
Abstract
Purpose of Review
The use of social media to conduct digital surveillance to address different health challenges is growing. This multidisciplinary review assesses the current state of methods and applied research used to conduct digital surveillance for prescription drug abuse.
Recent Findings
Fifteen studies met our inclusion criteria from the databases reviewed (PubMed, IEEE Xplore, and ACM Digital Library). The articles were characterized based on their overarching goals and aims, data collection and dataset attributes, and analysis approaches. Overall, reviewed studies grouped into two overarching categories as either being method-focused (advancing novel methodologies using social media data), applied-focused (generating new information on prescription drug abuse behavior), or having both elements. The social media platform most predominantly used was Twitter, with wide variation in sample size and duration of data collection. Several data analysis strategies were employed, including machine learning, temporal analysis, rule-based approaches, and statistical analysis.
Summary
Our review indicates that the field of prescription drug abuse digital surveillance is still maturing. Though many studies captured large volumes of data, the majority did not analyze data to characterize user behavior, a critical step needed in order to better explain the underlying risk environment for prescription drug abuse. Future studies need to better translate method-based approaches into applied research, use data generated from social media platforms other than Twitter, and take advantage of emerging data analysis strategies, including deep learning and multimodal approaches.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
A prescription drug abuse epidemic is currently underway in the USA and now constitutes a full-fledged public health crisis with no signs of slowing [1,2,3]. The patient safety harms of misuse of prescription opioids, depressants, and stimulants are multifaceted and associated with challenges including overprescribing or misprescribing, lack of training and funding for addiction treatment and prevention, diminished risk perception of abuse potential compared to illicit drugs, behavioral linkages to other forms of illicit substance abuse (such as transition to heroin addiction and the rise of synthetic fentanyl-related deaths), and other policies related to access, monitoring, and product formulations [3,4,5,6,7,8,9,10,11,12,13]. Though this public health problem continues to escalate—evidenced by data in 2015 from the National Survey on Drug Use and Health reporting over 50,000 deaths due to drug overdose (more than 60% related to opioids)—policy responses have been incomplete, likely influenced by a lack of sufficient data needed to understand the true extent and nature of the problem [14].
Critically, in order to effectively address the complex challenges of prescription drug abuse, robust public health surveillance is needed to accurately detect, measure, and report the prevalence of different forms of substance abuse behavior (e.g., classes of drugs abused, polydrug abuse, injection drug use), the incidence of prescription drug-related overdose and death, and changing perceptions, attitudes, and venues of access that enable prescription drug abuse behavior. Currently, data describing the overall risk environment for prescription drug abuse is largely derived from national population-based surveys that employ respondent-driven approaches (including interviews and self-administered questionnaires) to collect information about past drug use behavior [15,16,17]. This is coupled with data from the Centers for Disease Control and Prevention (CDC) National Vital Statistics System that reports drug-related overdose deaths generated from death certificates. However, survey-based instruments are subject to certain limitations such as recall bias and inherent delays in creating, employing, and compiling survey results [18]. Similarly, overdose data may be underestimated and only function as a measure of mortality as an endpoint, not necessarily reflecting underlying risk behavior.
In order to complement nationally representative surveys that may be generalizable to large population groups but may lack granularity, researchers have begun to recognize the power of mining and analyzing “big data” in a growing networked and social media-enabled society, a practice commonly known as “infoveillance” or “digital epidemiology” [19, 20]. Simultaneous advances of Web 2.0 (the interactive web) and the ubiquity of mobile and internet-connected devices have also enabled users to constantly create, share, and engage with online communities and also create their own digital identities/profiles [21, 22]. As an example, the popular microblogging platform Twitter generates more than 500 million messages per day published from more than 300 million active users, and 79% of all online Americans now use the world’s most popular social media platform Facebook [23].
The user-generated content created on such platforms can be obtained through accessing different application programming interfaces (API) that often enable real-time and/or retrospective data surveillance and monitoring. Hence, growing popularity of online social interaction by users and the concomitant increase in volume and access to social media data has resulted in digital surveillance emerging as an important interdisciplinary form of research, mainly focused on better understanding areas of the health, life sciences, and social behavioral fields. This also includes research that specifically focuses on identifying current and emerging trends and attitudes associated with prescription drug abuse [24, 25].
Hence, this article comprehensively reviews the literature to gain a better understanding of the current state of research methods and approaches in digital surveillance aimed at addressing prescription drug abuse. The primary goal of this review was to identify and characterize key approaches central to this form of area of inquiry, assess challenges and opportunities associated with the advancement of the methodologies and technologies utilized, and gain a better understanding of how the field will evolve in the future.
Methods
Our literature review was performed using keyword search queries on three scholarly databases including the Institute of Electrical and Electronics Engineers (IEEE) Xplore Digital Library (articles on information, communication, and engineering research), the Association for Computing Machinery (ACM) Digital Library (articles on advances in computer science research), and the PubMed/Medline database (articles that focus on the science/health literature). Our literature review was conducted between April and June 2017 and searches were limited to English-language articles. Our structured search queries included the parent key terms “social media” in combination with “prescription drug abuse” in preliminary searches. Our second-level searches included a combination of sub-category social media terms (including “Facebook,” “Instagram,” “Pinterest,” “Linkedin,” and “Twitter”). We chose these specific social media keywords as survey data from the Pew Research Center indicate they are the most popular social media platforms among online adult users in the USA [23].
In each of the databases, two advanced search functions were performed using the parent search terms “prescription drug abuse” AND “social media” (“AND” here is a boolean operator), and the sub-category terms “prescription drug abuse” AND “NAME OF PLATFORM” (i.e., Facebook). The advanced search settings were set to retrieve all literature which contained matching terms anywhere in the content and the metadata (title, abstract, author name, etc.). No restrictions were imposed on the date of publication. Once an output of indexed papers was retrieved, the abstract of each article was reviewed to evaluate its relevance to the scope of our review.
Our criteria for review study inclusion included the following conditions: (1) articles limited to research, review, and methods content types (i.e., excluding commentaries, case/field reports, editorials, indexed news articles, and other articles that did not present original data analysis or discussion/experimentation of methodological approaches); (2) articles that focused on prescription drug abuse, not other types of health behavior or forms of substance abuse (i.e., we excluded articles associated with tobacco, alcohol, cannabis, and illicit drug use); and (3) articles that focused on use of social media platforms (i.e., we excluded articles that reported use of other online technologies that were not social media platforms such as Internet forums). For articles that met these inclusion criteria, the full text was extracted for in-depth review and then characterized in terms of key attributes and themes. We note that in cases when a method-focused article was not specific about exact drug classes covered, we included the study as it was deemed applicable for characterizing overall prescription drug abuse surveillance or data analysis approaches.
Topics that were retrieved but excluded from this review included articles that utilized social media to detect adverse patient safety events associated with prescription drugs, articles focused on ethical considerations of social media-based research, articles describing use of wearable sensors and devices for studying drug abuse behavior, and articles focused on interventions aimed at changing drug abuse behavior that did not include a surveillance component. These topics were viewed as beyond the scope of this study but arguably deserve their own separate review in the context of how they leverage social media technologies [26, 27].
Results
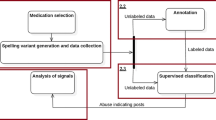
Our review of the literature and multiple scholarly databases yielded a total of 15 manuscripts that met the inclusion criteria. This included 33% (n = 5) retrieved from the IEEE Xplore Digital Library, 20% (n = 3) from the ACM Digital Library, and 47% (n = 7) from the PubMed/Medline database (see Fig. 1 for visual depiction of literature review search methodology and results). In terms of publication type characteristics, the majority of publications were published as journal articles (60%, n = 9) in comparison to conference-based publications (40%, n = 6, with nearly all conference publications extracted from the IEEE Xplore database).

Summary and visualization of review methodology and results
Despite imposing no date restrictions on our searches, we found that all articles satisfying our inclusion criteria were published after 2013. Interestingly, six were recently published in 2016, reflecting the rapidly emerging nature of the field and indicating that our findings represent up-to-date research methods and results. Additionally, several different prescription drug classes/products were examined in the studies reviewed including Adderall, Fentanyl, Oxycodone, OxyContin, Percocet, Valium, Vicodin, Xanax, and others. Based on our in-depth review of extracted articles, results were categorized into the following key attributes (a summary table of the goals, aims, and other characteristics of reviewed studies is provided in Table 1):
-
Overarching goals and aims of reviewed research: Our review was multidisciplinary given that the field of digital surveillance for prescription drug abuse resides at the intersection of health, behavioral, and technology sciences. Hence, we characterized reviewed articles based on what they were trying to achieve into two separate parent categories: (1) articles focused on developing methods for collecting, analyzing, and learning from data; and (2) articles focused on implications and applied results of data analysis.
-
Data collection and dataset attributes: We reviewed and categorized articles based on the methodologies deployed for data collection and management of social media data sets. We also characterized the datasets in terms of type (user profiles or social media messages), size, and timeframe.
-
Data analysis strategies: Finally, we reviewed and categorized the different types of data analysis strategies utilized. Strategies primarily focused on different uses of artificial intelligence and machine learning-based techniques, temporal analysis, and rule-based approaches.
Research Goals and Aims
Our first categorization examined articles to determine if they focused on advancing the methodology for digital surveillance or if they focused on applied approaches to generate new information about prescription drug abuse trends and behaviors. Methodology-focused articles generally consist of research articles whose primary goal is to innovate on newer techniques for utilizing social media data, but whose methods can also be applied to broader health and societal challenges. We found that 9 out of 15 articles (all three from the ACM Digital Library, four from IEEE Xplore, and two from PubMed) had a strong method focus wherein they describe in detail their data collection techniques and data analysis strategies. Five articles focused on both the underlying methods and technology and the real-world implication of their results and were categorized as being both methods and applied research. The article by Scott et al. did not fall under either of these categories as it discussed more generally the opportunities for exploring prescription drug abuse research through social media, but did not include its own original research methodology or data [24].
In terms of the primary aims of research articles reviewed, two major themes emerged. One set of articles focused on surveillance of prescription drug abuse-related posts where the goal was more narrowly focused simply on identifying and detecting posts/messages related to prescription drug abuse behavior but did not take the extra step to characterize behavior reported in social media content. The other set of articles focused on detecting and characterizing the behavior of users who post social media content related to prescription drug abuse. Overall, 67% of articles (n = 10) focused on surveillance and detection [15, 27, 29, 30•, 33, 34•, 35,40,39,37, 39, 40], whereas 33% (n = 5) focused on studying the behavior and attitudes of users who discuss prescription drug abuse on social media platforms [15, 28••, 31••, 32, 38].
Among the articles focused on surveillance, method-oriented papers generally proposed different strategies aimed at differentiating prescription drug abuse content from other non-relevant content generated by users. Given the large volume of content generated on social media platforms and the inherent noise in any free text platform that blur the lines between relevant and non-relevant information, this is a major challenge and subject to constant experimentation from a data collection, cleaning, and analysis perspective as discussed further.
Data Collection and Dataset Attributes
When reviewing the data collection and dataset attributes, we first focused on the social media platform types utilized in reviewed research. In this category, the majority of studies (60%, n = 9) used the microblogging site Twitter, three (20%) used the picture sharing site Instagram (e.g., sharing images such as a user sharing a picture of them holding numerous prescription pills but also allows textual comments), and three did not include actual data. All identified research accessed data streams via a public API (versus accessing datasets from commercial fee-based resellers). The high presence of Twitter-related research is likely due to the ease of public access through various Twitter APIs and the high volume of studies in other disciplines that have used Twitter data.
Depending on the goals of the work (as previously described), the data collected was either user-focused (i.e., examined the attributes of the user who generated the social media posts) [15, 31••, 34•, 37] or message-focused (i.e., examined the actual content of the social media post) [32, 40]. A user-focused data collection strategy typically involved the collection of an initial set of posts (i.e., textual messages called tweets on Twitter, and pictures and accompanying text on Instagram) from a public API in an applicable data format (e.g., JSON format). From this dataset, a set of posts that could possibly pertain to prescription drug abuse were then manually identified by human interpretation to identify a set of applicable users. As an example, Hanson et al. identified an initial 25 Twitter users who posted prescription drug abuse-related messages and then extracted their follower-followee graph to study the effects and interaction on their social circles [32]. The study found that users who discuss prescription drug abuse are oftentimes surrounded by like-minded users, possibly reinforcing negative substance abuse behavior.
In contrast, the data collection strategy for studies focused on message datasets first identified a search or a tracking entity/attribute (such as a keyword in the message of the tweet/post, key term, or hashtag that could be related to prescription drug abuse) in order to pre-filter subsequent data collection. For example, Seaman and Giraud-Carrier tracked the tweets for more than 70 prescription drug-related key terms that included both chemical and street names of commonly abused drugs, generating close to 1 million tweets [38]. The study found that prescription drugs are characterized by users as being “needed” in comparison to illicit drugs that were mostly characterized in combination with attitudes of “buying” and “selling.”
In some message-focused studies, the list of prescription drug keywords was determined prior to the study using other data sources (such as reference materials available from the National Institute on Drug Abuse) [15, 31••, 34•, 35, 38]. In other studies, a random set of social media posts were analyzed to determine appropriate selection of keywords that would track with prescription drug-related social media posts. Once the list of keywords was determined, then the corresponding social media platform API was filtered for collection of posts containing these keywords over a set period of time. The largest dataset reviewed was collected by Buntain and Golbeck and contained 821 M user posts and was filtered for 21 chemical names of drugs (e.g., Buprenorphine) and several drug slang names [28••].
Excluding the study by Buntain and Golbeck, the average size of Twitter and Instagram-related datasets was 2.16 M tweets/posts ranging from a minimum of 31.7 K to a maximum of 11 M. One study by Katsuki et al. utilized cloud computing services (Amazon Web Services) in combination with the API to optimize data collection by avoiding limit rates imposed by Twitter in order to collect a more generalizable dataset to the entire Twitter firehose [34•]. It is notable that some of the studies (primarily method-based articles) did not use any data as they were limited to proposing a theoretical framework/methodology for identifying drug abuse-related posts on social media, but did not actually test their methods on live datasets [24, 29, 36]. In terms of the duration of the datasets, the data collection timeframes ranged from 1 to 13 months (average of 5 months).
Data Analysis Strategies
Though data collection approaches were relatively structured and tied to the type of social media platform utilized, data analysis strategies reviewed included a wide and diverse range of methodologies deployed in an attempt to better understand characterizations of prescription drug abuse topics discussed in the social media sphere. The primary strategies of data analysis included application of machine learning, temporal analysis, rule-based approaches, and use of statistical analysis (e.g., descriptive statistics, correlations).
In the first category of machine learning strategies, several researchers employed automated machine learning techniques to analyze large volumes of data. Some of these studies used supervised machine learning models, which typically involved manually labeling (by human annotation and coding), a randomly selected subset of posts collected from the public API, and then categorizing them as either related to prescription drug abuse or as non-relevant (i.e., a binary categorization) [34•, 35]. Following this manual annotation, a machine classifier was trained on this test dataset to further automatically detect and categorize messages related to prescription drug abuse from the remaining and much larger dataset.
Machine learning that relies on a training phase using human annotation also involves choosing the right features as inputs for the classifiers (features can be thought of as some measurable property of the entity of interest). In the studies we reviewed, typically, only content-based features were used to train the classifiers. Content-based features are built based on the content of the post created by the user. For example, Kalyanam et al. postulated that the presence of adjectives or verbs related to substance abuse risk behavior (e.g., overdose, withdrawal) in tweets could be indicative of self-reporting of prescription drug abuse behavior on social media [15]. These specific terms were then analyzed to summarize patterns in the Twitter text corpus and found a high proportion of polydrug abuse-related discussion, including abuse of multiple classes of prescription drugs and combination use with other illicit drugs. Similarly, Phan et al. proposed that the presence of words like “high,” “stoned,” and “addicted” in a post which also contained drug names like OxyContin would suggest that the content is also highly related to prescription drug abuse [35]. This study focused on testing and validating different classification algorithms in real-time to assess precision in accurately detecting drug abuse-related tweets.
While such content-based features can possess discriminative properties that are capable of characterizing and distinguishing between different content, research indicates that metadata that surrounds the content (like the timestamp on the post or the number of times the post was viewed and shared) is also equally important in enabling machine learning algorithms to accurately distinguish different types of content [41]. Once the content-based features are built, supervised machine classifiers that were used for this type of machine learning included Naive Bayes, support vector machines, logistic regression, and decision trees.
Another class of machine learning involved unsupervised techniques (which require minimal human annotation for training purposes), with the most common used for topic modeling [15, 30•] and grouping similar data into clusters, called clustering [31••]. Ding et al. and Kalyanam et al. employed topic models like latent Dirichlet allocation (LDA) and biterm topic model (BTM) to detect clusters of commonly co-occurring words (also known as topics) to summarize the content present in posts, and subsequently extracted topics and related posts which had a strong indication of being related to prescription drug abuse [15, 30•]. Ding et al. used LDA to identify drug-related topics from Instagram post comments and used neural networks to identify changes in drug abuse terminology and hashtags. Kalyanam et al. used BTM to isolate macro themes related to prescription drug abuse behavior, finding that polydrug abuse was the most prevalent risk behavior discussion topic associated with three commonly abused prescription drugs.
In contrast to supervised machine classifiers that only use content-based features, these unsupervised models employ a variety of other features that might be available either in the message or metadata (e.g., information about the user profile) of the social media dataset. Some of these features include geolocated GPS data (e.g., clustering posts near college campuses) and hierarchical clustering on the follower-followee network (clustering based on the graph of the social network) [31••, 40]. Importantly, these unsupervised techniques were capable of generating and interpreting patterns from the entire dataset without reliance on an initial human-trained dataset [15].
In the second category of data analysis strategies, some studies analyzed prescription drug abuse-related tweets from a longitudinal and geospatial analysis perspective [31••, 37, 38, 40]. In many of these studies, the data were not geographically limited to the USA or any other jurisdiction. This required the data to be converted to a common time zone prior to conducting temporal analysis and also normalizing data to population density. For example, geocoded data was analyzed to determine geographic origin and potential user demographics associated with drug abuse-related tweets. Buntain and Golbeck geocoded 223 tweets for the slang term “oxy” (i.e., OxyContin) reporting concentration in pacific northwestern states, Hanson et al. used geolocated tweets to identify college and university clusters with the highest Adderall-related tweeters, and Katsuki et al. geocoded over 2000 tweets for various chemical and street names finding a positive relationship between prescription drug abuse tweets and areas with higher youth density [28••, 31••, 34•].
The methodology for temporal analysis typically involved plotting the volume of social media posts over time and conducting a visual examination and interpretation of the plot for the purposes of understanding the temporal patterns of drug abuse behavior [31••, 37, 38, 40]. Hanson et al. used temporal data of tweets associated with the drug Adderall to determine the average number of tweets per day of the week (finding that more tweets occurred on the weekdays) and during periods of the year (i.e., particular months of the year) [31••]. One of their main findings was detection of large spikes in Adderall-related Twitter conversations in December and May, months corresponding to college final exam periods. In another example, Seaman and Giraud-Carrier found an increase in the volume of drug abuse posts in the winter months, contrasted with a decrease of these posts during the summer months indicating consistent patterns that could be associated with the prevalence of depression [38]. The temporal analysis conducted by Buntain and Golbeck also involved a linear regression fit of the volume-vs-time plot. The aim of performing a regression fit is to learn the relationship of the dependent variable (in this case, the volume of posts) as a function of the independent variable (in this case, time), though results presented in this study focused on measuring the popularity trends of illicit drug keywords not prescription drugs [28••].
Finally, machine learning approaches are generally thought of as employing models that are implicitly able to learn the differences between two binary classes based on some training set. In contrast, rule-based approaches are those in which rules are hard coded into the methodology as opposed to being learned from training data. These rules are created by inferring from earlier studies or from field experts. Four studies employed some form of rule-based approach to identify prescription drug abuse-related posts on social media [32, 33, 36, 38]. Based on an earlier study, Hanson et al. divided the tweets they collected into eight different categories of risk and abuse behaviors to deduce conclusions about the prevalence and behavior of drug abuse and its association with reinforcing risk behaviors and social norms [32]. Relatedly, Jenhani et al. proposed an innovative hybrid framework of both rule and machine learning-based approaches to identify prescription drug abuse-related posts and presented the performance gains obtained using the hybrid approaches over several non-hybrid baselines [33]. They first used grammatical and linguistic rules to summarize the content in a structured manner (e.g., as subject, verb, object). In combination with these structured outputs, they used other features such as sentence length as inputs for use in supervised machine learning models and demonstrated better performance (shown through evaluation measures such as accuracy, precision, and recall) in detecting prescription drug abuse-related content.
Insights and corroborations were also generated through conventional statistical measures. For example, Hanson et al. used measures like mean, standard deviation, and Pearson correlation to study participation in social circles on social media and its association with an individual’s drug abuse behavior. They also used graph-based analyses including modeling the influence of prescription drug abuse behavior between users (or nodes) through weighted edges [32].
Discussion
Our review of the literature on digital surveillance of prescription drug abuse indicates that in terms of the overarching goals, the majority of studies focused on surveillance methods rather than attempting to understand the attitudes, motivations, and user characterizations of prescription drug substance abuse behavior that occurs on social media. Though social media platforms have the advantage of readily lending themselves to minimally invasive “social listening,” there is clearly a need for more concerted efforts to translate methodologically focused research to applied findings. This translation could better elucidate what underlying factors are fueling the prescription drug abuse crisis and better inform healthcare practitioners, law enforcement officials, drug regulators, patient advocacy groups, and the public about possible solutions. Relatedly, we also observed a clear difference in the nature of studies published in the IEEE and ACM digital libraries compared to those published in PubMed. IEEE/ACM articles placed very little focus on the implications of results, while PubMed-indexed research generally gave equal weight to both methods and implications.
As noted in our “Results” section, we performed searches for prescription drug abuse-related studies that use any type of social media and specifically for the most popular platforms of Facebook, Instagram, Pinterest, LinkedIn, and Twitter. Among these, none of the studies utilized data generated on Facebook, Pinterest, or LinkedIn. Due to the nature of social network sites specializing for specific purposes and different strategies of content curation, it is not surprising that LinkedIn did not include studies meeting our inclusion criteria (e.g., LinkedIn is used for professional networking purposes and does not generally contain user-generated content about substance abuse behavior). Conversely, Twitter was the most popular platform as it includes large volumes of user-generated content self-reporting various forms of human behavior and is highly accessible [34•]. In contrast, though Facebook also includes high volumes of user-generated behavioral content, its public API only contains a small sample of data generated by Facebook users, in part due to privacy issues and the openness of its API. One glaring omission in the literature is the lack of any published studies that combine data observations and conduct comparative analysis of prescription drug abuse-related content from multiple social media sites.
While Pinterest and Instagram also have APIs that are relatively straightforward to use, we found only three studies using Instagram and none using Pinterest. One primary reason why image-based social media sites do not include more published research is the difficulty of using data science and machine learning techniques to analyze image data. Enormous advances have been made in the field of deep learning and neural networks in the past 5 years, especially convolutional neural networks for image understanding [42]. These techniques are at the core of many systems at Google, Amazon, Apple, and Facebook. However, these tools have apparently been underutilized in the context of prescription drug abuse surveillance. Only one article by Ding et al. used these techniques to analyze the text content of tweets (not images) to determine how the vocabulary changes overtime [30•]. Especially for image-based data (like Instagram), the use of convolutional neural nets could remarkably improve the surveillance of prescription drug abuse-related posts by more accurately triangulating content that both communicate substance abuse behavior through a message (text) and a related image generated in the post [39].
In terms of the types of data analysis methodologies utilized, we note that the majority of machine learning algorithms used only one modality of data (e.g., the textual content of user posts) to train their models. While different types of features are used to train both supervised and unsupervised models, the simultaneous utilization of different features (also known as multiple modalities) under a single model is still underexplored in the literature. In the field of machine learning, it is well accepted that using more than one modality (or “type” of input) achieves better results (also known as “multiple kernel learning”) as extremely relevant information usually lies at the intersection of these modalities [43]. For example, if a tweet has a message including a substance abuse keyword (e.g., name of drug or verb such as “high”), an embedded image depicting substance abuse (e.g., selfie of an individual holding or ingesting a pill), and also includes geocoded metadata indicating an area with a high rate of overdose, then the combination of this content may help to provide more resolution to surveillance data and substance use behavior. Some papers used both text and the image modalities [30•, 39, 40]; however, the usage was restricted to retrieval tasks (e.g., retrieving images based on a text search). In this area, techniques to fully leverage machine learning and the availability of different types of data have room for development.
Other studies that were ultimately excluded from our final results based on drug class (e.g., cannabis and synthetic cannabinoids) reinforced the utilization of social media to potentially detect substance abuse users by examining their online profiles. A study by Baumgartner and Peiper collected a user-focused dataset comprised of a total of 11 M users with the aim of identifying emerging communities of cannabis users. They began with a seed set of users (six user profiles that were pre-identified and screened to be related to drug abuse) and then collected information about these user’s followers network [44]. They also collected the periphery network of the followers’ followers or otherwise known as the two-hop network to expand the scope of their user dataset. After subsequent analysis, they identified communities of “medical,” “recreational,” and “illicit” use of cannabis and further categorized these communities into finer granularity and studied their characteristics.
Other interesting results that emerged from this review not related to our central theme of methods or characterization of behavior included studies establishing a clear link between prescription drug abuse, social media marketing, and online sale of controlled substances by illicit Internet pharmacies [15, 34•, 45]. These websites aggressively market the direct-to-consumer sale of prescription drugs often without the requirement for a valid prescription, despite this activity expressly prohibited by law in the USA under the Ryan Haight Online Pharmacy Consumer Protection Act (2008) [25]. Katsuki et al. establish a formal empirical link between tweets containing prescription drug abuse-related keywords and illicit online pharmacies by identifying a subset of tweets and Twitter users (8171 in total) with imbedded hyperlinks that redirect users to direct purchase of controlled substances online [34•]. Importantly, these results can form the basis for future digital surveillance approaches to monitor, detect, and report illicit online pharmacies that are in violation of Federal law. It can also aid efforts by other organizations (such as the US Food and Drug Administration, US Drug Enforcement Agency, Interpol, and the World Health Organization) that have highlighted the public health dangers posed by illicit online pharmacies and their association with contributing to prescription drug abuse [25, 46, 47].
Limitations
This review has certain limitations. First, we note that though this review was thorough and utilized structured inclusion criteria for extraction of study results, we did not conduct a systematic review of the literature. This was related to the relatively nascent nature of the field as methods and approaches to digital surveillance continue to mature and evolve in part due to rapid advances in technology. This limits the generalizability of our results. Further, though the concept of open science (enabling open deposit, sharing and access to scientific data) is gaining traction among researchers, academic institutions, and journals, we did not review datasets associated with reviewed studies to confirm data collection or management strategies herein described as we deemed it outside of the scope of this study and not all datasets were available in the public domain.
Conclusion
Based on our multidisciplinary review, there is clear evidence of the utility of social media platforms as an important resource for performing digital surveillance for prescription drug abuse. More importantly, through the data generated on social media platforms, public health professionals, clinicians, substance abuse counselors, and policymakers can gain direct insight about specific and emerging behavioral aspects of substance abusers that may evade detection in traditional survey and surveillance instruments. Despite this potential, the field of prescription drug abuse digital surveillance is still evolving and has yet to fully mature. Though many studies we reviewed captured large volumes of data, the majority did not translate these methods by attempting to characterize user behavior, a crucial step in understanding the underlying risk factors that are fueling the current prescription drug abuse epidemic. Future research also needs to better utilize and possibly combine user-generated data from different social media platforms, while also leveraging other innovative data analysis strategies—including deep learning and multiple modalities—to better understand the totality of the social media prescription drug abuse risk environment. Finally, in order to fully realize the potential of emerging methods and technologies, the formation and collaboration of cross-disciplinary research teams that facilitate interaction among experts across health, behavioral, and computer science is essential to the success of advancing digital surveillance in the fight against prescription drug abuse.
References
Papers of particular interest, published recently, have been highlighted as: • Of importance •• Of major importance
Voelker R. Opioid overdoses continue to climb. JAMA. 2016;315:550.
Rudd RA, Aleshire N, Zibbell JE, Gladden RM. Increases in drug and opioid overdose deaths—United States, 2000–2014. Morb Mortal Wkly Rep. 2016;64:1378–82.
Schuchat A, Houry D, Guy GP. New data on opioid use and prescribing in the United States. JAMA. American Medical Association. 2017.
Meldrum ML. The ongoing opioid prescription epidemic: historical context. Am J Pub Health. American Public Health Association. 2016;106(8):1365–1366.
Nelson LS, Juurlink DN, Perrone J. Addressing the opioid epidemic. JAMA. American Medical Association. 2015;314:1453–4.
Becker WC, Fiellin DA. Abuse-deterrent opioid formulations—putting the potential benefits into perspective. N Engl J Med. 2017;376:2103–5.
Califf RM, Woodcock J, Ostroff S. A proactive response to prescription opioid abuse. N Engl J Med. 2016;374:1480–5.
Centers for Disease Control and Prevention (CDC). CDC grand rounds: prescription drug overdoses—a U.S. epidemic. Morb Mortal Wkly Rep. 2012;61:10–3.
Frank RG, Pollack HA. Addressing the fentanyl threat to public health. N Engl J Med. 2017;376:605–7.
Strathdee SA, Beyrer C. Threading the needle—how to stop the HIV outbreak in rural Indiana. N Engl J Med. 2015;373:397–9.
McHugh RK, Nielsen S, Weiss RD. Prescription drug abuse: from epidemiology to public policy. J Subst Abus Treat. 2015;48:1–7.
Longo DL, Compton WM, Jones CM, Baldwin GT. Relationship between nonmedical prescription-opioid use and heroin use. N Engl J Med. 2016;374:154–63.
Florence CS, Zhou C, Luo F, Xu L. The economic burden of prescription opioid overdose, abuse, and dependence in the United States, 2013. Medical Care. 2016;54:901–6.
Untangling the web of opioid addictions in the USA. Lancet. 2017;389:2443.
Kalyanam J, Katsuki T, Lanckriet GR, Mackey TK. Exploring trends of nonmedical use of prescription drugs and polydrug abuse in the Twittersphere using unsupervised machine learning. Addict Behav. 2017;65:289–95.
Han B, Compton WM, Jones CM, Cai R. Nonmedical prescription opioid use and use disorders among adults aged 18 through 64 years in the United States, 2003–2013. JAMA. 2015;314:1468–78.
McCabe SE, West BT. Medical and nonmedical use of prescription stimulants: results from a national multicohort study. Journal of the American Academy of Child & Adolescent Psychiatry. 2013;52:1272–80.
Harrison L, Hughes A. Introduction—the validity of self-reported drug use: improving the accuracy of survey estimates. NIDA Res Monogr. 1997;167:1–16.
Hay SI, George DB, Moyes CL, Brownstein JS. Big data opportunities for global infectious disease surveillance. PLoS Med. 2013;10:e1001413.
Salathé M, Bengtsson L, Bodnar TJ, Brewer DD, Brownstein JS, Buckee C, et al. Digital epidemiology. Bourne PE, editor. PLoS Comp Biol. 2012;8:e1002616.
A digital revolution in health care is speeding up [Internet]. economist.com. 2017 [cited 2017 Jul 7]. Available from: https://www.economist.com/news/business/21717990-telemedicine-predictive-diagnostics-wearable-sensors-and-host-new-apps-will-transform-how
Villanti AC, Johnson AL, Ilakkuvan V, Jacobs MA, Graham AL, Rath JM. Social media use and access to digital technology in US young adults in 2016. J Med Internet Res. 2017;19:e196.
Greenwood S, Perrin A, Duggan M. Social Media Update 2016 [Internet]. pewinternet.org. 2016 [cited 2017 Jul 7]. Available from: http://www.pewinternet.org/2016/11/11/social-media-update-2016/
Scott KR, Nelson L, Meisel Z, Perrone J. Opportunities for exploring and reducing prescription drug abuse through social media. J Addict Dis. 2015;34:178–84.
Mackey TK, Liang BA, Strathdee SA. Digital social media, youth, and nonmedical use of prescription drugs: the need for reform. J Med Internet Res. 2013;15:e143.
Golder S, Ahmed S, Norman G, Booth A. Attitudes toward the ethics of research using social media: a systematic review. J Med Internet Res. 2017;19:e195.
Shaw JM, Mitchell CA, Welch AJ, Williamson MJ. Social media used as a health intervention in adolescent health: a systematic review of the literature. Digital Health. 2015;1:205520761558839.
•• Buntain C, Golbeck J. This is your Twitter on drugs: any questions? WWW '15 Companion. New York: ACM; 2015. p. 777–82. Study that uses crucial techniques for temporal analysis like window-smoothing and linear regression to determine trends in drug abuse.
Cameron D, Smith GA, Daniulaityte R, Sheth AP, Dave D, Chen L, et al. PREDOSE: a semantic web platform for drug abuse epidemiology using social media. J Biomed Inform. 2013;46:985–97.
• Ding T, Roy A, Chen Z, Zhu Q, Pan S. Analyzing and retrieving illicit drug-related posts from social media. 2016 I.E. International Conference on Bioinformatics and Biomedicine (BIBM). IEEE; 2016. pp. 1555–60. First and only study to utilize the power of neural networks and deep learning in study design.
•• Hanson CL, Burton SH, Giraud-Carrier C, West JH, Barnes MD, Hansen B. Tweaking and tweeting: exploring Twitter for nonmedical use of a psychostimulant drug (Adderall) among college students. J Med Internet Res. 2013;15:e62. Study that utilizes multiple approaches to data analysis including temporal and geospatial analysis to identify trends in Adderall drug-abuse behavior
Hanson CL, Cannon B, Burton S, Giraud-Carrier C. An exploration of social circles and prescription drug abuse through Twitter. J Med Internet Res. 2013;15:e189.
Jenhani F, Gouider MS, Said LB. A hybrid approach for drug abuse events extraction from Twitter. Procedia Computer Science. 2016;96:1032–40.
• Katsuki T, Mackey TK, Cuomo R. Establishing a link between prescription drug abuse and illicit online pharmacies: analysis of Twitter data. J. Med Internet Res. 2015;17:e280. First study to establish empirical link between twitter content and illegal prescription drug sales by online pharmacies
Phan N, Chun SA, Bhole M, Geller J. Enabling real-time drug abuse detection in tweets. 2017 I.E. 33rd International Conference on Data Engineering (ICDE). IEEE pp. 1510–4 2017.
Raja BS, Ali A, Ahmed M, Khan A, Malik AP. Semantics enabled role based sentiment analysis for drug abuse on social media: a framework. 2016 I.E. Symposium on Computer Applications & Industrial Electronics (ISCAIE). IEEE; pp. 206–11 2016.
Sarker A, O'Connor K, Ginn R, Scotch M, Smith K, Malone D, et al. Social media mining for toxicovigilance: automatic monitoring of prescription medication abuse from Twitter. Drug Saf. 2016;39:231–240.
Seaman I, Giraud-Carrier C. Prevalence and attitudes about illicit and prescription drugs on Twitter. 2016 I.E. International Conference on Healthcare Informatics (ICHI). IEEE. pp. 14–7 2016.
Yang X, Luo J. Tracking illicit drug dealing and abuse on Instagram using multimodal analysis. ACM Transactions on Intelligent Systems and Technology (TIST). ACM; 2017;8:58–15.
Zhou Y, Sani N, Luo J. Fine-grained mining of illicit drug use patterns using social multimedia data from Instagram. 2016 I.E. International Conference on Big Data (Big Data). IEEE. pp. 1921–30 2016.
Kalyanam J, Mantrach A, Saez-Trumper D, Vahabi H, Lanckriet G. Leveraging social context for modeling topic evolution. KDD '15. New York: ACM; 2015. p. 517–26.
Krizhevsky A, Sutskever I, Hinton GE. ImageNet classification with deep convolutional neural networks. NIPS'12 2012;1097–1105.
Bach FR, Lanckriet GR, Jordan MI. Multiple kernel learning, conic duality, and the SMO algorithm. ICML '04. New York: ACM Press; 2004. p. 6.
Baumgartner P, Peiper N. Utilizing big data and Twitter to discover emergent online communities of cannabis users. Subst Abuse. 2017;11:1178221817711425.
Mackey TK, Liang BA. Global reach of direct-to-consumer advertising using social media for illicit online drug sales. J Med Internet Res. 2013;15:e105.
Mackey TK, Nayyar G. Digital danger: a review of the global public health, patient safety and cybersecurity threats posed by illicit online pharmacies. Br Med Bull. 2016;118:110–26.
Forman RF. Availability of opioids on the Internet. JAMA. 2003;290:889.
Author information
Authors and Affiliations
Contributions
JK and TM jointly collected the data, designed the study, conducted the data analyses, and wrote the manuscript. All authors contributed to the formulation, drafting, completion, and approval of the final manuscript. There was no involvement of anyone other than the authors in the conception, design, collection, planning, conduct, analysis, interpretation, writing, and discussion to submit this work. Authors report no other financial relationships with any organizations that might have an interest in the submitted work.
Corresponding author
Ethics declarations
Conflict of Interest
Janani Kalyanam declares that she has no conflict of interest.
Tim K. Mackey is a non-compensated member of the academic advisory panel of the Alliance for Safe Online Pharmacies (ASOP), a 501(c)(4) social welfare organization engaged on the issue of illicit online pharmacies. He received funding for a separate ASOP pilot research grant exploring prescription drug abuse risks online not related to this study.
Human and Animal Rights and Informed Consent
This article does not contain any studies with human or animal subjects performed by any of the authors.
Additional information
This article is part of the Topical Collection on Adolescent / Young Adult Addiction
Rights and permissions
About this article

Cite this article
Kalyanam, J., Mackey, T.K. A Review of Digital Surveillance Methods and Approaches to Combat Prescription Drug Abuse. Curr Addict Rep 4, 397–409 (2017). https://doi.org/10.1007/s40429-017-0169-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40429-017-0169-4