
Abstract
This study aims to predict and model the compressive strength of self-compacting concrete (SCC) across various fly ash content ranges. The research utilized two approaches: hierarchical regression (HR) and artificial neural networks (ANN) for modeling six variables influencing the process (cement content, fly ash content, water-to-binder ratio (W/B), coarse aggregate, fine aggregate, and superplasticizer). The fly ash content varied from 0 to 60% of the total weight of cement. The findings emphasize that the compressive strength of SCC is significantly affected by all the independent variables studied, except for superplasticizer. The statistical evaluation using the Pearson correlation (R), determination coefficient (R2), Adjusted R2, Predicted R2, root mean square error (RMSE), mean square error (MSE) and mean absolute percentage error (MAPE) demonstrate that both ANN and HR are robust tools for predicting compressive strength of SCC. Additionally, the ANN and HR models show strong correlations with experimental data, with the ANN model displaying superior accuracy. As the performance indices showed, the ANN model had a higher predictive accuracy than HR. The ANN model had a higher determination coefficient (R2) of 98.51%, compared to 95.25% for HR, indicating a higher accuracy.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Concrete is a prevalent construction material worldwide, with much of the existing knowledge in concrete technology originating from highly developed regions [1]. Over recent years, special concrete types like self-compacting concrete (SCC) have gained popularity. SCC, which originated in Japan during the late 1980s, is capable of flowing under its self-weight. This feature permits for effortless placement of concrete without the need for extra consolidation in intricate formwork, densely reinforced structural components, or areas that are difficult to reach. This not only conserves time and lowers overall expenses, but it also improves the work environment and sets the stage for automation in concrete construction. SCC is an innovative, consistent, and compact concrete when hardened, exhibiting mechanical properties and durability akin to conventional consolidated concrete. Numerous scholars have set forth principles for the composition of SCC mixtures. These include decreasing the volume ratio of aggregate to cementitious material, augmenting the volume of paste and the water-to-cement ratio (w/c), meticulously managing the maximum size of coarse aggregate particles and their total volume, and making use of admixtures that enhance viscosity [2].
Superplasticizers are typically necessary to achieve high workability in SCC, while viscosity-modifying admixtures help eliminate segregation. However, chemical admixtures can be expensive, potentially increasing material costs. Offsetting this, the use of mineral additions, known as supplementary cementing materials, can improve concrete slump without escalating costs. These SCMs, such as fly ash, silica fume, blast furnace slag, or limestone filler, are by-products of various manufacturing processes. When used as partial replacements for Portland cement, they reduce the quantity of cement required, thus lowering the energy and CO2 footprint of concrete, while also enhancing workability and long-term concrete properties [3, 4]. Fly ash (FA), a residue from coal combustion transported by flue gases, is widely utilized in diverse concrete applications. Incorporating FA in concrete develops strength and durability depending on its reactivity, particle size distribution, and carbon content. Typically, FA is used to partially replace cement or fine aggregates, aiming to attain desired concrete properties. Studies have shown that using FA in SCC reduces the required superplasticizer dosage to achieve a similar slump flow compared to concrete made solely with Portland cement [5, 6].
Several studies have attempted to optimize SCC mix proportions by incorporating FA, suggesting that around 30% cement replacement with FA results in exceptional workability [7]. Though, due to variations in material constituents’ quality and quantity, coupled with different design specifications, founding a universal relationship between fly ash and cement ratio, plasticizer, and w/c ratio presents a challenge. Different properties of SCC have been predicted using AI and ML methods in the last few decades [8, 9]. The output and input variables in a data set have a nonlinear relationship that can be modeled with high accuracy by these algorithms. Engineering problems have been solved successfully using various ML algorithms such as support vector machines (SVMs), artificial neural networks (ANNs), response surface method (RSM), genetic programming (GP), and others [8,9,10].
In civil engineering, these techniques have been employed to develop models predicting concrete properties [11]. In the context of SCC, researchers have utilized these techniques to propose predictive models. For instance, Asteris et al. [12] developed a back propagation neural network prediction model for compressive of SCC containing different mineral admixture. Silva and Štemberk [13] created shrinkage prediction models for SCC using a combination of fuzzy logic and genetic algorithms. Using RSM and ANN, Ofuyatan et al. [14] created models to estimate the compressive, tensile and impact strength of SCC with silica fume and polyethylene terephthalate waste as partial replacements of cement and sand. The RSM model had a good accuracy (R2 ≥ 0.92) for the mechanical properties. The ANN model performed better as it captured the data variability with a high R2 value (R2 > 0.93) for training, testing and validation. However, most of studies primarily rely on experimental data from their environments, limiting the generalizability of results. In contrast, our study compiles a comprehensive database from diverse data sources, including international literature, enabling broader applicability.
In this study, a comparison was made between a hierarchical regression analysis and an ANN-based model to predict the compressive strength of SCC, considering factors like cement content, fly ash content, W/B ratio, fine aggregate, coarse aggregate and superplasticizer. The evaluation of each method’s efficiency was based on comparing metrics such as the coefficient of variation (R2), root mean square error (RMSE), mean absolute percentage error (MAPE), mean square error (MSE), and Pearson correlation (R) for both models. Significant data was collected to construct a comprehensive database including various mixtures of fly ash SCC. Notably, this study marks the first comparison of HR and ANN in predicting the compressive strength of SCC with fly ash.
Data collection
The dataset for this study was compiled from diverse sources and used to train and test both the ANN and HR models. A total of 165 (Appendix A) distinct experimental data points were collected from various literature sources [15, 16]. In the suggested models, the data is structured into six input factors that comprise cement content, fly ash content, W/B ratio, coarse aggregate, fine aggregate and superplasticizer. The output parameters forecasted by both the ANN and HR models relate to the compressive strength of SCC. The limit values for the input and output factors utilized in the ANN and HR models are provided in Table 1
The models underwent evaluation through a process involving statistical analysis and comparison with other experimental findings. The process of feature engineering for the models involves common steps:
-
(1)
Data collection Gather the raw data that will be used to train the model.
-
(2)
Data cleaning Handle missing values, remove duplicates, and deal with outliers. This step ensures that the quality of data fed into the model is good.
-
(3)
Feature selection Identify and select the most relevant features to use in the model. This can reduce overfitting, improve accuracy, and reduce training time.
-
(4)
Data splitting Split the data into training, validation, and test sets to evaluate the performance and generalizability of the ANN model. Figure 1 provides a more comprehensive overview of the study’s methodology.

Flow chart of the steps of the both HR and ANN models
Mathematical models
Hierarchical regression (HR)
Hierarchical regression Analysis is a statistical technique used to predict the relationship between a dependent variable (Y) and an independent variable (x) by employing a polynomial equation of nth degree. Essentially, it’s a specific application of multiple linear regression within the realm of machine learning. The process involves integrating polynomial terms into the multiple linear regression equation, effectively transforming it into polynomial regression. In this methodology, the original features are modified into polynomial features up to the desired degree (2, 3, …, n), which are then utilized in a linear framework. This approach provides several advantages, including the ability to estimate the quadratic impact of the variables being examined and identify potential interactions among various variables. The standard formula for a quadratic polynomial model is outlined as follows [17]:
In this quadratic polynomial model, Y represents the predicted response, where α0 is the constant term (intercept), αi represents the linear coefficients, αij corresponds to the coefficients for interactions, and αii represents the quadratic coefficients. The variables xi and xj are used to denote the selected independent variables.
For predicting the compressive strength (CS) of SCC, CS is considered as the dependent parameter. The amounts of cement, fly ash, water-to-binder ratio (W/B), fine aggregate, coarse aggregate, and superplasticizer are regarded as independent variables (Table 1).
To assess the significance of the model, various metrics were employed, including Pearson correlation (R), the determination coefficient (R2), Adj. R2, Pred. R2, root mean square error (RMSE), mean squared error (MSE) and mean absolute percentage error (MAPE). The equations of statistical error analysis were presented as follow [18]:
where N represents the overall number of inputs, and Opred, Oexp and Oave represent the predicted value, target value and average of predicted values, respectively.
One possible approach to assessing the predictive ability of the model for the value out of the limitation is by using the predicted R2. Higher values of predicted R2 indicate better predictive capability. If the predicted R2 is significantly lower than the R2, it may suggest overfitting.
Artificial neural network (ANN)
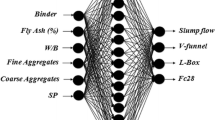
An Artificial Neural Network is a flexible assembly of extensively parallel structures, engineered to address complex issues by leveraging the collective strength of simple computing units, often known as artificial neurons [19]. The principle of ANNs is that an interrelated network of straightforward processing units can understand the complex relationships between input and output factors. In ANN modeling, there’s no requirement for prior understanding of the functional relations between the parameters [20], and the ANN methodology has been successfully applied to resolve reverse problems [21]. As depicted in Fig. 2, an ANN is consisted from an input layer, an output layer, and one or more hidden layers.

Typical architecture of a back-propagation ANN
Each neuron functions as a processing unit, receiving one or multiple inputs and generating an output signal by means of a transfer function. Each connection is associated with a weight that indicates the influence on the present processing unit from a set of inputs or another processing unit in the prior layer. At the outset, linking weights and bias values are allocated randomly, and then they are fine-tuned according to the results of the training procedure.
Numerous training methods are at one’s disposal, such as back propagation and cascade correlation schemes. The back-propagation algorithm, a widely used gradient descent technique, was employed for minimizing the error in each training pattern by adjusting the weighting incrementally [22]. The assessment of this effectiveness, or generality, is done by testing the network with new data sets. A successful learning procedure entails choosing a suitable network setup, which includes determining the number of hidden layers and their corresponding neurons. The function of the neurons in these hidden layers is to discern the connection between the inputs and outputs of the network [23].
Deciding on the size of the hidden layer can be complex and is somewhat reliant on the quantity and quality of training arrays. There’s no one-size-fits-all rule for choosing the number of neurons in the hidden layer. The neuron count in an ANN should be appropriate for precise modeling of the particular problem, however also limited to promote the network’s ability to generalize. Past research has tried to connect the number of neurons to the input and output variables, as well as the training patterns [23]. Nonetheless, these rules cannot be universally applied [24]. Some researchers have proposed an upper bound for the necessary number of neurons in the hidden layer, suggesting it should be one more than twice the number of input points; however, even this rule does not guarantee optimal generalization of the network.
In order to develop a robust back propagation network, it’s often beneficial to perform a parametric analysis by adjusting the number of neurons in the hidden layer and assessing the subsequent stability of the ANN. The construction of ANN typically involves two or three key stages, often known as ‘training,’ ‘validation,’ and ‘testing.’ During the training phase, the network is exposed to training data and modifications are made based on the errors observed. Both input and desired output data are used to fine-tune the ANN’s output and reduce discrepancies.Validation is used to assess the ANN ability to generalize and to stop training when generalization improvements stop. Testing does not influence training but provides an independent evaluation of ANN performance through and after training [25].
The statistical significance of the ANN model was assessed using several measures, including the R2, adj. R2, pred. R2, Pearson R, MSE, MAPE and RMSE. Moreover, it’s crucial to verify the predictive capability of the proposed ANN and HR models for the compressive strength of SCC, using new data derived from extra experimental findings provided by other researchers, which were not included in the training data.
Results and discussion
Derivative HR statistical model
The modeling process consisted of two primary stages: initially identifying an appropriate model and subsequently checking its efficacy. The process commenced by employing a second-order polynomial model, as depicted in Eq. (1). Following this, parameters with P-values exceeding 0.05 were systematically removed, refining the model iteratively until only significant parameters (P < 0.05) remained [26,27,28].
The initial analysis emphasized the relationship between compressive strength and six independent variables (cement C, fly ash F, water-binder-ratio W/B, fine aggregate S, coarse aggregate G, superplasticizer SP). Numerous trials were adopted to investigate the impact of the number of terms and the span of exponents on the predictive accuracy of the model.
Subsequently, the most optimal model derived from multivariable HR regression was presented in Eq. (6), encompassing the six independent variables. After establishing this model, the subsequent step involved evaluating its adequacy through residual plots [29, 30]. Using the gathered experimental data, a second-order polynomial model was formulated, following Eq. (1). The regression model fitting the response is expressed in Eq. (6).
The model described by Eq. (6) reveals that all the independent variables investigated significantly influenced compressive strength, except for superplasticizer. Notably, cement and fly ash had a primary impact on compressive strength, appearing in multiple terms within the derivative model. Table 2 further substantiates the significance of the linear terms of cement and fly ash for compressive strength, as indicated by their P-values being below 0.05%. The interaction among most variables significantly impacted the response within Eq. (6).
To ensure the efficiency of the model, the residuals plot should display a structureless pattern. The normal plot of residuals for the response, illustrated in Fig. 3, exhibits residuals closely aligning with a straight line, implying a normal scattering of errors. This suggests that the terms incorporated in the model hold significance.

Normal probability plot of residuals for compressive strength of HR model
The significance of the model was assessed using the F test and P-value. The P-values for the model were below 0.05, underscoring their significance. Typically, a model is considered significant if the F value is higher [31]. As shown in Table 2, the F value of 199.18 emphasizes the model’s substantial significance.
The accuracy of the statistical models can be confirmed by analyzing the variance proportions (R2), making sure that the discrepancy between the adjusted R2 and the pred. R2 is less than 20% [32]. In this study, the model demonstrated a notably high determination coefficient, R2, at 95.25%, signifying that only 4.75% of the variation couldn’t be accounted for this model. This underscores the robust statistical significance of the model and its suitable fit, suggesting a significant relation between the actual values and those predicted by the model.
Table 2 further confirms that the difference between the adjusted R2 and predicted R2 was less than 20%, validating the model’s practicality for response. Additionally, the adjusted R2 values closely aligned with the R2, suggesting the absence of unnecessary terms in the model. All the P-values in Table 2, established through ANOVA, demonstrated that the lack of fit had an insignificant relationship with pure error.
Artificial neural network ANN
In this study, the MATLAB program’s ANN toolbox (nftool) was utilized for the necessary computations. A feed-forward network with one hidden layer was trained using a back-propagation training algorithm with the Levenberg–Marquardt back propagation algorithm.
If the trust-region algorithm failed to provide a satisfactory fit and suitably limit the coefficients, the Levenberg–Marquardt algorithm was selected [33]. As it is presented in Fig. 4, the transfer functions are the hyperbolic tangent sigmoid for both hidden and output layer.

The architecture of the (6-7-1) ANN
The training, validation, and testing sets for an ANN can have different percentages depending on the project or data size. A common way is to use 70% for training, 15% for validation, and 15% for testing [34]. The aim is to have enough data in the training set to build a good model, enough data in the validation set to adjust hyperparameters and select the best model during training, and enough data in the test set to measure the final model’s performance [35]. These percentages are not fixed and can be changed based on factors such as the total data amount and the model complexity [34, 35]. For instance, if there are a lot of data, you might use a smaller percentage for training and give more to the validation and test sets. On the other hand, with less data, you might need a larger training set to prevent underfitting [34]. In this study, 91 out of 131 specimens (70% of the total data) were used to train the ANN model in this set. To check the reliability of the results, 20 out of 131 specimens (15% of the total data) were used for validation. The remaining 20 specimens (15% of the total data) were used for testing.
The number of neurons in the hidden layer was ascertained by training various ANN with varying numbers of neurons and matching the forecast outcomes with the anticipated response. The ideal number of hidden neurons was found to be 7 for a single hidden layer of the (6-7-1) ANN, as depicted in Fig. 4. Table 3 summarizes the parameters used for ANN training.
The ANN models’ predictions were not affected by the number of neurons in the input layer or the input data expressions in practical scenarios, according to the ANN models analysis. However, the results contradicted the common belief and showed that the lowest standard deviation values were obtained by normalizing within the [min–max] range. The ANN models were trained for epochs ranging from 6 to 20. Training usually stops before reaching the maximum number of epochs to avoid overfitting the data. This improves the network’s generalization. Training also stops if the cross-validation results do not improve beyond a certain tolerance. This shows that the advanced multilayer feed-forward neural network models can predict the compressive strength with high accuracy and low computational effort. It is important to know that the optimal architecture of a neural network model provided by the authors may not be very helpful to other researchers and engineers in practice without the specific values of the ANN weights. However, if the suggested ANN structure also includes the specific numerical values of the weights, it can be very useful. This allows the ANN model to be easily implemented in an MS-Excel file, making it accessible to anyone interested in modeling. Therefore, Table 4 shows the final weights for both hidden layers and bias. By using the properties specified in Table 1 and applying the assigned weights and bias values across the layers of an ANN according to Fig. 4, it is possible to estimate the expected compressive strength.
Remarkably high Pearson R-values of 0.99374, 0.98507, 0.99386, and 0.99254 were attained for training, validation, testing, and overall, respectively.
The calculation of CS using (6-7-1) ANN is less common compared to HR analysis due to the advantages of HR, including not requiring specialized software, generating easily interpretable regression constants, and assessing the importance of various input factors.
Validation and comparison of HR and (6-7-1) ANN models by
Statistical analysis error
In this study, both HR and ANN models were employed to predict the compressive strength of SCC incorporating fly ash. The correlation between the experimental and computed values was used to validate the effectiveness of these mathematical models. The high correlation confirmed that the mathematical models accurately reflected the predicted results. The statistical analysis in Table 5 showed the high-quality predictions made by both HR and (6-7-1) ANN models. However, the (6-7-1) ANN model had a clear advantage in data fitting and estimation capabilities over HR. The (6-7-1) ANN model had a higher determination coefficient (R2) of 98.51%, compared to 95.25% for HR, indicating a higher accuracy. The statistical analysis in Table 5 supported the accuracy and quality of predictions obtained by both HR and (6-7-1) ANN models. The actual and predicted values of compressive strength for both models were plotted in Fig. 5a, b. It was observed that the deviations of the residuals were notably smaller and more regular for (6-7-1) ANN compared to HR. The HR model exhibited higher variation than the ANN model as presented in Fig. 6a, b. It’s important to note that while HR provides a regression equation for prediction and demonstrates the effects of experimental parameters and their interactions on the response, ANN offers flexibility in adapting to any experimental plan to construct the model. The ANN allows for incorporating new experimental data, contributing to a reliable and adaptable model. Thus, interpreting the compressive strength of SCC data through an ANN architecture is more rational and consistent.

Experimental versus predicted values for compressive strength a (6-7-1) ANN model and b HR model

Time series plots for experimental and predicted CS for the two models a ANN (6-7-1) model and b HR model
Comparison with the findings of other researchers
The effectiveness of the trained (6-7-1) ANN and HR models is determined by their capacity to extrapolate predictions from the training data and to handle new, unfamiliar data effectively in the range of input factors used during training. Thus, it was crucial to validate the capability of the proposed (6-7-1) ANN and HR models to predict SCC compressive strength for new data attained from further results from other researchers. The models were represented with a total of 20 unseen records and were tasked with predicting SCC compressive strength for each set of values within the six prominent factors [5, 18, 36,37,38,39]. Table 6 presents a comparison among the values computed by the proposed models and the new data records used for validation. This accurately depicts the calculated relative error in each calculation, as defined by Eq. (4).
where Oexp is the experimental output and Opred is the output estimated by the ANN and HR models.
The evaluation of the (6-7-1) ANN model and the HR models were expressed through the total relative error. This measurement demonstrates that employing the suggested models enables accurate prediction of the 28-day compressive strength of SCC with varying proportions of fly ash.
Limitations
The ANN model can be used when the experimental values for (cement, fly ash, W/B, fine aggregate, coarse aggregate and SP) tests are available to the researcher or practitioner. It is important to note that the HR and ANN models can only give reliable predictions within the parameter values range shown in Table 1. If the parameter values are outside this range, the prediction may not be trustworthy.
Conclusions
In the current study, an analysis was carried out to examine the impact of modifying the quantities of cement, fly ash, water-to-binder ratio, fine aggregate, coarse aggregate, and superplasticizer on the compressive strength of self-compacting concrete. The hierarchical regression and artificial neural network models were utilized to assess and predict the compressive strength, drawing upon experimental data from prior literature.
Key conclusions from this study include:
-
Both ANN and HR models, built on prior experimental outcomes, proved to be effective and efficient in forecasting compressive strength. Leveraging these models allowed us to gather valuable insights with fewer trial mixtures.
-
In terms of predictive accuracy, the tested ANN models outperformed HR, as evidenced by superior performance indices. The comparison highlighted that ANN models yielded a high Pearson R, approaching 1 (0.99254). The results underscored ANN’s efficacy in predicting compressive strength for SCC with diverse fly ash proportions. However, to enhance the ANN model’s versatility, a more extensive and diverse training database would be beneficial.
-
The utilization of ANN for compressive strength prediction is less common compared to HR, primarily because the latter offers advantages such as not requiring specific software, producing easily applicable regression constants, and evaluating the importance of different input factors. However, employing ANN for predicting compressive strength in SCC at 28 days is particularly advantageous when dealing with nonlinear functional relationships, where traditional methods may fall short.
References
Zongjin L (2011) Advanced concrete technology. Wiley, Hoboken
EFNARC (2005) The European guidelines for self-compacting concrete,” Eur. Guidel Self Compact Concr. p. 63, [Online]. Available: http://www.efnarc.org/pdf/SCCGuidelinesMay2005.pdf
Neville AM (2005) Properties of concrete, 4th edn. Pearson Education Limited
Khatib JM (2008) Performance of self-compacting concrete containing fly ash. Constr Build Mater 22(9):1963–1971. https://doi.org/10.1016/j.conbuildmat.2007.07.011
Liu M (2010) Self-compacting concrete with different levels of pulverized fuel ash. Constr Build Mater 24(7):1245–1252. https://doi.org/10.1016/j.conbuildmat.2009.12.012
Barbhuiya S (2011) Effects of fly ash and dolomite powder on the properties of self-compacting concrete. Constr Build Mater 25(8):3301–3305. https://doi.org/10.1016/j.conbuildmat.2011.03.018
Sanni SH, Khadiranaikar RB, Ash F (1989) Performance of self compacting concrete incorporating fly ash. J Mech Civil Eng 15:33–37
Sadrossadat E, Basarir H, Karrech A, Elchalakani M (2022) An engineered ML model for prediction of the compressive strength of eco-SCC based on type and proportions of materials. Clean Mater 4:100072. https://doi.org/10.1016/j.clema.2022.100072
Siddique R, Aggarwal P, Aggarwal Y, Gupta SM (2008) Modeling properties of self-compacting concrete: support vector machines approach. Comput Concr 5(5):461–473. https://doi.org/10.12989/cac.2008.5.5.461
Boukhatem B, Kenai S, Tagnit-Hamou A, Ghrici M (2011) Application of new information technology on concrete: an overview. J Civ Eng Manag 17(2):248–258. https://doi.org/10.3846/13923730.2011.574343
Alzabeebee S, Al-Hamd RKS, Nassr A, Kareem M, Keawsawasvong S (2023) Multiscale soft computing-based model of shear strength of steel fibre-reinforced concrete beams. Innov Infrastruct Solut 8:1. https://doi.org/10.1007/s41062-022-01028-y
Asteris PG, Kolovos KG, Douvika MG, Roinos K (2016) Prediction of self-compacting concrete strength using artificial neural networks. Eur J Environ Civ Eng 20:s102–s122. https://doi.org/10.1080/19648189.2016.1246693
Da Silva WRL, Štemberk P (2013) Expert system applied for classifying self-compacting concrete surface finish. Adv Eng Softw 64:47–61
Ofuyatan OM, Agbawhe OB, Omole DO, Igwegbe CA, Ighalo JO (2022) RSM and ANN modelling of the mechanical properties of self-compacting concrete with silica fume and plastic waste as partial constituent replacement. Clean. Mater 4:100065. https://doi.org/10.1016/j.clema.2022.100065
Siddique R, Aggarwal P, Aggarwal Y (2011) Prediction of compressive strength of self-compacting concrete containing bottom ash using artificial neural networks. Adv Eng Softw 42(10):780–786. https://doi.org/10.1016/j.advengsoft.2011.05.016
Belalia Douma O, Boukhatem B, Ghrici M, Tagnit-Hamou A (2017) Prediction of properties of self-compacting concrete containing fly ash using artificial neural network. Neural Comput Appl 28:707–718. https://doi.org/10.1007/s00521-016-2368-7
Neter J (1983) Applied Linear Regression Models.pdf. p. 561
Turk K, Karatas M, Gonen T (2013) Effect of fly ash and silica fume on compressive strength, sorptivity and carbonation of SCC. KSCE J Civ Eng 17(1):202–209. https://doi.org/10.1007/s12205-013-1680-3
Yeh IC (1998) Modeling of strength of high-performance concrete using artificial neural networks. Cem Concr Res 28(12):1797–1808. https://doi.org/10.1016/S0008-8846(98)00165-3
Oreta AWC (2004) Simulating size effect on shear strength of RC beams without stirrups using neural networks. Eng Struct 26(5):681–691. https://doi.org/10.1016/j.engstruct.2004.01.009
Dias WPS, Pooliyadda SP (2001) Neural networks for predicting properties of concretes with admixtures. Constr Build Mater 15(7):371–379. https://doi.org/10.1016/S0950-0618(01)00006-X
Öztaş A, Pala M, Özbay E, Kanca E, Çaǧlar N, Bhatti MA (2006) Predicting the compressive strength and slump of high strength concrete using neural network. Constr Build Mater 20(9):769–775. https://doi.org/10.1016/j.conbuildmat.2005.01.054
Rachmatullah MIC, Santoso J, Surendro K (2021) Determining the number of hidden layer and hidden neuron of neural network for wind speed prediction. PeerJ Comput Sci 7:1–19. https://doi.org/10.7717/PEERJ-CS.724
Alshihri MM, Azmy AM, El-Bisy MS (2009) Neural networks for predicting compressive strength of structural light weight concrete. Constr Build Mater 23(6):2214–2219. https://doi.org/10.1016/j.conbuildmat.2008.12.003
I. G. and Y. B. and Courville A (2016) Deep Learning, 29:7553. [Online]. Available: http://deeplearning.net/
Harith IK, Hassan MS, Hasan SS (2022) Liquid nitrogen effect on the fresh concrete properties in hot weathering concrete. Innov Infrastruct Solut 7:1. https://doi.org/10.1007/s41062-021-00731-6
Harith IK, Hussein MJ, Hashim MS (2022) Optimization of the synergistic effect of micro silica and fly ash on the behavior of concrete using response surface method. Open Eng 12(1):923–932. https://doi.org/10.1515/eng-2022-0332
Nadir W, Harith IK, Ali AY (2022) Optimization of ultra-high-performance concrete properties cured with ponding water. Int J Sustain Build Technol Urban Dev 13(4):454–471. https://doi.org/10.22712/susb.20220033
Harith IK, Hassan MS, Hasan SS, Majdi A (2023) Optimization of liquid nitrogen dosage to cool concrete made with hybrid blends of nanosilica and fly ash using response surface method. Innov Infrastruct Solut 8(5):1–15. https://doi.org/10.1007/s41062-023-01107-8
Harith IK (2023) Optimization of quaternary blended cement for eco-sustainable concrete mixes using response surface methodology. Arab J Sci Eng. https://doi.org/10.1007/s13369-023-08071-6
Han H, Yu R, Li B, Zhang Y, Wang W, Chen X (2019) Multi-objective optimization of corrugated tube with loose-fit twisted tape using RSM and NSGA-II. Int J Heat Mass Transf 131:781–794
Aziminezhad M, Mahdikhani M, Memarpour MM (2018) RSM-based modeling and optimization of self-consolidating mortar to predict acceptable ranges of rheological properties. Constr Build Mater 189:1200–1213
Gavin HP (2019) The Levenberg-Marquardt algorithm for nonlinear least squares curve-fitting problems. Duke Univ. pp. 1–19, [Online]. Available: http://people.duke.edu/~hpgavin/ce281/lm.pdf
Bai Y, Chen M, Zhou P, Zhao T, Lee JD, Kakade S (2021) How important is the train-validation split in meta-learning ?
Xu Y, Goodacre R (2018) On splitting training and validation set: a comparative study of cross-validation, bootstrap and systematic sampling for estimating the generalization performance of supervised learning. J Anal Test 2(3):249–262. https://doi.org/10.1007/s41664-018-0068-2
Dinakar P, Kartik Reddy M, Sharma M (2013) Behaviour of self compacting concrete using Portland pozzolana cement with different levels of fly ash. Mater Des 46:609–616. https://doi.org/10.1016/j.matdes.2012.11.015
Leung HY, Kim J, Nadeem A, Jaganathan J, Anwar MP (2016) Sorptivity of self-compacting concrete containing fly ash and silica fume. Constr Build Mater 113:369–375. https://doi.org/10.1016/j.conbuildmat.2016.03.071
Naik TR, Kumar R, Ramme BW, Canpolat F (2012) Development of high-strength, economical self-consolidating concrete. Constr Build Mater 30:463–469. https://doi.org/10.1016/j.conbuildmat.2011.12.025
Zhu W, Bartos PJM (2003) Permeation properties of self-compacting concrete. Cem Concr Res 33(6):921–926. https://doi.org/10.1016/S0008-8846(02)01090-6
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no confict of interest.
Human and animal rights
This study does not contain any studies with human participants or animals performed by any of the authors.
Informed consent
For this type of study, formal consent is not required.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A: Experimental database of self-compacting concrete
Appendix A: Experimental database of self-compacting concrete
See Table 7.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Harith, I.K., Abbas, Z.H., Hamzah, M.K. et al. Comparison of artificial neural network and hierarchical regression in prediction compressive strength of self-compacting concrete with fly ash. Innov. Infrastruct. Solut. 9, 62 (2024). https://doi.org/10.1007/s41062-024-01367-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s41062-024-01367-y