
Abstract
In this paper, we propose a fast adaptive algorithm for solving nonlinear inverse problems in Hilbert spaces. The iterative process of the proposed method combines classical two point gradient method and adaptive accelerate strategy. In practice, it is often encountered that the reconstruction solution has special feature, such as sparsity and slicing smoothness. To capture the special feature of solution, convex functions are utilized to be penalty terms in iterative format. Meanwhile, a complete convergence analysis is given to show the theoretical rationality of the algorithm. The numerical simulations are provided to demonstrate the effectiveness and acceleration effect of the proposed method.
Similar content being viewed by others
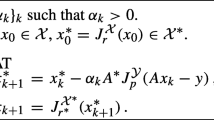

Avoid common mistakes on your manuscript.
1 Introduction
In this paper, we are interested in nonlinear inverse problem that can be formulated as
Here \(F:\mathcal {D}(F)\subset \mathcal {X}\rightarrow \mathcal {Y}\) is a nonlinear operator with its definition domain \(\mathcal {D}(F)\). The core of the inverse problem is to try to get an approximate solution to problem (1) by knowing the composition of the data y and the forward operator F (Engl and Ramlau 1996; Kaltenbacher et al. 2008; Ito and Jin 2014; Schtster et al. 2012; Leonardo et al. 2015). Algorithmically, using gradient descent method applied to the functional
we obtain the classical Landweber iteration (Hanke et al. 1995; Scherzer 1998) of the form
Theoretically, the complete convergence analysis of this method has been widely studied. It is well known that, under the general assumptions of the next section, the rate of convergence of \(x_n\rightarrow x^*\) (\(x^*\) is the true solution to Eq. (1).) as \(n\rightarrow \infty \) will, in general, be arbitrarily slow (Kaltenbacher et al. 2008). Therefore, it is necessary to study acceleration strategies, to apply it to practice satisfactorily.
Recently, an accelerated gradient method which applied on the convex problem
was proposed in Hubmer and Ramlau (2018) with the form
Here, \(\omega >0\) is the step size, and \(\alpha \ge 3\). This is called the Nesterov acceleration strategy. It has proved that the convergence rate for Nesterov method is \(\mathcal {O}(n^{-2})\). By applying this method to problem (1) and replacing \((n-1)/(n+\alpha -1)\) with the combination parameter \(\lambda _n\), we obtain the so-called two point gradient method (Hubmer and Ramlau 2017) of the form
In addition, the adaptive strategy uses a novel idea to solve nonlinear inverse problems (Kaltenbacher et al. 2008; Beck and Teboulle 2003). The key point of this method is to make the item after each iteration closer to the true solution by projecting the initial iteration point onto the strip containing the true solution set. We apply this method to replace the step size used in the iteration with the adaptive step size, the details of which will be discussed later.
In the case that the true solution of (1) has a priori features such as sparsity and slicing smoothness and so on, we consider \(\varTheta :\mathcal {X}\rightarrow (-\infty ,\infty ]\). Meanwhile, we introduce the Bregman distance by \(\varTheta \)
where \(x\in \mathcal {X}\) and \(\xi \in \partial \varTheta (x)\). Inspired by the above approaches, the sought solution of (1) with desired feature can be obtained by minimizing the following functional
with Tikhonov parameter \(\beta >0\) and initial choice \(x_0\in \mathcal {X}\), \(\xi _0\in \partial \varTheta (x_0)\) (Jin and Lu 2014; Wald 2018; Jin 1999). By splitting the terms of F and \(\varTheta \), we obtain the adaptive two point gradient iteration with convex penalty term (ATPG-\(\varTheta \))
This method inherits the acceleration advantage of the two point gradient method (Nesterov), and uses the adaptive step size to improve the search direction. In addition, when we encounter true solutions with special features, we use convex penalty terms for reconstruction. In this paper, we verify the complete convergence analysis of the proposed method and obtain satisfactory results in several numerical simulations.
The subsequent paper is structured as follows: some hypotheses and follow-up useful results are introduced in Sect. 2. In Sect. 3, we give the iteration scheme in detail and show the convergence analysis of ATPG-\(\varTheta \). Several numerical simulations are present to show the effectiveness and acceleration of the method in Sect. 4. Finally, we summarize our conclusions in Sect. 5.
2 Preliminaries
In the following, we discuss some of the necessary tools and assumptions for subsequent analysis.
2.1 Basic tools
Define a convex function \(\varTheta :\mathcal {X}\rightarrow (-\infty ,\infty ]\) with its effective domain \(\mathcal {D}(\varTheta ):=\{x\in \mathcal {X}:\varTheta (x)<\infty \}\). If \(\mathcal {D}(\varTheta )\ne \emptyset \), we call it proper. Moreover, it is strongly convex of the proper lower semi-continuous function \(\varTheta \) if there has \(c_0>0\) such that
for all \(0\le s\le 1\) and \(\tilde{x},x\in \mathcal {X}\). The subdifferential is defined by
For \(\xi \in \partial \varTheta (x)\) is the subgradient of x. Meanwhile, there holds
if \(\varTheta \) is a strongly convex function.
For a proper, lower semi-continuous, convex function \(\varTheta :\mathcal {X}\rightarrow (-\infty ,\infty ]\), we define its Legendre–Fenchel conjugate with the form
Consequently,
Then the Bregman distance can be redefined as
According to the reference (Zalinescu 2002; Schirotzek 2007), we know that \(\varTheta ^*\) is Fréchet differentiable and its gradient \(\nabla \varTheta ^*\) is Lipschitz continuous with the form
where \(c_0\) is shown in (7).
In this paper, we choose an initial guess \(\xi _0\in \mathcal {X}\) and
2.2 Assumption
To ensure the convergence property of the proposed method, we give the following assumptions, which are mild in iterative methods (Kaltenbacher et al. 2008).
Assumption 2.1
Let the function \(\varTheta :\mathcal {X}\rightarrow (-\infty ,\infty ]\) be proper, lower semi-continuous, and strongly convex in the sense of (6).
Assumption 2.2
Define \(B_\rho (x_0):=\{x\in \mathcal {X}:\Vert x-x_0\Vert {\le }\rho \}\) be the closed ball around \(x_0\).
- A1:
-
(1) has a solution \(x^*\in \mathcal {D}(\varTheta )\) satisfying
$$\begin{aligned} D_{\xi _0}\varTheta (x^*,x_0)\le c_0\rho ^2. \end{aligned}$$ - A2:
-
The G\({\hat{a}}\)teaux derivative \(F'(\cdot )\) is bounded, i.e.,
$$\begin{aligned} \left\| F'(x)\right\| \le C_F,~~~ \forall x\in B_{3\rho }(x_0) \end{aligned}$$with the constant \(C_F>0\).
- A3:
-
For some \(0<\eta <1\), the \(tangential\; cone\; condition\) (TCC) of F holds, namely
$$\begin{aligned} \left\| F(x)-F(\tilde{x})-F'(x)(x-\tilde{x})\right\| \le \eta \left\| F(x)-F(\tilde{x})\right\| ,~ \forall x, \tilde{x}\in B_{3\rho }(x_0). \end{aligned}$$(11)
Corollary 2.1
Under (11) in Assumption 2.2, the following statement holds
with \(x^*\), \(\forall x,\tilde{x}\in B_{3\rho }(x_0)\) and y is the data of (1).
Proof
For a rigorous proof of this corollary the reader is referred to Kaltenbacher et al. (2008). \(\square \)
3 Convergence analysis
In the setting of nth iteration, the parameters \(r_n,u_n,t_n\) are decided by
and
where \(c_1,c_2\) are given positive numbers. As for the selection of combination parameter \(\lambda _n\), it will be given in detail in Algorithm 2. To understand the principle of the adaptive two point gradient iteration with convex penalty term (ATPG-\(\varTheta \)) more clearly, we give the following flowchart.

Without loss of generality, we stop the iteration using the residual limit, i.e., defining the stopping index \(n_*\) and constant \(C_*\) by
Lemma 3.1
For any \(x,\tilde{x}\in \mathcal {D}(\varTheta ),\xi \in \partial \varTheta (x),{\tilde{\xi }}\in \partial \varTheta (\tilde{x})\), there holds
Proof
According to (8), (9) and (10) that
\(\square \)
Define
Lemma 3.2
Let Assumptions 2.1 and 2.2 hold. For any solution \(x^*\) of (1) in \(B_{2\rho }(x_0)\cap \mathcal {D}(\varTheta )\), we have
Define the adaptive step size \(t_n\) in each iteration with the form
where \(c_1,c_2\) are given positive numbers. Define further that
Then we have
Proof
By means of the definition of Bregman distance and \(\zeta _n\), and (14), there has
It follows from the definition of the proposed method, we have
\(\square \)
Corollary 3.1
Let conditions in Lemma 3.2 hold, there exists
Proof
In Eq. (17) is easily obtained by adding (15) and (16). \(\square \)
In the following Proposition, we need two necessary conditions for combination parameters \(\{\lambda _n\}\). First, assume that
holds. Moreover, let
Proposition 3.1
Let Assumptions 2.1 and 2.2 hold. Assume that the coupling condition
holds with \(\gamma >1\). Then we have
Moreover, there holds
Proof
We show the first assertions by induction. Due to \(\xi _{-1}=\xi _0=\zeta _0\) and \(x_{-1}=x_0=z_0\), the conclusion is obvious at \(n=0\). Now we assume that the assertions hold for all \(0\le n\le m\) for some integer \(m\ge 0\). By means of (17) and (20), there holds
Combining \(\lambda _0\ge 0,\gamma >1,t_n\ge 0\) with the hypothesis \(\varDelta _{m}\le 0\) that \(\varDelta _{m+1}\le 0\). Then we have
It follows from (7) that \(\Vert x^*-x_{m+1}\Vert ^2\le \rho ^2\). Since \(x^*\in B_\rho (x_0)\) implies that \(x_{m+1}\in B_{2\rho }(x_0)\). According to (15) and (19), there holds
which implies \(z_{m+1}\in B_{3\rho }(x_0)\).
Using (22) and \(\varDelta _{n}\le 0\), there holds
i.e.,
Together with the definition of norm and the boundedness of forward operator F, we obtain that
According to the definition of adaptive step size, we have
Apply it to (23) and add it from \(n=0\) to infinity, there has
Then the assertion (21) holds. \(\square \)
In the above analysis, we used several assumptions about the combination parameters \(\{\lambda _n\}\). Based on this, we will discuss the selection rule of \(\{\lambda _n\}\), so as to meet the necessary conditions and achieve the acceleration effect.
Algorithmically, we consider that the stopping criterion (13) has not been satisfied, then there has the sufficient coupling condition:
where \(L:=\frac{4c_0\varPsi }{\gamma }\min \{\frac{c_1}{C_F^2},c_2\}\). Combining (24) with Nesterov acceleration technique, we adopt the choice of combination parameter \(\lambda _{n}\) that
In addition, we need a more demanding condition to satisfy the subsequent convergence analysis, i.e,
To satisfy this condition we choose a function \(f:\mathbb {R}^+\rightarrow \mathbb {R}^+\) satisfying
Then, the diagram in Algorithm 2 of solving \(\{\lambda _n\}\) is given.

It is easy to check that
Moreover, conditions (18)–(20), (24) and (26) can be satisfied respectively.
Proposition 3.2
Consider problem (1) for which Assumptions 2.1 and 2.2 hold. Let \(\{x_n\}\subset B_{2\rho }(x_0)\cap \mathcal {D}(\varTheta )\) and \(\{\xi _n\}\subset \mathcal {X}\) be such that
-
1.
\(\xi _n\in \partial \varTheta (x_n)\) for all n;
-
2.
for any solution \(x^*\) of (1) in \(B_{2\rho }(x_0)\cap \mathcal {D}(\varTheta )\) the sequence \(\{D_{\xi _{n}^\delta }\varTheta (x^*,x_{n})\}\) is monotonically decreasing;
-
3.
\(\lim \limits _{n\rightarrow \infty }\Vert F(x_n)-y\Vert =0\);
-
4.
there is a subsequence \(\{n_k\}\) with \(n_k\rightarrow \infty \) such that for any solution \(x^*\) of (1) in \(B_{2\rho }(x_0)\cap \mathcal {D}(\varTheta )\) there holds
$$\begin{aligned} \lim \limits _{l\rightarrow \infty }\sup \limits _{k\ge l}\mid \langle \xi _{n_k}-\xi _{n_l},x_{n_k}-x^*\rangle \mid =0. \end{aligned}$$(28)
Then there exists a solution \({\hat{x}}\) of (1) in \(B_{2\rho }(x_0)\cap \mathcal {D}(\varTheta )\) such that
If, in addition, \(x^\dagger \in B_{\rho }(x_0)\cap \mathcal {D}(\varTheta )\) and \(\xi _{n+1}-\xi _n\in \overline{\mathcal {R}\left( F'(x^\dagger )^*\right) }\) for all n, then \({\hat{x}}=x^\dagger \).
Proof
The proof can refer to Jin and Wang (2013, Proposition 3.6). \(\square \)
In the following, we present the main theoretical result of this paper, namely the convergence of the proposed method.
Theorem 3.1
(Convergence) Consider problem (1) for which Assumptions 2.1 and 2.2 hold. Then there hold
Proof
Here we only need to verify conditions (1–4) in Proposition 3.2. From the above discussion, conditions (1–3) are clearly valid.
Now we consider condition (4) in Proposition 3.2. The first case is that at some finite n, \(F(z_n)=y\), then \(\lambda _n(\xi _n-\xi _{n-1})=0\) according to (20). Thus, \(\zeta _n=\xi _n\). It follows \(\Vert r_n\Vert =0\) that \(\xi _{n+1}=\zeta _n=\xi _n=\zeta _{n+1}\). Hence, \(z_{n+1}=x_{n+1}=z_n\) and \(F(z_{n+1})=F(z_n)=y\). Repeat the above operations to obtain \(F(z_m)=y\) for all \(m\ge n\). Consequently, the statement of Proposition is true in this case.
The other case is \(\Vert F(z_n)\ne y\Vert \) for all \(n\in \mathbb {N}^+\), and we can pick a monotonically increasing sequence \(\{n_k\}\). Let \(n_k\) be the first integer meeting
Then we have
For \(0\le l<k<\infty \), we have
Then we have
Using the definition of adaptive step size, and (12), (29), we get
\(\square \)
Therefore, we obtain that
where \(C_s=\frac{3c_2\gamma }{(\gamma -1)\varPsi }(1+\eta )\). Combining the monotonicity of \(\{D_{\xi _{n}}\varTheta (x^*,x_{n})\}\) and (26), we can get condition (4) in Proposition 3.2. Then \(\lim _{n\rightarrow \infty }D_{\xi _{n}}\varTheta ({\hat{x}},x_{n})=0\). In view of (7), we also have \(\lim _{n\rightarrow \infty }\Vert x_n-{\hat{x}}\Vert =0\), which complete the proof of Proposition.
4 Numerical simulations
In this section, we show some numerical examples to illustrate the effectiveness of the proposed method. For comparison purposes, we define the following related methods.
-
1.
Landweber: The classical Landweber iteration (2).
-
2.
Landweber-\(\varTheta \): The classical Landweber iteration (2) with convex penalty term.
-
3.
ATPG-\(\varTheta \): Adaptive two point gradient method with convex penalty term, as the scheme (5).
Numerically, we need to solve
in each iteration (Boţ 2012). We can restrict the form of the operator \(\varTheta \) for different features of the sought solution, such as when the solution is sparse, we can choose \(\varTheta \) be
Then the explicit formula of (30) can be written as
In addition, when the solution has the property of piecewise continuity, we can choose
with \(\beta >0\). And TV(x) denotes the total variation of x (Rudin et al. 1992; Beck and Teboulle 2009a, b). Then (30) can be written as
Next, we conduct numerical simulations in two types of cases and adopt the parameter identification model with the form
Here, \(\varOmega \subset \mathbb {R}^d,d\le 3\) is a bounded domain with Lipschitz boundary \(\partial \varOmega \). And the function \(f\in \mathcal {H}^{-1}(\varOmega )\), \(g\in \mathcal {H}^{1/2}(\varOmega )\) are given. Assume that the sought solution \(x^\dagger \in L^2(\varOmega )\). The key idea on elliptic equation shows that (33) has a unique solution for every x in the domain
with some \(\gamma _0>0\). Consequently, in this problem, the nonlinear operator \(F:\mathcal {X}\rightarrow \mathcal {Y}\) is defined as the parameter-to-solution mapping \(F(x):=y(x)\). We know that F is Fréchet differentiable (Jin and Maass 2012). And its Fréchet derivative as well as the adjoint can be found by the following principle:
where A(x) is defined by \(A(x)y:=-\varDelta y+xy\). It is known that \(F'(x)\) is locally Lipschitz continuous so as the tangential cone condition (11) holds (Real and Jin 2020).
4.1 Sparsity
Considering the sparse nature of the solution, we give the following parameter settings:
-
Let \(\varOmega =[0,1]\), \(f_1(x)=300e^{-10(x-0.5)^2}\), and the boundary data \(y(0)=1\), \(y(1)=6\), the sparse solution
$$\begin{aligned} x^\dagger (t)= \left\{ \begin{array}{ll} 0.5,&{}\quad t\in [0.292,0.300], \\ 1,&{}\quad t\in [0.500,0.508], \\ 0.7,&{}\quad t\in [0.700,0.708],\\ 0,&{}\quad \text{ otherwise }. \end{array} \right. \end{aligned}$$ -
In the finite difference process of the forward problem, the grid size is set to \(h=1/N\) with the grid \(N=128\).
-
Set \(\eta =0.1\), \(\tau =2\) and \(C_F=0.1\). Moreover, we take \(f(n)=1/n^{1.1}\) in Algorithm 2.
In Table 1, we consider several different \(C_*=1\%,0.1\%,0.01\%\) of (13) for comparison. At the same time, several reference indicators are listed such as iteration steps \(n_*\), CPU time T and relative error \(\Vert x_{n_*}^\delta -x_*\Vert /\Vert x_*\Vert \).
By comparison, it is found that under different \(C_*\), the effect of iteration steps and computation time is obvious, which reflects the superiority of ATPG-\(\varTheta \) method over Landweber-\(\varTheta \) method. The resource consumption of ATPG-\(\varTheta \) method (iteration and computation cost) is only about 10\(\%\) that of Landweber-\(\varTheta \) method. Meanwhile, under the same conditions, the relative error of ATPG-\(\varTheta \) is smaller than that of Landweber-\(\varTheta \) after the iteration stops, that is, it is closer to the true solution.
As can be seen more clearly from Fig. 1, the iterative acceleration advantage of ATPG-\(\varTheta \) will be more obvious. At the same time, we can see that the combined parameter gradually approaches 1 as the iteration progresses to achieve a better speedup effect.

Reconstructed data generated at \(C_*=0.01\%\) in sparsity problem
More visually, Fig. 2 shows the refactoring results for different scenarios. The left column represents the reconstruction results after 1000 iterations for different methods, and the right column represents 5000 iterations. First of all, we find that in the iterative method without convex penalty (first row), the propagation results are more oscillating, and the sparse points cannot be caught. By comparing the results of the second and third rows, it can be seen that under the same conditions, the reconstruction results of ATPG-\(\varTheta \) are more satisfactory.

The reconstruction results
4.2 Piece-wise continuity property
Next, we consider the case of piecewise continuity, and simulate the two dimensions separately (Rudin et al. 1992; Zhu and Chan 2008).
4.2.1 One-dimensional case
In one-dimensional case, some related parameters are set as follows
-
Let \(\varOmega =[0,1]\), and the boundary data \(y(0)=1\), \(y(1)=6\), the sought solution
$$\begin{aligned} x^\dagger (t)= \left\{ \begin{array}{ll} 1.5,&{}\quad t\in [0.1563,0.3120], \\ 2.5,&{}\quad t\in [0.3120,0.5469], \\ 1.3,&{}\quad t\in [0.5469,0.7813],\\ 0.5,&{}\quad t\in [0.7813,1.0],\\ 0,&{}\quad \text{ otherwise }. \end{array} \right. \end{aligned}$$And \(f_2(x)=x^\dagger (1+5x)\).
-
In the finite difference process of the forward problem, the grid size is set to \(h=1/N\) with the grid \(N=128\).
-
Set \(\eta =0.1\), \(\tau =1.05\) and \(C_F=0.1\). Moreover, we take \(f(n)=1/n^{1.1}\) in Algorithm 2.
Table 2 shows the numerical results for different values of \(C_*\). It is obvious that ATPG-\(\varTheta \) has great advantages both in terms of iteration speed and computational consumption. Moreover, the relative error will be smaller after the iteration stops.
Similar to the analysis in the above example, Fig. 3 intuitively shows the wide applicability of the proposed method. On the one hand, the first line shows that the reconstruction results without convex penalties are not satisfactory. On the other hand, under the same conditions, the results of ATPG-\(\varTheta \) in the third row are obviously better than those of Landweber-\(\varTheta \) in the second row.

The reconstruction results
Figure 4 shows parameters such as residual curve and relative error curve, which can directly see the difference between the two methods.

Parametric curves in 500 iterations
4.2.2 Two-dimensional case
In two-dimensional case, some related parameters are set as follows:
-
Let \(\varOmega =[0,1]\times [0,1]\), and the sought solution
$$\begin{aligned} x^\dagger (t)= \left\{ \begin{array}{ll} 0.25,&{}\quad \textrm{if}~(x-0.35)^2+(y-0.75)^2\le 0.2, \\ 0.5,&{}\quad \textrm{if}~ (x-0.65)^2+(y-0.36)^2\le 0.18,\\ 0,&{}\quad \text{ otherwise }. \end{array} \right. \end{aligned}$$And \(f_3(x)=-5e^{x}e^{-2y}+x^\dagger e^{x}e^{-2y}\).
-
In the multigrid process of the forward problem, the grid size is set to \(h=1/N^2\) with the grid \(N=32\times 32\).
-
Set \(\eta =0.1\), \(\tau =1.1\) and \(C_F=0.1\). Moreover, we take \(f(n)=1/n^{1.1}\) in Algorithm 2.
As in the analysis of the results of the first two examples, Table 3 also shows the same conclusion in the two-dimensional case. It shows that ATPG-\(\varTheta \) is still very powerful and practical in this case.
In Fig. 5, we can see the reconstruction results of the three types of methods. The first picture shows that reasonable approximate solutions can not be obtained without convex penalty terms. We can see that there is no proper feedback at the inflection point. Meanwhile, under the same conditions, the reconstruction result of ATPG-\(\varTheta \) is closer to the sought solution.
5 Conclusions
In this paper, we propose an accelerated method (ATPG-\(\varTheta \)) for solving inverse problems. This method can be regarded as a combination of two-point gradient method and adaptive step size. In addition, the convex penalty term is proposed to solve the case that the true solution has special properties. In the theoretical analysis, we analyze the iteration mechanism of ATPG-\(\varTheta \), and verify the strong convergence of the method. Numerically, we show numerical results with different properties of the true solution. ATPG-\(\varTheta \) has outstanding acceleration advantage and reconstruction effect.
In the following research, we will continue to study the acceleration method of inverse problem solving and apply it to a wider range of practical applications.

The reconstruction results
Data availability
Not applicable.
Change history
01 September 2023
This article has been retracted. Please see the Retraction Notice for more detail: https://doi.org/10.1007/s40314-023-02439-y
References
Beck A, Teboulle M (2003) Mirror descent and nonlinear projected subgradient methods for convex optimization. Oper Res Lett 31(3):167–175
Beck A, Teboulle M (2009a) Fast gradient-based algorithms for constrained total variation image denoising and deblurring problems. IEEE Trans Image Process 18(11):2419–2434
Beck A, Teboulle M (2009b) A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J Imaging Sci 2(1):183–202
Boţ RT (2012) Iterative regularization with a general penalty term-theory and application to L\(^1\) and TV regularization. Inverse Prob 28:104010
Engl HW, Ramlau R (1996) Regularization of inverse problems. Kluwer Academic Publishers, Dordrecht
Hanke M, Neubauer A, Scherzer O (1995) A convergence analysis of the Landweber iteration for nonlinear ill-posed problems. Numer Math 72:21–37
Hubmer S, Ramlau R (2017) Convergence analysis of a two-point gradient method for nonlinear ill-posed problems. Inverse Prob 33:095004
Hubmer S, Ramlau R (2018) Nesterov’s accelerated gradient method for nonlinear ill-posed problems with a locally convex residual functional. Inverse Prob 34:095003
Ito K, Jin BT (2014) Inverse problems: Tikhonov theory and algorithms. World Scientific, New York
Jin QN (1999) Applications of the modified discrepancy principle to Tikhonov regularization of nonlinear ill-posed problems. SIAM J Numer Anal 36:475–490
Jin QN, Lu X (2014) A fast nonstationary iterative method with convex penalty for inverse problems in Hilbert spaces. Inverse Prob 30:045012
Jin BT, Maass P (2012) Sparsity regularization for parameter identification problems. Inverse Prob 28(12):123001
Jin QN, Wang W (2013) Landweber iteration of Kaczmarz type with general non-smooth convex penalty functionals. Inverse Prob 29:1400–1416
Kaltenbacher B, Neubauer A, Scherzer O (2008) Iterative regularization methods for nonlinear ill-posed problems. de Gruyter & Co., Berlin
Leonardo SB, Fermín SV, Maria CC (2015) Automatic stopping rule for iterative methods in discrete ill-posed problems. J Comput Appl Math 34:1175–1197
Real R, Jin QN (2020) A revisit on Landweber iteration. Inverse Prob 36(7):075011
Rudin LI, Osher S, Fatemi E (1992) Nonlinear total variation based noise removal algorithms. Physica D 60(1–4):259–268
Scherzer O (1998) A modified Landweber iteration for solving parameter estimation problems. Appl Math Optim 38:45–68
Schirotzek W (2007) Nonsmooth analysis, vol 266(1). Springer, Berlin, pp 1–56
Schtster T, Kaltenbacher B, Hofmann B, Kazimierski K (2012) Regularization methods in Banach spaces. de Gruyter & Co., Berlin
Wald A (2018) A fast subspace optimization method for nonlinear inverse problems in Banach spaces with an application in parameter identification. Inverse Prob 34:085008
Zalinescu C (2002) Convex analysis in general vector spaces. World Scientific, New York
Zhu MQ, Chan TF (2008) An efficient erimal dual hybrid gradient algorithm for total variation image restoration. CAM report, 08-34. UCLA, Los Angeles
Acknowledgements
This work was supported by the National Natural Science Foundation of China (Nos. 62072157, 61802116), the Key Technologies Research and Development Program of Henan Province (Nos. 222102210110, 232102210190, 232102211028) and the Natural Science Foundation of Henan Province (No. 202300410102).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
There is no conflict of interest in the manuscript.
Additional information
Communicated by Kelly Cristina Poldi.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article has been retracted. Please see the retraction notice for more detail: https://doi.org/10.1007/s40314-023-02439-y
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Ren, G., Gao, G. RETRACTED ARTICLE: A fast adaptive algorithm for nonlinear inverse problems with convex penalty. Comp. Appl. Math. 42, 188 (2023). https://doi.org/10.1007/s40314-023-02316-8
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40314-023-02316-8