
Abstract
The tunnel desilter is a simple and economical fluidic device which is the most suitable over other alternative devices for the region if water is abundantly available. The flow mechanism in the tunnel desilter is so complex that it is difficult to estimate the sediment removal efficiency accurately using a conventional regression. Hence, in the present study AI-based techniques, adaptive neurofuzzy interface system (ANFIS) and artificial neural network (ANN), were employed to estimate the sediment removal efficiency of the tunnel desilter using the data-sets collected by conducting the laboratory test. Findings of the sensitivity analysis showed that the size of the sediment was the most significant parameter followed by the concentration in the estimation of removal efficiency. The results of AI-based modeling were also compared with the available conventional predictive regression models, and it was found that the triangular membership function-based ANFIS model outperformed the other considered models. Further, ANN was also found to be giving comparable results.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The site engineers have been facing the acute problem of silting in the canal since the canal system regulated by headworks came into existence. When carrying capacity of canal is less than sediment load intensity, canal tends to aggrade resulting in reduction of its discharging capacity. In case of power canals, the sediment laden water damages the blades of the hydraulic turbine, thereby affecting the power generation (Garde and Kothyari 2004). The sediment deposited in the canals has to be cleaned manually or mechanically necessitating closure with inevitable revenue loss besides physical cleaning of the canal itself is a costly affair. Hence, it is extremely important that the quantity and quality of sediment carried by canal are controlled. Broadly, two primary silt control measures are used, and one is preventive measures which include sediment excluder (Garde and Pande 1976; Kothyari et al. 1994; UPIRI 1975) that is installed at the mouth of the canal head regulator in the river to check the entry of sediments before it finds its way into the canal. Although the sediment excluder is efficient, a large amount of sediment is bound to enter off taking canal. The other primary measures employed in the canal are called curative measures which include sediment ejectors to eject the sediments which enter the canal despite taking care to arrest the sediments in the river itself. Further, there exist secondary silt control measures as well, such as river training works constructed upstream of the head regulator to secure proper curvature of the approach channel, proper alignment of the canal head regulator, provision of a raised sill for the head regulator, under sluice pocket along with requisite length or divide wall and the river regulation, but the evidence from experience suggests that these secondary measures are not equally effective, and sediment finds its way into the pocket and enters the canal.
Curative measures which are constructed in the canal include mainly traditional settling basins, vortex settling basins, vortex tubes and tunnel desilter devices. The traditional settling basins were examined by Garde et al. (1990), Raju et al. (1999), Saxena (1996), Schrimpf (1991), Singh (1987), Srivastava (1997), Dongre (2002) and Singh et al. (2008), but it suffers from three disadvantages: First, it requires a relatively larger area, second is long residence time, and thirdly, it is affected by the interruption during physical cleaning; however, these difficulties have been addressed in vortex settling chambers which were studied by Athar et al. (2002, 2003), Curi et al. (1979), Mashauri (1986), IPRI (1989) and Paul et al. (1991), but these devices are not useful when sediment has to be removed for higher discharge in the canal and where very fine materials do not need to be removed in the case of the irrigation channel where it is beneficial for the crop. Vortex tube ejectors (Blench 1952; Robinson 1962; Lawrence and Sanmuganathan 1981; Atkinson 1994a, b; Orak and Asareh 2015; Moradi et al. 2013; Dashtbozorgi and Asareh 2015) have their own shortcomings and have been found to be ineffective in removing the suspended loads.
Tunnel desilter device has an advantage over other discussed devices as it is simple, effective and does not suffer from the limitations that the above desilter suffers if water availability in the region is not a problem. It consists of a horizontal diaphragm slab a little above the canal bed which separates the sediment laden bottom layers from the top layers. Under diaphragm slab, there are tunnels which carry these bottom layers into an escape channel to the river downstream of diversion head work through shortest path, while relatively sediment-free top layer water is passed over the diaphragm slab to the canal on the downstream of the tunnel desilter. The general view of a typical tunnel desilter is shown in Fig. 1. The basic hydraulic principle utilized in the design of tunnel desilter is that in a mobile channel, sediment is transported as bed and suspended load. The vertical eddy component of the current throws up the finer particles which are held in suspension and carried by the stream. The coarser material too heavy to be thrown in the suspension moves along the bed by rolling or sliding and hopping or bouncing, but there is no clear line of demarcation between the bed load and the suspended load due to continual interchange of particles leaving and returning to the bed. The concentration of material in lower layers is, however, greater than that in the upper ones. Therefore, the water extracted from the lower layers carries comparatively more sediment, thereby reducing the sediment concentration in the canal downstream of the tunnel desilter. The definition sketch showing hydraulic principle of sediment removal by the tunnel desilter is shown in Fig. 2a, b.

General view of tunnel desilter without diaphragm slab

Definition sketch showing hydraulic principle of tunnel desilter
Tunnel desilter has been studied by UPIRI (1975), Garde and Pande (1976), Dhillon et al. (1977) and IS-6004 (1980), but all these work with heavy reliance on physical model studies which suffer from the problems of scale effect where the hydraulic principles are mainly utilized and the rest of the design is performed on the basis of the thumb rules evolved from the existing structures (Uppal 1966). Despite availability of number of models (Atkinson and Lawrence 1984; Gautam 2005; Singh 2016), the issue for the estimation of removal efficiency of tunnel desilter remains inclusive. It is realized that the conventional regression technique has been applied in forming the model without knowing the complexity of phenomenon which takes place in sediment ejection process. So these days, the soft computing tools due to their own rationality and intelligence have increasingly been used in the field of water resources and environmental engineering which does not need any information on the mechanism of any processes; besides, it overcomes the issue related to scale effect and also avoids the time, energy and cost incurred in fabricating and running the physical models (Solomatine and Xue 2004; Pal et al. 2012, 2013; Ansari and Athar 2013; Tiwari et al. 2017; Kumar et al. 2018a, b; Sihag et al. 2017a, b; Parsaie et al. 2018; Sihag et al. 2018). Although the estimation of removal efficiency of desilter by soft computing tools has been studied by a few researchers (Tiwari et al. 2018; Singh 2016; Singh et al. 2016, 2008) no study is so far reported in the literature for the use of ANN and ANFIS in estimation of removal efficiency of tunnel desilter.
The principal aim of the present investigation outlines the estimation of removal efficiency of tunnel desilter by applying AI-based ANN and ANFIS techniques using data collected by conducting experiment in the hydraulic laboratory. The estimated model of removal efficiency of tunnel desilter by these soft computing tools (AI-based) has also been compared and validated with observed data and the existing conventional inductive relations carried out by the prior authors including relative importance of each input parameter on the model of the tunnel desilter removal efficiency.
2 Proposed AI-Based Methods
2.1 Overview of ANFIS
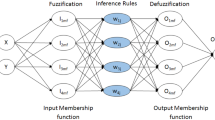
ANFIS is a formidable tool for modeling complex nonlinear systems based on input and output data. It uses fuzzy reasoning of fuzzy logic and learning capacity of neural network to generate output. Figure 3 depicts the basic structural design (Jang et al. 1997) of first-order Sugeno fuzzy model of ANFIS having 2 inputs (a and b), 4 rules and 1 output (c). The said model of Sugeno fuzzy type (Takagi and Sugeno 1993) has 4 fuzzy rules (if–then), given as:
where X1, X2, Y1 and Y2 are fuzzy sets of input a and b, fij (i, j = 1,2) are the outputs within the fuzzy specified region by the fuzzy rule, for input a and b, mij, nij and qij (i, j = 1,2) are the design parameters that are evaluated during the training process.

Structure of ANFIS
Figure 3 contains five layers; each layer executes different function explained below:
Layer 1 (Input nodes): Every node is an adaptive node, and produced membership grade of input and output given by this layer is:
$$O_{\;\;Xi}^{1} = \mu_{Xi} \left( a \right),\quad i \, = 1,2,$$(5)$$O_{\;\;\;Yi}^{1} = \mu_{Yj} \left( b \right),\quad \, j \, = 1,2,$$(6)where a and b are crisp inputs; Xi and Yj are fuzzy set; low-, medium-, high-class size membership function is applied, which could be of any shape such as triangular, trapezoidal, general bell-shaped, Gaussian function.
Layer 2 (Rule nodes): All nodes are fixed nodes and labeled as Π, which plays the role of a simple multiplier, and output is given as below:
$$O_{\;\;ij}^{2} = W_{ij} = \mu_{Xi} \left( a \right) \, \mu_{Yj} \left( b \right), \, \quad i, \, j \ldots = 1,2,$$(7)Layer 3 (Average nodes): Every node is again fixed node and labeled as N and plays a normalization role in the network, and output is given as below:
$$O^{3}_{ij} = \bar{W}_{ij} = \frac{{W_{ij} }}{{W_{11} + W_{12} + W_{21} + W_{22} }},\quad i, \, j \, \ldots = 1,2,$$(8)Layer 4 (Consequent nodes): Every node is adaptive node and output is product of normalized firing strength and first-order polynomial and is given as below.
$$O^{4}_{ij} = \bar{W}_{ij} f_{ij} = \bar{W}_{ij} \left( {m_{ij} a \, + \, n_{ij} b \, + \, q_{ij} } \right),\quad i,j \ldots = \, 1,2.$$(9)Layer 5 (Output nodes): The only node output in the layer is the summation output of the system.
$$\begin{aligned} O^{5}_{ij} & = \mathop \sum \limits_{1}^{2} \mathop \sum \limits_{1}^{2} \bar{W}_{ij} f_{ij} = \mathop \sum \limits_{1}^{2} \mathop \sum \limits_{1}^{2} \bar{W}_{ij} \left( {m_{ij} a + n_{ij} b + q_{ij} } \right) \\ & = \mathop \sum \limits_{1}^{2} \mathop \sum \limits_{1}^{2 } \left[ {\left( {W_{ij} a} \right)m_{ij} + \left( {W_{ij} b} \right)n_{ij} + \left( {W_{ij} } \right)q_{ij} } \right] \\ \end{aligned}$$(10)
2.2 ANN
A neural network is a form of artificial intelligence that imitates some function of the human brain. Neural networks are general purpose computing tools that can solve complex nonlinear problems (Fischer 1998). The network comprises a large number of simple processing elements linked to each other by weighted connections according to a specified architecture. These networks learn from the training data by adjusting the connection weights (Bishop 1995). There is a range of artificial neural network architecture designed and used in various fields. In this study, a feed-forward neural network with back-propagation learning algorithm is used.
The basic element of a back-propagation neural network is the processing node. Each processing node behaves like a biological neuron and performs two functions. Initially, it sums the values of its inputs, which is then passed through an activation function to generate an output. Any differentiable function can be used as activation function, \(\varPsi\). A back-propagation neural network, showing the input layer, one hidden layer and the output layer, with interconnecting links being associated with weights is shown in Fig. 4.

A back-propagation neural network
All the processing nodes are arranged into layers, each fully interconnected to the following layer. There is no interconnection between the nodes of the same layer. In a back-propagation neural network, generally, there is an input layer that acts as a distribution structure for the data being presented to the network. This layer is not used for any type of processing. After this layer, one or more processing layers follow, called the hidden layers. The final processing layer is called the output layer.
All the interconnections between each node have an associated weight. When a value is passed from the input layer, down these interconnections, these values are multiplied by the associated weight and summed to derive the net input (\(n_{j}\)) to the unit
in which \(w_{ji}\) is the weight of the interconnection to unit j from unit i (called input) and \((o_{i} )\) is the output of the unit i. The net input obtained by the above equation is then transformed by the activation function to produce an output \((o_{j} )\) for the unit j. The sigmoid function is defined as:
The shape of the sigmoid function can be modified by multiplying \(n_{j}\) by a constant, called the gain parameter, which is often set to the value one (Schalkoff 1992). The values of the interconnecting weights are not set by the analyst but are determined by the network during the training process, starting with randomly assigned initial weights. There are a number of algorithms that can be used to adjust the interconnecting weights to achieve minimal overall training error in multi-layer networks (Bishop 1995). The generalized delta rule, or back-propagation (Rumelhart et al. 1985), is one of the most commonly used methods. This method uses an iterative process to minimize an error function over the network output and a set of target outputs, taken from the training data-set. The training data consist of a pair of data vectors. The training data vector is the pattern to be learned, and the desired output vector is the set of output values that should be produced by the network. The goal of training is to minimize the overall error difference between the desired and the actual outputs of the network.
The process of training begins with the entry of the training data to the network. These data flow forward through the network to the output units. At this stage, the network error, which is the difference between the desired and actual network output, is computed. This error is then fed backward through the network toward the input layer with the weights connecting the units being changed in relation to the magnitude of the error. This process is repeated until the error rate is minimized or reaches an acceptable level, or until a specified number of iterations has been accomplished.
The statistical measures used by Tiwari et al. (2018) [i.e., coefficient of correlation (CC), root-mean-square error (RMSE) and Nash–Sutcliffe model efficiency coefficient (NSE)] were employed to measure the performance of the AI-based and conventional models.
3 Published Relations in the Literature
Removal efficiency of tunnel desilter is dependent on a number of relevant factors that contribute to sediment removal process. A very few tunnel desilter prediction removal efficiency formulae are available in the literature, but those too are based on conventional regression methods. These models either overestimate the tunnel desilter removal efficiency, resulting in an uneconomical tunnel desilter design, or underestimate the tunnel desilter removal efficiency which may lead to costly desilter device due to nonfunctional or failures. Under the current practice of tunnel desilter design, one refers to one of the existing models for a specific purpose or on the basis of thumb rules based on existing structures. Thus, in the study, existing conventional models are evaluated and their performance is compared by using test data-set. This way, the relative performance of existing conventional models is evaluated using the observed data-sets. The performance of these conventional regression models is further compared to that of the more complex artificial intelligence-based models which include ANN and ANFIS.
For the traditional models and equations developed by prior authors, the present study would assess the performance of four popular conventional relations and these conventional predictive equations are arranged in Table 1.
4 Experimental Program
The experimental tests were carried out in a prismatic channel of width, 0.45 m; depth, 1.2 m; and length, 16.50 m, of hydraulic laboratory of Civil Engineering Department, National Institute of Technology, Kurukshetra (India), and are schematically depicted in Fig. 5. A re-circulating arrangement of water supply was established by pumping water using a submersible pump with maximum discharge capacity of 15 l/s from a sump to an overhead tank from where water flows under gravity to test channel through baffle wall which was used to dampen the turbulence in the flow of water. At a suitable distance of 7 m from the inlet of test channel, the model of the tunnel desilter which spans the full width of the channel was placed such that sediment does not remain in turbulence which may cause the sediment load to remain in suspension and prevent it being ejected out to the desired extent; at the same point of time, it should not be located far downstream from the inlet of the main channel; otherwise, the sediment would tend to settle down earlier. Nine different models made up of steel sheet were prepared by varying numbers of main and subtunnels from three to five; and a view of typical model used in the test is shown in Fig. 6. A sediment-feeding device was employed for feeding the sediment into the flow of inlet channel. It consists of a funnel-like hopper for retaining sediment material and a fork plate beneath the slit of the hopper in order to guide the silt material toward the inlet channel. The sediment particles fell from the hopper through a slit onto the guide plate, while the electric motor with damper shakes the sediment guide plate. The rate of required sediment feeding to the canal could be regulated by changing the slope of the moveable plate, vibration speed of motor and calibration of opening between the slit provided at bottom of the hopper and the sediment guide plate. The sediment-feeding rate is found to be fairly steady unlike Athar et al. (2003) who employed sediment-feeding device consisted of a hollow circular cylinder of 2.5 cm diameter, with a split along its length. The cylinder could be held on bed of the test channel and worked through a cable system operated from the top of the channel. The cable system would open out the cylinder along its length; thereby, the sediment contained in the cylinder would be emptied onto the bed of the canal. This initiates a fair amount of the sediment to be carried near the bed as bed load, also suddenly, a fair amount of silt material will be poured into the model at an unsteady rate, and consequently, the sediment-feeding rate and its concentration at the inlet channel do not remain constant.

Schematic sectional view of experimental setup

A typical view of model without diaphragm slab
The view of the new sediment feeder is shown in Fig. 7. From lower portion of the tunnel desilter, sediment laden water was allowed to eject through an escape channel. The collected sediments were dried and weighed to find the efficiency of the tunnel desilter. To ensure quality, credibility and reliability, some of the experiments have been repeated thrice. A total of 252 observation sets were collected from experimentation. The details and the range of experimental matrix are summarized in Table 2.

A view of sediment feeder device
4.1 Data-set
The work discussed in the paper gives the development of models using different methods for estimation of tunnel desilter efficiency by the use of data collected by conducting the experiment in laboratory as discussed above. In the study, two different types of model structures have been used in the development which includes ANN and ANFIS. Conventional existing regression-based models are assessed for the purpose of comparison with the two artificial intelligence-based ANN and ANFIS models. So, the main motivation of the work is to advance the modeling methods by examining more robust and efficient methods that can result in more efficient, effective, accurate and precise models for tunnel desilter removal efficiency. In this regard, the present study examines the utility of two AI-based models (ANFIS and ANN) for tunnel desilter removal efficiency estimation and compares their performances to the conventional existing regression-based models.
The data-set consisting of 252 observations was used and obtained from the laboratory experiments. Out of 252 observations arbitrarily selected, 172 observations were used for training, whereas the remaining 80 were used for testing the models. Input data-set consists of sediment size (S) in mm, sediment concentration (C) in ppm, extraction ratio (R) in percent, whereas tunnel desilter removal efficiency (η) in percent was considered as output. The characteristics of training and testing data-set are depicted in Table 3.
5 Application of ANFIS and ANN
In the study, ANFIS was employed to model the relationship between inputs and output. The model was executed using MATLAB-based fuzzy logic, and a Sugeno-type approach is shown in Fig. 8 (Sugeno and Takagi 1985). There are no hard fast rules for producing an ANFIS model (Cui et al. 2010). Four membership functions, i.e., triangular membership function (trimf), trapezoidal membership function (trapmf), generalized bell-shaped membership function (gbellmf) and Gaussian membership function (gaussmf), were used for input in ANFIS model. The ‘trapmf’ membership functions were found to be the best for each input.

Sugeno-type approach of ANFIS
A hybrid learning procedure was employed to train the ANFIS model, and in the ANFIS training method, forward pass and a backward pass are composed by each epoch. In the forward pass, a training set of input patterns or an input vector is presented to the ANFIS, neuron output is planned on the layer-by-layer basis, and rule resulting variables are recognized. As soon as the resultant variables are recognized, an authentic network output vector y1 is determined and the error vector (e) is computed as (e = y1 − y2) as y2 is actual output. This process finishes at desired epochs, Jang (1993). Figure 9 illustrates the structure of the ANFIS model for tunnel desilter using training data-set, and Fig. 10 is the rule viewer of the model. The final triangular-based MFs of ANFIS model are shown in Fig. 11.

Structures of the model for tunnel desilter using training data-set

Rule viewer for tunnel desilter using triangular MFs

Final triangular membership functions with three input variables
Specifications of the developed ANFIS model are as follows:
Number of nodes: 58 nodes, 18 linear parameters, 24 nonlinear parameters, 172 training data pairs and 18 fuzzy rules.
Large number of trials was performed to find optimal values of user-defined parameters of ANN. CC, RMSE and NSE were used to find optimum parameters. Table 4 provides value of user-defined parameter working well with ANN for the data-set.
6 Results and Discussion
Performance evaluation parameters CC, RMSE and NSE values obtained using test data-set were employed to compare the performance of AI-based models which include triangular, trapezoidal, generalized bell-shaped and Gaussian MFs-based ANFIS, ANN models and four conventional models which include Atkinson (1994a), Singh (2016), Curi et al. (1979) and Paul et al. (1991). Table 5 shows the value of performance evaluation parameters of different models for training and testing data-set.
Figures 12 and 13 show the plot of the observed and estimated removal efficiency of tunnel desilter using triangular, trapezoidal, generalized bell-shaped and Gaussian MFs-based ANFIS and ANN on training and testing data-set, respectively. From Fig. 13, it is clear that estimated values of all the models were very close to perfect agreement line, but triangular MFs-based ANFIS has been found to be closer, and this fact has been further reinforced when it was compared in terms of statistical measures where triangular MFs-based ANFIS also achieved the highest value of CC, NSE (0.8681, 0.7431) and lowest value of RMSE (7.2542) which is shown in Table 5. Figures 14 and 15 depict the graph between the observed and estimated value of tunnel desilter removal efficiency using existing conventional models proposed by previous researchers on training and testing data-sets, respectively. All aforesaid empirical models except Singh (2016) were performing extremely poor, values of result were far away from perfect agreement line, and the Singh (2016) model itself was also not performing comparatively well in comparison with AI-based models. This was attributed to the fact that these conventional models did not have the capacity to consider the aspects that were responsible for complex nonlinear phenomenon which took place during sediment removal in the tunnel desilter.

Observed and estimated values of trapping efficiency using ANFIS and ANN models with training data-set

Observed and estimated values of trapping efficiency using ANFIS and ANN models with testing data-set

Observed and estimated values of removal efficiency using conventional empirical models with training data-set

Observed and estimated values of removal efficiency using conventional empirical models with testing data-set
Figures 16, 17 and 18 present comparative graph between observed value and estimated value of removal efficiency of tunnel desilter using two best AI-based models (triangular MFs-based ANFIS and ANN) and one best conventional model (Singh 2016), the variation of estimated values of removal efficiency using triangular MFs-based ANFIS, ANN and Singh (2016) in comparison with observed removal efficiency values and variation of relative error values of removal efficiency using triangular MFs-based ANFIS, ANN and Singh (2016) in comparison with observed removal efficiency values, respectively, on the test data. From Fig. 16 and Table 5, it is clear that triangular MFs-based ANFIS outperformed all aforesaid discussed models, which was followed by ANN in AI-based regression models. However, the model given by Singh (2016) performed poorly in comparison with any AI-based model and this fact was further substantiated in Fig. 17 where values of the result estimated by triangular MFs-based ANFIS were much closer to the observed value than any other aforesaid model which was again corroborated in Fig. 18 which shows the residual error given by triangular MFs-based ANFIS was the least.

Observed and predicted values of trapping efficiency using two AI-based models and one best conventional model with test data-set

Variation of estimated values of removal efficiency using ANFIS, ANN and Singh (2016) in comparison with observed trapping efficiency values using test data

Variation of relative error values of removal efficiency using triangular MFS-based ANFIS and ANN in comparison with observed trapping efficiency values using test data
The characteristics of observed and estimated values obtained by AI-based approaches and conventional predictive equations are presented in Table 6. Single-factor ANOVA results shown in Table 7 suggest that there was no significant difference between observed and estimated values of removal efficiency of tunnel desilter using AI-based models.
6.1 Sensitivity Analysis of Effective Parameters
To determine the relative significance of each input parameter to the model of the tunnel desilter removal efficiency using ANFIS and ANN approaches, sensitivity analysis was conducted using test data-set. Various input combinations as shown in Tables 8 and 9 were considered by removing one input parameter at a time in each case, and its influence on the tunnel desilter removal efficiency was evaluated in terms of CC, NSE and RMSE as primary criteria. Results from Tables 8 and 9 suggest that size (S) of the sediment was the most significant parameter followed by the concentration (C) for modeling the tunnel desilter removal efficiency.
7 Conclusion
The sincere attempt was made to analyze the tunnel desilter sediment removal efficiency from a completely new perspective in this work, and it was concluded that
- (I)
The triangular MFs-based ANFIS model had the highest value of CC = 0.868, NSE = 0.7431 and lowest value of RMSE = 7.2542 in comparison with other discussed models which indicates that this model outperforms other aforesaid AI-based as well as conventional models in the estimation of the tunnel desilter removal efficiency.
- (II)
The ANN model was also achieving comparable, satisfactory and desirable results as its statistical parameters of CC = 0.8639, NSE = 7.4627 and RMSE = 0.7281 which is nearest to triangular MFs-based ANFIS, and it might be used in modeling the tunnel desilter removal efficiency.
- (III)
Results of the work showed that estimating tunnel desilter removal efficiency with conventional models leads to apparently incredible errors as statistical parameters of CC and NSE are quite low and RMSE is high in comparison with AI-based models except Singh (2016).
- (IV)
Single-factor ANOVA results suggest that there was insignificant difference between observed and estimated values of ANFIS and ANN models.
- (V)
Findings of the sensitivity analysis showed that the size of the sediment was the most significant parameter followed by its concentration for the estimation of removal efficiency.
Abbreviations
- a :
-
Nondimensional bed layer thickness (2S) relative to depth of flow (D)
- C :
-
Sediment concentration (ppm)
- D :
-
Flow depth (m)
- d u :
-
Diameter of under flow outlet which is equal to the width of subtunnel (m)
- k :
-
Von Karman’s constant = 0.4
- n :
-
Number of observations
- Q i :
-
Discharge in inlet channel, i.e., discharge in subtunnel (m3/s)
- R :
-
Extraction ratio (%)
- S :
-
Sediment size (mm)
- \(U_{*}\) :
-
Shear velocity (m/s)
- \(U_{*}^{{\prime }}\) :
-
Grain shear velocity (m/s)
- V :
-
Mean velocity of flow (m/s)
- x i :
-
Observed values
- \(\bar{x}\) :
-
Mean observed values
- y i :
-
Predicted values
- \(\bar{y}\) :
-
Mean predicted values
- z :
-
Any depth of water from the bed level (m)
- α:
-
Ratio of height of diaphragm slab to depth of water in case of tunnel-type silt ejector
- \(\eta\) :
-
Sediment removal efficiency
- \(\omega\) :
-
Fall velocity of the sediment particle (m/s)
- \(\gamma_{\text{f}}\) :
-
Weight density of fluid (KN/m3)
- \(\gamma_{\text{s}}\) :
-
Weight density of sediment (KN/m3)
- W :
-
Vertical upward velocity (m/s)
- W′:
-
Width of channel
References
Ansari MA, Athar M (2013) Artificial neural networks approach for estimation of sediment removal efficiency of vortex settling basins. ISH J Hydraul Eng 19(1):38–48
Athar M, Kothyari UC, Garde RJ (2002) Sediment removal efficiency of vortex chamber type sediment extractor. J Hydraul Eng 128(12):1051–1059
Athar M, Kothyari UC, Garde RJ (2003) Distribution of sediment concentration in the vortex chamber type sediment extractor. J Hydraul Res 41(4):427–438
Atkinson E (1994a) Vortex-tube sediment extractors. I: trapping efficiency. J Hydraul Eng 120(10):1110–1125
Atkinson E (1994b) Vortex-tube sediment extractors. II: design. J Hydraul Eng 120(10):1126–1138
Atkinson E, Lawrence P (1984) A quantitative design method for tunnel type sediment extractors. In: Fourth congress, Asian and Pacific Division, Indian Association for Hydraulic Research, Chiang Mai-Thailand, pp 77–81
Bishop CM (1995) Neural networks for pattern recognition. Oxford University Press, Oxford
Blench T (1952) Discussion of model and prototype studies of sand traps, by RL Parshall. Trans ASCE 117:213
Cui ZD, Tang YQ, Yan XX, Yan CL, Wang HM, Wang JX (2010) Evaluation of the geology-environmental capacity of buildings based on the ANFIS model of the floor area ratio. Bull Eng Geol Environ 69(1):111–118
Curi KV, Esen II, Velioglu SG (1979) Vortex type solid liquid separator. Progr Water Technol 7(2):183–190
Dashtbozorgi S, Asareh A (2015) Study of the rate of sediment trapping and water loss in the vortex tube structure at different placement angles. J Sci Res Dev 2(5):104–110
Dhillon GS, Aggarwal RK, Kotwal AN (1977) Model prototype conformity study of sediment ejectors on Upper Bari Doab Hydel Channel. In: Proceedings, 46th Research Session of CBIP, 3, 47–56
Dongre NB (2002) Settling basin design. M.Tech. thesis, Department of Civil Engineering, Indian Institute of Technology, Roorkee, India
Fischer MM (1998) Computational neural networks: a new paradigm for spatial analysis. Environ Plan A 30(10):1873–1891
Garde RJ, Kothyari UC (2004) Sediment management in hydroelectric projects. In: Proceeding of ninth international symposium on river sedimentation, Tsinghua University Press, Yichang (China), pp 19–28
Garde RJ, Pande PK (1976) Use of sediment transport concepts in design of tunnel-type sediment excluders. ICID Bull 25(2):101–111
Garde RJ, Raju KGR, Sujudi AWR (1990) Design of settling basins. J Hydraul Res 28(1):81–91
Gautam SR (2005) Computer aided design of tunnel type silt ejector. M.E. thesis of Civil Engineering in Hydraulics and Flood Control Engineering, Delhi College of Engineering University of Delhi, Delhi
Irrigation and Power Research Institute (IPRI) (1989) Design Norms for Vortex Settling Basin. Report no. HY/R/17/89–90, Amritsar, Punjab
IS: 6004 (1980) Criteria for Hydraulic design of Sediment Ejector for Irrigation and Power Channels. Indian standard Institution, Manak Bhawan, 9, Bahadur Shah Zafar Marg, New-Delhi
Jang JS (1993) ANFIS: adaptive-network-based fuzzy inference system. IEEE Trans Syst Man Cybern 23(3):665–685
Jang JSR, Sun CT, Mizutani E (1997) Neuro-fuzzy and soft computing: a computational approach to learning and machine intelligence. IEEE Trans Autom Control 42(10):1482–1484
Kothyari UC, Pande PK, Gahlot AK (1994) Design for tunnel-type sediment excluder. J Irrig Drain Eng 120(1):36–47
Kumar M, Ranjan S, Tiwari NK, Gupta R (2018a) Plunging hollow jet aerators-oxygen transfer and modelling. ISH J Hydraul Eng 24(1):61–67
Kumar M, Tiwari NK, Ranjan S (2018b) Prediction of oxygen mass transfer of plunging hollow jets using regression models. ISH J Hydraul Eng. https://doi.org/10.1080/09715010.2018.1435311
Lawrence P, Sanmuganathan K (1981) Field verification of vortex tube design method. In: Proceedings of the South-East Asian regional symposium on problems of soil erosion and sedimentation, held at Asian Institute of Technology, January 27–29, 1981/edited by T. Tingsanchali, H. Eggers. The Institute, Bangkok
Mashauri DA (1986) Modelling of vortex settling chamber for primary clarification of water. PhD thesis, Tampere University of Technology, Tampere University of Tampere, Finland
Moradi A, Hasoonizade H, Kashkuli HA, Jahromi HM, Sedghi H (2013) Investigation of the effect of vortex tube structure with 60 and 90 degree angles on Sedimentation entrance trap efficiency to intakes at 180-degree bend location. Int J Agric Crop Sci 5(23):2885–2889
Orak SJ, Asareh A (2015) Effect of gradation on sediment extraction (trapping) efficiency in structures of vortex tube with different angles. WALIA J 31(S4):53–58
Pal M, Singh NK, Tiwari NK (2012) M5 model tree for pier scour prediction using field dataset. KSCE J Civil Eng 16(6):1079–1084
Pal M, Singh NK, Tiwari NK (2013) Pier scour modelling using random forest regression. ISH J Hydraul Eng 19(2):69–75
Parsaie A, Haghiabi AH, Saneie M, Torabi H (2018) Prediction of energy dissipation of flow over stepped spillways using data-driven models. Iran J Sci Technol Trans Civ Eng 42(1):39–53
Paul TC, Sayal SK, Sakhuja VS, Dhillon GS (1991) Vortex settling chamber design considerations. J Hydrol Eng ASCE 117(2):172–189
Raju KR, Kothyari UC, Srivastava S, Saxena M (1999) Sediment removal efficiency of settling basins. J Irrig Drain Eng 125(5):308–314
Robinson AR (1962) Vortex tube and trap. Trans ASCE 127:391–433
Rumelhart DE, Hinton GE, Williams RJ (1985) Learning internal representations by error propagation (No. ICS-8506). California University, San Diego La Jolla Inst for Cognitive Science
Saxena M (1996) Effect of flushing on efficiency of settling basins. M.E. thesis, Department of Civil Engineering, University of Roorkee, Roorkee (UP)
Schalkoff RJ (1992) Pattern classification: statistical, structural and neural approaches
Schrimpf W (1991) Discussion of design of settling basins by RJ Garde, KG Ranga Raju and AWR Sujudi. J Hydraul Res IAHR 29(1):136–142
Sihag P, Tiwari NK, Ranjan S (2017a) Modelling of infiltration of sandy soil using Gaussian process regression. Model Earth Syst Environ 3(3):1091–1100
Sihag P, Tiwari NK, Ranjan S (2017b) Prediction of unsaturated hydraulic conductivity using adaptive neuro-fuzzy inference system (ANFIS). ISH J Hydraul Eng. https://doi.org/10.1080/09715010.2017.1381861
Sihag P, Tiwari NK, Ranjan S (2018) Support vector regression-based modeling of cumulative infiltration of sandy soil. ISH J Hydraul Eng. https://doi.org/10.1080/09715010.2018.1439776
Singh KK (1987) Experimental study of settling basins. M.E. thesis, Department of Civil Engineering, University of Roorkee, Roorkee UP, India
Singh BK (2016) Study of sediment extractor doctoral thesis. National Institute of Technology, Kurukshetra
Singh KK, Pal M, Ojha CSP, Singh VP (2008) Estimation of removal efficiency for settling basins using neural networks and support vector machines. J Hydrol Eng 13(3):146–155
Singh BK, Tiwari NK, Singh KK (2016) Support vector regression based modeling of trapping efficiency of silt ejector. J Indian Water Resour Soc 36(1):41–49
Solomatine DP, Xue Y (2004) M5 model trees and neural networks: application to flood forecasting in the upper reach of the Huai River in China. J Hydrol Eng 9(6):491–501
Srivastava S (1997) Effect of flushing on the efficiency of settling basins. M.E. thesis, Department of Civil Engineering, University of Roorkee, Roorkee, UP, India
Sugeno M, Takagi T (1985) Fuzzy identification of systems and its applications to modeling and control. IEEE Trans Syst Man Cybern 1:116–132
Takagi T, Sugeno M (1993) Fuzzy identification of systems and its applications to modeling and control. In: Readings in fuzzy sets for intelligent systems, pp 387–403
Tiwari NK, Sihag P, Ranjan S (2017) Modeling of infiltration of soil using adaptive neuro-fuzzy Inference system (ANFIS). J Eng Technol Educ 11(1):13–21
Tiwari NK, Sihag P, Kumar S, Ranjan S (2018) Prediction of trapping efficiency of vortex tube ejector. ISH J Hydraul Eng. https://doi.org/10.1080/09715010.2018.1441752
UPIRI (1975) Sediment excluders and ejectors design monograph (45-H1-6)
Uppal HL (1966) Sediment control in river and canal, CBIP (India), Publication Number-79
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Tiwari, N.K., Sihag, P., Singh, B.K. et al. Estimation of Tunnel Desilter Sediment Removal Efficiency by ANFIS. Iran J Sci Technol Trans Civ Eng 44, 959–974 (2020). https://doi.org/10.1007/s40996-019-00261-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40996-019-00261-3