
Abstract
Motion control for an uncertain swarm robot system consisting of N robots is considered. The robots interact with each other through attractions and repulsions, which mimic some biological swarm systems. The uncertainty in the system is possibly fast time varying and bounded with unknown bound, which is assumed to be within a prescribed fuzzy set. On this premise, an adaptive robust control is proposed. Based on the proposed control, an optimal design problem under the fuzzy description of the uncertainty is formulated. This optimal problem is proven to be tractable, and the solution is unique. The solution to this optimal problem is expressed in the closed form. The performance of the resulting control is twofold. First, it assures the swarm robot system deterministic performances (uniform boundedness and uniform ultimate boundedness) regardless of the actual value of the uncertainty. Second, the minimization of a fuzzy-based performance index is assured. Therefore, the optimal design problem of the adaptive robust control for fuzzy swarm robot systems is completely solved.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
A swarm system can be found in species such as ant colonies, bird flocking, animal herding, bacteria molding [1, 2], which is an aggregation of multiple agents. The agents in swarm systems interact with each other through attractions and repulsions. Based on the relatively simple strategies, they mimic some complex global behaviors. Such exotic collective behavior is called “swarm intelligence” or “collective intelligence,” which has fascinated the interest of researchers for many years. With the development of the technology such as sensing, information processing and computation, the swarm concept has been applied in engineering. As a result, there are swarm mechanical systems, including systems composed of multiple robots, satellites and vehicles.
Control design is the key to determine the motion of system. Hence, it is crucial in the study of swarm mechanical systems. There are two approaches for the control design of swarm mechanical systems: kinematic approaches and dynamic approaches. The kinematic approaches concern the formulation and analysis of the ideal performance unaware of its implementation. In [3], a kinematic control for platoons of autonomous vehicles is proposed based on the definition of suitable task functions, which are handled in the framework of singularity-robust task-priority kinematics. In [4], a kinematic model for swarm aggregations is built. It suggests that this model can be viewed as an approximation for some swarms with point mass dynamics. In [5], the properties and modeling of self-organized fish schools are investigated. In [6], the control law based on a distributed swarm aggregation algorithm is designed for multiple kinematic robots. The dynamic approaches, on the other hand, emphasize on how to achieve the performance by taking the dynamic characteristics of agents into account. In [7], a sliding-mode control for swarms is proposed to force the motion to meet the kinematic model. In [8], issues in both the kinematic and dynamic domains of swarm systems are addressed. In [9], a novel robust decentralized adaptive control based on fuzzy logic is proposed for the multi-agent systems. In [10], the dynamics and control for robot swarms are considered.
In practice, the uncertainty is an unavoidable plague. Hence, it is inevitable in dynamic modeling. Since the uncertainty enters the line of sight, the description of the uncertainty has become a major task. In this paper, the uncertainty is possibly fast time varying and bounded with unknown bound. The only known information is that the bound lies within a prescribed and compact fuzzy set. That is, only the bound of the uncertainty is fuzzy. Instead of Takagi–Sugeno (T–S)-type fuzzy or other if–then rules-based fuzzy, the fuzzy set theory is employed to describe the uncertainty bound. Based on the fuzzy uncertainty description, we consider a swarm robot system consisting of N robots and devote to the control design problem.
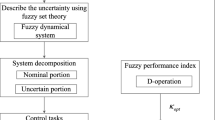
The main contributions of this paper are fourfold. First, we creatively introduce the swarm intelligence into the multi-robot systems (thereby the swarm robot systems), which is accomplished by the design of the function \(G_{ij}\). Based on this, we design the kinematic and dynamic models for the swarm robot systems. Second, we treat the kinematic performance as a constraint and then obtain the analytic (i.e., closed form) constraint force by employing Udwadia–Kalaba approach. The constraint force obeys the Lagrange’s form of d’Alembert’s principle, and it can be adopted as the ideal control input. Motivated by the constraint force, we propose the nominal control actions of the swarm robot systems. Third, in combination with the fuzzy description of the uncertainty, an adaptive robust control is proposed to compensate the uncertainty. The resulting control is deterministic, which renders the system uniform boundedness and uniform ultimate boundedness regardless of the uncertainty. Fourth, the optimal design of the adaptive robust control is completed by choosing a control parameter to minimize a fuzzy-based performance index. This optimization problem is proven to be tractable, with the solution to be existent, unique and in closed form.
2 Fuzzy Swarm Robot System
2.1 Kinematic Model
Consider a swarm system consisting of N robots moving on the ground. For robot \(i\in {{\mathcal {N}}}\), \({{\mathcal {N}}}=\left\{ 1,2,\ldots ,N\right\}\), the position is described by the coordinate \(q_i=[x_i, y_i]^{\mathrm{T}}\), the velocity is described by \(\dot{q}_i=[\dot{x}_i, \dot{y}_i]^{\mathrm{T}}\), the kinematic model of robot i is governed by
where t is the time, and the function \(G_{ij}(q_{i},q_{j}): {{\mathbf{R}}^{n}}\times {{\mathbf{R}}^{n}}\rightarrow {{\mathbf{R}}}\) is \(C^{1}\) (i.e., the first-order derivative of \(G_{ij}\) exists). Let \(g_{ij}(q_{i},q_{j}):=\nabla _{q_{i}}G_{ij}(q_{i},q_{j})\), where the function \(g_{ij}: {{\mathbf{R}}^{n}}\rightarrow {{\mathbf{R}}}\) can represent the attraction and repulsion between agents i and j [4]. The functions \(G_{ij}(q_{i},q_{j})\) and \(g_{ij}(q_{i},q_{j})\) comply with the properties and performances in [8, 11].
2.2 Dynamic Model
Suppose the acceleration is described by \(\ddot{q}_i=[\ddot{x}_i, \ddot{y}_i]^{\mathrm{T}}\), the mass is described by \(m_i\), the dynamic model of robot i is governed by
where \(\sigma _{i}\in {\varSigma _{i}}\subset {{\mathbf{R}}^{p_{i}}}\) is the uncertain parameter with \(\varSigma _{i}\) (the possible bound of \(\sigma _{i}\)) compact but unknown, \(F_i(\sigma _i)\) is the drag force, \(\tau _{i}(t)\) is the control input.
Assumption 1
The inertia matrix \(M_i(\sigma _i)\) is positive definite: For each \(\sigma _{i}\), \(M_i(\sigma _i)>0\).
Assumption 2
(1) Let \(x^i=[{{q_i}^{\mathrm{T}}}\;{{\dot{q}_i}^{\mathrm{T}}}]^{\mathrm{T}}\). Its initial condition is denoted by \(x^i_0.\) For each entry of \(x^i_{0}\), namely \(x^i_{0j}\), \(j=1,2,\ldots ,2n\), there exists a fuzzy set \(X^i_{0j}\) in a universe of discourse \(\varXi ^i_{j} \subset \mathbf{R}\) characterized by a membership function \(\mu _{\varXi ^i_{j}}\): \(\varXi ^i_{j} \rightarrow [0,1]\). That is
Here \(\varXi ^i_{j}\subset \mathbf{R}\) is compact and is known. (2) For each entry of vector \(\sigma _i\), namely \(\sigma _{ij}\), \(j=1,2,\ldots ,p_i\), the function \(\sigma _{ij}(\cdot )\) is Lebesgue measurable. (3) For each \(\sigma _{ij}\), there exists a fuzzy set \(S_{ij}\) in a universe of discourse \(\varSigma _{ij} \subset \mathbf{R}\) characterized by a membership function \(\mu _{\varSigma _{ij}}\): \(\varSigma _{ij} \rightarrow [0,1]\). That is
Remark 1
The system, in which the uncertainty is described by fuzzy theory, is called fuzzy system. Assumption 2 suggests to use fuzzy theory to describe the possible value of the uncertainty. This method of uncertainty description is different from probability theory, Takagi–Sugeno fuzzy model, Mamdani fuzzy model or other fuzzy inference if–then rule-based models. We call system (2) under the description of Assumption 2 fuzzy swarm robot system.
3 Ideal Control of Swarm Robot System
Employing Udwadia–Kalaba approach [12,13,14,15,16,17], we treat kinematic performance (1) of robot i as a constraint of system (2); then, the ideal control of swarm robot system can be obtained as follows.
First, we differentiate (1) with respect to t; then, we have
By creatively treating (6) as a second-order constraint, the control input can be selected as
This control assures agent i to meet kinematic performance (1). It is model-based and can be implemented as a feedback control. This control is ideal. One only can use it under the following two provisions. First, the initial condition of robot i must be the same as (1). Second, the model of robot i must be known, including the value of the uncertain parameter \(\sigma _i(t)\). In practice, however, the provisions are likely not met. Therefore, an adaptive robust control design is needed.
4 Adaptive Robust Control Design
Taking the uncertainty into account, we first decompose the system parameters \(M_{i}(\sigma _{i})\) and \(F_{i}(\sigma _{i})\). We consider \({\bar{M}}_i\), \(\Delta M_i(\sigma _i)\), \({\bar{F}}_{i}\) and \(\Delta F_i(\sigma _i)\) such that
where \(\bar{M}_{i}\) and \(\bar{F}_{i}\) are the “nominal” portions of the system parameters, and \(\Delta {M}_{i}\) and \(\Delta {F}_{i}\) are the corresponding uncertain portions. We assume that \(\bar{M}_{i}\) is positive definite (since the nominal portion \(\bar{M}_{i}\) is the designer’s direction, \(\bar{M}_{i}>0\) is always feasible). Furthermore, the functions \(\bar{M}_{i}(\cdot )\), \(\Delta {M_{i}}(\cdot )\), \(\bar{F}_{i}(\cdot )\), \(\Delta {F_{i}}(\cdot )\) are all continuous.
Let \(D_{i}(\sigma _{i}):={M}^{-1}_{i}(\sigma _{i})\), \(\bar{D}_{i}:=\bar{M}^{-1}_{i}\), \(\Delta {D_{i}}(\sigma _{i}):=D_{i}(\sigma _{i})-\bar{D}_{i}\), \(E_{i}(\sigma _{i}):=\bar{M}_{i}M^{-1}_{i}(\sigma _{i})-I_{i}\), we further have \(\Delta {D_{i}}(\sigma _{i}):=\bar{D}_{i}E_{i}(\sigma _{i})\), \(D_{i}=\bar{D}_{i}+\Delta {D_{i}}\). For given constant matrix \(P_{i}\in {\mathbf{R}^{n\times {n}}}\), \(P_i>0\), let
Assumption 3
-
1.
There exists a (possibly unknown) scalar \(\rho _{E_{i}}>-\,1\) such that,
$$\begin{aligned} \min _{\sigma _i\in \varSigma _i}\lambda _{\min } \left( W_{i}(\sigma _{i})+W^{\mathrm{T}}_{i}(\sigma _{i}) \right) \ge {2\rho _{E_{i}}}>-2. \end{aligned}$$(10) -
2.
The unknown scalar \(\rho _{E_{i}}\) belongs to a known fuzzy number.
Let
We now propose a performance measure:
Our adaptive robust control consists of three portions: \(\tau _{i1}\), \(\tau _{i2}\) and \(\tau _{i3}\). \(\tau _{i1}\) and \(\tau _{i2}\) are proposed based on the nominal system (no uncertain parameters involved), which is given by
where \(\kappa _{i}>0\) is a scalar parameter. \(\tau _{i1}\) is motivated by (7).
Assumption 4
(1) There are a (possibly unknown) constant vector \(\alpha _{i}\in {\mathbf{R}^{k_{i}}}\) and a known function \(\varPi _{i}(\cdot )\) such that
where the function \(\varPi _{i}(\alpha _{i})\) is (i) \(C^{1}\); (ii) concave [11]; (iii) nondecreasing with respect to each component of its argument \(\alpha _{i}\). (2) Each entry of \(\alpha _{i}\) (namely \(\alpha _{ij}\), \(j=1, 2,\ldots , k_{i}\)) belongs to a known fuzzy number.
Remark 2
The \(\rho _{E_{i}}\) and \(\alpha _{ij}\) (\(j=1, 2,\ldots , k_{i}\)) are relative to the uncertain parameter \(\sigma _{i}\). As fuzzy numbers, \(\rho _{E_{i}}\) and \(\alpha _{ij}\) are described by their corresponding membership functions. Their membership functions can be determined by fuzzy arithmetic and decomposition theorem. Based on Assumption 3 and the fact that the universes of discourse \(\varSigma _{ij}\) (\(j=1, 2,\ldots , p_i\)) are known, we can evaluate the value of \(\rho _{E_{i}}\).
The adaptive parameter vector \(\hat{\alpha }_i\) is governed by the following adaptive law
where \(\bar{\kappa }_{i}\in {\mathbf{R}}>0\), \(\hat{\alpha }_{ij}(t_{0})>0\) (\(\hat{\alpha }_{ij}\) denotes the j-th component of the vector \(\hat{\alpha }_{i}\), \(j=1,2,\ldots ,\kappa _{i}\)). Notice that the parameter \(\kappa _{i}\) determines not only control \(\tau _{i2}\) but also the adaptive parameter. The third portion of the control is proposed as
where \({\gamma _{i}}=l_i\Vert \mu _{i}\Vert ^{\omega _i}\), \(\mu _{i}=\beta _{i}\varPi _{i}(\hat{\alpha }_{i})\). Both \(\omega _i\in \mathbf{R}>0\) and \(l_i\in \mathbf{R}>0\) are design parameters. Therefore, the adaptive robust control is given by
Theorem 1
Subject to Assumptions 1, 2, 3, 4, control (18) renders system (2) uniformly bounded (i.e., for\(\Vert \delta (t_0)\Vert <r\), there is a\(d(r)>0\)such that\(\Vert \delta (t)\Vert <d(r)\)for all\(t\ge t_0\)) and uniformly ultimately bounded (i.e., for\(\Vert \delta (t_0)\Vert <r\), there exists a\({\underline{d}}>0\)such that for all\({\bar{d}}>{\underline{d}}\), there is a time interval\(T({\bar{d}}, r)<\infty\) with \(\Vert \delta (t)\Vert <{\bar{d}}\)for all\(t\ge t_0+T({\bar{d}}, r)\)).
Proof
Consider the Lyapunov function candidate
The derivative of \(V_{i}\) is given by
For the term \(2\beta ^{\mathrm{T}}_{i}P_{i}\dot{\beta }_{i}\), according to (2), (8), (13), (14), (17) and the definition of \(D_i\), \(\bar{D}_{i}\), \(\Delta {D}_{i}\), \(E_i\), we have
Since \(\mu _{i}=\beta _{i}\varPi _{i}(\hat{\alpha }_{i})\), by (9) and (15), we further have
According to (10) and Rayleigh’s inequality, we have
As a result, we have
By \({\gamma _{i}}=l_i\Vert \mu _{i}\Vert ^{\omega _i}\) and \(\mu _{i}=\beta _{i}\varPi _{i}(\hat{\alpha }_{i})\),
A simple algebra shows that
According to the concavity of \(\varPi _{i}(\alpha _{i})\), we have
Therefore, we have
For the term \(2(1+\rho _{E_{i}})(\hat{\alpha }_{i}-\alpha _{i})^{\mathrm{T}}\kappa ^{-1}_{i}\dot{\hat{\alpha }}_{i}\), by substituting adaptive law (16), we have
Substituting (32) and (33) into (23), we have
Let \(\bar{\eta }_{1i}=\min \{2k_{i}, 2(1+\rho _{E_{i}})\bar{\kappa }_{i}\}\), \(\bar{\eta }_{2i}=2(1+\rho _{E_{i}})\bar{\kappa }_{i}\times \left\| \alpha _{i}\right\|\), \(\bar{\eta }_{3i}=2(1+\rho _{E_{i}}){\bar{\xi }}_i\), \(\eta _{1i}=\frac{3\bar{\eta }_{1i}}{4}\), \(\eta _{2i}=\frac{\bar{\eta }^2_{2i}}{\bar{\eta }_{1i}}+\bar{\eta }_{3i}\). Based on \(({\sqrt{\bar{\eta }_{1i}}}\left\| \delta _{i}\right\| /2-{\bar{\eta }_{2i}}/{\sqrt{\bar{\eta }_{1i}}})^2\ge 0\), we have
Let \(\eta _{1}=\min \nolimits _{i\in {{\mathcal {N}}}}{\eta _{1i}}\), \(\eta _{2}=\max \nolimits _{i\in {{\mathcal {N}}}}{\eta _{2i}}\). Then we have
where \(\eta =\eta _{1}\), \(\theta =N\eta _{2}\). According to the result of (36), we conclude that \(\dot{V}\) is negative definite for all \(\left\| \delta \right\|\) such that
Since each universe of discourse \(\varSigma _{ij}\) is compact (hence closed and bounded), the uncertainty \(\sigma _i\) is bounded. Thus, both \(\eta\) and \(\theta\) are bounded. Therefore, \(\dot{V}\) is negative definite when \(\left\| \delta \right\|\) is sufficiently large. According to [18], we conclude that the solution of system (2) under control (18) is uniformly bounded and uniformly ultimately bounded. According to (22) and Rayleigh’s inequality, we have
Let \(\xi _{1i}=\min \{\lambda _{{\mathrm{min}}}(P_{i}),(1+\rho _{E_{i}})\kappa ^{-1}_{i}\}\), \(\xi _{2i}=\max \{\lambda _{\max }(P_{i}), (1+\rho _{E_{i}})\kappa ^{-1}_{i}\}\). Thus, we have
Let \(\xi _{1}=\min \nolimits _{i\in {{\mathcal {N}}}}{\xi _{1i}}\), \(\xi _{2}=\max \nolimits _{i\in {{\mathcal {N}}}}{\xi _{2i}}\), we have
According to [19], we conclude the uniform boundedness with
The uniform ultimate boundedness is also proven by taking \({\underline{d}}=R\sqrt{{\xi _{2}}/{\xi _{1}}}\). For given \(\overline{d}>{\underline{d}}\),
□
Remark 3
The uniform boundedness and uniform ultimate boundedness of the controlled system are guaranteed deterministically regardless of the uncertainty. Since the design parameter \(\kappa _i\) impacts on both control \(\tau _{i2}\) and \(\tau _{i3}\) (\(\kappa _i\) determines the rate of adaptation and \(\tau _{i3}\) is relative to adaptive parameter), the optimization of \(\kappa _i\) will be very important to system performances. In the next section, we will find the optimal choice of \(\kappa _i\).
5 Control Parameter Optimization
According to (34) and Rayleigh’s inequality,
Let \(\hat{\eta }=\min \{\frac{2}{\lambda _{\max }(P_{i})},\bar{\kappa }_i\}\), \(\hat{\theta }_i=(1+\rho _{E_{i}})\bar{\kappa }_{i}{\left\| \alpha _{i}\right\| }^2+2(1+\rho _{E_{i}}){\bar{\xi }}_i\). According to (22), then we have
Notice that (48) is a differential inequality, not a differential equation. Next, we will analyze (48) according to the procedure in [21].
Definition 1
[20] Let \(\omega (\psi ,t)\) be a scalar function of the scalar \(\psi\) and t in some open-connected set \({\mathcal {D}}\). A function \(\psi (t)\), \(t_{0}\le t \le {\bar{t}}\), \({\bar{t}} > t_{0}\) is a solution to the differential inequality
on \([t_{0},{\bar{t}})\) if \(\psi (t)\) is continuous on \([t_{0},{\bar{t}})\) and its derivative on \([t_{0},{\bar{t}})\) satisfies (49).
In general, the solution to differential inequality (49) is not unique and not available. Thus, the analysis will be more difficult.
Theorem 2
[20] Let\(\omega (\phi (t),t)\)be continuous on an open-connected set\({{\mathcal {D}}}\in \mathbf{R}^2\)such that the initial value problem for the scalar equation
has a unique solution. If\(\phi (t)\)is a solution of (50) on\(t_0 \le t \le {\bar{t}}\)and\(\psi (t)\)is a solution of (49) on\(t_0 \le t \le {\bar{t}}\)with\(\psi (t_0) \le \phi (t_0)\), then\(\psi (t) \le \phi (t)\)for\(t_0 \le t \le {\bar{t}}\).
Theorem 2 provides an upper bound for the nonunique solution of (49). Since the solution of (49) is not unique and not available and the solution of (50) is unique, we often explore the upper bound of the solution to differential inequality (49) instead of the solution itself.
Theorem 3
[21] Consider differential inequality (49) and differential equation (50). Suppose that for some constant\(L>0\), the function\(\omega (\cdot )\)satisfies the Lipschitz condition
for all points\((\nu _{1},t)\), \((\nu _{2},t) \in {\mathcal {D}}\). Then, any function\(\psi (t)\)that satisfies differential inequality (49) for\(t_0 \le t \le {\bar{t}}\)also satisfies the inequality
for\(t_0 \le t \le {\bar{t}}\).
In order to solve differential inequality (48), we consider the differential equation
The function \(-\kappa _i\hat{\eta }_i r_i+\hat{\theta }_i\) satisfies the Lipschitz condition with \(L=\kappa _i\hat{\eta }_i\). Solving (53), then we get
for all \(t\ge t_0\).
Similarly, for any \(t_{s}\) and any \(\tau \ge t_{s}\), we can get
Here \(V_{is}=V_{i}(t_{s})=\beta ^{\mathrm{T}}_{i}(t_{s})P_{i}\beta _{i}(t_{s})+(1+\rho _{E_{i}})\,[\hat{\alpha }_{i}(t_{s})-\alpha _{i}]^{\mathrm{T}}\kappa ^{-1}_{i}[\hat{\alpha }_{i}(t_{s})-\alpha _{i}]\), \(t_{s}\) is the time when control (18) is activated, which is not necessary to be \(t_0\). Let
In (57), the \(\varGamma _i(\kappa _i, \tau , t_s)\) is a reflection of the system’s transient performance. For each \(\kappa _i\), \(t_s\), as \(\tau\) approaches to \(\infty\), \(\varGamma _{i} (\kappa _i, \tau , t_s)\) approaches to zero. In (58), the \(\varGamma _{i\infty }(\kappa _i)\) is relevant to the steady-state portion of the system’s performances.
Definition 2
For a fuzzy set \({\mathcal {A}}=\{\upsilon , \mu _{N}(\upsilon ) \mid \upsilon \in {A}\}\) and any function \(f(\upsilon ): A\rightarrow {\mathbf{R}}\), the D-operation of \(f(\upsilon )\) is defined as
Remark 4
For any crisp constant \(c \in \mathbf{R}\), \(D[c f(\upsilon )]=c D[f(\upsilon )]\). The D-operation represents a defuzzification algorithm or a fuzzy-theoretic average. In the special case that \(f(\upsilon )=\upsilon\), the expression of D-operation is identical to the center of gravity defuzzification method.
We now propose the following performance index: For any \(t_s\), let
Here, the performance index is composed of two portions: \(J_{i1}\) and \(J_{i2}\). \(\bar{\alpha }_{i}>0\) is the weighting factor of \(J_{i1}\), and \(\bar{\beta }_{i}>0\) is the weighting factor of \(J_{i2}\). By the D-operation, \(J_{i1}\) can represent the average of the system’s overall transient performance and \(J_{i2}\) can represent the average of the steady-state performance.
Our optimal design problem can be stated as follows: For given \(P_i\), \(\bar{\kappa }_i\), \(\bar{\alpha }_{i}\) and \(\bar{\beta }_{i}\), choose the optimal value of the parameter \(\kappa _i>0\) such that the performance index \(J_{i}(\kappa _i, t_s)\) is minimized. By the integral operation, we have
Taking the D-operation of (63), we have
Substituting (64) and (65) into (60), then we get
Let \(\lambda _{i1}=\frac{1}{2\hat{\eta }_i}D\left[ V^2_{is}\right]\), \(\lambda _{i2}=\frac{1}{2\hat{\eta }^3_i}D\left[ \hat{\theta }^2_i\right]\), \(\lambda _{i3}=\frac{1}{\hat{\eta }^2_i}\times D\left[ V_{is}\hat{\theta }_i\right]\), \(\lambda _{i4}=\frac{1}{\hat{\eta }^2_i}D\left[ \hat{\theta }^2_i\right]\), then we can rewrite (66) as
The optimal design problem can be stated as follows: For any \(t_{s}\),
To solve this problem, we take the first-order derivative of \(J_{i}\) with respect to \(\kappa _i\); then, we have
Let \(\tilde{a}:=\lambda _{i1}\bar{\alpha }_{i}\), \(\tilde{b}= -\,2\left( \lambda _{i3}\bar{\alpha }_{i}-\lambda _{i4}\bar{\beta }_{i}\right)\), \(\tilde{c}=3\lambda _{i2}\bar{\alpha }_{i}\). Then we rewrite (69) in the form of
The stationary condition
leads to the following algebraic quadratic equation:
Theorem 4
Suppose\(D\left[ V^2_{is}\right] \ne 0\), \(D\left[ V_{is}\hat{\theta }_i\right] \ne 0\), \(D\left[ \hat{\theta }^2_i\right] \ne 0\), \(\tilde{b}<0\), \(\tilde{b}^2-4\tilde{a}\tilde{c}\ge 0\). For given\(\lambda _{i1}\), \(\lambda _{i2}\), \(\lambda _{i3}\), \(\lambda _{i4}\), the optimal solution\(\kappa _{{\mathrm{iopt}}}\)exists and is unique, which globally minimizes performance index (66).
Proof
Since \(D\left[ V^2_{is}\right] \ne 0\), then we have \(\lambda _{i1}\ne 0\). According to \(\lambda _{i1}\ne 0\), we get \(\tilde{a}\ne 0\). Therefore, the solutions of algebraic quadratic equation (72) are given by
Since \(\tilde{b}^2-4\tilde{a}\tilde{c}\ge 0\), we conclude that the solutions \(\kappa _{i1}\) and \(\kappa _{i2}\) are real solutions. Taking the second-order derivative of \(J_{i}\) with respect to \(\kappa _i\) yields
Substituting \(\kappa _i=\kappa _{i1}=\left( {-\,\tilde{b}-\sqrt{\tilde{b}^2-4\tilde{a}\tilde{c}}}\right) /{2\tilde{a}}\) into \(\frac{\partial {J^2_{i}}}{\partial {\kappa ^2_{i}}}\) yields
Substituting \(\kappa _i=\kappa _{i2}=\left( {-\,\tilde{b}+\sqrt{\tilde{b}^2-4\tilde{a}\tilde{c}}}\right) /{2\tilde{a}}\) into \(\frac{\partial {J^2_{i}}}{\partial {\kappa ^2_{i}}}\) yields
Therefore, the optimal \(\kappa _{{\mathrm{iopt}}}\) [i.e., the solution \(\kappa _i\) of (68)] is given by
The minimal performance index is given by
□
The optimal design problem is completely solved.
Remark 5
The current setting also applies in the special case that the fuzzy sets are crisp (i.e., \(D\left[ V^2_{is}\right] =V^2_{is}\), \(D\left[ \hat{\theta }^2_i\right] =\hat{\theta }^2_i\), \(D\left[ V_{is}\hat{\theta }_i\right] =V_{is}\hat{\theta }_i\)). With the optimal \(\kappa _{{\mathrm{iopt}}}\), adaptive robust control (18) renders system (2) uniform boundedness and uniform ultimate boundedness. Furthermore, the optimal design of the parameter \(\kappa _i\) globally minimizes the performance index \(J_{i}(\kappa _i, t_s)\).
6 Simulation Results
We consider a swarm robot system consisting of three robots to verify the effectiveness of proposed control. Each robot moves in a two-dimensional space. The position is described by \(q_i=[x_i, y_i]^{\mathrm{T}}, i=1,2,3\). The equation of motion of robot i is given by
Here, \(M_i=\left[ \begin{array}{cc}m_i(\sigma _i)&{}\quad 0\\ 0&{}\quad m_i(\sigma _i)\end{array}\right]\).
For comparison purpose, we consider two types of control for the swarm robot system: adaptive robust control (18) and the linear-quadratic regulator (LQR) control. We chose LQR for comparison because it has been used as a benchmark for many new controls for comparisons in the past. The most common robustness measures attributed to the LQR are a one-half gain reduction in any input channel, an infinite gain amplification in any input channel or a phase error of plus or minus sixty degrees in any input channel. In addition, the LQR is also robust with respect to uncertainty in the real coefficients of the model (e.g., coefficients in the system matrix) and certain nonlinearities, including control switching and saturation.
For the adaptive robust controller,
We decompose the mass \(m_i\) as \(m_i={\bar{m}}_i+\Delta m_i\). \({\bar{m}}_i\) is the nominal portion, and \(\Delta m_i\) is the uncertain portion. Then we have
In the same concept, \(F_i\) is decomposed as
Suppose \(\Delta {m}_{i}\) is “close to 5” (belongs to a fuzzy set). Its associated membership function (triangular type) is given by
Suppose \(\Delta {f}_{i}\) is “close to 0.2” (belongs to a fuzzy set). Its associated membership function (triangular type) is given by
For the adaptive law, Assumption 4 is met by choosing
where \(\alpha _{i1}, \alpha _{i2}, \alpha _{i3}\) are unknown constant parameters. For simplicity without loosing validity, an alternative choice of \(\varPi _i\) can be given as
where \(\alpha _1 = \max \{\alpha _{i1}, \alpha _{i2}, \alpha _{i3}\}\). Then we have adaptive law for the i-th vehicle as follows:
Here \(\beta _i\) is defined as (12). Following steps (13), (14) and (17), we finally have control (18). We firstly choose Condition 1 for simulations: \(\bar{m}_{i}=50\), \(\Delta {m}_{i}(t)=5\sin {t}\), \(\kappa _{i}=\bar{\kappa }_i=1\), \(\omega _i=1\), \(l_i=1\), \(P_i = I\), \(\bar{f}_i=10\), \(\Delta {f}_{i}(t)=2\sin {t}\). The initial values are: \(x_{1}(0) =0\), \(y_{1}(0)=0\), \(x_{2}(0)=3\), \(y_{2}(0)=4\), \(x_{3}(0)=5\), \(y_{3}(0)=0\), \(\dot{x}_{1}(0)=0.1\), \(\dot{y}_{1}(0)=0.1\), \(\dot{x}_{2}(0)=0.2\), \(\dot{y}_{2}(0)=0.2\), \(\dot{x}_{3}(0)=0.3\), \(\dot{y}_{3}(0)=0.3\), \(\hat{\alpha }_{1}(0)=0.2\), \(\hat{\alpha }_{2}(0)=0.2\), \(\hat{\alpha }_{3}(0)=0.2\). Then, we have \(V_{1s} = 49.58\), \(V_{2s} = 104.06\), \(V_{3s} = 89.87\), \(\tilde{a}_1 = 1229.1, \tilde{b}_1 = -\,87.1, \tilde{c}_1 = 1.2\), \(\tilde{a}_2 = 5414.2, \tilde{b}_2 = -\,184.6, \tilde{c}_2 = 1.2\), \(\tilde{a}_3 = 4038.1, \tilde{b}_3 = -\,159.2, \tilde{c}_3 = 1.2\). Thus, the algebraic quadratic equations are given by (\(\bar{\alpha }_i=\bar{\beta }_i=1\))
The optimal \(\kappa _{1{\mathrm{opt}}},\kappa _{2{\mathrm{opt}}},\kappa _{3{\mathrm{opt}}}\) is given by
Therefore, the adaptive robust controller is completely designed.
Figure 1 shows the trajectories of three robots under the optimal control [proposed control (81) with optimal parameters (90)]. The robots aggregate toward the center when they are far away from the center. They never collide with each other. In Fig. 2, we show the trajectories of three robots under the nonoptimal control (proposed control (81) with nonoptimal parameters \(\kappa _{1}= 1,\kappa _{2}= 0.8,\kappa _{3}= 0.85\)). It can be seen that, even though the behaviors of three robots are similar to those with optimal parameters: aggregations and repulsions, the performance is inferior to the optimal control. Figure 3 depicts the trajectories of robots under LQR control, and all the robots move to the lower left, which departs from the swarm performance.

The trajectories of three robots under optimal control

The trajectories of three robots under nonoptimal control

The trajectories of three robots under LQR control
Next, we explore the control effort (i.e., \(\Vert \tau \Vert\)) and following error (i.e., \(\Vert \beta \Vert\)) for three cases: (i) with the optimal adaptive robust control, (ii) with the nonoptimal adaptive robust control, (iii) with the LQR control. Here,
In Figs. 4 and 5, the system performances under optimal adaptive robust control, nonoptimal adaptive robust control and LQR control are compared. As shown in Fig. 4, there is no significant difference of \(\Vert \tau \Vert\) between optimal control and nonoptimal control. The maximum value under optimal parameters is about 62, while the maximum value under nonoptimal is about 74. Both maximum values of \(\Vert \tau \Vert\) under adaptive controls (optimal and nonoptimal) are higher than that under LQR control. This is simply because that a learning process is necessary to adjust the adaptive parameters. When the adaptive parameters are close to their real value adequately, the performances are better. Although \(\Vert \tau \Vert\) under LQR control is smaller than that under optimal control at the very beginning, it decreases much more slowly than the other two controls. Figure 5 depicts the history of \(\Vert \beta \Vert\) under different controls. The errors under the adaptive controls are much more smaller than the error under LQR control. Meanwhile, the errors under the optimal adaptive robust control and nonoptimal adaptive robust control quickly fall in a very small region, while LQR control error decreases much more slowly. Compared with the performance under nonoptimal control, the optimal control is superior.

The comparison of control effort under optimal control, nonoptimal control and LQR control

The comparison of the following error under optimal control, nonoptimal control and LQR control
To show the robustness of the proposed optimal control, we apply the control to another different initial condition. Condition 2: \(\Delta {m}_{i}(t)=5\sin {10t}\), \(\Delta {f}_{i}(t)=2\sin {10t}\). \(x_{1}(0) =0\), \(y_{1}(0)=5\), \(x_{2}(0)=5\), \(y_{2}(0)=3\), \(x_{3}(0)=0\), \(y_{3}(0)=0\), \(\dot{x}_{1}(0)= -\,0.1\), \(\dot{y}_{1}(0)= -\,0.1\), \(\dot{x}_{2}(0)=0.3\), \(\dot{y}_{2}(0)=0.1\), \(\dot{x}_{3}(0)= -\,0.4\), \(\dot{y}_{3}(0)=0.2\). The comparisons of control effort \(\Vert \tau \Vert\) and the following error \(\Vert \beta \Vert\) are shown in Fig. 6a, b, respectively. Obviously, although the initial condition (position and velocity) is changed under Condition 2 and the uncertainties are in a higher frequency, the system performances are consistent to those under Condition 1. Both of \(\Vert \tau \Vert\) and \(\Vert \beta \Vert\) converge to a steady status quite soon.

The comparisons of control effort \(\Vert \tau \Vert\) and the following error \(\Vert \beta \Vert\) under optimal control with respect to different initial conditions
Since the uncertainty in system is time varying, we may not have much information about it. The magnitude and the frequency of the variation of the uncertainty will certainly affect the control effort and system performance. Suppose the uncertainty in the mass is \(\Delta m_i = A\sin (\omega t)\), \(A\in [0,10], \omega \in [0,5]\). Let
Here, \(T = 5\) is the simulation time. The relations between \(\bar{\tau },\bar{\beta },\beta _{\max }\) and \(A,\omega\) are shown in Figs. 7, 8 and 9, respectively. The conclusions of these results are twofold: i) The magnitude of the uncertainty and the frequency of the variation of the uncertainty have influences on the \(\bar{\tau },\bar{\beta }\) and \(\beta _{\max }\). These indices increase as A and \(\omega\) increase. ii) The influences due to A and \(\omega\) are limited. The magnitudes of variations of \(\bar{\tau },\bar{\beta },\beta _{\max }\) are tiny. Their percentages are only 1.45%, 0.75%, 2.05%, respectively. This means the proposed optimal control has strong robustness.
For comparison, we investigate the performance index \(\bar{\tau }\) under LQR control. The result is shown in Fig. 10. It can be seen that the average control torque under LQR control is almost double of that under the proposed control with optimal parameters.

The average control effort \(\bar{\tau }\) with respect to A and \(\omega\)

The average following error \(\bar{\beta }\) with respect to A and \(\omega\)

The maximum following error \(\beta _{\max }\) with respect to A and \(\omega\)

The average control effort \(\bar{\tau }\) under LQR control with respect to A and \(\omega\)
7 Conclusion
Taking the uncertainty into account, we propose an optimal adaptive robust control design for the swarm robot system, which is deterministic. The uncertainty in the system is assumed to be fast time varying and bounded. Fuzzy set theory is introduced to describe the uncertainty of the system. Here the fuzzy set theory is not if–then rule-based, which is different from the fuzzy logic theory. The desired system performance is twofold: deterministic and fuzzy. The deterministic performance is to render the system uniform boundedness and uniform ultimate boundedness. The fuzzy performance consists of transient performance and steady-state performance, which is guaranteed by a fuzzy-based performance index. The control design parameter \(\kappa _{i}\) is selected as the optimization parameter such that the performance index is minimized. By solving the optimization problem, the closed-form expressions of the solution and the minimized performance index are obtained.
References
Okubo, A.: Dynamical aspects of animal grouping: swarms, schools, flocks, and herds. Adv. Biophys. 22(2), 1–94 (1986)
Mogilner, A., Edelstein-Keshet, L., Bent, L., Spiros, A.: Mutual interactions, potentials, and individual distance in a social aggregation. J. Math. Biol. 47(4), 353–389 (2003)
Antonelli, G., Chiaverini, S.: Kinematic control of platoons of autonomous vehicles. IEEE Trans. Robot. 22(6), 1285–1292 (2006)
Gazi, V., Passino, K.M.: A class of attractions/repulsion functions for stable swarm aggregations. Int. J. Control 77(18), 1567–1579 (2004)
Parrish, J.K., Viscido, S.V., Grünbaum, D.: Self-organized fish schools: an examination of emergent properties. Biol. Bull. 202(3), 296–305 (2002)
Dimarogonas, D.V., Kyriakopoulos, K.J.: Connectedness preserving distributed swarm aggregation for multiple kinematic robots. IEEE Trans. Robot. 24(5), 1213–1223 (2008)
Gazi, V.: Swarm aggregations using artificial potentials and sliding-mode control. IEEE Trans. Robot. 21(6), 1208–1214 (2005)
Chen, Y.H.: Artificial swarm system: boundedness, convergence, and control. J. Aerosp. Eng. 21(4), 288–293 (2008)
Ranjbar-Sahraei, B., Shabaninia, F., Nemati, A., Stan, S.D.: A novel robust decentralized adaptive fuzzy control for swarm formation of multiagent systems. IEEE Trans. Ind. Electron. 59(8), 3124–3134 (2012)
Gazi, V., Fidan, B., Marques, L., Ordonez, R.: Robot swarms: Dynamics and control. In: Kececi, E.F., Ceccarelli, M. (eds.) Mobile robots for dynamic environments, pp. 79–107. ASME, New York (2015)
Zhao, X., Chen, Y.H., Zhao, H.: Control design based on dead-zone and leakage adaptive laws for artificial swarm mechanical systems. Int. J. Control 90(5), 1077–1089 (2016)
Rosenberg, R.M.: Analytical Dynamics of Discrete Systems. Olenum Press, New York (1977)
Chen, Y.H.: Second-order constraints for equations of motion of constrained systems. IEEE/ASME Trans. Mechatron. 3(3), 240–248 (1998)
Udwadia, F.E., Kalaba, R.E.: Analytical Dynamics: A New Approach. Cambridge University Press, Cambridge (2007)
Udwadia, F.E., Wanichanon, T., Cho, H.: Methodology for satellite formation-keeping in the presence of system uncertainties. J. Guid. Control Dyn. 37(5), 1611–1624 (2014)
Udwadia, F.E.: A new approach to stable optimal control of complex nonlinear dynamical systems. J. Appl. Mech. 81(3), 031001 (2014)
Zhao, R., Chen, Y.H., Jiao, S.: Optimal robust control for constrained fuzzy dynamic systems: semi-infinite case. Int. J. Fuzzy Syst. 18(4), 557–569 (2016)
Chen, Y.H., Leitmann, G.: Robustness of uncertain systems in the absence of matching conditions. Int. J. Control 45(5), 1527–1542 (1987)
Corless, M., Leitmann, G.: Continuous state feedback guaranteeing uniform ultimate boundedness for uncertain dynamic systems. IEEE Trans. Autom. Control 26(5), 1139–1144 (1981)
Hale, J.K.: Ordinary Differential Equation. Wiley, New York (1969)
Chen, Y.H.: Performance analysis of controlled uncertain systems. Dyn. Control 6(2), 131–142 (1996)
Klir, G., Yuan, B.: Fuzzy Sets and Fuzzy Logic: Theory and Applications. Prentice-Hall, Englewood Cliffs (1995)
Acknowledgements
The authors wish to thank the referees for their helpful comments and suggestions.
Funding
The research is supported by National Natural Science Foundation of China (Grant No. 51705116), Science and Technology Major Project of Anhui (Grant No. 17030901036) and Fundamental Research Funds for the Central Universities (Grant Nos. JZ2018HGBZ0096/JZ2018HGTA0217/JZ2018HGTB0261).
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
We outline the fuzzy mathematics.
Membership function A function that the values assigned to the elements of the universal set fall within a specified range and indicate the membership grade of these elements in the set in question, is called membership function [22].
Fuzzy set A set \(\varOmega\) on the universe of discourse set X is a fuzzy set if the elements of set A are mapped into real numbers in [0, 1] by the membership function \(\mu _\varOmega : X\rightarrow [0,1].\)
\(\alpha\)-cut and strong\(\alpha\)-cut For a given fuzzy set \(\varOmega\) defined on X and any number \(\alpha \in [0,1]\), the \(\alpha\)-cut of fuzzy set \(\varOmega\) is defined as \({{}^{\alpha }}{\varOmega }=\{x \mid \mu _{\varOmega }(x)\ge \alpha \}\), and the strong \(\alpha\)-cut of fuzzy set \(\varOmega\) is defined as \({{}^{\alpha +}}{\varOmega }=\{x \mid \mu _{\varOmega }(x)> \alpha \}.\)
Fuzzy numbers To qualify as a fuzzy number, a fuzzy set \(\varOmega\) must possess the following properties: (i) \(\varOmega\) is a normal fuzzy set; (ii) \(\varOmega\) is convex; (iii) the support of \(\varOmega\) must be bounded; (iv) for each \(\alpha \in (0, 1]\), \({{}^{\alpha }}{\varOmega }\) is a closed interval in \(\mathbf{R}\).
Fuzzy arithmetic Let \(\varOmega _1\), \(\varOmega _2\) denote two fuzzy numbers, and \({{}^{\alpha }}{\varOmega _{1}}=[a_1, b_1]\), \({{}^{\alpha }}{\varOmega _{2}}=[a_2, b_2]\), \(a_1<b_1\), \(a_2<b_2\). Then, the fuzzy arithmetic is provided as follows:
Decomposition theorem The fuzzy set \(\varTheta\) can be decomposed as
where \(\cup\) is the union of the fuzzy sets (i.e., sup over \(\alpha \in [0,1]\)), \({\tilde{\varTheta }}_{\alpha }\) is a special fuzzy set on the universe set X defined by the membership function \(\mu _{{\tilde{\varTheta }}_{\alpha }} = \alpha I(x)\), the function I(x) is defined as
Rights and permissions
About this article

Cite this article
Dong, F., Chen, YH. & Zhao, X. Optimal Design of Adaptive Robust Control for Fuzzy Swarm Robot Systems. Int. J. Fuzzy Syst. 21, 1059–1072 (2019). https://doi.org/10.1007/s40815-019-00626-w
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40815-019-00626-w