
Abstract
Stability is an important measure to consider when dealing with dam structural health management system. Dams are hydraulic structures built with impenetrable materials which serve as a barrier to the flow of water. Geodetic and geotechnical observables such as seepage clarity and flow, water level, piezometric water level, pressure, temperature variation, deformation and loading conditions are often measured for dam safety control. This study is focussed on piezometric water level which is an important parameter to support seepage analysis of dams. The efficiency of least squares support vector machine (LSSVM), group method of data handling (GMDH), M5 prime and Gaussian process regression (GPR) were explored for the first time in piezometric water level prediction. These methods were then compared with the widely used backpropagation neural network (BPNN), support vector machine (SVM) and radial basis function neural network (RBFNN). The seven methods were tested on experimental data collected at four different piezometers located at different positions of the dam for a period of 2 years 4 months in Ghana. It was generally observed from the prediction outputs that all the methods applied could produce very reasonable and applicable results. However, ranking the results according to root mean square error (RMSE), percent mean absolute relative error (PMARE), Correlation Coefficient (R), Loague and Green (LG), and variance accounted for (VAF) revealed the GMDH as the best prediction approach for all the piezometers. It was concluded that the implemented artificial intelligent techniques constitute reliable computational tools for dam piezometric water level prediction.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Engineers need to analyse the movements of structures to enable them to compare the real-world behaviour against the design and theoretical models. This activity is conducted to enhance the safety measurement system of the structures. Dam is one of the most important engineering structures which requires constant deformation monitoring for its safety (Scaioni 2018). This is because dams are subjected to external loads that can cause deformation of the dam structure, as well as its foundations. For that matter, the safety of the dam may then be threatened if there is an indication of any abnormal behaviour. Monitoring through measurement and visual observation of the loads on the dam and its response to them can help in identifying any abnormal behaviour of the dam. However, to facilitate the monitoring of hydraulic structures such as dam, it is very critical for the dam to be permanently equipped with proper instrumentation and monitoring points in accordance with the goals of the observation, the dam size, and the site conditions (De Granrut et al. 2019).
Generally, the safety control of dam requires the measurement of important geodetic and geotechnical observables such as water levels, temperature variations, loading conditions, seepage water clarity and flows, piezometric water levels, pressure, deformations among others (Rankovic et al. 2014). In dam deformation monitoring, piezometers are usually installed on some selected points on the dam to monitor how the water blocked by the dam could escape through the dam and its surroundings. Accurate information on piezometric water level is of crucial importance in seepage analysis of a dam, as well as the dam strength as time proceeds (Salajegheh et al. 2018).
Due to the critical role played by piezometric water level in dam safety analysis, a lot of scholars have engaged themselves in developing prediction tools using statistical, deterministic, and artificial intelligent (AI) methods (De Granrut et al. 2019; Rankovic et al. 2014; Salajegheh et al. 2018; Tinoco et al. 2020). However, some identifiable challenges have been found to be associated with the statistical or deterministic methods because of their inability to correctly learn, adapt and generalise on the data set. These methods lack flexibility, robustness, and tolerance to data sets variations. Besides, the external factors that controls piezometric water level have complex nonlinear characteristics which make the statistical and deterministic methods insufficient in terms of achieving high forecasting accuracy (Tinoco et al. 2020). Therefore, using these statistical or deterministic methods for piezometric water level prediction have shown some practical limitations due to their shortfalls to accommodate the imprecisions and uncertainties contain in a data set (Zadeh 1994). By means of addressing these identified challenges, there has been a surge in the approval rating and application of AI in literature due to its reliability to overcome the purported practical limitations exhibited by the statistical and deterministic techniques. Thus, the AI can produce highly accurate prediction of piezometric water level on a dam (Kong-A-Siou et al. 2014).
Although different variants of AI exist, the most dominant found in literature for the prediction of dam piezometric water level is the artificial neural network (ANN), classification and regression tree (CART), support vector machine, k-nearest neighbour, and random forest (Kong-A-Siou et al. 2014; Ranković et al. 2014; Tinoco et al. 2018, 2020; De Granrut et al. 2019). Other scholars have also introduced hybrid intelligent techniques (eg, particle swarm optimization and ANN (PSO-ANN), and harmony search learning algorithm and ANN (HS-ANN)) where the nature inspired algorithms (PSO and HS) were used to optimise the AI methods to improve their prediction performance (Salajegheh et al. 2018).
Review of these studies showed that piezometers are fixed at separate locations on dams, and each are monitored to identify any source of leakage and designing a solution to rectify the problem in the seepage analysis. This individual monitoring is important because the seepage flow can lead to dam failure and loss of properties. With this scenario, scholars have found it prudent to not rely on a unified prediction model where all the data from different piezometers on a dam are combined. The question that arises from such practice is, how can one determine which location on the dam has leakage and which piezometer is given that information? Therefore, for industrial application where safety is paramount, there is the need to monitor and develop prediction models for each piezometer for the dam’s structural health monitoring system and safety protocols. This can lead to saving human lives, properties and will not bring production to a halt which could have tremendous impact on the economy of the country. It is in view of the enumerated points that have led to scholars (Tinoco et al. 2020; De Granrut et al. 2019; Salajegheh et al. 2018; Rankovic et al. 2014) researching into piezometric water level prediction of dam have been developing individual models for each piezometer.
Moreover, as highlighted by different authors, the AI methods are generally not equivalent and thus vary in terms of their fine-tuning effort for different hyper parameters defined, computational speed, and their level of tolerance towards noisy data (Tinoco et al. 2020). In addition, the No Free Lunch theorem indicates that no single AI method can boast of having superiority of solving all predictive analytic problems (Buabeng et al. 2021). In view of the preceding discussion, it is practical to generally explore the prediction potency of other AI methods in dam piezometric water level. In this study, the goal is to assess the predictive efficiency and generalisation strength of seven different AI methods that have prospect of being used for dam piezometric water level monitoring. The methods applied are the backpropagation neural network (BPNN), group method of data handling (GMDH), radial basis function neural network (RBFNN), least squares support vector machine (LSSVM), support vector machine (SVM), M5 prime and Gaussian process regression (GPR). The selected methods were applied because they are found to have wide area of application in dam deformation studies. Furthermore, there has been close to no application in literature on evaluating the prediction competence of GMDH, LSSVM, M5 prime and GPR in dam piezometric water level prediction. The achieved results in this study showed that all the applied and tested methods can produce reasonable predictions. However, in this case study the GMDH stand out as the most efficient AI method for predicting piezometric water level of dam.
Study area and data used
Study area
The study is focussed on a gravity dam (hereafter Dam X) located in Ghana. Dam X is 108 m high above the lowest load-bearing part of the structure, 90 m above the riverbed with 492 m long crest and a maximum and minimum operating level of 185 and 167 m, respectively. The dam is made up of the main dam and two additional saddle dams (saddle dams 1 and 2). Saddle dam 1 is a rock-fill embankment dam which is found 500 m southeast to the main dam and is 37 m above ground level with a 300-m-long crest (Dietz et al. 2014). Saddle dam 2 is a zoned earth fill type located at 1 km southwest of the main dam with a height of 7 m and 580 m crest length. Saddle dams 1 and 2 have a crest elevation of 187 m above mean sea level. A maximum reservoir capacity of 12,570 million cubic metres is created by the main and saddle dams. Dam X spillway is made up of five radial gates each 15 m wide with an elevation of 169 m and a maximum discharge of 10,450 cubic metres per second. Dam X has a single outlet at its right bank which was converted from one of the diverted tunnels.
Data used
As part of the safety measurement system on Dam X, weekly observations are made on the dam to obtain geodetic, geotechnical, and environmental variables needed for the dam’s safety analysis. To test the prediction efficiency of the various AI methods applied, weekly data collected from January 2013 to April 2015 (2 years 4 months) was used to train and test the employed methods. The data used consist of temperature, pressure, modulus (modulus of elasticity of the dam material in which the piezometers are installed), rainfall and piezometric water level. Piezometric water level has been found to have strong relations with these observables which has been duly confirmed in literature (Bonelli and Royet 2001; Ranković et al. 2014; Fine and Millero 1973). For this work, the available data set comprising of four different piezometers (P01, P02, P03 and P04) for Block 12 which is one out of the thirty-four blocks of the dam was used for the modelling. These networks of piezometers have been installed and distributed under the main dam, Saddle dams 1 and 2, respectively. Table 1 provides the summary descriptive statistics of the various piezometer data set used.
Methodology
Backpropagation neural network
The BPNN is a type of supervised ANN approach which is used to solve both linear and nonlinear mathematical problems (Rumelhart et al. 1986). The structure of BPNN considered in this study consisted of input layer, one hidden layer and output layer (Fig. 1). The input layer is made up of the four predictor variables in which per the data used comprises of temperature, modulus, pressure, and rainfall. The output layer is made up of one response variable since the objective is to predict piezometric water level. To acquire the best results for the Block 12 piezometers, various network structures were designed differently with respect to the individual four piezometers (P01, P02, P03 and P04). The uncertainty surrounding the number of hidden neurons to be used was overcome by testing various number of neurons and selecting those that gave best output results for each network architecture designed. In performing BPNN training, a recurring cycle of back propagating the estimated error between the predicted and desired output is done with the objective of adjusting the weights to improve prediction accuracy. It is important to state that the network weight adaptation which is an indispensable part of BPNN was accomplished using suitable training algorithm. In this study, the Levenberg–Marquardt algorithm (Yu and Wilamowski 2011) was used to train the BPNN.

Structure of BPNN with four input variables and one hidden layer for predicting piezometric water level
Group method of data handling
GMDH proposed first by Ivakhnenko (1966) is considered a type of polynomial neural network. Its computational flexibility abounds in its ability to describe a mathematical relation of a nonlinear system between input and output variables. The GMDH architecture is feed-forward in nature with multilayer of polynomial neurons. Inspired by itself organising nature, the method automatically identifies system variables to create a continuous model based on the input–output variable mapping relationship (AlBinHassan and Wang 2011). This automatic processing of the data set enables optimal variable interactions and good convergence on the linear or nonlinear regression surface. In the data processing, a sequential pruning system is implemented on the various constructed layers with an optimization technique to automatically determine the optimum GMDH structure (Assaleh et al. 2013). Here, the process begins by creating multi-hidden layers of which the preliminary layer receives and distributes each input predictor variable. Subsequently, the successive layers created uses the number of neurons from a previous layer as input. This process is only terminated when the preceding layer’s stopping criterion (eg, mean square error) is better than the proceeding layer (Ivakhnenko 1966, 1971). The general GMDH architecture used in this study to predict piezometric water level is presented in Fig. 2. Four predictor variables (temperature, modulus, pressure, and rainfall) constituted the input data while the output is the piezometric water level.

GMDH architecture with four input variables and multiple hidden layers for predicting piezometric water level
Radial basis function neural network
The RBFNN is a supervised ANN approach which constitute a single hidden layer with interconnected input and output layers (Fig. 3). The RBFNN input layer number of nodes equals the predictor variables (temperature, pressure, modulus, and rainfall) with one output response variable (piezometric water level). The input layer nodes are directly connected to the nonlinear units found in the hidden layer. Here, the received inputs predictor variables data are sent directly to the hidden layer chamber where they are weighted and processed before transmitting them to the output layer. Essential component that greatly impact on RBFNN performance is the fine-tuning of certain adjustable parameters defined by the basis function type considered. In the hidden layer, basis function with parameter centres and widths are used to handle the nonlinearity existing in the data set. To achieve faster convergence, a suitable approach is usually applied to determine the centres of the basis function. Methods such as gradient descent, clustering and least squares are mostly used in literature (Broomhead and Lowe 1988). In this study, the least squares method was employed because a fixed value was set to define the width parameter of the radial basis function. The Moore–Penrose pseudo inverse (Broomhead and Lowe 1988) was then used to calculate the interconnected weights between the hidden and output layers. Several network architectures were designed for each piezometer and those that produced best prediction performance based on the lowest residual prediction errors were selected.

The general architecture of RBFNN having four input variables, single hidden layer and one output
Gaussian process regression
GPR is a nonparametric kernel-based Bayesian regression approach which can adequately work on smaller dataset and can provide information about the uncertainties associated with its predictions (Rasmussen and Nickisch 2010). The method works by computing probability distribution over all allowable fitted functions on the data set. Here, a mean and covariance functions are specified to assume a Gaussian process prior. The mean function represents the expected values of the function at input variables which considers the average of all the functions of the distribution evaluated at the input. At the initial stage, the choice of the kernel defines a prior process of which a zero value is set for the mean function. The covariance kernel function which allows for multidimensional inputs considers the inter-dependency between the functional values of the different inputs. In the Gaussian process prior, the chosen mean function and covariance kernel function form is adjusted throughout the model selection. In this study, the widely used covariance kernel function of squared exponential was applied (Kang et al. 2015). It is important to note that the training data set was used to compute the posterior. Hence, to predict the testing data, calculations were performed out of the posterior distribution by weighting all the predictive distribution. In the GPR model formulation, the same four predictor variables (temperature, modulus, pressure, and rainfall) and response variable (piezometric water level) were used.
Support vector machine
The concept of SVM first proposed by Vapnik (1998) and extended to a regression type of problem by Drucker et al. (1997) is a supervised learning approach. The fundamental principle of SVM is to try and find an optimum separating hyperplane to achieve the largest margin of the training data. For one to compute the margin and achieve the best hyperplane solution, a minimum constrained quadratic optimisation problem must be solved. The optimisation problem is usually solved using the Lagrange function and Lagrange multipliers which must fulfill the Karush–Kuhn–Tucker (KKT) situation (Farag and Mohamed 2004). In the light of this, the original constrained quadratic problem is then reduced into a dual optimisation problem. A solution to this duality enables the SVM to provide a fitted function on the training data which is used later to predict the testing data. It must be noted that in the SVM, a nonlinear kernel basis function is applied to map the input data from a lower to higher dimensions where a linear model is built in the feature space of the high dimension. In this study, the same predictor and response variables used by the other described methods in this study were applied to create the SVM model.
Least squares support vector machine
LSSVM proposed by Suykens and Vandewalle (1999) is the least squares formulation of SVM for solving nonlinear problems in predictive analytic and classification. LSSVM is considered to belong to Gaussian processes and regularisation networks but emphasises on exploiting primal–dual interpretations (Suykens et al. 2002). Unlike SVM where convex optimisation problems are encountered, the LSSVM provides a redefinition of the optimisation problem leading to linear KKT systems. Here, the optimisation problem has a minimised risk bound with linear equations with constraints based on the structural risk minimisation rule. The Lagrange function and Lagrange multipliers are used to solve the optimisation problem. It is worth stating that the LSSVM performs nonlinear transformation by mapping its input data to a high dimensional feature space. The LSSVM was applied in this study as a regression technique to fit a function on the training data which was later used to predict unseen (testing) data. The same predictor and response variables used by the earlier described methods were used in the model building process.
M5 prime
The M5 prime is a binary decision tree approach with nonparametric ability and can automatically handle the input–output mapping relationship at the leaf nodes (Quinlan 1992; Ghasemi et al. 2020). This method can work well on both categorical and continuous data set. The method can handle high dimensionality and complex problems. The M5 prime applies synergistic model formulation procedures by using data splitting and pruning to fit the model to the data. In the splitting stage, the data is divided into different sub-space to build the decision tree. The data division is based on the standard deviation reduction criterion where the sub-space standard deviation values of a node is considered as an error measure of that node and computing the desired error reduction because of evaluating each attribute at the node. Attributable to the splitting, the parent node always carries large standard deviation than the child node. After analysing all possible splitting steps, the one that produces the maximum expected error reduction is selected. At this point, an overgrown tree is usually created which overfit the data. To control the overfitting condition, a pruning method is applied to the overgrown tree where the subtrees that are pruned are replaced with linear regression functions. The same predictor and response variables used by the earlier described methods were used in the model building process.
Model building
Studies have shown that a significant difficulty in developing prediction model is the ability to design models to solve extremely and equally complex problems (Engelbrecht 2007). In this study, piezometric water level prediction models based on GMDH, LSSVM, M5 prime, GPR, BPNN, RBFNN and SVM were developed. For the model development, MATLAB programme was used. To fit these models, four parameters, namely, temperature, pressure, modulus, and rainfall were taken as predictor variables, and the piezometric water level served as the response variable. The four predictor variables were used because of their superior influence on the piezometric water level. Moreover, the used predictor variables agree with the normal practice of several authors in piezometric water level prediction (Bonelli and Royet 2001; Ranković et al. 2014; Fine and Millero 1973).
A total of 121 data points were used to develop and test the various models. First, 80 observations (66%) of the entire data having a span of 1 year 6 months. The fitting capability of the developed models were put to test using the remaining 41 observations which span for 10 months. These training and testing data sets were purposively selected using the widely applied hold-out cross validation approach to build the various prediction models. It must be noted that the study applied hold-out cross-validation approach which follows the general scientific practice by scholars researching into the prediction of piezometric water level using AI techniques (Tinoco et al. 2020; De Granrut et al. 2019; Salajegheh et al. 2018Rankovic et al. 2014). The purposive sampling was carried out in this study because of the time series nature of the data set and thus random sampling is not appropriate. These selected training and testing data points enabled the model to give a good representation of the underlying function between the input–output variables. The RMSE was used as a criterion to determine the best performing model during training and testing phases. That is, a model is found suitable when it produces the lowest RMSE in both training and its corresponding testing.
To enhance model convergence, the predictor variables used to develop the models were first scaled into the interval [– 1, 1] using Eq. (1) (Muller and Hemond 2013). The motive was to ensure constant variability in the predictor variables since they have different physical units of measurement. Furthermore, the influence of large values on the smaller recorded value in the modelling process is eliminated:
where ai is the normalised result, hi is the measured predictor variable, hmin and hmax take minimum and maximum values of hi while fmax and fmin are 1 and −1, respectively.
Model performance evaluators
It is imperative to find the optimum model that correctly fit to the data and produced the lowest prediction residual. This is because the prediction residual is a measure of model adequacy and that the lower it is the better the suitability of the model to be used for a prediction task. In the light of this, performance metrics such as root mean square error (RMSE), percent mean absolute relative error (PMARE), Correlation Coefficient (R), Loague and Green (LG), and variance accounted for (VAF) were used. Equations (2) to (6) are their mathematical expressions (Adoko et al. 2011; Ali and Abustan 2014):
where Obsi and Predi are the measured and predicted piezometric water level with their average corresponding values given as \(\overline{{{\text{Obs}}}}\) and \(\overline{{{\text{Pred}}}}\), respectively. The Abs and var indicate the absolute and variance of the corresponding terms and i vary from 1 to N with N representing the total data.
Results and discussion
The practicality of the models was examined using the testing data set. The reason is that the testing data did not contribute to the model training and thus can be used to legitimately assess the model correctness. The various performances of the developed predictive models are presented in the subsequent sections.
Test performance of the BPNN model
The BPNN model was applied to predict piezometric water level for four different piezometers (P01, P02, P03 and P04) located on the dam. In all the four piezometers BPNN models developed, the Levenberg Marquardt backpropagation algorithm (Arthur et al. 2020) was used to train the neural network system for 5000 epochs with a momentum coefficient of 0.7 and learning rate of 0.03. For the various BPNN models developed, the hyperbolic tangent activation function was used in the hidden layer whilst the linear activation function was used in the output layer. The hyperbolic tangent activation used was influenced by the data normalised interval of [− 1, 1]. The linear activation function was the most suitable in the output layer because we are dealing with a regression problem. The uncertainty surrounding the number of hidden neurons to be used was overcome by applying the widely used sequential trial and error procedure where various number of neurons were tested and those that gave the best output results based on the lowest RMSE was considered the optimum network architecture. In the model training, the hidden neurons were varied from 1 to 50 in each of the BPNN model developed for the P01, P02, P03 and P04. Table 2 presents the optimum number of hidden nodes for each of the designed BPNN structure for each piezometer.
A matrix presentation of the various statistical indicators applied to access the validity of the developed BPNN models are given in Table 3. It is observed that the BPNN produced very low values of RMSE and PMARE for all the piezometers and achieved higher values of R, LG and VAF, respectively. Since the RMSE and PMARE values are approaching zero, this signify that the BPNN predictions do not differentiate much from the observed piezometric water level data. This was confirmed from the results recorded by the dimensionless indicators (R, LG and VAF) where a close to perfect association between the predicted and observed was established. Therefore, with regards to these results, it can be stated that the BPNN is an excellent model for predicting piezometric water level.
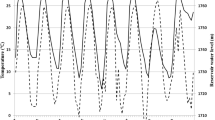
Figure 4 presents the fitted piezometric water level values produced by the BPNN against the observed. A study of Fig. 4 indicates that the BPNN was able to fit very well to the observed data leading to very low prediction residuals. This means that a higher agreement was achieved between the predicted and the observed piezometric water level.

Testing results of the observed and predicted piezometric water level from BPNN for a Piezometer 1 (P01) b Piezometer 2 (P02) c Piezometer 3 (P03) d Piezometer 4 (P04)
Test performance of the GMDH model
Table 4 presents the GMDH best performing models for the various piezometers. In Table 4, the GMDH prediction models had one layer with one neuron and two used variables in the input layer. It must be noted that the two used variables out of the initial four input variables fed into the GMDH system were pressure (X3) and rainfall (X4), respectively. This phenomenon is typical of GMDH where only variables deemed relevant are selected to form the final model. This means that the GMDH feature extraction tool identified the modulus and temperature variables less significant and thus was not considered during the model development phase.
A matrix representation of the GMDH model efficiency for the four piezometers are shown in Table 5. A negligible RMSE and PMARE results recorded by GMDH for all the piezometers signify a perfect fit to the observed data with marginal variability between the predicted and observed piezometric water level. This assertion can be confirmed from the GMDH achieved R, LG and VAF values. A diagram illustrating the GMDH predictions for P01, P02, P03 and P04 against their corresponding observed data are presented in Fig. 5. From Fig. 5, a close to identical prediction outcomes that matches with the observed data were produced by the GMDH models developed. The consistency in the GMDH outputs position it to be a reliable prediction tool.

Testing results of the observed and predicted piezometric water level from BPNN for a P01 b P02 c P03 d P04
Test performance of the RBFNN model
The best performing RBFNN models for P01, P02, P03 and P04 had [4-30-1] which indicate four input variables, thirty hidden nodes and one output. The Gaussian activation function (Gui-Shen 2013) was used as the radial basis function in the hidden layer. Table 6 presents the adjustable width parameter values that produced the best RBFNN architecture for each piezometer.
The RBFNN models’ performance assessment results are presented in Table 7. Interpreting the obtained lower values of RMSE and PMARE as well as the higher rates of R, LG and VAF indicate that the RBFNN predictions are consistent with the observed piezometric water level. This can be confirmed in Fig. 6 where a very strong linear dependency is observed for the RBFNN predictions against the observed piezometric water level.

Testing results of the observed and predicted piezometric water level from RBFNN for a P01 b P02 c P03 d P04
Test performance of the GPR model
One major component that contributes to the successful application of GPR is the covariance function. In this study, the covariance kernel function of squared exponential which is widely used in literature was employed to develop the GPR models for the various piezometers. Table 8 presents the optimum GPR models corresponding basis function values. From Table 9, it can be observed that the utilised performance indicators had very close RMSE and PMARE values found within the zero range and R, LG and VAF values close to 1 or 100%. These results endorse the GPR as an accurate estimation model for piezometric water level prediction. It can also be seen from Fig. 7 that the predicted outputs from the GPR had stronger association with the observed data.

Testing results of the observed and predicted piezometric water level from RBFNN for a P01 b P02 c P03 d P04
Test performance of the SVM model
The regularisation (γ) and epsilon (β) adjustable hyper-parameters of the SVM was fine-tuned using chronological trial and error process (Tseng et al. 2016). At the end of the SVM training, the optimum γ and β hyper-parameter values that gave the best prediction outputs for all the four piezometers were 50 and 1 × 10–8. The type of kernel function used was a polynomial with first order. The SVM gave RMSE and PMARE values very close to zero with R, VAF and LG values approaching 1 or 100% (Table 10). These indicate that the SVM has good predictive efficiency. The closeness of the SVM prediction outcomes and the observed piezometric water level for the four piezometers are demonstrated in Fig. 8.

Testing results of the observed and predicted piezometric water level from SVM for a P01 b P02 c P03 d P04
Test performance of the LSSVM model
The performance of the LSSVM is dependent on the hyper-parameters (regularised (γ) and width (σ)) of the kernel function used. In this study, the optimum values for the hyper parameters of the radial basis kernel function used were refined by means of the simplex search algorithm (De Brabanter et al. 2011). The γ and σ values that produced the best LSSVM predictions for each piezometer are presented in Table 11.
The LSSVM prediction efficiency was investigated using RMSE, PMARE, R, LG and VAF (Table 12). It is agreeable that when the RMSE and PMARE values move towards the ideal zero error value, higher corresponding values of R, LG and VAF are also recorded. Therefore, there is clear indication that the LSSVM models developed for each piezometer are excellent predictors. Figure 9 shows that the LSSVM models predictions fall on the least squares line of best fit and thus they are applicable in monitoring piezometer water level.

Testing results of the observed and predicted piezometric water level from LSSVM for a P01 b P02 c P03 d P04
Performance of M5 prime model
In developing the M5 prime model, the method of ensembles was used to fine-tune the hyper-parameters to grow the individual trees. In that regard, a minimum observation of 3 was set for splitting at a node with a minimum training observation and splitting threshold set at 1 and 1 × 10–6, respectively. The fine-tuning results (Fig. 10) showed that while growing the tree the best number of variables needed to be randomly sampled as candidates at each split was 3. Although using three variables (curve 3) or 4 (curve 4) produced the least out-of-bag mean squared error for growing 500 trees, three variables were chosen in this study to reduce the computational complexity of the M5 prime model. It must be noted that identical out-of-bag results were obtained for all the piezometers. Hence, three variables were used throughout the model development phase.

Error decline curve for candidate variables required for each split during training as the number of trees increases
The computational prowess of M5 prime with respect to the generalisation capability are presented in Table 13. Interpreting the obtained results (RMSE, PMARE, R, LG and VAF) and analysing Fig. 11, it is depicted that the M5 prime predictions showed some deviations from the observed piezometric water level. This reflected in the achieved residual indicators (RMSE and PMARE) which were of higher values. Although encouraging results were achieved (Table 13), the M5 prime prediction efficacy for piezometric water level is limited in this case study.

Testing results of the observed and predicted piezometric water level from M5 prime for a P01 b P02 c P03 d P04
Comparison of the various models
All the seven predictive models were compared based on their RMSE, PMARE, R, LG and VAF (Tables 3,5,6,7,8,9,10,11,12 and 13). The RMSE value explains the extent at which the model prediction residuals are deviating from the ideal zero error. From the results, all the models produced very competitive RMSE results which signify that their residual predictions are much approximating to the zero-error value. With regards to the PMARE, a model is rated excellent if its PMARE value is found between the interval [0, 5] (Ali and Abustan 2014). By virtue of that, it can be stated that all the models developed can be used as predictors for piezometric water level. This is also confirmed by the R, LG and VAF results. The reason is that the R explains the degree of conformity between the model outcome and the observed. It is observed from the results that the least recorded R value was 0.98. This implies that the various models have stronger linear dependency strength between their outputs and the observed. The LG value varies from 1 to − ∞ with 1 signifying higher prediction accuracy. Analysing the results obtained (Tables 3,5,6,7,8,9,10,11,12 and 13), it was noticed that in all cases very reasonable approximate LG values between 0.88 and 0.99 were achieved. Therefore, it can be stated that the models produced closely related results that agree with the observed data. It is stated in Temeng et al. (2021) that a model producing a VAF value above 80% is classified to be an excellent predictor while between 20 and 80% signify a good predictor with 20% less value depicting a worse predictor. Based on the VAF values produced by each model, they can be categorised as excellent predictors which indicate the individual model’s prediction strength. The overall analyses denote that the models could all produce competitive results and thus applicable for piezometric water level monitoring. The competitiveness of the developed models for predicting each piezometer can additionally be visualised in Fig. 12 where closely associated predictions to the observed data were noticed.

Developed models predictions for each piezometer (P01, P02, P03 and P04) against the observed piezometer water level
Due to the highest prediction accuracy needed for stability assessment by structural health managers to make informed decision, a model is required to meet their standard of operation. Therefore, comparing all the methods applied the GMDH was found superior and thus selected as the best performing model. It is indicative from the results that the GMDH produced the lowest RMSE and PMARE values and highest values of R, LG and VAF when compared with the other investigated methods. The GMDH has demonstrated good generalisation power and can be attributed to its self-organising nature. This is because the variable selection and variable interactions to create the underlying function in the model building are automatically executed. Hence, human involvement is very limited in its model development and thus leading to improved prediction accuracy.
Conclusion
This study evaluated the performances of seven AI methods of BPNN, GMDH, RBFNN, GPR, SVM, LSSVM and M5 prime for dam piezometric water level prediction. Out of these stated methods, the GMDH, LSSVM, M5 prime and GPR were applied and tested for the first time to predict piezometric water level. The models predictive strength were tested on a weekly piezometric water level data for Dam X located in Ghana. The models results were compared using different statistical evaluators, including RMSE, PMARE, R, LG and VAF. From the outcomes of the study, it is concluded that:
-
All the seven AI methods implemented produced very competitive accurate piezometric water level prediction results.
-
In all cases, the GMDH model produced superior prediction performance and was selected as the most suitable among all the methods applied.
-
The high generalisation strength of the GMDH approach was attributed to its self-organising nature where manual tasking is eliminated where variable selection and variable interactions as well as data processing are automatically executed.
References
Adoko AC, Zuo QJ, Wu L (2011) A fuzzy model for high-speed railway tunnel convergence prediction in weak rock. Electron J Geotech Eng 16:1275–1295
AlBinHassan NM, Wang Y (2011) Porosity prediction using the group method of data handling. Geophysics 76:O15–O22
Ali MH, Abustan I (2014) A new novel index for evaluating model performance. J Nat Resources Dev 4:1–9
Arthur CK, Temeng VA, Ziggah YY (2020) Performance evaluation of training algorithms in backpropagation neural network approach to blast-induced ground vibration prediction. Ghana Min J 20:20–33
Assaleh K, Shanableh T, Kheil YA (2013) Group method of data handling for modeling magnetorheological dampers. Intell Control Autom 4:70–79
Bonelli S, Royet P (2001) Delayed response analysis of dam monitoring data. Dams in a European content, ICOLD European symposium, Geiranger, NOR, 25–27 June 2001, Norway, pp 91–99.
De Brabanter K, Karsmakers P, Ojeda F, Alzate C, De Brabanter J, Pelckmans K, De Moor B, Vandewalle J, Suykens JAK (2011) LS-SVMlab Toolbox User’s Guide: Version 1.8, pp.1–115. Available online: https://www.esat.kuleuven.be/sista/lssvmlab/ (accessed on 5th May 2021).
Broomhead DS, Lowe D (1988) Multivariate functional interpolation and adaptive networks. Complex Syst 2:321–355
Buabeng A, Simons A, Frempong NK, Ziggah YY (2021) A novel hybrid predictive maintenance model based on clustering, smote and multi-layer perceptron neural network optimised with grey wolf algorithm. SN Appl Sci 3:593. https://doi.org/10.1007/s42452-021-04598-1
De Granrut M, Simon A, Dias D (2019) Artificial neural networks for the interpretation of piezometric levels at the rock-concrete interface of arch dams. Eng Struct 178:616–634
Dietz AJ, Hees S, Seuren G, Veldkamp F (2014) Water dynamics in the seven African countries of Dutch policy focus: Benin, Ghana, Kenya, Mali, Mozambique, Rwanda, South Sudan. Report on Ghana: the African Studies Centre Leiden and commissioned by VIA Water, Programme on water innovation in Africa. https://aquaforall.org/viawater/files/asc_water_ghana_3.pdf (accessed on 5th May 2021)
Drucker H, Burges CJ, Kaufman L, Smola A, Vapnik V (1997) Support vector regression machines. Adv Neural Inf Process Syst 9:155–161
Engelbrecht AP (2007) Computational intelligence: an introduction. John Wiley and Sons
Farag A, Mohamed RM (2004) Regression using support vector machines: Basic foundation. Technical Report, University of Louisville.
Fine RA, Millero FJ (1973) Compressibility of water as a function of temperature and pressure. J Chem Phys 59:5529–5536
Ghasemi E, Gholizadeh H, Adoko AC (2020) Evaluation of rockburst occurrence and intensity in underground structures using decision tree approach. Engineering with Computers 36:213–225
Gui-Shen Y (2013) Marathon grades time series forecasting based on improved radial basis function neural network. Int J Appl Math Stat 39:236–242. https://doi.org/10.4236/ica.2013.41010
Ivakhnenko AG (1966) Group method of data handling a rival of the method of stochastic approximation. Soviet Automatic Control 13:43–71
Ivakhnenko AG (1971) Polynomial theory of complex systems. IEEE Trans Syst Man Cybern 4:364–378
Kang F, Han S, Salgado R, Li J (2015) System probabilistic stability analysis of soil slopes using Gaussian process regression with Latin Hypercube sampling. Comput Geotech 63:13–25
Kong-A-Siou L, Fleury P, Johannet A, Estupina VB, Pistre S, Dörfliger N (2014) Performance and complementarity of two systemic models (reservoir and neural networks) used to simulate spring discharge and piezometry for a karst aquifer. J Hydrol 519:3178–3192
Muller VA, Hemond FH (2013) Extended artificial neural networks: incorporation of a priori chemical knowledge enables use of ion selective electrodes for in-situ measurement of ions at environmentally relevant levels. Talanta 117:112–118
Quinlan JR (1992) Learning with continuous classes. In: Proceedings of 5th Australian joint conference on artificial intelligence. World Scientific, Singapore, pp. 343–348.
Ranković V, Novaković A, Grujović N, Divac D, Milivojević N (2014) Predicting piezometric water level in dams via artificial neural networks. Neural Comput Appl 24:1115–1121
Rasmussen CE, Nickisch H (2010) Gaussian processes for machine learning (GPML) toolbox. J Mach Learn Res 11:3011–3015
Rumelhart DE, Hinton GE, Williams RJ (1986) Learning internal representations by backpropagating errors. Nature 323:533–536
Salajegheh R, Mahdavi-Meymand A, Zounemat-Kermani M (2018) Evaluating performance of meta-heuristic algorithms and decision tree models in simulating water level variations of dams’ piezometers. J Hydraulic Struct 4:60–80
Scaioni M, Marsella M, Crosetto M, Tornatore V, Wang J (2018) Geodetic and remote-sensing sensors for dam deformation monitoring. Sensors 18:1–25
Suykens JAK, Vandewalle J (1999) Least square support vector machine classifiers. Neural Process Lett 9:293–300. https://doi.org/10.1023/A:1018628609742
Suykens JAK, Van Gestel T, De Brabanter J, De Moor B, Vandewalle J (2002) Least squares support vector machines. World Sci Singapore. https://doi.org/10.1142/5089
Tinoco J, De Granrut M, Dias D, Miranda T, Simon AG (2020) Piezometric level prediction based on data mining techniques. Neural Comput Appl 32:4009–4024
Tinoco J, De Granrut M, Dias D, Miranda TF, Simon AG (2018) Using soft computing tools for piezometric level prediction. In: Third international dam world conference 2018, Foz do Iguacu Brazil.
Tseng TLB, Aleti KR, Hu Z, Kwon YJ (2016) E-quality control: a support vector machines approach. J Comput Design Eng 3:91–101
Vapnik VN (1998) Statistical learning theory. John Wiley and Sons, New York
Yu H, Wilamowski BM (2011) Levenberg-marquardt training, Industrial Electronics Handbook.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Ziggah, Y.Y., Issaka, Y. & Laari, P.B. Evaluation of different artificial intelligent methods for predicting dam piezometric water level. Model. Earth Syst. Environ. 8, 2715–2731 (2022). https://doi.org/10.1007/s40808-021-01263-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40808-021-01263-9