
Abstract
The bearing capacity of soil in general is considered a key parameter in the field of geotechnical engineering, requiring field investigations and extensive testing to eliminate design errors. Reinforced sand beds, however, present unique complexities for conventional computational techniques, as these methods may fall short in fully capturing the interaction between parameters that control ultimate bearing capacity. Consequently, nature-inspired soft computing (SC) techniques, inspired by the resilience and adaptability inherent in natural systems, have been utilized and evaluated in simulating and predicting the reinforced soil bearing capacity in geotechnical engineering. These include support vectors machines (SVM), ensemble tree (ET), Gaussian’s process regressions (GPR), regression trees (RT), and artificial neural network (ANN). A thorough evaluation of SC techniques was executed for their computational efficiency and prediction accuracy. The hypermeter values of all SC techniques were optimized using Bayesian optimization with the goal of reducing prediction error. The results showed that ANN-SC technique outperformed the other techniques based on three performance measures: mean absolute errors (MAE), coefficients of determination (R2), and root mean square errors (RMSE). Furthermore, normalized importance analysis was conducted using the best-performed model (ANN), and the findings demonstrated that the soil average particle size/reinforcement width (D50/Aw) had the highest relative importance on the ANN-predicted bearing capacity, followed by friction angle and depth of first reinforcement layer. The python code (using PyNomo library) was employed to develop a nomograph to facilitate the application of the ANN model findings. This neuro-nomograph uses the weights and biases from the optimal ANN model to offer a simplified tool to predict reinforced soil bearing capacity. Furthermore, the performance of this novel neuro-nomograph was validated using physical bearing capacity test results. The comparison showed a coefficient of variation (COV) of 0.13 and a mean ratio of test to predicted bearing capacities (UBCtest/UBCpred) of 1.11, which suggests the minimal scatter and, thus, confirm the high precision of the developed neuro-nomograph predictions of the reinforced soil bearing capacities.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Geotechnical engineering, a specialized discipline, deals with the complexities of earth materials behaviors, the aspects of water–soil interactions, and soil–structures interactions. Yet, modeling the behavior of soil with inclusions remains a challenge when using conventional techniques. Soft computing (SC) are advanced modeling techniques, including machine learning, artificial neural networks (ANN), and fuzzy logic, which deal with approximation and uncertainty to solve complex problems [1]. Using soft computing (SC) techniques has recently become popular in modeling complex behavior in geotechnical applications due to its predictive capabilities when compared to conventional techniques and methods [2]. In the context of shallow foundations, two predominant factors drive their design: the ultimate bearing capacity and settlement, often referred to as serviceability [3].
Previous studies have successfully applied SC techniques for solving geotechnical engineering problems, specifically predictions of reinforced foundations behavior [4,5,6,7,8,9,10,11,12,13,14,15,16,17]. For reinforced sands, in particular, and given the complexity and often uncertainty in their bearing capacity and settlement analysis, SC techniques have attracted broad interest as an effective alternative to normal regression [18]. Related previous attempts to model the reinforced soil behavior are summarized in Table 1.
Soleimanbeigi and Hataf [5] investigated the possibility of using backpropagation and feedforward ANNs to predict reinforced sands’ ultimate bearing capacity of shallow foundations. However, the developed ANN model ignored several practical parameters such as the effect of the geogrid’s aperture size and soil gradation parameters. Sahu et al. [7, 8] implemented neuro-fuzzy and ANN modeling techniques to estimate the bearing capacity of inclined loading on shallow strip footing on reinforced sands with specific type of geogrid reinforcement. The authors reported an R2 of 0.997 and 0.994 for neuro-fuzzy and ANN modeling, respectively. Raja and Shukla [18] used ANN to model the settlement of reinforced foundations using numerical simulation results; therefore, the effect of geogrid geometry and soil gradation was not included in the study. The authors reported an R2 of 0.962 with best-performed ANN. More recently, Kumar et al. [19] utilized advanced predictive models such as extreme learning machine (ELM) and multivariate adaptive regression splines (MARS) to model the bearing capacity; the R2 of ELM and MARS regression was 0.976 and 0.995, respectively. However, the authors did not include the effect of reinforcement in their analysis.
Previous studies relied heavily on well-established SC techniques, innovative models such as support vector machines (SVM) [20] and Gaussian process regression (GPR) [21], despite their increasing usage, have not attracted substantial interest in the geotechnical community as The emergence of advanced models inspired by natural systems [22] provides a chance for evaluating more intricately coupled systems, like reinforced soils. Yet, existing literature deals with soil and reinforcement reinforcing inclusions as independent entities, and less focus as a grand integrated system, where the overall behavior of the system is a result of interaction between soil particles and geogrid. In addition, the SC techniques adopted by previous studies yield models that are perceived complex and impractical for field engineers. These models, often considered ‘black boxes,’ offer limited accessibility for practitioners due to their lack of explicit equations for practical implementation.
In the same context, the pursuit of analytical solutions for the bearing capacity of reinforced soils continues to be of interest to researchers. Existing analytical solutions, such as those detailed by Sharma et al. [23], have largely been limited to square footing. Although Chen and Abu-Farsakh [24] addressed this limitation in their work, these analytical solutions are typically based on Terzaghi’s and Meyerhof’s approach with bearing capacity factors and coefficients [24]. Therefore, these analytical solutions fail to integrate the effect of individual and interrelated impacts of soil particle and reinforcement sizes.
In this research, a large database of physical testing of footings with different sizes on reinforced soil was collected from several peer-reviewed studies. The collected dataset encompasses diverse properties of soil, reinforcements, and foundations. The collected dataset was investigated using several SC techniques, namely support vectors machines (SVM), ensemble tree (ET), Gaussian's process regressions (GPR), regression trees (RT) and artificial neural network (ANN). These models were chosen due to their widespread adoption in geotechnical engineering, particularly in examining the behavior of shallow foundations [25]. Beyond traditional SC models, user-friendly nomograph, leveraging results from the top-performing SC model was developed. The upshot is a powerful tool that equips both on-site engineers and researchers to leverage the insights of advanced AI models within seconds, using nothing more than a piece of paper. This simplified nomograph is believed to enable site engineers and researchers to use the developed comprehensive artificial intelligent models within seconds using only a piece of paper. This combination of sophisticated modeling with practical design is a significant leap forward, fostering greater precision, speed, and efficiency in geotechnical engineering.
Data Collection and Preprocessing
For this study, comprehensive dataset was collected from various peer-reviewed articles. These papers explored the ultimate bearing capacities of reinforced dry compacted sands through experimental studies. Specifically, Table 2 summarizes the sources that were incorporated in the dataset.
The collected dataset covered a wide range of laboratory models and sizes. A total of 261 bearing capacity test results were collected and employed in the dataset. For each of experiments, 15 variables were collected and recorded, in addition to the ultimate bearing capacity. Table 3 shows the variables in the collected dataset, with an explanation of each symbol and the units of measurements. Figure 1 shows a schematic of experimental bearing capacity test setup and the 15 variables defined in the collected dataset. The collected variables aimed to cover both physical and mechanical aspects of the geogrid-reinforced soil; the collected physical variables were (B, L, N, Aw, AL, b/B, h/B, D10, D30, D50, D60, and u/B) and mechanical variables were (Dr, ϕ, and T). It should be mentioned that the dataset for reinforced sand beds analysis with under hydrostatic groundwater conditions are scarce in the literature; therefore, tests with dry sands with hygroscopic water content 1–3% were only included. In addition, data used here are limited to experiments conducted on surface footings as data associated with footings placed at an impediment depth is extremely limited.

General schematic diagram for physical testing model
While various other variables could have been considered for this investigation, we chose to exclude them. This decision was influenced by the fact that many studies did not report specific results, including those related to soil geochemistry, particle shape, and others.
Several variables were not readily available from the original dataset, and it is believed to improve the predictions of the response [41]. Especially those variables that combine the effects of multiple parameters. For instance, D50 may be considered as an important parameter that may incorporate the effects of other particle size percentages. The particle sizes (D10, D30, D50, and D60) were normalized by reinforcement aperture width, Aw. In addition, the width and spacing of the reinforcement layers and the depth of the first reinforcement layer were normalized by the footing width. Overall, the dataset included 15 variables, as well as the response variable, i.e., bearing capacity.
Statistical Analysis of Collected Dataset
Before using the dataset for SC modeling, a statistical analysis was conducted to determine the statistical indices of analysis input parameters in the collected dataset. Table 4 summarizes the statistical features of the parameters adopted in this study. The mean and standard deviation of the ultimate bearing capacity were 375.64 and 309.18 kPa, respectively. Moreover, a matrix plot between all parameters is shown in Fig. 2, with correlation coefficient values following linear fittings. The matrix shows the highest correlation for the UBC with ϕ and Dr with coefficients of 0.69 and 0.56, respectively.

Matrix plot showing distribution and correlation coefficients values assuming linear correlations for all input parameters used in the current study
It is worth noting that the footings dimensions covered in this study vary from 50 to 610 mm. This range covers the scale effect between all parameters, as discussed by Ahmad et al. [42] and Mehjardi and Khazaei [43].
Ahmad et al. [42] conducted several experimental tests on geogrid-reinforced soils response to investigate the scale effects. Their results have shown that the scale effect vanishes for footings with a width of more than 600 mm (strip footing). Moreover, Mehjardi and Khazaei [43] studied the scale effect on the behavior of geogrid-reinforced soils under the circular footing. They stated that the scale effect vanishes for footings with diameter more than 120 mm.
Modeling Approaches
SC are computational methods that can “learn” from input datasets to develop predictive abilities. The idea behind SC is finding common similarities between previous dataset input and their consequent output. This is attained by modifying pairs of input and output from the dataset to the model and then tweaking the connection biases and weights of the model to minimize the errors between the model-predicted available outputs (i.e., training). The issue under deliberation in this research requires a supervised regression SC approach (provided output). From various available existing supervised regression techniques, those selected were Gaussian process regression (GPR), support vector machine (SVM), regression trees (RT), ensemble trees (ET), and artificial neural networks (ANN).
Gaussian Process Regression (GPR)
Gaussian process regressions take inspiration from the concept of Gaussian distributions in statistics, which are often observed in natural phenomena. GPR models capture the uncertainty in data by representing it as a distribution over possible functions, allowing for more robust predictions and accounting for natural variations and noise. GPR models are powerful tools used for solving difficult ML problems. Their importance is owed to the fact that they are flexible non-parametric models. Another key advantage of GPR models is their ability to mimic the smoothness and noise parameters from the training dataset [44]. A GPR is a stochastic process in which random variables are assumed to follow a Gaussian distribution. There are four main types of Gaussian processes: squared exponential (SE), exponential (EX), matern (MN), and rational quadratic (RQ). The kernel functions in GPR mainly determine how the response at one input point (\(x\)) is affected by responses at other point (x′), which is also called input distance (x − x′). The difference between these processes is the utilized kernel function (K) as illustrated in Eqs. (1)–(4)
where \(x\) and x′ are input vectors that are either in training or testing datasets, parameter \(l\) defines the characteristic length-scale that depends on input distance, and \({\sigma }_{f}^{2}\) is the single standard deviation. Parameter \(l\) briefly defines how far the input values \(x,\) can be for the response values to become uncorrelated.
\(Q\) s vector parameter ~ \(N(\mathrm{0,1})\), it should be noted here that having γ = 2 turns the EX kernel to squared exponential as shown in Eq. (3).
where \({k}_{v}\) is the Bessel function [45], Γ is the gamma function, and ν is the gamma distribution shape parameter. It is worth noting that Matern 5/2 or 3/2 models are obtained by replacing the ν by 5/2 and 3/2 values, respectively.
where α is a scale-mixture parameter.
Support Vector Machine (SVM)
The design of support vector machines (SVM) is inspired by the way biological systems separate different classes of data. SVMs aim to find an optimal hyperplane that maximally separates data points from different classes, mimicking the concept of decision boundaries in nature. SVM is a machine learning technique that employs kernel functions to transform data into a high-dimensional feature space. In this space, a linear model is used to accommodate any complex nonlinear relationships [46]. The main idea behind SVM modeling is the computation of a linear regression function in a high-dimensional feature space, where the input data are mapped via a nonlinear function. This technique has been garnering more attention recently and has been used by several researchers. There are several types of SVM, such as linear, quadratic, and cubic. Equation (5) illustrates the mathematical kernel function of these models.
where \(p\) is a parameter that is specified by the user to express weather the kernel is linear, quadratic, or cubic. Furthermore, SVM can be further divided into coarse, medium, and fine Gaussian by setting kernel scale to \(\sqrt{p \times 4}\), \(\sqrt{p}\) and \(\sqrt{p/4}\), respectively, where \(p\) is the number of predictors.
Regression Trees (RT)
Regression trees (RT) mimic the branching structure of natural decision-making processes. Inspired by the hierarchical organization of natural systems, regression trees recursively split data into subsets based on feature values, creating a tree-like structure that represents the decision process and captures complex relationships in the data. RT are a type of empirical tree representation used for segmenting data by applying a sequence of simple rules. Decision-tree modeling involves generating a set of rules that can be used for prediction through the repetitive process of splitting. One of the most common tree methods is the regression decision tree. A major advantage of the decision tree is that the resulting model provides a clear picture of the importance of the significant factors affecting the accuracy of the prediction model. The tree is composed of roots, leaves, and branches [47]. Usually, numeric records are sorted according to the tree, starting from the root at the topmost node. At every internal node, a conditional test is conducted to decide the corresponding path among the tree branches. There are various criteria to judge the conditional testing at each node, for instance summation of square error. The eventual prediction of the tree model is obtained from the leaf at the end of the path. In essence, partitioning the data is done by lessening the deviance from the mean of the output features, which is mathematically summarized in Eq. (6).
where \(\overline{Y }\) and \({Y}_{i}\) are the mean of the output and target features. Given that the cut point splits the data into two mutually exclusive subsets, right and left, the deviance reduction (\({\Delta }_{j \mathrm{Total}}\)) is redefined as shown in Eq. (7):
where \({D}_{\mathrm{Left}}\) and \({D}_{\mathrm{Right}}\) are the deviances of left and subsets, respectively.
Furthermore, various types of regression trees can be obtained by varying required minimum leaf sizes, such as complex, medium, and fine trees. The fine, medium, and coarse tree has a minimum of 4, 12, and 36 leaves, respectively.
Ensemble Trees (ET)
Ensemble trees (ET) draw inspiration from the collective behavior and cooperation seen in natural systems. By combining multiple decision trees into an ensemble, they leverage the wisdom of the crowd to make more accurate predictions. Each tree in the ensemble learns from different subsets of the data, mimicking the diversity and collaboration found in ecosystems. An ET technique is a set of separate weak models (number of learners) that, when combined (number of predictors), provide a reliable mathematical prediction. There are two types of ensemble decision trees: boosted and bagged trees [48]. Bagged trees (parallel) consist of combining different ensembled bootstraps into separated decision trees, all tresses are then combined into one decision tree, where the final decision is computed by averaging the trees results. Boosted trees (sequential), on the other hand, are also an ensemble of regression trees but have a cost function that combines the final models. Ensemble trees use subsets of the original data to produce a series of sequential averagely performing models. Whereafter, the models are improved by combining them using a certain cost function, such as Eq. (8).
where \({\widehat{y}}_{\mathrm{bag}}\) is a target value resulted from average results, \(\widehat{Y}w(x)\) is the detected target value for observation \(x\) in bootstrap sample \(u\), and \(U\) is the number of bootstrap samples.
Artificial Neural Networks (ANN)
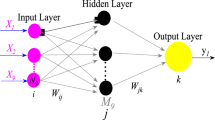
Artificial neural networks draw inspiration from the structure and functionality of biological neural networks in the brain. With interconnected nodes (neurons) organized in layers, ANNs process information and learn from data in a way that resembles the adaptability and parallel processing capabilities of the human brain, enabling them to model complex patterns and make predictions. Numerous numbers of studies in geotechnical engineering have utilized the ANNs for assessing the collected data due to their familiarity and robustness [17]. The basic structure of an ANN models consists of nodes, connection (weights), transfer function, and bias forming the input, hidden and output layers. The ANN model used in this study is a typical ANN with one hidden layer feedforward ANN, linear output neurons, sigmoid activation function and Levenberg–Marquardt backpropagation training algorithm. A total of 10 artificial neural network models were tested in the current study. The neurons were varied from 10 to 50 neurons with 10-step intervals, to come up with the best, least complex model. The equation of single neuron can be written as in Eq. (9).
where \(N\) is the neuron numerical value, \(f\) is the activation function, \(c\) is the bias, \(W\) is weight matrix (dimension 1 × n), \(I\) is the input matrix (dimension 1 × n), and \(n\) is the number of variables.
Optimization of SC Models’ Hypermeters
This study aims to investigate the best-performing model to predict the bearing capacity of shallow foundations. To obtain the best-performing hypermeters for each SC technique described earlier, Hyperparameter Optimization option in Machine learning toolbox was utilized. The use of optimized hypermeter will ensure the highest accuracy possible for a certain SC technique.
This option navigates through possible hypermeters using Bayesian optimization with the goal of reducing prediction error [49]. Additional information on the comprehensive and computations for optimization of hypermeters can be found in statistics and machine learning toolbox [49].
Independent Variable Importance
Independent variable importance was executed for best-performing model following Nowruzi and Ghassemi [50] importance method; variables with relative importance of 40% or less were excluded and the best-performed model was retrained. This procedure was designed to produce the highest possible accurate results with the least number of variables, which would significantly reduce the computation time and model complexity.
Results and Discussion
Before the implementation of SC models, the collected dataset was randomly divided into three sets: training, cross-validation, and testing with percentages of 70, 15, and 15%, respectively, with similar dataset ranges. The training set (70%) was used to calibrate the SC models by reducing prediction errors, whereas the cross-validation set (15%) was utilized to avoid overfitting the collected data. The accuracy and performance of the trained SC models were assessed using the testing dataset (15%).
The performance and accuracy measures considered in this study were: (1) coefficients of determination (R2), mean absolute error (MAE) in kPa, and (3) root mean square error (RMSE) in kPa. The SC techniques in this study were accessed using the Machine Learning and Statistics Toolbox in MATLAB R2022a. The accuracy of the used SC techniques is summarized graphically in Fig. 3 and numerically in Table 5 for testing and validation datasets. It should be mentioned that all models had validation results that are close to testing dataset results, as shown in Table 5, which confirms that none of the models has observed overfitting.

Graphical representation of performance measures for all used SC models
Modeling Results
The optimized hypermeter values for all models are summarized in Table 6, following the optimization methodology using Bayesian optimization in statistics and machine learning toolbox [49]. The accuracies of the models varied depending on models used, complex and medium RT models have shown the highest R2 (0.99), while fine RT model had the lowest R2 value of 0.73. The complex RT model had the lowest RMSE and MAE of 168.42 and 98.8 kPa, respectively, among RT modeling techniques. Furthermore, fine, coarse, and quadratic SVM models had relatively low R2 results as shown in Table 5 and Fig. 3, while linear and medium Gaussian SVM models had R2 of 0.98 and 0.96, respectively. Regarding ET modeling, Boosted ET model had better performance compared to bagged ET with R2, MAE and RMSE values of 0.99, 107.69, and 184.68 kPa, respectively.
The RMSE and MAE value differences for GPR models were not significant. RMSE values of all GPR models ranged between 119.26 and 132.59 kPa for Matern 5/2 and Exponential GPR, respectively. Finally, ANN detailed optimization results are summarized in Fig. 3 for the 10 ANN models used in the current study. Initially, all 14 variables were considered as inputs for the ANN models. ANN modeling began with 10 neurons and increased up to 50 neurons by 10 neurons each step, resulting in five ANN models shown in Fig. 3 as dashed lines. The highest R2 and lowest RMSE were achieved with the more complex neural network model (50 neurons), with values of 0.989 and 45.71 kPa, respectively, which reveal that ANN model at 50 neurons has the best performance with lowest RMSE and MAE and highest R2.
Best Performing Model
The results in Table 5 for testing and validation of SC techniques reveal that ANN outperformed all other SC techniques with R2, MAE, and RMSE values of 0.99, 27.36, and 45.71 kPa, respectively. The performance of SC techniques is dependent on several concepts including the dataset itself. For the methodology and datasets used in this study, ANN outperformed other SC technique, which in line with previous studies [51,52,53] (Fig. 4).

RMSE and R-squared of the ANN model with and without low importance variables
Normalized Variables Importance
Normalized variable importance was calculated for the best-performing SC technique (i.e., ANN model). Results of variable importance are summarized in Fig. 5. It was shown that the highest normalized variable importance scores were for D50/Aw, friction angle (ϕ), depth to footing ratio (u/B), and relative density (Dr), all of which related to soil properties and referred internally to the interaction of the soil-geogrid matrix. This observation suggests that practitioners should prioritize the soil gradation (D50) and geogrid aperture size (Aw) when compared to enhancing soil properties such as ϕ and Dr. ϕ and Dr are considered important parameters as well relative to other parameters. The particle size has the highest effect on bearing capacity of reinforced sands, as the geogrid efficiency depends mainly on its applicability of confining the soil particles within geogrid cells. After assuring the occurring of soil confinement, soil friction angle is then to be considered. It would then be pointless and gratuitous to have soil with a high friction angle or density without proper confinement. Thus, this logical flow of soil-geogrid matrix behavior sounds logical from the flow of obtained importance results.

Variable importance of best-performed ANN model
On the other hand, the least variable importance was observed for footing length (L), number of reinforcement layers (N) and the normalized width of reinforcement layers (b/B). This refers to the fact that those variables were interrelated in the neural network model by other parameters. For example, the number of layers were impeded in spacing between geogrid layers (h/B) if more than one layer exists.
To investigate the least important parameters impact on predicting the ultimate bearing capacities of reinforced soil, all variables with relative importance of 40% or less were eliminated (from length of footing L to (D60/Aw)). Then, the preceding ANN procedure was repeated using only the remaining important parameters (from normalized depth of first layer (u/B) to D50/Aw), resulting in five new artificial neural network models. Figure 4 summarizes the results of the five new ANN models excluding the least important variables.
Overall, no significant changes in performance measures were spotted in ANN models without the least important parameters. The results obtained at 10 neurons without least important had an R2 and RMSE values of 0.969 and 76.3 kPa, respectively, compared to 0.975 and 72.03 kPa in the model including all variables. However, the new ANN model excluding the least important variable had very low improvement with an increasing number of neurons. However, sacrificing minor values of accuracy may be more practical to reduce the model complexity by using a smaller number of input variables.
Developing the ‘Neuro-nomograph’
Among all SC techniques, the ANN models have shown the lowest RSME and MAE. Researchers and geotechnical engineers require simpler and practical tools for obtaining accurate results from the trained SC models rather than computations that requires specialized computational software such as MATLAB or SPSS, which may not always be available. Thus, some researchers demonstrated simplified computational methods to obtain the response of given dataset using the artificial neural network model developed. For example, Soleimanbeigi and Hataf [5] explained how to utilize the weights from their ANN model to obtain the settlement results of reinforced sand from given inputs. An additional example is found in Shahin et al. [54], where the authors developed a two-neurons ANN-based equation for predicting sand elastic settlement. To make this method practical for engineers and researchers, the authors reduced the number of neurons to obtain a simpler ANN that can be modeled using an equation.
In this article, a relatively more user-friendly graphical method was adopted known as the nomograph. Nomographs, which were first used in 1795 by the French government, introduced a powerful tool for performing simple and complex calculations in a variety of applications with a relatively low time and effort [55]. The nomograph (also known as nomogram) is a diagram that mimics a numerical formula, where each variable is represented by a graduated line, and the solution can be obtained by connecting the required variables’ values by straight lines ending with the solution value. The numerical formula is mimicked by changing the graduated lines (variables) scales, orientation, and distances from each other [56].
As a result, applications of nomographs are considered useful in several fields: compaction properties of soils [57], earth dams safety factors [58], bearing capacity and elastic settlement [59], probabilistic seismic hazard [60], hazard distances from a blast wave [61], punching shear capacity of slabs [62], tunnels’ safety factors in cohesive soils [63], and many others.
Previous researchers have developed nomographs derived from regression equations between variables. In this research, the trained model weights of the best-performed ANN model were used to develop the nomographic diagram. This approach is rarely used in literature, which gives a remarkable add-on value to the trained ANN model. The Python 3.9 language and PyNomo library were used to develop an adapted neuro-nomograph shown in Fig. 6. PyNomo is a nomograph-generating program based on the Python text developed by Glasser and Doerfler [64]. Additional information on the origins and development of PyNomo programming code can be found in [64].

Neuro-nomograph for predicting bearing capacity of reinforced soil
To obtain a precise graphical solution for a traditional regression formula, PyNomo software calibrates the variable scales, distances, and orientations to mimic the regression equation. On the other hand, in this research, the traditional formula was substituted with the ANN formula that was exported from Machine Learning Toolbox in MATLAB. The exported formula from MATLAB can be summarized using Eq. (10):
where \({w}_{\mathrm{I}}\) is the weights matrix for input layer; \({w}_{\mathrm{H}}\) is the weights matrix for hidden layer; \(I\) is the input matrix; b is the matrix of biases and \(k\) is a single-value bias value. \({w}_{\mathrm{I}}\), \({w}_{\mathrm{H}}\), b, and \(k\) are constants that were obtained from Machine Learning Toolbox in MATLAB after ANN model training.
The adopted nomograph (Fig. 6) can be utilized to predict the ANN-ultimate bearing capacity of reinforced sands. Parameters used in developing the adapted neuro-nomograph were the most important in terms of soil (friction angle), geogrid (tensile strength), and the interrelated parameters between both of them (depth and width of the geosynthetic, in addition to D50/Aw). An example shown as a dashed line with procedure explained is found in Fig. 7.

Example of how to use the neuro-nomograph for reinforced soil bearing capacity prediction
Neuro-nomograph Validation
The easiness of neuro-nomograph found in this study is attractive. Yet, it must be ensured that these graphs can yield accurate predictions. Therefore, 20 random ultimate bearing capacity results that were not used in the training of ANN model (testing dataset) are used to check the accurateness of the neuro-nomographs. Figure 8 shows measured UBC values versus predicted UBC values using the neuro-nomograph. The close proximity of the points to the 1:1-line attests to the model validity. Furthermore, the predicted values are positioned within a ± 0.5 standard deviation and confidence intervals of ± 5% of measured values and with an R2 of 0.98. Such results agree with the previously obtained ANN model for the most significant parameters using MATLAB (Fig. 5). Additionally, the ratio of measured ultimate bearing capacity to those predicted from the developed neuro-nomograph (UBCtest/UBCpred) have shown variation coefficient (COV) of 0.13 and mean of 1.11, respectively, verifying the validity of the adapted neuro-nomograph.

Validation of adapted neuro-nomograph using 20 random test results
Practical Applications
The developed ‘neuro nomograph’ is believed to be a helpful design aid tool for practitioners in designing reinforced shallow foundations as quick estimations harnessing the power of SC models. Moreover, the outcomes of this study suggest that although ϕ and Dr are considered important parameters for reinforced foundation design, designers and practitioners should prioritize the soil gradation (D50) and geogrid aperture size (Aw) when compared to enhancing mechanical soil properties.
Limitations of Models and Nomographs
The nomographs and models obtained are governed by the collected dataset used. Results of this study are not expected to have accurate estimations of bearing capacities when extrapolated to values above the maximum or below the minimum values for the different input parameters used in the current study shown in Table 4.
Conclusions
Ultimate bearing capacity (UBC) of reinforced sands is one of the key parameters in designing geotechnical engineering structures. In this article, several soft computing (SC) approaches were applied to estimate the bearing capacity of reinforced dry sands using results from a total of 261 tests collected from the literature. The following conclusions can be drawn:
-
1.
Artificial neural network (ANN) outperformed all SC techniques, including regression trees, ensembled trees, support vector machine, gaussian process regression, in terms of accuracy measures such as R2, MAE, and RMSE. ANN achieved an R2 value of 0.99, MAE of 27.36 kPa, and RMSE of 45.71 kPa, indicating its superior performance in predicting the ultimate bearing capacities of reinforced soil.
-
2.
The performance of the SC techniques varied depending on the specific models used. Complex and medium regression trees models showed the highest R2 value of 0.99, while fine regression trees model had the lowest R2 value of 0.73. Boosted ensembled trees model performed better than bagged ensembled trees model for RT modeling techniques. Linear and medium Gaussian SVM) models had relatively high R2 values of 0.98 and 0.96, respectively, while quadratic SVM models had lower R2 results.
-
3.
GPR models showed relatively low differences in RMSE values, ranging between 119.26 and 132.59 kPa for different GPR models. ANN models achieved the lowest RMSE of 45.71 kPa, indicating its superior predictive performance compared to GPR models.
-
4.
The variable importance analysis revealed that the most significant variables for predicting the ultimate bearing capacities of reinforced soil were D50/Aw (soil gradation and geogrid aperture size), friction angle (ϕ), depth to footing ratio (u/B), and relative density (Dr). These variables were related to soil properties and the interaction of the soil-geogrid matrix. Footing length (L), number of reinforcement layers (N), and normalized width of reinforcement layers (b/B) were found to be least important among input parameters used in the neural network model.
-
5.
A neuro-nomograph, a graphical tool based on the trained ANN model, was developed to provide a simplified and practical method for obtaining accurate results without the need for specialized computational software. The neuro-nomograph showed good accuracy in predicting the ultimate bearing capacities of reinforced sands, with predicted values positioned within a ± 0.5 standard deviation and confidence intervals of ± 5% of measured values.
The “neuro-nomograph” is a useful design aid tool for practitioners in designing reinforced shallow foundations, providing quick estimations harnessing advanced computation models. The study emphasizes prioritizing soil gradation and geogrid aperture size over mechanical soil properties in reinforced foundation design.
Data Availability
The data generated/analyzed during the study are available from the corresponding author on reasonable request.
References
Alotaibi E, Nassif N, Barakat S (2023) Data-driven reliability and cost-based design optimization of steel fiber reinforced concrete suspended slabs. Struct Concr 24:1859–1867
Shahin MA (2015) A review of artificial intelligence applications in shallow foundations. Int J Geotech Eng 9(1):49–60
Kurian NP (2005) Design of foundation systems: principles and practices (3 rev. and enl edn.). Alpha Science International, Harrow, Middlesex
Alotaibi E, Omar M, Arab MG, Tahmaz A (2022) Prediction of fine-grained soils shrinkage limits using artificial neural networks. In: 2022 Advances in science and engineering technology international conferences (ASET). IEEE, pp 1–5
Soleimanbeigi A, Hataf N (2005) Predicting ultimate bearing capacity of shallow foundations on reinforced cohesionless soils using artificial neural networks. Geosynth Int 12(6):321–332
Hung CC, Ni SH (2007) Using multiple neural networks to estimate the screening effect of surface waves by in-filled trenches. Comput Geotech 34(5):397–409
Sahu R, Patra CR, Sivakugan N, Das BM (2017) Bearing capacity prediction of inclined loaded strip footing on reinforced sand by ANN. In: International congress and exhibition, sustainable civil infrastructures: innovative infrastructure geotechnology, Springer, Cham, pp 97–109
Sahu R, Patra CR, Sivakugan N, Das BM (2017) Use of ANN and neuro fuzzy model to predict bearing capacity factor of strip footing resting on reinforced sand and subjected to inclined loading. Int J Geosynth Ground Eng 3(3):29
Moayedi H, Hayati S (2018) Modelling and optimization of ultimate bearing capacity of strip footing near a slope by soft computing methods. Appl Soft Comput 66:208–219
Dutta RK, Rao TG, Sharma A (2019) Application of random forest regression in the prediction of ultimate bearing capacity of strip footing resting on dense sand overlying loose sand deposit. J Soft Comput Civil Eng 3(4):28–40
Dutta RK, Khatri VN, Gnananandarao T (2019) Soft computing-based prediction of ultimate bearing capacity of footings resting on rock masses. Inter J Geol Geotech Eng 5(2):1–14
Dal K, Cansiz OF, Ornek M, Turedi Y (2019) Prediction of footing settlements with geogrid reinforcement and eccentricity. Geosynth Int 26(3):297–308
Asghari V, Leung YF, Hsu SC (2020) Deep neural network-based framework for complex correlations in engineering metrics. Adv Eng Inf 44:101058
Chen C, Mao F, Zhang G, Huang J, Zornberg JG, Liang X, Chen J (2021) Settlement-based cost optimization of geogrid-reinforced pile-supported foundation. Geosynth Int 28(5):541–557
Pant A, Ramana GV (2022) Novel application of machine learning for estimation of pullout coefficient of geogrid. Geosynth Int 29(4):342–355
Raviteja KVNS, Kavya KVBS, Senapati R, Reddy KR (2023) Machine-learning modelling of tensile force in anchored geomembrane liners. Geosynth Int. https://doi.org/10.1680/jgein.22.00377
Shahin MA, Jaksa MB, Maier HR (2009) Recent advances and future challenges for artificial neural systems in geotechnical engineering applications. Adv Artif Neural Syst 2009:9
Raja MNA, Shukla SK (2021) Predicting the settlement of geosynthetic-reinforced soil foundations using evolutionary artificial intelligence technique. Geotext Geomembr 49(5):1280–1293
Kumar M, Kumar V, Biswas R, Samui P, Kaloop MR, Alzara M, Yosri AM (2022) Hybrid ELM and MARS-based prediction model for bearing capacity of shallow foundation. Processes 10(5):1013
Samui P, Sitharam TG, Kurup PU (2008) OCR prediction using support vector machine based on piezocone data. J Geotech Geoenviron Eng 134(6):894–898
Kumar M, Samui P (2020) Reliability analysis of settlement of pile group in clay using LSSVM, GMDH. GPR Geotech Geol Eng 38(6):6717–6730
Assadi-Langroudi A, O’Kelly BC, Barreto D, Cotecchia F, Dicks H, Ekinci A, van Paassen L (2022) Recent advances in nature-inspired solutions for ground engineering (NiSE). Int J Geosynth Ground Eng 8(1):3
Sharma R, Chen Q, Abu-Farsakh M, Yoon S (2009) Analytical modeling of geogrid reinforced soil foundation. Geotext Geomembr 27(1):63–72
Chen Q, Abu-Farsakh M (2015) Ultimate bearing capacity analysis of strip footings on reinforced soil foundation. Soils Found 55(1):74–85
Ebid AM (2021) 35 Years of (AI) in geotechnical engineering: state of the art. Geotech Geol Eng 39(2):637–690
Alotaibi E, Omar M, Shanableh A, Zeiada W, Fattah MY, Tahmaz A, Arab MG (2021) Geogrid bridging over existing shallow flexible PVC buried pipe–experimental study. Tunn Undergr Space Technol 113:103945
Aria S, Shukla SK, Mohyeddin A (2019) Behaviour of sandy soil reinforced with geotextile having partially and fully wrapped ends. In: Proc instit civil eng ground improve, pp 1–14
Alotaibi E, Omar M, Arab MG, Shanableh A, Zeiada MY, Tahmaz A, (2019) Experimental investigation of the effect of geogrid reinforced backfill compaction on buried pipelines response. In: The 4th world congress on civil, structural, and environmental engineering
Abu-Farsakh M, Chen Q, Sharma R (2013) An experimental evaluation of the behavior of footings on geosynthetic-reinforced sand. Soils Found 53(2):335–348
Latha GM, Somwanshi A (2009) Bearing capacity of square footings on geosynthetic reinforced sand. Geotext Geomembr 27(4):281–294
Adams MT, Collin JG (1997) Large model spread footing load tests on geosynthetic reinforced soil foundations. J Geotech Geoenviron Eng 123(1):66–72
Das BM, Omar MT (1994) The effects of foundation width on model tests for the bearing capacity of sand with geogrid reinforcement. Geotech Geol Eng 12(2):133–141
Das BM, Shin EC, Omar MT (1994) The bearing capacity of surface strip foundations on geogrid-reinforced sand and clay—a comparative study. Geotech Geol Eng 12(1):1–14
Yetimoglu T, Wu JT, Saglamer A (1994) Bearing capacity of rectangular footings on geogrid-reinforced sand. J Geotech Eng 120(12):2083–2099
Omar MT, Das BM, Puri VK, Yen SC (1993) Ultimate bearing capacity of shallow foundations on sand with geogrid reinforcement. Can Geotech J 30(3):545–549
Omar MT, Das BM, Puri VK, Yen SC, Cook EE (1993) Shallow foundations on geogrid-reinforced sand. Transport Res Rec 1414:59–64
Omar MT, Das BM, Yen SC, Puri VK, Cook EE (1993) Ultimate bearing capacity of rectangular foundations on geogrid-reinforced sand. Geotech Test J 16(2):246–252
Khing KH, Das BM, Puri VK, Cook EE, Yen SC (1993) The bearing-capacity of a strip foundation on geogrid-reinforced sand. Geotext Geomembr 12(4):351–361
Guido VA, Chang DK, Sweeney MA (1986) Comparison of geogrid and geotextile reinforced earth slabs. Can Geotech J 23(4):435–440
Guido VA, Biesiadecki GL, Sullivan MJ (1985) Bearing capacity of a geotextile-reinforced foundation. In: International conference on soil mechanics and foundation engineering. A. A. Balkema, Rotterdam, Netherlands, pp 1777–1780
Junhua W, Haozhe C, Shi Q (2013) Estimating freeway incident duration using accelerated failure time modeling. Saf Sci 54:43–50
Ahmad H, Mahboubi A, Noorzad A (2020) Scale effect study on the modulus of subgrade reaction of geogrid-reinforced soil. SN Appl Sci 2(3):1–22
Mehrjardi GT, Khazaei M (2017) Scale effect on the behaviour of geogrid-reinforced soil under repeated loads. Geotext Geomembr 45(6):603–615
Rasmussen CE, Nickisch H (2010) Gaussian processes for machine learning (GPML) toolbox. J Mach Learn Res 11:3011–3015
Abramowitz M, Stegun IA (1965) Handbook of mathematical functions. Dover Publications, New York, p 361
Noble WS (2006) What is a support vector machine? Nat Biotechnol 24(12):1565–1567
Loh WY (2011) Classification and regression trees. Wiley Interdiscip Rev Data Min Knowl Discov 1(1):14–23
Zhou ZH, Tang W (2003) Selective ensemble of decision trees. In: Wang G, Liu Q, Yao Y, Skowron A (eds) International workshop on rough sets, fuzzy sets, data mining, and granular-soft computing. Springer, Berlin, Heidelberg, pp 476–483
The MathWorks, Inc. (2022) Statistics and machine learning toolbox (R2022a). Natick, Massachusetts, United States. Retrieved from https://www.mathworks.com/help/stats/
Nowruzi H, Ghassemi H (2016) Using artificial neural network to predict velocity of sound in liquid water as a function of ambient temperature, electrical and magnetic fields. J Ocean Eng Sci 1(3):203–211
Güven İ, Şimşir F (2020) Demand forecasting with color parameter in retail apparel industry using artificial neural networks (ANN) and support vector machines (SVM) methods. Comput Ind Eng 147:106678
Kumar AR, Goyal MK, Ojha CSP, Singh RD, Swamee PK (2013) Application of artificial neural network, fuzzy logic and decision tree algorithms for modelling of streamflow at Kasol in India. Water Sci Technol 68(12):2521–2526
Moraes R, Valiati JF, Neto WPG (2013) Document-level sentiment classification: an empirical comparison between SVM and ANN. Expert Syst Appl 40(2):621–633
Shahin MA, Maier HR, Jaksa MB (2002) Predicting settlement of shallow foundations using neural networks. J Geotech Geoenviron Eng 128(9):785–793
Evesham HA (1986) Origins and development of nomography. Ann Hist Comput 8(4):324–333
Papayannopoulos P (2020) Computing and modelling: analog vs. analogue. Stud Hist Philos Sci A 83:103–120
Omar M, Shanableh A, Hamad K, Tahmaz A, Arab MG, Al-Sadoon Z (2019) Nomographs for predicting allowable bearing capacity and elastic settlement of shallow foundation on granular soil. Arab J Geosci 12(15):485
Mendoza FC, Gisbert AF, Izquierdo AG, Bovea MD (2009) Safety factor nomograms for homogeneous earth dams less than ten meters high. Eng Geol 105(3/4):231–238
Omar M, Hamad K, Al Suwaidi M, Shanableh A (2018) Developing artificial neural network models to predict allowable bearing capacity and elastic settlement of shallow foundation in Sharjah, United Arab Emirates. Arab J Geosci 11(16):464
Douglas J, Danciu L (2020) Nomogram to help explain probabilistic seismic hazard. J Seismol 24(1):221–228
Kashkarov S, Li Z, Molkoy V (2020) Blast wave from a hydrogen tank rupture in a fire in the open: hazard distance nomograms. Inter J Hydro Energy 45(3):2429–2446
Alotaibi E, Mostafa O, Nassif N, Omar M, Arab MG (2021) Prediction of punching shear capacity for fiber-reinforced concrete slabs using neuro-nomographs constructed by machine learning. J Struct Eng 147(6):04021075
Zhang X, Wang M, Li J, Wang Z, Tong J, Liu D (2020) Safety factor analysis of a tunnel face with an unsupported span in cohesive-frictional soils. Comp Geotech 117:103221
Glasser L, Doerfler R (2019) A brief introduction to nomography: graphical representation of mathematical relationships. Int J Math Educ Sci Technol 50(8):1273–1284
Author information
Authors and Affiliations
Contributions
All authors contributed writing the original draft. Conceptualization: MO, MA, and AT. Data curation: EA and DHM. Formal analysis: EA and AT. Investigation: MO, MA and DHM. Methodology: MO, MA and HE. Project administration: MO and AS. Resources: MO and AS. Software: EA and HE. Supervision: AS, HE and MO validation: AT, MA and DHM. Visualization: EA, MO and AS. Writing—review and editing: MO, MA and EA.
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Omar, M., Alotaibi, E., Arab, M.G. et al. Harnessing Nature-Inspired Soft Computing for Reinforced Soil Bearing Capacity Prediction: A Neuro-nomograph Approach for Efficient Design. Int. J. of Geosynth. and Ground Eng. 9, 53 (2023). https://doi.org/10.1007/s40891-023-00472-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40891-023-00472-9