
Abstract
This study proposes a discrete probability model for the modeling of count datasets. Some important properties are derived, including characteristic and moment-generating functions, mean, variance, index of dispersion, skewness, kurtosis, and risk measures (actuarial measures). The maximum likelihood estimation approach has been used to estimate parameter estimates for the proposed distribution. The convergence of the estimators is assessed via a simulation study. In the end, applications to four practical datasets are given to show the usefulness of the proposed distribution over famous discrete distributions. It is manifest that the proposed model provides a better fit than competitive models.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Count data occur in a variety of sectors, such as the number of patients, medical visits, catastrophic earthquakes each year, traffic accidents in a month, trees in the forest, number of fires, and the number of microorganisms growing in an hour. The Poisson distribution is a standard distribution for modeling count observations. Sometimes the existing models do not follow the properties of datasets and do not provide efficient results. So, a more flexible probability distribution is required to analyze count datasets with varying behavior. Several probability models are introduced using different discretization approaches. The reader can consult a comprehensive review by [9] on discrete models, datasets, and discretization techniques. Some examples are: Poisson Lindley [25], discrete Pareto [19], discrete Lindley [15], discrete inverse Weibull [17], Poisson Ailamujia [16], discrete Ramus-Louzada [13], Poisson XLindley [3], Poisson moment exponential [2], discrete power-Ailamujia [5], discrete moment exponential [1], Poisson Mirra [21] and new discrete Ramos-Louzada [4].
Assume a random variable \(X\) having XLindley distribution [10] with the probability density function (PDF) and cumulative distribution function (CDF), respectively:
and
The XLindley distribution attracted a lot of attention due to its adaptability. Various authors further generalized it for more complicated and different types of datasets. For example, for unit interval datasets, the Unit-XLindley [14] distribution; for count observations, the Poisson XLindley [3]; and for continuous datasets, the Power XLindley [22].
Let a random variable \(X\) follow a continuous random variable with PDF over range \(R\), then the resulting probability mass function (PMF) for a new discrete random variable \(Y\) is obtained using relation:
In this study, we used the discretization approach given in Eq. (3) to propose a new discrete XLindley (DXL) distribution. The DXL model included some intriguing characteristics, including closed-form formulas for the mean, variance, and moment-generating function. It is an excellent candidate for modeling over-dispersed nature datasets. In the end, we validated the importance of the proposed distribution using four datasets from diverse fields.
The structure of the study is as follows: We proposed a new probability model in Sect. 2. In Sect. 3, statistical properties are derived. The proposed distribution's parameter estimation is covered in Sect. 4. In Sect. 5, the adaptability of the new distribution is demonstrated by the analysis of four datasets. Finally, Sect. 6 brings our research to a conclusion.
2 Derivation of new distribution
A new discrete probability distribution is derived using the discretization methodology stated in Eq. (3). The PMF of DXL distribution is given below:
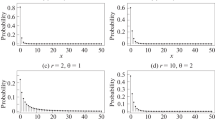
where \(0<\alpha ={e}^{-\theta }<1\). The DXL PMF behavior for different values of a parameter is given in Fig. 1.

PMF graphs of the DXLD for various parameter settings
It is found that the PMF exhibits declining, increasing and then, decreasing and unimodal form. So asymmetric datasets can be modeled using the suggested approach. The DXL model's CDF can be written as follows:
where \(\alpha >0\). The corresponding survival function is:
The hazard function (HF) is:
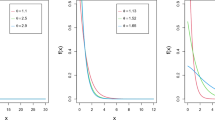
Figure 2 makes available the HF visualization of the DXL distribution for some choices of parameters. We observe that the failure rate pattern of the proposed model is increasing.

Visualization of HF for various parameter values
3 Statistical properties
In this section, some statistical properties of DXL distribution are derived and studied.
3.1 Moment-generating function (mgf)
The mgf of DXL distribution with parameter \(\alpha \) is given by:
The first four moments about the origin of DXL are:
and
The first four moments about the mean can be derived using the following relation \({\mu }_{r}=E{\left(Y-{\mu }_{1}^{^{\prime}}\right)}^{r}\).
The Dispersion Index and Coefficient of variation can be obtained by using formulas:
\(DI=\frac{Variance}{Mean}\) and \(CV=\frac{SD}{Mean}\)
The formula to calculate the coefficient of skewness and kurtosis are:
The descriptive measures given in Table 1 compute numerically using some parameter values to illustrate the behavior of the DXL distribution.
According to the results tabulated in Table 1, the DXL model can be an appropriate choice to investigate asymmetric “positively skewed” and dispersion data having a leptokurtic shape.
3.2 Actuarial measures
One of the most difficult challenges in the field of actuarial sciences is estimating market risk. When buying and selling anything, a risk estimate is necessary. A risk estimate is required when purchasing and selling anything. We evaluated the value at risk (VaR) and tail value at risk (TVaR), two significant actuarial variables for the DXL distribution.
The VaR of DXL distribution is attained as \({y}_{p}=F\left(y\right)\), where y is gained by solving the nonlinear equation given below:
TVaR stands for conditional tail expectation and is calculated as follows:
Table 2 shows the values of Value at Risk and Tail Value at Risk for some choices of parameters.
4 Parameter estimation
Assume \({y}_{1},{y}_{2},\dots ,{y}_{n}\) to be a random sample of size \(n\) from the DXL distribution. The Log-likelihood function is given by:
The log-likelihood equation is obtained by differentiating the above equation with respect to the parameter α:
It is noted that Eq. (11) cannot have an explicit solution. This goal must be solved numerically using an iterative technique like Newton–Raphson. For this purpose, we use the fitdistrplus (version 1.1–8) package of the R (version 4.2.2, 2022) software [23].
5 Simulation study
We run a simulation study with finite sample sizes to test the long-term correctness of the MLEs of the DXLD parameter. Using various parameter values, we created samples of n = 5, 10, 25, 50, 100, and 200 from the DXLD. We study the five parameter scenarios as follows: α = 0.2, 0.4, 0.6, 0.8, and 0.9. In this scenario, the iteration is repeated 10,000 times. As a result, we computed the average estimate (AVEs), absolute average bias (AABs), and mean square error (MSEs) given by
Table 3 summarizes the findings. As can be observed, the MSEs associated with each estimate fall as the sample size increases. This demonstrates the MLEs' consistent performance.
On the basis of simulation criteria, the MLE approach performs well in estimating the DXL distribution parameter.
6 Empirical study
The DXL distribution will be examined via four datasets originating from various domains. We evaluate our model's effectiveness by contrasting it with the Poisson distribution (PD), the Poisson XLindley distribution (PXLD) [3], the discrete inverted Topp–Leone distribution (DITLD) [12], the discrete Bilal distribution (DBD) [6], the discrete Burr–Hatke distribution (DBHD) [11], the discrete Rayleigh distribution (DRD) [24], and the discrete Pareto distribution (DPrD) [19]. The MLE approach is used to estimate the parameters. Moreover, different discrimination criteria, such as the Akaike information criterion (AIC) and Bayesian information criterion (BIC), are employed to identify the best-fit probability distribution. Furthermore, Kolmogorov–Smirnov (KS) statistics and Chi-Square are used to assess the suitability of competing models. The mathematical expressions of Chi-Square and Kolmogorov–Smirnov statistics are given as follows:
where \({e}_{k}\) and \({o}_{k}\) are expected and observed frequencies of the kth class, respectively.
Example I
The first dataset is about a biological experiment, originally analyzed [7]. The data are given in Table 5. In an experiment conducted at random on 8 hills with 15 repetitions, the investigator tallies the number of borers per hill of corn. Table 4 portrays MLEs with respective standard errors (SE) of competitive distributions. We also compute the 95% confidence intervals (CI) for the estimates. Moreover, to get a closer picture, we reported the observed frequencies (OF) and empirical expected frequencies (EF) with respective goodness-of-fit (GF) measures in Table 5.
According to Table 5, our proposed distribution provides the minimum values of the mentioned discriminant criteria and the highest p values for the biological experiment dataset. Figures 3 and 4 show the fitted PMF, CDF, and PP plots, which back up the empirical data.

Fitted PMF for the first dataset

Fitted CDF (left panel) and PP (right panel) plots for the first dataset
Example II
The second application is associated with the failure of 15 electronic machines during an accelerated life examination [20]. The data are: 1, 5, 6, 11, 12, 19, 20, 22, 23, 31, 37, 46, 54, 60, and 66. Table 6 provides the MLEs with their SE for all fitted models along with their 95% CI. Furthermore, in Table 7, the observed and empirically expected frequencies with respective GF measures are reported.
From the findings listed in Table 7, it is found that the DXL distributions work quite well for discussing the second dataset. The fitted CDF and PP plots are displayed in Fig. 5, which supports the empirical results provided in Table 7.

Fitted CDF (left panel) and PP (right panel) plots for the second dataset
Example III
The next discrete dataset is about the number of epileptic seizure tallies [8]. Similarly, the MLEs, SE, and 95% confidence interval for this dataset are presented in Table 8. The observed and expected frequencies and GF are given in Table 9.
According to Table 8, it is found that the DXL distribution appears to be the best among all the competitive models considered. The fitted PMF is graphically displayed in Figs. 6 and 7 which supports the results provided in Table 9.

Fitted PMF for the third dataset

Fitted CDF (left panel) and PP (right panel) plots for the third dataset
Example IV
The fourth dataset is related to the number of forest fires in Greece between July 1 and August 31, 1998. This dataset is reported in [18]. Table 10 shows the MLEs for the competing models, standard errors, and 95% CI for the estimations. Table 11 shows the GF measures for the distributions that were examined.
From Table 11, it can be observed that the DXL distribution appears to be the best choice for analyzing the fourth dataset. In Fig. 8, the fitted CDF and PP plots are plotted, which also supports the findings listed in Table 11.

Empirical CDF (left panel) and PP (right panel) plots for the fourth dataset
7 Conclusion
The discrete XLindley distribution is a novel discrete distribution derived in this article. The proposed model may be the best solution for modeling asymmetric data with overdispersion phenomena. Several properties of the new model have been derived. It was discovered that all of its attributes can be stated in closed forms, which makes the new model more appealing because it can be used in many studies, particularly time series and regression. To estimate the model parameter, the maximum likelihood estimation approach is applied. Actuarial indicators such as the value at risk and tail value at risk of the proposed distribution are calculated to quantify market risk in a portfolio of instruments. To illustrate the flexibility of the proposed discrete model, four distinctive real datasets are utilized in various fields. Finally, we hope that the DXL distribution attracts a wider set of applications in various fields.
Data availability
The data are given in the manuscript.
References
Afify, A.Z., Ahsan-ul-Haq, M., Aljohani, H.M., Alghamdi, A.S., Babar, A., Gómez, H.W.: A new one-parameter discrete exponential distribution: properties, inference, and applications to COVID-19 data. King Saud Univ. J. Sci. 1, 102199 (2022)
Ahsan-ul-Haq, M.: On poisson moment exponential distribution with applications. Ann. of Data Sci. 2022, 1–16 (2022)
Ahsan-ul-Haq, M., Al-Bossly, A., El-Morshedy, M., Eliwa, M.S.: Poisson XLindley distribution for count data: statistical and reliability properties with estimation techniques and inference. Comput. Intell. Neurosci. 2022, 1–16 (2022)
Ahsan-ul-Haq, M., Zafar, J.: A new one-parameter discrete probability distribution with its neutrosophic extension: mathematical properties and applications. J Data Sci Anal Int (2023). https://doi.org/10.1007/s41060-023-00382-z
Alghamdi, A.S., Ahsan-ul-Haq, M., Babar, A., Aljohani, H.M., Afify, A.Z.: The discrete power-Ailamujia distribution: properties, inference, and applications. AIMS Math. 7(5), 8344–8360 (2022)
Altun, E., El-Morshedy, M., Eliwa, M.S.: A study on discrete Bilal distribution with properties and applications on integer-valued autoregressive process. Revstat. Stat. J. 18, 70–99 (2020)
Beall, G.: The fit and significance of contagious distributions when applied to observations on larval insects. Ecology 21, 460–474 (1940)
Chakraborty, S.: On some distributional properties of the family of weighted generalized Poisson distribution. Commun. Stat. - Theory Methods 39, 2767–2788 (2010)
Chakraborty, S.: Generating discrete analogues of continuous probability distributions-A survey of methods and constructions. J. Stat. Distrib. Appl. 2, 1–30 (2015)
Chouia, S., Zeghdoudi, H.: The XLindley distribution: properties and application. J. Stat. Theory Appl. 20, 318 (2021)
El-Morshedy, M., Eliwa, M.S., Altun, E.: Discrete burr-hatke distribution with properties, estimation methods and regression model. IEEE Access 8, 74359–74370 (2020)
Eldeeb, A.S., Ahsan-ul-Haq, M., Babar, A.: A discrete analog of inverted topp-leone distribution: properties, estimation and applications. Int. J. Anal. Appl. 19, 695–708 (2021)
Eldeeb, A.S., Ahsan-ul-Haq, M., Eliwa, M.S.: A discrete Ramos-Louzada distribution for asymmetric and over-dispersed data with leptokurtic-shaped: properties and various estimation techniques with inference. AIMS Math. 7, 1726–1741 (2021)
Eliwa, M.S., Ahsan-ul-Haq, M., Al-Bossly, A., El-Morshedy, M.: A unit probabilistic model for proportion and asymmetric data: properties and estimation techniques with application to model data from SC16 and P3 algorithms. Math. Probl. Eng. 2022, 1–13 (2022)
Gómez-Déniz, E., Calderín-Ojeda, E.: The discrete Lindley distribution: properties and applications. J. Stat. Comput. Simul. 81, 1405–1416 (2011)
Hassan, A., Shalbaf, G.A., Bilal, S., Rashid, A.: A new flexible discrete distribution with applications to count data. J. Stat. Theory Appl. 19, 102–108 (2020)
Jazi, M.A., Lai, C.D., Alamatsaz, M.H.: A discrete inverse Weibull distribution and estimation of its parameters. Stat. Methodol. 7, 121–132 (2010)
Karlis, D., Xekalaki, E., Lipitakis, E.A.: On some discrete valued time series models based on mixtures and thinning. Proceedings of the fifth hellenic-european conference on computer mathematics and its applications, 872–877 (2001)
Krishna, H., Pundir, P.S.: Discrete Burr and discrete Pareto distributions. Stat. Methodol. 6, 177–188 (2009)
Lawless, J.F.: Statistical models and methods for lifetime data, vol. 362. Wiley, Hoboken (2011)
Maya, R., Irshad, M.R., Chesneau, C., Nitin, S.L., Shibu, D.S.: On discrete poisson-mirra distribution: regression, INAR (1). Process Appl Axioms 11, 1–27 (2022)
Meriem, B., Gemeay, A.M., Almetwally, E.M., Halim, Z., Alshawarbeh, E., Abdulrahman, A.T., Hussam, E.: The power XLindley distribution: statistical inference, fuzzy reliability, and COVID-19 application. J. Funct. Spaces 2022, 1–21 (2022)
R Core Team. (2022). R: a language and environment for statistical computing. R foundation for statistical computing: Vienna, Austria, 2021. Available online: https://www.R-project.org/
Roy, D.: Discrete rayleigh distribution. IEEE Trans. Reliab. 53, 255–260 (2004)
Sankaran, M.: The discrete poisson-lindley distribution. Biometrics 26, 145–149 (1970)
Author information
Authors and Affiliations
Contributions
All authors contribute equally.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Eldeeb, A.S., Ahsan-ul-Haq, M. & Babar, A. A new discrete XLindley distribution: theory, actuarial measures, inference, and applications. Int J Data Sci Anal 17, 323–333 (2024). https://doi.org/10.1007/s41060-023-00395-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41060-023-00395-8