
Abstract
This paper bestows a distributed adaptive scheme for diagnosing inaccurate data (anomaly) in wireless sensor networks. Faults occurring in sensor nodes are routine owing to the sensor device itself and the harsh environment in which the sensor nodes are deployed. It is mandatory for the WSNs to discover the anomaly and take actions to avoid further seediness of the network lifetime for confirming data accuracy. In this standpoint, we propose two perspectives for diagnosing and alleviating anomalies. The first view depicts input space partitioning by subtractive clustering method with robust density measure. Later, Takagi–Sugeno fuzzy inference model is applied for selection of several parameters and its membership functions, and rule-based construction is practiced to spot anomalies in distributed clustering wireless sensor network. By exploring combined correlation analysis with second perspective, the eliminated anomalous data are replaced by imputed data. Experimental results infer accuracy and reliability with a reduced amount of energy consumption than the state-of-the-art techniques.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Wireless sensor networks (WSNs) applications surge very fast over the past by collecting information and monitoring the solutions. They are enumerated as group of interlinked sensors of various forms around the specified area [1, 2]. Battery power is an important limitation learned by various designers in WSNs since it hammers the overall performance of the whole system and be handled with care. The data deviating from its peers are coined by the term “Outliers” or “Anomalies” which originates from the field of statistics [3]. All sensors may fail in unreliable and harsh environments. Faulty sensors result in noisy and random readings due to interferences. The main reasons for anomalies are
-
1.
Failure of sensor nodes/node anomaly
-
a.
Battery power drains to 0 %.
-
b.
Bugs may short-circuit sensor nodes.
-
c.
Environmental changes.
-
a.
-
2.
Miscomputation process/data aggregation anomaly
-
a.
Inappropriate data aggregation
-
1.
Inner cluster
-
2.
Outer cluster
-
1.
-
b.
Inability to analyze huge data
-
a.
-
3.
Miscommunication process/network anomaly
-
a.
Original values of sensor nodes may be routed in wrong directions due to loss of connectivity
-
a.
Large numbers of highly correlated data are demanded by redundant data, and energy is drained in huge amount which in turn will be processed and collected by the base station. Network lifetime is boosted by providing fused information and purging redundant transmission through data aggregation [4]. If anomalies are not spotted during the data aggregation process, the data inaccuracy ensues [6]. Data aggregation follows cluster structure, where cluster head performs data aggregation process. The data collected by cluster head from one or more sensing nodes are smeared to aggregation functions. Sink often receives the aggregated value [5] [7]. In this context, some faulty nodes may be present, producing incorrect readings that deviate from the exact output. Cluster head (aggregator) may perform inaccurate calculation, resulting in anomaly.
The existence of any anomaly will end in inaccurate query results and thwart the system’s efficiency. Thus, it is acute in identifying and replacing incorrect information so as to improve the query accuracy and reliability. In this paper, we focus at the snag of determining inaccurate readings with high reliability in sensor networks. Obviously, an ingenuous approach to this problem is to accumulate all readings to a sink, where fuzzy-based analysis is performed to finalize anomalous data. In this proposed work, we spotlight the anomaly diagnosis process in cluster head in view of the fact that data accuracy may be increased gradually by concentrating on every individual sensor’s reading. The anomaly disclosure of each sensor must be broadcasted to a cluster center for shaping a core decision. The cluster center performs data aggregation beyond considering the readings from anomalous sensor nodes [8]. In this lap, base station receives accurate data, though the reliability is depraved. The cluster center forecasts reliability of each received detection result throughout the making of exclusive final decision. When the final decision is not significant, the cluster center will mandate the sensor which has sent the acknowledged result with the lowermost reliability to retransmit. To rise above this issue, the imputed data are predicted based on correlation between sensor’s readings. This prospective fuzzy-based model will scrutinize the anomalies originated by sensor nodes, and the readings are mitigated by the clean imputed value. Accordingly, the global accuracy and reliability of the distributed sensor network are elevated.
Pertaining to the above observation in the proposed system, two strategies in finding anomaly diagnosis and relief measures are dealt. The first standing concentrates on forming optimal clusters with subtractive clustering method proceeding from robust density measures that focus on creating input space for the fuzzy inference model. The second phase puts across the fuzzy logic technique with Takagi–Sugeno (TS) fuzzy inference model [9]. It receives inputs from first juncture for identifying parameters and its relationships. Anomaly will be uncovered by crossing second juncture with increase in accuracy and short in curing anomalous data. Anomalous data are removed in aggregation process which worsens the performance of entire network. Missing of data in data stream lowers reliability while receiving fused data at base station. To overcome this issue, fuzzy rules are applied to replace anomalous data by estimating imputed data exploiting correlation technique.
The leftovers of the paper are organized as follows: Section 2 is granted with some significant related literature review for our proposed algorithm. Section 3 clarifies the network model and problem statement. Section 4 mounts the proposed approach and methodology of the three junctures. Section 5 concludes the experimental evaluation based on both unreal and real datasets with comparison results. Finally, Sect. 6 concludes this paper.
2 Related Work
Wireless sensor networks face challenge as long as base station requires accurate data. Anomalies are cultured by cumulating data accuracy in WSNs. The norms for anomaly detection are to establish a normal profile of the monitored object, and anomaly is the significant deviation from this normal profile [3]. Anomaly detection techniques are generally ordered into: statistical detection methods, data-mining-based methods, and rule-based (fuzzy logic) methods [10]. Statistical anomaly detection methods build both normal profile during a training phase and current profile during the detection phase. Data-mining-based methods can systematize the process of finding meaningful activities and fascinating features like classification-based intrusion detection. Mostly, they are computational intensive and yield very high false alarm rates. In particular, statistical-based techniques provide good detection rate with less false alarm rate by involving a mathematical model that requires more computational time. In WSNs, all sensor nodes monitor the surroundings, store data in the main memory, and interconnect the data between neighbor nodes by evaluating the computation process where energy is required for all the operations mentioned above. Meanwhile, capacities of the sensor nodes restrict its use for essential threads. In [11], Pottie postulates that the energy anticipated for communication is more than the energy required for computation. Data aggregation consumes cluster structure in hierarchical fashion by transporting data from source to sink in saving computational memory though summarizing data from sensor nodes. Throughout this process, annoying anomalous data are detected in making meaningful data aggregation process.
Chitradevi et al. [12] projected anomaly detection centered on distributed agglomerative clustering method by removing anomalies at both local and global levels. Using cluster distance and density measures, optimal clusters are grouped keeping anomalies lower with cheap computational and communication complexity. Zhang et al. [13] have anticipated an ellipsoidal-based support vector machine in classifying sensor node data as anomaly using ellipsoidal SVM-based online anomaly detection and adaptive anomaly detection for multivariate data. They used the time window concept for classifying deviations from normal behavior of the system. This system hurts computational complexity by periodically updating a normal profile. Zhang et al. [14] recommended statistical-based outlier detection based on time series and geostatic analysis using spatial and temporal correlation theories. Variogram model develops a way of exhibiting temporal correlation by decent auto-regressive moving average (ARMA) and spatial correlation model.
Kapitanova’s et al. [15] offered overall fuzzy logic system by means of spatial and temporal semantics for event detection by decreasing the number of rules in merging simple rules and pruning undesirable rules in the rule-based system. They utilized fuzzy logic as an alternative in taking fixed thresholds and crisp values, where the accuracy of fire event detection is increased. Liang et al. [16] suggested dual sliding window detection for increasing the revealing rate of event discovery. Conversely, they elaborate the outcome of fuzzy logic and the power of spatial and temporal possessions of the data in classifying detection rate.
In [17], the authors deliberated inputs similar to packet delivery ratio, energy, distance, packet loss and receiving signal strength to determine the jamming attacks in WSN using fuzzy-based optimization techniques. Finding anomalies after these attacks are difficult. In [18], imperialist clustering algorithm (ICA) is altered using fuzzy logic controller, which is implemented to vary the incorporation operator in the competition phases of ICA achieving less detection rate on an average of 87 %. Kumaragea et al. [19] recommended a fuzzy data modeling for distributed anomaly detection in dissimilar real datasets. Scalability and sensitivity are less while employing large number of nodes. In our previous work [20], we used relative correlation clustering technique for distinguishing anomaly. This model employs clustering and re-clustering process with relative combinational correlation technique [20].
A fuzzy prototype suitable for estimating schemes and functions is the Takagi and Sugeno’s fuzzy model which is connected with fuzzy rules and possesses a job special format with a functional-type consequent. This model concentrates on nonlinear dynamic systems with best proven results. In [21], TS fuzzy modeling algorithm using input–output data online in the presence of noise, extended Kalman filter (EKF) is used which deals with the minimum-variance state estimator in case of linear dynamic systems having white noise with zero-mean value. Likewise, switched and hybrid nonlinear systems use observer-based fault-tolerant control and robust fault-tolerant tracking control, respectively [22] [23]. For a real linear drive system in [24], Kalman filter also called as the residual generator is effective in fault diagnosis and fault-tolerant problems. In [25], authors present a well-organized hybrid fuzzy clustering style for Takagi–Sugeno (TS) fuzzy modeling based on a hybrid fuzzy clustering scheme. The method travels through various phases for constructing an optimal Takagi–Sugeno fuzzy model from sample data. Gustafson–Kessel clustering algorithm is developed, resulting in an optimal input–output space fuzzy partition matrix.
In [26], MIMO TS model is used to select suitable cluster. MIMO TS models are constructed from numerical data by using fuzzy cluster algorithm based on weighted fuzzy expected value (WFEV). Results obtained from this model achieve high performance against its peers if TS model is applied for adaptive fuzzy model sensor node (ATSFMSN) routing protocol. This model focuses only on fuzzy clustering algorithm based on weighting factor and fails in identifying inconsistent data. In [27], subtractive clustering-based clustering routing algorithm for wireless sensor networks is used to choose the cluster heads and generate the cluster heads where the node density is high. Their results provide the reasonable arrangement of cluster head, longer lifetime of the first node, and even longer lifetime of the network to balance the energy consumption of all the nodes in the network. Here data density measure is calculated based on Euclidean distance which will not yield optimal cluster head. In our proposed system, we use the Mahalanobis distance for shaping the cluster radius in factor space. Mahalanobis distance generates hyper ellipsoid clusters with similar volume. In [28], the authors focus on the routing algorithm based on subtractive clustering so as to reduce communication of WSNs and terminated flooding. Cluster head selection adopts subtractive clustering to produce cluster node with new cost function. Though it provides effective survival time and saves network energy, it fails in providing data accuracy whenever anomaly occurs. In our proposed system, input space partitioning is performed by using subtractive clustering with Mahalanobis distance by dealing with spatial relationships among the various sensor nodes. Optimal clusters are formed using this spatial correlation analysis with mean and standard deviation.
Proactive correlated fuzzy system with spatial, temporal, and attribute act is applied with fuzzy C-means clustering for refining data accuracy [29]. Similarly, the proposed system spots anomaly and determines imputed data in WSNs. It is evident from the literature survey that an ideal anomaly detection system should harvest high accuracy with negligible energy consumption. The proposed system integrates fuzzy logic techniques like subtractive clustering and TS fuzzy inference model for the improvement of reliability and accuracy in WSNs. The main contributions of the proposed work are summarized:
-
1.
Input space portioning is performed for creating optimal clusters using well-conditioned subtractive clustering.
-
2.
Diagnosing anomalies with the help of robust TS fuzzy model increase data accuracy.
-
3.
Replacing anomaly with imputed data increases data integrity.
3 Network Model and Problem Statement
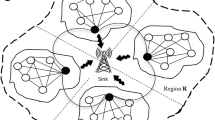
We put on the wireless sensor network as a large connected network with totally n sensor nodes denoted by 1, 2, 3 … n. The nodes are dispersed randomly in some physical domain and are stationary after deployment. The transmission range for each node is static, and link between the nodes is bidirectional. The system can be modeled as communication graph G = {S, E}, where S = {1, 2….n}, and E = {(S x , S y ): S x and S y are any two nodes in same cluster}. A cluster is a unit disk having radius equivalent to center node’s transmission range. A suitable clustering protocol for implementing distributed clustered wireless sensor network is anticipated by grouping several clusters into deployment area. The center node is the aggregator though the node that is a one hop neighbor of the aggregators of two different clusters is the outshine node. After the self-ruling cluster formation, only aggregator and outshine nodes got elected in a fully distributed fashion which participates in the inter-cluster communication despite the fact that sensing nodes in each cluster communicate with their aggregator node (and to other nodes when required). Figure 1 portrays the distributed sensor clustered architecture.

Clustered network framework
As discussed earlier, WSNs consist of many types of anomaly (like node or link failure) and avoids erroneous calculation in aggregation. Earlier, we worked on finding the animalized or normal node in the sensor network. In this critique, the total number of nodes was alienated into a number of clusters. Each cluster has an aggregator, and some acts as outshine nodes for dispatching the message from cluster to base station. The anomaly is discovered by the aggregator node in respective clusters, and the message is being forwarded to all nodes of the clusters and other aggregators. Entire clusters will be operating simultaneously. Each aggregator accomplishes data aggregation process, and the fused information is spawned and advanced to the base station. In this recommended model, optimized clusters are formed initially followed by replacing anomalous data with imputed data to be done by the aggregator in each cluster.
4 Proposed Methodology
The fuzzy-based anomaly detection and alleviation system starts by input space partitioning, where subtractive clustering is employed and accompanied by detecting erroneous data perfectly and replacing completely using TS fuzzy modeling. The proposed model is embodied in Fig. 2. A fuzzy model structure can be epitomized by a set of fuzzy IF–THEN rules. A rule-based fuzzy model obliges rule antecedent, rule consequent, and assembly of membership functions. The stages in the system comprise.

Schematic representation of anomaly diagnosis and relief measure model
-
1.
Fuzzification: Input and output variables are defined by mapping the crisp input into linguistic values.
-
2.
Inference: Fuzzy inference holds number of fuzzy IF–THEN rules. Rule-based database delineates the membership functions of the fuzzy sets used in the fuzzy rules. Main processes executed by inference engine are:
-
a.
Aggregation: Compute the IF part (antecedent) of the rules. The antecedent variables replicate information about the process operating environments.
-
b.
Composition: Compute the THEN part (consequence) of the rules. The consequent variables are a linear regression model nearby the given functioning condition.
-
a.
-
3.
Defuzzification: The output variable calculated in the composition juncture is transformed to real output stage.
In analyzing the conventional techniques, it is inferred whether the data are incorrect or not and lack in replacing the incorrect data. To solve this concern, we use a number of correlation analysis for identifying imputed data and are substituted at the place of spotted data as anomaly.
Data accuracy will be upgraded by recognizing the anomaly with the support of aforesaid techniques, thereby dropping the computational power in sensors which reduces the sensor’s battery power utilization rate by increasing the lifetime of all sensors. At the end of TS anomaly diagnosis model, base station reaches maximum accuracy and reliability is increased by using additional rules for calculating accurate imputed data.
4.1 Subtractive Clustering Method
Clustering slices a dataset into few groups in such a way that the similarities inside the groups are bigger among its peers. Clustering is to separate the data space into a few groups with kindred data, and grouping strategies are utilized broadly to sort out and classify data, as well as valuable for data compression and model development. Moreover, the greater part of the information congregated in numerous issues appear to have some immutable properties that lend themselves to standard groupings [30]. Discovering these groupings or attempting to arrange the information is not a straightforward job for people unless the information is of low dimension. Generally, clustering process is well arranged into off-line and online process. Online grouping is a technique in which every data vector is employed to overhaul the cluster as indicated by its vector position. In off-line mode, the structure is given a preparing dataset, which is utilized to locate the bunch by examining all the data vectors in the preparing set. When the cluster focuses are found settled, they are utilized later to order new input vectors.
In this proposed work, input space model is erected with subtractive clustering methods which are chiefly utilized as a part of off-line clustering procedure. Subtractive clustering method (SCM) is similar to mountain clustering [31, 32], except in determining the data density measure at every reasonable position in the factor space. It employs the positions of the data focusing to figure the density measure, lessening the quantity of counts essentially. SCM comprehends computational intricacy utilizing cluster information rather than lattice problem as focused in mountain clustering [33, 34].
The computation is currently relative to the issue size of the input which is the sensed values from the sensors. On the other hand, the real cluster centers are not always situated at one of the data points. SCM decreases computational complexity and gives a suitable conveyance among cluster centers.
Consider assortment of data collected from sensor nodes {X 1, X 2…. , X n } which are the vectors in the dimensional space. Without forfeiture of sweeping statement, we expect that the element space is standardized so that all the data are confined by a unit of hyper solid shape. We assume every data point as a possibility for cluster centers which describes data density measure (DDM) of the point to serve as a cluster center. A data density measure for cluster center is computed by Eq. (1). The possibility of cluster center Xi is designated as \({\text{DDM}}_{i}\) After the density measure of each data point, it will have a high \({\text{DDM}}_{i}\) value that is selected as the dominant cluster center. Let \(X_{{cc_{1} }}\) be the possibility point of cluster center and \({\text{DDM}}_{{c_{1} }}\) be its density measure. \({\text{DDM}}_{i}\) for every data point is revised by Eq. (2).
where, Mahalanobis distance is denoted as \({\text{md}}\) and \(r_{a}\) \(r_{b}\) are positive constants. \(r_{a }\) is outlining hyper solid shape cluster radius in factor space [35]. Usually \(r_{b} = 1.5 r_{a}\) where \(r_{b}\) is used to isolate from maliciously spaced cluster center. \({\text{md}}\) is designed by the given following Eq. (3), where \(\mu_{m}\) is the mean and \(\sigma_{m}\) is the standard deviation of \(X_{i}\) or \(X_{{cc_{1} }}\)
where,
Succeeding the \({\text{DDM}}\), every data point is analyzed and the highest possibility point is elected as a next cluster center. The process produces sufficient numbers of cluster centers by performing n number of iterations. At last, the cluster center is fixed and the data density measure relates to the remaining updated data points. Halting condition for the likelihood of cluster center calculation can be established in [31].
Input space structuring is prepared by subtractive clustering with cluster centers. These cluster centers would be sensibly employed as the centers for the fuzzy reasoning in a Sugeno fuzzy model. We expect the center for the \(i{\text{th}}\) cluster is \(C_{i}\) in factor space. \(C_{i}\) can be divided into segment vectors \({\text{IP}}_{i}\) and \({\text{OP}}_{i}\) where \({\text{IP}}_{i}\) is the input part holding the input elements of \(C_{i}\) \({\text{OP}}_{i}\) is the output part containing yield elements of \(C_{i}\). At this point, given a data vector X, the extent to which fuzzy rule \(i\) is satisfied by the membership function \(\vartheta_{i}\) Where ||…|| denotes the Euclidean distance.
4.2 Takagi–Sugeno Fuzzy Modeling
Fuzzy-based modeling chiefly based on Takagi–Sugeno (TS) fuzzy systems permit in gaining highly accurate models with trivial number of rules [9]. TS models are universal approximators and achieve high accuracy with a small number of rules [36, 38]. Whenever number of rules in TS model is increased, lower approximation error rises and the quality of the modeling algorithm can be critical. It is relatively easy to alter them into nonlinear state model by supporting formal analysis to be used in control engineering. A fuzzy model construction can be characterized by a set of fuzzy IF–THEN rules. A rule-based fuzzy model involves rule antecedent, rule consequent, and structure of membership functions.
The modified inference approach is a universal approximation of any smooth nonlinear system which was proposed by Takagi and Sugeno [9, 37]. TS fuzzy model is embodied by a small set of fuzzy IF–THEN rules that refer local input–output functions of nonlinear systems. Rule of continuous TS fuzzy model is of the following form:
If x 1 (t) is M k1 and x 2 (t) is M k2 …. and x n (t) is M kn
where x 1 , x 2, x n are input variables and y(t) is the output variable, M k1 , M k2 …M ij are fuzzy sets. A, B, and C are matrices of proper dimensions, and r is the number of fuzzy IF–THEN rules. Suppose W i is a firing strength of the logical expression x 1 is M k1 and x 2 is M k2 … and x n is M kn is Rule i, then the overall output is obtained via weighted mean value, by escaping the time-consuming process of defuzzification which is essential in Mamdani model [39, 40]. In this model, defuzzification is performed by various methods, such as centroid of area, bisector of area, mean of maximum, smallest of maximum, and largest of maximum. These operations are consuming more time for its calculation. To overcome this issue, we use TS model which never requires defuzzification.
Consider the nonlinear system below:
here x 1 and x 2 are premises variables and input variable limit are denoted as x 1 ϵ[a,m 1 ,b] and x 2 ϵ[c,m 2 ,d],where a, b, c, d, m 1 , and m 2 are literal constants. Common steps for two inputs fuzzy inference system are described as follows:
- Step 1:
-
To determine the fuzzy variables and membership functions or fuzzy sets
- Step 1.1:
-
For simplicity, assume two fuzzy variables x 1 and x 2
- Step 1.2:
-
To acquire membership functions, we must calculate the minimum and maximum values of x 1 (t) and x 2 (t) where x 1 ϵ[a, m 1, b] and x 2 ϵ[c, m 2, d], and are clearly obtained as follows:
Therefore, x 1 and x 2 can be represented by membership functions T1, T2, T3 and H1, H2, H3, respectively, and are denoted by:
- Step 2:
-
Model rule evaluation
- Rule 1 :
-
If x 1(t) is high and x 2(t) is high, then \(\dot{x}\left( t \right) = A_{1} x\left( t \right)\)
- Rule 2 :
-
If x 1(t) is high and x 2(t) is low, then \(\dot{x}\left( t \right) = A_{2} x\left( t \right)\)
- Rule 3 :
-
If x 1(t) is high and x 2(t) is middle, then \(\dot{x}\left( t \right) = A_{3} x\left( t \right)\)
- Rule 4 :
-
If x 1(t) is low and x 2 (t) is high, then \(\dot{x}\left( t \right) = A_{4} x\left( t \right)\)
- Rule 5 :
-
If x 1(t) is low and x 2(t) is low, then \(\dot{x}\left( t \right) = A_{5} x\left( t \right)\)
- Rule 6 :
-
If x 1(t) is low and x 2(t) is middle, then \(\dot{x}\left( t \right) = A_{6} x\left( t \right)\)
- Rule 7 :
-
If x 1(t) is middle and x 2(t) is high, then \(\dot{x}\left( t \right) = A_{7} x\left( t \right)\)
- Rule 8 :
-
If x 1(t) is middle and x 2(t) is low, then \(\dot{x}\left( t \right) = A_{8} x\left( t \right)\)
- Rule 9 :
-
If x 1(t) is middle and x 2(t) is middle, then \(\dot{x}\left( t \right) = A_{9} x\left( t \right)\)
- Step 3:
-
Defuzzification process of the system incorporates with \(A_{i} x\left( t \right)\)
$$A_{i} x(t) = \left\lfloor {\begin{array}{*{20}l} 0 \hfill & {m_{1} \,{\text{or}}\,m_{2} } \hfill & 1 \hfill \\ {\hbox{max} ({\text{high}})} \hfill & {\text{mid(middle)}} \hfill & {\hbox{min} ({\text{low}})} \hfill \\ \end{array} } \right\rfloor$$(6)$$\dot{x}\left( t \right) = \mathop \sum \limits_{i = 1}^{r} u_{i} \left( {x\left( t \right)} \right)A_{i} x\left( t \right)$$(7) - Step 4:
-
Final outputs of fuzzy model evaluation
$$\dot{x}\left( t \right) = \mathop \sum \limits_{i = 1}^{r} u_{i} \left( {x\left( t \right)} \right)\{ A_{i} x\left( t \right) + B_{i} p\left( t \right)\}$$(8)$$y\left( t \right) = \mathop \sum \limits_{i = 1}^{r} u_{i} \left( {x\left( t \right)} \right)C_{i} x\left( t \right)$$(9)where weighting function w i is standardized as
$$u_{i} \left( {x\left( t \right)} \right) = \frac{{w_{i} x\left( t \right)}}{{\mathop \sum \nolimits_{i = 1}^{r} w_{i} x\left( t \right)}}$$(10)
We think through some input variables from real dataset for evaluating the overall performance of our proposed methodology. Three linguistic variables are declared as low (L), middle (M), and high (H). Input variable membership functions are created by using above-said three linguistic variables and are used to analyze the sensing range of sensor’s attributes. Figure 3 displays the temperature membership functions. Figure 4 depicts the humidity membership functions. Similarly, we can consider any input variable from the real datasets and its membership function is designed based on fuzzy limits. Figures 5, 6, 7, and 8 show voltage, ambient temperature, surface temperature, and relative humidity, respectively. Fuzzy rules are generated based on fuzzy limits that are specified in the membership functions.

Temperature membership function

Humidity membership function

Voltage membership function

Ambient temperature membership function

Surface temperature membership function

Relative humidity membership function
Input values for our fuzzy inference system are the node distance from cluster head, time difference of each sensor readings, and input variable correlation. The fuzzy input distance is represented using triangular functions as shown in Fig. 9, where the linguistic terms close, medium, and far represent the range of contribution for that input. The fuzzy input time is denoted using triangular functions as shown in Fig. 10, where the terms small, average, and long represent the level of involvement for that input. The fuzzy input variable correlation is fuzzified using triangular functions as shown in Figs. 3, 4, 5, 6, 7, and 8 , where the gears low, middle, and high represent the magnitude of participation for that input.

Time membership function

Distance membership function
Distance, time, and variable correlation are affirmed as input variables for declaring result in anomaly detection system in Table 1. The anomaly detection confidence levels of the proposed system are classified as normal and anomaly. Normal data are directed to the cluster head or base station. Anomalous data are detached, and its corresponding imputed data are replaced by combined correlation analysis of particular sensor nodes [40, 41]. To finish, accurate imputed data are inserted and anomaly free dataset is analyzed by the cluster head for aggregation process.
Incomplete data are common in WSNs and may rise due to hardware glitches, packet collisions, signal strength diminishing, and environmental nosiness. These incomplete data are created manually by removing anomalous data. The removal of anomalous data at cluster head leads to missing data [42]. To solve this, fuzzy inference systems discover imputed data by analyzing spatial, temporal, and attribute correlation among the sensor nodes. Suppose sensor node X generates anomalous data and sensor node Y generates normal data and if the correlation between sensor nodes X and Y is high, then Y can impute data from X and vice versa. Apart considering from spatial distance between sensor nodes, time difference and variable correlation of two sensor nodes and its neighbor nodes are considered too.
5 Experimental Results
The proposed anomaly diagnosis system is tested by using both unreal and real datasets, and the results are obtained by incessant experiments. This is performed in terms of anomaly detection rate, specificity and false alarm rate for both unpolluted and polluted datasets. The proposed methodology is experimented with the help of datasets acquired from Intel Berkeley Research Lab (IBRL) [43] which uses 54 Mica2Dot sensors with 4 attributes (temperature, humidity, voltage, and light). Fifty-four sensor nodes were deployed in the laboratory between February 28, 2004, and April 5, 2004. The nodes collected approximately 2.3 million readings. The data in the dataset are selected at the time of exportation, namely March 2004 (30-day period) during the time interval 00:00 am to 03:59 am, and the dataset acquired from SensorScope project, located at the Grand-St-Bernard (GSB) pass at 2400 m between Switzerland and Italy [44] during the period of 2 months between September 2007 and October 2007. The 23 sensor nodes sense the environment with several attributes such as ambient temperature, humidity, soil moisture, wind direction, and wind speed accordingly.
5.1 Performance Evaluation
The performance of proposed methodology is usually calculated by a confusion matrix. An illustration of the confusion matrix is designed in Table 2 which depicts columns (predictable class) and rows (actual class). In the table, true negative (TN) signifies the number of normal data correctly classified, and true positive (TP) is the number of abnormal data properly classified. False positive (FP) is the number of normal data classified as abnormal, and false negative (FN) is the number of abnormal data classified as normal. Other common evaluation metrics are accuracy which is a measure of the proposed system to predict the anomaly correctly. Sensitivity or recall (detection rate) is a degree of a system to detect positive abnormal cases and specificity is the ability of the system to spot negative normal cases. False alarm rate (FAR) is the capability of the system to detect positive normal cases. The evaluation metrics are described with the help of the confusion matrix. Positive projection rate (PPR) or precision is defined as the proportion of positive test results that are true positives. The measures are described below:
5.2 Estimation on Datasets
For assessing the proposed method, the datasets are normalized by identifying and removing extreme values initially. Scatter plot and Chi-square tests are used to prompt cleaned data as customary data. Initially, data are cleaned manually by identifying extreme values and missing values. Most of the values are either missing or damaged. The rest of the data is labeled as normal for evaluations. Specifically, in IBRL dataset, 30-day period between March 1, 2004, and March 30, 2004, is considered as normal data. On completion, two sets of data are considered for evaluation such as normal data without corruption ratio and normal data with corruption ratio. For this purpose, random sets of corrupted data are injected at various clusters. Anomalies were interleaved often in one or many nodes in each cluster at the frequency of data corruption between 5 and 70 %. We implement the proposed algorithm using the MATLAB package for a simulated wireless sensor node on the two datasets generated already. On visualizing the IBRL dataset, the proposed system is smeared with several numbers of clusters ranging from 5 to 10 from subtractive clustering algorithm for finding optimal number of clusters in the dataset. Figure 11 portrays the number of clusters used for evaluating anomaly detection technique from IBRL. By eagle-eyeing the GSB dataset, the subtractive clustering is applied for gathering optimal number of clusters oscillating from 3 to 5. Figure 12 displays the finest cluster used for assessing anomaly detection technique in GSB.

Subtractive clustering in IBRL a 5 clusters, b 6 clusters, c 7 clusters, d 8 clusters, e 9 clusters, f 10 clusters

Subtractive clustering in GSB a 3 clusters, b 4 clusters, c 5 clusters
Each cluster reading is experimented by using TS fuzzy inference system with fuzzy rules. The fuzzy results are sectored into normal and abnormal cases. Abnormal data are removed, and its corresponding imputed data are predicted based on fuzzy rules with correlation level of sensor nodes. By applying subtractive clustering, we obtain several numbers of optimal clusters ranging from low to high in the IBRL dataset. At least 19 and to a maximum of 75 iterations are performed with optimal accept and reject ratio yielding suitable cluster centers. Gradual increase in number of clusters increases computational complexity and communicational complexity. Inadequate number of clusters could not analyze anomalous data optimally. By considering both datasets, optimal clusters range is selected based on objective function of subtractive clustering. The computational complexity of subtractive clustering is varied based on number of clusters. Thus, computational complexity is denoted by O (ns) where n is the number of iterations and s is the number of nodes. The memory space requirement for the proposed approach is O ( 1 ) for storing the value of cluster center.
Generally, multivariate analysis technique is used to detect outliers based on correlation, i.e., by identifying relationship among the variables that are participated in the outlier detection process. Multivariate outlier deviates from the usual correlation structure in multi-dimensional space defined by the variables. Figures 13 and 14 gives a brief depiction of attribute correlation, temporal and spatial correlation involved in the evaluation using the real dataset without any corruption ratio. Three attributes (temperature, humidity, and voltage) and other attributes (ambient temperature, surface temperature, and relative humidity ranging from 0 to 100 %) are multivariate and are normalized from IBRL and GSB datasets, respectively. To show spatial correlation, we have calculated the correlation coefficients between the two sensors at each observation based on distance measure, where Mahalanobis distance [27] is applied for estimating nearest less spacious sensor nodes. Temporal correlation is illustrated with different time intervals at time t − 1 and t of a particular sensor node. Additionally, attribute correlation illustrates internal relationship among the physical phenomena attributes.

Correlation analysis of IBRL dataset without corruption a attribute correlation, b temporal correlation, c spatial correlation

Correlation analysis of GSB dataset without corruption a attribute correlation, b temporal correlation, c spatial correlation
Figure 15 displays data distribution based on IBRL dataset with three physical phenomena attributes. Anomalous data are randomly generated at various clusters. To provide baseline for our results, we perform fuzzy-value experiments with TS fuzzy model. Initially, data corruption level is increased from 6 to 85 %. Figure 15 shows the result of predicted anomaly data at 15 % corruption level. Anomalous data are detected and isolated from clusters ranging from 5 to 10. Detection accuracy is not degraded while increasing number of clusters. Henceforth, our proposed fuzzy inference system detects anomaly with high accuracy based on fuzzy rules.

Anomaly detection variation of IBRL dataset with corruption level. Six cases are considered and evaluated by fuzzy inference engine. Lines with times symbol indicates anomaly data, lines with bullets indicates normal data. Five clusters in 1st left row, 6 clusters in 2nd left row, 7 clusters in 3rd left row, 8 clusters in 1st right row, 9 clusters in 2nd right row, 10 clusters in 3rd right row
Figure 16 shows data dissemination based on GSB dataset. The three physical phenomena attributes disseminations with anomalous data are randomly generated at various clusters. This illustration shows the result of predicted anomaly data at 19 % corruption level. Anomalous data are detected and separated for various numbers of cluster ranging from 3 to 5. Figures 15 and 16 conclude most of the deviation in data is accurately identified by the correlation analysis among the attributes; fuzzy inference rules are framed along with this correlation exposing high detection rate. The fuzzy inference engine plays an important role in the reduction of FAR by increasing the detection rate. Fuzzy inference engine that incorporates with sensors location and its correlation information generated by the correlation analysis accurately classifies the anomalous and normal data and has high sensitivity with less false alarm rate. The results for the IBRL and GSB dataset with different range of corruption levels are given in Tables 3, 4, 5, 6, and 7.

Anomaly detection variation of GSB dataset with corruption level. Three cases are considered and evaluated by fuzzy inference engine. Lines with times symbols indicates anomaly data, lines with bullets indicates normal data. Three clusters in top left corner, 4 clusters in top right, 5 clusters in 2nd row
Efficient output is ensued from 6 clusters of the IBRL dataset and 3 clusters of the GSB dataset having very high accuracy with less false alarm rate over the range of clusters from 5 to 10 and 3 to 5. Corruption level range is formed into four groups, 6–25 %, 26–45 %, 46–65 %, and 66–85 %. Table 3 shows the performance of proposed methodology with less than 6 % corruption level. It is fascinated tough to predict anomaly below 6 % since the deviation from original and anomalous data is less. Percentage of prediction is increased at the various ranges of corruption levels above 6 % as shown in Tables 4, 5, 6 7. Specifically, the proposed method considers fuzzy logic offering of 1 % false alarm and 99.87 % detection rate till 65 % of the nodes in the network. Even for corruption level between 66 and 85 %, the average false alarm created is simply 1.52 % and 1.84 in IBRL and GSB dataset, respectively.
Figures 17 and 18 illustrate the performance of the proposed system for evaluating IBRL and GSB dataset. It is observed that the approach in [19] has less sensitivity and high false alarm rate compared to subtractive clustering (SC) with fuzzy inference system (FIS). The proposed method offers 0 % false alarm rate and 100 % detection rate till 45 % of the nodes in the network are found to be anomalous. Even for corruption level between 46 and 85 %, the average false alarm created is 0.956 % in IBRL and 2.56 % in GSB dataset, respectively. Therefore, it is clear that the proposed system achieves significant improvement in detecting accuracy compared to the conventional fuzzy technique in [19].

Sensitivity and false alarm rate for altering corruption level in IBRL dataset

Sensitivity and false alarm rate for altering corruption level in GSB dataset
The results are represented in Fig. 19 for comparison with the variation in sensitivity and specificity obtained for our proposed method on the same datasets. The graphs illustrate the proposed method preserves a very high degree of accuracy in defining normal data with the false alarm rate being between 0 % and 0.5 % in all occurrences. However, while the sensitivity values for the proposed scheme are more or less retained at an acceptable range between 99 % and 99.5 % for GSB data and a high 98–98.5 % for IBRL, the results for varying number of clusters gradually reach sustainable sensitivity rate. Therefore, it is evident that the proposed method achieves significant gains in detection accuracy.

Comparison of sensitivity and specificity variation by varying cluster size for dataset based on IBRL(left) and GSB(right)
Figure 20 depicts the final performance of our proposed methodology with high accuracy, while increasing number of nodes (clusters) by using unreal dataset, which is simulated for analyzing the scalability of the proposed methodology. As shown in Fig. 20, anomaly detection and misdetection fractions are attractively stable while increasing numbers of nodes from 100 to 1000. At the same time, large numbers of nodes yield moderate computational and communication complexity with the help of subtractive clustering with slight increase in space complexity. This result implies that our subtractive clustering with fuzzy logic-based anomaly detection has very fastidious scalability as it works well under different network sizes.

Scalability comparison
Table 8 explains the complexity of different state-of-the-art anomaly detection approaches. To understand the performance of the proposed approach, it is essential to relate it with state-of-the-art anomaly detection techniques. To evaluate the efficiency of the SC with FIS model, the computational complexity, communication overhead and memory complexity are considered. The computational complexity incurred by our model is O(ndc) related to the calculation of n number of new of records at time, d-dimension of the observations, and c number of clusters. The communication overhead is O(nd), and memory complexity is O(ndr), where r represents number of rules. Table 8 shows v- intermediate values, p-spatial correlation, and q- temporal correlation in the remaining techniques. Less number of rules saves more memory space. Our method proves high accuracy compared to other available peer methods. Computational complexity, communicational complexity, and memory complexity are slightly reduced when compared to other techniques.
6 Conclusion
In this paper, a system which employs fuzzy-based anomaly detection is industrialized using fuzzy logic to classify anomalous and normal data. Two real datasets are evaluated with various numbers of clusters generated by subtractive clustering. After cataloging of data, normal data are labeled as customary and incorrect readings as anomaly. The overall accuracy and reliability are increased by imputing data. The experimental result proves that the proposed anomaly diagnosis and relief measures model outperforms existing work in various aspects like anomaly detection accuracy, false alarm, sensitivity, and specificity in decision-making support.
References
Akyildiz, I.F., Su, W., Sankara subramaniam, Y., Cayirci, E.: Wireless sensor networks: a survey. Comput. Netw. 38, 393–422 (2002)
Dargie W., Poellabauer C. In: Shen X., Pen D.Y. (eds.), Fundamentals of Wireless Sensor Networks. 3rd edn, Wiley (2010)
Xie, Miao, Han, Song, Tian, Biming, Parvin, Sazia: Anomaly detection in wireless sensor networks: a survey. J. Netw. Comput. Appl. 34, 1302–1325 (2011)
Sun, Bo, Shan, Xuemei, Kui, Wu, Xiao, Yang: Anomaly detection based secure in-network aggregation for wireless sensor networks. IEEE Syst. J. 7(1), 13–25 (2013)
Roy, S., Conti, M., Setia, S., Jajodia, S.: Secure data aggregation in wireless sensor networks. IEEE Inf. Forens. Secur. 7(3), 1040–1052 (2012)
Mitchell, Robert, Chen, Ing-Ray: A survey of intrusion detection in wireless network applications. Comput. Commun. 42, 1–23 (2014)
Xu, H., Huang, L., Zhang, Y., Huang, H., Jiang, S., Liu, G.: Energy efficient cooperative data aggregation for wireless sensor networks. J. Parallel Distrib. Comput 70(9), 953–961 (2010)
Forero, P., Cano, A., Giannakis, G.: Distributed clustering using wireless sensor networks. IEEE J. Sel. Top. Signal Process. 5(4), 702–724 (2011)
Takagi, T., Sugeno, M.: Fuzzy Identification of systems and its applications to modeling and control. IEEE Trans. Syst., Man, Cybern. 15(1), 116–132 (1985)
O’Reilly, C., Gluhak, A., Imran, M.A., Rajasegarar, S.: Anomaly detection in wireless sensor networks in a non-stationary environment. IEEE Commun. Surv. Tutor. 16(3), 1–20 (2013)
Pottie, G.J., Kaiser, W.J.: Wireless integrated network sensors. ACM Commun. 43(5), 51–58 (2000)
Chitra Devi, N., Palanisamy, V., Baskaran, K., Prabeela, S.: Efficient distributed clustering based anomaly detection algorithm for sensor stream in clustered wireless sensor network. Eur. J. Sci. Res. 54(4), 484–498 (2011)
Zhang, Yang, Meratnia, Nirvana, Havinga, P.J.M.: Distributed online outlier detection in wireless sensor networks using ellipsoidal support vector machine. J. Ad Hoc Netw. 11, 1062–1074 (2012)
Zhang, Y., Hamm, N.A.S., Meratina, N., Stein, A., Van de Voort, M., Havinga, P.J.M.: Statistics based outlier detection for wireless sensor networks. Int. J. Geogr. Inf. Sci. 1–20 (2011)
Kapitanova, K., Son, S.H., Kang, K.-D.: Using fuzzy logic for robust event detection in wireless sensor networks. J. Ad Hoc Netw. 10, 709–722 (2011)
Liang Q, Wang L.: Event detection in wireless sensor networks using fuzzy logic system. In: International Conference on Computational Intelligence for Homeland Security and Personal Safety, IEEE, pp. 52–55 (2005)
Sasikala, E., Rengarajan, N.: An intelligent technique to detect jamming attack in wireless sensor networks (WSNs). Int. J. Fuzzy Syst. 7(1), 76–83 (2015)
Shamshirband, S., Amini, A., Anur, N., Kiah, M., Teh, Y., Furnell, S.: D-FICCA: a density based fuzzy imperialist competitive clustering algorithm for intrusion detection in wireless sensor networks. J. Meas. Elsevier 55, 212–226 (2014)
Kumaragea, Heshan, Khalil, Ibrahim, Tari, Zahir, Zomaya, Albert: Distributed anomaly detection for industrial wireless sensor networks based on fuzzy data modeling. J. Parallel Distrib. Comput. 73, 790–806 (2013)
Barakkath Nisha, U., Maheswari, N.U., Venkatesh, R., Yasir Abdullah, R.: Robust estimation of incorrect data using relative correlation clustering technique in wireless sensor networks. In: IEEE International Conference on Communication and Network Technologies, Issue 1, pp. 314–318 (2014)
Kalman, R.E.: A new approach to linear filtering and prediction problems. Trans. ASME-J. Basic Eng. 82, 35–45 (1960)
Yang, H., Jiang, B., Staroswiecki, M.: Observer-based fault-tolerant control for a class of switched nonlinear systems. IET Control Theory Appl. 5, 1523–1532 (2007)
Yang, H., Cocquempot, V., Jiang, B.: Robust fault tolerant tracking control with application to hybrid nonlinear systems. IETControl Theory Appl 3(2), 211–224 (2009)
Huang, S., Tan, K.K., Lee, T.H.: Fault diagnosis and fault-tolerant control in linear drives using the Kalman filter. IEEE Trans. Ind. Electron 59(11), 4285–4292 (2012)
Chen, Shui-Li, Fang, Yuan, Yun-Dong, Wu: A new hybrid fuzzy clustering approach to Takagi-Sugeno fuzzy modeling. Int. J. Digital Content Technol. Appl. 6(18), 341–350 (2012)
Afifi, W.A., Hefny, H.A.: Adaptive TAKAGI-SUGENO fuzzy model using weighted fuzzy expected value in wireless sensor network. In: International Conference on Hybrid Intelligent Systems (HIS), IEEE, pp. 221–231 (2014)
Chen, J.-J., FAN, X.-P., QU, Z.-H., YANG, X., LIU, S.-Q.: Subtractive clustering based clustering routing algorithm for wireless sensor networks. Inf. Control 7, 201–219 (2008)
Lizhe, Yu., Tiaojuan, Ren, Zhangquan, Wang, Banteng, Liu: Research on vehicle networking clustering routing algorithm based on subtractive clustering. Appl. Mech. Mater. 644–650, 2366–2369 (2014)
Barakkath Nisha, U., Uma Maheswari, N., Venkatesh, R., Yasir Abdullah, R.: Improving data accuracy using proactive correlated fuzzy system in wireless sensor networks. KSII Trans. Internet Inf. Syst. 9(9), 3515–3537 (2015)
Neamatollahi, P., Mashhad I., Taheri H., Naghibzadeh M., Yaghmaee M.: A hybrid clustering approach for prolonging lifetime in wireless sensor networks. IEEE International Symposium on Computer Networks and Distributed Systems, pp. 170–174 (2011)
Chiu, S.: Fuzzy model identification based on cluster estimation. J. Intell. Fuzzy Syst. 2, 267–278 (1994)
Kim, D.W., Lee, K.Y., Lee, D., Lee, K.H.: A Kernel-based subtractive clustering method. Pattern Recognit. Lett. 26, 879–891 (2005)
Nikhil, R.P., Chakraborty, D.: Mountain and subtractive clustering method: improvements and generalizations. Int. J. Intell. Syst. 15, 329–341 (2000)
Yager, R.R., Filev, D.P.: Approximate clustering via the mountain method. IEEE Trans. Syst., Man Cybern. 24(8), 1279–1284 (1994)
De Maesschalck, R., Jouan-Rimbaud, D., Massart, D.L.: The Mahalanobis distance. J. Chemo Metrics Intell. Lab. Syst. Elsevier 50(1), 1–18 (2000)
Jang, J.-S.R., Sun, C.-T., Mizutani, E.: Neuro-Fuzzy and Soft Computing, 3rd edn. Prentice hall, Upper Saddle River (1997)
Sugeno, M., Kang, G.: Structure identification of fuzzy model. Fuzzy Sets Syst. 28(1), 15–33 (1988)
Zadeh, L.A.: Soft computing and fuzzy logic. ACM J. Softw. 11(6), 48–56 (1994)
Zimmermann, H.J.: Fuzzy Set Theory and Its Applications, 3rd edn. Publisher kluwer Academic Publishers Norwell, Norwell (1996)
Vuran, M.C., Akan, B., Akyildiz, I.F.: Spatio-temporal correlation: theory and applications for wireless sensor networks. Comput. Netw. Int. J. Comput. Telecommun. Netw. 45(3), 245–259 (2004)
Liu, Z., Xing, W., Zeng, B., Wang, Y., Lu, D.: Distributed spatial correlation-based clustering for approximate data collection in WSNs. In: IEEE International Conference on Advanced Information Networking and Applications, pp. 56–63 (2013)
Ishibuchi, H. Nakashima, T., Kuroda, T.: A hybrid fuzzy GBML algorithm for designing compact fuzzy rule-based classification systems. In: IEEE International Conference on Fuzzy Systems, pp. 248–252 (1999)
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Barakkath Nisha, U., Uma Maheswari, N., Venkatesh, R. et al. Fuzzy-Based Flat Anomaly Diagnosis and Relief Measures in Distributed Wireless Sensor Network. Int. J. Fuzzy Syst. 19, 1528–1545 (2017). https://doi.org/10.1007/s40815-016-0253-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40815-016-0253-2