
Abstract
The Kenyan coast is constantly under persistent cloud cover which hinders mapping using optical images. Up-to-date land-cover information in such areas is sometimes missing from national mapping initiatives. This study uses a computed composite image based on a mean of cloud and shadow free Function of Mask masked multi-temporal Landsat 8 images acquired during long-dry season in a pilot area. We test the effectiveness of the composite to map mangrove forest using random forest (RF) and support vector machines (SVM) machine learning algorithms integrated with context from Markov random fields (MRF(s)). MRFs was chosen because it is computationally efficient hence can be scaled out nationally. The MRF frameworks are compared to pixel-based classification using threefold independent validation samples. SVM–MRFs and RF–MRFs methods have the highest overall accuracy compared to pixel-based classification. However, visual assessment of predicted land-cover using aerial photograghs established that SVM–MRFs framework corresponded well to land-cover in the study area. This framework also managed to map classes with limited ground reference data better than RF–MRFs. Generally, context in both techniques played a discriminative role especially in heterogeneous regions. Therefore, scaling out this approaches would go a long way in generating mangrove forest map inventory in persistent cloud cover regions which is useful for land-based emission estimation.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Clouds and shadows in optical images obscure features on the earth surface thereby inhibit mapping and other remote sensing applications. At times the images can be used with moderate cloud cover percentage. Nonetheless, in such cases cloud masks are still necessary in order to exclude cloud and shadow areas from further analysis. Despite this challenge, optical satellites still play a role in land-cover mapping. One such satellite mission is the Landsat program. With the pioneering Landsat 1 satellite launched in 1972, it is thus far the longest running enterprise for acquisition of freely available satellite imagery capturing global land conditions and dynamics (Loveland and Dwyer 2012). Such longstanding mission coverage guarantees current and historical data access globally. The datasets have considerable rich spectral information and medium spatial resolution ideal for national, regional and global applications. This is why Landsat has been adopted in Kenya to monitor land-cover changes for purposes of supporting the System for Land-based Emissions Estimation (SLEEK 2019). SLEEK is a Kenyan government initiative that aims to develop a robust Measurement, Reporting and Verification (MRV) system to estimate land-based emissions and provide this data to drive development in the country.
SLEEK uses selected cloud-free landsat images acquired during the dry season (i.e., January–February or July–August) of a given year. In areas where cloud-free images are not available, a cloud cover threshold of 20% is used to select images. However, areas like Mount Kenya and particularly the Kenya coast always have some proportion of cloud cover in the morning when Landsat acquires images (Fig. 1). Consequently, data gaps exist on subsequent classified images. This especially affects accurate monitoring of mangroves and coastal terrestrial forests extent which may lead to over estimation of carbon emissions. Mangroves are valuable locally and global for ecosystem services (storm protection, breeding ground for fisheries and water quality enhancement Barbier et al. 2008), goods (fuel wood, medicine, food, and construction materials Kirui et al. 2013), and rich carbon sequestration (Donato et al. 2011). Due to their diverse benefits, the coastal terrestrial forests and mangroves are the most vulnerable habitats (FAO 2007) and require monitoring and conservation. In Kenya, studies like (Kirui et al. 2013) used Landsat to detect mangrove land-cover changes along the coast strip but noted cloud cover challenges. Another study by (Bunting et al. 2018) also encountered cloud cover challenges while mapping tropical mangroves from Landsat images. Despite the problem of cloud cover, SLEEK requires canopy cover densities of Forests which are then aggregated within the Intergovernmental Panel on Climate Change (IPCC) land-cover classes for Green House Gas (GHG) emissions reporting. We therefore explore the use of Landsat within the same framework to discriminate mangrove forest and other land-cover at the Kenyan coast. Efforts to map mangroves in different parts of the Kenyan coast using other satellite sensors also exist. For instance, Gang and Agatsiva (1992) and Neukermans et al. (2008) used SPOT 1 and Quickbird data to map mangroves species in Mida Creek (Kilifi) and a small area of Gazi bay, respectively. Kairo et al. (2002) used aerial photographs coupled with intense ground data collection to assess the status of mangroves within and adjacent to Kiunga marine protected area. Most of these studies focused on mapping mangroves along the Kenyan coastal strip and excluded other coastal terrestrial forests and land-cover. Our study focuses on discriminating the densities of the coastal terrestrial forests and mangroves from other land-cover. This contribution will be important for GHG inventory mapping in the Kenyan coast which to the best of our knowledge no efforts exists.
Landsat images can still be exploited for historical and future MRV of land-cover despite cloud cover challenges. One approach is to use automatic cloud masking and gap filling techniques. For instance, the automated cloud-cover assessment (ACCA) algorithm within the Landsat 7 processing system has been used to estimate cloud cover scores (percentage) for each scene (Irish 2000; Irish et al. 2006). However, the ACCA algorithm does not detect shadows (Hallahan and Prepperneau 2013). Jin et al. (2013) used blue, shortwave infrared and thermal infrared bands of Landsat ETM+ to extract cloud and shadow areas. Masked areas were then filled using a reference image acquired at a different date but with non-overlapping clouds. The same concept is used to extract cloud and shadow in Landsat 8 by Candra et al. (2017) using differences in reflectance values of visible, near-infrared and shortwave infrared bands between target and reference images. Temporal information has also been used to detect clouds (Hagolle et al. 2010; Zhu and Woodcock 2014; Gómez-Chova et al. 2017; Mateo-García et al. 2018). Even so, these studies still require a cloud-free reference image to detect clouds and shadows in a target image using spectral thresholds or some other function like correlation of pixels. Finding a reference image with non-overlapping clouds may mean that the date of acquisition is further away from the target image, e.g., in a different season. Moreover, use of a cloud-free reference image to detect cloud pixels in a target based on spectral changes image casts the cloud detection task as a change detection problem. We adopt the Function of Mask (Fmask) algorithm by Zhu et al. (2015) to mask out clouds and shadows following findings from Foga et al. (2017) which established that the technique had the best accuracy compared to other algorithms. This is in agreement with a study by Baetens et al. (2019) which established that Fmask and MAJA (Lonjou et al. 2016) perform similarly while Sen2Cor (Richter et al. 2012) had the lowest accuracy. However, MAJA algorithm is not easy to use and is also computationally intensive. Our idea is to subsequently leverage on the masked images to compute a multi-temporal mean composite cloud and shadow-free image within a dry season and use it for land-cover mapping.
A supervised pixel-based classification approach based on Random Forests (RF) is used by SLEEK for national land-cover mapping. This mapping frameworks was designed such that pixel-based classification results are subjected to majority filtering. Majority filtering minimizes independently labelled pixels that give rise to “salt and pepper” in classified maps. While this creates visually appealing maps, it propagates errors of pixel-based classifiers. This study introduces use of a context-based classifier into SLEEK’s land-cover mapping using Markov random field(s) (MRFs) (Geman and Geman 1984). MRF has conventionally been widely used to integrate context during image classification. For example, classification of hyperspectral images (Cao et al. 2018), image denoising (Cao et al. 2011), mapping of distribution of classes in sub-pixel classification (Kasetkasem et al. 2005), super-resolution mapping using MRF integrated with RF (Sanpayao et al. 2017) and spatial-temporal image classification (Jeon and Landgrebe 1992; Solberg et al. 1996; Melgani and Serpico 2003; Liu et al. 2006, 2008; Moser and Serpico 2011). In Forest applications, MRFs has been used to map forest Li et al. (2014), monitor forest encroachment (Tiwari et al. 2016), and forest map revision (Solberg 1999). Our study seeks to improve the capacity of mapping mangrove forest in the persistent cloudy Kenyan coast. We use spatial context integrated into RF and support vector machines (SVM) machine learning approaches to map mangroves and other land-cover from a cloud-free multi-temporal Landsat 8 image composite. MRFs integrates context with comparable accuracy to advanced conditional random fields (CRF(s)) by Lafferty et al. (2001) as demonstrated in Kenduiywo et al. (2014) despite its limiting conditional independence assumption. Nonetheless, MRFs simplistic assumption poses an advantage of computational efficiency hence can be easily scaled out to large areas.
Materials and methods
Study area
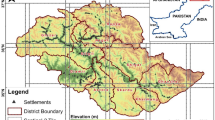
The proposed approach was tested in part of Kwale county, a region characterized by persistent cloud cover due to proximity to Indian ocean. It is located at approximately \(-4.34^\circ \) Latitude and \(39.33^\circ \) Longitude and is 30 km South–West of Mombasa and 15 km inland along the Kenyan coastal region (Fig. 1). There are tropical (coastal terrestrial) and mangrove forests in the area. The tropical forest is gazetted for conservation purposes. Those within our study area include Shimba Hills, Jombo, Mrima, Marenji, Gonja, Buda, and Mailungaji. The Mangrove forest covers an area of about 8000 ha and are found in Gazi, Vanga, Shimoni, Funzi, Sii Island and Tunza.

Landsat path (P) and row (R) tiles over Kenya showing areas prone to persistent cloud cover. The study area is within tile P163R63 in Kwale county
Data
We used Landsat 8 level 1 Tier 1 products which are already terrain corrected and consistently geo-referenced within \(\le 12\,\hbox {m}\) radial mean square error hence suitable for any time series analysis applications (Young et al. 2017). A total of ten images acquired between June 5 and October 27, 2017, within the long dry season corresponding to path 166 and row 63 of the Landsat tiling system (Fig. 1) were used.
Ground reference data were collected to aid classification in the study area. The data were collected through field work campaigns and supplemented with existing aerial photograph and Google Earth images covering parts of the study area. We identified a total of nine land-cover classes in the area, namely: cropland (annual and perennial), forest (dense and open), mangrove forest (dense, moderate, and open), grassland, otherland (settlements, rocks, beach sand and bare areas), and water. The dense, moderate, and open forest categories are defined based on canopy cover density > 65%, 40–65%, and 15–40%, respectively. These land-cover classes are defined following the IPCC guidelines on land-cover change inventory (Eggleston et al. 2006). The definition also satisfies land-based emissions modelling, government’s functions across the land-based sector, and can be mapped using available data at national scale (DRSRS 2016).
Figure 2 summarizes the approach that we adopted in this study. The fundamental steps of our methods include cloud- and shadow-free temporal composite image generation, land-cover mapping, and validation. The entire framework was developed so as to map mangrove forest and other land-cover under persistent cloud cover in Kwale.

A framework for land-cover mapping under persistent cloud cover in Kenya
Cloud-free image generation
In order to deal with the issue of persistent cloud cover, we generated cloud-free images using multi-temporal images acquired during the long dry season of 2017. First, we acquired Landsat 8 images within June 5–October 27, 2017, and selected bands 1–7. The selected bands in each image scene were then atmospherically corrected. This is because ground surface reflectance is of interest than at sensor reflectance in vegetation mapping applications. In addition, atmospheric correction is necessary in order to account for variation of atmospheric conditions in multi-temporal images. Therefore, we used a simple absolute atmospheric correction method based on dark object subtraction proposed by Chavez (1996). This approach uses information within an image scene for atmospheric correction. Other advanced techniques normally require ancillary data about atmospheric conditions at the time of image acquisition and are difficult to implement if such information is not available. In addition, we preferred the simple approach because sometimes atmospheric corrections techniques have been reported to introduce other errors (Schroeder et al. 2006). After the images were atmospherically corrected, each pixel had values between 0–1.
We then masked out clouds and shadows from the atmospherically corrected images using Fmask algorithm by Zhu et al. (2015). Fmask uses an object-based cloud and cloud shadow matching algorithm to generate cloud, cloud shadow, and snow masks for each individual image. It relies on rules (thresholds) based on cloud physical properties to distinguish potential cloud pixels from clear sky pixels. On the other hand, near infrared and short-wave infrared are used to extract potential cloud shadows using flood-fill transformation. The potential clouds with their shadows are then matched based on similarity measurements (Zhu and Woodcock 2012). This study used Fmask 4.0 (developed using version 3.3 of Fmask (Zhu et al. 2015) and MFmask (Qiu et al. 2017)) with cloud probability threshold set to 10% and dilation of cloud and cloud shadow pixels set to 1 pixel. We arrived at these parameters after visually assessing the ability of different values to extract cloud and shadow.
Finally, a cloud- and shadow-free image was generated using the masked images. This was done by taking a mean aggregate of surface reflectance of each cloud- and shadow-free pixel in each corresponding band within the 10 multi-temporal images. Pixels that were masked as cloud or shadow in the entire multi-temporal set were retained as no data. In general, this approach produces a cloud- and shadow-free temporal mean composite image with no season effects and no or few missing data areas.
Supervised image classification
We integrated context to RF and SVM pixel-based machine learning classifiers for forest mapping using MRFs. The MRF model integrates contextual information into the pixel-based classifiers under a Bayesian framework. In principle, the objective of image classification is to predict the most probable labels \(\mathbf {y} = \{ y_1, y_2, \ldots , y_n \}\) for n pixels from training data of k classes given an image \(\mathbf {x} = \{x_1, x_2, \ldots , x_n \}\). The labels \(\mathbf {y}\) can be predicted within the Bayesian framework by determining Maximum A Posterior (MAP) estimate of the posterior as
where \(P(\mathbf {x}|\mathbf {y})\) is the likelihood and \(P(\mathbf {y})\) denotes the prior knowledge injected on labels \(\mathbf {y}\) in MRFs using spatial context. MRFs assumes that pixels/features are conditional independent given the labels in the likelihood function, i.e.,
The prior \(P(\mathbf {y})\) is modelled as a MRF over labels with positivity, Markovianity, and homogeneity (Tso and Mather 2009). With reference to the three properties, MRFs classification treats the prior model as a homogeneous and isotropic Potts model with only pairwise clique potentials, i.e.,
where \(i \text { and } j\) are adjacent sites and \(\beta \) is the spatial interaction parameter that controls smoothing of land-cover based on similarity of adjacent labels. Equation 2 enabled us to develop a framework that combines the discriminative power of RF and SVM with the contextual spatial modelling attribute of MRFs as motivated by Cao et al. (2018) who integrated MRFs and deep learning for hyperspectral image classification. The framework can be expressed as
where \(Z(\mathbf{x} )\) is a data normalizing constant known as the partition function.
The first term of Eq. 4 (initial class labels) is estimated using RF and SVM, respectively. This gives us a chance to compare the conventional maximum likelihood classification (MLC), RF, SVM, RF MRFs integration (RF–MRFs) and SVM MRFs integration (SVM–MRFs) for forest mapping.
RF–MRFs
We used RF (Breiman 2001) to estimate \(P(\mathbf {y}_i|\mathbf {x}_i)\) in Eq. 4 within the RF–MRFs framework. RF is an ensemble of several decision tree classifiers \(D_T\) where each tree is generated using a random vector sampled independently from training set. Each tree then casts a placement vote for the most popular class given an input vector x. For instance, if the number of votes cast for a given class label y by RF is \(V_y\), then our \(P(\mathbf {x}_i|\mathbf {y}_i)\) at pixel location i is:
where \(\mathbf {x}_i\) is a pixel-wise feature vector, i.e., the 7 bands of Landsat 8. We set \(D_T=500\) because over 200 trees RF stabilizes (Hastie et al. 2011) and node size as 1. Spatial context of neighboring pixels N was then modelled using the second term of Eq. 4 based on the class probabilities estimated from Eq. 5 using RF package (Liaw and Wiener 2002) in R software. The MAP estimate of the class labels \(\hat{y}\) was finally estimated iteratively using iterated conditional modes (ICM) (Besag 1986).
SVM–MRFs
In SVM–MRFs, SVM is used to estimate the first term of Eq. 4. SVM is a recently developed method of pattern recognition with supervised learning. It has gained popularity in image classification because of key attributes like excellent generalization capabilities and high empirical accuracy, robustness to the Hughes phenomenon, independence to statistical distribution models, and moderate computational complexity (Vapnik 2000; Bruzzone and Persello 2009). It classifies an image by distinguishing patterns using hyperplanes for which the separating margin is optimal. We adopt a nonlinear decision boundary using the Gaussian Radial Basis Function (RBF) kernel, which has two parameters, namely kernel parameter \(\sigma \) and penalty C (see Vapnik 2000 as details are beyond this scope). We set \(\sigma =10\) and \(C=20\) based on test performed over various parameter values and subsequently choosing a pair with low training error. The pixel-wise initial class probabilities (first term of Eq. 4) are estimated using a sigmoid function (Platt 1999) available in R’s kernlab package (Karatzoglou et al. 2004) which maps SVM outputs into probabilities.
Validation
Supervised image classification requires training and validation data to train and test the accuracy of algorithm, respectively. We used k-fold independent validation (where \(k=3\)) to train and assess the accuracy of the classification approaches used in this study and all reference data for mapping. The reference data were divided into threefolds using stratified random sampling tool by Buja and Menza (2013) with a minimum spatial threshold of 100 m between polygons of the same category. The spatial threshold ensures that samples of one category are spread out in different locations while stratified random sampling ensured representation of minority classes as advocated by Stehman (2009). We then randomly sampled equal number of pixels per class in each of the threefolds so as to maintain equal number of pixel counts in their confusion matrices. The folds were used iteratively to train and test each classification technique and their error matrices computed. Accuracy measures based on overall accuracy (OA), producer accuracy, user accuracy, and F1-score (Sokolova et al. 2006) we subsequently computed from the error matrices. Finally, we performed a test to determine if the error matrice from the best contextual framework was different from that of the other techniques using the significance test (Z) by Congalton and Green (2008).
Results and discussion
Our first task was to generate a cloud- and shadow-free composite image that can be used for forest and other land-cover mapping as per the IPCC definition. We generated a cloud- and shadow-free mean temporal composite image (Fig. 3) using bands 1–7 of Landsat 8 images acquired during the long-dry season. The temporal mean produced a visually appealing composite image compared to quantile. There was no difference between median composite and mean; however, the median composite took more time to generate hence the reason we adopted the mean. However, the mean temporal composite image still has some data gaps especially in Shimba hills forest as illustrated by black spots in Fig. 3.

Landsat 8 mean temporal composite image (RGB: 543) overlaid with ground reference data
An overview of performance of pixel and context-based land-cover classification using the mean temporal composite image in Fig. 3 is illustrated by box-plots in Fig. 4. Pixel-based techniques performed equally well in mapping different land-cover with MLC having the lowest OA. RF–MRFs framework has the highest average OA (94.02%) followed by RF (93.78%), SVM–MRFs (93.25%), SVM (92.75%), and MLC (87.73%) respectively. In both approaches, spatial context modelled by MRFs slightly improved accuracy of pixel-based machine learning approaches.

Box plots of overall accuracy for different approaches as computed during threefold independent validation
Producer and user accuracy of land-cover maps generated by algorithms used in this study is illustrated in Fig. 5. To begin with, Fig. 5a quantifies the probability that any pixel in a given land-cover category has been correctly classified via producer accuracy. In this case, MLC has the lowest correctly classified pixels in all land-cover classes except for open mangrove and open forest where it has the highest accuracy. RF has the highest accuracy in mapping moderate mangrove forest only. Context improved the producer accuracy of dense forest, cropland, and water in RF–MRFs method and dense mangrove, grassland, and otherland in SVM–MRFs framework. On other hand, Fig. 5b illustrates the probability that each mapped land-cover class represents that category on the ground using user accuracy. Basically, context improved the user accuracy of cropland, grassland, and open forest in SVM–MRFs technique and otherland in RF–MRFs. Dense Forest and water has the highest user accuracy in MLC technique. Dense mangrove and open mangrove has a high accuracy in RF. Lastly SVM has the highest accuracy in moderate forest.

Producer and user accuracy of land-cover classes in the study area computed during threefold independent validation
Generally, pixel-based and context methods performed differently in discriminating land-cover as depicted by combined measure of producer and user accuracy using F1-score in Fig. 6. Water had the most stable discrimination in all mapping approaches except for minor deviations in MLC, SVM and SVM–MRFs. This validation measure illustrates that addition of context increases detection accuracy of all land-cover categories except for mangrove forest (dense, moderate and open) where the accuracy reduces slightly. For instance, integration of context to RF and SVM decreased the accuracy of dense mangrove while the addition of context to SVM maintained the same accuracy. MLC has the lowest accuracy in mapping all types of land-cover classes. There is more accuracy fluctuation in mapping open forest and open mangrove as illustrated by the error bars.

A bar graph plot with standard deviation error bars computed from threefold independent-validation illustrating how each technique mapped different land-cover classes based on F1-score
An assessment of how each approach discriminated different land-cover depicted their strength. Figure 7 shows Sii island with dense mangrove forest surrounded by sandy beaches as seen from an aerial photo in Fig. 7a. SVM detected the mangrove forest and the beach (otherland). Addition of context via SVM–MRFs aided elimination of a few independent mislabelled pixels. In contrast, RF classification only detected mangrove forest and a completely dry beach on the western part of Sii island but missed other parts of the beach. However, under-classification of otherland as noted in Fig. 5b seems to have favored RF in other areas where SVM miss-classified part of a forest South of Shimba hills as otherland (Fig. 8d). Nonetheless, the under-classification of RF is quite evident even with addition of context as depicted by Fig. 11. Integration of spatial context using RF–MRFs framework did not aid recognition of missed areas. Lastly, MLC approach over-classified the beaches compared to other approaches (Fig. 7f) and still missed to detect the part of a beach in North Western tip of the island. In the rest of the paper, we will focus on evaluating results of RFs–MRFs and SVM–MRFs since these frameworks are intended as an improvement of the pixel-based machine learning approaches.

A dense mangrove island as mapped using different approaches. Here, the SVM–MRFs better capture the beaches and the mangrove region
We evaluated how conventional MLC and context-based techniques performed in mapping one of protected forest blocks in Shimba hills (Fig. 8). The forest is managed by the Kenya Forest Service for conservation and sustainability. It is also considered and conserved as a water tower by the Kenya water tower agency. Hence, the land-cover within the forest consist of dense and moderate forest, and grassland. The areas under grass are as result of controlled tree harvesting and subsequent replanting. Consequently, the areas that have been mapped by all the approaches as cropland are false negatives. Nonetheless, the Northern tip of the forest block consist of bare areas that are positively identified by SVM–MRFs though some parts are still miss-classified as cropland. Context-based approaches positively identified grassland areas in the forest while the MLC method miss-classified them as cropland. Spectral artifacts due to masking out of clouds that were dominant in parts of Shimba hills led to SVM–MRFs miss-recognizing a part of the forest as otherland.

An illustration of Shimba hills gazetted forest as mapped by MLC, SVM–MRFs and RF–MRFs (for legend see Fig. 7g)
Dense mangrove forest in Shimoni area was recognized by both pixel-based MLC and context coupled machine learning methods (Fig. 9). The machine learning approaches integrated with context have some false negative pixels (otherland) within dense mangrove area. However, the false negative pixels are actually dense mangrove forest as illustrated by the aerial photograph. Despite the use of context, the false negative independent pixels were not eliminated. MLC pixel-based approach also faced the same challenge. Otherland is captured well by SVM–MRFs in most areas with few cropland false negative pixels compared to the other two approaches. The remainder of the area consists of grass patches and open forest which is mapped well by SVM–MRFs compared to other techniques. There is little dense low lying trees to the North of the area as captured by SVM–MRFs but over-classified by MLC and RF–MRFs. Overall, SVM–MRFs has illustrated the capability to discriminate dense mangrove and open coastal forest in Shimoni area.

Mangrove and open forest in Shimoni area as shown by the aerial photograph and subsequent Landsat 8 classification outputs (legend in Fig. 7g)
The RF–MRFs framework captured cropland better compared to MLC and SVM–MRFs (Fig. 10). Basically, MLC and SVM–MRFs failed to discriminate plowed areas within the farms from otherland as illustrated by Fig. 10a hence the false negatives. All the techniques mapped some areas as grassland within cropland. However, evidence from the high resolution photograph indicates absence of grass. In consideration of grassland false negative pixels, RF–MRFs still mapped the farms well compared to the other techniques.

Illustration of how cropland was recognized by different methods
RF–MRFs and SVM–MRFs frameworks have retrospectively illustrated good discrimination of forest under persistent cloud cover with SVM–MRFs maintaining high accuracy in most of the classes. Figure 11 shows how each land-cover class in the study area was mapped. Generally, SVM–MRFs detected otherland better than RF–MRFs. For instance, the mean temporal composite image in Fig. 3 depicts that most parts North West of Shimba hills consist of grassland and otherland which are discriminated well by SVM–MRFs (Fig. 11b). However, the RF–MRFs approach under-classified otherland (Fig. 11a). In addition, this framework over-classifiers grassland in the areas to the South of shimba hills at the expense of open-forest. On the other hand, the SVM–MRFs maintains a balance of grassland, open forest and otherland present in that region. This is a well-known challenge in RF as it needs large enough training data with minimum spatial autocorrelation in order to capture well characteristics of each class (Millard and Richardson 2015). This explains why RF had low accuracy in representing other unpopular classes like open mangrove and open forest (Fig. 5a). Therefore, the SVM–MRFs is still a preferred framework because according to Z statistic test results its error matrix is significantly different compared to those of MLC and RF–MRFs by Z values of 16.39 and 2.65, respectively, at 95% (\(Z_{\alpha /2} =1.96\)) confidence level. Nonetheless, both RF–MRFs and SVM–MRFs framework meet the recommendation of Anderson et al. (1976); Thomlinson et al. (1999) for a minimum overall accuracy of 85% and a threshold of 75% accuracy per class as per Thomlinson et al. (1999). However, when working with limited ground reference data, the SVM–MRFs would suffice. Overall, context improved the mapping of dense forest, dense mangrove, grassland, and water.

Maps generated by RF–MRFs and SVM–MRFs framework illustrating terrestrial and mangrove forest among other land-cover
Conclusion
The aim of this study was to develop an approach that can discriminate mangrove forest from other land-cover in areas with persistent cloud cover in the Kenyan coast. We used a mean composite Landsat 8 image computed from multi-temporal cloud- and shadow-free images acquired within the long dry season to overcome cloud limitations. This was done through a pilot study conducted in Kwale; an area prone to cloud cover hence up-to-date land-cover information of the region lacks in annual greenhouse gas reporting. Moreover, the area has rich mangrove trees which are important carbon sequesters. None accounting of the mangrove forests in annual reports means that carbon sequestration could be under reported. Basically, maps produced by classifying the temporal composite image had higher accuracy even with pixel-based classifiers. This therefore means that the cloud extraction process could serve as an alternative to land-cover mapping in cloud persistent coastal strip. Our study also established that a probability threshold of 10% and pixel dilation of 1 was sufficient enough to detect clouds and shadows using Fmask. Furthermore, integration of spatial context into pixel-based classification further improved mapping accuracy. Spatial context has been advocated for classification as it minimizes the “salt and pepper” effect common in pixel-based classifications and is able to deal with image artifacts due to missing data. However, in homogenous areas like the dense forest in Shimba hills, its impact on mapping accuracy was negligible. In principle, MRFs is a probabilistic contextual classifier that is used for denoising or eliminating independent mislabelled pixels in a principled manner. In this way it performs well within class categories that are heterogeneous or have “salt and pepper” effect within dominant classes. In addition, Shimba hills is a protected forest which means there is minimal or no human interference to the forest ecosystem hence it remains dominantly uniform. Consequently, MRFs faced no challenge to land-cover categories in this region thus making minimal improvement in accuracy.
This study has demonstrated that mangrove and other coastal forest excluded from national reporting due to cloud cover can be mapped using Landsat data. This will go a long way in supporting estimation of land based emissions in Kenya which normally requires baseline land-cover map inventory. We have additionally illustrated that spatial context improves mangrove forest discrimination. In future, we hope to scale out the approach to persistent cloud cover regions nationally and integrate Sentinel 1 and 2 to fill remaining data gaps after F-Mask temporal composites are generated.
References
Anderson JR, Hardy EE, Roach JT, Witmer RE (1976) A land use and land cover classification system for use with remote sensor data. Development 2001(964):28
Baetens L, Desjardins C, Hagolle O (2019) Validation of Copernicus Sentinel-2 cloud masks obtained from MAJA, Sen2Cor, and FMask processors using reference cloud masks generated with a supervised active learning procedure. Remote Sens 11:433. https://doi.org/10.3390/rs11040433
Barbier EB, Koch EW, Silliman BR, Hacker SD, Wolanski E, Primavera J, Granek EF, Polasky S, Aswani S, Cramer LA, Stoms DM, Kennedy CJ, Bael D, Kappel CV, Perillo GME, Reed DJ (2008) Coastal ecosystem-based management with nonlinear ecological functions and values. Science 319(5861):321–323. https://doi.org/10.1126/science.1150349
Besag J (1986) On the statistical analysis of dirty pictures. J R Stat Soc Ser B (Methodol) 48(3):259–302. https://doi.org/10.2307/2345426
Breiman L (2001) Random forests. Mach Learn 45(1):5–32. https://doi.org/10.1023/A:1010933404324
Bruzzone L, Persello C (2009) A novel context-sensitive semisupervised SVM classifier robust to mislabeled training samples. IEEE Trans Geosci Remote Sens 47(7):2142–2154. https://doi.org/10.1109/TGRS.2008.2011983
Buja K, Menza C (2013) Sampling Design Tool for ArcGIS - Instruction Manual. In: NOAA, Silver Spring, MD
Bunting P, Rosenqvist A, Lucas RM, Rebelo L, Hilarides L, Thomas N, Hardy A, Itoh T, Shimada M, Finlayson CM (2018) The global mangrove watch—a new 2010 global baseline of mangrove extent. Remote Sens 10(10):1669. https://doi.org/10.3390/rs10101669
Candra DS, Phinn S, Scarth P (2017) Cloud and cloud shadow removal of Landsat 8 images using Multitemporal Cloud Removal method. In: 2017 6th international conference on agro-geoinformatics, pp 1–5. https://doi.org/10.1109/Agro-Geoinformatics.2017.8047007
Cao X, Zhou F, Xu L, Meng D, Xu Z, Paisley J (2018) Hyperspectral image classification with Markov random fields and a convolutional neural network. IEEE Trans Image Process 27(5):2354–2367. https://doi.org/10.1109/TIP.2018.2799324
Cao Y, Luo Y, Yang S (2011) Image denoising based on hierarchical Markov random field. Pattern Recognit Lett 32(2):368–374. https://doi.org/10.1016/j.patrec.2010.09.017
Chavez PS (1996) Image-based atmospheric corrections-revisited and improved. Photogramm Eng Remote Sens 62(9):1025–1035
Congalton RG, Green K (2008) Assessing the accuracy of remotely sensed data: principles and practices, 2nd edn. CRC Press, Cambridge
Donato DC, Kauffman JB, Murdiyarso D, Kurnianto S, Stidham M, Kanninen M (2011) Mangroves among the most carbon-rich forests in the tropics. Nat Geosci 4:293
DRSRS (2016) The land cover change mapping program—technical manual. In: Technical report. Directorate of Resource Surveys and Remote Sensing (DRSRS)
Eggleston S, Buendia L, Miwa K, Ngara T, Tanabe K (2006) 2006 IPCC guidelines for national greenhouse gas inventories. In: Technical report. Intergovernmental Panel on Climate Change (IPCC)
FAO (2007) The world’s mangrove forest 1980–2005: a thematic study prepared in the framework of the global forest resources assessment 2005. In: FAO forestry paper, pp 1–77
Foga S, Scaramuzza PL, Guo S, Zhu Z, Dilley RD, Beckmann T, Schmidt GL, Dwyer JL, Hughes MJ, Laue B (2017) Cloud detection algorithm comparison and validation for operational Landsat data products. Remote Sens Environ 194:379–390. https://doi.org/10.1016/j.rse.2017.03.026
Gang PO, Agatsiva JL (1992) The current status of mangroves along the Kenyan coast: a case study of Mida Creek mangroves based on remote sensing. Hydrobiologia 247(1):29–36
Geman S, Geman D (1984) Stochastic relaxation, gibbs distributions, and the bayesian restoration of images. IEEE Trans Pattern Anal Mach Intell PAMI 6(6):721–741. https://doi.org/10.1109/TPAMI.1984.4767596
Gómez-Chova L, Amorós-López J, Mateo-García G, Muñoz-Marí J, Camps-Valls G (2017) Cloud masking and removal in remote sensing image time series. J Appl Remote Sens 11(1):1–15. https://doi.org/10.1117/1.JRS.11.015005
Hagolle O, Huc M, Pascual DV, Dedieu G (2010) A multi-temporal method for cloud detection, applied to FORMOSAT-2, VEN\(\mu \)S, LANDSAT and SENTINEL-2 images. Remote Sens Environ 114(8):1747–1755. https://doi.org/10.1016/j.rse.2010.03.002
Hallahan N, Prepperneau C (2013) Cloud detection and removal techniques for Landsat 8 imagery. In: Technical report. Oregon State University
Hastie T, Tibshirani R, Friedman J (2011) The elements of statistical learning: data mining, inference, and prediction, 2nd edn. Springer. https://doi.org/10.1007/978-0-387-84858-7
Irish RR (2000) Landsat 7 automatic cloud cover assessment. In: Algorithms for multispectral, hyperspectral, and ultraspectral imagery VI. International Society for Optics and Photonics, vol 4049, pp 348–355
Irish RR, Barker JL, Goward SN, Arvidson T (2006) Characterization of the Landsat-7 ETM+ automated cloud-cover assessment (ACCA) algorithm. Photogramm Eng Remote Sens 72(10):1179–1188
Jeon B, Landgrebe DA (1992) Classification with spatio-temporal interpixel class dependency contexts. IEEE Trans Geosci Remote Sens 30(4):663–672. https://doi.org/10.1109/36.158859
Jin S, Homer C, Yang L, Xian G, Fry J, Danielson P, Townsend PA (2013) Automated cloud and shadow detection and filling using two-date Landsat imagery in the USA. Int J Remote Sens 34(5):1540–1560
Kairo JG, Kivyatu B, Koedam N (2002) Application of remote sensing and GIS in the management of mangrove forests within and adjacent to Kiunga Marine Protected Area, Lamu, Kenya. Environ Dev Sustain 4(2):153–166
Karatzoglou A, Smola A, Hornik K, Zeileis A (2004) kernlab-an S4 package for kernel methods in R. J Stat Softw 11(9):1–20. https://doi.org/10.18637/jss.v011.i09
Kasetkasem T, Arora MK, Varshney PK (2005) Super-resolution land cover mapping using a markov random field based approach. Remote Sens Environ 96(3):302–314. https://doi.org/10.1016/j.rse.2005.02.006
Kenduiywo BK, Tolpekin VA, Stein A (2014) Detection of built-up area in optical and synthetic aperture radar images using conditional random fields. J Appl Remote Sens 8(1):83618–83672. https://doi.org/10.1117/1.JRS.8.083672
Kirui KB, Kairo JG, Bosire J, Viergever KM, Rudra S, Huxham M, Briers RA (2013) Mapping of mangrove forest land cover change along the Kenya coastline using Landsat imagery. Ocean Coast Manag 83:19–24. https://doi.org/10.1016/J.OCECOAMAN.2011.12.004
Lafferty JD, McCallum A, Pereira F (2001) Conditional random fields: probabilistic models for segmenting and labeling sequence data. In: Proceedings of the eighteenth international conference on machine learning, Morgan Kaufmann, San Francisco, CA, USA, pp 282–289
Li X, Du Y, Ling F (2014) Super-resolution mapping of forests with bitemporal different spatial resolution images based on the spatial-temporal Markov random field. IEEE J Sel Top Appl Earth Observ Remote Sens 7(1):29–39
Liaw A, Wiener M (2002) Classification and Regression by randomForest. R News 2(3):18–22
Liu D, Kelly M, Gong P (2006) A spatial-temporal approach to monitoring forest disease spread using multi-temporal high spatial resolution imagery. Remote Sens Environ 101(2):167–180. https://doi.org/10.1016/j.rse.2005.12.012
Liu D, Song K, Townshend JRG, Gong P (2008) Using local transition probability models in Markov random fields for forest change detection. Remote Sens Environ 112(5):2222–2231. https://doi.org/10.1016/j.rse.2007.10.002
Lonjou V, Desjardins C, Hagolle O, Petrucci B, Tremas T, Dejus M, Makarau A, Auer S (2016) MACCS-ATCOR joint algorithm (MAJA). In: SPIE 10001, remote sensing of clouds and the atmosphere XXI, Edinburgh, United Kingdom, vol 10001. https://doi.org/10.1117/12.2240935
Loveland TR, Dwyer JL (2012) Landsat: building a strong future. Remote Sens Environ 122:22–29. https://doi.org/10.1016/j.rse.2011.09.022
Mateo-García G, Gómez-Chova L, Amorós-López J, Muñoz-Marí J, Camps-Valls G (2018) Multitemporal cloud masking in the Google earth engine. Remote Sens 10(7):1079. https://doi.org/10.3390/rs10071079
Melgani F, Serpico S (2003) A Markov random field approach to spatio-temporal contextual image classification. IEEE Trans Geosci Remote Sens 41(11):2478–2487. https://doi.org/10.1109/TGRS.2003.817269
Millard K, Richardson M (2015) On the importance of training data sample selection in random forest image classification: a case study in peatland ecosystem mapping. Remote Sens 7(7):8489–8515
Moser G, Serpico SB (2011) Multitemporal region-based classification of high-resolution images by Markov random fields and multiscale segmentation. In: IEEE international geoscience and remote sensing symposium, Vancouver, BC, Canada, pp 102–105. https://doi.org/10.1109/IGARSS.2011.6048908
Neukermans G, Dahdouh-Guebasand F, Kairo JG, Koedam N (2008) Mangrove species and stand mapping in Gazi Bay (Kenya) using Quickbird satellite imagery. J Spatial Sci 53(1):75–86. https://doi.org/10.1080/14498596.2008.9635137
Platt JC (1999) Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. In: Advances in large margin classifiers. MIT Press, pp 61–74
Qiu S, He B, Zhu Z, Liao Z, Quan X (2017) Improving Fmask cloud and cloud shadow detection in mountainous area for Landsats 4–8 images. Remote Sens Environ 199:107–119. https://doi.org/10.1016/J.RSE.2017.07.002
Richter R, Louis J, Müller-Wilm U (2012) Sentinel-2 MSI—Level 2A products algorithm theoretical basis document. In: Technical reports, vol 49. European Space Agency, Paris
Sanpayao M, Kasetkasem T, Isshiki, Rakwatin P, Chanwimaluang T (2017) A super-resolution land cover mapping based on a random forest and Markov random field model. In: 14th international conference on ECTI-CON, pp 553–556. https://doi.org/10.1109/ECTICon.2017.8096297
Schroeder TA, Cohen WB, Song C, Canty MJ, Yang Z (2006) Radiometric correction of multi-temporal Landsat data for characterization of early successional forest patterns in western Oregon. Remote Sens Environ 103(1):16–26. https://doi.org/10.1016/j.rse.2006.03.008
SLEEK (2019) System for land-based emissions estimation in Kenya. http://www.sleek.environment.go.ke/. Accessed 1 April 2019
Sokolova M, Japkowicz N, Szpakowicz S (2006) Beyond accuracy, F-score and ROC: a family of discriminant measures for performance evaluation. In: Sattar A, Kang BH (eds) AI 2006: Advances in artificial intelligence, Lecture notes in computer science, vol 4304. Springer, Berlin, pp 1015–1021
Solberg AHS (1999) Contextual data fusion applied to forest map revision. IEEE Trans Geosci Remote Sens 37(3):1234–1243
Solberg AHS, Taxt T, Jain AK (1996) A Markov random field model for classification of multisource satellite imagery. IEEE Trans Geosci Remote Sens 34(1):100–113. https://doi.org/10.1109/36.481897
Stehman SV (2009) Sampling designs for accuracy assessment of land cover. Int J Remote Sens 30(20):5243–5272. https://doi.org/10.1080/01431160903131000
Thomlinson JR, Bolstad PV, Cohen WB (1999) Coordinating methodologies for scaling landcover classifications from site-specific to global: steps toward validating global map products. Remote Sens Environ 70(1):16–28
Tiwari LK, Sinha SK, Saran S, Tolpekin VA, Raju PLN (2016) Markov random field-based method for super-resolution mapping of forest encroachment from remotely sensed ASTER image. Geocarto Int 31(4):428–445. https://doi.org/10.1080/10106049.2015.1054441
Tso B, Mather PM (2009) Classification methods for remotely sensed data, 2nd edn. CRC Press, Boca Raton
Vapnik VN (2000) The nature of statistical learning theory. Springer, New York. https://doi.org/10.1007/978-1-4757-3264-1
Young NE, Anderson RS, Chignell SM, Vorster AG, Lawrence R, Evangelista PH (2017) A survival guide to landsat preprocessing. Ecology 98(4):920–932. https://doi.org/10.1002/ecy.1730
Zhu Z, Woodcock CE (2012) Object-based cloud and cloud shadow detection in Landsat imagery. Remote Sens Environ 118:83–94. https://doi.org/10.1016/J.RSE.2011.10.028
Zhu Z, Woodcock CE (2014) Automated cloud, cloud shadow, and snow detection in multitemporal Landsat data: an algorithm designed specifically for monitoring land cover change. Remote Sens Environ 152:217–234. https://doi.org/10.1016/j.rse.2014.06.012
Zhu Z, Wang S, Woodcock CE (2015) Improvement and expansion of the Fmask algorithm: cloud, cloud shadow, and snow detection for Landsats 4–7, 8 and Sentinel 2 images. Remote Sens Environ 159:269–277. https://doi.org/10.1016/j.rse.2014.12.014
Acknowledgements
We wish to thank SLEEK under the Department of Resource Surveys and Remote Sensing (DRSRS) for aerial imagery and Forest2020 under Kenya Forest Service (KFS) for ground reference data. This research was funded by the Australian government through the SLEEK programme facilitated by the Clinton Change Initiative(CCI).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Kenduiywo, B.K., Mutua, F.N., Ngigi, T.G. et al. Mapping mangrove forest using Landsat 8 to support estimation of land-based emissions in Kenya. Model. Earth Syst. Environ. 6, 1619–1632 (2020). https://doi.org/10.1007/s40808-020-00778-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40808-020-00778-x