
Abstract
Streamflow forecasts are fundamental to the effective operation of flood control reservoirs and levee systems. Therefore, streamflow forecasting is of great importance. In this paper, the HEC-HMS conceptual model and SARIMA time-series model are compared to forecast streamflow in Maroon basin in the southwest of Iran to evaluate their ability and accuracy in monthly streamflow forecasting. First, the continuous rainfall–runoff was simulated monthly before the forecasting period by the HEC-HMS model. The monthly data from October 1991 to 2010 were used for verification. Also the data from 2011 to 2017 were used for calibrated HEC-HMS model. Streamflow forecast was conducted from 2018 to 2021 at the Idanak hydrometric station. To validate the SARIMA model based on the autocorrelation function, the partial autocorrelation of the residuals, Port-Manteau test, Akaike criterion and plotting the residual time series diagram on normal probability paper were used. The results showed that the accuracy of the HEC-HMS model in forecasting streamflow is higher than SARIMA model, the Root Mean Square Error (RMSE) of predicted and observed discharges for HEC-HMS and SARIMA models are 2.8 and 3.4 m3/s, respectively.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Streamflow forecasts are fundamental to the effective operation of flood control reservoirs and levee systems. Forecasts may also support emergency operations by providing estimates of the timing and extent of expected hazardous or damaging flood conditions. Forecasts are based on recent meteorological and hydrological conditions in basin, and may also incorporate predicted future meteorological conditions. Although most often used to predict flood conditions, streamflow forecasts may also support water supply, hydropower, environmental flow requirements, and other operational needs. The use of statistical time series and hydrologic models has a relatively long history in forecasting stream flow. The stream flow estimation and forecasting are important. Various softwares have been developed to do this important task and are used extensively throughout the world so far. With the proper stream forecasting can lead to proper management of irrigation decisions, flood forecasting, water resources and much more (Ni et al. 2019; Fathian et al. 2019a, b; Tongal and Booij 2018; Shafizadeh-Moghadam et al. 2018). Can et al. (2009) reviewed the monthly average flow data in the Cekerek basin of Turkey and fitted an SARIMA (1.0.0) * (0.1.1)12 to it. Their results indicated the efficiency and accuracy of the mentioned model. Yurekli et al. (2005) fitted ARIMA (0.1.1) model for monthly data at the Asacquardaric station in the Carrasco River. Valipoor et al. (2012) performed the monthly forecasting of inflow into the Dez dam reservoir by the neural network autoregressive model. The results of their research showed that the best model for forecasting the inflow into the Dez dam reservoir is the neural network autoregressive model that can forecast the inflow of 5-year lead time. Valipoor et al. (2015) studied the capability of Seasonal Autoregressive Integrated Moving Average (SARIMA) and Autoregressive Integrated Moving Average (ARIMA) models to forecast the long-term runoff in the United States. The results showed that the accuracy of SARIMA model is more than ARIMA model. Using the model of artificial intelligence and time series, they estimated the monthly flow of the river (Mehdizadeh et al. 2019a, b). Flow modeling efficiency was improved using the AR (TAR) hybrid threshold model with the GARCH approach (Fathian et al. 2019a, b). They used time series models to model monthly flow (Mehdizadeh et al. 2019a, b). Using machine learning method, modeling precipitation-runoff (Adnan et al. 2021).
According to the results, the Artificial Neural Network (ANN) and Least-Square Support Vector Regression (LS SVR) models have the best performance in flow prediction in linear and nonlinear conditions, respectively (Modaresi et al. 2018). The results show that small floods during El Nino are important in flood management (Hooshyaripor et al. 2020). Singh and Manik (2015) simulated continuous streamflow using the Soil Moisture Accounting (SMA) loss algorithm in the Dahir basin of India. The results indicated that the HEC-HMS model has acceptable ability to simulate the stream flow. Sintayehu (2015) simulated the upstream flow of the Nile River basin using the HEC-HMS model and the results showed that SMA and linear reservoir parameters have the most effect on the basin hydrograph. Khezrian Nezhad et al. (2012) predicted the runoff using the quantitative forecasting of precipitation through the output of numerical forecasting models of the atmosphere. They used the WRF model to forecast precipitation and the HEC-HMS model to forecast runoff. The results show that the predicted runoff values are less than the observed values. Supe et al. (2015) performed the rainfall–runoff process using the HEC-HMS model for the Van River Basin by the SMA loss algorithm. They found that the HEC-HMS calibrated model could be used to forecast runoff in the Van River Basin. Razmkhah et al. (2016) modeled precipitation and runoff using SMA penetration losses in the HEC-HMS model in the Karun 3 dam basin. The modeling results showed that according to the Nash–Sutcliffe criterion the SMA method provides an appropriate estimation of penetration. The results of the sensitivity analysis of the model showed that the hydraulic conductivity, Clark conservation coefficient and concentration time are the most important parameters for maximum flood simulation. Goumindoga et al. (2016) studied rainfall-runoff modeling in ten different basins with and without runoff statistics (no stations) using the HEC-HMS model in Zimbabwe. Also, the share of each of the sub-basins was calculated without statistics in production of the basin's outflow runoff. The results showed that the HEC-HMS model appropriately predicts the amount of runoff and peak discharge of the basins with statistics. Koch et al. (2013) modeled continuous rainfall-runoff by the HEC-HMS model in the Aggtelek Karst region using the SMA loss algorithm. In order to validate the runoff, the HEC-HMS model was used Wei et al. (2018). The main purpose of this paper is to evaluate the accuracy of the conceptual HEC-HMS model in monthly stream flow forecasting in Maroon basin and compare it with the predicted stream flow using the SARIMA time series model. The main purpose of this study is to compare the performance of the HEC-HMS conceptual model and SARIMA time series model in predicting the monthly flow of the Maroon River. Also the distinguish between of this research with previous study in present study is using of a new section in the HEC-HMS software called forecasting, which present full description in the materials section about it.
Materials and methods
Introduction of the case study
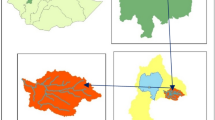
Maroon basin with an area of about 3824 km2 is located in the geographic coordinates \({49}^{^\circ }{50}^{^{\prime}}-{51}^{^\circ }{10}^{^{\prime}}\) E \({30}^{^\circ }{30}^{^{\prime}}{-31}^{^\circ }{20}^{^{\prime}}\) N at the heights of Behbahan city in Khuzestan province of Iran. Maroon basin is surrounded by Zohreh and Karun basins in Khuzestan and Kohgiluyeh and Boyer Ahmad provinces. A major part of Maroon basin is mountainous. Meanwhile the northern and eastern sides are higher than other parts. The Maroon basin is divided into four sub-basins based on the topography and position of hydrometric stations using ArcGIS software. Figure 1 shows Maroon basin with the sub-basins and the position of the rain gauge and hydrometric stations. Figure 2 illustrates the schematics of the geometric model of Maroon basin in the HEC-HMS model environment. Table 1 shows the geometric characteristics of four sub-basins with conceptual model of Maroon basin in HEC-HMS model. Precipitation data are provided by the rain gauge stations affiliated to the Ministry of Energy. The flow rates at the Idanak hydrometric station with \({24}^{^\circ }{50}^{^{\prime}}\) E \({36}^{^\circ }{30}^{^{\prime}}\) N coordinates are used to calibrate the model.

The Maroon Basin with the structure of the HEC-HMS conceptual model

Schematic of soil moisture accounting algorithm in HEC-HMS
Streamflow forecast using the HEC-HMS model
The HEC-HMS model is a semi-distributed conceptual model that has the ability to simulate losses, snowmelt, sub-basin routing and river flow routing. Streamflow forecast usually involves the simulation of past and future conditions. Forecast starts with selection of a forecast lead-time. Lead-time usually represents the last available time for meteorological observations of precipitation, temperature, and other variables. If observations of streamflow, stage or reservoir pool elevation are available, the last available value will be generally near the time of forecast too. The simulation is started few hours or days before the time of forecast. The results computed between the start time and the forecast time, may be called the "look back" period. When the observations of current basin conditions are available, they may be compared with computed results from the look back period to make calibration adjustments that improve model performance. Meteorological observations are not available after the forecast time and predictions of future values are used. For example, quantitative precipitation forecast (QPF) provides the meteorological prediction of future precipitation depths. Similar predictions are used for other meteorological variables such as temperature. The future streamflow response is simulated based on the predicted meteorological conditions. This period of time in the future may be called the "forecast". The SMA loss algorithm was used to simulate continuous rainfall-runoff process in Maroon basin. The SMA loss algorithm has the ability to model hydrological systems for long periods continuously (HEC 2008). This loss algorithm introduces the basin using a series of storage layers (Bennett 1998). When the precipitation takes place, the first layer with filled capacity is the interception storage capacity. The second layer of storage is the depression storage capacity. The third layer of storage is soil profile storage capacity. The excessive water of these storages appears as surface runoff. The soil profile loses part of its water due to evapotranspiration and part of its water due to percolation into groundwater layers and groundwater reserves are linked to a linear reservoir model for modeling the base flow. Figure 2 also shows the schematic and conceptual scheme of the SMA loss algorithm. The Clark's unit hydrograph model was used to transform precipitation to runoff, due to its general usage in large basins and acceptable performance. Linear reservoir model was also used to estimate the base flow in each sub-basin with the SMA model (Bennett 1998). The Muskingum method was used for routing the flow in all reaches. In addition, the upstream region of Maroon basin is mountainous; therefore the temperature index method was used for simulation of precipitation and snowmelt runoff.
Model calibration and validation
Different statistical criteria were used for evaluation of accuracy and performance of the HEC-HMS model. Equations 1 to 4 show the statistical criteria including Coefficient of determination (R2), Nash–Sutcliffe (NS) coefficient, Percent of Total Volume Error (PTVE) and Root Mean Square Error (RMSE), respectively. In Eqs. 1 to 4, n is equal to the number of flow data, \({\mathrm{O}}_{\mathrm{i}}\) and \({\mathrm{S}}_{\mathrm{i}}\) are the observed and simulated flow data in the time step i, \(\overline{\mathrm{O} }\) is the mean observed discharge and Cov is the covariance of the observed discharge.
The Nash–Sutcliffe coefficient represents the model's efficiency which has recently been used in hydrological contexts. The Nash–Sutcliffe coefficient can take values of the infinite negativity to one, where the one indicates a perfect fit and 100% consistency between the observed and simulated values.
SARIMA models
Box et al. (1994) developed the SARIMA model for seasonal time series. If the periodic behavior is observed at specified intervals (S) in a time series, this time series has a seasonal period and the SARIMA model is used for its modeling. The ARIMA model is shown as ARIMA (p, d, q) (P, D, Q)s where the (P, D, Q) is the seasonal component of the model, (p, d, q) is the non-seasonal component of the model and S is the season’s length of period. The general form of the model is shown as follows using the backward transformer operator (B):
where φ (B) and θ (B) are the p and q order polynomials, respectively. \(\Phi ({B}^{s})\) and \(\Theta ({B}^{s})\) are polynomials in \({B}^{s}\) of the P and Q order. p is the non-seasonal auto correlated order, d is the number of differentials, q is the seasonal auto correlated order, D is the number of seasonal differentials, Q is the seasonal autoregressive integrated moving average and S is the length of the season. The time series models consist of the following four steps that are repeated:
-
1.
Identification of the pattern At this stage, the stability of the mean and variance of the data was evaluated by mapping the autocorrelation function (ACF) and partial autocorrelation function (PACF). Autocorrelation function is one of the most important tools for testing data dependency. This function measures the correlation between observations at different intervals and is used to examine a single time series in the time domain. This function often provides an insight into the probabilistic pattern that produces the data which is used to identify and fit the appropriate stochastic model to data. In addition to autocorrelation between \((x_{t} ,x_{t + k} )\), if the correlation between \((x_{t} ,x_{t + k} )\) is intended followed by deleting the elimination of the relationship between \((x_{t + 1} ,x_{t + 2} ,....,x_{t + k - 1} )\) variables, the partial autocorrelation function (PACF) is used. The behavior of these functions in the correlation graph is one of the most important criteria for estimating the time series pattern. In the case of lack of statistics, at first the intended series is stabilized by the suitable differential series and the data conversion is stabilized by the Box-Cox method in the mean and the variance and then the series is stabilized. Therefore, at this stage, by analyzing the variance of the differentiated data and PACF and ACF diagrams the p, q, P and Q orders are specified.where n is the total number of data, m = (p + q + p + q) and RSS is the residual sum of squares. The chosen model should have the smallest amounts of (AIC) and (SBC).
-
2.
Fitting the pattern (Estimation of Parameters) At this stage, it is possible to use the Akaike Information Criterion (AIC) by identifying the appropriate patterns in the previous step to compare several patterns and choose the best one. The modified Akaike Information Criterion (AIC) is calculated from the following equation. In addition to the modified AIC, the Schwartz Bayesian Criterion (SBC) is used.where n is the total number of data, m = (p + q + p + q) and RSS is the residual sum of squares. The chosen model should have the smallest amounts of (AIC) and (SBC).
$$\mathrm{AIC}=\mathrm{n}\times \mathrm{LN}\left(\frac{2\mathrm{\pi RSS}}{\mathrm{n}}\right)+1+2\mathrm{m\phi }\left(\mathrm{B}\right),$$(6)$$\mathrm{SBC}=\mathrm{n}\times \mathrm{LN}\left(\mathrm{MSE}\right)+2\mathrm{m}\times \mathrm{LN}\left(\mathrm{MSE}\right),$$(7)
-
1.
Diagnosis of the pattern correctness To check the accuracy of the model, the residual chart is evaluated in terms of normality and statistics.where, n is the number of observations. This test statistic is the modified Q statistic or Liung-Box (LBQ) and has a distribution under the H0. m is the number of estimated parameters in the model. If the value of the Q statistic is greater than the corresponding value of the chi square table, the H0 is rejected. Sometimes the H0 is also called the model's adequacy hypothesis.
-
2.
Forecast using the Box-Cox transformation the values of the predicted data series were corrected by the discharge values. The results were evaluated as the final predicted discharge data for the intended years. To model the discharge data of the above stations, the Minitab software has been used which is based on Box-Jenkins approach. In addition the Port-Manteau test is useful for examining the adequacy of the model. This test uses the autocorrelation of the residuals to test the zero hypothesis H0:P1 = P2 = …. = PK = 0 along with the following test statistic.where, n is the number of observations. This test statistic is the modified Q statistic or Liung-Box (LBQ) and has a distribution under the H0. m is the number of estimated parameters in the model. If the value of the Q statistic is greater than the corresponding value of the chi square table, the H0 is rejected. Sometimes the H0 is also called the model's adequacy hypothesis.
$$\mathrm{Q}=\mathrm{n}\left(\mathrm{n}+2\right)\sum_{\mathrm{h}=1}^{\mathrm{k}}{\left(\mathrm{n}-\mathrm{h}\right)}^{-1 }\widehat{{\mathrm{p}}_{2}^{\mathrm{h}}},$$(8)
Discussion
Modeling with HEC-HMS
The monthly data from October 1991 to 2010 were used for calibration. Also the data from 2011 to 2017 were used for validation of calibrated HEC-HMS model. Stream flow forecast was conducted from 2018 to 2021 at the Idanak hydrometric station. After each implementation of the HEC-HMS model, the simulated hydrograph was compared with observed hydrograph to evaluate the model. Also, the statistical indices of the model error were calculated and compared with the values of statistical indices in the previous run. If the accuracy of the precipitation-runoff simulation was not recognized to be proper, the simulation operation would be resumed until obtaining satisfactory results. Figures 3, 4 and 5 compare the observed and simulated hydrographs in the calibration, validation and prediction stages of the HEC-HMS model. Figure 7 also shows the dispersion curves between the observed discharges and the predicted discharges for the HEC-HMS model. According to Figs. 3 and 4, it can be concluded that the HEC-HMS model has a good accuracy in estimating the streamflow with low discharge and baseflow relative to the peak discharges. The reason is that the available data including precipitation, streamflow, air temperature and evapotranspiration to simulate the continuous rainfall-runoff process over a minimum of 1 water year are monthly values. But the estimated time parameters of the sub-basins including the time of concentration, lag time, and Clark's storage coefficient are hourly values. The flow hydrograph at the hydrometric station during a water year was also as the baseflow with low discharge and a few streamflows with peak discharge on most days of the year. According to Table 4, the PTVE between the observed and simulated streamflows at the calibration stage of the model is 14.4% which indicates that the model underestimated the total volume of streamflow but with relatively acceptable accuracy. The RMSE of the observed and simulated discharges at the calibration stage of the model is 27.5 which indicates the high accuracy of the model in rainfall-runoff simulation. The value of the NS coefficient for the calibration stage is 0.83 which is acceptable. The amounts of NS coefficient and the RMSE between the observed and simulated hydrographs in the calibration stage are 0.83 and 27.5 which indicate the suitable calibration of the model and the acceptability of model accuracy in simulation of rainfall–runoff in Maroon basin. In addition, according to Table 4, the PTVE between the observed and simulated streamflows in the validation stage of the model is 14.4% which is similar to the calibration stage of the model, indicates the underestimation of the model in estimating the total volume of streamflow but with relatively acceptable accuracy. In addition, according to Fig. 5, it can be seen that changes in predicted hydrographs are relatively reasonable. According to Table 4, the amounts of NS coefficient and the RMSE between the observed and predicted hydrographs are 0.7 and 16.62 m3/s which these values indicate the acceptable accuracy of the model in predicting runoff in the Maroon basin. In addition, considering that the PTVE between the observed and predicted hydrographs are equal to 14.3% over the predicted period, it can be concluded that the predicted values are less than the corresponding observed values.

Comparison of monthly simulated and observed hydrographs at Idanak station in model calibration

Comparison of monthly simulated and observed hydrographs at Idanak station in model validation

Comparison of monthly predicted and observed hydrographs at Idanak station
SARIMA time series modeling
In this paper, it is attempted to identify and fit the best SARIMA linear model to forecast the monthly discharge of the Idanak hydrometric station for the years 1991–2021. Figures 6 and 7 show the autocorrelation and partial autocorrelation functions in which the seasonal variations are fully apparent. Figure 8 shows the time series diagram of the monthly discharge of the Idanak hydrometric station after stability in the mean and variance. Figure 9 also shows the results of the Box-Cox transformation of the monthly discharges. To choose the best model in terms of using the least estimated parameters, the modified Akaikes criterion is used. Tables 2 and 3 illustrate a summary of statistical parameters of the fitted ARIMA model and illustrate the Akaikes criteria on the monthly discharge of the Idanak station. As mentioned earlier, one of the methods for verifying the fitted pattern series is to analyze the residual patterns. A logical method for testing the model error is to test the normality of data and plot the autocorrelation functions of model residuals. If the fitted model is a suitable model, the autocorrelation function of the residual samples does not show any structures, in other words, it remains in the confidence interval for all delays. In Figs. 10 and 11, the autocorrelation and partial autocorrelation functions of the residuals are presented for the SARIMA (1,0,2)*(2,0,2)12 models which are the superior model. However, the independence of the residuals can be accepted by the correlations limits. It is observed that the assumption of the normality of the residual is correct. The conventional method to test the suitability of the model based on the residual’s autocorrelation is the Port-Manteau test. The results of the Port-Manteau test (Q (r)) statistic for the studied station are presented in Table 2 for the fitted SARIMA statistical models. To judge the H0 hypothesis, the value of the statistic obtained from Port-Manteau was compared with the value λ2 at a significant level of 5%. As observed in the table, this statistic is less than the corresponding value λ2 in the station for both fitted SARIMA models. The seasonal components (P, D, Q) and the non-seasonal components (p, d, q) are presented in Table 2 for the best fitted model for the monthly discharges of the station. The results obtained from the study of correlation between the actual and predicted flow rates for the SARIMA models are recorded in Table 3 for the studied stations. The results showed that among SARIMA models, the SARIMA (1,0,1)*(2,0,2)12 model with R2 equal to 0.65 and minimum SB equal to 129 is prioritized to model the monthly discharge of the station. Figure 12 shows the scatter diagram of the predicted monthly runoff discharge rates with the HEC-HMS model and the SARIMA(1,0,1)*(2,0,2)12 time series relative to the observed monthly runoff in the Idanak hydrometric station. Table 4 showed some statistical criterial between observed and monthly predicted stream flow with HEC-HMS and SARIMA model.

Autocorrelation function diagram of the Idanak monthly discharge time series

Partial autocorrelation function diagram of the Idanak monthly discharge time series

Time series scatter diagram of the Idanak monthly discharge after being stationary

Time series scatter diagram of the Idanak monthly discharge after Box-Cox transformation

Autocorrelation function diagram of the residuals of the model SARIMA(1,0,1)*(2,0,2)12

Autocorrelation function diagram of the residuals of the model SARIMA(1,0,1)*(2,0,2)12

Scatter diagram of monthly observed and predicted streamflows with HEC-HMS and SARIMA(1,0,1)*(2,0,2)12 models
Conclusion
The rainfall–runoff simulation with the HEC-HMS model shows a good accuracy in estimating the streamflow with low discharge and baseflow relative to the peak discharges. Input data of existing models include precipitation, streamflow, air temperature and evapotranspiration to simulate the rainfall–runoff process over a minimum of 1 water year continuously. But the estimated time parameters in the sub-basins include the time of concentration, the lag time, and Clark's storage coefficient in an hourly manner. Considering the amounts of NS coefficient and the RMSE between the observed and simulated hydrographs it is concluded that the accuracy of stream forecast by the HEC-HMS model in Maroon basin is acceptable. In addition given the PTVE between the observed and predicted hydrographs for the studied period, it can be concluded that the predicted streamflow values are less than the corresponding observed values. On the other hand, the analysis of the correlogram of time series of the monthly flow data indicated that these data were completely consistent with the SARIMA multiplicative seasonal model. Based on the behavior of autocorrelation functions, the partial autocorrelation of residuals and Port-Manteau test values obtained from the fitting of models, the validation of the fitted models were confirmed. To select the best SARIMA model, the Akaike and Port-Manteau criteria were used and the SARIMA(1,0,1)*(2,0,2)12 with the lowest Akaike statistic was selected as the superior model. According to the statistical criteria, the HEC-HMS hydrologic model is more accurate than the SARIMA(1,0,1)*(2,0,2)12 time series model in forecasting the monthly streamflow of Maroon basin.
Availability of data and material
Data not available.
Change history
05 June 2023
A Correction to this paper has been published: https://doi.org/10.1007/s40899-023-00862-x
References
Adnan RM, Petroselli A, Heddam S, Santos CAG, Kisi O (2021) Short term rainfall-runoff modelling using several machine learning methods and a conceptual event-based model. Stoch Env Res Risk Assess 35(3):597–616
Anon (2000) Hydrologic modeling system HEC–HMS: technical reference manual. U.S. Army Corps of Engineers, Hydrologic Engineering Center, Davis, Calif
Bennett T (1998) MS thesis, Development and application of a continuous soil moisture accounting algorithm for the Hydrologic Engineering Center-Hydrologic Modeling System HEC-HMS, Dept. Of Civil and Environmental Engineering, Univ. of California, Davis, Calif
Box GEP, Jenkins GM, Reinsel GC (1994) Time Series Analysis Forecasting and Control, 3rd. ed., Englewood cliff, N.J Prentice Hall
Can I, Selim S (2009) Stochastic modeling of mean monthly flows of Carrasco river. In water and Environment Journal
Fathian F, Fakheri Fard A, Ouarda TBMJ, Dinpashoh Y, Mousavi-Nadoushani SS (2019a) Modeling streamflow time series using nonlinear SETAR-GARCH models. J Hydrol 573:82–97
Fathian F, Mehdizadeh S, Sales AK, Safari MJS (2019b) Hybrid models to improve the monthly river flow prediction: integrating artificial intelligence and non-linear time series models. J Hydrol 575:1200–1213
Gumindoga W, Rwasoka DT, Nhapi I, Dube T (2016) Ungauged runoff simulation in Upper Manyame Catchment, Zimbabwe: Application of the HEC-HMS model. Physics and Chemistry of the Earth, Parts A/B/C. In: Press, Corrected Proof
HEC (2008) HEC-HMS, User’s manual version 3.3. Hydrologic engineering center, California
Hooshyaripor F, Faraji-Ashkavar S, Koohyian F, Tang Q, Noori R (2020) Annual flood damage influenced by El Niño in the Kan River basin, Iran. Nat Hazards Earth Syst Sci 20(10):2739–2751
Khezrian NN, Hajjam S, Mirzaei A, Meshkavati AH (2012) Prediction of runoff of Tireh basin using quantitative prediction of rainfall as the WRF model output. J Clim Res 12:53–68 ((In Persian))
Koch R, Bene K (2013) Continuous hydrologic modeling with HMS in the Aggtelek Karst region. Hydrology 1(1):1–7
Mehdizadeh S, Fathian F, Adamowski JF (2019a) Hybrid artificial intelligence-time series models for monthly streamflow modeling. Appl Soft Comput 80:873–887
Mehdizadeh S, Fathian F, Safari MJS, Adamowski JF (2019b) Comparative assessment of time series and artificial intelligence models to estimate monthly streamflow: a local and external data analysis approach. J Hydrol 579:124225
Modaresi F, Araghinejad S, Ebrahimi K (2018) A comparative assessment of artificial neural network, generalized regression neural network, least-square support vector regression, and K-nearest neighbor regression for monthly streamflow forecasting in linear and nonlinear conditions. Water Resour Manage 32(1):243–258
Ni L, Wang D, Singh VP, Wu J, Wang Y, Tao Y, Zhang J (2019) Streamflow and rainfall forecasting by two long short-term memory-based models. J Hydrol 124296
Razmkhah H, Saghafian BA, Ali AM, Radmanesh F (2016) Rainfall_Runoff Modeling Considering Soil Moisture Accounting Algorithm, Case Study: Karoon III River Basin. Water Resour 43(4):699–710
Shafizadeh-Moghadam H, Valavi R, Shahabi H, Chapi K, Shirzadi A (2018) Novel forecasting approaches using combination of machine learning and statistical models for flood susceptibility mapping. J Environ Manag 217:1–11
Singh WR, Jain MK (2015) Continuous Hydrological Modeling using Soil Moisture Accounting Algorithm in Vamsadhara River Basin, India. J Water Resour Hydraulic Eng 4(4):398–408
Sintayehu LG (2015) Application of the HEC-HMS Model for Runoff Simulation of Upper Blue Nile River Basin. J Hydrol Curr Res 6(2):2–8
Supe MS, Taley SM, Kale MU (2015) Rainfall - Runoff Modeling using HEC-HMS for Van River Basin. Int J Res Eng Sci Technol 1(8):20–28
Tongal H, Booij MJ (2018) Simulation and forecasting of streamflows using machine learning models coupled with base flow separation. J Hydrol 564:266–282
Valipour M (2015) Long –term runoff using SARIMA and ARIMA models the United States. J Meteorol Appl 22:592–598
Valipour M, Banihabib M, E and Behbahani S. M. R. (2012) Monthly Inflow Forecasting Using Autoregressive Artificial Neural Network. J Appl Sci 12(20):2139–2147
Wei ZL, Xu YP, Sun HY, Xie W, Wu G (2018) Predicting the occurrence of channelized debris flow by an integrated cascading model: A case study of a small debris flow-prone catchment in Zhejiang Province, China. Geomorphology 308:78–90
Yurekli K, Kurunc K, Ozturk F (2005) Application of linear stochastic models to monthly flow data of kellkit stream. Ecol Model 183:67–75
Acknowledgements
This article has been prepared with the assistance and financial support of the Vice Chancellor for Research and Technology of University of Zabol and the grant number IR-UOZ-GR-0303, by which the author expresses his gratitude and appreciation.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this article was revised due to change in the author name.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Ahmadpour, A., Mirhashemi, S., Haghighat jou, P. et al. Comparison of the monthly streamflow forecasting in Maroon dam using HEC-HMS and SARIMA models. Sustain. Water Resour. Manag. 8, 158 (2022). https://doi.org/10.1007/s40899-022-00686-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40899-022-00686-1