
Abstract
The use of fuzzy time series has attracted considerable attention in studies that aim to make forecasts using uncertain information. However, most of the related studies do not use a learning mechanism to extract valuable information from historical data. In this study, we propose an evolutionary fuzzy forecasting model, in which a learning technique for a fuzzy relation matrix is designed to fit the historical data. Taking into consideration the causal relationships among the linguistic terms that are missing in many existing fuzzy time series forecasting models, this method can naturally smooth the defuzzification process, thus obtaining better results than many other fuzzy time series forecasting models, which tend to produce stepwise outcomes. The experimental results with two real datasets and four indicators show that the proposed model achieves a significant improvement in forecasting accuracy compared to earlier models.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Thanks to advances in information technology, the amount of data that are collected and stored is increasing at a rapid rate. Such data are not just stored in crisp values, but also fuzzy ones, such as business monitoring indicators, signals, scores and ordinal scales. Traditional time series methods cannot deal with forecasting problems in which the values used are linguistic terms, which are inherently vague. To deal with such obstacles, Song and Chissom [1] pioneered the theory of fuzzy time series, and building on this Sullivan and Woodall [2] later proposed a discrete Markov model for establishing the fuzzy relationships matrix determined by the probability distributions of linguistic values. Similarly, Hsu et al. [3] applied the fuzzy Markov relation matrix to fuzzy time series forecasting. Based on Song and Chissom’s research framework, Chen [4] derived first-order fuzzy logic relationship groups to reduce the overhead of matrix manipulation. Chen and Hwang [5] extended fuzzy time series to multi-factor problems, and proposed a two-factor first-order time-variant forecasting algorithm. Huarng [6] then enhanced Chen’s model [4] by integrating domain-specific heuristic knowledge to establish a high-order time-invariant fuzzy time series forecasting model. Meanwhile, Chen [7] generalized their previous work [4] to deal with high-order time series, and high-order models have subsequently received more attention in the literature. Own and Yu [8] combined the concepts of fuzzy logic relationship groups and domain-specific heuristic knowledge, and proposed a forecasting model using a trend heuristic for fuzzy time series, while Lee et al. [9] similarly extended Chen’s model [7] to allow two-factor high-order time-invariant forecasting. Although high-order models have been shown to improve forecasting accuracy, there is a significant problem with regard to determining an appropriate order number and order redundancy. However, this issue was recently resolved by Li and Cheng [10], who deterministically identified the fuzzy relationships without choosing an appropriate order number in advance. They proposed a deterministic one-factor high-order time-variant fuzzy time series model, which utilizes a backtrack algorithm to establish the fuzzy relationship rules, instead of repeating the same process used in earlier works.
With a focus on developing the framework of deterministic fuzzy time series, the authors of the current work have been conducting various studies to improve the forecasting accuracy and broaden the scope of related applications. For example, we extended Li and Cheng’s research framework to include a two-factor high-order time-invariant fuzzy time series model [11]. Li and Cheng [12] also proposed a random hidden Markov model for two-factor one-order time-invariant fuzzy time series problems. Later, Li et al. [13] proposed a deterministic vector model for long-term fuzzy time series forecasting. They then proposed another deterministic vector forecasting model, adopting the techniques of sliding windows and a fuzzy clustering method, for one-factor time-invariant fuzzy time series problems [14].
Along with the aforementioned studies, there are a number of works on fuzzy time series that do not focus on the forecasting model, but instead on incorporating techniques, like neural networks and genetic algorithms, to deal with issues such as determining the fuzzy relationships and the partition of the universe of discourse. Huarng and Yu [15, 16] applied neural networks and a type 2 fuzzy set to refine the fuzzy relationships they uncovered. Yu also used relationship refinement [17] and a weighting scheme [18] to improve the appropriateness of fuzzy relationships. Chen and Chung [19], as well as Lee et al. [20], used genetic algorithms (GA) to adjust the length of each interval for one- and two-factor high-order forecasting models, respectively. Cheng et al. [21] proposed a fuzzy time series forecasting model with a two-stage linguistic partition method. Joshi and Kumar [22] proposed a computational model of forecasting for fuzzy time series based on intuitionistic fuzzy sets, in which the degree of nondeterminacy is used to establish fuzzy logical relations.
Although many researchers are active in the field of fuzzy time series, as outlined above, there are still a number of issues that need further discussion. For example, most existing studies do not use a learning mechanism to extract valuable information from historical data. Conjecturing that a GA can be used to learn more valuable information from historical data to help forecasting tasks, we propose an evolutionary fuzzy relational matrix-based forecasting model, denoted as the EFRM model, which adopts an evolutionary learning mechanism to establish a fuzzy relationship matrix. Moreover, to support a more flexible decision-making process, this novel model takes into consideration the causal relationships among the linguistic terms that are ignored in some of the other fuzzy time series forecasting models. The evolutionary fuzzy relation matrix can naturally smooth the defuzzification process, which leads to more reasonable results than many fuzzy time series forecasting models that tend to result in stepwise outcomes.
We conducted experiments with two well-known datasets to evaluate the proposed EFRM model. The first set is the daily temperature in Taipei from June to September for the years 1993–1996 [5, 12, 23]. The second dataset is the daily closing price of Google stock collected during the period from 1 January 2009 to 6 October 2010. We implemented four measures, including root mean square error (RMSE), trend accuracy in direction (TAD) [13, 14], percent mean absolute deviation (PMAD), and mean absolute percentage error (MAPE), to evaluate the performance of the proposed method. The results show that the proposed model achieves a significant improvement in forecasting accuracy compared to the original one.
The remainder of this paper is organized as follows. The next section introduces the essential concepts of fuzzy time series. Section 3 highlights the important issues in developing the proposed model. Section 4 describes the EFRM forecasting model, and Sect. 5 presents the experimental results and compares those from the proposed and original models. Finally, a summary of the paper and directions for future research are presented in Sect. 6.
2 Underlying Theories and Techniques
In this section, we briefly review the theories and techniques that are related to this research, which include fuzzy time series (FTS) and genetic algorithms (GA).
2.1 Fuzzy Time Series
Song and Chissom [1] first defined fuzzy time series, as follows.
Definition 1
Let \(Y(t) \in R^{1} (t = 0,\;1,\;2, \ldots )\) be the universe of discourse in which fuzzy sets \(f_{i} (t)\) (\(i = 1,\;2, \ldots\)) are defined, and let \(F(t)\) be a collection of \(f_{i} (t)\). \(F(t)\) is then called a fuzzy time series on \(Y(t)\;(t = 0,\;1,\;2, \ldots )\).
Song and Chissom [1] defined the fuzzy relations that exist among fuzzy time series, which are based on the assumption that the values of fuzzy time series \(F(t)\) are fuzzy sets, and the observation of time \(t\) is caused by the observations of the previous times.
Definition 2
If for any \(f_{j} (t) \in F(t)\), there exist \(f_{i} (t - 1) \in F(t - 1)\) and a fuzzy relation \(R_{ij} (t,\;t - 1)\) such that \(f_{j} (t) = f_{i} (t - 1) \circ R_{ij} (t,\;t - 1)\), where ‘\(\circ\)’ is the max–min composition, then \(F(t)\) is said to be caused by \(F(t - 1)\) only. Denote this as
Definition 3
If for any \(f_{j} (t) \in F(t)\), there exist \(f_{i} (t - 1) \in F(t - 1)\) and a fuzzy relation \(R_{ij} (t,{\kern 1pt} \;t - 1)\) such that \(f_{j} (t) = f_{i} (t - 1) \circ R_{ij} (t,\;t - 1)\), then let \(R(t,\;t - 1) = \cup_{i,j} R_{ij} (t,\;t - 1)\), where ‘\(\cup\)’ is the union operator, then \(R(t,\;t - 1)\) is called the fuzzy relation between \(F(t)\) and \(F(t - 1).\) A fuzzy relational equation is thus defined as \(F(t) = F(t - 1) \circ R(t,\;t - 1)\).
The first-order and kth order models are formed by applying the ‘or’ and ‘and’ operators of fuzzy relation equations.
Definition 4
Suppose \(F(t)\) is caused by \(F(t - 1)\) only or by \(F(t - 1)\) or \(F(t - 2)\) or … or \(F(t - k)\), \(k > 0\). This relation is denoted as \(F(t - 1) \to F(t)\) or \(F(t - 2) \to F(t)\) or … or \(F(t - k) \to F(t)\), and can be expressed as follows:
or
where ‘\(\cup\)’ is the union operator and ‘\(\circ\)’ is the composition. \(R(t,\;t - 1)\) is called the fuzzy relation between \(F(t)\) and \(F(t - 1)\). \(R_{o} (t,{\kern 1pt} \;t - k)\) is defined as a fuzzy relationship between \(F(t)\) and \(F(t - 1)\) or \(F(t - 2)\) or … or \(F(t - k)\). Equation (2) is called the first-order model of \(F(t)\).
Definition 5
Suppose that \(F(t)\) is caused by \(F(t - 1)\), \(F(t - 2)\), …, and \(F(t - k)\) (\(k > 0\)) simultaneously, then their relations can be represented as
Equation (3) is called the kth order model of \(F(t)\), and \(R_{a} (t,{\kern 1pt} {\kern 1pt} {\kern 1pt} t - k)\) is a relational matrix expressing the fuzzy relationship between \(F(t - 1)\), \(F(t - 2)\), …, \(F(t - k)\), and \(F(t)\).
2.2 Genetic Algorithm
A genetic algorithm (GA), first proposed by Holland [24] for optimization problems, is a heuristic search method based on genetics and the evolutionary mechanism. GA have been proven to be very effective for solving search and optimization problems [25–28], and applied in various areas, such as machine learning, bioinformatics, computational sciences, economics, manufacturing, and other fields.
A GA mimics the evolutionary processes that occur in nature by manipulating a population of potential solutions to a search or optimization problem. Representations of the possible solutions are usually encoded in binary strings, similar to the chromosomes of individuals in nature. A selection mechanism is implemented so that the better solutions survive and reproduce, based on a fitness value that evaluates the quality of each chromosome.
A GA begins with an initial random population, and genetic operators are then applied iteratively in order to get better solutions. First, a selection operator chooses a pair of chromosomes as parents. The probability of selection is in proportion to the chromosome’s fitness value. The chromosomes with higher fitness values thus have greater changes of being put into the gene pool for reproduction, which follows the rule of “survival of the fittest.” New combinations of genes are generated from previous ones, the so-called parents, by a crossover operator which exchanges and recombines parts of the genes from each parent. Repeated selection and crossover result in the continuous evolution of the gene pool and the generation of better individuals that are more likely to survive. Another operator, called mutation, is used to sporadically and randomly alter genes, to avoid being trapped in a locally optimal solution.
A GA applies these operators iteratively until a predetermined number of iterations are reached, or the fitness value converges to a preset criterion.
3 Issues in Designing Evolutionary Fuzzy Relational Models
In this section, we discuss the important issues in developing evolutionary fuzzy relational models that are often ignored in the FTS literature.
Fuzzy relations are vital in constructing good fuzzy time series models, and such models can be categorized into two groups according to how they deal with these. The first group is implemented based on a relational matrix (e.g., [3, 29], and our EFRM model), and the other is based on rule grouping (e.g., [4, 10]). This study focuses on the first group, and thus how to construct the fuzzy relational matrix is the key issue with regard to obtaining better results in time series forecasting, and this is the focus of many related studies.
Song and Chissom [29] proposed an approach to fuzzy relational matrixes that has been adopted by many other works. In their model, the first-order fuzzy logical relationship matrix is calculated by the formula \(R\left( {t,\;t - 1} \right) = R = \mathop \cup \limits_{i = 1}^{n} R_{i}\), as defined in Definitions (2) and (3). One needs to determine the degree of each fuzzy relation to construct the forecasting model, and deciding on the membership for each element in R is a key issue in this. Song and Chissom used triangular fuzzy numbers to achieve this, as follows:
where \(f(u_{i} ) = \left\{ {\begin{array}{*{20}l} 1 \hfill & {{\text{if}}\;i = j,} \hfill \\ {0.5} \hfill & {{\text{if}}\;i = j - 1\;{\text{or}}\;j + 1.} \hfill \\ 0 \hfill & {{\text{otherwise}} .} \hfill \\ \end{array} } \right.\)
Hsu et al. [3] extended this approach to a bivariate fuzzy time series forecasting model. Due to the fuzzy operations, the elements of R can only be 0, 0.5, or 1. The membership degree is thus discrete, and may not be reasonable in practice. This is because in this approach each fuzzy relationship is treated as being equally important, which may not reflect the reality of the problem being examined. For example, when a rule repeatedly occurs, it should be more important than those that occur only once. Many researchers have thus worked on ways to determine the matrix R.
Yu [18] stated that repeated rules should not be seen as useless and thus ignored, but instead when there are numerous RHS (right-hand side) mapping to a LHS (left-hand side), the model should take the frequency and recency into account. The fuzzy logical relationship of adding time weight into time series can be rewritten as shown in Table 1. The example rule is \(A_{1} \to A_{1} ,\;A_{2} ,\;A_{1} ,\;A_{1} ,\) in which the time period increases from left to right.
Li and Cheng [10] modified the matrix R based on a hidden Markov process. They took the repeated transitions into consideration when estimating the model parameters, and expressed the complete parameter set of the hidden Markov model. Their approach also used a probability density function and relied on the frequency of state transitions. However, in this method, one needs to determine the probability space in advance.
All the aforementioned methods work on modifying the matrix R with predetermined weights or the prior probability of the Markov model. Such manually developed forecasting models depend heavily on the subjectivity of the users, which can lead to a lack of reliability. Therefore, based on its ability to learn from historical data, we apply a GA to automatically construct the fuzzy relational matrix in this work.
4 Evolutionary Fuzzy Relational Matrix-Based Forecasting Model
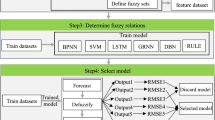
In this section, we present the EFRM forecasting model for fuzzy time series, the flow chart of which is shown in Fig. 1. The details of the model are described in the following subsections.

The EFRM framework
4.1 Define the Universe of Discourse and Fuzzify the Time Series
For most of the fuzzy time series methods in the literature, the universe of discourse is partitioned into equal-width intervals which, however, may not be able to reflect the distribution of the real data in cases where the distribution of continuous values is not uniform. In this paper, we define the intervals based on the concept of percentiles, which thus takes into account the distribution of the data.
Step 1 Define and Partition the Universe of Discourse. The universe of discourse U is defined as U = [D min, D max], where D min and D max are the minimal and maximal values in the historical data, respectively. We then partition the universe of discourse based on the percentile of the data. Suppose the universe of discourse is partitioned into k intervals, the sequence of these can be defined as
where P i is the i × [100/(2k − 1)] percentile and [.] is the Gaussian operator.
Step 2 Define fuzzy sets A 1, A 2, …, A k as linguistic variables in the universe of discourse U. The centroid of the interval \(I_{i}\) is defined as the median of the data located inside the interval, which can be written as
The membership functions for these fuzzy sets of linguistic values are based on the triangular fuzzy numbers A 1 = (D min, D min, C 2), A 2 = (C 1, C 2, C 3), …, A k = (C k−1, D max, D max), as illustrated in Fig. 2.

Linguistic fuzzy sets of unequal-width partitions
Step 3 Fuzzify the raw time series data by computing their membership degrees to all linguistic fuzzy sets. We denote µ i as the membership function of fuzzy set A i . For the crisp data x t at time t, the membership degrees µ i ’s can then be calculated by the following formulas.
The crisp data x t are fuzzified as A j with the maximum membership degree µ j (x t ). The corresponding fuzzy time series F n of X t is represented as F n = f 1 f 2…f j …f n , where \(f_{i} \in \{ A_{ 1} ,\;A_{ 2} ,\; \ldots ,\;A_{k} \}\) [10].
4.2 Construct the Evolutionary Forecasting Model
The proposed fuzzy forecasting model is based on the concept of fuzzy logical relationships, which can reduce the computational time required by simplifying the calculating process.
In this step, we establish fuzzy logical relationships based on the fuzzy time series:
where the fuzzy logical relationship, \(A_{i} \to A_{j}\), indicates the causal relation between two consecutive fuzzy states, \(F\left( {t - 1} \right) = A_{i}\) and \(F\left( t \right) = A_{j}\). That is, if the fuzzified state at time t−1 is \(A_{i}\), then the fuzzified state at time t is \(A_{j}\).
The fuzzy logical relationships can be illustrated by a graph, in which an edge connecting two fuzzy states represents the fuzzy relationship between them. Figure 3 shows an example graph for the case of six fuzzy states.

A fuzzy relation map
The fuzzy logical relationships can also be represented by a fuzzy logical matrix, as follows:
where r ij is the fuzzy relationship if for some time t, \(F\left( {t - 1} \right) = A_{i} \to F\left( t \right) = A_{j}\), and it is zero if no such causal relationship exists in the historical data.
The fuzzy relationship matrix R can be automatically learned using a real-coded GA [30]. The chromosome is the fuzzy relationship matrix reformatted in the form of a real-numbered vector, defined as follows.
where r ij ’s are real numbers between 0 and 1.
The fitness function in the GA is used to evaluate the quality of the chromosomes. As in our previous paper, the prediction model is
where \(\hat{x}\left( t \right)\) is the forecasted value at time t, and \(x\left( {t - 1} \right)\) is the actual value at time (t−1). A good chromosome should represent a fuzzy relationship matrix that can obtain good predictions, which are usually measured by the mean squared error,
Therefore, a reasonable candidate for the fitness function can be defined based on the following formula.
where \(\varepsilon\) is a constant value (\(\varepsilon = 1\)). The range of the above fitness function is between 0 and 1, and the larger the value of the fitness function, the lesser the prediction error.
Once the chromosome and fitness function are determined, the genetic operators of selection, crossover, and mutation are used to create a new population. The learning process stops when the value of the fitness function converges to a preset criterion, or when the maximum number of generations is reached.
Applying a GA to learn the fuzzy relational matrix R would increase computational burden of the forecasting model. The time complexity of a GA is problem dependent, and is still largely unknown except for a few cases under specific conditions [31]. The execution time of a GA depends on the number of iterations and the genetic operations, such as selection, crossover, and mutation. It also depends on how the genetic operations are implemented. For example, the time complexity of Roulette wheel selection can be anywhere from O(n 2) when being done naively, to O(log n), or even O(n). In contrast, crossover and mutation only take O(n). An intuitive dominating term of the time complexity of a GA is O(g*n*m), where g is the number of generations (or iterations), n is the size of the population, and m is the size of individuals (or chromosomes). Therefore, in the proposed EFRM, the time complexity for learning an optimal fuzzy relation matrix R is dominated by O(g*n*k 2), since, as defined earlier, the size of a chromosome is k 2. In many applications, the number of iterations in a GA is decided experimentally.
4.3 Forecasting and Defuzzification
The proposed method is categorized as a time-invariant fuzzy time series forecasting one, which does not change with time and can use both linguistic and numeric forecasting variables. In the forecasting step, with the fuzzy relationship matrix R being calculated by GA, the forecasting can be carried out by the following formula.
where \(Fx\left( t \right) = \left[ {\mu_{1t} ,\;\mu_{2t} ,\; \ldots ,\;\mu_{kt} } \right]\), with the membership degree \(\mu_{it}\) corresponding to linguistic variable A i , for i = 1,2, …, k, and the operator ‘\(\circ\)’ is a conventional matrix multiplication. The predicted linguistic variable \(A_{{i^{*} }}\) is the one with the maximal membership degree in \(F\hat{x}\left( t \right) = \left[ {\hat{\mu }_{1t} ,\;\hat{\mu }_{2t} , \cdots ,\;\hat{\mu }_{kt} } \right]\). That is,
In the defuzzification step, we adopt the commonly used fuzzy mean for defuzzification [3, 4], which is carried out using the following formula:
where C i is the peak of the triangular fuzzy number and
4.4 Comparison of EFRM and Other FTS Methods
A fuzzy time series method is mainly composed of four steps: (1) defining the universe of discourse and fuzzifying the time series, (2) constructing the forecasting model, (3) applying the forecasting method, and (4) carrying out defuzzification. Each step influences the prediction accuracy of the forecasting model. As mentioned in Sect. 3, most of the FTS methods in the literature focus on steps (2) and (3) [10]. Table 2 summarizes the details of the modeling and forecasting steps of EFRM model and some similar FTS methods. To examine the forecasting ability of the relational matrix learned by a GA and to make a fair comparison with other methods, we fix the steps of fuzzification and defuzzification for each method.
5 Experiments and Analysis
In this section, we evaluate the effectiveness of the proposed EFRM method and undertake a performance comparison with other methods by conducting an experiment with two datasets. The details of this are described in the following subsections.
5.1 Evaluation Measures
We use four measures to evaluate the EFRM method, including root mean square error (RMSE), trend accuracy in direction (TAD), percent mean absolute deviation (PMAD), and mean absolute percentage error (MAPE). Of these, RMSE, PMAD, and MAPE are for prediction accuracy, while TAD is for trend accuracy in direction [32]. These are defined as follows.
(1) Root mean squared error (RMSE) | \({\text{RMSE}} = \sqrt {\frac{{\sum\nolimits_{i = 1}^{n} {\left( {\hat{x}_{i} - x_{i} } \right)^{2} } }}{n}{\kern 1pt} ,}\) |
(2) Percent mean absolute deviation (PMAD) | \({\text{PMAD}} = \frac{{\sum\nolimits_{i = 1}^{n} {\left| {\hat{x}_{i} - x_{i} } \right|} }}{{\sum\nolimits_{i = 1}^{n} {\left| {x_{i} } \right|} }}{\kern 1pt} ,\) |
(3) Mean absolute percentage error (MAPE) | \({\text{MAPE}} = \frac{{\sum\nolimits_{i = 1}^{n} {\left| {\frac{{\hat{x}_{i} - x_{i} }}{{x_{i} }}} \right|} }}{n}{\kern 1pt} ,\) |
(4) Trend accuracy in direction (TAD) | \({\text{AD}}_{i} = \left\{ {\begin{array}{*{20}l} {1,} \hfill & {{\text{if}}\;\left( {\hat{x}_{i} - x_{i - 1} } \right) \times \left( {x_{i} - x_{i - 1} } \right) > 0,} \hfill \\ {0,} \hfill & {{\text{otherwise}},} \hfill \\ \end{array} } \right.\) |
where \(\hat{x}_{i}\) is the forecasted value, \(x_{i}\) is the actual value, and n is the number of forecasted values.
For the accuracy measures, RMSE, PMAD, and MAPE, lower values indicate better performances. TAD values vary from 0, indicating a totally incorrect forecasting trend, to 1, indicating perfect trend accuracy with regard to the direction.
5.2 Demonstration of the Proposed EFRM Model
In order to demonstrate the proposed EFRM model, we present its forecasting process using a dataset of the temperature in Taipei from June to September for the years 1993–1996, which is often used in fuzzy time series studies [5, 12, 23]. The data are divided into two parts, i.e., that for the years 1993, 1994, and 1995 data are used as the training set to construct the forecasting model, and that for 1996 data are used as the testing set to evaluate forecasting performance. The steps of the EFRM model are as follows:
Step 1 Define the universe of discourse U and partition it into several unequal length intervals μ 1, μ 2, …, and μ n , based on the percentile distribution, as described in subsection 4.1. For example, the universe of discourse U = [21.6, 32.2] is partitioned into six unequal length intervals μ 1, μ 2, …, and μ 6, where μ 1 = [21.6, 25.4], μ 2 = [25.4, 27.7], μ 3 = [27.7, 28.7], μ 4 = [28.7, 29.7], μ 5 = [29.7, 30.5], μ 6 = [30.5, 32.2]. We then compute the centroid of each interval and denote these as c 1 = 21.6, c 2 = 26.6, c 3 = 28.4, c 4 = 29.2, c 5 = 29.9, c 6 = 32.2. The six fuzzy numbers are as follows: A 1 = (21.6, 21.6, 26.6), A 2 = (21.6, 26.6, 28.4), A 3 = (26.6, 28.4, 29.2), A 4 = (28.4,29.2, 29.9), A 5 = (29.2, 29.9, 32.2), A 6 = (29.9, 32.2, 32.2).
Step 2 Define six fuzzy sets A 1, A 2, …, A 6 as linguistic variables on the universe of discourse U. The linguistic fuzzy sets are defined as A 1 = (freezing), A 2 = (cold), A 3 = (cool), A 4 = (mild), A 5 = (warm), A 6 = (hot). The membership functions of these fuzzy sets of linguistic values are illustrated in Fig. 4.

The six fuzzy numbers
Step 3 When the fuzzy sets have been properly defined, the raw time series can be fuzzified by computing the membership degrees of all six fuzzy sets, and the fuzzy set with the maximal membership degree is assigned. For example, the temperature for 2 June 1993, was 25.3 °C, and the membership degree vector was [0.26 0.74 0 0 0 0], and thus the corresponding fuzzy set is A 2. The fuzzified training data for 1993 are shown in Table 3.
Step 4 Establish fuzzy logical relationships and a fuzzy relational map based on the historical fuzzified temperature data obtained in step 3, and the results are as shown in Table 4.
The corresponding fuzzy relation matrix R is as follows:
Step 5 According to the description in Subsect. 4.2, the chromosome is as follows:
In this example, we set the size of the population at 1000, crossover rate at 0.9, mutation rate at 0.1, and the maximum number of generations at 10,000. The process of genetic learning leads to the fuzzy relationship matrix and corresponding evolutionary fuzzy relation map, as shown in Fig. 5.

Evolutionary fuzzy relationship map for the temperature dataset
Step 6 Once the desired optimal fuzzy relation matrix R is obtained by the GA, the forecast can be carried out by the following formula,
For example, the temperature of 2 June 1996 is
The predicted linguistic value is determined according to the maximal membership degree in the above vector, so in this case it is A 2. The defuzzified forecasting value can be calculated as follows.
Table 5 is the forecasted results of the average temperature from June to September 1996.
5.3 Evaluation and Analysis of EFRM Model
Two datasets are used to evaluate the proposed EFRM model. The first set is the daily temperature in Taipei from June to September for the years 1993–1996 [5, 12, 23]. The second dataset is the daily closing price of Google stock for the period from 1 January 2009 to 6 October 2010 (http://finance.yahoo.com/q/hp?s=GOOG+Historical+Prices).
5.3.1 Experiments Forecasting the Daily Temperature
The temperature data were divided into training and testing sets, as stated in Subsect. 5.2. To determine the learning parameters in the GA, we conduct a grid search of the population = {600, 800, 1000, 1200}, crossover rate = {0.6, 0.7, 0.8, 0.9}, and mutation rate = {0.01, 0.05, 0.10, 0.15}, and it reaches an optimal combination of population = 10,000, crossover rate = 0.9, and mutation rate = 0.1. The forecasting performance of the proposed method was also compared with those of other fuzzy time series approaches [3, 4, 10, 29] using various metrics.
The experimental results and the comparisons with other methods are shown in Table 6. One can see that for the measures of RMSE, PMAD, and MAPE, the proposed EFRM model obtained the lowest values compared to the methods presented by Li and Cheng, Song and Chissom, Chen, and Wu. This indicates that the proposed model has better forecasting ability than the others. Moreover, the proposed model also obtained a significantly larger TAD than the others, which indicates that it fits the trend of the target time series quite well.
Figure 6 compares the forecasted values for the proposed model (in red), with the real values (in purple), and the results from the other models. The results indicate that when applied to the temperature dataset, EFRM has better forecasting ability, in terms of accuracy and trend, than the other methods examined here.

5.3.2 Experiments Forecasting the Daily Closing Price of Google Stock
There are a total of 444 records in the dataset of the daily closing price of Google stock. The first 252 records are used as training data and the remaining 192 as testing data. A similar grid search for the GA learning parameters is conducted as in the daily temperature experiment, and an optimal combination is obtained at the population = 1000, crossover rate = 0.6, and mutation rate = 0.01.
Figure 7 shows the evolutionary fuzzy relational map for the daily closing price of Google stock, and demonstrates the causal relationships among the linguistic terms. The experimental results of forecasting performance using the proposed method are compared with those from other fuzzy time series methods [3, 4, 10, 29] using various metrics, as shown in Table 7. Since the GA is a random process, to make sure the results are not due to a one time coincidence, we repeated the experiment 30 times. We then conducted a paired z-test to compare the performance of the proposed model with that of the benchmark methods presented in the literature. Similar to the previous experiment, the results show that EFRM achieves better RMSE, PMAD, and MAPE, with statistical significance (p value < significance level of 0.05), as compared to the best benchmark methods with respect to each measure. Similar to the previous experiment, for the measures of RMSE, PMAD and MAPE, the proposed model obtained the lowest values compared to those obtained from the methods in Li and Cheng [10], Song and Chissom [29], Chen [4], and Wu [3]. This indicates that the proposed model can produce more accurate forecasts than the other methods. Moreover, we can also see that our model and those presented by Song and Chissom and Chen all fit the trend of the target time series quite well, while the method in Li and Cheng is much worse at this.

Evolutionary fuzzy relation map for daily closing price of Google stock
Figure 8 compares the results from our model (in red) with the real values (in purple) and the results of the other models. It can be seen that when applied to the dataset for the daily closing price of Google stock, EFRM has better forecasting ability, in terms of accuracy and trend, than the other methods examined in this work. One can see that the forecasted curves produced by Song and Chissom [29], Chen [4], Wu [3], and Li and Cheng [10] tend to produce stepwise outcomes. In contrast, thanks to the use of an evolutionary fuzzy relation matrix, the forecasted curve produced by EFRM is smoother, which is more reasonable with regard to the original time series.

6 Conclusions
In this study, we proposed an evolutionary fuzzy forecasting model in which a learning technique for a fuzzy relational matrix was designed to fit the historical data. This novel model is more comprehensive than previous ones, as it takes into consideration the causal relationships that exist among linguistic terms. The experimental results show that the evolutionary learning mechanism can actually improve the forecasting performance in terms of accuracy and trend. Moreover, the fuzzy relationship map can provide visualized information that can help in decision making. Thanks to the evolutionary fuzzy relation matrix, the forecasted curve produced by EFRM is smoother, which is more reasonable with regard to the original time series. Directions for future work include enhancing the proposed model to deal with two-factor fuzzy time series, as well as time-variant forecasting problems.
References
Song, Q., Chissom, B.S.: Fuzzy time series and its models. Fuzzy Sets Syst 54, 269–277 (1993)
Sullivan, J., Woodall, W.H.: A comparison of fuzzy forecasting and Markov modeling. Fuzzy Sets Syst 64, 279–293 (1994)
Hsu, Y.Y., Tse, S.M., Wu, B.: A new approach of bivariate fuzzy time series analysis to the forecasting of a stock index. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 11, 671–690 (2003)
Chen, S.M.: Forecasting enrollments based on fuzzy time series. Fuzzy Sets Syst. 81, 311–319 (1996)
Chen, S.M., Hwang, J.R.: Temperature prediction using fuzzy time series. IEEE Trans. Syst. Man Cybern. B Cybern. 30, 263–275 (2000)
Huarng, K.: Heuristic models of fuzzy time series for forecasting. Fuzzy Sets Syst. 123, 369–386 (2001)
Chen, S.M.: Forecasting enrollments based on high-order fuzzy time series. Cybern. Syst. 33, 1–16 (2002).
Own, C.M., Yu, P.T.: Forecasting fuzzy time series on a heuristic high-order model. Cybern. Syst. 36, 705–717 (2005)
Lee, C.H.L., Liu, A., Chen, W.S.: Pattern discovery of fuzzy time series for financial prediction. IEEE Trans. Knowl. Data Eng. 18, 613–625 (2006)
Li, S.T., Cheng, Y.C.: Deterministic fuzzy time series model for forecasting enrollments. Comput. Math. Appl. 53, 1904–1920 (2007)
Li, S.T., Cheng, Y.C.: An enhanced deterministic fuzzy time series forecasting model. Cybern. Syst. 40, 211–235 (2009)
Li, S.T., Cheng, Y.C.: A stochastic HMM-based forecasting model for fuzzy time series. IEEE Trans. Syst. Man Cybern. B Cybern. 40, 1255–1266 (2010)
Li, S.T., Kuo, S.C., Cheng, Y.C., Chen, C.C.: Deterministic vector long-term forecasting for fuzzy time series. Fuzzy Sets Syst. 161, 1852–1870 (2010)
Li, S.T., Kuo, S.C., Cheng, Y.C., Chen, C.C.: A vector forecasting model for fuzzy time series. Appl. Soft Comput. 11, 3125–3134 (2011)
Huarng, K., Yu, H.K.: A type 2 fuzzy time series model for stock index forecasting. Phys. A 353, 445–462 (2005)
Huarng, K., Yu, T.H.-K.: The application of neural networks to forecast fuzzy time series. Phys. A 363, 481–491 (2006)
Yu, H.K.: A refined fuzzy time-series model for forecasting. Phys. A 346, 657–681 (2005)
Yu, H.K.: Weighted fuzzy time series models for TAIEX forecasting. Phys. A 349, 609–624 (2005)
Chen, S.M., Chung, N.Y.: Forecasting enrollments using high-order fuzzy time series and genetic algorithms. Int. J. Intell. Syst. 21, 485–501 (2006)
Lee, L.W., Wang, L.H., Chen, S.M.: Temperature prediction and TAIFEX forecasting based on fuzzy logical relationships and genetic algorithms. Expert Syst. Appl. 33, 539–550 (2007)
Cheng, C.H., Huang, S.F., Teoh, H.J.: Predicting daily ozone concentration maxima using fuzzy time series based on a two-stage linguistic partition method. Comput. Math. Appl. 62, 2016–2028 (2011)
Joshi, B.P., Kumara, S.: Intuitionistic fuzzy sets based method for fuzzy time series forecasting. Cybern. Syst. 43(1), 34–47 (2012)
Lee, L.W., Wang, L.H., Chen, S.M., Leu, Y.H.: Handling forecasting problems based on two-factors high-order fuzzy time series. IEEE Trans. Fuzzy Syst. 14, 468–477 (2006)
Holland, J.H.: Adaptation in Natural and Artificial Systems. University of Michigan Press, Ann Arbor (1975)
Goldberg, D.E.: Genetic Algorithm in Search, Optimization, and Machine Learning. Addison-Wesley, Reading (1989)
Davis, L.: Handbook of Genetic Algorithms. Von Nostrand Reinhold, New York (1991)
Gen, M., Cheng, R.: Genetic Algorithms and Engineering Design. Wiley-Interscience, New York (1997)
Man, K.F., Tang, K.S., Kwong, S.: Genetic Algorithms. Springer, London (1999)
Song, Q., Chissom, B.S.: Forecasting enrollments with fuzzy time series—part I. Fuzzy Sets Syst. 54, 1–10 (1993)
Herrera, F., Lozano, M., Verdegay, J.L.: Tackling real-coded genetic algorithms: operators and tools for behavioural analysis. Artif. Intell. Rev. 12, 265–319 (1998)
Jun, J., Yao, X.: Drift analysis and average time complexity of evolutionary algorithms. Artif. Intell. 127, 57–85 (2001)
Liu F, Du P, Weng F, Qu J (2007) Use clustering to improve neural network in financial time series prediction. In: IEEE Third International Conference on Natural Computation, vol. 2, pp. 89–93
Acknowledgments
The authors gratefully appreciate the financial support provided by the National Science Council, Taiwan, R.O.C., under contracts NSC 101-2410-H-434-001 and NSC99-2410-H-006-054-MY3.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Kuo, SC., Chen, CC. & Li, ST. Evolutionary Fuzzy Relational Modeling for Fuzzy Time Series Forecasting. Int. J. Fuzzy Syst. 17, 444–456 (2015). https://doi.org/10.1007/s40815-015-0043-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40815-015-0043-2