
Abstract
We investigate a new variant of the hybrid flow shop problem (HFSP) considering machine blocking and both sequence-independent and sequence-dependent setup times. Since the HFSP is NP-hard, we propose heuristic algorithms along with priority rules based on the traditional SPT and LPT rules. We carried out computational experiments on simulated problem instances to test the performance of the priority rules. The objective function adopted was makespan minimization, and we used the rate of success and the relative deviation as performance criteria. The results indicate superiority of LPT-based rules. On instances with sequence-independent setup times, the LP rule, which is based on the non-increasing sorting of total processing times, outperformed other rules in most tested instances. In instances with sequence-dependent setup times, the LPS rule, which is based on the non-increasing sum of processing time and average setup times, outperformed other rules in most tested instances.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In production planning of manufacturing systems, the efficient scheduling of jobs plays a key role for the achievement of low-cost and competitive advantage in businesses. Among the variants of scheduling problems in the literature, one that has attracted research efforts in recent years due to its practical importance is the hybrid flow shop problem (HFSP).
In the HFSP, a set of jobs with fixed production sequence are processed in a set of production stages, each one composed of multiple machines, in which at least one of these stages has more than one machine. According to Ebrahimi et al. [2], these machines can be classified in identical parallel machines, uniform parallel machines or unrelated parallel machines. The problem is to find a schedule which optimizes an objective function, usually makespan minimization, mean flowtime, or total tardiness. The HFSP is a NP-hard problem, since it is a generalization of the classical flow shop, which is known to be NP-hard for three or more production stages [5]. Therefore, obtaining optimal solutions in acceptable computational times is a difficult task when solving large real-world problems.
According to Ruiz and Vázquez-Rodríguez [16], the hybrid flow shop environment is found in several real-world applications, such as electronics, production of paper, textile and concrete, manufacturing of photographic films, civil construction projects, Internet service architectures and load transportation systems.
Traditionally, the setup time is considered as a part of the processing times. However, this assumption leads to problems in the scheduling process. Therefore, an explicit consideration for setup times has been considered [10, 12].
This paper aims at investigating a new variant of the hybrid flow shop problem considering both machine blocking and both sequence-independent and sequence-dependent setup times. According to our thorough literature review, this variant has not been reported yet, despite its practical importance. We propose a new constructive method for the problem, based on priority rules, which can provide good solutions with low computational effort.
The remainder of this paper is organized as follows: in Sect. 2, the literature review is presented, in Sect. 3, the scheduling problem treated in this paper is stated in Sect. 4, we propose a constructive algorithm; in Sect. 5, we discuss some results from computational experiments; finally, in Sect. 6 we draw some conclusions and suggestions for future works.
2 Literature review
The HFSP is a widely studied combinatorial optimization problem with several industrial applications. Linn and Zhang [8] carried out a survey on the HFSP in which a classification of studies in this area is proposed based on three categories: problems with two stages, problems with three stages and problems with more than three stages. Vignier et al. [17] present a state-of-the-art review on the HFSP divided in two sections: problems with two stages and general problems with k stages.
Kis and Pesch [7] performed a literature update paper reviewing the subsequent studies approaching the HFSP. Wang [18] and Quadt and Kuhn [14] also present literature reviews for the HFSP, which they call flexible flow shop scheduling problem and flexible flow line problem, respectively.
Numerous-research articles have been published on this topic. This study reviews research on the flexible flow shop scheduling problem (FFSSP) from the past and the present. The solution approaches reviewed range from the optimum to heuristics and to artificial intelligence search techniques. We not only discuss the details from the selected methods and compare them, but also provide insights and suggestions for future research.
Ruíz and Vasquéz-Rodríguez [16] present a literature review focused on solution procedures, discussing the features of the variants of the problem. In addition, they point out existing gaps and have suggested future works. Ribas et al. [15] offer a robust literature review with an innovative taxonomy for the HFSP.
Choong et al. [1] describe two metaheuristics for the HFSP: the first one mixes particle swarm optimization (PSO) with simulated annealing (SA), while the second one is a hybrid of PSO and tabu search (TS). The objective function is minimizing the completion time of all the tasks. The hybrid PSO-SA algorithm reached the best results. The authors suggest that new variants of the HFSP with precedence constraints are worth investigating.
Hidri and Haouari [6] study a variant of the HFSP with multiple centers in which each center has a set of identical machines working in parallel. These authors propose new lower and upper bounds for the mentioned variant. The computational results show an improvement of the existing bounds. These authors suggest the development of exact methods for solving the studied variant.
Mousavi et al. [11] present a bi-objective variant of the HFSP with sequence-dependent setup times. The objective functions are both the minimization of makespan and total tardiness. The authors propose a bi-objective heuristic (BOH) for the determination of a Pareto front approximation. The proposed BOH outperformed a multi-objective simulated annealing (MOSA). These authors suggest the incorporation of new realistic assumptions, such as machine availability constraints and unrelated parallel machines at each stage.
Elmi and Topaloglu [3] studied hybrid flow shop robotic cells with multiple robots. They have taken of account blocking constraints, multiple part types, unrelated parallel machines and machine eligibility constraints. A mixed integer linear programming model is proposed, which could not be solved satisfactorily. A simulated annealing algorithm is developed for providing high-quality solutions in acceptable computational times. The authors suggest the consideration of dual gripper multiple robots and stochastic processing times.
Luo et al. [9] approached the HFSP with the consideration of energy consumption of machines. They adopted two objectives: minimizing the makespan and the electric power cost. Three multi-objective metaheuristics are tested: multi-objective ant colony optimization (MOACO), non-dominated sorting genetic algorithm II (NSGAII) and strength Pareto evolutionary algorithm II (SPEAII). The results indicate that this multi-objective approach is valuable in practice, since high-energy operations can be shifted to off-peak periods, during which energy cost is lower.
Zhang et al. [19] cast the vehicle scheduling problem in a maritime terminal as a variant of HFSP with a special type of blocking constraints and multiple product families, considering the makespan as the objective to be minimized. A constructive heuristic is proposed for solving the problem under study with low computational times.
Fattahi et al. [4] studied a HFSP with assembly operations, considering the minimization of makespan as an objective. A branch-and-bound (B&B) algorithm is proposed for solving the problem and a greedy randomized adaptive search procedure (GRASP) construction phase algorithm is applied to obtain upper bounds. This hybridization reduced substantially the computational times. Although the B&B has shown promising results, the instances under consideration were small (7, 10, 15 or 25 jobs products; 2 production stages; 2, 3 or 4 machines per stage).
Ebrahimi et al. [2] investigated a HFSP with sequence-dependent family setup times. They adopted two objective functions: minimization of both makespan and total tardiness. Two multi-objective metaheuristics are tested for solving the proposed variant: a NSGAII and a multi-objective genetic algorithm (MOGA), that are compared with a multiphase genetic algorithm (MPGA). The NSGA II outperformed the other algorithms. The authors suggest that taking into account stochastic due dates makes this study closer to the real-world problems.
3 Problem statement
The problem of flow shop scheduling with multiple machines, also known as either hybrid flow shop problem (HFSP) or flow shop with parallel machines, consists of a multistage flow shop in which each stage k ∈ {1,…, g}, g ≥ 2 is composed of m k parallel machines. Each machine is capable of processing a single job operation per turn. A multistage flow shop is considered a hybrid flow shop if at least one production stage has more than one machine.
The problem consists in scheduling a set of jobs J = {1,…, n} in which each job has only one operation in each stage so as to optimize one or more objective-functions. In this paper, we adopted as objective-function the makespan. The operations must be performed sequentially, passing through all stages. Other usual assumption considers that an operation once started cannot be either preempted or subdivided in simultaneous sub operations. Each job j ∈ J has a known processing time p jk corresponding to stage k ∈ {1,…, g}. Figure 1 shows a general schematic representation of the HFSP with g production stages.

Hybrid flow shop problem with g production stages
The HFSP may be seen as a combination of the classical flow shop, which has one machine in each production stage (m k = 1, g > 1), with the problem of parallel machines with a single stage (m ≥ 2, g = 1), which have been intensively studied. The HFSP is NP-hard even when only one stage has more than one machine. This fact prevents the application of exact methods to problems which arise in industry.
The least complex setting of the HFSP considers the machine setup times as already included in the operation processing times. This setting has received considerable attention from many researchers. However, this assumption can decrease the quality of solutions in many applications which require an explicit treatment of setup times. In general, the sum of setup and processing times is realistic when setup times are independent of the operation sequence or when variability is negligible. Even then, considering setup times as making part of the processing times, implicitly assumes a scheduling model in which the setup of a machine M(k) is made only after finishing the previous operation of the current job to be processed on such a machine, even if this machine is idle.
In this paper, we approached a variant of the classical HFSP, with an added degree of complexity, with the following characteristics:
-
Machine setup times are explicitly separated from processing times;
-
We consider both sequence-independent and sequence-dependent setup times;
-
In contrast to the classical HFSP, machine setup is anticipated as soon as a machine has finished the processing of a job and is idle;
-
The production system does not allow intermediate storage of jobs between production stages due to technological or operational constraints of any nature, which has as a consequence the blocking of machines.
Although the aforementioned characteristics are typical of many relevant production environments in industry, to the extent of our knowledge there has been little research on the performance of alternative scheduling policies.
Consider an illustrative example with five jobs, three machines, two machines per stage and three stages. The processing times and sequence-independent setup times are presented in the Tables 1 and 2, respectively. Figure 2 shows an illustrative solution for the variant under proposition, the sequence {1, 2, 3, 4, 5}, whose makespan is 280 time units. In Fig. 2 we also have two types of non-productive times: In gray we have setup times, while we have machine blocking times in yellow, which represent the buffer zero constraints. A given machine cannot receive other jobs until the subsequent machine begins the effective processing of the current job.

A feasible solution for the proposed variant
4 Description of the proposed constructive heuristics
In this work, by virtue of the originality of studying the HFSP with sequence-dependent anticipated setup and machine blocking, we propose a constructive heuristic method based on priority rules. These rules define a job ordering to be followed during the scheduling, which is performed one job at a time. It is worth noting that the possibility of machine blocking prevents the scheduling by production stage, since the scheduling of jobs in a particular stage depends on the jobs already scheduled in the subsequent stage. Moreover, priority rules have great practical importance, since they are simple and provide solutions with little computational effort.
In practice, the most used priority rules are the following: shortest processing time (SPT), longest processing time (LPT), earliest due date (EDD), minimum slack time (MSL), first-in-first-out (FIFO) and last-in-last-out (LIFO). There are also weighted variants of these rules. It is well known (see e.g., [13]) that SPT rule minimizes the mean flow time for the classical single machine scheduling problem, and LPT rule is a heuristic for minimizing the makespan of jobs scheduled in the traditional parallel machines scheduling model. In Sects 4.1 and 4.2 below, we treat the cases for sequence-independent and sequence-dependent setup times separately.
4.1 Sequence-independent setup times
In this case, we propose seven priority rules, from which three of them are based on SPT rule, three ones subsequent are based on LPT and the remaining rule is a random one just for comparison purposes. At first, we describe some notations. Let:
-
\(p_{jk}\): processing time of job j ∈ {1, 2,…, n} in production stage k ∈ {1, 2,…, g}; (All machines in stage k are identical ones);
-
\(s_{jk}\): setup time of a machine in stage k ∈ {1, 2,…, g} for processing job j ∈ {1, 2,…, n};
-
\(P_{j} = \sum\nolimits_{k = 1}^{g} {p_{jk} }\): sum of processing times of job j in all production stages;
-
\(S_{j} = \sum\nolimits_{k = 1}^{g} {s_{jk} }\): sum of setup times for job j in all production stages;
-
\(PS_{j} = \sum\nolimits_{k = 1}^{g} {\left( {p_{jk} + s_{jk} } \right)}\): sum of processing time and setup time for job j over all stages.
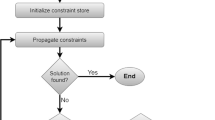
The proposed rules are described in Table 3, while Fig. 3 describes the proposed constructive heuristic for job scheduling.

Proposed constructive heuristic for job scheduling with sequence-independent setup times
As aforementioned, we use as objective function, the makespan.
4.2 Sequence-dependent setup times
In this case, we propose 11 priority rules, from which 5 are based on SPT rule and 5 are based on LPT one and the remaining rule is a random one just for comparison purposes. We add some notation to the one already described in Sect. 4.1. Let:
-
\(s_{ijk}\): setup time of a machine in stage k ∈ {1, 2,…, g} for processing job j ∈ {1, 2,…, n} when preceded by job i ∈ {1, 2,…, n} with i ≠ j. When i = j, s ijk = s jjk is the setup time when job j is the initial job scheduled to be processed in stage k; (There is no preceding job yet).
-
\(S^{\prime}_{jk} = \frac{1}{n}\sum\nolimits_{i = 1}^{n} {s_{ijk} }\): average setup time in stage k taking into account all preceding jobs of job j and the setup time when job j is the initial one in stage k;
-
\(\underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle-}$}}{S}_{j} = \mathop \sum \nolimits_{k = 1}^{g} s^{\prime}_{jk}\): sum of average setup times in all stages for job j;
-
\(P\underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle-}$}}{S}_{j} = \mathop \sum \nolimits_{k = 1}^{g} \left( {p_{jk} + S^{\prime}_{jk} } \right)\): sum of processing time and average setup time for job j over all stages;
-
\(s_{jk}^{\hbox{max} } = \max_{{i \in \{ 1,2, \ldots ,n\} }} s_{ijk}\): maximum setup time for job j in stage k;
-
\(s_{jk}^{\hbox{min} } = \min_{{i \in \{ 1,2, \ldots ,n\} }} s_{ijk}\): minimum setup time for job j in stage k;
-
\(PS_{j}^{\hbox{max} } = \mathop \sum \nolimits_{k = 1}^{g} \left( {p_{jk} + s_{jk}^{\hbox{max} } } \right)\): sum of the processing times and maximum setup times for job j over all stages;
-
\(PS_{j}^{\hbox{min} } = \mathop \sum \nolimits_{k = 1}^{g} \left( {p_{jk} + s_{jk}^{\hbox{min} } } \right)\): sum of the processing times and minimum setup times for job j over all stages.
The proposed rules are described in Table 4, while Fig. 4 describes the proposed constructive heuristic for job scheduling.

Proposed constructive heuristic for job scheduling with sequence-dependent setup times
5 Computational experiments
5.1 Experimental design
We used as parameters for the computational experiments the number of jobs (n), the number of production stages (g), the number of parallel identical machines per stage (m k ) and the setup intervals (s). The values of these parameters were defined based on the literature review, as presented in Table 5. We considered a fixed interval for the processing times, with random values uniformly distributed between 1 and 99. The total number of instance classes is given by 10 (n) × 2 (g) × 2 (m k ) × 3 (s) = 120. For each class, we randomly generated 100 test instances aiming at reducing the sampling error, which gives a total of 12,000 test instances.
In Table 1 all problem classes were considered according to the combination of the 10 sets of n jobs (10, 20, 30,…,100), with the 2 sets of stages g (3, 7), 2 sets of parallel machines m k (3, 7) and 3 sets of setup times s ([1, 25], [26, 75], [76, 125]). This scheme results in 120 test problem classes. In the computational experimentation, we solved 100 problems for each class, totalizing 12,000 tested problems.
On the other hand, as presented in Table 6, the 12 sub-classes (A, B, C,…, K, L) are related to the 12 parameter combinations g, mk, and s. Thus, the subclass A has 100 test problems with n = 10, 100 test problems with n = 20, and so on, until 100 test problems with n = 100. Each subclass presents 1000 test problems, composed of 100 test problems for each value of n. Therefore, the total number of evaluated test problems is 12 × 1000 = 12,000.
5.2 Statistics used in the analysis of the computational experiments
The results obtained in the computational experiments were analyzed by the success rate and the mean relative deviation for all the priority rules in Tables 3 and 4. The success rate (SR) is calculated as the number of times that a given rule results in the best solution (with or without a draw) divided by the number of test instances in a given instance class. The relative deviation (RD) is the variation percentage corresponding to the best solution founded by the methods. If the relative deviation is equal to zero for a given method, it returned the best solution for that instance. One can observe that more than one method may provide the best solution.
Thus, the better algorithm is the one providing a lower value of mean relative deviation (the simple average of the relative deviations) for a given class of problems. The relative deviation (RD h ) for the method h for a given problem is calculated as in Eq. (1):
in which D h is the makespan returned by the method h and D* is the best makespan returned by the tested methods.
In this work there were not considered the average computational times of a given method for the comparative evaluation because the characteristics of the proposed algorithms should not imply in differences with statistical significance. Furthermore, such computational times are relatively smalls due to the fact that usually constructive heuristic methods have high computational efficiency.
5.3 Results and discussion
To present the results in a summarized way, we grouped the instance classes according to the parameter “number of jobs” (n) in 12 groups. Table 6 gives the labels for each group and the corresponding values for the remaining experimental parameters.
In the Sects. 5.3.1 and 5.3.2, we show the results for sequence-independent and sequence-dependent setup times, respectively.
5.3.1 Sequence-independent setup times
Several priority rules alternate as the best rule for a given set of instances with regard to the SR. Therefore, the SR results are analyzed concomitantly with results obtained for RD. Table 7 and Fig. 5 present results obtained considering SR. Table 8 and Fig. 6 present results obtained considering RD. Table 9 summarizes the comparison of best priority rules for each instance class.

Comparison of average SR for each proposed priority rule over class instances with sequence-independent setup times

Comparison of average percent relative deviation for each proposed priority rule by instance category with sequence-independent setup times
The obtained results clearly point to a better performance of the LP priority rule. The worst priority rules were LS, SS and RAND. Regarding the SR indicator, one can notice a superiority earlier stated for the LP rule, however, without a tendency for the increase of the RS for small and medium size test instances. The positive tendency occurs for test instances with a number of jobs greater than 80.
As expected, the random dispatch rule RAND presented in general the worst performance, what indicates that structured rules lead to better results. It is worth noting that most of the structured rules which did not have good performance are based on the traditional priority rule SPT. It is well known that in production planning environments with parallel machines, this rule does not present good results when the objective function is related to the makespan minimization, as it was the case with the SPT-based priority rules SP, SS and SPS.
On the other hand, the priority rules that performed best in the tested instances were LP and LPS, which are based on the traditional LPT. In production environments with parallel machines, the LPT rule seeks to balance the machines workload so as to minimize the makespan. The LS rule does not present good results for the variant under study.
5.3.2 Sequence-dependent setup times
Table 10 and Fig. 7 present results obtained considering SR. Table 11 and Fig. 8 present results obtained considering RD. Table 12 summarizes the comparison of best priority rules for each instance class.

Comparison of average SR for each proposed priority rule over class instances with sequence-dependent setup times

Comparison of average percent relative deviation for each proposed priority rule by instance category with sequence-dependent setup times
In general, for problem instances with number of stages g = 3, the priority rule LPS has achieved the best performance, with the exception for problem instances with setup times in the interval [1, 25], in which the priority rule LPSmin performed better than the LPS one. In the case of the HFSP with a greater number of production stages (g = 7), the priority rule LPS also showed the best results, with the exception of the instance class L, for which LPS performed best only for instances with number of machines n ≥ 90. As expected, the random rule RAND showed the worst results.
It is worth noting that most of the structured rules which did not have good performance are based on the traditional priority rule SPT. It is well known that in production-planning environments with parallel machines, this rule does not present good results when the objective function is related to the makespan minimization, as it was the case with the SPT-based priority rules SP, SS, SPS, SPSmax and SPSmin.
On the other hand, the priority rules that performed best in the tested instances were LP, LPS, LPSmax and LPSmin, which are based on the traditional LPT. In production environments with parallel machines, the LPT rule seeks to balance the machines workload so as to minimize the makespan.
6 Concluding remarks
In this paper, we have investigated a new variant for the hybrid flow shop scheduling problem (HFSP) considering both machine blocking and both sequence-independent and sequence-dependent setup times. The HFSP objective is minimizing the total time to complete the schedule (makespan). We developed constructive heuristic algorithms based on priority rules. We also proposed seven priority rules in the case of sequence-independent and eleven priority rules in the case of sequence-dependent setup times, respectively, based on the SPT and LPT rules.
Computational experiments were carried out to evaluate the performance of the alternative proposed rules. We used the rate of success and the relative deviation statistics as performance measures. Computational times were not used for comparison purposes since their differences among priority rules were negligible. In most tested problem instances, the priority rules based on the SPT one generated the worst solutions. On the other hand, the priority rules based on the LPT showed the best performance. In particular, the LP rule outperformed all other tested priority rules in most cases with sequence-independent setup times, while LPS rule outperformed other tested priority rules in most cases with sequence-dependent setup times.
Our purpose in this paper was to compare alternative priority rules, not to compare the priority rule scheduling method with scheduling based on mathematical programming. This is why we do not provide quality measures based on lower bounds or optimal solutions as they require developing and solving mathematical programming models. Priority rules are often used in practice and comparing alternative rules is relevant from both a practical as well as a theoretical standpoint.
As extensions of this work, we recommend the use of metaheuristics to improve the solutions generated by the priority rules. In addition, the development of integer linear programming models for the variants under study is suggested, since the models can be used to determine optimal solutions for small-size problem instances. Future studies could also investigate the behavior of the proposed priority rules considering other objective functions, such as total tardiness minimization. There is no guarantee that LPT-based rules will also have good performance when applied to different objective functions. Finally, it is worth studying multi-objective variants of the HSFP due to the fact that in many real industrial settings, the scheduling problems have a multi-objective nature.
References
Choong F, Phon-Amnuaisuk S, Alias MY (2011) Metaheuristic methods in hybrid flow shop scheduling problem. Expert Syst Appl 38:10787–10793
Ebrahimi M, Fatemi Ghomi SMT, Karimi B (2014) Hybrid flow shop scheduling with sequence dependent family setup time and uncertain due dates. Appl Math Model 38:2490–2504
Elmi A, Topaloglu S (2013) A scheduling problem in blocking hybrid flow shop robotic cells with multiple robots. Comput Oper Res 40:2543–2555
Fattahi P, Hosseini SMH, Jolai F, Tavakkoli-Moghaddam R (2014) A branch and bound algorithm for hybrid flow shop scheduling problem with setup time and assembly operations. Appl Math Model 38:119–134
Garey MR, Johnson DS, Sethi R (1976) The complexity of flowshop and jobshop scheduling. Math Oper Res 1(2):117–129
Hidri L, Haouari M (2011) Bounding strategies for the hybrid flow shop scheduling problem. Appl Math Comput 217(21):8248–8263
Kis T, Pesch E (2005) A review of exact solution methods for the non-preemptive multiprocessor flowshop problem. Eur J Oper Res 164:592–608
Linn R, Zhang W (1999) Hybrid flow shop scheduling: a survey. Comput Ind Eng 37(1):57–61
Luo H, Du B, Huang GQ, Chen H, Li X (2013) Hybrid flow shop scheduling considering machine electricity consumption cost. Int J Prod Econ 146:423–439
Moccellin JV, Nagano MS (2011) Heuristic for flow shop sequencing with separated and sequence-independent setup times. J Braz Soc Mech Sci Eng 33:74–78
Mousavi SM, Zandieh M, Amiri M (2011) An efficient bi-objective heuristic for scheduling of hybrid flow shops. Int J Adv Manuf Technol 54:287–307
Nagano MS, Araujo DC (2014) New heuristics for the no-wait flowshop with sequence-dependent setup times problem. J Braz Soc Mech Sci Eng 36:139–151
Pinedo ML (2008) Scheduling: theory, algorithms and systems, 3rd edn. Springer, New York
Quadt D, Kuhn H (2007) A taxonomy of flexible flow line scheduling procedures. Eur J Oper Res 178(3):686–698
Ribas I, Leisten R, Framinan JM (2010) Review and classification of hybrid flow shop scheduling problems from a production system and a solutions procedure perspective. Comput Oper Res 37:1439–1454
Ruiz R, Vázquez-Rodríguez JA (2010) The hybrid flow shop scheduling problem. Eur J Oper Res 205:1–18
Vignier A, Billaut JC, Proust C (1999) Les problèmes d’ordonnancement de type flow-shop hybride: état de l’art. RAIRO 33(2):117–183
Wang H (2005) Flexible flow shop scheduling: optimum, heuristics and artificial intelligence solutions. Expert Syst 22:78–85
Zhang Y, Liang X, Li W, Zhang Y (2013) Hybrid flow shop problem with blocking and multi- product families in a maritime terminal. In: 2013 IEEE 10th International Conference on Networking, Sensing and Control (ICNSC)
Acknowledgements
The support of the National Council for Scientific and Technological Development (CNPq) is acknowledged and appreciated.
Author information
Authors and Affiliations
Corresponding author
Additional information
Technical Editor: Fernando Antonio Forcellini.
Rights and permissions
About this article

Cite this article
Moccellin, J.V., Nagano, M.S., Pitombeira Neto, A.R. et al. Heuristic algorithms for scheduling hybrid flow shops with machine blocking and setup times. J Braz. Soc. Mech. Sci. Eng. 40, 40 (2018). https://doi.org/10.1007/s40430-018-0980-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40430-018-0980-4