\prime}}}^{t} \). The best alternative(s) can be selected according to the biggest collective value derived in the aggregation phase.
Remark 1
Based on the linguistic hierarchy, Massanet et al. (2014) proposed a QGDM method which assumes that the performance values of alternatives take the form of discrete fuzzy numbers. A discrete fuzzy number assigns a [0, 1]-value to each possible linguistic term of a linguistic expression. Then a unification algorithm similar to the one reviewed in Sect. 4.1.1 is proposed.
4.3 Multi-granularity QGDM based on hierarchical tree
Huynh and Nakamori (2005) proposed the following QGDM approach based on the hierarchical tree mentioned in Sect. 3 to make the multi-granularity linguistic framework more flexible. The framework of the QGDM problem is described as the following matrix:
where x mp is the linguistic performance value of the alternative a m provided by the expert e p , m = 1, 2, …, M, and p = 1, 2, …, P.
4.3.1 Unification phase
Based on the mapping Γ t and its pseudo-inversion \( \Gamma _{t}^{ - } \) described in Sect. 3, the linguistic information expressed by different levels of a hierarchical tree is unified by the following transformation function Φ:
where Eq. (18) is used to transform the linguistic terms of the level t to the terms of the level t + a, while the terms of the level t + a can be transformed into the terms of the level t by Eq. (19).
To avoid the loss of information, Huynh and Nakamori (2005) suggested choosing the LTS with the highest granularity to serve as the BLTS. All linguistic performance values expressed by the experts are transformed to into the linguistic values in this BLTS.
4.3.2 Aggregation and exploitation phase
Instead of fuzzy sets, this approach makes use of random preferences based on the so-called satisfactory principle to exploit the ranking of alternatives. The unified performance matrix, formed by the normalization of performance values of alternatives provided by the experts, induces random set preferences for the alternatives. Then the least prejudiced distributions of the random preferences for the alternatives can be derived by the pignistic transformation of these random set preferences. At last, the alternatives are ranked based on these least prejudiced distributions and the satisfactory principle.
4.4 Multi-granularity QGDM based on fuzzy numbers
Jiang et al. (2008), Fan and Liu (2010) and Zhang and Guo (2012) proposed the solutions for the multi-granularity QGDM problems. In the three papers, the multi-granularity performance values are transformed into fuzzy numbers according to the semantics of terms for the purpose of unification.
A specific multi-granularity LTS \( S^{\text{MG}} = \{ S^{q} |q = 1,2,3,4\} \) is considered in Jiang’s approach (Jiang et al. 2008), where the granularities of S 1, S 2, S 3 and S 4 are 9, 7, 5 and 9. Based on the principle that the collective performance of each alternative is expected to be as close to each expert’s opinion as possible, a linear goal programming model is developed to minimize the deviation degrees between them [see Jiang et al. (2008) for more details]. By solving this model, the collective performance of the alternative a m is derived. The exploitation phase is conducted by constructing a dominance relation to represent the possibility degree of one alternative over another.
The approach of Fan and Liu (2010) focuses on the very framework mentioned at the beginning of Sect. 4. Especially, they assumed that the performances take the form of an uncertain linguistic term of a certain set of the multi-granularity LTSs, and the weighting vector of criteria provided by the expert takes the form of uncertain linguistic terms as well. All the information is represented by trapezoidal fuzzy numbers. The weighted performance of the alternative a m with respect to the criterion c n provided by the expert e p is computed by the multiplication of trapezoidal fuzzy numbers defined in Kaufmann and Gupta (1991). Following the framework of the classical TOPSIS, the distance of each alternative a m from the fuzzy positive ideal solution and the fuzzy negative ideal solution are calculated. Finally, the closeness coefficient of each alternative a m is used to rank alternatives.
The focused framework of Zhang and Guo (2012) is similar to the one of Fan and Liu (2010). Moreover, they assumed that the weights of criteria are incomplete. In the unification phase, the performance values are transformed into trapezoidal fuzzy numbers. The aggregation phase is completed by two different levels of aggregation. First, the collective performance value of the alternative a m provided by the expert e p is calculated by a trapezoidal fuzzy weighted averaging operator. Then a multi-objective optimization model is constructed to derive the overall performance values. The exploitation phase is done by a process based on the classical TOPSIS as well.
4.5 Multi-granularity QGDM based on unbalanced LTSs
In Xu (2009), the performance values of each alternative a m with respect to all criteria provided by the set of experts are collected by the following matrix:
where m = 1, 2, …, M. Especially, the multi-granularity LTS is formed by a set of unbalanced LTSs defined in Eq. (3) and denoted by \( S^{\text{MG}} = \{ S^{{(t_{p} )}} |p = 1,2, \ldots ,P\} \). Thus, \( \tilde{r}_{mn}^{(p)} = [(r_{mn}^{(p)} )^{L} ,(r_{mn}^{(p)} )^{R} ] \) in each decision matrix is an uncertain term based on the unbalanced LTS \( S^{{(t_{p} )}} \).
4.5.1 Unification phase
Xu (2009) proposed the following transformation functions to convert linguistic terms between any two unbalanced LTSs, denoted by \( S^{{(t_{1} )}} \) and \( S^{{(t_{2} )}} \) without loss of generality based on the linguistic virtual model. Given \( s_{\alpha }^{{(t_{1} )}} \in S^{{(t_{1} )}} \) and \( s_{\beta }^{{(t_{2} )}} \in S^{{(t_{2} )}} \), the pair of transformation functions F and F −1 is defined as:
If the decision maker selects one LTS, denoted by S (t), to serve as the basic unbalanced LTS, then the information in \( \tilde{R}^{(p)} \) can be unified and denoted by \( \dot{R}^{(p)} = (\dot{r}_{mn}^{(p)} )_{M \times N} = ([(\dot{r}_{mn}^{(p)} )^{L} ,(\dot{r}_{mn}^{(p)} )^{R} ])_{M \times N}, \) k = 1, 2, …, K.
4.5.2 Aggregation phase
Associated with the weight vector λ = {λ 1, λ 2, …, λ P }, the entries in \( \dot{R}^{(p)} \) {p = 1, 2, …, P} are aggregated by the uncertain linguistic weighted averaging (ULWA) operator (Xu 2004):
Then the collective uncertain linguistic decision matrix is formed by \( \dot{R} = (\dot{r}_{mn}^{{}} )_{M \times N} \).
To measure the consensus degree within the group, Xu (2009) developed an interactive algorithm based on some measures defined as follows:
Definition 5 (Xu 2009)
Let \( s_{1}^{(t)} = [s_{{\alpha_{1} }}^{(t)} ,s_{{\beta_{1} }}^{(t)} ] \in S^{(t)} \) and \( s_{1}^{(t)} = [s_{{\alpha_{1} }}^{(t)} ,s_{{\beta_{1} }}^{(t)} ] \in S^{(t)} \) be two uncertain linguistic terms, then the deviation degree between s (t)1 and \( s_{2}^{(t)} \) is defined by
where 2t − 1 is the granularity of the unbalanced LTS S (t).
Based on Definition 5, the similarity degree of decision matrices can be calculated as follows:
Definition 6 (Xu 2009)
Let \( \dot{R}^{(p)} = (\dot{r}_{mn}^{(p)} )_{M \times N} \) (p = 1, 2, …, P) be the unified linguistic decision matrices provided by the experts and \( \dot{R} = (\dot{r}_{mn}^{{}} )_{M \times N} \) be the collective linguistic decision matrix, then the similarity degree between \( \dot{R}^{{(p_{1} )}} \) and \( \dot{R}^{{(p_{2} )}} \) is defined by
where p 1, p 2 ∊ {1, 2, …, P}, and the similarity degree between \( \dot{R}^{(p)} \) and \( \dot{R} \) is defined by
Given σ ∊ [0, 1] representing the threshold of acceptable similarity, \( \rho (\dot{R}^{{(p_{1} )}} ,\dot{R}^{{(p_{2} )}} ) > \sigma \), then \( \dot{R}^{{(p_{1} )}} \) and \( \dot{R}^{{(p_{2} )}} \) are called of acceptable similarity. Similarly, if \( \rho (\dot{R}^{(p)} ,\dot{R}) > \sigma \), then \( \dot{R}^{(p)} \) and \( \dot{R} \) are said to be of acceptable similarity. Xu (2009) demonstrated that if \( \dot{R}^{(p)} \) and \( \dot{R}^{{(p^{\prime})}} \) are of acceptable similarity for all \( p^{\prime} \in \{ 1,2, \ldots ,P\} \backslash \{ p\} \), then \( \dot{R}^{(p)} \) and \( \dot{R} \) are of acceptable similarity as well.
In the process of QGDM, if \( \rho (\dot{R}^{(p)} ,\dot{R}) \le \sigma \), then several rounds of interaction with the expert \( e_{p} \). First, we return \( \dot{R}^{(p)} \) and \( \dot{R} \) to the expert e p , inform him/her to revaluate the elements with small similarity degrees. Second, we recalculate \( \rho (\dot{R}^{(p)} ,\dot{R}) \) if the necessary information is provided by the expert e p . Then the algorithm is stopped if acceptable similarity is reached or the number of rounds is equal to the predefined maximum value.
After the interactive algorithm, the ULWA operator is used once again to aggregate all linguistic information in the same row of \( \dot{R} \) to obtain the overall performance value of alternatives. The resultant value of the alternative a m is denoted by an uncertain linguistic term \( \dot{r}_{m}^{{}} \), where m = 1, 2, …, M.
4.5.3 Exploitation phase
The exploitation phase is conducted by ranking all uncertain linguistic terms \( \dot{r}_{m}^{{}} \) (m = 1, 2, …, M). To do that, \( \dot{r}_{m}^{{}} \) is compared with \( \dot{r}_{n}^{{}} \)(n = 1, 2, …, M). For convenience, let \( x_{mn} = P(\dot{r}_{m}^{{}} \ge \dot{r}_{n}^{{}} ) \), where \( P(\dot{r}_{m}^{{}} \ge \dot{r}_{n}^{{}} ) \) is the possibility degree of one uncertain linguistic term is greater than another proposed in Xu (2006), then a complementary binary relation is constructed as \( {\text{PR}} = (x_{mn} )_{M \times M} \). Summarizing all entries in each row of PR, we have \( x_{m} = \sum\nolimits_{n = 1}^{M} {x_{mn} } \), m = 1, 2, …, M. Then the alternatives can be ranked in descending order according to the values of x m (m = 1, 2, …, M).
4.6 Multi-granularity QGDM with antonyms-based aggregation
Torra (2001) presented a class of aggregation functions that allow the information sources to operate on different domains where each domain is represented by means of negation functions. Generally, the negation functions defined in Sect. 2 correspond to satisfy that the pair \( \left\langle {s_{\alpha } , s_{\tau - \alpha } } \right\rangle \) are equally informative, where s α and s τ−α ∊ S = {s 0, s 1, …, s τ }. However, the equal informativeness may not be appropriate in some situations because it may be suitable to have different linguistic terms with different quantities of information (Torra 2001). In this case, to define negation function is easier than to define a precise semantics as the negation functions can be interpreted as antonyms (de Soto and Trillas 1999). Thus, different from the description in Sect. 2, Torra (2001) considered some weakening conditions of the negation function to avoid equal informativeness as shown in the following definition:
Definition 7 (Torra 1996)
A function Neg from a linguistic tem set S to the parts of S (denoted by \( \mathcal{P}(S) \)) is a negation function if it satisfies:
-
1.
Neg is not empty and convex;
-
2.
if \( s_{\alpha } < s_{{\alpha^{\prime}}} \), then \( {\text{Neg}}(s_{\alpha } ) \ge {\text{Neg}}(s_{{\alpha^{\prime}}} ) \) for all s α , \( s_{{\alpha^{\prime}}} \in S; \)
-
3.
if \( s_{\alpha } \in {\text{Neg}}(s_{{\alpha^{\prime}}} ) \), then \( s_{{\alpha^{\prime}}} \in {\text{Neg}}(s_{\alpha } ) \).
To define the aggregation function, Torra (2001) introduced a unified domain at first so that a transformation function can be defined to map each term in the original domains into the new one. Then the new aggregation function can be defined. Given two LTSs \( S^{i} = \{ s_{0}^{i} ,s_{1}^{i} , \ldots ,s_{{\tau_{i} }}^{i} \} \) (i = 1, 2) from a multi-granularity LTS, let Neg1: \( S^{1} \to \mathcal{P}(S^{1} ) \) and Neg2: \( S^{2} \to \mathcal{P}(S^{2} ) \) be the negation functions, the new domain is defined as follows:
Definition 8 (Torra 2001)
Let S 1 and S 2 be two LTSs with the corresponding negation functions Neg1 and Neg2, then the unified LTS S c is defined by a set of τ c terms: \( S^{c} = \{ s_{0}^{c} ,s_{1}^{c} , \ldots ,s_{{\tau_{c} }}^{c} \} \), where \( \tau_{c} = {\text{LCM}}(\left| {{\text{Neg}}_{1} } \right|,\left| {{\text{Neg}}_{2} } \right|) - 1 \), LCM is the least common multiple, \( \left| {{\text{Neg}}_{i} } \right| = \sum\nolimits_{{s_{\alpha }^{i} }} {\left| {{\text{Neg}}_{i} (s_{\alpha }^{i} )} \right|} \) having | · | returns the cardinality of a set. The negation function of S c is defined by \( {\text{Neg}}_{c} (s_{\alpha }^{c} ) = s_{{\tau_{c} - \alpha }}^{c} \). Note that \( \left| {{\text{Neg}}_{c} } \right| = \tau_{c} \).
Based on this definition, the transformation functions can be defined to map S 1 and S 2 into the parts of S c as follows:
Definition 9 (Torra 2001)
Let S 1, S 2, Neg1 and Neg2 be defined as above and S c be their corresponding unified linguist term set, then the transformation functions T 1: \( S^{1} \to \mathcal{P}(S^{c} ) \) and T 2: \( S^{2} \to \mathcal{P}(S^{c} ) \) are defined as: \( T_{j} (s_{\alpha }^{j} ) = \{ s_{\beta }^{c} \in S^{c} |s_{{\beta^{\prime}}}^{c} \le s_{\beta }^{c} \le s_{{\beta^{\prime\prime}}}^{c} \}, \) where \( \beta^{\prime} = (\sum\nolimits_{{s_{\gamma }^{j} < s_{\alpha }^{j} }} {\left| {{\text{Neg}}_{j} (s_{\gamma }^{j} )} \right|} ){{ \cdot {\text{LCM}}(\left| {{\text{Neg}}_{1} } \right|,\left| {{\text{Neg}}_{2} } \right|)} \mathord{\left/ {\vphantom {{ \cdot {\text{LCM}}(\left| {{\text{Neg}}_{1} } \right|,\left| {{\text{Neg}}_{2} } \right|)} {\left| {{\text{Neg}}_{j} } \right|}}} \right. \kern-0pt} {\left| {{\text{Neg}}_{j} } \right|}} \), \( \beta^{\prime\prime} = (\sum\nolimits_{{s_{\gamma }^{j} < s_{\alpha }^{j} }} {\left| {{\text{Neg}}_{j} (s_{\gamma }^{j} )} \right|} ){{ \cdot {\text{LCM}}(\left| {{\text{Neg}}_{1} } \right|,\left| {{\text{Neg}}_{2} } \right|)} \mathord{\left/ {\vphantom {{ \cdot {\text{LCM}}(\left| {{\text{Neg}}_{1} } \right|,\left| {{\text{Neg}}_{2} } \right|)} {(\left| {{\text{Neg}}_{j} } \right| - 1)}}} \right. \kern-0pt} {(\left| {{\text{Neg}}_{j} } \right| - 1)}} \) and j = 1, 2.
Then a general aggregation function, denoted by \( {\mathbb{C}}_{c} \), of two terms can be defined as the aggregation of their translation in S c, based on an aggregation function over the intervals in S c.
Definition 10 (Torra 2001)
Let S 1, S 2, S c, Neg1, Neg2 and Neg c be defined as above, and T 1, T 2 be the transformation functions of S 1 and S 2 into S c. Then the aggregation of \( s_{{\alpha_{1} }}^{1} \in S^{1} \) and \( s_{{\alpha_{2} }}^{2} \in S^{2} \) is: \( {\mathbb{C}}_{*} (s_{{\alpha_{1} }}^{1} ,s_{{\alpha_{2} }}^{2} ) = {\mathbb{C}}_{c} (T_{1} (s_{{\alpha_{1} }}^{1} ),T_{2} (s_{{\alpha_{2} }}^{2} )) \), where \( {\mathbb{C}}_{c} \) is an aggregation function over the intervals in \( S^{c} \).
All the aggregation functions that focus on only one domain can be used for \( {\mathbb{C}}_{c} \), such as the linguistic OWA operator (Delgado et al. 1993; Xu 2008) (note that, in fact, this kind of operators aggregate the limits of intervals and then form the resultant intervals). Based on the abovementioned definitions, Torra (2001) defined an extension of the aggregation function \( {\mathbb{C}}_{*} \) to combine n ≥ 2 linguistic terms.
4.7 QGDM with multi-granularity and non-homogeneous information
Li (2010) proposed another solution for multi-criteria group decision making problems with both quantitative and qualitative information taking the form of multi-granularity linguistic terms, fuzzy numbers, interval values and real numbers. The proposed approach is based on a relative closeness method like the classical TOPSIS method to specify the idea of providing a maximum “group utility” for the “majority” and a minimum of an individual regret for the “opponent”.
The framework of Li (2010) is similar to the one of Zhang and Guo (2012). Especially, the set of criteria C = {c 1, c 2, …, c N } is divided into four subsets, where C 1 is the set of qualitative criteria evaluated by a predefined multi-granularity LTS, C 2, C 3 and C 4 are, respectively, the set of criteria expressed by fuzzy numbers, interval values and real numbers, and \( C_{t} \cap C_{{t^{\prime}}} = \phi \), \( \cup_{t = 1}^{4} C_{t} = C \).
In the unification phase, the linguistic performance values with respect to the criteria in C 1 are transformed into trapezoidal fuzzy numbers as done in Fan and Liu (2010) and Jiang et al. (2008). Another normalization procedure should be taken into account if some criteria in C t (t = 2, 3, 4) are cost attributes. Then the decision information can be transformed into a collection of fuzzy decision matrices. The aggregation phase is constructed by several steps:
-
Step 1 Determine the weights of criteria of the group by the weights given by each expert.
-
Step 2 Compute the distances between alternatives and the positive ideal solution as well as the negative ideal solution for each expert.
-
Step 3 Obtain the degrees of relative closeness of alternatives to the ideal solution for each expert.
-
Step 4 Compute the weights of the experts using the weights of the criteria provided by individuals and the weights of the criteria of the group derived in Step 1.
-
Step 5 Calculate the degrees of relative closeness of alternatives to the ideal solution for the group. A parameter used for synthesizing the individual relative closeness to the group’s one can reflect the group’s decision making strategy, such as voting “by majority rule”, “by consensus” or “with veto”.
The exploitation phase is completed immediately by ranking the alternatives according to the decreasing order of the values derived in Step 5.
4.8 QGDM based on transformation relationships among multi-granularity linguistic terms
Yu et al. (2010) proposed another technique, referred to as transformation relationships among multi-granularity linguistic terms (TRMLTs), to unify the linguistic terms with different granularities defined by any form of Eqs. (1), (2), (4) and (5) based on the virtual terms model.
First, let \( S^{(t)} = \{ s_{0}^{t} ,s_{1}^{t} , \ldots ,s_{{\tau^{t} }}^{t} \} \) be a LTS of S MG defined by Eq. (1), where t = 1, 2, …, Q, and extend S (t) to the continuous term set \( \bar{S}^{(t)} = \{ s_{{\alpha_{t} }}^{{}} |\alpha_{t} \in [0,\dot{\tau }_{t} ]\}, \) where \( \dot{\tau }_{t} ( \gg \tau_{t} ) \) is a natural number. Then the TRMLTs based on S (t) is defined by \( {{(\alpha_{t} - 1)} \mathord{\left/ {\vphantom {{(\alpha_{t} - 1)} {(\dot{\tau }_{t} - 1)}}} \right. \kern-0pt} {(\dot{\tau }_{t} - 1)}}{ = }{{(\alpha_{{t^{\prime}}} - 1)} \mathord{\left/ {\vphantom {{(\alpha_{{t^{\prime}}} - 1)} {(\dot{\tau }_{{t^{\prime}}} - 1)}}} \right. \kern-0pt} {(\dot{\tau }_{{t^{\prime}}} - 1)}}, \) \( t,t^{\prime} = 1,2, \ldots ,Q \).
Second, let S (t) in S MG be the LTS defined by Eq. (2), t = 1, 2, …, Q, then the TRMLTs with respect to LTS S (t) can be defined as: \( {{\alpha_{t} } \mathord{\left/ {\vphantom {{\alpha_{t} } t}} \right. \kern-0pt} t} = {{\alpha_{{t^{\prime}}} } \mathord{\left/ {\vphantom {{\alpha_{{t^{\prime}}} } {t^{\prime}}}} \right. \kern-0pt} {t^{\prime}}}, \, t,t^{\prime} = 1,2, \ldots ,Q. \)
Third, let S (t) in S MG be the LTS defined by Eq. (4), t = 1, 2, …, Q, and extend S (t) to the continuous version \( \bar{S}^{(t)} = \{ s_{{\alpha_{t} }} |\alpha_{t} \in [{1 \mathord{\left/ {\vphantom {1 {\lambda_{t} }}} \right. \kern-0pt} {\lambda_{t} }},\lambda_{t} ]\} \) with \( \lambda_{t} ( \gg t) \) being a natural number. Then the TRMLTs based on S (t) is defined as: \( {{(\left[\kern-0.15em\left[ {\alpha_{t} } \right]\kern-0.15em\right] - 1)} \mathord{\left/ {\vphantom {{(\left[\kern-0.15em\left[ {\alpha_{t} } \right]\kern-0.15em\right] - 1)} {(t - 1)}}} \right. \kern-0pt} {(t - 1)}} = {{(\left[\kern-0.15em\left[ {\alpha_{{t^{\prime}}} } \right]\kern-0.15em\right] - 1)} \mathord{\left/ {\vphantom {{(\left[\kern-0.15em\left[ {\alpha_{{t^{\prime}}} } \right]\kern-0.15em\right] - 1)} {(t^{\prime} - 1}}} \right. \kern-0pt} {(t^{\prime} - 1}}), \, t,t^{\prime} = 1,2, \ldots ,Q \), where \( \alpha_{t} \cdot \alpha_{{t^{\prime}}} \ge 0 \) and
Finally, let \( S^{(t)} \) in S MG be the LTS defined by Eq. (5), t = 1, 2, …, Q, and extend S (t) to the continuous version \( \bar{S}^{(t)} = \{ s_{{\alpha_{t} }} |\alpha_{t} \in [{1 \mathord{\left/ {\vphantom {1 {\lambda_{t} }}} \right. \kern-0pt} {\lambda_{t} }},\lambda_{t} ]\} \) with \( \lambda_{t} ( \gg t) \) being a natural number. Then the TRMLTs based on S (t) is defined as: \( {{t(1 - \left[\kern-0.15em\left[ {\alpha_{t} } \right]\kern-0.15em\right])} \mathord{\left/ {\vphantom {{t(1 - \left[\kern-0.15em\left[ {\alpha_{t} } \right]\kern-0.15em\right])} {((t - 1)\left[\kern-0.15em\left[ {\alpha_{t} } \right]\kern-0.15em\right])}}} \right. \kern-0pt} {((t - 1)\left[\kern-0.15em\left[ {\alpha_{t} } \right]\kern-0.15em\right])}} = {{t^{\prime}(1 - \left[\kern-0.15em\left[ {\alpha_{{t^{\prime}}} } \right]\kern-0.15em\right])} \mathord{\left/ {\vphantom {{t^{\prime}(1 - \left[\kern-0.15em\left[ {\alpha_{{t^{\prime}}} } \right]\kern-0.15em\right])} {((t^{\prime} - 1)\left[\kern-0.15em\left[ {\alpha_{{t^{\prime}}} } \right]\kern-0.15em\right])}}} \right. \kern-0pt} {((t^{\prime} - 1)\left[\kern-0.15em\left[ {\alpha_{{t^{\prime}}} } \right]\kern-0.15em\right])}}, \, t,t^{\prime} = 1,2, \ldots ,Q, \) where \( \ln \alpha_{t} \cdot \ln \alpha_{{t^{\prime}}} \ge 0 \).
Furthermore, the aggregation phase of the QGDM approach developed in Yu et al. (2010) is conducted using the linguistic weighted averaging operator, and the ranking of alternatives is exploited in accordance with the overall aggregated values.
4.9 A comparative analysis
We have reviewed a series of studies related to the management of multi-granularity linguistic information in QGDM problems. Characteristics of the proposed approaches are summarized in Table 1.
5 Application review
Multi-granularity LTS is a straightforward and useful tool to represent the uncertainty of granularity whenever qualitative criteria are involved. Till now, it has been successfully applied to various areas (Herrera-Viedma et al. 2003, 2005, Martínez et al. 2005; Wang and Xiong 2011; Chang et al. 2007; Wang et al. 2009; Chuu 2007, 2009; Zhang and Chu 2009, 2011; Zhu and Hipel 2012; Porcel et al. 2012). Some characteristics of the researches are summarized in Table 2. We shall give a brief review on this issue in this section.
Herrera-Viedma et al. (2005) proposed a model of consensus support system to assist the decision makers to solve the QGDM problems with multi-granularity linguistic preference relations. The unification phase and the aggregation phase of the focused QGDM are conducted based on the approach of Herrera et al. (2000). The exploitation phase is done according to the aggregated collective preference relation. Herrera-Viedma et al. (2003) implemented an information retrieval system based on a multi-granularity LTS with four fixed LTSs. The unification phase is also the same as in Herrera et al. (2000). This unification tool is also applied in Chang et al. (2007), Wang et al. (2009) and Chuu (2007). Besides, Chuu (2009) focused on the selection of advanced manufacturing technology and proposed an integrated approach to manage both multi-granularity linguistic information and numerical values. Zhang and Chu (2009) also use multi-granularity LTSs in a non-homogeneous setting.
In Martínez et al. (2005), a QGDM problem with Safety and Cost analysis was considered. All criteria were conducted in a multi-granularity linguistic domain. The original numerical performance values with respect to quantitative criteria were transformed into linguistic terms within a linguistic hierarchy defined in Herrera and Martínez (2001) (the one of Fig. 4). Thus, based on the linguistic two-tuple model, it is natural that the unification phase follows the formulae of Eq. (15). In the aggregation phase, two arithmetical averaging operators were considered for aggregation in two distinct levels. Finally, the exploitation phase applies a choice degree to derive a ranking of alternatives similar to the idea of Herrera et al. (2000), Roubens (1989), and Fodor and Roubens (1994).
Recently, Wang and Xiong (2011) focused on a QGDM problem with quality function deployment in the context of multi-granularity LTSs. According to the background, they formed the multi-granularity LTS by the unbalanced LTSs defined by Eq. (3). The proposed decision making approach is based on the one proposed in Xu (2009).
Zhu and Hipel (2012) proposed a gray target QGDM approach based on a multi-granularity LTS and applied to vendor evaluation of a commercial airplane. The linguistic information was unified using the technique of Herrera and Martínez (2001). The linguistic two-tuples OWA operator was used for aggregating the considered linguistic information. The lower and upper values of a target distance were used for the exploitation of the alternatives’ ranking. Moreover, the linguistic hierarchy proposed in Herrera and Martínez (2001) has been successfully applied in several decision support systems, such as the recommender system for the selective dissemination of research resources (Porcel et al. 2012) (associated with specific similarity measures).
6 Further directions
Among the abovementioned literature, one can conclude that the use of multi-granularity LTSs is a direct and useful way to deal with uncertainties in qualitative evaluations and has been successfully applied in many distinct practical areas. However, there are some debatable issues to be figured out. As stated by Dubois (2011), the use of membership functions characterized by fuzzy sets is just for the sake of practical convenience, but encoding linguistic terms by numbers is neither more meaningful nor more robust than purely numerical techniques. Moreover, most of the studies focus on the processing of multi-granularity linguistic information, but few of them concentrate on the development of a proper set of LTSs, especially the semantics of terms, for specific applications. Hereinafter, we point out some potential directions for further investigations from the aspects of both theoretical models and applications.
As the theoretical aspect, the unification techniques need to be much more concise. The existing techniques, such as unified by fuzzy sets, fuzzy numbers, linguistic two-tuples and virtual terms are conducted based on the semantics of basic terms and are more or less complex, which results into the fact that the unified linguistic values are usually not in the original domain any more. If the unification can be done by the ordered structure of a LTS, the process of unification would be easier. A possible way to achieve this is the use of the weakened linguistic hedges with inclusive interpretation (De Cock and Kerre 2004). Take the linguistic hierarchy shown in Fig. 4 for example, the middle term \( s_{2}^{(2)} \) in the second level can be denoted by “more or less \( s_{4}^{(3)} \)”, where \( s_{4}^{(3)} \) is the middle term in the third level, the linguistic hedge “more or less” is modeled by means of similarity relations defined on the domain and the LTS \( S^{(3)} \) in the third level serves as the BLTS in this case.
Furthermore, preference relations are powerful tools for decision making, but there is little literature focused on group decision making by preference relations with multi-granularity linguistic information. In fact, according to the complexity of real problems, different individuals may prefer to express their preference relations by linguistic information with distinct granularities taking the form of either basic terms, uncertain terms, hesitant fuzzy linguistic terms (Rodriguez et al. 2012) or extended hesitant fuzzy linguistic terms (Wang 2015; Wang and Xu 2015). Herrera-Viedma et al. (2005) only started this area by a simple case.
For the purpose of practical applications, most of the existing researches have focused on the pure QGDM problems whose criteria are all qualitative. As mentioned in Li (2010) and Zhang et al. (2015), multiple kinds of non-homogeneous information may be included in a complex problem, thus it is interesting to conduct the non-homogeneous information or even multi-format non-homogeneous information in group decision making.
7 Concluding remarks
Multi-granularity LTSs are helpful for the QGDM problems when the granularities of uncertainty of distinct sources are different. This paper has presented a systematic overview on the management of multi-granularity linguistic information from both theoretical and applied aspects. The existing models of representing multi-granularity linguistic information have been reviewed at first. Then the QGDM approaches in this setting have been reviewed according to the general framework of linguistic approaches. Moreover, we have summarized the studies focusing on the applications of multi-granularity LTSs and put forward the key points involved with three phases of the QGDM framework. Finally, we have pointed out some possible directions for further research.
References
Bordogna G, Fedrizzi M, Pasi G (1997) A linguistic modeling of consensus in group decision making based on OWA operators. IEEE Trans Syst Man Cybern A 27:126–133
Chang SL, Wang RC, Wang SY (2007) Applying a direct multi-granularity linguistic and strategy -oriented aggregation approach on the assessment of supply performance. Eur J Oper Res 177:1013–1025
Chen ZF, Ben-Arieh D (2006) On the fusion of multi-granularity linguistic label sets in group decision making. Comput Ind Eng 51:526–541
Chuu SJ (2007) Evaluating the flexibility in a manufacturing system using fuzzy multi-attribute group decision-making with multi-granularity linguistic information. Int J Adv Manuf Technol 32:409–421
Chuu SJ (2009) Selecting the advanced manufacturing technology using fuzzy multiple attributes group decision making with multiple fuzzy information. Comput Ind Eng 57:1033–1042
De Cock M, Kerre EE (2004) Fuzzy modifiers based on fuzzy relations. Inf Sci 160:173–199
de Soto AR, Trillas E (1999) On antonym and negate in fuzzy logic. Int J Intell Syst 14:295–303
Delgado M, Verdegay J, Vila M (1992) Linguistic decision-making models. Int J Intell Syst 7:479–492
Delgado M, Verdegay JL, Vila M (1993) On aggregation operations of linguistic labels. Int J Intell Syst 8:351–370
Delgaodi M, Vila M, Voxman W (1999) On a canonical representation of fuzzy numbers. Fuzzy Sets Syst 93:125–135
Dubois D (2011) The role of fuzzy sets in decision sciences: old techniques and new directions. Fuzzy Sets Syst 184:3–28
Espinilla M, Liu J, MARTinez L (2011) An extended hierarchical linguistic model for decision-making problems. Comput Intell 27:489–512
Fan ZP, Liu Y (2010) A method for group decision-making based on multi-granularity uncertain linguistic information. Expert Syst Appl 37:4000–4008
Fodor JC, Roubens M (1994) Fuzzy preference modelling and multicriteria decision support. Springer, Berlin
Herrera F, Herrera-Viedma E (2000) Linguistic decision analysis: steps for solving decision problems under linguistic information. Fuzzy Sets Syst 115:67–82
Herrera F, Martinez L (2000) A 2-tuple fuzzy linguistic representation model for computing with words. IEEE Trans Fuzzy Syst 8:746–752
Herrera F, Martínez L (2001) A model based on linguistic 2-tuples for dealing with multigranular hierarchical linguistic contexts in multi-expert decision-making. IEEE Trans Syst Man Cybern B 31:227–234
Herrera F, Herrera-Viedma E, Martínez L (2000) A fusion approach for managing multi-granularity linguistic term sets in decision making. Fuzzy Sets Syst 114:43–58
Herrera-Viedma E, López-Herrera AG (2007) A model of an information retrieval system with unbalanced fuzzy linguistic information. Int J Intell Syst 22:1197–1214
Herrera-Viedma E, Cordón O, Luque M, Lopez A, Muñoz A (2003) A model of fuzzy linguistic IRS based on multi-granular linguistic information. Int J Approx Reason 34:221–239
Herrera-Viedma E, Martinez L, Mata F, Chiclana F (2005) A consensus support system model for group decision-making problems with multigranular linguistic preference relations. IEEE Trans Fuzzy Syst 13:644–658
Huynh VN, Nakamori Y (2005) A satisfactory-oriented approach to multiexpert decision-making with linguistic assessments. IEEE Trans Syst Man Cybern B 35:184–196
Jiang YP, Fan ZP, Ma J (2008) A method for group decision making with multi-granularity linguistic assessment information. Inf Sci 178:1098–1109
Kaufmann A, Gupta MM (1991) Introduction to fuzzy arithmetic: theory and applications. Arden Shakespeare, London
Kbir MA, Benkirane H, Maalmi K, Benslimane R (2000) Hierarchical fuzzy partition for pattern classification with fuzzy if-then rules. Pattern Recogn Lett 21:503–509
Levrat E, Voisin A, Bombardier S, Bremont J (1997) Subjective evaluation of car seat comfort with fuzzy set techniques. Int J Intell Syst 12:891–913
Li DF (2010) A new methodology for fuzzy multi-attribute group decision making with multi-granularity and non-homogeneous information. Fuzzy Optim Decis Mak 9:83–103
Martínez L, Liu J, Yang JB, Herrera F (2005) A multigranular hierarchical linguistic model for design evaluation based on safety and cost analysis. Int J Intell Syst 20:1161–1194
Massanet S, Riera JV, Torrens J, Herrera-Viedma E (2014) A new linguistic computational model based on discrete fuzzy numbers for computing with words. Inf Sci 258:277–290
Porcel C, Tejeda-Lorente A, Martínez M, Herrera-Viedma E (2012) A hybrid recommender system for the selective dissemination of research resources in a technology transfer office. Inf Sci 184:1–19
Rodriguez RM, Martinez L (2013) An analysis of symbolic linguistic computing models in decision making. Int J Gen Syst 42:121–136
Rodriguez RM, Martinez L, Herrera F (2012) Hesitant fuzzy linguistic term sets for decision making. IEEE Trans Fuzzy Syst 20:109–119
Roubens M (1989) Some properties of choice functions based on valued binary relations. Eur J Oper Res 40:309–321
Torra V (1996) Negation functions based semantics for ordered linguistic labels. Int J Intell Syst 11:975–988
Torra V (2001) Aggregation of linguistic labels when semantics is based on antonyms. Int J Intell Syst 16:513–524
Wang H (2015) Extended hesitant fuzzy linguistic term sets and their aggregation in group decision making. Int J Comput Intell Syst 8:14–33
Wang XT, Xiong W (2011) An integrated linguistic-based group decision-making approach for quality function deployment. Expert Syst Appl 38:14428–14438
Wang H, Xu ZS (2015) Some consistency measures of extended hesitant fuzzy linguistic preference relations. Inf Sci 297:316–331
Wang SY, Chang SL, Wang RC (2009) Assessment of supplier performance based on product -development strategy by applying multi-granularity linguistic term sets. Omega 37:215–226
Xu ZS (2004a) Uncertain linguistic aggregation operators based approach to multiple attribute group decision making under uncertain linguistic environment. Inf Sci 168:171–184
Xu ZS (2004b) A method based on linguistic aggregation operators for group decision making with linguistic preference relations. Inf Sci 166:19–30
Xu ZS (2004c) EOWA and EOWG operators for aggregating linguistic labels based on linguistic preference relations. Int J Uncertain Fuzzy Knowl Syst 12:791–810
Xu ZS (2005) Deviation measures of linguistic preference relations in group decision making. Omega 33:249–254
Xu ZS (2006) An approach based on the uncertain LOWG and induced uncertain LOWG operators to group decision making with uncertain multiplicative linguistic preference relations. Decis Support Syst 41:488–499
Xu ZS (2008) Linguistic aggregation operators: an overview. In: Fuzzy sets and their extensions: representation, aggregation and models. Springer Berlin Heidelberg, pp 163–181
Xu ZS (2009) An interactive approach to multiple attribute group decision making with multigranular uncertain linguistic information. Group Decis Negot 18:119–145
Xu ZS (2012) Linguistic decision making: theory and methods, in. Springer, Berlin
Yu XH, Xu ZS, Zhang XM (2010) Uniformization of multigranular linguistic labels and their application to group decision making. J Syst Sci Syst Eng 19:257–276
Zadeh LA (1975) The concept of a linguistic variable and its application to approximate reasoning—I. Inf Sci 8:199–249
Zadeh LA (1996) Fuzzy logic = computing with words. IEEE Trans Fuzzy Syst 4:103–111
Zadeh LA (1997) Toward a theory of fuzzy information granulation and its centrality in human reasoning and fuzzy logic. Fuzzy Sets Syst 90:111–127
Zhang ZF, Chu XN (2009) Fuzzy group decision-making for multi-format and multi-granularity linguistic judgments in quality function deployment. Expert Syst Appl 36:9150–9158
Zhang ZF, Chu XN (2011) Risk prioritization in failure mode and effects analysis under uncertainty. Expert Syst Appl 38:206–214
Zhang Z, Guo C (2012) A method for multi-granularity uncertain linguistic group decision making with incomplete weight information. Knowl Based Syst 26:111–119
Zhang XL, Xu ZS, Wang H (2015) Heterogeneous multiple criteria group decision making with incomplete weight information: a deviation modeling approach. Inf Fusion 25:49–62
Zhu J, Hipel KW (2012) Multiple stages grey target decision making method with incomplete weight based on multi-granularity linguistic label. Inf Sci 212:15–32
Acknowledgments
The authors thank Editor-in-Chief and two anonymous reviewers for their helpful comments and suggestions, which have led to an improved version of this paper. The work was supported by the National Natural Science Foundation of China (No. 61273209) and the Central University Basic Scientific Research Business Expenses Project (No. skgt201501).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Xu, Z., Wang, H. Managing multi-granularity linguistic information in qualitative group decision making: an overview. Granul. Comput. 1, 21–35 (2016). https://doi.org/10.1007/s41066-015-0006-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41066-015-0006-x