
Abstract
The T-NH{Y} family is developed and study in this paper. Various statistical properties such as the mode, quantile, moments and Shannon entropy were derived. Two special distributions namely, exponential-NH{log-logistic}and Gumbel-NH{logistic} were developed. Plots of the failure rate functions for these distributions for some given parameter values indicated that the hazard rate functions can exhibit different types of non-monotonic failure rates. Two applications using real datasets on failure times revealed that the exponential-NH{log-logistic} distribution provides better fits to the datasets than the other fitted models.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Arriving at a sound statistical inference for any given dataset heavily depends on the use of appropriate statistical model. Thus, selecting an appropriate model for analyzing this barrage of datasets generated from different fields of study often pose a challenge to researchers. This is because when an inadequate model is selected for a particular dataset, it will reduce the power and efficiency of the statistical test associated with that dataset. To improve the precision when fitting the data, statistical data analysts are therefore interested in using a model that leads to no or less loss of information. Among these models often used, probability distributions play an integral role. However, identifying an appropriate distribution that best describes the traits of a given dataset is often a challenge despite the existence of several probability distributions. This can be ascribed to the fact that no single distribution can be identified as best for all kinds of datasets.
To fill this lacuna, researchers are proposing techniques for generalizing existing distributions. These techniques seek to improve the performance of the distributions or make them more flexible in modeling datasets with traits such as skewness, kurtosis, monotonic and non-monotonic (bathtub, modified bathtub, upside-down bathtub and modified upside-down bathtub) failure rates. One of the techniques used in literature in recent time by researchers is the quantile based approach of Aljarrah et al. [3] which is often referred to as the \( T - R\{ Y\} \) family. This method is an extension of Alzaatreh et al. [7] transformed-transformer (T-X) family of distributions.
Suppose \( F_{T} (x) = P(T \le x),F_{R} (x) = P(R \le x) \) and \( F_{Y} (x) = P(Y \le x) \) are the cumulative distribution functions of the random variables \( T,R \) and \( Y \) respectively. Let the inverse distributions (quantile functions) of the random variables be given by \( Q_{T} (u),Q_{R} (u) \) and \( Q_{Y} (u) \), where \( Q_{z} (u) = Inf\{ z:F_{Z} (z) \ge u\} \), \( 0 \le u \le 1 \). Also, if the density functions of \( T,R \) and \( Y \) exists, and are represented by \( f_{T} (x),f_{R} (x) \) and \( f_{Y} (x) \) respectively. If we assume that \( T,Y \in (\varphi_{1} ,\varphi_{2} ) \) for \( - \infty \le \varphi_{1} < \varphi_{2} \le \infty \), then the cumulative distribution function (CDF) of the random variable \( X \) in the \( T - R\{ Y\} \) family of Aljarrah et al. [3] is given by:
The corresponding probability density function (PDF) and hazard rate function are
and
respectively. \( \tau ( \cdot ) \) denotes the hazard rate function of the random variables.The \( T - R\{ Y\} \) method have been adopted by number of researchers to develop new families of distributions and these include: extended generalized Burr III family [11]; T-exponential{Y} class [22]; generalized Burr family [16]; T-normal family [6]; T-Pareto family [10]; T-gamma{Y} family [5]; Lomax-R {Y} family [14]; Weibull-R{Y} family [9] and T-Weibull family [4].
In this study, we assume that the random variable \( R \) follows that Nadarajah-Haghighi (NH) distribution [15] and proposed the T-NH{Y} family of distributions.
Our motivation for developing this family of distributions are: to produce distributions capable of modeling data sets that exhibit monotonic and non-monotonic failure rates; to produce heavy-tailed distributions; to make kurtosis more flexible as compared to the baseline distribution; to generate distributions with left-skewed, right-skewed, symmetric and reversed-J shapes; and to provide better parametric fit to given data sets than other existing distributions. The remaining parts of the article are presented as follow: the T-NH{Y} family is presented in Sect. 2, the statistical properties of the proposed family are given in Sect. 3, the special distributions are proposed in Sect. 4, the estimation of the parameters are presented in Sect. 5, Sect. 6 presents the Monte Carlo simulations, the empirical applications are given in Sect. 7 and the conclusions of the study are given in Sect. 8.
2 T-NH {Y} Family of Distributions
Given that the underlying distribution of the random variable \( R \) is NH with CDF and PDF given by; \( F_{R} (x) = 1 - \exp (1 - (1 + \gamma x)^{\alpha } ),x > 0,\gamma > 0,\alpha > 0 \) and \( f_{R} (x) = \alpha \gamma (1 + \gamma x)^{\alpha - 1} \exp (1 - (1 + \gamma x)^{\alpha } ) \) respectively. Then, the CDF of the T-NH{Y} family is:
The PDF and hazard function of the family are respectively given by:
and
Remark 1
If \( X \) follows the T-NH{Y} family of distributions, then the following holds:
-
(i)
If \( \alpha = 1 \), then the T-NH{Y} family becomes the T-exponential{Y} family.
-
(ii)
\( X{ = }\frac{1}{\gamma }\left\{ {\left[ {1 - \log (1 - F_{Y} (T))} \right]^{{\tfrac{1}{\alpha }}} - 1} \right\} \).
-
(iii)
\(Q_{X} (u) = \frac{1}{\gamma }\left\{ {\left[ {1 - \log (1 - F_{Y} (Q_{T} (u)))} \right]^{{\tfrac{1}{\alpha }}} - 1} \right\},u \in [0,1] \)
-
(iv)
If \( Y = {\text{ NH}}(\alpha ,\gamma ) \), then \( X = \, T \).
-
(v)
If \( T = \, Y \), then \( X = \, NH(\alpha ,\gamma ) \).
2.1 Some Sub-families of T-NH{Y}
In this sub-section, two sub-families of the T-NH{Y} family are discussed. These are: the T-NH{log-logistic} and T-NH{logistic} families.
2.1.1 T-NH{log-logistic} Family
If the random variable \( T \) is defined on the support \( (0,\infty ) \) and \( Y \) follows the log-logistic (LL) distribution with quantile function \( Q_{Y} (u) = \lambda [(1 - u)^{ - 1} - 1]^{{\tfrac{1}{\beta }}} \). The CDF and PDF of the T-NH{LL} family are respectively given by:
and
The T-NH{LL} family reduces to the T-exponential{LL} family when the parameter \( \alpha = 1 \).
2.1.2 T-NH{logistic} Family
If the support of the random variable \( T \) is defined on the interval \( ( - \infty ,\infty ) \) and the distribution of the random variable \( Y \) is logistic (L) with quantile function \( Q_{Y} (u) = - \frac{1}{\lambda }\log (u^{ - 1} - 1) \). Then, the CDF and PDF of the T-NH{L} family are respectively given by;
and
When \( \alpha = 1 \), the T-NH{L} family becomes the T-exponential{L} family.
3 Statistical Properties of T-NH{Y} Family
This section presents some statistical properties of the T-NH{Y} family of distributions.
3.1 Mode
The mode of the T-NH{Y} family is presented in this sub-section.
Proposition 1
The mode of the T-NH{Y} family of distributions can be obtained from the solution of the equation:
where \( {\Psi (f)} = {{f^{\prime}}/f} \).
Proof
Finding the first derivative of the logarithm of Eq. (5) with respect \( x \) and equating it to zero completes the proof.□
3.2 Transformation
Lemma 1
Given that the random variable \( T \) has CDF \( F_{T} (x) \), then the random variable:
-
(i)
\( X = \frac{1}{\gamma }\left\{ {\left[ {1 + \log \left( {1 + (T/\lambda )^{\beta } } \right)} \right]^{{\tfrac{1}{\alpha }}} - 1} \right\} \) has the T-NH{LL} distribution.
-
(ii)
\( X = \frac{1}{\gamma }\left\{ {\left[ {1 + \left( {\lambda T + \log (1 + \exp ( - \lambda T))} \right)} \right]^{{\tfrac{1}{\alpha }}} - 1} \right\} \) has the T-NH{L} distribution.
Proof
The proof easily follows from Remark 1 (ii).□
3.3 Quantile Function
Quantile functions are useful in statistical analysis. For instance, they can be used to compute measures of shapes of a distribution and generate random observations during simulation experiments.
Lemma 2
The quantile functions of the T-NH{LL} and T-NH{L} are respectively given by:
-
(i)
\( Q_{X} (u) = \frac{1}{\gamma }\left\{ {\left[ {1 + \log \left( {1 + (Q_{T} (u)/\lambda )^{\beta } } \right)} \right]^{{\tfrac{1}{\alpha }}} - 1} \right\},u \in [0,1] \).
-
(ii)
\( Q_{X} (u) = \frac{1}{\gamma }\left\{ {\left[ {1 + \left( {\lambda Q_{T} (u) + \log (1 + \exp ( - \lambda Q_{T} (u)))} \right)} \right]^{{\tfrac{1}{\alpha }}} - 1} \right\},u \in [0,1] \).
Proof
The proof of this Lemma can easily be derived from Remark 1 (iii).□
3.4 Moments
Moments are used to estimate measures of central tendencies, shapes and dispersions. This subsection presents the moments of the T-NH{Y} family and its sub-families.
Proposition 2
The kth non-central moment of the T-NH{Y} family is given by:
Proof
The proof follows from Remark 1 (ii).□
Corollary 1
The kth non-central moments of T-NH{LL} and T-NH{L} are respectively given by:
-
(i)
\( E(X^{k} ) = E\left[ {\frac{1}{{\gamma^{k} }}\left\{ {\left[ {1 + \log (1 + (T/\lambda )^{\beta } )} \right]^{{\tfrac{1}{\alpha }}} - 1} \right\}^{k} } \right],\quad k = 1,2, \ldots \).
-
(ii)
\( E(X^{k} ) = E\left[ {\frac{1}{{\gamma^{k} }}\left\{ {\left[ {1 + \left( {\lambda T + \log (1 + \exp ( - \lambda T))} \right)} \right]^{{\tfrac{1}{\alpha }}} - 1} \right\}^{k} } \right],\quad k = 1,2, \ldots \).
Proof
The proof of Corollary 1 follows from Lemma 1.□
Proposition 3
The upper bound for the moment of the T-NH{Y} family is given by:
where
Proof
From Theorem 1 of Aljarrah et al. [3], if \( R \) is a non-negative random variable and \( E[(1 - F_{Y} (T))^{ - 1} ] < \infty \), then \( E(X^{k} ) \le E(R^{k} )E[(1 - F_{Y} (T))^{ - 1} ] \). From Nadarajah and Haghighi [15], the \( k{\text{th}} \) non-central moment of the NH distribution is \( \alpha \gamma \exp (1){\text{I}}(k,0,1) \). Substituting and simplifying yields the proof of Proposition 3.□
Corollary 2
The upper bound for the moments of T-NH{LL} and T-NH{L} are respectively given by:
-
(i)
\( E(X^{k} ) \le \alpha \gamma \exp (1){\text{I}}(k,0,1)[1 + E((T/\lambda )^{\beta } )] \).
-
(ii)
\( E(X^{k} ) \le \alpha \gamma \exp (1){\text{I}}(k,0,1)E[(1 - (1 + \exp ( - \lambda T))^{ - 1} )^{ - 1} ] \).
Proof
Substituting the CDFs of the LL and L distributions into Proposition 3 and simplifying gives the results obtained in Corollary 2.□
3.5 Entropy
Entropies are useful measures of uncertainty. Although different types of entropies exist in literature, in this sub-section, we derived the Shannon entropy of the T-NH{Y} family and its sub-families. The Shannon entropy of a random variable \( X \) with PDF \( f_{X} (x) \) is defined as \( \eta_{X} = - E[\log (f_{X} (X))] \) [19].
Proposition 4
The Shannon entropy of the T-NH{Y} family is given by:
where \( \eta_{T} \) is the Shannon entropy of the random variable \( T \).
Proof
Since \( X = Q_{R} (F_{Y} (T)) \), it implies that \( T = Q_{Y} (F_{R} (X)) \). Thus,
This implies that
Substituting the PDF of the random variable \( R \) and simplifying completes the proof.□
Corollary 3
The Shannon entropies of the T-NH{LL} and T-NH{L} are respectively given by:
-
(i)
\( \begin{aligned} \eta_{X} & = \eta_{T} - \log (\alpha \gamma ) - 1 + \log (\beta \lambda^{ - \beta } ) + (\beta - 1)E(T) - 2E[\log (1 + (T/\lambda )^{\beta } )] \\ & \quad + (1 - \alpha )E[\log (1 + \gamma X)] + E[(1 + \gamma X)^{\alpha } ] \\ \end{aligned} \).
-
(ii)
\( \begin{aligned} \eta_{X} & = \eta_{T} - \log (\alpha \gamma ) - 1 + \log (\lambda ) - \lambda E(T) - 2E[\log (1 + \exp ( - \lambda T))] \\ & \quad + (1 - \alpha )E[\log (1 + \gamma X)] + E[(1 + \gamma X)^{\alpha } ] \\ \end{aligned} \).
Proof
The Proof of Corollary 3 follows by substituting the PDFs of LL and L distributions in Proposition 4.□
4 Special Distributions
This section presents some new probability distributions arising from the T-NH{LL} and T-NH{L} families using different distributions of the random variable \( T \).
4.1 Exponential-NH{LL} Distribution
Suppose the random variable \( T \) follows the standard exponential distribution, that is \( T - {\text{exponential}}(1) \). The CDF and PDF of the Exponential-NH{LL} (ENHLL) distribution are respectively given by:
and
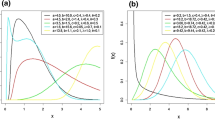
Figure 1 shows the plot of the density function of the ENHLL distribution for some given parameter values. The density function exhibits right skewed, decreasing and approximately symmetric shapes for the chosen parameter values.

Plots of the density function of the ENHLL distribution
The hazard rate function of the ENHLL distribution is given by:
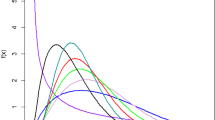
The hazard rate function plot for some selected parameter values are presented in Fig. 2. The hazard rate function exhibit different kinds of shapes such as decreasing, bathtub and upside-down bathtub.

Hazard rate function plot of the ENHLL distribution
To generate random observations from the ENHLL distribution, the quantile function is need. Hence, the quantile function of the ENHLL distribution is given by:
Substituting \( u = 0.25,0.5 \) and 0.75 yields the first quartile, median and third quartile of the ENHLL distribution respectively.
4.2 Gumbel-NH{L} Distribution
This section presents the Gumbel-NH{L} (GNHL) distribution. Given that \( T \sim {\text{Gumbel}}(0,1) \) with CDF \( F_{T} (x) = \exp ( - \exp ( - x)) \) and PDF\( f_{T} (x) = \exp ( - x - \exp ( - x)) \). The CDF and PDF of the GNHL distribution are respectively given by:
and
The plot of the density function of the GNHL distribution for some selected parameter values is shown in Fig. 3. The density function exhibit reversed-J and right skewed shapes for the chosen parameter values.

Density function plot of the GNHL distribution
The hazard rate function of the GNHL distribution is given by:
The hazard rate function plot of the GNHL distribution for some chosen parameter values is presented in Fig. 4. The hazard rate function of the GNHL distribution exhibit decreasing, bathtub and upside-down bathtub shapes for the given parameter values.

Hazard rate function plot for the GNHL distribution
The quantile function of the GNHL distribution is given by:
Putting \( u = 0.25,0.5 \) and 0.75 gives the first quartile, median and upper quartile of the GNHL distribution respectively.
5 Parameter Estimation
The section presents three procedures for estimating the parameters of the ENHLL distribution.
5.1 Maximum Likelihood Method
The maximum likelihood method is the most common parameter estimation technique used in literature. Given that \( X \sim {\text{ENHLL}}(\alpha ,\beta ,\gamma ,\lambda ) \), \( \varvec{\vartheta}= (\alpha ,\beta ,\gamma ,\lambda )^{T} \), \( z = \exp ((1 + \gamma x)^{\alpha } - 1) - 1 \) and \( \overline{z} = \exp ((1 + \gamma x)^{\alpha } - 1) \). For a single observation \( x \) of \( X \) from the ENHLL distribution, the log-likelihood function \( \ell = \ell (\varvec{\vartheta}) \) is given by:
The first partial derivatives of the log-likelihood function with respect to \( \varvec{\vartheta}= (\alpha ,\beta ,\gamma ,\lambda )^{T} \) are:
and
For a random sample of \( m \) observations \( x_{1} ,x_{2} , \ldots ,x_{m} \) from the ENHLL distribution, the total log-likelihood function is given by \( \ell_{m}^{*} = \sum\nolimits_{j = 1}^{m} {\ell_{j} (\varvec{\vartheta})} \), where \( \ell_{j} (\varvec{\vartheta}),j = 1,2, \ldots ,m \) is defined in Eq. (23). To obtain the estimates of the parameters, the first partial derivatives with respect to the parameters are equated to zero and the resulting system of equations solved simultaneously. However, apart from the equation for the parameter \( \lambda \), the rest of the resulting system of equations are not tractable and have to be solved numerically to obtain the estimates of the parameters. Thus, the estimates are obtained by solving the nonlinear system of equation \( ({{\partial \ell_{m}^{*} } \mathord{\left/ {\vphantom {{\partial \ell_{m}^{*} } {\partial \alpha }}} \right. \kern-0pt} {\partial \alpha }},{{\partial \ell_{m}^{*} } \mathord{\left/ {\vphantom {{\partial \ell_{m}^{*} } {\partial \beta }}} \right. \kern-0pt} {\partial \beta }},{{\partial \ell_{m}^{*} } \mathord{\left/ {\vphantom {{\partial \ell_{m}^{*} } {\partial \gamma }}} \right. \kern-0pt} {\partial \gamma }},{{\partial \ell_{m}^{*} } \mathord{\left/ {\vphantom {{\partial \ell_{m}^{*} } {\partial \lambda }}} \right. \kern-0pt} {\partial \lambda }})^{T} = 0 \). Solving the system of equation using numerical methods can sometimes be time consuming. Hence, we can efficiently find the maximum likelihood estimates of the parameters by maximizing the total likelihood equation directly using MATLAB, MATHEMATICA and R software. In this study, the mle2 function in the bbmle package of the R software is used [8].
To find confidence interval for the parameters of the ENHLL distribution, a \( 4 \times 4 \) observed information matrix \( I(\varvec{\vartheta}) = \{ I_{pq} \} \) for \( p,q = \alpha ,\beta ,\gamma ,\lambda \) is needed. The multivariate normal \( N_{4} ({\mathbf{0}},I(\widehat{\varvec{\vartheta}})) \) distribution can be employed to construct approximate confidence interval for the parameters under the usual regularity conditions. \( I(\widehat{\varvec{\vartheta}}) \) is the total observed information matrix evaluated at \( \widehat{\varvec{\vartheta}} \). A \( 100(1 - \rho )\% \) asymptotic confidence interval (ACI) for each parameter \( \vartheta_{p} \) is given by:
where \( se(\widehat{\vartheta }_{p} ) \) is the standard error of the estimated parameter and is obtained as \( se(\widehat{\vartheta }_{p} ) = \sqrt {I_{pp} (\widehat{\vartheta })} ,p = \alpha ,\beta ,\gamma ,\lambda \), and \( z_{{{\raise0.5ex\hbox{$\scriptstyle \rho $} \kern-0.1em/\kern-0.15em \lower0.25ex\hbox{$\scriptstyle 2$}}}} \) is the upper \( ({\rho \mathord{\left/ {\vphantom {\rho 2}} \right. \kern-0pt} 2}) \)th quantile of the standard normal distribution.
5.2 Ordinary and Weighted Least Squares
The methods of ordinary least squares (OLS) and weighted least squares (WLS) were proposed by Swain et al. [20]. Given that \( x_{(1)} ,x_{(2)} , \ldots ,x_{(m)} \) are order statistics of a random sample of size \( m \) from the ENHLL distribution. The OLS estimates \( \widehat{\alpha }_{LSE} ,\widehat{\beta }_{LSE} ,\widehat{\gamma }_{LSE} ,\widehat{\lambda }_{LSE} \) for the parameters of the ENHLL distribution can be obtained by minimizing function:
with respect to \( \alpha ,\beta ,\gamma \) and \( \lambda \). Alternatively, the following nonlinear equations can be solved numerically to obtain the OLS estimates. That is
where\( \varOmega_{1} (x_{(j)} |\alpha ,\beta ,\gamma ,\lambda ) = \frac{\partial }{\partial \alpha }F_{X} (x_{(j)} |\alpha ,\beta ,\gamma ,\lambda ), \, \varOmega_{2} (x_{(j)} |\alpha ,\beta ,\gamma ,\lambda ) = \frac{\partial }{\partial \beta }F_{X} (x_{(j)} |\alpha ,\beta ,\gamma ,\lambda ), \) \( \varOmega_{3} (x_{(j)} |\alpha ,\beta ,\lambda ,\gamma ) = \frac{\partial }{\partial \gamma }F_{X} (x_{(j)} |\alpha ,\beta ,\lambda ,\gamma ) \) and \( \varOmega_{4} (x_{(j)} |\alpha ,\beta ,\gamma ,\lambda ) = \frac{\partial }{\partial \lambda }F_{X} (x_{(j)} |\alpha ,\beta ,\gamma ,\lambda ) \).The WLS estimates \( \widehat{\alpha }_{WLS} ,\widehat{\beta }_{WLS} ,\widehat{\gamma }_{WLS} ,\widehat{\lambda }_{WLS} \) of the ENHLL distribution parameters are obtained by minimizing the function:
with respect to the parameters. Also, the WLS estimates of the parameters can be obtained by solving the following nonlinear equation numerically. That is
where \( \varOmega_{1} ( \cdot |\alpha ,\beta ,\gamma ,\lambda ), \, \varOmega_{2} ( \cdot |\alpha ,\beta ,\gamma ,\lambda ), \, \varOmega_{3} ( \cdot |\alpha ,\beta ,\gamma ,\lambda ) \) and \( \varOmega_{4} ( \cdot |\alpha ,\beta ,\gamma ,\lambda ) \) are the same as defined above.
6 Monte Carlo Simulation
This section presents Monte Carlo simulation results for the estimators of the parameters of the ENHLL distribution. The average absolute bias (AB) and mean square error (MSE) of the maximum likelihood estimator (MLE), OLS and WLS estimators for the parameters are presented in Tables 1 and 2 for some parameters values. The simulations results revealed that the ABs and MSEs of the estimators’ decreases as the sample size increases. This means that the MLE, OLS and WLS estimators are consistent. However, it was also evident that in most cases the MLE had the least values of the AB and MSE for the different parameter values employed for the simulation exercise.
7 Empirical Applications
The section presents empirical applications of the ENHLL distribution using two real datasets. The first dataset comprises the failure time of 36 appliances subjected to automatic life test. The data can be found in Lawless [12] and are given by: 11, 35, 49, 170, 329, 381, 708, 958, 1062, 1167, 1594, 1925, 400, 2451, 2471, 2551, 2565, 2568, 2694, 2702, 2761, 2831, 3034, 3059, 3112, 3214, 3478, 3504, 4329, 6367, 6976, 7846, 13,403. The second dataset which comprises the failure times of 100 cm polyster/viscose yarn subjected to 2.3% strain level in textile experiment in order to examine the tensile fatigue characteristics of the yarn. The dataset can be found in Quesenberry and Kent [18] and are: 86, 146, 251, 653, 98, 249, 400, 292, 131, 169, 175, 176, 76, 264, 15, 364, 195, 262, 88, 264, 157, 220, 42, 321, 180, 198, 38, 20, 61, 121, 282, 224, 149, 180, 325, 250, 196, 90, 229, 166, 38, 337, 65, 151, 341, 40, 40, 135, 597, 246, 211, 180, 93, 315, 353, 571, 124, 279, 81, 186, 497, 182, 423, 185, 229, 400, 338, 290, 398, 71, 246, 185, 188, 568, 55, 55, 61, 244, 20, 284, 393, 396, 203, 829, 239, 236, 286, 194, 277, 143, 198, 264, 105, 203, 124, 137, 135, 350, 193, 188. The performance of the ENHLL distribution is compared with the Weibull NH (NH) [17], Topp-Leone NH (TLNH) [21], Kumaraswamy NH (KNH) [13] and Exponentiated NH (ENH) [2] using the Akaike information criterion (AIC), consistent Akaike information criterion (CAIC), Bayesian information criterion (BIC), \( - 2\ell \), Cramér-von Mises (W*) and Anderson–Darling (AD) test statistics. The smaller the values of the model selection criteria and the goodness-of-fit statistics, the better the model. The PDFs of the WNH, TLNH, KNH and ENH distributions are respectively given by:
and
Often the choice of statistical distributions for modeling a given dataset can easily be made if the nature of the failure rate of the dataset is known. To establish the nature of the failure rate of a given dataset, the total time on test (TTT) plot developed by Aarset [1] can be used. Plotting
where \( i = 1, \ldots ,n \) and \( x_{(j)} (j = 1, \ldots ,m) \) are the order statistics obtained from the sample of size \( n \), against \( i/n \) gives the TTT plot. Figure 5 shows the TTT plots for the datasets. From the TTT plots, the appliances dataset exhibit modified bathtub failure rate since the curve first display convex shape, followed by concave shape and then convex shape again. The yarn data has increasing failure rate since the curve exhibit concave shape.

TTT plots for a appliances and b yarn datasets
Tables 3 and 4 shows the maximum likelihood estimates for the parameters, their corresponding standard errors and confidence intervals (CI) for the appliances and yarn datasets respectively.
Tables 5 and 6 shows the model selection criteria and goodness-of-fit statistics for the appliances and yarn datasets. The results revealed that the ENHLL distribution provides better fit to the datasets compared to the other fitted distributions since for all the model selection criteria and goodness-of-fit statistics it has the least values.
Figures 6 and 7 displays the histograms, fitted densities, empirical CDFs and fitted CDFs of the distributions for the appliances and yarn datasets respectively. From both plots, the ENHLL distribution mimics the shapes of the datasets well than the other fitted distributions.

Fitted densities and CDFs for the appliances dataset

Fitted densities and CDFs for the yarn dataset
8 Conclusion
This study presents a new class of distributions called the T-NH{Y} family using the T-R{Y} framework. Statistical properties such as mode, quantile function, moments and Shannon entropy of the family are derived. Two special distributions, that is the ENHLL and GNHL distributions are proposed and the shapes of their densities and hazard rate functions for some given parameter values studies. The plots of the hazard rate functions revealed that the ENHLL and GNHL can exhibit different types of non-monotonic failure rates. This makes the ENHLL and GNHL distributions suitable for modeling datasets that exhibit these kinds of failure rates. Three estimations techniques; maximum likelihood, ordinary least squares and weighted least squares are employed in estimating the parameters of the ENHLL distribution and Monte Carlo simulations performed to examine how this methods perform. The findings revealed that the three techniques are all consistent as the sample size increases but in most cases the maximum likelihood tends to have smaller values of the average absolute bias and mean square error. Empirical illustrations with two failure time datasets revealed that the ENHLL distribution provides better fit to the datasets than other generalizations of the NH distribution in literature.
References
Aarset AS (1987) How to identify a bathtub hazard rate. IEEE Trans Reliab 36:106–108
Abdul-Moniem IB (2015) Exponentiated Nadarajah and Haghighi’s exponenetial distribution. Int J Math Anal Appl 2(5):68–73
Aljarrah MA, Lee C, Famoye F (2014) On generating T-X family of distributions using quantile functions. J Stat Distrib Appl 1(1):1–17
Almheidat M, Famoye F, Lee C (2015) Some generalized families of Weibull distribution: properties and applications. Int J Stat Probab 4:18–35
Alzaatreh A, Lee C, Famoye F (2016) Family of generalized gamma distributions: properties and applications. Hacettepe J Math Stat 45:869–886
Alzaatreh A, Lee C, Famoye F (2014) T-normal family of distributions: a new approach to generalize the normal distribution. J Stat Distrib Appl 1(1):1–18
Alzaatreh A, Lee C, Famoye F (2013) A new method for generating families of continuous distributions. Metron 71(1):63–79
Bolker B (2014) Tools for general maximum likelihood estimation. R Development Core Team
Ghosh I, Nadarajah S (2018) On some further properties and application of Weibull-R family of distributions. Ann Data Sci 5(3):387–399
Hamed D, Famoye F, Lee C (2018) On families of generalized Pareto distributions: properties and applications. J Data Sci 16(2):377–396
Jamal F, Aljarrah MA, Tahir MH, Nasir MA (2018) A new extended generalized Burr-III family of distributions. Tbilisi Math J 11(1):59–78
Lawles JF (1982) Statistical models and methods for lifetime data. Wiley, New York
Lima SRL (2015) The half normal generalized family and Kumaraswamy Nadarajah–Haghighi distribution. Master thesis, Universidade Federal de Pernumbuco
Mansoor M, Tahir MH, Cordeiro GM, Alzaatreh A, Zubair M (2017) A new family of distributions to analyze lifetime data. J Stat Theory Appl 16(4):490–507
Nadarajah S, Haghighi F (2011) An extension of the exponential distribution. Stat J Theor Appl Stat 45(6):543–558
Nasir A, Aljarrah M, Jammal F, Tahir MH (2017) A new generalized Burr family of distributions based on quantile function. J Stat Appl Probab 6(3):499–504
Peña-Ramírez FA, Guerra RR, Cordeiro GM (2018) A new generalization of the Nadarajah–Haghighi distribution. XXVIII Simposio Internacional de Estadística 23(27):1–12
Quesenberry CP, Kent J (1982) Selecting among probability distributions used in reliability. Technometrics 24(1):59–65
Shannon CE (1948) A mathematical theory of communication. Bell Syst Tech J 27:379–432
Swain JJ, Venkatraman S, Wilson JR (1988) Least-Squares estimation of distribution functions in Johnson’s translation system. J Stat Comput Simul 29:271–297
Yousof HM, Korkmaz MÇ (2017) Topp–Leone Nadarajah–Haghighi distribution. J Stat Stat Actuar Sci 2:119–128
Zubair M, Alzaatreh A, Cordeiro GM, Tahir MH, Mansoor M (2018) On generalized classes of exponential distribution using T-X family framework. Filomat 32(4):1259–1272
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interests
The authors declare that there is no conflict of interests regarding the publication of this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Nasiru, S., Abubakari, A.G. & Abonongo, J. Quantile Generated Nadarajah–Haghighi Family of Distributions. Ann. Data. Sci. 9, 1161–1180 (2022). https://doi.org/10.1007/s40745-020-00271-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40745-020-00271-3