
Abstract
This paper presents the application of oppositional krill herd algorithm (OKHA)-based reinforced learning neural network (RLNN) controller to study the discrete-mode automatic generation control (AGC) problems in the deregulated environment considering superconducting magnetic energy storage (SMES) system for three-area hydrothermal power system. The dynamic responses using OKHA-based RLNN controller for various loading conditions are compared with the proportional–integral–derivative (P–I–D) controllers whose gains are also optimized using OKHA. Area control error (ACE) is used as input to both P–I–D and RLNN controllers, and the weights of neural networks have been adjusted online for RLNN controllers. Sensitivity analyses have been performed to investigate the robustness of the controllers that are subject to change in SMES parameters and loading conditions. Investigation reveals that OKHA-based RLNN controllers give better dynamic performances compared to gains of P–I–D controllers obtained using OKHA considering SMES units for different loading conditions.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Traditional power system structure has gone through many changes after deregulation of power sector, and most of the countries in the world have power regulating authorities who have set up restructured rules to improve power supply, which has resulted in the deregulation of AGC. The generation companies (GENCOs), distribution companies (DISCOs), transmission companies (TRANSCOs) and independent system operator (ISO) autonomously play a role in the competitive market. So, consumers have the opportunity to choose the providers of electricity and GENCOs that sell power to various DISCOs at competitive prices and each DISCO in an area has the freedom to have a contract with any GENCO in any other area to buy power. The total agreement is represented in a matrix called DISCO participation matrix (DPM) (Donde et al. 2001). More research works on the deregulation system have been incorporated in the literature (Christie and Bose 2001; Kumar et al. 1997; Tan et al. 2012; Demiroren and Zeynelgil 2007; Sinha et al. 2012; Arya and Kumar 2016; Balamurugan and Lekshmi 2016; Sahu et al. 2016; Nizamuddin and Bhatti 2014). The changes of the tie-line power flow and frequency deviations have occurred due to sudden load perturbation of demands from the customer side in the areas of power system. In this context, fixed gain controllers are not capable of handling the changes of the operating points.
Moreover, in case of load disturbances, the oscillations in the power–frequency and tie-line power flow persist for a long duration even with the supplementary controller. To compensate the sudden load changes, an active power source with first response such as superconducting magnetic energy storage (SMES) can take measuring action most effectively. In the literature Banerjee et al. (1990a, b), Tripathy et al. (1991), Tripathy et al. (1994) and Bhatt et al. (2011), the SMES is located in each area of the two-area system for AGC. Demroren (2003, 2004) has investigated the performance of a neural network controller for automatic generation control of a power system including the SMES unit. Abraham et al. (2007) have incorporated SMES unit as an active power source with fast response of frequencies and tie-power responses in an interconnected hydrothermal power system to compensate the sudden change of load.
Mostly integral controllers are used for AGC controllers, these types of controllers are slow acting, and nonlinearities cannot be taken into account to control the generating units using these controllers. The inherent nonlinearities in the system have led researchers to consider neural network techniques, and a nonlinear artificial neural network (ANN) controller is built with high efficiency of performance (Djukanovic et al. 1995). Supervised ANN controllers have been used by the investigators (Djukanovic et al. 1995; Beaufays et al. 1994) for better dynamic performance in the AGC system. But a considerable computational time is required for the database for training of the neural network controller using supervised learning algorithm. Reinforced learning algorithms (Ahamed et al. 2002, 2006) have also been used to get the optimal control output for the AGC system. The limitations in Djukanovic et al. (1995), Beaufays et al. (1994) and Ahamed et al. (2002, 2006) are the schemes offline and training sets are generated a priori by random variations of load and as a result the control action is discrete in nature. A back propagation through time algorithm (Zeynelgil et al. 2002) is used as neural network learning rule, and a multilayer perception neural network (MLPNN) controller for each area is used to overcome the limitations. MATLAB/Simulink model (Saikia et al. 2011) has been used to simulate the AGC system using reinforced learning neural network (RLNN) controller, and in both cases, the deregulated environment and SMES unit have not been considered. The fixed values of parameters have been considered while designing the RLNN controller based on trial and error method. Recently developed bio-inspired optimization techniques such as particle swarm optimization (Gozde et al. 2011), cuckoo search algorithm (Dash et al. 2014), firefly algorithm (Padhan et al. 2014; Sekhar et al. 2016), ant lion optimizer algorithm (Raju et al. 2016), bacterial foraging algorithm (Dhillon et al. 2016), grey wolf optimization (Guha et al. 2015) have been successfully applied for designing the controller parameters for load frequency control of interconnected power system. Also, krill herd algorithm (KHA) (Gandomi and Alavi 2012; Guha 2015, 2016), biogeography-based optimization (Guha 2014) and oppositional krill herd algorithm (OKHA) (Tizhoosh 2005; Dutta et al. 2016; Alam 2016) have been successfully applied in the various fields of power system including AGC. However, no literature has investigated the optimization of RLNN parameters for improving the dynamic responses of AGC system including the SMES unit. The present work has incorporated the physical constraints of SMES unit in the AGC while designing the RLNN controller, and the parameters of RLNN controller have been optimized using OKHA to improve its performance. The discrete-mode power system model of AGC with SMES unit has been used for designing the OKHA-based RLNN controller to make it more realistic.
In view of the above, the present work considers SMES unit in a discrete-mode AGC of three-area deregulated hydrothermal power system, and the main contributions of the present work are:
-
(i)
to optimize the gains of proportional–integral–derivative (P–I–D) controllers for a discrete-mode AGC of three-area deregulated hydrothermal power system using OKHA considering SMES unit.
-
(ii)
to design OKHA-based RLNN controller for the same power system and compare its performance with that obtained in step (i) for different loading conditions.
-
(iii)
to perform the sensitivity analysis for investigating the robustness of the OKHA-based RLNN controller that is subject to change in SMES parameters and loading conditions.
2 Dynamic Models of Three-Area Deregulated Power System
In the present work, two reheat thermal units and one hydrothermal unit with two GENCOs and two DISCOs have been considered in area 1, area 2 and area 3, respectively, as shown in Fig. 1.

Three-area restructured power system
In Fig. 1, three areas have been connected through tie-lines so that any GENCO can supply power to any DISCO of any area. In this deregulated environment, DISCOs of any area can buy power from different GENCOs of any area at competitive prices and the whole transaction can be presented using DISCO participation matrix (DPM) as follows:
Here cpf is the contract participation factor and the total number of entries of column for DISCOj in the DPM is \(\sum\nolimits_{i = 1}^{6} {{\text{cpf}}_{ij} = 1}\).
For example, in the above DPM matrix, cpf42 is the fraction of the total load power contracted by DISCO2 from GENCO4. In the case of more than one GENCO in each area, area control error (ACE) signal must be shared by the GENCOs in proportion to their contributions in each area and it can be represented by the coefficients, called ACE participation factors (ap) and for each area \(\sum\nolimits_{i = 1}^{n} {{\text{ap}}_{i} = 1}\) where n is the number of GENCOs in each area. The scheduled steady-state power flow through the three tie-lines, i.e. \(\Delta P_{\text{tie12}}^{\text{scheduled}}\), \(\Delta P_{\text{tie23}}^{\text{scheduled}}\) and \(\Delta P_{\text{tie31}}^{\text{scheduled}}\), can be expressed as follows (Demiroren and Zeynelgil 2007; Arya and Kumar 2016):
where ΔPL is the change in load demand. The tie-line power flow errors are given as (Demiroren and Zeynelgil 2007; Arya and Kumar 2016):
The ACE signals in the three areas can then be expressed as follows:
where B1, B2 and B3 are the bias factors, ΔF1, ΔF2 and ΔF3 are the frequency deviations for area 1, area 2 and area 3, respectively, and contracted power supplied by ith GENCO is given by:
The aforesaid three-area deregulated hydrothermal power system has been represented in the state space form for the analysis of the dynamic performance of the system. Figure 2 shows the block diagram of the above system, and the SMES blocks have been incorporated in each area. The system parameters are given in “Appendix”.

Three-area deregulated hydrothermal power system with the SMES
3 SMES Configuration in the Power System
The thyristor-controlled SMES unit configuration is shown in Fig. 3. The SMES unit has a DC superconducting coil and 12-pulse converter which are connected through a star–delta or star–star transformer to the AC grid through a power conversion system (PCS). The superconducting coils have current of hundreds of thousands of amperes, and no ac power system normally operates at these current levels. During the normal operation of the power system, the superconducting coil may be charged to a set value from the grid and also conducts current with negligible losses because it is maintained at very low temperatures (Banerjee et al. 1990a, b; Tripathy et al. 1991; Tripathy et al. 1994; Bhatt et al. 2011; Demroren 2003; Demiroren and Yesil 2004). The stored energy is almost released through the PCS to the power system as alternating current during the sudden rise of load demand. When the governor as well as other control mechanisms starts working to set the new equilibrium condition of the power system, the coil current changes back to its initial value. Similar action also occurs during the sudden release of loads. The excess energy of some portion is absorbed as the system returns to its steady state because the coil immediately gets charged towards its full value.

So, the DC voltage across the inductor varies continuously within a certain range of positive and negative values by the control of the converter firing angle. The inductor is initially charged to its rated current by applying a small positive voltage, and the coil is superconducting because the rated value of current is maintained constant by reducing the voltage across the inductor to zero. Neglecting the transformer and converter losses, the DC voltage is given by (Tripathy et al. 1994):
where \(E_{\text{d}}\) = inductor dc voltage in kV, \(\phi\) = firing angle in degrees, \(I_{\text{d}}\) = inductor current in kA, \(R_{\text{c}}\) = equivalent resistance in \({\text{k}}\Omega\) and \(V_{\text{do}}\) = maximum circuit bridge voltage in kV. The change of commutation angle \(\phi\) is controlled by charging and discharging of the SMES. Converter acts in the converter mode (charging mode) when \(\phi < 90^{ \circ }\), as well as the converter acts in the inverter mode (discharging mode) when \(\phi > 90^{ \circ }\).
4 Control of SMES Unit
When sudden changes of loading occur in any of the three areas, the frequency falls, power is to be pumped back, and the control voltage \(E_{\text{d}}\) becomes negative since the current through the inductor and the thyristors cannot change its direction. The change of incremental voltage applied to the inductor is expressed as:
where \(\Delta E_{\text{d}}\) = incremental change in converter voltage, Tdc = converter time delay, Ksmes = gain of control loop, and \(\Delta E_{\text{r}}\) = input signal to the SMES control logic. The inductor current deviation is given by:
In this work, ACE of ith area is considered as the input signal to the SMES control logic (i.e. \(\Delta E_{\text{di}} = {\text{ACE}}_{i}\)). Thus, from Eq. (13),
If Eq. (15) is used, the inductor current in the SMES unit will return to its nominal value very slowly. Figure 4 shows the block diagram representation of SMES incorporating the negative inductor current deviation, and the dynamic equations for both the inductor voltage and current deviation of the SMES unit area are given below:

(Reproduced with permission from Abraham et al. 2007)
SMES block diagram with negative inductor current deviation feedback
5 State Space Representation of the System
For the present analysis, the dynamic model in state space form can be written as:
where X, U, \(P_{1}\) and \(P_{2}\) are the state, control, load disturbance vectors and un-contracted power demand vectors, respectively, and A, B, \(\varGamma\) and \(\varUpsilon\) are the real constant matrices depending on the system parameters and operating points.
The discrete time analysis of the above continuous time system is modelled by the first-order linear difference equation (Kothari et al. 1989):
where \(\varPhi = e^{AT}\); \(\varPsi = (e^{AT} - I)A^{ - 1} B\); \(\varLambda = (e^{AT} - I)A^{ - 1} \varGamma\); \(\lambda = (e^{AT} - I)A^{ - 1} \varUpsilon\); T = sampling period; t = KT, K = 0, 1, 2….
In the present work, the value of T has been considered as 0.01 s.
6 Oppositional Krill Herd Algorithm (OKHA)
Gandomi and Alavi (2012) have proposed the krill herd algorithm (KHA) based on the herding behaviour of krill individuals where in the search process, an individual krill always tries to move towards the highest density of food. The position of the individual krill is updated towards the value of objective function, i.e. the distance of the food from the highest density of the krill swarm by the process of induced movement foraging and random diffusion (Guha 2015, 2016).
6.1 Induced Movement
The movement of the ith krill can be defined as (Gandomi and Alavi 2012):
and
where \(M^{\hbox{max} }\) = maximum induced speed and it is taken 0.01 m/s, \(\omega_{n}\) = inertia weight of motion induced in the range [0, 1]. \(M_{i}^{\text{old}}\) = last motion induced, \(\xi_{i}^{\text{new}}\) = local effect provided by the neighbours, \(\xi_{i}^{\text{target}}\) = effect of target direction provided by the best krill individual.
The effect of the neighbours in a krill movement individual can be expressed as follows (Gandomi and Alavi 2012):
where \(Q^{\text{b}}\) = best fitness values of the krill individuals, \(Q^{\text{w}}\) = worst fitness values of the krill individuals, \(Q_{i}\) = fitness value of the ith krill individual, \(Q_{z}\) = fitness value of the zth neighbour, p = total number of neighbours, G = relative position of the krill, τ = small positive number.
The sensing distance for each krill individual is determined as follows (Gandomi and Alavi 2012):
where \(d_{i}\) = sensing distance for the ith krill individual, N = no of krill individual.
The lowest fitness of an individual krill is known target vector and the effect of the individual krill with the best fitness on the ith individual krill have been incorporated in the following formula which leads to global optima and is expressed as (Gandomi and Alavi 2012):
where \(C^{\text{b}}\) = coefficient with the best fitness to the ith krill individual and is expressed as:
where R = random values between 0 and 1, I = no of actual iteration, Imax = maximum no of iterations.
6.2 Foraging Motion
The food location and previous experience about food locations are the main effective parameters of foraging motion, and it can be expressed for the ith krill individual as follows (Gandomi and Alavi 2012):
and
where \(V_{\text{f}}\) = foraging speed and it is taken 0.02 m/s, \(\omega_{\text{f}}\) = inertia weight of foraging motion in the range [0, 1], \(\gamma_{i}^{\text{f}}\) = attractive of food, \(\gamma_{i}^{\text{b}}\) = effect of the best fitness of the ith krill.
The iteration of food centre is expressed as (Gandomi and Alavi 2012):
The food attraction for the ith krill individual is expressed as:
where food coefficient, \(C^{\text{f}} = 2\left( {1 - ({I \mathord{\left/ {\vphantom {I {I_{\hbox{max} } }}} \right. \kern-0pt} {I_{\hbox{max} } }})} \right)\).
The best fitness effect of the ith krill individual is defined as:
where \(Q_{{i{\text{b}}}}\) = previously best position of the ith krill individual.
6.3 Physical Diffusion
It can be expressed as:
where \(D^{\hbox{max} }\) = maximum diffusion speed in the range [0.002, 0.010] m/s, \(\delta\) = random directional vector and its arrays are random values between − 1 and 1.
Equation (32) has decreased the random speed linearly with the time and works on the basis of a geometrical annealing schedule as follows (Gandomi and Alavi 2012):
6.4 Motion Process of the KHA
The foraging motion and motion induced by other krill individuals work together to make KHA a powerful algorithm (Gandomi and Alavi 2012). The position vector of a krill individual during the interval t to (\(t + \Delta t\)) is given by,
\(\Delta t\) completely depends on the search space and it seems it can be expressed as (Gandomi and Alavi 2012):
where n = total number of variables, \({\text{Ub}}_{j}\) = upper bounds of the jth variables, \({\text{Lb}}_{j}\) = lower bounds of the jth variables, \(C_{t}\) = constant number between [0, 2].
6.5 Application of the Genetic Operators
The genetic reproduction mechanisms such as crossover and mutation are incorporated into KHA for improving the performance of the algorithm (Gandomi and Alavi 2012). The jth components of the ith krill may be updated by,
where \(r = 1,2, \ldots ,i - 1,\;i + 1, \ldots ,N\) and crossover probability, \(C_{\text{r}} = 0.2Q_{{i{\text{b}}}}\).
The adaptive mutation operation is expressed as:
where \(p,q = 1,2, \ldots ,i - 1,\;i + 1, \ldots ,K \,\) and mutation probability, \({\text{Mu}} = 0.05/Q_{{i{\text{b}}}}\), \(\mu = 0\;{\text{to}}\;1\).
6.6 Opposition-Based Learning
Tizhoosh (2005) has incorporated the opposition-based learning (OBL) in computational intelligence which enhances the search abilities of the conventional population-based optimization techniques for solving nonlinear optimization problem. The main idea behind OBL is to consider the opposite of an assumption or a guess and compare it with the original assumption, thereby improving the chances to find a solution faster. The OBL concepts have been developed depending on two factors, opposite number and opposite point. Let \(x \in [a,b]\) be the real number and \(P\left( {x_{1} ,x_{2} , \ldots x_{n} } \right)\) be a point in n-dimensional coordinate system with \(x_{i} \in [a_{i} ,b_{i} ]\), then,
For fitness function f(x), if \(x \in [a,b]\) is an initial (random) guess and \(\hat{x}\) is its opposite value, then in every iteration we calculate f(x) and \(f(\hat{x})\). If \(f(\hat{x}) > f(x)\), then update the value of x with \(\hat{x}\); otherwise keep it the same. Therefore, the population proceeds towards the best solution through simultaneous computation and evaluation of the current point.
7 Optimization of Gains of P–I–D Controllers Using OKHA
In the present work, the following objective function is proposed for optimizing the P–I–D gains using OKHA (Gandomi and Alavi 2012; Tizhoosh 2005; Alam 2016):
In this case, inertia weight of motion induced (\(\omega_{n}\)) and inertia weights of foraging motion (\(\omega_{f}\)) have been considered 0.9 and 0.8, respectively, at the beginning of search process. The value of maximum induced speed (\(M^{\hbox{max} }\)), foraging speed (\(V_{\text{f}}\)) and maximum diffusion speed (\(D^{\hbox{max} }\)) are 0.01, 0.02 and 0.004 m/s, respectively. Also, the population size is taken as 50 and the number of iterations has been considered as 100. The optimal set of P–I–D controller gains has been investigated by OKHA to reduce the value of the above objective function, and the ranges of KP, KI and KD have been considered \(0 \le K_{\text{P}} \le 1\), \(0 \le K_{\text{I}} \le 1\) and \(0 \le K_{\text{D}} \le 1\), respectively.
8 Design of OKHA-Based RLNN Controller
In the present work, there are three control areas and each area has one OKHA-based RLNN controller. Figure 5 shows the OKHA-based RLNN controller structure with associated signals as well as the plant which represents state space blocks of a particular control area, and this figure also shows the error signals in the tie-lines that are used to bring up the RLNN controller weights. In this case, one neuron in the input layer, four numbers of neurons in the hidden layer and one neuron in the output layer have been considered and the tie-line error signals given by Eqs. (5, 6, 7) are used as error signals and the learning rates, \(\alpha\) and \(\sigma\), control the convergence speed and stability of the weights during learning. Similarly, the momentum constant \(\beta\) is also used to improve the convergence. \(\Delta W1_{ij}^{\text{old}}\) and \(\Delta W2_{ij}^{\text{old}}\) are the one step previous updates for the weights.

(Reproduced with permission from Saikia et al. 2011)
Construction of OKHA-based RLNN controller with plant
The initial values of all the weights in this AGC problem are considered as ‘0’, and \(\alpha\), \(\sigma\) and \(\beta\) have been optimized using OKHA by optimized the objective function given by Eq. (40). The ranges of \(\alpha\), \(\sigma\) and \(\beta\) have been considered \(0 \le \alpha \le 0.02\), \(- 1 \le \beta \le 0\) and \(0 \le \sigma \le 1\), respectively. The log-sigmoidal activation functions have been used at the hidden layer.
The RLNN controllers input in the ith area are given by:
The hidden layers input neurons for ith area are given by:
where Nh = hidden number of neuron (here, Nh = 4), Wij = hidden layers input weight vector.
The output from the hidden layer after passing through the log-sigmoid activation function is given by:
The control signal generated from the output layer is calculated as:
where W2ij = hidden layers output weight vector.
The weights of the output layer are then updated through the least mean square rule as given below:
The back propagated error to the hidden layer from the output layer is as follows:
The derivative of output of log-sigmoid function with respect to its associated input weights is given by:
Therefore, the weights of hidden layer are updated using the following equation,
The MATLAB functions have been developed using the above equations, and the algorithm is given below:
-
Step-1: Read \(N_{h}\) and initialize \(\alpha ,\beta \;{\text{and}}\;\sigma\) parameters for RLNN controller.
-
Step-2: Initialize \(W1_{ij} = 0,\;W2_{ij} = 0,\;\Delta W_{1} = 0\;{\text{and}}\;\Delta W_{2} = 0\).
-
Step-3: Set iteration count \(j = 1\).
-
Step-4: Obtain ACE, Yi from the system, \(j = 1\).
-
Step-5: If \(j = N_{h}\), go to Step-7,
-
Step-6: Advance \(j = j + 1\).
-
Step-7: Out control signal ‘z’ to the system and \(j = 1\).
-
Step-8: If \(j = N_{h}\), go to Step-10,
-
Step-9: Advance \(j = j + 1\).
-
Step-10: Initialize \(j = 1\).
-
Step-11: If \(j = N_{h}\), go to Step-4,
-
Step-12: Advance \(j = j + 1\) and go to Step-11.
-
Step-14: Calculate induced motion using Eq. (19), foraging motion using Eq. (27) and physical diffusion using Eq. (32).
-
Step-15: Implement the genetic operation using Eqs. (36) and (37).
-
Step-16: Implement the opposition-based learning using Eqs. (38) and (39).
-
Step-17: Update krill position, i.e. the value of \(\alpha ,\;\beta \;{\text{and}}\;\sigma\) using Eq. (34).
-
Step-18: If stop criterion is not reached, go to Step-13.
-
Step-19: Find the optimal value of \(\alpha ,\;\beta \;{\text{and}}\;\sigma .\)
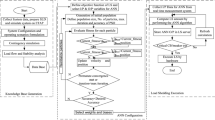
The flow chart for finding out the \(\alpha ,\;\beta \;{\text{and}}\;\sigma\) parameters of RLNN controller using OKHA is shown in Fig. 6.

Flow chart for finding optimized value of \(\alpha ,\;\beta \;{\text{and}}\;\sigma\) for RLNN controller using OKHA
9 Results and Discussion
Three different cases for analysing the performance of AGC system using both RLNN controller and P–I–D controller have been considered as follows:
Case 1:
In this case, the load has been changed in area 1 and ACE participation factors are taken as ap11 = 0.65, ap12 = 0.35, ap21 = 0.65, ap22 = 0.35, ap31 = 0.5, ap32 = 0.5. The load demand value is considered in this case as ∆PL1 = 0.05 pu MW, ∆PL2 = 0.05 pu MW, ∆PL3 = 0.0, ∆PL4 = 0.0, ∆PL5 = 0.0, ∆PL6 = 0.0. The DISCO participation matrix (DPM) is considered as follows:
Case 2:
For the second case, the ACE participation factors are considered as ap11 = 0.75, ap12 = 0.25, ap21 = 0.55, ap22 = 0.45, ap31 = 0.35, ap32 = 0.65 and the load demands are considered as ∆PL1 = 0.05 pu MW, ∆PL2 = 0.05 pu MW, ∆PL3 = 0.05 pu MW, ∆PL4 = 0.05 pu MW, ∆PL5 = 0.05 pu MW, ∆PL6 = 0.05 pu MW. The DISCO participation matrix (DPM) values are assumed as follows:
Case 3:
In this case, the DISCO infringes an agreement by demanding additional power than the pre-specified value. Then, the GENCOs must supply the extra load demand in the same area to that DISCO. So, the agreement violation occurs under second operation case and in this case it is considered that DISCO1 stipulates 0.05 p.u MW extra power. So, the full amount of local load for the area-1 is 0.15 p.u MW, i.e. [(DISCO1 load + DISCO2 load) = (0.05 + 0.05) + 0.05 = 0.15 p.u MW]. Similarly, the full amount of load for area-2 is 0.1 p.u MW, i.e. (DISCO3 load + DISCO4 load = 0.1 p.u MW). The full amount of load for area-3 is the same as that area-2. The loads without agreement of DISCO1 are reproduced in generations both of GENCO1 and GENCO2, for the same area.
In this work, the gains of P–I–D controllers in deregulated operation are optimized using OKHA for each area in the three-area power system. For AGC after deregulation, for case-2, OKHA is used for both optimizing the gains of P–I–D controllers and the parameters of RLNN controller, and the values of gains of P–I–D controllers and the parameters of RLNN controller are given in Table 1. The P–I–D controller for each area designed using OKHA is substituted by RLNN controller, and the values of objective function J are given in Table 2 for case-2. The convergent characteristics of objective functions using OKHA for P–I–D and RLNN controllers are shown in Fig. 7. From Fig. 7, it is seen that the smooth curve for change of the value of objective function for both P–I–D and RLNN controller using OKHA ensures consistency in the convergence.

Convergent characteristics of objective functions using OKHA
Figure 8 shows the comparison of dynamic responses with and without SMES considering P–I–D controllers for case-1. It is clearly seen that SMES has great effect in terms of peak deviation and settling time. So SMES should be incorporated while analysing the dynamic performance of the system. Figure 9 shows the comparison of dynamic responses of frequency deviation for the first case for area-1 with RLNN controller and ANN controller using back propagation through time algorithm, and from this figure, it is seen that RLNN controller gives better dynamic response in terms of peak deviation and settling time. A transport time delay of feedback signal, i.e. area control error (ACE) of 50 ms has been incorporated into the system to find out its impact in the dynamic performance of the system. Figure 10 shows the comparison of responses with and without time delay in the feedback control for the OKHA-based RLNN controller for case-1. It is seen that the effect of time delay on the dynamic responses of the system is negligible.

Dynamic response of frequency deviation for area-1, P–I–D controller with and without considering SMES unit

Dynamic response of frequency deviation for the first case for area-1 with SMES

Dynamic response of frequency deviation for the first case for area-1 with SMES
The comparison of frequency deviations in each area (\(\Delta F_{1} ,\;\Delta F_{2} \;{\text{and}}\;\Delta F_{3}\)) and the deviations of three tie-line powers (\(\Delta P_{\text{tie12}}^{\text{error}} ,\;\Delta P_{\text{tie23}}^{\text{error}} \;{\text{and}}\;\Delta P_{\text{tie31}}^{\text{error}}\)) for the first case considering SMES with P–I–D and RLNN controller are shown in Fig. 11, and Fig. 12 shows the comparison of the same variables for the second case. For the case of agreement violation, extra load occurs in area-1 and Fig. 13 shows the comparison of the same variables for case-3. From Figs. 11, 12 and 13, it is seen that the performance of OKHA-based RLNN controller gives better responses in terms of peak overshoot and settling time as compared to P–I–D controller designed using OKHA for frequency deviations in each area and the deviations of three tie-line powers.

Dynamic responses of \(\Delta F_{1} ,\;\Delta F_{2} ,\;\Delta F_{3} ,\;\Delta P_{\text{tie12}}^{\text{error}} ,\;\Delta P_{\text{tie23}}^{\text{error}} \;{\text{and}}\;\Delta P_{\text{tie31}}^{\text{error}}\) for case-1 considering SMES with P–I–D and RLNN controller

Dynamic responses of \(\Delta {F}_{ 1} ,\, \Delta {F}_{ 2} ,\, \Delta {F}_{ 3} ,\, \Delta {P}_{\text{tie12}}^{\text{error}} ,\, \Delta {P}_{\text{tie23}}^{\text{error}}\; {\text{and}} \; \Delta_{\text{tie31}}^{\text{error}}\) for case-2 considering SMES with P–I–D and RLNN controller

Dynamic responses of \(\Delta F_{1} ,\;\Delta F_{2} ,\;\Delta F_{3} ,\;\Delta P_{\text{tie12}}^{\text{error}} ,\;\Delta P_{\text{tie23}}^{\text{error}} \;{\text{and}}\;\Delta P_{\text{tie31}}^{\text{error}}\) for case-3 considering SMES with P–I–D and RLNN controller
The effect of variations of system parameters of SMES (L, Tdc, Ksmes, Ido and Kid) and loading conditions on the dynamic responses have been observed for sensitivity analysis of the considered SMES-based deregulated three-area hydrothermal power system. The loading conditions for case-2 and system parameters of SMES are changed by ± 40% from their nominal values taking one at a time and the peak overshoot, settling time (2%) and the values of objective function J are calculated, and the results are given in Table 3. From Table 3, it is clear that the effects of variations on system parameters and loading conditions are negligible on the performances of the system.
10 Conclusions
In the present work, RLNN controllers and P–I–D controllers have been analysed in discrete-mode AGC of a three-area deregulated hydrothermal power system considering SMES unit in each area. The gains of P–I–D controllers and the parameters of RLNN controllers for the considered power system have been optimized using OKHA. The results reveal that the OKHA-based RLNN controllers give better dynamic responses than P–I–D controllers in terms of peak deviations and settling times for different loading conditions. Sensitivity analyses have also been performed to investigate the robustness of the RLNN controllers by changing loading conditions and parameters of SMES units. From the sensitivity analysis, it is seen that OKHA-based RLNN controllers are quite robust. Discrete-mode analyses have been performed for the practical realization of the RLNN controllers.
References
Abraham RJ et al (2007) Automatic generation control of an interconnected hydrothermal power system considering superconducting magnetic energy storage. Int J Electr Power Energy Syst 29:571–579
Ahamed TPI et al (2002) A reinforcement learning approach to automatic generation control. Int J Electr Power Syst 63(1):9–26
Ahamed TPI et al (2006) A neural network based automatic generation controller design through reinforcement learning. Int J Emerg Electr Power Syst 6:11–31
Alam MS et al (2016) Optimal solutions of load frequency control problem using oppositional krill herd algorithm. In: IEEE 1st international conference on control, measurement and instrumentation (CMI), pp 6–10
Arya Y, Kumar N (2016) AGC of a multi-area multi-source hydrothermal power system interconnected via AC/DC parallel links under deregulated environment. Int J Electr Power Energy Syst 75:127–138
Balamurugan S, Lekshmi RR (2016) Control strategy development for multi source multi area restructured system based on GENCO and TRANSCO reserve. Int J Electr Power Energy Syst 75:320–327
Banerjee S et al (1990a) Application of magnetic energy storage unit as continuous VAr controller. IEEE Trans Energy Convers Syst 5(1):39–45
Banerjee S et al (1990b) Application of magnetic energy storage unit as load frequency stabilizer. IEEE Trans Energy Convers Syst 5(1):46–51
Beaufays F et al (1994) Application of neural network to load frequency control in power systems. Int J Neural Netw 7(1):183–194
Bhatt P et al (2011) Comparative performance evaluation of SMES–SMES, TCPS–SMES and SSSC–SMES controllers in automatic generation control for a two-area hydro–hydro system. Int J Electr Power Energy Syst 33:1585–1597
Christie RD, Bose A (2001) Load frequency control issues in power system operations after deregulation. IEEE Trans Power Syst 11(3):1191–1200
Dash P et al (2014) Comparison of performances of several Cuckoo search algorithm based 2 DOF controllers in AGC of multi-area thermal system. Int J Electr Power Energy Syst 55:429–436
Demiroren A, Yesil E (2004) Automatic generation control with fuzzy logic controllers in the power system including SMES units. Int J Electr Power Energy Syst 26:291–305
Demiroren A, Zeynelgil HL (2007) GA application to optimization of AGC in three-area power system after deregulation. Int J Electr Power Energy Syst 29:230–240
Demroren A (2003) Automatic generation control for power system with SMES by using neural network controller. Int J Electr Power Compon Syst 31(1):1–25
Demroren A (2004) Automatic generation control using ANN technique for multi-area power system with SMES units. Int J Electr Power Compon Syst 32(2):193–213
Dhillon SS et al (2016) Multi objective load frequency control using hybrid bacterial foraging and particle swarm optimized PI controller. Int J Electr Power Energy Syst 79:196–209
Djukanovic M et al (1995) Conceptual development of optimal load frequency control using artificial neural networks and fuzzy set theory. Int J Eng Intell Syst Electr Eng Commun 3(2):95–108
Donde V et al (2001) Simulation and optimization in an AGC system after deregulation. IEEE Trans Power Syst 6(3):481–489
Dutta S et al (2016) Unified power flow controller based reactive power dispatch using oppositional krill herd algorithm. Int J Electr Power Energy Syst 80:10–25
Gandomi AH, Alavi AH (2012) Krill herd: A new bio-inspired optimization algorithm. Int J Commun Nonlinear Sci Numer Simul 17(12):4831–4845
Gozde H et al (2011) Automatic generation control application with craziness based particle swarm optimization in thermal power system. Int J Electr Power Energy Syst 33:8–16
Guha D et al (2014) Optimal design of superconducting magnetic energy storage based multi-area hydro-thermal system using biogeography based optimization. In: 4th International conference of emerging applications of information technology, pp 52–57
Guha D et al (2015) Application of Krill Herd algorithm for optimum design of load frequency controller for multi-area power system network with generation rate constraint. In: Proceedings of the 4th international conference on frontiers in intelligent computing: theory and applications (FICTA), pp 245–257
Guha D et al (2016) Krill herd algorithm for automatic generation control with flexible AC transmission system controller including superconducting magnetic energy storage units. The Journal of Engineering, Online ISSN 2051-3305
Guha D et al (2015) Load frequency control of interconnected power system using grey wolf optimization. Int J Swarm Evol Comput 27:97–115
Kothari ML et al (1989) Discrete-mode automatic generation control of a two-area reheat thermal system with new area control error. IEEE Trans Power Syst 4(2):730–738
Kumar J et al (1997) AGC Simulator for price-based operation part I: a model. IEEE Trans Power Syst 12(2):527–532
Nizamuddin I, Bhatti TS (2014) AGC of two area power system interconnected by AC/DC links with diverse sources in each area. Int J Electr Power Energy Syst 55:297–304
Padhan S et al (2014) Application of firefly algorithm for load frequency control of multi-area interconnected power system. Int J Electr Power Compon Syst 42(13):1419–1430
Raju M et al (2016) Automatic generation control of a multi-area system using ant lion optimizer algorithm based PID plus second order derivative controller. Int J Electr Power Energy Syst 80:52–63
Sahu BK et al (2016) A novel hybrid LUS–TLBO optimized fuzzy-PID controller for load frequency control of multi-source power system. Int J Electr Power Energy Syst 74:58–69
Saikia LC et al (2011) Automatic generation control of a multi area hydrothermal system using reinforced learning neural network controller. Int J Electr Power Energy Syst 33:1101–1108
Sekhar GTC et al (2016) Load frequency control of power system under deregulated environment using optimal firefly algorithm. Int J Electr Power Energy Syst 74:195–211
Sinha S et al (2012) Application of AI supported optimal controller for automatic generation control of a restructured power system with parallel AC–DC tie lines. Int J Eur Trans Electr Power 22(5):645–661
Tan W et al (2012) Decentralized load frequency control in deregulated environments. Int J Electr Power Energy Syst 4:16–26
Tizhoosh HR (2005) Opposition-based learning: a new scheme for machine intelligence. In: International conference on computational intelligence for modelling control and automation (CIMCA), Austria, vol 1, pp 695–701
Tripathy SC et al (1991) Dynamics and stability of wind and diesel turbine generators with superconducting magnetic energy storage unit on an isolated power system. IEEE Trans Energy Convers Syst 6(4):579–585
Tripathy SC et al (1992) Adaptive automatic generation control with superconducting magnetic energy storage in power systems. IEEE Trans Energy Convers 7(3):434–441
Tripathy SC et al (1994) Automatic generation control with superconducting magnetic energy storage in power system. Int J Electr Mach Power Syst 22(3):317–338
Zeynelgil HL et al (2002) The application of ANN technique to automatic generation control for multi-machine power system. Int J Electr Power Energy Syst 24:345–354
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
State space model matrices:
For the considered three-area deregulated hydrothermal power system, the system matrix [A] is of the order of \(24 \times 24\) and its nonzero elements are given below:
The control matrix [B] is of the order of \(24 \times 3\) and its nonzero elements are given below:
The disturbance matrix [\(\varGamma\)] is of the order of \(24 \times 6\), and its nonzero elements are given below:
The matrix [\(\gamma\)] is of the order of \(24 \times 3\), and its nonzero elements are given below:
The parameters values of the power system (Arya and Kumar 2016):
SMES unit data (Abraham et al. 2007): L = 13.65 H, Tdc = 0.03 s, Ksmes = 100 kV/unit MW, Kid = 0.2 kV/kA, Id0 = 0.45 kA.
Rights and permissions
About this article

Cite this article
Das, M.K., Bera, P. & Sarkar, P.P. Oppositional Krill Herd Algorithm-Based RLNN Controller for Discrete-Mode AGC in Deregulated Hydrothermal Power System Using SMES. Iran J Sci Technol Trans Electr Eng 42, 309–325 (2018). https://doi.org/10.1007/s40998-018-0062-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40998-018-0062-8