
Abstract
Slope stability assessment is necessary to evaluate the safety of natural or man-made slopes. This analysis is crucial for determining the potential risk that could result in landslides or other hazardous situations. This research investigates the landslide predictability of crucial locations in Kalimpong, Darjeeling Himalayas, which are characterized by complicated geology in tough terrains. The study concentrated on the factor of safety determination process for dry and saturated conditions utilizing the GeoStudio commercial software “SLOPE/W” based on limit equilibrium method and provide an analytical comparison using computational intelligence and machine learning approaches. Support vector machine, decision tree, random forest, logistic regression, naïve Bayes, k-nearest neighbors algorithm, and AdaBoost are used as machine learning classifiers having a strong capability of predicting slope failures and perils. Five parameters, namely cohesion, internal friction angle, unit weight, slope angle, and slope height, are chosen as random variables and stability condition as output. Inter-criteria correlation (CRITIC)-based method is utilized to perform sensitivity analysis denoting the greatest impacting parameter, i.e., slope height. Novel ensemble approach R-Boost is identified to give maximum accuracy in comparison to all seven machine learning methods. By multifold cross-validation, R-Boost has the greatest forecasting skill, with an average classification accuracy of 0.725 and in terms of area under the curve, random forest (RF) represents an average value of 0.81, followed by R-Boost at 0.798. Among all predictive models, particularly R-Boost followed by RF provides quite similar results as obtained by SLOPE/W. This technique will be particularly beneficial in preventing, anticipating, and reducing the impact of these sorts of catastrophic disasters, which function as substantial barriers to the nation's socioeconomic progress
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Slope failures are the easiest natural hazard to prevent, reduce, or resolve (Collins and Znidarcic 2004). Landslides occur on a large portion of land surfaces except snow-covered areas in India (Chawla et al. 2018). This translates to a total area of 0.42 million km2, out of which 43% area is found in the North-Eastern Himalayan Region (NEHR) according to GSI 2014. According to the National Crime Records Bureau's (NCRB) statistics on inadvertent fatalities (2010–2019), landslides kill around 304 people in India each year. Surprisingly, recent changes in global climatic conditions have resulted in catastrophic weather events that increase the likelihood of landslides (Zou et al. 2021) and their frequency is being aggravated by uncontrolled urbanization and unorganized land-use changes in steep terrains (Khanna et al. 2021; Phong et al. 2021; Pourghasemi et al. 2012). The Kalimpong district is located in the NEHR and is susceptible to small- and large-scale landslides, particularly during the monsoon season, which lasts from July to September. The Kalimpong area has a steeply slanting mountainous topography that is constantly drained by heavy rains, making it very prone to landslides. The major town is located on a ridge near the Teesta River, but other rivers like Relli, Neora, Geesh, Leesh, Jaldhaka, and Murti, as well as several tiny streams, drain Kalimpong. These water bodies create active denudation among slopes on the valley side by erosion, which makes them steeper. The interCuvial (Area occurring between two phases or streams) area has been narrowed, making the environment more prone to landslides. The average monthly rainfall in Kalimpong during the rainy season, from June to September, runs from 119 to 417 cm (https://worldclim.org). Anthropogenic infrastructure projects such as roads, communities, hydropower projects, and so on loosen the slope material at the price of vegetative cover. This permits the loose debris to glide downslope with only a minimal lubrication from water. All of these elements combine to make Kalimpong an alluring site for landslide research. It is also critical to demarcate the danger-prone zones after which suitable steps may be implemented to limit the risks to people as well as property (Roy et al. 2022).
In general, slope stability is determined by shear strength as a function of normal stress on the slip surface, cohesion, and internal friction. The factor of safety (FoS) reflects the slope's stability, which is determined by calculating the ratio of “shear strength” to “shear stress” generated. A slope generally collapses when the produced shear stress exceeds the available shear strength of the soil (Kabir et al. 2023). Limit equilibrium analysis techniques (LEMs), a basic and conventional analytical tool for slope stability investigations, may be used to compute FoS and are widely utilized in slope stability studies because of their simplicity, low version complexity, and rapid processing durations (Mafi et al. 2021). Both the static as well as dynamic scenarios for multi-dimensional (2D and 3D) environments (Azarafza et al. 2014; Agam et al. 2016) can be used with LEM. The FoS is estimated using several equilibrium approaches. Some of the most well-known approaches include Fellenius, Bishop, Janbu, Modified Swedish, Morgenstern-Price etc., (Alejano et al. 2011). Maximum approaches out of this produce similar findings when calculating FoS, with the variance in projected values often being less than 6% (Huang et al. 2012). In recent decades, LEM has been proposed and extensively researched for slope stabilization evaluation (Yue and Kang 2021; Liu et al. 2015; Wang et al. 2011; Cheng et al. 2007; Zhu et al. 2005; Zhu et al. 2003). Regardless of their utilitarian value, the LEM technique has remained the method of choice for optimum utilization of a number of methodologies based on the nature of issue to be addressed (e.g., circular, non-circular) and the desired precision of the findings (Matthews et al. 2014). The method of slices is also utilized for identifying the most critical slip surface, taking into account the consideration of probabilistic soil parameters. (Johari and Rahmati 2019). Traditional stability analysis methods, which are impacted by the stabilization process, struggle to deliver reliable conclusions due to the uncertainties while assessing FoS values. To address this issue, researchers applied computational intelligence methodologies that give a very precise forecast of the slope condition, failure mechanism, and danger of slide (Azarafza et al. 2022; Zhu et al. 2003; Ahangari Nanehkaran et al. 2022; Li and Yang 2019; Mathe and Ferentinou 2021). Meanwhile, machine learning approaches have attracted a lot of attention for minimizing uncertainty in FoS computations.
Artificial intelligence (AI), and particularly machine learning, has offered great assistance for determining the stability of slopes in terms of FoS calculation utilizing prognostic models. Such models conjecture FoS based on the rate of machine learning and specified accuracy of models. These algorithms try to construct techniques for comprehending the existing state of “target data”, learning, and operating to learn using “training data”. It employs a variety of algorithms that are categorized as “shallow” or “deep” learning approaches in order to produce likelihoods or predictions (Raschka et al. 2020). The precision of the predictions is directly related to the algorithms’ learning mechanism, which can be a counterpart to learning models such as controlled, unstructured, or reinforcement learning (Schmidhuber 2015). The last 25 years have seen the effective use of AI and ML techniques in the fields of engineering and sciences (Asteris et al. 2021a, b, c; 2022; Johari et al. 2016; Harandizadeh et al. 2021; Zhao et al. 2021; Zhang et al. 2021; Armaghani et al. 2021; Zhou et al. 2021a,b; 2016; Yang et al. 2020; Kardani et al. 2021). ML models are also utilized in order to calculate findings for slope stability analysis that can offer insights into prospective slope collapse processes and rates through predictive modeling, risk assessment, and uncertainty analysis (Bui et al. 2020; Erzin and Cetin 2012; Abdalla et al. 2015; Verma et al. 2016; Samui 2013; Sakellariou and Ferentinou 2005; Ferentinou and Sakellariou 2007). MATLAB-based coded program (Johari and Fooladi 2020; Kalantari et al. 2023), ANFIS, and other algorithms are also used to forecast the FoS of slopes and made comparisons of those predictions with results of LEM approach (Mohamed and Kasa 2014). In different research, particle swarm optimization (PSO) technique is also used to compare the FoS of slopes with 3D-FEM (Kalatehjari et al. 2014). They demonstrated effective use of PSO under 3D circumstances, but less effective use under 2D slope stability conditions. In order to forecast slope stability in comparison to the LEM slope stability study, many researchers (Ferentinou and Sakellariou 2007; Lu and Rosenbaum 2003; Sakellariou and Ferentinou 2005) employed artificial neural networks (ANN), a fundamental and common AI model. The LEM and ANN model findings were discovered to be in agreement, and the categorization of sample observations based on the anticipated failure mechanism was made possible. In different research, while comparing support vector machine (SVM) model and contrasted it with ANN outcomes, it was shown that SVM was able to achieve a little greater accuracy (Samui 2008). Gradient boosting was used to determine the FoS and its connection to the triggering factors on slope instabilities (Zhou et al. 2019). A similar comparison was made with support vector regression (SVR) and the radial basis function (Wei et al. 2021a). Different artificial intelligence-based methods were employed to forecast the FoS values for slopes with the necessary precision, which was then applied for slope stabilization (Qi and Tang 2018). The “extreme learning machine” (Liu et al. 2014), “attribute recognition method” (Tao et al. 2021), ANN (Wei et al. 2021b), “fuzzy comprehensive evaluation method” (Wang and Lin 2021), “aggregative indicator method” (Yan et al. 2019), “particle swarm optimization” (Gupta et al. 2016) and “cloud model” (Cui et al. 2021) have all produced a number of promising results. Taking into account the stress on the body of slope, demonstrating its deformation and stability and corresponding back failure mechanism play a crucial role in the prediction of slope stability using numerical simulation techniques and the limit equilibrium approach.
Therefore, in this study, critical sites from Kalimpong are identified and utilized for the assessment of future risk prediction under dry and saturated conditions. This scope is fulfilled by calculating the factor of safety by LEM and denoting them as stable or unstable. Then, machine learning techniques are utilized to train the machine learning models and testing them for real-site data samples. The disciplines of computer science, database hypothesis, data analysis, probabilistic theory, and other scholarly fields are all necessary for using machine learning algorithms, which have major advantages including quick processing and good generalization. Standard machine learning techniques may be able to solve some systems and issues that are challenging to solve using conventional experimentation and simulation techniques. The seven traditional ML algorithms used in this research offer the benefits of a straightforward structure, good prediction, and high classification accuracy. Python (a programming language) and fundamental machine learning techniques are used in this study to evaluate the accuracy of the prediction models. Additionally, random cross-validation is used to further determine the models' accurateness. In the end, a versatile, exact, and trustworthy slope stability forecasting model is produced. Also, innovative approaches are designed to enhance the accuracy of models for such scattered datasets like data scaling, ensembling which can be achieved by normalizing or standardizing real-valued input and output variable and a new stack model R-Boost is developed in this research to get maximum accuracy in output prediction.
2 Study Area
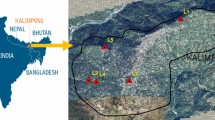
Kalimpong is a small peninsula town in the Indian state of West Bengal, close to the border of Nepal. It is 1250 m above sea level and is recognized for its moderate temperatures and natural beauty. Kalimpong is surrounded by lush green hills and is known for its tea plantations, flowers, and breathtaking Himalayan vistas. It is hemmed on the western side by the Teesta River and on the eastern side by the Relli River. The average temperature in this region is between 27 and 5 °C. The strong monsoons in this region generate devastating floods that annually cut off Kalimpong from the remaining state. Because of its location and natural characteristics, Kalimpong, like many other high regions, is prone to collapses. During the summer, the region suffers strong rainfall, which often results in landslides, also due to the steep slopes and loose soil. Despite many efforts, it continues to be a severe threat to Kalimpong and the surrounding communities. Local leaders and individuals must be vigilant and take the appropriate precautions to prevent and mitigate its effects in the region (Das et al. 2022). Figure 1 shows the geographic location of Kalimpong in India and a Google image of Kalimpong with critical sites marked (L1-6) in Mahakal Dara Bhalukhop, Chandraloke, Upper Tashiding, Ngassey Busty, Mongbol Road, and Deolo, respectively. Figure 2 represents the site images of these locations after the recurring landslide with their latitudes and longitudes in caption while soil samples were collected from these locations later.

(Source: USGS)
a Geographic location of Kalimpong in India. b Google image of Kalimpong with locations 1–6

Post-landslide images of critical locations
2.1 Geology
Kalimpong is situated in the Eastern Himalayas, a region known for its complex geological features. The region is characterized by the collision of the “Indian” and “Eurasian” tectonic plates, which has resulted in the formation of the Himalayan mountain range. The eastern flanks of Kalimpong are rather flat and safe, however the western face is primarily steep and rocky. The town of Kalimpong is primarily made up of soft phyllite, Archean gneiss, and schists. The area has several cracks and joints that increase the chance of rock decomposition and dissolution, leading to the formation of unconsolidated substance (Dikshit and Satyam 2018). The mountainous soils found in the area are marked by heavy organic matter and water-holding ability, which can cause volume growth. The bedrock in the region is a golden to silver-colored quartz mica schist of the Daling series, with small variations. The constant percolation of water at the bottom layer of the soil horizon is linked with coarse textures in the middle part of the soil resulting in a reduction in soil shear strength (Abraham et al. 2020). These geological features shape the landscape and natural resources of Kalimpong. Because of the geological activity in the region, the Eastern Himalayas are also prone to earthquakes. In the past, the shocks caused significant damage to infrastructure and human lives. An elevation map of Kalimpong shown in Fig. 3 provides information regarding the topography of a slope, which is a crucial factor for understanding the forces operating on it.

(Source: USGS)
Elevation map of Kalimpong
2.2 Geohydrology
Kalimpong, like other steep places, has a complicated water system affected by the region's geography, geology, and temperature. The power of the soil to receive water boosts soil mass and, finally, soil unit area. Landslides become more possible when pore pressure rises due to growing soil water absorption. Water flow weathers the rocks along the edges of streams and rivers, causing rock and other materials to break over time, resulting in slides. The rainy season in Kalimpong produces high-intensity rainfall, making it the region's peak landslide season. A number of smaller channels known as kholas (second- and third-order streams) and jhoras (mainly first- and second-order streams) drain the area. The jhoras get their water from a large number of long-lasting regular springs at the hill's top (Source: Save the Hills). The region is crossed by five subbasins, all of which are Teesta River sources (Mukherjee and Mitra 2001). First-order streams in the Teesta region combine to create second- and higher-order streams (Fig. 4).

(Source: USGS)
Geohydrological details showing streams of 1, 2, and 3 orders
3 Methodology
The study of geotechnical traits of crucial sites' soil at different places in Kalimpong is important so as to find the strength of the soil. For analysis of landslides, soil samples were collected from the slope’s bottom, center, and top parts after the occurrence.These were procured by an instrument “Core Cutter” at an approximate depth of 0.5 m. All of these placid samples were carefully transferred to a laboratory and tested for various qualities, viz. grain size distribution (Fig. 5), Atterberg limits as per IS: 2720(Part-5), water content, maximum dry density IS: 2720(Part-7), cohesion, and internal friction angle as per ASTM standards. In situ bulk density measurement was also done by core cutter method. The data obtained are to be utilized for LEM modeling by SLOPE/W software in GeoStudio. As geotechnical research shows, the presence of sand in the sample and the undrained and drained study of soil samples has also been done using direct shear test and triaxial shear test (consolidated drained), but since worst conditions are described to identify future risk threshold, only drained parameters are noted here by representing the Mohr–Coulomb failure envelope (Fig. 6).

Grain-size distribution curve

Mohr–Coulomb failure envelope
3.1 SLOPE/W Results
The present study measures the FoS for a variety of critical cut slopes with varying soil properties in Kalimpong using the Morgenstern–Price (M–P) method (Morgenstern and Price 1965), in GeoStudio 2021.4 with the help of Slope/W software, confirmed by field survey. This part explains the full approach, including mathematical modeling and field validation. Figure 7 depicts the SLOPE/W results for various samples at L1-6 for dry (bulk) and saturated conditions, respectively, and the soil properties along with computed factor of safety are represented in Table 1.


SLOPE/W results for L1-6 under dry and saturated conditions
3.2 Data Collection and Processing of Slope Field Cases
In this research, 97 field instances of slope stability analysis were analyzed, including 12 cases of crucial sites from the Kalimpong area, the findings of which are reported above, and 85 cases from pertinent literature based on “slope stability” assessment (Sah et al. 1994; Zhou and Chen 2009; Li and Wang 2010). Each sample depicts a field study related to slope engineering, which embraces five input parameters (i.e., five independent factors). The stability of the slope will then be assessed using a signal (one dependent component), either "stable" or "failure." Table 2 shows the distribution range of each component. To make it easier to apply ML models, “failure” and “stable” are ticketed as 0 and 1, respectively, at the time of prediction and later converted to the same.
3.3 Sanity of the Data
Each group of data was matched based on five independent characteristics, yielding one dependent outcome. Because the data are merged, each sample attribute is significant and distinct, with an accurate indication. Among these 97 dataset rows, 41 are categorized as "stable," whereas the remaining 56 are categorized as "failure." There is a ratio of 1:1.36 between these two groupings, indicating that the signs are distributed almost equally. To more immediately examine the data's validity, a violin chart (strip plot for revealing underlying data by points) is used. Figure 8a–e shows the violin plots for UW, C, Phi, SA, and SH for both “Stable” and “Failure” categories. The white circle at the center of each plot shows the median. The box's range includes the first and third quartiles. The 95% confidence level is indicated by a narrow black line existing in each violin plot. The silhouette or boundary of each violin provides an approximation of the normal kernel density for the supplied feature. The findings indicate that the data are stable and follow a normal distribution.

Normal kernel density violin plots for different input parameters
3.4 Attributes of the Information Dissemination
This section examines different statistics of each feature to check whether the data/parameters are having a “skewness” distribution. Because the five sources have distinct SI units and meanings, they are all evaluated independently. The unit weight's minimum, maximum, mean, mode, median, and standard deviation are 13.97, 31.30, 20.827, 18.5, 19.97, and 3.79 kN/m3, indicating that it follows the normal distribution. Table 3 also displays all statistical data values such as mean, median, mode, min, max, standard deviation, and dispersion. Figure 9 depicts a parametric distribution, as well as the mean (mu) and standard deviation (sigma) for normal distribution and rate parameter (lambda) for exponential distribution. However, the slope height in Fig. 9d demonstrates that it fits exponential distribution in a better manner as compared to normal distribution in other indices with rate parameter lambda = 0.01379. Also, mean and standard deviation for exponential distribution is the inverse of rate parameter, which comes out to be 72.49 for slope height. The remaining parameters, UW, C, Phi, and SA, demonstrate normal distribution.

Distribution histogram of different indexes
3.5 Assessment of Correlations Among Parameters
It is crucial to first investigate the relation between the five attributes (i.e., factors) before making a conclusion on prediction models. The significant relationship between these features may influence the models’ accuracy used in prediction and lead to indecorous inferences that controvert the reality. The equation to calculate Pearson's correlation coefficient between any two elements is represented by Eq. (1) (Cohen et al. 2009).
where r is the coefficient of correlation of x and y (range − 1 to 1), xi is the x variable value, yi is the y variable value, \(\overline{x }\) = the mean of x values, and \(\overline{y }\) = the mean of y values. Table 4 contains a matrix with the association values of all five qualities. If the correlation value of two components approaches 1, they are regarded to have a strong correlation. Otherwise, the relationship between these two elements is weak. According to Table 4, correlation between cohesion and internal friction angle is − 0.22, which shows that materials are negatively correlated with each other. The slope angle and friction have the highest positive relationship, with an r value of 0.522 (among the five characteristics considered in Table 4). However, two entities with a correlation coefficient up to 0.5 are not inextricably related. As a result, the five qualities exhibit an ignorable connection. To better explain the relationship between the five qualities chosen for this paper and to more clearly illustrate the variables' ranges and affiliations, the correlation matrix of the factors influencing the stability of the concerned slopes is displayed in Fig. 10 by blending using the drawing software.

Correlation matrix
4 Prediction from Models
4.1 Conventional ML Models
In this work, seven supervised models—support vector machine (SVM), decision tree (DT), k-nearest neighbors (KNN), logistic regression (LR), random forest (RF), and AdaBoost—and one probabilistic model naïve Bayes (NB) are used. A supervised machine learning approach called SVM may be applied to classification, regression, and outlier identification. It is a kind of linear classifier that seeks the most effective hyperplane for categorizing the data. The gap between the two classes is maximized by choosing the hyperplane in this fashion (Samui 2008). For classification and regression analysis, decision tree is a supervised machine learning method. It is a graphical representation of all the possible solutions to a decision based on certain conditions. In a decision tree, each node represents a decision, and each edge represents the outcome of that decision (Hwang et al. 2009) Since kNN is a non-parametric method, it makes no assumptions about how the data will be distributed. To get the categorization or regression value of a particular data point, it only examines the k-nearest neighbors (Cheng and Hoang 2016). A logistic function is used in the linear model of logistic regression to represent the likelihood that the output variable will fall into a certain class (Bhagat et al. 2022). Multiple decision trees are trained in the random forest algorithm using arbitrary subsets of the training data, and the final prediction is achieved by averaging the predictions of each individual tree (Xie et al. 2022). A supervised machine learning technique called AdaBoost (adaptive boosting) is utilized for classification and regression analysis. It is an ensemble learning technique that combines a number of weak learners to increase the model's performance and accuracy (Lin et al. 2021). Naïve Bayes is a probabilistic ML algorithm that is used for classification. It is based on Bayes' theorem and presupposes that the input characteristics are conditionally independent of one another (Feng et al. 2018).
4.2 Consideration of Impacting Parameters on Slope Stability
Slope stability is influenced by both numerical and qualitative parameters. The numerical parameters include cohesiveness, slope height and angle, pore water pressure, unit weight, internal friction angle, and others. Qualitative parameters include failure patterns, physical characteristics and quality of soil and rocks, subsurface water, and more. Here, the objective is to determine whether a slope is stable or failing, and this is based on numerical calculations. However, converting qualitative characteristics into quantitative values is the biggest issue while field instances data are not sufficient. Therefore, ML algorithms are used to develop prediction models based on five indicators: C, SA, SH, Phi, UW, and the dependent component related to assessment of slopes is classified as "stable" or else "failure". Interstitial water pressure is not included in the prediction models because it is often unclear in field instances and value assignment is based on diverse standards. This study focuses on 99 slope data case sets and concludes that the five chosen indicators accurately reflect slope stability. Thus, interstitial water pressure is excluded to ensure sufficient accuracy and reliability in the prediction models.
4.3 ML Models Analysis
Standard cross-validation techniques, such as 2, 3, 5, 10, and 20-fold is applied on the original testing data. To create the model for slope stability forecasting, 29 samples are selected at random as the test set and the rest data are considered as the training set. After repeating the aforementioned random choice five times, the model's final forecast result is the average of the five prediction outcomes. For ease of reckoning in this article, randomized cross-validation is performed using programming language Python. Only the scatter plots and linear fitting curves between unit weight on horizontal axis (x) and various parameters on vertical axis (y) are displayed in this article due to space restrictions. Figure 11 also represents the fitting line equation, its slope and intercept, Pearson’s coefficient (r) and coefficient of determination (COD).

Regression fitting line and scatter plots of different parameters
4.4 Valuation of Models
The common prediction model assessment metrics include classification accuracy (CA), precision (P), recall (R), the F1 score (F1) and the area under the curve (AUC). The combination of forecasting and reality is classified into four categories: true positive (TP), true negative (TN), false positive (FP), and false negative (FN). According to Eq. (2), CA measures how well the model can correctly predict both positive and negative instances shown (Begum et al. 2021).
Precision is a metric used in machine learning to evaluate the accuracy of a model's positive predictions, as indicated by Eq. (3) (Begum et al. 2021).
Equation (4) (Chen et al. 2022) gives recall, which is the inverse of accuracy.
The F1 score indicated by Eq. (5) provides a balance between precision and recall, and is particularly useful in situations where there is an uneven class distribution or where the cost of false positives and false negatives is similar. The higher the F1 score, the better the model's performance in correctly classifying both positive and negative instances. If recall is considered to be on the horizontal axis and accuracy is considered to be on the vertical axis, the 'PR' curve may be calculated [further details can be found in (Begum et al. 2021)]. Models outside of the slope provide better outcomes in general.
Equations (6) and (7) calculate the true-positive rate (TPR) and false-positive rate (FPR).
ROC is a graphical plot that illustrates the trade-off between the true-positive rate (TPR) and the false-positive rate (FPR) of a binary classifier as the decision threshold is varied. A higher AUC value indicates more success for a model.
5 Examination of Results from Predictions
5.1 Model Assessment Based on the Unprocessed Data
Seven distinct machine learning approaches and one stacking approach of random forest and AdaBoost i.e., R-Boost is introduced to conduct the random cross assessment. Table 4 shows the classification accuracy, precision, recall, F1, and AUC values derived from Eqs. (2–7). AUC is an important metric in machine learning because it provides a reliable and easy-to-interpret measure of a model's performance in binary classification problems, especially when the dataset is imbalanced. In terms of AUC, RF represents an average value of 0.81, while R-Boost has an AUC of 0.798 followed by LR with a value of 0.74. Also in terms of classification accuracy, R-Boost has the greatest forecasting skill in terms of CA, with an average of 0.725. AdaBoost and RF comes in second with an average accuracy of 0.723. AdaBoost also produces strong results since it converts a high bias low variance model to a low bias low variance model, which aids in the development of an ideal machine learning model that provides a highly accurate estimate. It is also simpler to use, requiring less adjustment than algorithms such as SVM. Here, however, the R-Boost algorithm developed gives maximum CA because it first applies random forest to the dataset in order to generate an initial array of decision trees. The decision trees are then given an AdaBoost enhancement to increase their efficiency and precision. This method can increase the model's precision and decrease its variance, making it more reliable and better able to handle complicated datasets with numerous characteristics to more explicitly characterize the correctness of each model. Accuracy is one of the indicators that the model's behavior is inaccurate for regarding skewed data. When both F1 and AUC values are taken into account, excellent prediction models may be developed. According to the findings in Table 4, forecast models with F1 values more than 70% comprise R-Boost, AdaBoost, and RF. Furthermore RF, R-Boost, and LR have AUC values greater than 74%. As a result, RF and R-Boost are regarded to be the most accurate predictor on the basis of AUC and CA, which also adds value to the novelty factor of this research paper.
5.2 Sensitivity Analysis
Here we focus on the sensitivity analysis by weight determination criteria in which the importance factor is computed for each input parameter. Inter-criteria correlation (CRITIC)-based method is utilized to perform this activity by making use of coefficient of variation, which is equal to (standard deviation/average) for individual parameter given by Ij. The objective weight (Wj) of any criteria j is determined using Eq. (8) (Krishnan et al. 2021).
In accordance with the five input parameters, weightage plays an important role. Weightage of each parameter is shown in Fig. 13. The values of weightage in percentage comes out to be 2.7, 12, 7.5, 6.3, and 71.5 for UW, C, Phi, SA, and SH respectively. According to the findings, slope height has a greater influence on slope stability than cohesiveness while unit weight has the least shown in Fig. 12.

Weightage indicator of each parameter
5.3 ROC Curve
The receiver operating characteristic (ROC) curve is a graphical depiction of a binary classifier system's performance. Area under ROC (ROC-AUC) in the curve for current scenario, as shown in Fig. 13, indicated that RF provided the greatest overall accuracy when used to quantify the level of competence for all models. Strong machine learning algorithms RF and R-Boost can forecast FoS for various earth slopes and give appropriate outcomes based on the ROC curve findings. In the interim, SVM can be recommended as an alternate method that produces acceptable and accurate results. Based on these ROC curves, RF has the maximum overall accuracy with AUC = 0.81 in comparison to other classifiers, while R-Boost has an AUC of 0.798 followed by LR with a value of 0.74, respectively. Naïve Bayes has the lowest AUC of 0.654. It is conceivable to state in this regard that the use of RF and R-Boost can give FoS with dependable and accurate results that are in excellent agreement with LEMs. This type of ML technology can help in the development of an optimal approach for determining the stability state of such slopes and providing relevant stabilization measures for them.

ROC curve
5.4 Comparison with GeoStudio Results
The modeling was done in stages, beginning with geometrical modeling and progressing through border conditions, behavioral specifications, materials, and mechanical modeling. In the phase of geometrical modeling, each slope is created based on the geographic conditions, angle and height of the slope's surface as well as other geometric index qualities. The boundary criteria are implemented via the “external boundary”, which is a secure polyline encircling the soil region needs to be studied. Also, it can be drawn manually in SLOPE/W by drawing the regions using appropriate coordinates. The present work used schematic coordinates. Table 5 contains details regarding the stability prediction based on best models and SLOPE/W program data. With their reasoning method, predictive models, particularly R-Boost followed by RF, deliver similar or close results to stability condition, as mentioned in Table 5 where S and F represent stable and failure, respectfully.
6 Conclusions
To investigate the effects of topography, weather, and other climatic conditions on slopes, a thorough numerical examination is conducted under static conditions for dry and saturated conditions, respectively, by LEM and further simulated by machine learning models. The major findings of this study are summarized as follows:
-
1.
The current study is concerned with the modeling and assessment of stability grades at crucial sites in Kalimpong identified by site visits and landslide inventory maps. Limit equilibrium software (SLOPE/W) is utilized to carry out factor of safety and slip surfaces determining the future perspective of stability in these locations. The comparison of FoS derived from simulation studies shows that under dry conditions, all slopes are stable, while in saturated conditions, two slopes are stable (marginally) while four are unstable which justifies the vulnerable impact of rainfall on the study area under both dry and saturated condition.
-
2.
Five parameters namely cohesion, internal friction angle, unit weight, slope angle, and slope height are chosen as random variables and output being stability condition. By Inter-criteria-based correlation (CRITIC) method, the outcomes indicate that height of the slope is having the greatest impact on slope stability while cohesion is second.
-
3.
Cross-validation in different number of folds and seven distinct machine learning approaches with a novel stacking approach R-Boost is used to conduct the random cross assessment. In terms of AUC, RF represents an average value of 0.81, while R-Boost has an AUC of 0.798 followed by LR with a value of 0.74, and in terms of classification accuracy, R-Boost has the greatest forecasting skill in terms of CA, with an average of 0.725. Among all predictive models, particularly R-Boost followed by RF, provides similar results as obtained by SLOPE/W.
-
4.
The current study includes a comprehensive analysis as well as evidence from experiments, which show that slopes typically fail under saturated circumstances or are marginally stable, which is supported by machine learning models. This technique will be highly beneficial in minimizing, anticipating, and reducing the impact of such catastrophes disasters, which are one of the major impediments to the nation's socioeconomic progress.
References
Abdalla JA, Attom MF, Hawileh R (2015) Prediction of minimum factor of safety against slope failure in clayey soils using artificial neural network. Environ Earth Sci 73:5463–5477
Abraham MT, Satyam N, Pradhan B, Alamri AM (2020) IoT-based geotechnical monitoring of unstable slopes for landslide early warning in the Darjeeling Himalayas. Sensors 20(9):2611. https://doi.org/10.3390/s20092611
Agam M, Hashim M, Murad M, Zabidi H (2016) Slope sensitivity analysis using Spencer's method in comparison with general limit equilibrium method. Procedia Chem 19:651–658. https://doi.org/10.1016/j.proche.2016.03.066
Ahangari Nanehkaran Y, Pusatli T, Chengyong J, Chen J, Cemiloglu A, Azarafza M, Derakhshani R (2022) Application of machine learning techniques for the estimation of the safety factor in slope stability analysis. Water 14(22):3743. https://doi.org/10.3390/w14223743
Alejano L, Ferrero AM, Ramírez-Oyanguren P, Fernández MÁ (2011) Comparison of limit-equilibrium, numerical and physical models of wall slope stability. Int J Rock Mech Min Sci 48(1):16–26
Armaghani DJ, Mamou A, Maraveas C, Roussis PC, Siorikis VG, Skentou AD, Asteris PG (2021) Predicting the unconfined compressive strength of granite using only two non-destructive test indexes. Geomech Eng 25(4):317–330
Asteris PG, Cavaleri L, Ly HB, Pham BT (2021a) Surrogate models for the compressive strength mapping of cement mortar materials. Soft Comput 25(8):6347–6372
Asteris PG, Koopialipoor M, Armaghani DJ, Kotsonis EA, Lourenço PB (2021b) Prediction of cement-based mortars compressive strength using machine learning techniques. Neural Comput Appl 33(19):13089–13121
Asteris PG, Skentou AD, Bardhan A, Samui P, Pilakoutas K (2021c) Predicting concrete compressive strength using hybrid ensembling of surrogate machine learning models. Cement Concr Res 145:106449
Asteris PG, Lourenço PB, Roussis PC, Adami CE, Armaghani DJ, Cavaleri L, Chalioris CE, Hajihassani M, Lemonis ME, Mohammed AS, Pilakoutas K (2022) Revealing the nature of metakaolin-based concrete materials using artificial intelligence techniques. Constr Build Mater 322:126500. https://doi.org/10.1016/j.conbuildmat.2022.126500
Azarafza M, Hajialilue Bonab M, Derakhshani R (2022) A novel empirical classification method for weak rock slope stability analysis. Sci Rep 12(1):14744. https://doi.org/10.1038/s41598-022-19246-w
Azarafza M, Nikoobakht S, Asghari-Kaljahi E, Moshrefy-Far M (2014) Stability analysis of jointed rock slopes using block theory (case study: gas flare site in phase 7 of South Pars Gas Complex). In: Paper presented at the Proceedings of the 32th National & 1st International Geosciences Congress of Iran
Begum N, Maiti A, Chakravarty D, Das BS (2021) Diffuse reflectance spectroscopy based rapid coal rank estimation: a machine learning enabled framework. Spectroch Acta Part a: Molec Biomol Spectroscopy 263:120150
Bhagat NK, Mishra AK, Singh RK, Sawmliana C, Singh P (2022) Application of logistic regression, CART and random forest techniques in prediction of blast-induced slope failure during reconstruction of railway rock-cut slopes. Eng Fail Anal 137:106230
Bui XN, Nguyen H, Choi Y, Nguyen-Thoi T, Zhou J, Dou J (2020) Prediction of slope failure in open-pit mines using a novel hybrid artificial intelligence model based on decision tree and evolution algorithm. Sci Rep 10(1):1–17. https://doi.org/10.1038/s41598-020-66904-y
Chawla A, Chawla S, Pasupuleti S, Rao A, Sarkar K, Dwivedi R (2018) Landslide susceptibility mapping in Darjeeling Himalayas, India. Adv Civil Eng. https://doi.org/10.1155/2018/6416492
Chen J, Huang H, Cohn AG, Zhang D, Zhou M (2022) Machine learning-based classification of rock discontinuity trace: SMOTE oversampling integrated with GBT ensemble learning. Int J Min Sci Technol 32(2):309–322
Cheng MY, Hoang ND (2016) Slope collapse prediction using Bayesian framework with k-nearest neighbor density estimation: case study in Taiwan. J Comput Civ Eng 30(1):04014116
Cheng YM, Lansivaara T, Wei WB (2007) Two-dimensional slope stability analysis by limit equilibrium and strength reduction methods. Comput Geotech 34(3):137–150
Cohen I, Huang Y, Chen J, Benesty J, Benesty J, Chen J, Huang Y, Cohen I (2009) Pearson Correlation Coefficient. In: Noise Reduction in Speech Processing. Springer Topics in Signal Processing, vol 2. Springer, Berlin and Heidelberg. https://doi.org/10.1007/978-3-642-00296-0_5
Collins BD, Znidarcic D (2004) Stability analyses of rainfall induced landslides. J Geotech Geoenviron Eng 130(4):362–372
Cui W, Wang XH, Zhang GK, Li HB (2021) Identification of unstable bedrock promontory on steep slope based on UAV photogrammetry. Bull Eng Geol Env 80:7193–7211. https://doi.org/10.1007/s10064-021-02333-z
Das S, Sarkar S, Kanungo DP (2022) GIS-based landslide susceptibility zonation mapping using the analytic hierarchy process (AHP) method in parts of Kalimpong Region of Darjeeling Himalaya. Environ Monitor Assess 194(4):234. https://doi.org/10.1007/s10661-022-09851-7
Dikshit A, Satyam DN (2018) Estimation of rainfall thresholds for landslide occurrences in Kalimpong, India. Innovat Infrastr Solut 3:1–10. https://doi.org/10.1007/s41062-018-0132-9
Erzin Y, Cetin T (2012) The use of neural networks for the prediction of the critical factor of safety of an artificial slope subjected to earthquake forces. Scientia Iranica 19(2):188–194
Feng X, Li S, Yuan C, Zeng P, Sun Y (2018) Prediction of slope stability using naive Bayes classifier. KSCE J Civ Eng 22:941–950
Ferentinou M, Sakellariou M (2007) Computational intelligence tools for the prediction of slope performance. Comput Geotech 34(5):362–384. https://doi.org/10.1016/j.compgeo.2007.06.004
Gupta S, Mishra U, Singh VP (2016) Design of minimum cost earthen channels having side slopes riveted with different types of riprap stones and unlined bed by using particle swarm optimization. Irrigat Drain 65(3):319–333. https://doi.org/10.1002/ird.1965
Harandizadeh H, Armaghani DJ, Asteris PG, Gandomi AH (2021) TBM performance prediction developing a hybrid ANFIS-PNN predictive model optimized by imperialism competitive algorithm. Neural Comput Appl 33:16149–16179
Huang CZ, Cao YH, Sun WH (2012) Generalized limit equilibrium method for slope stability analysis. In: Paper presented at the Applied Mechanics and Materials
Hwang S, Guevarra IF, Yu B (2009) Slope failure prediction using a decision tree: a case of engineered slopes in South Korea. Eng Geol 104(1–2):126–134
Johari A, Fooladi H (2020) Comparative study of stochastic slope stability analysis based on conditional and unconditional random field. Comput Geotech 125:103707
Johari A, Rahmati H (2019) System reliability analysis of slopes based on the method of slices using sequential compounding method. Comput Geotech 114:103116
Johari A, Javadi AA, Najafi H (2016) A genetic-based model to predict maximum lateral displacement of retaining wall in granular soil. Scientia Iranica 23(1):54–65
Kabir MU, Islam MS, Nazrul FB, Shahin HM (2023) Comparative stability and behaviour assessment of a hill slope on Clayey sand hill tracts. Int J Eng Trends Technol 71:11–24. https://doi.org/10.14445/22315381/ijett-v71i1p202
Kalantari AR, Johari A, Zandpour M, Kalantari M (2023) Effect of spatial variability of soil properties and geostatistical conditional simulation on reliability characteristics and critical slip surfaces of soil slopes. Transport Geotech 39:100933
Kalatehjari R, Rashid ASA, Ali N, Hajihassani M (2014) The contribution of particle swarm optimization to three-dimensional slope stability analysis. The Scient World J. https://doi.org/10.1155/2014/973093
Kardani N, Bardhan A, Samui P, Nazem M, Zhou A, Armaghani DJ (2021) A novel technique based on the improved firefly algorithm coupled with extreme learning machine (ELM-IFF) for predicting the thermal conductivity of soil. Engineering with Computers, 1–20
Khanna K, Martha TR, Roy P, Kumar KV (2021) Effect of time and space partitioning strategies of samples on regional landslide susceptibility modelling. Landslides 18:2281–2294. https://doi.org/10.1007/s10346-021-01627-3
Krishnan AR, Kasim MM, Hamid R, Ghazali MF (2021) A modified CRITIC method to estimate the objective weights of decision criteria. Symmetry 13(6):973. https://doi.org/10.3390/sym13060973
Li J, Wang F (2010) Study on the forecasting models of slope stability under data mining. In: Earth and space: engineering, science, construction, and operations in challenging environments, pp. 765–776
Li Y, Yang X (2019) Soil-slope stability considering effect of soil-strength nonlinearity. Int J Geomech 19(3):04018201. https://doi.org/10.1061/(asce)gm.1943-5622.0001355
Lin S, Zheng H, Han C, Han B, Li W (2021) Evaluation and prediction of slope stability using machine learning approaches. Front Struct Civil Eng 15(4):821–833
Liu Z, Shao J, Xu W, Chen H, Zhang Y (2014) An extreme learning machine approach for slope stability evaluation and prediction. Nat Hazards 73:787–804. https://doi.org/10.1007/s11069-014-1106-7
Liu SY, Shao LT, Li HJ (2015) Slope stability analysis using the limit equilibrium method and two finite element methods. Comput Geotech 63:291–298
Lu P, Rosenbaum M (2003) Artificial neural networks and grey systems for the prediction of slope stability. Nat Hazards 30:383–398. https://doi.org/10.1023/b:nhaz.0000007168.00673.27
Mafi R, Javankhoshdel S, Cami B, Jamshidi Chenari R, Gandomi AH (2021) Surface altering optimisation in slope stability analysis with non-circular failure for random limit equilibrium method. Georisk: Assess Manag Risk Eng Sys Geohaz 15(4):260–286. https://doi.org/10.1080/17499518.2020.1771739
Mathe L, Ferentinou M (2021) Rock slope stability analysis adopting Eurocode 7, a limit state design approach for an open pit. IOP Conf: Series Earth Environ Sci. https://doi.org/10.1088/1755-1315/833/1/012201
Matthews C, Farook Z, Helm P (2014) Slope stability analysis–limit equilibrium or the finite element method. Ground Eng 48(5):22–28
Mohamed T, Kasa A (2014) Application of fuzzy set theory to evaluate the stability of slopes. Appl Mech Mater. https://doi.org/10.4028/www.scientific.net/AMM.580-583.566
Morgenstern NU, Price VE (1965) The analysis of the stability of general slip surfaces. Geotechnique 15(1):79–93. https://doi.org/10.1680/geot.1965.15.1.79
Mukherjee A, Mitra A (2001) Geotechnical study of mass movements along the Kalimpong approach road in the Eastern Himalayas. Indian J Geol 73(4):271–280
Phong TV, Phan TT, Prakash I, Singh SK, Shirzadi A, Chapi K, Ly HB, Ho LS, Quoc NK, Pham BT (2021) Landslide susceptibility modeling using different artificial intelligence methods: a case study at Muong Lay district, Vietnam. Geocarto Int 36(15):1685–1708. https://doi.org/10.1080/10106049.2019.1665715
Pourghasemi HR, Pradhan B, Gokceoglu C (2012) Application of fuzzy logic and analytical hierarchy process (AHP) to landslide susceptibility mapping at Haraz watershed. Iran Natural Haz 63:965–996. https://doi.org/10.1007/s11069-012-0217-2
Qi C, Tang X (2018) Slope stability prediction using integrated metaheuristic and machine learning approaches: a comparative study. Comput Ind Eng 118:112–122. https://doi.org/10.1016/j.cie.2018.02.028
Raschka S, Patterson J, Nolet C (2020) Machine learning in python: Main developments and technology trends in data science, machine learning, and artificial intelligence. Information 11(4):193. https://doi.org/10.3390/info11040193
Roy P, Ghosal K, Paul PK (2022) Landslide susceptibility mapping of Kalimpong in Eastern Himalayan Region using a Rprop ANN approach. J Earth Syst Sci 131(2):130. https://doi.org/10.1007/s12040-022-01877-2
Sah NK, Sheorey PR, Upadhyaya LN (1994) Maximum likelihood estimation of slope stability. In: International journal of rock mechanics and mining sciences & geomechanics abstracts, Vol. 31, No. 1, pp. 47–53. Pergamon
Sakellariou M, Ferentinou M (2005) A study of slope stability prediction using neural networks. Geotech Geol Eng 23:419–445. https://doi.org/10.1007/s10706-004-8680-5
Samui P (2008) Slope stability analysis: a support vector machine approach. Environ Geol 56:255–267
Samui P (2013) Support vector classifier analysis of slope. Geomat, Nat Haz Risk 4(1):1–12. https://doi.org/10.1080/19475705.2012.684725
Schmidhuber J (2015) Deep learning in neural networks: an overview. Neural Netw 61:85–117. https://doi.org/10.1016/j.neunet.2014.09.003
Tao Y, Xue Y, Zhang Q, Yang W, Li B, Zhang L, Qu C, Zhang K (2021) Risk assessment of unstable rock masses on high-steep slopes: an attribute recognition model. Soil Mech Found Eng 58(2):175–182. https://doi.org/10.1007/s11204-021-09724-0
Verma A, Singh T, Chauhan NK, Sarkar K (2016) A hybrid FEM–ANN approach for slope instability prediction. J Instit Eng: Series A 97:171–180. https://doi.org/10.1007/s40030-016-0168-9
Wang Z, Lin M (2021) Finite element analysis method of slope stability based on fuzzy statistics. Earth Sci Res J 25(1):123–130. https://doi.org/10.15446/esrj.v25n1.93320
Wang Y, Cao Z, Au SK (2011) Practical reliability analysis of slope stability by advanced Monte Carlo simulations in a spreadsheet. Can Geotech J 48(1):162–172
Wei W, Li X, Liu J, Zhou Y, Li L, Zhou J (2021a) Performance evaluation of hybrid WOA-SVR and HHO-SVR models with various kernels to predict factor of safety for circular failure slope. Appl Sci 11(4):1922. https://doi.org/10.3390/app11041922
Wei X, Zhang L, Yang HQ, Zhang L, Yao YP (2021b) Machine learning for pore-water pressure time-series prediction: Application of recurrent neural networks. Geosci Front 12(1):453–467. https://doi.org/10.1016/j.gsf.2020.04.011
Xie H, Dong J, Deng Y, Dai Y (2022) Prediction model of the slope angle of rocky slope stability based on random forest algorithm. Math Probl Eng 2022:1–10
Yan G, Hu R, Luo J, Weiss M, Jiang H, Mu X, Xie D, Zhang W (2019) Review of indirect optical measurements of leaf area index: recent advances, challenges, and perspectives. Agricult Forest Meteorol 265:390–411
Yang H, Wang Z, Song K (2020) A new hybrid grey wolf optimizer-feature weighted-multiple kernel-support vector regression technique to predict TBM performance. Eng Comput. https://doi.org/10.1007/s00366-020-01217-2
Yue ZQ, Kang XY (2021) Different contributions of two shear strength parameters to soil slope stability with limit equilibrium method based slice techniques. IOP Conf Ser: Earth Environ Sci 861(6):062009. https://doi.org/10.1088/1755-1315/861/6/062009
Zhang H, Nguyen H, Bui XN, Pradhan B, Asteris PG, Costache R, Aryal J (2021) A generalized artificial intelligence model for estimating the friction angle of clays in evaluating slope stability using a deep neural network and Harris Hawks optimization algorithm. Eng Comput. https://doi.org/10.1007/s00366-020-01272-9
Zhao J, Nguyen H, Nguyen-Thoi T, Asteris PG, Zhou J (2021) Improved Levenberg–Marquardt backpropagation neural network by particle swarm and whale optimization algorithms to predict the deflection of RC beams. Eng Comput. https://doi.org/10.1007/s00366-020-01267-6
Zhou J, Li X, Mitri HS (2016) Classification of rockburst in underground projects: comparison of ten supervised learning methods. J Comput Civ Eng 30(5):04016003. https://doi.org/10.1061/(asce)cp.1943-5487.0000553
Zhou J, Li E, Yang S, Wang M, Shi X, Yao S, Mitri HS (2019) Slope stability prediction for circular mode failure using gradient boosting machine approach based on an updated database of case histories. Saf Sci 118:505–518. https://doi.org/10.1016/j.ssci.2019.05.046
Zhou J, Qiu Y, Khandelwal M, Zhu S, Zhang X (2021) Developing a hybrid model of Jaya algorithm-based extreme gradient boosting machine to estimate blast-induced ground vibrations. Int J Rock Mech Min Sci 145:104856. https://doi.org/10.1016/j.ijrmms.2021.104856
Zhou J, Shen X, Qiu Y, Li E, Rao D, Shi X (2021b) Improving the efficiency of microseismic source locating using a heuristic algorithm-based virtual field optimization method. Geomech Geophys Geo-Energy Geo-Resour 7(3):89. https://doi.org/10.1007/s40948-021-00285-y
Zhou KP, Chen ZQ (2009) Stability prediction of tailing dam slope based on neural network pattern recognition. In: 2009 Second international conference on environmental and computer science, IEEE, pp. 380–383
Zhu D, Lee C, Jiang H (2003) Generalised framework of limit equilibrium methods for slope stability analysis. Geotechnique 53(4):377–395. https://doi.org/10.1680/geot.53.4.377.37322
Zhu DY, Lee CF, Qian QH, Chen GR (2005) A concise algorithm for computing the factor of safety using the Morgenstern Price method. Can Geotech J 42(1):272–278
Zou S, Abuduwaili J, Duan W, Ding J, De Maeyer P, Van De Voorde T, Ma L (2021) Attribution of changes in the trend and temporal non-uniformity of extreme precipitation events in Central Asia. Scient Reports 11(1):1–11. https://doi.org/10.1038/s41598-021-94486-w
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Ethics Approval
I certify that the information given is true and complete to the best of my knowledge. I understand that if I have deliberately given any false information or have withheld any information regarding any situation, I am liable for prosecution for fraud and/or perjury.
Consent for Publication
This manuscript has not been submitted for any other purpose.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Bansal, V., Sarkar, R. Prophetical Modeling Using Limit Equilibrium Method and Novel Machine Learning Ensemble for Slope Stability Gauging in Kalimpong. Iran J Sci Technol Trans Civ Eng 48, 411–430 (2024). https://doi.org/10.1007/s40996-023-01156-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40996-023-01156-0