
Abstract
We consider a two-person trading game in continuous time where each player chooses a constant rebalancing rule b that he must adhere to over [0, t]. If \(V_t(b)\) denotes the final wealth of the rebalancing rule b, then Player 1 (the “numerator player”) picks b so as to maximize \(E[V_t(b)/V_t(c)]\), while Player 2 (the “denominator player”) picks c so as to minimize it. In the unique Nash equilibrium, both players use the continuous-time Kelly rule \(b^*=c^*=\varSigma ^{-1}(\mu -r\mathbf 1 )\), where \(\varSigma \) is the covariance of instantaneous returns per unit time, \(\mu \) is the drift vector, and \(\mathbf 1 \) is a vector of ones. Thus, even over very short intervals of time [0, t], the desire to perform well relative to other traders leads one to adopt the Kelly rule, which is ordinarily derived by maximizing the asymptotic exponential growth rate of wealth. Hence, we find agreement with Bell and Cover’s ( Manag Sci 34(6):724–733, 1988) result in discrete time.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
1.1 Literature review
Kelly (1956) obtained the eponymous Kelly rule (“Fortune’s Formula”; Poundstone 2010) by maximizing the asymptotic growth rate of one’s capital when gambling on repeated horse races where the posted odds diverge from the true win probabilities. Famously (Thorp 2017), the Kelly rule was employed by card counter Edward O. Thorp to size his bets at the Nevada blackjack tables. Thorp went on to use the same principle (of the “log-optimal” constant-rebalanced portfolio) in money management on Wall Street. For the general discrete-time portfolio problem, the Kelly investor willingly foregoes the tangency portfolio (of maximum Sharpe ratio) in exchange for the highest possible asymptotic capital growth rate. Breiman (1961) showed that in the long run, a Kelly gambler will almost surely outperform any “essentially different strategy”, (by an exponential factor) and he has the shortest mean waiting time to reach a distant wealth goal.
In a pair articles, Bell and Cover (1980, 1988) prove a short-term optimality property of the discrete-time Kelly rule. They show that the Kelly rule emerges as the solution of a wide class of “investment \(\phi \)-games” where the goal is for one investor to outperform the other (in the sense of an increasing function \(\phi (\cdot )\) of the ratio of the two players’ final wealths). Both papers use an artifice whereby, before the game itself, each player is allowed to make a “fair randomization” of his initial dollar, by exchanging it for any random variable distributed over \([0,\infty )\) whose mean is at most 1.
1.2 Contribution
This paper studies a similar game in continuous time, where each player commits to a rebalancing rule that must be used continuously over the interval [0, t]. The unique Nash equilibrium (that constitutes a saddle point of the expected ratio of wealths at t) is for both players to use the continuous-time Kelly rule. This result, which matches that of Bell and Cover (1988), holds for the general market with n correlated stocks \((i=1,...,n)\) in geometric Brownian motion. This being done, we show that the continuous-time Kelly rule is the basis for the solution of a “continuous-time investment \(\phi \)-game” analogous to the discrete-time version solved by Bell and Cover.
2 Model
We consider a continuous-time trading game between two players. There is a risk-free bond whose price \(B_t=\mathrm{e}^{rt}\) evolves according to d\(B_t/B_t=r\,\mathrm{d}t\) and a single stock whose price \(S_t\) follows the geometric Brownian motion
where \(\mu \) is the drift, \(\sigma \) is the volatility, and \(W_t\) is a standard Brownian motion. At \(t=0\) each player chooses a constant rebalancing rule \(b\in \mathbb {R}\) that he must adhere to for \(0\le t\le T\). A rebalancing rule b is a fixed-fraction betting scheme that maintains the fraction b of wealth in the stock and \(1-b\) in the bond at all times. Let \(V_t(b)\) denote the wealth at t of a \(\$1\) deposit into the rebalancing rule b. At instant t, the trader holds \(bV_t(b)/S_t\) shares of stock and \((1-b)V_t(b)\mathrm{e}^{-rt}\) bonds. This portfolio will be held over the differential time interval \([t,t+\mathrm{d}t]\), after which point it must be rebalanced again. The players are free to use any amount of leverage (\(b>1\) or \(b<0\)), if desired.
Player 1 (the “numerator player”) chooses the rebalancing rule \(b\in \mathbb {R}\) and Player 2 (the “denominator player”) chooses a rebalancing rule \(c\in \mathbb {R}\). We consider the two-person zero-sum game with payoff kernel \(E[V_T(b)/V_T(c)]\). The numerator player seeks to maximize the expected ratio of his final wealth to that of the opponent’s. The denominator player seeks to minimize this quantity.
2.1 Payoff computation
Each player’s wealth follows a geometric Brownian motion
Solving, we obtain
The ratio of final wealths is
Thus, since the ratio of final wealths is log-normally distributed (Shonkwiler 2013), we have, after simplification,
After a monotonic transformation, we may rewrite the payoff kernel as
which is the exponential growth rate of \(E[V_t(b)/V_t(c)]\).
2.2 Equilibrium
Player 1’s best response correspondence is
Player 2’s best response function is
Thus, the unique Nash equilibrium is \(b=c=(\mu -r)/\sigma ^2\), which happens to be the continuous-time Kelly rule (Luenberger 1997). Ordinarily, the Kelly (1956) rule is derived by maximizing the asymptotic continuously compounded capital growth rate
Hence, even over very short intervals of time [0, t] the desire to outperform other traders in the market dictates the use of the Kelly rule \(b^*=(\mu -r)/\sigma ^2\). We have thus derived a short-term optimality property of the continuous-time Kelly rule that matches the results obtained by Bell and Cover (1988) in discrete time.
2.3 Several correlated stocks
We extend the above result to the general market with n correlated stocks that follow the geometric Brownian motions (Bjork 1998)
where \(\mu =(\mu _1,...,\mu _n)'\) is the drift vector, \(\sigma =(\sigma _1,...,\sigma _n)'\) is the vector of volatilities, and \(\varSigma \) is the covariance of instantaneous returns per unit time, e.g. \(\varSigma _{ij}=\mathrm{Cov}(\mathrm{d}S_{it}/S_{it},\mathrm{d}S_{jt}/S_{jt})/\mathrm{d}t.\) The \(W_{it}\) are correlated unit Brownian motions, with \(\rho _{ij}=\mathrm{corr}(\mathrm{d}W_{it},\mathrm{d}W_{jt})\) and \(\varSigma _{ij}=\rho _{ij}\sigma _i\sigma _j\). We assume that \(\varSigma \) is invertible. In this context, a rebalancing rule is a vector \(b=(b_1,...,b_n)'\in \mathbb {R}^n\), where the gambler continuously maintains the fixed fraction \(b_i\) of wealth in stock i at all times. He keeps the fraction \(1-\sum \nolimits _{i=1}^nb_i\) of wealth in bonds. As in the univariate case, this permits the freest possible use of leverage, if desired.
Each player’s final wealth \(V_t(b)\) follows the geometric Brownian motion
The solution of this stochastic differential equation is
This can be verified directly by applying Ito’s Lemma for several diffusion processes (Wilmott 2001) to the function \(F(W_1,...,W_n,t)=\exp \big \{(r+(\mu -r\mathbf 1 )'b-b'\varSigma b/2)t+\sum \nolimits _{i=1}^nb_i\sigma _i W_{i}\big \}.\) The ratio of final wealths is
Thus, the ratio of final wealths is log-normally distributed, with
After monotonic transformation, we obtain the simplified payoff kernel
Player 1’s best response correspondence is
where \((\varSigma c)_i=\sum \nolimits _{j=1}^n\rho _{ij}\sigma _i\sigma _jc_j\) is the \(i\mathrm{th}\) coordinate of the vector \(\varSigma c\). Assuming \(\varSigma \) is invertible, Player 2’s best response function is
Intersecting the best responses, we find that the unique Nash equilibrium is \(b=c=\varSigma ^{-1}(\mu -r\mathbf 1 )\), which is the multivariate Kelly rule in continuous time. We thus have the identity
Thus, since the Kelly rule \(b^*\) is Player 1’s maximin strategy, we have \(E[V_t(b^*)/V_t(c)]\ge 1\) for all c, and since the Kelly rule \(c^*\) is Player 2’s minimax strategy, we have \(E[V_t(b)/V_t(c^*)]\le 1\) for all b.
3 Investment \(\phi \)-game
Based on the fact that the Kelly rule \(b^*=c^*\) guarantees \(E[V_t(b^*)/V_t(c)]\ge 1\) for all c and \(E[V_t(b)/V_t(c^*)]\le 1\) for all b, we can obtain a general result analogous to that of Bell and Cover (1988). First we need some definitions.
Definition 1
By a “fair randomization” of the initial dollar is meant a random variable W with support \([0,\infty )\) and \(E[W]\le 1\).
Definition 2
For any increasing function \(\phi (\cdot )\), the “primitive \(\phi \)-game,” with value \(v_\phi \), is the two-person, zero-sum game with payoff kernel \(E[\phi (W_1/W_2)]\), where player 1 chooses a fair randomization \(W_1\) and player 2 chooses a fair randomization \(W_2\). The value of the primitive \(\phi \)-game is \(v_\phi =\mathop \mathrm{sup}_{W_1}\,\,\mathop \mathrm{inf}_{W_2}\,\,E[\phi (W_1/W_2)]=\mathop \mathrm{inf}_{W_2}\,\,\mathop \mathrm{sup}_{W_1}\,\,E[\phi (W_1/W_2)]\). The random wealths \(W_1\) and \(W_2\) are independent of each other.
Definition 3
For any increasing function \(\phi (\cdot )\), the “investment \(\phi \)-game” is the two-person, zero-sum game with payoff kernel \(E[\phi (\frac{W_1V_t(b)}{W_2V_t(c)})]\), where player 1 chooses a rebalancing rule b and a fair randomization \(W_1\) of the initial dollar, and player 2 chooses a rebalancing rule c and a fair randomization \(W_2\) of his initial dollar. The random wealths \(W_1\) and \(W_2\) are independent of all stock prices and independent of each other.
Theorem 1
The investment \(\phi \)-game has the same value \(v_\phi \) as the primitive \(\phi \)-game. In equilibrium, both players use the continuous-time Kelly rule \(b^*=\varSigma ^{-1}(\mu -r\mathbf 1 )\), and the players use the same minimax randomizations \((W_1^*,W_2^*)\) that solve the primitive \(\phi \)-game.
Proof
First, we show that \(E[\phi (\frac{W_1^*V_t(b^*)}{W_2V_t(c)})]\ge v_\phi \) for any fair randomization \(W_2\) and any rebalancing rule c, where \(b^*\) is the Kelly rule. Note that \(W_2V_t(c)/V_t(b^*)\ge 0\) is a fair randomization, since \(E[V_t(c)/V_t(b^*)]\le 1\). The inequality \(E[V_t(c)/V_t(b^*)]\le 1\) follows from direct substitution of \(b^*=\varSigma ^{-1}(\mu -r\mathbf 1 )\) into the expected wealth ratio. Thus, since \(W_1^*\), is Player 1’s minimax solution in the primitive \(\phi \)-game, we must have \(E[\phi (\frac{W_1^*V_t(b^*)}{W_2V_t(c)})]\ge v_\phi \).
Similarly, we show that \(E[\phi (\frac{W_1V_t(b)}{W_2^*V_t(c^*)})]\le v_\phi \) for any fair randomization \(W_1\) and any rebalancing rule b, where \(c^*\) is the Kelly rule. Note that \(W_1V_t(b)/V_t(c^*)\ge 0\) is a fair randomization, since \(E[V_t(b)/V_t(c^*)]\le 1\). Thus, since \(W_2^*\) is Player 2’s minimax solution of the primitive \(\phi \)-game, we must have \(E[\phi (\frac{W_1V_t(b)}{W_2^*V_t(c^*)})]\le v_\phi \).
Thus, we have shown that \((W_1^*,b^*)\) forces the payoff to be \(\ge v_\phi \) and \((W_2^*,c^*)\) forces the payoff to be \(\le v_\phi \) when \(b^*\) and \(c^*\) are equal to the Kelly rule and \((W_1^*,W_2^*)\) are the minimax strategies from the primitive \(\phi \)-game. This proves the theorem. \(\square \)
Example 1
As in Bell and Cover (1980), we let \(\phi (x)=1_{[1,\infty )}(x)\) be the indicator function of \([1,\infty )\). This turns the payoff kernel into \(P\{W_1V_t(b)\ge W_2V_t(c)\}\). The equilibrium amounts to the Kelly rule \(b^*=c^*\) and the fair exchange of the initial dollar for a uniform(0, 2) variable. The value of the game is 1 / 2.
4 Simulation of a sample play of the game
To illustrate, we use the example of “Shannon’s Demon” in continuous time. In Shannon’s classic discrete-time example, there is cash (that pays no interest) and a “hot stock” that each period either doubles or gets cut in half in price, each with \(50\%\) probability. The continuous-time analogue is to set \(r=0\) and
with \(\sigma =\mathrm{log}\,2=0.693.\) The equilibrium of our game is for both players to use the rebalancing rule \(b=0.5\). For the sake of argument, assume that Player 1 behaves correctly, but Player 2 (perhaps confused by the \(24\%\) annual drift rate) chooses to put all his money into the stock, and hold.
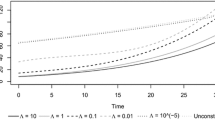
Player 1’s wealth at t is e\(^{0.06t+0.3465W_t}\), and Player 2’s wealth at t is e\(^{0.693W_t}\). The expected wealth ratio is e\(^{0.12t}\). In Fig. 1 we have simulated a single play of the game, with horizon \(T=300\). At time t, the probability that Player 1 has more wealth than Player 2 is \(N(0.173\sqrt{t}),\) where \(N(\cdot )\) is the cumulative normal distribution function. At \(t=50\), there is an \(89\%\) chance that Player 1 has more wealth. At \(t=100\) this number rises to \(96\%\).

Simulation of one play of the game, with \(b=0.5\) and \(c=1\)
5 The general stochastic differential game
Finally, we show that the restriction to constant rebalancing rules entails no loss of generality. We do this below for the one-stock case; the proof for several stocks is similar. Let \(M_{1t}\) and \(M_{2t}\) be the wealths of the numerator and denominator player, respectively. We now allow the players’ portfolios to depend on the most general state vector, which is \((S_t,t,M_{1t},M_{2t})\). Player 1’s trading strategy is now denoted \(b(S,t,M_1,M_2)\), and Player 2’s strategy is \(c(S,t,M_1,M_2)\). We show that in equilibrium, both players still adhere to the constant rebalancing rule \(b(S,t,M_1,M_2)=c(S,t,M_1,M_2)=(\mu -r)/\sigma ^2\).
First, assume that the denominator player uses the Kelly rule \(c=(\mu -r)/\sigma ^2.\) We show that the numerator player’s best response is to use the same control policy. Let \(J(S,t,M_1,M_2)\) be the numerator player’s maximum value function. His HJB equation is
The boundary condition is \(J(S,T,M_1,M_2)=M_1/M_2\). We guess that \(J(S,t,M_1,M_2)\equiv M_1/M_2\), which obviously satisfies the boundary condition. Under this guess, Player 1’s HJB equation simplifies to
where \(c=(\mu -r)/\sigma ^2.\) This value of c makes the maximand identically 0, so of course \(b^*=c\) is a maximizer. Thus, substitution of \(J\equiv M_1/M_2\) has turned the HJB equation into an identity. This proves that the numerator player’s best response to the Kelly rule is to play the Kelly rule himself.
We can repeat the above calculation, this time assuming that the numerator player’s policy is \(b(S,t,M_1,M_2)\equiv (\mu -r)/\sigma ^2.\) Using J again to denote the denominator player’s (minimum) value function, we get the same HJB equation and boundary condition, except that \(\mathop {\mathrm{Max}}_{b}\,\,\{\cdot \cdot \cdot \}\) is replaced by \(\mathop {\mathrm{Min}}_{c}\,\,\{\cdot \cdot \cdot \}\). We again make the guess \(J\equiv M_1/M_2\), which turns Player 2’s HJB equation into the identity
The unique minimizer is \(c=b=(\mu -r)/\sigma ^2\). This completes the proof that the constant control policies \(b(S,t,M_1,M_2)=c(S,t,M_1,M_2)=(\mu -r)/\sigma ^2\) are best responses to each other. The proof for several stocks is similar, except that \((\mu -r)(b-c)+\sigma ^2(c^2-bc)\) is replaced by \((\mu -r\mathbf 1 )'(b-c)+c'\varSigma c-b'\varSigma c.\)
6 Conclusion
For the continuous-time two-person trading game where Player 1 seeks to maximize the expected ratio of his wealth to that of Player 2 (and Player 2 seeks to minimize this ratio), the unique Nash equilibrium is for both players to use the (possibly leveraged) Kelly rebalancing rule \(b=\varSigma ^{-1}(\mu -r\mathbf 1 )\). More generally, we showed that the Kelly rule is the basis for the solution of a “continuous-time investment \(\phi \)-game” that is the analog of the discrete-time version solved by Bell and Cover (1980, 1988). For practically any criterion \(\phi ((W_1V_t(b))/(W_2V_t(c)))\) of short-term relative performance, the correct behavior is for both players to use the Kelly rule \(b^*=c^*\) in conjunction with appropriate fair randomizations \((W_1^*,W_2^*)\) of the initial dollar. Thus, the continuous-time Kelly rule (which is renowned for its optimal asymptotic growth rate) is desirable even for a trader whose goal is to perform well relative to other traders over very short periods of time.
References
Bell, R., Cover, T.M.: Competitive optimality of logarithmic investment. Math. Oper. Res. 5(2), 161–166 (1980)
Bell, R., Cover, T.M.: Game-theoretic optimal portfolios. Manag. Sci. 34(6), 724–733 (1988)
Bjork, T.: Arbitrage Theory in Continuous Time. Oxford University Press, Oxford (1998)
Breiman, L.: Optimal gambling systems for favorable games. In: Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, Vol. 1. Contributions to the Theory of Statistics. The Regents of the University of California, Oakland (1961)
Kelly, J.: A new interpretation of information rate. Bell Syst. Tech. J. 35, 917–926 (1956)
Luenberger, D.G.: Investment Science. OUP Catalogue, Oxford (1997)
Poundstone, W.: Fortune’s Formula: The Untold Story of the Scientific Betting System that Beat the Casinos and Wall Street. Hill and Wang, New York (2010)
Shonkwiler, R.W.: Finance with Monte Carlo. Springer, Berlin (2013)
Thorp, E.O.: A Man for All Markets: From Las Vegas to Wall Street. How I Beat the Dealer and the Market. Random House, New York (2017)
Wilmott, P.: Paul Wilmott Introduces Quantitative Finance. Wiley, New York (2001)
Acknowledgements
I thank the Editor and an anonymous reviewer for helpful comments that improved the paper.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Garivaltis, A. Game-theoretic optimal portfolios in continuous time. Econ Theory Bull 7, 235–243 (2019). https://doi.org/10.1007/s40505-018-0156-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40505-018-0156-5